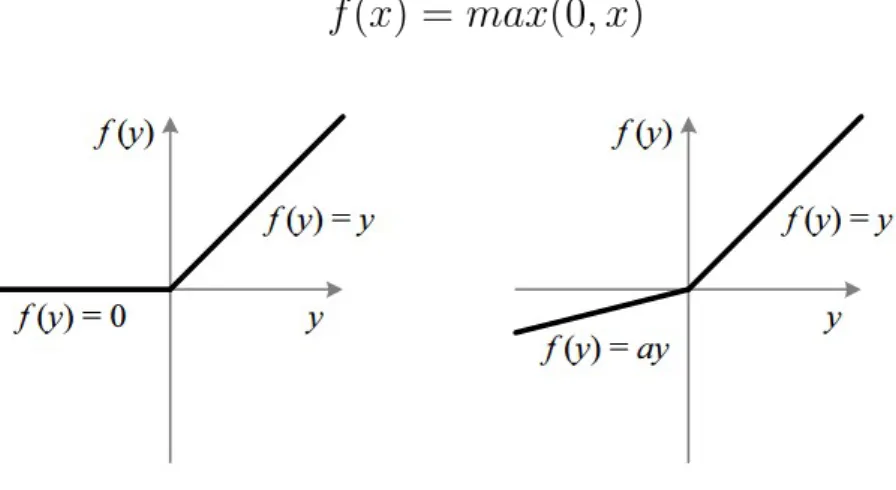Access counts across all scheduling periods Page 2 Page 3 Page 4 Page 5 Page 6 Page 7 Page 8 Page 9 Page 10 DRAM to NVM Number of components Memory component's access delays Configuration for performance estimation. Figure 9: DRAM hit rate for kleio and our scheduler, normalized between 0% for History and 100% for Oracle Page Scheduler, RNNs for 100 pages and 1:8 DRAM to NVM ratio.
Introduction
Thesis Topic
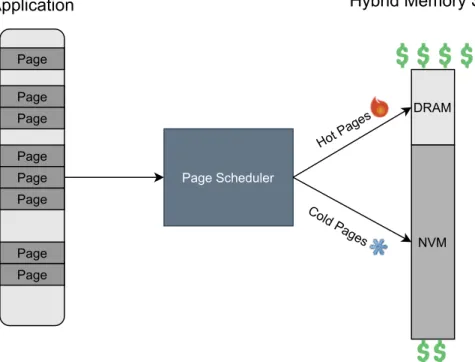
In our case, we are mainly interested in designing an efficient page scheduler in one HMS scenario. The usage of the page scheduler module we are trying to build is shown in Figure 1.1.
Motivation
A well-designed page scheduler ensures that frequently accessed pages (hot pages) are available on our system's high-performance memory modules (DRAM), while the least important pages, those accessed infrequently (cold pages), remain on slower persistent memory. Specifically, a state-of-the-art system-level dynamic page management solution for heterogeneous storage systems uses immediately observable behavior to make decisions about the best future page placement.
Approach and Contributions
The Page Planner approach will combine both the advanced history-based policy and Machine Intelligence, implemented using RNNs and more specifically LSTMs. We will evaluate our Page-Scheduler against the current state-of-the-art implementations found in modern hybrid memory systems.
Thesis Overview
We will soon identify recurrent neural networks as an effective and practical technique for the page scheduling problem, as it is also documented in the articles [8, 9]. We will attempt to quantify the performance improvements achieved using a range of workloads from popular suites such as Rodinia 3.1 [16] and PARSEC [17].
Related Work
Hardware Solutions
Software Solutions
To conclude, operating system level solutions rely on page access information available on the kernel page tables. Most system-level solutions leverage existing NUMA-based page migration support or extend the NUMA-based data balancing policy.
Machine Learning Solutions
It is a user-extensible heap manager that can be used by middleware solutions to improve the performance of systems with heterogeneous memory components. Finally, this thesis is heavily influenced by Kleio [9], who pioneered the idea of using machine learning to improve resource management in hybrid memory systems.
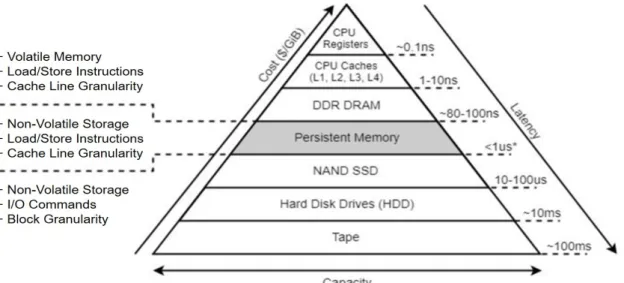
Persistent Memory & Memory Management
Persistent Memory
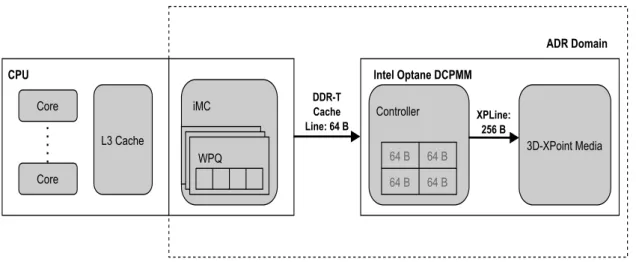
The first scalable commercially available non-volatile memory hardware is Intel Optane DC Persistent Memory Module, which is based on the aforementioned 3D XPoint technology. Before DCPMM became commercially available, researchers used emulation to validate and test their non-volatile memory applications. In direct application mode, the DCPMM is directly exposed as non-volatile memory device separated from DRAM.
Programs can now use the non-volatile memory either as an accelerated block device (Storage over App Direct Mode) or access it directly using CPU instructions on memory-mapped files (App Direct Mode).
Page Migration
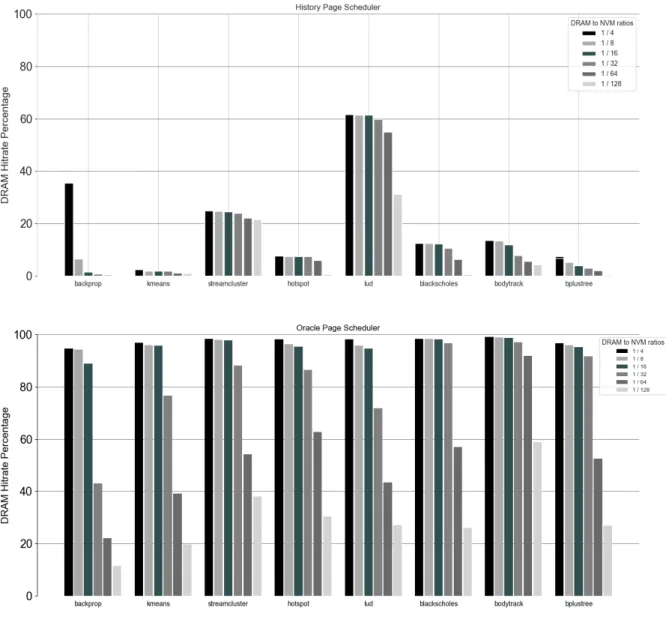
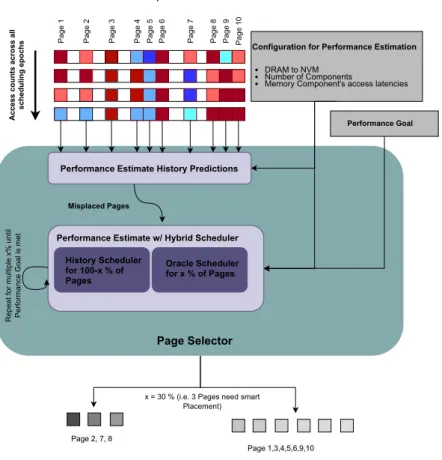
The history page scheduler would periodically move pages, probably using the move_pages()2 system call, so that the ones that are hot in the current scheduling period/interval are allocated to DRAM until there is capacity. 1A page fault occurs when a program tries to access a block of memory that is not stored in physical memory or RAM. We compare the historical page scheduler implementation with the Oracle page scheduler, which uses advance knowledge to periodically migrate application pages so that those that are really highly available are placed in DRAM in the next scheduling epoch until capacity is full (Figure 3.4). .
We observe that there is a significant gap in the achieved versus the achievable application performance.
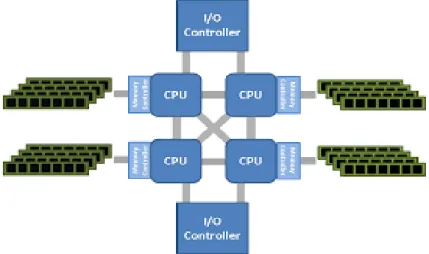
Page Migration Challenges
There are a few design possibilities when it comes to extending the current latest history page scheduler. Many researchers prefer this approach because of the support of the development community and the high versatility that instrumentation offers. However, the consistency of the results this technique provides and the absence of real hardware support are certainly the main contributors to binary instrumentation's popularity.
Core functionalities of the Page Scheduler we aim to construct are the page movement/migration across different memory components.
Machine Learning & Deep Neural Networks
Machine Learning Background
In most cases, the effectiveness of the result is directly linked to the reward system. Therefore, it affects every aspect of the model, ranging from the computational efficiency of training to the network's ability to converge and make accurate predictions. In this way, the learning time is reduced, significantly improving the efficiency of the network.
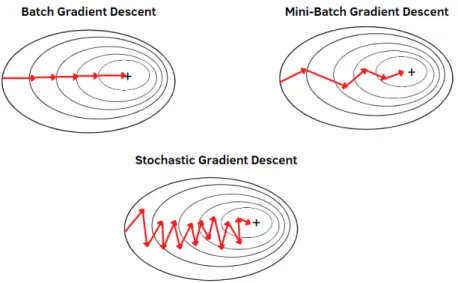
In most cases, modified versions of the gradient descent algorithm are used, which differ in the amount of data they use.
Page Scheduling as a Machine-Learning problem
In the context of a page scheduler, these data points can be the sequence of pages accessed during an application execution time interval. A page scheduler can deploy an RNN to learn the page access pattern and make predictions about future page accesses. Using these predictions, the page scheduler can now separate pages based on their hotness (frequency of access).
We will elaborate on the layout and the selected hyperparameters of the network we constructed and evaluated in the chapters that follow.
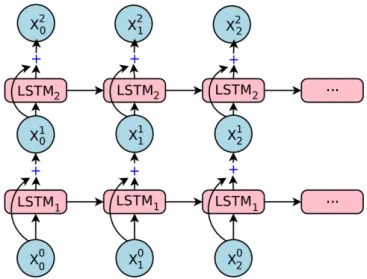
Neural Network Input
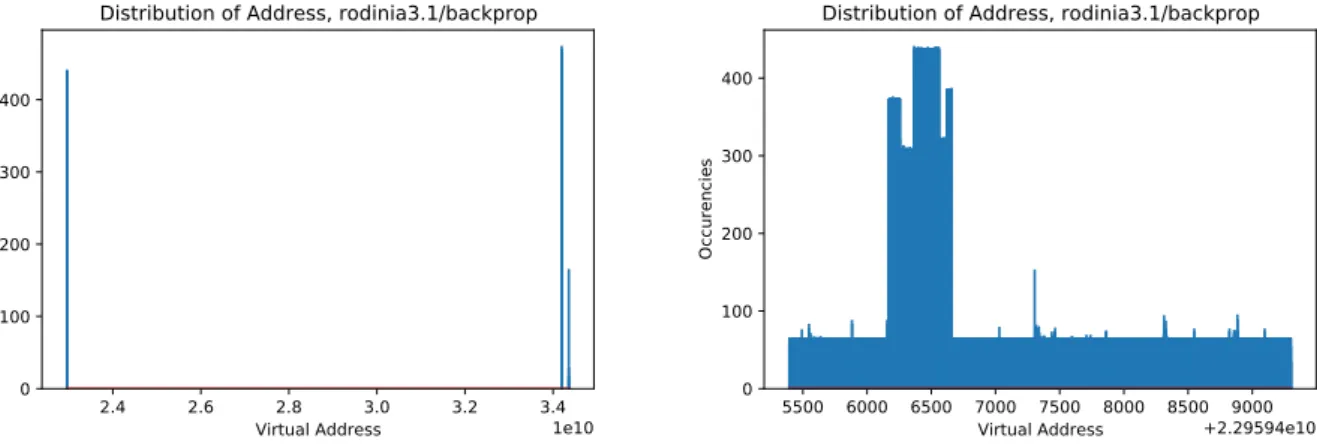
4.9: If normalization is done over the entire address space with a 32-bit float, there will actually be only three values. Due to floating point resolution, this information is lost when normalization occurs across the address space. Model Inaccurate When Using K-means Clustering: To combat the inaccuracy caused by the standardization of addresses, a common practice, as presented in [8], is to reduce the output value space by discretizing it into frequently occurring values (classes) and training different RNNs in clusters of the address space covered by the application.
Moreover, this is the reason why clustering techniques of the address space in memory regions were implemented by Hashemi et al.
Proposed Page Scheduler Architecture
Critical Metrics
In Figure 5.1 we can observe the relationship between the percentage of pages located across memory components using Machine Intelligence and the obtained performance speed compared to using only the most recent (history-based) approach. For example, in terms of the backprop application (rodinia suite 3.1), we can bridge the performance gap of history-based scheduler and oracle by 60%, handling only 20% of the pages in an intelligent way. There is certainly a need to explore how the frequency of Page Scheduling will affect performance.
However, choosing a truly high migration rate to achieve a high DRAM hit rate is practically impossible, due to the fact that the frequent page scheduler inference and the sheer amount of page movement between memory components would likely kill performance. boost obtained from the high DRAM hit rate.
Page Scheduler Overview
The scheduler used in this example is the naive history-based scheduler, which only takes information from the current period and makes predictions about page visits for the next period. To understand in detail how the page scheduler works, simply look at Figure 5.3. Therefore, the page selector will choose Page 4 as one of the pages that need special attention.
In this particular scenario, shown in Figure 5.3, we can see that the page selector has decided that four of the pages require special attention and the other six do not.
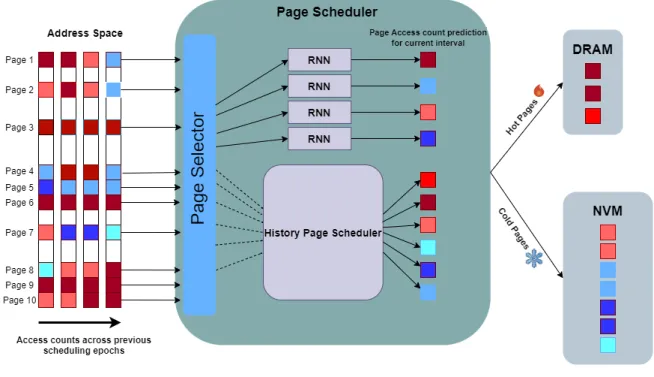
Page Scheduler Components
This approach involves the explicit separation of the pages into two subsets according to their effect on performance. Important components of the Page Scheduler we want to construct are Access Count Predictors. We will use a clustering technique of the address space in memory areas similar to Hashemi et al. [8].
For example, based on Figure 4.10, after observing the global distribution of reference addresses supported by rodinia 3.1, the address space will have three address groups.
Technical Implementation
Benchmark workloads
Bplustree (rodinia 3.1) belongs to the domain of Graph Theory: BPlustree is an application that traverses B+trees. Blackscholes (PARSEC) belongs to the domain of Finance: The blackscholes application is an Intel RMS benchmark. Stream Cluster (PARSEC) belongs to the domain of Data Mining: Developed by Princeton University, this RMS kernel solves the online clustering problem: for a stream of input points, it finds a predetermined number of medians, such that each point is assigned to its nearest center.
Stream clustering is a common operation that requires organizing large volumes or continuously produced data under real-time conditions, such as network intrusion detection, pattern recognition, and data mining.
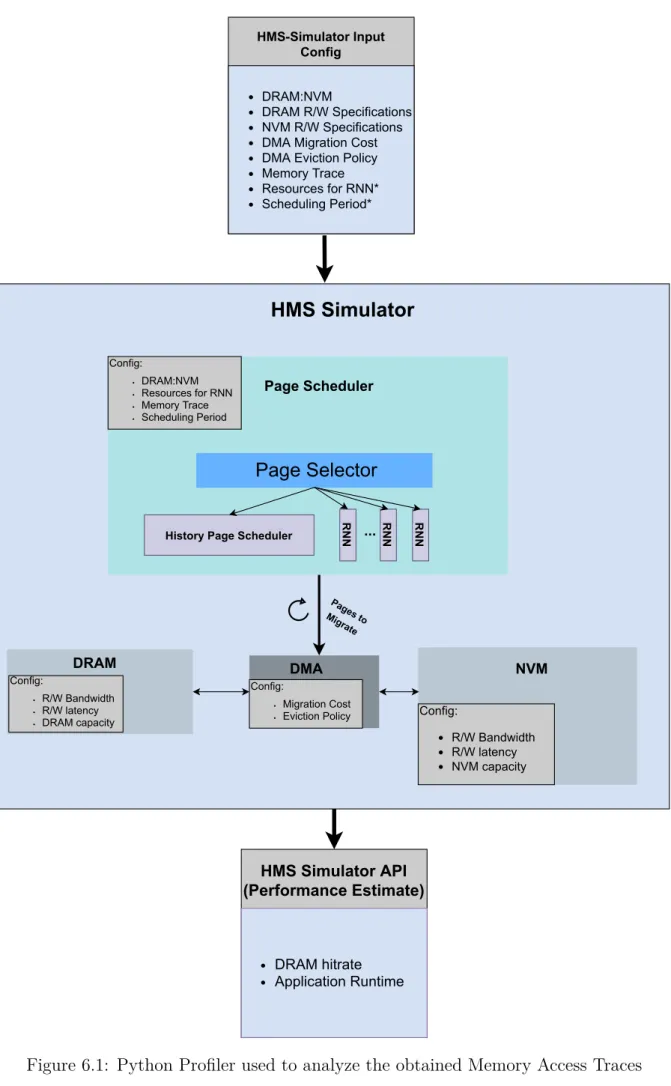
Collecting Memory Access Traces
Hybrid Memory System Simulator
Recurrent Neural Networks Details
As for the RNN input, we need to use as much information as possible to achieve high prediction accuracy. A really important parameter of the neural network was the choice of loss function. In this chapter, we perform a trial evaluation of the page scheduler to evaluate its performance.
Therefore, in this chapter we will not only evaluate the actual performance improvements that our Page Scheduler offers, but also the prediction accuracy of RNNs per page.
RNN Prediction Accuracy
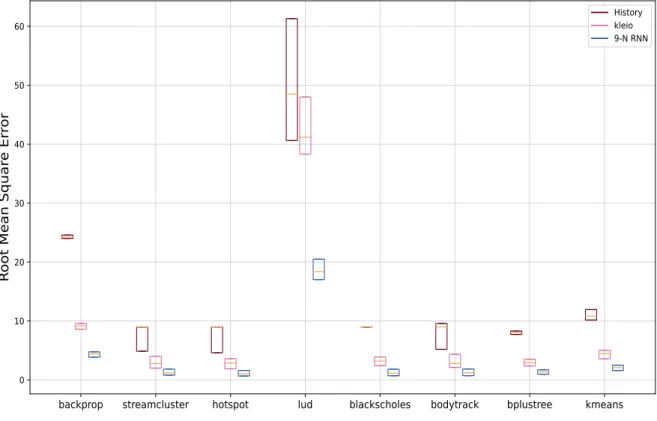
We show how close to the Oracle Page Scheduler (i.e. upper limit of performance) our Page Scheduler can perform. We treat the decisions of the History Page scheduler as predictions and plot the corresponding mean squared error. Clearly, the History Page Scheduler predicts that a page in the next epoch will receive the same access.
After observing Figure 7.1, we understand that our proposed implementation of RNN model which is thoroughly described in section 6 leads to better page access count predictions compared to the naive history-based page scheduler and the scheduler proposed by [9].
Application Performance
Apart from the history page scheduler, we compare our implementation with the one proposed by [9], as described in the paper. After following as closely as possible the implementation described in the paper, we deploy neural networks for the same 100 pages in which we deployed RNNs and evaluate the prediction accuracy achieved by those models. In some cases, the performance speed achieved by Kleio is quite close to that of our page scheduler (hotspot, kmeans, stream cluster, body track).
Overall, we can clearly see that the prediction accuracy of the trained RNNs is such that it can provide an application performance similar to that which would be possible with oracular knowledge of the number of page hits.
Eviction Policy
Energy Consumption
Conclusions
Thesis Summary
Future Work
Bibliography
Gavrilovska, “Kleio: A Hybrid Memory Page Scheduler with Machine Intelligence,” in Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing, Ser. Awad, “Page migration support for segmented non-volatile memories,” in Proceedings of the International Symposium on Memory Systems, Ser. Litz, “Qos Ssd Improvements Through Machine Learning,” in Proceedings of the ACM Symposium on Cloud Computing, ser.
Liu, "Memif: Towards programmering heterogeneous memory asynchronously," in Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages en.