Agradeço a minha mãe Cleunice, minha avó Valentina e meu avô Euclydes por cuidarem de mim com tanto amor todos esses anos. Agradeço também aos meus tios José Carlos, Paulo César e Antônio e minhas tias Bete, Renata e Charlene, pelos grandes valores que aprendi, que levarei por toda a minha vida. Por fim, gostaria de agradecer aos amigos de Rio Preto, da graduação e do GSPD, e ao Povo de Sempre, de Andradina.
Motiva¸ c˜ ao
Objetivo
Organiza¸ c˜ ao do texto
Este capítulo tem como objetivo apresentar os conceitos sobre sistemas distribuídos e sistemas de arquivos distribuídos necessários para o entendimento deste trabalho. Posteriormente, o foco mantém-se no estudo dos vários sistemas de ficheiros distribuídos existentes, descrevendo-os brevemente e obtendo informação sobre como lidar com algumas questões específicas, como a sincronização, consistência e detecção. Tais informações serviram de base para a implantação de componentes no sistema de arquivos distribuído FlexA.
Sistemas distribu´ıdos
Sistemas de arquivos distribu´ıdos
Isso pode ser feito usando um tipo especial de replicação: caches. Replicação ativa: O sistema informa a cada réplica, enviando parâmetros, quais operações realizar na presença de uma atualização de dados. Um desafio para a detecção de falhas é distinguir se elas são causadas por defeitos nos nós da rede ou na própria rede.
Exemplos de SADs
Se na verificação do token, ao abrir o arquivo, informar que a versão está desatualizada, o cliente solicita uma atualização de seu arquivo (PATE, 2003; COULOURIS et al., 2011). O iniciador é o nó mestre, onde são mantidas as informações de conexão de todos os nós de armazenamento. Sua arquitetura é baseada em clusters de servidores que possuem hardware de baixo custo e, dada essa característica, o monitoramento de erros, a detecção de erros e a recuperação automática do sistema devem ser constantes ((MCKUSICK; QUINLAN, 2010)).
É ele quem armazena os metadados: a identificação (namespaces) de arquivos e peças, o mapeamento de arquivos para peças e a localização de réplicas de peças. Com base na análise das estimativas de throughput de dados nos sistemas do Google, o GFS precisava aumentar ainda mais sua escalabilidade. Além disso, devido à limitação de um servidor master lidando com todas as solicitações, o novo GFS possui servidores de metadados.
Ao enviar, o cliente serializa os arquivos em blocos de 128 megabytes e solicita ao NameNode que localize três DataNodes para armazenar as réplicas. Dentre outras, o NameNode utiliza heartbeats para funções como solicitar replicação de dados para outros servidores, cadastrar novos servidores (SHVACHKO et al., 2010). O Ceph é um DSS que usa agrupamento dinâmico de metadados, replicação de dados e detecção e recuperação de erros para fornecer alta escalabilidade, confiabilidade e desempenho.
Para evitar um desequilíbrio na utilização dos servidores de dados, o Ceph utiliza um algoritmo que distribui aleatoriamente novos dados para o ODS.

Considera¸ c˜ oes finais
A seção 3.1 apresenta as alterações feitas na arquitetura original do FlexA, que permitiram uma nova forma de acessibilidade, o que implicou na necessidade de sincronizar as partes entre o grupo de escrita e as réplicas. Com as réplicas instaladas, a próxima seção discute como lidar com problemas de consistência entre versões de arquivos replicados.
Sincroniza¸ c˜ ao das por¸ c˜ oes entre o grupo de escrita e r´ eplicas
Os servidores primários que receberam os segmentos de arquivo, por sua vez, replicam para 2 servidores secundários por padrão e armazenam os metadados com a localização dos segmentos replicados. Para garantir que todos os servidores primários tenham a localização de todas as porções enviadas aos secundários, os metadados dos arquivos replicados são sincronizados entre os arquivos primários. A primeira fase consiste na eleição de um líder e construção da mensagem contendo os metadados com a localização completa dos trechos replicados.
Após enviar as porções para as réplicas e salvar a localização dos dados replicados, o líder envia os metadados para o primeiro sucessor no anel. Antes de enviar os shards para as réplicas, os servidores primários verificam a localização dos shards replicados e enviam suas novas versões para o mesmo local. . O cliente solicita a um dos servidores primários os metadados com a localização das partes do arquivo solicitado.
O servidor primário consulta seu banco de dados e retorna uma mensagem com a localização das partições armazenadas no primário e nas réplicas. Se o número de servidores primários exceder o número de partes serializadas do arquivo, os servidores que não receberem as partes serão atualizados apenas com os metadados dos arquivos. Quando há mais primários ativos do que a quantidade de shards, os metadados são enviados para os servidores primários que não receberam shards.
A Figura 3.7 mostra a replicação de seções para arquivos menores que 10 MB e a Figura 3.8 para arquivos maiores que 10 MB.

Manuten¸ c˜ ao da consistˆ encia entre as por¸ c˜ oes replica- das
O primário recebe a mensagem e compara a versão da réplica com a de seu banco de dados. O número da versão do arquivo na réplica é menor do que no primário (parte desatualizada). Não há entrada no banco de dados (a peça não existe porque o arquivo foi deletado).
Para peças desatualizadas, o servidor principal envia dados e metadados da versão mais atual para as réplicas. Para peças atualizadas, é enviada uma mensagem que simplesmente confirma que a versão é a mais atual. E, finalmente, para pedaços que não existem mais no primário, o servidor envia uma mensagem para a réplica para deletar os dados e metadados.
Detec¸ c˜ ao de falhas nos servidores prim´ arios e secun- d´ arios
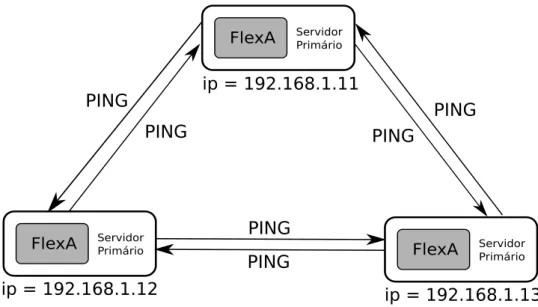
A primeira, após rastrear a rede com o módulo Communicator e preencher a localização dos servidores no arquivo hosts.dat, envia mensagens de ping para a lista de servidores ativos encontrados, conforme Figura 3.9. Cada primário gera uma lista de endereços IP (Internet Protocol) dos nós testados ao executar ping nos servidores listados em hosts.dat. Se o ping do nó atingir o tempo limite (timeout), o campo relacionado ao servidor especificado será substituído por NULL.
No final de cada votação da lista de IPs nohosts.dat, a lista de IPs gerada é comparada com a lista esperada. Quando há falhas e o ping de um determinado servidor atinge o tempo limite, o servidor principal que identificou o problema interrompe o probe e envia uma solicitação de verificação do servidor considerado inativo para os demais servidores. O objetivo desta solicitação é detectar se realmente houve um downtime no servidor principal ou se houve algum problema com a rede à qual ele estava conectado.
O primário ativo que recebeu a solicitação espera um intervalo de tempo de 2 segundos para que o primata inativo tenha a chance de restabelecer sua atividade. Se a queda for confirmada, é chamada uma eleição que escolhe um servidor secundário para se tornar o novo primário.
Considera¸ c˜ oes finais
O objetivo deste capítulo é apresentar os testes para validação das implementações desenvolvidas em FlexA. Inicialmente, serão apresentados os testes de desempenho, que consistiram em coletar e comparar as taxas de transferência nas operações de escrita e leitura da versão desenvolvida do FlexA e outros DSS. Logo após, é apresentado o teste de validação e desempenho para identificação de erros entre as primárias.
Ambiente de testes
Testes de desempenho
Como ferramenta de aquisição de dados, utilizamos scripts de avaliação escritos em Python (PYTHON, 2013) que realizam operações repetidas de leitura e escrita para cada tamanho de arquivo. Ao final de cada sequência de teste, é criado um arquivo contendo a média dos tempos medidos. Esse tipo de ferramental possibilitou focar os testes apenas nas operações de escrita e leitura, o que ajudou a gerar e entender os resultados.
Quando o desvio padrão da iteração atual da sequência menos o desvio padrão da anterior diferia, módulo, em menos de 1% da média, significava que havia convergência para um determinado valor da sequência. As Tabelas 4.1 e 4.2 mostram para quais valores na sequência do teste houve convergência na escrita e na leitura, respectivamente. Os testes foram realizados com 32 clientes fazendo requisições simultâneas, distribuídos entre máquinas virtuais.
Isso provavelmente se deve à sobrecarga dos servidores primários, pois são os únicos que recebem as solicitações. O throughput, medido em megabytes por segundo (MB/s), na escrita e na leitura com 1 cliente no FlexA inicial e evoluído, mostrado nas Figuras 4.2 e 4.3, foi praticamente o mesmo. Com 4, 8 e 16 clientes concorrentes (Figuras 4.6 a 4.11), o desempenho do FlexA e do NFS desenvolvidos é muito semelhante para gravação de arquivos de até 10 MB.
O NFS apresentou bom rendimento ao gravar arquivos de até 10 MB, mas para 25 MB e acima houve uma queda repentina em seu desempenho, possivelmente devido à sobrecarga do único servidor que recebe todas as solicitações.

Desempenho na sincroniza¸ c˜ ao entre servidores prim´ a- rios e secund´ arios
Testes de detec¸ c˜ ao de falhas no processo do m´ odulo Coletor
Testes de detec¸ c˜ ao de falhas por queda em prim´ arios
Considera¸ c˜ oes finais
Este trabalho apresenta uma revisão de sistemas de arquivos distribuídos, com foco em recursos como replicação e sincronização, consistência e detecção de erros. Além disso, ele também apresentou o sistema de arquivos distribuído FlexA com uma lista de seus recursos e funcionalidades.
Considera¸ c˜ oes finais
Problemas encontrados
Dire¸ c˜ oes futuras
Publica¸ c˜ oes
Dissertação (Trabalho de Conclusão de Curso) — Instituto de Biociências, Letras e Ciências Exatas, Universidade Estadual Paulista, São José do Rio Preto, 2011. Para utilizar o sistema é necessário ter instalado o interpretador Python 2.7, pacote netifaces para gerenciamento de rede interface e o pacote pycrypto que fornece um conjunto de algoritmos de criptografia. Em cada parte do sistema, você deve criar o arquivo de configuração com o módulo Communicator usando o comando python com.py -r.
Em seguida, você precisa iniciar o módulo coletor dos servidores primário, secundário e cliente com os comandos python coletor server.py, python coletor replica.pyepython coletor cliente.py, respectivamente. Nos servidores cliente e secundário, o rastreamento é feito com o comando python com.py -b e nos servidores primários epython com.py -bs. Suas requisições podem ser feitas ao módulo cliente FlexA com as opções -p e -g, para escrever e ler arquivos.
Neste apêndice serão apresentadas tabelas e gráficos com os resultados das operações de escrita e leitura do FlexA na versão inicial e desenvolvida, NFS e Tahoe-LAFS.
Testes de desempenho no FlexA inicial
Testes de desempenho no FlexA desenvolvido
Testes de desempenho no NFS
Testes de desempenho no Tahoe-LAFS








