Available Online at www.ijecse.org ISSN- 2277-1956
Approach for Developing Scientific News Aggregators
Using ATOM Feeds
Farha Shaikh 1, Anand Rajawat 2
1M.E. IV Sem, 2 Associate Professor 1,2
Shri Vaishnav Institute Of Technology & Science, Indore Shri Vaishnav Institute Of Technology & Science, Indore
Abstract- Scientists want to stay connected with everything that is new and innovative in the world, so they constantly read and analyze several online scientific resources such as magazines and journals. A user needs to do a lot of searching through on the web to locate the articles which are important to their interest. The idea of a news aggregator is not new to scientific world. A news aggregator is a software application, which periodically reads several sources and displays them on a separate page such as Google news. The information is stored in XML format. A scientific news aggregator helps in structuring online resources into useful contents. These contents are automatically fetched from several online resources available on the Internet and categorized on a separate page. Mostly, RSS feeds are used to done this job. Atom feeds are more detailed and having advance feature than RSS feeds, helps to improve the performance of scientific news aggregator by giving more updated information. A modern view of an aggregator offers a friendly user interface for users by merging the news content. We are working on an interesting approach for the design and implementation of news aggregators which will collect and aggregate data from the web to acquire unstructured information and transform it into data that could be understood and dynamically processed. The proposed approach will combine various mechanisms in order to connect to the data sources specified, identify the categories of articles, extract the corresponding pieces of news and automatically place them into the knowledge database and automatically extract the new pieces of information in the knowledge base and display them on the Science News section
I- INTDODUCTION
Universal scientific news sites such as sciencedaily.com! Scientific news or .npr.org scientific news attracts millions of users each month.
II. BACKGROUND
We brief introduce the principles and terminology about scientific news feeds. Although several versions of scientific news feeds identify formats that are compatible to a varying degree, they convey more or less the same content at a high level [7]. A feed in Atom terminology is a put at which related entries are published and is identified by a URL from which feed documents are fetched [8]. A feed text contains a list of entries as well as metadata about the feed itself such as the feed title and the published date. Every entry in turn contains a list of rudiments including the title of the entry, the link from which detailed information can be obtained, and the summary of the entry. The scientific news feed standards are anxious only with the document format. From a web server's perspective, fetching a feed document is the same as fetching a regular web document, using the original HTTP[5]. Thus, subscribing to a scientific news feed does not mean that feed documents are delivered automatically upon a change. It just means that subscribers fetch the matching URL frequently, either physically or through a client-side setup. Likewise, publishing a feed does not mean that publishers documents to subscribers. It is subscribers and their applications that should ensure the timely update of scientific news feeds. Nevertheless, these terms are used conventionally, and in this paper as well, to emphasize of readers regarding scientific news feeds. Starting as a means of syndicating web sites, the scientific news feed technology has evolved so much as to be used in various ways. For example, Mozilla web browsers provide Live Bookmarks [1], which treat a feed as a folder and the contained entries as bookmarks in it, while Microsoft's new operating system, code-named \Longhorn," supports this technology from a broader perspective [7]. In this paper, we focus on its most important functionality, delivering scientific news summaries. In particular, we explore the potential of sharing scientific news feeds among peers to expedite the dissemination and reduce the server loads.
III.ATOM SYNDICATION FORMAT
The Atom suite consists of the Atom Syndication Format [8] and the Atom feed The Atom Syndication Format is a XMLbased format for publishers to syndicate content in the form of so called Web or scientific news feeds. The Atom feeds, on the other hand, is an application-level protocol for publishing, editing, and deleting Web resources. The Atom Syndication Format consists of two kinds of documents: feed documents and entry documents. A feed document is, as the name suggests, the representation of an Atom feed. It contains metadata about the feed and some or all of the entries associated with the feed. An entry document describes exactly one feed item outside the context of an Atom feed. It is worth mentioning that Atom documents must be well formed XML but are not required to be valid XML because the specification does not include a Document Type Definition (DTD) for them. Atom is designed to be an extensible format and so foreign markup is allowed almost anywhere in an Atom document. The Atom feed describes how a feed can be manipulated by a client. The so called service document describes the location and capabilities of one or more collections, i.e., feeds, which are grouped into workspaces. That information is needed by clients for authoring to commence. Both, the Atom Syndication Format as well as the Atom Publishing Protocol, are fully based on the REST architectural style and thus extremely Web-friendly. This, and the above mentioned extensibility, led to the adoption of Atom feed for the implementation of various kinds of Web services. The most prominent examples might be the Google Data Protocol (GData) [9] and Microsoft’s Open Data Protocol (OData) [10]. They use Atom’s extensibility to implement APIs for their services. It is thus arguable that Atom is one of the world’s most successful RESTful Web service stories.
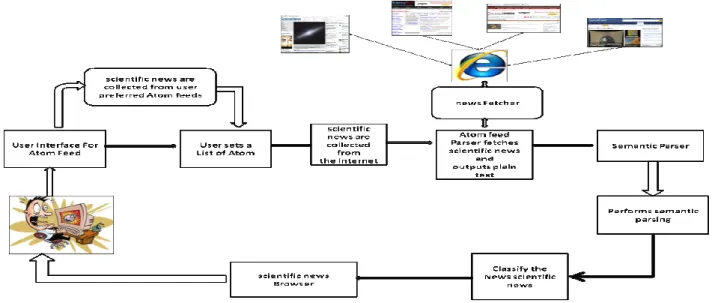
IV. THE SYSTEM ARCHITECTURE
classifying, clustering and delivering personalized Scientific news information extracted both form the Web and from Scientific news feeds. The system is made by the modules depicted in Figure 1. It has
New fetcher: This component gathers scientific news from a set of selected isolated news sources. It supports
different syndication formats, such as Atom [3] and RSS [4]. Besides, it is possible to feed the system with selected information extracted from remote Web pages. Currently, we selected a list of Scientific news sources consisting of about 1000 different Web journals. For competence reason, the space of Scientific news sources is partitioned and this module is composed by several processes which run in parallel. The data is collected 24h per day, and the stream of information is stored into a local database
The Scientifics NEWS Classifier: The image workstation module analyzes in sequence stored in the classified
database It tries to enrich any scientific news with an associated image. In the easy case he scientific news source has previously associated an image to given news in the RSS/Atom feed. This association is expressed as an HTML fragment, so we can easily download. The image nearby and create a suitable thumbnail of it. In other situations, we have scientific news, extracted by a Web page or by a RSS/Atom feed, with no associated image which refers to a Web page. We download locally any image contained in and use many heuristics to identify the most suitable image to be associated. We take in account contextual information (e.g. where the image is placed in the HTML source) as well as content information (e.g. image’s size, colors and other features).
The feature selection index: We use a feature selection index to design an efficient method for extracting
meaningful terms from the scientific news. As suggested in [9]. Feature data base is built at preprocessing time and then used for selecting and ranking on-the-fly key features used for scientific News classification and clustering.
The scientific news classifier: All the news in news data base needs to be classified. The categories defined in the
system are given in figure 1. We use a naive bayesan classifier. Note that a (relatively large) part of the RSS/Atom feed is already manually classified from the originating news source. As a consequence, the key idea for classifying is to use the classifier in a mixed mode: as soon as already classified scientific news by a scientific news source is seen, the classifier is switched in training mode; the remaining unclassified scientific news is categorized with the classifier in categorizing mode. The scientific news clustering: We adopt a variant k-means algorithm with distance threshold for creating a flat clustering structure, where the number of clusters is not known a-priori. This is much useful for discovering similar scientific news or scientific news mirrored by many sources.
The scientific news ranker Ranking news is a task rather different than Web page ranking. From one side, we can
expect a less amount of spam since the scientific news come from controlled sources. From other hand, when a scientific news is posted it is a fresh kind of information. Therefore, there is almost no hyperlink pointing to it. In a companion paper [6], we describe a scientific news ranking algorithm which ranks both scientific news and sources, and takes in account many different factors such as:
(1) Scientific news freshness
(2) Scientific news clustering aggregation
(3) Importance of the source posting the scientific news. Our running prototype have used a ranking algorithms based on (1) and (2) for months.
Implementation Atom Feed
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <?xml-stylesheettype="text/xsl"href="http://
http://esciencenews.com//your_xslt.xsl"?> <feed xmlns="http://www.w3.org/2005/Atom"> <id>http:// http://esciencenews.com//atom.xml</id> <title> scientific news </title>
<updated>2012-11-01T00:00:02Z</updated>
<link rel="self" href="http:// esciencenews.com /atom.xml" type="application/atom+xml" />
<author> <name>scientific news </name> <uri>http:// esciencenews.com </uri> <email>[email protected]</email>
</author> <entry> <title>
wind.concentrates.pollutants.with.unexpected.order.urban.enviro nment </title>
<category term="Some Category"/> <id>http://
http://esciencenews.com/topics/biology.nature.html</id> <published>2012-11-01T00:00:00Z</published> <updated>2012-11-01T00:00:00Z</updated> <link
href="http://http://esciencenews.com/topics/mathematics.econo mics.html"/><summary> Wind concentrates pollutants with unexpected order in an urban environment.</summary> <content> http://esciencenews.com/latest_science </content>
</entry> </feed>.
Classified and Clustered scientific news coming from news database are indexed by this module, which produces
an inverted list index. For each scientific news we store the source, the url, the title, the associated category, the description, a rank value, and the publication date.
User interface for atom feed Query and scientific news Browsing interface: The index is accessed by the search
and browsing interface. A typical user can access the scientific news by category, search within any category and search all the indexed scientific news. All the results are available with a public Web interface. Besides, we provide an atom feeds search mode. Using this feature, a user can submit a list of keywords and she receives a permanent XML feed with the most updated scientific news about that topic. In this way, acts as a public aggregator for scientific news feeds.
Personalized alerting agent: We integrated a alerting system, which produces a personalized daily summary of the
scientific news chosen by users. In fact, each user can login into the system and record a private set of queries. As soon as fresh and related scientific news appears into the system, it is aggregated into a on interface sent daily to the user. Information about users is stored in a local database
History Tracker: Helper modules provide other services available through the Web interface. They are:
(i) Top Ten, the most accesses scientific news for each category;
(ii) Top scientific news Sources, the most active scientific news sources for each category;
(iii) newest scientific news the list of most frequent named entities dynamically extracted at query time from each category.
V. SCIENTIFIC NEWS AGGREGATORS
Service (SRS). These supplemental semantic descriptions of the service’s properties can in consequence lead to higher level of automation for tasks like discovery, composition, and invocation. Since most Semantic Web Service technologies use ontologies as the underlying data model they also provide means for tackling the interoperability problem at the semantic level and, more importantly, enable the integration of Web services within the Semantic Web. After a number of efforts semantic annotation of SOAP-based services is now preferably addressed by the W3C recommendation Semantic Annotations for WSDL and XML Schema.
FIG 1: SYSTEM ARCHITECTURE FOR SCIENCTIFICE NEWS AGGREGATOR
VI. CONCLUSION
Today, we appear to be besieged with information: on News paper, Television, at the radio, but mostly on the Internet. Sometimes, the user needs to do a lot of searching and browsing in order to find what he is looking for. In this context, the idea of news aggregators becomes more and more popular. Search represents another challenge, because of the intended purposes and the un-uniformity of the web content, as there are many concepts, standards and ongoing projects that present another philosophy to information search. Various implementations of search prove the necessity and the imminence of adopting the semantic Web [10]. Science NEWS confirmed its potential as a scientific news aggregator, based on knowledge base developed on the concept of atom feeds. Our application proved its capacity to take over unstructured information from the Web and transform it into data that can be understood and dynamically processed by machines. However, the end-users of our site are people interested in the scientific world, so the application has a friendly interface
Reference
[1] Antonellis, I., Bouras, C., and Poulopoulos, V., “Personalized news categorization through scalable text classification.”, Proceedings of the 8th Asia-Pacific Web Conf, Harbin, China, 2006. pp. 391-401.
[2] Bacan, H., I. S. Pandzic, and D. Gulija, “Automated News Item Categorization”, Proceedings of the 19th Annual Conference of The Japanese Society for Artificial Intelligence, Springer-Verlag, Kitakyushu, Japan, 2005, pp. 251-256.
[3] Shaikh Mostafa Al Masum1, Helmut Prendinger2, Mitsuru Ishizuka1” Emotion Sensitive News Agent: An Approach Towards User Centric Emotion Sensing from the News Japan 2007 IEEE/WIC/ACM International Conference on Web Intelligence,pp124 -614
[4] K. G. Anagnostakis and M. B. Greenwald. Exchange-based incentive mechanisms for peer-to-peer _le sharing. In Proceedings of the 24th IEEE International Conference on Distributed Computing Systems (ICDCS), pages 524{533, 2004.
[7] R. C. Morin, “Howto rss feed state,” Internet (Visitada em10/05/2005), 2005, uRL: http://www.kbcafe.comrssrssfeedstate.html. [8] Zhao, C., L. Wan, and Y. Yu, ”Construction of a Distributed Learning Resource Management System Based on RSS Technology,”
Proceedings of the 36th Annual Frontiers in Education Conference, October 2006, pp. 3-6.
[9] Sia, K.C., J. Cho, and H.K. Cho, ”Efficient Monitoring Algorithm for Fast News Alerts,” IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 7, July 2006, pp. 950-961.