A HOLISTIC FRAMEWORK FOR USER
SARA REGINA MATTOS GUIMARÃES
A HOLISTIC FRAMEWORK FOR USER
RECOMMENDATION IN SOCIAL NETWORKS
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação do Instituto de Ciências Exatas da Univer-sidade Federal de Minas Gerais como re-quisito parcial para a obtenção do grau de Mestre em Ciência da Computação.
Orientador: Wagner Meira Jr.
Coorientador: Renato Martins Assunção
Belo Horizonte
SARA REGINA MATTOS GUIMARÃES
A HOLISTIC FRAMEWORK FOR USER
RECOMMENDATION IN SOCIAL NETWORKS
Dissertation presented to the Graduate Program in Computer Science of the Fed-eral University of Minas Gerais in partial fulfillment of the requirements for the de-gree of Master in Computer Science.
Advisor: Wagner Meira Jr.
Co-Advisor: Renato Martins Assunção
Belo Horizonte
c
2013, Sara Regina Mattos Guimarães. Todos os direitos reservados.
Guimarães, Sara Regina Mattos
G963h A Holistic Framework for User Recommendation in Social Networks / Sara Regina Mattos Guimarães. — Belo Horizonte, 2013.
xxii, 66 f. : il. ; 29cm
Dissertação (mestrado) — Universidade Federal de Minas Gerais — Departamento de Ciência da
Computação
Orientador: Wagner Meira Jr.
Coorientador: Renato Martins Assunção
1. Computação Teses. 2. Redes de relações sociais -Teses. 3. Sistemas de recomendação - -Teses.
Acknowledgments
First of all, I am grateful to God, who has created me and sustained my life until this very day.
I wish to express my sincere thanks to my advisors, Wagner Meira Jr. and Renato Assunção, for their guidance and knowledge throughout this work. Additionally, I would like to thank Professor Adriano César Pereira for guiding my first steps into research, and Professor Mohammed Zaki for hosting me at the Rensselaer Polytechnic Institute.
I would like to extend my gratitude to all the colleagues and friends at e-Speed Lab, and specially Arlei, with whom I worked closely in different projects, including part of this work. I am also thankful for all friendships built during these years, which made everything funnier.
I am grateful to my dear parents and brothers, for all the support, the patience, the encouragement and the prayers.
I am also tremendously thankful to my lovely husband, Marco Túlio. He was always there to support and help me, and surely this work could not be completed without him.
“The grass withers and the flower fades, but the word of our God stands forever.”
Resumo
Com a crescente popularização das redes sociais, encontrar usuários de interesse tem se tornado uma tarefa cada vez mais difícil, fazendo com que tais redes, como o Twitter ou o Facebook por exemplo, sejam ótimos cenários para a aplicação de sistemas de recomendação. Neste trabalho, nós realizamos uma extensa avaliação de algoritmos para recomendação de usuários baseados em conteúdo, difusão de informação e métodos colaborativos. Nossos experimentos utilizam duas bases de dados reais do Twitter.
Neste trabalho, uma nova forma de representar usuários para algoritmos basea-dos em conteúdo e tf-idf é proposta. Essa nova representação captura os interesses basea-dos usuários de uma forma mais completa, também levando em consideração o conteúdo postado pelas pessoas que eles seguem. Nossos experimentos mostram que essa nova representação supera a tradicionalmente usada. Nós aplicamos algoritmos colabora-tivos representacolabora-tivos do estado-da-arte para recomendação de itens no nosso cenário de recomendação de usuários. Nós também apresentamos e avaliamos o ProfileRank, um novo modelo baseado em difusão para medir influência de usuários e relevância de conteúdos. O ProfileRank também é aplicado na tarefa de recomendação de usuários. Pesquisas anteriores apontam que existe valor em combinar diferentes algoritmos de recomendação, uma vez que cada algoritmo tem seus pontos fortes e pontos fracos. Entretanto, trabalhos anteriores focaram em classes específicas de algoritmos de re-comendação, ou em formas ingênuas de combinar diferentes algoritmos. Em contraste, neste trabalho nós apresentamos um arcabouço híbrido e holístico que simultanea-mente leva em conta algoritmos baseados em conteúdo, difusão, técnicas colaborativas e informação de usuários. Nosso arcabouço aprende como combinar diferentes fontes de evidência (incluindo o resultado de outros algoritmos) dos próprios dados, usando usando para isso um modelo de Regressão Logística. Dessa forma, ao invés de deter-minar a importância de cada fonte manualmente, ou pior - dar o mesmo peso para as diversas fontes, a ênfase apropriada dada para cada fonte de evidência do nosso mod-elo é extraída dos dados. Nossos experimentos mostram que nosso arcabouço supera algoritmos do estado da arte para recomendação de usuários.
Abstract
As social networks grow larger and larger, finding users of interest becomes an increasingly difficult task, making these networks, such as Twitter and Facebook, great scenarios for the application of recommender systems. In this work, we perform an extensive evaluation of content-based, collaborative-based, diffusion-based algorithms for user recommendation. We perform experiments on two real datasets from Twitter. In this work, a new user representation for tf-idf content-based algorithms is proposed. This representation captures the users’ interests more fully, by also taking into account the content posted by the people they follow. Our experiments show that this new representation outperforms the traditional one. We apply state-of-the-art collaborative filtering item recommendation algorithms in our user recommendation scenario. We also introduce and evaluate ProfileRank, a new diffusion-based model for measuring user influence and content relevance. ProfileRank is also applied to the task of user recommendation.
Previous research has shown that there is value in combining different recommen-dation algorithms, as each algorithm has strengths and weaknesses. However, previous works have focused on specific classes of recommendation algorithms, or on naïvely combining different algorithms. In contrast, in this work we present a holistic hybrid framework that simultaneously takes into account content-based, collaborative-based, diffusion-based and user-based information. Our framework learns how to combine different sources of evidence (including the output from other algorithms) from the data itself, by using a Logistic Regression model. Therefore, instead of manually de-termining the importance of each source, or worse - weighting all the sources equally, the appropriate emphasis given to each of the sources in our model comes from the data. Our experiments show that our algorithm outperforms current state-of-the-art algorithms for user recommendation.
List of Figures
3.1 Word Cloud of a given user, for each user representation. . . 14
3.2 LDA model. . . 16
3.3 TW-SOCCER dataset distributions for number of followers, followees and tweets for each user . . . 20
3.4 TW-LARGE dataset distributions for number of followers, followees and tweets for each user . . . 21
4.1 Modeling diffusion data using ProfileRank. . . 24
6.1 Sampling target user’s followees for training and test sets. . . 39
6.2 An illustration of the evaluation methodology. . . 40
6.3 Mean ROC curve for TF-IDF based algorithms. . . 42
6.4 Distribution of distance between content posted and followed by targets user. 42 6.5 Mean ROC curve for content-based algorithms. . . 43
6.6 Mean ROC curve for diffusion-based algorithms. . . 44
6.7 Mean ROC curve for collaborative-based algorithms. . . 45
6.8 Mean ROC curve for different algorithms. . . 46
6.9 ROC AUCs for different algorithms on stratified target users for both datasets. . . 47
6.10 Mean ROC curve for hybrid algorithms. . . 49
6.11 Bias in sampling methodology. . . 52
6.12 New negative test sampling. . . 53
6.13 Mean ROC curve for different algorithms in new experiments. . . 54
6.14 Mean ROC curve for best algorithms in new experiments. . . 55
6.15 ROC AUCs for different algorithms on stratified target users, for both datasets using new sampling. . . 57
List of Tables
3.1 Some LDA topics discovered on Twitter, for each dataset. . . 17
6.1 Datasets summary. . . 38
6.2 LDA parameters used for experiments. . . 43
6.3 ProfileRank parameters used for experiments. . . 44
6.4 Pairwise rank correlations among algorithms. . . 48
6.5 ROC AUC, Precision @1,5,10 and Recall@1,5,10 results for all algorithms. 50 6.6 Logistic weights for each feature used by logistic. . . 51
6.7 Average of followers in the positive and negative set, for different sampling configurations. . . 54
6.8 Logistic weights for each feature used by logistic in new experiments. . . 56
Contents
Acknowledgments ix
Resumo xiii
Abstract xv
List of Figures xvii
List of Tables xix
1 Introduction 1
1.1 Motivation . . . 1
1.2 Contributions . . . 3
1.3 Outline . . . 4
2 Related Work 5 3 User Recommendation 11 3.1 Content-Based Algorithms . . . 12
3.1.1 Pure text: TF-IDF . . . 12
3.1.2 LDA . . . 15
3.2 Collaborative-Based Algorithms . . . 18
3.3 User-Based Features . . . 19
4 ProfileRank: A Diffusion-Based Algorithm 23 4.1 A New Information Diffusion Model . . . 23
4.2 General Principle . . . 25
4.3 Information Diffusion Model . . . 26
4.4 Efficient Solution using the Power Method . . . 29 4.5 Using Relevance and Influence for Content and User Recommendation . 30
5 Holistic Hybrid Framework 33
5.1 Logistic Regression . . . 33 5.2 Feature Selection for Our Framework . . . 34 5.3 Holistic Hybrid Framework . . . 35
6 Experimental Evaluation 37
6.1 Datasets . . . 37 6.2 Evaluation Methodology . . . 38 6.3 Evaluation Metrics . . . 40 6.4 Empirical Results . . . 41 6.4.1 Content-Based Algorithms . . . 42 6.4.2 Diffusion-Based Algorithms . . . 44 6.4.3 Collaborative-Based Algorithms . . . 45 6.4.4 All Non-Hybrid Algorithms . . . 45 6.4.5 Hybrid Algorithms . . . 49 6.5 Evaluation Analysis . . . 51 6.5.1 Identifying the Bias and Resampling the Data . . . 51 6.5.2 Results with New Sampling . . . 54
7 Conclusion 59
Bibliography 61
Chapter 1
Introduction
1.1
Motivation
With the advent of digital information systems and the Internet, the dissemi-nation of information went through a revolution. Suddenly, anyone was allowed to publish whatever they wanted, without the need of a professional publisher, printer, distributer, etc. However, even with the Internet, there still was some cost associated with distributing information: one had to either learn or hire someone in order to build and maintain a Website, and to make the Website known to the public (with the use of marketing, SEO, etc). Also, in order to get constant updates, users had to visit the websites they liked repeatedly.
The Web resources evolved significantly in the last 20 years, making it much eas-ier to disseminate user-generated content through blogs, comment sections, and social networks, among others. A notable example is Twitter, an online social information network launched in 2006. Twitter enabled massive content generation and dissemi-nation by simplifying everything. It allows users to post 140-character text messages (calledtweets) to a constantly updatingpublic timeline of user messages. Users receive other users’ tweets by explicitly following them. And, most importantly, (almost) ev-eryone participates. As of 2013, Twitter has over 200 million active users, including the president of the United States1 and most media celebrities, generating over 400 million tweets each day [Wickre, 2013]. Since anyone may post content to it, Twitter is also revolutionizing real-time news, as regular folk tweet about current events before the traditional media even knows about it. A notable example was the news about Osama Bin Laden’s death, which reached Twitter before any major news outlet reported it.
1https://twitter.com/BarackObama
2 Chapter 1. Introduction
Actually, a user live-tweeted about the attack even before it was over, without knowing exactly what was going on2.
Twitter is a typical scenario where Information Overload [Simon, 1971] takes place – or as its more recent, social media domain name: Social Overload [Guy et al., 2013]. No user on Twitter has the time, or the patience, to look through 200 million active users, and filter out which ones are interesting. Much has been done in terms of identifying the most “important” users [Cha et al., 2010; Weng et al., 2010], but different people have completely different interests. This is where recommender systems come in, offering recommendations that are tailor-made to particular users, where the user on the receiving end of the recommendations is called a target user. The task of recommending other users on Twitter is different from the traditional scenario, where items (such as songs, movies or products) are recommended to users [Adomavicius and Tuzhilin, 2005; Ricci et al., 2011]. In Twitter, the objects of the recommendation (other users) are not well-defined, and are constantly being updated, as new content is posted. The proportions are also different. The well known Netflix dataset [Bennett et al., 2007], for example, which deals with movie recommendation, contained 17,700 movies that could be recommended. In Twitter, a recommender system has to choose from over 200 million users.
Previous research on recommending users on Twitter has focused on recommen-dations based on user features (non-personalized), on content-based, on diffusion-based and on collaborative based approaches or on hybrids, which combine two or more strate-gies [Hannon et al., 2010; Armentano et al., 2011a,b; Pennacchiotti and Gurumurthy, 2011].
In this work we propose a holistic hybrid framework, that simultaneously takes into account content-based, diffusion-based, collaborative-based and user-based infor-mation. Content-based information is useful for obvious reasons: Twitter is used in order to disseminate content. Diffusion-based information takes into account how users create and propagate information across time, in order to establish the influence that certain users have, or the interestingness of certain content. We propose a new diffusion-based model as a byproduct of our work on hybrid algorithms, called ProfileRank. Information about which users are the most influential is clearly useful for a hybrid recommender system. Collaborative-based information leverages the network structure in order to predict the importance of a user v with respect to another user u. Finally, information about the users helps the algorithms determine what kind of user is being dealt with. For example, a certain user v might post only content related to soccer
1.2. Contributions 3
which fits nicely to what interests user u, a soccer aficionado. However, if v has very few followers, this might indicate thatv’s content is not considered very useful by most people, even though it is about soccer - and thus v is probably not a good recommen-dation for u. On the other hand, ifv is followed by most ofu’s friends,v may be a good recommendation after all. It is clear, then, that each source of information (content, diffusion, collaborative or user-based) provides different insights into what might be a good recommendation for u.
In contrast to previous work on hybrids (which aggregated strategies naïvely), our framework learns how to combine different sources of evidence from the data itself, by using a Logistic Regression model. Therefore, instead of manually determining the importance of each source, or worse - weighting all the sources equally, the appropriate emphasis given to each of the sources in our model comes from the data. Our hybrid is general, in the sense that it is easy to incorporate or remove other algorithms or features into the model. Using real data from Twitter, we evaluate our framework and show that it outperforms current state-of-the-art techniques.
In building our hybrid, we found that the traditional tf-idf content-based ap-proach was lacking, thus we also propose a new way of representing users and potential followees. Instead of representing users by what they post, we represent users as a combination of what they post and the content posted by the users they follow. Most users are passive, while other users tweet only about a subset of their interests. How-ever, we can assume that users usually follow people that disseminate content they are interested in (by definition). For example, a certain user might be interested in sports, politics and religion, but choose not to talk about politics and religion in order to avoid controversy - while at the same time following political and religious figures. Our experiments show that this new representation results in significant improvements on the accuracy of content-based algorithms based on traditional information retrieval techniques.
1.2
Contributions
The main contributions of this work are summarized as follows:
(a) New content-based modeling: We propose a new representation for pure-text content-based algorithms that captures the users’ interests more fully.
4 Chapter 1. Introduction
(c) Framework design: We design and implement a framework that is able to com-bine multiple sources of evidence of users’ preferences simultaneously.
(d) Evaluation of the proposed framework: We evaluate our new framework using Twitter real data, showing that it makes effective user recommendations.
These contributions are also published in the following papers:
• Uma Estratégia Baseada em Difusão de Informação para Determinação de Conteúdos Relevantes e Usuários Influentes em Redes Sociais. Hérico Valiati, Arlei Silva, Sara Guimarães, Wagner Meira Jr.,In Revista de Informática Aplicada (RITA), 2013.
• ProfileRank: Finding relevant content and influential users based on information diffusion. Silva, A., Guimarães, S., Meira, Jr., W., and Zaki, M., In Proceedings of the 7th Workshop on Social Network Mining and Analysis (SNAKDD), 2013.
• A Holistic Hybrid Algorithm for User Recommendation on Twitter.
Sara Guimarães, Marco Túlio Ribeiro, Renato Assunção, Wagner Meira Jr., In Journal of Information and Data Management, 2013.
1.3
Outline
Chapter 2
Related Work
The popularization of Internet-based communication and interactivity platforms resulted in a tremendous interest in understanding social interactions at large scale [Watts, 2007]. Powered by the remarkable success of Twitter, Facebook, Youtube, and the blogosphere, social media is taking over traditional media as the major platform for content distribution. The combination of user-generated content and online social networks is the engine behind this revolution in the way people share news, videos, memes, opinions, and ideas in general. As a consequence, understanding how users and information interact in information diffusion processes is a fundamental step towards the design of effective information diffusion mechanisms, recommender systems, and viral marketing/advertising campaigns on the Web.
In particular, the characterization of the dynamics of information propagation in social media applications, such as blogs [Gruhl et al., 2004] and other online communi-ties [Cha et al., 2009; Leskovec et al., 2007], has supported several discoveries regarding the potential of viral marketing strategies and the role played by influentials – people who affect the behavior of others. Due to its growing popularity over the past years, Twitter has become a standard social laboratory for understanding information diffu-sion and influence [Cha et al., 2010; Kwak et al., 2010], but some of these studies have been focused on straightforward statistics of successful influence, such as the number of followers, retweets, and mentions.
In directed networks, where relationships are not reciprocal, social interactions can depict influence interactions [Silva et al., 2011]. For instance, Twitter users receive the tweets from those users they follow and a user’s number of followers has been considered a measure of influence [Cha et al., 2010].
Much work has been done on identifying influential users on Twitter. Weng et al. [2010], for example, tried to identify influential users in certain topics. Bigonha et al.
6 Chapter 2. Related Work
[2010] measure the influence of a user based on her network position and her behavior - the interaction with other users, the polarity of her opinions and the quality of her tweets. Cha et al. [2010] observe that popular users (users with many followers) are not necessarily influential in terms of spawning retweets or mentions, although there is an obvious correlation. Based on this potential correlation, Krutkam et al. [2010] tried to leverage influence-related information (such as the number of followers and the number of topic-related lists the user is listed in) in order to recommend followees for users interested in Thai News (their recommendations are not personalized).
However, finding influential users is not the same as recommending interesting users, as a certain user might not be interested in certain profiles, regardless of their influence in general or in a certain topic. This is one motivation for Garcia and Amatri-ain [2010] to use the activity (number of tweets) of users, in addition to popularity, in order to make recommendations. In this work, we do not restrict ourselves only to user measures, such as influence and activity. Instead, we incorporate simple user measures (such as number of followers) with more sophisticated and personalized techniques such as collaborative, content-based and diffusion-based methods. This contrasts sharply with several current proposals which disregard the simple user measures in favor of content and/or collaborative based techniques [Hannon et al., 2010; Pennacchiotti and Gurumurthy, 2011].
Recommendation on Twitter is a problem that has been studied from multiple points of view. Kywe et al. [2012] propose a taxonomy of recommendation tasks on Twitter based on the type of function being helped by the recommendation (such as following a user, retweeting a tweet or mentioning a certain user in a tweet). In this work, we deal with the task denotedFollowee Recommendation - recommending users that are likely to be of interest to a specific user.
Even though finding influentials and recommending users are different tasks, we can not disregard the similarities between both of them, since many times influential users may be good recommendations for most part of Twitter users. This is specially true if the model is able to identify personalized influentials, e.g., the influence of a user over another particular user, since with that we may be able to perform good user recommendations.
7
a user and a piece of information, in the sense that relevant information satisfies a user’s information needs, being a fundamental concept also in information retrieval and recommender systems research [Baeza-Yates and Ribeiro-Neto, 1999; Ricci et al., 2011].
Considering the similarities between finding influential users and performing user recommendations, added to the fact that influence is also seen in information diffusion scenarios, we propose a diffusion-based method that identifies influential users and use this information in order to provide user recommendation. We named our diffusion based method as ProfileRank [Silva et al., 2013].
ProfileRank is a diffusion based model that measures the degree of influence of one user over another, and, because of that, it can be used in the prediction of follower relationships on Twitter, which is exactly the user recommendation problem explored in Chapter 4. More specifically, our diffusion model is interested in predicting these re-lationships based solely on content and time information. Our effort is similar to Weng et al. [2010] and Romero et al. [2011] in the sense that we study new models for iden-tifying influential users based on diffusion traces. However, while TwitterRank [Weng et al., 2010] and Influence-Passivity [Romero et al., 2011] rely on the social network structure in order to identify influential users, ProfileRank measures user influence and content relevance based only on diffusion data, i.e., user-content associations over time. In fact, TwitterRank is a variation of PageRank [Page et al., 1999] over the follower network induced by a particular topic.
ProfileRank, on the other hand, is a variation of PageRank [Page et al., 1999; Franceschet, 2011] over a directed user-content bipartite graph. Similar to HITS [Klein-berg, 1998], PageRank is a link analysis algorithm designed to measure the importance of a node in a hyperlinked environment, such as the Web. PageRank is based on random walks in graphs, an idea also applied in the computation of relevance scores between nodes [Tong et al., 2006, 2008] and in content recommendation [Baluja et al., 2008]. Nevertheless, our work is the first that applies random walks in a directed user-content bipartite graph to measure user influence and content relevance in diffusion data. We should emphasize that our model is supported by a formulation that is different from those of PageRank and HITS, as detailed in Chapter 4.
8 Chapter 2. Related Work
shown to outperform traditional methods based on k-nearest neighbors and matrix factorization when the task is ranking, in both movie and e-commerce recommenda-tion, which makes it a good candidate for ranking potential followees on Twitter. Also, while most of the research in recommender systems focuses on datasets where ratings are available, BPR-MF is designed to implicit feedback scenarios - such as following a user on twitter. To the extent of our knowledge, BPR-MF has not been used for user recommendation on Twitter until this work. We show that it greatly outperforms pure content-based techniques, a class discussed next. We use BPR-MF as a representative of the state-of-the-art in collaborative filtering techniques, both as a baseline and as a component in our hybrid framework.
Twitter has its own user recommender service, called WTF (Who To Follow)
[Gupta et al., 2013]. WTF suggests Twitter accounts that a user may be interested in following, based on shared interests, common connections, and a number of other factors. In a nutshell Twitter uses two algorithms: an egocentric random walk (per-sonalized PageRank) and SALSA which is a bipartite random walk (similar to HITS algorithm). The exact recommendation algorithm is however unknown, as the authors declare that the “standard" production algorithm blends results from approximately 20 different algorithms, but never present which ones they are. The evaluation method-ology they use is also difficult for researchers outside of Twitter, as they use snapshots of the network at different times in order to make quality assessments, as well as do online A/B tests with live users.
As for pure content-based methods to recommend users, Pennacchiotti and Gu-rumurthy [2011] investigated the use of topic models, also known as Latent Dirichlet Allocation (LDA) [Blei et al., 2003]. They compare their approach with another pure content-based method, the traditional Vector Space Model with tf-idf weights [Baeza-Yates and Ribeiro-Neto, 1999]. Their preliminary results show that LDA outperforms tf-idf. In this work, we argue that LDA and tf-idf work well in different circumstances, and are complementary - and therefore should be used together. Further, we present a new way of representing users for tf-idf, which we show to be superior to the previ-ous alternatives. Finally, instead of ignoring network and global user information, we incorporate these methods as components in our hybrid framework.
9
TF-IDF weighting scheme. We discuss their user representation in relation to ours in Chapter 5. The way they aggregate their collaborative and content algorithms is by either combining their scores (the authors do not specify how), or by using what seems to be a variation of Borda Count (again, not fully specified). These approaches suffer from many drawbacks, especially if they are used to combine different algorithms. For example, when one of the algorithms being combined is substantially inferior to the others, it could affect the final result negatively. The authors themselves note that the hybrid versions of Twittomender did not outperform their best collaborative algorithm in terms of precision.
Chapter 3
User Recommendation
In this chapter, we present some algorithms for user recommendation based on the content that users post and also present two classes of important sources of in-formation usually used to perform user recommendation: collaborative and user-based approaches. We discuss why they are good fonts of evidence for providing good rec-ommendations, and also provide a new representation for users and potential followers for pure-text content-based algorithms.
An important source of information about a specific user’s preferences is the history of what the user has read, watched, bought or said. It is intuitive that people consume what they are attracted to, and this is translated to what they post and/or read. If a user posts some content on a social network, either this user spoke her mind or agreed with someone else. In either cases, it is reasonable to assume that this content somewhat reflects this users’ interests.
In the same sense, if someone has the same interests you have, it is very likely that you will like that person. Translating to the online world, if a particular user
u generates content about subjects that are similar to what another user v posts, v
will probably find the u’s content interesting. Furthermore, v will be interested in
u. Therefore, analyzing the text generated and/or consumed by a user may give us evidence on whom this user is likely to want to follow. Our implicit assumption is that a target user is more likely to follow other users that are similar, which is consistent with the homophily effect where individuals tend to bond with similar people [McPherson et al., 2001]. In Section 3.1 we present some content-based algorithms based on pure-text and also topic modeling, and introduce a new user representation that seems to better capture users’ interests.
A widely used technique for performing personalized recommendation is collabo-rative filtering. The assumption behind collabocollabo-rative-based algorithms is that if a user
12 Chapter 3. User Recommendation
uhas the same preferences as a user v in a given subject A, that user u is more likely to have the same preference as user v in another subject B than a randomly chosen user.
What collaborative-based algorithms do is that they find users with similar in-terests and/or preferences according to their past behavior, which is considered to be previous feedback (in our social network scenario, the feedback is an implicit interac-tion of following someone). After this initial phase, the recommender system performs recommendations for a user preference based on the preferences of similar users [Schafer et al., 2001]. In Section 3.2 we present the collaborative-based algorithms we used to perform user recommendations in this work.
As for the user-based features, social networks have significant information about the users that is easily obtained. Some of the users’ characteristics have been considered useful in measuring the influence or importance of a user. In Section 3.3 we discuss some features related to the users that gives good insights about each user’s popularity and activeness, which will be incorporated into our hybrid model.
3.1
Content-Based Algorithms
In this section we present some content-based algorithms used for the user recom-mendation task proposed in this work. Section 3.1.1 presents a basic yet very common and well accepted algorithm that uses only the text that users post: TF-IDF. We give the intuition behind this technique, and also propose a new way to represent users, which takes into account both the content they post and the content they consume. This representation seems to better capture the users’ interests. In Section 3.1.2, we use a model in order to extract topics from the content that users post. Using topics is an attempt to aggregate the users’ interests in such a way that goes beyond the very words that they post, and it is shown to achieve good results in this task.
3.1.1
Pure text: TF-IDF
3.1. Content-Based Algorithms 13
content posted by her followers, as the user has no control whatsoever on who follows her.
Kwak et al. [2010] identified that 77.9% of Twitter’s connections are unilateral relationships and out of all relations only 22.1% are reciprocate. He also pointed out that 67.6% of all users are not followed by any of their followees. This probably indicates that those users see Twitter as a source of information rather than a network to build relationships or to keep in touch with friends.
Taking this into account, when using pure text, we decided to represent each user in two different ways:
1. Each user is represented by the content (the words) of her own tweets.
2. Each user is represented by the combination of the content of her own tweets and the content posted by her followees.
Representation 1 is the standard for text-based recommendation [Pennacchiotti and Gurumurthy, 2011]. To give some intuition for having both, we made a word cloud using Wordle1 for each of the two user representations discussed above. The results can be seen in Figure 3.1. We selected a specific user (whose account name was omitted), and presented a word cloud for the content posted by her, and a word cloud for the content posted by her and her followees. It is hard to determine what this given user is interested in by looking at the word cloud formed by her own tweets, in Figure 3.1a. However, by looking at the content posted by her and her followees in Figure 3.1b, her interests become more clear. Words like groovy (a programming language),
grails (a groovy framework) and maven (a build manager for Java projects) indicate that this user is interested in programming. Words like broncos (a reference to the Denver Broncos) and marshall (a reference to Brandon Marshall, a football player) are evidence that the user is also interested in American Football.
When representing the content in each of the two options, we used TF-IDF-IDF weighting scheme, where the weight of each termtfor a certain useruis proportional to the frequencytft,u of the usage oft (either by the useruor by her followees, depending on the representation) and inversely proportional to t’s occurrence throughout the dataset (idft), as shown in Equation 3.1, where N is the number of users in the dataset and nt is the number of users who have used at least once the term t. The intuition is that the term t should receive a large weight if it is common in the text of user u
(hence, characterizingu) and, at the same time, it is not common in the dataset (hence, discriminating who uses it). This weighting scheme has been successfully applied in
14 Chapter 3. User Recommendation
(a) User is represented by her own content
(b) User is represented as a combination of her own content and her followees’
3.1. Content-Based Algorithms 15
a variety of contexts, including traditional Information Retrieval [Baeza-Yates and Ribeiro-Neto, 1999]. Finally, we discarded stop words and words appearing less than 5 times in the dataset.
tf_idft,u =tft,u∗idft
tft,u =
1 +log(f reqt,u), if f reqt,u >0
0, if f reqt,u = 0
idft=log(N/nt)
(3.1)
A straightforward algorithm for recommending users on social networks is to calculate the similarity between a target user u and every other user, and then to recommend the users that are most similar to u. The similarity score between two users, u1 and u2, represented as vectors of length n with entrieswui, is calculated using the cosine similarity, as shown in Equation 3.2. The TF-IDF weights depend on the representation being used.
sim(u1, u2) =
Pn
i=1w i
u1 ×wiu2
q Pn
i=1(wu1i )2×
q Pn
i=1(wiu2)2
(3.2)
Hannon et al. [2010] always used the same representation for both the target users and all the other users. We use this strategy, with the representation 1 (users are represented by their own tweeted words) as a baseline. We name this algorithm
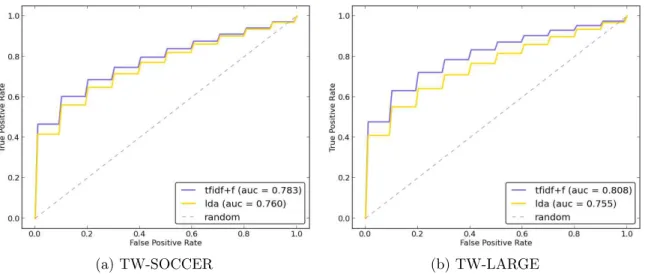
tfidf, and it is the same as S1 in Hannon et al. [2010]. However, as we argued before, it makes sense to represent the user by the combination of the tweets he or she posted and the tweets posted by his/her followees (representation 2), in order to discover this user’s interests more fully - while representing all the other users with their own tweets (representation 1), since the target user can only benefit from the content they post, and not by the content they receive. We name this new algorithm tfidf+f, and we show in Chapter 6 that it greatly outperforms tfidf.
3.1.2
LDA
16 Chapter 3. User Recommendation
topics from documents in a non-supervised way [Blei et al., 2003]. Each document in a collection is seen as a mixture of different topics or themes. The proportion of each topic changes from document to document and the document-specific composition gives the signature of each document in the collection.
What is striking in the LDA algorithm is that the topics are generated automati-cally, without requiring the pre-specification of themes or the labeling of the documents with topics or keywords. The topics do not come out with labels such as “sports”, but rather as a distribution over the frequencies of words - from which a label can be man-ually assigned (if desired). Table 3.1 shows the most representative words of a few topics that were discovered using LDA on Twitter as explained next. It is clear that, from the words, distinct topics can be easily identified.
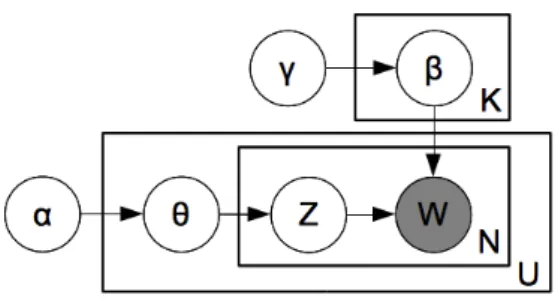
In the traditional use of LDA, each documentu∈U is represented by a multino-mial distribution θu over each one of the K topics. This distribution is traced from a Dirichlet prior, using α as parameter. The topics are also represented as multinomial distributionsβk derived from another Dirichlet prior with parameterγ. The generative model states that each word position n in a document stream is assigned a topic zu,n drawn from θu, and that the word in that position wu,n is drawn from the distribution
βzu,n. Figure 3.2 is a representation of how this model works.
Figure 3.2: LDA model.
Pennacchiotti and Gurumurthy [2011] applied LDA to recommend users on twit-ter. For each useru, they concatenated all tweets sent byucreating a single document containing all the words tweeted. LDA is then applied to the collection of documents and each user is represented by the distribution of topics of their tweets. The algo-rithm for recommending users becomes analogous to tfidf. Users that are similar to a target user u by means of the cosine similarity are recommended to u. We name this algorithm aslda.
3.1. Content-Based Algorithms 17
Topic Assigned Label Top Words
11 São Paulo spfc tricolor saopaulo silva sp paulista saopaulofc
33 Flamengo flamengo fla mengo mengao adriano crf mundo flamenguista 56 Vasco vasco gama vascaino vascainos virada vascaina dinamite 59 Curses c* p**** f*** tomar c****** m**** p** toma torce pqp 66 Tickets ingressos jogo feira venda torcida estreia torcedores vendidos 80 Palmeiras palmeiras felipao marcos kleber paulista verdao assuncao 84 Santos santos neymar ganso elano santista adilson oliveira maikon 86 Promotions camisa oficial sorte ganhar spfc kit retro adesivo
93 Emotions amor vida coracao paixao raca mundo orgulho historia peito 99 Soccer zagueiro lateral atacante jogador atletico reforco meia 111 Atletico-MG atletico galo richarlyson mineiro contrato contratado 133 Sports jogos vitorias ganhou campeonato empates casa derrotas 134 Sports Fans torcida clube imprensa torcedores presidente torcedor 183 Soccer Match gol bola jogo tempo marca area vitoria ataque minutos
(a) TW-SOCCER
Topic Assigned Label Top Words
8 Food food beer eat coffee chocolate ice cream day chicken eating 13 Christianity god lord jesus pray love faith heart prayer life christ
24 News fire police los angeles news near la station city california 29 Finances market bank money cash tax up billion dollar banks 35 Photography photo photography photos day flickr project camera 49 Apple iphone app apple store apps mac ipod itunes touch tablet 60 Science science human brain more new s life scientists one history 64 Music music new band rock album guitar live songs paul cover 67 Movies film movie movies trailer new films best man harry tv john 74 Sports sports game nba shaq lakers team football year out real kobe 78 Education education learning classroom students school teachers great 103 Books writing book write reading writers story writer great read 107 U.S. Politics health care reform bill obama senate house public healthcare 118 Comics new comic please up today’s comics out strip check humor 129 News news journalism media online newspaper newspapers 137 Sports vs game cup ufc usa fight united usmnt chuck football fans 152 Health health flu swine cancer care medical healthcare study vaccine 155 Volunteering help need relief philippines victims donations red typhoon 156 Video Games game games xbox ps now gaming live new video coming wii
(b) TW-LARGE
18 Chapter 3. User Recommendation
3.2
Collaborative-Based Algorithms
Collaborative filtering has been shown to be an effective approach to recom-mender systems. This approach analyses past interactions between user and items to generate personalized recommendations based on other users with similar behavior. Traditionally, it is used for item recommendation. However, in this paper, we are using collaborative filtering in order to recommend users to another users to follow. This means that the “item" being recommended is a user, so this turns to be a user-user recommendation instead of the original user-item recommendation.
As in the original scenarios this approach is normally used, we do not have any direct input from the users regarding their preferences, since following someone is not considered to be an explicit feedback. In particular, we lack substantial evidence on which users the target user dislikes. This, along with all the other similarities, make collaborative-based algorithms to be potentially good algorithms in performing user recommendation.
The first collaborative-based algorithm we applied to the task of recommending followees on social networks is Weighted Regularized Matrix Factorization (WRMF), a state-of-the-art matrix factorization technique for Collaborative Filtering introduced by Hu et al. [2008]. The application is straightforward: when a user ufollows another user v, we add the relation u−v as feedback.
We applied Bayesian Personalized Ranking for Matrix Factorization (BPR-MF) [Rendle et al., 2009] to the same task. BPR-MF is a optimization of the original WRMF algorithm, and uses the exact same setup.
We used an open source implementation of WRMF and BPR-MF, by Gantner et al. [2011]2. BothWRMFandBPR-MFare shown to be efficient recommendation algorithms in Chapter 6, whereBPR-MF is usually better than WRMF.
Hannon et al. [2010] proposed many content, collaborative-filtering and hybrid algorithms. Out of all of them, the one with the highest precision was a pure collabora-tive filtering algorithm (named S6, for strategy 6), which we have replicated here. This algorithm works as follows: instead of using their own words, users are represented by the IDs of their followers. Then, TF-IDF weights are applied (according to Equa-tion 3.1), and user recommendaEqua-tion is performed using cosine similarity (according to Equation 3.2). We named this algorithmTM-S6 (Twittomender Strategy 6).
In Chapter 6 we show that collaborative-based algorithms are efficient for the task of recommending users to be followed.
3.3. User-Based Features 19
3.3
User-Based Features
Each user in a social network has a set of features, such as stated location, number of posted content, number of followers, number of followees, etc. Some of these features are useful in measuring the global influence, or importance of a user, as well as how active the user is. In this work, we considered three user-based features: number of tweets, number of followers and number of followees. The intuition behind using these features for recommendation is simple. Users who post a lot of content (high number of tweets) are more likely to be good users to follow, since they have a lot to share. Users who have a lot of followers have already demonstrated that they are considered interesting by a large number of people, and therefore are likely to be interesting to other people as well. Finally, there is some reciprocity on Twitter, so the number of followees a user has also provides valuable information about the user.
Figures 3.3 and 3.4 present the distribution of these features over the users in both our datasets, presented in Section 6.1. As the figures show, these distributions are similar to power law distributions, indicating that most of the users rarely tweet, follow and are followed by few users. In contrast, a small number of users tweet very intensively, and follow and are followed by a large number of users.
20 Chapter 3. User Recommendation
(a) Number of followers per user (b) Number of followees per user
(c) Number of tweets per user
3.3. User-Based Features 21
(a) Number of followers per user (b) Number of followees per user
(c) Number of tweets per user
Chapter 4
ProfileRank: A Diffusion-Based
Algorithm
In Section 3.1, we presented some content-based algorithms to perform user rec-ommendations, as well as a new user representation that seems to better capture the users’ interests. Content-based algorithms focus on the text (words) itself, but do not take into account the path traveled by a content inside the network. That’s where a diffusion-based model comes into play. Even though both types use the content, algorithms that focus on information diffusion are more interested on the propagation of a content in the network than the specific words and/or semantic meaning of the content, which is the case of the content-based algorithms we presented.
In this chapter, we describe ProfileRank, which is a new model for content rele-vance and user influence based on diffusion data. We start by presenting the motivation behind a diffusion model in Section 4.1, and also give some general principles behind the model in Section 4.2. In Section 4.3 we show how the model is implemented and we also propose an efficient solution in Section 4.4.
To conclude the chapter, we show in Section 4.5 how the proposed diffusion model can be used as a content and user recommendation, and therefore how we intend to use the scores obtained by ProfileRank into our hybrid algorithm in order to perform user recommendations, which is the task proposed by this work.
4.1
A New Information Diffusion Model
Two key concepts in information diffusion are influence and relevance. In social networks, influence can be defined as the capacity to affect the behavior of others [Fried-kin, 2006]. However, in information diffusion scenarios, influence is usually a measure
24 Chapter 4. ProfileRank: A Diffusion-Based Algorithm
C RT@user_0 A
0 @user_0 1
2 3
@user_1
@user_2 @user_3
A
BB | !BB?
RT@user_0 B B
RT@user_1 C
(a) Twitter
user_0,A,t0 user_0, B, t1 user_1,A,t2 user_1, C,t3 user_2, B, t4 user_3, C,t5
(b) Diffusion data (c) Diffusion model
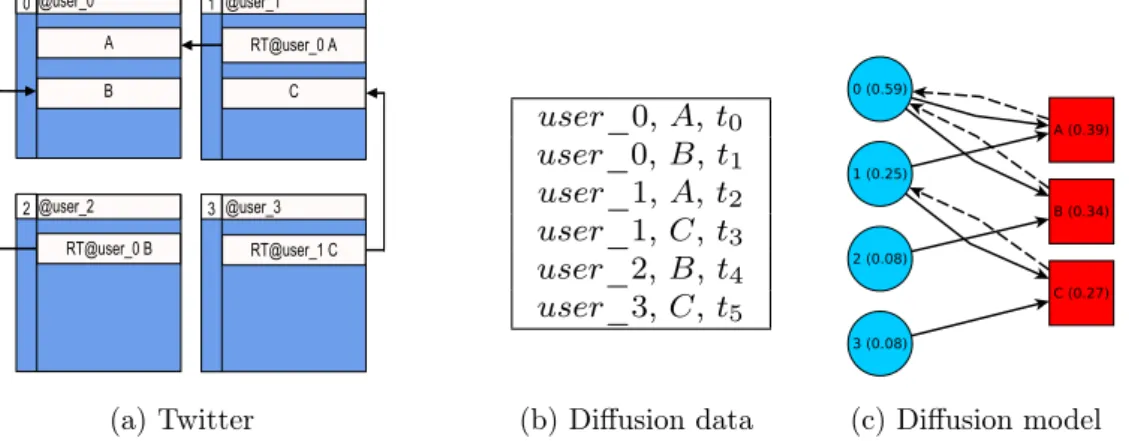
Figure 4.1: Modeling diffusion data using ProfileRank. (a) Illustrative Twitter dataset with 4 users (user_0, user_1, user_2, user_3) and 3 tweets (A, B, C). (b) Diffusion data. (c) ProfileRank diffusion model. Circles and squares represent users and content, respectively. ProfileRank measures user influence and content relevance using random walks over a user-content graph. Scores are shown inside each vertex.
of the ability of popularizing information. In other words, an influential is someone who propagates information widely, producing large diffusion cascades [Leskovec et al., 2007]. Relevance is a relationship between a user and a piece of information, in the sense that relevant information satisfies a user’s information needs, being a fundamental concept also in information retrieval and recommender systems research [Baeza-Yates and Ribeiro-Neto, 1999; Ricci et al., 2011].
ProfileRank is based on the principle that relevant content is created and propa-gated by influential users and influential users create relevant content. If we consider Twitter as an information diffusion platform and tweets as content propagated through retweets, ProfileRank can be intuitively described in terms of the behavior of arandom tweeter (or twitterer) that navigates through Twitter profiles by clicking on random tweets. Every click on a tweet leads the random tweeter to the profile of the author of the tweet. We measure user influence as the frequency with which the random tweeter visits a given profile. Likewise, content relevance is measured as the frequency with which the random tweeter clicks on a tweet.
4.2. General Principle 25
[Kleinberg, 1998] algorithms.
Readers who are familiar with PageRank may see ProfileRank as an application of the idea of PageRank to Twitter. However, instead of using the Twitter social interactions, like TwitterRank [Weng et al., 2010], ProfileRank is based on content propagation. This approach is motivated by previous work, which has shown that content propagation expresses social influence better than the Twitter network [Cha et al., 2010].
An interesting property of ProfileRank is that it can be personalized in order to compute user influence and content relevance from the perspective of a particular user. Hence, we can apply ProfileRank to content and user recommendation tasks. That’s why we are interested in using ProfileRank as a diffusion-based algorithm in order to perform user recommendations on Twitter.
4.2
General Principle
ProfileRank is based on an integrated view on user influence and content relevance in information diffusion. It was designed according to the following principle:
A piece of content is relevant if it is created and propagated by influential users, and influential users create relevant content.
As a consequence, information diffusion data enables an elegant circular definition of content relevance and user influence, which resembles ranking algorithms for infor-mation retrieval, such as PageRank [Page et al., 1999; Franceschet, 2011] and HITS [Kleinberg, 1998].
We call information diffusion data a sequence of occurrences of content. Each occurrence of a piece of content is defined as a tuple in the form < u, c, t >, where u
is a user from the set of users U, c is a piece of content from the content set C, and t
26 Chapter 4. ProfileRank: A Diffusion-Based Algorithm
whenever a user propagates a given piece of content, we may assume that this content is somehow relevant to such user.
At this point, it is important to explain how this nomenclature reflects in our experiments: we considered tweets as content, Twitter users as users, and retweets as content propagation.
Although our model may be applied to other scenarios different from Twitter, it can be easily described based on the behavior of a random tweeter, following the idea of the random surfer usually applied in the description of PageRank. Our random tweeter starts from a random Twitter profile and keeps clicking on tweets at random. The random tweeter is redirected to the profile of the author of a tweet by clicking on it. The relevance of a tweet is the relative frequency that the random tweeter clicks on a tweet. Moreover, the frequency that the random tweeter visits a user’s profile is a measure of this user’s influence. Figure 4.1a shows the edges through which our fictitious random tweeter navigates for a illustrative set of tweets and retweets.
This proposed general principle supports the definition of global relevance and influence functions. However, it is straightforward to reformulate this principle in order to support personalized relevance and influence functions.
A piece of content cis relevant to a user uif it is created and propagated by users that are influential to u and a user v is influential to u if v creates content that is relevant to u.
We can also describe this principle based on the behavior of a random tweeter. Nevertheless, instead of starting the navigation from a random Twitter profile, the random tweeter starts from the profile of the user for which the content relevance and the user influence evaluations are being personalized.
In the next section, we describe how the principles described in this section are applied by ProfileRank, which is a new information diffusion model that estimates the relevance of content and the influence of users based on diffusion data.
4.3
Information Diffusion Model
4.3. Information Diffusion Model 27
DEFINITION (Information Diffusion Graph) An information diffusion graph is a bipartite graph G(U, C, F, E), where U is the user set, C is the content set, and
E and F are sets of edges that associate users to content and the other way around, respectively. For each user u∈ U and piece of content c∈C, there is a directed edge
(u, c) ∈ E if the user u has created or propagated the content c and a directed edge
(c, u)∈F if u createdc.
Figure 4.1c presents the bipartite graph built from the data shown in Figure 4.1b. Edges in E give relevance to content based on the influence of users who propagated it. Moreover, edges in F give influence to users according to the relevance of the content they create. We materialize the two principles described in the last section as random walks through G. We begin by describing how global content relevance and user influence are computed in our model and then show how this model can be adapted to compute personalized content relevance and user influence.
The bipartite graph G can be represented by a user-content matrix M and a content-user matrix L. The matrix M = (mi,j) is a |U| × |C| matrix where mi,j =
1/qi and qi is the number of pieces of content the user ui has created or propagated. Moreover, L= (li,j)is a |C| × |U|matrix whereli,j = 1 if the useruj created the piece of content ci and li,j = 0, otherwise. Based on M and L, content relevance and user influence can be defined as:
r=iM
i=rL
where r is a content relevance (line) vector (i.e., r[j] is the relevance of the content
cj) and i is a user influence (line) vector (i.e., i[j] is the influence of the user uj). In this definition, we assume that we already have one of the vectors (r or i) in order to compute the other one, which is not a realistic case. Nevertheless, r and i can be computed recursively as follows:
r(k) =r(k−1)LM
i(k) =i(k−1)M L
where k ≥ 0 and r(0) and i(0) are uniform vectors (i.e., vectors where all values are equal and sum to 1).
28 Chapter 4. ProfileRank: A Diffusion-Based Algorithm
useruis reached because it will not be able to leaveu’s profile. PageRank also needs to deal with dangling pages and we apply a similar solution, creating an edge(u, c) from every dangling user to a ghost piece of content c and adding an edge (c, u) from the ghost content to every user u ∈ U. As a consequence, there is a non-zero probability that the random tweeter will leave a dangling user’s profile. In the graph shown in Figure 4.1c,user_0 is a dangling user, but we do not add a ghost piece of content in this example for clarity.
A bucket is a strongly connected subgraph of the bipartite graph. When the random tweeter reaches a bucket, it is not able to leave it. We can see a dangling user as a bucket of size 1. In order to prevent the random tweeter from getting stuck in a bucket, we add a damping factor d in our model. This factor determines a small probability that the random tweeter will teleport from the current to a random profile. We add the damping factord to the definition of r and i as follows:
r(k) =dr(k−1)LM + (1−d)u
i(k) =di(k−1)M L+ (1−d)u
whereu is a uniform vector. We can reformulate these equations to obtain their exact solutions in a non-recursive fashion:
r= (1−d)u(I−dLM)−1 (4.1)
i= (1−d)u(I−dM L)−1 (4.2)
whereI is an identity matrix. In the next section, we discuss why this formulation is not computationally efficient. Two more important questions to be addressed immediately are: (1) Do these equations have a solution? and (2) Are these solutions unique?
Equations 4.1 and 4.2 have at least one solution becauseM LandLM are product of stochastic matrices, and thus they are stochastic themselves. The solutions not only exist, but they are unique, once Equations 4.1 and 4.2 are written with matrix inverses, and by the definition of a matrix inverse,randiare unique if we assume that a inverse always exists, and it does in this case becauseI−dM Lis a diagonally dominant matrix. In Figure 4.1c, we give the values of user influence and content relevance computed by ProfileRank using a damping factor of 0.85. The most influential user is user_0
(i(user_0) = 0.59) because the two pieces of content produced by user_0(A and B)
4.4. Efficient Solution using the Power Method 29
than user_0. The most relevant piece of content is A (r(A) = 0.39) because it was created and propagated by influential users (user_0and user_1).
Devising personalized values of content relevance and user influence using Pro-fileRank is straightforward. In these scenarios, instead of starting from an arbitrary user, we assume that the random tweeter starts from a specific profile for which the model is being personalized. In the same way, instead of jumping to a random tweet with a non-zero probability, the random tweeter always jumps back to the original profile according to the damping factor. This behavior can be induced by substituting the uniform vector u by a vector 1j, which is a vector with all elements equal to 0, except the positionj that is set to 1, whereuj is the user for which the model is being personalized.
At this point, it is important to emphasize how ProfileRank is different from other link analysis techniques, specially PageRank and HITS. ProfileRank computes user influence and content relevance based on a user-content bipartite directed graph, instead of the (non-bipartite) directed graph employed by PageRank and HITS. Profil-eRank’s graph is represented by two matrices, a user-content (M) and a content-user (L) matrix, and enables the computation of different score functions (influence and relevance) for different types of nodes (users and content) based on diffusion data.
4.4
Efficient Solution using the Power Method
In the last section, we described the equations that define user’s influence and content relevance in our model. In order to apply this model in real settings, we need to solve such equations efficiently. In real information diffusion data, the matrices M
and L are likely to be very large and sparse. Therefore, an efficient solution for our model must take these properties into consideration.
30 Chapter 4. ProfileRank: A Diffusion-Based Algorithm
4.5
Using Relevance and Influence for Content and
User Recommendation
It is important to give some formal definitions for the score functions generated by ProfileRank, that will be used in the remaining of this work. We define content relevance and user influence function w.r.t. a given information diffusion dataset as follows.
DEFINITION (Content Relevance Function) Given an information diffusion datasetD= (U, C, T), a content relevance function r :C→R gives the relevance r(c)
of a piece of contentc∈C based on D.
DEFINITION (User Influence Function) Given an information diffusion dataset D = (U, C, T), a user influence function i : U → R gives the influence i(u)
of a useru∈U based on D.
A content relevance function simply gives a global relevance value for a given piece of content based on an information diffusion dataset. In a similar fashion, a user influence function gives a global influence value for a given user.
It is important to emphasize that these definitions are global in the sense that they do not provide relevance and influence measures for a particular user, which is the common case in recommendation tasks [Ricci et al., 2011]. We define personalized versions of a content relevance and a user influence function as follows.
DEFINITION (Personalized Content Relevance Function) Given an in-formation diffusion dataset D = (U, C, T), a personalized content relevance function
r:C×U →R gives the relevance r(c, u) of a piece of content c∈C for a useru ∈U
based on D.
4.5. Using Relevance and Influence for Content and User
Recommendation 31
a personalized version of a user influence function.
DEFINITION (Personalized User Influence Function) Given an information diffusion dataset D = (U, C, T), a personalized user influence function i: U ×U → R
gives the influence r(u, v) of a useru∈U over a user v ∈U based on D.
Given a pair of users (u,v), a personalized user influence function givesu’s degree of influence over v. While the personalized content relevance function may support content recommendation, personalized user influence is useful for user recommenda-tion. On Twitter, for instance, where users interact through follower relationships, user recommendation helps Twitter users in finding new followees (i.e., users to be followed) in the network. Since the Facebook subscription feature works very similarly to a follower relationship on Twitter, enabling users to receive the updates from each other, user recommendation is useful to Facebook users as well.
At this point, it should be clear that ProfileRank can be applied to content and user recommendation tasks, once it can be personalized in order to compute user in-fluence and content relevance from the perspective of a particular user. In fact, it was already shown that ProfileRank is effective in providing good recommendations on those scenarios [Silva et al., 2013]. For this reason, we will incorporate ProfileRank into the recommendation algorithm we present in this work, using it as another font of evidence in order to provide diffusion-based information to our algorithm. In Chap-ter 6 we use the scores given by the User Influence Function and by the Personalized User Influence Function, and name them profilerank_global and profilerank, re-spectively. However, since the task of this work is providing user recommendations, we will use only the scores generated by both the user influence functions introduced in this section, even though the original work shows it can be applied for content recommendation as well.
Chapter 5
Holistic Hybrid Framework
As the results in Chapter 6 will show, some of the proposed algorithms from the previous chapters are complementary, in the sense that they work well in different sce-narios, and do not generate rankings that are too similar. Also, the rankings produced by the several different algorithms are very diverse, which motivates finding a way of aggregating them.
As we mentioned in Chapter 2, previous attempts of combining different algo-rithms or sources of evidence relied on naïve approaches. Hannon et al. [2010], for example, either use a variation of borda count or a simple combination of scores. This may work relatively well when the number of algorithms being combined is small, and on the same scale of quality (although their hybrids did not perform better than pure collaborative-based algorithms). A better approach, however, is learning how the different algorithms and features impact user recommendation from the data itself.
In this chapter, we present a holistic hybrid framework that simultaneously takes into account content-based, diffusion-based, collaborative-based and user-based infor-mation. In Section 5.1 we explain how we combined all these source of inforinfor-mation. In Section 5.2, we present the features that were selected to be used in our hybrid model. Finally we discuss in Section 5.3 what makes our framework holistic and hybrid, and show how it is set apart from previous hybrid algorithms.
5.1
Logistic Regression
Our framework learns how to combine different sources of evidence (including the output from other algorithms) from the data itself, by using a Logistic Regression model [Hosmer and Lemeshow, 2000].
34 Chapter 5. Holistic Hybrid Framework
What we would expect from an algorithm for user recommendation in social networks is that it would output, for each pair of users u, v, and a vector of given featuresX, an estimate ofP(u→v|X), where u→v denotes the event that u follows
v. In this case, if u was our target user, we would rank every other user v by this estimate, producing a final recommendation list. Since the following relationship is binary (either u follows v or not), we use Binomial Logistic Regression in order to estimate P(u → v|X). We now proceed to explain how we model the hybridization problem using Logistic Regression.
The conditional probability modeled by Logistic Regression is shown in Equation 5.1. X is a vector of features, which may include features that relate u and v (such as the similarity between the two, given by any of the aforementioned algorithms) or features that are specifically about u or specifically about v (such as the number of followers thatv has). Since the final objective is ranking every other user with respect tou, for recommendation it does not make sense to include features that are specifically about the target useru, sinceuwill remain fixed (and therefore this kind of feature will have the same value every time). It is common to add a synthetic constant feature to
X, called intercept. In the equation, ρ is a vector of weights that has |X| dimensions, such thatρk corresponds to the weight given to the feature Xk.
P(u→v|X) = 1
1 +e−ρTX (5.1)
Let there be a training set{ui, vi, Xi, yi}ni=1of sizen, containing tuplesui, vi, Xi, yi where yi = 1 if ui → vi and yi = 0 otherwise, and Xi is the set of features related to ui and vi. We then apply an optimization method in order to get the optimal vector of weights ρ with respect to this training set. In this case, we used a Dual Coordinate Descent method, with L2 regularization, proposed by Yu et al. [2011]1. In our experiments, we used the validation set referred in Section 6.2 as the training set for logistic regression. It is worth noticing again that no users in the validation set are present in the test set.
5.2
Feature Selection for Our Framework
For the feature vector Xi, we used a combination of the previously mentioned content-based, diffusion-based and collaborative-based algorithms and user-based
5.3. Holistic Hybrid Framework 35
tures. Therefore, let there be two users, ui and vi. The vector Xi would be composed of a subset, or all of the following:
1. The similarity score betweenui and vi, given by tfidf+f 2. The similarity score betweenui and vi, given by lda
3. The similarity score betweenui and vi, given by profilerank 4. The similarity score betweenui and vi, given by BPR-MF 5. The similarity score betweenui and vi, given by WRMF 6. The similarity score betweenui and vi, given by TM-S6 7. The number of followers of vi.
8. The number of followees of vi. 9. The number of tweets posted by vi.
Features 1-2 are content-based features, Feature 3 is a diffusion-based fea-ture, Features 4-6 are collaborative-based features and Features 7-9 are user-based features. Note that the scores given by the previously mentioned algorithms were turned into features for logistic regression (Features 1-6). Since the range of possible values for features 1-6 is very different than for features 7-9, we performed a standard feature scaling, centering the data and scaling it to unit standard deviation.
5.3
Holistic Hybrid Framework
Using the logistic model described in Section 5.1 and as selected features the ones presented in Section 5.2, we use this new holistic hybrid framework to the task of user recommendation.
Our framework ishybrid in the sense that it combines multiple attributes in order to perform the recommendations. It isholistic once the attributes being combined come from different sources of information: whether being content, collaborative, diffusion or user-based. Therefore, we have a better overview of what the users’ preferences are and recommending followees becomes an easier task.
36 Chapter 5. Holistic Hybrid Framework
A plus to our hybrid framework is that adding or removing algorithms and user-based features in our hybrid is straightforward: it just means adding or removing features. The nine features we listed in Section 5.2 are just a particular instantiation of this generic hybrid framework, one that we show to outperform all of the baselines. Another advantage of Logistic Regression is that the weights are discovered from the data, meaning that if low-performing algorithms are added as features, the final result is not compromised, since they will have low (or even negative) weights associated to them.