FUNDAÇÃO GETULIO VARGAS
ESCOLA DE ADMINISTRAÇÃO DE EMPRESAS DE SÃO PAULO
MARCELO KISAHLEITNER
ANÁLISE DE TÉCNICAS DE DATA MINING NA AQUISIÇÃO DE CLIENTES DE CARTÃO DE CRÉDITO NÃO CORRENTISTAS
MARCELO KISAHLEITNER
ANÁLISE DE TÉCNICAS DE DATA MINING NA AQUISIÇÃO DE CLIENTES DE CARTÃO DE CRÉDITO NÃO CORRENTISTAS
Dissertação apresentada à Escola de Administração de Empresas de São Paulo da Fundação Getúlio Vargas, como requisito para obtenção do título de Mestre em Administração de Empresas.
Campo de Conhecimento:
Data Mining, Knowledge Discovery in Data Bases, CRM, Telemarketing.
Orientador:
André Luiz Silva Samartini
Kisahleitner, Marcelo.
Análise de técnicas de Data Mining na aquisição de clientes de cartão de crédito não correntistas / Marcelo Kisahleitner. - 2008.
94 f.
Orientador: André Luiz Silva Samartini.
Dissertação (MPA) - Escola de Administração de Empresas de São Paulo. 1. Mineração de dados (Computação). 2. Cartões de crédito. 3. Clientes - Contatos. 4. Telemarketing. I. Samartini, André Luiz Silva. II. Dissertação (MPA) - Escola de Administração de Empresas de São Paulo. III. Título.
MARCELO KISAHLEITNER
ANÁLISE DE TÉCNICAS DE DATA MINING NA AQUISIÇÃO DE CLIENTES DE CARTÃO DE CRÉDITO NÃO CORRENTISTAS
Projeto de dissertação apresentado à Escola de Administração de Empresas de São Paulo da Fundação Getúlio Vargas, como requisito para obtenção do título de Mestre em Administração de Empresas
Campo de Conhecimento:
Data Mining, Knowledge Discovery in Data Bases, CRM, Marketing Direto.
Data de Aprovação: __/__/____
Banca Examinadora:
________________________________________ Prof. Dr. André Luiz Silva Samartini (Orientador) FGV-EAESP
________________________________________ Prof. Dr. Abraham Laredo Sicsú
FGV-EAESP
________________________________________ Prof. Dr. Luiz Carlos Murakami
AGRADECIMENTOS
Meus sinceros agradecimentos:
Aos meus pais, que sempre me apoiaram e incentivaram-me a buscar um algo a mais.
À minha filha, por ser minha inspiração diária e, apesar de ainda não ter consciência disso, motivar-me a buscar o melhor sempre.
Ao meu orientador André, por sua visão do todo, sua paciência nos momentos de indefinição, sua clareza de pensamento, e sua enorme disposição em ajudar.
Ao Ricardo, que acreditou no meu potencial e me criou condições de cursar o MPA com o apoio da empresa.
Ao Jamal, que soube entender o que é um processo de elaboração de dissertação, e deu todo o seu apoio nos momentos necessários.
À minha colega de trabalho Lívia, que me incitou ao aprofundamento no fascinante mundo da modelagem estatística, e sempre esteve disposta a sanar minhas (muitas) dúvidas conceituais. Também não posso esquecer-me de mencionar o André e a Elaine, por suas valiosas contribuições.
Ao professor Laredo, por sua leitura cuidadosa do material na fase de qualificação e seus comentários extremamente enriquecedores, coerentes, consistentes, e desafiadores.
A meus colegas e professores do MPA, cujo elevado nível intelectual e suas grandiosas experiências profissionais, tornaram-me uma pessoa muito mais enriquecida em saber.
RESUMO
O trabalho busca analisar e entender se a aplicação de técnicas de Data Mining em processos de aquisição de clientes de cartão de crédito, especificamente os que não possuem uma conta corrente em banco, podem trazer resultados positivos para as empresas que contam com processos ativos de conquista de clientes. Serão exploradas três técnicas de amplo reconhecimento na comunidade acadêmica: Regressão Logística, Árvores de Decisão, e Redes Neurais. Será utilizado como objeto de estudo uma empresa do setor financeiro, especificamente nos seus processos de aquisição de clientes não correntistas para o produto cartão de crédito. Serão mostrados resultados da aplicação dos modelos para algumas campanhas passadas de venda de cartão de crédito não correntistas, para que seja possível verificar se o emprego de modelos estatísticos que discriminem os clientes potenciais mais propensos dos menos propensos à contratação podem se traduzir na obtenção de ganhos financeiros. Esses ganhos podem vir mediante redução dos custos de marketing abordando-se somente os clientes com maiores probabilidades de responderem positivamente à campanha.
A fundamentação teórica se dará a partir da introdução dos conceitos do mercado de cartões de crédito, do canal telemarketing, de CRM, e das técnicas de data mining. O trabalho apresentará exemplos práticos de aplicação das técnicas mencionadas verificando os potenciais ganhos financeiros.
Os resultados indicam que há grandes oportunidades para o emprego das técnicas de data mining nos processos de aquisição de clientes, possibilitando a racionalização da operação do ponto de vista de custos de aquisição.
PALAVRAS-CHAVE:
ABSTRACT
This paper intends to analyze and understand the use of Data Mining techniques in processes of Customer Acquisition for Credit Cards, more specifically the customers that do not have a checking account, may bring positive results to the companies that base have active processes of customer acquisition. Three techniques that are widely known and accepted in the academy will be analyzed: Logistic Regression, Decision Trees, and Neural Networks. The subject of the study will be a company of the financial sector, focusing its processes of credit card customer acquisition. Some results of previous campaigns using the models, will be shown In order to verity if the use of statistical models - that are able to discriminate the prospects with higher propensities to acquire, from the prospects with lower propensities - may result in financial gains, by reducing marketing costs.
The theoretical fundamentals will cover the basics of the Credit Card Market, the Telemarketing Channel, and the data mining techniques. This research will present some practical examples exploring the techniques, to verify the potential financial gains.
The results show that are great opportunities in using the data mining techniques regarding processes of customer acquisition, making possible the cost rationalization concerning the costs of acquisition.
KEY-WORDS:
LISTA DE ILUSTRAÇÕES
ESQUEMAS
Esquema 1 - Fluxo de Informações no Telemarketing 17
Esquema 2 - Pureza: esquemas de divisão 34
Esquema 3 – Neurônio Humano 38
Esquema 4 - Topologias de redes neurais 41
Esquema 5 - Cronograma de Desenvolvimento e validação dos modelos 48
Esquema 6 - Workflow dos modelos 62
Esquema 7 - Topologia de Redes Neurais – 1 e 5 camadas escondidas 63 Esquema 8 - Árvore de Decisão – Gini com 3 níveis de profundidade 70
GRÁFICOS
Gráfico 1 - Evolução dos Cartões no Brasil 19
Gráfico 2 - A Curva Logística (Curva S) 32
Gráfico 3 - Curva de Lorentz e o Índice Gini 35
Gráfico 4 – Conceituação de Overfitting 52
Gráfico 5 - Transformação da variável Renda – Original e transformada 56
Gráfico 6 - Transformação de variável: Idade 57
Gráfico 7 - Agrupamento Interativo – Estados X informação de capital/interior 58 Gráfico 8 - Transformação da variável Ano do Pré-aprovado 59 Gráfico 9 - Regressão Logística – Lift – Backward, Forward, e Stepwise 62 Gráfico 10 – Lift Comparativo Redes Neurais – 1 e 5 camadas escondidas 64 Gráfico 11 - Lift para três árvores de decisão – Gini, Entropia, e Chi-quadrado 65 Gráfico 12 - Resultado Regressão Logística – Variáveis e seus Valores-T 66 Gráfico 13 – Classificação: Previsto X Real – Regressão logística 68
Gráfico 14 - Índice Gini X Nº de folhas 71
Gráfico 15 - Anel da Árvore de Decisão Gini 73
Gráfico 16 - Tabela de Classificação - Árvore de decisão 74
Gráfico 17 - Pesos Rede Neural 76
Gráfico 18 – Rede Neural - Erro médio X Iterações 77 Gráfico 19 - Tabela de classificação - Rede neural 77
Gráfico 21 - Curva ROC – Todos os modelos 80
Gráfico 22 - Captured Response dos modelos 81
Gráfico 23 - Lift - Back Test novembro/2007 83
Gráfico 24 - Captured Response - Back Test novembro/2007 84
Gráfico 25 - Lift - Back Test dezembro/2007 85
Gráfico 26 - Captured Response - Back Test dezembro/2007 86
EQUAÇÕES
Equação 1 - Transformação logit - Regressão logística múltipla 31 Equação 2 - Modelo de Regressão Logística Múltipla 31
Equação 3 – Gini - Integral 35
Equação 4 - Gini - Somatório 35
LISTA DE TABELAS
Tabela 1 – Evolução do mercado de cartões de crédito no Brasil 19
Tabela 2 - Comparação das técnicas de modelagem 43
Tabela 3 - Variáveis Analisadas no Modelo 49
Tabela 4 - Retornos históricos de cartão 52
Tabela 5 - Exemplo variáveis dummy 54
Tabela 6 - Agrupamento Interativo – Estado / Capital X Interior 58 Tabela 7 - Regressão Logística – Teste de Significância 66 Tabela 8 - Regressão Logística – Análise Detalhada dos Coeficientes 67 Tabela 9 - Regressão Logística – Risco Relativo 67
Tabela 10 - Resumo das folhas – Árvore Gini 72
Tabela 11 - Rede Neural - Pesos 76
Tabela 12 - Coeficientes de Kolmogorov-Smirnov 82
Tabela 13 - Back Test novembro/2007 83
LISTA DE ABREVIATURAS E SIGLAS
ABECS Associação Brasileira de Empresas de Cartões de Crédito e Serviços ABT Associação Brasileira de Telesserviços
EPS Empresa Prestadora de Serviços de Telemarketing IC Intervalo de Confiança
CRM Customer Relationship Management KDD Knowledge Discovery in Data bases ACSP Associação Comercial de São Paulo ANOVA Análise de variância
RBS Rede Globo Sul KS Kolmogorov -Smirnov
SEMMA Sample, Explore, Modify, Model, Asses SAC Serviço de Atendimento ao Consumidor PA Ponto de Atendimento
SQL Structured Query Language MIS Management Information System DDD Código de Discagem Direta à Distância
SUMÁRIO
1. INTRODUÇÃO 14
1.1 Objetivo da Dissertação e Motivação 14
1.2 O Mercado de Cartões De Crédito no Brasil 19
2. REVISÃO DE LITERATURA 21
2.1 Customer Relationship Management (CRM) 21
2.2 Telemarketing 22
2.3 Knowledge Discovery in Databases (KDD) 25
2.4 Data Mining 28
2.5 Regressão Logística 31
2.6 Árvores de Decisão 33
2.7 Redes Neurais Artificiais 38
2.8 Comparação dos Modelos 43
3. METODOLOGIA 45
3.1 Metodologia de Pesquisa 45
3.2 Recursos Computacionais Utilizados 46
3.3 Descrição e seleção das variáveis 47
3.4 Seleção das amostras 51
3.5 Transformação das variáveis 54
3.6 Desenvolvimento dos modelos 60
4. RESULTADOS DOS MODELOS 66
4.1 Regressão Logística: 66
4.2 Árvore de Decisão - Gini 70
4.3 Rede Neural – 1 Camada Escondida 76
4.4 Avaliação dos Modelos 79
5. CONCLUSÃO 87
APÊNDICES 89
Apêndice B – Exemplo da base de dados 89
1. INTRODUÇÃO
1.1 Objetivo da Dissertação e Motivação
Atualmente, a utilização do produto cartão de crédito vem tomando proporções significativas como meio de pagamento, o que começou a ocorrer desde a estabilização da economia brasileira, após a criação do Plano Real em 1994, como destaca o Jornal Monitor Mercantil Digital (2007). A estabilidade econômica também influenciou fortemente na maior utilização de sofisticadas metodologias estatísticas no mercado de produtos de crédito como um todo e, em particular, no mercado de cartões de crédito, segundo palestra proferida no SAS Institute Inc. (2007). Uma série de modelos estatísticos vem sendo usada para auxiliar na concessão, no acompanhamento, na cobrança e na retenção de clientes. Regressão logística, análise discriminante, análise de sobrevivência, árvores de decisão, inferência bayesiana e redes neurais são algumas das técnicas utilizadas, sendo que a regressão logística é provavelmente a mais utilizada e conhecida.
No contexto desse mercado de competição imperfeita, com grande concentração e, portanto, extremamente competitivo, é que se encontra a oportunidade de melhorar os processos de aquisição de clientes. Segundo Banasiewicz (2004), a baixa produtividade e o baixo retorno sobre o investimento em campanhas de aquisição de novos clientes se dão em grande parte devido a negligências metodológicas – especialmente no que se refere a abordar uma grande massa de clientes com ofertas muito genéricas. Na maioria das empresas, esse fator é agravado em decorrência das áreas de negócio encontrarem-se divididas por produtos, o que dificulta sobremaneira o estabelecimento de uma visão voltada ao cliente. Em outras palavras, o foco das campanhas de aquisição usualmente se dá no cumprimento de metas de vendas de produtos, e não na aquisição de clientes que venham a trazer valor para as organizações no longo prazo, sejam fiéis, e tenham um relacionamento sólido.
mala direta “quente”, ou seja, para um cliente que já tem um relacionamento com a empresa, chega a ser de até 50%.
Espera-se que o aprofundamento da utilização dos modelos preditivos na oferta de produtos bancários e não bancários, em especial cartão de crédito – Canal telemarketing - permita uma significativa redução nos custos de aquisição de clientes, em decorrência do aumento da eficiência dos contatos, sendo que o projeto em questão será feito em uma grande empresa brasileira do setor financeiro, ocultando-se as informações sigilosas mediante mascaramento ou aplicação de um fator de escala.
Muito embora a modelagem estatística já venha sendo utilizada há muito tempo na concessão de crédito – etapa que precede a disponibilização do público para abordagem de vendas – e nas ações de venda cruzada, ela não vinha sendo utilizada na oferta de produtos de cartão de crédito para não correntistas para a empresa em questão, conforme mencionado por Witten e Frank (2005). E um dos grandes objetivos desse trabalho é justamente introduzir o uso de técnicas já tradicionais de Data Mining para buscar mostrar que há possibilidades de se melhorar os processos de aquisição de clientes para o produto cartão de crédito na empresa financeira que será analisada, conforme proposto por Rygielski et al. (2002). Em que pese o fato das
As ações de telemarketing para aquisição de clientes não correntistas partem do Bureau Cadastral montado pela empresa. O Bureau é composto basicamente por todos os CPF do Brasil - ativos, pendentes, e cancelados - enriquecidos com informações cadastrais adquiridas junto a empresas como Serasa (http://www.serasa.com.br), ACSP – Associação Comercial de São Paulo (http://www.acsp.com.br), RBS – Rede Globo Sul, Experian (http://www.experian.com.br), Equifax (http://www.equifax.com.br), Data Listas (http://www.datalistas.com.br), entre outras. Além disso, para os CPFs que já possuem algum relacionamento com a empresa, o Bureau é enriquecido com informações provenientes das bases internas, como o cadastro de correntistas, cartonistas, segurados, mutuários, acionistas, etc.
Um dos grandes desafios na operação de aquisição de clientes não correntistas é o número limitado de variáveis disponíveis, uma vez que Bureau Cadastral, como o próprio nome diz, contém apenas informações demográficas e dados de localização, como CEP, Logradouro, e telefones, sexo, idade, renda demográfica, etc. Essas variáveis serão analisadas com mais profundidade no decorrer do trabalho.
Finalmente, levando-se em consideração a preocupação de vários autores, entre eles Hosmer e Lemeshow (2000), e Berry e Linoff (2004), a proliferação de softwares estatísticos extremamente poderosos, como o SAS e o SPSS, permitem a qualquer um elaborar modelos bastante sofisticados, mas com o risco de – por não entenderem os fundamentos da modelagem estatística – gerarem resultados desprovidos de valor teórico e prático, bem como modelos viesados em decorrência de falhas no processo de amostragem, fenômenos como multicolinearidade na regressão logística e linear - variáveis correlacionadas que comprometem a estabilidade do modelo, ou heterocedasticidade (na regressão linear) conforme Bussab e Morettin (2006) e Hosmer e Lemeshow (2000). Em contrapartida, é preocupante também ter estatísticos que não tenham envolvimento e conhecimento do negócio, qualquer que seja ele, pois as ferramentas em si podem não atingir todo o potencial de agregação de valor se não estiverem em um contexto de negócios bem definido.
que servem de insumo para a área de crédito calcular o limite pré-aprovado (considerando, obviamente, as variáveis importantes para a concessão de crédito).
Esquema 1 - Fluxo de Informações no Telemarketing
As informações de pré-aprovação, aliadas às informações de localização propiciadas pelo Bureau Cadastral vão para a área de CRM Analítico desenvolver e aplicar os modelos estatísticos, e efetuar ajustes históricos de retorno por grupo de clientes (passo importante para dar uma boa previsibilidade de retorno para a operação, e que não será abordado neste trabalho). Além disso, são definidas as elegibilidades dos produtos nos quesitos idades mínimas e máximas a serem abordadas, praças nas quais se devem oferecer os produtos, etc. Em um próximo passo são enviadas as ofertas (leads) para a área de CRM Operacional, que aplica as informações de localização - endereço e telefone(s), e envia os arquivos para as EPS (Empresas Prestadoras de Serviço), que irão procurar localizar os clientes e fazerem as vendas. Cada situação de retorno é registrada pela EPS e devolvida para a área de CRM Analítico poder retroalimentar os modelos de probabilidade de resposta. Ou seja, o simples fato de um cliente ter recusado uma oferta em um mês, já faz sua probabilidade de resposta em uma oferta subseqüente cair significativamente.
Em suma, o que se buscará no presente trabalho é avaliar as técnicas de Data Mining mais usuais – regressão logística, árvores de decisão e redes neurais, verificar sua
Bureau Cadastral
Política de Crédito
CRM Analítico CRM
1.2 O Mercado de Cartões De Crédito no Brasil
O mercado de cartões de crédito no Brasil encontra-se em fase de crescimento acelerado e possui atualmente 93 milhões de cartões. Em 2007, houve um aumento de 17% em quantidade de cartões, 19% em transações realizadas e um aumento da ordem de 21% do faturamento do setor em relação ao ano anterior, passando de R$ 152 bilhões para R$ 183 bilhões (ABECS, 2007). Quando comparamos com o ano de 2000 verificamos um crescimento acumulado de quase 200% na quantidade de cartões emitidos, conforme a tabela 1 e o gráfico 1.
Tabela 1 – Evolução do mercado de cartões de crédito no Brasil
Ano 2000 2001 2002 2003 2004 2005 2006 2007
Nº Cartões milhões 29 38 42 45 53 68 79 93
Variação % 31% 11% 7% 18% 28% 16% 18%
Nº Transações bilhões 0,7 0,8 1 1,1 1,4 1,7 2 2,4
Variação % 14% 25% 10% 27% 21% 18% 20%
Valor Transações R$ bilhões 48,4 63,6 73 88 101,3 123 151,2 182,9
Variação % 31% 15% 21% 15% 21% 23% 21%
Fonte: ABECS (2007)
Gráfico 1 - Evolução dos Cartões no Brasil Fonte: ABECS (2007)
29 38 42 45 53 68 79 93 0 10 20 30 40 50 60 70 80 90 100
2000 2001 2002 2003 2004 2005 2006 2007
Qu an tidad e (m ilh õ e s) Ano
Abaixo encontram-se algumas definições importantes sobre o mercado de Cartões de Crédito, conforme ABECS (2007):
Emissores: são Instituições Financeiras que emitem e administram cartões próprios ou de terceiros e concedem financiamento direto aos portadores ou a Administradoras, que por sua vez são instituições não financeiras que emitem e administram cartões próprios ou de terceiros, mas não financiam diretamente os seus clientes. O relacionamento dos clientes se dá diretamente com os Emissores.
Credenciadores: empresas responsáveis pela filiação, gerenciamento e
relacionamento com os estabelecimentos comerciais e pelas condições comerciais. As empresas credenciadoras atualmente em operação no Brasil são: Redecard, Visanet, Amex (Banco Bankpar), e Hipercard.
Bandeiras: são instituições que autorizam o uso de sua marca e de sua tecnologia por emissores e Credenciadores. As principais bandeiras do mercado brasileiro são Visa,
MasterCard, Diners Club, Redeshop e American Express.
Processadoras: são empresas que prestam serviços operacionais relacionados a administração de cartões. As principais marcas do mercado brasileiro são Orbitall, Cardsystem e Equifax/Unnisa.
Variantes: limites de crédito diferenciados, dentro de um mesmo emissor, associados à renda do cliente. Sua nomenclatura varia de Electronic (menores limite e renda), passando por Nacional, Internacional, Gold, e Platinum – em ordem crescente de limite de crédito. As principais diferenças se dão basicamente em relação à cobrança de anuidades, possibilidade de uso no exterior, e benefícios associados, como assistências em viagens e outras comodidades para os cartões de variantes superiores.
Parceiros: empresas que atuam em outra área e fazem acordo com os emissores para oferecer um cartão com sua marca, produto também conhecido como co-branded.
2. REVISÃO DE LITERATURA
2.1 Customer Relationship Management (CRM)
Conforme Ye (2004), CRM pode ser divido em estratégico e operacional. As questões estratégicas são mais focadas no poder descritivo do CRM Mining, enquanto as
questões operacionais estão mais alinhadas com as capacidades preditivas do Data Mining. Na empresa em questão, a área de CRM é responsável pela parte operacional, ou seja, é responsável pelo desenvolvimento dos modelos preditivos e pela seleção do público a ser abordado pelo canal telemarketing ativo como um todo, embasando-se nos modelos citados.
Ademais, é de fundamental importância que a empresa selecione muito bem os seus clientes, pois como advoga Reichheld (2001), uma empresa não pode ser tudo para todos os clientes, ou seja, deve-se selecionar entre os clientes mais propensos a contratar o produto e, dentre estes os mais rentáveis, visando a um relacionamento de longo prazo, e objetivando-se a redução dos custos, uma vez que os recursos são escassos. Essa afirmação vai ao encontro da proposta da dissertação, que é justamente arbitrar as ofertas de cartão de crédito baseando-se na propensão devolvida pelos modelos estatísticos e verificando-se o caixa gerado em função do Valuation por Variante.
2.2 Telemarketing
Segundo ABT (2008), telemarketing é definido como “toda e qualquer atividade desenvolvida através de sistemas de telemática e múltiplas mídias, objetivando ações padronizadas e contínuas de marketing”. Essa definição se aplica tanto às ações ativas de telemarketing, que serão abordadas neste trabalho, como em ligações recebidas pela empresa por iniciativa do cliente, tipicamente direcionadas aos SACs – Serviços de Atendimento ao Consumidor. A definição inicial de Telemarketing, no entanto, era basicamente “vendas pelo telefone”, conforme Schneider (1985). Essa definição foi bastante criticada e, portanto ampliada por diversos autores, como Johnson e Meiners (1987), Coppett e Staples (1993), o que mostra o quanto as “vendas por telefone” evoluíram.
Outra definição mais completa do que é telemarketing é encontrada em Stone e Wyman (1992), tradução nossa: “Telemarketing utiliza sistemas de informação e telecomunicação sofisticados, combinados com vendas pessoais e habilidades em serviço, para auxiliar as empresas a ficarem em contato próximo com seus clientes atuais e potenciais, incrementarem as vendas, e aumentarem a produtividade dos negócios”. A definição ainda é complementada definindo que “negócios com programas bem-sucedidos de marketing enxergam o telemarketing como uma parte estratégica de toda a estratégia de marketing”. Outra consideração importante dos autores se dá em relação à vantagem competitiva, pois segundo eles o telemarketing ativo permite vencer a competição por clientes aumentando o número de contatos que se faz com cada cliente. Adicionalmente, este trabalho procura explorar ainda mais os contatos, tornando-os mais efetivos pela aplicação dos modelos estatísticos. É interessante também nesse ponto definir Telemarketing Ativo que, de acordo com Blois e Sargeant (2000) é “comunicação telefônica iniciada pela empresa”. Os autores ainda detalham os tipos de ligação como “frias” – quanto não ocorre uma segmentação prévia dos clientes, ou seja, não se estipula uma propensão à contratação, e ligações “quentes”, quando os clientes são previamente segmentados e a oferta é mais direcionada.
uso inicial se deu como instrumento de apoio de serviço para os clientes. Mas foi só nos anos 60 que o Telemarketing começou a proliferar nos EUA, após a AT&T introduzir um serviço que barateava o custo das ligações. Nos anos seguintes, a desregulamentação e o aumento na competição entre as operadoras de telefonia os EUA contribuíram para a diminuição dos custos do canal.
Na empresa em questão, a área de CRM tem a função também de fomentar a área gestora do Canal Telemarketing com informações pertinentes ao retorno esperado de cada ação. Portanto, um dos objetivos da dissertação é desenvolver modelos de propensão que retornem uma probabilidade de contratação ajustada aos retornos históricos, o que permitirá à área gestora do canal ajustar a capacidade da sua operação, que é mensurada em Pontos de Atendimento (PA). Para os gestores do canal duas variáveis são de fundamental importância: quantidade de clientes e o retorno esperado, uma vez que as empresas terceirizadas, ou Empresas Prestadoras de Serviços (EPS), como são mais conhecida, são remuneradas em função do retorno esperado.
Schneider (1985) aponta cinco grandes benefícios do canal telemarketing:
Contato pessoal - tirando as vendas pessoais, o telemarketing permite a
interação humana com o operador de telemarketing, o que dá um toque de pessoalidade nas ações de vendas, e em conseqüência provê melhores taxas de retorno do que mala direta e e-mail marketing.
Flexibilidade: Os scripts - ver Harless (2004) – são flexíveis e permitem ao
operador mudar a direção da conversa na medida em que vai obtendo retorno do cliente potencial, bem como de acordo com a receptividade. Além disso, os scripts podem ser testados e melhorados ao longo da campanha, e caso haja melhorias sensíveis nos testes, os scripts oriundos destes podem ser facilmente incorporados na própria campanha para os clientes que ainda não foram contatados.
Possibilidade de mensuração: Telemarketing é facilmente mensurável.
Compressão do tempo: o telemarketing oferece algum degrau de compressão
do tempo da campanha, o que é bastante útil na venda de produtos sazonais ou relacionados à moda.
Efetividade: Quando comparado com outras mídias diretas, o Telemarketing é o
que apresenta as maiores taxas de retorno (vendas sobre quantidade de clientes disponibilizada) e de conversão (vendas sobre quantidade de clientes efetivamente contatados). A Mala Direta gera retornos típicos de 1,5% a 2%, enquanto uma mesma campanha no Telemarketing pode gerar retornos de 18% a 20%. Além disso, o Telemarketing pode atuar em conjunto com uma Mala Direta, eventualmente reforçando a mensagem e alavancando os retornos.
2.3 Knowledge Discovery in Databases (KDD)
Antes de adentrar na definição do que é Data Mining, que tem na aplicação das suas técnicas para a otimização da venda de cartões de crédito o escopo desta dissertação, é interessante definir com clareza o que é a KDD, ou descoberta de conhecimento em bases dados, por ser uma generalização da qual deriva o Data Mining, segundo Rigdon (1997), e Rygielski et al. (2002). De acordo com Hair et al.
(2005), as empresas atuais estão fortemente motivadas a compreenderem diversos relacionamentos entre as informações, e para tanto passaram a desenvolver sistemas formais com o objetivo de registrar todos os eventos importantes em um banco de dados, sendo que a garimpagem de dados representa “descoberta de conhecimento em bancos de dados, ou KDD”. Segundo eles, o KDD compreende as seguintes etapas:
Estabelecimento de acesso aos dados relevantes
Seleção do conjunto de eventos (dados) a serem analisados. Limpeza dos dados para que sejam compreendidos pelo algoritmo Desenvolvimento e uso de regras para selecionar relações interessantes
Desenvolvimento de um relatório de relações que podem afetar o desempenho da empresa.
No projeto em questão passaremos por cada uma dessas etapas, sendo que o objetivo final é mostrar que há condições para que as empresas melhorem o seu desempenho, tenham redução nos custos de contato, e possam maximizar o valor trazido pelos novos clientes.
Segundo Fayyad et al. (1996), o termo KDD foi criado em 1989 para se referir ao
amplo processo de descoberta de conhecimento em bases de dados, e para enfatizar o “alto nível” das aplicações de determinadas técnicas de Data Mining.
De acordo com Frawley et al. (1992), tradução nossa: “descoberta de conhecimento é
desconhecidas, a partir de bases de dados”. Detalhando a definição de KDD, os autores sugerem a seguinte nomenclatura:
Fatos (dados) – F: podem ser os registros em uma base de dados, contendo os
atributos de cada cliente (ID ou CPF).
Linguagem – L: Pode ser uma linguagem do tipo Structured Query Language
(SQL), que se destina a recuperar informações de bancos de dados, por exemplo. Ou ainda, pode ser uma linguagem de alto nível que descreva em português, o que a regra está estabelecendo em termos de conhecimento sobre uma base de dados (ver exemplo de padrão abaixo).
Intervalo de Confiança – C: Como a busca de padrões se dá por inferência
estatística, é de fundamental importância que se estabeleça um intervalo de confiança (IC) adequado em função do tamanho da amostra.
Declaração – S: Descrição na linguagem L do padrão descoberto na base de
dados. Seu propósito é descrever o comportamento (o que o padrão concluiu) e operacionalizar a descoberta (aplicar em uma base de dados e extrair as informações desejadas a partir do modelo estabelecido).
Padrão = Declaração S em L que descreve um relacionamento entre um
subconjunto FS de F com o intervalo de confiança C, tal que S seja mais
simples do que a enumeração de todos os fatos em FS. Em outras palavras, o
padrão permite que se identifiquem grupos de atributos que tenham um comportamento em comum. No caso da modelagem da propensão à compra de um cartão de crédito, o interesse é descobrir um padrão de comportamento que explique a contratação ou não do produto. Por exemplo, pode-se chegar a uma regra do tipo (na linguagem L): clientes do sexo masculino, com idade maior do que trinta anos e que residam na grande são Paulo têm a probabilidade 2,1% de contratar um cartão de crédito.
Um Padrão de interesse, de acordo com uma medida de interesse estabelecida
computador que monitore todos os Fatos em uma base de dados, neste contexto,
denomina-se Descoberta de Conhecimento em Bases de Dados, ou KDD.
Frawley et al. (1992) ainda detalham as seguintes definições:
Padrões e Linguagens: Os autores consideram somente os padrões que podem ser expressos em linguagem de alto nível.
Grau de Certeza: Como raramente uma descoberta de conhecimento é verdadeira para toda a base de dados, é importante delinear o grau de certeza que o usuário pode depositar no que foi descoberto, e este é estipulado mediante exame da integridade dos dados, o tamanho da amostra e, possivelmente, do conhecimento prévio de negócios.
Interesse: Embora inúmeros padrões possam ser extraídos de uma base de dados, somente os que forem interessantes são considerados conhecimento. Os padrões devem ser novos e utilizáveis, além de não triviais.
Eficiência: Os tempos de processamento dos algoritmos gerados devem ser previsíveis e aceitáveis.
Os autores Apte et al. (2002) acrescentam que “as técnicas de KDD enfatizam
estruturas explanatórias escaláveis, confiáveis, e totalmente automatizadas, as quais demonstraram que certas vezes complementam, e algumas vezes até suplantam o conhecimento de um analista especialista humano, contribuindo para a melhoria do processo de tomada de decisão”. Os autores também mencionam que a grande quantidade de informações disponíveis nas bases de dados, a demanda competitiva para a rápida construção e implantação de análises de dados, bem como a necessidade de entregar aos usuários finais resultados prontamente inteligíveis, que os auxiliem nos processos críticos de tomada de decisão, estão contribuindo para o forte desenvolvimento do KDD.
2.4 Data Mining
De acordo com Fayyad et al. (1996), o termo Data Mining tem sido comumente
utilizado por estatísticos, analistas de dados e pela comunidade de MIS (Management Information Systems), enquanto KDD tem sido mais utilizado pelos pesquisadores que estudam Inteligência Artificial e Machine Learning. KDD refere-se ao processo como um todo de descoberta de conhecimento útil a partir de bases de dados, enquanto Data Mining refere-se à aplicação de algoritmos para extração dos padrões sem os passos adicionais do KDD (como incorporação de conhecimento prévio e interpretação apropriada dos resultados).
Segundo Rao et al. (2005), o termo Data Mining, ou Mineração de Dados, tem sido
considerado ao mesmo tempo um pária e um “queridinho” dos estatísticos. Para os estatísticos clássicos, Data Mining significa abandonar as raízes probabilísticas da análise estatística. De fato, ainda segundo os autores, isso realmente ocorre, uma vez que as bases de dados nas quais os algoritmos de Data Mining são aplicados são adquiridos oportunamente e foram originalmente desenhados para outros fins. Essas bases de dados não são coletadas seguindo os conceitos tradicionais de amostragem – ver Stephan (1941) e Bussab e Morettin (2006), por exemplo, embora se possa fazer o uso de amostragem balanceada, como advogam SAS Institute Inc. (2006), SAS Institute Inc. (2003), Matignon (2007), Ye (2004), Maimon e Rokach (2005), entre outros. Portanto, as inferências para situações gerais, a partir de bases de dados específicas, não são válidas no sentido usual da estatística, levando-se em consideração a mensuração do risco. Independentes disso, as técnicas de Data Mining vêm provando o seu valor no mercado. Por outro lado, tem havido um interesse considerável na comunidade estatística para esse novo paradigma de dados.
Rao et al. (2005) ainda contrastam a análise estatística clássica com Data Mining,
afirmando que enquanto na análise confirmatória é assumido um modelo estatístico, e a partir dele são feitas inferências nos parâmetros, no Data Mining, ou Análise Exploratória de Dados, não se tem um modelo a priori, o que pode levar a erros
da premissa que os dados são gerados a partir de um modelo estocástico. A segunda – dos mineradores de dados – faz uso de algoritmos, e trata o mecanismo de geração dos dados como desconhecido.
Berry e Linoff (2004) trazem uma visão um tanto quanto mais prática do que é Data Mining, e dizem que fundamentalmente o CRM, fundamentado em técnicas de Data Mining busca reproduzir nas grandes empresas – ou seja, que possuem um grande volume de clientes e de informações sobre esses clientes – um “relacionamento” parecido com o que ocorre no pequeno comércio, aonde o dono desenvolve de fato um relacionamento singular com cada um de seus clientes, conhecendo seus gostos e sabendo o quanto investir do seu tempo em cada um deles. Portanto, Data Mining, em um sentido mais estreito, é basicamente um conjunto de ferramentas e técnicas para suportar uma visão centrada no cliente. E em um sentido mais amplo, é uma atitude que implica que as ações de negócio deveriam ser baseadas em aprendizado, decisões baseadas em informação são melhores que decisões não baseadas nelas, e que medir resultados é benéfico para os negócios. Data Mining também é um processo e uma metodologia para aplicação das técnicas e ferramentas. Para eles, há quatro requisitos para que a empresa aprenda com os seus clientes:
Notar o que os clientes (ou potenciais clientes) estão fazendo;
Lembrar o que a empresa e os clientes estão fazendo ao longo do tempo; Aprender com o que foi lembrado;
Agir em cima do que foi aprendido para tornar os clientes mais rentáveis.
modelos bem desenvolvidos e validados, as campanhas passarão a abordar os clientes mais propensos ao invés de abordar aleatoriamente.
Ainda segundo Berry e Linoff (2004), há dois tipos de abordagens em Data Mining – Estudos Supervisionados e Não Supervisionados, sendo que no projeto em questão empregaremos técnicas de Data Mining Supervisionadas, isto é, procura-se explicar alguma variável resposta mediante a categorização das variáveis preditoras. No caso, a contratação ou não de cartão de crédito. Avançando na classificação das atividades que podem ser desenvolvidas empregando-se técnicas de Data Mining, adotaremos a Previsão – que procura prever o comportamento futuro de uma variável resposta em função da classificação das variáveis explicatórias. Ou seja, procura examinar um novo objeto - um novo cliente potencial, por exemplo - e alocá-lo em uma classe pré-definida discreta – contrata cartão de crédito, por exemplo. As demais atividades possíveis são: Classificação, que procura alocar um novo objeto em uma classe pré-definida. Por exemplo, classificar clientes para concessão de crédito como baixo, médio, ou alto risco. Estimação - para variáveis resposta contínuas, Regras de associação – tipicamente market basket analysis, Clustering (agrupamento) –
segmentação de população em grupos de comportamento homogêneo Jain (1990),
Estudos de perfil– determinação de perfis que determinam explicações ou descrições
2.5 Regressão Logística
A regressão logística – ver Hosmer e Lemeshow (2000) e Witten e Frank (2005), por exemplo - é aplicada tipicamente em situações nas quais a análise de dados procura descrever o relacionamento entre uma variável resposta qualitativa e uma ou mais variáveis preditoras. Usualmente, a variável resposta é discreta, resultando em dois ou mais valores possíveis. A regressão logística tornou-se, em muitas áreas do conhecimento a metodologia padrão para casos nesta situação.
No projeto em questão, a variável resposta será binária adotando-se o valor 1 para eventos de contratação de cartão de crédito, e 0 para não eventos de contratação de cartão de crédito.
Para o uso efetivo na modelagem faz-se a transformação abaixo, chamada de logit
(equação 1). A transformação logit permite trazer alguns dos benefícios da regressão
linear, como ser linear em seus parâmetros, poder ser contínua, e poder variar de -, dependendo da faixa de x. Enquanto a distribuição dos erros na regressão linear é normal, na regressão logística ela segue uma distribuição binomial.
Dado um vetor de um conjunto de p variáveis independentes x‟ = (x1, x2,..., xp), e
definindo a probabilidade condicional P(Y=1 | x) = , temos a transformação logit da regressão logística múltipla dada pela equação 1 e o modelo da regressão logística múltipla dado pela equação 2.
Equação 1 - Transformação logit - Regressão logística múltipla
Equação 2 - Modelo de Regressão Logística Múltipla
a variável resposta do tipo dicotômica, o valor esperado médio deve situar-se no intervalo [0,1], conforme se observa no gráfico 2.
Gráfico 2 - A Curva Logística (Curva S) Fonte: Weisstein (2008).
Os autores ainda destacam dois pontos importantes acerca da formulação da regressão logística para variáveis dicotômicas:
A média condicional da equação de regressão deve ser formulada para que fique entre 0 e 1, condição satisfeita pela equação 1;
A distribuição dos erros segue a distribuição binomial e não a normal, e será a estatística utilizada para a análise dos erros e conseqüente ajuste dos estimadores.
2.6 Árvores de Decisão
Berry e Linoff (2004) definem Árvores de Decisão como ferramentas bastante poderosas e amplamente populares para classificação e predição, sendo seu grande atrativo o fato de que árvores de decisão representam regras que podem ser expressas em linguagem comum, de modo que os seres humanos possam entendê-las. Além disso, essas regras podem ser aplicadas em bases de dados via comandos SQL para recuperar registros pertencentes a uma determinada categoria. No contexto da empresa em análise, o fato desta técnica ser facilmente compreensível em termos de linguagem de negócio facilitará o entendimento dos gestores e a conseqüente adoção do processo de modelagem.
A árvore de decisão pode ser definida como uma estrutura que pode ser usada para dividir uma grande quantidade de registros sucessivamente em conjuntos menores de registros, aplicando-se uma seqüência simples de regras de decisão. A cada divisão sucessiva, os membros do subconjunto resultante tornam-se cada vez mais semelhantes entre si. Um modelo de árvores de decisão, portanto, consiste em conjunto de regras para dividir uma população grande e heterogênea em pequenos grupos homogêneos de acordo com a variável resposta desejada – no caso, a contratação ou não de um cartão de crédito.
Para uma definição mais técnica das árvores de decisão, ver Safavian e Landgrebe (1991).
O aspecto mais importante de uma árvore de decisão, segundo Berry e Linoff (2004), é como se faz a divisão dos grupos em grupos menores, de maneira que os novos nós tenham mais pureza (vide Esquema 2) que os seus antecessores em relação à
variável resposta. Para se encontrar a melhor divisão, parte-se de um subconjunto de dados de treinamento (parte da amostra) pré-classificados, isto é, no qual se conhece a variável resposta para todos os casos. O objetivo das divisões é montar uma árvore na qual se associe um novo registro a alguma classe que tenha um determinado comportamento em relação à variável resposta.
subseqüentes em que se predomine uma única classe. O esquema 2 ilustra bem o conceito de pureza:
Portanto, o processo de montagem da árvore passa por diversas iterações até achar a divisão que leva à maior pureza, sucessivamente, até que não seja mais possível fazer divisões – quer por falta de registros, quer por uma divisão adicional não aumentar a pureza.
Para variáveis categóricas, os testes empregados para a avaliação das divisões – ainda segundo Berry e Linoff (2004) são:
Gini, também conhecido como diversidade populacional, é usualmente utilizado na mensuração de desigualdade de renda nos países. Pode-se ver em Abounoori e McCloughan (2003) que o índice Gini é derivado da curva de Lorenz, cuja função é l=l(z), aonde z é proporção acumulada da variável explicativa e l é a proporção
Dados Originais
1) Divisão Ruim 2) Divisão Ruim
3) Boa Divisão
Fonte: Adaptado de Berry e Linoff (2004)
4) Divisão perfeita
acumulada da variável resposta, ou no caso, o quanto os clientes que contratam cartão. O conceito do índice Gini é mostrado no gráfico 3.
Gráfico 3 - Curva de Lorentz e o Índice Gini
O índice Gini é definido como na equação 3:
Equação 3 – Gini - Integral
O índice Gini é positivo em relação à variável resposta e quanto mais próximo da unidade maior é a concentração, ou igualdade. Aproximando a integral definida por uma somatória, chega-se à equação 4, que equivale a duas vezes à soma das áreas dos trapézios.
Equação 4 - Gini - Somatório
0 10 20 30 40 50 60 70 80 90 100
0 10 20 30 40 50 60 70 80 90 100
% d e c lie n te s q u e c o n tr atam c ar tão Decis
Este critério de separação dá a probabilidade de dois itens escolhidos aleatoriamente pertencerem à mesma classe Berry e Linoff (2004). Para uma população 100% pura o índice Gini seria igual a 1 (probabilidade de 100%), dado que é atribuído o valor 1 para a área do triângulo entre as retas de igualdade perfeita, desigualdade perfeita, e o eixo x (vide gráfico 3). Para se calcular o índice Gini deve-se pegar a soma dos quadrados das proporções entre as classes de cada lado da divisão resultante, ponderando-se pela quantidade de itens que ficaram em cada nó (já que a divisão não é necessariamente em partes iguais). A título de exemplo, vamos calcular o índice para os nós do Esquema 2. O nó contendo a população inicial tem seu índice Gini calculado como , tendo em vista que há a mesma quantidade de itens de cada classe neste nó, e que a chance de retirar a mesma classe em uma seleção aleatória com reposição é de 0,5. O mesmo se aplica para a divisão número 1 do mesmo esquema, para ambos os nós. O índice Gini da divisão 2 é:
para o nó da esquerda, e para o nó da direita. Ponderando-se, temos o índice da divisão 2 igual a Para a divisão número 3, o índice ficaria: , para os dois nós. E, finalmente, para a última divisão, teríamos o maior grau de pureza, pois em decorrência da separação perfeita o índice Gini para os dois nós é igual a 1, bem como o índice para a divisão como um
todo: .
Entropia, originada do campo de conhecimento conhecido como Teoria da Informação, também conhecida como Valor Informacional (IV – Informational Value) de Kullbak. Para mais detalhes sobre origem e conceituação do termo ver Williams (1977) e Vetschera (2000). Para medir a efetividade das divisões nas árvores de decisão, a Entropia procura mensurar – segundo Berry e Linoff (2004) – a complexidade informacional resultante das divisões. Se o nó subseqüente tiver poucas classes, é simples descrevê-lo do ponto de vista informacional e, portanto, sua entropia será pequena. Por outro lado, se a divisão não for bem sucedida, haverá muitas classes a serem descritas, com o conseqüente aumento na entropia. Para um único nó, a fórmula da Entropia para o Esquema 2, ficaria:
Teste Chi-quadrado ( 2). Trata de um teste que mede a significância estatística da relação entre duas variáveis qualitativas, e foi criado por Karl Pearson em 1900. É definido como a soma dos quadrados das diferenças padronizadas entre os valores esperados e os valores observados. Ou seja, é uma medida da probabilidade de que a relação observada deva-se somente ao acaso. Quando utilizado na medição da pureza das divisões das árvores de decisão, altos valores de 2 implicam que a distância entre o valor observado e o valor esperado é grande, e não é devida somente ao acaso.
O algoritmo de árvores de decisão baseado nessa estatística é o CHAID, ou Chi-square Automatic Interaction Detector.
O estudo de Hamza e Larocque (2005) mostra que a diferença entre os critérios de separação Gini e Entropia são desprezíveis para variáveis dependentes binárias, o que será comprovado na análise dos resultados dos modelos. De fato, até o critério de separação chi-quadrado deu resultados muito próximos.
Além disso, há outros algoritmos para controlar o crescimento das árvores de decisão, baseados em diferentes filosofias, tais como o CART, ID3, e C5. Para detalhes do funcionamento, o que foge do escopo desta dissertação, consultar Berry e Linoff (2004), Breiman (1998), Ye (2004), Rao et al. (2005), Klösgen e Zytkow (2002), entre
2.7 Redes Neurais Artificiais
De acordo com Bigus (1996), Skapura (1996), e Berry e Linoff (2004), as redes neurais artificiais procuram emular as suas contrapartes biológicas, ou seja, o cérebro humano, conforme esquema 3, que detalha um neurônio.
Esquema 3 – Neurônio Humano Fonte: Ruiz (2007)
rede neural resulta em uma série de pesos atribuídos internamente através da rede, e que não são facilmente interpretáveis. Ou seja, não é possível explicar o porquê de uma determinada solução, como seria fácil explicar com um modelo de regressão logística ou uma árvore de decisão.
De acordo com Freeman e Skapura (1991), o surgimento das redes neurais se deu juntamente com a invenção dos computadores digitais, nos anos 40. Desde então, os computadores têm sido utilizados na modelagem de neurônios individuais e grupos de neurônios – as redes neurais.
O primeiro sistema baseado em redes neurais foi o Perceptron, que procurava emular
um neurônio humano, mas continha algumas limitações relacionadas à linearidade das soluções e outras limitações teóricas. Na linha de evolução veio o ADALINE (Adaptive Linear Neuron) que, embora muito semelhante ao Perceptron, era capaz fazer transferências lineares, mas também padecia de limitações teóricas. Essas limitações somente foram superadas quando da introdução da propagação reversa1 por John Hopfield em 1982, que permite treinamento das redes neurais de maneira a evitar as armadilhas teóricas dos modelos anteriores, adicionando múltiplas camadas intermediárias (ou escondidas). Como resultado, as redes neurais passaram a ser capazes de lidar com a maioria dos problemas de ordem prática, usualmente não lineares.
Segundo Maimon e Rokach (2005), as redes neurais artificiais compartilham duas características com os neurônios biológicos: 1) processamento paralelo de informações e 2) aprendizado e generalização a partir da experiência. Ainda segundo os autores, a grande popularidade do emprego das redes neurais como técnica de Data Mining vem do fato de que não se faz necessário assumir hipóteses sobre as variáveis preditoras (valores missing, distribuições, correlações, etc.), uma vez que as redes neurais são excelentes em situações que requerem reconhecimento de padrões que expliquem a contratação de cartão de crédito, por exemplo, sendo que as explicações saem do aprendizado da rede, o que é ideal no mundo do Data Mining principalmente tendo em vista que os dados são abundantes mas padrões que façam sentido nem sempre o são. Além disso, segundo Freeman e Skapura (1991), as redes neurais podem seguir modelos não-lineares e não necessitam da introdução de
parâmetros, o que permite capturar melhor os dados do mundo real. Ou seja, a rede não precisa de um algoritmo que traduza um problema em uma ou mais equações, mas funciona buscando a repetição de padrões de ativação das conexões que reproduza exemplos anteriores mediante treinamento.
As Redes Neurais mais utilizadas são as do tipo multi-layer feedforward neural networks, ou multi-layer perceptrons (MLP), que são ideais nas aplicações de negócios que tenham como características a necessidade de se modelar relações entre diversas variáveis preditoras e uma ou poucas variáveis resposta.
No esquema 4 encontram-se alguns exemplos de redes neurais do tipo feedforward, nas quais há apenas um caminho para o fluxo de informações entre as entradas e a(s) saída(s). As variáveis de entrada, X1 a X4 poderiam ser: Idade, Renda, Sexo, e UF,
Esquema 4 - Topologias de redes neurais Fonte: Adaptado de Berry e Linoff (2004)
W2
W1
W3
W4
Rede neural simples que aceita quatro entradas e produz uma saída. O resultado do treinamento dessa rede é equivalente à técnica de regressão
logística, na qual w1 a w4 são os
coeficientes, a função de ativação é a
logística e a saída é do tipo:
Saída
Entrada X1
Saída
Rede neural com uma camada intermediária (escondida), que torna a rede mais poderosa, pois é capaz de reconhecer mais padrões.
Saída
Aumentar o tamanho das camadas escondidas ou adicionar camadas torna a rede mais poderosa, mas
cria o risco de overfitting.
Usualmente, apenas uma camada escondida é necessária.
Entrada X2
Entrada X3
Entrada X4
Entrada X1
Entrada X2
Entrada X3
Entrada X4
Entrada X1
Entrada X2
Entrada X3
O neurônio artificial, utilizado nas redes neurais, combina as entradas em um único valor, que então é transformado para gerar a saída, o que é conhecido como função de ativação. As funções de ativação mais comuns são baseadas no modelo do
neurônio biológico, no qual as saídas combinadas mantêm-se muito baixas até que até que elas atinjam um valor limite. Quando esse valor é atingido, a unidade de neurônio artificial á ativada, e o valor da saída fica alto. Como sua contraparte
biológica, o neurônio artificial tem a propriedade de pequenas alterações nas entradas poderem gerar valores bastante altos nas saídas, e grandes alterações nas entradas poderem gerar valores pequenos nas saídas, apresentando um comportamento não linear, segundo Damásio (1998). A função de ativação tem duas partes: a função de combinação, que junta todas as entradas em um valor, sendo que cada entrada tem
um peso. A função de combinação mais comum é a soma ponderada, na qual cada
entrada é multiplicada pelo seu peso, sendo feita a soma no final. A segunda parte da função de ativação, ainda segundo Berry e Linoff (2004), é a função de transferência,
que junta todas as combinações na saída do neurônio artificial. Funções típicas de transferência são a logística (sigmóide), linear, e tangente hiperbólica. Para os fins da dissertação a função de transferência mais adequada é a logística, pois esta produz uma saída dicotômica, que no caso representará a contratação ou não de um cartão de crédito.
O treinamento da rede neural mediante propagação reversa (back propagation) funciona da seguinte maneira:
A rede processa um exemplo de treinamento, empregando os pesos inicialmente estabelecidos nas conexões e calcula as saídas;
A propagação reversa calcula o erro pela diferença entre o resultado esperado e o resultado real;
2.8 Comparação dos Modelos
Para fins de comparação das técnicas de modelagem estatística empregadas serão empregados alguns critérios subjetivos, que refletem em grande parte a opinião do autor, e alguns critérios objetivos, suportados pelas validações técnicas apresentadas no item anterior. A tabela 2 mostra uma visão geral dos pontos fortes e fracos de cada tipo de ferramenta de modelagem.
Tabela 2 - Comparação das técnicas de modelagem
Segundo Vach et al. (1996) e Schumacher et al. (1996) ilustram vários pontos da
técnica de redes neurais comparada com a regressão logística. Os destaques ficam para o fato de que as redes neurais não fornecem informações diretas sobre o valor de um único parâmetro na previsão (como é o caso da regressão logística, que mostras os coeficientes da equação logística ajustada pelo método da máxima verossimilhança). Ou seja, não há estratégias simples e claras que permitam interpretar os pesos ajustados pela rede neural. Outro aspecto levantado é que as redes neurais necessitam de amostras grandes para fazer bom uso da sua flexibilidade, além do que seu emprego faz mais sentido em problemas de reconhecimento de padrões, tendo em vista que não faz muito sentido interpretar variações em nuances de cinza (em um problema de reconhecimento de imagens, por exemplo). A conclusão final dos autores é que, para problemas na área biomédica, o emprego de redes neurais não traz ganhos mensuráveis de performance, não dá
Critério Regressão Logística Árvores de Decisão Redes Neurais
Facilidade na explicação do resultado
Velocidade de processamento Flexibilidade no desenho Flexibilidade na aplicação a problemas diversos
Robustez Estatística KS
Curva ROC Lift
Sensibilidade a mudanças nas informações de entrada Risco de Overfitting
Necessidade de trabalhar a informação "missing"
indicações claras do que está ocorrendo na estimação, e que portanto o seu uso não se justifica.
3. METODOLOGIA
3.1 Metodologia de Pesquisa
A metodologia adotada na dissertação será de uma pesquisa preditiva. Segundo (Collis e Hussey, 2005), a pesquisa preditiva “oferece uma explicação para o que está acontecendo em determinada situação. O objetivo da pesquisa preditiva é generalizar a partir da análise, prevendo certos fenômenos com base em relações gerais e hipotéticas”. (Hair, Babin et al., 2005) definem a pesquisa causal como “um projeto que teste se um evento causa outro evento ou não, ou seja, X causa Y?”. Uma relação causal implica que uma mudança em um evento provoca uma mudança correspondente em outro evento. “A causalidade significa que uma mudança em X (a causa) faz com que ocorra uma mudança em Y (o efeito)”. Ainda, “a causalidade está associada à comprovação de uma associação não espúria, o que significa que a relação é verdadeira e realmente não se deve a algo mais que simplesmente afeta tanto a causa quanto o efeito.” No projeto em questão um dos grandes objetivos é desenvolver modelos estatísticos que expliquem quais os perfis de clientes potenciais (causas) mais propensos a contratarem um cartão de crédito (efeito) e avaliar se há possibilidade de ganhos financeiros nas campanhas de marketing direto, especificamente no canal telemarketing. De acordo com (Collis e Hussey, 2005), a pesquisa será do tipo quantitativa, seguindo o paradigma positivista. “De acordo com os positivistas, as leis fornecem a base da explanação, permitem a antecipação de fenômenos, prevêem a sua ocorrência e, conseqüentemente, permitem que sejam controlados. A explicação consiste em estabelecer relações causais entre as variáveis
estabelecendo leis causais e ligando-as a uma teoria dedutiva ou integrada”. Em
relação à coleta de dados, Hair et al. (2005) declaram que os dados observacionais
3.2 Recursos Computacionais Utilizados
3.3 Descrição e seleção das variáveis
O objetivo a ser atingido é o de desenvolver e analisar modelos estatísticos que identifiquem os clientes não correntistas mais propensos a contratarem um cartão de crédito através do canal telemarketing. Serão empregadas três metodologias: regressão logística, árvores de decisão e redes neurais.
A variável resposta será a compra ou não de um cartão de crédito, ou seja, será uma variável do tipo dicotômica.
Para fins de desenvolvimento e validação do modelo, serão extraídas amostras de cinco meses de informações históricas cuja variável resposta, conseqüentemente, já seja conhecida. Serão utilizados seis meses para desenvolvimento do modelo – quatro meses dividindo-se a amostra em bases de desenvolvimento e treinamento – e dois meses para a validação efetiva do modelo, conforme desenhado no esquema 5, após a escoragem.
Os dados analisados neste estudo são provenientes de uma grande instituição financeira brasileira, que atua fortemente no mercado de cartões de crédito. Por motivos de sigilo foi gerada uma base de dados artificial, que não reflete os retornos reais das ações de telemarketing de cartão de crédito, embora mantenha todas as características de distribuição das variáveis. Os CPFs que identificam os clientes foram criptografados, para evitar riscos durante a manipulação e garantir o sigilo total dos clientes da empresa.
Variável resposta (IND_VENDA):
Esquema 5 - Cronograma de Desenvolvimento e validação dos modelos
As variáveis independentes a serem analisadas na modelagem estão descritas na tabela 3, e são basicamente de informações demográficas, do tipo CEP, faixa de renda, sexo, além de variáveis do comportamento histórico dos clientes no canal telemarketing. É importante ressaltar que, para um cliente ser potencial para uma oferta de cartão de crédito, a Área de Crédito já terá feito estudos de capacidade de pagamento e liberado o cliente para a contratação do produto. Segundo Witten e Frank (2005), o uso de informações em geral - e pessoais em particular - para Data Mining, geram uma série de implicações éticas. A operação de telemarketing dificilmente aborda o cliente uma única vez, especialmente quando se trata da venda de outros produtos que não o cartão de crédito. Para cada disponibilização, o cliente entra usualmente em um período de carência de oferta por três meses (dependendo do motivo da recusa). Portanto, uma informação presente no que se convencionou “memória de CRM”, e que discrimina fortemente a variável resposta (conforme ficará claro na etapa de desenvolvimento do modelo), é resultado da quantidade de vezes que o cliente já foi contatado pelo telemarketing. Essa variável mostra que, quanto maior a quantidade de contatos seguidos de recusa, menor é a chance de conversão da venda. Por outro lado, há uma variável que mostra se o cliente já contratou algum outro produto anteriormente no canal telemarketing, o que indica que o cliente é receptivo ao canal.
Abr/07
Mai/07
Jun/07
Jul/07
Ago/07
Set/07
Out/07
Nov/07
Dez/07
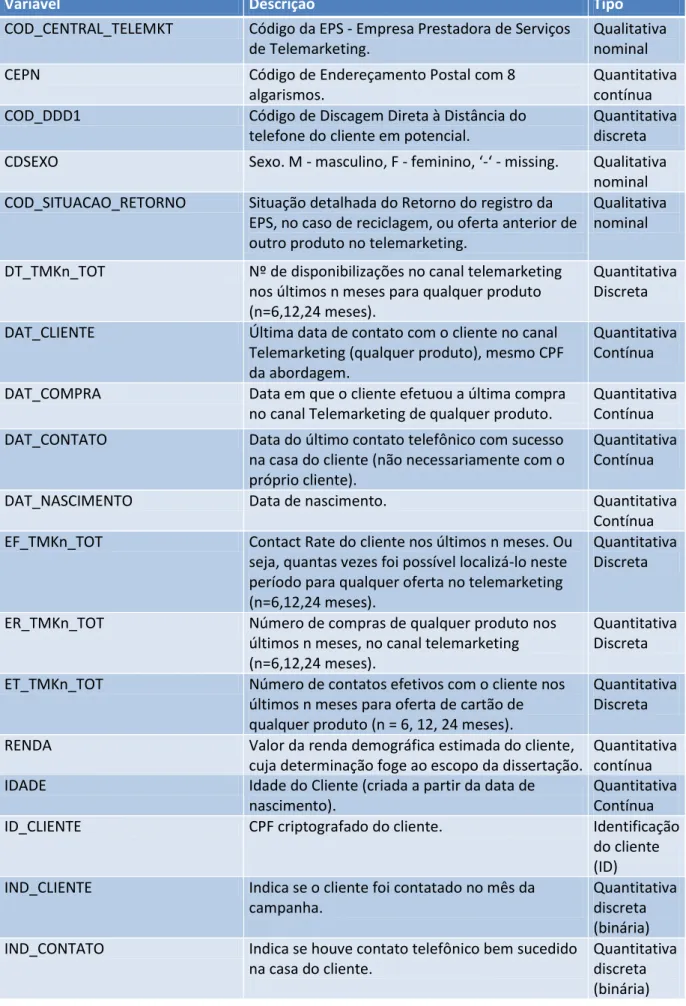
Tabela 3 - Variáveis Analisadas no Modelo
Variável Descrição Tipo
COD_CENTRAL_TELEMKT Código da EPS - Empresa Prestadora de Serviços de Telemarketing.
Qualitativa nominal
CEPN Código de Endereçamento Postal com 8
algarismos.
Quantitativa contínua
COD_DDD1 Código de Discagem Direta à Distância do
telefone do cliente em potencial.
Quantitativa discreta
CDSEXO Sexo. M - masculino, F - feminino, ‘-‘ - missing. Qualitativa
nominal COD_SITUACAO_RETORNO Situação detalhada do Retorno do registro da
EPS, no caso de reciclagem, ou oferta anterior de outro produto no telemarketing.
Qualitativa nominal
DT_TMKn_TOT Nº de disponibilizações no canal telemarketing
nos últimos n meses para qualquer produto (n=6,12,24 meses).
Quantitativa Discreta
DAT_CLIENTE Última data de contato com o cliente no canal
Telemarketing (qualquer produto), mesmo CPF da abordagem.
Quantitativa Contínua
DAT_COMPRA Data em que o cliente efetuou a última compra
no canal Telemarketing de qualquer produto.
Quantitativa Contínua
DAT_CONTATO Data do último contato telefônico com sucesso
na casa do cliente (não necessariamente com o próprio cliente).
Quantitativa Contínua
DAT_NASCIMENTO Data de nascimento. Quantitativa
Contínua
EF_TMKn_TOT Contact Rate do cliente nos últimos n meses. Ou
seja, quantas vezes foi possível localizá-lo neste período para qualquer oferta no telemarketing (n=6,12,24 meses).
Quantitativa Discreta
ER_TMKn_TOT Número de compras de qualquer produto nos
últimos n meses, no canal telemarketing (n=6,12,24 meses).
Quantitativa Discreta
ET_TMKn_TOT Número de contatos efetivos com o cliente nos
últimos n meses para oferta de cartão de qualquer produto (n = 6, 12, 24 meses).
Quantitativa Discreta
RENDA Valor da renda demográfica estimada do cliente,
cuja determinação foge ao escopo da dissertação.
Quantitativa contínua
IDADE Idade do Cliente (criada a partir da data de
nascimento).
Quantitativa Contínua
ID_CLIENTE CPF criptografado do cliente. Identificação
do cliente (ID)
IND_CLIENTE Indica se o cliente foi contatado no mês da
campanha.
Quantitativa discreta (binária)
IND_CONTATO Indica se houve contato telefônico bem sucedido
na casa do cliente.
IND_VENDA Indica se o cliente aceitou ou não a oferta de cartão de crédito (1 = sim, 0 = não).
Variável Dependente (Target)
SIG_UF Unidade Federativa (Estado). Qualitativa
Nominal
VARIANTE Variante ofertada. Electronic, Nacional,
Internacional, Gold. Da menor para a maior.
Qualitativa Ordinal
R_GENERICA_n Número de recusas genéricas nos últimos n
meses (n=6, 12 24 meses).
Quantitativa Discreta
REG_DDD Enriquece a variável SIG_UF dividindo-as em:
capital e interior, a partir do código de DDD (ex: SP-capital, RJ-interior).
Qualitativa Nominal
MESREF_RISCO Ano em que o cliente obteve crédito
pré-aprovado para cartão de crédito.
Quantitativa Discreta
REC_ER_n Recência de compra de cartão considerando os
últimos n meses (6, 12, 24 meses).
Quantitativa Discreta
CDESTCIV Código do Estado Civil. 1 = Casado, 2 = Solteiro, 4
= Separado/divorciado, 5 = Viúvo, 6 = União Estável, 7 = Outros, 8 = Sem Informação