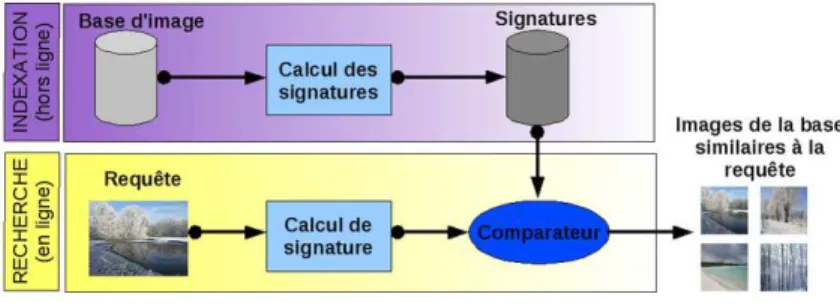
Dans ce stage, nous traitons la problématique de la recherche d'images à partir d'un contenu sur une base de données d'images du concours ImageClef. Dans un premier temps, je détaillerai notre participation au concours imageClef et la solution proposée en présentant les différentes techniques issues de la littérature. Dans ce rapport qui va suivre, je vais détailler les différents aspects de mon stage, je vais vous présenter les techniques et méthodes utilisées pour le problème d'écart sémantique, notre participation au concours ImageClef 2013, le travail effectué en équipe et la valeur ajoutée.
Notre travail se positionne sur le deuxième volet : la création d'un moteur d'identification d'images à partir d'un ensemble de photos de plantes. L'écart sémantique entre la représentation d'une image sur une machine et son interprétation (descripteur d'image). Contrairement à un moteur de recherche d'images traditionnel tel que google search image, qui pour une image végétale donnée fournit comme résultat un ensemble de photos de plantes, notre système doit être capable de trouver l'espèce végétale recherchée.
Compte tenu de la complexité de l'identification des plantes et de l'intérêt de la communauté scientifique, un concours international ImageClef est organisé chaque année pour évaluer les différentes techniques proposées par les groupes de recherche. Dans la partie suivante, je présenterai différentes notions de traitement d'image et l'état de l'existant.

Point d’int´erˆet
Harris Corner Detector
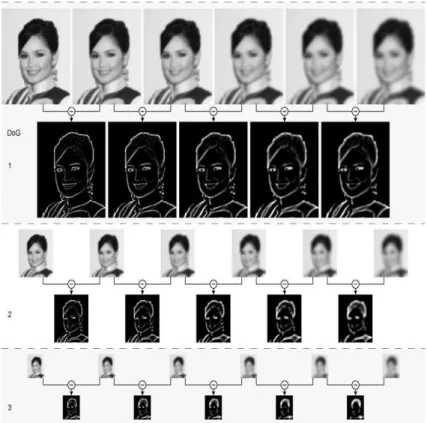
On calcule les dérivées premières des dérivées gaussiennes (écart-type σD). a) Lisser une image à l'aide d'une gaussienne. On calcule les termes de la matrice d'autocorrélation Ξ en calculant une moyenne locale des dérivées sous la forme d'une gaussienne (écart type σI, typiquement σI = 2σD) Ξ =σI. L'étape 1.a consiste à appliquer un filtre gaussien pour lisser l'image et supprimer le bruit (voir figure 5).
Le filtre de Sobel est appliqué par convolution de l'image avec deux noyaux 3x3 (voir Figure 6). Le détecteur Harris est l'un des plus utilisés dans le domaine de la vision artificielle.

Harris Color Detector
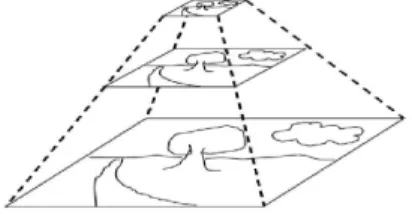
Pour résoudre le problème de la variance par rapport à l'échelle, j'introduirai la notion d'espace d'échelle.
Espace d’´echelle
Descripteur visuel local d’image
SIFT
Pour chaque carré 4x4, on calcule un histogramme des orientations quantifiées dans 8 directions, pondérées par :. Pour être invariant en rotation, l'orientation locale du point d'intérêt θ(x, y) est utilisée comme origine de l'orientation des gradients. Pour obtenir ce vecteur, considérons une zone de 16x16 pixels autour d'un point d'intérêt, divisée en 4x4 zones de 4x4 pixels chacune.
Dans chaque zone, un histogramme des orientations des gradients d'intensité (orientation des contours dans l'image) est calculé, voir Figure 12. Un descripteur SIFT n'est pas sensible à l'orientation de l'image, ni au changement d'échelle (zoom ).
Apprentissage non supervis´e
K-Means
Apprentissage supervis´e
Machine ` a vecteurs de support (SVM)
L'efficacité d'un SVM réside dans la maximisation de la marge (la variable w), contrairement à un réseau de neurones où le but est de trouver la ligne de partage entre les deux ensembles (ici la ligne noire), un SVM maximise la marge qui est la distance entre la ligne verte et la ligne rouge sans augmenter le taux d'erreur.
RANSAC
LSH
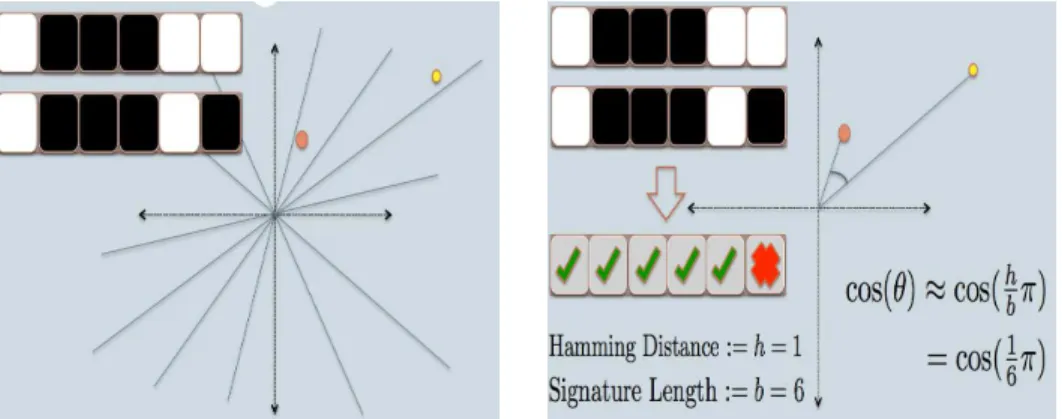
Autrement dit, si la distance entre 2 points est inférieure à un seuil R, alors la probabilité qu'ils soient dans la même case doit être plus grande. Plus clairement, le but est de faire une transformation de la représentation des données pour réduire la complexité de calcul. Dans la figure 17, nous partitionnons notre espace avec plusieurs plans choisis au hasard mais de manière homogène.
A la fin de toutes les opérations, chaque point est représenté par un vecteur binaire de taille égale au nombre de plans. La distance entre deux points est la distance de Hamming, qui représente le nombre de carrés où la valeur est différente.
Bog-of-words(Bow)
Chaˆıne de r´esolution
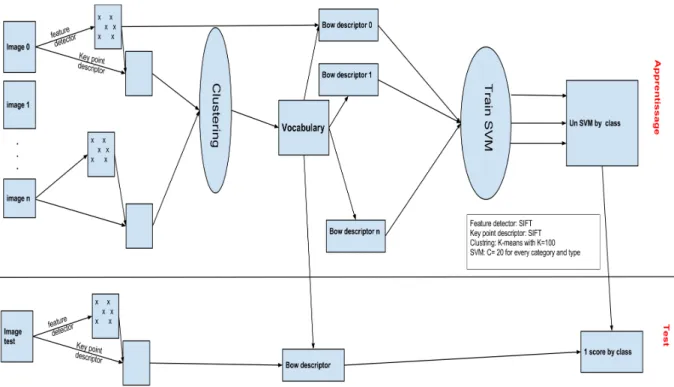
Durant la première partie de mon stage, j'ai mis en place une chaîne de traitement complète pour traiter les images du concours ImageCLEF. Ce dernier peut être utilisé pour le traitement des données du Laos3 au sein du laboratoire. Le clustering pour la génération d'index se fait avec l'algorithme K-means de 100 clusters.
Nous utilisons les métadonnées des fichiers XML pour extraire des informations telles que : le type de contenu, l'arrière-plan de l'image. La complexité de l'application engendrée par les différentes étapes et la quantité d'informations à gérer (pour une image donnée, le nombre de points d'intérêt est d'environ 1000) est très importante. Le but était de minimiser le temps d'exécution de l'application en réduisant les itérations au maximum, et d'autre part d'éviter la saturation de la RAM due à la taille des données.
Le flux d'informations transféré d'un module à un autre est stocké dans des fichiers (tels que des descripteurs d'images ou des SVM). Derrière ce dernier, nous avons un ensemble de descripteurs pour chaque image avec le vocabulaire de chaque autorité. L'étape suivante est l'apprentissage automatique sur ces données selon deux critères : la classe et l'organe.
La même configuration de SVM(s) est utilisée pour les différents corps avec le paramètre C= 20, qui représente la somme des distances d'erreur. La taille d'un vecteur est de 250 ce qui correspond au nombre de classes dans nos données. La dernière étape est le test, qui consiste à rechercher une certaine image de sa classe.
Impl´ementation
Resultat et analyse
La configuration des différents composants de notre système n'est pas optimisée. Le manque de temps pour étudier les différents paramètres (1 mois) nous a limité à utiliser une configuration moins gourmande en espace mémoire et plus rapide en exécution. Développer une API pour faciliter la mise en œuvre et la modification des solutions pour les futures participations.
D´eveloppement de l’API
BOWTrainer : tout algorithme d'apprentissage qui génère du vocabulaire doit implémenter cette classe. CvStatModel : Tout algorithme qui génère notre modèle, tel que SVM, doit implémenter cette classe. Données : Représente les données de notre moteur de recherche, dans notre cas des images de plantes.
Il doit implémenter les fonctions getPoi(), getDescriptor(), getBow() qui permettent respectivement de récupérer les points d'intérêt, leurs descripteurs et la génération de back-of-words. System : Représente notre système qui va générer le vocabulaire et le modèle grâce aux fonctions : VOCGen(), training(). La fonction loadData() permet de charger les données en mémoire grâce à l'ImageClef-Parser, qui permet de parser les fichiers XML.
Optimisation des param`etres
Nombre de cluster
Les points d'intérêt des deux images seront concentrés sur les contours de la peau et aux centres. Le caractère distinctif dans le cas des feuilles doit être supérieur à celui des arbres et cela en raison du nombre de points d'intérêt des feuilles inférieur à celui des arbres, qui portent donc plus d'informations que celui des arbres.

La somme de distance des erreurs du SVM (C)
Les donn´ees
En tant qu'étudiant en Système d'Information des Connaissances, ce stage m'a permis de voir les différentes techniques de fouille de données appliquées aux problèmes de vision artificielle et plus précisément de recherche de contenu. Les différents articles que j'ai lus m'ont permis de voir la complexité d'un moteur de recherche d'images pour le contenu. Le problème de l'écart sémantique, qui existe toujours, et la configuration des différents paramètres de la chaîne de solution, comme le nombre de clusters, le taux d'erreur, le filtre gaussien pour la détection des points d'intérêt, le modèle.
Implémentez des descripteurs de texture pour les tiges et des descripteurs de forme pour les feuilles. Le laboratoire I3S est une unité mixte de recherche (UMR) de près de 300 personnes partagée par l'Université Nice-Sophia Antipolis (UNS), le Centre National de la Recherche Scientifique (CNRS) et à l'Institut National de Recherche en Informatique et Automatique. Il est composé majoritairement d'enseignants-chercheurs de l'UNS (83 permanents et 17 associés) des sections 27 et 61 du Conseil National des Universités (CNU).
Ils interviennent principalement dans les départements Informatique et Electronique de l'Ecole Polytechnique Universitaire (Polytech'Nice - Sophia) et de l'UFR Sciences, ainsi que dans les départements Informatique, Réseaux & T'el'. l'IUT. Au sein de ces structures éducatives, ils assument de nombreuses responsabilités de filières, de spécialités, d'années de formation ou de départements.
Pr´esentation ´equipe KEIA
HGM] Julien Barbe Vera Bakic Alexis Joly Herv'e Go¨eau, Pierre Bonnet and Jean-Fran¸cois Molino. HGM12] Alexis Joly Itheri Yahiaoui Daniel Barthelemy Nozha Boujemaa Herv´e Goeau, Pierre Bonnet and Jean-Fran¸cois Molino.