ELIMINAÇÃO DE TESTES DE OVERFLOW PARA
RODRIGO SOL
: Mariza Andrade da Silva Bigonha
: Fernando Magno Quintão Pereira
c
2010, Rodrigo Sol.
Todos os direitos reservados.
Sol, Rodrigo
S684e Eliminação de Testes de Overflow para Compiladores de Trilhas / Rodrigo Sol. — Belo Horizonte, 2010
xxii, 62 f. : il. ; 29cm
Dissertação (mestrado) — Universidade Federal de Minas Gerais
Orientador: Mariza Andrade da Silva Bigonha
Co-Orientador: Fernando Magno Quintão Pereira
1. Computação - Tese 2. Compiladores
(Computadores) - Tese. I. Orientador II. Título.
Para os meus pais
Quando decidi ”suspender” minha vida por dois anos para investir nessa empreitada, ainda não tinha noção do que estava pela frente. Não imaginava que iria conviver com pessoas tão inteligentes e companheiras e menos ainda, que ficaria com o coração apertado por saber que esta convivência diária está chegando ao fim.
Inocentemente, achava que o mestrado me traria resposta para questões técnicas complicadas. Ledo engano! O mestrado só me trouxe mais dúvidas sobre questões mais complicadas ainda. Certeza mesmo é que eu estava no lugar certo, na hora certa. Um desses acasos da evolução, que alguns ainda chamam de destino. Como eu poderia saber que logo aos 30 segundos do primeiro tempo eu iria conhecer as três pessoas mais importantes dessa jornada: André, Andrei e Fernando.
São para eles que dedico especial agradecimento. Não seria possível suportar a pressão sem o companheirismo do André e do Andrei, também não seria possível completar essa jornada sem a sabedoria e a gentileza do Fernando.
Em todo agradecimento sempre existe o risco de se esquecer pessoas importantes. A vocês peço desculpas antecipadamente pela memória fraca. Mas, eu não poderia deixar de citar: os professores do LLP Roberto e Mariza Bigonha e também os amigos do LLP Terra, César e Leo (não aposte nada com esse cara). As contribuições do David Mendelin e do Christopher Guiolin também foram fundamentais para o sucesso deste trabalho.
Também não poderia deixar de agradecer pessoas que contribuíriam indireta-mente, mas de forma muito importante para esta jornada: Meus pais, que como sempre me apoiaram e a Carol, que teve paciência infinita com minha falta de disponibilidade nesses anos.
A todos vocês: muito obrigado!
“The First Rule of Program Optimization: Don’t do it. The Second Rule of Program Optimization (for experts only!): Don’t do it yet.”
(Michael A. Jackson)
Resumo
Compilação de trilhas é uma nova técnica utilizada por compiladoresjust-in-time (JIT)
como o TraceMonkey, o compilador de JavaScript do navegador Mozilla Firefox. Di-ferente dos compiladores just-in-time tradicionais, um compilador de trilhas trabalha somente com uma parte do programa fonte, geralmente um caminho linear de instru-ções que são frequentemente executadas dentro de um laço.
Como uma trilha é compilada durante a interpretação de um programa, o com-pilador just-in-time tem acesso aos valores manipulados em tempo de execução. A capacidade de acessar esses valores permite ao compilador a possibilidade de produzir código de máquina mais otimizado.
Nesta dissertação é explorada a oportunidade de prover uma análise que remove testes de overflow desnecessários de programas JavaScript. Para mostrar que algumas operações não podem causar overflows é utilizada uma técnica denominada análise de largura de variáveis.
A otimização proposta é linear em tamanho e espaço com o número de instruções presentes na trilha de entrada, e é mais efetiva que as análises de largura de variável tradicionais porque utiliza valores conhecidos em tempo de execução.
A otimização proposta foi implementada no navegador Mozilla Firefox, e testada em mais de 1.000 programas JavaScript de diversas coleções, incluindo os 100 sítios mais visitados da Internet segundo o índice Alexa.
Foram produzidos códigos binários para as arquiteturas x86 e ST40-300. Na média, a otimização proposta foi capaz de remover 91.82% dos testes de overflow nos programas presentes na coleção de programas de teste do TraceMonkey. A otimização proposta prove uma redução do tamanho do código binário de 8.83% na plataforma ST40 e de 6.63% na plataforma x86. A otimização aumenta o tempo de execução do compilador TraceMonkey em 2.53%.
Palavras-chave: compilação de trilhas, otimização de código, javascript, testes de overflow.
Abstract
Trace compilation is a new technique used by just-in-time (JIT) compilers such as TraceMonkey, the JavaScript engine in the Mozilla Firefox browser. Contrary to traditional JIT machines, a trace compiler works on only part of the source program, normally a linear path inside a heavily executed loop. Because the trace is compiled during the interpretation of the source program the JIT compiler has access to the values manipulated at runtime. This observation gives to the compiler the possibility of producing binary code specialized to these values. In this thesis we explore this opportunity to provide an analysis that removes unnecessary overflow tests from Ja-vaScript programs. Our optimization uses range analysis to show that some operations cannot produce overflows. The analysis is linear in size and space on the number of instructions present in the input trace, and it is more effective than traditional range analyses, because we have access to values known only at execution time. We have implemented our analysis on top of Firefox’s TraceMonkey, and have tested it on over 1000 scripts from several industrial strength benchmarks, including the scripts present in the top 100 most visited webpages in the Alexa index. We generate binaries to either x86 or the embedded microprocessor ST40-300. On the average, we eliminate 91.82% of the overflows in the programs present in the TraceMonkey test suite. This optimization provides an average code size reduction of 8.83% on ST40 and 6.63% on x86. Our optimization increases TraceMonkey’s runtime by 2.53%.
Keywords: trace compilation, code optimization, javascript, overflow tests
Lista de Figuras
2.1 Java. Do código fonte ao código de máquina . . . 11
2.2 Um exemplo de programa (direita) com o respectivo grafo de fluxo de con-trole (esquerda). . . 21
2.3 Exemplo de código de máquina que poderia ser produzido pelo compilador de trilhas. . . 23
2.4 O compilador JIT Mozilla TraceMonkey. . . 24
2.5 Um pequeno exemplo de um programa JavaScript e sua representação em bytecodes. . . 25
2.6 Esta figura ilustra o casamento entre a trilha gravada e o segmento LIR que foi produzida pelo sistema de trilhas. . . 27
2.7 O código LIR, logo após a inserção do prólogo e do epílogo, e a semântica do códigox86 produzido pelo Nanojit. . . 28
2.8 Avaliação parcial . . . 29
2.9 Um exemplo em que o conhecimento de valores de tempo de execução pro-picia a geração de código mais eficiente. . . 31
3.1 Grafo de restrições para a trilha mostrada na Figura 2.6 .Os números dentro das caixas mostram quando os vértices foram criados . . . 36
3.2 Propagação de faixas para vértices aritméticos. . . 37
3.3 Propagação de restrições para vértices relacionais. . . 38
3.4 Segmento LIR antes de ser passado ao Nanojit . . . 40
3.5 Componentes . . . 42
3.6 Classes . . . 44
3.7 Efetividade do algorítmo em termos de percentual de testes de overflow removidos por script (Cima) Alexa; média geométrica 53.50%. (Baixo) Trace-Test; média geométrica: 91.82%; Hardware: mesmos resultados para ST4 e x86. Os 224 scripts estão ordenados pela média de efetividade. . . . 47
3.8 Redução de tamanho por script em duas diferentes arquiteturas. (Cima)
ST4; média geométrica 8.83%. (Baixo) x86; média geométrica: 6.63%
Benchmark: Trace-Test. Os 224 scripts estão ordenados pela média de redução . . . 48 3.9 Tempo de Execução. Os 224 scripts estão ordenados pela média de
incre-mento no tempo de execução . . . 49 3.10 Um gráfico do tipo pizza mostrando as razões que impediram o algoritmo
de remover testes deoverflow. . . 50 3.11 Um histograma para as instruções presentes nosbenchmarks Trace-Teste e
PeaceKeeper, comparados aosbytecodes encontrados na coleçãoAlexa. Eixo X: As instruções i estão ordenadas por suas frequências na coleção Alexa. Quanto mais suave a onda, mais similar ao Alexa é a coleção. . . 51
Lista de Listagens
2.1 Tipo dinâmico em Ruby . . . 12
2.2 Criação de um objeto em JavaScript . . . 13
2.3 Encapsulamento de dados emJavaScript . . . 14
2.4 Criação de um objeto em JavaScript . . . 14
2.5 Exemplo de sub-classe em JavaScript . . . 15
2.6 Exemplo de compilação JIT . . . 17
Conteúdo
ix
Resumo xiii
Abstract xv
Lista de Figuras xvii
1 Introdução 1
1.1 Definição do Problema . . . 5
1.2 Solução Proposta . . . 5
1.3 Contribuições . . . 6
1.4 Organização do Texto . . . 7
2 Revisão de Literatura 9 2.1 Linguagens Interpretadas . . . 9
2.1.1 Portabilidade . . . 10
2.1.2 Tipo Dinâmico . . . 11
2.1.3 Reflexão . . . 12
2.2 JavaScript . . . 13
2.2.1 Características de JavaScript . . . 13
2.2.2 Interpretador SpiderMonkey . . . 15
2.3 CompiladoresJust-In-Time . . . 16
2.3.1 Classificação dos compiladores just-in-time . . . 18
2.3.2 Implementações de Compiladores Just-In-Time . . . 19
2.4 Compilação de Trilhas . . . 20
2.4.1 TraceMonkey . . . 22
2.5 Avaliação Parcial de Programas . . . 27
2.5.1 Avaliadores Parciais: On-line eoff-Line . . . 28
2.6 Avaliadores Parciais e Geração de Código . . . 29 2.6.1 Desmembramento de Laços . . . 30 2.6.2 Eliminação de Testes de Overflow . . . 31 2.7 Análise de Largura de Variáveis . . . 31 2.8 Conclusão . . . 32
3 Remoção de Testes de Overflow Via Análise Sensível ao Fluxo 33 3.1 Construção do Grafo de Restrições . . . 34 3.2 Propagação de Faixas de Restrições . . . 37 3.3 Análise de Complexidade do Algoritmo Proposto . . . 39 3.4 Implementação do Algoritmo . . . 41 3.5 Experimentos . . . 43 3.5.1 Benchmarks . . . 44 3.5.2 O Hardware . . . 45 3.5.3 Eficácia do Algoritmo Proposto . . . 46 3.5.4 Avaliação da Redução do Tamanho do Código em Função da
Eliminação dos Testes de Overflow . . . 46 3.5.5 Avaliação do Efeito do Algoritmo em Relação ao Tempo de
Exe-cução do TraceMonkey . . . 47 3.5.6 Análise dos Testes de Overflow não Removidos do Programa . . 49 3.5.7 Análise do Ganho Obtido Devido ao Conhecimento dos Valores
das Variáveis em Tempo de Execução . . . 50 3.5.8 Análise dos Resultados de Efetividade entre as Coleções
Trace-Test e Alexa . . . 50 3.6 Conclusão . . . 52
4 Conclusão 53
4.1 Trabalhos Futuros . . . 54
Bibliografia 57
Capítulo 1
Introdução
Compilação de código é o problema de transformar um programa escrito em uma lin-guagem de programação de alto nível em uma cadeia de bits – zeros e uns – que serão lidos pelo processador de um computador [Aho et al., 2006]. Esta sequência de bits é denominada um programa em linguagem de máquina. As linguagens de programação são normalmente classificadas em duas categorias: linguagens estaticamente compila-das e linguagens dinamicamente compiladas [Webber, 2005]. Programas escritos em linguagens estaticamente compiladas são completamente lidos pelo compilador antes de serem transformados em linguagens de máquina. Exemplos de linguagens de pro-gramação deste tipo incluem C, C++, SML, Haskell, além de uma vasta gama de outras linguagens de grande importância acadêmica e industrial. As linguagens dina-micamente compiladas também são comuns. Neste caso programas são interpretados, isto é, em vez de eles serem diretamente traduzidos para linguagem de máquina, estes programas são lidos por um outro programa, o interpretador. O interpretador se en-carrega de executar todas as ações previstas pelo programa interpretado no hardware
alvo.
Um programa é composto por diversas funções ou subprogramas, que recebem parâmetros de entrada e os utilizam para gerar um valor de saída. Durante a inter-pretação de um programa, o interpretador se encarrega de inferir quais são as funções mais utilizadas, e a partir desta informação, ele compila tais funções para código de máquina. Este modo de compilação, baseado em funções denomina-se compilação di-nâmica tradicional[Aho et al., 2006]. Este processo de decidir durante a interpretação, compilar parte de um programa para linguagem de máquina, Aycock, [Aycock, 2003], também o denominacompilação dinâmica, ou compilaçãojust-in-time. Dentre os exem-plos de linguagens dinamicamente compiladas, citam-se Ruby [Thomas Chad Fowler, 2005], Python [Bird et al., 2009a], Prolog [Sterling Shapiro, 1986], Lua [Ierusalimschy
2 Capítulo 1. Introdução
et al., 2007] eJava [Gosling et al., 2005a]. É importante notar que esta distinção entre linguagens de programação não é rígida. Java, por exemplo, é uma linguagem normal-mente compilada dinamicanormal-mente. Embora existam também sistemas que compilem Java estaticamente.
Linguagens como PHP, Java, Perl, Ruby, JavaScript e Lua estão entre as mais populares do mundo. Java, por exemplo, é a segunda colocada no websiteTiobe, que mede o índice de popularidade de linguagens de programação [Jansen, 2009]. Em outro exemplo, PHP é a primeira colocada em buscas de emprego de programação no web-site Craigslist [Authors, 2009]. JavaScript, uma linguagem dinamicamente compilada, é utilizada por programadores em todo o mundo para o desenvolvimento de aplicações para internet [Flanagan, 2001]. Linguagens tais como PHP, Perl e Bash são populares porque suas curvas de aprendizado tendem a ser mais suaves que as curvas de apren-dizado de linguagens como C, C++ e Fortran. A popularidade de Java deve-se, em primeiro lugar, à sua portabilidade, e em segundo lugar, às poderosas abstrações para a programação orientada por objetos que a linguagem provê.
A despeito da grande popularidade, programas em linguagens dinamicamente tipadas tendem a ser menos eficientes que programas em linguagens estaticamente tipadas. Tal fato não é um defeito da linguagem, propriamente dita, mas do ambiente de execução onde tal linguagem é utilizada. Programas escritos nestas linguagens são geralmente interpretados. A interpretação é normalmente um processo mais lento que a execução de programas escritos em código de máquina. Tal lentidão deve-se ao fato da interpretação de cada instrução do programa alvo demandar a execução de dezenas, quando não centenas, de instruções da máquina real.
Segundo Richards [Richards et al., 2010], dentre as linguagens dinamicamente compiladas,JavaScripté a linguagem de programação usada para dar suporte as rotinas
client-side de aplicações web mais popular. De acordo com o relatório Alexa 20101
,
JavaScript é usada em 97 dos 100 mais populares sites da web. Assim, é fundamental queJavaScript se beneficie de ambientes de execução mais eficientes.
Web Browsers normalmente interpretam programas escritos em JavaScript. Mas, para obter eficiência na execução, programas nessa linguagem podem ser compilados durante sua interpretação usando um compilador do tipo just-in-time (JIT). Existem muitas formas de se realizar compilações JIT [Aycock, 2003]. Em 2006, Gal [Gal, 2006], e depois, Chang [Chang et al., 2009] apresentaram uma nova técnica de com-pilação dinâmica e a denominaram comcom-pilação de trilhas ou trace compilation. Uma trilha de programa é uma sequência linear de código que representa um caminho no
1
3
grafo de fluxo de controle de um programa. Compiladores de trilhas são compiladores que, diferentemente dos compiladores convencionais para linguagens dinâmicas, operam sobre laços individuais em vez de funções. Essa escolha está baseada na expectativa de que os programas gastam mais tempo executando comandos dentro de loops [Chang et al., 2009]. Uma definição formal de compiladores de trilhas pode ser vista na Seção 2.4.
Otimizações de código consistem no processo de modificar um determinado có-digo de forma a fazê-lo trabalhar de forma mais eficiente, ou seja, otimizações buscam aumentar a velocidade de execução, diminuir a quantidade de memória utilizada ou consumir menos recursos da máquina [Sarkar, 2008]. Otimizações de código podem ser independentes ou dependentes de arquitetura [Aho et al., 2006]. Otimizações in-dependentes de arquitetura geralmente são aplicadas em representações intermediárias geradas pelos front-ends dos compiladores. Otimizações dependentes de arquitetura são otimizações realizadas na linguagem de representação da máquina alvo. Várias técnicas de otimização de código foram desenvolvidas nas últimas décadas, entre elas estão as melhorias na alocação de registradores, paralelismo de instruções, elimina-ção de código morto, reduelimina-ção de força, propagaelimina-ção de constantes e otimizaelimina-ção para multiprocessadores, entre outras [Sarkar, 2008].
Otimizações de código costumam demandar alto processamento para serem reali-zadas. Por isso, normalmente são aplicadas em uma fase de compilação das linguagens estáticas. Uma vez gerado o código binário otimizado, cada execução se beneficia das otimizações sem arcar com o ônus do seu tempo de processamento. Esse cenário é diferente quando otimizações são aplicadas em compiladores de linguagens dinâmicas. Neste caso, o custo do processamento de cada otimização realizada na compilação é somado ao tempo global de execução. Consequentemente, muitas otimizações que são largamente aplicadas à compilação de linguagens estáticas têm custo proibitivo para aplicação na compilação de linguagens dinâmicas.
A compilação de trilhas trouxe uma nova proposta de geração de código, diferente da compilação dinâmica tradicional, e abriu diversas oportunidades de pesquisa na área de otimização de código.
4 Capítulo 1. Introdução
Dada a natureza dos compiladores de trilha, novas otimizações também podem ser criadas especificamente para esse tipo de compilador. Diferente dos compiladores para linguagens estáticas, compiladores de trilhas podem utilizar informações de tempo de execução para influenciar as escolhas durante a etapa de otimização. Esta é a principal motivação para o desenvolvimento deste projeto de dissertação.
Um exemplo de compiladorjust-in-time é o compiladorTraceMonkey dobrowser
Mozila Firefox 3.x [Gal et al., 2009], que traduz as trilhas de programas mais execu-tadas para código de máquina. O compilador TraceMonkey, entre outras otimizações, tenta realizar algumas especializações simples de tipo em programas JavaScript. Isto significa que, por exemplo, embora Javascript veja números como valores de ponto-flutuante, o TraceMonkey tenta manipulá-los como inteiros toda vez que é possível, partindo do pressuposto de que trabalhar com inteiros é muito mais rápido que tratar aritmética de ponto flutuante. Contudo, para aplicar essa otimização é necessário as-segurar que a semântica do programa permaneça inalterada. Por exemplo, JavaScript assume aritmética de precisão arbitraria, uma propriedade que não pode ser garantida com inteiros de 32 bits. Assim, em JavaScript, caso uma operação entre dois números inteiros produza um valor acima de 32 bits, esse valor é automaticamente convertido para um número de ponto flutuante. Isso implica que cada operação aritmética de soma ou multiplicação deve ser protegida por um teste de overflow, que verifica o tamanho do resultado produzido. Uma otimização possível neste caso seria a eliminação desses testes de overflow caso os valores sejam conhecidos em tempo de execução. Overflow
é o fenômeno que ocorre quando o resultado de uma operação aritmética é maior que o espaço alocado pelo computador para armazenar esse resultado.
Testes de overflow são pervasivos no código de máquina produzido pelo Trace-Monkey, um problema de desempenho já reconhecido pela comunidade Mozilla2
. Testes deoverflow dão origem a dois problemas principais:
• cada teste pode forçar uma saída antecipada do módulo de trilhas, complicando otimizações que demandam o reposicionamento de instruções, como eliminação de redundância parcial [Briggs et al., 1994] eescalonamento de instruções [Berns-tein Rodeh, 1991],
• instruções que tratamoverflowsaumentam o tamanho do código. Cerca de 12.3% do código x86 produzido por cada script compilado pelo TraceMonkey é refe-rente ao tratamento de ocorrências de testes de overflow. Este dado se refere ao conjunto de scripts de teste presente no TraceMonkey. Esse código extra é
2
1.1. Definição do Problema 5
uma complicação em pequenos dispositivos que executam JavaScript, como, por exemplo, os da família ST de microcontroladores3
.
Dados esses dois problemas principais, o objetivo deste trabalho é desenvolver uma nova otimização de código para compiladores de trilhas. Essa otimização deve ser capaz de diminuir os efeitos colaterais causados pela especialização de tipos de ponto-flutuante para inteiros. Ou seja, a otimização deve ser capaz de eliminar o maior número possível de testes de overflow no código binário final. O algorítmo a ser desenvolvido e implementado deve ser ser executado em tempo e espaço lineares para não comprometer o desempenho do compilador.
1.1
Definição do Problema
Seja P um programa formado por uma trilha de código. Assuma que algumas das operações de P sejam sucedidas por um teste que verifica a ocorrência de umoverflow. O problema de interesse consiste em determinar quais, dentre essas operações, não podem causar um overflow.
1.2
Solução Proposta
O problema será detalhado por meio de uma análise sensível ao fluxo, cujo objetivo será demonstrar a redundância de alguns testes deoverflows, e os resultados alcançados serão apresentados nesta dissertação. A análise proposta deverá ser executada em tempo linear no número de instruções da trilha , e deverá ser implementada em um compilador de porte industrial. Resalte-se que essa análise não deverá depender de um compilador específico, podendo ser implementada em qualquer compilador do tipo JIT
que utilize o paradigma de compilação por trilhas para a geração de código.
O algoritmo proposto realizará análise de largura de variáveis de acordo com as propostas de [Harrison, 1977] e [Patterson, 1995], na tentativa de estimar os maiores e menores valores que podem ser atribuídos para qualquer variável. Entretanto, nossa abordagem diferirá dos trabalhos de Harrison e Patterson porque usaremos valores conhecidos em tempo de execução de forma a colocar limites nas faixas de valores que uma variável inteira pode assumir durante a execução do programa. Esta estratégia corresponde a um tipo de avaliação parcial [Jones et al., 1993], feita em tempo de execução, uma vez que a análise é invocada por um compilador just-in-time enquanto a aplicação alvo está sendo executada. De posse desses valores, a otimização poderá
3
6 Capítulo 1. Introdução
realizar uma análise de largura de variáveis muito mais agressiva que nos termos da implementação tradicional.
Em relação à implementação, a otimização proposta deverá ser similar aquela do algoritmo ABCD que atua na eliminação de testes para verificação de limites de arranjo [Bodik et al., 2000]. Entretanto, existem diferenças importantes:
• o algorítmo proposto é mais simples, justamente por ser executado em trilhas, ou seja, em uma sequência linear de instruções. Também por esse motivo, o algoritmo deve ser linear no número de variáveis de programa e não quadrático como em outras análises que mantêm cadeias de definição e uso de variáveis.
• o algoritmo realiza toda a análise de uma só vez na trilha, bastando uma leitura completa do fluxo de instruções da trilha enquanto está sendo gerada. O ABCD, por exemplo, executa sobre demanda. Além dessas diferenças, existe o fato que são usados valores de tempo de execução das variáveis, o que permite a otimização ser menos conservativa[Burke et al., 1999].
1.3
Contribuições
Como resultado do trabalho realizado, destacamos as seguintes contribuições:
• A formalização de um algoritmo que realiza a eliminação de testes de overflow em trilhas de código, gerado durante a compilação just-in-time de uma linguagem alvo.
• A implementação deste algoritmo no compilador TraceMonkey. TraceMonkey é usado pelo navegador Mozilla FireFox para compilar dinamicamente programas escritos em JavaScript.
• A instrumentação do navegador Mozilla Firefox a fim de obter dados estatísticos acerca dos programas produzidos durante a compilação de trilhas de JavaScript.
• Adaptação doNanojit[Gal et al., 2009] a fim de permitir que o mesmo removesse os testes de overflow apontados como desnecessários pela análise realizada.
• Disponibilização de todas as técnicas e algoritmos de compilação desenvolvidos durante este projeto à comunidade de software livre. Incluindo também outros
1.4. Organização do Texto 7
• Publicação de 02 artigos em conferência e periódico reconhecidos pela comunidade de Linguagens de Programação.
1.4
Organização do Texto
Esta dissertação está organizada em quatro capítulos. No Capítulo 1 foi fornecida uma visão básica dos fundamentos que norteiam este trabalho. No Capítulo 2, oferecemos uma revisão da literatura disponível dos principais tópicos deste projeto. No Capítulo 3 concentramos a nossa contribuição. A descrição de cada capítulo dessa dissertação, pode ser vista a seguir:
Capítulo 1 - Introdução Neste capítulo é apresentada uma introdução aos funda-mentos da otimização de códigos, dos compiladores just-in-time e das possibili-dades de se criar novas otimizações que sejam especializadas para esse tipo de compilador.
Capítulo 2 - Revisão de Literatura
Neste capítulo, é apresentada a literatura disponível sobre os alicerces deste tra-balho, tais como compiladores just-in-time, otimizações de código e técnicas de avaliação parcial de programas.
Capítulo 3 - Remoção de Testes de Overflow Via Análise Sensível ao Fluxo
Neste capítulo são apresentadas nossas contribuições. O capítulo inicia-se apre-sentando a nova otimização proposta por esta dissertação. Em seguida, tratamos da implementação dessa nova análise em um compilador de porte industrial. Fi-nalmente, apresentamos os experimentos utilizados para validar o trabalho.
Capítulo 4 - Conclusão
Capítulo 2
Revisão de Literatura
Neste capítulo, são apresentados os fundamentos que suportam a criação da nova oti-mização de código proposta nesta dissertação. Seção 2.1 apresenta as principais ca-racterísticas das linguagens interpretadas, a saber, portabilidade, tipagem dinâmica e reflexão. Seção 2.2 apresenta um estudo de caso da linguagem JavaScript, e de um interpretador para essa linguagem, o SpiderMonkey. Em seguida, nas Seções 2.3 e 2.4 são descritos os aspectos fundamentais dos compiladores just-in-time e dos compila-dores de trilhas. Seção 2.5 introduz uma técnica de otimização de código conhecida como Avaliação Parcial de Programas. Na Seção 2.6, é discutido como a utilização de técnicas de avaliação parcial de programas pode contribuir para a construção de otimizações de código mais eficientes. Finalmente, na Seção 2.7, é apresentada uma técnica chamada Análise de Largura de Variável, técnica esta que serve de base para a otimização proposta nesta dissertação.
2.1
Linguagens Interpretadas
Linguagens interpretadas são aquelas linguagens que são diretamente executadas por um interpretador de programas sem a necessidade de terem sido previamente com-piladas. Nas linguagens compiladas, o programa é convertido de uma vez para uma representação binária que pode ser executada uma ou mais vezes diretamente pelo pro-cessador. Nas linguagens interpretadas, cada instrução é executada individualmente pelo interpretador sem a necessidade de se gerar código de máquina [Parr, 2009].
Teoricamente, qualquer linguagem pode ser interpretada ou compilada, fator que faz dessa designação uma questão prática, e ligada à forma de implementação da lin-guagem em si, não sendo uma propriedade das linguagens de programação [Aycock, 2003].
10 Capítulo 2. Revisão de Literatura
No passado, o projeto de linguagens de programação era bastante influenciado pela decisão de usar um compilador ou um interpretador. Caso, por exemplo, da linguagem Smalltalk que foi projetada para ser interpretada, e permitia que objetos genéricos interagissem uns com os outros de forma dinâmica [Deutsch Schiffman, 1984]. Atualmente, interpretadores costumam receber como entrada uma representa-ção intermediária. No passado, era comum que os interpretadores compilassem cada instrução individualmente, o que causava, por exemplo, a recompilação da mesma ins-trução várias vezes, por exemplo, se ela fosse executada dentro de uma estrutura de repetição [Parr, 2009].
A maioria das linguagens interpretadas que têm maior penetração nos dias de hoje usa uma representação intermediária. Esse é o caso da linguagemJava e também das linguagens Python e Ruby. Nesses casos, o interpretador pode:
• gerar uma representação em forma de bytecodes como nas linguagens Java [Gos-ling et al., 2005b] e Python [Bird et al., 2009b].
• A representação pode ser dada via uma árvore de sintaxe abstrata, como é o caso da linguagem Ruby [Thomas Chad Fowler, 2005].
Dentre as principais vantagens das linguagens interpretadas estão os sistemas de tipo e escopo dinâmicos, a facilidade de realizar reflexão, o que enseja o uso de recursos de meta-programação e principalmente o fato de serem altamente portáteis.
A principal desvantagem da interpretação está relacionada ao desempenho. A interpretação tende a ser mais lenta que a execução de código de máquina direta-mente na unidade de processamento hospedeiro. Uma técnica para minimizar esse efeito negativo é chamada de compilação just-in-time, que converte os trechos mais frequentemente executados em código de máquina. Compiladores just-int-time serão abordados na Seção 2.3.
2.1.1
Portabilidade
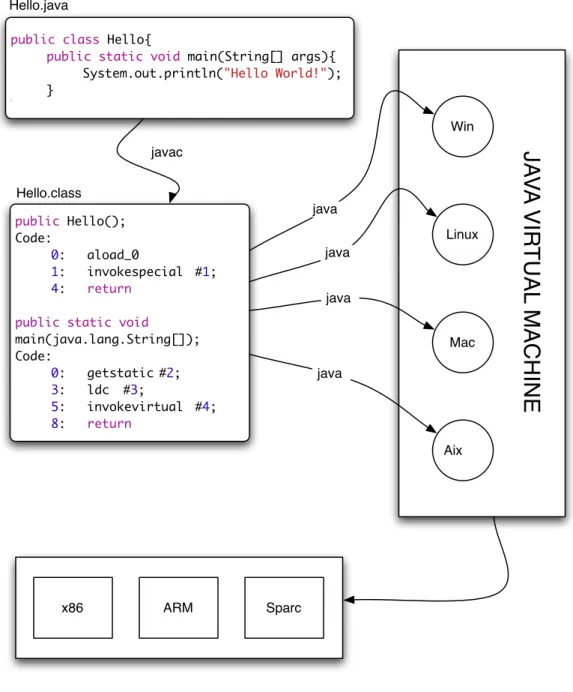
Um dos motivos do grande sucesso e aceitação da linguagem Java, nos meios acadêmicos e principalmente na indústria, está na facilidade de portar Java para diversos ambientes. A frase “Write once, run anywhere” [Gosling et al., 2005b] foi repetida à exaustão pela
Sun, então proprietária da linguagem, para destacar a portabilidade deJava.
Um programa escrito em Java é transformado em bytecodes que pode ser inter-pretado e também compilado em qualquer plataforma que tenha uma máquina virtual
2.1. Linguagens Interpretadas 11
public class Hello{
public static void main(String[] args){ System.out.println("Hello World!"); }
}
public Hello(); Code:
0: aload_0
1: invokespecial #1;
4: return
public static void
main(java.lang.String[]); Code:
0: getstatic #2;
3: ldc #3;
5: invokevirtual #4;
8: return
Hello.java Hello.class javac Win Linux Mac Aix java java java java
JA
V
A
VIR
TUAL
MACHINE
x86 ARM Sparc
Figura 2.1: Java. Do código fonte ao código de máquina
2.1.2
Tipo Dinâmico
12 Capítulo 2. Revisão de Literatura
não [Williams et al., 2010].
Entre as linguagens que utilizam sistemas de tipo dinâmicos estão: JavaScript,
Lua e Erlang. Linguagens que utilizam esse sistema de tipos tendem a ser mais flexí-veis, permitindo, por exemplo, que sejam adicionadas funcionalidades e modificações nos tipos em tempo de execução. Esses sistemas de tipo apresentam uma dificuldade adicional na depuração de programas, uma vez que podem gerar exceções em tempo de execução, quando, por exemplo, uma variável tem um tipo inesperado de dado. Esse tipo de erro pode ser difícil de ser localizado [Williams et al., 2010].
Uma das vantagens dessa abordagem está na flexibilidade. A Listagem 2.1 apre-senta um trecho de código em Ruby onde o interpretador automaticamente muda o tipo da variável para permitir um número maior sem precisar de intervenções sintáti-cas do programador. Nesse sintáti-caso, o interpretador se torna eficiente por trabalhar com números pequenos, sempre que possível, e caso o número exceda um certo limite, o tipo da variável é automaticamente modificado para alcançar a corretude necessária. Uma das desvantagens da tipagem dinâmica está relacionada com os encargos acrescenta-dos às verificações de tipo em tempo de execução. Esse aspecto contribui para que os programas interpretadas sejam menos eficientes.
Listagem 2.1: Tipo dinâmico em Ruby
1 num = 1000000
2 num .c l a s s
3 #Imprime : FixNum
4 num = num ∗ 999999999999999
5 num .c l a s s
6 #Imprime : BigNum
2.1.3
Reflexão
2.2. JavaScript 13
2.2
JavaScript
JavaScript é uma linguagem de programação orientada por objetos baseada no modelo
object-prototype [Ungar Smith, 1987]. JavaScript se tornou a principal linguagem de programação utilizada na construção de interfaces gráficas de aplicações web. JavaS-cript foi criada em 1995 por Breandon Eich, quando ele trabalhava no desenvolvimento do navegador Netscape. A implementação de uma linguagem de script no navegador
Netscape surgiu da necessidade de adicionar maior interatividade aos documentos no formato HTML (HyperText Markup Language). Inicialmente, os programadores utili-zavam JavaScript para fazer validações de formulários e para construir animações.
A sintaxe deJavaScript hoje é definida pela especificaçãoECMA-262, tendo evo-luído bastante desde a primeira versão. AtualmenteJavaScript é parte fundamental do ecossistema de aplicações da internet. A junção de JavaScript, à possibilidade de fazer requisições assíncronas e o padrão de organização de informações XML deram origem ao assíncrono chamado AJAX (Assincronous JavaScript and XML) que permitiu o desenvolvimento de aplicações para internet mais próximas em termos de usabilidade daquelas desenvolvidas para desktop.
2.2.1
Características de
JavaScript
JavaScript contém um pequeno conjunto de tipo de dados, sendo primitivos os tipos booleano, numérico e string e possui alguns valores especiais como null e undefined. Todas as outras estruturas de dados do JavaScript são do tipo object.
Em JavaScript, objetos são implementados como uma coleção de propriedades nomeadas. ComoJavaScript é uma linguagem interpretada, novas propriedades podem ser facilmente adicionadas a um dado objeto em tempo de execução. A Listagem 2.2 mostra a criação de um objeto JavaScript, e em seguida a adição de duas propriedades em tempo de execução.
Listagem 2.2: Criação de um objeto em JavaScript
1 c a r r o = new Object ;
2 c a r r o . c o r = ’ a z u l ’ ;
3 c a r r o . ano = 1 9 8 3 ;
14 Capítulo 2. Revisão de Literatura
Encapsulamento
JavaScript suporta metódos como membros de uma classe e atributos privados. A Listagem 2.3 mostra como os dados são encapsulado em JavaScript.
Listagem 2.3: Encapsulamento de dados em JavaScript
1 f u n c t i o n Carro ( ) {
2 var c o r = ’ a z u l ’ ;
3 var ano = 1 9 8 3 ;
4 t h i s. getCor = f u n c t i o n ( ) { 5 return t h i s. c o r ;
6 } ;
7 }
Polimorfismo
Duas classes em JavaScript são capazes de responder pela mesma coleção de métodos. A Listagem 2.4 apresenta um exemplo de uso de polimorfismo em
JavaScript.
Listagem 2.4: Criação de um objeto em JavaScript 1 f u n c t i o n a c e l e r a r ( c a r r o ) {
2 c a r r o . a c e l e r a r ( ) ;
3 p r i n t ( c a r r o . v e l o c i d a d e ) ;
4 }
5 f u n c t i o n Carro ( ) { t h i s. v e l o c i d a d e = 0 ; }
6 Carro . p r o t o t y p e . a c e l e r a r = f u n c t i o n ( ) {
7 t h i s. v e l o c i d a d e += 1 ; 8 }
9 f u n c t i o n CarroDeCorrida ( ) {
10 t h i s. v e l o c i d a d e = 0 ; 11 }
12 CarroDeCorrida . p r o t o t y p e . a c e l e r a r = f u n c t i o n ( ) {
13 t h i s. v e l o c i d a d e += 5 0 ; 14 }
15 c a r r o = new Carro ;
16 c a r r o D e C o r r i d a = new CarroDeCorrida ;
17 a c e l e r a r ( c a r r o ) ;
18 a c e l e r a r ( c a r r o D e C o r r i d a ) ;
2.2. JavaScript 15
Herança
JavaScript suporta a criação de subtipos que herdam o comportamento do ob-jeto pai. A Listagem 2.5 apresenta um exemplo de utilização de subtipo em
JavaScript.
Listagem 2.5: Exemplo de sub-classe em JavaScript
1 f u n c t i o n Carro ( ) {
2 t h i s. v e l o c i d a d e = 0 ; 3 }
4 Carro . p r o t o t y p e . a c e l e r a r = f u n c t i o n ( ) {
5 t h i s. x += 1 ; 6 }
7 CarroDeCorrida . p r o t o t y p e = new Carro ;
8 CarroDeCorrida . p r o t o t y p e . c o n s t r u c t o r = CarroDeCorrida ;
9 f u n c t i o n CarroDeCorrida ( ) {
10 Carro . c a l l (t h i s) ;
11 t h i s. t u r b o = f a l s e ; 12 }
13 CarroDeCorrida . p r o t o t y p e . a c e l e r a r = f u n c t i o n ( ) {
14 Carro . p r o t o t y p e . a c e l e r a r . c a l l (t h i s) ;
15 t h i s. t u r b o = true; 16 }
17 f 1 = new CarroDeCorrida ;
18 p r i n t ( ( f 1 instanceof Carro ) + ’ , ’
19 + ( f 1 instanceof CarroDeCorrida ) ) ;
20 f 1 . DoIt ( ) ;
21 p r i n t ( f 1 . v e l o c i d a d e + ’ , ’ + f 1 . t u r b o ) ;
22 \\ Imprime true,true, em s e s e g u i d a : 1 ,true
JavaScript simula a herança de linguagens orientadas por objetos como Java ou
C++ via uma técnica conhecida por Delegação. O mecanismo de delegação foi usado por David Ungar na implementação de Self [Ungar Smith, 2007], e aparece em outras linguagens também baseadas em prototipagem de objetos, como Lua.
2.2.2
Interpretador SpiderMonkey
O SpiderMonkey é um interpretador concebido para ser rápido. Ele executa bytecodes
16 Capítulo 2. Revisão de Literatura
SpiderMonkey contém um compilador de JavaScript, o TraceMonkey, e um sistema de coleta de lixo.
Da mesma forma que muitos outros interpretadores, o SpiderMonkey tem uma estrutura monolítica de processamento, onde uma grande função implementa uma es-trutura de controle do tipo switch. Para cada um dos tipos de bytecodes existentes, um bloco de código capaz de realizar o processamento necessário é associado a esta estrutura de repetição. Essa escolha de projeto certamente contribui para que o Spi-derMonkey alcance altos índices de desempenho, porém torna o seu entendimento uma tarefa complexa, sendo um grande desafio estendê-lo com novos recursos.
2.3
Compiladores
Just-In-Time
Plezbert, em [Plezbert Cytron, 1997], define os compiladoresjust-in-time como siste-mas que executam código de forma interpretativa, siste-mas compilam o código para código nativo sobre demanda. Segundo Plezbert, esses sistemas utilizam um único fluxo de execução para alternar o controle entre a compilação do código nativo para a execução do código nativo. Entre as vantagens dos compiladores just-in-time destacadas por Plezbert estão:
• o fato de os compiladores just-in-time serem capazes de evitar a perda de de-sempenho por ter que compilar todas as unidades de código anteriormente à sua execução. Por esse motivo, ele destaca ainda dois outros benefícios correlaciona-dos:
– a melhora de desempenho de programas que tem seu fluxo de execução orientados por eventos causados pelo usuário.
Este é o caso de programas em JavaScript que executam em um browser para validar um formulárioHTML. A execução do código só se faz necessária se e quando o usuário submeter o formulário para o servidor. A utilização de um compilador just-in-time evitaria, por exemplo, que um formulário que nunca tenha sido submetido para validação fosse previamente compilado desperdiçando recursos computacionais.
– A diminuição do tempo de espera entre a compilação integral e o ínico de interpretação.
• A diminuição do tempo de espera para iniciar a execução do programa.
2.3. Compiladores Just-In-Time 17
execução. No caso dos compiladoresjust-in-time esse custo é amortizado ao longo da execução. Apesar de ser verdade, em termos práticos, esse último argumento levantado por Plezbert se mostra frágil. Normalmente, uma vez que um programa foi totalmente compilado, ele pode ser executado diversas vezes sem a necessidade de ser compilado novamente. Isto faz com que a espera apontada por Plezbert aconteça apenas uma vez. Nas outras execuções, o usuário já tem o ganho de ter o programa sendo executado diretamente pelo processador, sem o ônus do tempo da compilação.
Compiladores just-in-time, são velhos aliados daqueles que defendem as lingua-gens interpretadas. Desde o trabalho pioneiro de John McCarthy [McCarthy, 1960], o criador da linguagem Lisp, vários compiladores just-in-time têm sido projetados e implementados, como a máquina virtual Java[Gosling et al., 2005a] e o compilador da linguagem Smalltalk [Deutsch Schiffman, 1984].
Compiladores just-in-time, representam uma abordagem mista, mesclando os princípios tradicionais que pautam os interpretadores e compiladores. Um compilador
just-in-time, inicia-se interpretando instruções de uma dada linguagem intermediária, porém, para alcançar um desempenho mais efetivo, ele realiza compilações de segmen-tos de código ou instruções individuais para código de máquina. Uma vez compilados, estes segmentos são mantidos em uma estrutura de cache para que possam ser reapro-veitados no futuro se o fluxo de execução do programa retornar o controle para aquele determinado trecho já compilado.
A Listagem 2.6 apresenta um programa na linguagem C que realiza compilação
just-in-time de uma instrução na arquitetura x86. Esse programa carrega um pequeno trecho de código em um arranjo, e passa esse arranjo como o endereço de uma função a ser executada. O trecho de código coloca o valor 1234 no registrador EAX, que é, normalmente, o lugar onde armazenam-se valores de retorno de funções. Este programa foi obtido na USENET1
.
Listagem 2.6: Exemplo de compilaçãoJIT 1 #include <s t d i o . h>
2 #include < s t d l i b . h> 3 i n t main (void) { 4 char∗ program ; 5 i n t (∗f n p t r ) (void) ; 6 i n t a ;
7 program = m a l l o c ( 1 0 0 0 ) ; /∗ Space f o r t h e code ∗/
1
18 Capítulo 2. Revisão de Literatura
8 program [ 0 ] = 0xB8 ; /∗ mov eax , 1 2 3 4 h ∗/
9 program [ 1 ] = 0 x34 ;
10 program [ 2 ] = 0 x12 ;
11 program [ 3 ] = 0 ;
12 program [ 4 ] = 0 ;
13 program [ 5 ] = 0xC3 ; /∗ r e t ∗/
14 f n p t r = (i n t (∗) (void) ) program ;
15 a = f n p t r ( ) ; /∗ c a l l t h e code ∗/
16 p r i n t f ( " R e s u l t = %X\n" , a ) ; /∗ show r e s u l t ∗/
17 }
John Aycock, [Aycock, 2003], fornece uma visão abrangente sobre compilação
just-in-time, ele trata da questão central da utilidade de compiladores just-in-time: a melhoria de desempenho das linguagens interpretadas. Aycock afirma que programas interpretados tendem a a ser mais portáveis por assumir uma representação indepen-dente de máquina, porém esse mesmo fator faz com que o desempenho desse tipo de programa seja inferior a de programas que são complados.
2.3.1
Classificação dos compiladores
just-in-time
Aycock, [Aycock, 2003], classifica os compiladoresjust-in-timeconsiderando quatro pro-priedades fundamentais: invocação, invocação, executabilidade, concorrência e tempo real.
Uma explicação para cada uma dessas definições é apresentada a seguir.
Invocação
Os compiladoresjust-in-time podem ser classificados pela forma que são invocados. Um compilador pode ser explicitamente chamado pelo usuário, que indica quais segmentos do código devem ser compilados. Os compiladoresjust-in-time podem também ter sua invocação implícita. Nesse caso, o compilador decide de forma autônoma quando e o que será compilado. Uma invocação implícita é transparente para o usuário.
Executabilidade
2.3. Compiladores Just-In-Time 19
• a representação original do programa fonte que é traduzida para uma determinada representação alvo, e
• a própria representação alvo da tradução.
Caso essas duas representações sejam a mesma, o compilador é considerado como não-executável. Isto acontece, por exemplo, quando o compiladorjust-in-time somente realiza otimizações on-the-fly, ou seja, quando o propósito do compilador é apenas oti-mizar uma dada representação, sem a responsabilidade de executar essa representação alvo, e sem se responsabilizar pela troca de contexto entre a execução do código de máquina e o interpretador.
Um compilador just-in-time é considerado poliexecutável se ele for capaz de exe-cutar mais de uma representação. Nesse caso, o compilador é responsável pela execução da transformação realizada, bem como por restaurar o estado do interpretador após a execução do segmento de código de máquina.
Concorrência
Esta propriedade é caracterizada pela forma com que o compilador just-in-time realiza a execução dos programas. Ele pode ser dependente da execução do programa, ou seja, enquanto a execução do programa está sendo realizada o compilador fica em estado de espera e aguarda a conclusão da execução. Nesse caso, o compilador não é considerado concorrente. Se o compilador for capaz de realizar outras atividades enquanto um programa por ele traduzido está sendo executado, então ele é considerado concorrente.
Tempo Real
Um compilador just-in-time é considerado de tempo real se ele puder garantir os re-quisitos necessários dos sistemas de tempo de real.
Para Timo [Timo, 2010], a classificação de compiladores JIT está desatualizada, uma classificação mais adequada aos dias de hoje deveria incluir se o compilador é ou não baseado em trilhas.
2.3.2
Implementações de Compiladores
Just-In-Time
20 Capítulo 2. Revisão de Literatura
lista vários benefícios da utilização de compiladoresjust-in-time, incluindo uma melhor compilação para arquiteturas específicas e possibilidade de se utilizar informações de tempo de execução para produzir código nativo mais eficiente. Os compiladores just-in-timetentam encontrar trechos de código denominadoshot spot durante a interpretação dos programas.
O termo hot spot se refere a uma técnica que identifica os trechos de códigos que são frequentemente executados. Uma vez identificados, esses segmentos são compilados. O compilador para a linguagem Fortran foi um dos primeiros a adotar esse tipo de otimização. Já em 1974, o sistema utilizava um contador para identificar a frequência que determinados blocos básicos eram executados. Quanto maior fosse o contador associado a um bloco, maior eram as otimizações a ele aplicadas. A máquina virtual original do Smalltalk foi uma das primeiras a receber esse tipo de otimização, os blocos básicos mais executados eram compilados para código nátivo. De acordo com Timo, a linguagem de programaçãoSelf foi a primeira a introduzir significativas contribuições em relação à evolução dos compiladoresjust-in-time. Self permite que os programadores definam previamente quais objetos devem ser mandatoriamente compilados.
2.4
Compilação de Trilhas
Embora o conceito de compilação just-in-time seja antigo e bem sólido na Ciência da Computação, a compilação de trilhas para programas escritos em linguagem interpre-tadas é uma ideia nova. O primeiro compilador de trilhas, influenciado pelo trabalho de Balaet al.[Bala, 2000], foi descrito por Andreas Gal em sua tese de doutorado [Gal, 2006; Gal et al., 2006]. Por ser uma ideia nova, a literatura contém apenas a descrição de duas implementações: Uma é o Projeto Tamarim-Trace [Chang et al., 2009]. Um compiladorJIT implementado a partir do Tamarim-central, o motor do sistema flash
da Adobe. O outro compilador é o TraceMonkey. TraceMonkey foi construído como um componente doSpiderMonkey, o interpretador original deJavaScript utilizado pelo
browser Mozilla FireFox. A Seção 2.4.1 apresenta em detalhes o funcionamento do com-piladorTraceMonkey, uma vez que ele é o compilador escolhido para a implementação da otimização proposta nesta dissertação.
Uma descrição detalhada do compilador Tamarim-Trace é dado por Chang et al.[Chang et al., 2009], e uma introdução do uso de especialização de tipos durante a compilação de trilhas é fornecida por Gal et al[Gal et al., 2009].
2.4. Compilação de Trilhas 21
a = 1;
for (i = 0; i < 15; i++) {
a += 7;
if (i % 3 == 0 ) {
a += 13;
}
}
a = 1 i = 0
(i < 15)?
a = a + 7 (i % 3 == 0)?
a = a + 13
i = i + 1
1 2 3 4 5
(a)
(b)
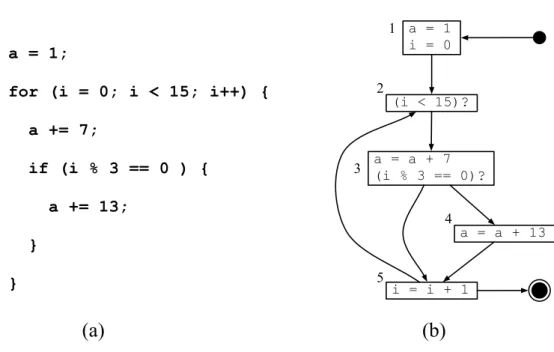
Figura 2.2: Um exemplo de programa (direita) com o respectivo grafo de fluxo de controle (esquerda).
Um programa é composto de sequências de instruções. Algumas dessas instru-ções podem ser avaliadas várias vezes durante a execução do programa. Por exemplo, a Figura 2.2(a) mostra um programa que contém uma iteração de 0 a 14. Em cada iteração, este programa adiciona o número 7 à variável a. Nas iterações que são
múl-tiplos de 3, isto é, {0,3,6,9,12}, o programa também adiciona à variável a o número
13. No fim da execução desse programa o valor de a é 171. Esse programa contém
diferentes caminhos. Esses caminhos determinam uma estrutura que, no jargão de compiladores, é conhecida como grafo de fluxo de controle (GFC). O GFC é mostrado na Figura 2.2(b). Um GFC é constituído por blocos básicos e por arestas de fluxo. Diferentes blocos básicos são conectados por arestas de fluxo, as quais determinam a ordem de execução entre estes blocos básicos. Segundo Allen [Allen, 1970] um bloco básico é uma porção de código do programa que possui algumas propriedades desejadas que o torna altamente passível de ser analisado. O exemplo dado possui cinco blocos básicos.
22 Capítulo 2. Revisão de Literatura
executados. Esta é a contribuição do novo modelo de geração de código conhecido como compilação de trilhas.
A compilação dinâmica de trilhas consiste em compilar somente os ca-minhos mais executados de um programa, interpretando os caca-minhos menos executados.
A principal diferença entre um compilador dinâmico tradicional e um compilador de trilhas é que, enquanto o primeiro produz código para todo o programa, o segundo compila somente os caminhos mais executados, no caso da Figura 2.2(b) seriam com-pilados os ciclos{2,3,5} e{2,3,4,5}. Dado que um compilador de trilhas não precisa ler todo o código a ser compilado, ele gasta menos tempo com o processo de compila-ção. A desvantagem dessa abordagem é que ela pode gerar código redundante, como mostra o exemplo da Figura 2.3. Além disto, uma vez que o compilador tradicional enxerga todo o programa, existem situações onde este conhecimento global o ajuda a produzir melhores códigos. Ainda assim, a compilação de trilhas mostra-se uma alter-nativa promissora à compilação tradicional. Diversos experimentos foram realizados e mostram que o compilador de trilhas pode ser até 10 vezes mais eficiente que seu concorrente[Gal, 2006].
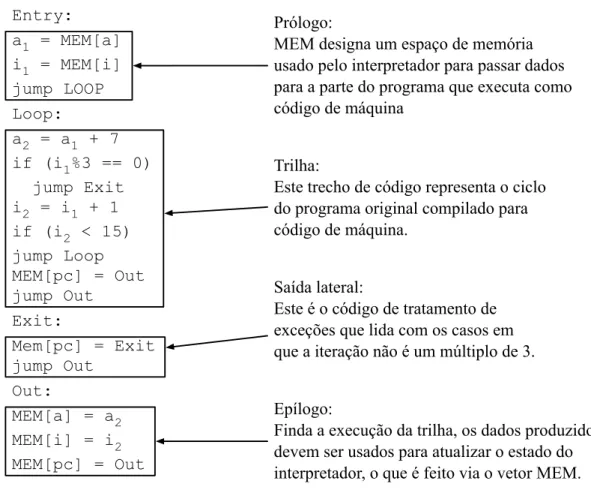
O programa produzido pelo compilador de trilhas para o ciclo{2,3,5}é mostrado na Figura 2.3. A memória do computador é utilizada para que o interpretador passe informações para o código de máquina produzido pelo compilador dinâmico, e vice-versa. Uma parte da trilha gerada, conhecida comoepílogo é usada para enviar dados ao programa em código de máquina. Uma outra parte da trilha, conhecida comoprólogo
é usada pelo programa em código de máquina para enviar resultados computados de volta para o interpretador. Além disto, existem blocos especiais, denominados saídas laterais, que lidam com situações excepcionais que podem ocorrer durante a execução da trilha. Por exemplo, caso somente o ciclo {2,3,5} seja compilado, então código de tratamento de exceções deve ser gerado para lidar com os casos em que a aresta entre os Blocos 3 e 4 é tomada.
2.4.1
TraceMonkey
Para produzir código de máquina para programasJavaScript, oTraceMonkey utiliza o compilador Nanojit 2
. O processo completo de compilação utiliza três representações intermediárias, um caminho que é reproduzido pela Figura 2.4.
2
2.4. Compilação de Trilhas 23
Entry:
a1 = MEM[a]
i1 = MEM[i]
jump LOOP
Loop:
a2 = a1 + 7
if (i1%3 == 0)
jump Exit
i2 = i1 + 1
if (i2 < 15)
jump Loop MEM[pc] = Out jump Out
Exit:
Mem[pc] = Exit jump Out
Out:
MEM[a] = a2
MEM[i] = i2
MEM[pc] = Out
Prólogo:
MEM designa um espaço de memória usado pelo interpretador para passar dados para a parte do programa que executa como código de máquina
Trilha:
Este trecho de código representa o ciclo do programa original compilado para código de máquina.
Saída lateral:
Este é o código de tratamento de exceções que lida com os casos em que a iteração não é um múltiplo de 3.
Epílogo:
Finda a execução da trilha, os dados produzidos devem ser usados para atualizar o estado do interpretador, o que é feito via o vetor MEM.
Figura 2.3: Exemplo de código de máquina que poderia ser produzido pelo compilador de trilhas.
1. AST: árvore de sintaxe abstrata produzida por um programa em JavaScript
2. Bytecodes: um conjunto de instruções de pilha que é diretamente interpretado pelo SpiderMonkey
3. LIR: representação de baixo nível em formato de código de três endereços que o Nanojit recebe como entrada.
SpiderMonkey não foi originalmente concebido como um compiladorjust-in-time, fato que explica o porquê do número excessivo de passos intermediários entre o pro-grama fonte e o código binário. Segmentos de instruções LIR – uma trilha no jargão utilizado pelo TraceMonkey – são produzidas de acordo com um algorítmo muito sim-ples [Gal et al., 2009]:
24 Capítulo 2. Revisão de Literatura
jsparser jsemitter jsinterpreter JIT
file.js AST Bytecodes
LIR x86
spiderMonkey nanojit
trace engine
Figura 2.4: O compilador JIT Mozilla TraceMonkey.
2. Se o interpretador encontra um desvio condicional durante a interpretação do programa, então ele incrementa seu contador. O processo de verificar e incre-mentar contadores é chamado, de acordo com o jargão do TraceMonkey, de fase de monitoramento .
3. Se um contador contiver um valor maior que 1, e não existir ainda nenhuma trilha para este contador, então o motor de gravação de trilhas começa a traduzir os
bytecodes em segmentos de LIR enquanto eles são interpretados. Este processo é chamado de fase de gravação .
4. Uma vez que o motor de trilhas encontra o desvio condicional original, aquele que iniciou o processo de gravação, o segmento LIR gerado é passado para o Nanojit.
5. O compiladorNanojit traduz o segmento LIR, incluindo os testes deoverflow em código de máquina que é colocado diretamente na memória principal. O fluxo do programa então é alterado e começa a execução do código de máquina.
6. Após o começo da execução do código de máquina ou em caso de uma exceção acontecer, por exemplo, uma falha em um teste de overflow ou a saída precoce da trilha, a execução retorna ao interpretador.
2.4.1.1 Dos Bytecodes para LIR
2.4. Compilação de Trilhas 25
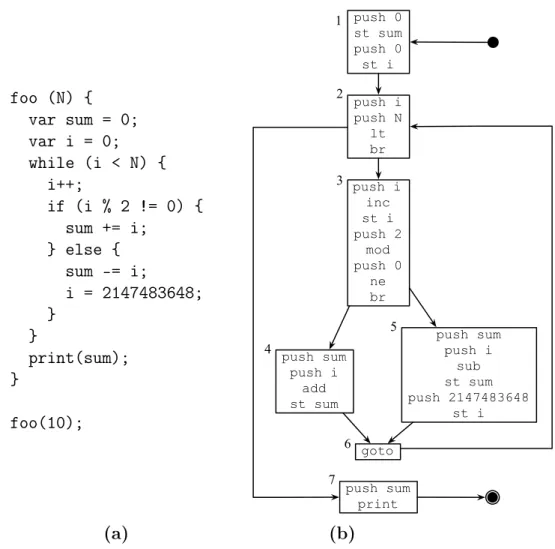
foo (N) { var sum = 0; var i = 0; while (i < N) {
i++;
if (i % 2 != 0) { sum += i;
} else { sum -= i;
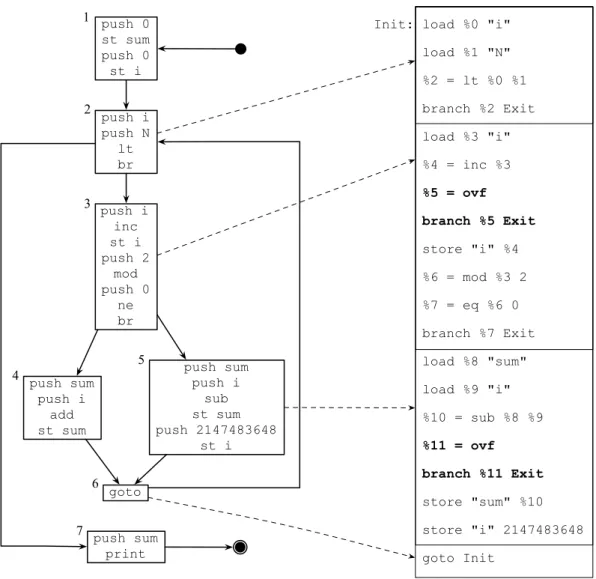
i = 2147483648; } } print(sum); } foo(10); push 0 st sum push 0 st i push i push N lt br push i inc st i push 2 mod push 0 ne br push sum push i add st sum push sum push i sub st sum push 2147483648 st i goto push sum print 1 2 3 4 5 6 7 (a) (b)
Figura 2.5: Um pequeno exemplo de um programa JavaScript e sua representação em bytecodes.
26 Capítulo 2. Revisão de Literatura
ele sabe que está dentro de uma repetição, que irá começar a fase de gravação que produzirá segmentos LIR. Entretanto, este segmento não corresponde à primeira parte visitada do programa. Na segunda iteração da repetição, o Bloco Básico 5 é visitado em vez do Bloco Básico 4. Neste caso, o segmento gravado é formado pelos Blocos Básicos 2, 3, 5 e 6.
Isto acontece porque uma trilha que é monitorada pelo sistema de trilhas não é necessariamente a trilha que é gravada em formato de segmento LIR. É difícil re-mover testes de overflow durante a fase de gravação. Um teste condicional, tal como
a < N, onde N é constante auxilia a colocar limites nas faixas de valores que a pode
assumir. Entretanto, para saber que N é constante, é necessário garantir que o
seg-mento completo que foi gravado não contém comandos que possam modificar o valor deN. Embora não seja possível remover testes de overflow diretamente durante a fase de gravação, é possível coletar restrições para as faixas de valores das variáveis nesse passo. Com base nesses dados, testes deoverflow são eliminados do segmento LIR tão logo ele seja enviado para execução noNanojit.
Continuando o exemplo, a Figura 2.6 mostra o casamento da trilha gravada e o segmento LIR produzido pelo sistema de trilhas.
2.4.1.2 Do LIR para o Código de Máquina
Antes de passar o segmento LIR para o Nanojit, o interpretador argumenta esse seg-mento com duas sequências de instruções. O prólogo e o epílogo. O prólogo contém código que mapeia valores aferidos pelo interpretador para o ambiente de execução onde o código binário é produzido e executado. O epílogo contém código para realizar o pro-cesso de mapeamento inverso. ONanojit produz código de máquina para plataformas comox86, ARM e ST40 a partir do segmento LIR gerado no interpretador.
Testes de overflow são implementados como saídas laterais (side-exit), uma sequência de instruções que tem duas funções:
1. recuperar o estado do programa logo depois do overflow acontecido, e
2. saltar a execução da trilha, voltando o controle para o interpretador.
2.5. Avaliação Parcial de Programas 27 push 0 st sum push 0 st i push i push N lt br push i inc st i push 2 mod push 0 ne br push sum push i add st sum push sum push i sub st sum push 2147483648 st i goto push sum print 1 2 3 4 5 6 7
Init: load %0 "i"
load %1 "N"
%2 = lt %0 %1
branch %2 Exit
load %3 "i"
%4 = inc %3
%5 = ovf
branch %5 Exit
store "i" %4
%6 = mod %3 2
%7 = eq %6 0
branch %7 Exit
load %8 "sum"
load %9 "i"
%10 = sub %8 %9
%11 = ovf
branch %11 Exit
store "sum" %10
store "i" 2147483648
goto Init
Figura 2.6: Esta figura ilustra o casamento entre a trilha gravada e o segmento LIR que foi produzida pelo sistema de trilhas.
2.5
Avaliação Parcial de Programas
A avaliação parcial de programas é uma técnica de geração automática de código cujo objetivo é aumentar a eficiência de programas em termos de tempo de execução [Jones et al., 1993]. Suponha um programa P que tenha duas entradas, identificadas como in1 e in2. O resultado da avaliação parcial de P em relação à entrada in1 é um novo
programa P in1, designado por residual ou especializado. O programa P in1, quando
executado sobre a entrada restante in2, produz o mesmo resultado que a execução deP
28 Capítulo 2. Revisão de Literatura
Init: load %0 "i" load %1 "N" %2 = lt %0 %1 branch %2 Exit load %3 "i"
%4 = inc %3 %5 = ovf branch %5 Exit
store "i" %4 %6 = mod %3 2 %7 = eq %6 0 branch %7 Exit load %8 "sum" load %9 "i"
%10 = sub %8 %9 %11 = ovf branch %11 Exit
store "sum" %10 store "i" 2147483648 goto Init
Prologue: load %11 ITP[i] store "i" %11 load %12 ITP[N] store "N" %12 load %13 ITP[sum] store "sum" %13 goto Init
Exit:
load %14 "i" store ITP[i] %11 load %15 "N" store ITP[N] %12 load %16 "sum" store ITP[sum] %13 return
Prologue: pushl ... movl ... movl ... movl ... jmp Init Init:
leal ...
incl ... jvf RS1
movl ... andl ... testb ... je Exit movl ... leal ...
subl ... jvf RS2
movl ... movl ... cmpl ... jb Init Exit:
movl ... movl ... movl ... popl ... leave
(LIR) (x86)
RS1:
movl ... movl ... movl ... movl ... jmp Exit
RS2:
movl ... movl ... movl ... movl ... jmp Exit
Figura 2.7: O código LIR, logo após a inserção do prólogo e do epílogo, e a semântica do códigox86 produzido pelo Nanojit.
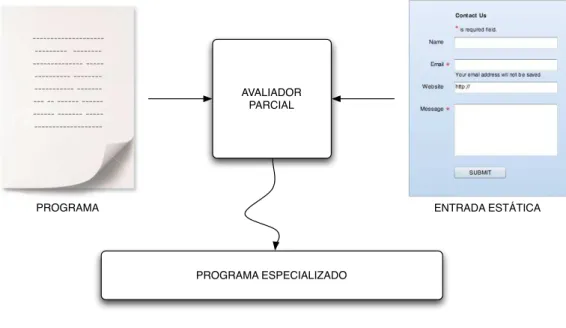
da avaliação parcial é o ganho em eficiência, pois se parte dos dados de entrada de um programa é conhecida, as estruturas do programa que dependem apenas dessa parte podem ser previamente computadas e o programa especializado contém apenas o código necessário para processar os dados ainda não conhecidos. Esse processo é descrito pela Figura 2.8.
2.5.1
Avaliadores Parciais:
On-line
e
off-Line
Sumii [Sumii Kobayashi, 1999] classifica as técnicas de avaliação parcial de programas em dois tipos,on-line e off-line.
2.6. Avaliadores Parciais e Geração de Código 29
--- -- --- --- ---- -- -- -- -- --- ---
---PROGRAMA ENTRADA ESTÁTICA
AVALIADOR PARCIAL
PROGRAMA ESPECIALIZADO
Figura 2.8: Avaliação parcial
Um avaliador parcial é denominado como sendo on-line, quando utiliza como argumentos um programa e um conjunto de entradas estáticas para realizar o processamento e gerar diretamente o programa especializado para o conjunto de entradas.
Avaliadores parciais off-line
Os avaliadores parciais denominados off-line trabalham em duas fases distintas. Na primeira fase é realizada uma análise para propagar informações abstratas sobres os valores estáticos correntes e sobre os valores dinâmicos contidos no código. Na segunda fase acontece a especialização.
Os avaliadores parciais on-line são considerados mais poderosos, uma vez que a avaliação parcial depende dos valores correntes, porém existe uma desvantagem em relação àqueles classificados como off-line. Estes costumam ser mais rápidos que os do tipo on-line.
2.6
Avaliadores Parciais e Geração de Código
30 Capítulo 2. Revisão de Literatura
Entretanto, na compilação dinâmica, o programa é compilado durante à sua execução. Desta forma, o compilador tem acesso a alguns dos valores manipulados pelo programa. A avaliação parcial não é utilizada na compilação dinâmica tradicional, pois neste paradigma funções inteiras são traduzidas para código de máquina, e tais funções devem ser gerais o suficiente para serem invocadas diversas vezes com entradas possivelmente diferentes. A compilação de trilhas, por outro lado, abriu novas oportunidades para o emprego da avaliação parcial. Existem pelo menos duas otimizações de código que podem se beneficiar das técnicas de avaliação parcial e podem ser implementadas em um compilador de trilhas: o desmembramento de laços e a eliminação de testes de overflow. Essas otimizações são detalhadas respectivamente nas próximas duas seções. A otimização proposta nesta dissertação baseia-se em técnicas de avaliação parcial de programas. Essa técnica tem sido usada para realizar várias otimizações de código. Shankar [Shankar et al., 2005] apresentam uma otimização que utiliza técnicas de ava-liação parcial de programas para especializar programas escritos na linguagem Java. Shultz [Schultz et al., 2003] realizaram otimização semelhante a Shankar, também especializando programas no compilador just-in-time de Java. Vários ambientes de execução empregam esse tipo de técnica. Dentre eles, destacam-se: o compilador para a linguagem Python,Psyco JIT, descrito por Rigo em [Rigo, 2004] e também o ambi-ente de execução do Matlab [Elphick et al., 2003; Chevalier-Boisvert et al., 2010] e do Maple [Carette Kucera, 2007].
No contexto da compilação just-in-time a avaliação parcial tem sido usada mais como uma forma de especialização de tipo, ou seja, desde que o compilador possa provar que um valor pertence a determinado tipo de dado ele pode usar o tipo mais apropriado na geração de código de máquina [Chevalier-Boisvert et al., 2010; Chambers Ungar, 1989; Gal et al., 2009].
2.6.1
Desmembramento de Laços
Desmembramento de Laços é uma técnica originalmente concebida para maximizar a quantidade de paralelismo em um programa [Kennedy Allen, 2001]. Essa otimização é candidata a ser melhorada via utilização de informações de tempo de execução.
A Figura 2.9 ilustra essa otimização. Durante a execução do programa na Fi-gura 2.9(a), o compilador sabe que o valor da variáveln é, por exemplo, 4. Neste caso,
2.7. Análise de Largura de Variáveis 31
a = 1;
n = read();
for (i = 0; i < n; i++) {
a += 7;
if (i % 3 == 0 ) {
a += 13;
}
}
(a)
Entry:
a1 = MEM[a] jump LOOP
Loop:
a2 = a1 + 7
a3 = a2 + 13 a4 = a3 + 7
a5 = a4 + 7 a6 = a5 + 13 MEM[pc] = Out jump Out
Out:
MEM[a] = a6
MEM[pc] = Out
(b)
Figura 2.9: Um exemplo em que o conhecimento de valores de tempo de execução propicia a geração de código mais eficiente.
2.6.2
Eliminação de Testes de
Overflow
Overflow é o fenômeno que ocorre quando o resultado de uma operação aritmética é maior que o espaço alocado pelo computador para armazenar este resultado. Em
JavaScript, caso uma operação entre dois números inteiros produza um valor acima de 32 bits, este valor é automaticamente convertido para um número de ponto-flutuante. Isto implica que cada operação aritmética de soma ou multiplicação deve ser guardada por um teste que verifica o tamanho do resultado produzido. Contudo, caso valores em tempo de execução sejam conhecidos, podemos eliminar tais testes usando dos recursos da avaliação parcial. Esse é o caso do laço da Figura 2.3(a), caso o valor de n seja no
máximo 4, como no exemplo anterior. Neste caso, a variável i será sempre menor que
4, e overflowsnão podem ocorrer devido a operações que escrevem nesta variável.
2.7
Análise de Largura de Variáveis
32 Capítulo 2. Revisão de Literatura
Normalmente, esses algoritmos confiam em provadores de teoremas para realizar tal tarefa. Esta abordagem parece ser muito lenta para ser aplicada em compiladores just-in-time. Bodiket al.[Bodik et al., 2000] descreveram uma especialização de análise de largura de variáveis para a remoção de testes de limites de arranjos. Este algorítmo ficou conhecido como ABCD, e ele foi projetado para ser utilizado em compiladores
just-in-time. Zhendong and Wagner [Su Wagner, 2005] descreveram um algoritmo de análise de largura de variáveis que pode resolver o problema em tempo polinomial. Stephensonet al.[Stephenson et al., 2000] usou uma análise em tempo polinomial para inferir a largura de cada variável inteira usada em um dado programa fonte. A otimi-zação proposta nesta dissertação difere-se de todas estas abordagens anteriores, já que estas trabalham com representações estáticas do programa fonte. Este fato restringe severamente a quantidade de informações que as análises de largura de variáveis podem confiar. Conhecendo os valores das variáveis em tempo de execução, pode-se realizar uma otimização muito mais agressiva e rápida.
2.8
Conclusão
Neste capítulo foram abordados todos os fundamentos necessários para o desenvolvi-mento e implementação da nova otimização de código, apresentada no Capítulo 3, capaz de minimizar o número de testes de overflow em trilhas. Inicialmente, foram mostra-das, as principais características das linguagens de programação interpretadas. Em seguida, foram apresentados a linguagem de programação JavaScript e seus recursos.
JavaScript foi escolhida para ilustrar o funcionamento de uma linguagem interpretada porque a implementação da otimização proposta foi feita em um compilador de Ja-vaScript. Na sequência, descreveram-se os fundamentos dos compiladoresjust-in-time, contendo uma classificação desses compiladores em subtipos bem definidos.