UNIVERSIDADEFEDERALDO RIO GRANDE DO NORTE Programa de P´os-Gradua¸c˜ao em Engenharia El´etrica
Modelagem de Superf´ıcies Seletivas de
Freq¨
uˆ
encia e Antenas de Microfita
utilizando Redes Neurais Artificiais
Patric Lacouth da Silva
Orientador: Prof. Dr. Adaildo Gomes D’Assun¸c˜ao
Disserta¸c˜ao de Mestrado
apre-sentada ao Programa de P´os-Gradua¸c˜ao em Engenharia El´etrica da UFRN (´area de concentra¸c˜ao: Telecomunica¸c˜oes) como parte dos requi-sitos para obten¸c˜ao do t´ıtulo de Mestre em Ciˆencias.
Silva, Patric Lacouth.
Modelagem de Superf´ıcies Seletivas de Freq¨uˆencia e Antenas de Microfita utilizando Redes Neurais Artificiais, / Patric Lacouth da Silva - Natal, RN, 2006
65 p. : il.
Orientador: Adaildo Gomes D’Assun¸c˜ao
Disserta¸c˜ao (Mestrado) - Universidade Federal do Rio Grande do Norte. Centro de Tecnologia. Programa de P´os-Gradua¸c˜ao em Engenharia El´etrica.
1. Dispositivos de Microondas - Disserta¸c˜ao. 2. Redes Neurais Artificiais - Disserta¸c˜ao. 3. Antenas de microfita - Disserta¸c˜ao. I. D’Assun¸c˜ao, Adaildo Gomes. II. Universidade Federal do Rio Grande do Norte. III. T´ıtulo.
Freq¨
uˆ
encia e Antenas de Microfita
utilizando Redes Neurais Artificiais
Patric Lacouth da Silva
Disserta¸c˜ao de Mestrado aprovada em 09 de Junho de 2006 pela banca examinadora composta pelos seguintes membros:
Prof. Dr. Adaildo Gomes D’Assun¸c˜ao (orientador) . . . UFRN
Prof. Dr. Humberto Abdalla J´unior . . . UNB
Prof. Dr. Paulo Henrique da Fonseca Silva . . . CEFET-PB
Aos meus pais, C´ıcero Lopes e Auricl´eia Lacouth, por sempre acreditarem e
apoi-arem minhas decis˜oes, a minha irm˜a, Patr´ıcia Lacouth, que esteve sempre presente
com paciˆencia e compreens˜ao.
Ao meu orientador, Professor Adaildo Gomes D’Assun¸c˜ao, que acreditou e tornou
poss´ıvel a realiza¸c˜ao deste trabalho com sua paciˆencia e sabedoria.
Aos meus trˆes grandes amigos, Danilo Lima, M´arcio Passos e Rafael Marrocos
que contribuiram e estiveram sempre presentes em todo o curso de mestrado.
Ao Professor Adri˜ao Duarte pelas id´eias e d´uvidas respondidas.
Ao Professor Ronaldo Martins que foi sempre compreens´ıvel e paciente com a
parte pr´atica do trabalho.
Aos Professores do CEFET-PB que incentivaram para o in´ıcio do mestrado.
Ao CNPQ pelo apoio financeiro.
Sum´ario i
Lista de Figuras iii
Lista de Tabelas v
Lista de S´ımbolos e Abreviaturas vi
Resumo viii
Abstract ix
1 Introdu¸c˜ao 1
2 Redes Neurais Artificiais 4
2.1 Introdu¸c˜ao . . . 4
2.2 Redes Neurais Artificiais e Eletromagnetismo . . . 4
2.3 Modelagem Neural de Dispositivos de Microondas . . . 5
2.4 Gera¸c˜ao de Dados . . . 6
2.4.1 Gera¸c˜ao de dados a partir de medi¸c˜oes . . . 6
2.4.2 Gera¸c˜ao de dados a partir de simula¸c˜oes . . . 7
2.5 Neurˆonio Perceptron . . . 7
2.6 A Rede Perceptron de M´ultiplas Camadas . . . 8
2.6.1 Treinamento de Redes MLP . . . 10
2.7 Redes de Fun¸c˜ao de Base Radial . . . 15
2.7.1 Treinamento utilizando sele¸c˜ao auto-organizada dos centros . . 17
2.7.2 Treinamento utilizando sele¸c˜ao supervisionada dos centros . . 18
2.8 Compara¸c˜ao entre redes MLP e RBF . . . 19
2.9 Overlearning e Underlearning . . . 20
3 Superf´ıcies Seletivas de Freq¨uˆencias 22
3.1 Introdu¸c˜ao . . . 22
3.2 Caracter´ısticas de FSS . . . 22
3.3 Elementos de FSS . . . 23
3.4 Arranjos Passivos e Arranjos Ativos . . . 25
3.5 T´ecnicas de Medi¸c˜ao . . . 26
3.6 T´ecnicas de An´alise . . . 26
3.7 Aplica¸c˜oes . . . 27
3.8 Conclus˜ao . . . 28
4 Antenas de Microfita 30 4.1 Introdu¸c˜ao . . . 30
4.2 Configura¸c˜oes de Patches . . . 32
4.3 Arranjo de Antenas . . . 34
4.4 M´etodos de Alimenta¸c˜ao . . . 35
4.5 Conclus˜ao . . . 37
5 Resultados Experimentais 39 5.1 Introdu¸c˜ao . . . 39
5.2 Modelagem Neural de Superf´ıcies Seletivas de Freq¨uˆencia . . . 39
5.3 Modelagem Neural de Antenas de Microfita tipo E-Shaped . . . 51
5.4 Modelagem Neural de Antenas de Microfita com patch afilado . . . . 54
5.5 Modelagem Neural de Arranjo TSA . . . 58
6 Conclus˜oes 60
2.1 Neurˆonio perceptron. . . 8
2.2 Exemplo de uma fun¸c˜ao tangente hiperb´olica. . . 9
2.3 Exemplo de configura¸c˜ao t´ıpica de uma rede perceptron de m´ultiplas camadas. . . 10
2.4 Exemplo de configura¸c˜ao t´ıpica de uma rede RBF . . . 15
2.5 Exemplo de uma fun¸c˜ao de base radial do tipo sample. . . 17
3.1 Exemplos de tipos de c´elulas condutoras utilizadas em superf´ıcies sele-tivas de freq¨uˆencia. (a) Elementospatches e (b) Elementos de abertura. 23 3.2 Exemplos de patches utilizados em FSS. . . 24
3.3 Exemplo de sistema de medi¸c˜ao de FSS. . . 27
3.4 Exemplo de uma aplica¸c˜ao de Superf´ıcies Seletivas de Freq¨uˆencias . . 28
4.1 Antena de Microfita com patch retangular. . . 30
4.2 Exemplos dos patches condutores mais comuns. . . 32
4.3 Geometria de um patch E-Shaped. . . 33
4.4 Geometria de um patch afilado. . . 34
4.5 Exemplo de um arranjo TSA. Os elementos s˜ao separados por hastes met´alicas e o arranjo ´e suportado por um plano terra em z = -t. . . . 35
4.6 Alimenta¸c˜ao atrav´es de uma linha de microfita. . . 36
4.7 Alimenta¸c˜ao utilizando cabo coaxial. . . 37
4.8 Alimenta¸c˜ao utilizando acoplamento por abertura. . . 37
4.9 Alimenta¸c˜ao atrav´es de acoplamento por proximidade eletromagn´etica. 38 5.1 Exemplo de uma estrutura FSS. . . 40
5.2 Resposta da rede MLP para diferentes valores de h . . . 41
5.3 Evolu¸c˜ao do erro da rede MLP para o primeiro conjunto de treinamento. 42 5.4 Erro de treinamento do segundo exemplo. . . 43
5.6 Resposta da rede MLP para diferentes valores de w . . . 45
5.7 Erro de treinamento do terceiro exemplo. . . 45
5.8 Resposta da rede MLP para diferentes valores de ǫr . . . 47
5.9 Erro de treinamento para exemplo da varia¸c˜ao de ǫr. . . 47
5.10 Sa´ıda da rede MLP para diferentes valores de L . . . 48
5.11 Erro ao longo do processo de aprendizagem do quinto conjunto de treinamento. . . 49
5.12 Compara¸c˜ao entre dados medidos e simulados . . . 50
5.13 Exemplo de um patch E-shaped. . . 51
5.14 Conjunto de treinamento utilizada na modelagem da antena E-Shaped. 52 5.15 Curva de aprendizagem para o conjunto de treinamento da antena E-Shaped. . . 53
5.16 Generaliza¸c˜ao da rede treinada com dados da antena E-Shaped. . . . 54
5.17 Exemplo de um patch afilado . . . 55
5.18 Resultados da RNA para o conjunto de treinamento (—), e compa-ra¸c˜ao com MoM (∗) . . . 56
5.19 Resultados da RNA para valores fora do conjunto de treinamento (—), e compara¸c˜ao com MoM (∗) . . . 56
5.20 Erro durante o processo de treinamento da modelagem da antena de patch afilado . . . 57
5.21 Exemplo de uma antena slot utilizada no arranjo TSA, todas as di-mens˜oes est˜ao em cm. . . 58
2.1 Compara¸c˜ao entre gera¸c˜ao de dados medidos e simulados. . . 7
2.2 Fun¸c˜oes de ativa¸c˜ao mais utilizadas. . . 9
5.1 Dados da geometria e treinamento do 1o conjunto de FSS. . . 40
5.2 Dados da geometria e treinamento do 2o conjunto de FSS (Freestan-ding). . . 42
5.3 Dados da geometria e treinamento do 3o conjunto de FSS . . . 44
5.4 Dados da geometria e treinamento do 4o conjunto de FSS . . . 46
5.5 Dados da geometria e treinamento do 5o conjunto de FSS . . . 48
5.6 Parˆametros estruturais da antena planar com fendas paralelas . . . . 52
5.7 Parˆametros estruturais da antena planar com patch afilado. . . 55
α Termo momento
∆ Valor de atualiza¸c˜ao dos pesos sin´apticos
η Coeficiente de aprendizagem
Γ Coeficiente de reflex˜ao
λ Comprimento de onda
∇ Gradiente
σ Desvio Padr˜ao
σ Vetor de centros das Fun¸c˜oes de Base Radial
θ Bias
ϕ() Fun¸c˜ao de base radial
BP Backpropagation
d Vetor de sa´ıdas desejadas
E() Fun¸c˜ao Custo
Ei Onda plana incidente
Er Onda plana refletida
Et Onda plana transmitida
Emed Energia m´edia do erro quadr´atico
I Vetor de entrada da rede
Rprop Resilient BackPropagation
T Coeficiente de transmiss˜ao
Tr Conjunto de treinamento
w Vetor de pesos sin´apticos
x Vetor de parˆametros de entrada
y Vetor de comportamento dos dispositivos
y′() Aproxima¸c˜ao do Modelo Neural para vetor de comportamenty
ANN Artificial Neural Network
CPW Coplanar Waveguide
EBG Eletromagnetic Bandgap
FDTD Finite Difference Time Domain
FEM Finite Element Method
FSS Frequency Selective Surface
MLP Multilayer Perceptron
MoM Method of Moments
RBF Radial Basis Function
RF R´adio Freq¨uˆencia
RFID Radio Frequency Identification
RNA Redes Neurais Artificiais
Este trabalho tem como principal objetivo a aplica¸c˜ao de Redes Neurais Artifi-ciais, RNA, na resolu¸c˜ao de problemas de dispositivos de RF/microondas, como por exemplo a predi¸c˜ao da resposta em freq¨uˆencia de algumas estruturas em uma regi˜ao de interesse.
As Redes Neurais Artificiais se apresentam como uma alternativa aos m´etodos atuais de an´alise de estrutura de microondas, pois s˜ao capazes de aprender, e o mais importante generalizar o conhecimento adquirido, a partir de qualquer tipo de dado dispon´ıvel, mantendo a precis˜ao da t´ecnica original utilizada e aliando o baixo custo computacional dos modelos neurais. Por esse motivo, as redes neurais artificiais s˜ao cada vez mais utilizadas para a modelagem de dispositivos de microondas. S˜ao utili-zados neste trabalho os modelosPerceptron de M´ultiplas Camadas e de Fun¸c˜oes de Base Radiais. S˜ao descritas as vantagens/desvantagens de cada um desses modelos, assim como os algoritmos de treinamento referentes a cada um deles.
Dispositivos planares de microondas, como Superf´ıcies Seletivas de Freq¨uˆencias e as antenas de microfita, ganham cada vez mais destaque devido `as necessidades crescentes de filtragem e separa¸c˜ao de ondas eletromag´eticas e `a miniaturiza¸c˜ao de dispositivos de R´adio-Freq¨uˆencia. Por isso ´e de importˆancia fundamental o estudo dos parˆametros estruturais desses dispositivos de forma r´apida e precisa.
Os resultados apresentados, demonstram as capacidades das t´ecnicas neurais para modelagem de Superf´ıcies Seletivas de Freq¨uˆencia e antenas.
Palavras-chave: Dispositivos de Microondas, Redes Neurais Artificiais, Super-f´ıcies Seletivas de Freq¨uˆencia, Antenas de Microfita.
This work has as main objective the application of Artificial Neural Networks, ANN, in the resolution of problems of RF/microwaves devices, as for example the prediction of the frequency response of some structures in an interest region.
Artificial Neural Networks, are presently a alternative to the current methods of analysis of microwaves structures. Therefore they are capable to learn, and the more important to generalize the acquired knowledge, from any type of available data, keeping the precision of the original technique and adding the low computational cost of the neural models. For this reason, artificial neural networks are being increasily used for modeling microwaves devices. Multilayer Perceptron and Radial Base Functions models are used in this work. The advantages/disadvantages of these models and the referring algorithms of training of each one are described.
Microwave planar devices, as Frequency Selective Surfaces and microstrip an-tennas, are in evidence due the increasing necessities of filtering and separation of eletromagnetic waves and the miniaturization of RF devices. Therefore, it is of fun-damental importance the study of the structural parameters of these devices in a fast and accurate way.
The presented results, show to the capacities of the neural techniques for mode-ling both Frequency Selective Surfaces and antennas.
Keywords: Microwave Devices, Artificial Neural Networks, Frequency Selective Surfaces , Microstrip Antennas.
Introdu¸
c˜
ao
O avan¸co tecnol´ogico ocorrido nos ´ultimos anos no desenvolvimento de estru-turas e dispositivos com tecnologia planar decorre da necessidade crescente de se conceber circuitos, com dimens˜oes e peso cada vez menores, para as mais diversas aplica¸c˜oes (na ´area aeroespacial, nas comunica¸c˜oes sem fio, em redes de sensores, no rastreio de produtos e animais - RFID, na terapia e tratamento cl´ınico, etc) [Campos, 1999] [REDPRAIRIE, 2003]. Nas ´areas aeroespaciais e de comunica¸c˜oes, observa-se que uma aten¸c˜ao especial tem sido dedicada ao estudo de superf´ıcies seletivas de freq¨uˆencia (Frequency Selective Surfaces - FSS) [Campos et al., 2002]
As superf´ıcies seletivas de freq¨uˆencia s˜ao estruturas peri´odicas bidimensionais que se comportam como filtros eletromagn´eticos passa-alta, passa-baixa ou passa-faixa, de acordo com sua configura¸c˜ao. As estruturas peri´odicas tˆem um grande n´umero de aplica¸c˜oes e tˆem contribu´ıdo significativamente para melhorar o desempenho dos circuitos de comunica¸c˜oes com destaque especial para a sua utiliza¸c˜ao nos sistemas de antenas de miss˜oes espaciais comoVoyager, GalileoeCassini[Romeu and Ramhmat-Samii, 2000].
Antenas em tecnologia planar (microfita) s˜ao muito utilizadas devido as suas v´arias vantagens como tamanho, peso, facilidade de constru¸c˜ao, conformidade e facilidade de integra¸c˜ao com circuitos impressos, al´em de apresentarem bom desem-penho el´etrico [Yang et al., 2001]. Atualmente essas antenas est˜ao embutidas em diversos aparelhos el´etricos/eletrˆonicos usados na comunica¸c˜ao via r´adio e em es-ta¸c˜oes de transmiss˜ao/recep¸c˜ao. Devido a todas essas caracter´ısticas esse modelo de antena tem sido utilizado em v´arias aplica¸c˜oes comerciais e militares como an-tenas de celulares, dispositivos Bluetooth, atividades biom´edicas, avi˜oes, sat´elites e m´ısseis [Balanis, 1997].
Apesar das superf´ıcies seletivas de freq¨uˆencia e antenas de microfita serem es-truturas pequenas e de simples constru¸c˜ao, muitas configura¸c˜oes desses dispositivos apresentam complexidades que dificultam a an´alise atrav´es de m´etodos eletromagn´e-ticos convencionais (M´etodo da Linha de Transmiss˜ao, Potenciais Auxiliares, etc.), ou exigem um elevado custo computacional das t´ecnicas num´ericas (M´etodo dos Mo-mentos, Elementos Finitos, etc.), apresentando assim um cen´ario onde a utiliza¸c˜ao de redes neurais artificiais para resolu¸c˜ao de determinados problemas torna-se uma alternativa aos m´etodos tradicionais [Gupta and Zhang, 2000].
As Redes Neurais, tamb´em chamadas de Redes Neurais Artificiais (RNAs), s˜ao sistemas processadores de informa¸c˜ao inspirados na habilidade do c´erebro humano de aprender de observa¸c˜oes e generalizar por abstra¸c˜ao. O fato das redes neurais artificiais serem capazes de aproximar rela¸c˜oes de entrada/sa´ıda arbitr´arias [Silva, 2002] tem levado a sua utiliza¸c˜ao para aplica¸c˜oes totalmente diferentes, resultando no seu uso nas mais diversas ´areas como reconhecimento de padr˜oes, processamento de voz, controle, aplica¸c˜oes m´edicas e muitas outras. A introdu¸c˜ao de redes neurais no campo do eletromagnetismo marca o nascimento de uma alternativa n˜ao conven-cional para problemas de projetos e modelamentos de estruturas [Gupta and Zhang, 2000].
Diversas caracter´ısticas interessantes, sobre redes neurais artificiais, s˜ao apresen-tadas [Silva, 2002]:
• Nenhum conhecimento sobre o mapeamento ´e necess´ario para o desenvolvi-mento de uma RNA. As rela¸c˜oes s˜ao inferidas atrav´es de exemplos de treina-mento.
• As RNAs podem generalizar, o que significa que elas s˜ao capazes de responder a exemplos novos, dentro da regi˜ao de interesse, definida na fase de treinamento.
• As Redes Neurais Artificiais, teoricamente, s˜ao capazes de aproximar qualquer mapeamento cont´ınuo n˜ao linear.
de estruturas citadas anteriormente. Os dispositivos escolhidos para o modelamento foram superf´ıcies seletivas de freq¨uˆencia formadas por elementos do tipo patch so-bre um substrato diel´etrico, antenas de microfita retangulares de fendas paralelas incorporadas sobre o patch condutor [da Silva and D’Assun¸c˜ao, 2006] [Yang et al., 2001], antenas de microfita compatch afilado, e arranjo de antenasslot com fendas (Tapered Slot Array - TSA) [Chio and Schaubert, 2000].
As redes neurais artificiais aplicadas a problemas de eletromagnetismo podem ser treinadas a partir de diversos tipos de dados, que podem ser obtidos atrav´es de simula¸c˜oes ou medi¸c˜oes. Neste trabalho, s˜ao apresentados os resultados obtidos utilizando as duas op¸c˜oes, para o caso da FSS [Campos, 1999] e da antena afilada optou-se por utilizar dados simulados obtidos atrav´es do m´etodo dos momentos. No caso da antena de microfita com fendas, o treinamento das redes neurais artificiais foi executado utilizando amostras de valores medidos. Em rela¸c˜ao ao arranjo TSA os dados foram obtidos a partir de resultados encontrados na literatura [Chio and Schaubert, 2000].
S˜ao apresentados no Cap´ıtulo 2 os conceitos de Redes Neurais Artificiais, compa-ra¸c˜oes entre os modelos MLP (Perceptronde m´ultiplas camadas) e RBF (Fun¸c˜oes de Base Radial), descri¸c˜ao dos algoritmos de treinamento utilizados durante o trabalho, compara¸c˜ao entre a gera¸c˜ao de dados medidos e simulados.
Nos Cap´ıtulos 3 e 4, s˜ao descritos os comportamentos eletromagn´eticos das Su-perf´ıcies Seletivas de Freq¨uˆencia e das antenas de microfita, suas aplica¸c˜oes, t´ecnicas de medi¸c˜ao, configura¸c˜oes e aplica¸c˜oes. Apresentando os dispositivos modelados no trabalho.
No Cap´ıtulo 5, s˜ao apresentados os resultados obtidos atrav´es dos modelos neu-rais para a modelagem de cinco estruturas FSS, para as antenas de microfita com fendas paralelas, para antena planar com patch afilado e para o arranjo de antenas
slot, bem como, a evolu¸c˜ao do erro de aprendizagem de cada rede neural artificial treinada.
Redes Neurais Artificiais
2.1
Introdu¸
c˜
ao
Na sua forma mais geral, uma rede neural ´e uma m´aquina que ´e projetada para modelar a maneira como o c´erebro realiza uma tarefa particular ou fun¸c˜ao de inte-resse. A rede ´e normalmente implementada utilizando-se componentes eletrˆonicos ou ´e simulada por programa¸c˜ao em um computador. Para alcan¸carem bom desempe-nho, as redes neurais empregam uma interliga¸c˜ao maci¸ca de c´elulas computacionais simples denominadas “neurˆonios” ou “unidades de processamento” [Haykin, 2001].
Em 1943, McCulloch, um neurobiologista, e Pitts, um estat´ıstico, publicaram um artigo intitulado: A logical calculus of ideas imminet in nervous activity. Esse artigo inspirou o desenvolvimento do computador digital. Aproximadamente na mesma ´epoca, Frank Rosenblatt tamb´em motivado pelo mesmo artigo iniciando sua pesquisa sobre modelamento do olho humano, que eventualmente levou `a primeira gera¸c˜ao de redes neurais artificiais, conhecidas como perceptron [Hu and Hwang, 2002].
2.2
Redes Neurais Artificiais e Eletromagnetismo
As redes neurais artificiais se apresentam como modelos alternativos para o pro-jeto e modelagem de circuitos e estruturas que trabalham na faixa de microondas. A capacidade de aprendizagem e generaliza¸c˜ao de dados podem produzir uma fer-ramenta r´apida e eficiente para circuitos integrados de microondas, mesmo quando as formula¸c˜oes te´oricas n˜ao est˜ao dispon´ıveis. Trabalhos recentes tˆem utilizado as redes neurais artificiais para o modelamento de linhas de microfita, descontinuidades
CPW, projeto e an´alise de antenas [Chistodoulou and Georgiopoulos, 2001]. Uma vez treinados com um conjunto de dados relevantes os modelos neurais s˜ao computa-cionalmente mais eficientes do que m´etodos eletromagn´eticos e mais precisos que os m´etodos emp´ıricos. A principal dificuldade das t´ecnicas que utilizam redes neurais artificiais ´e a necessidade de um n´umero de amostras relativamente grande, uma vez que as simula¸c˜oes/medi¸c˜oes devem executar v´arias combina¸c˜oes de caracter´ısticas do dispositivo.
2.3
Modelagem Neural de Dispositivos de
Micro-ondas
Seja, x um vetor que cont´em os parˆametros de um dispositivo de microondas qualquer, ey um vetor contendo o comportamento em freq¨uˆencia desse dispositivo. A rela¸c˜ao te´orica entre x e y pode ser representada como:
y=f(x) (2.1)
A rela¸c˜ao f pode ser n˜ao-linear e multidimensional. Na pr´atica o modelo te´orico dessa rela¸c˜ao pode ainda n˜ao estar dispon´ıvel (como por exemplo para um novo dispositivo semicondutor), ou a teoria existente do problema pode ser complicada de implementar ou possua um elevado custo computacional [Gupta and Zhang, 2000]. Para superar essas limita¸c˜oes, modelos neurais para substituir a rela¸c˜aof, precisa e eficientemente podem ser desenvolvidos atrav´es de dados, obtidos por medi¸c˜oes ou simula¸c˜oes, chamados de conjunto de treinamento. O conjunto de treinamento ´e caracterizado por pares de entrada/sa´ıda, {(xk, dk), k ∈ Tr}, onde dk representa a
sa´ıdaysimulada ou medida com rela¸c˜ao a entradaxk, eTro conjunto de treinamento.
As sa´ıdas e entradas, ent˜ao podem ser relacionadas:
dk=f(xk) (2.2)
O modelo neural pode ser defindo:
y =y′(x, w) (2.3)
E(w) =
k∈Tr
Ek(w) (2.4)
onde Ek(w) ´e o erro entre a predi¸c˜ao da rede neural e ak-´esima amostra de
treinamento.
O treinamento de redes neurais artificiais orientadas para o modelamento de dispositivos de microondas envolve considera¸c˜oes sobre gera¸c˜ao dos dados de trei-namento, escolha do crit´erio de erro e sele¸c˜ao do algoritmo de treinamento. Com os modelos resultantes espera-se capturar rela¸c˜oes entrada/sa´ıda cont´ınuas, n˜ao-lineares e multidimensionais, diferentemente de modelos neurais desenvolvidos para classifica¸c˜ao bin´aria de padr˜oes e aplica¸c˜oes de processamento de sinais [Gupta and Zhang, 2000].
2.4
Gera¸
c˜
ao de Dados
O primeiro passo no desenvolvimento de um modelo neural ´e a gera¸c˜ao e coleta de dados para treinamento e teste da rede neural. Para gera¸c˜ao de dados ´e necess´ario obter uma resposta dk para cada amostra xk de entrada. O n´umero total de
amos-tras, a serem geradas ´e escolhido de modo que o modelo neural consiga representar da melhor forma o problema original. Existem dois tipos de dados em aplica¸c˜oes de microondas, os medidos e os simulados. A escolha do tipo de dado gerado depende tanto da aplica¸c˜ao quanto da disponibilidade dos dados [Gupta and Zhang, 2000].
2.4.1
Gera¸
c˜
ao de dados a partir de medi¸
c˜
oes
2.4.2
Gera¸
c˜
ao de dados a partir de simula¸
c˜
oes
A obten¸c˜ao de dados por simula¸c˜oes eletromagn´eticas possui v´arias vantagens so-bre as medi¸c˜oes, pois nesse caso qualquer parˆametro pode ser facilmente modificado, uma vez que ´e necess´ario apenas uma altera¸c˜ao num´erica e n˜ao envolve qualquer mu-dan¸ca f´ısica. Os erros introduzidos nos dados simulados devido aos arredondamentos s˜ao muito menores do que os produzidos pelas tolerˆancias dos equipamentos de me-di¸c˜ao. Mas a gera¸c˜ao de dados por simula¸c˜oes tamb´em apresenta suas desvantagens. Primeiro, a teoria do problema deve ser desenvolvida para implementa¸c˜ao do simu-lador. Esses simuladores, geralmente, s˜ao limitados pelas suposi¸c˜oes assumidas na an´alise te´orica. Uma compara¸c˜ao entre dados medidos e simulados ´e apresenta na Tabela 2.1 [Gupta and Zhang, 2000].
Tabela 2.1: Compara¸c˜ao entre gera¸c˜ao de dados medidos e simulados.
Base de compara¸c˜ao Modelo Neural desenvolvido usando dados medidos
Modelo Neural desenvolvido usando dados simulados
Disponibilidade da
Teo-ria/Equa¸c˜oes do Problema
O modelo pode ser desenvolvido
mesmo se a Teoria do problema n˜ao
´
e conhecida, ou ´e muito dif´ıcil de implementar.
O modelo s´o pode ser desenvolvido
se a Teoria/Equa¸c˜oes do problemas
forem conhecidas e poss´ıveis de
im-plementa¸c˜ao.
Suposi¸c˜oes
Nenhuma suposi¸c˜ao ´e assumida e o
modelo ´e capaz de incluir todo os
efeitos, (efeitos de bordas, radia¸c˜ao
esp´uria, etc.).
Freq¨uentemente envolve suposi¸c˜oes
que podem limitar a capacidade do simulador.
Mudan¸ca de Parˆametros
A gera¸c˜ao de dados pode gerar
mui-tos cusmui-tos e ser complicada de apli-car.
´
E relativamente f´acil de mudar
qualquer parˆametro em um
simu-lador.
Praticidade para obter a resposta desejada.
O modelo s´o pode ser
desenvolvi-dos sobre as respostas poss´ıveis de
medi¸c˜ao.
Qualquer resposta pode ser mode-lada, uma vez que possa ser com-putada por um simulador.
2.5
Neurˆ
onio
Perceptron
S
q
u
a
w
1x
1w
jx
jw
Nx
NFigura 2.1: Neurˆonio perceptron.
Na Figura 2.1, o neurˆonio consiste de duas partes: a fun¸c˜ao da rede e a fun¸c˜ao de ativa¸c˜ao. A fun¸c˜ao da rede determina como as entradas da rede xj ; 1≤j ≤N
s˜ao combinadas dentro do neurˆonio. Neste caso, uma combina¸c˜ao linear de pesos ´e utilizada, tal que:
u=
N
j=1
wjxj +θ (2.5)
onde wj; 1≤j ≤N s˜ao os parˆametros conhecidos como pesos sin´apticos. A
quanti-dadeθ ´e chamada debias e ´e usada para determinar o limiar de atua¸c˜ao do modelo. A sa´ıda do neurˆonio, denotada por “a” na Figura 2.1, est´a relacionada `a entrada “u” atrav´es de uma transforma¸c˜ao linear ou n˜ao-linear chamada fun¸c˜ao de ativa¸c˜ao [Hu and Hwang, 2002].
a =f(u) (2.6)
Em v´arios modelos de redes neurais, diferentes fun¸c˜oes de ativa¸c˜ao tem sido propostas. As mais comuns s˜ao mostradas na Tabela 2.2 [Hu and Hwang, 2002].
2.6
A Rede Perceptron de M´
ultiplas Camadas
A rede perceptron de m´ultiplas camadas (Multilayer Perceptron- MLP) consiste de um modelo alimentado adiante e em camadas de neurˆonios perceptron. Cada neurˆonio na MLP possui uma fun¸c˜ao de ativa¸c˜ao n˜ao-linear que ´e continuamente diferenci´avel. As fun¸c˜oes de ativa¸c˜ao mais empregadas s˜ao a fun¸c˜ao sigm´oide e a tangente hiperb´olica. A Figura 2.2, apresenta o comportamento de uma fun¸c˜ao tangente hiperb´olica que ´e utilizada neste trabalho.
Tabela 2.2: Fun¸c˜oes de ativa¸c˜ao mais utilizadas.
Fun¸c˜ao de Ativa¸c˜ao F´ormula Derivada Coment´arios
Sigm´oide f(u) = 1
1+e−u/T f(u)[1−f(u)]/T
Muito utilizada; a deri-vada pode ser computada
diretamente def(u)
Tangente Hiperb´olica f(u) =tanh(Tu) (1−[f(u)]2)/T T = Constante de
Suavi-dade
Tangente Inversa f(u) = π2tan−1(u
T)
2
πT(1+(u/T)2) Menos usada
Bin´aria
f(u) =
j
1 seu >0
−1 seu <0
A derivada n˜ao existe em
u= 0
Gaussiana de base radial f(u) =
expˆ
−||u−c||2/σ2˜ −2(u−c)f(u)/σ2
Usada em redes de fun¸c˜ao
de base radial
Linear f(u) =au+b a
−10 −5 0 5 10
−1 −0.5 0 0.5 1
Figura 2.2: Exemplo de uma fun¸c˜ao tangente hiperb´olica.
denominada camada de entrada. A Figura 2.3 ilustra uma configura¸c˜ao popular da rede MLP onde as interconex˜oes est˜ao presentes apenas entre neurˆonios de camadas vizinhas [Hu and Hwang, 2002].
O1
θ θ
θ
I1
I2
Figura 2.3: Exemplo de configura¸c˜ao t´ıpica de uma rede perceptron de m´ultiplas camadas.
Como pode-se notar atrav´es da Figura 2.3, uma rede neuralmultilayer perceptron
´e um processador paralelo distribu´ıdo constitu´ıdo de unidades de processamento simples, que tem a propens˜ao natural para armazenar conhecimento experimental e torn´a-lo dispon´ıvel para o uso. Ela se assemelha ao c´erebro em dois aspectos [Haykin, 2001]:
• O conhecimento ´e adquirido pela rede a partir de seu ambiente atrav´es de um processo de aprendizagem.
• As conex˜oes ponderadas entre os neurˆonios, conhecidas como pesos sin´apticos, s˜ao utilizadas para armazenar o conhecimento adquirido pela RNA.
2.6.1
Treinamento de Redes MLP
Basicamente, os algoritmos diferem entre si pela forma como ´e formulado o ajuste dos parˆametros livres da rede [Haykin, 2001].
As redes MLP tˆem sido aplicadas com sucesso para resolver diversos proble-mas, atrav´es do seu treinamento de forma supervisionada com um algoritmo muito conhecido como algoritmo de retropropaga¸c˜ao de erro.
Basicamente, a aprendizagem por retropropaga¸c˜ao de erro consiste de dois passos atrav´es das diferentes camadas da rede: um passo para frente, a propaga¸c˜ao, e um passo para tr´as, a retropropaga¸c˜ao. No passo para frente, um padr˜ao de atividade (vetor de entrada) ´e apresentado a camada de entrada da rede e seu efeito se propaga adiante camada por camada. Finalmente, um conjunto de sa´ıdas ´e produzido como a resposta real da rede. Durante o passo de propaga¸c˜ao os pesos sin´apticos da rede s˜ao todos fixos. Durante o passo para tr´as, por outro lado, os pesos sin´apticos s˜ao todos ajustados de acordo com uma regra de corre¸c˜ao de erro. Especificamente, a resposta real da rede ´e subtra´ıda de uma resposta desejada para produzir um sinal de erro. Este sinal de erro ´e ent˜ao propagado para tr´as atrav´es da rede, contra a dire¸c˜ao das conex˜oes sin´apticas. Os pesos s˜ao ajustados para fazer com que a resposta real da rede se mova para mais perto da resposta desejada, em um sentido estat´ıstico. O algoritmo de Retropropaga¸c˜ao de erro ´e tamb´em referido na literatura como algoritmo backpropagation [Haykin, 2001].
Nesta se¸c˜ao ser˜ao apresentados os algoritmos que foram utilizados nos processos de treinamento das redes neurais artificiais utilizadas no trabalho.
Algoritmo de Treinamento Backpropagation
O algoritmo de treinamento por retropropaga¸c˜ao ´e um m´etodo de aprendiza-gem supervisionada, ou seja, ´e necess´ario o conhecimento pr´evio de rela¸c˜oes de en-trada/sa´ıda de forma que possam ser utilizadas para o treinamento da rede.
Considere um conjunto de dados de treinamento formados pelo vetor de entra-das representado por x, em que x= [x1, x2, . . . , xi, . . . , xI], e que o vetor de
respos-tas desejadas representado por d, onde d = [d1, d2, . . . , dk, . . . , dK]. O objetivo do
processo de treinamento ´e que a resposta da rede, representada aqui por y, onde
y= [y1, y2, . . . , yk, . . . , yK], seja pr´oxima ao vetor d.
Na itera¸c˜aon, onde o n-´esimo padr˜ao de treinamento,x(n), ´e apresentado `a rede, o sinal de erro na sa´ıda do neurˆonio k´e dado por:
Somando-se os valores instantˆaneos da energia do erro de todos os neurˆonios da camada de sa´ıda, obt´em-se o valor instantˆaneo da energia do erro, como se segue:
E(n) = 1 2K
K
k=1
ek(n)2 (2.8)
A energia m´edia do erro quadr´atico ´e obtida somando-se os E(n) para todas as itera¸c˜oes e ent˜ao normalizando em rela¸c˜ao ao n´umero total de exemplos, N, como expressado a seguir:
Emed=
1 N
N
n=1
E(n) = 1 2N N n=1 K k=1
ek(n)2 (2.9)
A energia m´edia do erro quadr´atico, Emed, ´e fun¸c˜ao de todos os parˆametros
livres da rede, e representa a fun¸c˜ao de custo como uma medida do desempenho da aprendizagem.
Cada itera¸c˜ao do algoritmo ´e realizada com o objetivo de minimizar a fun¸c˜ao custo, ou seja, o vetor dos pesos sin´apticos,w, ´e ajustado atrav´es de um processo de otimiza¸c˜ao. O m´etodo do gradiente decrescente ´e um dos processos de otimiza¸c˜ao mais comumente usados para treinar redes MLP, e ´e descrito como segue:
∆w=−η∇E(n) (2.10)
em que η ´e a taxa de aprendizagem.
A partir dos c´alculos dos gradientes locais da fun¸c˜ao custo, E(n), na camada de sa´ıda, k, e na camada oculta, j, obtˆem-se as rela¸c˜oes para os ajustes dos pesos sin´apticos [Haykin, 2001]:
• Para a camada de sa´ıda
∆wkj =ηek(n)gk′(vk(n))yj (2.11)
• Para a camada oculta
∆wji=g′j(vj(n)) K
k
sendo g′
j e gk′ as derivadas das fun¸c˜oes de ativa¸c˜ao gj e gk referentes as camadas
ocultas e de sa´ıda, respectivamente, e vj o produto interno entre os pesos e as
entradas do neurˆonio j.
Apesar desta regra de aprendizado ser bastante simples, a escolha de uma taxa de aprendizado apropriada ´e uma tarefa dif´ıcil. Outro problema do m´etodo do gradiente ´e a influˆencia da derivada parcial nos valores dos ajustes calculados. Al´em disso, mesmo que sob certas circunstˆancias a convergˆencia para um m´ınimo (local) possa ser provada, n˜ao h´a garantias que o m´ınimo global da fun¸c˜ao seja encontrado. Uma id´eia inicial para tornar o aprendizado mais est´avel, reduzindo as oscila¸c˜oes dos pesos durante o treinamento da rede MLP, ´e a inclus˜ao do termo momento:
∆w(n) =−η∇E(n) +α∆w(n−1) (2.13)
A constante positiva α controla a influˆencia do ajuste anterior sobre o ajuste atual dos pesos, ´e denominada termo momento. Deve-se observar que, apesar de ser bem aplicada em muitas tarefas de aprendizado, esta n˜ao ´e uma t´ecnica geral para ganhos de estabilidade e acelera¸c˜ao da convergˆencia. ´E comum, no uso do m´etodo do gradiente com o termo momento, reduzir a taxa de aprendizado para evitar instabilidade no processo de aprendizado [Silva, 2002].
Ap´os a determina¸c˜ao de ∆w, a atualiza¸c˜ao dos pesos se resume a:
w(n+ 1) =w(n) + ∆w (2.14)
Algoritmo de Treinamento Rprop
O Rprop (Resilient BackPropagation) ´e um eficiente esquema de aprendizagem que executa a adapta¸c˜ao direta da atualiza¸c˜ao dos pesos sin´apticos baseado na in-forma¸c˜ao do gradiente local. Um diferen¸ca crucial em rela¸c˜ao ao algoritmo anterior ´e que o esfor¸co da adapta¸c˜ao n˜ao ´e prejudicado pelo comportamento do gradiente. Para diminuir esse comportamento, ´e introduzido um valor de atualiza¸c˜ao ∆ij para
∆(ijt) = ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩
η+∗∆(t−1)
ij se ∂E
(t−1)
∂wij ∗
∂E(t)
∂wij >0 η−∗∆(t−1)
ij se ∂E
(t−1)
∂wij ∗
∂E(t)
∂wij <0 ∆(ijt−1) caso contr´ario
(2.15)
onde 0<η−<1< η+ e t representa o n´umero de ´epocas no treinamento em lote.
Seguindo a regra anterior, toda vez que a derivada parcial correspondente ao pesowij muda seu sinal em rela¸c˜ao ao passo de tempo anterior, indica que a ´ultima
atualiza¸c˜ao foi muito alta e o algoritmo passou por um m´ınimo local, ent˜ao o valor de atualiza¸c˜ao ∆ij ´e decrescido pelo fator deη−. Caso a derivada mantenha o mesmo
sinal, o valor atualiza¸c˜ao ´e incrementado de forma a acelerar a convergˆencia.
Uma vez que o valor de atualiza¸c˜ao, ∆ij, para cada peso ´e adaptado, a atualiza¸c˜ao
dos pesos segue uma regra simples: se a derivada for positiva (aumentando o erro), o peso ser´a reduzido pelo seu valor de atualiza¸c˜ao, caso a derivada seja negativa, o valor de atualiza¸c˜ao passar´a ent˜ao a ser positivo [Riedmiller and Braun, 1993]:
∆w(ijt) =
⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩
−∆(ijt) se ∂E(t)
∂wij >0 +∆(ijt) se ∂E∂w(ijt) <0 0 caso contr´ario
(2.16)
wij(t+1) =wij(t)+ ∆wij(t) (2.17)
No entanto, existe uma exce¸c˜ao: se a derivada parcial trocar de sinal, isto ´e o passo anterior for grande demais e o m´ınimo foi ultrapassado, ent˜ao a atualiza¸c˜ao do peso, ∆wij, ´e revertido:
∆wij(t) =−∆w(ijt−1) se ∂E
(t−1)
∂wij ∗
∂E(t) ∂wij
<0 (2.18)
Por causa disso, a derivada supostamente dever´a mudar seu sinal novamente no passo seguinte, para evitar que ocorra uma puni¸c˜ao novamente do valor de atualiza-¸c˜ao, n˜ao deve haver adapta¸c˜ao do valor de atua¸c˜ao no passo posterior, e uma forma pr´atica de evitar isso ´e fazendo com que ∂E(t−1)
∂wij = 0.
Os valores de atualiza¸c˜ao e os pesos somente s˜ao modificados depois que todo o conjunto de treinamento ´e apresentado a rede, o que caracteriza aprendizagem por lote oubatch [Riedmiller and Braun, 1993].
ajuste dos pesos, ele pode ser escolhido de acordo com a magnitude dos pesos iniciais, por exemplo ∆0 = 0,1 [Riedmiller and Braun, 1993]. A escolha desse valor n˜ao ´e cr´ıtica, j´a que seu valor ´e adaptado enquanto o treinamento ocorre [Silva, 2002].
No treinamento da rede atrav´es do algoritmo Rprop, a fim de se evitar uma va-ria¸c˜ao excessiva dos pesos, define-se um parˆametro para o valor m´aximo de ajuste, ∆max. De forma a evitar esse fenˆomeno o valor ∆max = 50 foi sugerido por
[Ri-edmiller and Braun, 1993]. Os fatores de acr´escimo e decr´escimo s˜ao fixados em η+= 1,2 e η− = 0,5. Estes valores s˜ao baseados em considera¸c˜oes te´oricas e
em-p´ıricas. Sendo assim o n´umero de parˆametros fica reduzido a dois, ∆0 e ∆max
[Ri-edmiller and Braun, 1993] [Silva, 2002].
2.7
Redes de Fun¸
c˜
ao de Base Radial
As redes Neurais de fun¸c˜ao de base radial (Radial Base Function - RBF) s˜ao casos especiais de redes multicamadas alimentadas adiante. Para a constru¸c˜ao de uma rede de fun¸c˜ao de base radial em sua forma mais b´asica, s˜ao necess´arias trˆes camadas com pap´eis totalmente diferentes. A camada de entrada ´e constitu´ıda por n´os de alimenta¸c˜ao que conectam a rede ao seu ambiente. A segunda camada, a unica´ camada oculta da rede, aplica uma transforma¸c˜ao n˜ao-linear do espa¸co de entrada para o espa¸co oculto; na maioria das aplica¸c˜oes, o espa¸co oculto ´e de alta dimensionalidade. A camada de sa´ıda ´e composta por pondera¸c˜oes lineares (pesos sin´apticos), que fornecem a resposta da rede ao padr˜ao de sinal aplicado na entrada [Haykin, 2001].
entrada da rede
camada oculta
camada de saida I1
I2
I3
I4
O1
O1
ϕ()
ϕ()
ϕ()
ϕ()
θ
Para um conjunto de entradas, I, a sa´ıda de uma rede RBF pode ser expressa como se segue [Haykin, 2001]
Ok= J
j=0
wjkϕ(x) (2.19)
onde wjk representa os pesos sin´apticos referentes `a camada de sa´ıda e ϕ() fun¸c˜oes
de base radial, que realizam a transforma¸c˜ao n˜ao-linear atrav´es da norma entre um centro pr´e-determinado e os dados de entrada.
H´a uma classe grande de fun¸c˜oes de base radial. As seguintes fun¸c˜oes s˜ao de particular interesse no estudo de redes neurais artificiais: [Silva, 2002]
• Fun¸c˜ao Multiquadr´atica
ϕ(I) =
||I||2+c2j
1/2
(2.20)
• Fun¸c˜ao Multiquadr´atica Inversa
ϕ(I) = 1
||I||2+c2
j
1/2 (2.21)
• Fun¸c˜ao Gaussiana
ϕ(I) = exp −||I|| 2
2σ2
j
(2.22)
• Fun¸c˜ao Sample
ϕ(I) = sen(σj||I−cj|| 2
σj||I−cj||2
(2.23)
A Figura 2.5 apresenta o comportamento de uma fun¸c˜ao sample.
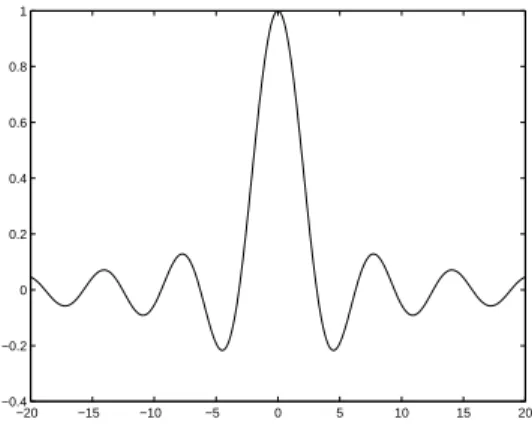
Existem diferentes estrat´egias de aprendizagem que podem ser usadas no projeto de uma rede RBF. O ponto importante ´e que as camadas de uma rede RBF realizam tarefas diferentes, e assim ´e razo´avel separar a otimiza¸c˜ao das camadas ocultas e da sa´ıda da rede usando t´ecnicas diferenciadas e talvez operando em escalas de tempo distintas [Haykin, 2001]. Dentre os tipos de treinamento da rede RBF, destacam-se [Silva, 2002]:
• Sele¸c˜ao auto-organizada dos centros.
• Sele¸c˜ao aleat´oria dos centros.
−20 −15 −10 −5 0 5 10 15 20 −0.4
−0.2 0 0.2 0.4 0.6 0.8 1
Figura 2.5: Exemplo de uma fun¸c˜ao de base radial do tipo sample.
2.7.1
Treinamento utilizando sele¸
c˜
ao auto-organizada dos
centros
Na sele¸c˜ao auto-organizada dos centros ´e necess´ario a utiliza¸c˜ao de um algoritmo de agrupamento que particione o conjunto de treinamento em subgrupos, cada um dos quais o mais homogˆeneo poss´ıvel. Uma das solu¸c˜oes ´e o uso do algoritmo das
k-m´edias, que coloca os centros das fun¸c˜oes de base radial apenas naquelas regi˜oes do espa¸co de entrada onde os dados mais significativos est˜ao presentes. O algoritmo das k-m´edias atua como segue [Haykin, 2001]:
1. Inicializa¸c˜ao. Escolha valores aleat´orios para os centros iniciais ck(0); a ´unica
restri¸c˜ao ´e que estes valores iniciais sejam diferentes.
2. Amostragem. Retire um vetorxdo espa¸co de entrada. O vetorx´e apresentado `a entrada do algoritmo na itera¸c˜ao n.
3. Casamento de Similaridade. Considere que k(x) represente o ´ındice do centro com o melhor casamento com o vetor de entrada x. Encontre k(x) usando a distˆancia Euclidiana m´ınima como crit´erio para determinar qual centro ser´a escolhido.
4. Ajuste os centros das fun¸c˜oes de base radial, usando a regra de atualiza¸c˜ao:
ck(n+ 1) =
ck(n) +η[x(n)−ck(n)], k=k(x)
ck(n), caso contr´ario
(2.24)
onde η ´e um parˆametro da taxa de aprendizagem no intervalo de 0< η <1. 5. Continua¸c˜ao. Incremente n de 1, volte para o passo 2 e continue o
O algoritmo de agrupamento dek-m´edias descrito ´e, de fato, um caso especial de um processo de aprendizagem competitiva conhecido como mapa auto-organiz´avel [Haykin, 2001].
Com os centros j´a determinados deve-se ent˜ao calcular os valores dos desvios-padr˜ao,σ, que representam o espalhamento das fun¸c˜oes de base radial e que podem ser calculados com a seguinte f´ormula:
σ= √dmax
2m1
(2.25)
onde dmax e m1 correspondem a distˆancia m´axima entre os centros escolhidos e a quantidade de centros, respectivamente.
Os ´unicos parˆametros que realmente s˜ao aprendidos nesta abordagem s˜ao os pesos lineares referentes `a camada perceptron da rede RBF. Neste caso, de forma a utilizar um procedimento direto para a determina¸c˜ao da matriz de pesos, w, foi utilizado um procedimento conhecido como m´etodo da pseudoinverva.
No m´etodo da pseudoinversa, ´e poss´ıvel determinar a matriz de pesos,w, em um ´
unico passo uma vez que se tenha conhecimento das respostas desejadas, d, como segue:
w=G+d (2.26)
A matriz G+ ´e a pseudoinversa da matriz G, que ´e a resposta da camada RBF, ap´os o treinamento, para todos os valores de entrada I, sendo definida por :
G=gij =ϕ(Ij, ci), j = 1,2, ..., N;i= 1,2, ..., m1 (2.27)
Onde N ´e a quantidade de vetores de treinamento da rede, eIj ´e o j-´esimo vetor
de entrada.
2.7.2
Treinamento utilizando sele¸
c˜
ao supervisionada dos
cen-tros
Nessa abordagem, todos os parˆametros livres da rede RBF s˜ao ajustados no processo de aprendizagem.
uma “escala de tempo diferente” comparada `as fun¸c˜oes de ativa¸c˜ao n˜ao-lineares das unidades ocultas. Assim, como as fun¸c˜oes de ativa¸c˜ao da camada oculta evoluem lentamente de acordo com alguma estrat´egia de otimiza¸c˜ao n˜ao-linear, os pesos da camada de sa´ıda se ajustam rapidamente atrav´es de uma estrat´egia de otimiza¸c˜ao linear.
O m´etodo do gradiente descendente pode ser usado em um procedimento de corre¸c˜ao do erro [Haykin, 2001], de modo a ajustar os pesos sin´apticos, wj, o vetor
de centros, cj e os desvios padr˜ao, σj, das fun¸c˜oes de base radial.
Segundo o m´etodo do gradiente descendente, o ajuste dos pesos sin´apticos ´e proporcional ao gradiente negativo da fun¸c˜ao custo, dessa forma tem-se para o ajuste dos pesos sin´apticos: [Fernandes, 2004]
∆wj =−ηw
∂E(n) ∂wj
=−ηw K
k=1
ek(n)ϕj(x(n)) (2.28)
Para o ajuste dos centros, mais uma vez aplicando o m´etodo do gradiente, tem-se:
∆cj =−ηc
∂E(n) ∂cj
=−2ηcwj(n) K
k=1
ek(n)ϕj(x(n))σj(x(n)−cj). (2.29)
De maneira bem similar, obt´em-se a express˜ao para o ajuste dos desvios padr˜ao das fun¸c˜oes de ativa¸c˜ao, definida abaixo:
∆σ2j =−ησ
∂E(n) ∂σ2
j
=−2ησwj K
k=1
ek(n)ϕj(x(n))||
x−cj||2
σ2
j
(2.30)
Essa estrat´egia de aprendizagem supervisionada dos centros e das variˆancias exige um esfor¸co computacional mais elevado que as outras estrat´egias. [Fernandes, 2004].
2.8
Compara¸
c˜
ao entre redes MLP e RBF
geralmente, processa o produto interno entre o vetor de entrada e o vetor de pesos sin´apticos do neurˆonio em quest˜ao. Por outro lado, a fun¸c˜ao de ativa¸c˜ao em cada neurˆonio oculto em uma rede RBF processa a norma entre os vetores de entrada e os centros de cada neurˆonio. Dessa forma, redes MLP constroem aproxima¸c˜oes globais para o mapeamento n˜ao-linear entre entrada/sa´ıda. Conseq¨uentemente, elas s˜ao ca-pazes de generalizar em regi˜oes do espa¸co de entrada onde h´a poucos ou nenhum dado de treinamento dispon´ıvel. Inversamente redes RBF desenvolvem aproxima-¸c˜oes locais para as n˜ao-linearidades entre a entrada e a sa´ıda. Como resultado, redes de fun¸c˜ao de base radial aprendem rapidamente. Em redes RBF um neurˆonio oculto influencia a sa´ıda da rede apenas para as entradas que est˜ao pr´oximas ao seu centro, requerendo assim um maior n´umero de neurˆonios ocultos para cobrir todo o espa¸co de entrada [Gupta and Zhang, 2000].
2.9
Overlearning
e
Underlearning
A habilidade de uma rede neural artificial de estimar uma sa´ıda, O, precisa-mente quando lhe ´e apresentada uma entrada,I, nunca utilizada durante o processo de treinamento ´e chamada de capacidade de generaliza¸c˜ao. A capacidade de gene-raliza¸c˜ao est´a diretamente ligado `as condi¸c˜oes de treinamento da rede que podem ser divididas em [Gupta and Zhang, 2000]:
• Overlearning ´e um fenˆomeno no qual a RNA memoriza os dados de treina-mento mas n˜ao consegue generalizar corretamente. Em outras palavras, o erro de treinamento ´e pequeno, mas o erro de valida¸c˜ao ´e muito maior que o erro de treinamento. Poss´ıveis raz˜oes para essa situa¸c˜ao, incluem a presen¸ca de muitos neurˆonios ocultos ou insuficientes dados de treinamento. Neurˆonios em dema-sia nas camadas ocultas acarretam muita liberdade na rela¸c˜ao entrada/sa´ıda da rede.
2.10
Qualidade da aprendizagem
versus
Quanti-dade de Neurˆ
onios Ocultos
A defini¸c˜ao da quantidade de neurˆonios ocultos em uma RNA ´e um fator deter-minante que afeta diretamente o treinamento e a capacidade de aprendizagem. ´E uma quest˜ao delicada durante o processo de defini¸c˜ao da estrutura da rede, uma vez que na maioria dos casos essa escolha ´e feita por tentativa e erro.
Quando o n´umero de neurˆonios ocultos ´e pequena, o melhor valor do erro de valida¸c˜ao tender´a a ser elevado uma vez que a rede neural n˜ao possui “liberdade” suficiente para seguir as n˜ao-linearidades apresentadas pelas amostras de treina-mento. Mais neurˆonios ocultos siginificam maior “liberdade”, ent˜ao a rede estar´a apta para aprender melhor as tendˆencias dos dados de treinamento e alcan¸car um menor erro de valida¸c˜ao. No entanto, muitos neurˆonios podem causar overlearning
no treinamento da rede.
2.11
Conclus˜
ao
Neste cap´ıtulo foi descrita a teoria das Redes Neurais Artificiais de forma que elas possam ser utilizadas na modelagem de dispositivos de microondas, sendo assim a base para o desenvolvimento deste trabalho.
Foram feitas considera¸c˜oes sobre a gera¸c˜ao de dados para treinamento das redes, apresentados e comparados os modelos MLP e RBF, bem como, seus respectivos algoritmos de treinamento, vantagens da aplica¸c˜ao de cada modelos.
Superf´ıcies Seletivas de
Freq¨
uˆ
encias
3.1
Introdu¸
c˜
ao
O interesse em superf´ıcies seletivas de freq¨uˆencias (Frequency Selective Surfaces
- FSS) tem crescido atrav´es dos anos, e conseq¨uentemente as mais variadas aplica-¸c˜oes est˜ao sendo investigadas, como filtros eletromagn´eticos para antenas refletoras, radares, estruturas absorvedoras e de banda eletromagn´etica proibida.
Superf´ıcies seletivas de freq¨uˆencias s˜ao estruturas planares compostas de uma camada met´alica sobre um ou mais substratos diel´etricos. As FSS possuem ar-ranjos bidimensionais descritos por c´elulas que podem conter patches met´alicos ou aberturas. Quando expostas `a radia¸c˜ao eletromagn´etica as caracter´ısticas peri´odi-cas da camada met´alica ressoam em determinadas freq¨uˆencias que dependem das propriedades do diel´etrico, da geometria e dos espa¸camento utilizados nas c´elulas condutoras [Bossard et al., 2005].
Muitos parˆametros de projeto e princ´ıpios s˜ao associados com a estrutura peri´o-dica, tais como o tipo e a forma do elemento, as dimens˜oes das c´elulas unit´arias, os tipos de materiais diel´etricos e as espessuras dos substratos empregados, os l´obulos de gradeamento, entre outros [Wu, 1995].
3.2
Caracter´ısticas de FSS
Uma superf´ıcie peri´odica ´e basicamente um conjunto de elementos idˆenticos or-ganizados em arranjos bidimensionais infinitos [Munk, 2000].
Os arranjos constru´ıdos com elementos patch se caracterizam por apresentarem comportamento similar aos filtros rejeita-faixa, enquanto que estruturas que utilizam c´elulas de abertura possuem caracter´ısticas de um filtro passa-faixa [Campos, 1999]. Exemplos desses modelos de superf´ıcies s˜ao apresentados na Figura 3.1, onde a regi˜ao escura corresponde `as ´areas met´alicas.
(a) (b)
Figura 3.1: Exemplos de tipos de c´elulas condutoras utilizadas em superf´ıcies sele-tivas de freq¨uˆencia. (a) Elementos patches e (b) Elementos de abertura.
Outra forma de classificar uma FSS refere-se `a espessura dos elementos condu-tores, que podem ser descritos como “finos” ou “espessos”. S˜ao classificados como “finos” quando possuem espessura menor que 0,001 λ, onde λ representa o compri-mento de onda da freq¨uˆencia de ressonˆancia da estrutura. Geralmente esse tipo de FSS ´e leve, pequena, possui custo de confec¸c˜ao mais baixo e pode ser fabricada utili-zando tecnologia de circuitos impressos convencionais. Por outro lado, as estruturas denominadas “espessas” s˜ao pesadas e requerem um preciso e custoso manuseio de blocos de metais, para obter o efeito desejado desse tipo de estrutura. Geralmente s˜ao utilizados guias de onda empilhados. A vantagem desse tipo de arranjo ´e a rela-¸c˜ao entre a freq¨uˆencia de transmiss˜ao e a freq¨uˆencia de reflex˜ao (ft/fr), ou banda de
separa¸c˜ao que pode ser reduzida para 1,15 (= 14,0 GHz / 12,2 GHz), que ´e requerida para aplica¸c˜oes de comunica¸c˜ao via sat´elites multifrequenciais. Existem tamb´em es-truturas FSS denominadas freestanding, que s˜ao arranjos de patches ou c´elulas de abertura dispostos livremente no ar sem a presen¸ca de um substrato diel´etrico.
3.3
Elementos de FSS
Estruturas de FSS com elementos do tipo abertura podem ser usadas para fornecer caracter´ısticas passa-faixa. Em outras palavras, para a freq¨uˆencia de opera¸c˜ao da antena o sinal passa atrav´es da estrutura com um m´ınimo de perdas de inser¸c˜ao. Consequentemente, para freq¨uˆencias fora da banda o sinal ´e refletido [Campos, 1999]. Para se obter a resposta desejada em uma estrutura FSS ´e fundamental deter-minar o formato do elemento dentro das c´elulas do arranjo. Existem na literatura diversas pesquisas com as mais variadas formas de elementos, sendo as mais co-muns a retangular e a circular. A Figura 3.2 ilustra algumas poss´ıveis formas em superf´ıcies seletivas de freq¨uˆencia: patches em formato circular, retangular, cruz, anel, espira retangular dupla, triangular, dipolo e tripolo. Um modelo interessante ´e apresentado em [Romeu and Ramhmat-Samii, 2000], onde a FSS ´e constru´ıda uti-lizando patches com geometria fractal, como ilustrado na Figura 3.2, obtendo assim um comportamento multi-banda.
Circular Retangular Cruz
Anel Espira Retangular
Dupla Triangular
Fractal Dipolo Tripolo
Figura 3.2: Exemplos de patches utilizados em FSS.
direcionada coerentemente como se uma reflex˜ao estivesse ocorrendo, onde o ˆangulo de reflex˜ao ´e igual ao ˆangulo de incidˆencia. Isto acontece pois as correntes induzidas em cada dipolo possuem um atraso de fase relativo aos elementos vizinhos. Este atraso de fase faz com que o espalhamento das ondas de todos os elementos seja coerente com a dire¸c˜ao de reflex˜ao [Wu, 1995].
Para elementos em forma de espiras quadradas ou circulares, a ressonˆancia ocorre quando o comprimento de cada meia espira ´e m´ultiplo de meio comprimento de onda. Em outras palavras, cada meio comprimento est´a atuando como um elemento de di-polo. O comprimento total da espira, ent˜ao, precisa ser de um comprimento de onda [Wu, 1995]. Dessa forma, conclui-se que a medida da circunferˆencia de uma espira circular para aplica¸c˜oes em FSS deve ser m´ultipla de um comprimento de onda. No caso de uma espira circular impressa sobre um substrato diel´etrico, o comprimento el´etrico da circunferˆencia deve ser de um comprimento de onda efe-tivo, enquanto que a dimens˜ao f´ısica da circunferˆencia dever´a ser menor que um comprimento de onda no espa¸co livre [Campos, 1999].
Finalmente, quando a dimens˜ao do elemento ´e totalmente diferente das dimens˜oes ressonantes, a onda incidente passar´a atrav´es da superf´ıcie seletiva de freq¨uˆencia como se a estrutura fosse transparente, ocorrendo uma pequena perda devido ao diel´etrico e `a condu¸c˜ao do cobre [Wu, 1995].
3.4
Arranjos Passivos e Arranjos Ativos
Fundamentalmente, qualquer estrutura peri´odica pode ser excitada de duas ma-neiras: por uma onda plana incidente Ei, ou por geradores individuais conectados a cada elemento. No segundo caso, os geradores de tens˜ao devem possuir a mesma amplitude e varia¸c˜oes lineares de fase ao longo do arranjo ativo, de forma de carac-terizar a estrutura como uma superf´ıcie peri´odica.
No caso de arranjos passivos, uma onda incidente ´e parcialmente transmitida atrav´es da estrutura, Et, e o restante refletida, Er. Sob condi¸c˜oes resonantes a
amplitude do sinal refletido pode ser igual a Ei quando Et = 0. ´E usual definir o
coeficiente de reflex˜ao como [Munk, 2000]:
Γ = E
r
Ei (3.1)
onde Er eEi em geral est˜ao referidos ao plano do arranjo. De forma similar o
T = E
t
Ei (3.2)
3.5
T´
ecnicas de Medi¸
c˜
ao
V´arios m´etodos tˆem sido utilizados para medir as propriedades de reflex˜ao e transmiss˜ao de superf´ıcies seletivas de freq¨uˆencia. O desempenho de transmiss˜ao pode ser medida em temperatura ambiente utilizando uma FSS de tamanho finito em uma cˆamara anec´oica. Usualmente para as medi¸c˜oes s˜ao utilizadas cornetas padr˜oes como antenas transmissoras e receptoras. Configurando as antenas cornetas para polariza¸c˜ao de vertical para horizontal, pode-se medir caracter´ısticas de transmiss˜ao TE e TM das superf´ıcies seletivas de freq¨uˆencia colocadas entre as duas cornetas. A princ´ıpio, com esta configura¸c˜ao ´e poss´ıvel medir a reflex˜ao causada pela FSS. No entanto dados errados ser˜ao obtidos devido a forte difra¸c˜ao causada pelas bordas da superf´ıcie medida. Essas difra¸c˜oes podem ser atribu´ıdas `as dimens˜oes da FSS que geralmente s˜ao significativamente menores que a largura de banda da cornetas. A Figura 3.3 ilustra uma configura¸c˜ao de equipamentos para a medi¸c˜ao de FSS. Para medi¸c˜oes de precis˜ao recomenda-se a utiliza¸c˜ao de lentes em conjunto com as cornetas, uma vez que devido ao efeito das lentes a superf´ıcie passa a ser iluminada por um feixe Gaussiano de menor largura, reduzindo significativamente os efeitos da difra¸c˜ao nas bordas [Wu, 1995].
3.6
T´
ecnicas de An´
alise
Divisor 3 dB Analisador de Rede
Gerador de Sinais RF Acoplador
Direcional
Acoplador Direcional Corneta
Transmissora CornetaReceptora FSS
Referência
Figura 3.3: Exemplo de sistema de medi¸c˜ao de FSS.
capaz de fornecer detalhes das repostas em freq¨uˆencia e da polariza¸c˜ao, junto com o entendimento f´ısico da sua opera¸c˜ao. Quanto ao uso do m´etodo dos momentos no dom´ınio espectral pela t´ecnica anterior, ´e verificado um grande esfor¸co computaci-onal, sendo desaconselh´avel para a an´alise de FSS com elementos mais complexos, como por exemplo espiras quadradas duplas [Campos, 1999].
Em [Campos, 1999] ´e feita uma an´alise de onda completa de FSS do tipo patch
sobre um substrato di´eletrico utilizado o m´etodo dos momentos em conjuto com o m´etodo da linha de transmiss˜ao. ´E com base nesse trabalho que ser˜ao criados os conjuntos de treinamento para a utiliza¸c˜ao em redes neurais artificias com ob-jetivo de desenvolver um modelo que alie a precis˜ao do MoM com a velocidade de processsamento das RNAs para a an´alise de superf´ıcies seletivas de freq¨uˆencia.
3.7
Aplica¸
c˜
oes
ampli-fica¸c˜ao, oscila¸c˜ao e multiplexa¸c˜ao [Campos, 1999] [Munk, 2000].
Arranjos de grades ativas podem ser, no futuro, usadas em sistemas de radar, de radiodifus˜ao e de comunica¸c˜oes em estado s´olido, de baixo custo e alta potˆencia. V´arios arranjos de grades ativas tˆem sido desenvolvidos com detetores, defasado-res, multiplicadodefasado-res, osciladodefasado-res, amplificadores e chaveadores. Nestes arranjos de grades a potˆencia ´e proporcional `a ´area sendo a impedˆancia do circuito equivalente determinada pelas dimens˜oes da c´elula unit´aria.
Banda X
Banda Ku
FSS
Figura 3.4: Exemplo de uma aplica¸c˜ao de Superf´ıcies Seletivas de Freq¨uˆencias
As superf´ıcies seletivas de freq¨uˆencia tem sido muito usadas como sub-refletores para comunica¸c˜oes via sat´elite, onde apenas um sub-refletor principal pode separar diferentes bandas de freq¨uˆencia. Para melhorar as capacidades do sub-refletor FSS que operam em multifrequˆencias s˜ao usadas [Ohira et al., 2004], como ilustrado na Figura 3.4. Superf´ıcies seletivas de freq¨uˆencia tamb´em s˜ao utilizadas para aumentar ou diminuir a largura de banda de um arranjo de antenas [Gerini and Zappelli, 2005]. A aplica¸c˜ao mais conhecida ´e o anteparo da porta do forno de microondas dom´estico, que possui a caracter´ıstica de um filtro passa-faixa, deixando passar a freq¨uˆencia de luz vis´ıvel e rejeitando a faixa de microondas [Campos, 1999].
3.8
Conclus˜
ao
tip´ıcos e compara¸c˜oes entre arranjos passivos e ativos.
Explica¸c˜oes sobre as t´ecnicas de an´alise e medi¸c˜ao de FSS foram inclu´ıdas de forma a criar bases de compara¸c˜oes para os modelos neurais desenvolvidos para a an´alise dessas estruturas.
Antenas de Microfita
4.1
Introdu¸
c˜
ao
Uma antena de microfita consiste de uma fina camada met´alica, que atua como elemento radiador, separada de seu plano terra por uma camada composta de um substrato diel´etrico. Sua alimenta¸c˜ao pode ser feita de v´arias maneiras sendo as mais comuns por cabo coaxial, por linha de microfita e por acoplamento eletromagn´etico. Apesar das antenas de microfita terem surgidos h´a mais de meio s´eculo, esses disposi-tivos apenas come¸caram a ganhar aten¸c˜ao no d´ecada de 70 [Carver and Mink, 1981]. Freq¨uentemente, as antenas de microfita s˜ao denominadas, tamb´em, como antenas
patch. O elemento irradiante da antena de microfita pode ser quadrado, retangular, em forma de fita (dipolo), circular, el´ıptico, triangular dentre outros. A Figura 4.1 apresenta um exemplo comum de antena de microfita com patch retangular.
Substrato
Patch Condutor
Plano Terra
Figura 4.1: Antena de Microfita com patch retangular.
Antenas de microfita possuem v´arias vantagens comparadas com antenas de mi-croondas convencionais e, conseq¨uentemente, muitas aplica¸c˜oes se enquadram nas faixas de freq¨uˆencias de utiliza¸c˜ao dessas antenas, que ´e de aproximadamente 100 MHz a 50 GHz. Algumas das principais vantagens das antenas de microfita compa-radas `as antenas comuns de microondas s˜ao [Bhartia et al., 2001]:
• Peso reduzido, pequeno volume, perfil fino.
• Baixo custo de fabrica¸c˜ao, viabilizando a produ¸c˜ao em larga escala.
• Possibilidade de polariza¸c˜ao linear e circular com uma simples linha de ali-menta¸c˜ao.
• Polariza¸c˜ao dupla e freq¨uˆencia dupla de ressonˆancia podem ser facilmente ob-tidas.
• N˜ao h´a necessidade de algum tipo de cavidade protetora.
• Podem facilmente ser projetadas para operar em conjunto com circuitos inte-grados de microondas.
• Linhas de alimenta¸c˜ao e redes de casamento podem ser fabricadas simultane-amente com a estrutura da antena.
Contudo, antenas de microfita tamb´em possuem algumas limita¸c˜oes em rela¸c˜ao `as outras antenas [Bhartia et al., 2001]:
• Largura de banda estreita e problemas de tolerˆancia associados.
• Baixo ganho.
• Grande perda por impedˆancia em estruturas de arranjos.
• Maioria das antenas de microfita irradiam em meio plano.
• Complexas estruturas de alimenta¸c˜ao s˜ao necess´arias para arranjos de alto-desempenho.
• Polariza¸c˜ao pura ´e dif´ıcil de alcan¸car.
• Fraca radia¸c˜ao end-fire.
• Radia¸c˜ao extra das linhas de alimenta¸c˜ao e jun¸c˜oes.
• Excita¸c˜ao de ondas de superf´ıcie.
• Antenas de microfita fabricadas em substrato com constante diel´etrica de alto valor s˜ao recomendados para integra¸c˜ao com outros circuitos. No entanto, o uso de uma alta constante diel´etrica causa baixa eficiˆencia e estreita largura de banda.
de antenas. As ondas de superf´ıcie associadas com a baixa eficiˆencia, aumento do acoplamento m´utuo, ganho reduzido e degrada¸c˜ao do padr˜ao de radia¸c˜ao podem ser reduzidas com a utiliza¸c˜ao de estruturas de banda eletromagn´etica proibida (EBG - eletromagnetic bandgap) [Bhartia et al., 2001].
Sistemas de antenas de microfita s˜ao empregados em grande n´umero nas comu-nica¸c˜oes sem fio, pois eles se adaptam bem a qualquer superf´ıcie, s˜ao de pequenas dimens˜oes e podem fornecer igual, ou melhor performance el´etrica do que as arqui-teturas cl´assicas. Al´em disso, antenas integradas diretamente nos equipamentos de comunica¸c˜ao, tendem a ser mais confi´aveis e possuem um custo de instala¸c˜ao muito menor. Desta forma, ´e extremamente importante o desenvolvimento de estudos a respeito desta tecnologia, tendo em vista a importˆancia para as comunica¸c˜oes sem fio, as aplica¸c˜oes militares e na ´area de telefonia.
4.2
Configura¸
c˜
oes de
Patches
Ao longo dos anos v´arias configura¸c˜oes da camada condutora de antenas de mi-crofita tem sido propostas e investigadas. A Figura 4.2 apresenta alguns do formatos mais utilizados e uma pequena descri¸c˜ao de suas vantagens e desvantagens [Godara, 2002].
(a) (b)
(d) (e)
(c)
Figura 4.2: Exemplos dospatches condutores mais comuns.
possuir uma maior impedˆancia, simplesmente por que s˜ao geralmente maiores que os outros formatos. Os patches quadrados tamb´em s˜ao utilizados para gerar polariza¸c˜oes circulares.
2. Ospatches com formatos el´ıpticos, Figura 4.2b, s˜ao tamb´em muito utilizadas, logo ap´os os retangulares. As antenas com essas configura¸c˜oes possuem dimen-s˜oes ligeiramente menores que as correspondentes retangulares, resultando em baixo ganho e menor largura de banda. Uma das principais raz˜oes para que esse tipo de estrutura tenha sido intensivamente investigado ´e a sua sime-tria inerente, permitindo que an´alises a partir de m´etodos de onda-completa no dom´ınio espectral fossem computacionalmente mais eficientes do que para configura¸c˜oes retangulares.
3. As geometrias triangulares e de setor de disco, como apresentadas nas Figuras 4.2c e 4.2d, s˜ao menores que as equivalentes retangulares, mas com largura de banda e ganho menores. Patches triangulares tamb´em tendem, em geral a apresentar altos n´ıveis de polariza¸c˜ao cruzada, por causa da sua falta de simetria. Antenas com dupla polariza¸c˜ao podem ser desenvolvidas usando essas formas de condutores. No entanto, tipicamente, apresentam uma largura de banda pequena.
4. Antenas de microfita com condutores em forma de an´eis concˆentricos, Figura 4.2e, s˜ao as que apresentam as menores dimens˜oes e ,novamente, um fun¸c˜ao de perdas em largura de banda e ganho. Um dos problemas associados com an´eis concˆentricos ´e que n˜ao ´e um processo simples a alimenta¸c˜ao em modos de ordem menor obtendo um bom casamento de impedˆancia na freq¨uˆencia de ressonˆancia. Formas de excita¸c˜ao sem contato s˜ao tipicamente prefer´ıveis [Godara, 2002].
L
W (Xf,Yf)
Ps
Ws Ls
Figura 4.3: Geometria de umpatch E-Shaped.
fendas em um patch retangular, como ilustrado na Figura 4.3. Antenas constru´ıdas com elemento radiador com este formato apresentam um comportamento de du-pla freq¨uˆencia (dual-frequency), e a Figura 4.4 apresenta a geometria de um patch
retangular modificado para apresentar um aumento na largura de banda.
Figura 4.4: Geometria de um patch afilado.
4.3
Arranjo de Antenas
Geralmente uma antena possui um diagrama de radia¸c˜ao amplo e baixos valores de diretividade. Em determinadas aplica¸c˜oes s˜ao necess´arias projetos de antenas com alta diretividade para satisfazer a demanda de comunica¸c˜oes de longa distˆancia e isto s´o ´e poss´ıvel aumentando o comprimento el´etrico da antena. Aumentar as dimens˜oes de um elemento irradiador na maioria dos casos leva ao ganho de caracter´ısticas mais diretivas. Outra forma de aumentar o tamanho da antena, sem necessariamente modificar um elemento individual, ´e formar um conjunto de elementos irradiantes em configura¸c˜oes geom´etricas. Essa nova antena, formada por multielementos, ´e conhecida como arranjo, ou array.
Em v´arios casos, os elementos do arranjo s˜ao idˆenticos, isso n˜ao ´e regra, mas ´e geralmente mais conveniente, simples e mais pr´atico. Os elementos individuais do arranjo podem ter diversas formas como dipolos, aberturas e patches de microfita dentre outros.
Em um arranjo de elementos idˆenticos, existem cinco parˆametros importantes de projeto:
1. A configura¸c˜ao geom´etrica do arranjo (linear, circular, retangular, esf´erica, etc.)
2. A rela¸c˜ao de deslocamento entre os elementos individuais. 3. A amplitude de excita¸c˜ao dos elementos individuais. 4. A excita¸c˜ao de fase dos elementos individuais. 5. O padr˜ao relativo dos elementos individuais.
Antenas de fendas afiladas s˜ao bastante ´uteis para serem integradas em arranjos de antenas, principalmente os que requerem uma largura de banda maior e a necessi-dade de um arranjo de fase de alta performance [Chio and Schaubert, 2000] [Schau-bert et al., 1994]. A Figura 4.5 ilustra um arranjo composto de antenas de fendas, tamb´em conhecido como Tapered Slot Array-TSA.
z Cavidade
y
tx a
t
x
Hastes de Fixação Metálicas
Figura 4.5: Exemplo de um arranjo TSA. Os elementos s˜ao separados por hastes met´alicas e o arranjo ´e suportado por um plano terra em z = -t.
4.4
M´
etodos de Alimenta¸
c˜
ao
sido desenvolvidas, entre elas as de alimenta¸c˜ao por acoplamento eletromagn´etico, e de acoplamento por abertura.
A sele¸c˜ao da t´ecnica de alimenta¸c˜ao ´e governada por v´arios fatores, sendo que a considera¸c˜ao mais importante ´e a eficiˆencia na transferˆencia de potˆencia entre a estrutura radiante e alimenta¸c˜ao, ou seja, o casamento de impedˆancias entre as duas estruturas. A radia¸c˜ao indesejada pode aumentar o n´ıvel dos l´obulos laterais e a amplitude de polariza¸c˜ao cruzada do diagrama de radia¸c˜ao. Minimizar a radia¸c˜ao esp´uria e seus efeitos no diagrama de radia¸c˜ao ´e um dos importantes fatores na escolha do m´etodo de alimenta¸c˜ao [Bhartia et al., 2001]. Na a Figura 4.6 pode-se visualizar o m´etodo mais comum de alimenta¸c˜ao de antenas de microfita, feito atrav´es de uma linha de microfita.
L
W
h
er Substrato
Figura 4.6: Alimenta¸c˜ao atrav´es de uma linha de microfita.
As conex˜oes de alimenta¸c˜ao coaxiais, nas quais o condutor interno de um cabo ´e conectado diretamente ao patch e o condutor externo conectado ao plano terra, tamb´em s˜ao muito utilizadas. Esse tipo de alimenta¸c˜ao ´e de f´acil constru¸c˜ao e casamento de impedˆancias, criando pouca radia¸c˜ao indesejada. No entanto, tamb´em possui uma largura de banda estreita e ´e de dif´ıcil modelagem principalmente em substratos espessos. A Figura 4.7 apresenta um exemplo de alimenta¸c˜ao atrav´es de conex˜ao coaxial.