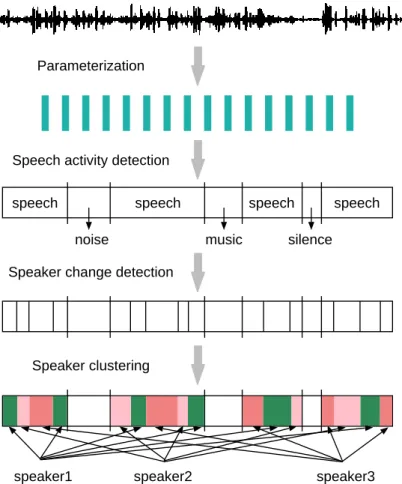
Deux utilisations principales de la structuration du locuteur peuvent être trouvées dans la littérature. Un autre problème restant dans le domaine de la structuration du locuteur est la détection des paroles qui se chevauchent.
General architecture of speaker diarization systems
Most current speaker diarization systems are based on a framework derived from the speaker segmentation system proposed by Gish [Gishet al., 1991]. The various implementations of loudspeaker diarization systems will be explained later in this chapter.
Grounds for speaker diarization
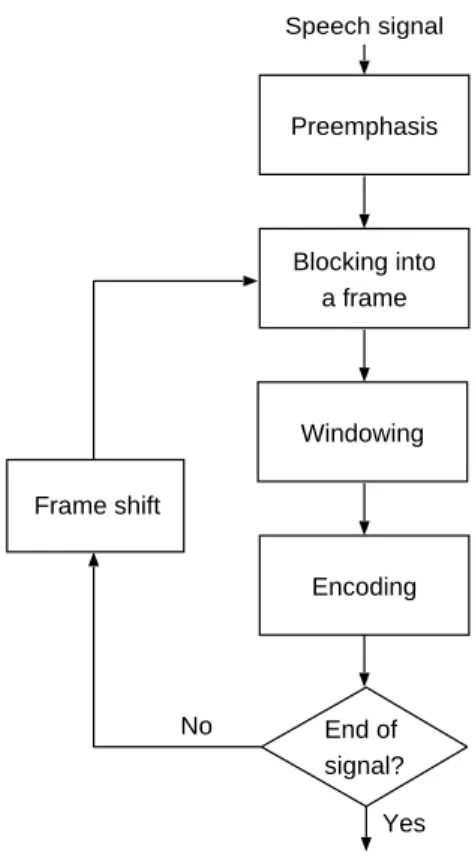
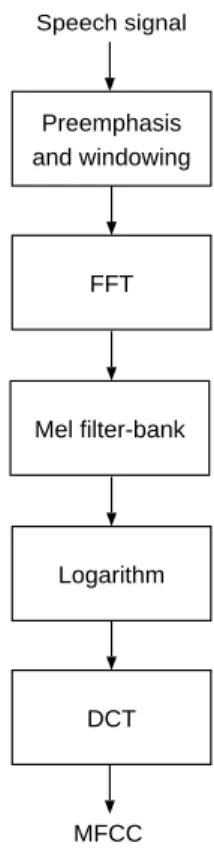
Front-end parameterization
Most speech signal analysis methods are based on this short-term stationary assumption. The LPC model exploits this correlation to reduce the amount of data without losing important vocal tract information in the speech signal.
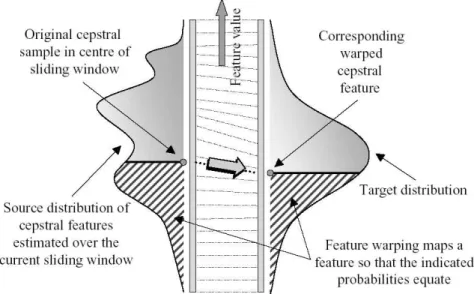
Feature warping normalization
This dynamic information can be plotted by high-order time derivatives (typically using first- and second-order derivatives) [Furui, 1986] of the cepstral coefficients. The delta and delta-delta parameters are the popular approximations of the first- and second-order derivatives.
Statistical speaker modeling
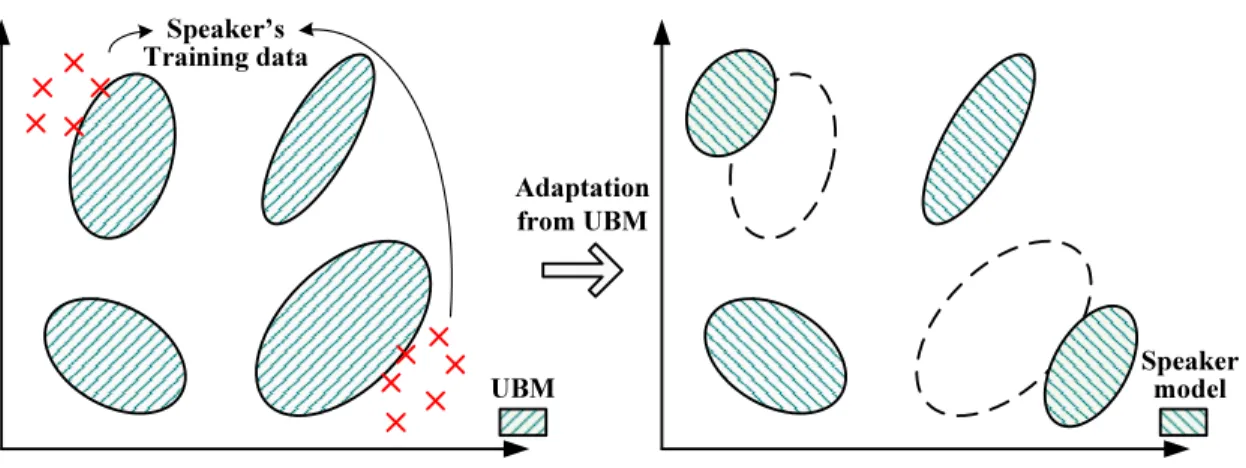
Model initialization is an important factor affecting the training performance of the GMM loudspeaker model. The UBM may or may not be bandwidth dependent in terms of the composition of recording channels (broadband/telephone).
Speaker diarization
Speech Activity Detection (SAD)
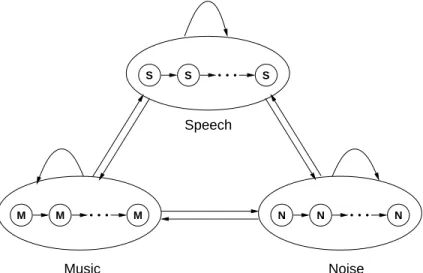
Additionally, the SAD detector presented in [Meignier et al., 2006] also uses speech and non-speech models with a set of morphological rules. For example, the speaker diarization system developed at Cambridge University [Hainet al., 1998; Sinhaet al., 2005] uses a GMM-based SAD detector with the acoustic models for broadband speech, narrowband speech, speech over music, and pure music.
Speaker change detection
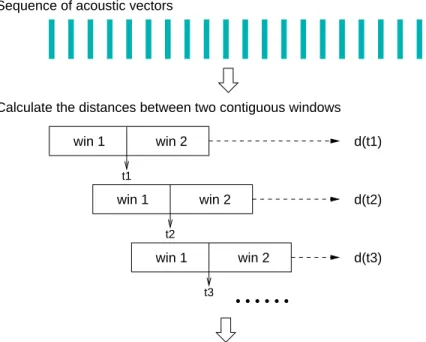
In the work of [Delacourt and Wellekens, 1999; Delacourt and Wellekens, 2000], some other measures of distance (e.g. the Kullback Leibler metric) are also used in the first step of this two-stage segmentation. In the case of the speaker change detection, two audio segments X1 and X2 can be regarded as the two distributions A and B, respectively. In [Delacourtet al., 1999b; Delacourt and Wellekens, 2000], the KL2 distance is used in the first step of the two-pass speaker change detector.
Speaker clustering
An initial implementation of loudspeaker clustering using the KL2 distance metric is described in [Siegleret al., 1997], where a certain threshold is applied to the distance as a stopping criterion. A distance threshold stopping criterion is used in the speaker clustering of [Benet al., 2004], while the BIC criterion is used as a stopping criterion in [Moraruet al., 2005]. The speaker clustering presented in [El Khouryet al., 2007] combines the EVSM-based clustering technique with a prosodic-based clustering, i.e.
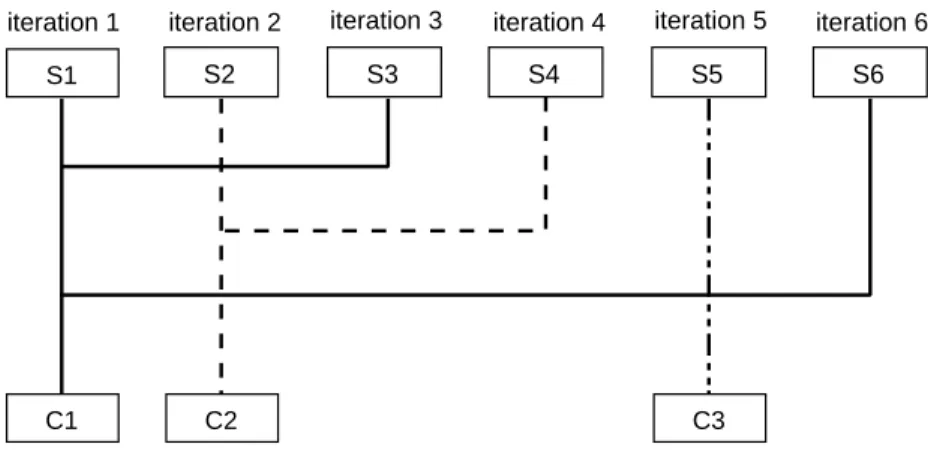
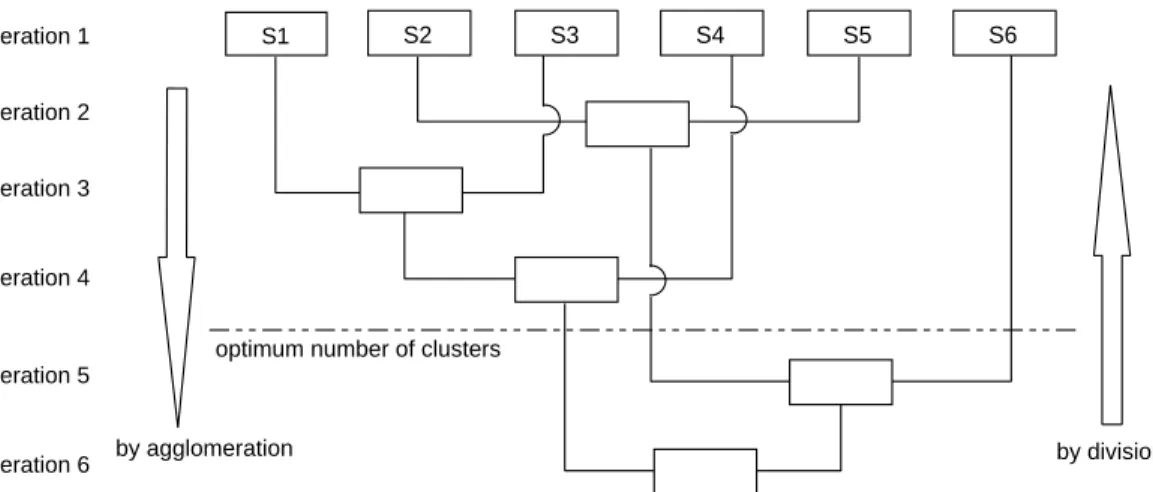
Integrated segmentation and clustering
This iterative algorithm detects speakers (ie, a cluster) one at a time, with segmentation and new speaker detection performed at each iteration using the speaker models detected in the previous iteration. A new state corresponding to speaker Si is added to the previous HMM and the transition probabilities are updated according to some rules. Finally, at the end of this chapter, an introduction to main speaker diarization evaluations (i.e., the NIST Rich Transcription evaluations and the French Technolangue ESTER evaluation) is given.
Overall speaker diarization error rate (DER)
The first section of this chapter presents the key performance metric, referred to as the Speaker Generalization Error Rate (DER), that was proposed in the NIST Rich Transcription evaluations. The primary metric for the speaker diarization task is the overall speaker diarization error rate (DER) used in the framework of Rich Transcription (RT) speaker diarization estimates [NIST, 2003; NIST, 2004; NIST, 2006]. Given the optimal mapping, the overall speaker diarization error rate (DER) is calculated over an entire audio file, including overlapping regions where multiple reference speakers speak.
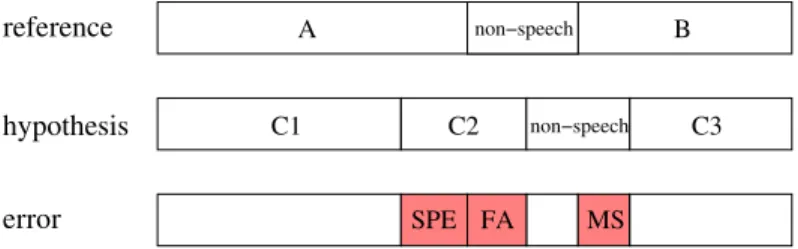
Clustering metrics
Speaker Match Error (SPE): The portion of the speaker time that is not attributed to a correct speaker (i.e. the mapped reference speaker is not the same as the hypothesis speaker). The speaker match error presented earlier can be interpreted as a combination of cluster purity and coverage errors. Thus, starting with an initial segmentation, the cluster purity error will be the lowest possible match error on this segmentation after performing an agglomerative clustering.
Speaker diarization evaluations
- NIST evaluation campaigns
- ESTER evaluation campaign
- Feature extraction
- Speech Activity Detection (SAD)
- Acoustic change detection
- Iterative GMM segmentation/clustering procedure
- Viterbi re-segmentation
- Bandwidth and gender labeling
This chapter provides descriptions of basic and advanced loudspeaker diarization systems. This set of acoustic parameters is used in all steps of the c-std system, except for acoustic change detection, where only static properties are used. The GMM models consist of 64 components with diagonal covariance matrices and were trained on the LDC 1996/1997 English Broadcast News data, which are also used to train the speech recognition models.
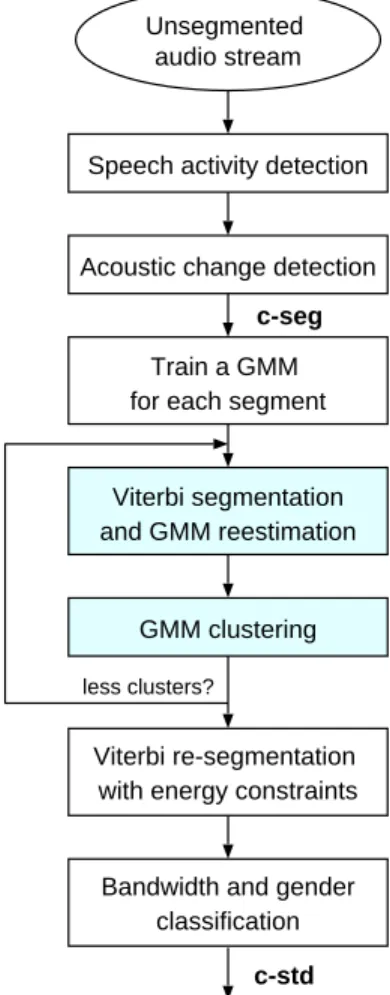
Multi-stage diarization for broadcast news
BIC clustering
BIC = (ni+nj) log|Σ| −nilog|Σi| −njlog|Σj| −λP (4.3) where Σ is the covariance matrix for the merged cluster (ciandcj), Σiof clusterci, Σjof cluster cj, andni and nj are respectively the number of the acoustic frames in clustersci and cj. Singular covariance matrices were not a problem due to the minimal length constraint during the acoustic change detection. In our BIC clustering procedure, the size of the two merged clusters is used, i.e. n=ni+nj, to calculate the penalty P, as described in [Cettolo, 2000].
SID clustering
After the BIC clustering phase, state-of-the-art speaker recognition methods [Schroeder and Campbell, 2000; Barras and Gauvain, 2003] was used to improve the quality of speaker clusters. Then feature distortion normalization is performed as presented in Section 2.2.2, which transforms the histogram of the cepstra coefficients into a Gaussian distribution [Pelecanos and Sridharan, 2001] on each segment using a sliding window of 3 seconds to reduce the effect of the acoustic environment. The GMM for each residual cluster is obtained by maximum a posteriori (MAP) fitting [ Gauvain and Lee , 1994 ] of the means of the matching UBM.
SAD post-filtering
RT-04F experiments
- Databases description
- System configurations
- RT-04F development results
- Local vs. global BIC on RT-04F development data
- SID clustering threshold
- Feature warping effects
- Iteration count of MAP adaptation
- RT-04F evaluation results
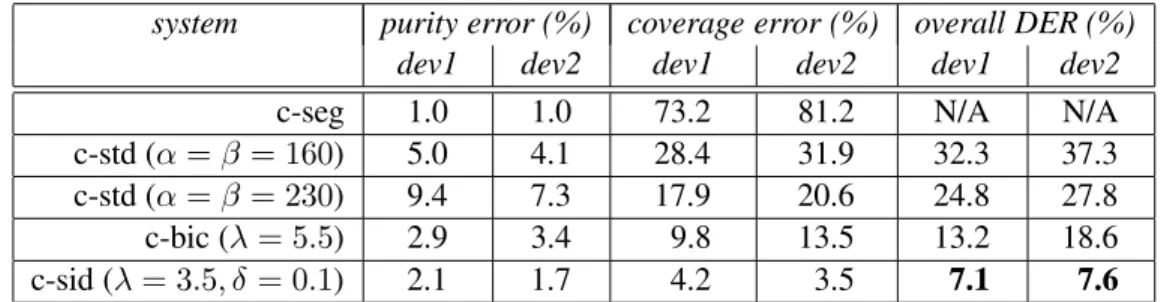
The effect of the SID clustering threshold δ on the speaker match error and the clustering error was measured on both the dev1 and dev2 data. Since feature warping was only performed in the SID clustering stage of the standard c-sid system (called “fw_sid”), the contrast experiments were designed to perform the function. The optimal values of the BIC penalty weight λ on the RT-04F development data reported in Section 4.3.4 (i.e., 7.0 for the c-bic system and 2.5 for the c-side) are also examined on the test data.
ESTER experiments
- Database description
- Results on ESTER development data
- SID clustering threshold
- ESTER evaluation results
Therefore, the best threshold for stopping SID clustering depends largely on the specific data. The results on the ESTER evaluation data are given in Table 4.9, with the optimization parameters set to the development data. For the c-sid system presented with the best performance, the display and total diarization errors in the ESTER evaluation data are given in Figure 4.9.

Robustness of the multi-stage diarization system
BIC penalty weight λ vs. show duration
To investigate the correlation between the value of the BIC penalty weight λ and the duration of the BN shows, the BIC clustering phase is performed without any stopping threshold, i.e. BIC clustering results using different penalty weight values on the 1 hour, first 30 min, and 30 min datasets. , where loudspeaker matching errors are obtained using an optimal a posteriori threshold to stop the BIC clustering process. The optimal BIC clustering threshold value decreases as the penalty weight λ increases and appears to be linearly related to the λ value, roughly formulated as 3800−800λ based on the results given in Figure 4.11.
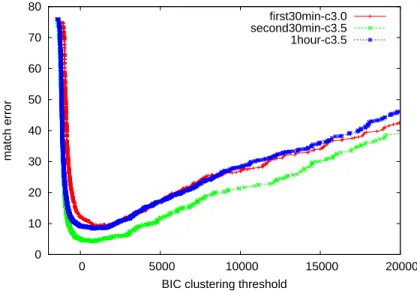
SID clustering threshold δ vs. show duration
However, the results given in Figure 4.11 suggest that the initial BIC criterion needs some modification in penalty modeling, e.g. However, in general, a lower optimal value of the threshold δ gives the best clustering performance into shorter duration broadcasts. For the three datasets, the smallest loudspeaker matching error is achieved when the value of δ is between 1.0 and 1.5.
Conclusions on the robustness experiments
Similar diarization progress is achieved in the ESTER development data with δ set to 1.5 (c.f. Table 4.8).
Conclusions
- Audio input conditions
- Speaker turn duration analysis
- Total speech time per speaker analysis
- Speaker count analysis
For that reason, the speaker's turn duration is examined on broadcast news and meeting datasets. The average speaking duration of the conference meetings is much shorter (only 5.6 seconds) than for the broadcast news and lectures. The duration of the speaker varies greatly across the various excerpts in the broadcast news and lecture domains.
Modifications to BN diarization system for meetings
Log-likelihood ratio (LLR) based SAD
In the field of meetings, there are a small number of speakers in both conference meetings and lecture meetings. This detector calculates the LLR between speech patterns and non-speech patterns for each audio frame and replaced the Viterbi decoding with a simple LLR smoothing followed by a decision module. Speech and non-speech GMMs were trained on approximately 2 hours of far-field data from UKA workshops recorded in 2003, which were used as test data in the CHIL 2004 evaluation.
Applying voicing factor to SAD
In this way, the energy normalization focuses primarily on the voiced frames and can be more robust to different SNR configurations. This method can be sensitive to music, but is not expected to be a problem in the context of conferences and lectures.
RT-06S experimental results on lectures
- Performance measures and databases description
- Audio input selection
- Results with different SAD on RT-06S development data
- Models with different number of Gaussians in LLR-based SAD
- Varied prior probabilities for S/NS models in LLR-based SAD
- RT-06S MDM lecture development results
- RT-06S evaluation results
The "slr-mt" system uses the smooth LLR-based SAD method with a prior probability of 0.2 for the non-speech model and 0.8 for the speech model. These results are obtained with a prior probability of 0.4 for the non-speech model and 0.6 for the speech model. The effect of the prior probabilities for the speech and non-speech models used in LLR-based SAD was also studied.

RT-07S experimental results on conferences and lectures
- Database description
- LLR-based SAD with different acoustic features
- SID clustering with UBMs trained on different acoustic features
- RT-07S evaluation results
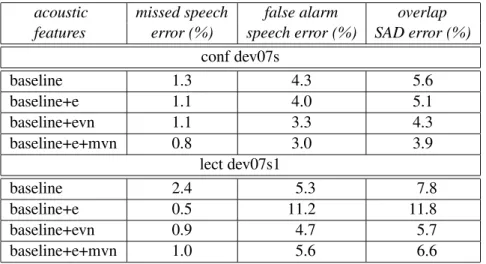
The ICSI diarization system gave the best performance on the reading MDM test data (i.e., an overlap DER of 13.7%). This baseline feature set provides an overlap DER of 36.2% on the conference development data and 17.5% on the lecture development data. The diarization system uses the same SAD acoustic models and UBM trained on the “baseline+e+mvn” and the “12plp+∆+∆logE+w” feature sets for both the conference and the lecture evaluation data, respectively.
Conclusions
The mismatch between the conference training data and the lecture trial data results in a relatively larger SAD error in the lecture development data. The adapted diarization system provides similar diarization results on the beamformed MDM signals for both the RT-07S conference data and the lecture evaluation data (ie, DER overlap of 26.1% for the conference dataset and 25.8% for the lecture dataset). The DER rate increases to 29.5% for the SDM conference data, while for the SDM lecture data the error rate remains very close to that obtained for the MDM shaped beam condition.
Introduction
Performance is assessed by the equal error rate (EER) of the frame-level overlapping speech detection. This chapter aims to address overlapping speech detection in a two-speaker conversation with an a priori knowledge of the two speaker voices in isolation. Performance was assessed using the equal error rate (EER) of the frame-level overlapping speech detection.
LLR-based overlapping speech detection
Using Mel frequency cepstral parameters
The proposed LLR-based overlapping speech detection technique is first performed with the Mel-frequency cepstral parameters used in a standard transcription system [Gauvain et al., 2003]. The MFCCs are extracted from the signal every 10ms using a 30ms window on a 0-3800Hz band and the 39-dimensional feature vector consists of 12 cepstral coefficients, ∆ and ∆∆coefficients plus the energy with ∆en ∆∆log energy. It is similar to the feature set used in the baseline diarization system for broadcast news 4.1, except for the energy and extraction of different passbands.
Using autocorrelation features
Rk will show values close to 1 in the audio frequency range, and the distribution of coefficients should thus be related to the height characteristics of the loudspeaker. In the case of superimposed speech, the maximum of the autocorrelation function for the superimposed signal reflects a distribution that simultaneously characterizes the height of both loudspeakers. The default settings of the calculation of autocorrelation features are given as follows: the autocorrelation coefficients are calculated in a 40ms analysis window at a 10ms frame shift, with Fmin = 75Hz, Fmax = 600Hz and K = 16.
Combining LLRs based on MFCC and autocorrelation features
These features are further processed in exactly the same way as the MFCC features for GMM training, including the ∆and∆∆dynamic plus energy and ∆ and ∆∆log-energy features, except that mean and variance normalization is not performed.
Experimental results
- Sampling of the autocorrelation features
- Autocorrelation window size
- DET curves for different feature sets
- EER obtained on different gender combinations
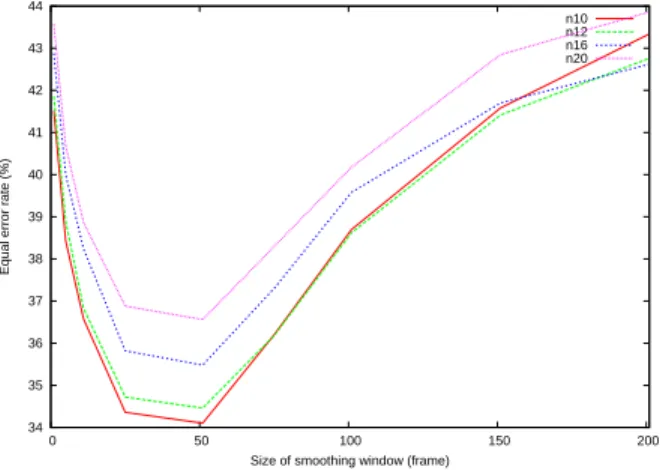
The autocorrelation features with different scaling numbers of the output coefficients (i.e. using different values of K) are investigated within the proposed overlapping speech detection scheme. It is shown that the detection error decreases as the number of output autocorrelation features is reduced. The lowest EER of 34% is obtained using 10 output autocorrelation features with the smoothing window size set to 50 frames (i.e., 0.5 seconds).
Conclusions
Zhu, "The LIMSI 2006 TC-STAR Transcription Systems", I Proceedings of 2007 International Conference on Acoustics Speech and Signal Processing (IEEE, ICASSP'03), Honolulu,. I Proceedings of International Conference on Acoustics Speech and Signal Processing (IEEE, ICASSP 2006), sider Toulouse, Frankrig, maj 2006. In Proceedings of International Conference on Acoustics Speech and Signal Processing (IEEE, ICASSP 2003), HongKong, april 2003.
An illustration of the general architecture of speaker diarization systems
Block diagram of a general front-end parameterization processor
Schematic representation of MFCC parameterization
Schematic representation of LPCC parameterization
Warping of the source feature distribution to a target distribution (after Pelecanos,
Example of the MAP adaptation from a UBM given the training data from a
An example of 3-state ergodic HMM
Illustration of Viterbi decoder with a 3-classes HMM topology, where the con-
Illustration of a metric-based speaker change detector using two adjacent sliding
Example of the sequential clustering approaches
Example of the hierarchical clustering techniques
Illustration of the overall speaker diarization error rate (DER) used in the NIST
Block diagram of the baseline audio partitioning system
Block diagram of the multi-stage speaker diarization system for Broadcast News. 76
Speech time per speaker in each show of the RT-04F dev1 and dev2 datasets
The databases used in the RT-04F evaluation
The purity, coverage and overall diarization error rates from the c-std, c-bic and
Per-show and total diarization results on two RT-04f development databases from
Diarization error rates of performing feature warping at different clustering stages
Results of different iteration counts for the MAP adaptation in the SID clustering
Performances of c-bic, c-sid and p-asr systems on the RT-04F evaluation data
The databases used in the ESTER evaluation
The purity, coverage and overall diarization error rates from the c-std, c-bic and
Performances of c-bic and c-sid systems on the ESTER evaluation data
Speaker match error (SPE) obtained on the datasets 1hour, first30min and sec-
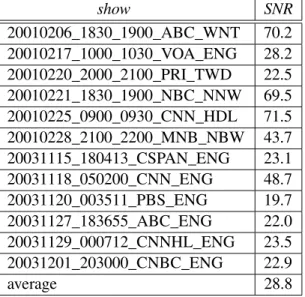
SNR estimations on the RT-04F broadcast news development dataset
SNR estimations on the RT-06S conference development dataset
SNR estimations on the RT-06S lecture development dataset
Average speaker turn duration in the broadcast news and conference and lecture