FUNDAÇÃO GETULIO VARGAS
ESCOLA BRASILEIRA DE ADMINISTRAÇÃO PÚBLICA
E DE EMPRESAS
ANDRÉIA BRANDÃO DALTRO SODRÉ
KittyCat:
A Cognitive Model of Structural-Form Discovery
Ficha catalográfica elaborada pela Biblioteca Mario Henrique Simonsen/FGV
Sodré, Andréia Brandão Daltro
KittyCat : a cognitive model of structural-form discovery / Andréia Brandão Daltro Sodré. – 2014.
50 f.
Dissertação (mestrado) - Escola Brasileira de Administração Pública e de Empresas, Centro de Formação Acadêmica e Pesquisa.
Orientador: Alexandre Linhares. Inclui bibliografia.
1. Cognição. 2. Desenvolvimento cognitivo. 3. Aprendizagem organizacional. 4. Probabilidades. 5. Tenenbaum, Joshua B. , 1972- . 6. Kemp. Charles. I. Linhares, Alexandre. II. Escola Brasileira de Administração Pública e de Empresas. Centro de Formação Acadêmica e Pesquisa. III. Título.
ANDRÉIA BRANDÃO DALTRO SODRÉ
KITTYCAT: A COGNITIVE MODEL OF STRUCTURAL-FORM DISCOVERY
Dissertation delievered to Fundação
Getulio Vargas – FGV, as part of the requirements to obtain the title of Master in
Business Administration, advised by
Professor Ph.D. Alexandre Linhares.
RIO DE JANEIRO
ABSTRACT
Cognition is a core subject to understand how humans think and behave. In that sense,
it is clear that Cognition is a great ally to Management, as the later deals with people and is
very interested in how they behave, think, and make decisions. However, even though
Cognition shows great promise as a field, there are still many topics to be explored and
learned in this fairly new area.
Kemp & Tenembaum (2008) tried to a model graph-structure problem in which,
given a dataset, the best underlying structure and form would emerge from said dataset by
using bayesian probabilistic inferences. This work is very interesting because it addresses a
key cognition problem: learning. According to the authors, analogous insights and
discoveries, understanding the relationships of elements and how they are organized, play a
very important part in cognitive development. That is, this are very basic phenomena that
allow learning. Human beings minds do not function as computer that uses bayesian
probabilistic inferences. People seem to think differently.
Thus, we present a cognitively inspired method, KittyCat, based on FARG computer
models (like Copycat and Numbo), to solve the proposed problem of discovery the
underlying structural-form of a dataset.
Key words: Cognition, Cognitive-model, Structural-Form Discovery, FARG, Kemp
TABLE OF FIGURES
Figure 1: KT Step 1 ... 11
Figure 2: KT Step 2 ... 11
Figure 3: KT Step 3 ... 12
Figure 4: KT Step 4 ... 12
Figure 5: KT Step 5 ... 12
Figure 6: KT Step 6 ... 13
Figure 7: KT Step 7 ... 13
Figure 8: KT Step 8 ... 13
Figure 9: KT Step 9 ... 14
Figure 10: KT Step 10 ... 14
Figure 11: KT Step 11 ... 14
Figure 12: KT Step 12 ... 15
Figure 13: Copycat Step 1... 23
Figure 14: Copycat Step 2... 24
Figure 15: Copycat Step 3... 24
Figure 16: Copycat Step 4... 25
Figure 17: Copycat Step 5... 26
Figure 18: Copycat Step 6... 26
Figure 19: KittyCat Step 1 ... 31
Figure 20: KittyCat Step 2 ... 32
Figure 21: KittyCat Step 3 ... 33
Figure 22: KittyCat Step 4 ... 34
Figure 23: KittyCat Step 5 ... 34
Figure 24: KittyCat Step 6 ... 35
Figure 25: Atlas ... 38
Figure 26 : (a) Spectrum extracted from justices' votes; (b) Hierarchy of the Bush cabinet. ... 47
SUMMARY
ABSTRACT ... 2
TABLE OF FIGURES ... 3
SUMMARY ... 4
1 INTRODUCTION. THE IMPORTANCE OF COGNITION TO MANAGEMENT ... 6
2 KEMP & TENENBAUM’S MODEL ... 9
2.1 The imposition of structure ... 9
3 KT-STRUCTURES ... 11
4 FLUID CONCEPTS, FARG ARCHITECTURE AND THE COGNITIVE FLOW OF INFORMATION PROCESSING ... 16
4.1 Introduction to FARG architectures ... 16
4.2 Basic Components of the FARGitecture ... 17
4.3 High-level FARG Concepts ... 19
4.4 FARG Models ... 19
ANALTERNATIVE PROPOSAL TO KEMP & TENENBAUM’S MODEL... 28
5.1 Model Overview ... 28
5.2 System Architecture ... 28
5.3 Example ... 31
CRITICISM OF KEMP & TENENBAUM’S MODEL FROM A FARG PHILOSOPHY ... 36
7 CONCLUSION & FUTURE RESEARCH ... 41
7.1 Why is discovery of form important to Artificial Intelligence and computational cognitive science? ... 41
7.2 Why is this type of work important to management? ... 41
7.3 Future Research ... 42
REFERENCES ... 43
APPENDIX A ... 46
Hierarchical Bayesian model: forms, structures, and data ... 47
6
1 INTRODUCTION. THE IMPORTANCE OF COGNITION TO
MANAGEMENT
Consider this summary of the case history of Polaroid’s transition from instant to
digital imaging given by Gavetti et al. (2005) in his paper. This case was result of extensive
fieldwork that the aforementioned author conducted at Polaroid and I take the liberty of
paraphrasing here for illustrative purposes.
Polaroid, founded in 1937, was a successful company in the photography industry
driven by instant-imaging products (camera and films) until the early 90’s. During its time,
Polaroid’s senior managers developed certain beliefs such as that all profits in this industry
were in the consumables — hence their untouchable “razor/blade” model — and that its
commercial success originated only from technological breakthroughs.
In the 1980’s, after noticing some weakness in the market, Polaraid ventured into
digital-imaging technologies and spent a substantial amount of money on R&D, even though
there was no market for these technologies yet. Digital-imaging managers started to question
the strategic implications of this new business model because it would shift the core to
hardware instead of consumables. At the same time, there were two other projects that
embraced the razor/blade model that had been successful so far. Because of these projects,
the conflict between senior managers who still believed in the razor/blade model and
managers of the new “hardware model” was not apparent.
In the early 1990’s, Polaroid had developed a working prototype of digital camera much superior to similar products by competitors, and digital-imaging managers believed
that this camera was essential for them to play a leading role in the consumer market.
However, senior managers opposed a camera with no printing device, as it wasn’t consistent
with the razor/blade model, which they were unwilling to abandon despite the continuous
evidence provided by the digital-imaging managers of how the emerging digital-imaging
landscape conflicted with their software-centered view. Thus, the digital camera release was
delayed and search efforts were pushed towards digital-imaging products agreeable with the
7
Due to this failure and the inconsistency of digital-imaging with their traditional
business model, Polaroid turned away from digital imaging and when it started selling its
megapixel camera it was too late already and the camera had little success. By the end of the
decade, Polaroid had lost most of its early strength in the digital imaging.
After analysing the presented Polaroid case history, Gavetti arguments in his paper
that this case history displays the crucial role of cognition.
Polaroid’s early development of leading-edge technological capabilities in digital
imaging is hard to explain without considering the belief in technology’s primacy. For over
a decade, this belief led to massive investments in search efforts despite the lack of a tangible
payoff. Then, when a market for digital products emerged, senior managers discouraged
search activities that were inconsistent with their theory of how to be profitable in the
photography business, effectively destroying Polaroid’s core digital-imaging capabilities. The evidence suggests that cognition can be central to capability development by affecting
the efforts undertaken (Gavetti et al., 2005; Gavetti, 2005; Gavetti and Warglien, 2007).
Furthermore, in this case Gavetti brings attention to the contrast between top
managers’ cognitive inertia and digital-imaging managers’ rejection of a software-centered view for their emerging business, and how the fact that these top managers ignored cognition
at lower levels and decided which beliefs to guide the organization led it to rather negative
results. He highlighted the importance of studying the interplay between “cognitions”
differently situated in the hierarchy and in his paper he developed a model that shows that
managers’ cognitive representations of their strategic decision problem guide organizational search, and consequently the accumulation of capabilities. This is one of the many examples
that illustrates the importance of a deep understanding of cognition and how its application
to management can improve an organization’s chances of succeeding.
Cognitive science is as old as the times of Aristotle. However, cognition as we
currently know it is a relatively new field of study, which started to take its shape in the
1950’s with advances in the area of artificial intelligence (Simon, 1980). Its core interest is the understanding of the human mind. A very remarkable and interesting trait of cognitive
science is its interdisciplinarity, since it has important connections with anthropology,
8
other disciplines. This characteristic makes it a very versatile science that can be of service
to many other areas — including management, in which we can find the underrated topic of
managerial cognition.
The beginning of managerial cognition is marked by the classic work of Schendel
and Hofer (1979), “Strategic Management: A New View of Business Policy and Planning”,
in which they describe a six step process to strategic management. Even though the cognitive
aspects are not explicitly mentioned, the process described by the authors is composed of
thinking activities that require cognition, therefore, managerial cognition was implicit in
their paradigm. According to Madhavaram et al. (2011), there seems to be an implicit
consensus among researchers that “managerial cognition is how and what managers think about and understand various firm issues that require action”. This definition limits
managerial cognition to the act of high-level thinking (e.g., strategy planning, analysis, etc).
However cognition is not limited to high-level thinking since numerous empirical studies
indicate that behavior is often cognitive and calculative (Simon, 1955; Porac et al., 1989).
Also, taking into account that behavior happens in all hierarchical levels and areas of
companies, it is not correct to limit managerial cognition to managers or the strategic level.
Thus, in a more proper and complete manner (more inclusive of all people in a
company), the definition of the academy of management, used by Forbes (1999, p.416) states
that managerial cognition is “how organization members model reality and how such models interact with behaviors”.
After this brief introduction of managerial cognition, one might still wonder what
might be the importance of this topic to the good study and pratice of management. Stubbart
provides a simple and fine explanation that syntheses exactly the relevance of managerial
cognition.
The chief appeal of cognitive sciences is that they promise to
fill the “missing link” between environment conditions and strategic
action. Environmental and organizational forces affect action
through executives’ thinking, and actions derived from thinking.
Organizational adaptation is an intelligent thinking process.
9
Stubbart (1989) realized that managerial cognition is the aforementioned unnamed
missing link in Schendel and Hofer (1979) strategic management paradigm and proposed
that cognitive science principles could assist in managing complexities in strategic
management processes, in which managerial cognition plays a critical role.
2 KEMP & TENENBAUM’S MODEL
In their 2008 paper “The discovery of structural form”, Charles Kemp and Joshua B.
Tenenbaum proposed a very interesting computational model that learns different structures
and identifies the best form for a given dataset. It uses probabilistic inferences over a
pre-determined set of graphs, which were chosen due to their popularity, meaning they are useful
for describing the world and are more salient in the human mind when scientists seek formal
descriptions of a domain. In this study, graphs were chosen to represent structures and graph
grammars were used as a unifying language for expressing a wide range of structural forms
because the writers assume that the most natural forms are those that can be derived from
simple generative processes. In Kemp & Tenenbaum (2008), each structure can be formed
from “a single context-free production that replaces a parent node with two child nodes and
specifies how to connect the children to each other and to the neighbors of the parent node”.
2.1 The imposition of structure
Structures are imposed by most analytical methods. Clustering methods will always
find disjoint sets in data. Ranking (or order-based) methods project entities into a domain
that must be isomorphic to either N , Z , or R . Decision tree methods will create branchpoints
to classify the data, and so forth. Nature, on the other hand, is indifferent to our methods.
Nature presents us with a bewildering array of different forms and structures—as do
societies, firms, and other complex systems. Humans find structures by studying data and
carefully comparing and contrasting this information to previously experienced structures.
Linhares and Freitas (2010); Linhares and Chada (2013).Our analytical methods, however,
10
It may suggest hypotheses which are not warranted. A ranking of living
beings, scala naturae (or “the great chain of being”), was the unquestioned christian
doctrine until Carl Linnaeus proposed the tree alternative; this “great chain of being”
hypothesis—which goes upwards from rocks, plants, animals, man, spirit, angels and
god—suggested a hierarchy of beings that proceeds towards `greatness'; while the tree
of life hypothesis suggests a common ancestor, speciation, and the exploitation of niches.
Moreover, the imposition of structures may blind us to important relations
hidden in the data. Prisoners generally self-organize into groups (gangs). Clustering is
able to capture the increased intra-group interaction that dimensionality-reducing
methods (such as χ 2 or the use of z -values) cannot. Ranking prisoners in order of 'violence propensity', or guards in terms of 'abuse of power propensity', will create the
previously mentioned rank anomalies and will most likely neither reflect nor predict
violence between individuals in any meaningful way. One needs to know how
individuals interact, not how they rank in a single dimension.
There is, however, no need to presuppose a form when analyzing data. Cognitive
scientists Charles Kemp and Joshua Tenenbaum have developed and algorithm enabling the
automatic discovery of form. While Kemp and Tenenbaum have published their work as a
11
3 KT-STRUCTURES
In this section, a run of Kemp & Tenenbaum's model will be demonstrated. In this
specific round, the model is trying to discover the best tree structure available in a dataset of
american politicians. It is interesting to note that the model is forcing the dataset to fit in the
determined form of a tree and testing the better structure inside it. Furthermore, from the
start, all the components are part of the form already (they are not added one-by-one) and
start branching out from the same node of the tree.
Let's consider that the point from which all the elements are deriving as a point of
level zero and we shall call it root node.
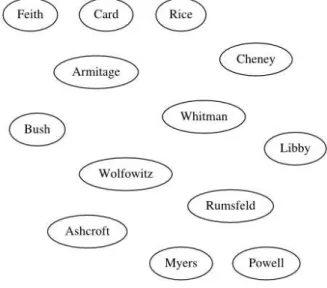
Figure 1: KT Step 1
In the first step, we can observe that the model started constructing the tree structure
by separating the compenents “Bush” and “Cheney”, creating a new chunk from the
remaining dataset elements. Both become second-level nodes in relation to the root node,
whereas the rest of the elements are gathered together in a single first-level group. Thus the
tree structure is presenting two levels in total and the entire dataset is part of it already.
Figure 2: KT Step 2
Next, the structure adopted a triple-branch format, in which “Bush” was set aside on
a group of its own going back to the first level; “Cheney” was joined by “Rumsfeld”,
“Powell” and “Rice” on another second-level group; and the rest of the components were also grouped in another chunk in the second level. Apparently the system started realizing
12
Figure 3: KT Step 3
The third step consisted of the model separating “Powell” and “Rice” into a new
second -level group containing only these two components.
Figure 4: KT Step 4
In the fourth step, the tree structure begins to develop a third level: “Libby” and “Rumsfeld”, components that previously belonged to the second level started a new third
-level group together, leaving the “Cheney” alone in their previous second-level group. The rest of the structure remained unaltered.
Figure 5: KT Step 5
After that, the model moved “Powell” to a second-level branch by itself and joined
13
Figure 6: KT Step 6
Next, the model separated “Libby” and “Rumsfeld” into two different groups with a
single component in the third level that branched out from the same first level node.
Figure 7: KT Step 7
In the next step, the model moved “Rice” to be by itself at the second level, as it did
to “Powell” in step 5.
Figure 8: KT Step 8
In the following step, the model performed several actions: it swapped positions
between “Wollowitz” and “Rumsfeld”, letting the first be on a third level branch that derives from the same node at the first level that branches to “Cheney” at second level and “Libby” at third level; and the “Rumesfeld” moved to a second-level group that branches out from
the same node from which the group of “Myers”, “Armitage”, “Whitman” and “Feith”
14
Figure 9: KT Step 9
After that, the model separated “Card” and “Ashcroft” and left them as two
components coming straight from the main node to the second level. In total, the structure
currently presents seven first-level nodes, nine second-level nodes and six third-level nodes.
Figure 10: KT Step 10
Next, the model disconects “Whitman” from its previous group keeping it at third
level like before, and branching out from the same node the group does.
Figure 11: KT Step 11
15
Figure 12: KT Step 12
Finally, at step 12, the model performed several actions. “Armitage” and “Whitman” were part of the same cluster and were split apart. It moved “Armitage”, keeping it as a
third-level leaf node, and connected it to the first-level node from which “Powell” branches out.
“Whitman” was also maintained as a third-level leaf node and reallocated to branch out from
the same first-level node from which “Rice” does. Finally, “Wollowitz” got split from the
cluster it belonged with “Libby” and was placed alone as a second degree node, branching
out directly from the root node.
As a result, we have a tree-structure of the Bush cabinet. The structure logical and a
good representation of this group of American politics, however, it is not the best solution.
A hierarchy structure is the best solution to represent Bush's cabinet. We can notice
similarities of the optimal tree-structure to the hierarchical structure. For example, “Bush” is
alone on its branch and it is the only first-level leaf-node. The other leaf-nodes have lower
levels than him, showing he is the top level. When the tree-structure wants to represent
people under another person's power, it connects to the node from which the person with the
power branches out and it adds another level (e.g., “Armitage” is a third-level leaf node, connected to the first-leaf node from which branches out the second-leaf node “Powell”.
That means “Armitage” reports to “Powell”). The final structure has one first-level leaf-node, seven second-level leaf-nodes, five third-level leaf-nodes, comprising eight clusters
16
4 FLUID CONCEPTS, FARG ARCHITECTURE AND THE COGNITIVE
FLOW OF INFORMATION PROCESSING
4.1 Introduction to FARG architectures
In Indiana University, located in Bloomington, there is a house called “Center for Research on Concepts and Cognition”, or CRCC, that works as the headquarters the group
of researchers, lead by Douglas Hofstadter, known as Fluid Analogies Research Group, or
FARG, as they refer to it. The name, though silly sounding (purposefully so), encompasses
the main beliefs and values that guide this group in its scientific endeavours. In the words of
Hofstadter, “the term fluid [...] exudes quite a clear image of flexibility, mutability, nonrigidity, adaptability, subtlety, pliancy, continuousness, smoothness, slipperiness,
suppleness”. For the FARGonauts (as the members refer to themselves) this ilustrates the properties of thoughts, which they believe emerge from several small, independent, invisible
and parallel subcognitive acts.
FARG focus on modeling mental processes on computer programs, however it is a
very hard attempt to explicit this group's central research ideas and goals. Nevertheless,
Hofstadter (1995) has presented a list of the most important themes that appear frequently:
He talks about “the inseparability of perception and high-level cognition”, which basically states that the models generated by FARG attempts to model how human
perception works, and that they believe this perceptual architecture is the heart of
cognition. For instance, in the model Copycat (which will be explained more in depth
further on), the program perceives relationships between the letters and the strings, and
it makes analogies.
There is the easiness of reconfiguring multi-level cognitive representations
and how those are connected by bonds of different types and strenghts, meaning that the
model is flexible and can turn some other new way to solve the proposed problem.
Another recurrent theme is the idea of subcognitive pressures, which means
that when a concept is more “important” it will have more influence on the direction
17
These many pressures act commingling, in a nondeterministic parallel
architecture in which the several processes coexist peacefully.
The simultaneous exploration of various potential possibilities according to
their degree of promise. So the program can look for several ways of answering the
proposed question and will keep on looking further on the options that seem more
appealing.
One very important theme to this group is analogy making and variations on
a theme in high level cognition. Hofstadter believes that analogy is the core of cognition
so this theme is always central to this group's researches.
The presence of deeper and shallower aspects of cognitive representations.
The degree of these aspects pose great influence on the contextual pressures imposed by
the system, the deeper aspects being more immune to said pressures, and the shallower
is more likely to yield to these pressures (to which we use the term “to slip”).
The role played by the inner structure of concepts and conceptual
neighborhoods.
The present work does not attempt to explain in depth the aforementioned themes
because not all of them are used in the proposed work discussed on section five.
Nevertheless, it is important to mention all the recurrent themes providing the reader with a
more high-level understanding of what concerns FARG apart from the present approach.
4.2 Basic Components of the FARGitecture
Although each model generated by the Fluid Analogies Research Group is different
and unique in its own way, there are some components that frequently reoccur in the models.
These components seem very characteristic of the type of architecture used by the group.
Therefore, this section lists a few of these components that work as an identifying trademark
of FARG models.
Slipnet
The Slipnet is a structure that attempts to model the human mind's subtly
18
memory that stores the concept types and its basic representation is that of a network of
interrelated concepts, in which concepts are nodes and conceptual relationships are links
with a numerical length (the “conceptual distance” between two nodes).Simply put, it works
as a storage for the knowledge that the system will use to solve its proposed problem.
One important feature of the Slipnet is that it is dynamic and responds according to
the situation it is presented with: it activates concepts and modifies conceptual distances
gradually according to the system's perceived relevance of the concepts. This phenomenon
encourages certain slippages to happen while the occurance of others becomes more remote.
Workspace
The Workspace is the area where structures are formed and the actions occur. It can
be visualized as a work site where there are various different randomly-distributed structures
which will be worked on simultaneously by the several small agents (codelets). The
structures are constructed and descontructred as necessary, in order to build up a coeherent
vision of the entire set of structures. The several different actions played in the Workspace
can go from scanning to describing, bonding, grouping, destroying and so on. The
Workspace can be compared to a working memory, which functions as temporary storage
and place for manipulation of information. (Baddeley, 1992; Baddeley & Hitch, 1974)
Coderack & Codelets
Codelets are small, simple agents that perform all the aformentioned acts in the
Workspace. Their actions as single units are very insignificant, so what is most important is
the emergent effect of their actions as a group . There are two types of codelets: bottom-up
codelets, which work on the Workspace in a random, unfocused manner; and top-down
codelets, which act in a more purposeful and specific manner, focusing on a particular goal.
When a codelet is created, it is stored on the Coderack — a codelet storage area where those
entities await for their turn to run — and is given a urgency-value, a number which determines its probability of being chosen from the selection of codelets in the Coderack.
The Coderack is replenished with codelets constantly and the selection of codelets inside of
it adjusts itself automatically according to the system's requirements, which influences the
19
4.3 High-level FARG Concepts
Commingling Pressures
Pressures are implicit shifting forces, consequences of several interconnected events
in the whole system, that push certain types of processes to occur. Even though they are not
represented explicitly in the architecture, they are present in the system and perform a very
influential role. Basically, emergent pressures will determine the direction and action taken
by the system.
Parallel Terraced Scan
The parallel terraced scan is a simultaneous exploration of several different potential
pathways. Even though the system works with only one viewpoint at a time, there are several
parallel processes occuring that are unconscious and determined by the present pressures of
the system. These unconscious parallel processes play a big influence on the direction taken
by the system. For example, imagine a group of scout ants exploring a territory. There will
be a main line of ants going towards an objective and some random ants going around
different paths, reporting back, and changing the course of the main line to a more suitable
one with more potential direction.
Temperature
Temperature is a variable that monitors the stage of processing of the system and
controls the degree of randomness used in the decision-making. It assists overall system in
shiftingt from an initial bottom-up, open-minded mode to the top-down, closed-minded one.
Since the system does not have any information at the beginning, it does not matter which
codelets will run first, what to focus on and so on. However, the more the system explores
the situation, the more it becomes aware of the presented picture and it can start sending
more top-down, specific codelets that will strengthen the current viewpoint. The system
starts out with a high temperature and it decreases to lower temperatures the clearer its
viewpoint gets; thus, the value of the temperature demonstrates the present quality of the
system's understanding and its proximity to the best solution.
20
In this section we discuss the FARG models which most inspired the proposed model
of this thesis, so the reader can better understand its origins and the similarities to the
previous models. These models are discussed in depth in the book Fluid Concepts and
Creative Analogies - Computer models of the fundamental mechanisms of thought by
Douglas Hofstadter and other FARG researchers.
Numbo
Numbo is a computer model based on the game “Le compte est bon”. Since By
simulating this game, Numbo displays the human mental behavior of fluidly grouping, taking
apart, and restructuting components in order to achieve a goal.
The game works as following: given five brick numbers (from 1 to 50) and three
possible arithmetical equations (addition, subtraction, and multiplication) how would you
arrange the brick numbers and arithmetical equations in order to achieve the target number
(from 1 to 150)?
An example of a puzzle by Numbo is to achieve the target 114 using the bricks 11,
20, 7, 1, 6. The answer is 20 x 6 - 7 + 1 or (20 - 1) x 6.
The name Numbo is inspired by another FARG model called Jumbo. Jumbo is a
computer model that solves the anagram puzzle Jumble. Since the present problem is very
similar to Jumble, but with numbers, the game was named Numble and the computer model
Numbo.
Numbo has three elements in its architecture: the Pnet, the Cytoplasm and the
codelets.
The Pnet is the network that has all the knowledge needed to solve the puzzle. It
activates concepts during the process of solving the puzzle. This concepts are nodes, which
are called Pnodes, and are stored inside the Pnet. Only very simple things are stored in the
Pnet, however, the activation of this simple things can help to find a solution to a complex
problem.
The cytoplasm is analogous to the workspace: it is the place where the building and
dismantling of structures happen. It begins with independent structures (called cyto-nodes)
21
(e.g., brick, target, block), status (e.g., taken or free), and attractiveness (e.g., numerical value
that influences the nodes usage likelihood).
Finally there are the codelets, which are the small agents that work on the cyto-nodes
in the cytoplasm. The codelets are stored in the Coderack. They can perform many different
simple operations on the Pnet (e.g, activiting Pnodes), on the cytoplasm (e.g., comparing a
cyto-node to a target node) and on the Coderack (e.g., creating other codelets).
Copycat
Copycat is, according to the definition provided in the book Fluid Concepts and
Creative Analogies - Computer models of the fundamental mechanisms of thought , “a
computer program designed to be able to discover insightful analogies, and to do so in a
psychologically realistic way.” (Hofstadter & FARG, 1995, pp.205).
As the authors Hofstadter and Mitchell suggest, the domain in which Copycat
operates is very small but subtle. The main example of what Copycat does is illustrated by
the following puzzle: suppose the letter-string abc were changed to abd; how would you
change the letter-string iijjkk in “the same way”? In other words, given a letter-string that
was transformed into another one, you are supposed to transform a new letter-string
following (or copying, hence the name Copycat) the same intrinsic rules used by the previous
two letter-strings. Therefore it finds the answer of a letter-strings analogy puzzle.
Regarding its architecture, Copycat consists of four main components: a Slipnet, a
Workspace, a Coderack and temperature.
The Slipnet, as noted in the previous section, it is the source of knowlegde used by
the system to solve the proposed problem. It activates concepts and conceptual relationships
according to the way the program understands the situation at each codelet run, so it adjusts
itself dynamically, running until the system achieves the best result possible. An interesting
fact about the Slipnet is it adjusts itself after every codelet run; however when a new problem
is presented, the Slipnet returns to its original state and all of the adjustments are made from
scratch again. So, in this sense, Slipnet does not learn after solving a problem. Furthermore,
another important feature from Slipnet is that it allows concepts to slip from one to the other
22
The Workspace is the site where structures are formed as the problem is worked on
by small agents, called codelets. At first, it is a bunch of unconnected raw data that, with
time, will start getting descriptions and being linked by perceptual structures, using the
information withheld in the Slipnet. The many tiny actions held in the Workspace such as
scanning, describing, bonding, destructing, grouping and so on will render the system a
coherent vision — viewpoint — and the increasing pressures will work in the direction sugested by said viewpoint. Even though there several objects in the Workspace and there
are several parallel processes and explorations occuring, it is simply not possible to give
attention to all of the elements present in the space; therefore, the system has to decide on
what objects to focus on, which is determined by the object's salience. The salience is a
function of the object's importance (the number of descriptions and degree of activated
concepts connect to it) and its unhappiness (few or no connections to other objects in the
Workspace).
The other important Copycat component is the Coderack, which stores the codelets.
The codelets are small agents that work upon the structures in the Workspace. A list of the
actions that a codelet may take on Copycat's Workspace is: scanning, describing, grouping,
bridge-building, destruction, bonding. One can also describe codelets as the proxies for the
pressures present in the system. This means that when the pressures are standard or
commomplace for all situations, bottom-up codelets are sent to the Workspace; whereas
when there are specific pressures, top-down codelets are summoned.
The temperature is the variable that demonstrates the present quality of the system's
understanding and its proximity to the best solution. The tendency is that the temperature
should start high and decrease as the structures are formed. However, the temperature does
decrease in a constant steady manner, and sometimes it even increases.
Next, we demonstrate how Copycat works to solve the aforementioned puzzle
displaying the steps it has executed until the best-fitting solution emerged.
Suppose the string abc were changed to abd; how would you change the
23
Figure 13: Copycat Step 1
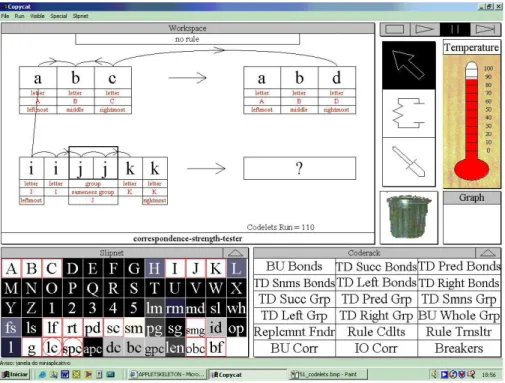
The first figure representing Copycat captures the moment when the program has run
110 codelets. The system does not have much structure at this point, hence the high
temperature. It has recognized each individual letter, created a brigde between the letters c
and d from the initial string and the target string, it has mapped leftmost letter a from the
initial string to the leftmost letter i at the string iijjkk, and it has noticed some bonds between
the neighbor letters. It has found bonds of sameness (as in j and j), successorship (as in a
and b or i and j) and predecessorship (as in b and c). It is interesting to note that, in the string
abc, the letter b is described as having competing bonds of both successorship and
predecessorship, which demonstrates some conflict of interpretation in the system; it will
have to deal with dissonant ideas competing against each other. Note that the system still
couldn't find a rule to make a transformation of the iijjkk letter-string. Also, the system has
created a chunk with the two j's, but still hasn't realized the sameness bond between the two
24
Figure 14: Copycat Step 2
The second figure displays the state of the program after a total of 260 codelets have
run. Some structure has emerged and an initial rule appeared (“replace letter category of rightmost letter by successor”). The temperature has dropped due to the emerging structure. Other chunks have been formed (ii and kk) and the abc string has adopted a successorship
bond only between the individual letters, in a staircase fashion, as the program notices it as
successor group. Also, now the system connects the rightmost c of the abc string to the
rightmost k of the iijjkk string.
25
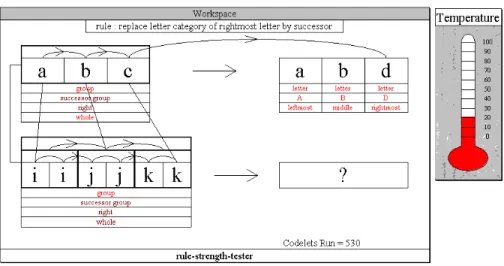
The following figure shows the state of the system after executing only 20 more
codelets. Now the rightmost c of the abc string is connected to the kk chunk. However, a
predecessorship bond has been found between the jj and the ii chunk, which is causing
conflict in the program. Due tp the destabilizing effect of the competing bonds in the system,
the temperature has risen, even though more codelets have been executed. This shows that
the temperature does not only drop, it rises when the system gets further away from a strong
solution.
Figure 16: Copycat Step 4
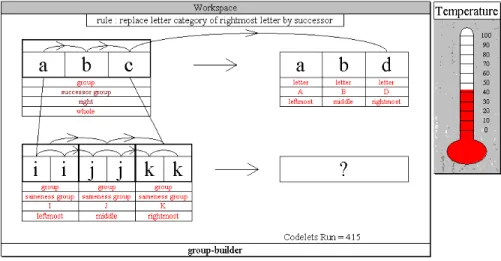
The next figure shows the situation of the system after 415 codelets have run. A
successorship bond has been found between the ii and jj chunks and between the jj and kk
chunks, also, the system notices that the chunk jj is the in the middle of the iijjkk string. The
26
Figure 17: Copycat Step 5
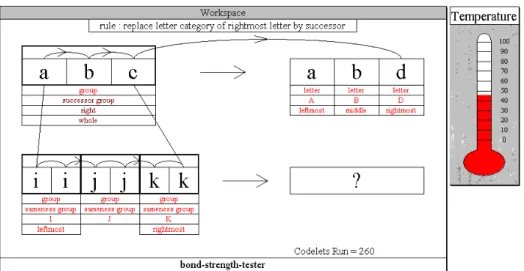
In figure 5, after 530 codelets executed, the system finally realizes the that iijjkk is
a successor group and also it connects b, the middle component of the abc string, to the
chunk jj, the middle component of the iijjkk string. However, a is still connected only to the
letter i, and c went back to being connected only to the letter k (instead of to the chunks ii
and kk, respectively).
Figure 18: Copycat Step 6
This last figure shows the final result of the program after 695 codelet executions.
Finally, the system has mapped a to the chunk ii, b to the chunk jj and c to the chunk kk.
27
group by successor”, it applies this rule to iijjkk, producing the letter-string iijjll as the
28
5 ANALTERNATIVE PROPOSAL TO KEMP & TENENBAUM’S MODEL
In this section, we will present an alternate proposal to Kemp & Tenenbaum's model
inspired by the FARG programs described in the previous section: KittyCat. The name
KittyCat is an hommage to the inspirations for this model: the work of Kemp & Tenembaum
(by discreetly using their names initials, KT, in the word Kitty) and the FARG models, which
have the tradition of using cat in their names (e.g.,Copycat, Metacat, Musicat). Furthermore,
the name seems fitting since a kitty-cat is a small type of feline, and this work still is in its
infancy compared to other FARG models that have already been implemented.
5.1 Model Overview
KittyCat is intented to solve the same puzzle proposed by Kemp & Tenenbaum (i.e.,
finding out the intrinsic best-fitting form and structure of a dataset) in a more fluid and
cognitivel-plausible fashion, simulating more precisely how the human mind would behave.
Kemp & Tenenbaum's model can work with three different kinds of input data —feature
data, similarity data, and relational data — and so will KittyCat. Even though the form of
the input can differ, the output will always consist of the same type of object: a graph
structure with a label indicating the category of the resulting structure.
The model should work with any of the three different kinds of input data. Each type
of data includes a set of entites (e.g., months of the year, animals, cities of the world, etc).
Each entity will start out being represented as single independent node, and during each run,
the nodes will be analysed, categorized, grouped and linked together in clusters until they
are organized in the structure and form that best suits them. For clarification, we we follow
Kemp & Tenembaum's usage of the word structure to mean the large-scale organization of
nodes (e.g., a ring, a hierarchy, a tree, etc) whilst the form is the particular organization of
the nodes within the structure (e.g., in the previous example of the Bush Cabinet, it is possible
to rearrange its form in a way that Bush is not the top of the hierarchy anymore).
5.2 System Architecture
KittyCat is comprised of the following major components: Atlas, Workspace,
29
Workspace
It is interesting to begin describing the Workspace first because it contains the puzzle
to be solved. The Workspace may contain objects of the following types: nodes, links, groups
of nodes, labels, structures, and annotations. In its initial state, the Workspace contains the
independent individual entities of the presented dataset scattered around it. These entities are
nodes, for the expected output of this program is a graph structure constituted of said nodes.
It is important to realize that the Workspace only works with its present situation, so if
something has been discovered in a past codelet run, the new discovery should be identified
in the Workspace for the future runs, e.g. by using annotations or labeling of the nodes,
groups, structures, or any other element.
Consider a run where the input is a feature matrix and the model has discovered a
linear structure with three nodes in it. The model will label the structure (“linear”, “group 1”), groups (“group with 3 nodes in a linear structure”), links (“successorship”) and the nodes (“first”, “second”, “last”); and it will also put annotations on the links (“stronger”, “4 similar features”), on the group (“group with similarity on 4 common features”,), and on the nodes (“features 4, 8, 9, 10 seem interesting”, etc).
With these informations, the model will be able to continue modifying the Workspace
in more focused way, even though it will keep exploring other possibilities due to the parallel
terraced scan previously explained. The elements lables and annotations may change after a
new codelet run, new links may be formed, old links may be destructed, groups can be
dismantled or formed, structures may arise and disappear, and nodes may change
connections. All these actions will keep occuring in the Workspace until the best structure
and the best form emerge from the nodes.
Atlas
Atlas plays the role of the Slipnet in CopyCat, in the sense that it stores the concepts
that will be activated to solve the presented problem. The difference is that Atlas will activate
graph figures when the program discovers in the Workspace a structure similar to what it has
“seen before”. The idea is that activating certain types of graph structures would aid other
30
If a match is found to some graph, then that could activate the slipnet for forms that are
appropriate for that graph (the one found in atlas). The finding of the structure can lead to
faster form emergence. Only the possible forms that match with the activated structure are
activated on the Atlas, whereas the ones that did not would remain innactive.
A few of the concepts or nodes we can find in the Atlas are graph structures (partition,
chain, ring, cylinder, tree, hierarchy, order, etc), “stronger”, “similar”, “weaker”, “parent
node”, “child node”, “group”, “first”, “last”, “second”, “third”.
As an example, consider that the program has to form a structure with the following
items: August, January, March, April, February, November, May, December, July,
September, June, and October. The model will analyze the situation and verify whether there
are graphs in Atlas that look similar to the proposed puzzle. Then, it might perceive a chain
structure, activating the chain concept in the Atlas. Later, it might trigger a codelet to verify
if the last item in the chain pattern is connected to the first item, thus leading to the discovery
of a ring structure. Note that the model does select a pre-determined structure to construct
(e.g., forcing the elements to form a ring). It recognizes in the Workspace patterns that are
recorded in the Atlas and it acts according to the activated concepts at each moment.
Coderack
The Coderack works the same way it does in the previous FARG models, as the
storage place where the codelets (small working agents) await for their turn to run. The
Coderack replenishes itself constantly with codelets and adjusts the codelet population
according to the new discoveries of the model. Like all other models, there are bottom-up
and top-down codelets, and codelets are randomly chosen from the Coderack based on
urgency level and Temperature. A few types of codelets that can be found on this model are:
scanning codelet (low-level codelets that discover interesting characteristics,
relations and so on)
labeling codelet (labels the elements in the Workspace)
annotation codelet (adds annotations to the elements in the Workspace)
linking codelet (creates links between the nodes)
31
{label, annotation, link, group} breaker codelet (destroys or erases previous
constructions)
structure finding codelet (finds structures in the groups of nodes that match
with the Atlas content)
stem codelet (creates any other codelet)
Thermometer
The Thermometer indicates the temperature of the Workspace. The temperature is a
variable that monitors the progress of the model. The Thermometer begins indicating a high
temperature, and then it decreases to lower temperature as the final optimal result of the
system becomes clearer. The most interesting aspect of the temperature is that, when it is
high, the system does not have a clarity on what is supposed to do, so it will act randomly
and make drastic operations (e.g., destroying a whole structure); however, when it is low,
the program acts in a more consistent manner. In that sense, the temperature plays great
influence on the urgency-levels bestowed upon the codelets in the Coderacks, thus
influencing the procedures of the model.
5.3 Example
In this section, we present how KittyCat would solve the same problem solved by
Kemp & Tenembaum in section three (3 KT-Structures).
32
In the beginning, tthere is no structure apparent in the system's Workspace
whatsoever. All the components are scattered around randomly around the workspace as
single individual units. There are no bonds or connections mapped between the components.
The system still has no idea of what type of form should be used to organize the dataset of
these components, nor does it know the best structure within the best fitting form. So far, it
is all very unclear, and bottom-up forces should be used to try to find some kind of
relationship between the components. There is no hypothesis or theory to guide the process
at this stage. So the process is completely driven by the initial data, in a bottom-up fashion.
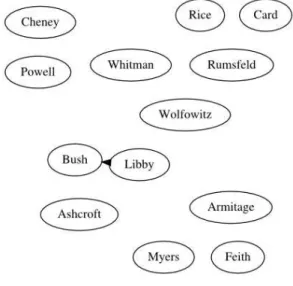
Figure 20: KittyCat Step 2
Finally, after some exploration, a relationship has emerged between the component
Libby and Bush, in which there is a connection from Libby, acting as a initial node, to Bush,
acting as an ending node. Since there are only two components and one connection, the form
so far could be perceived as a simple linear form. All the other components are still loose at
the workspace, awaiting more scannings to be designated to their proper arrangement. The
system is in a highly disorganized form and it is, at this point, not considering and
33
Figure 21: KittyCat Step 3
Many additional rounds, and the system has come up with a ring form with a structure
that works from Libby, to Bush, and ending with Cheney that shall connect itself to Libby
to close the ring. In parallel, a bond has emerged from Rumsfeld to Myers, creating a simple
linear form with them. Very few components have been grouped up together yet. An analogy
to be made is that this stage is as if the system was building a puzzle and has grouped a few
pieces together, including pieces from different parts of the puzzle, but it still cannot figure
out what the final picture will be.
An initial form is activated: the system starts to consider the possibility that the
Cheney–Libby–Bush cycle may be the defining form underlying this data. However, this theory will quickly be discarded, as the system is unable to expand this cyclic form, or to
34
Figure 22: KittyCat Step 4
In the next scenario, the system has realized that the ring form was incorrect and has
dismantled it into a linear form, structured in a fashion that it starts with Bush, that connects
with Cheney and this latter connects itself to Libby. In addition, a new connection has been
mapped connecting Powell to Armitage. It is interesting to note that in this instance, the
system has unmade the first connnection it had found in its earlier steps (Libby to Bush
connection) as well as the ring connection. This is a clear demonstration that the system is
flexible and fluid, in a sense that it can “change its mind” about some past action or try to
find other solutions that might seem more appealing at a given time.
35
This next step is of pivotal importance, for a hint of a draft of a complete picture
starts to emerge. Analysing the picture, it is possible to say that the conclusion should arise
soon, even though it is not completely clear the final form it will take. Almost all of the
components now have connections, except for two, and they are assembled in 5 chunks,
which should be connected somehow to create the final form with its best-fitting structure.
Rumsfeld now is connected to Feith and to Myers. The system presents a big chunck
originating from Bush, that connects to Wolfowitz, Rice, Ashcroft, and finally Cheney, this
latter connecting to Libby. This big form seems like a hierarchy, as does the form generated
by the trio Rumsfeld, Feith and Myers.
Figure 24: KittyCat Step 6
At last, in a sudden flash, the system finally realized the form and the structure the
dataset should adopt that would best suit it. All the loose chunks were connected to Bush,
becoming part of the previously biggest, and now only, chunk of the dataset. The components
adopted a form of hierarchy, the form that the system had identified in a few steps before
36
6 CRITICISM OF KEMP & TENENBAUM’S MODEL FROM A FARG
PHILOSOPHY
After the brief review of FARG and a brief description of a FARG-like system given
above, one should ask: how does the FARG system differs from Kemp and Tenenbaum's?
Moreover, and more importantly, why should a FARG system be proposed as an
alternative?
Let us enumerate some crucial issues:
K&T's system employs Breadth-first Search
Kemp and Tenenbaum's system works by first selecting a previously fixed form and
working on it until it has modelled the entire dataset into that form. The system employs a
single, unique `graph grammar' at a time. Only after fully processing a particular form may
it move to try the next possible form, and a comparison of results is brought out in the end,
finally selecting the form with the `best-fit'.
This approach does not seem flexible and fluid, as the human mind is. For starters, it
follows a rigid sequence between the forms. Moreover, it is completely unable to `change its
mind' and reconfigure the model into another form–regardless of the dataset; regardless of how the form seems to be unable to account for the data. This is something that humans do
quite capably (Hofstadter and FARG, 1995; Linhares, 2000; Linhares and Brum, 2007;
Hawkings and Blakeslee, 2004).
Works from the whole to the individual unit
Kemp and Tenembaum's system starts with an overwhelming cluster containing all
entities, FARG systems start at the other extreme: entities have no connection to each other.
FARG systems employ linking (perceived) related entities, not on splitting clusters. In fact,
37
Consider now, for instance, how humans play games, such as Sudoku, or Chess, etc.
It seems that one wants to find relations between pieces, or between Sudoku's quasi-empty
permutations. It seems that the mind is under a process of joining entities.
It certainly does not seem as if one has a bad (i.e., low-quality) global view of the
entire space, as implied by Kemp and Tenembaum's starting point and subsequent cluster
splits. Consider, for example, Kemp and Tenembaum's example of geography, in which the
latitudes and longitudes (of cities) are given as input. Let us think in terms of countries.
Imagine we have a map of the world's nations bearing no names on it, and we should fill in
the names. Kemp and Tenembaum's system would begin by placing random names in all
nations (i.e., a low-quality, all encompassing cluster). It would then proceed to divide this
all-encompassing view into more reasonable clusters, gradually finding that the USA and
Canada are close. A person, on the other hand, may be unaware of where Moldova is, but
may still join countries that have been strongly associated, such as USA–Canada, Brazil–
Argentina, Germany–France, or China–Japan. It seems that it is more psychologically
plausible to start from isolated elements and slowly bring them together than to start with a
random, all-entities-included stochastically, viewpoint.
Atlas graphs
Here is one characteristic which is lacking in both Kemp & Tenembaum's model and
FARG, though it is FARG-like, and may bring a contribution to future models. Imagine a
slipnet for a form-finding system. As seen above, items on the slipnet may bring top-down
pressures (i.e., hypothesis, or expectation-driven pressures) to reconfigure one's view. Such
a slipnet would certainly contain all possible forms available to the system, such that if the
bottom-up discovery process activates a (set of) particular form(s), there should be increased
`attention', or energy expended exploring those possibilities first. At this point we go over
technical details that may be of interest in devising a computational model: Atlas graphs are
38
Figure 25: Atlas
Atlas of graphs: This is the entire family of graphs with up to 6 nodes. Given that
each of these graphs are associated with some forms, but not with most, they may enable a
faster, and more fluid, activation of top-down forms.
In Figure 13 we see an `Atlas graph' with all possible graphs with up to 6 nodes. In a
FARG system, by finding some initial relations, one of these graphs will be active—and the
triggering of its corresponding graph in the Atlas is very fast. Because each graph in the
Atlas will be associated with some, but not all, top-down slipnet `form' nodes, the activation
of a graph in Atlas may activate suitable slipnet nodes, bringing pressures towards a
particular form. These pressures may, if strong enough, eventually force the system to
reconfigure the entire system state, in order to align the data with the expectation brought
39
Consider the example of the purple graph at the lowest rightmost position: this graph
is associated with circular forms. Therefore, if the system creates a graph like this one, the
circular form should be activated, and the system may attempt to reconfigure all the nodes
(those within and outside the 6-node graph) in a circular manner.
This would be a more fluid approach to the design of the system. Kemp and
Tenenbaum's model remains fixed in a single form throughout a run, inspite of any evidence
that there may be a particular underlying form worthy of consideration. This is exactly akin
to what Hofstadter describes below: entering a bookstore and reading the first book
cover-to-cover, instead of browsing the possibilities and exploring only those that seem attractive.
This point, is, of course, related to the idea of a temperature-managed system.
Temperature (frustration, entropy, etc) & parallel terraced scan
The flow of information processing in FARG systems is given by Temperature.
Temperature enables what Hofstadter has termed `parallel terraced scan':
On entering a bookstore, do you read the first book you come across from cover to
cover, then the next one, and so on? Of course not. There is a profound need for protecting
oneself from this sort of absurdity. People develop ways of quickly eliminating books of
little interest to them and homing in on the good possibilities. This is the idea of the terraced
scan: a parallel investigation of many possibilities to different levels of depth, quickly
throwing out bad ones and homing in rapidly and accurately on good ones. (The term is
mine, but much of the idea was present in an implicit form in Hearsay II.)
The terraced scan moves by stages: first one performs very quick superficial tests,
proceeding further only if those tests are passed. Each new stage involves more elaborate
and computationally more expensive tests, which, if passed, can lead to a further stage - and
so on. Furthermore, "passing a test" is not an all-or-nothing affair; each test produces a score,
indicating how promising this line of investigation appears at that stage. One uses this score
to determine the urgency of follow-up codelets (if indeed the score is high enough to warrant
any). This provides the desired layeredness to the evaluation of the quality of a potential
40
If a system has true (hardware) parallelism, it can perform quick tests on many items
in parallel, slower tests on a smaller number of items in parallel, and so on. On the other
hand, if the hardware is serial, the various tests making up the parallel explorations must
instead be interleaved, so that many possibilities can be simultaneously probed, with some
being in the earliest stages of testing, and others at various stages further along in the
scanning process. Hofstadter and FARG (1995), p. 107.
If one wants an `optimal' form-discovery system, it may make sense to apply the flow
of information-processing of Kemp and Tenembaum's model, given by a strict breadth-first
search. However, does that seem psychologically plausible? Aren't we faced with confusion,
cognitive dissonance, hesitation, as we face an unknown problem? Do not things seem to get
easier as we struggle to represent the problem? It seems that Hofstadter's model captures
something crucial about both System 1 thinking and System 2 thinking: the ability to quickly
accept (or discard) information (System 1 thinking), and the ability to engage in attention, or
energy-intensive problems. We note here that in Hofstadter's philosophy, the very idea of
System 1 versus System 2 seems too binary, too clean-cut, too detached from each other, as
his models provide a smooth and fluid interplay between both systems. Instead of a chasm
between System 1 and System 2, one has a whole continuum between these two forms of
thought. A clear example of this apears in the Numbo project: people quickly ``see'' that
20x20=400 , but not the results of 17x23 . Yet, people seem to know that the result is `close'
41
7 CONCLUSION & FUTURE RESEARCH
7.1 Why is discovery of form important to Artificial Intelligence and
computational cognitive science?
Consider a robot, a chess-playing program, a data mining system, and so on.
At one point, the system must be pre-programmed to deal with numbers; and more
specifically what kinds of numbers: a 32-bit integer is completely different from a 64-bit
float. And both numbers are different from a string such as `Hello world'. And all of those
are different from a branching point, given by a tree, which is still different from a loop. The
process of discovery of form enables the system to discover, on its own, given only the
dataset, that numbers belong to orders, trees belong to hierarchies, loops belong to cycles,
and so forth. By providing the first analysis of the discovery of form problem we believe that
Kemp and Tenenbaum's work brings us a monumental contribution.
Numerous things that should previsouly be explicitly pre-programmed can now be
discovered, and, if devised under a FARG philosophy, re-configured on the fly. What
initially looks like a vector, or a sequence, of integers can adapt a float, such as 3.1415. All
it takes is for the system to have discovered that numbers are formed by an order, and the
system will be able to correctly place (or process) the float between the integers previously
seen.
Numbo, for instance, has trees, chunks, and numbers. All of these can be discovered,
instead of pre-set by a programmer. Much like the human minds discovers a large number
of relationships and dynamics.
7.2 Why is this type of work important to management?
As we have mentioned in the introduction, cognition plays a great strategy role on
management and companies benefit immensely when they properly use managerial
cognition. Cognitive Science is a very new study field and its application to management are
even more recent. KittyCat is a cognitive model that simulates how to discover structure and
form within a dataset in a cognitively-plausible manner. This model allows us to understand
how the human mind works. Therefore, this model contributes to increase our knowledge on
42
However, even though these subjects are new, they show great promise as interesting
areas that will increase our knowledge of many fields related to management, for example,
behavior and decision-making. A practical consequence of this work is its contributions to
managers improving their management strategies as well as their decision-making.
Cognitive science principles could assist in managing complexities in strategic
management processes.
7.3 Future Research
In summary, we have studied the discovery of form problem from a FARG
philosophy. The suggestions for future improvements are listed below:
We limited ourselves to describing in detail how KittyCat works with the
most interesting type of input data — a matrix of feature data. Further exploration of how
the model works with the other two types of input data featured on Kemp &
Tenembaum's work would be interesting.
Future research should find ways to allow KittyCat to work with a greater
number of types of input data or, ideally, any type of data .
To better simulate how a human mind works, KittyCat should understand
more about the world and be able to work with an input entities that are specified using
natural language text (e.g., “tray”, “lamp post”, “man”, “tripod”, “dog”). The objective
is to make the model work without a predetermined set of features and derive new
features from fuzzy concepts. For instance, if we give KittyCat the previous list of
example words of natural language, the model should find the structure and form among
them. A fuzzy concept that has to come up to achieve the result is the number of legs (or
supports) each object has (e.g., a tray has zero legs, a lamp post has one, a man has two
legs, a tripod has three legs, a dog has four legs). Thus, a good structure is an order that
begins with the tray and ends with the dog, according to the number of legs.
This paper describes theoretically how KittyCat works, thus leaving the
43
REFERENCES
ABE, M. (2009). "Counting your customers" one by one: A hierarchical bayes extension to
the pareto/nbd model. Marketing Science, 28:541–553.
ASSAF, A. G. and JOSIASSEN, A. (2012). Time-varying production efficiency in the health
care foodservice industry: A bayesian method. Journal of Business Research, 65(5):617–
625.
ASSAF, A. G., JOSIASSEN, A., and GILLEN, D. (forthcoming). Measuring firm
performance: Bayesian estimates with good and bad outputs. Journal of Business Research.
BADDELEY, A. and HITCH, G. (1974) Working Memory. Psychology of learning and
motivation volume 8, pp. 47-89
BADDELEY, A. (1992) Working Memory. Science 255, pp 556-559
FORBES, D. P. (1999). Cognitive approaches to new venture creation. International Journal
of Management Reviews, 1(4):415–439.
GAVETTI, G. (2005). Cognition and hierarchy: Rethinking the microfoundations of
capabilities development. Organization Science, 16(6):599–617.
GAVETTI, G., LEVINTHAL, D., RIVKIN, J., and (2005). Strategy making in novel and
complex worlds: The power of analogy. Strategic Management Journal, 26(8):691–712.
GAVETTI, G. and WARGLIEN, M. (2007). Recognizing the new: A multi-agent model of
analogy in strategic decision-making. Revise and resubmit, Administrative Science
Quarterly.
HAWKINGS, J. and BLAKESLEE, S. (2004). On Intelligence. Times Books, 1 edition.
HOFSTADTER, D. and FARG (1995). Fluid Concept and Creative Analogies: Computer
Models of The Fundamental Mechanisms of Thought. Basic Books, New York, NY.
KEMP, C. and TENENBAUM, J. (2008). The discovery of structural form. Proceedings of