1 { cálculo do consumo médio de um veículo, tendo em conta a distância total e os 2 valores dos litros consumidos em cada abastecimento efectuado } 3. 1 { esta é a descrição de um algoritmo; ele relata sua finalidade, que, neste caso, 2 é apenas ilustrar esta documentação em si e também as 3 regras de organização visual para algoritmos.

Considerações finais
Ressalte-se que quando há continuação na segunda linha, a organização visual não fica prejudicada, mantendo-se as tabelas necessárias. Se forem necessários mais de alguns segundos para saber se o comando usa mais de uma linha ou onde está o delimitador final de um comando, então a organização visual não é boa.
Conceitos básicos para o desenvolvimento de algoritmos
- Primeiras palavras
- Por que dados têm tipos
- Representação das informações e processamento dos algoritmos
- Tipos abstratos de dados
- Modelo de computador
- Formalização da notação de algoritmos
- Entrada, saída e atribuição
- Regras para a formação de identificadores
- Considerações finais
Assim, o mundo externo é tudo o que não pertence ao computador, e o mundo interno é o que está armazenado na memória e o que é manipulado pela unidade de processamento. Até agora, sabe-se que toda a execução de um algoritmo é de responsabilidade da unidade de processamento e que o algoritmo é armazenado na memória.

Expressões algorítmicas
- Primeiras palavras
- Matemática e precisão da notação
- Expressões em algoritmos
- Linearidade das expressões, operadores e precedência
- Expressões aritméticas
- Expressões literais
- Expressões relacionais
- Expressões lógicas
- Ordem global de precedências de operadores
- Uso de parênteses nas expressões
- Organização visual nas expressões
- Considerações finais
Expressões usadas em outros lugares também podem ser observadas, principalmente quando se usa parênteses. Todas as expressões devem usar espaços entre operadores e operandos para tornar a expressão mais clara.

Estratégia de desenvolvimento de algoritmos
- Primeiras palavras
- Organização para resolver problemas
- Estratégia de abordagem para desenvolvimento de algoritmos
- Abordagem top-down
- Abordagem do problema
- Resolução de problemas por refinamentos sucessivos
- Considerações finais
O termo, que poderia ser traduzido como abordagem top-down, pode ser entendido como uma abordagem que vai do mais geral ao mais específico. Na forma de algoritmo não projetado para implementação em computador, a solução para o problema de arrumação pode ser vista no Algoritmo 4-1. Uma vez que a solução global esteja em vigor, que deve ser completa e consistente, mais detalhes podem ser especificados e alguns comandos do algoritmo podem ser reescritos.
Claro que o detalhe pode ser refinado conforme a necessidade até ficar totalmente compreensível para quem vai executá-lo (mesmo que esse “alguém” seja um computador capaz de comandar um robô com visão e bom gosto, e capaz de dobrar roupas sem engordurar neles). Por exemplo, um livro didático pode ser consultado ou um especialista (ou amigo) pode ser consultado. Finalmente, o algoritmo pode ser avaliado se pode ser melhorado, verificando se não há mais problemas com os cálculos e os resultados produzidos.
Também pode ser visto que nas linhas 14 e 15 foi decidido não aplicar refinamentos por considerar desnecessários. Para criar um algoritmo, a fase de escrita é apenas a terceira etapa; antes disso, é preciso entender o problema e saber resolvê-lo (não algoritmicamente);

Comandos condicionais
- Primeiras palavras
- Situações de decisão
- Alteração condicional do fluxo de execução
- Condicionais simples e completos
- Aninhamento de comandos
- Comandos de seleção múltipla
- Testes de mesa
- Considerações finais
A instrução condicional completa está escrita no formato abaixo, especificando uma condição lógica e dois grupos de instruções. A lógica de execução do comando é simples: a expressão lógica é avaliada e seu resultado calculado; se true, apenas o primeiro conjunto de comandos (especificado em then) é executado; se o resultado for falso, apenas o segundo conjunto de comandos (especificado por else) será executado. A delimitação dos conjuntos de atribuição é feita de então para else para a parte "if true" e de else até o final if para a parte "if false".
Os mesmos princípios de execução válidos para o algoritmo são obedecidos para o conjunto de comandos subordinados, como execução sequencial e execução de um comando somente após a conclusão do anterior. O conjunto de comandos "internos" a um se pode incluir qualquer tipo de comando, como comandos, leituras ou outros comandos condicionais. Uma forma alternativa de realizar a verificação é utilizar o comando de seleção múltipla, também conhecido como case.
Se houver correspondência, o conjunto de comandos especificado será executado; caso contrário, os comandos são ignorados. Portanto, o valor da variável será comparado a cada elemento da lista de seleção (cada linha é um elemento).
Comandos de repetição
- Primeiras palavras
- Por que fazer de novo?
- Fluxo de execução com repetição
- Condições de execução de repetição: estado anterior, critério de término, estado posterior
- Aplicações práticas de repetições
- Considerações finais
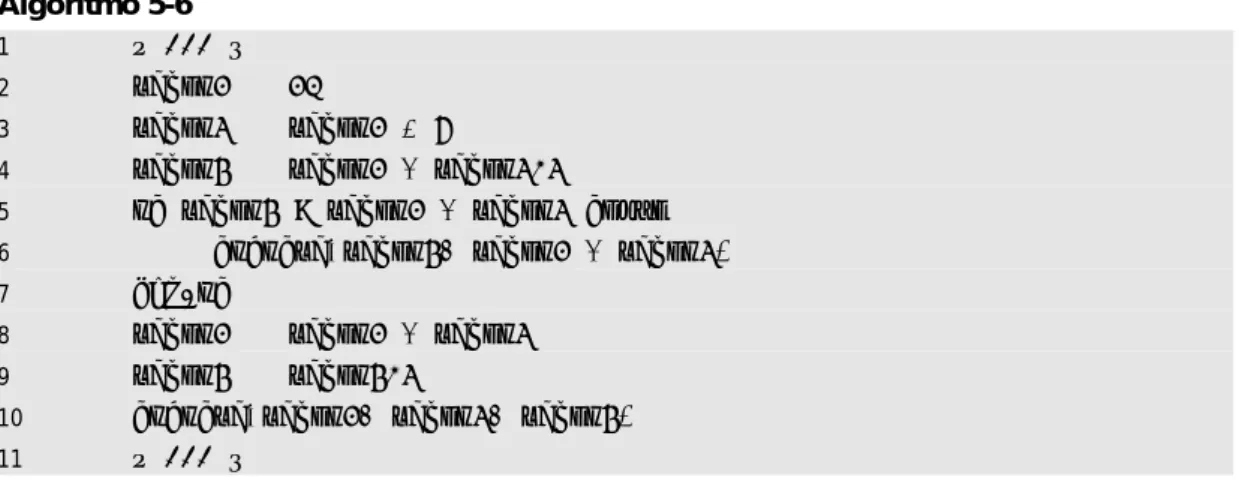
Em seguida, o conjunto especificado de comandos é executado uma vez, desde que o valor da variável de controle seja válido e utilizável. Pode-se notar que em todos os casos o comando para a variável de controle (valor, em todos os exemplos) termina com um valor igual. Uma saudação simples para cada nome é escrita na tela, a menos que o nome digitado seja "end", que encerra o loop e o algoritmo termina com a mensagem final de adeus (linha 19).
A Figura 6-2(a) mostra a execução do algoritmo quando os nomes Otávio, Pedro e Adalberto são escritos, seguidos de "fim" para finalizar. Outro exemplo também é apresentado na Figura 6-2(b), que mostra o comportamento do algoritmo quando "end" é a primeira (e única) entrada do algoritmo. Como "Adalberto" é diferente de "end", uma terceira iteração é realizada com uma mensagem para Adalberto e a leitura do valor de "end".
Para outros comandos, é preciso ter mais cuidado, pois não há variável de controle. A primeira é que, se for digitado "end" na primeira informação para nome (e qualquer valor para preço e tipo), o valor BigPrice chega ao final inalterado, o que informa que não houve entrada e, portanto, não há entrada.

Ponteiros
- Primeiras palavras
- Uma questão de organização
- Ponteiros e endereços na memória
- Memória e endereçamento
- Acesso à memória com ponteiros
- Considerações finais
Uma variável de tipo inteiro armazena valores inteiros, variáveis reais armazenam valores reais, literais armazenam textos e variáveis de tipo lógico armazenam verdadeiro ou falso. 1 { dadas duas variáveis, uma inteira e uma literal, escreva os 2 endereços de memória onde elas estão armazenadas. 16 write("A variável real está no endereço:", realAddress) 17 write("A variável literal está no endereço:", literalAddress) 18 algoritmo end.
Também é bom saber que se uma variável precisa de muitas unidades de memória (o que obviamente é verdade para variáveis literais), o operador & retorna o endereço da primeira unidade, ou seja, o "início" da área de memória. Variáveis do tipo ponteiro são variáveis como qualquer outra que possuem um identificador, ocupam sua própria parte da memória e também possuem seu próprio endereço. Como uma variável de ponteiro contém o endereço de outra variável, diz-se que ela "aponta para uma variável".
Uma maneira de pensar sobre essa terminologia um tanto confusa é lembrar que os termos "ponto" e "endereço" têm significados semelhantes nesse contexto. Assim como uma variável tem seu tipo para saber o que está armazenado na área de memória reservada para ela, o ponteiro também deve conhecer esse tipo para armazenar os dados de forma coerente.
Estruturas compostas heterogêneas
Primeiras palavras
Preenchendo fichas
Conceito de estruturas compostas de dados
- Declaração e uso de registros
Por exemplo, enquanto a variável point1 especifica o registro inteiro, point1.x especifica apenas o campo x da variável point1, que tem o tipo real. Nesse caso, o uso de log não é obrigatório, pois poderiam ter sido utilizadas variáveis separadas para cada coordenada de cada ponto, utilizando seis valores reais (x1, y1, z1, x2, y2 e z2, por exemplo). Para ilustrar, propõe-se um problema semelhante ao anterior: "Sabendo que existe um conjunto de pontos e que também é conhecido o número de elementos, determine qual deles está mais próximo da origem".
1 { determina, em R3, qual de um conjunto de pontos está mais próximo 2 da origem, dado o número de elementos do conjunto. A parte ruim é que, para leituras e gravações, apenas as especificações campo a campo da variável composta são válidas. Em particular, o uso de registros como campos de outro registro pode ser indicado no terceiro exemplo, como o uso de tTransaction e tDate.
O acesso aos campos internos também é feito com o operador ., como por exemplo operation.transactionPrincipal.value, sendo a operação uma variável declarada do tipo tOperaçãoBankária. Não custa lembrar que operation.transactionMain é um registro do tipo tTransaction e pode, portanto, ser atribuído diretamente a outra variável ou campo do mesmo tipo.

Considerações finais
Sub-rotinas
- Primeiras palavras
- Separando para organizar
- Conceituação de sub-rotinas e fluxo de execução
- Procedimentos
- Parâmetros formais
- Regras de escopo de declarações
- Funções
- Considerações finais
Em algoritmos, uma sub-rotina é um conjunto completo de instruções com uma função bem definida no contexto do algoritmo. 18 resultado.numerador Å número1.numerador * número2.denominador + 19 número1.denominador * número2.numerador 20 resultado.denominador Å número1.denominador * número2.denominador 21. 35 resultado.numerador Å número1.numerador * número2.denominador + 36 número1 .denominador * número2.numerador 37 resultado.denominador Å número1.denominador * número2.denominador 38 simplificarRacional(resultado).
Também é conveniente considerar uma sub-rotina como uma solução geral para um problema específico (como a simplificação de números racionais). Por fim, o conjunto de comandos corresponde à lista de comandos que devem ser executados para completar o objetivo da sub-rotina. A declaração da lista de parâmetros é feita, conforme visto, entre parênteses após o identificador da sub-rotina.
Os parâmetros formais das sub-rotinas obedecem à mesma regra de escopo das declarações locais da sub-rotina. Esta seção fornece uma maneira de escrever uma sub-rotina que pode ser usada como uma nova função.

Estruturas compostas homogêneas
- Primeiras palavras
- Lembrar é, muitas vezes, importante
- Estruturação dos dados
- Declaração e uso de arranjos unidimensionais
- Aplicações práticas de arranjos unidimensionais
- Declaração e uso de arranjos bidimensionais
- Aplicações práticas de arranjos bidimensionais
- Arranjos multidimensionais
- Considerações finais
- Estruturas compostas mistas
Assim, um grupo é uma única variável, que é formada por um grupo homogêneo (ou seja, do mesmo tipo) de valores. Para declarar um array unidimensional em um algoritmo, basta utilizar um indicador do número de elementos que a variável composta irá armazenar, o que é feito por um valor inteiro entre colchetes posicionado imediatamente após o identificador. Como as posições de um array são independentes, a linha 20, ao utilizar índices diferentes, revisa cada valor lido separadamente, comparando-o com a média calculada.
Assim, a solução pode criar um array de 150 posições para nomes e para médias, mas apenas o número necessário de posições é utilizado (correspondente ao número de alunos da turma). Esse registro contém um inteiro para armazenar a quantidade de elementos do conjunto (de zero a 50, neste caso) e um array de valores reais que armazenam os próprios valores. Para que a união seja realizada, é feita a cópia de um dos conjuntos e a esta cópia são adicionados um a um os elementos do segundo conjunto.
Uso de uma matriz como repositório de elementos, incluindo um procedimento para adicionar um novo elemento. Uma matriz é um arranjo bidimensional (linhas e colunas) de elementos, todos do mesmo tipo.

- Primeiras palavras
- Listas mais sofisticadas
- Declaração e uso de arranjos de registros
- Considerações finais
21 read(wine.name, wine.productername, wine.distributorname, 22 wine.type, wine.harvest year, wine.potyear, . 23 wine.price, wine.units) 24 end procedure. 29 write(vinho.nome, vinho.nomedoprodutor, vinho.nomedodistribuidor, 30 vinho.tipo, vinho.ano da colheita, vinho.potyear, . 31 vinho.preço, vinho.unidades) 32 procedimento final. Para esta solução, você pode visualizar a disposição dos registros como uma tabela, onde cada linha é uma posição na disposição, e organizar os campos como colunas.
Aqui, um cuidado especial deve ser tomado para distinguir o parâmetro wine (do tipo tWine), que faz parte do procedimento readVinho para a variável wine, da parte principal do algoritmo, que é um array de 300 posições do tipo tListWines; o escopo é diferente. Pode-se ressaltar também que na parte principal do algoritmo será válido escrever vin[i].name, pois vin[i] é um registro e name é um de seus campos. No primeiro caso, wine é um array de entradas, wine[i] é a entrada no índice i e finalmente wine[i].name é o literal contido neste campo para a posição i no array.
Na segunda especificação, wine.name[i], wine deve ser uma entrada para a qual um dos campos é name, onde name é um arranjo no qual a posição i é selecionada. Portanto, nesta segunda situação, existe um array no registrador e não um array de registradores, como discutido nesta unidade.








