Universidade Federal do Rio Grande do Norte
Centro de Ciˆencias Exata e da Terra
Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica
Maria Jucimeire dos Santos
Uma Estrat´
egia Aleat´
oria Chamada de
MOSES
Maria Jucimeire dos Santos
Uma Estrat´
egia Aleat´
oria Chamada de
MOSES
Disserta¸c˜ao apresentada ao Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Orientador:
Prof. Juan Alberto Rojas Cruz
Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial Centro de Ciências Exatas e da Terra – CCET.
Santos, Maria Jucimeire dos.
Uma estratégia aleatória chamada de MOSES / Maria Jucimeire dos Santos. - Natal, 2013.
73 f. : il.
Orientador: Prof. Dr. Juan Alberto Rojas Cruz.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Programa de Pós-Graduação em Matemátca Aplicada e Estatística.
1. Cadeias de Markov – Dissertação. 2. Convergência – Dissertação. 3. Estratégia evolutiva – Dissertação. 4. Grandes desvios – Dissertação. 5. Probabilidade – Estatística – Dissertação. I. Cruz, Juan Alberto Rojas. II. Título.
Dedicat´
oria
Agradecimentos
Primeiramente agrade¸co a Deus que me deu sa´ude e for¸cas para vencer essa batalha. E colocou na minha vida pessoas maravilhosas que contribu´ıram bastante para realiza¸c˜ao deste trabalho.
A minha m˜ae Maria de F´atima que n˜ao tenho nem palavras para descrever o quanto foi importante nessa etapa da minha vida. Caminhou ao meu lado em todos os momentos, a distˆancia e o pouco estudo n˜ao foram obst´aculos para que ela compreendesse cada fase pela qual estava passando.
Ao meu pai Juarez que sempre acreditou em mim, torceu e fez o que pode para que eu alcan¸casse esse sonho.
Aos meus irm˜aos Jairo e Juciane, pelo amor, dedica¸c˜ao e carinho. Exemplos de apoio uns aos outros.
Ao meu sobrinho Juan Victor que por v´arias vezes me fez esquecer as minhas preocupa¸c˜oes e entrar no seu mundo m´agico, onde tudo ´e brincadeira.
A minha cunhada Gercileide que desde a gradua¸c˜ao tem colaborado para eu atingir meus objetivos. Sempre pedindo a Deus o meu sucesso.
Ao meu orientador Juan Rojas pela sugest˜ao do tema, por sua paciˆencia, seus ensinamentos e conselhos.
A Antonio um anjo que surgiu na minha vida, sempre se dispˆos a me ajudar, a me ouvir. Obrigada pelas sugest˜oes, discuss˜oes e ensinamentos.
A Rafael que me ensinou utilizar o software Matlab e contribui na programa¸c˜ao do meu algoritmo.
A Michele que alimentou este sonho e sempre esteve ao meu lado, me apoiando e me guiando.
A Al´ecia, amiga com a qual tenho uma d´ıvida impag´avel. Obrigada pelo apoio recebido desde a minha gradua¸c˜ao em Caic´o e tamb´em pelo impulso para a minha vinda a natal.
meus objetivos.
As minhas amigas de Caic´o Mariane, Gerlˆania, Denizy e Marluce que sempre contei com elas para compartilhar minhas alegrias, tristezas e dificuldades.
As minhas amigas Ta´ıs, Suzara, Iselda, Gabi, Monara e Carlinha pela aten¸c˜ao, carinho, companheirismo, gargalhadas, momentos de descontra¸c˜ao e todo apoio.
As Mipibuenses pela convivˆencia, em especial a todas que incentivaram e co-laboraram de alguma forma para realiza¸c˜ao deste trabalho.
Aos meus amigos Alcilene, Fabiana, Rafael e Luiz. A amizade de vocˆes me fortalece.
A minha amiga Paulinha pela for¸ca, carinho e amizade. Sempre t˜ao ocupada e mesmo assim encontrava tempo para me ouvir.
A todos os professores do mestrado pelos ensinamentos e conselhos.
Aos meus colegas de mestrado Rafaela, Alex, Aldemir, Ivanildo, Marcio, Jose-mir e Elisˆangela, companheiros de momentos de ang´ustia, de estudos e reflex˜oes. E a todos os demais colegas do PPGMAE pela for¸ca e carinho.
A Paulinho e Elvis, monitores da escola de ver˜ao, colegas e amigos. Obrigada por me ajudar desde o in´ıcio.
A professora Viviane que esteve presente na pr´e-qualifica¸c˜ao. Obrigada pelos conselhos.
Ao professor Andr´e Gustavo que esteve presente na qualifica¸c˜ao. Suas cr´ıticas e sugest˜oes me fortaleceram para a defesa.
A professora Daniele que aceitou o nosso convite para estar presente na defesa de mestrado. Obrigada pelas sugest˜oes.
Em especial agrade¸co a professora D´ebora que esteve presente em todas as etapas desse trabalho, pr´e-qualifica¸c˜ao, qualifica¸c˜ao e defesa. Obrigada por todas as cr´ıticas e sugest˜oes. Sua presen¸ca na defesa foi muito importante para mim.
Agrade¸co a todos os funcion´arios do CCET em especial a Liandra, Russinho e a Rafael secret´ario.
A Capes pelo apoio financeiro.
Resumo
Neste trabalho estudamos uma estrat´egia aleat´oria chamada de MOSES, que foi introduzida por Fran¸cois em 1996. Resultados assint´oticos desta estrat´egia; com-portamento das distribui¸c˜oes estacion´arias da cadeia associada a estrat´egia, foram derivados por Fran¸cois, em 1998, da teoria de Freidlin e Wentzell [8]. Detalhamentos destes resultados est˜ao neste trabalho. Por outro lado, notamos que uma aborda-gem alternativa da convergˆencia desta estrat´egia ´e poss´ıvel sem fazer uso da teoria de Freidlin e Wentzell, obtendo-se a visita quase certa da estrat´egia `as popula¸c˜oes uniformes que contˆem o m´ınimo. Algumas simula¸c˜oes no Matlab s˜ao apresentadas neste trabalho.
Abstract
This paper we study a random strategy called MOSES, which was introduced in 1996 by Fran¸cois. Asymptotic results of this strategy; behavior of the stationary distributions of the chain associated to strategy, were derived by Fran¸cois, in 1998, of the theory of Freidlin and Wentzell [8]. Detailings of these results are in this work. Moreover, we noted that an alternative approach the convergence of this strategy is possible without making use of theory of Freidlin and Wentzell, yielding the visit almost certain of the strategy to uniform populations which contain the minimum. Some simulations in Matlab are presented in this work.
Sum´
ario
1 Cadeias de Markov 3
1.1 Processos Estoc´asticos . . . 3
1.2 Cadeias de Markov . . . 4
1.2.1 Cadeias de Markov Irredut´ıveis . . . 5
1.2.2 Convergˆencia da Cadeia de Markov . . . 6
1.2.3 Cadeias de Markov N˜ao-Homogˆeneas . . . 8
2 Estrat´egia Aleat´oria MOSES 12 2.1 Algoritmos Evolutivos . . . 12
2.2 Cotas para as Probabilidades de Transi¸c˜ao . . . 15
2.2.1 Dinˆamica da estrat´egia . . . 16
3 Comportamento Assint´otico da estrat´egia MOSES 24 3.1 x-grafo . . . 24
3.2 Princ´ıpio dos Grandes Desvios . . . 29
3.3 Convergˆencia da Estrat´egia MOSES . . . 29
4 Convergˆencia Quase Certa da Estrat´egia MOSES 39 5 Estrat´egia MOSES no Matlab: Algumas Simula¸c˜oes 44 5.1 Testes Sobre Tempo M´edio da Primeira Visita da estrat´egia MOSES ao M´ınimo . . . 45
5.2 MOSES Versus Simulated Annealing em Paralelo . . . 48
SUM ´ARIO 1
Apˆendice 54
Programas . . . 54
Estrat´egia MOSES . . . 54 Simulated Annealing em Paralelo . . . 57
Introdu¸
c˜
ao
Neste trabalho apresentamos um tipo de estrat´egia aleat´oria chamada MOSES (Estrat´egia Evolutiva Sele¸c˜ao-Muta¸c˜ao) introduzida em 1996, por Fran¸cois [6].
A dinˆamica da estrat´egia emprega muta¸c˜ao e sele¸c˜ao (sem cruzamento). O objetivo de MOSES ´e encontrar o m´ınimo global de uma fun¸c˜aof :E →R, chamada
de fun¸c˜ao objetivo, ondeE´e um conjunto finito. Uma vizinhan¸ca para cada elemento em E ´e determinado por um grafo g = (E, A), estas vizinhan¸cas determinam as muta¸c˜oes da estrat´egia.
Este trabalho ´e baseado no artigo “An evolutionary strategy for global mini-mization and its Markov chain analysis” de Fran¸cois [7].
Cap´ıtulo 1
Cadeias de Markov
O intuito deste cap´ıtulo ´e servir como suporte para a leitura deste trabalho. Apresentamos os resultados essenciais da teoria de cadeia de Markov homogˆenea e n˜ao-homogˆenea, uma vez que a estrat´egia MOSES possui uma estrutura Markoviana.
1.1
Processos Estoc´
asticos
Defini¸c˜ao 1.1.1. Um Processo Estoc´astico ´e uma fam´ılia de vari´aveis aleat´orias definidas sobre o mesmo espa¸co amostral Ω. Se a fam´ılia ´e enumer´avel o processo
´e denotado por {Xt}t∈N. Se a fam´ılia ´e n˜ao-enumer´avel o processo ´e denotado por
{Xt}t∈[0,∞). No primeiro caso, o processo ´e dito um processo a tempo discreto,
enquanto no segundo caso ´e dito a tempo cont´ınuo.
Um processo estoc´astico pode ser visto como uma fun¸c˜ao de duas vari´aveis
Xt(w) =X(t, w).
Parat fixo, a fun¸c˜ao ´e uma vari´avel aleat´oria e para w fixo temos uma fun¸c˜ao real de t que ´e chamada de trajet´oria.
Defini¸c˜ao 1.1.2. O conjunto S de todos os valores assumidos pelo processo ´e cha-mado espa¸co de estados.
1.2 Cadeias de Markov 4
tempo t. Se o processo no tempo t−1 se encontra no estado i, a probabilidade condicional de no tempot estar no estado j ´e representado por
P(Xt =j|Xt−1 =i),
esta probabilidade ´e chamada de probabilidade de transi¸c˜ao.
1.2
Cadeias de Markov
Um Processo Estoc´astico {Xt}t∈N com espa¸co de estados S = {i1, i2, i3, . . .},
satisfaz `a propriedade de Markov se para todote todos os estados{i1, i2, . . . , it} ∈S temos
P(Xt =it|Xt−1=it−1, Xt−2 =it−2, . . . , X1 =i1) =P (Xt = it|Xt−1=it−1).
Defini¸c˜ao 1.2.1. Um processo a tempo discreto, com espa¸co de estados enumer´avel, que satisfaz `a propriedade de Markov ´e chamado de cadeia de Markov.
Uma cadeia de Markov ´e dita homogˆenea quando as probabilidades de transi¸c˜ao n˜ao mudam no tempo, isto ´e, para todos os estados i, j∈S temos que:
P(Xt+1 =j|Xt =i) =P (X2 =j|X1 =i), ∀t≥1.
A cadeia de Markov ´e dita n˜ao-homogˆenea se as probabilidades de transi¸c˜ao mudam com o tempo. No caso homogˆeneo temos
pij =P (Xt =j|Xt−1 =i), ∀ t≥1.
A probabilidade de transi¸c˜ao em n passos pn
ij ´e definida:
pnij =P(Xt+n =j|Xt =i), n≥0, i, j ∈S.
Dada uma cadeia de Markov homogˆenea{Xt}t∈N com espa¸co de estados finito
S = {1,2, . . . , n}, existem n2 probabilidades de transi¸c˜ao p
ij, i = 1,2, . . . , n e
1.2 Cadeias de Markov 5 P =
p11 p12 · · · p1n
p21 p22 · · · p2n
... ...
pn1 pn2 · · · pnn
.
Como veremos adiante, esta matriz n˜ao ´e s´o uma boa maneira de guardar as informa¸c˜oes das probabilidades de transi¸c˜ao, as suas potˆencias determinam o com-portamento da cadeia. Observe as seguintes propriedades das matrizes de transi¸c˜ao:
(i) Todas as entradas s˜ao n˜ao-negativas, pois representam probabilidades;
(ii) As somas das entradas em cada linha ´e sempre 1.
Uma matriz quadrada que satisfaz as propriedades acima ´e chamada deMatriz Estoc´astica.
1.2.1
Cadeias de Markov Irredut´ıveis
Seja P = (pij)i,j∈S a matriz de transi¸c˜ao de uma cadeia homogˆenea. As equa¸c˜oes deChapman-Kolmogorovfornecem um m´etodo para calcular as proba-bilidades de transi¸c˜ao emn passos. Essas equa¸c˜oes s˜ao:
pnij+m=
∞
X
k=0
pnikpmkj, ∀ n, m≥0, ∀ i, j∈S.
Se considerarmos P(n) como a matriz das probabilidades de transi¸c˜ao em n
passospn
ij, ent˜ao a equa¸c˜ao anterior afirma que:
P(n+m) =P(n)·P(m),
onde o ponto representa a multiplica¸c˜ao das matrizes. Assim,
P(n) =P ·P(n−1)= P ·P ·P(n−2)=· · · =Pn
dessa forma, P(n) pode ser calculada multiplicando a matriz P por ela mesma n
vezes.
Defini¸c˜ao 1.2.2. O estado j ´e dito ser acess´ıvel a partir do estado i se existe um
n∈N, tal quepn
1.2 Cadeias de Markov 6
i→j ej →i, ou seja, existe um n1 ∈N tal que pnij1 >0e existe um n2 ∈N tal que
pn2
ji >0. Denotamos por i↔j.
Defini¸c˜ao 1.2.3. Quando todos os estados da cadeia se comunicam dizemos que a cadeia ´eirredut´ıvel.
Defini¸c˜ao 1.2.4. Definimos oper´ıodo de um estado i como sendo
d(i) =mdc{n≥1;pnii >0}.
Se d(i) = 1 dizemos que o estado i´e aperi´odico.
Proposi¸c˜ao 1.2.1. Se i↔ j, ent˜ao d(i) =d(j).
Pela Proposi¸c˜ao 1.2.1 podemos concluir que se uma cadeia ´e irredut´ıvel ent˜ao todos os estados tˆem o mesmo per´ıodo. Dessa forma, se um estado tem per´ıodo
d= 1, ou seja, ´e aperi´odico, ent˜ao todos os outros estados s˜ao aperi´odicos. Quando isso ocorre dizemos que a cadeia ´eaperi´odica.
1.2.2
Convergˆ
encia da Cadeia de Markov
Defini¸c˜ao 1.2.5. Seja P uma matriz de transi¸c˜ao de uma cadeia de Markov. Se para todo j ∈ S existe lim
n→∞p (n)
ij = πj e
∞
X
j=1
πj = 1, ent˜ao dizemos que a cadeia ´e
erg´odica.
Defini¸c˜ao 1.2.6. Uma distribui¸c˜ao de probabilidade {πj, j∈S} ´e chamada
distri-bui¸c˜ao estacion´aria da cadeia de Markov com matriz de transi¸c˜aoP = (pij)i,j∈S, S =
{1,2,3, . . .}, se
πj =
X
l∈S
πlplj, ∀ j.
Em forma matricial
π =πP =πP2 =πP3=. . .
1.2 Cadeias de Markov 7
Teorema 1.2.2. Seja {Xn} uma cadeia de Markov com espa¸co de estados finito,
irredut´ıvel e aperi´odica com matriz de transi¸c˜aoP = (pij)i,j∈S. Ent˜ao lim n→∞p
(n)
ij = πj,
onde π= (πj)´e a distribui¸c˜ao estacion´aria.
Observe que o teorema acima garante a existˆencia do comportamento limite da cadeia e tamb´em mostra uma forma de encontrar esse limite, bastando para isso encontrar a distribui¸c˜ao estacion´aria.
Corol´ario 1.2.3. Toda cadeia de Markov homogˆenea irredut´ıvel, aperi´odica com espa¸co de estados finito possui uma ´unica distribui¸c˜ao estacion´aria e converge para
ela.
Defini¸c˜ao 1.2.7. Para quaisqueri, j ∈S, a probabilidade de que partindo do estado
i, a primeira visita do processo ao estado j se dˆe no passo n´e dada por,
fijn =P(Xn =j, Xn−1 =6 j, ..., X1 6=j|X0 =i).
Defini¸c˜ao 1.2.8. Para os estados i, j fixos, sejaf∗
ij =
∞
X
n=1
fij(n). Onde f∗
ij representa
a probabilidade de visitar o estadoj dado que o processo partiu do estadoi. Sei=j,
f∗
ii =
∞
X
n=1
fii(n) denota a probabilidade de retornar ao estadoi.
Defini¸c˜ao 1.2.9. O estado j ´e dito ser recorrente se f∗
jj = 1. Se fjj∗ < 1, ent˜ao o
estado j ´e dito transiente.
Defini¸c˜ao 1.2.10. Se f∗
jj= 1, definimos o tempo m´edio de recorrˆencia ao estado j
como µj =
∞
X
n=1
nfjj(n).
Defini¸c˜ao 1.2.11. Seja j um estado recorrente,
(i) µj =∞ ⇒ j ´e recorrente nulo, (ii) µj <∞ ⇒ j ´e recorrente positivo.
Teorema 1.2.4. Seja P a matriz de transi¸c˜ao de uma cadeia de Markov irredut´ıvel e recorrente positiva. Ent˜ao 1
n
n
X
k=1
p(ijk) converge quandon→ ∞e o limite ´e 1
µj
1.2 Cadeias de Markov 8
µj ´e o tempo m´edio de recorrˆencia do estado j. O vetor π =
1 µ1 , 1 µ2 , . . . ´e uma
distribui¸c˜ao estacion´aria de P.
Teorema 1.2.5. Para cada cadeia de Markov irredut´ıvel com espa¸co de estados S
existe uma sequˆencia {πj, j ∈S} tal que para cadai e j ∈S lim n→∞ 1 n n X k=1
p(ijk)
=πj. (1.1)
Teorema 1.2.6. Seja S o espa¸co de estados de uma cadeia de Markov irredut´ıvel. Se S ´e finito, ent˜ao a cadeia de Markov possui uma ´unica distribui¸c˜ao estacion´aria.
A demonstra¸c˜ao do Teorema 1.2.4 pode ser encontrada em Isaacson [11] e as demonstra¸c˜oes dos Teoremas 1.2.5 e 1.2.6 s˜ao encontradas em Parzen [13].
1.2.3
Cadeias de Markov N˜
ao-Homogˆ
eneas
Uma Cadeia de Markov N˜ao-Homogˆenea ´e descrita por um vetor inicial f(0)
e uma sequˆencia de matrizes de transi¸c˜ao{Pk}∞k=1, onde f(0) ´e uma distribui¸c˜ao de
probabilidade sobre os estados, isto ´e:
fi(0)≥0, i= 1,2, ... e
∞
X
i=1
fi(0) = 1.
Defini¸c˜ao 1.2.12. Sejam P1, P2, ...matrizes de transi¸c˜ao de uma cadeia de Markov
n˜ao-homogˆenea com vetor inicial f(0). Definimos:
f(k)=f(0)P1·P2·...·Pk e f(m,k)=f(0)Pm+1·...·Pk.
Definimos o j-´esimo elemento de f(k) por f(k)
j = P(Xk =j) e definimos o (i, j)-´esimo elemento deP(m,k)=P
m+1·Pm+2·...·Pk porPi,j(m,k)=P(Xk = j|Xm=i).
Analogamente para g(k), g(m,k) e g(m,k)
1.2 Cadeias de Markov 9
O objetivo principal da teoria de cadeia de Markov n˜ao-homogˆenea ´e o com-portamento de f(k) e f(m,k) quando k → ∞. Pode acontecer quef(k) convirja para
o mesmo vetor fixo q, independentemente do vetor inicial f(0) utilizado, isto ´e, um
vetor limite existe e ´e independente da escolha do vetor inicial. Neste caso, a in-forma¸c˜ao sobre f(k), para k grande, d´a-nos pouca ou nenhuma informa¸c˜ao sobre
f(0), ou seja, o efeito de f(0) ´e perdido ao longo do tempo. Quando f(m,k) → q
quando k → ∞, ∀ m ∈ N, independe de f(0), este comportamento ´e conhecido
como convergˆencia com perda de mem´oria e ´e chamado deergodicidade forte. ´E poss´ıvel ter tamb´em convergˆencia sem perda de mem´oria e perda de mem´oria sem convergˆencia. No ´ultimo caso o efeito da distribui¸c˜ao inicial ´e perdido, ou seja, f(k)
e g(k) est˜ao em algum sentido pr´oximos, mas n˜ao necessariamente existe uma
con-vergˆencia def(k) nem deg(k). Esse comportamento ser´a chamado deergodicidade
fraca.
Para efeito de estudar a convergˆencia da cadeia de Markov ´e comum usar a seguinte norma.
Defini¸c˜ao 1.2.13. Se f = (f1, f2, f3, ...)´e um vetor, definimos a norma de f por
kfk=
∞
X
i=1
|fi|.
E se A= (aij) ´e uma matriz quadrada, definimos a norma de Apor
kAk= sup i
∞
X
i=1
|aij|.
Defini¸c˜ao 1.2.14. Uma cadeia de Markov n˜ao-homogˆenea ´e chamada fracamente erg´odica se para todo m
lim
k→∞f(0)sup,g(0)
f(m,k)−g(m,k)
= 0
onde f(0) e g(0) s˜ao vetores iniciais.
Quando o espa¸co de estados ´e finito o conceito de ergodicidade fraca ´e equiva-lente a: lim n→∞ P
(m,m+n)
ij −P
(m,m+n)
kj
1.2 Cadeias de Markov 10
Outra equivalˆencia para o conceito de ergodicidade fraca ´e:
lim k→∞δ P
(m,k)
= 0, ∀m≥0,
onde δ(Q) = 1−α(Q) e α(Q) ´e o coeficiente erg´odico de Dobrushin definido por
α(Q) = 1−max i,k∈S
X
j∈S
[qij −qkj]+, com [qij −qkj]+= max{0, qij −qkj}. Podemos reescrever o coeficiente erg´odico de Dobrushin como
α(P) = min i,k∈E
X
j∈E
min (Pij, Pkj). Outra desigualdade importante ´e a seguinte:
δ(P Q)≤δ(P)δ(Q).
Defini¸c˜ao 1.2.15. Uma cadeia de Markov n˜ao-homogˆenea ´e chamada fortemente erg´odica se existir um vetor q= (q1, q2, ...), comkqk= 1e qi ≥0, parai= 1,2,3, ...
tal que para todo m
lim k→∞supf(0)
f(m,k)−q
= 0,
onde f(0) ´e um vetor inicial.
Os dois teoremas a seguir s˜ao resultados fundamentais sobre a ergodicidade forte.
Denotamos por℘a classe das matrizes estoc´asticasP para as quais existe pelo menos um autovetor `a esquerda n˜ao negativoψ correspondendo ao autovalor 1 e tal que kψk= 1.
Teorema 1.2.7. Seja{Pn}uma sequˆencia de matrizes de transi¸c˜ao correspondentes
a uma cadeia de Markov n˜ao-homogˆenea fracamente erg´odica comPn ∈℘ para todo
n. Se existir uma sequˆencia correspondente de autovetores ψn satisfazendo
X
j
1.2 Cadeias de Markov 11
ent˜ao a cadeia ´e fortemente erg´odica.
Teorema 1.2.8. Seja{Pn}uma sequˆencia de matrizes de transi¸c˜ao correspondentes
a uma cadeia de Markov n˜ao-homogˆenea com Pn ∈ ℘. Se kPn−Pk → 0 quando
Cap´ıtulo 2
Estrat´
egia Aleat´
oria MOSES
2.1
Algoritmos Evolutivos
Os algoritmos evolutivos s˜ao processos de pesquisa global que procuram o
m´ınimo global de uma fun¸c˜ao f :E→R, ondeE ´e finito.
Em [5] ´e apresentado um quadro b´asico para algoritmos evolutivos que ´e o
seguinte:
1. Inicializa com uma popula¸c˜ao de solu¸c˜oes em E;
2. Avalia cada solu¸c˜ao na popula¸c˜ao;
3. Prop˜oe algumas mudan¸cas aleat´orias na popula¸c˜ao;
4. Usa um crit´erio de rejei¸c˜ao para validar cada altera¸c˜ao e avaliar as novas
solu¸c˜oes;
5. Se um crit´erio de parada ´e satisfeito, retorna a melhor solu¸c˜ao; caso contr´ario,
vai para etapa 3;
Exemplos desses algoritmos evolutivos s˜ao os algoritmos gen´etico, Simulated
2.1 Algoritmos Evolutivos 13
formadas por indiv´ıduos, onde cada indiv´ıduo possui representa¸c˜ao bin´aria. O
algo-ritmo pode ser descrito como segue:
Escolhe aleatoriamente uma popula¸c˜ao inicial
Repete:
• Execute sele¸c˜ao;
• Execute cruzamento;
• Execute muta¸c˜ao;
at´e que algum crit´erio de parada seja satisfeito.
Dada uma popula¸c˜ao (b1, b2, . . . , bn) a probabilidade que o indiv´ıduo bi fa¸ca parte da pr´oxima gera¸c˜ao ´e usualmente definida como:
P(bi´e selecionado) =
f(bi) n
X
j=1
f(bj)
.
A muta¸c˜ao da popula¸c˜ao (b1, b2, . . . , bn) para a popula¸c˜ao
´
b1,b´2, . . . ,b´n
acon-tece com a seguinte probabilidade:
Pbi→ b´i
=pHm(bi,bi)´ (1−pm)l−H(bi,
´
bi)
ondeHbi,b´i
´e distˆancia Hamming (n´umero de posi¸c˜oes em que os bits
correspon-dentes s˜ao diferentes) entre os caracteres bi e ´bi. Uma referˆencia elementar sobre os algoritmos gen´eticos pode ser, por exemplo, [14] e [4].
O Algoritmo Simulated Annealing ´e uma t´ecnica utilizada em problemas de otimiza¸c˜ao combinat´oria, isto ´e, min
x f(x), x ∈E, onde f :E →
R, E finito. O
termo Annealing ´e associado a um processo utilizado para fundir um metal, onde
este ´e aquecido a uma temperatura elevada e em seguida ´e resfriado lentamente de
2.1 Algoritmos Evolutivos 14
otimiza¸c˜ao ´e realizado por n´ıveis em que h´a a simula¸c˜ao dos n´ıveis de temperatura
no resfriamento. Em cada n´ıvel, dado um pontou∈E, v´arios pontos na vizinhan¸ca de u s˜ao gerados e o correspondente valor de f ´e calculado. Cada ponto gerado ´e aceito ou rejeitado de acordo com uma certa probabilidade. Esta probabilidade
de aceita¸c˜ao decresce de acordo com o n´ıvel do processo, ou equivalentemente, de
acordo com a temperatura (veja [9]).
Neste cap´ıtulo, abordamos uma estrat´egia aleat´oria chamada MOSES que pode
ser vista como uma simplifica¸c˜ao do algoritmo gen´etico cl´assico, uma vez que existe
muta¸c˜ao e sele¸c˜ao; por´em n˜ao acontece cruzamento, o que evita trabalhar com
representa¸c˜ao bin´aria e simplifica muito o tratamento matem´atico do mesmo. Esta
estrat´egia objetiva identificar o m´ınimo global de uma fun¸c˜aof, chamada de fun¸c˜ao objetivo,f :E→ R, ondeE ´e um conjunto finito, no qual ´e definida uma estrutura
de grafog = (E, A), sendoEo conjunto dos v´ertices do grafo eAdenota o conjunto das arestas. Essa estrutura define uma vizinhan¸ca para cada v´ertice emE.
A dinˆamica da estrat´egia MOSES emprega mecanismos de muta¸c˜ao e sele¸c˜ao.
A muta¸c˜ao atua como um passeio aleat´orio no grafo g e o processo de sele¸c˜ao atua identificando o indiv´ıduo com a menor imagem e tamb´em selecionando os indiv´ıduos
a serem mutados para o menor elemento da popula¸c˜ao atual. Os parˆametros
asso-ciados `a estrat´egia MOSES, tais como o tamanho da popula¸c˜ao, probabilidades
de muta¸c˜ao e a geometria do problema (do grafo g = (E, A)) determinam a con-vergˆencia para um m´ınimo global (veja os Teoremas 3.3.5 e 3.3.7). No Cap´ıtulo 4,
obtemos resultados sobre a convergˆencia da estrat´egia MOSES, estes resultados n˜ao
imp˜oe condi¸c˜oes sobre o tamanho da popula¸c˜ao.
No caso da estrat´egia MOSES o tamanho da popula¸c˜ao ´e fixo e ´e igual a um
inteiro n≥2. O parˆametro que controla o n´umero de indiv´ıduos a serem mutados em cada gera¸c˜ao ´e denotado por pT. Esse parˆametro pode depender da gera¸c˜ao, ´e tomado no intervalo (0,1) e ´e visto como probabilidade de muta¸c˜ao.
A estrat´egia MOSES pode ser resumida da seguinte maneira:
2.2 Cotas para as Probabilidades de Transi¸c˜ao 15
2. Repete
• DadoN um n´umero aleat´orio com distribui¸c˜ao binomial bin(n, pT).
• Seleciona o indiv´ıduo ´otimo ˆxda popula¸c˜ao.
• Substitui os N primeiros indiv´ıduos pela muta¸c˜ao e os n− N outros indiv´ıduos por ˆx.
• AtualizapT.
A grande caracter´ıstica de MOSES ´e que a busca ´e hier´arquica. Indiv´ıduos
realizam diferentes graus de pesquisa de acordo com sua posi¸c˜ao na popula¸c˜ao. Aos
indiv´ıduos das primeiras posi¸c˜oes ´e permitido fazer longas caminhadas. Essa
hierar-quia ´e obtida do n´umero aleat´orio de descendentes por muta¸c˜ao em cada gera¸c˜ao. A
probabilidade de quek indiv´ıduos sejam mutados ´e dada pela distribui¸c˜ao binomial
bin(n, pT). Dessa forma, para todo 0≤k≤n, temos:
P (N =k) =
n k
pkT (1−pT)n−k.
V´arios crit´erios podem ser utilizados para conter a evolu¸c˜ao. Um crit´erio
natu-ral ´e assumir que o parˆametro de muta¸c˜aopT diminua para zero. A grande vantagem da estrat´egia MOSES em rela¸c˜ao ao algoritmo gen´etico ´e que a an´alise matem´atica
do procedimento pode ser descrita em detalhes, devido ao fato que a estrat´egia
MOSES n˜ao utiliza cruzamento em sua dinˆamica. A constru¸c˜ao da estrat´egia, e
especificamente, a escolha da distribui¸c˜ao binomial, ´e motivada pela aplica¸c˜ao do
formalismo do princ´ıpio dos grandes desvios que ser´a abordado posteriormente.
2.2
Cotas para as Probabilidades de Transi¸
c˜
ao
Nesta se¸c˜ao descrevemos formalmente a estrat´egia MOSES e obtemos cotas
2.2 Cotas para as Probabilidades de Transi¸c˜ao 16
que f ´e uma fun¸c˜ao injetora arbitr´aria, definida num conjunto finito qualquer, de-notado por E, f : E → R. Al´em disso, existe um ´unico ponto m´ınimo global e
´e denotado por a∗. ´E importante destacar que a hip´otese da fun¸c˜ao ser injetora
n˜ao ´e t˜ao restritiva, pois caso contr´ario, podemos fazer uma perturba¸c˜ao tornando
a fun¸c˜ao injetora (ver anexo). Por outro lado, no Cap´ıtulo 4, apresentamos uma
nova abordagem para a an´alise da convergˆencia de MOSES que n˜ao precisa desta
hip´otese.
Nota¸c˜oes e defini¸c˜oes: Fixamos um n´umero inteiron≥2 e definimos o conjunto das popula¸c˜oes de tamanhonporX =En. Isto ´e, uma popula¸c˜aox´e simplesmente um vetor de tamanho n, com entradas em E. Dizemos que:
x∈X ⇔x= (x1, x2, . . . , xn), xi ∈E, ∀i= 1, . . . , n.
A popula¸c˜ao uniforme (a, . . . , a) com a∈E ´e identificada pela nota¸c˜ao (a) = (a, . . . , a).
Denotamos ˆx como o m´ınimo de uma popula¸c˜ao: ˆ
x∈ {x1, x2, . . . , xn}, f(ˆx)≤f(xi), ∀ i= 1, . . . , n.
Como foi comentado na introdu¸c˜ao, a vizinhan¸ca N(xi) de cada indiv´ıduo xi esta associada a um grafog = (E, A) conexo e tal que:
1. N(xi) ={yi ∈E/yi6=xi,(xi, yi)∈A}, |N(xi)| ≥2; 2. sim´etrico, isto ´e,
xi ∈N(xj), se e somente se, xj ∈N(xi);
2.2.1
Dinˆ
amica da estrat´
egia
2.2 Cotas para as Probabilidades de Transi¸c˜ao 17
i) identifica ˆx0
ii) Gera um n´umero aleat´orioNda distribui¸c˜ao binomialbin n, PT(1)
, ondePT(t) =
exp (−1/T(t)), com t= 1,2, ...e T(t)→0
iii) X1 = x1 = (y1, y2, . . . , yN,xˆ0,xˆ0, . . . ,xˆ0) onde os yi s˜ao escolhidos em N(xi)∩ (E\ {xˆ0}), i ∈ {1,2, . . . , n}, com probabilidade uniforme.
Etapa 2:
i) identifica ˆx1
ii) Gera um n´umero aleat´orio N da distribui¸c˜ao binomial bin n, PT(2)
iii) X2 = x2 = (z1, z2, . . . , zN,xˆ1,xˆ1, . . . ,xˆ1) onde zi s˜ao escolhidos em N(yi)∩ (E\ {xˆ1}), i ∈ {1,2, . . . , n}, com probabilidade uniforme.
...
Assim obtemos um conjunto de vetores aleat´orias X0, X1, X2, . . . com espa¸co
de estadosX, onde X ´e o conjunto de todas as popula¸c˜oes e a distribui¸c˜ao deXt ´e determinada somente pela distribui¸c˜ao deXt−1. Logo, X0, X1, X2, . . .´e uma cadeia
de Markov.
`
A dinˆamica da estrat´egia MOSES tem associada uma cadeia de Markov com
espa¸co de estadosX (o conjunto de todas as popula¸c˜oes). A seguir descrevemos de maneira expl´ıcita as probabilidades de transi¸c˜ao.
Seja qT(t) a matriz de transi¸c˜ao no tempot, isto ´e
qT(t)(x, y) =P
XtT+1(t) =y|XtT(t) =x.
Para efeito de simplificar a nota¸c˜ao escrevemos T =T (t), assim
qT (x, y) =P XtT+1 =y|XtT =x
.
2.2 Cotas para as Probabilidades de Transi¸c˜ao 18
n´umeros inteiros sucessivos i∈ {1, . . . , n}, definido como
I(x, y) ={1≤i≤n; yi 6= ˆx}. O n´umero de elementos neste subconjunto ´e denotado por
C(x, y) =|I(x, y)|.
A transi¸c˜ao entre xey ´e poss´ıvel se, e somente se, π(x, y)6= 0, onde
π(x, y) = Y i∈I(x,y)
1N(xi)∩(E\{ˆx})(yi)
|N(xi)∩(E\ {xˆ})|
Y
i /∈I(x,y)
1{ˆx}(yi).
Nesse caso, a probabilidade de transi¸c˜ao da popula¸c˜ao xpara y ´e dada por:
qT (x, y) =P(N =C(x, y))π(x, y).
A quantidade C(x, y) representa o n´umero de indiv´ıduos da popula¸c˜ao y que s˜ao diferentes de ˆx. Durante a an´alise, esta quantidade ´e vista como um custo de comunica¸c˜ao de uma etapa entre as popula¸c˜oes x e y. Ele expressa a dificuldade para a cadeia XT
t
se deslocar de xpara y em uma ´unica etapa. Observa¸c˜ao 2.2.1. Note que a matriz de transi¸c˜ao qT ´e irredut´ıvel.
De fato, sejam x, y∈X duas popula¸c˜oes quaisquer, onde
x= (a1, a2, . . . , an) e
y= (b1, b2, . . . , bn),
sendo ai, bi ∈ E, i = 1, . . . , n. Como o grafo g = (E, A) ´e conexo, para todo i ∈
{1, . . . , n}existe um caminho em g = (E, A), ligandoai com bi;
2.2 Cotas para as Probabilidades de Transi¸c˜ao 19
a2 →a22 →a23 →. . .→ar2 →b2
...
an →a2n →a3n →. . .→ arn →bn.
Dessa forma, podemos construir as seguintes popula¸c˜oes em X:
x= (a1, a2, . . . , an)
x1 = a21, a22, . . . , a2n
x2 = a31, a32, . . . , a3n
...
xr−1= (ar1, ar2, . . . , arn)
y = (b1, b2, . . . , bn)
x→x1→ x2 →. . .→xr−1→ y
Portanto, para duas popula¸c˜oes quaisquer x, y ∈ X existe r ∈ N tal que
qr
T (x, y)> 0.
Al´em disso, observe que a matriz de transi¸c˜ao qT ´e aperi´odica. De fato, pela Proposi¸c˜ao 1.2.1 ´e suficiente mostrar que existe um estado aperi´odico. Para isto,
considere uma popula¸c˜ao uniforme x = (a, a, . . . , a), note que q1
T(x, x) > 0, (se
N =bin(n, pT) = 0 ent˜ao todos os indiv´ıduos s˜ao mutados para o ponto m´ınimo da popula¸c˜ao) assim o estado x´e aperi´odico. Portanto, a cadeia ´e aperi´odica.
O fato de que a matriz de transi¸c˜ao qT seja irredut´ıvel e finita garante a existˆencia de uma ´unica distribui¸c˜ao estacion´aria (Teorema 1.2.6), que permite usar
teoria de Freidlin e Wentzell. Tamb´em temos que a matriz qT ´e erg´odica, pois ´e irredut´ıvel, aperi´odica e finita (Corol´ario 1.2.3).
2.2 Cotas para as Probabilidades de Transi¸c˜ao 20
qT, a qual ´e fundamental no estudo assint´otico da cadeia associada `a estrat´egia. Proposi¸c˜ao 2.2.1. Seja y uma popula¸c˜ao que ´e acess´ıvel a partir dexem um ´unico passo, ent˜ao a probabilidade de transi¸c˜ao satisfaz a seguinte desigualdade:
1
2nπ(x, y)e
−C(x,y)/T ≤q
T (x, y)≤2nπ(x, y)e−C(x,y)/T.
Demonstra¸c˜ao. ConsidereC(x, y) =k, logo:
P (N =C(x, y)) =P (N =k) =
n k
(pT)k(1−pT)n−k,
onde pT =e(−1/T). Observemos:
i) (1−pT)n ≤
n k
(1−pT)n−k
De fato (1−pT)≤1 ent˜ao (1−pT)n ≤(1−pT)n−k. Sendo assim,
(1−pT)n ≤
n k
(1−pT)n−k.
ii) n k
(1−pT)n−k ≤max
k n k .
De fato, como (1−pT)≤1 ent˜ao (1−pT)n−k ≤1. Sendo assim, n k
(1−pT)n−k ≤
n k
≤max
k n k .
iii) max k n k
2.2 Cotas para as Probabilidades de Transi¸c˜ao 21 De fato, max k n k ≤ n X k=0 n k
1k1n−k = (1 + 1)n = 2n.
De i), ii) e iii) conclu´ımos que: (1−pT)n ≤
n k
(1−pT)n−k ≤max
k n k
≤2n.
Multiplicando (pT)kπ(x, y) por toda a desigualdade abaixo (1−pT)n ≤
n k
(1−pT)n−k ≤2n.
Obtemos:
(1−pT)n(pT)kπ(x, y)≤
n k
(1−pT)n−k(pT)kπ(x, y)≤2n(pT)kπ(x, y).
Isto ´e,
(1−pT)n(pT)kπ(x, y)≤P(N =k)π(x, y)≤2n(pT)kπ(x, y). Como k=C(x, y) e pT =e−1/T, ent˜ao
(1−pT)n e−1/T
k
π(x, y)≤qT (x, y)≤2n e−1/T
k
π(x, y).
Como pT ↓0 podemos considerar pT ≤1/2 logo (1−pT)≥ 1/2, (1−pT)n ≥ (1/2)n. Portanto,
1
2nπ(x, y)e
−C(x,y)/T ≤q
2.2 Cotas para as Probabilidades de Transi¸c˜ao 22
Corol´ario 2.2.2. lim
T→0−T lnqT (x, y) =C(x, y).
Demonstra¸c˜ao. Aplicando logaritmo na desigualdade da proposi¸c˜ao anterior:
ln
1 2n
+lne−C(Tx,y)
+ln (π(x, y))≤lnqT (x, y)≤ln (2n)+
lne−CT(x,y)
+ln (π(x, y)).
Isto ´e, ln 1 2n
−C(x, y)
T + ln (π(x, y))≤lnqT (x, y)≤ln (2
n)−C(x, y)
T + ln (π(x, y)).
Multiplicando−T pela desigualdade anterior, obtemos:
−T ln (2n)−T
−C(x, y)
T
−T ln (π(x, y))
≤ −T lnqT (x, y)
≤ −T ln
1 2n −T
−C(x, y)
T
−T ln (π(x, y)).
Portanto,
−Tln (2n) +C(x, y)−T ln (π(x, y))
≤ −TlnqT(x, y)
≤ −Tln
1
2n
+C(x, y)−Tln (π(x, y)).
Sendo assim, quando T →0, obtemos:
C(x, y)≤ lim
T→0−TlnqT(x, y)≤C(x, y).
Logo,
lim
2.2 Cotas para as Probabilidades de Transi¸c˜ao 23
Essas estimativas s˜ao o ponto de partida para desenvolver a an´alise da
es-trat´egia e aplicar o formalismo dos grandes desvios.
Cap´ıtulo 3
Comportamento Assint´
otico da
estrat´
egia MOSES
Neste cap´ıtulo apresentamos resultados assint´oticos sobre o comportamento
da distribui¸c˜ao estacion´aria da cadeia de Markov associada `a estrat´egia MOSES.
Esses resultados s˜ao derivados da teoria dos grandes desvios de Freidlin e Wentzell
[8]. Iniciamos o cap´ıtulo apresentando o conceito de x-grafo que ´e necess´ario para descrever a teoria dos grandes desvios.
3.1
x
-grafo
Defini¸c˜ao 3.1.1. Um x-grafo g ´e um grafo orientado que n˜ao cont´em nenhuma aresta partindo de x e, tal que, para qualquer y 6=x existe um ´unico caminho em g
ligando y a x.
3.1 x-grafo 25
~~
!!
// x oo
//
OO
oo
^^
>> ``
Figura 3.1: x-grafo
Denotamos por G(x) o conjunto de todos osx-grafos.
Mostramos a seguir uma defini¸c˜ao mais geral de x-grafo que pode ser encon-trada em Freidlin e Wentzell [8]:
Defini¸c˜ao 3.1.2. Seja L um conjunto finito, cujos elementos s˜ao denotados pe-las letras i, j, k, m, n, e etc, e seja W um subconjunto em L. Um grafo orientado constitu´ıdo por arestas m → n(m∈L\W, n ∈L, n 6=m) ´e chamado W-grafo caso satisfa¸ca as seguintes condi¸c˜oes:
1. Cada ponto m∈L\W ´e um ponto inicial de exatamente uma aresta; 2. N˜ao existem ciclos no grafo.
A condi¸c˜ao 2 pode ser substitu´ıda pela seguinte condi¸c˜ao:
2′. Para qualquer pontom∈L\W existe uma sequˆencia de arestas que levam ele
para algum ponton∈W.
Denotamos por G(W) o conjunto dos W-grafos. Dado um grafo g e um conjunto de n´umeros pmn associados a cada aresta (m → n) do grafo, definimos
π(g) = Y
(m→n)∈g
pmn.
A seguir apresentamos uma maneira alternativa de descrever a distribui¸c˜ao
3.1 x-grafo 26 ´
E importante destacar que esta representa¸c˜ao da distribui¸c˜ao estacion´aria atrav´es
de x-grafo ´e fundamental para estabelecer a teoria dos grandes desvios de Freidlin e Wentzel. Uma referˆencia que trata com detalhes ´e Catoni [1].
Lema 3.1.1. Considere uma cadeia de Markov com espa¸co de estados L e proba-bilidades de transi¸c˜ao pij. Suponha que cada estado pode ser alcan¸cado a partir de
qualquer outro estado em um n´umero finito de passos.
Ent˜ao a distribui¸c˜ao estacion´aria da cadeia ´e
!
X
i∈L
Qi
"−1
Qi, i∈L
, onde
Qi =
X
g∈G{i}
π(g). (3.1)
Demonstra¸c˜ao. Como os n´umeros Qi s˜ao positivos ent˜ao ´e suficiente verificar:
Qi=
X
j∈L
Qjpji, (i∈L). Ou seja,
Qi
X
k6=i
pik=
X
j6=i
Qjpji. (3.2)
Substituindo os n´umeros definidos pela F´ormula (3.1) em (3.2), ent˜ao em ambos
os lados obtemos a soma π(g) sobre todos os grafos g satisfazendo as seguintes condi¸c˜oes:
1. Cada ponto m ∈ L ´e o ponto de partida de exatamente uma aresta m →
n(n6=m, n∈L);
2. No grafo existe exatamente um ciclo fechado e esse ciclo cont´em o pontoi. Exemplo 3.1.1. Considere uma cadeia de Markov com espa¸co de estados{A, B, C}
3.1 x-grafo 27
P =
1 2 0
1 2
1 0 0
0 1 0
.
Encontraremos a distribui¸c˜ao estacion´aria usando o lema acima. Primeiro
analisamos todos osA-grafos. Note:
π(gA1) = 1·0, π(gA2) = 1·1, π(gA3) = 0·0.
Logo,
QA= π(gA1) +π(gA2) +π(gA3) = 0 + 1 + 0 = 1.
Analisando todos os B-grafos:
π(gB1) = 0·0, π(gB2) =
1
2·1, π(gB3) = 0·1.
3.1 x-grafo 28
QB =π(gB1) +π(gB2) +π(gB3) = 0 +
1 2+ 0 =
1 2. Analisando todos os C-grafos:
π(gC1) = 1·
1
2, π(gC2) = 0·0, π(gC3) = 0·
1 2. Logo,
QC =π(gC1) +π(gC2) +π(gC3) =
1
2 + 0 + 0 = 1 2. Pelo lema anterior, a distribui¸c˜ao estacion´aria da cadeia ´e
!
X
i∈L
Qi
"−1
Qi, i∈L
. Assim,
µ(A) = QA
QA+QB +QC
= 1
1 +1 2 +
1 2
= 1 2,
µ(B) = QB
QA+QB+QC =
1 2
1 +1 2 + 12
= 1 4, e µ(C) = QC
QA+QB +QC =
1 2
3.2 Princ´ıpio dos Grandes Desvios 29
3.2
Princ´ıpio dos Grandes Desvios
Uma teoria desenvolvida por Freidlin e Wentzell [8] chamada princ´ıpio dos
grandes desvios diz que se as matrizes de transi¸c˜ao (qT)T≥0 associada a uma cadeia
de Markov irredut´ıvel com espa¸co de estados finito X satisfaz: 1
2nπ(x, y)e
−C(x,y)/T ≤q
T (x, y)≤2nπ(x, y)e−C(x,y)/T, (3.3) ent˜ao
∀ x∈X, lim
T→0−T lnµT (x) =W(x)−Wmin,
onde
W(x) = min g∈G(x)
X
(y→z)∈g
V1(y, z), ∀ x∈X e
V1(x, y) = inf
(r−1
X
k=0
C(xk, xk+1), x0 =x, xk ∈X, xr =y, r≥2
)
.
W(x) ´e chamado de energia virtual eV1(x, y) custo de comunica¸c˜ao em v´arios
pas-sos. Al´em disso, valor m´ınimo deW ´e denotado porWmineW∗={x, W (x) =Wmin}. Uma consequˆencia do princ´ıpio dos grandes desvios que ´e ´util no estudo da
estrat´egia MOSES (que pode ser encontrado em Suzuki [14]) ´e o lema a seguir.
Lema 3.2.1. Se um subconjunto X− de X satisfaz:
1. Para cada x∈X+ :=X\X−, existe y ∈X− tal que C(x, y) = 0, e
2. Para cada par de x∈X+ e y ∈X−, C(y, x)> 0,
ent˜ao a distribui¸c˜ao estacion´aria limite limT→0µT(x) =µ∞(x)> 0, se x∈X−.
3.3
Convergˆ
encia da Estrat´
egia MOSES
Nesta se¸c˜ao descrevemos resultados sobre o comportamento assint´otico da
3.3 Convergˆencia da Estrat´egia MOSES 30
para o ´otimo global.
Trabalhamos com caminhos em E e tamb´em em X, a diferen¸ca entre eles ´e que os caminhos emE s˜ao caminhos no grafog= (E, A) e os caminhos em X =En s˜ao as trajet´orias da cadeia de Markov.
De acordo com Cerf [2], se um subconjunto U ⊂X satisfaz a condi¸c˜ao
∀x∈X ∃(ˆx)∈U tal que V1(x,(ˆx)) = 0,
ent˜ao a energia virtualW pode ser calculada emU com
V (x, y) = inf
(r−1
X
k=0
C(xk, xk+1), x0 =x, xk ∈/U(1≤k < r), xr =y, r≥2
)
.
Note que o subconjuntoUformado pelas popula¸c˜oes uniformes satisfaz essa condi¸c˜ao. Os resultados a seguir fazem uso desse resultado. Al´em disso, para as popula¸c˜oes
uniformes (a) e (b) utilizamos a nota¸c˜ao V (a, b) e W (a) em vez de V ((a),(b)) e
W((a)).
Lema 3.3.1. Seja a6=a∗ onde a∗ ´e o ponto m´ınimo de f. Ent˜ao temos
V (a, a∗) =d(a, a∗).
Onde d(a, a∗)´e a distˆancia no grafo g.
Demonstra¸c˜ao. i) Mostrar que V (a, a∗)≥d(a, a∗).
De fato, considerex1, x2, ..., xr ∈/U tais que:
a→x1→ x2 →x3 →...→xr →a∗. Definimos:
br =
a∗, se a∗ ∈x
r
3.3 Convergˆencia da Estrat´egia MOSES 31
br−1=
br, se br ∈xr−1
ar−1, onde ar−1 ∈xr−1 e (ar−1, br)∈A.
br−k =
br−k+1, se br−k+1∈xr−k
ar−k, ondear−k ∈xr−k e (ar−k, br−k+1)∈A.
b0 =a.
Sea∗∈x
rent˜aoC(xr, a∗) = 0. Neste caso, da sequˆencia (b0, b1, ..., br) obtemos um caminho (c0, c1, ..., cm) onde ci ∈E e m≤r, da´ı, d(a, a∗)≤m. Como as popula¸c˜oesxi, i= 1, ..., r n˜ao s˜ao uniformes ent˜ao C(xk, xk+1)≥1. Portanto,
C(a, x1) +C(x1, x2) +...+C(xr, a∗)≥1 + 1 +....+ 1 =r≥d(a, a∗). Se a∗ ∈/ x
r ent˜ao C(xr, a∗) ≥ 1 e V (a, a∗) ≥ r+ 1. Formamos o caminho (c0, c1, ..., cm) em g a partir da sequˆencia (b0, b1, ..., br), sendo m ≤ r + 1. Portanto,
d(a, a∗)≤m≤r+ 1≤V (a, a∗). ii) Mostrar que V (a, a∗)≤d(a, a∗).
Considere um caminho em g = (E, A) que realiza d(a, a∗) : a
0 = a → a1 →
· · · →ar= a∗ e o caminho emX
x0 = (a, a, a,· · · , a)
↓
x1= (a1, a, a,· · · , a)
↓
3.3 Convergˆencia da Estrat´egia MOSES 32
xk =
ak,˜bk,˜bk,· · · ,˜bk
↓
· · ·
xr=
a∗,˜br,˜br,· · · ,˜br
↓
xr+1= (a∗, a∗, a∗,· · · , a∗).
Denotamos ˜b1 =ae
∀k = 2,· · · , r, ˜bk =
ak−1, se f (ak−1)< f
˜bk−1 ˜
bk−1, caso contr´ario.
Sendo assim, temos que∀ k= 0,· · · , r−1, C(xk, xk+1) = 1. Logo,
r−1
X
k=0
C(xk, xk+1) +C(xr, xr+1) =r+ 0 =d(a, a∗),
ou seja,
r−1
X
k=0
C(xk, xk+1) =d(a, a∗).
Por defini¸c˜ao de ´ınfimo, temos que:
inf
(r−1
X
k=0
C(xk, xk+1), x0 = (a), xk ∈/U(1≤k < r), xr = (a∗), r ≥2
)
≤d(a, a∗),
isto ´e,
V (a, a∗)≤d(a, a∗).
Portanto, de i) e ii), obtemos:
3.3 Convergˆencia da Estrat´egia MOSES 33
Lema 3.3.2. A distribui¸c˜ao estacion´aria limiteµ∞(x)se concentra nas popula¸c˜oes
uniformes.
Demonstra¸c˜ao. Segue-se diretamente do Lema 3.2.1 onde X− s˜ao popula¸c˜oes
uni-formes. De fato, se x = (x1, x2, . . . , xn) e tomando y = (ˆx,x, ...,ˆ xˆ), onde ˆx = arg min
xi f(xi), ent˜ao oC(x, y) = 0.
Lema 3.3.3. Suponha que existe um a∗ ∈E tal que:
∀a, b∈E, a, b6=a∗, V (a, a∗)< V (a∗, b).
Ent˜ao, para todo a6=a∗, W(a∗)< W (a).
Demonstra¸c˜ao.
Figura 3.2: a-grafo Figura 3.3: a∗-grafo
Seja a∈E, tal quea6=a∗ eg uma-grafo emU, tal que:
W (a) = X
(u→v)∈g
3.3 Convergˆencia da Estrat´egia MOSES 34
Como a6=a∗ eg ´e um a-grafo em U ent˜ao existe b∈U tal que a∗ →b∈g.
A partir dessea-grafo podemos construir uma∗-grafo, retirando a arestaa∗→
b emg e introduzindo a aresta (a→a∗). Denotamos essea∗-grafo por g′.
Sendo assim, temos:
W(a∗)≤W (a)−V (a∗, b) +V (a, a∗).
Como V (a, a∗)< V (a∗, b), isto ´e,V (a, a∗)−V (a∗, b)<0, ent˜ao
W (a∗)< W(a).
Teorema 3.3.4.Sejan > n∗. A distribui¸c˜ao estacion´aria da cadeia XtT
concentra-se na popula¸c˜ao uniforme (a∗) quando T vai para zero, onde a∗ ´e o ponto m´ınimo
de f e n∗ = max
a6=a∗d(a, a
∗).
Demonstra¸c˜ao. Sejam (a) e (b) popula¸c˜oes uniformes, a, b6=a∗. Temos
n > n∗ = max
a6=a∗d(a, a
∗)≥d(a, a∗).
Comoa6=a∗ ent˜ao pelo Lema 3.3.1, temos que
V (a, a∗) =d(a, a∗).
Logo,
n > d(a, a∗) =V (a, a∗). (3.4) Comoa∗´e o m´ınimo global, ent˜ao o caminho do menor custo que existe de (a∗)
3.3 Convergˆencia da Estrat´egia MOSES 35
∀b6=a∗, V (a∗, b)≥n. (3.5)
De (3.4) e (3.5), obtemos:
V (a∗, b)> V (a, a∗).
Sendo assim, pelo Lema 3.3.3
W (a∗)< W(a).
Para estabelecer a convergˆencia em probabilidade da estrat´egia para o ponto
de ´otimo global fazemos uso do resultado de Trouv´e [15]. Antes disso, ´e necess´ario
introduzir um ´ındice geom´etrico que ´e utilizado para obter a convergˆencia da
es-trat´egia MOSES para a solu¸c˜ao m´ınima. Esse ´ındice geom´etrico ´e definido como
d∗ = max
a6=a∗b:f(minb)<f(a)d(a, b). (3.6) Note que esse ´ındice geom´etrico s´o depende da fun¸c˜ao f e do grafo muta¸c˜ao, da´ı o nome de ´ındice geom´etrico.
3.3 Convergˆencia da Estrat´egia MOSES 36
O Teorema a seguir foi estabelecido por Trouv´e [15] para cadeias nas quais as
probabilidades de transi¸c˜ao qT satisfa¸cam
kTe−C(x,y)/T ≤qT (x, y)≤KTe−C(x,y)/T e lim
T→0−TlnkT = limT→0−TlnKT = 0
Teorema 3.3.5 (Trouv´e [15]). Existe uma constanteH1 n˜ao negativa, tal que para
toda sequˆencia decrescente T(t)t≥1 convergindo para zero, temos
sup x∈X
P(Xt ∈/W∗|X0=x)→0
quando t→ ∞. Se, e somente se,
∞
X
t=1
e−H1/T(t)=∞.
Em Trouv´e, uma descri¸c˜ao expl´ıcita deH1´e dada em termos da decomposi¸c˜ao
de X em ciclos. Dessa forma, a defini¸c˜ao de H1 ´e bastante complicada. Mas,
Catoni [1] apresenta uma descri¸c˜ao alternativa de H1 que n´os utilizaremos. Catoni
caracterizaH1 em termos de caminhos de (Xt). Assim, para cada caminho,
3.3 Convergˆencia da Estrat´egia MOSES 37
entre xe y em X, defina
H(γxy) = max
0≤k<r{W(xk) +C(xk, xk+1)}
onde o m´aximo ´e tomado sobre todos os v´ertices emγxy. SejaH(x, y) o menor valor poss´ıvel deH(γxy) sobre todos os caminhosγxy dexpara y. A quantidadeH(x, y) ´e chamada altitude de comunica¸c˜ao entre x e y. Ent˜ao, seguindo os resultados de Catoni, H1 ´e dado por
H1 = max
x6=(a∗)H(x,(a
∗))−W(x).
Para MOSES, um limite superior de H1 pode ser obtido. Esse limite ´e
H1≤d∗.
A seguir apresentamos esse lema que pode ser encontrado em Fran¸cois [7].
Lema 3.3.6. Temos que H1≤d∗.
A demonstra¸c˜ao pode ser encontrada em Fran¸cois [7]. O resultado a seguir
es-tabelece condi¸c˜oes suficientes para convergˆencia em distribui¸c˜ao da estrat´egia
MO-SES.
Teorema 3.3.7. Seja n > n∗. Suponha que: ∞
X
t=1
e−d∗/T(t)=∞.
Ent˜ao temos
P(Xt = (a∗)|X0 =x)→1
quando t tende para infinito.
Demonstra¸c˜ao. Pelo Lema 3.3.6 temos
3.3 Convergˆencia da Estrat´egia MOSES 38
onde H1 ´e uma constante n˜ao negativa. Sendo assim,
−d∗ ≤ −H1.
Da´ı,
−d∗/T(t)≤ −H1/T(t)⇒e−d∗/T(t)≤e−H1/T(t).
Portanto,
∞
X
t=1
e−d∗/T(t)≤
∞
X
t=1
e−H1/T(t). (3.7)
Por hip´otese,
∞
X
t=1
e−d∗/T(t)=∞. (3.8) Portanto, de (3.7) e (3.8), obtemos
∞
X
t=1
e−H1/T(t)=∞.
Sendo assim, pelo Teorema 3.3.5:
sup x∈X
P(Xt ∈/ W∗|X0 =x)→0,
quandot→ ∞.Portanto, o complementar
P(Xt ∈W∗|X0=x)→1,
quandot→ ∞. Pelo Teorema 3.3.4 temos W∗ ={(a∗)}. Logo,
P(Xt ∈ {(a∗)} |X0=x)→1,
quandot→ ∞. Isto ´e,
P (Xt = (a∗)|X0= x)→1,
Cap´ıtulo 4
Convergˆ
encia Quase Certa da
Estrat´
egia MOSES
Neste cap´ıtulo apresentamos uma abordagem alternativa da convergˆencia da
estrat´egia MOSES sem fazer uso da teoria de Freidlin e Wentzell. Para isto,
faze-mos uso de um resultado geral em cadeia de Markov n˜ao-homogˆenea, que pode ser
encontrado em [4] ´e o seguinte:
Teorema 4.0.8. Seja {Xn}n∈N uma cadeia de Markov com espa¸co de estados S.
Suponha que existe um subconjunto n˜ao vazio S∗ ⊂S, um n´umero natural n
0∈Ne
uma sequˆencia {δk}k∈N tal que:
min i∈S,j∈S∗P
((k−1)n0,kn0)(i, j)≥δ
k (4.1)
e
X
k≥1
δk =∞. (4.2)
Ent˜ao S∗ ´e visitado infinitas vezes com probabilidade um e a cadeia de Markov ´e
fracamente erg´odica.
Demonstra¸c˜ao. Seja N = X n≥0
40
S∗. Observe que temos a seguinte rela¸c˜ao:
(N <∞)⊂ ∪n≥1An,
onde An = (Xm ∈/S∗, m≥n). Assim, para provar que P (N <∞) = 0 ´e sufi-ciente mostrar que P(An) = 0, ∀ n. Considerando B1 = (Xnn0 ∈/ S
∗), B 2 =
X(n+1)n0 ∈/S∗
, . . . , Bk+1= X(n+k)n0 ∈/S∗
, da´ı segue queAn ⊂(B1, B2, . . . , Bk+1),
∀k ∈N. Da propriedade da cadeia de Markov, obtemos
P (B1, B2, . . . , Bk+1)≤P(Bk+1|Bk). . . P(B2|B1).
Vamos provar que
P(B2|B1)≤1−δn+1.
Seja ¯Bk o complementar do conjunto Bk. Assim,
P B¯2|B1
= X i∈S∗
P X(n+1)n0 =i|B1
e
P X(n+1)n0 =i|B1
= 1
P(B1)
X
j /∈S∗
P X(n+1)n0 =i|Xnn0 =j
P(Xnn0 =j).
De (4.1) temosP X(n+1)n0 =i|Xnn0 =j
≥δn+1. Sendo assim
P B¯2|B1
≥δn+1
ou
P(B2|B1)≤1−δn+1.
Por um argumento similar, obtemos:
41
Segue da inequa¸c˜ao anterior que
P(B1, B2, . . . , Bk+1)≤(1−δn+1) (1−δn+2). . .(1−δn+k).
Note que a desigualdade acima mant´em para todo k ∈ N. De (4.2) segue que
P(An) = 0, portanto P(N <∞) = 0, ou ´e equivalente, P (N =∞) = 1.
Agora, precisamos verificar se a cadeia de Markov ´e fracamente erg´odica.
Ob-serve a seguinte inequa¸c˜ao
α(P) = min i,k∈E
X
j∈E
min (Pij, Pkj)≥min i∈S Pij0 onde j0 ´e qualquer elemento deS. Da hip´otese, segue que:
α P(k−1)n0,kn0≥δ
k
assim
δ P(k−1)n0,kn0≤(1−δ
k). Da inequa¸c˜aoδ(P Q)≤δ(P)δ(Q) e de (4.2) segue que
lim k→∞δ P
(m,k)
= 0,∀m≥0.
A seguir mostramos que a estrat´egia MOSES visita a popula¸c˜ao uniforme (a∗)
com probabilidade igual a um, onde a∗ ´e o ponto de m´ınimo global da fun¸c˜ao.
´
E necess´ario lembrar que a estrat´egia MOSES objetiva encontrar o m´ınimo
global de uma fun¸c˜ao f : E → R, onde E ´e um conjunto finito e ´e assumido que
existe uma estrutura de grafog = (E, A) emE, a qual determina vizinhan¸casN(e), para cada e ∈ E, e este grafo g ´e conexo. Inicialmente, ´e dada uma sequˆencia
pT(t) t≥1 que determina as muta¸c˜oes. Em cada etapa da estrat´egia s˜ao formadas
42
fixo.
Dada a popula¸c˜ao Xt = (et1, et2, . . . , etn) a nova popula¸c˜ao Xt+1´e dada por
(bt1, bt2, . . . , btm, x∗, . . . , x∗) onde x∗ = arg min{f(et1), f(et2), . . . , f(etn)} e m ´e
amostrado de uma vari´avel aleat´oria binomial com parˆametros n e pT, sendo bti ∈
N(eti) com P(bti =x) = |N(1eti)| onde N(eti) ´e a vizinhan¸ca de eti determinada pelo grafo g.
Teorema 4.0.9. A estrat´egia MOSES visita infinitas vezes com probabilidade 1 a popula¸c˜ao uniforme (a∗), se
∞
X
t=1
(pT)D = ∞ e D o diˆametro de g (Diˆametro ´e a
maior distˆancia entre dois v´ertices quaisquer no grafo g).
Demonstra¸c˜ao. Pelo Teorema 4.0.8 ´e suficiente mostrar que existe uma constantek
tal que
P (Xt+D = (a∗)|Xt =x)> pDT ·k, , ∀t∈N, ∀x∈X.
Seja x = (a1, a2, ..., an) uma popula¸c˜ao qualquer, pela conectividade de g existem
e1, e2, . . . , em ∈Etais quee1 ∈N(a1), ei+1∈N(ei) eem =a∗(a∗´e o ponto m´ınimo global de f em≤D).
Consideremos as sequˆencias de popula¸c˜oes:
x1 = (e1, ax1, . . . , ax1), onde ax1 = arg min{f(a1), f(a2), . . . , f(an)}
x2 = (e2, ax2, . . . , ax2), onde ax2 = arg min{f(e1), f(ax1)}
x3 = (e3, ax3, . . . , ax3), onde ax3 = arg min{f(e2), f(ax2)}
...
xm= (a∗, axm, . . . , axm), onde axm = arg min
f(em−1), f axm−1
xm+1= (a∗, a∗, . . . , a∗)
Dessa forma,
P(Xt+1= x1|Xt =x) =n·PT ·(1−PT)(n−1)· 1
43
P(Xt+2 =x2|Xt+1=x1) =n·PT ·(1−PT)(n−1)· 1
|N(e1)|
...
P (Xt+m+1 =xm+1|Xt+m =xm) = (1−PT)n. Assim,
P (Xt+D = (a∗, a∗, . . . , a∗)|Xt =x)≥(PT)m·(1−PT)(n−1)·(m)·C onde C n˜ao depende de t. Logo,
P(Xt+D = (a∗, a∗, . . . , a∗)|Xt =x)≥(PT)D ·(1−PT)(n−1)·(D)·C, comopT ↓0,(1−pT)≥ 12 ent˜ao
P (Xt+D = (a∗, a∗, . . . , a∗)|Xt =x)≥(PT)D(1/2)(n−1)(D)·C = (PT)D ·k.
Observa¸c˜oes importantes: Com esta abordagem n˜ao ´e necess´ario supor que a
fun¸c˜ao seja injetora, al´em disso, as escolhas dos sucessores nas vizinhan¸cas podem
ser feitas em toda a vizinhan¸caN(xi) e sem a restri¸c˜aoN(xi)− {x∗}, como tamb´em
Cap´ıtulo 5
Estrat´
egia MOSES no Matlab:
Algumas Simula¸
c˜
oes
Neste cap´ıtulo apresentamos resultados observados a partir da implementa¸c˜ao
da estrat´egia MOSES no software Matlab. Nele, realizamos alguns testes com o
intuito de estudar o tempo m´edio em que a estrat´egia atinge o ponto de ´otimo pela
primeira vez (m´ınimo global). Tamb´em comparamos a eficiˆencia do MOSES em
rela¸c˜ao ao Simulated Annealing. As fun¸c˜oes usadas para realizar esses testes foram
as seguintes:
f(x, y) = 0,2 (x−5)2+ (y−5)2
+ 2 sin (10 (x+y−10)) + 2, (5.1)
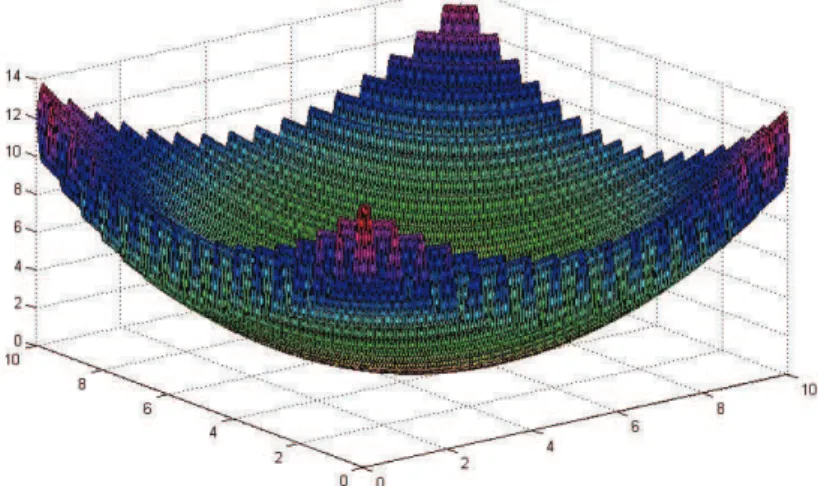
g(x, y) = 6 +x2−3 cos (2πx) +y2−3 cos (2πy). (5.2) definidas nos intervalos [0,10]2 e [−2,5]2, respectivamente. A primeira fun¸c˜ao teste
f foi utilizada por Fran¸cois [7] e a segunda fun¸c˜ao ´e referenciada a Neto [6].
Gr´aficos, tabelas e figuras s˜ao usados para ilustrar o comportamento da
5.1 Testes Sobre Tempo M´edio da Primeira Visita da estrat´egia MOSES
ao M´ınimo 45
5.1
Testes Sobre Tempo M´
edio da Primeira
Vi-sita da estrat´
egia MOSES ao M´ınimo
Para verificarmos a eficiˆencia da estrat´egia MOSES foram realizadas simula¸c˜oes
com as fun¸c˜oes citadas acima. Vale ressaltar que essas fun¸c˜oes apresentam v´arias
oscila¸c˜oes, o que implica a existˆencia de diversos m´ınimos locais, dificultando a
determina¸c˜ao do m´ınimo global da fun¸c˜ao. Veja as figuras abaixo:
Figura 5.1: Gr´afico da fun¸c˜ao (5.1)
Figura 5.2: Gr´afico da fun¸c˜ao (5.2)
A tabela 5.1 mostra o comportamento do tempo m´edio da primeira visita da
estrat´egia ao m´ınimo da fun¸c˜ao f quando o tamanho da popula¸c˜ao ´e n = 500 e
pt = t −1
5.1 Testes Sobre Tempo M´edio da Primeira Visita da estrat´egia MOSES
ao M´ınimo 46
Ambas as tabelas foram obtidas mediante 50 repeti¸c˜oes da estrat´egia e a popula¸c˜ao
inicial foi gerada aleatoriamente. As vizinhan¸cas utilizadas na estrat´egia MOSES
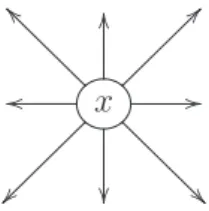
s˜ao compostas de 8 v´ertices como ilustra a figura abaixo:
x
__ OO ??
oo //
Figura 5.3: Vizinhan¸ca dex
Tempo m´edio da primeira visita de MOSES ao m´ınimo, com pt =t(−1/D), n= 500, popula¸c˜ao inicial aleat´oria
Diˆametro D 5 10 30 35 40 45 55 60 70 80 700 800 1000 Tempo M´edio 1 1 11 44 3 51 29 30 60 13 327 429 491
Tabela 5.1:
Tempo m´edio da primeira visita de MOSES ao m´ınimo, com pt = exp(1)1 , n= 500, popula¸c˜ao inicial aleat´oria
Diˆametro D 5 10 30 35 40 45 55 60 70 80 700 800 1000 Tempo M´edio 1 1 14 44 4 52 30 25 45 10 456 544 760
Tabela 5.2:
Note que o tempo m´edio associado `a primeira tabela ´e menor do que na segunda
o que talvez pode ser explicado pelo fato da probabilidade utilizada na primeira
tabela ser bem maior do que a utilizada na segunda tabela. De fato, pt = t(−1/D) tende a zero quando t tende ao infinito.
Tamb´em estimamos o tempo m´edio de retorno ap´os fazer pequenas altera¸c˜oes
na dinˆamica da estrat´egia, mais especificamente, n˜ao colocamos a restri¸c˜ao de o
indiv´ıduo n˜ao poder mutar para o m´ınimo da gera¸c˜ao anterior (essa restri¸c˜ao, como
comenta Fran¸cois, ´e de car´ater t´ecnico que facilita o tratamento matem´atico da
convergˆencia da estrat´egia). Com essa altera¸c˜ao da estrat´egia, n˜ao identificamos
diferen¸ca em rela¸c˜ao ao tempo m´edio.
As figuras 5.4 e 5.5 s˜ao obtidas da seguinte maneira: Gera-se 2000 popula¸c˜oes
5.1 Testes Sobre Tempo M´edio da Primeira Visita da estrat´egia MOSES
ao M´ınimo 47
Figura 5.4:
Figura 5.5:
Nos gr´aficos anteriores, a estrat´egia foi processado com o mesmo diˆametro
D= 252, mesma probabilidadept = 1/exp (1) (do n´umero de muta¸c˜oes) e a evolu¸c˜ao foi iniciada em (0,0), por´em diferem no tamanho das popula¸c˜oes, sendon= 500 no primeiro gr´afico en= 100 no segundo. Observe que, no primeiro caso, o m´ınimo da fun¸c˜ao ´e encontrado mais r´apido do que no segundo caso.
Conclu´ımos esta se¸c˜ao enumerando algumas considera¸c˜oes a respeito das an´alises
dos testes realizados:
• Notamos que o diˆametro tem efeito direto no tempo m´edio de alcance do
m´ınimo da fun¸c˜ao, por´em em qualquer caso o tempo m´edio ´e finito que n˜ao ´e
´obvio, dado que a cadeia ´e homogˆenea.
5.2 MOSES Versus Simulated Annealing em Paralelo 48
diˆametro) n˜ao foi necess´aria para a determina¸c˜ao do m´ınimo da fun¸c˜ao, o
que ´e coerente com os resultados obtidos no Cap´ıtulo 4 (Teorema 4.0.9).
Mesmo assim, n˜ao conseguimos estabelecer rela¸c˜oes entre todos os parˆametros:
ta-manho da popula¸c˜ao, diˆametro, probabilidade de muta¸c˜ao e o tempo m´edio. E as
simula¸c˜oes n˜ao deram ind´ıcios para essa rela¸c˜ao, pelo menos n˜ao percebemos.
5.2
MOSES Versus Simulated Annealing em
Pa-ralelo
Com o intuito de observarmos a eficiˆencia da estrat´egia aleat´oria MOSES,
rea-lizamos a implementa¸c˜ao do algoritmo Simulated Annealing em Paralelo no Software
Matlab, para compararmos o desempenho desses dois algoritmos.
Como j´a foi dito no Cap´ıtulo 2, o Simulated Annealing ´e um t´ecnica utilizada
para encontrar o m´ınimo global da fun¸c˜aof :S →R, sendoSfinito. Neste contexto,
o processo de otimiza¸c˜ao ´e realizado por n´ıveis. Em cada n´ıvel ´e dado um ponto
u ∈ S, v´arios pontos na vizinhan¸ca de u s˜ao gerados e o correspondente valor de
f ´e calculado. Cada ponto gerado ´e aceito ou rejeitado de acordo com uma certa probabilidade. Esta probabilidade de aceita¸c˜ao decresce de acordo com o n´ıvel do
processo.
Resultados te´oricos sobre a convergˆencia desse algoritmo podem ser
encontra-dos, por exemplo, no artigo de Cruz e Dorea [3].
Para efeito de compara¸c˜ao da estrat´egia MOSES e o Simulated Annealing
fixamos um tamanho da popula¸c˜ao n para MOSES e realizamosn simula¸c˜oes inde-pendentes no Simulated Annealing, o que n´os chamamos de Simulated Annealing em
5.2 MOSES Versus Simulated Annealing em Paralelo 49
∀i= 1,· · · , n, bi =
aim, com a1(aim/ai)
ai, caso contr´ario. onde
at(aim/ai) = min
1,exp
−1
ct
(f(aim)−f(ai))
e ct = [D(f (j)−f(i))]/log (t+ 1) como sugeriram Cruz e Dorea [3]. A vizinhan¸ca utilizada na implementa¸c˜ao dos algoritmos Simulated Annealing em Paralelo e o
MOSES nesta se¸c˜ao, foi a seguinte:
x
OO
oo //
Os testes foram realizados com as fun¸c˜oes f eg apresentadas no in´ıcio deste cap´ıtulo, com probabilidade pt = t(
−1
D) e n = 500. Variamos a popula¸c˜ao inicial para cada teste, com o objetivo de verificar o grau de dificuldade para os algoritmos
encontrarem o m´ınimo. A seguir apresentamos tabelas informando esses resultados.
• Nas tabelas abaixo a popula¸c˜ao inicial ´e centrada em (0,0) e a fun¸c˜ao teste ´e
f,pt =t( −1
D) en= 500.
Tempo m´edio da primeira visita de MOSES ao m´ınimo Diˆametro D 5 10 30 35 40 45 55 60 70 80 Tempo M´edio 5 9 61 67 123 155 169 179 244 250
Tempo m´edio da primeira visita