UNIVERSIDADE PRESBITERIANA MACKENZIE PROGRAMA DE
P ´
OS-GRADUAC
¸ ˜
AO EM
ENGENHARIA EL ´
ETRICA
Mateus Interciso
REPRESENTAC
¸ ˜
AO TERN ´
ARIA EM ALGORITMOS EVOLUTIVOS
PARA A OBTENC
¸ ˜
AO DE AUT ˆ
OMATOS CELULARES BIN ´
ARIOS
Orientador: Prof. Dr. Pedro Paulo Balbi de Oliveira
P ´
OS-GRADUAC
¸ ˜
AO EM
ENGENHARIA EL ´
ETRICA
Mateus Interciso
REPRESENTAC
¸ ˜
AO TERN ´
ARIA EM ALGORITMOS EVOLUTIVOS
PARA A OBTENC
¸ ˜
AO DE AUT ˆ
OMATOS CELULARES BIN ´
ARIOS
Dissertac¸˜ao apresentada ao Programa de P´os-Graduac¸˜ao em Engenharia El´etrica da Universidade Presbite-riana Mackenzie como parte dos requisitos para a obtenc¸˜ao do t´ıtulo de Mestre em Engenharia El´etrica, na ´area de concentrac¸˜ao em Engenharia da Computac¸˜ao.
Orientador: Prof. Dr. Pedro Paulo Balbi de Oliveira
I61r Interciso, Mateus.
Representação ternária em algoritmos evolutivos para a obtenção de autômatos celulares binários/ Mateus Interciso. – 2011.
61 f. : il. ; 30 cm.
Dissertação (Mestrado em Engenharia Elétrica) – Universidade Presbiteriana Mackenzie, São Paulo, 2011.
Bibliografia: f. 46S47.
1. Autômato celular. 2. Algoritmos genéticos. 3. Tarefa da
classificação da densidade. 4. Problema da paridade. 5. Representação ternária. I. Título.
Na sobrevivˆencia dos indiv´ıduos e rac¸as favorecidas, durante a luta constante e recorrente pela existˆencia, vemos uma forma poderosa e incessante de selec¸˜ao.
A busca por regras de autˆomatos celulares que efetuem corretamente uma determinada tarefa pode ser imposs´ıvel de ser efetuada manualmente, dado o enorme tamanho dos espac¸os de busca usualmente envolvidos. Uma forma para conseguir encontrar boas regras para a execuc¸˜ao do problema em quest˜ao tem sido a utilizac¸˜ao de algoritmos gen´eticos (AGs) para evoluir uma populac¸˜ao inicialmente aleat´oria, at´e o objetivo desejado; nesses AGs cada indiv´ıduo ´e normal-mente representado como uma regra de transic¸˜ao candidata. Em problemas formulados para resoluc¸˜ao por um autˆomato celular bin´ario, uma alterac¸˜ao recentemente estudada na literatura para a representac¸˜ao dos indiv´ıduos foi a utilizac¸˜ao detemplates (moldes) com a presenc¸a de um s´ımbolo extra, capaz de representar os demais s´ımbolos. Tal esquema de “representac¸˜ao tern´aria” ´e utilizada no presente trabalho, visando avaliar seu efeito no processo de busca re-alizado por AGs. O estudo ´e feito para duas tarefas cl´assicas de autˆomatos celulares unidi-mensionais bin´arios, a tarefa de classificac¸˜ao da densidade e o problema da paridade, ambas tradicionais no contexto da utilizac¸˜ao de AGs para encontrar regras de transic¸˜ao com alta per-formance. Ao comparar os resultados de AGs originais encontrados na literatura com suas vers˜oes implementadas com representac¸˜ao tern´aria, mostra-se que a representac¸˜ao tern´aria ´e capaz de melhorar a qualidade dos resultados. Em particular, analisam-se condic¸˜oes em que o uso da representac¸˜ao tern´aria se mostra mais efetivo, bem como apontam-se efeitos de alguns aspectos de implementac¸˜ao. Poss´ıveis trabalhos futuros pertinentes ao estudo s˜ao discutidos ao final.
Palavras-chave:Autˆomatos celulares, algoritmos gen´eticos, tarefa da classificac¸˜ao da densidade, problema da paridade, representac¸˜ao tern´aria.
ABSTRACT
The search for cellular automata (CAs) rules capable of executing a determined task can be impossible to be achieve manually, given the huge size of the search space usually involved. A method for being able to find rules capable of executing the task at hand has been the usage of genetic algorithms (GAs) to evolve an initially random population, until the desired objective; each individual of those GAs are usually represented by a candidate transition rule. In problems formulated for the resolution by a binary cellular automaton, a recently used modification on the representation of the individuals was the usage of templates with the presence of an extra symbol, capable of representing every other valid symbol. Such schema of “ternary represen-tation” is used on the present work, aiming for it’s net effect on the search process on the GAs. This study is made for two classical tasks of binary unidimensional cellular automata, the den-sity classification task and the parity problem, both traditional in the context of using GAs for searching transition rules with high performance. By comparing the results of the original GAs and their versions implemented with the ternary representation, it’s shown that the ternary rep-resentation is able to improve the quality of the results. Particularly, it is analized the condition in which the usage of the ternary representation presents to be more effective, as well as some effects of the actual implementation. Possible future works are presented at the end.
Keywords:Cellular automata, genectic algorithms, density classification task, parity problem, ternary representation.
2.1 Cruzamento de ponto ´unico. . . p. 7
3.1 Demonstrac¸˜ao visual de um AC . . . p. 11
3.2 Regra 40 . . . p. 12
3.3 Regra 84 . . . p. 12
3.4 Regra 30 . . . p. 13
3.5 Regra 110 . . . p. 14
3.6 Regra 90 . . . p. 14
3.7 CI utilizada. . . p. 17
3.8 100 iterac¸˜oes da melhor regra encontrada em [WOLZ; OLIVEIRA, 2008]. . . p. 17
3.9 300 execuc¸˜oes distintas do CMD. . . p. 20
3.10 Detalhamento das regras do CMD. . . p. 21
3.11 300 execuc¸˜oes distintas do MCH. . . p. 23
3.12 Detalhamento das regras do MCH. . . p. 24
3.13 300 execuc¸˜oes distintas do OOO. . . p. 26
3.14 Detalhamento das regras do OOO. . . p. 27
3.15 Gr´afico comparativo com os AGs. . . p. 28
3.16 Execuc¸˜oes para o PP utilizando MCH e CMD. . . p. 31
3.17 Detalhamento dos resultados obtidos para o PP. . . p. 32
4.1 Execuc¸˜oes utilizando a representac¸˜ao tern´aria do CMD. . . p. 35
4.2 Execuc¸˜oes utilizando a representac¸˜ao tern´aria do MCH. . . p. 36
4.3 Execuc¸˜oes utilizando a representac¸˜ao tern´aria do OOO. . . p. 37
4.4 Execuc¸˜oes do MCH para o PP e representac¸˜ao tern´aria. . . p. 39
4.6 Detalhamento dos resultados do MCH com representac¸˜ao tern´aria para o PP. . p. 41
3.1 Representac¸˜oes de regras de transic¸˜ao. . . p. 10
3.2 LUT da regra 110. . . p. 15
3.3 Regra 110 utilizando moldes. . . p. 16
3.4 Contagem das regras encontradas pelos AGs estudados. . . p. 28
3.5 Diferenc¸a entre os AGs utilizados. . . p. 28
4.1 Tempo de execuc¸˜ao total de cada AG para a DCT. . . p. 34
4.2 Contagem das regras encontradas para orientac¸˜ao ´unica. . . p. 38
Lista de S´ımbolos
lTamanho de uma cadeia . . . p. 5
PConjunto de indiv´ıduos em uma populac¸˜ao . . . p. 5
iIndiv´ıduo de uma populac¸˜ao . . . p. 5
f Grau de adaptac¸˜ao de um indiv´ıduo . . . p. 5
GQuantidade de gerac¸˜oes de um AG . . . p. 5
gGerac¸˜ao de um algoritmo gen´etico . . . p. 6
pPonto de cruzamento . . . p. 6
mQuantidade de bits a sofrerem mutac¸˜ao . . . p. 7
pmProbabilidade de mutac¸˜ao . . . p. 7
EQuantidade de melhores indiv´ıduos a serem mantidos na pr´oxima gerac¸˜ao . . . p. 8
#Representac¸˜ao de todos os s´ımbolos poss´ıveis em um indiv´ıduo . . . p. 8
ΣConjunto de poss´ıveis estados de um autˆomato celular . . . p. 9 δ Regra de transic¸˜ao de um autˆomato celular . . . p. 9
ηVizinhanc¸a de uma c´elula . . . p. 9
rRaio da vizinhanc¸a de uma c´elula . . . p. 9
T Quantidade m´axima de iterac¸˜oes de um autˆomato celular . . . p. 16
ρQuantidade de 1s sobre 0s . . . p. 16
LTamanho de um reticulado . . . p. 16
IConfigurac¸˜oes Iniciais criadas comρ escolhido de uma distribuic¸˜ao uniforme . . . p. 18
pcProbabilidade de cruzamento entre dois indiv´ıduos de um algoritmo gen´etico . . . p. 18
BConfigurac¸˜oes Iniciais criadas comρ escolhido de uma distribuic¸˜ao binomial . . . p. 18
F Aptid˜ao do melhor indiv´ıduo de um algoritmo gen´etico . . . p. 18
p#Probabilidade de um bit ser # . . . p. 33
uAlgoritmo utilizando orientac¸˜ao ´unica . . . p. 33
Lista de Abreviaturas
ACs Autˆomatos celulares . . . p. 1
AGs Algoritmos gen´eticos . . . p. 1
LUT Tabela de transic¸˜oes de um autˆomato celular . . . p. 9
ECA Autˆomatos Celulares Elementares . . . p. 9
CI Configurac¸˜ao Inicial de um reticulado . . . p. 10
DCT Tarefa da Classificac¸˜ao da Densidade . . . p. 16
GKL Regra criada manualmente por Gacs, Kurdyumov e Levin . . . p. 17
MCH Algoritmo presente em [MITCHELL; CRUTCHFIELD; HRABER, 1994] . . . p. 18
OOO Algoritmo presente em [OLIVEIRA; OLIVEIRA; OMAR, 2001] . . . p. 18
1 Introduc¸ ˜ao p. 1
1.1 Motivac¸˜ao . . . p. 2
2 Algoritmos gen´eticos p. 5
2.1 Operadores Gen´eticos . . . p. 6
2.1.1 Selec¸˜ao . . . p. 6
2.1.2 Cruzamento . . . p. 6
2.1.3 Mutac¸˜ao . . . p. 7
2.2 A nova populac¸˜ao . . . p. 7
2.3 Representac¸˜ao tern´aria e moldes . . . p. 8
3 Autˆomatos Celulares p. 9
3.1 Utilizando moldes e a representac¸˜ao tern´aria em ACs . . . p. 15
3.2 A tarefa da classificac¸˜ao da densidade . . . p. 16
3.2.1 CMD . . . p. 19
3.2.2 MCH . . . p. 21
3.2.3 OOO . . . p. 25
3.2.4 Resultados . . . p. 27
3.3 O Problema da Paridade . . . p. 29
3.3.1 Resultados . . . p. 29
4 Alterac¸˜ao nos AGs p. 33
4.1 Resultados para a DCT . . . p. 34
4.2 Resultados para o PP . . . p. 38
1
Introduc¸˜ao
Autˆomatos celulares (ACs) foram inicialmente propostos por John Von Neumann, ao
estu-dar m´aquinas com caracter´ısticas de auto-replicac¸˜ao. ACs s˜ao m´aquinas descentralizadas,
ca-pazes de apresentar um poder computacional equivalente a uma M´aquina de Turing [SARKAR,
2000; WOLFRAM, 2002]. Uma das caracter´ısticas de um AC ´e a alta complexidade que ele
pode alcanc¸ar utilizando simples regras de transic¸˜ao, como ´e demonstrado e estudado por
Wol-fram [2002]; outra caracter´ıstica estudada em [HOLLAND, 1992], ´e a capacidade de
auto-organizac¸˜ao de um AC, que a partir de um cen´ario inicialmente ca´otico, consegue evoluir
du-rante o tempo para um cen´ario organizado.
Algumas tarefas que s˜ao triviais para uma computac¸˜ao centralizada, se tornam
extrema-mente complexas em sistemas descentralizados como ACs, pois cada agente deve resolver
localmente um problema de escopo global. O estudo em computac¸˜ao via ACs pode trazer
benef´ıcios em melhor utilizac¸˜ao de mem´oria, processamento paralelo, criptografia, modelagem
de sistemas f´ısicos, entre outras ´areas. Como cada AC necessita resolver apenas um pequeno
problema local e n˜ao o problema global como um todo, esse estudo tamb´em pode otimizar essas
tarefas com uma margem de sucesso significativa [WOLFRAM, 2002].
Cada AC segue uma simples regra de transic¸˜ao local, onde o grande problema, ´e
justa-mente encontrar a regra correta para efetuar a computac¸˜ao desejada, devido `a enorme
quanti-dade de regras poss´ıveis [CENEK; MITCHELL, 2009]. Uma forma de obtenc¸˜ao dessas regras
´e a utilizac¸˜ao de algoritmos evolutivos (como por exemplo algoritmos gen´eticos, AGs), que
se-jam capazes de evoluir uma populac¸˜ao inicialmente aleat´oria de regras, para encontrar aquela
que melhor execute a tarefa dada [CENEK; MITCHELL, 2009]. Um dos grandes problemas
desses algoritmos, ´e justamente o tempo necess´ario para se encontrar o melhor indiv´ıduo. Em
[HOLLAND, 1996] ´e utilizada a noc¸˜ao de moldes como uma forma de representac¸˜ao gen´erica
pro-2
cessamento, ao possibilitar o AG de “escolher” qual a melhor soluc¸˜ao para o problema dado
entre um conjunto de moldes [HOLLAND, 1992, 1996].
A representac¸˜ao de ACs para os problemas estudados ´e uma representac¸˜ao bin´aria, ou seja,
cada bit da regra de transic¸˜ao pode estar contido em dois poss´ıveis estados. Ao adicionarmos a
noc¸˜ao de moldes utilizamos um terceiro estado, capaz de representar qualquer um dos estados
poss´ıveis do AC; a isso ´e chamado de representac¸˜ao tern´aria. A representac¸˜ao do AC ´e efetuada
por um conjunto de moldes e uma orientac¸˜ao, capazes de representar uma regra bin´aria.
´
E objetivo desse trabalho, verificar os ganhos na utilizac¸˜ao da representac¸˜ao tern´aria, para
a busca de regras bin´arias de ACs capazes de executar algumas tarefas cl´assicas de ACs.
1.1
Motivac¸˜ao
Para que um AC efetue corretamente a tarefa dada, ´e necess´ario encontrar uma regra de
transic¸˜ao capaz de executar a tarefa em quest˜ao. A quantidade poss´ıvel de regras, possui um
tamanho exponencial com relac¸˜ao `a vizinhanc¸a do AC, resultando muitas vezes em um espac¸o
de busca onde ´e invi´avel efetuar uma busca manual [STONE; BULL, 2009]. Uma forma de se
efetuar uma busca nesse enorme espac¸o de regras ´e a utilizac¸˜ao de algoritmos evolutivos, que
partem de uma populac¸˜ao de regras candidatas aleat´orias e, baseando-se em teorias evolutivas,
s˜ao efetuadas recombinac¸˜oes e alterac¸˜oes nessa populac¸˜ao; de forma a buscar as melhores regras
poss´ıveis para um determinado problema [CENEK; MITCHELL, 2009].
Em [HOLLAND, 1999] foi estudado como seria poss´ıvel atingir um regime dinˆamico
or-denado, tendo-se inicialmente apenas um comportamento dinˆamico ca´otico. Dentre as v´arias
formas estudadas por Holland tamb´em foram apresentados autˆomatos celulares e algoritmos
gen´eticos; nesse estudo os AGs constituem de um grupo de indiv´ıduos, gerados inicialmente
de forma aleat´oria, onde cada indiv´ıduo ´e representado por cadeias de cromossomos utilizando
uma representac¸˜ao bin´aria. Esses indiv´ıduos passam por recombinac¸˜oes e alterac¸˜oes como
selec¸˜ao, cruzamento e mutac¸˜ao [HOLLAND, 1992].
Como as regras de ACs com apenas dois estados poss´ıveis s˜ao bin´arias, essa abordagem
evolutiva pode ser utilizada de forma simples e direta para buscar a melhor regra capaz de
efetuar uma computac¸˜ao espec´ıfica [CENEK; MITCHELL, 2009]. Ao utilizar essa abordagem,
de forma aleat´oria, e cada indiv´ıduo ´e testado para saber qual o seu grau de aptid˜ao para o
prob-lema dado. Um conjunto com os indiv´ıduos que possu´ırem melhor aptid˜ao, ´e ent˜ao utilizado
para efetuar o cruzamento e a mutac¸˜ao gerando uma nova populac¸˜ao; ´e poss´ıvel ainda manter
os indiv´ıduos mais aptos para o determinado problema, inalterados na pr´oxima gerac¸˜ao como
uma forma de elitismo [CRUTCHFIELD; MITCHELL; DAS, 2002; MITCHELL; HRABER;
CRUTCHFIELD, 1993; CENEK; MITCHELL, 2009; STONE; BULL, 2009].
Em [STONE; BULL, 2009] foi utilizada a id´eia dos moldes, que apesar de serem
comu-mente utilizados nos sistemas classificadores de aprendizagem por m´aquina, como por
exem-plo em [HOLLAND, 1996] e [HOLLAND, 1992], sua utilizac¸˜ao em AGs para encontrar
re-gras de ACs ´e uma id´eia relativamente nova. No trabalho apresentado em [STONE; BULL,
2009], utilizam-se os moldes para introduzir a noc¸˜ao de “mem´oria” para o AG apresentado em
[CRUTCHFIELD; MITCHELL; DAS, 2002], por´em pouco se estuda sobre a utilizac¸˜ao dos
moldes e qual o ganho do AG ao utilizar essa forma de representac¸˜ao.
Neste trabalho foram escolhidos os algoritmos apresentado em [OLIVEIRA; OLIVEIRA;
OMAR, 2001], [CRUTCHFIELD; MITCHELL; DAS, 2002] e [MITCHELL; CRUTCHFIELD;
HRABER, 1994] como base para estudar os ganhos encontrados ao utilizar os moldes, como
foram propostos em [STONE; BULL, 2009] para efetuar duas tarefas cl´assicas de ACs: a
tarefa da classificac¸˜ao da densidade (density classification task, DCT) e o problema da paridade
(parity problem, PP). Essas tarefas procuram respectivamente, classificar se uma determinada
configurac¸˜ao bin´aria inicial possui mais c´elulas em estado 1 do que em estado 0, ou se possui
um n´umero par ou ´ımpar de c´elulas no estado 1.
Os algoritmos base utilizados s˜ao AGs extremamente simples, por´em capazes de encontrar
regras que efetuem a DCT e o PP com sucesso parcial; tendo sido amplamente estudado por
Mitchell, entre outros, em [MITCHELL; CRUTCHFIELD; HRABER, 1994], [MITCHELL;
HRABER; CRUTCHFIELD, 1993], [CRUTCHFIELD; MITCHELL, 1995], [CRUTCHFIELD;
MITCHELL; DAS, 2002], [STONE; BULL, 2009] e [OLIVEIRA; OLIVEIRA; OMAR, 2001].
Devido `a simplicidade do AG escolhido, a adaptac¸˜ao para a utilizac¸˜ao dos moldes ´e simples
e permite focar o trabalho nos ganhos ao se utilizar moldes para as tarefas escolhidas.
At-ualmente a melhor regra para a DCT possui uma efic´acia de≈88.985%, para configurac¸˜oes
iniciais (CIs) geradas utilizando-se uma distribuic¸˜ao binomial para definir a quantidade de 1s
4
´e desconhecido, por´em o mesmo AG apresentado em [WOLZ; OLIVEIRA, 2008] encontrou
caracter´ısticas interessantes sobre o PP.
O trabalho ´e dividido da seguinte forma: no Cap´ıtulo 2 ´e apresentado o funcionamento dos
algoritmos gen´eticos e os moldes; no Cap´ıtulo 3 s˜ao apresentados os autˆomatos celulares, a
tarefa da classificac¸˜ao da densidade e o problema da paridade, assim como as soluc¸˜oes tomadas
como base para a evoluc¸˜ao gen´etica dessas tarefas e, ´e apresentada a forma como foi feita a
utilizac¸˜ao da representac¸˜ao tern´aria nos indiv´ıduos; no Cap´ıtulo 4 s˜ao mostradas as alterac¸˜oes
nos AGs base, e os resultados obtidos para as duas tarefas estudadas; e finalmente no Cap´ıtulo
2
Algoritmos gen´eticos
Algoritmos gen´eticos (AGs) s˜ao algoritmos de busca baseados em abstrac¸˜oes dos
mecanis-mos de evoluc¸˜ao biol´ogica, onde uma populac¸˜ao de soluc¸˜oes candidatas a um problema dado,
por meio de operadores gen´eticos como cruzamento (crossover), mutac¸˜ao e selec¸˜ao, s˜ao
ca-pazes de evoluir durante uma quantidade de gerac¸˜oes, com o intuito de encontrar a melhor
forma de se resolver um determinado problema [CENEK; MITCHELL, 2009]. Historicamente
AGs datam da d´ecada de 50, por´em foi apenas a partir da d´ecada de 70 com maior poder
com-putacional e a metodologia apresentada por Holland [1975] entre outros trabalhos na ´area, que
eles comec¸aram a ser utilizados na pr´atica para resolver problemas reais [B ¨ACK; HAMMEL;
SCHWEFEL, 1997].
Como AGs s˜ao fortemente inspirados na gen´etica, cada indiv´ıduo da populac¸˜ao ´e
con-siderado, analogamente `a gen´etica, a um “cromossomo” representando uma poss´ıvel soluc¸˜ao
candidata ao problema dado. Normalmente esse cromossomo ´e representado por uma cadeia
bin´aria de caracteres de tamanho l (a0a1a2a3...an...an+1an+2an+3...al−1), com 0 <n<l. A metodologia b´asica de um AG (conforme descrita em [HOLLAND, 1996]) ´e a seguinte:
1. ´E gerada uma populac¸˜ao inicialP;
2. Cada indiv´ıduo ida populac¸˜ao ´e avaliado para o problema em quest˜ao, a partir do qual
´e gerado um valor f para cada indiv´ıduo (fitness, ou aptid˜ao) que representa o qu˜ao bem
adaptado ele se encontra para o problema dado;
3. S˜ao aplicados operadores gen´eticos (como selec¸˜ao, cruzamento e mutac¸˜ao) nos indiv´ıduos
da populac¸˜ao, de forma a ocorrer uma recombinac¸˜ao das melhores soluc¸˜oes encontradas
at´e o momento e com isso uma nova populac¸˜ao;
6
5. Quando terminar todas as gerac¸˜oes g, o indiv´ıduoi com melhor aptid˜ao ´e o melhor
in-div´ıduo encontrado pelo AG.
2.1
Operadores Gen´eticos
Aqui s˜ao brevemente apresentados e descritos, os operadores gen´eticos mais comuns (selec¸˜ao,
cruzamento e mutac¸˜ao). Esses operadores, s˜ao respons´aveis por criar uma nova populac¸˜ao
para efetuar uma busca, com o intuito de encontrar as melhores soluc¸˜oes capazes de resolver o
problema desejado. Uma vez esses operadores tendo sido executados, teremos a populac¸˜ao da
pr´oxima gerac¸˜ao (Pg+1).
2.1.1
Selec¸ ˜ao
Para que uma recombinac¸˜ao dos indiv´ıduos da populac¸˜ao possa ser efetuada, ´e necess´ario
escolher dentre toda a populac¸˜ao, quais i indiv´ıduos da populac¸˜ao g est˜ao aptos a serem
es-colhidos para sofrerem a ac¸˜ao dos operadores gen´eticos. Normalmente essa selec¸˜ao ´e feita de
forma aleat´oria, onde cada indiv´ıduo possui uma probabilidade proporcional `a sua aptid˜ao f de
ser selecionado. Dessa forma, s˜ao escolhidos pares de indiv´ıduos da populac¸˜aoPg com alto
f, e o cruzamento ´e aplicado nesses pares, seguido de outros operadores, como por exemplo a
mutac¸˜ao [HOLLAND, 1992].
2.1.2
Cruzamento
O operador gen´etico de cruzamento, ´e o operador respons´avel pela recombinac¸˜ao das soluc¸˜oes
encontradas at´e o momento, com o objetivo de encontrar boas estruturas que n˜ao foram geradas
inicialmente. Esse operador, ´e baseado na forma em que ocorre a recombinac¸˜ao dos genes na
gen´etica a partir de uma reproduc¸˜ao sexuada. A utilizac¸˜ao de uma reproduc¸˜ao sexuada no lugar
de uma reproduc¸˜ao assexuada, onde n˜ao ocorre o cruzamento entre dois indiv´ıduos, garante
maior variedade no novo indiv´ıduo.
O cruzamento pode ser feito de diversas formas, a mais comum ´e o cruzamento de ponto
´unico. Esse tipo de cruzamento funciona escolhendo um pontopaleat´orio (0<p<l), para cada
conjunto de pares de estruturas previamente escolhidas; a esses pares ´e dado o nome de “pais”. ´
de “filhos”, com uma sequˆencia de bits de um pai at´e o bit que se encontra no ponto p−1
escolhido, e uma sequˆencia de bits do ponto pat´e o bit l−1 do outro pai; como demonstrado
na Figura 2.1. Esse tipo de cruzamento ´e o mais comumente utilizado, pois ´e simples e garante
a explorac¸˜ao de v´arias estruturas candidatas `a soluc¸˜ao [HOLLAND, 1992].
a0a1...ap...ap+1ap+2...al−1
b0b1...bp...bp+1bp+2...bl−1
a0a1...ap...bp+1bp+2...bl−1
b0b1...bp...ap+1ap+2...al−1
p
Figura 2.1: Cruzamento de ponto ´unico.
2.1.3
Mutac¸˜ao
Uma forma de introduzir maior aleatoriedade na escolha dos indiv´ıduos da pr´oxima gerac¸˜ao,
sem perder bons indiv´ıduos, ´e a utilizac¸˜ao do operador gen´etico da mutac¸˜ao. Esse operador ´e
um dos mais simples poss´ıveis, e funciona alterando um n´umerom de bits em cada estrutura
selecionada, para um outro valor (no caso bin´ario, para o complemento do valor atual).
Esse n´umeromcostuma ser um valor muito pequeno, pois caso contr´ario estar´ıamos apenas
escolhendo novas estruturas de forma completamente aleat´oria, e qualquer estrutura que consiga
resolver o problema dado de forma eficiente, poderia ser perdida; mantendo-se m pequeno
garante-se que bons indiv´ıduos n˜ao ser˜ao perdidos [HOLLAND, 1992].
Selecionando-se corretamente o valor dem´e poss´ıvel garantir que bons indiv´ıduos que n˜ao
foram testados, aparec¸am em gerac¸ ˜oes futuras para serem avaliados [HOLLAND, 1992].
A forma mais comum de mutac¸˜ao, ´e a utilizac¸˜ao de uma probabilidade pmmuito pequena
(pm≈1%), essa probabilidade ´e aplicada em cada bit da estrutura em que se deseja efetuar a
mutac¸˜ao; utilizando-se um valor correto depmpode-se garantir que≈mbits ser˜ao alterados na
estrutura [CRUTCHFIELD; MITCHELL; DAS, 2002].
2.2
A nova populac¸˜ao
Ap´os a aplicac¸˜ao dos operadores gen´eticos, ´e necess´ario inserir os novos indiv´ıduos na
populac¸˜ao da pr´oxima gerac¸˜ao (Pg+1). Existem duas maneiras principais de efetuar essa inserc¸˜ao, de forma elitista e de forma n˜ao elitista [HOLLAND, 1992; CRUTCHFIELD; MITCHELL,
8
A forma elitista simplesmente seleciona um n´umeroEdos melhores indiv´ıduos da populac¸˜ao
Pg(aqueles com maior f), e os mant´em sem nenhuma alterac¸˜ao para a pr´oxima populac¸˜ao;
to-dos os outrosPg−Eindiv´ıduos s˜ao descartados e recriados aplicando-se os operadores gen´eticos
apenasa partir deE [MITCHELL; CRUTCHFIELD; HRABER, 1994].
J´a na forma n˜ao elitista, escolhem-se aleatoriamente indiv´ıduos da populac¸˜ao a serem
sub-stitu´ıdos pelos novos indiv´ıduos; a escolha dos indiv´ıduos a serem alterados pode ser
influen-ciada pelo f de cada indiv´ıduo, dando maior chance de substituic¸˜ao a indiv´ıduos com menor
f, ou seja, a escolha pode se comportar como sendo o oposto da escolha para os indiv´ıduos
selecionados para sofrerem a ac¸˜ao dos operadores gen´eticos [HOLLAND, 1996].
2.3
Representac¸˜ao tern´aria e moldes
Em [HOLLAND, 1975] ´e definida a noc¸˜ao de “templates” (moldes), onde um indiv´ıduo
´e representado por um conjunto de moldes, e cada molde representa uma parte do indiv´ıduo.
Tamb´em ´e definido um s´ımbolo especial chamado de “don’t care”, esse s´ımbolo (representado
por #) ´e utilizado para representar todos os s´ımbolos poss´ıveis, minimizando a representac¸˜ao
do indiv´ıduo. Como estamos trabalhando com uma representac¸˜ao bin´aria, ao adicionarmos esse
terceiro s´ımbolo temos a representac¸˜ao tern´aria.
Como exemplo, podemos ter o indiv´ıduo representado pelos moldes “11001#0010” e “001#
01#101”, considerando que o indiv´ıduo possui uma representac¸˜ao bin´aria e estamos utilizando
3 s´ımbolos#, esses dois moldes s˜ao capazes de representar 23=8 indiv´ıduos diferentes, ou seja:
11001000100010010101, 11001000100010011101, 11001000100011010101, 110010001000
11011101, 11001100100010010101, 11001100100010011101, 11001100100011010101, e
fi-nalmente, 11001100100011011101.
Esse tipo de estrutura possui dois benef´ıcios principais: (i) permite maior generalizac¸˜ao do
algoritmo evolutivo, possibilitando a explorac¸˜ao de novas soluc¸˜oes que poderiam demorar muito
a aparecer apenas via os operadores gen´eticos e, (ii) ajuda a evitar que o algoritmo evolutivo
fique estagnado em uma soluc¸˜ao localmente ´otima, por´em n˜ao globalmente ´otima [HOLLAND,
1992]. O ganho em mem´oria tamb´em ´e muito importante, no exemplo anterior, conseguimos
3
Autˆomatos Celulares
Autˆomatos celulares (ACs) foram primeiramente propostos por Von Neumann na d´ecada
de 40, e est˜ao entre os mais antigos modelos de computac¸˜ao natural. Von Neumann propˆos
os ACs com o objetivo de projetar um sistema artificial capaz de auto-reproduc¸˜ao, por´em com
caracter´ısticas de computac¸˜ao universal (ou seja, capazes de emular uma M´aquina de Turing).
Eles foram primeiramente definidos em um reticulado de tamanho finito, onde cada c´elula ´e um
autˆomato finito interconectado com as c´elulas vizinhas [KARI, 2005].
Cada c´elula possui um conjuntoΣde estados poss´ıveis, e a troca de um estado para o outro ´e dada por uma regraδ de transic¸˜ao que, dada uma vizinhanc¸a η de c´elulas em um raio r, a
c´elula transita para um dos estados deΣ[CRUTCHFIELD; MITCHELL, 1995].
Normalmente s˜ao utilizados reticulados de 1, 2 ou 3 dimens˜oes, os quais podem se
com-portar como a ideia original (reticulado de tamanho finito), ou trabalhar de forma toroidal, onde
os lados extremos do reticulado se juntam. Em [WOLFRAM, 2002] foi mostrado que mesmo
simples ACs (1 dimens˜ao,Σ=2 er=1) s˜ao capazes de apresentar computabilidade universal. As regras de um AC seguem uma simples tabela de transic¸˜ao, criada de acordo com as
poss´ıveis vizinhanc¸as de cada c´elula (Lookup table, LUT de agora em diante). Para o AC
mais simples poss´ıvel (1 dimens˜ao,Σ=2 er=1), temosl(η) =3 (onde a vizinhanc¸a ´e dada pela c´elula central, e as c´elulas imediatamente a direita e a esquerda), e o tamanho l de δ
(a quantidade de transic¸˜oes poss´ıveis) ´e dado porl(δ) =Σl(η)=8, resultando emΣl(δ)=256 diferentes regras de transic¸˜ao [CRUTCHFIELD; MITCHELL, 1995]; a esse pequeno n´umero de
regras denomina-se Autˆomatos Celulares Elementares (Elementary Cellular Automata, ECA).
Wolfram nomeia as regrasδ pela representac¸˜ao decimal da sa´ıda da LUT, iniciando sempre
pela vizinhanc¸a com a totalidade de 1s (do lado esquerdo) para a vizinhanc¸a com a totalidade
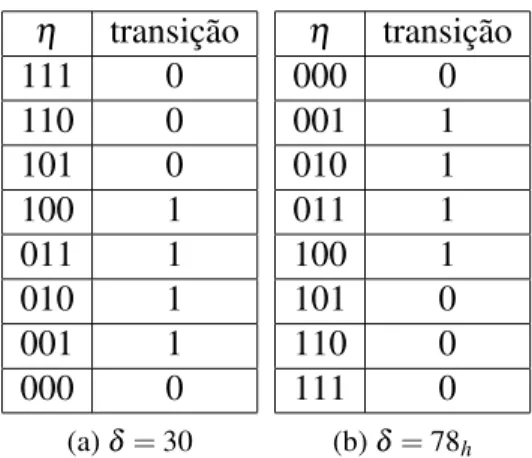
de 0s no lado direito; por exemplo, para a regraδ=30 temos a LUT apresentada na Tabela 3.1a
10
a regraδ =30. Esse tipo de representac¸˜ao, ´e aceito como a representac¸˜ao e nomeac¸˜ao padr˜ao
para os ACs [WOLFRAM, 2002].
Existem outras representac¸˜oes poss´ıveis, como por exemplo a utilizada por Mitchell,
Crutch-field e Hraber [1994] e CrutchCrutch-field, Mitchell e Das [2002], onde a LUT demonstrada na Tabela 3.1b,
´e dada pela vizinhanc¸aη com a totalidade de 0s (do lado direito), para a com a totalidade de 1s
(do lado esquerdo), e a nomeac¸˜ao da regra ´e dada pela representac¸˜ao hexadecimal da sa´ıda da
LUT, que neste caso seria a regraδ =78h.
η transic¸˜ao 111 0 110 0 101 0 100 1 011 1 010 1 001 1 000 0
(a)δ =30
η transic¸˜ao 000 0 001 1 010 1 011 1 100 1 101 0 110 0 111 0
(b)δ =78h
Tabela 3.1: Representac¸˜oes de regras de transic¸˜ao.
No presente trabalho ser´a utilizada a representac¸˜ao definida por Wolfram, para definir todos
os ACs. Para demonstrar visualmente ACs bin´arios, s˜ao utilizadas c´elulas brancas para
repre-sentar o estado 0 e, c´elulas pretas para o estado 1. Como estamos trabalhando com ACs em 1
dimens˜ao, cada linha do reticulado representa uma iterac¸˜ao completa do AC, partindo de uma
configurac¸˜ao inicial (CI) do reticulado. A Figura 3.1 demonstra a representac¸˜ao descrita, onde
a Figura 3.1a apresenta a demonstrac¸˜ao visual da CI “0000100000”, e a Figura 3.1b demonstra
10 iterac¸˜oes da regraδ =30 para a CI apresentada na Figura 3.1a. Esse tipo de representac¸˜ao
´e considerada a representac¸˜ao padr˜ao para ACs bin´arios e unidimensionais, e ser´a utilizada
(a) Exemplo de demonstrac¸˜ao visual
da CI 0000100000.
(b) Exemplo de demonstrac¸˜ao visual
de um AC iterado 10 vezes, a partir
da CI apresentada na Figura 3.1a.
Figura 3.1: Demonstrac¸˜ao visual da iterac¸˜ao da regraδ =30 durante 10 iterac¸˜oes, partindo da CI 0000100000.
Como demonstrativo da utilizac¸˜ao computacional dos ACs, em [WOLFRAM, 2002] ´e
demonstrada sua complexidade e utilizac¸˜ao pr´atica em um profundo estudo, onde foi dado
in-teresse particular aos ECAs, pois eles s˜ao capazes de apresentar padr˜oes temporais complexos
(iterac¸˜oes da regraδ por um determinado n´umero de iterac¸˜oes a partir de CI), apesar de serem
muito simples; alguns ECAs conseguem at´e mesmo apresentar caracter´ısticas de computac¸˜ao
universal [WOLFRAM, 2002].
Em [WOLFRAM, 1984] foram definidas 4 classes de ACs, da mais simples (classe 1)
para a mais complexa (classe 4). A classe 1 apresenta sempre ACs de padr˜oes simples, e
praticamente todas as diferentes CIs levam para o mesmo estado final; a classe 2 apresenta
padr˜oes com diversos estados finais, por´em sempre com pequenas estruturas capazes de se
manterem durante as iterac¸˜oes; a classe 3 apresenta grande complexidade e, aparentemente
possui um padr˜ao temporal aleat´orio; j´a a ´ultima classe, a classe 4, apresenta caracter´ısticas de
estruturas organizadas, com longos transientes e o aparecimento de estruturas, que s˜ao capazes
de se propagar durante a execuc¸˜ao do AC. ACs com computabilidade universal tˆem ocorrido
tipicamente nessa ´ultima classe.
A Figura 3.2a apresenta a regra 40, um AC de classe 1. Esse AC em particular sempre ir´a
terminar suas iterac¸˜oes em uma configurac¸˜ao homogˆenea de 0s, independente se a CI ´e apenas
a c´elula central no estado 1 e todas as outras no estado 0 (Figura 3.2b) ou uma CI com uma
12
1 È 0
(a)δ=40 (retirado de [MEDIA, 2010]).
(b) Evoluc¸˜ao da regra 40 durante 25
iterac¸˜oes com a CI possuindo apenas a
c´elula central no estado 1.
(c) Evoluc¸˜ao da regra 40 durante 25
iterac¸˜oes com CI possuindo c´elulas
aleat´orias no estado 1.
Figura 3.2: Regra 40 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.
A Figura 3.3a por sua vez, ´e a demonstrac¸˜ao da regra 84, um AC que se encontra na classe
2. Pode ser visto que, tanto para uma simples CI com apenas a c´elula central no estado 1
(Figura 3.3b) e uma CI com uma quantidade aleat´oria de c´elulas no estado 1 (Figura 3.3c),
esse AC leva a diferentes configurac¸˜oes finais, por´em o seu comportamento durante as iterac¸˜oes
continua aparentemente s´ımples.
1 È 0
(a)δ=84 (retirado de [MEDIA, 2010]).
(b) Evoluc¸˜ao da regra 84 durante 25
iterac¸˜oes com a CI possuindo apenas a
c´elula central no estado 1.
(c) Evoluc¸˜ao da regra 84 durante 25
iterac¸˜oes com CI possuindo c´elulas
aleat´orias no estado 1.
Figura 3.3: Regra 84 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.
Por sua vez, a Figura 3.4a apresenta a regra 30, um AC que se encontra na classe 3. ACs
a c´elula central no estado 1 (Figura 3.4b), quanto para CIs com v´arias c´elulas no estado 1
(Figura 3.4c).
1 È 0
(a)δ=30 (retirado de [MEDIA, 2010]).
(b) Evoluc¸˜ao da regraδ =30 durante 25
iterac¸˜oes com a CI possuindo apenas a
c´elula central no estado 1.
(c) Evoluc¸˜ao da regra 30 durante 25
iterac¸˜oes com CI possuindo c´elulas
aleat´orias no estado 1.
Figura 3.4: Regra 30 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.
A regra 110 demonstrada na Figura 3.5a, ´e uma das regras com caracter´ısticas de computac¸˜ao
universal; a utilizac¸˜ao dessa regra para esse fim depende de sua CI. ´E poss´ıvel perceber que o
comportamento dela para uma CI simples, apenas a c´elula central da CI no estado 1, (Figura 3.5b)
possui um padr˜ao de evoluc¸˜ao temporal aparentemente aleat´orio, por´em as estruturas que
apare-cem tendem a se tornar um padr˜ao; o mesmo pode ser percebido em uma CI mais complexa,
com v´arias c´elulas no estado 1, (Figura 3.5c); essa regra se encontra na classe 4.
J´a na Figura 3.6a vemos a regra 90, apresentando um comportamento muito mais
comu-mente encontrado em ECAs, a criac¸˜ao de um padr˜ao que se repete ap´os um certo n´umero de
iterac¸˜oes. ´E poss´ıvel perceber que para uma CI simples (Figura 3.6b) ela apresenta um padr˜ao
bem definido. Essa regra em particular consegue “construir” o famoso triˆangulo de Sierpinsky,
por´em a partir de uma CI mais complexa (Figura 3.6c) n˜ao mais se observa a construc¸˜ao do
triˆangulo de Sierpinsky, mas apenas um padr˜ao de evoluc¸˜ao temporal aleat´orio; essa regra ´e
14
1 È 0
(a)δ=110 (retirado de [MEDIA, 2010]).
(b) Evoluc¸˜ao da regra 110 durante 25
iterac¸˜oes com a CI possuindo apenas a
c´elula central no estado 1.
(c) Evoluc¸˜ao da regra 110 durante 25
iterac¸˜oes com CI possuindo c´elulas
aleat´orias no estado 1.
Figura 3.5: Regra 110 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.
1 È 0
(a)δ =90 (retirado de Media [2010]).
(b) Evoluc¸˜ao da regra 90 durante 25
iterac¸˜oes com a CI possuindo apenas a
c´elula central no estado 1.
(c) Evoluc¸˜ao da regra 90 durante 25
iterac¸˜oes com CI possuindo c´elulas
aleat´orias no estado 1.
Figura 3.6: Regra 90 como definida em Wolfram [2002] e iterada durante 25 iterac¸˜oes.
Esses diferentes tipos de comportamento s˜ao o que motivaram Wolfram e muitos outros,
a estudarem a complexidade capaz de ser gerada via ACs, em diferentes trabalhos, como por
exemplo em [HOLLAND, 1999] onde s˜ao estudadas v´arias formas de computac¸˜ao natural,
ca-pazes de encontrar ordem a partir de um estado inicialmente aleat´orio, entre as quais, redes
neurais artificiais, algoritmos gen´eticos e autˆomatos celulares. ´E esse tipo de complexidade
que permite a utilizac¸˜ao de ACs para resolver alguns problemas e efetuar simulac¸˜oes,
princi-palmente simulac¸˜oes f´ısicas, onde (por exemplo) o comportamento de gases chegou inclusive a
3.1
Utilizando moldes e a representac¸˜ao tern´aria em ACs
Para utilizarmos a representac¸˜ao tern´aria (como foi definida no Cap´ıtulo 2.3) para auxiliar
no processo de busca via AGs, ´e necess´ario criar uma estrutura diferente para definir as regras
de ACs. Essa estrutura ´e composta de um conjunto de moldes, onde cada molde representa uma
poss´ıvel vizinhanc¸a η, com a poss´ıvel utilizac¸˜ao do s´ımbolo #, e a transic¸˜ao referente a esse
conjunto de moldes; essa transic¸˜ao ´e conhecida como a orientac¸˜ao de um conjunto de moldes. A
orientac¸˜ao ´e o estado para o qual uma das c´elulas da vizinhanc¸a (normalmente a c´elula central),
ir´a transitar caso algum molde do conjunto de moldes seja encontrado nos reticulados iterados
da CI, caso nenhum molde seja encontrado, a mesma c´elula ir´a transitar para o complemento
da orientac¸˜ao definida; todos os moldes de uma mesma estrutura possuem a mesma orientac¸˜ao
[STONE; BULL, 2009].
Como exemplo vamos transformar a regra 110 para esse tipo de estrutura. A LUT dessa
regra ´e mostrada na Tabela 3.2a e a estrutura que representa essa LUT, utilizando apenas a
vizinhanc¸aη que possui transic¸˜ao para o estado 1 ´e mostrada na Tabela 3.2b.
η transic¸˜ao 111 0 110 1 101 1 100 0 011 1 010 1 001 1 000 0
(a) LUT da regra 110.
η transic¸˜ao 110 1 101 1 011 1 010 1 001 1
(b) estrutura que repre-senta a regra 110 com transic¸˜ao 1.
Tabela 3.2: LUT da regra 110, completa e apenas utilizando a transic¸˜ao para o estado 1.
´
E poss´ıvel perceber que ao utilizar esse tipo de estrutura economizamos na mem´oria
uti-lizada para representar a regra, pois estamos apenas buscando pelas vizinhanc¸as que possuem
uma transic¸˜ao para o estado 1, caso nenhuma vizinhanc¸a seja encontrada, sua transic¸˜ao ´e
con-siderada como sendo para o estado 0 [STONE; BULL, 2009].
Ao adicionarmos o s´ımbolo # podemos minimizar ainda mais a quantidade de moldes, pois
´e poss´ıvel “transformar” os moldes 011 e 010 em apenas um molde 01#[STONE; BULL, 2009];
16
η transic¸˜ao
110 1
101 1
01# 1
001 1
Tabela 3.3: Regra 110 utilizando moldes e o s´ımbolo #.
´
E poss´ıvel perceber um maior ganho ao se utilizar essa representac¸˜ao, quando trabalhamos
com ACs de raio maior do que 1. Como exemplo, para ACs der=3, temosl(δ) =27=128, ou
seja, 128 vizinhanc¸as distintas e um espac¸o total de 2128regras diferentes. Se utilizarmos uma
m´edia de 8.8 moldes por estrutura, e 2 s´ımbolos # por molde (como foi feito em [STONE;
BULL, 2009]), assumindo que n˜ao exista repetic¸˜ao entre os moldes de uma mesma
estru-tura, ´e poss´ıvel representar em m´edia 36 vizinhanc¸as por estrutura; utilizando esses parˆametros
diminu´ımos aproximadamente 28% na quantidade necess´aria dos moldes de uma estrutura,
rep-resentada com todas as vizinhanc¸as e sem a utilizac¸˜ao do s´ımbolo #.
3.2
A tarefa da classificac¸˜ao da densidade
A tarefa da classificac¸˜ao da densidade (Density classification task, DCT), ´e uma tarefa
cl´assica em ACs. A DCT consiste em encontrar um AC bin´ario (Σ=2) que, ap´os ser iterado por at´eT iterac¸˜oes em qualquer CI, encontre uma configurac¸˜ao homogˆenea onde todas as c´elulas
se encontrem no estado 1, caso a CI possua mais 1s do que 0s (a quantidade de 1s sobre 0s, a
densidade de 1s em um reticulado, ´e chamada deρ), ou uma configurac¸˜ao uniforme de 0s caso
contr´ario. Usualmente, esse teste ´e feito em um reticulado unidimensional, de tamanhoL´ımpar
(normalmenteL=149), e ACs bin´arios comr=3, totalizando 2128diferentes regras poss´ıveis,
um espac¸o muito grande para efetuar uma busca exaustiva.
Apesar de ser uma tarefa simples para sistemas centralizados, essa tarefa se torna
extrema-mente complexa em sistemas descentralizados como ACs, pois o AC deve ser capaz de tomar
uma decis˜ao local que reflita uma condic¸˜ao global da qual ele n˜ao sabe o estado [OLIVEIRA;
OLIVEIRA; BORTOT, 2006]; foi provado em [LAND; BELEW, 1995] que n˜ao existe um ´unico
AC capaz de executar a DCT com sucesso para todas as CIs.
Devido `a enorme quantidade de regras poss´ıveis para executar a DCT (2128 poss´ıveis
execute a DCT com uma alta taxa de acertos, essa ´e uma tarefa comumente utilizada para
estudar a utilizac¸˜ao de AGs para encontrar, de forma autom´atica, boas regras que sejam
ca-pazes de executar a DCT com uma boa margem de sucesso [CRUTCHFIELD; MITCHELL;
DAS, 2002]. A melhor regra atualmente, ´e reportada em [WOLZ; OLIVEIRA, 2008] e possui
efic´acia de 88.985% para 500.000 CIs comρ escolhido de forma aleat´orio em uma distribuic¸˜ao
binomial; escolherρ a partir de uma distribuic¸˜ao binomial torna as CIs muito mais complexas
para serem avaliada pelo AC. Um exemplo de sua iterac¸˜ao ´e ilustrada na Figura 3.8 para uma
CI de teste comL=149 eρ=55.7947%. A mesma CI (ilustrada na Figura 3.7) ´e utilizada nas
demais ilustrac¸˜oes das iterac¸˜oes dos ACs encontrados pelos diferentes AGs implementados. O
AC encontrado em [WOLZ; OLIVEIRA, 2008] foi capaz de encontrar a classificac¸˜ao correta
(ρT =100%) ap´os aproximadamente 100 iterac¸˜oes.
Outra forma de se encontrar regras para a DCT, ´e a sua criac¸˜ao manual. Das regras
cri-adas manualmente, a regra GKL (nomeada pelos nomes de seus autores, Gacs, Kurdyumov
e Levin) proposta em [GACS; KURDYUMOV; LEVIN, 1978], ´e considerada a melhor regra
criada manualmente para a DCT. Aparentemente, essa regra possui uma estrat´egia capaz de
minimizar o erro conforme se aumenta a quantidade m´axima de iterac¸˜oes (T) [MITCHELL;
CRUTCHFIELD; HRABER, 1994]. Em [MITCHELL; CRUTCHFIELD; HRABER, 1994] foi
estudado o motivo que um AG simples, n˜ao ´e capaz de encontrar a regra GKL de forma
au-tom´atica, mesmo ele sendo criado com esse objetivo.
Figura 3.7: CI utilizada para demonstrativo das regras encontradas pelos diversos AGs utiliza-dos,ρ =55.7047%.
18
Neste trabalho foram estudados 3 AGs para encontrar boas regras para a DCT, os
algo-ritmos definidos em [MITCHELL; CRUTCHFIELD; HRABER, 1994] (que ser´a chamado de
MCH), uma simples modificac¸˜ao do mesmo em [OLIVEIRA; OLIVEIRA; OMAR, 2001] (que
ser´a chamado de OOO), e outro algoritmo definido em [CRUTCHFIELD; MITCHELL; DAS,
2002] (que ser´a chamado de CMD). Apesar de semelhantes, esses AGs apresentam pequenas
diferenc¸as capazes de influenciar no resultado final.
Todos os AGs estudados partem do mesmo AG:
1. Gera-se uma populac¸˜aoPaleat´oria, onde cada indiv´ıduoi ´e um AC capazes de executar
a DCT;
2. Para cada gerac¸˜aogdo AG at´e a gerac¸˜ao finalG:
(a) S˜ao geradas I CIs aleat´orias, utilizando-se uma distribuic¸˜ao uniforme para o valor ρ;
(b) Cada indiv´ıduo da populac¸˜aoPg, ´e executado para todas asICIs por um m´aximo de
T iterac¸˜oes e, a quantidade de classificac¸˜oes corretas do AC ´e a aptid˜ao (“fitness”) f
do AC. Nenhum cr´edito ´e dado a classificac¸˜oes incompletas (que n˜ao conseguiram
chegar a um estado homogˆeneo de 1 ou 0);
(c) A elite E de ACs com melhor f ´e copiada sem alterac¸˜ao para a pr´oxima populac¸˜ao
Pg+1;
(d) o restante da populac¸˜aoPg+1−E ´e gerada utilizando-se:
i. Cruzamento com pc probabilidade de ocorrer, com pais sempre oriundos da
eliteE e;
ii. ´E efetuada mutac¸˜ao nos filhos resultantes do cruzamento, com probabilidade
pmpor bit;
3. S˜ao geradas B CIs aleat´orias, utilizando-se uma distribuic¸˜ao binomial para o valor ρ,
resultando em um teste mais complexo para os ACs gerados pelo algoritmo; e
4. O indiv´ıduo dePGcom maior f ´e executado em at´e no m´aximoT vezes para todas asB
CIs, a quantidade de classificac¸˜oes corretas ´e a aptid˜ao final (F) do indiv´ıduo.
´
E importante frisar, que todos os AGs criam os indiv´ıduos da populac¸˜ao inicial (P0)
no tempo de execuc¸˜ao do AG, al´em da qualidade das soluc¸˜oes n˜ao ser afetada por esse tipo de
distribuic¸˜ao inicial [MITCHELL; CRUTCHFIELD; HRABER, 1994]. Esse fato tamb´em foi
observado no presente trabalho.
Todos os AGs foram executados em um cluster possuindo 14 n´os, dentre eles 6 com 4
n´ucleos AMD Opteron de 2GHz e 8 com 2 n´ucleos AMD Opteron de 1.4 GHz. A forma de
paralelismo escolhida para a execuc¸˜ao dos testes, foi utilizar OpenMPI para distribuir as threads
no cluster, onde cada thread ´e respons´avel por uma execuc¸˜ao completa do AG.
3.2.1
CMD
Em [CRUTCHFIELD; MITCHELL; DAS, 2002], foram estudadas as estrat´egias dos ACs
encontrados por um simples AG para a tarefa da DCT, e como essas estrat´egias se comportavam
para CIs de tamanho L=149, L= 499 e L=999. O AG apresentado utiliza os seguintes
parˆametros: P=100, I =100, T =2∗L, B=104, E =20, G=100, pc =100% e pm =
1.1516%.
Esse AG ´e capaz de evoluir trˆes tipos diferentes de estrat´egias para a execuc¸˜ao da DCT:
• Default: Estrat´egias do tipo default s˜ao muito boas em resolver CIs com ρ <50% ou
ρ>50%, mas s˜ao incapazes de resolver CIs para ambos os casos. Esse tipo de estrat´egia
apresenta efic´acia de≈50% para qualquer tamanhoL.
• Block-expanding: Esse tipo de estrat´egia consegue “expandir”a vizinhanc¸a de cada c´elula,
de forma que as c´elulas vizinhas efetuem sua expans˜ao levando em conta n˜ao apenas sua
pr´opria vizinhanc¸a, mas tamb´em a vizinhanc¸a de outras c´elulas. Essa estrat´egia costuma
levar a efic´acias de≈60%, por´em ao aumentar o tamanhoL, esse valor diminui.
• Particle: Esse tipo de estrat´egia ´e a respons´avel por apresentar os ACs com melhor
efic´acia (acima de 70%), por´em tamb´em s˜ao as mais dif´ıceis de se encontrar. ACs que
em-pregam esse tipo de estrat´egia s˜ao capazes de “transmitir” a densidade da vizinhanc¸a de
cada c´elula para as c´elulas adjacentes e, dessa forma, muitas vezes efetuar corretamente
a DCT. Essas estrat´egias s˜ao as que melhor mant´em a efic´acia para tamanhos maiores de
L.
20
independentes. ´E poss´ıvel perceber as 3 faixas, que caracterizam as estrat´egias apresentadas
anteriormente. Das 300 execuc¸˜oes, 120 possuem performance abaixo de 60%, 175 entre 60.01%
e 70%, e apenas 4 possuem performance maior que 70.01%.
As Figuras 3.10a e 3.10b, mostram respectivamente 100 iterac¸˜oes da melhor e da pior regra
encontrada pelo CMD para a CI apresentada na Figura 3.7. J´a as Figuras 3.10c e 3.10d, mostram
o f do melhor indiv´ıduoPg encontrado em cada gerac¸˜aogdo AG, respectivamente para a pior
e a melhor regra encontrada entre as 300 execuc¸˜oes distintas do AG.
O tempo total de execuc¸˜ao do AG para encontrar as 300 regras apresentadas foi de 8 horas
e 45 minutos.
335 946 353 665 655 739 599 279 694 834 806 851 712
(a) 100 iterac¸˜oes da pior regra encontrada
uti-lizando o CMD.
1 622 592 825 149 487 511 997 191 488 012 273
(b) 100 iterac¸˜oes da melhor regra encontrada
uti-lizando o CMD.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 335946353665655739599279694834806851712
(c) f da pior regra encontrada em cada gerac¸˜ao
do AG.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 1622592825149487511997191488012273
(d)fda melhor regra encontrada em cada gerac¸˜ao
do AG.
Figura 3.10: Detalhamento das regras do CMD.
3.2.2
MCH
Em [MITCHELL; CRUTCHFIELD; HRABER, 1994], foi estudado um dos AGs mais
sim-ples poss´ıveis para encontrar boas regras para a DCT. L´a estudou-se como o AG conseguia
evoluir boas regras, o motivo do AG n˜ao encontrar regras com alta performance todas as vezes,
e o motivo pelo qual esse simples AG n˜ao ´e capaz de encontrar regras superiores ou equivalentes
`a regra GKL, cujo desempenho ´e da ordem de 80% [MITCHELL; CRUTCHFIELD; HRABER,
1994].
O AG possui as seguintes alterac¸˜oes:
• AsI CIs s˜ao geradas utilizando-seexatamente 50% de CIs comρ <50% e 50% com
ρ>50%;
22
de Poisson de m´edia 320 e;
• A mutac¸˜ao ´e feita emexatamentembits de cada AC resultante do cruzamento. O valor
pmpode ser inferido a partir dem.
Os parˆametros utilizados foram: P=100, I=100,B=104,E=20,G=100, pc=80%,
m=2 (o equivalente a pm=1.5625%) eL=149. Os resultados de 300 execuc¸˜oes distintas do
AG, podem ser vistos na Figura 3.11, e as 100 iterac¸˜oes da pior e da melhor regra encontradas
pelo AG, podem ser vistas respectivamente, nas Figuras 3.12a e 3.12b; o f dos melhores
in-div´ıduos de cada gerac¸˜aogdo AG, nas execuc¸˜oes respons´aveis por encontrar a pior e a melhor
regra s˜ao mostrados nas Figuras 3.12c e 3.12d respectivamente.
Ambas as regras conseguiram executar a DCT para a CI com sucesso, por´em a regra de pior
performance se encontra na classificac¸˜ao “default”de [CRUTCHFIELD; MITCHELL; DAS,
2002], o que significa que ela consegue executar a classificac¸˜ao de forma correta, apenas para
CIs com ρ >50%. A evoluc¸˜ao do f durante o AG, da melhor regra, est´a de acordo com o
trabalho original, onde ´e poss´ıvel verificar as diferentes “´epocas”do AG (cada ´epoca ´e
carac-terizada por um salto no f dos ACs encontrados) [MITCHELL; CRUTCHFIELD; HRABER,
24
340 282 160 439 462 956 348 565 670 998 868 812 008
(a) 100 iterac¸˜oes da pior regra encontrada
uti-lizando o MCH.
333 552 500 509 258 600 421 908 018 833 288 856 200
(b) 100 iterac¸˜oes da melhor regra encontrada
uti-lizando o MCH.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 340282160439462956348565670998868812008
(c) f da pior regra encontrada em cada gerac¸˜ao
do AG.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 333552500509258600421908018833288856200
(d)fda melhor regra encontrada em cada gerac¸˜ao
do AG.
Figura 3.12: Detalhamento das regras do MCH.
O tempo total de execuc¸˜ao para as 300 execuc¸˜oes distintas do AG foi de 3 horas e 26
minutos. Dessas 300 execuc¸˜oes, 17 est˜ao abaixo de 60% de performance, 204 entre 60.01% e
70% e 79 regras acima de 70.01%.
´
E importante apontar que das alterac¸˜oes apresentadas, a mais significativa ´e a utilizac¸˜ao de
um n´umero aleat´orio com distribuic¸˜ao de Poisson para a quantidade de iterac¸˜oes de cada AC,
pois isso diminui a possibilidade de se encontrar regras com ciclo duplo, isto ´e, ACs com a
caracter´ıstica de comportamento c´ıclico de per´ıodo 2 que, portanto, n˜ao convergem para um
´unico estado homogˆeneo; a prop´osito, este ´e o caso da melhor regra encontrada pelo CMD,
conforme ilustrado na Figura 3.10b.
Tamb´em foi demonstrado em [MITCHELL; CRUTCHFIELD; HRABER, 1994] que
3.2.3
OOO
Em [OLIVEIRA; OLIVEIRA; OMAR, 2001], foram estudadas as caracter´ısticas intr´ınsecas
dos ACs encontrados pelo MCH; como por exemplo o ρ de cada regra e a sensitividade `a
vizinhanc¸a, dentre outros parˆametros. Em nossas execuc¸˜oes n˜ao estamos estudando esses
parˆametros, apenas os resultados do AG utilizado.
Os parˆametros do AG utilizados foram: P=100,I=100,B=104,E=20,G=100, pc=
80%, pm=2% e L=149. Diferentemente do AG original, a forma de mutac¸˜ao utilizada em
[OLIVEIRA; OLIVEIRA; OMAR, 2001] ´e feita com probabilidadepmem cada bit, a utilizac¸˜ao
de pm =2% garante m≈2. A quantidade de iterac¸˜oes de cada AC tamb´em ´e dada por um
n´umero vari´avel de vezes [OLIVEIRA; OLIVEIRA; OMAR, 2001]; por´em a distribuic¸˜ao de
probabilidade, utilizada para se encontrar o n´umero para definir o tempo total de iterac¸˜oes de
cada AC, n˜ao ´e especificada no artigo original. Dessa forma, aqui tamb´em utiliza-se a mesma
distribuic¸˜ao do MCH (distribuic¸˜ao de Poisson), com m´edia 298.
A efic´acia da melhor regra encontrada em 300 execuc¸˜oes distintas pode ser vista na Figura 3.13,
e 100 iterac¸˜oes da pior e melhor regras encontradas pelo AG podem ser vistas nas Figuras 3.14a
e 3.14b, respectivamente. O f das melhores regras encontrados, em cada gerac¸˜aognas execuc¸˜oes
respons´aveis por encontrar a pior e melhor regra do AG, s˜ao mostrados nas Figuras 3.14c e
3.14d respectivamente. O tempo total de execuc¸˜ao do AG para encontrar as 300 regras foi de
3 horas e 44 minutos; dessas 300 execuc¸˜oes, 39 possuem performance menor que 60%, 220
26
277 910 614 967 827 334 053 006 880 536 310 901 760
(a) 100 iterac¸˜oes da pior regra encontrada
uti-lizando o OOO.
338 516 985 978 337 537 125 333 578 344 457 831 424
(b) 100 iterac¸˜oes da melhor regra encontrada
uti-lizando o OOO.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 277910614967827334053006880536310901760
(c) f da pior regra encontrada em cada gerac¸˜ao
do AG.
0 20 40 60 80 100Geração 0 20 40 60 80 100 Fitness
Evolução da regra 338516985978337537125333578344457831424
(d)fda melhor regra encontrada em cada gerac¸˜ao
do AG.
Figura 3.14: Detalhamento das regras do OOO.
3.2.4
Resultados
Na Figura 3.15, temos a plotagem do resultado de 300 execuc¸˜oes distintas dos AGs. ´E
poss´ıvel perceber que os melhores resultados est˜ao no OOO e MCH, esses AGs apresentam uma
faixa de performance m´edia entre 65% e 70%, e poucos resultados abaixo de 50%. Por sua vez o
CMD apresenta piores resultados, com uma m´edia de aproximadamente 60% e v´arios resultados
entre 35% e 50%. Na Tabela 3.4 podemos ver uma contagem dos resultados para algumas faixas
de performance espec´ıficas, fica claro por essa tabela que os melhores AGs realmente s˜ao OOO
e MCH, uma vez que eles s˜ao extremamente parecidos fica dif´ıcil especificar qual AG ´e o
melhor de todos. A Tabela 3.5 por sua vez, mostra as diferenc¸as entre os parˆametros nos AGs
28
Figura 3.15: Gr´afico comparativo com os 3 AGs em 300 execuc¸˜oes distintas, sem a utilizac¸˜ao da representac¸˜ao tern´aria.
fi(%) OOO MCH CMD
≤50 33 16 60
(50,60] 6 1 61
(60,70] 220 204 175
(70,80] 40 79 4
>80 1 0 0
Tabela 3.4: Contagem das regras encontradas pelos 3 AGs estudados.
AG P E pc pm m L B T
CMD 100 20 100% 1.1516% ≈2 149 104 298
MCH 100 20 80% 1.5626% 2 149 104 ≈320
OOO 100 20 80% 2% ≈2 149 104 ≈298
3.3
O Problema da Paridade
O Problema da Paridade (PP) ´e muito parecido com a DCT, e tamb´em ´e considerado um
teste padr˜ao para algoritmos evolutivos. Ele consiste em encontrar uma regraδ, que consiga
em no m´aximoT iterac¸˜oes encontrar um estado homogˆeneo de 0s caso a quantidade de 1s na
CI seja par, ou 1s caso a quantidade seja ´ımpar; para qualquer CI. De acordo com [LEE; XU;
CHAU, 2001] este problema ´e considerado muito mais complexo de ser resolvido do que a
DCT, pois basta trocar um bit em qualquer iterac¸˜ao para alterar a sa´ıda final desejada, por´em
em [WOLZ; OLIVEIRA, 2008] o oposto ´e provado.
O mesmo algoritmo utilizado em [WOLZ; OLIVEIRA, 2008] para a DCT, foi utilizado
para o PP. Foram encontrados ´otimos resultados para CIs de tamanho ´ımpar e CIs de tamanho
primo, por´em para CIs de tamanho par o mesmo n˜ao ´e verdade. Boas regras encontradas para
CIs pequenas de tamanho par, n˜ao conseguem resolver CIs maiores, apresentando resultados
muito pequenos (≤ 52%). O motivo dessas caracter´ısticas ainda ´e uma quest˜ao em aberto
[WOLZ; OLIVEIRA, 2008].
Para verificar se a representac¸˜ao tern´aria ´e capaz de auxiliar no processo evolutivo para o
PP, foram escolhidos dois dos AGs utilizados para a DCT onde a ´unica alterac¸˜ao feita foi a
func¸˜ao que calcula a adaptac¸˜ao da regra (fitness). O c´alculo da adaptac¸˜ao considera apenas
CIs que, caso apresentem um n´umero par de 1s, ap´os no m´aximoT iterac¸˜oes do AC encontre
um reticulado homogˆeneo de c´elulas no estado 0, ou 1 caso a CI tenha um n´umero ´ımpar de
1s; todas as outras caracter´ısticas dos AGs permanecem inalteradas. Os AGs escolhidos foram
MCH e CMD; OOO n˜ao foi escolhido devido a sua enorme similaridade com MCH.
3.3.1
Resultados
As Figuras 3.16a e 3.16b, apresentam os resultados de 300 execuc¸˜oes distintas para o MCH
e CMD aplicado no PP, respectivamente. ´E poss´ıvel verificar que esses AGs n˜ao apresentam
bons resultados para o PP, sendo poss´ıvel inclusive afirmar que MCH apresenta resultados
pi-ores, pois est˜ao na faixa entre 45% e 50%, enquanto os resultados do CMD est˜ao na faixa de
50%. Esses resultados indicam que, tanto CMD quanto MCH est˜ao encontrando ACs altamente
especializados em CIs com um n´umero par de 1soucom um n´umero ´ımpar de 1s, por´em nunca
30
n´umero par e um n´umero ´ımpar de 1s, que a melhor regra encontrada classificou corretamente,
para MCH e CMD respectivamente; o ´unico AG que teve execuc¸˜oes capazes de encontrar ambos
os casos, foi o CMD. Essa caracter´ıstica ´e encontrada em regras de comportamento dinˆamico
classificado como “nulo”; em que a regra n˜ao ´e capaz de efetuar uma computac¸˜ao e leva
rap-idamente a um estado homogˆeneo [LI; PACKARD, 1990], o mesmo comportamento de ACs
(a) 300 execuc¸˜oes distintas do MCH para o PP.
(b) 300 execuc¸˜oes distintas do CMD para o PP.
32
(a) Detalhamento de 300 execuc¸˜oes distintas do MCH para o PP.
(b) Detalhamento de 300 execuc¸˜oes distintas do CMD para o PP.
4
Alterac¸˜ao nos AGs
Para alterar os AGs foi preciso se atentar a 3 detalhes principais: (i) a criac¸˜ao da populac¸˜ao
inicial, (ii) a utilizac¸˜ao dos operadores gen´eticos, e (iii) a traduc¸˜ao de um conjunto de moldes
para uma regra bin´aria de AC. Essas trˆes alterac¸˜oes permaneceram em todos os AGs testados e
´e baseada de acordo com [STONE; BULL, 2009].
Para se manterρ na populac¸˜ao inicial de forma uniforme, para cada indiv´ıduo da populac¸˜ao
P´e escolhido um n´umeromd em uma distribuic¸˜ao uniforme (0<md<MDmax),md ´e a
quan-tidade de moldes que esse indiv´ıduo possuir´a; al´em disso, cada bit do molde possui uma
prob-abilidadep#de ser um s´ımbolo #, essa probabilidade ´e um n´umero escolhido para garantir que
≈2 bits por molde sejam o s´ımbolo #. Criando os indiv´ıduos dessa forma, ´e poss´ıvel garantir
o mesmo comportamento dos outros AGs para a populac¸˜ao inicial, ou seja, ao efetuarmos a
traduc¸˜ao dos moldes para uma regra bin´aria, encontramosρ ≈50% nos indiv´ıduos com maior
F entre a populac¸˜ao [STONE; BULL, 2009]. Em nossos estudos utilizamosMDmax=9,
inspi-rados no trabalho original em [STONE; BULL, 2009].
Foram testadas duas formas diferentes de orientac¸˜oes, a orientac¸˜ao ´unica e a orientac¸˜ao
dupla, demonstradas respectivamente, pelos subscritos u e d na nomenclatura dos AGs. Na
orientac¸˜ao ´unica,todos os indiv´ıduos s˜ao criados com a mesma orientac¸˜ao; em nossos testes
fixamos para a orientac¸˜ao 1, por´em poderia ter sido feita analogamente para a orientac¸˜ao 0.
j´a na orientac¸˜ao dupla utilizada em [STONE; BULL, 2009], os indiv´ıduos recebem de forma
aleat´oria uma orientac¸˜ao inicial, 1 ou 0, e permanecem com a mesma at´e o final do AG.
O cruzamento ´e efetuado de acordo com [STONE; BULL, 2009]: caso md >0 nos dois
pais selecionados, ´e escolhido 1 molde de cada pai para serem trocados. J´a a mutac¸˜ao pode
ser efetuada em cada bit de cada molde, o bit selecionado para sofrer a mutac¸˜ao, ter´a 50% de
34
O processo de traduc¸˜ao de um conjunto de moldes, para uma regra binomial, funciona
criando-se inicialmente uma LUT com a orientac¸˜ao de cada η poss´ıvel para o complemento
da orientac¸˜ao encontrada no indiv´ıduo, busca-se ent˜ao nessa LUT as vizinhanc¸asη
represen-tadas por cada molde, para essas vizinhanc¸as atribui-se a orientac¸˜ao original; o resultado dessas
orientac¸˜oes ´e a regra binomial equivalente. Apesar de esse processo ser simples, ele ´e executado
apenas no final dos algoritmos, pois dessa forma ´e poss´ıvel explorar os ganhos de performance
e mem´oria que a utilizac¸˜ao desses moldes nos traz.
Para a execuc¸˜ao dos AGs, e validac¸˜ao dos resultados comparados aos resultados dos AGs
originais, os mesmos parˆametros foram mantidos, assim como a criac¸˜ao das CIs.
4.1
Resultados para a DCT
Os resultados de 300 execuc¸˜oes distintas do CMD, MCH e OOO com a representac¸˜ao
tern´aria e ambas orientac¸˜oes, podem ser vistos nas Figuras 4.1a e 4.1b para o CMD, 4.2a e
4.2b para o MCH, e 4.3a e 4.3b para o OOO, respectivamente para as orientac¸˜oes ´unica e dupla.
J´a nas Figuras 4.1c, 4.2c e 4.3c ´e poss´ıvel perceber as diferenc¸as entre os resultados com e sem
a representac¸˜ao tern´aria para os mesmos AGs. O tempo de execuc¸˜ao total de cada AG pode ser
visto na Tabela 4.1.
Orientac¸˜ao/AG CMD MCH OOO
Orientac¸˜ao ´unica 2 horas e 1 minuto 6 horas e 9 minutos 4 horas e 36 minutos
Orientac¸˜ao dupla 4 horas e 50 minutos 4 horas e 26 minutos 2 horas e 58 minutos
(a) 300 execuc¸˜oes distintas doCMDu. (b) 300 execuc¸˜oes distintas doCMDd.
(c) Comparativo do CMD com e sem a utilizac¸˜ao da representac¸˜ao tern´aria.
36
(a) 300 execuc¸˜oes distintas doMCHu. (b) 300 execuc¸˜oes distintas doMCHd.
(c) Comparativo do MCH com e sem a utilizac¸˜ao da representac¸˜ao tern´aria.
(a) 300 execuc¸˜oes distintas doOOOu. (b) 300 execuc¸˜oes distintas doOOOd.
(c) Comparativo do OOO com e sem a utilizac¸˜ao da representac¸˜ao tern´aria.
Figura 4.3: Execuc¸˜oes utilizando a representac¸˜ao tern´aria do OOO.
Nas Tabelas 4.2 e 4.3, ´e poss´ıvel ver os resultados quantificados nas mesmas faixas de
performances apresentadas anteriormente na Tabela 3.4, para os AGs com orientac¸˜ao ´unica
e dupla respectivamente. ´E poss´ıvel verificar claramente que a representac¸˜ao ´unica traz os
melhores resultados para todos os AGs; sendo que de todos os AGs testados, MCHu tem o
melhor resultado encontrado.
´
38
6971337806416870490831360 (a nomenclatura das regras ´e efetuada de acordo com a representac¸˜ao
decimal da LUT, conforme explicado no Cap´ıtulo 3) ´eexatamentea regra GKL, regra essa que
o AG original apresentado em [MITCHELL; CRUTCHFIELD; HRABER, 1994] tenta
encon-trar, por´em n˜ao ´e capaz. Com a utilizac¸˜ao da representac¸˜ao tern´aria e orientac¸˜ao ´unica, isso foi
poss´ıvel.
fi(%) OOOu MCHu CMDu
≤50 94 3 129
(50,60] 17 0 32
(60,70] 163 273 134
(70,80] 23 19 3
>80 3 5 2
Tabela 4.2: Contagem das regras encontradas pelos 3 AGs estudados com a representac¸˜ao tern´aria o orientac¸˜ao ´unica.
fi(%) OOOd MCHd CMDd
≤50 179 153 184
(50,60] 16 19 15
(60,70] 98 127 97
(70,80] 5 1 4
>80 2 0 0
Tabela 4.3: Contagem das regras encontradas pelos 3 AGs estudados com a representac¸˜ao tern´aria o orientac¸˜ao dupla.
4.2
Resultados para o PP
As Figuras 4.4a, 4.4b, 4.5a e 4.5b, mostram os resultados para MCHu, MCHd, CMDu,
CMDd respectivamente para o PP. Por sua vez, as Figuras 4.6a, 4.6b, 4.7a e 4.7b, mostram a
quantidade de classificac¸˜oes corretas para CIs com um n´umero ´ımpar e par de 1s, paraMCHu,
(a) 300 execuc¸˜oes distintas doMCHupara o PP.
(b) 300 execuc¸˜oes distintas doMCHdpara o PP.
40
(a) 300 execuc¸˜oes distintas doCMDupara o PP.
(b) 300 execuc¸˜oes distintas doCMDdpara o PP.
(a) Detalhamento de 300 execuc¸˜oes distintas doMCHupara o PP.
(b) Detalhamento de 300 execuc¸˜oes distintas doMCHdpara o PP.
42
(a) Detalhamento de 300 execuc¸˜oes distintas doCMDupara o PP.
(b) Detalhamento de 300 execuc¸˜oes distintas doCMDdpara o PP.
´
E poss´ıvel verificar, que apesar da representac¸˜ao tern´aria n˜ao apresentar um ganho na
performance final dos AGs para o PP, algumas das regras encontradas com a utilizac¸˜ao da
representac¸˜ao tern´aria, s˜ao capazes de identificar CIs tanto com um n´umero par e quanto com
um n´umero ´ımpar de 1s. Essas regras j´a n˜ao pertencem mais `a classe de regras “nulas”, pois
elas s˜ao capazes de efetuar uma computac¸˜ao um pouco mais complexa [LI; PACKARD, 1990].

![Figura 3.3: Regra 84 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.](https://thumb-eu.123doks.com/thumbv2/123dok_br/18110175.323211/27.892.183.756.745.1030/figura-regra-como-definida-wolfram-iterada-durante-iterac.webp)
![Figura 3.4: Regra 30 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.](https://thumb-eu.123doks.com/thumbv2/123dok_br/18110175.323211/28.892.169.773.196.542/figura-regra-como-definida-wolfram-iterada-durante-iterac.webp)
![Figura 3.5: Regra 110 como definida por Wolfram [2002] e iterada durante 25 iterac¸˜oes.](https://thumb-eu.123doks.com/thumbv2/123dok_br/18110175.323211/29.892.183.755.117.460/figura-regra-como-definida-wolfram-iterada-durante-iterac.webp)





