Since this layer is fully interpretable, we used quantitative measures to describe the distribution of the learned spectro-temporal modulations. The idea is that on top of the spectrum, spectro-temporal wavelets or gabor spots can be defined that drive both behavioral responses and brain signals. Therefore, what is needed is a model that can learn the features of the spectro-temporal representations relevant to the task.
Therefore, the model makes direct and testable predictions about the auditory representation as a function of the task. Schematic illustration of the space of functions and different approaches to obtain spectro-temporal representations of sounds. The sound is then decomposed into filter banks divided based on the Mel scale after log compression (Mel filter banks), comparable to the resolution of the human cochlea.
The calculations for the Mel filter banks of the audio can be performed directly on the GPU thanks to Cheuk et al. We used quantitative measurements to describe the structure of the distribution of the learned spectro-temporal convolutions. To obtain a measure of the separability of the learned STRFs, we approximated the 2D distribution P(ω,Ω) of the filters using Kernel Density Estimation with Gaussian filters.
However, they only look at one view and aspect of learned distributions at a time.
EXPERIMENTAL SETUP
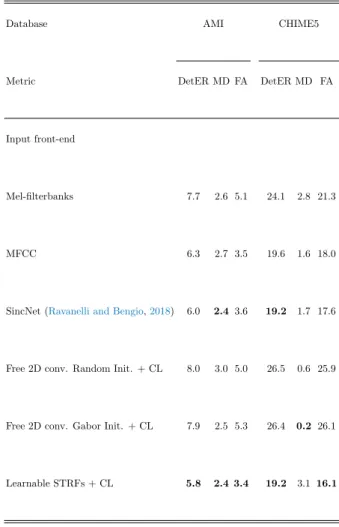
We evaluated learnable STRFs (64 filters) with a shrinkage layer (CL) as well as free 2D convolution with a shrinkage layer (CL). The shrinkage layer is a convolution layer that takes the results at each time step of Learnable STRFs to reduce the number of dimensions of Z. Data augmentation is performed directly on the waveform using additive noise based on the MUSAN database (Snyder et al., 2015) with a random target signal-to-noise ratio ranging from 5 to 20 dB.
We used the metrics implementation from pyannote.metrics (Bredin, 2017) and all experiments were performed with pyannote.audioBredin et al. The goal of the speaker verification task in speech processing is to accept or reject the hypothesis that a given speaker uttered a given sentence. We examined this task because spectro-temporal modulations are thought to encode speaker-specific information (Elliott and Theunissen, 2009; Lei et al., 2012).
We followed the same procedure as Coria et al. 2020) to conduct experiments with two versions of the VoxCeleb databases: VoxCeleb2 (Chung et al., 2018) is used for training and VoxCeleb1 (Nagraniet al., 2017) is divided into two parts for a development and testing sets. We investigated the use of Learnable STRFs for Urban sound classification, specifically to test the use of spectrotemporal modulations for sound types other than animal (human or bird) vocalizations (M lynarski and McDermott, 2018). We followed the same evaluation procedure as Salamon and Bello (2017) to evaluate the experiments with the UrbanSound8K database (Salamon et al., 2014).
We used the codebase of Arnault et al. 2020) for training and evaluation of both approaches. The main approach is to use Mel-filterbanks with the CNN10 architecture from Kong et al. In the learnable STRFs approach, the first convolutional layer of the CNN10 architecture (a 3x3 free 2D convolution with 64 filters) is replaced by a learnable STRFs layer (64 filters) on top of the Mel filter banks described in Section II.
To compare the approaches, we calculated the mean, Min, Max accuracy over the permutations. Maximum amplitude; Mean, Std, Skewness, Kurtosis, Entropy, first, second and third quartiles of the frequency power spectrum; Mean, Std, Skewness, Kurtosis, Entropy of temporal envelope). The MPS representation is the 2D Fourier Transform amplitude spectrum applied to the spectrum representation of the sound waveform.
RESULTS AND DISCUSSIONS
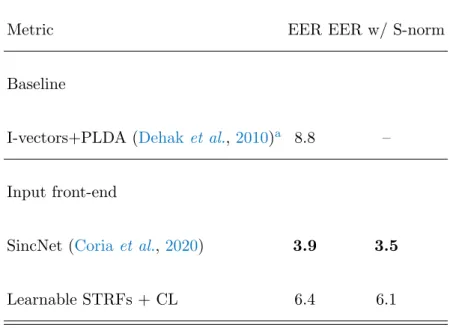
In general, the performance of learnable STRFs is the same for all tasks with different baselines. It improves upon the state-of-the-art model with SincNet on the AMI dataset and matches the performance on the CHIME5 dataset. CL stands for contraction layer, that is, a convolution (transformation) layer that reduces the size of the tensor dimension after convolution (free 2D conversion or learnable STRF) on Mel-filterbanks.
CL stands for contraction layer, it is a convolutional layer that reduces the size of the tensor dimension after convolution (Learnable STRF). We evaluated speaker verification performance with and without S-normalization Coria et al. We also reported the basic performance of I-vector combined with probabilistic linear discriminant analysis (PLDA) (Dehaket al., 2010).
One of the hypotheses is that the learning of the harmonic structure is more difficult with the output Learnable STRFs layer than directly with the Mel filterbanks. The accuracy of the learnable STRFs is above the baseline approach of Salamon and Bello (2017) and is on par (slightly below) with the CNN10 architecture using Mel filterbanks. This suggests that the varying magnitudes of focus on the Melfilterbanks representations enhance performance, both in time and frequency.
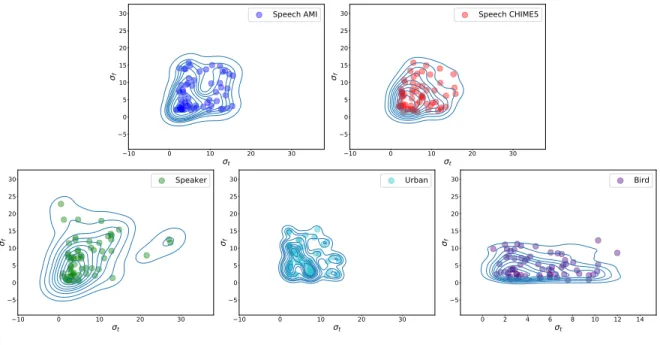
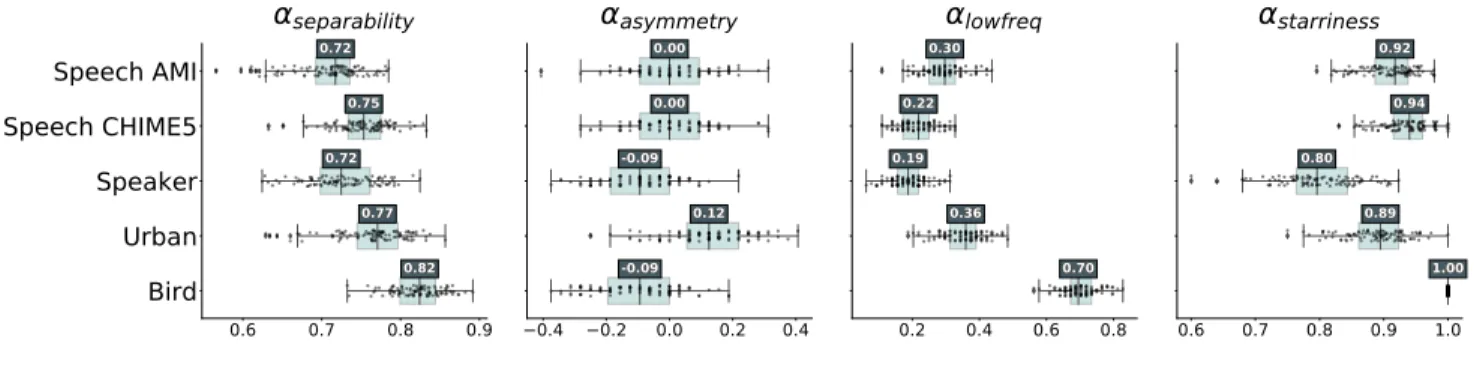
The Learnable STRFs models are decoded with a simple linear layer, so the closest baseline is the combination of the MPS with the LDA. Within the space allowed by Nyquist's theorem and the size of the convolutions, all learned STRFs still concentrated in low spectral and temporal modulations (see Figure 3). We found that the Gaussian envelopes of the learned STRFs can be characterized more by a continuum of values, rather than by a set of specific values.
Finally, the modulation distributions of the learned STRFs and Gaussian envelopes of the speech tasks on the AMI and CHIME5 datasets and the speaker task are seen more. Temporal and Spectral Modulation of Learned STRFs for Solving Speech Activity Detection on the AMI Dataset (Speech AMI) and on CHIME5 (Speech CHIME5), Speaker Verification on VoxCeleb (Speaker), Urban Sound Classification on Urban8k (Urban), Zebra Finch Call Typska classification (bird). For clarity, we only show a subset of the Bird and Urban STFR tasks learned.
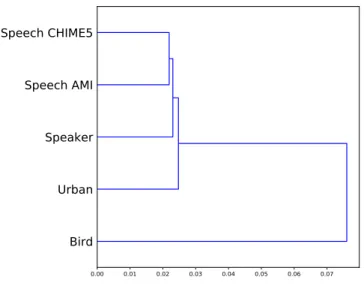
Hierarchical clustering of the tasks: Speech activity detection on the CHIME5 dataset (Speech CHIME5) and on the AMI (Speech AMI), Urban Sound Classification on Urban8k (Urban), Speaker Verification on VoxCeleb (Speaker) Zebra Finch Call Type Classification (Bird) . We also observed that the learned STRFs from the Speaker task moved away from the low spectral modulations and yielded the lowest low-pass coefficient (αlowf req ≈0.19).
CONCLUSION AND FUTURE WORK
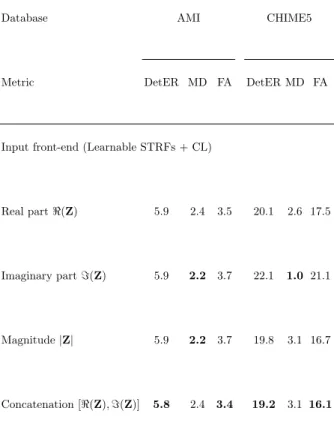
These task-specific modulations were globally congruent with previous work based on three approaches: spectro-temporal analysis of different audio signals (Elliott and Theunissen, 2009), analysis of trained neural networks (Sch¨adler et al., 2012) and analysis of the auditory cortex (Hullett et al., 2016; Santoro et al., 2017). We performed a further Speech Activity Detection analysis of the selection of representations Z from the Learnable STRFs used in the subsequent neural network. The performance of the real part, the imaginary part and absolute values of the filter output are compared.
The results are shown in TableV. Compared to the concatenation of the real and imaginary parts, the performance for each part was the same. range on the AMI dataset, but were lower on the CHIME5 dataset. The fifth 'chime' speech separation and recognition challenge: dataset, task and baselines', in Proceedings of the 19th Annual Conference of the International Speech Communication Association (INTER-SPEECH 2018), Hyderabad, India. Robust cnn-based speech recognition with gabor filter kernels,” in the fifteenth annual conference of the international speech communications association.
Improving and evaluating spectro-temporal modulation analysis for speech intelligibility estimation,” in Interspeech 2019Annual Conference of the International Speech Communication Association, ISCA, pp. The vocal repertoire of the domesticated zebra finch: a data-driven approach to deciphering the information-carrying acoustic features of communication signals,” Animal cognition. Spectro-temporal analysis of speech using 2-d gabor filters,” in Eighth Annual Conference of the International Speech Communication Association.
Spectro-temporal gabor features for speaker Recognition”, in 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, pp. On the variance of the adaptive learning rate and beyond”, in International Conference on Learning Representations . Ecologische oorsprong van perceptuele groeperingsprincipes in het auditieve systeem”, Proceedings of the National Academy of Sciences.
A dataset and taxonomy for urban sound research," in Proceedings of the 22nd ACM international conference on Multimedia, pp. Reconstruction of the spectrotemporal modulations of real sounds from fmri response patterns," Proceedings of the National Academy of Sciences. Spectro-temporal modulation subspace overlay filterbank features for robust automatic speech recognition,” The Journal of the Acoustical Society of America.
Modulation spectra of natural sounds and ethological theories of auditory processing, "The Journal of the Acoustic Society of America. A scale for measuring psychological magnitude pitch," The Journal of the Acoustic Society of America.