Segmentação Fuzzy de Texturas e Vídeos
Tiago Souza dos Santos
Orientador: Prof. Dr. Bruno Motta de Carvalho
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Sistemas e Computação da UFRN como parte dos re-quisitos para obtenção do título de Mestre em Sistemas e Computação.
Santos, Tiago souza dos.
Segmentação Fuzzy de Texturas e Vídeos 64 p.
Orientador: Bruno Motta de Carvalho
Dissertação (mestrado) - Universidade Federal do Rio Grande do Norte. Cen-tro de Ciências Exatas e da Terra. Programa de Pós-Graduação em Sistemas e Computação.
1. Inteligência computacional - Dissertação. 2. Segmentação Fuzzy de Tex-turas e Vídeos 3. Kullback Leibler Divergence 4. Skew Divergence
Tiago Souza dos Santos
Dissertação de Mestrado aprovada em 17 de Agosto de 2012 pela banca examinadora composta pelos seguintes membros:
Prof. Dr. Bruno Motta de Carvalho (orientador) . . . DIMAp/UFRN
Prof. Dr. Selan Rodrigues dos Santos (interno) . . . DIMAp/UFRN
Agradeço primeiramente a Deus por me dar forças para lutar por mais um objetivo na mi-nha vida. Aos meus pais pelo apoio incondicional. Mimi-nha filha Ana Letícia que revitaliza minhas energias com a sua inocência, carinho e muitas travessuras. Em fim, a toda minha família que sempre acreditou em mim: Fátima, Simone, Cilene, JAQUELINE, Suzana.
Ao Professor Dr. Bruno Motta de Carvalho pela orientação e muita paciência em todos estes anos de pesquisa que trabalhamos juntos. Aos professores e funcionários do DIMAp e PPgSC, que foram peças fundamentais na minha formação.
A segmentação de uma imagem tem como objetivo subdividi-la em partes ou obje-tos constituintes que tenham algum conteúdo semântico relevante. Esta subdivisão pode também ser aplicada a um vídeo, porém, neste, os objetos estão presentes nos diversos quadros que compõem o vídeo. A tarefa de segmentar uma imagem torna-se mais com-plexa quando estas são compostas por objetos que contenham características texturais, com pouca ou nenhuma informação de cor. A segmentação difusa, do Inglês fuzzy, é uma técnica de segmentação por crescimento de regiões que determina para cada elemento da imagem um grau de pertinência (entre zero e um) indicando a confiança de que esse elemento pertença a um determinado objeto ou região existente na imagem, fazendo-se uso de funções de afinidade para obter esses valores de pertinência. Neste trabalho é apresentada uma modificação do algoritmo de segmentação fuzzy proposto por Carvalho [Carvalho et al. 2005], a fim de se obter melhorias na complexidade temporal e espacial. O algoritmo foi adaptado para segmentar vídeos coloridos tratando-os como volumes 3D. Para segmentar os vídeos, foram utilizadas informações provenientes de um modelo de cor convencional ou de um modelo híbrido obtido através de uma metodologia para a escolha dos melhores canais para realizar a segmentação. O algoritmo de segmentação
fuzzy foi aplicado também na segmentação de texturas, fazendo-se uso de funções de
afi-nidades adaptativas às texturas de cada objeto. Dois tipos de funções de afiafi-nidades foram utilizadas, uma utilizando a distribuição normal de probabilidade, ou Gaussiana, e outra utilizando a divergência Skew. Esta última, uma variação da divergência de
Kullback-Leibler, é uma medida da divergência entre duas distribuições de probabilidades. Por
fim, o algoritmo foi testado com alguns vídeos e também com imagens de mosaicos de texturas criadas a partir do álbum de Brodatz e outros.
Área de Concentração: Processamento Gráfico.
Palavras-chave: Segmentação de Imagens, Segmentação de Texturas, Segmentação de
Vídeos, Segmentação Fuzzy, Modelos de Cores, Divergência Skew, Divergência de
The segmentation of an image aims to subdivide it into constituent regions or objects that have some relevant semantic content. This subdivision can also be applied to videos. However, in these cases, the objects appear in various frames that compose the videos. The task of segmenting an image becomes more complex when they are composed of objects that are defined by textural features, where the color information alone is not a good descriptor of the image. Fuzzy Segmentation is a region-growing segmentation algorithm that uses affinity functions in order to assign to each element in an image a grade of membership for each object (between 0 and 1). This work presents a modification of the Fuzzy Segmentation algorithm, for the purpose of improving the temporal and spatial complexity. The algorithm was adapted to segmenting color videos, treating them as 3D volume. In order to perform segmentation in videos, conventional color model or a hybrid model obtained by a method for choosing the best channels were used. The Fuzzy Segmentation algorithm was also applied to texture segmentation by using adaptive affinity functions defined for each object texture. Two types of affinity functions were used, one defined using the normal (or Gaussian) probability distribution and the other using the Skew Divergence. This latter, a Kullback-Leibler Divergence variation, is a measure of the difference between two probability distributions. Finally, the algorithm was tested in somes videos and also in texture mosaic images composed by images of the Brodatz album.
Concentration Area: Graphics Processing and Computational Intelligence.
Key Words: Image Segmentation, Texture Segmentation, Video Segmentation, Fuzzy
Lista de Figuras iii
Lista de Tabelas v
Lista de Símbolos e Abreviaturas vi
1 Introdução 1
1.1 Motivação . . . 2
1.2 Objetivos . . . 2
1.3 Estrutura do Documento . . . 3
2 Referencial Teórico 4 2.1 Imagens Digitais . . . 4
2.1.1 Imagens Digitais Coloridas . . . 5
2.2 Modelos de Cores . . . 6
2.2.1 Modelo RGB . . . . 6
2.2.2 Modelo YCbCr . . . 6
2.2.3 Modelo HSI . . . 7
2.2.4 Modelo HSL . . . . 8
2.2.5 Modelo I1I2I3 . . . 10
2.3 Texturas . . . 10
2.4 Segmentação de Imagens . . . 13
2.4.1 Segmentação por Limiarização . . . 14
2.4.2 Segmentação Baseada em Regiões . . . 14
2.4.2.1 Crescimento de Regiões . . . 15
2.4.2.2 Divisão e Fusão de Regiões . . . 16
2.4.3 Segmentação Fuzzy . . . . 16
2.4.3.1 Algoritmos para Segmentação Fuzzy: MOFS e Fast MOFS . . . 20
3.2 Seleção de Canais de Cores . . . 26
3.3 Função de Afinidade . . . 30
3.4 Algoritmo Fast MOFS Revisado . . . . 30
3.4.1 Experimentos . . . 33
3.4.2 Vídeo Plane . . . 33
4 Segmentação Fuzzy de Texturas 38 4.1 Função de Afinidade Adaptativa . . . 38
4.2 Afinidade Usando-se Função Gaussiana . . . 40
4.3 Afinidade Usando-se Divergência Skew . . . 41
4.3.1 Escolha Automática do Tamanho da Vizinhança . . . 42
4.4 Experimentos . . . 43
4.4.1 Função Gaussiana . . . 44
4.4.2 Divergência Skew . . . 48
5 Conclusão 54 Referências 56 A Ferramenta FuSe - Fuzzy Segmentation Tool 61 A.1 Editando as Classes . . . 62
A.2 Escolhendo o Modelo de Cor . . . 63
2.1 Imagem Digital como uma matriz de pixels. . . . 5
2.2 Modelo RGB . . . 7
2.3 Representação gráfica do modelo de cor HSL. . . . 9
2.4 Uma mesma imagem segmentada de maneiras diferentes. . . 13
2.5 Limiarização para classificar os pixels de uma imagem em duas classes. . 14
2.6 Histograma de níveis de cinza de uma imagem que pode ser particionada em três classes por 2 limiares: T1e T2. . . 15
2.7 Exemplo de duas correntes e seus elos. . . . 18
2.8 Ilustração do Teorema 2.4.1. . . 20
3.1 Conjunto de Frames de um vídeo formando um volume. . . . 24
3.2 Vizinhanças usadas no algoritmo de segmentação. . . 25
3.3 Exemplo de oclusão em um vídeo. . . 25
3.4 Exemplo de distância entre as cores de dois objetos. . . 27
3.5 Distância entre as cores de três objetos usando-se os canais x e y . . . . . 29
3.6 Frame do vídeo sintético Plane com e sem ruído gaussiano . . . . 34
3.7 Exemplo de ajuste no conjunto de sementes. . . 35
3.8 Resultado da segmentação para o frame 16 do vídeo Plane original usando-se os modelos de cores RGB, HSI,YCbCr, I1I2I3, HSL, Hib3, Hib4e Hib5. 36 3.9 Resultado da segmentação para o frame 16 do vídeo Plane ruidoso usando-se os modelos de cores RGB, HSI,YCbCr, I1I2I3, HSL, Hib3, Hib4e Hib5. 37 4.1 Vizinhança usada para extrair característica a partir das sementes. . . 39
4.2 Texturas com diferentes granularidades. . . 39
4.3 Vizinhança usada para calcular a afinidade entre spels vizinhos adjacentes na segmentação de texturas. . . 39
4.4 Texturas do álbum de Brodatz utilizadas nos experimentos. . . . 44
4.5 Mosaicos do tipo M2 e o ground truth correspondente. . . . 44
4.6 Mosaicos do tipo M5 e o ground truth correspondente. . . . 45
4.7 Mosaico Z2-01 obtido com zoom da textura D105 do álbum de Brodatz. . 45
4.9 Resultado da segmentação dos mosaicos do tipo M5 usando funções gaus-sianas. . . 48 4.10 Resultado da segmentação do mosaico Z2-01 usando função gaussiana. . 49 4.11 Exemplo da textura de Brodatz D110 dividida em uma grade 16×16. . . 49 4.12 Gráfico mostrando o aumento da afinidade com o aumento da área da
vizinhança para todas as texturas do álbum de Brodatz utilizadas nesse trabalho . . . 50 4.13 Gráfico mostrando o aumento da afinidade com o aumento da área da
vizinhança para todas as texturas do álbum de Brodatz utilizadas nesse trabalho . . . 50 4.14 Resultado da segmentação dos mosaicos do tipo M5 usando a divergência
skew. . . . 52 4.15 Resultado da segmentação do mosaico Z2-01 usando a divergência skew. . 53
A.1 Janela principal da ferramenta FuSe. . . . 62 A.2 Janela Editar Classe. Em (a), editando uma classe para segmentar uma
textura; Em (b), editando uma classe para segmentar um vídeo . . . 63 A.3 Janela editar opções de canais. Em (a), opção híbrido automático
3.1 Configuração da máquina na qual foram realizados os experimentos. . . 33 3.2 Modelos de cores híbridos escolhidos para o vídeo Plane. . . . 35 3.3 Resultado da segmentação do vídeo Plane (Porcentagem de Acertos %). 35
4.1 Acurácias das segmentações dos mosaicos do tipo M2. . . . 46 4.2 Acurácias das segmentações dos mosaicos do tipo M5. . . . 46 4.3 Acurácias das segmentações dos mosaicos do tipo M5 usando a
divergên-cia skew. . . . 51
f(x,y) Função bidimensional de intensidade da luz;
V Conjunto de todos os spels a ser particionados;
M Quantidade de objetos a serem segmentados;
σ Função que mapeia cada c∈V em um vetor(M+1)-dimensional;
σc Vetor(M+1)-dimensional que armazena as afinidades de c para todos os m
obje-tos;
σc
0 Maior afinidade de c para os m objetos; σc
m Afinidade de c para m-ésimo objeto;
hc(0),c(1),···,c(K)i Corrente de k spels;
(c(k−1),c(k)) Elo entre os spels k−1 e k;
ψ-força Força de um elo;
ψm Função de afinidade do objeto m;
Ψ Conjunto das funções de afinidade dos m objetos;
Vm Conjunto das sementes do objeto m;
V
Conjunto de todos os Vm, com 0<m≤M;σm-corrente Correntehc(0), . . . , c(K)iondeσcm(k)>0 para todo 0≤k≤K;
scn-corrente Valor da maior força do objeto n(1≤n≤M)que parte de um pixel semente de Vne passa por c;
τ Função que mapeia cada c∈V em um parhτc,σci;
τc Afinidade máxima de c;
para 0<m≤M;
ch Conjunto dos canais de todos os modelos usados nesse trabalho;
µm Conjunto das médias dos canais de todos os modelos usados nesse trabalho para o objeto m;
µmx Média do canal x para o objeto m;
σm Conjunto dos desvios padrões das médias µm;
σm
x Desvio padrão para a médiaσm;
ρµ1,σ1 Função Gaussiana de densidade de probabilidade com média µ1 e desvio padrão σ1 para a média das médias entre todo par de spels c e d pertencentes a uma
determinada área;
ρµ2,σ2 Função Gaussiana de densidade de probabilidade com média µ2 e desvio padrão σ2para a média das diferenças absolutas entre todo par de spels c e d pertencentes
a uma determinada área;
Sm Conjunto de sementes do m-ésimo objeto;
ηm Número de sementes do m-ésimo objeto;
Asmi Conjunto de spels pertencentes a vizinhança da semente sim do objeto m, com
1≤i≤ηm;
Am={Ams1,Asm2,Ams3, . . . ,Amsη
m} Combinação de todos os conjuntos A
m sim, para
i=1,2,3, . . . ,ηm;
A
c eA
d Conjuntos de spels pertencentes as vizinhanças dos spels c e d respectivamente;K L
(pkq) Divergência de Kullback-Leibler entre p e q;S D
(pkq) Divergência skew entre p e q;Introdução
Em muitas aplicações faz-se necessário a subdivisão de uma imagem em objetos ou partes de objetos que tenham um conteúdo semântico relevante, processo este denomi-nado de Segmentação de Imagem. Encontrar e separar áreas com características seme-lhantes não é uma tarefa simples de ser implementada em um computador, muito embora, na maioria das vezes, seja uma tarefa simples para o sistema visual humano.
Uma imagem pode conter áreas com propriedades texturais. Estas propriedades estão entre as características empregadas pelo sistema visual humano na percepção das dife-rentes regiões de uma imagem, contendo informações sobre a distribuição espacial e a variação de luminosidade, além de descrever o arranjo estrutural das superfícies e rela-ções entre as regiões vizinhas [Pedrini e Schwartz 2008]. Quando a segmentação envolve imagens com propriedades puramente texturais, a complexidade em se definir um critério de homogeneidade intra-objeto torna-se ainda maior.
O algoritmo de segmentação difusa (do Inglês fuzzy) proposto em [Carvalho et al. 2001], é um método interativo de segmentação por crescimento de regiões que através de funções de afinidades atribui a cada elemento da imagem um valor de pertinência em relação a um determinado objeto. Este algoritmo vem sendo aplicado em segmentações de imagens obtendo-se, geralmente, bons resultados. Porém, quando a segmentação envolve imagens com propriedades puramente texturais, o processo de segmentação torna-se ainda mais complexo, sendo necessário a escolha de funções de afinidades que sejam mais robustas, adaptando-se a cada tipo de textura.
Da mesma forma que em uma imagem, também pode-se subdividir um vídeo em seus objetos ou regiões constituintes. Como um vídeo pode ser tratado como um volume 3D formado por um conjunto de quadros (ou frames), o algoritmo de segmentação fuzzy pode ser adaptado para segmentar também estes vídeos.
informa-ção de cor, por tanto, é uma importante característica para definir as funções de afinidade da segmentação fuzzy. Existem diversos modelos que quantificam características de cor como brilho, intensidade, saturação, dentre outras. Alguns exemplos de modelos são:
RGB, HSI, HSL, YCbCre I1I2I3 (ver Seção 2.2). Destarte, estes modelos serão utilizados
na segmentação de vídeos coloridos.
1.1
Motivação
Diversos são os sistemas computacionais que usam a segmentação como um pré-processamento efetuado nas imagens de entrada. Este pré-pré-processamento tem como ob-jetivo a extração de informações que sejam relevantes à aplicação. Na área médica po-demos citar diversas aplicações, tais como a quantificação de volumes de tecidos [Larie e Abukmeil 1998], diagnósticos [Taylor 1995], localização de patologias [Zijdenbos e Dawant 1994], dentre outras. Fora da área médica podemos citar o uso para a localização de objetos em imagens de sensoriamento remoto (estradas, florestas, alvos de guerra, etc.) [Awad 2008] [Bo e Jing 2010] [Bao-yun et al. 2011], sistemas para o reconhecimento de faces [Zhang et al. 2009], fiscalização automática de rodovias [Chen et al. 2011], dentre outros.
Estes são apenas alguns exemplos dentro de um vasto cenário de aplicações da seg-mentação de imagens. Estas aplicações necessitam de uma boa segseg-mentação para obter bons resultados, tornando a busca por melhorias neste processo uma tarefa de grande importância.
A segmentação Fuzzy é um método que mostrou-se bastante robusto, obtendo-se bons resultados em diversos tipos de imagens. Todavia, sua aplicação em imagens com pro-priedades texturais precisava de uma maior atenção, uma vez que, até o desenvolvimento deste trabalho, funções de afinidades eficientes que capturassem com precisão as caracte-rísticas das texturas ainda não tinham sido obtidas.
Uma extensão do algoritmo faz-se necessária para que o mesmo possa ser aplicado na segmentação de vídeos. Além disso, há uma necessidade do desenvolvimento de metodo-logias que utilizem da melhor maneira as informações de cores presentes no vídeo.
1.2
Objetivos
texturais. No primeiro, uma metodologia é proposta para a escolha de quais canais de cores, dentre os modelos descritos na Seção 2.2, serão utilizados pelo algoritmo para ex-trair das imagens as informações necessárias à segmentação. Já no segundo, deixando auto-ajustáveis as funções de extração de características e de cálculo de afinidade entre os elementos da imagem, buscou-se tornar o algoritmo mais adaptativo às propriedades de textura dos objetos envolvidos na segmentação, fazendo a área de extração de caracterís-ticas variar de acordo com a textura.
Como objetivos secundários tem-se a revisão do algoritmo Fast-MOFS, descrito em [Carvalho et al. 2005], e o desenvolvimento de um aplicativo para auxiliar nos experimen-tos, principalmente na segmentação de vídeos, onde é necessário lidar, geralmente, com dezenas ou centenas de frames. Aplicativo este denominado de Fuzzy Segmentation Tool
- FuSe.
1.3
Estrutura do Documento
Neste capítulo foi apresentada uma descrição dos problemas cujo trabalho em questão se propõe a resolver, listando também os principais objetivos e o que motivou a realização deste trabalho. No Capítulo 2 são apresentados alguns conceitos básicos importantes ao entendimento deste trabalho, enquanto que no Capítulo 2.4 é feita uma revisão sobre os principais algoritmos de segmentação de imagens da literatura, incluindo a segmentação
fuzzy de imagens e as adaptações aqui propostas a este algoritmo. Nos Capítulos 3 e 4 são
Referencial Teórico
Neste capítulo serão abordados os conceitos de Imagens Digitais, Modelos de Cores e Texturas. Este embasamento teórico faz-se necessário para o melhor entendimento do problema tratado neste trabalho bem como as abordagens das soluções adotadas. Desta forma, caso o leitor se sinta seguro quanto aos temas outrora citados, pode iniciar a sua leitura no capítulo subsequente.
2.1
Imagens Digitais
O termo imagem refere-se à função bidimensional de intensidade da luz f(x,y), em que x e y denotam as coordenadas espaciais, e o valor de f em qualquer ponto (x,y)
é proporcional ao brilho (ou níveis de cinza) da imagem naquele ponto [Gonzalez e Woods 2007]. Em uma imagem digital há uma discretização nos valores das coordenadas espaciais e no valor do brilho em cada um destes pontos. Cada ponto desta imagem digital é chamado de elemento da imagem, elemento da figura, pixels ou pels, estes dois últimos, abreviações de picture elements, ou elementos de figura em Português. Assim, uma ima-gem digital é uma matriz bidimensional onde cada célula desta matriz corresponde a um
pixel da imagem (ver Figura 2.1).
Figura 2.1: Imagem Digital como uma matriz de pixels.
X
Y
2.1.1
Imagens Digitais Coloridas
Devido à capacidade do sistema visual humano em diferenciar milhares de tons e intensidades de cores ao contrário das poucas dezenas de níveis de cinza [Pedrini e Schwartz 2008], uma imagem colorida pode ser mais representativa que uma monocro-mática. Experimentos mostraram que os sensores de percepção de cores do sistema visual humano podem ser divididos em três diferentes categorias: vermelho, verde e azul. Desta forma, as cores são vistas como combinações destas cores primárias.
As quantidades de vermelho, verde e azul necessárias para formar uma cor são cha-madas de coeficientes triestímulos e expressas como X , Y e Z, respectivamente. Uma cor é, então, especificada pelos seus coeficientes tricromáticos, definidos como:
x= X
X+Y+Z y= Y
X+Y+Z z= Z
X+Y+Z
(2.1)
Como em uma imagem colorida tem-se mais que apenas a informação de brilho em cada ponto, pode-se generalizar a resposta da função f , da definição de imagem vista anteriormente, como sendo um vetor n-dimensional, no qual n denota a quantidade de canais usados para representar as cores. Desta forma, tem-se:
f(x,y) =
f1(x,y)
f2(x,y)
.. .
2.2
Modelos de Cores
Os modelos de cores permitem a especificação de cores em um formato padronizado para atender a diferentes dispositivos gráficos ou aplicações que requerem a manipula-ção de cores. Desta forma, existem diversos modelos na literatura que tentam especificar as características de cores de maneira distinta. Neste trabalho serão utilizados 5 mode-los: RGB, HSL, HSI, YCbCr e I1I2I3. O RGB é um modelo muito usado em dispositivos
eletrônicos como Monitores, TV’s, Câmeras fotográficas, entre outros. Por outro lado, quando observamos objetos coloridos, o sistema cognitivo humano os descrevem em ter-mos de matiz, saturação e brilho [Gonzalez e Woods 2007], desta forma, os modelos HSI e HSL são muito utilizados em programas de edição de imagens. Os aplicativos Gimp [GIMP - GNU Image Manipulation Program 2001] e Inkscape [Inksacape - Open Source
vector graphics editor 1991], por exemplo, usam estes modelos por refletirem melhor a
forma com que os seres humanos descrevem as cores. O modelo YCbCrfoi escolhido por
ser largamente utilizado em vídeos digitais [Pedrini e Schwartz 2008]. Já o I1I2I3 será
usado pois, geralmente, tem-se obtido bons resultados em algoritmos de segmentação de imagens e também por ser um modelo que é facilmente obtido a partir do modelo RGB usando-se transformações lineares [Ohta et al. 1980].
A seguir é mostrada uma breve descrição com as principais característica destes mo-delos. Para maiores detalhes, inclusive sobre conversão a partir do modelo RGB, pode-se consultar [Azevedo e Conci 2003], [Gonzalez e Woods 2007] e [Pedrini e Schwartz 2008].
2.2.1
Modelo RGB
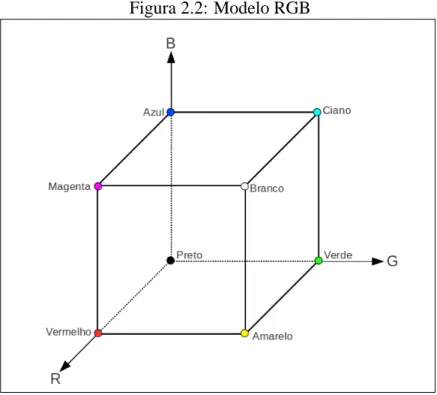
O modelo RGB pode ser geometricamente representado por um cubo (Figura 2.2). As coordenadas de cada ponto deste cubo representam as cores primárias vermelho (R, red), (G, Green) e Azul(B, Blue), respectivamente. Estas cores estão representadas em três vértices do cubo. As cores primárias complementares ciano, magenta e amarelo, estão em outros três vértices, o vértice junto à origem é o preto e o mais afastado da origem corresponde à cor branca.
No modelo RGB, a escala de cinza estende-se através da diagonal do cubo que vai da origem (preto) até o vértice mais distante (branco).
2.2.2
Modelo YC
bC
rFigura 2.2: Modelo RGB
Cb é a diferença entre a cor azul e um valor de referência, o componente Cr é a diferença
entre a cor vermelha e um valor de referência. A conversão do modelo RGB para o YCbCr é dada por
Y Cb Cr =
0.299 0.587 0.114
−0.169 −0.331 0.5 0.5 −0.419 −0.081
R G B
2.2.3
Modelo HSI
No modelo HSI uma cor é representada em termos do matiz (H, hue), saturação (S,
saturation) e intensidade (I, intensity). Havendo uma separação da informação de cor e de
intensidade. A cor é representada pelo matiz e pela saturação, enquanto que a intensidade, que descreve o brilho de uma imagem, é determinada pela quantidade de luz. Para obter esse modelo a partir do RGB, primeiro faz-se uma normalização dos valores R, G e B:
r= R
R+G+B,g= G
R+G+B,b= B
R+G+B (2.3)
I=1
3(R+G+B) (2.4)
S=1−3·min(r,g,b) (2.5)
H =
cos−1
1 2·
[(r−g)+(r−b)]
√
(r−g)2+(r−b)(g−b)
, se b≤g
2π−cos−1
1 2·
[(r−g)+(r−b)]
√
(r−g)2+(r−b)(g−b)
, caso contrário
. (2.6)
2.2.4
Modelo HSL
O modelo HSL é definido pelo matiz (H, hue), saturação (S, saturation) e luminosi-dade (L, lightness). A representação gráfica do modelo HSL é formada por dois cones de altura 1, cujas bases são coincidentes, como podemos ver na Figura 2.3.
O matiz é determinado pelos pontos no círculo da borda das duas bases comuns aos cones. A saturação varia de 0 a 1, conforme a distância ao eixo do cone. A luminosidade varia de 0 (preto) a 1 (branco) ao longo do eixo comum aos dois cones, onde se encontra a escala de cinza. Os matizes puros são encontrados no plano onde a luminosidade é igual a 0,5 e a saturação é igual a 1.
A conversão do modelo RGB para o HSL pode ser realizada por meio das seguintes equações: H=
60·((MG−−Bm)), se M=R
60·((MB−−Rm))+120, se M=G
60·((MR−−Gm))+240, se M=B
S=
0, se M=m
(M−m)
(M+m), se 0<L≤0,5
(M−m)
2−(M+m), se L>0,5
, (2.8)
L=M+m
2 . (2.9)
Onde m=min(R,G,B)e M=max(R,G,B).
2.2.5
Modelo I
1I
2I
3Este modelo foi obtido através de sucessivos experimentos de segmentação a fim de se obter características de cores eficientes [Ohta et al. 1980]. Nestes experimentos fo-ram usadas oito tipos de imagens diferentes e calculados, por transformações a partir do modelo RGB, mais de 100 características diferentes. Destas, as que obtiveram melhores resultados foram
I1=
R+G+B
3 (2.10)
I2=
R−B
2 (2.11)
I3=
2G−R−B
4 (2.12)
Quando comparado a outros 7 modelos ( RGB, Y IQ, HSI, Nrgb,XY Z, CIE(L∗u∗v), e CIE(L∗a∗b)), o I1I2I3foi o mais eficiente em termos de qualidade de segmentação e
em complexidade da transformação [Ohta et al. 1980].
2.3
Texturas
Diversas definições de texturas podem ser encontradas na literatura, inexistindo, por tanto, uma definição única e certa. Uma textura pode ser definida como constituinte de uma região macroscópica, em que sua estrutura é formada pela repetição de padrões, nos quais seus elementos ou primitivas encontram-se arranjados conforme uma regra de composição ([Tamura et al. 1978]). No trabalho de Rosenfeld e Troy [Rosenfeld e Troy 1970] textura é definida como um arranjo repetitivo de padrões sobre uma área, enquanto que, segundo Haralick [Haralick 1979], uma textura pode ser descrita pela interação entre as primitiva tonais que a compõem, estas ocorrendo em diferentes números e formas.
As texturas podem ser descritas usando-se três abordagens principais: estatística, es-trutural e espectral [Gonzalez e Woods 2007]. Na primeira, a textura é definida por um conjunto de medidas estatísticas locais extraídas do padrão (ex. entropia, correlação, mé-dia, contraste e variância), estes serão os tipos de texturas tratados neste trabalho. Na segunda abordagem utiliza-se a ideia de que texturas são compostas de primitivas dispos-tas de forma aproximadamente regular e repetitiva, de acordo com regras bem definidas. Nestas, pode-se observar um padrão de repetição com uma periodicidade bem definida. Como exemplo, pode-se citar a descrição da textura baseada em linhas paralelas regu-larmente espaçadas. Por último, a abordagem espectral baseia-se em propriedades do espectro de Fourier, sendo principalmente utilizadas na detecção de periodicidade.
Existem diversas técnicas que podem ser utilizadas para extrair a periodicidade de tex-turas, ou seja, encontrar uma janela mínima que possa caracterizar a estrutura da textura (suas primitivas).
Por exemplo, é possível encontrar a periodicidade e as primitivas de textura a partir de funções de autocorrelação, como proposto por Lin et al. [Lin et al. 1997]. Neste trabalho os autores empregaram uma operação de autocorrelação seguida da aplicação de um algoritmo para encontrar picos em uma versão suavizada desta função, uma vez que as funções de autocorrelação são em geral irregulares, o que dificultaria a detecção destes picos. Em seguida uma transformada de Hough generalizada é aplicada à grade de picos detectados. Esta operação, tem como objetivo encontrar os vetores de deslocamentos que descrevam os paralelogramos que definem as primitivas texturais da imagem. As áreas associadas a estes paralelogramos são as menores possíveis.
me-dida da área residual depois de cada iteração da sequência de filtros. O método proposto por Jan e Hsueh [Jan e Hsueh 1998] utiliza então matrizes de co-ocorrência para prever efetivamente o tamanho da janela para a classificação granulométrica. Já Parkkinen et al. [Parkkinen et al. 1990] usa matriz de co-ocorrência para calcular uma propriedade esta-tística denominada concordância, que é usada como indicação do período da estrutura.
No problema de classificação de texturas Gotlieb e Kreyszig [Gotlieb e Kreyszig 1990] usaram seis descritores estatísticos baseados em matrizes de co-ocorrências para classificar exemplos de textura do álbum de Brodatz [Brodatz 1966], reduziram os his-togramas de co-ocorrências,como usado por Valkealahti e Oja [Valkealahti e Oja 1998], para manter altas taxas de classificação mas com baixa complexidade de espaço, enquanto Manjunathi e Ma [Manjunath e Ma 1996] propuseram o uso da transformada wavelet Ga-bor para descrição e recuperação de texturas da base de dados de Brodatz [Brodatz 1966]. Várias técnicas tem sido aplicadas na segmentação de texturas. Um exemplo é a pro-posta por Unser e Eden [Unser e Eden 1989], onde eles extraem propriedades texturais locais usando transformações lineares otimizadas para maximizar a descriminação textu-ral. Com isso, eles estimam estatísticas locais na saída de um banco de filtros e geram uma sequência de multi-resolução utilizando um algoritmo de suavização Gaussiano iterativo. Matrizes de dispersão são então avaliadas para reduzir as características de texturas para uma única componente que é limiarizado para produzir a segmentação. Uma abordagem diferente é proposta por Hofmann et al. ??, que também realiza segmentação não super-visionada de texturas, mas faz isso com base em testes estatísticos como uma medida de homogeneidade. A segmentação é, então, formulada como um problema de clusterização que é resolvido calculando-se dissimilaridades através de filtros de Gabor multi-escalar.
Existem várias abordagens ([Chellappa 1989], [Manjunath e Chellappa 1991], [Robertson et al. 1995]) que segmentam texturas modelando o campo de intensidade da textura como um campo de Gauss-Markov ou como um campo randômico de Markov para representar a dependência espacial local entre as intensidades dos pixels. Entretanto, estas técnicas tem um custo computacional elevado pois necessitam de um grande número de iterações para poderem convergir. Lehmann [Lehmann 2011] propôs uma abordagem alternativa que modela imagens texturais bi-dimensionais em dois modelos escondidos de Markov autor-regressivo (HMM-AR) unidimensionais, um para as linhas e outro para as colunas. Então, a segmentação é feita por um algoritmo que é similar ao turbo decoding no contexto de error correcting codes, no qual o parâmetro desconhecido do HMM-AR é estimado usando o algoritmo de maximização das estimativas (Expectation-Maximization).
2.4
Segmentação de Imagens
Em muitas aplicações faz-se necessário a subdivisão de imagens digitais em objetos ou partes de objetos que tenham um conteúdo semântico relevante, determinando a forma e/ou a posição destes objetos para uma melhor interpretação das informações contidas na imagem. Este processo é denominado Segmentação de Imagens, e consiste em determinar a qual objeto pertence cada um dos pixels de uma imagem. A Segmentação é usada como um pré-processamento em diversas áreas, como por exemplo: compressão de imagens, edição de imagens, visão computacional, renderização não realística, entre outras.
A segmentação é um processo subjetivo que depende do grau de abstração usado para separar os objetos. Assim, não existe apenas uma maneira correta de subdividir uma imagem, como podemos ver na Figura 2.4. Nesta, tem-se duas maneiras diferentes de segmentar a imagem (a): em (b) cada toro foi considerado um objeto diferente, enquanto que em (c) toda a pilha de toros foi considerada como sendo um único objeto.
Figura 2.4: Uma mesma imagem segmentada de maneiras diferentes. Em (a) tem-se a imagem original e em (b) e (c) tem-se duas maneiras diferentes de segmentá-la.
(a) (b) (c)
Na segmentação usa-se, geralmente, duas abordagens para detectar os objetos da ima-gem: identificação de descontinuidades ou a identificação de similaridades. Na primeira abordagem procura-se por mudanças abruptas de intensidades, ou seja, linhas, bordas ou pontos. Já na segunda abordagem, a qual é usada neste trabalho, procura-se agrupar em uma mesma classe os elementos da imagem que possuam valores similares para um determinado conjunto de características como ocorre, por exemplo, nos algoritmos de limiarização, crescimento de regiões e divisão e fusão de regiões.
cada um). Já no segundo, o próprio algoritmo deve obter estas informações para poder particionar a imagem em seus objetos constituintes.
2.4.1
Segmentação por Limiarização
Suponha que deseja-se separar um objeto de um background em uma imagem mo-nocromática. A segmentação por thresholding, ou limiarização, consiste em encontrar um valor T de intensidade que possibilite a separação dos pixels da imagem nestas duas classes. Desta forma, os pixels que forem maiores que T pertencerão a um grupo e os que forem menores ou iguais pertencerão ao outro (Ver Figura 2.5).
Figura 2.5: Limiarização para classificar os pixels de uma imagem em duas classes.
Podemos perceber melhor este particionamento fazendo uso de um histograma, uma vez que este nos permite visualizar a distribuição dos níveis de cinza de uma imagem. Desta forma, dependendo da imagem, podemos definir valores de níveis de cinza que separam os objetos a partir da observação deste histograma. Na Figura 2.6 tem-se um exemplo de um histograma de uma imagem onde pode-se identificar 2 limiares, T1 e T2,
os quais nos permitem classificar os pixels da imagem como pertencendo a um entre três objetos: os pixels que tenham intensidade menor que o nível T1pertencem a um objeto, os
que tem nível entre T1 e T2 pertencem a um segundo objeto e os que tenham intensidade
maior que T2pertencem a um terceiro.
2.4.2
Segmentação Baseada em Regiões
Os algoritmos que usam esta abordagem procuram dividir a imagem em regiões que compreendam os objetos que se desejá segmentar. Em [Gonzalez e Woods 2007] faz-se uma formalização deste processo de segmentação, em que R é definido como sendo toda a região que compreende uma imagem I. Segmentar I é, então, particionar R em n regiões
Figura 2.6: Histograma de níveis de cinza de uma imagem que pode ser particionada em três classes por 2 limiares: T1e T2. Onde x é o nível de cinza e P(x)indica o número de
vezes que a intensidade x aparece na imagem.
(a)
n S i=1
Ri=R,
(b) Rié uma região conexa, com i=1,2, . . . ,n,
(c) Ri∩Rj=∅para todo i e j,i6= j,
(d) P(Ri) =V ERDADEIRO para i=1,2, . . . ,n, e
(e) P(Ri∪Rj) =FALSO para i6= j,
em que, P(Ri) é um predicado lógico sobre os pontos do conjunto Ri e ∅é o conjunto
vazio.
A condição (a) indica que a segmentação deve ser completa, ou seja, cada pixel deve pertencer a uma região. A segunda condição requer que os pixels pertencentes a uma re-gião estejam todos conectados. A condição (c) indica que as regiões devem ser disjuntas: um pixel só pode pertencer a uma única região. A condição (d) trata das propriedades que devem ser satisfeitas pelos pixels em uma região segmentada, indicando que os pixels que pertencem a esta região possuem características semelhantes. Já a condição (e) indica que Ri e Rj são diferentes no sentido do predicado P. Os algoritmos mais comuns de
segmentação baseadas em regiões utilizam os conceitos de crescimento de regiões e de divisão e fusão de regiões, os quais serão descritos a seguir.
2.4.2.1 Crescimento de Regiões
com um conjunto de pontos “sementes” e, a partir deles, cresce as regiões anexando a cada ponto semente aqueles pixels que possuam propriedades similares.
Uma dificuldade deste método está na escolha dos pixels sementes que representem adequadamente as regiões que se deseja segmentar, e outra é a escolha das propriedades que caracterizem os pixels que devam pertencer a cada uma das regiões.
2.4.2.2 Divisão e Fusão de Regiões
Diferente do método de crescimento de regiões, em que a partir de um pequeno con-junto de sementes os demais pixels da imagem são agregados até a região desejada ser atingida, o método de crescimento e divisão de regiões parte de uma subdivisão arbitrá-ria da imagem em regiões disjuntas e a partir de sub-divisões ou fusão estas regiões são ajustadas.
Existe um algoritmo simples que usa esta abordagem. Seja um predicado P, conforme visto na Seção 2.4.2, se uma região Ri qualquer tiver P(Ri) =FALSO, a região pode,
então, ser subdividida. Geralmente começa-se o processo de segmentação com apenas uma região compreendendo toda a imagem, e enquanto o predicado for falso para alguma região, a mesma será subdividida. Contudo, se apenas subdividirmos as regiões, podemos ter ao final da segmentação regiões adjacentes com características similares. Assim, torna-se necessário um processo de fusão destas regiões; Dadas duas regiões adjacentes, Ri e
Rj, se P(Ri∪Rj) =V ERDADEIRO as regiões serão unidas. Este processo de divisão e
fusão deve ser repetido até não ser mais possível realizar nem fusão e nem divisão nas regiões formadas.
2.4.3
Segmentação Fuzzy
A Segmentação Fuzzy é uma técnica de segmentação por crescimento de regiões que determina um grau de pertinência para cada elemento da imagem, entre zero e um, indi-cando a certeza desse elemento pertencer ou não a um determinado objeto existente na imagem [Herman e Carvalho 2001]. A partir dessas informações de pertinência, um al-goritmo de segmentação pode tomar uma decisão mais flexível sobre a classificação de cada pixel. Este método pode não satisfazer a condição (e) da definição de algoritmos de segmentação baseados em regiões (Seção 2.4.2) pois um elemento de uma imagem segmentada pelo método fuzzy pode pertencer a mais que um objeto simultaneamente.
Como no trabalho de Srinivasan et al. [Srinivasan et al. 2012], o algoritmo de segmen-tação fuzzy aqui proposto pode ser adaptado para a segmensegmen-tação de imagens com texturas coloridas, utilizando uma estratégia parecida com a aplicada na segmentação de vídeos (Capítulo 3). Xia et al. [Xia et al. 2006], propõe um algoritmo de agrupamento fuzzy no qual as funções de dissimilaridades levam em consideração não apenas as características de cada pixel, mas também a localização destas características.
O algoritmo de segmentação fuzzy (MOFS - Mult-Object Fuzzy Segmentation) des-crito por Herman e Carvalho [Herman e Carvalho 2001], o qual é estendido neste tra-balho, é um método semi-automático de segmentação onde o usuário escolhe um ou mais pixels sementes para representar as regiões em que se deseja subdividir a ima-gem. Este algoritmo utiliza o conceito de conectividade fuzzy introduzido por Rosenfeld [Rosenfeld 1979] e foi inspirado no trabalho desenvolvido por Udupa e Samarasekera [Udupa e Samarasekera 1996], sendo generalizado para espaços digitais arbitrários con-forme a definição de Herman [Herman 1998]. Um espaço digital é um par (V,π), onde
V é um conjunto e π é uma relação binária simétrica, tal que, os elementos de V estão conectados pela relaçãoπ. Devido à natureza geral da abordagem utilizada, os elementos de V são chamados de spels, do Inglês spatial elements, podendo referir-se a pixels em uma imagem, pontos em um plano ou voxels em um volume.
O objetivo da segmentação é, então, dividir o conjunto V em subconjuntos que com-ponham os objetos que deseja-se segmentar. Porém, esta divisão é feita de maneira Fuzzy. Assim, não se assume apenas que um elemento pertence ou não a um determinado objeto, mas sim, que os spels do conjunto V possuem um grau de pertinência em relação aos objetos envolvidos na segmentação. Esta certeza é indicada por um valor real entre 0 e 1, onde, 0 indica que um elemento definitivamente não pertence ao objeto e 1 indica que o elemento definitivamente pertence ao objeto.
Para formalizar o particionamento fuzzy de V foi criado o conceito de M-semisegmen-tação, do Inglês M-semisegmentation (onde M é o número de objetos). Uma
M-semiseg-mentação de V é uma funçãoσque mapeia cada c∈V em um vetor(M+1)-dimensional
σc= (σc
0,σc1, . . . ,σcM), no qual
1. σc0∈[0,1]— isto é,σc0é um valor não negativo e não maior que 1; 2. para todo m (1≤m≤M), o valor deσcmé 0 ouσc0; e
3. há pelo menos um m (1≤m≤M), tal queσcm=σc
0.
ondeσcmé o grau de pertinência do spel c em relação ao m-ésimo objeto, eσc0=max(σc
1, σc
2,···,σcM). Note que a definição acima permite que um spel pertença a mais que um
M-segmentação é definida como uma M-semisegmentaçãoσondeσc0é positivo para todo
spel c∈V .
Uma M-semisegmentação será definida por um grafo M-fuzzy, um conceito que co-meçará s ser definido a seguir.
Uma sequência de spels hc(0),c(1),···,c(K)i é chamada de corrente (chain) e seus
elos (links) são os pares ordenados (c(k−1),c(k)) de spels consecutivos na corrente. A força de um elo também é um conceito fuzzy, ou seja, para todo par ordenado de spels consecutivos da corrente, um valor real no intervalo[0,1]é atribuído a este par. Este valor é denominado força da ligação de c para d. Umaψ-força de um elo é um valor dado por uma função de afinidade fuzzyψ: V2→[0,1], isto é, uma função que retorna um valor real entre 0 e 1 para cada par ordenado de spels pertencentes a V . Estaψ-força é dita positiva se pertence ao intervalo(0,1].
Uma função de afinidade fuzzy deve ser reflexiva (ψ(c,c) =1) e simétrica (ψ(c,d) = ψ(d,c)). Ela deve ser específica para cada um dos objetos, uma vez que estes provavel-mente possuem características diferentes.
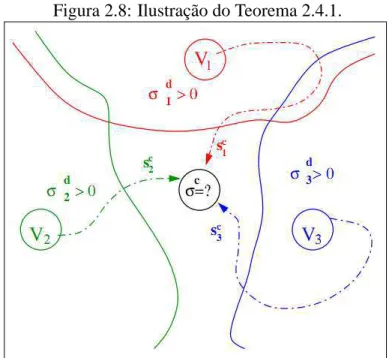
A Figura 2.7 mostra um exemplo com duas correntes que se interceptam em um spel C. Essa interceptação evidencia, como dito anteriormente, o fato de que a segmentação fuzzy permite que um mesmo elemento da imagem pertença simultaneamente a dois ou mais objetos. Nesta mesma figura pode-se ver, também, os elos entre os spels consecutivos.
Figura 2.7: Exemplo de duas correntes e seus elos.
positiva de c para d.
Um grafo M-fuzzy é um par (V,Ψ), onde V é um conjunto finito e não vazio e Ψ= (ψ1,ψ2,···,ψM), com ψm ( 1≤m≤M) sendo a função de afinidade fuzzy para o
m-ésimo objeto. Um grafo M-fuzzy semeado é uma tripla(V,Ψ,
V
), onde(V,Ψ)é um grafoM-fuzzy e
V
= (V1,V2,···,VM), onde V m⊆V , para 1≤m≤M, é o conjunto de todosos spels sementes do m-ésimo objeto. Um grafo M-fuzzy semeado(V, (ψ1, ···, ψM),
(V1, ···,VM))é considerado conectável se
1. o conjunto V é φψ-conectado, em que φψ(c,d) = min1≤m≤Mψm(c,d) para todo
c,d∈V , e
2. Vm6=∅, para pelo menos um m, 1≤m≤M.
Para uma M-semisegmentação σ de V e 1≤m≤M , uma correntehc(0), . . . , c(K)i
é definida como umaσm-corrente se σcm(k) >0, para 0≤k≤K. Além disso, para todo W⊆V e c∈V , será usado µσ,m,W(c)para denotar aψm-força máxima de umaσm-corrente
de um spel em W para c (essa força será 0 se tal corrente não existir).
Teorema 2.4.1 Se(V,Ψ,
V
)é um grafo M-fuzzy semeado (onde Ψ= (ψ1, ···, ψM) eV
= (V1, ···, VM)), então(i) existe uma M-semisegmentaçãoσde V com as seguintes propriedades: para todo
c∈V , se para 1≤n≤M
scn=
1 se c∈Vn,
maxd∈V(min(µσ,n,Vn(d),ψn(d,c))) caso contrário,
(2.13)
então para 1≤m≤M
σc m=
scm se scm≥scn, para 1≤n≤M,
0 caso contrário;
(2.14)
(ii) esta M-semisegmentação é única; e
(iii) é uma M-segmentação, uma vez que(V,Ψ,
V
)é conectável.hd(0),···,d(L),cide um spel semente em Vnpara c de modo queσd
(l)
n >0 (isto é, d(l)
per-tença ao n-ésimo objeto) para 0≤l≤L. Intuitivamente, o m-ésimo objeto pode afirmar
que c “pertence” a ele se, e somente se, scm é máximo. Isto confirma o que é proposto pela Condição (2.14): σcm tem um valor positivo somente para o objeto cujo valor de scm é o máximo. Além disso, esta propriedade nos mostra como um spel pode se relacionar com vários objetos, desde queσseja conhecida para todos os outros spels, e com a Condi-ção (2.14) satisfeita, pode-se calcular os valores de scnpara um spel c utilizando-se a Equa-ção (2.13). O Teorema 2.4.1 diz que existe uma, e somente uma, M-semisegmentaEqua-ção que satisfaz simultaneamente as proposições, e que esta M-semisegmentação é de fato uma
M-segmentação pelo fato do grafo M-fuzzy semeado ser conectado.
Figura 2.8: Ilustração do Teorema 2.4.1.
2.4.3.1 Algoritmos para Segmentação Fuzzy: MOFS e Fast MOFS
O algoritmo para segmentação fuzzy, chamado de MOFS - Multi-Objetct Fuzzy
Seg-mentation, foi proposto por Herman e Carvalho [Herman e Carvalho 2001] e é uma
so-lução gulosa1 para a segmentação fuzzy. Neste algoritmo foi utilizado uma estrutura de dados do tipo Heap Binário [Cormen et al. 2001], na qual todos os spels são inseridos com uma chave associadaσc0 e uma única vez. Os spels são, então, removidos do heap
em uma ordem decrescente do valor finalσc0. O problema deste algoritmo é que toda vez que o valorσc0for alterado essa atualização no heap será da ordem O(log N), com N sendo o número de spels do heap em determinado instante. A complexidade do algoritmo é da ordem O(N(log N+ML)), com N sendo a quantidade total de spels, M a quantidade de objetos, geralmente não superior a 10, e L é uma pequena constate que indica a quanti-dade de vizinhos usados no crescimento das regiões, neste trabalho esse valor pode ser 4 ou 6.
Em busca de uma maior eficiência na segmentação fuzzy, foi proposto por Carva-lho et al. [CarvaCarva-lho et al. 2005] um algoritmo mais eficiente, o qual foi denominado de Fast-MOFS (Algoritmo 2.1). Neste, foi feita uma discretização dos valores gerados pela função de afinidade. Supõe-se que um conjunto não vazio R de possíveis valores de afinidades fuzzy, os quais podem ser atribuídos aos spels de uma classe particular de problema, seja sempre um subconjunto do conjunto A. Sendo K a cardinalidade do conjunto A∪1, e 1= a1 >a2 >··· >aK >0 sendo os elementos de A. Por
exem-plo, em muitas aplicações, a qualidade da segmentação fuzzy não é significativamente afetada se cada valor da afinidade for arredondado para três casas decimais. Se for utili-zado este arredondamento para as afinidades dos spels, poderá ser utiliutili-zado um conjunto
A={0.001,0.002,···,0.999,1.000}, com K=1000 e ak=1.001−k/1000.
Nesta nova implementação foi utilizada uma matriz de dimensões M×K denominada U , onde M representa o número de objetos e K são os possíveis valores que a afinidade
pode assumir. Todo spel que pertença ao objeto m com afinidade k estará armazenada em uma lista ligada [Cormen et al. 2001] cujo nó cabeça é U[m][k]. Esta implementação é mais eficaz, com uma complexidade de espaço na ordem de O(M(K+V))se todas as estruturas de dados puderem ser armazenadas na memória principal.
Algoritmo 2.1: Fast MOFS
1 f o r c∈V do
2 f o r m←0 t o M do
3 σcm←0
4 end- f o r
5 end- f o r
6 f o r m←1 t o M do
7 f o r c∈Vm do
8 σc0←σcm←1
9 end- f o r
10 U[m][1]←Vm
11 f o r k←2 t o K do
12 U[m][k]←∅
13 end- f o r
14 end- f o r
15 f o r k←1 t o K do
16 f o r m←1 t o M do
17 w h i l e U[m][k]6=∅ do
18 remove um spel d do conjunto U[m][k]
19 C← {c∈V |σmc <min(ak,ψm(d,c)) and σc0≤min(ak,ψm(d,c))}
20 w h i l e C6=∅ do
21 remove um spel c do conjunto C
22 t←min(ak,ψm(d,c))
23 i f σc0<t t h e n
24 remove c do conjunto U[m][k]
25 f o r n←1 t o M do
26 σcn←0
27 end- f o r
28 end- i f
29 σc0←σcm←1
30 i n s e r e c no c o n j u n t o U[m][l] o n d e l é o i n t e i r o al =t
31 end- w h i l e
32 end- w h i l e
33 end- f o r
Segmentação Fuzzy de Vídeos
Chung et al. [Chung et al. 2008] propõe um método automático para segmentação de objetos de seu background em vídeos. Estes objetos devem ser aproximadamente estáticos porém rodeados por regiões em movimento. Já Byun et al. [Byun et al. 2003] propôs uma abordagem para detecção automática de faces em vídeos coloridos usando um algoritmo de decisão fuzzy. Este algoritmo detecta as faces usando a distribuição espacial das cores no modelo YCbCr. Estes dois métodos se mostram bastante limitados,
o primeiro pelo tipo de movimento presente nos objetos do vídeos, enquanto o segundo se restringe a segmentar faces detectando regiões que contenham cores semelhantes à peles faciais.
Neste trabalho, o algoritmo de segmentação Fuzzy descrito por Herman e Carvalho [Herman e Carvalho 2001] foi estendido para segmentar vídeos coloridos. Um vídeo é formado por uma sequência de uma ou mais imagens (também chamadas de quadros ou
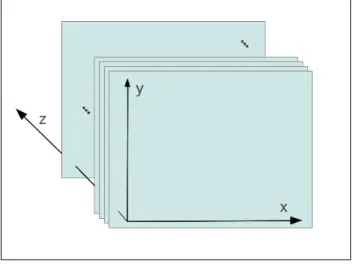
frames) de uma cena, capturadas ao longo do tempo. Este vídeo pode ser tratado como
um volume, como podemos ver na Figura 3.1. Este volume terá largura e altura (eixos x e y respectivamente) iguais as do vídeo de entrada, e a profundidade (eixo z) será igual a quantidade de frames do vídeo.
O algoritmo de segmentação implementado neste trabalho usa os vizinhos adjacentes de face para expandir as regiões a serem segmentadas (Figura 3.2). Caso a segmentação seja de uma imagem, os vizinhos de um pixel(x,y)serão:(x+1,y),(x−1,y),(x,y+1)e
(x,y−1)(Figura 3.2-a). Já se a segmentação for de um vídeo, caso em que este é tratado como um volume 3D, os vizinhos de um pixel(x,y,z)serão:(x+1,y,z),(x−1,y,z),(x,y+
Figura 3.1: Conjunto de Frames de um vídeo formando um volume.
Na Figura 3.3 podemos observar o primeiro e o septuagésimo frames de um vídeo sintético. Uma vez que todos os objetos em que deseja-se segmentar o vídeo encontram-se visíveis no primeiro frame, Figura 3.3-(a), pode-encontram-se escolher as encontram-semente necessárias para cada objeto neste frame. Porém, no septuagésimo frame o avião vem de uma oclusão total causada pela pilha de toros. Isso impossibilita que a região que compreende o avião cresça corretamente para os frames situados após a oclusão, sendo necessária a adição de mais pontos sementes em algum dos frames que sucedam a oclusão.
O aplicativo FuSe Tool (Fuzzy Segmentation Tool) foi desenvolvido para auxiliar a segmentação de imagens e vídeos. Nela o usuário pode navegar entre os frames de um vídeo e adicionar ou remover sementes nestes, fazendo uso de uma interface gráfica de fácil interação.
3.1
Segmentação com Múltiplos Canais
Figura 3.2: Vizinhanças usadas no algoritmo de segmentação. Em (a), vinhança de 4 usada em segmentações de apenas uma imagem; Em (b), vizinhança de 6 usada na seg-mentação de volumes.
(a) (b)
Figura 3.3: Exemplo de oclusão em um vídeo. Em (a), temos o primeiro frame, onde serão inseridas as sementes. Em (b), tem-se o septuagésimo frame, no qual o avião vem de uma oclusão causada pela pilha de torus.
3.2
Seleção de Canais de Cores
Como foi citado na seção anterior, existem diversos modelos de cores na literatura que tentam mensurar diversas características de cores, podendo estes serem mais adequados, ou não, para uma determinada aplicação. Desta forma, este trabalho propõe um método para adaptar o algoritmo de segmentação à imagem a ser processada, escolhendo-se as melhores características.
A ideia é encontrar os canais de cores que consigam um maior grau de separabilidade entre as classes envolvidas no processo. Assim, podemos adaptar a segmentação para cada tipo de imagem em tempo de execução do algoritmo, modificando os canais usados para segmentar, de acordo com a imagem que será segmentada, permitindo uma maior precisão do algoritmo.
Neste trabalho usamos cinco modelos de cores, todos descritos na seção anterior. Po-rém, a escolha não se restringirá a selecionar qual modelo melhor segmentaria a imagem, buscamos, sim, uma combinação híbrida, dentre os canais que compõem cada modelo, que obtenha os melhores resultados. Destarte, se usarmos três canais de cores na seg-mentação, por exemplo, poderiam ser escolhidos os canais: Red (do modelo RGB), Hue (do modelo HSI) e Y (do modelo YCbCr). Mas também poderiam ser todos os canais do
modelo RGB ou de qualquer outro modelo.
Considerando uma combinação sem repetições de três canais dentre os 15 possíveis (três para cada um dos modelos considerados), teremos C15,3=455 combinações
diferen-tes. Devemos escolher a combinação que nos forneça a maior distância entre as cores de cada objeto.
Na Figura 3.4 podemos observar dois objetos: o boneco azul com intensidade em
RGB dos seus pixels igual a (0,0,255) e o círculo magenta com intensidade igual a
(255,0,255). Pode-se, assim, calcular a distância entre as cores dos objetos usando-se a distância euclidiana no R3através da equação
d2= (r1−r2)2+ (g1−g2)2+ (b1−b2)2 (3.1)
Deste modo, para o problema em questão, teríamos a distância d2= (0−255)2+ (0−
0)2+ (255−255)2=2552.
Figura 3.4: Exemplo de distância entre as cores de dois objetos.
Usando-se esta abordagem surge o seguinte problema: os objetos que compõem uma cena em uma imagem natural não possuem uma cor constante como no exemplo da Fi-gura 3.4. Esta variação pode ser causada por ruídos adicionados durante a aquisição da imagem, por variações de iluminação ambiente onde a imagem foi capturada, ou até mesmo por uma característica intrínseca da textura do objeto em questão. Pode-se con-tornar essa situação calculado-se, para cada canal, a média das intensidades dos pixels em toda região do objeto e utilizar esta medida para o cálculo da distância. Porém, surge um outro problema: as regiões que compõem os objetos não são conhecidas, pois este é o pro-blema cuja solução é aqui abordada. Entretanto, pode-se trabalhar com uma amostragem dos pixels que compõem os objetos, fazendo-se uso de uma das características deste algo-ritmo de segmentação: a interatividade. Neste método, o usuário escolhe pontos sementes em cada um dos objetos que se pretende segmentar.
O algoritmo desenvolvido permite que sejam especificados, em tempo de execução, quais e quantos serão os canais utilizados. Assim, foram feitos testes com as combinações de três, quatro e cinco canais dentre os quinze possíveis. Porém, para fins didáticos, vamos exemplificar como funciona o cálculo utilizado para encontrar a melhor combinação de dois canais (a mesma ideia pode ser estendida para uma combinação com mais canais).
RGB={ch1,ch2,ch3},
HSI ={ch4,ch5,ch6},
HSL={ch7,ch8,ch9},
I1I2I3={ch10,ch11,ch12},
YCbCr={ch13,ch14,ch15}.
. (3.2)
formando o conjunto ch={ch1,ch2,ch3, . . . ,ch14,ch15}.
Para cada objeto m={1,2,3, . . . ,M}, com M sendo o número de objetos a serem segmentados, calcula-se
• A média das intensidades em cada um dos canais:
µm={µmch1,µmch2, . . . ,µmch15}; (3.3)
• O desvio padrão para cada uma destas médias:
σm
={σmch1,σmch2, . . . ,σmch15}. (3.4)
Desta forma, a cor de cada objeto m pode ser representado como uma elipse em um plano cartesiano(x,y), com x e y sendo um par de canais do conjunto ch. O centro desta elipse é o ponto formado pelos valores das médias(µmx,µmy), enquanto os semi-eixos são os valores dos desvios padrões σmx e σmy. A distância mínima entre as cores dos objetos usando-se os canais x e y pode ser encontrada calculando-se a distância mínima entre as elipses. A melhor combinação de canais será a que tiver a maior das distâncias mínimas entre as elipses.
Dependendo da quantidade de canais que se deseja obter, esta simples elipse pode se tornar um hiper-elipsoide, aumentando a complexidade no cálculo das distâncias. Desta forma, como pode ser visto na Figura 3.5, a representação do objeto m pode ser simplifi-cada usando-se uma circunferência com raio rm=MAX{σmx,σmy}e centro cm= (µmx,µmy).
Calcula-se, então, as distâncias entre todas as circunferências, obtendo-se a distância
D(x,y):
D(x,y)=MIN{d1(x,y),d2(x,y), . . . ,dn(x,y)} (3.5)
com n sendo a quantidade de distâncias entre os M objetos, dada por
n= M∗(M−1)
Este mesmo cálculo é feito para todas as combinações de canais, C15,2=105, sendo
escolhida a combinação(p,q)com a maior distância D(p,q).
3.3
Função de Afinidade
Pela definição de Segmentação Fuzzy vista no Capítulo 2.4.3, cada objeto a ser seg-mentado possui uma função de afinidade. Esta função precisa representar com o máximo de precisão este objeto, de maneira que os valores de pertinência para os spels, ou ele-mentos da imagem, que pertençam a este objeto sejam os maiores possíveis.
Para todo objeto m que esteja usando esta função de afinidade, com 1≤m≤M, e M
sendo o número total de objetos, considere os seguintes conjuntos
•
S
m ={s1,s2,s3, . . . ,sηm} – Conjunto das sementes do m-ésimo objeto, com ηm
sendo o número total de sementes para este objeto;
•
A
smi – Conjunto de spels pertencentes à vizinhança da semente s
m
i do objeto m, com
1≤i≤ηm;
•
A
m ={A
sm1,
A
sm2,A
sm3, . . . ,A
smηm} – Combinação de todos os conjuntosA
smim, parai=1,2,3, . . . ,ηm.
Usando-se todos os pares de spels (p,q) adjacentes e pertencentes ao conjunto
A
m, sãoobtidas duas gaussianas
• ρµm1,σm
1, com µ
m
1 eσm1 sendo a média e o desvio padrão das médias (
p+q
2 ),
respecti-vamente; e
• ρµm2,σm
2, com µ
m
2 e σm2 sendo a média e o desvio padrão das diferenças absolutas
(|p−q|), respectivamente.
A função de afinidade (ψm) entre dois spels adjacentes (c,d) em relação ao objeto m é
dada por
ψm(c,d) =
0 se c e d não são adjacentes
ρµm1,σm1(c+2d)+ρµm2,σm2(|c−d|)
2 caso contrário
. (3.7)