Je tiens tout particulièrement à remercier les membres du jury de m'avoir fait l'honneur d'y participer. Je tiens également à remercier Bernard Robinet pour la confiance qu'il m'a accordée et pour ses précieux conseils.
Introduction g´ en´ erale
Cette thèse se concentre sur la tâche particulière de reconnaissance des instruments de musique, abordée à travers une approche de classification automatique. Nous essayons de trouver des implémentations efficaces des différents modules qui composent le système de classification automatique que nous proposons.

Bases de donn´ ees pour la reconnaissance des instruments de musique
1. Introduction
2. Corpus mono-instrumental ( INS )
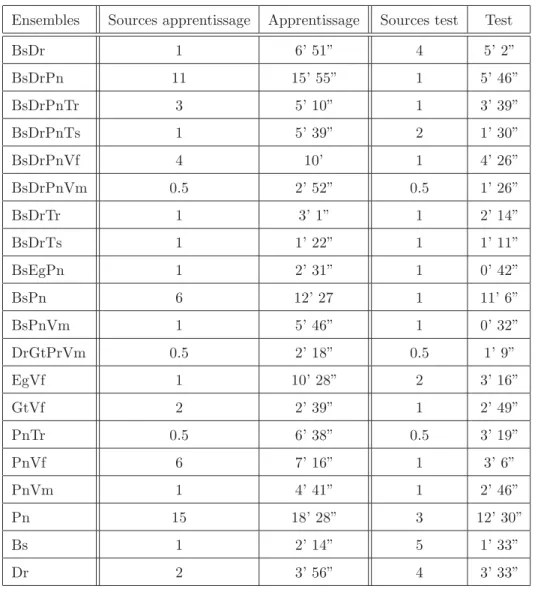
Cela nous permet d’envisager de réaliser l’apprentissage des classificateurs dans de meilleures conditions, mais également de tester les capacités de généralisation de nos schémas de classification de manière plus sophistiquée. Ressources" est le nombre de ressources différentes utilisées. "Formation" et "Test" représentent la taille des ensembles de formation et de test en minutes et secondes respectivement ; durée maximale et minimale.
3. Corpus multi-instrumental ( MINS )
Les 2/3 des sons sont inclus dans la base d'apprentissage et le tiers restant reste au test, lorsque cela n'entre pas en conflit avec la contrainte de séparation des sources d'apprentissage et de test. Enfin, lorsqu'une seule source est disponible, les 2/3 des données de cette source sont utilisés pour la formation et le 1/3 restant pour les tests.
PREMIERE PARTIE
Introduction de la premi` ere partie
Pr´ e-traitements et segmentation des signaux audio
Dans ce chapitre nous présentons les différents outils de traitement intervenant dans la phase de description du signal audio. Ceux-ci permettent d'obtenir une version intermédiaire du signal à partir de laquelle sont calculés les différents descripteurs qui seront présentés au chapitre IV.
Fr´ equence d’´ echantillonnage
Fenˆ etres d’analyse temporelle
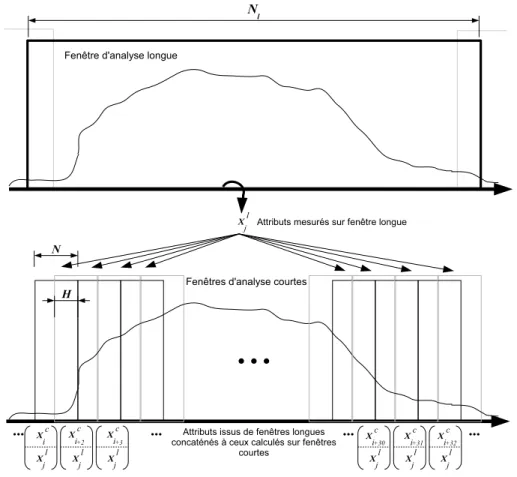
Paramètres et outils d'analyse du signal 33. III.2) – xl(n, m), marque le segment de signal (n) correspondant à la longue fenêtre d'analyse m.
Analyse spectrale
Dans nos expériences, nous utilisons une implémentation Matlab de CQT, fournie par Brown [Brown, ] et nous modifions le paramètre Q. Ici, nous utilisons également les fenêtres d'analyse de Hamming en limitant leur taille maximale à 1024 échantillons.
Transform´ ee en Ondelettes Discr` ete (TOD)
Calcul de l’enveloppe d’amplitude
- 2. Normalisation du signal
- 3. Segmentation du signal
Pour limiter l'effet des conditions d'enregistrement variables sur les performances de classification, nous effectuons deux opérations de normalisation de la forme d'onde du signal, qui ont.
D´ etection des segments de silence
Ces modèles permettent de détecter des fenêtres de silence pour un nouveau signal en affectant des observations de paramètres correspondant à ces fenêtres à la classe de silence si leur probabilité par rapport à cette classe est inférieure à un seuil prédéterminé. Nous nous basons sur les critères heuristiques suivants : fenêtres de silence considérées.
D´ etection des segments d’attaques
- Descripteurs pour la classification audio
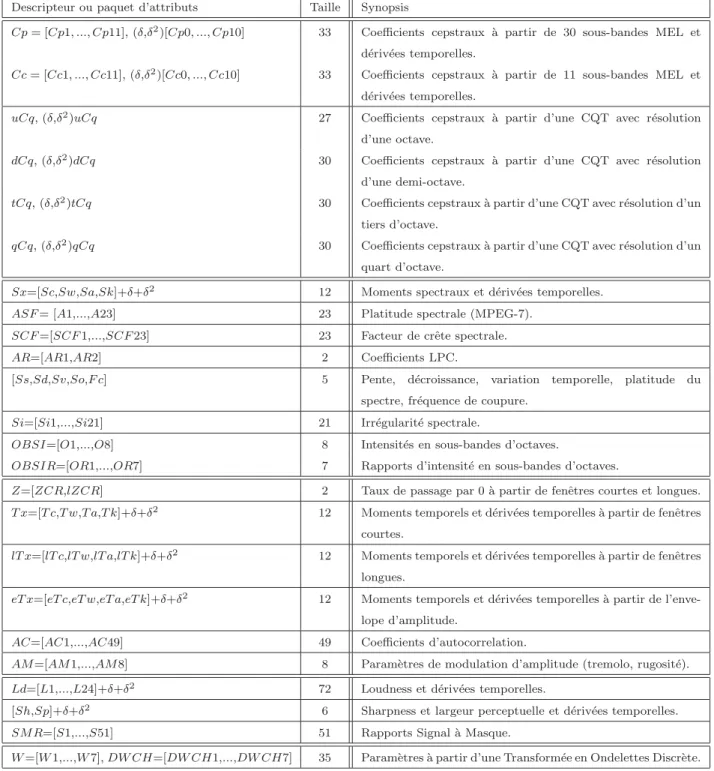
- 2. Descripteurs classiques
Ainsi, la fenêtre contenant l'attaque et un nombre fixe (de 2 à 4) de fenêtres qui la suivent constituent un segment que l'on marque comme transitoire. Les attributs que nous avons conservés sont mesurés sur des fenêtres d'analyse temporelles successives : ce sont des descripteurs instantanés.
Descripteurs cepstraux
- Mel-Frequency Cepstral Coefficients (MFCC)
- Coefficients Cepstraux ` a partir de la CQT
Les MFCC [Davis et Mermelstein, 1980] sont obtenus en considérant, pour le calcul du cepstre, une représentation fréquentielle selon une échelle de perception appelée échelle de fréquence MEL dont une expression analytique peut être donnée par . Notez que nous utilisons la boîte à outils Voicebox [Brooks, ] dans Matlab pour calculer MFCC.

Descripteurs spectraux
- Moments spectraux
- Mesures de platitude et de crˆ ete spectrales
- Autres descripteurs de la forme spectrale
Une alternative à la description de la planéité spectrale par kurtosis peut être obtenue en exploitant le rapport entre la moyenne géométrique et la moyenne arithmétique de l'amplitude spectrale [ISO/IEC, 2001]. L'irrégularité Si est alors calculée comme la dérivée fréquentielle du module CQT X(k) du signal (calculé avec une résolution d'un tiers d'octave).
Descripteurs temporels
- Taux de passage par z´ ero ou Zero Crossing Rates (ZCR)
- Moments statistiques temporels
- Coefficients d’Autocorrelation (AC)
- Attributs de Modulation d’Amplitude (AM)
Si l'on prête attention à l'intervalle de fréquence 4-8Hz, on obtient une caractérisation du trémolo, tandis que des mesures effectuées dans l'intervalle 10-40Hz permettent de déterminer le « grain » ou la « rugosité » des sons [ Martin, 1999, Eronen, 2001a]. Nous introduisons deux coefficients supplémentaires pour tenir compte du fait que les fréquences AM sont systématiquement mesurées, même lorsque le signal ne présente pas réellement de modulation d'amplitude, ils sont des produits de la fréquence AM et de l'amplitude AM (dans les deux intervalles).
Descripteurs perceptuels
- Loudness sp´ ecifique relative (Ld)
- Sharpness (Sh)
- Largeur perceptuelle (Sp-”Spread”)
La netteté représente la version « perceptible » du centre spectral calculée à partir de l'intensité sonore spécifique selon [Peeters, 2004]. Il s'agit d'une mesure de la différence entre l'intensité sonore spécifique maximale et l'intensité sonore totale [Peeters, 2004].
Param` etres bas´ es sur le comportement local de la transform´ ee en ondelettes
- 3. Nouvelles propositions
Trois paramètres sont calculés à partir de la branche B[s] correspondant à la singularité maximale (maximum de κ(s, u)), mais aussi à partir de la moyenne (sur) des branches B[s] ; c'est la pente de l'asymptote (aux petites échelles) et les deux premiers moments statistiques. Descripteur DW CH Pour le calcul des coefficients DW CH, les trois premiers moments statistiques et l'énergie des coefficients d'onde correspondant à la même échelle sont calculés dans 4 bandes de fréquences.
Intensit´ es des signaux de sous-bandes en octaves ( OBSI )
La figure IV-3-A montre une illustration de la discussion précédente en considérant le spectre d'une clarinette et d'un sax alto jouant la même note A5. Notez que le spectre de la clarinette représente plus d'énergie que le spectre du saxophone dans la deuxième sous-bande qui apparaît dans l'image, tandis que le spectre du saxophone alto représente plus d'énergie que le spectre de la clarinette dans les troisième et quatrième sous-bandes.
Rapports Signal ` a Masque ( SMR )
- 4. R´ ecapitulation
Il s’ensuit que l’énergie capturée dans chaque sous-bande d’octave, ainsi que le rapport énergétique d’une sous-bande à la précédente, seront différents pour deux instruments de structure harmonique différente. Le nouveau spectre est ensuite convolué par une fonction d'étalement dépendant de la fréquence, créant un spectre d'énergie partitionné.

DEUXIEME PARTIE
Fondements th´ eoriques
1. Classification supervis´ ee
Principe de d´ ecision
Dans notre cas, ces observations correspondront à une série de Nt fenêtres d'analyse temporelle consécutives et la question de la validité de l'hypothèse d'indépendance des xm se pose. Cela n’empêche pas cette hypothèse d’être largement utilisée en classification audio : en pratique elle permet de résoudre efficacement le problème de décision [R.
Sch´ emas de classification binaire
- Principe
- Fusion des d´ ecisions binaires
Hastie & Tibshirani proposent une solution efficace au problème de pooling de décisions binaires [Hastie et Tibshirani, 1998] qui permet d'obtenir des estimations des probabilités P(Ωq|x). Soit rqm(x) la probabilité que la classe correspondant à l'observationx soit Ωq dans le problème à deux classes s'écrit (Ωq vs Ωm).rqm(x).
Le Mod` ele de M´ elange Gaussien (GMM)
Pour une observation x donnée et un contexte à deux classes {Ωp,Ωq} la règle de décision est alors. Pour arriver à une décision globale, il faudra utiliser une technique permettant de combiner les résultats de différents classificateurs binaires.
Les κ plus proches voisins ( κ -NN)
- 2. Les Machines ` a Vecteurs Supports (SVM)
Pour l’exemple testxm, les κ-NN choisissent la classe Ωq0 si la plupart des κplus proches voisinsxv le sont. Mais en même temps, les κ des plus proches voisins de xv doivent rester très proches de xm pour que P(Ωq0|xv) soit une bonne approximation de P(Ωq0|xm).
Principe de Minimisation du Risque Structurel (SRM)
Lorsque le nombre d’exemples d’apprentissage l est faible, il s’avère que minimiser le risque Remp(α) n’implique pas nécessairement un risque R(α) minimal. En minimisant le risque empirique, il est possible d'obtenir un modèle efficace sur les exemples du set d'apprentissage, mais ce dernier ne garantit pas une performance satisfaisante en généralisation, c'est-à-dire sur de nouveaux exemples.
![Fig. V.3 Illustration du concept de dimension VC, d’apr` es [Burges, 1998]. Dans R 2 , en consid´ erant un ensemble de fonctions {f α } repr´ esentant des droites orient´ ees, de telle mani` ere que tous les points d’un cˆ ot´ e de la droite soient ´ etiqu](https://thumb-eu.123doks.com/thumbv2/1bibliocom/468051.72475/77.918.224.672.131.375/illustration-concept-dimension-burges-consid-fonctions-esentant-droites.webp)
Principe des Machines ` a Vecteurs Supports (SVM) lin´ eaires
Notez que nous choisissons de minimiser 12||w||2 au lieu de 12||w|| parce que cela facilite la résolution du problème. Il existe une autre réponse au problème des données non linéairement séparables, qui conduit à l’obtention de surfaces de décision non linéaires.

Calcul des SVM
Ainsi, on constate que l'hyperplan optimal dépend uniquement des vecteurs supports du problème (ns≤l) :. V.41) Le paramètre b peut être déterminé grâce à la condition (V.36) en choisissant un indice i tel que αi = 0, ou en faisant la moyenne des valeurs obtenues en utilisant tous les points connectés xi ´es ont desαi non nul ( pour une meilleure stabilité numérique). Les conditions KKT permettent également de déduire que les variables d'écart ξi sont nulles pour tous les vecteurs supports associés à des multiplicateurs αi tels que 0 < αi < C, ce qui permet de calculer b de la même manière ¸con qu'en cas séparable.
SVM non-lin´ eaires
- Noyaux
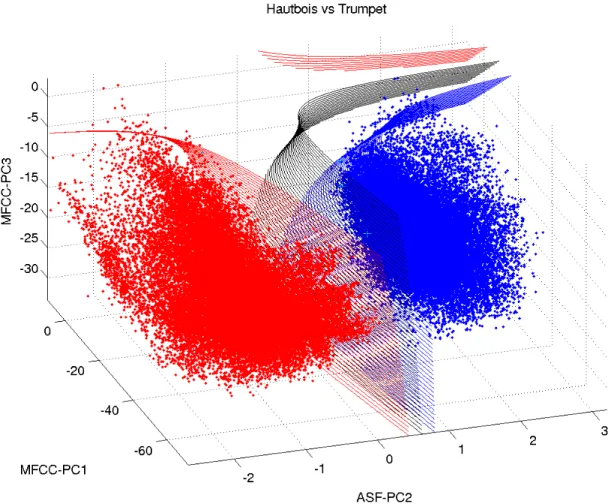
Un exemple de réalisation de SVM équipés d'un noyau polynomial de degré 2, sur des données audio réelles est donné en figure V.5. Visualisation des surfaces de décision induites par un noyau polynomial de degré 2 pour le SVM hautbois versus trompette.
Performances en g´ en´ eralisation des SVM
- Utilisation du principe SRM
Joachims propose une autre manière d'évaluer les performances de généralisation de SVM [Joachims, 2000], qui ne repose pas sur des hypothèses structurelles. Joachims montre que l'estimation d'erreur de généralisation ainsi obtenue s'avère efficace, notamment pour prédire les performances des SVM dans la tâche de classification de texte.
R´ ealisations multi-classes des SVM et SVM probabilis´ es
- 3. Clustering
Par conséquent, η est une limite supérieure du nombre d’erreurs commises dans les schémas qui classent chaque instance d’apprentissage à l’aide de machines calculées à partir de toutes les autres instances (erreurs d’exclusion). Le clustering se produit dans des tâches d'apprentissage non supervisées où les étiquettes des exemples de formation ne sont pas connues à l'avance.
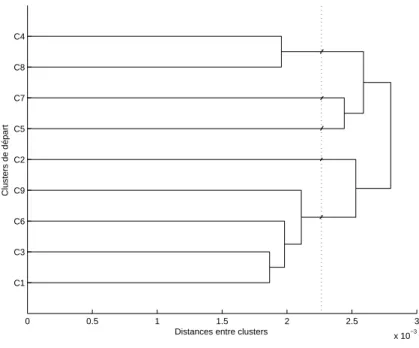
Principe du clustering hi´ erarchique
La pertinence de l'arbre de cluster ainsi obtenu peut être évaluée avec le coefficient de corrélation cophénétique. Par exemple, la distance cophénétique entre C1 et C6 est la distance entre les clusters C6 et C13, où C13 est le cluster contenant C1 et C3.
Crit` eres de proximit´ e
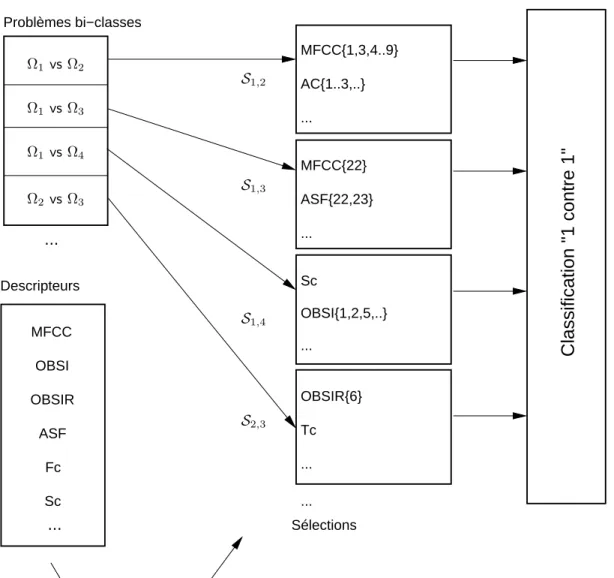
- S´ election automatique des attributs
- 1. Introduction
- 2. Normalisation des donn´ ees
- 3. Transformation des attributs par Analyse en Composantes Principales (PCA)Principales (PCA)
- 4. Algorithmes de S´ election des Attributs (ASA)
Le but de la sélection d'attributs est de produire un sous-ensemble « optimal » d'attributs à partir des variables D initialement considérées (généralement d << D). Une « sélection efficace » ne sélectionne pas les caractéristiques redondantes, même si elles peuvent être pertinentes, puisque de bonnes performances de classification sont obtenues en utilisant un sous-ensemble de caractéristiques complémentaires.
Algorithme de Fisher
Inertia Ratio Maximization using Feature Space Projection (IRMFSP)
Algorithmes de sélection d'attributs (ASA) 89 . par rapport à tous les problèmes bi-classes « 1 contre 1 » impliquant la classe Ωq. Pour prendre en compte la limitation de non-redondance des attributs sélectionnés, Peeters introduit une étape d'orthogonalisation dans l'algorithme, qui garantit qu'à chaque itération le dernier attribut sélectionné est décorrélé avec les attributs précédemment sélectionnés [Peeters, 2003].
Algorithme SVM-RFE (Recursive Feature Elimination)
A chaque récursion de l'algorithme SVM-RFE, l'attribut ayant le score le plus bas. S(f) //Mettre à jour le classement des attributs S ← S \f //Supprimer l'attribut avec le score le plus bas jusqu'à.
Algorithme MUTINF, bas´ e sur l’information mutuelle
Crit` ere de s´ eparabilit´ e des classes
Crit` ere d’entropie de repr´ esentation
Par conséquent, H peut être considéré comme une mesure de la redondance de l’ensemble d’attributs considéré. Par conséquent, nous obtenons un sous-ensemble d'attributs non redondants en maximisant H [Mitra et al., 2002].
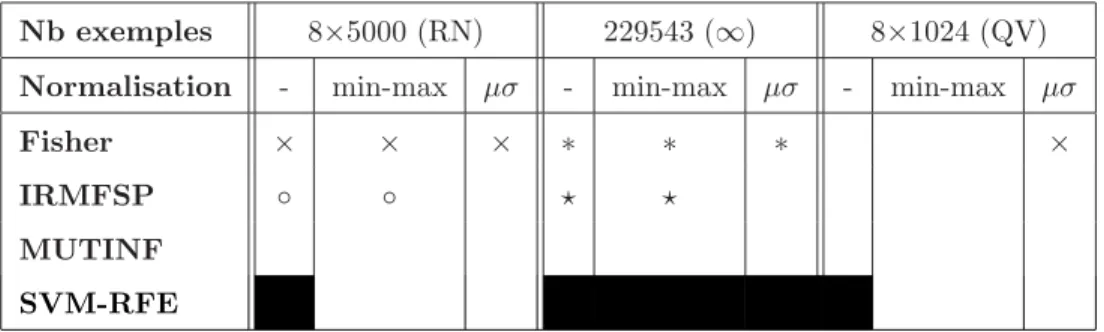
Influence de la taille de l’´ echantillon et de la normalisation
- Sorties des algorithmes de s´ election
- Performances des ASA relativement ` a la normalisation et l’´ echantillon
Tout d’abord, nous examinons la variation des caractéristiques sélectionnées lors de l’exécution des algorithmes, en fonction de l’échantillon utilisé et de la normalisation. La normalisation « min-max » ne modifie pas le résultat de la sélection IRMFSP effectuée sans normalisation.
Comparaison des performances des s´ elections
- Performances relatives des s´ elections
- Performances en relation avec la dimension cible
- Performances en relation avec les classificateurs
- 7. Variations sur les Algorithmes de S´ election des Attributs
Ensuite on remarque clairement l’amélioration des sélections IRMFSP et SVM-RFE. En revanche, associées à la classification GMM, les approches IRMFSP et SVM-RFE donnent les résultats les moins satisfaisants, alors qu'elles sont les plus efficaces dans un schéma de classification SVM.
![Tab. VI.4 Complexit´ e des ASA. Les algorithmes sont impl´ ement´ es en Matlab (MUTINF et SVM- SVM-RFE sont disponibles dans la toolbox Spider [Spider, ] qui reprend une impl´ ementation en C des SVM [LibSVM, ])](https://thumb-eu.123doks.com/thumbv2/1bibliocom/468051.72475/114.918.338.560.472.609/complexit-algorithmes-matlab-mutinf-disponibles-toolbox-spider-ementation.webp)
Un nouvel algorithme de s´ election : Fisher-based Selection of Feature Clusters (FSFC)
Deux critères de proximité ont été considérés : la distance Bhattacharryya et la divergence (voir section V-3-B), faisant ici l'hypothèse de densités de probabilité de « gaussianité » régissant les distributions de traits. De plus, nous exploitons directement la moyenne empirique et la covariance des propriétés dans le calcul des distances.

S´ election binaire
- 8. Conclusions sur la s´ election des attributs
- Etude exp´ erimentale pr´ eliminaire de la classification par SVMclassification par SVM
- 1. Introduction
- 3. Choix du param` etre C
- 4. Choix et param´ etrisation du noyau
- 6. D´ ecision en temps
- 7. Conclusions
Nous avons étudié un certain nombre d'algorithmes de sélection automatique d'attributs pour la tâche de reconnaissance d'instruments de musique. De plus, nous avons constaté que différents noyaux, lorsqu'ils sont correctement paramétrés, donnent lieu à des résultats de classification similaires, et nous avons conservé le noyau gaussien (qui permet des dimensions VC inférieures à celles obtenues par le noyau polynomial. Nous avons également proposé de nous contenter d'un noyau linéaire, lorsque cela suffit pour une bonne discrimination entre une paire de certaines classes, pour une réduction de la charge de calcul globale.
TROISIEME PARTIE
Introduction de la troisi` eme partie
Caract´ erisation sp´ ecifique ` a la
1. Organisation des attributs pour la reconnaissance des instruments
3 paramètres perceptuels sont classés parmi les 10 premiers attributs sélectionnés : la netteté Sh, l'étendue perceptuelle Sp et le coefficient d'intensité sonore Ld14. Le rapport signal sur masque (SMR) n’a pas été retenu par l’algorithme FSFC dans ce contexte, bien qu’il soit largement représenté dans les 40 clusters sélectionnés.
Attributs s´ electionn´ es sur les diff´ erents segments
Cela suppose que l'on puisse détecter les segments qui incluent les transitoires (convulsions), pour effectuer un traitement différencié de ces derniers et des segments non transitoires (le reste des segments). Les attributs sélectionnés pour les différents types de segments et pour les deux variantes de segmentation sont présentés dans le Tableau VIII.2.
Pouvoir de discrimination des diff´ erents segments
Nous comparons les différentes sélections d'attributs obtenues avec celle résultant de l'application de FSFC à toutes les données d'entraînement, indépendantes du type de segment et désignées par FS-R. On remarque que les attributs sélectionnés pour les segments non transitoires (AS-S2 et AS-S4) sont quasiment les mêmes que ceux retenus dans la sélection de référence.
Classification sur les diff´ erents segments
- 3. Conclusions
- Classification hi´ erarchique des instruments de musique, cas mono-instrumentalde musique, cas mono-instrumental
- 1. Introduction
- 2. Principe de classification hi´ erarchique
- 3. Taxonomies hi´ erarchiques des instruments de musique
De manière générale, les instruments les plus souvent confondus par le référentiel bénéficient du classement sur les segments transitoires. La classification hiérarchique a récemment été utilisée avec succès pour de nombreuses tâches de classification audio, en particulier la classification des instruments de musique [Martin, 1999, Eronen, 2001a, Peeters, 2003] et la classification des genres musicaux [Pachet et Cazaly, 2000, McKay et Fujinaga, 2004 , Li et Ogihara , 2005 ].
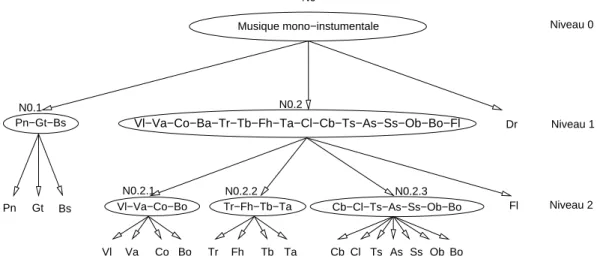
Taxonomie “naturelle” des instruments de musique : familles d’instruments
Cela implique l'utilisation d'une taxonomie hiérarchique des instruments dans le processus de classification [Martin, 1999]. Nous utilisons la taxonomie proposée par Peeters [Peeters, 2003] pour la construction d'un premier système de classification hiérarchique des instruments.
Inf´ erence de taxonomies automatiques
En utilisant la divergence avec ri = rj = 20 et σ2 = 0,5, on obtient le clustering le plus pertinent au regard du coefficient cophénétique (maximum dans ce cas). Parce que cette propriété n’est pas capturée par les attributs sélectionnés, elle ne peut en fait pas être « vue » par le système de classification, et n’est donc pas optimale à prendre en compte dans la taxonomie.

Classification ` a partir d’une taxonomie naturelle
Les décisions sont prises toutes les 4s comme pour le système de référence (Nt = 249). En revanche, la confusion entre les familles est réduite par le système hiérarchique.
Classification ` a partir d’une taxonomie automatique
Les cas de confusion résolus par le système CHF sont moins bien traités par CHA, par exemple (hautbois vs trompette), (trombone vs saxophone ténor), etc. On constate que les confusions entre instruments retrouvés dans les mêmes clusters de la taxonomie ne réduisent pas toujours : par exemple, le basson est souvent confondu avec le cor (24,8% du temps contre 10,8% avec CHF), et le saxophone ténor est plus souvent attribué.
R´ ecapitulation des performances des diff´ erents syst` emes
- 7. Conclusions
- Reconnaissance des instruments ` a partir d’extraits de musique multi-instrumentaled’extraits de musique multi-instrumentale
Le taux de reconnaissance moyen est de 66,4%, soit une amélioration de 2% par rapport au système CHA non équipé de sélection d'attributs binaires et une amélioration de 5,1% par rapport au système CHA. Dans ce chapitre, nous présentons notre système de reconnaissance des instruments de musique dans un contexte multi-instrumental.

La taxonomie automatique
Pour le test (blocs gris), seuls les attributs sélectionnés sont extraits du signal audio pour être utilisés dans la classification en utilisant la taxonomie et les SVM apprises en 2.a. Les niveaux de la taxonomie hiérarchique sont dérivés de ces différents clusterings, de sorte que les niveaux supérieurs sont issus de clusterings « grossiers » (faible nombre de clusters) et les niveaux inférieurs sont issus de clusterings « plus fins » (nombre élevé de clusters).
Attributs s´ electionn´ es
La troisième colonne du tableau présente les attributs les plus sélectionnés de chaque package, sur les 47 sous-ensembles obtenus. Les fonctionnalités les plus fréquemment choisies sont les SMR (dont 24 sont sélectionnées parmi les 47 sous-ensembles).
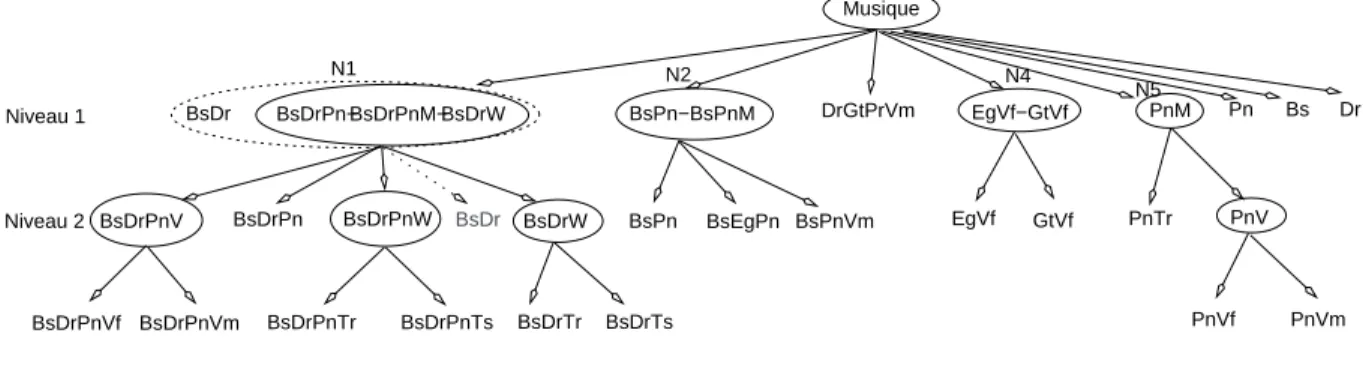
Classification
- 3. Conclusion
En fait, plusieurs exemples de la classe BsDrW ont nécessairement trouvé leur place dans les ensembles de formation et de tests liés aux classes BsDrPnV et BsDrPnW. Il en va de même pour les données de la classe BsDrW, qui contiennent certainement des exemples de BsDr.
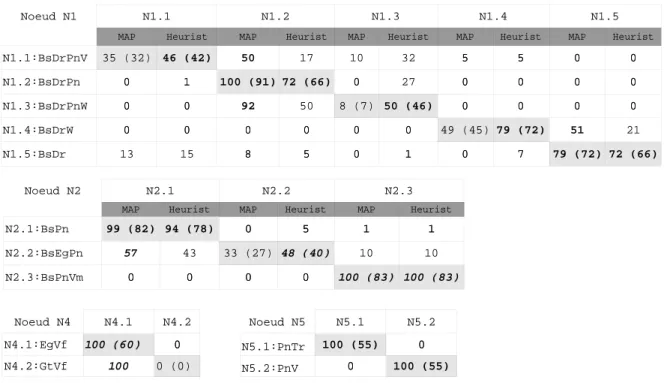
Conclusions et perspectives
Dans le cas d'un instrument, nous avons comparé les performances obtenues par un système de classification basé sur une taxonomie hiérarchique avec celles obtenues par une taxonomie naturelle des instruments. Une base de données d'extraits musicaux comprenant plusieurs instruments a également été créée pour tester les performances du système de reconnaissance multi-instruments.