Universidade Federal do Rio Grande do Norte
Centro de Ciˆencias Exatas e da Terra
Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica
Josemir Ramos de Almeida
Estima¸c˜
ao Cl´
assica e Bayesiana em Modelos de
Sobrevida com Fra¸c˜
ao de Cura
Josemir Ramos de Almeida
Estima¸c˜
ao Cl´
assica e Bayesiana em Modelos de
Sobrevida com Fra¸c˜
ao de Cura
Disserta¸c˜ao apresentada ao Programa de P´os-Gradua¸c˜ao em Matem´atica Aplicada e Estat´ıstica da Universidade Federal do Rio Grande do Norte, em cumprimento com as exigˆencias legais para obten¸c˜ao do t´ıtulo de Mestre.
´
Area de Concentra¸c˜ao: Probabilidade e Estat´ıstica
Orientador:
Prof. Dr. Bernardo Borba de Andrade
Co-orientador:
Prof. Dr. Heleno Bolfarine
Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial Centro de Ciências Exatas e da Terra – CCET.
Almeida, Josemir Ramos de.
Estimação clássica e bayesiana em modelos de sobrevida com fração de cura / Josemir Ramos de Almeida. - Natal, 2013.
86 f. il.:
Orientador: Prof. Dr. Bernardo Borba de Andrade. Co-orientador: Prof. Dr. Heleno Bolfarine.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Programa de Pós-Graduação em Matemática Aplicada e Estatística.
1. Análise de sobrevivência – Dissertação. 2. Modelos de longa duração – Dissertação. 3. Método de Laplace – Dissertação. 4. Método de Monte Carlo – Dissertação. 5. Cadeias de Markov – Dissertação. I. Andrade, Bernardo Borba de. II. Bolfarine, Heleno. III. Título.
Dedicat´
oria
Aos meus pais Maria de Lourdes R. de Almeida e Josaf´a P. de Almeida pela forma¸c˜ao de car´ater que eles me proporcionaram, pois sem eles n˜ao teria alcan¸cado meus objetivos pessoais e profissionais.
A minha irm˜a Mercicleide R. de Almeida, pela for¸ca, apoio e incentivo.
A minha noiva Elisˆangela da S. Rodrigues, pelo companheirismo e paciˆencia de estar ao meu lado todos esses anos.
Aos meus av´os maternos,in memoriam, Corina M. de Oliveira e Jeov´a R. de Oliveira.
Agradecimentos
A Deus, pois sem ele n˜ao faria sentido a existˆencia.
Aos meus pais, pelo apoio de todas as horas.
A minha irm˜a, pela for¸ca e incentivo.
A minha noiva, pelo companheirismo, dedica¸c˜ao e paciˆencia.
Aos professores Bernardo B. de Andrade e Heleno Bolfarine pelo conhecimento a mim oferecido, pela oportunidade de poder trabalhar com eles e pela paciˆencia e dedica¸c˜ao ao me orientar.
A banca examinadora pelo aceite do convite em avaliar este trabalho de dis-serta¸c˜ao, bem como pelas sugest˜oes e cr´ıticas que foram de grande valia para o aperfei¸coamento do mesmo.
Aos professores do PPGMAE, a citar: Carla Vivacqua, Pledson Guedes, Andr´e Pinho, D´ebora Borges e Nir Cohen.
A todos os colegas de mestrado do PPGMAE.
Aos meus professores de gradua¸c˜ao da Universidade Federal da Para´ıba (UFPB), pois de forma direta e indireta foi devido ao conhecimento dos mesmos que fui capaz de trilhar o caminho at´e o mestrado. Em particular ao professor Dr. Eufr´asio de A. Lima Neto.
Resumo
Em An´alise de Sobrevivˆencia, os modelos de longa dura¸c˜ao permitem a es-tima¸c˜ao da fra¸c˜ao de cura, que representa uma parcela da popula¸c˜ao imune ao evento de interesse. No referido trabalho abordamos os enfoques cl´assico e Bayesiano com base nos modelos de mistura padr˜ao e de tempo de promo¸c˜ao, utilizando diferentes distribui¸c˜oes (exponencial, Weibull e Pareto) para modelar os tempos de falhas. A base de dados utilizada para ilustrar as implementa¸c˜oes ´e descrita em Kersey et al. (1987) e consiste em um grupo de pacientes com leucemia que foram submetidos a um certo tipo de transplante. As implementa¸c˜oes espec´ıficas utilizadas foram de otimiza¸c˜ao num´erica por BFGS implementado em R (base::optim), aproxima¸c˜ao de Laplace (implementa¸c˜ao pr´opria) e o amostrador de Gibbs implementado no Open-Bugs. Descrevemos as principais caracter´ısticas dos modelos utilizados, os m´etodos de estima¸c˜ao e os aspectos computacionais. Tamb´em discutimos como diferentes prioris podem afetar nas estimativas Bayesianas.
Abstract
In Survival Analysis, long duration models allow for the estimation of the he-aling fraction, which represents a portion of the population immune to the event of interest. Here we address classical and Bayesian estimation based on mixture models and promotion time models, using different distributions (exponential, Weibull and Pareto) to model failure time. The database used to illustrate the implementations is described in Kersey et al. (1987) and it consists of a group of leukemia patients who underwent a certain type of transplant. The specific implementations used were numeric optimization by BFGS as implemented in R (base::optim), Laplace appro-ximation (own implementation) and Gibbs sampling as implemented in Winbugs. We describe the main features of the models used, the estimation methods and the computational aspects. We also discuss how different prior information can affect the Bayesian estimates.
Lista de Figuras
2.1 Formas da densidade da Pareto(p;k). . . 22
2.2 Formas da densidade da Weibull(γ;α).. . . 23
5.1 Gr´aficos das estimativas das sobrevivˆencias estimadas por Kaplan-Meier versus as sobrevivˆencias estimadas pelos modelos exponencial, Weibull e Pareto. . . 47
5.2 Curvas de sobrevivˆencia estimadas por Kaplan-Meier versus as sobre-vivˆencias estimadas pelos modelos exponencial, Weibull e Pareto. . . 47
5.3 Densidades a priori, a posteriori e verossimilhan¸ca perfilada dadas as especifica¸c˜oes 1), 2) e 3), respectivamente, para o MMPexp. . . 50
5.4 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), respectiva-mente, para o MMPexp. . . 51
5.5 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), res-pectivamente, para o MMPexp. . . 51
5.6 Densidades a priori, a posteriori e verossimilhan¸ca perfilada dadas as especifica¸c˜oes 1), 2) e 3), respectivamente (por linha), para o MTPexp. 54
5.7 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), respectiva-mente, para o MTPexp. . . 55
5.8 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), res-pectivamente, para o MTPexp. . . 55
5.9 Curvas de sobrevivˆencia dos modelos de mistura padr˜ao e tempo de promo¸c˜ao exponencial. . . 55
9
5.11 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) (superior), 3) e 4) (inferior), respectivamente, para o MMPwei. . . 59
5.12 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) (superior), 3) e 4) (inferior), respectivamente, para o MMPwei. . . 59
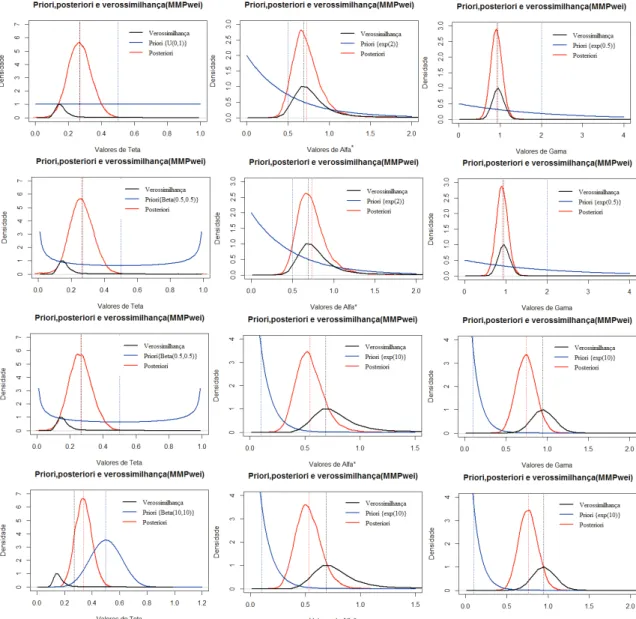
5.13 Densidades a priori, a posteriori e verossimilhan¸ca perfilada dadas as especifica¸c˜oes 1), 2), 3) e 4), respectivamente (por linha), para o MTPwei. . . 62
5.14 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) (superior), 3) e 4) (inferior), respectivamente, para o MTPwei. . . 63
5.15 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2), 3) e 4) (por coluna), respectivamente, para o MTPwei. . . 63
5.16 Curvas de sobrevivˆencia dos modelos de mistura padr˜ao e tempo de promo¸c˜ao Weibull. . . 64
5.17 Densidades a priori, a posteriori e verossimilhan¸ca perfilada dadas as especifica¸c˜oes 1), 2) e 3), respectivamente (por linha), para o MMPpar. 66
5.18 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), respectiva-mente (por coluna), para o MMPpar. . . 67
5.19 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), res-pectivamente (por coluna), para o MMPpar. . . 68
5.20 Densidades a priori, a posteriori e verossimilhan¸ca perfilada dadas as especifica¸c˜oes 1), 2) e 3), respectivamente (por linha), para o MTPpar. 71
5.21 Hist´orico das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) (superiores) e 3) (inferior), respectivamente, para o MTPpar. . . 72
5.22 Autocorrela¸c˜oes das itera¸c˜oes dadas as especifica¸c˜oes 1), 2) e 3), res-pectivamente (por coluna), para o MTPpar. . . 72
Lista de Tabelas
5.1 Estimativas dos parˆametros para o MMPexp. . . 49
5.2 Estimativas dos parˆametros para o MTPexp. . . 52
5.3 Estimativas dos parˆametros para o MMPwei. . . 57
5.4 Intervalos das estimativas dos parˆametros para o MMPwei. . . 57
5.5 Estimativas dos parˆametros para o MTPwei. . . 61
5.6 Intervalos das estimativas dos parˆametros para o MTPwei. . . 61
5.7 Estimativas dos parˆametros para o MMPpar. . . 66
5.8 intervalos das estimativas dos parˆametros para o MMPpar. . . 67
5.9 Estimativas dos parˆametros para o MTPpar. . . 70
Conte´
udo
1 Introdu¸c˜ao 14
1.1 Revis˜ao Bibliogr´afica . . . 14
1.2 Objetivos . . . 16
2 Conceitos B´asicos em An´alise de Sobrevivˆencia 18 2.1 Introdu¸c˜ao . . . 18
2.2 Fun¸c˜ao de Sobrevivˆencia . . . 19
2.3 Estimador de Kaplan-Meier . . . 20
2.4 Distribui¸c˜oes Probabil´ısticas . . . 21
2.4.1 Distribui¸c˜ao Pareto . . . 21
2.4.2 Distribui¸c˜ao Weibull . . . 22
2.4.3 Distribui¸c˜ao Exponencial . . . 23
3 Modelos de Longa Dura¸c˜ao 24 3.1 Introdu¸c˜ao . . . 24
3.2 Modelo de Mistura Padr˜ao (MMP) . . . 24
3.2.1 Modelo de Mistura Padr˜ao Exponencial (MMPexp) . . . 26
3.2.2 Modelo de Mistura Padr˜ao Pareto (MMPpar) . . . 26
3.2.3 Modelo de Mistura Padr˜ao Weibull (MMPwei) . . . 27
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) . . . 27
3.3.1 Modelo de Tempo de Promo¸c˜ao Exponencial (MTPexp) . . . 30
12
3.3.3 Modelo de Tempo de Promo¸c˜ao Weibull (MTPwei) . . . 31
4 M´etodos de Estima¸c˜ao 33 4.1 Inferˆencia Cl´assica . . . 33
4.1.1 Verossimilhan¸ca Perfilada . . . 34
4.2 Inferˆencia Bayesiana . . . 34
4.2.1 Teorema de Bayes . . . 35
4.2.2 Est´agios da Inferˆencia Bayesiana . . . 35
4.2.3 Distribui¸c˜oes de Probabilidade a Priori . . . 36
4.2.4 Distribui¸c˜ao de Probabilidade a Posteriori . . . 38
4.3 M´etodo de Laplace . . . 40
4.4 M´etodos de Simula¸c˜ao Estoc´astica . . . 42
4.4.1 Cadeias de Markov . . . 42
4.4.2 Diagn´ostico de Convergˆencia . . . 43
4.4.3 Amostrador de Gibbs . . . 43
5 Aplica¸c˜ao 45 5.1 Introdu¸c˜ao . . . 45
5.1.1 An´alise Convencional . . . 45
5.2 Diferentes modelos de fra¸c˜ao de cura . . . 48
5.2.1 Modelo de mistura padr˜ao exponencial (MMPexp) . . . 48
5.2.2 Modelo de tempo de promo¸c˜ao exponencial (MTPexp) . . . 52
5.2.3 Modelo de mistura padr˜ao Weibull (MMPwei) . . . 56
5.2.4 Modelo de tempo de promo¸c˜ao Weibull (MTPwei) . . . 60
5.2.5 Modelo de mistura padr˜ao Pareto (MMPpar) . . . 65
5.2.6 Modelo de tempo de promo¸c˜ao Pareto (MTPpar) . . . 69
6 Considera¸c˜oes Finais 74 6.1 Conclus˜oes . . . 74
13
A 79
A.1 M´etodo de Laplace . . . 79
A.2 Modelos de mistura padr˜ao . . . 81
A.2.1 Modelo de Mistura Padr˜ao Exponencial (MMPexp) . . . 81
A.2.2 Modelo de Mistura Padr˜ao Pareto (MMPpar) . . . 82
A.2.3 Modelo de Mistura Padr˜ao Weibull (MMPwei) . . . 83
A.3 Modelos de tempo de promo¸c˜ao . . . 84
A.3.1 Modelo de Tempo de Promo¸c˜ao Exponencial (MTPexp) . . . 84
A.3.2 Modelo de Tempo de Promo¸c˜ao Pareto (MTPpar) . . . 85
Cap´ıtulo 1
Introdu¸c˜
ao
Dados relacionados `a sobrevivˆencia de indiv´ıduos submetidos a certo trata-mento comumente envolvem um grupo de curados. Muitos dos modelos considerados na literatura n˜ao levam em conta tal caracter´ıstica, deixando portanto de explorar toda a informa¸c˜ao contida nos dados. Este ´e o caso do modelo de Cox e do modelo de tempo de falha acelerado.
A an´alise de sobrevivˆencia possui aplica¸c˜ao na maioria das ´areas do conhe-cimento, no entanto a ´area m´edica ´e a que mais se destaca, tanto pela aplica¸c˜ao quanto pela necessidade cada vez maior de m´etodos estat´ısticos que permitam uma an´alise adequada dos dados.
1.1 Revis˜
ao Bibliogr´
afica
A incorpora¸c˜ao de um componente de cura nos modelos de sobrevivˆencia j´a vem sendo estudado, desde o final dos anos 40, com os trabalhos de Boag (1949) e Berkson e Gage (1952). Os autores trabalharam sobre o problema de estimar a propor¸c˜ao de indiv´ıduos curados de cˆancer. Nesta se¸c˜ao, traremos algumas contri-bui¸c˜oes em diversas ´areas do conhecimento que seguiram a mesma proposta dos autores.
1.1 Revis˜ao Bibliogr´afica 15
Com o objetivo de estimar a propor¸c˜ao de curados de um conjunto de da-dos composto por 2682 pacientes acometida-dos de cˆancer do estˆomago, e utilizando o m´etodo de m´ınimos quadrados, Berkson e Gage (1952) utilizaram um modelo com-posto por uma combina¸c˜ao de duas distribui¸c˜oes, uma distribui¸c˜ao exponencial e uma distribui¸c˜ao degenerada. Com este modelo, os autores obtiveram sucesso no ajuste de outras bases de dados, como por exemplo, nos dados utilizados no estudo de Boag (1949).
Maller e Zhou (1996) fazem uma introdu¸c˜ao a an´alise de dados de sobre-vivˆencia, com ˆenfase em popula¸c˜oes que apresentam indiv´ıduos “imunes”ao evento de interesse. O livro traz outras abordagens como por exemplo, formula¸c˜ao de testes para a presen¸ca de imunes, propriedades do estimador de Kaplan-Meier, estima¸c˜ao n˜ao param´etrica, modelos param´etricos para uma amostra, propriedades para gran-des amostras em modelos com covari´aveis, entre outros temas.
Yakovlev e Tsodikov (1996), discutem pesquisas desenvolvidas e m´etodos de inferˆencia com significado biol´ogico a respeito de latˆencia de cˆancer. O material oferece novas abordagens na descri¸c˜ao estoc´astica do estudo do cˆancer, utilizando dados de recorrˆencia do tumor. Nos ´ultimos cap´ıtulos os autores abordam modelos de sobrevida com fra¸c˜ao de curados, bem como a escolha do tratamento mais adequado, baseando-se em informa¸c˜oes de covari´aveis, al´em de in´umeras aplica¸c˜oes em estudos reais.
Tsodikov (1998) apresenta o modelo de mistura padr˜ao e tempo de promo¸c˜ao, bem como um modelo de riscos proporcionais para dados de sobrevivˆencia de longa dura¸c˜ao. Apresenta tamb´em os m´etodos de estima¸c˜ao via m´axima verossimilhan¸ca parcial e marginal. Segundo o autor, os m´etodos de estima¸c˜ao s˜ao equivalentes para o modelo de risco proporcional com fra¸c˜ao de cura. Al´em disso, traz uma com-para¸c˜ao da eficiˆencia assint´otica dos dois m´etodos de estima¸c˜ao, e por fim sugere um algor´ıtimo para o ajuste do modelo de riscos proporcionais com fra¸c˜ao de cura.
Chen et al. (1999) abordam m´etodos Bayesianos para dados de sobrevida com fra¸c˜ao de cura. Prop˜oem um modelo que difere do modelo de mistura padr˜ao com uma estrutura de riscos proporcionais na presen¸ca de covari´aveis. Estabele-cem rela¸c˜oes matem´aticas com o modelo de mistura padr˜ao convencional, como por exemplo, apresentam uma fun¸c˜ao pr´opria de sobrevivˆencia para os n˜ao curados. Por fim, fazem uma aplica¸c˜ao a dados de melanoma.
pa-1.2 Objetivos 16
ram´etricos e semi param´etricos, modelos de riscos proporcionais, modelos com fra-gilidade, modelos de longa dura¸c˜ao, modelos de tempo de falha acelerado, modelos hier´arquicos de sobrevivˆencia, entre outros. Na abordagem Bayesiana os autores discutem especifica¸c˜oes de prioris informativas e n˜ao informativas, distribui¸c˜oes a posteriori, testes de hip´oteses Bayesianos, m´etodos MCMC, entre outros.
Peng et al. (2001) fazem um estudo de simula¸c˜ao para testar a presen¸ca de pacientes curados em dados de sobrevivˆencia de longo prazo. Utilizam m´axima ve-rossimilhan¸ca para o modelo de mistura padr˜ao gama com dados de leucemia.
Chen et al. (2002) tratam de modelos de longa dura¸c˜ao param´etricos e semi-param´etricos e prop˜oem abordagens Bayesianas. Realizam uma aplica¸c˜ao com dados cl´ınicos de melanoma conduzido pelo Eastern Cooperative Oncology Group.
Sinha et al. (2003) estudam um modelo de dois est´agios para o desenvolvimento do cˆancer com um estrutura de riscos proporcionais na presen¸ca de covari´aveis se-gundo uma abordagem Bayesiana. Trazem rela¸c˜oes matem´aticas do modelo proposto com os j´a existentes na literatura. Utilizam m´etodos MCMC para amostrar da distri-bui¸c˜ao a posteriori dos parˆametros. Utilizam uma classe de prioris n˜ao informativas e destacam que o modelo proposto ´e flex´ıvel tanto para uma modelagem Bayesiana param´etrica como para uma modelagem semiparam´etrica, bem como sua exten¸c˜ao multivariada.
Rodrigues et al. (2008) prop˜oem uma nova abordagem que unifica os modelos de sobrevivˆencia usuais com os modelos de longa dura¸c˜ao. O objetivo ´e fazer um estudo das teorias frequentista e Bayesiana, dada a inclus˜ao de um cen´ario de riscos competitivos.
Existem in´umeras referˆencias a respeito dos modelos de longa dura¸c˜ao, no entanto, faremos uso apenas das expostas acima.
1.2 Objetivos
Os modelos que apresentam um componente de cura s˜ao conhecidos como
modelos de longa dura¸c˜ao oumodelos com fra¸c˜ao de cura. O tema de estudo surgiu com o objetivo de explorar os modelos de sobrevivˆencia que tratam a presen¸ca de indiv´ıduos que, mesmo com a doen¸ca, ap´os submetidos a algum tipo de tratamento passam a se caracterizar como indiv´ıduos n˜ao sucept´ıveis ao evento de interesse.
A proposta deste trabalho ´e estudar esses tipos de modelos, em particular os
1.2 Objetivos 17
propostos por Boag (1949) e Berkson e Gage (1952), conhecidos como modelos de mistura padr˜ao e o modelo proposto por Yakovlev e Tsodikov (1996), conhecido como modelos de tempo de promo¸c˜ao, e fazer uma discuss˜ao entre as abordagens cl´assica e Bayesiana para o ajuste dos referidos modelos.
Cap´ıtulo 2
Conceitos B´
asicos em An´
alise de
Sobrevivˆ
encia
2.1 Introdu¸c˜
ao
Pode-se definir a an´alise de sobrevivˆencia como um conjunto de t´ecnicas es-tat´ısticas voltadas para o estudo do “tempo”at´e a ocorrˆencia de um evento de inte-resse.
Tais t´ecnicas s˜ao utilizadas com mais frequˆencia na ´area m´edica. No entanto, sua aplica¸c˜ao se estende a problemas de outras ´areas, por exemplo, aplica¸c˜oes em falhas de equipamento, a¸c˜oes e falhas de mercado, div´orcios, aposentadorias, de-ten¸c˜oes, etc.
Denotaremos porfalhaa ocorrˆencia de um determinado evento de interesse. Tal ocorrˆencia pode estar associada a uma observa¸c˜ao parcial ou incompleta da vari´avel resposta. Estas observa¸c˜oes parciais ou imcompletas denotaremos por censura, e a presen¸ca das mesmas ´e a principal caracter´ıstica de dados de sobrevivˆencia.
A an´alise de sobrevivˆencia difere dos m´etodos convencionais, pois estes n˜ao oferecem suporte para tratar dados com presen¸ca de censura. Al´em disso, ´e poss´ıvel considerar no estudo os dados censurados e os n˜ao censurados de forma a produ-zir boas estimativas dos parˆametros para o modelo em estudo. A estima¸c˜ao dos parˆametros pode ser atrav´es do m´etodo de m´axima verossimilha¸ca ou de m´etodos de simula¸c˜ao estoc´astica. Tais abordagens ser˜ao discutidas com mais detalhes nos pr´oximos cap´ıtulos.
Devido a presen¸ca de censura nos dados, a vari´avel resposta do modelo deve incorporar duas informa¸c˜oes: o tempo at´e a falha e o tempo de censura.
2.2 Fun¸c˜ao de Sobrevivˆencia 19
apresentada na forma (ti, δi), i= 1, ..., k, sendoti representado por ti = min(Ti;Ci), ondeTirepresenta o tempo de falha eCio tempo de censura, al´em dissoδirepresenta a vari´avel indicadora de falha ou censura, ou seja,
δi =1(Ti≤Ci), (2.1)
sendo1(·) a fun¸c˜ao indicadora.
2.2 Fun¸c˜
ao de Sobrevivˆ
encia
SejaT uma vari´avel aleat´oria cont´ınua n˜ao negativa, com fun¸c˜ao de densidade de probabilidade fT(t). Ent˜ao sua fun¸c˜ao de sobrevivˆencia ´e dada por:
ST(t) =P(T > t) =
Z ∞
t
fT(t)dt= 1−FT(t), t≥0. (2.2)
Tomando como exemplo um enfoque biol´ogico, pode-se descrever a fun¸c˜ao de sobrevivˆencia como a probabilidade de um indiv´ıduo sobreviver al´em de um tempo t especificado. Observe que a fun¸c˜ao de sobrevivˆencia pode ser escrita como o complementar da fun¸c˜ao de distribui¸c˜ao deT,FT(t).
O que nos leva as seguintes propriedades para ST(·):
P1) Mon´otona decrescente;
P2) Cont´ınua a esquerda;
P3) ST(0)=1;
P4) limt→∞ST(t)=0.
Por P4), a fun¸c˜ao de sobrevivˆencia decai para zero quando o tempo t tende a infinito. Tal comportamento caracteriza uma fun¸c˜ao pr´opria.
A fun¸c˜ao de densidade de probabilidade pode ser encontrada atrav´es da fun¸c˜ao de sobrevivˆencia, ou seja,
dST(t) dt =
d(1−FT(t)) dt =−
dFT(t)
2.3 Estimador de Kaplan-Meier 20
2.3 Estimador de Kaplan-Meier
Como j´a mencionado, a presen¸ca de censuras inviabiliza a an´alise dos dados por meio de t´ecnicas convencionais, como por exemplo, uma an´alise descritiva dos dados. Uma an´alise descritiva para dados de sobrevivˆencia tem como componente principal a estima¸c˜ao da fun¸c˜ao de sobrevivˆencia. Existem v´arios procedimentos para encontrar a fun¸c˜ao de sobrevivˆencia, dentre eles podemos citar, o estimador de Nelson-Aalen (Nelson, 1972 e Aalen, 1978), o m´etodo atuarial, que corresponde a uma das mais antigas t´ecnicas estat´ısticas para tratar tempos de falhas, e ´e indicado para grandes bases de dados. Este ´e um dos m´etodos mais utilizados em demo-grafia, cujo objetivo ´e descrever a mortalidade humana. Por fim, o estimador de Kaplan-Meier (Kaplan e Meier, 1958) tamb´em conhecido como estimador produto-limite. Os autores mostraram que este estimador ´e o estimador n˜ao param´etrico que maximizava a fun¸c˜ao verossimilhan¸ca de ST(t). Devido a sua facilidade de uso e baixo custo computacional, este estimador se tornou o mais difundido em an´alise de sobrevivˆencia, em particular nas ciˆencias biol´ogicas. Vale salientar que este es-timador possui boas propriedades estat´ısticas, como mostradas por Maller e Zhou (1996) e Lawlles (2003) e est´a implementado na maioria dos softwares estat´ısticos. A discuss˜ao de tais propriedades foge ao escopo deste trabalho.
Considere um estudo com n observa¸c˜oes ek tempos de falhas distintos, sendo k≤n. Seja ti, i= 1, ..., k, os tempos da i-´esima falha, tal quet1< t2< ... < tk.
Logo, pode-se definir o estimador de Kaplan-Meier para tm ≤t < tm+1 como sendo:
ˆ ST(t) =
1 , se t < t1 m
Y
i=1
1− di ni
, se tm ≤t < tm+1, m= 1, ..., k.
(2.3)
Sendo,
• t1, t2, ..., tk os k tempos distintos de falhas ordenados;
• di os n´umeros de falhas no instante ti;
• ni o n´umero de observa¸c˜oes sob risco nos tempos ti, ou seja, as observa¸c˜oes que n˜ao falharam nem foram censuradas at´e o instante anterior ati.
2.4 Distribui¸c˜oes Probabil´ısticas 21
2.4 Distribui¸c˜
oes Probabil´ısticas
Dentre as distribui¸c˜oes de probabilidade utilizadas para descrever os tempos de falhas, podemos citar a exponencial, Weibull, log-normal, log´ıstica, log-log´ıstica, Pareto, gama, gama generalizada, Rayleigh, normal inversa e Gompertz.
Neste trabalho utilizaremos as distribui¸c˜oes Pareto, Weibull e exponencial.
2.4.1 Distribui¸c˜
ao Pareto
A distribui¸c˜ao Pareto, tem esse nome em homenagem ao economista italiano Vilfredo Pareto. Nascido em Paris em 15 de julho de 1848, suas contribui¸c˜oes na Economia moderna e na Sociologia s˜ao vastas.
Tamb´em chamada de distribui¸c˜ao de Bradford, foi originalmente criada para descrever a distribui¸c˜ao de renda entre indiv´ıduos. Com uma vasta ´area de aplica¸c˜ao, ´e utilizada n˜ao s´o na economia como tamb´em nas ciˆencias sociais, na atu´aria e na geof´ısica.
Seja T uma vari´avel aleat´oria com distribui¸c˜ao Pareto(p;k), p, k >0, ent˜ao, suas fun¸c˜oes de densidade de probabilidade, fT(·), e de sobrevivˆencia, ST(·), s˜ao dadas, respectivamente, por:
fT(t) =
pkp
(k+t)p+11(0,∞)(t), (2.4)
ST(t) =
k k+t
p
1(0,∞)(t). (2.5)
Note-se que ´e comum que se defina como Pareto a vari´avel aleat´oria u = t+k, visto que pode acarretar problemas na otimiza¸c˜ao quando n˜ao considera-se tal transforma¸c˜ao, ou seja, t estaria no intervalo p < t <∞. Esta parametriza¸c˜ao ´e similar a implementada no software R (base::actuar).
A esperan¸ca e a variˆancia de T s˜ao dadas respectivamente por:
E(T) = 1
p−1, p > 1 ; V ar(T) = pk2 p−2−
pk p−1
2
, p >2.
2.4 Distribui¸c˜oes Probabil´ısticas 22
Figura 2.1 Formas da densidade da Pareto(p;k).
2.4.2 Distribui¸c˜
ao Weibull
A distribui¸c˜ao Weibull foi proposta originalmente por Fisher e Tippett em 1928, no estudo de valores extremos. Posteriormente, foi tamb´em desenvolvida de modo independente por Waloddi Weibull em 1939 em seus estudos sobre a resistˆencia de materiais. Ap´os o fim da II Guerra Mundial, as pesquisas no per´ıodo p´os-guerra deram ˆenfase `as an´alises de resistˆencia de materiais, o que resultou na associa¸c˜ao do nome de Waloddi Weibull a esta distribui¸c˜ao (Bailey e Dell, 1973).
SejaT uma vari´avel aleat´oria com distribui¸c˜ao Weibull (γ;α), γ, α >0. Ent˜ao sua fun¸c˜ao densidade de probabilidade e de sobrevivˆencia s˜ao dadas, respectiva-mente, por:
fT(t) = γ αγt
γ−1exp
−
t α
γ
1(0,∞)(t), (2.6)
ST(t) = exp
−
t
α
γ
1(0,∞)(t). (2.7)
Tem-se tamb´em que a esperan¸ca e a variˆancia deT, s˜ao dadas, respectivamente, por:
E(T) =αΓ
1 + 1 γ
; V ar(T) =α2
(
Γ
1 + 2 γ
−Γ
1 +1 γ
2) .
Sendo Γ(·) a fun¸c˜ao gama, dada por: Γ(z) =R0∞xz−1exp(−x)dx.
Devido `a sua flexibilidade, a distribui¸c˜ao de Weibull ´e amplamente utilizada
2.4 Distribui¸c˜oes Probabil´ısticas 23
n˜ao s´o em estudos industriais, por exemplo, na modelagem de falhas de equipa-mentos, como tamb´em em estudos cl´ınicos. A sua flexibilidade permite o ajuste de diversas formas, como pode ser visto na Figura 2.2.
Figura 2.2 Formas da densidade da Weibull(γ;α).
2.4.3 Distribui¸c˜
ao Exponencial
Corresponde a um modelo simples de apenas um parˆametro apresentando uma fun¸c˜ao de taxa de falha constante que caracteriza a falta de mem´oria da distribui¸c˜ao. ´
E bastante utilizada tanto na ´area industrial quanto na ´area m´edica. Cox e Snell (1981) aplicam este modelo com o objetivo de descrever o tempo de vida de pacientes com leucemia.
Seja T uma vari´avel aleat´oria com distribui¸c˜ao exponencial(λ), λ >0, ent˜ao, suas fun¸c˜oes de densidade e de sobrevivˆencia s˜ao dadas, respectivamente, por:
fT(t) =λexp(−λt)1(0,∞)(t), (2.8)
ST(t) = exp(−λt)1(0,∞)(t). (2.9)
Cap´ıtulo 3
Modelos de Longa Dura¸c˜
ao
3.1 Introdu¸c˜
ao
Modelos de fra¸c˜ao de cura, est˜ao se tornando cada vez mais populares na an´alise de dados provenientes de ensaios cl´ınicos de cˆancer. Os modelos que incor-poram uma taxa de cura tem sido utilizados para modelar o tempo de eventos para v´arios tipos de cˆancer nos quais uma propor¸c˜ao de pacientes s˜ao “curados”, incluindo o cancˆer da mama, linfoma no-Hodgkins, leucemia, cˆancer da pr´ostata, melanoma, e cˆancer de cabe¸ca e pesco¸co. Dentre o mais popular desses modelos est´a omodelo de mistura padr˜ao introduzido por Berkson e Gage (1952). Neste modelo, assumimos que uma certa fra¸c˜aoθ da popula¸c˜ao s˜ao de “curados”e o restante 1−θs˜ao de n˜ao curados (Chen et al. 1999).
3.2 Modelo de Mistura Padr˜
ao (MMP)
Uma abordagem para a an´alise de dados de sobrevivˆencia com imunes ´e ajustar um modelo param´etrico que ´e uma mistura de duas distribui¸c˜oes, uma representando o tempo de falha para o grupo de suscet´ıvel e a outra que permite uma distribui¸c˜ao degenerada para os tempos de sobrevivˆencia dos imunes. Vamos nos referir a esses tipos de modelos como modelos de mistura. Em contraste com Boag (1949), Berkson e Gage (1952) utilizaram um modelo constitu´ıdo por uma mistura de uma distri-bui¸c˜ao exponencial e uma distridistri-bui¸c˜ao degenerada, para permitir uma propor¸c˜ao de curados. Eles utilizaram este modelo para um grande conjunto de dados consistindo de 2682 pacientes acometidos de cˆancer de estˆomago (Maller e Zhou, 1996).
3.2 Modelo de Mistura Padr˜ao (MMP) 25
suscet´ıveis ao evento de interesse. Um indiv´ıduo ser´a suscet´ıvel ao evento seM = 1 com probabilidade 1−θ, e imune se M = 0, com probabilidade igual aθ (fra¸c˜ao de cura).
Observe que, teoricamente, os tempos de vida para os indiv´ıduos imunes s˜ao infinitos, ent˜ao estes ter˜ao fun¸c˜ao de distribui¸c˜ao igual a zero. Simplificando, tem-se:
P(T ≤t|M = 1) = FT(t) e P(T ≤t|M = 0) = 0.
Logo, obt´em-se uma mistura das duas subpopula¸c˜oes e pode-se escrever a fun¸c˜ao de sobrevivˆencia para a popula¸c˜ao, como sendo:
Spop(t) = P(T ≥t) = 1−P(T ≤t)
= 1−[P(T ≤t|M = 1)P(M = 1) +P(T ≤t|M = 0)P(M = 0)] = 1−[FT(t)(1−θ) + 0] = 1−[(1−ST(t))−θ(1−ST(t))]
= θ+ (1−θ)ST(t). (3.1)
Aqui,ST(t) ´e a fun¸c˜ao de sobrevivˆencia para o grupo dos n˜ao curados eθa propor¸c˜ao de curados.
Portanto, o modelo de mistura padr˜ao ´e caracterizado pela fun¸c˜ao de sobre-vivˆencia dado por (3.1) e pela fun¸c˜ao de densidade dada por:
fpop(t) =− ∂
∂tSpop(t) = (1−θ)fT(t), (3.2)
Para a constru¸c˜ao da fun¸c˜ao de verossimilhan¸ca do modelo de mistura, consi-dere ti = min(Ti;Ci) o tempo observado do i-´esimo indiv´ıduo, Mi = mi e p(mi) = P(Mi = mi) a fun¸c˜ao de probabilidade de Mi e δi a fun¸c˜ao indicadora de falha ou censura dada por (2.1).
Dessa maneira podemos escrever os seguintes vetores:
t= t1 t2 ... tn
, δ =
δ1 δ2 ... δn
, M=
M1 M2 ... Mn
3.2 Modelo de Mistura Padr˜ao (MMP) 26
completos no modelo de mistura padr˜ao, ´e dada por:
L∗M M P(θ;Dc) =
n
Y
i=1
[mifpop(ti;ψ)]δi[Spop(ti;ψ)]mi−δip(mi). (3.3)
Sendoψ o parˆametro, ou vetor de parˆametros associado `a distribui¸c˜ao deTi.
Como (3.3) ´e n˜ao observ´avel, pois depende das vari´aveis latentes Mi, ent˜ao utiliza-se uma fun¸c˜ao de verossimilhan¸ca marginal, que ´e dada por:
LM M P(θ;D) = n
Y
i=1
[fpop(ti;ψ)]δi[Spop(ti;ψ)]1−δi. (3.4)
3.2.1 Modelo de Mistura Padr˜
ao Exponencial (MMPexp)
Assumindo uma distribui¸c˜ao exponencial (λ), com fun¸c˜oes de densidade, (2.8), e sobrevivˆencia, (2.9), ent˜ao as fun¸c˜oes de verossimilhan¸ca e log-verossimilhan¸ca de
θ= (θ;λ)′ para o modelo de mistura padr˜ao exponencial s˜ao dadas, respectivamente,
por:
LM M P exp(θ;D) = [λ(1−θ)]
Pn
i=1δiexp
(
−λ n
X
i=1 δiti
)
×
n
Y
i=1
[θ+ (1−θ) exp(−λti)]1−δi, (3.5)
ℓM M P exp(θ;D) = log{λ(1−θ)} n
X
i=1 δi−λ
n
X
i=1 [δiti]
+ n
X
i=1
[(1−δi) log{θ+ (1−θ) exp(−λti)}]. (3.6)
3.2.2 Modelo de Mistura Padr˜
ao Pareto (MMPpar)
Seja T ∼ Pareto(p;k), p, k > 0, com fun¸c˜oes de densidade, (2.4), e de so-brevivˆencia, (2.5), ent˜ao as fun¸c˜oes de verossimilhan¸ca e log-verossimilhan¸ca de
θ= (θ;p;k)′ para o modelo de mistura padr˜ao Pareto, s˜ao dadas, respectivamente,
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 27
por:
LM M P par(θ;D) = ((1−θ)pkp)
Pn i=1δi
n
Y
i=1
" 1
k+ti
p+1#δi
×
n
Y
i=1
θ+ (1−θ)
k
k+ti
p1−δi
, (3.7)
ℓM M P par(θ;D) = n
X
i=1
δi[log(1−θ) +plog(pk)−(p+ 1) log(k+ti)]
+ n
X
i=1
(1−δi) log
θ+ (1−θ)
k k+ti
p
. (3.8)
3.2.3 Modelo de Mistura Padr˜
ao Weibull (MMPwei)
Seja T ∼Weibull(γ;α), γ, α >0, com fun¸c˜oes de densidade, (2.6), e de sobre-vivˆencia, (2.7), ent˜ao teremos as fun¸c˜oes de verossimilhan¸ca e log-verossimilhan¸ca deθ = (θ;α;γ)′ para o modelo de mistura padr˜ao Weibull, dadas, respectivamente,
por:
LM M P wei(θ;D) =
(1−θ)α−γγ
Pn i=1δi
n
Y
i=1
tγi−1exp
−
ti α
γδi
×
n
Y
i=1
θ+ (1−θ) exp
−
ti α
γ1−δi
, (3.9)
ℓM M P wei(θ;D) = log
(1−θ)α−γγ n
X
i=1 δi+
n
X
i=1 δi
(γ−1) log(ti)−
t i α γ + n X i=1
(1−δi) log
θ+ (1−θ) exp
− t i α γ . (3.10)
3.3 Modelo de Tempo de Promo¸c˜
ao (MTP)
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 28
Embora o modelo de mistura padr˜ao seja simples e bastante utilizado, o mesmo possui alguns inconvenientes. Primeiramente, os modelos de mistura padr˜ao n˜ao s˜ao capazes de modelar o mecanismo biol´ogico envolvido no processo cl´ınico. O que n˜ao ocorre, por exemplo, nos modelos de tempo de promo¸c˜ao (Yakovlev e Tsodikov, 1996), os quais s˜ao capazes de modelar o n´umero de causas, que competem entre si, para que ocorra o evento de interesse.
Em segundo lugar, na presen¸ca de covari´aveis, n˜ao se pode ter uma estrutura de riscos proporcionais, que ´e uma propriedade desej´avel para realizar an´alises nas covari´aveis. Al´em disso, quando inclu´ıdo covari´aveis atrav´es do parˆametroθ, via um modelo de regress˜ao binomial padr˜ao, a equa¸c˜ao (3.1) produz distribui¸c˜oes a poste-riori impr´oprias para muitos tipos de priores impr´oprias n˜ao-informativas, incluindo prioris uniformes para os coeficientes de regress˜ao (Chen et al. 2002).
Uma vantagem do crit´erio de riscos proporcionais, citado por Chen et al. (1999), ´e que a partir de uma perspectiva frequentista muitos resultados assint´oticos e computacionais exigem esse tipo de estrutura.
Yakovlev e Tsodikov (1996) propuseram o modelo de tempo de promo¸c˜ao, no qual os tempos de sobrevivˆencia de pacientes curados e n˜ao curados s˜ao incorporados simultaneamente.
Para constru¸c˜ao do referido modelo, suponha que tenhamos um n´umero de c´elulas potencialmente cancer´ıgenas associadas a uma vari´avel aleat´oria M com distribui¸c˜ao de Poisson (ϕ), ϕ > 0, dada por, P(M = m) = ϕmexpm!{−ϕ}, m = 0,1,2, .... Tais c´elulas s˜ao denominadasfatores latentes e portanto n˜ao observ´aveis. Seja tamb´em, um conjunto de vari´aveis aleat´orias latentesKj, j = 1,2, ..., M, repre-sentando o tempo at´e a ocorrˆencia do evento de interesse devido a j-´esima c´elula. Considerando as vari´aveis aleat´orias Kj, condicionadas a M, independentes e iden-ticamente distribu´ıdas.Definimos o tempo at´e a ocorrˆencia do evento de interesse, como sendo:
T = min{K0, K1, K2, ..., KM}, (3.11)
sendo K0, tal que P(K0 = ∞) = 1. Pode-se observar o tempo at´e o surgimento do tumor, sendo que, se um indiv´ıduo n˜ao apresentar c´elulas potencialmente can-cer´ıgenas, mesmo que o tempo de acompanhamento para este indiv´ıduo seja longo, o mesmo n˜ao desenvolver´a o tumor.
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 29
Portanto, a fun¸c˜ao de sobrevivˆencia de T ´e dada por:
Spop(t) =P(T > t) =
X
m≥0
P(T > t, M =m)
= P(T > t, M = 0) +X m≥1
P(T > t, M =m)
= P(T > t|M = 0)P(M = 0)
+ X
m≥1
P(T > t|M =m)P(M =m).
Como, P(T > t|M = 0) ´e a sobrevivˆencia dado o n´umero de c´elulas igual a zero, ent˜ao, o indiv´ıduo n˜ao apresentou c´elulas potencialmente cancer´ıgenas e o mesmo n˜ao ser´a acometido pelo evento de interesse, ou seja, P(T > t|M = 0) = 1. Ent˜ao,
Spop(t) = P(M = 0) +
X
m≥1
P(T > t|M =m)P(M =m)
= P(M = 0) +X m≥1
P(min{K1, K2, ..., Km}> t|M = m)P(M =m)
= P(M = 0) +X m≥1
P(K1 > t)P(K2 > t).· · · .P(Km> t)P(M =m)
= ϕ
0exp (−ϕ)
0! +
X
m≥1
[ST(t)]m
ϕmexp (−ϕ) m!
= exp (−ϕ)
" ∞ X
m=0
[ST(t)ϕ]m m!
#
.
Aproximando a express˜aoP∞m=0[ST(t)ϕ]m
m! em fun¸c˜ao de s´erie de Taylor, tem-se que,
P∞
m=0
[ST(t)ϕ]m
m! = exp (ST(t)ϕ).
Portanto, pode-se escrever a fun¸c˜ao de sobrevivˆencia associada ao modelo de tempo de promo¸c˜ao como sendo:
Spop(t) = exp (−ϕ) exp (ST(t)ϕ) = exp (−ϕFT(t)). (3.12)
Sendo, a fun¸c˜ao de densidade dada por:
fpop(t) =−
dSpop(t)
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 30
De modo que a fra¸c˜ao de cura ´e expressa como sendo:
θ= exp(−ϕ). (3.14)
Assim como no modelo de mistura padr˜ao M ´e n˜ao observ´avel, ent˜ao utiliza-remos a fun¸c˜ao de verossimilhan¸ca de θ = (ψ;ϕ)′, relativa `a distribui¸c˜ao marginal
de teδ, associados aos tempos Kj, dada por:
LM T P(θ;D) = n
Y
i=1
[ϕfT(ti;ψ) exp{−ϕFT(ti;ψ)}]δi[exp{−ϕFT(ti;ψ)}]1−δi. (3.15)
Segundo Sinha et al. (2003), as fun¸c˜oes de sobrevivˆencia e densidade para os n˜ao curados, s˜ao fun¸c˜oes pr´oprias dadas, respectivamente, por:
ST∗(t) = exp(−ϕFT(t))−exp(−ϕ) 1−exp(ϕ) ,
fT∗(t) =ϕf(t)exp(−ϕFT(t)) 1−exp(−ϕ) ,
Mesmo que os modelos de mistura padr˜ao e de tempo de promo¸c˜ao tenham sido formulados em diferentes situa¸c˜oes, ´e poss´ıvel escrever o modelo de tempo de promo¸c˜ao como um modelo de mistura padr˜ao (Sumathi e Aruna Rao, 2008). Com θ= exp(−ϕ) temos,
Spop(t) = exp (−ϕ) + (1−exp (−ϕ))
exp (−ϕFT(t))−exp (−ϕ) 1−exp (−ϕ) ,
e a fun¸c˜ao de sobrevivˆencia para os n˜ao curados ´e dada por:
ST∗(t) =P(T > t|M ≥1) = exp (−ϕFT(t))−exp (−ϕ) 1−exp (−ϕ) .
3.3.1 Modelo de Tempo de Promo¸c˜
ao Exponencial (MTPexp)
Seja T ∼ exponencial (λ), λ > 0, ent˜ao as fun¸c˜oes de verossimilhan¸ca e log-verossimilhan¸ca de θ= (ϕ;λ)′, para o referido modelo, s˜ao dadas, respectivamente,
3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 31
por:
LM T P exp(θ;D) = (ϕλ)
Pn
i=1δiexp
(
−λ n
X
i=1 δiti
)
× exp
(
−ϕ[1−exp(−λti)] n
X
i=1 δi+
n
X
i=1
(1−δi)
!)
,(3.16)
ℓM T P exp(θ;D) = log(ϕλ) n
X
i=1 δi−λ
n
X
i=1 δiti
− ϕ[1−exp(−λti)] n
X
i=1 δi+
n
X
i=1
(1−δi)
!
. (3.17)
3.3.2 Modelo de Tempo de Promo¸c˜
ao Pareto (MTPpar)
Seja T ∼ Pareto(p;k), p, k > 0, ent˜ao as fun¸c˜oes de verossimilhan¸ca e log-verossimilhan¸ca deθ= (θ;p;k)′, para o referido modelo, s˜ao dadas, respectivamente,
por:
LM T P par(θ;D) = (ϕpkp)
Pn i=1δi
n
Y
i=1
" 1
k+ti
p+1#δi
× exp ( −ϕ 1− k k+ti
p "Xn
i=1 δi+
n
X
i=1
(1−δi)
#)
,(3.18)
ℓM T P par(θ;D) = n
X
i=1
δilog(ϕpkp) + n
X
i=1
(p+ 1)δilog
k k+ti
p − ϕ 1− k k+ti
p "Xn
i=1 δi+
n
X
i=1
(1−δi)
#
. (3.19)
3.3.3 Modelo de Tempo de Promo¸c˜
ao Weibull (MTPwei)
respectiva-3.3 Modelo de Tempo de Promo¸c˜ao (MTP) 32
mente, por:
LM T P wei(θ;D) =
ϕγα−γ
Pn i=1δi
n
Y
i=1
tγi−1δi
× exp ( n X i=1 δi − t i α γ −ϕ
1−exp
− t i α γ) × exp ( −ϕ n X i=1
(1−δi)
1−exp
− t i α γ) , (3.20)
ℓM T P wei(θ;D) = log
ϕγα−γ n
X
i=1 δi+
n
X
i=1
δi[(γ−1) log(ti)]
+ n X i=1 δi − ti α γ −ϕ
1−exp
− ti α γ − ϕ n X i=1
(1−δi)
1−exp
− t i α γ . (3.21)
Cap´ıtulo 4
M´
etodos de Estima¸c˜
ao
4.1 Inferˆ
encia Cl´
assica
Seja T1, ..., Tn uma amostra aleat´oria de tamanho n da vari´avel aleat´oria T com fun¸c˜ao de densidade (ou de probabilidade) f(t|θ), com θ ∈ Θ, onde Θ ´e o
espa¸co param´etrico. A fun¸c˜ao de verossimilhan¸ca de θ correspondente `a amostra
aleat´oria observada, D = (n,t,δ), ´e dada por:
L(θ;D) =
n
Y
i=1
f(ti|θ).
Observe que, em an´alise de sobrevivˆencia, a contribui¸c˜ao das observa¸c˜oes n˜ao censuradas ´e dada pela fun¸c˜ao de densidade, f(t|θ). O que n˜ao acontece com as
observa¸c˜oes censuradas, que por sua vez tˆem contribui¸c˜ao para L(θ;D) dada pela
fun¸c˜ao de sobrevivˆencia,S(t|θ). Logo, teremos que reescrever a fun¸c˜ao de
verossimi-lhan¸ca de tal forma que possamos modelar adequadamente dados de sobrevivˆencia. Sendo, a fun¸c˜ao de verossimilhan¸ca para modelar dados com presen¸ca de censura dada por:
L(θ;D) =
n
Y
i=1
[f(ti|θ)]δi[S(ti|θ)]1−δi. (4.1)
Portanto, o estimador de m´axima verossimilhan¸ca de θ´e o valor de ˆθ∈Θ que
maximiza a fun¸c˜ao de verossimilhan¸ca L(θ;D). O estimador de m´axima
verossimi-lhan¸ca pode ser encontrado como a raiz da equa¸c˜ao de verossimiverossimi-lhan¸ca ℓ(θ;D) =
∂ℓ(θ;D)
∂θ = 0. No qualℓ(θ;D) ´e o logaritmo natural da fun¸c˜ao de verossimilhan¸ca de
θ (Bolfarine e Sandoval, 2010).
Para a maximiza¸c˜ao das fun¸c˜oes, ℓ(θ;D), nos modelos abordados no Cap´ıtulo
4.2 Inferˆencia Bayesiana 34
4.1.1 Verossimilhan¸ca Perfilada
Na estima¸c˜ao de um vetor de parˆametros via verossimilhan¸ca perfilada encontra-se as estimativas de m´axima verossimilhan¸ca dos demais parˆametros substituindo-os na fun¸c˜ao de verossimilhan¸ca e em seguida calcula-se a verossimilhan¸ca em cada ponto do parˆametro de interesse.
Considere um modelo estat´ıstico, em que θ ´e um vetor de parˆametros
desco-nhecidos, sendo θ = (θ;ψ) e suponha que inferˆencias realizadas no modelo envolva
apenas θ. Ent˜ao, a fun¸c˜ao de verossimilhan¸ca perfilada ´e obtida substituindo, na fun¸c˜ao de verossimilhan¸ca original, o parˆametros ψ por sua estimativa de m´axima verossimilhan¸ca,ψbθ, para um conjunto de valores fixados deθ.
Dessa forma pode-se escrever θb0 = (θ;ψbθ), sendoψbθa solu¸c˜ao de ∂log[L(θ)]
∂ψ = 0. Assim, a fun¸c˜ao de verossimilhan¸ca perfilada pode ser definida como:
Lper(θ) =L(θ;ψbθ). (4.2)
Sendoℓ(θ;ψ) = log[L(θ;ψ)], ent˜ao a fun¸c˜ao de log-verossimilhan¸ca perfilada paraθ ´e definida por:
ℓper(θ) =ℓ(θ;ψbθ) = sup ψ
[ℓ(θ;ψ)]. (4.3)
Logo, o estimador de m´axima verossimilhan¸ca perfilada, θbp, ´e encontrado como solu¸c˜ao da equa¸c˜ao:
∂ℓper(θ) ∂θ = 0.
4.2 Inferˆ
encia Bayesiana
Na inferˆencia Bayesiana admitimos que as incertezas s˜ao pass´ıveis de serem descritas, coerentemente, por uma distribui¸c˜ao de probabilidade. Assim, o procedi-mento de estima¸c˜ao consiste em descrever a incerteza inicial do pesquisador sobre o parˆametro, atrav´es da distribui¸c˜ao a priori, π(·), e em seguida, combinar essa informa¸c˜ao com aquela proveniente dos dados, resumida na fun¸c˜ao de verossimi-lhan¸ca. O resultado deste procedimento ´e uma distribui¸c˜ao de probabilidade,π(·|x), (distribui¸c˜ao a posteriori) e a inferˆencia sobre o parˆametro ´e feita feita atrav´es da caracteriza¸c˜ao dessa distribui¸c˜ao (Migon et al., 2008).
4.2 Inferˆencia Bayesiana 35
4.2.1 Teorema de Bayes
Pode-se dizer ainda que, o conhecimento inicial que se tem a respeito do parˆametro, expresso porπ(·), transforma-se em conhecimento final, dado pela distri-bui¸c˜ao a posteriori, π(·|x). Esta transforma¸c˜ao se deve ao Teorema de Bayes, dado as quantidades observadas.
A atualiza¸c˜ao da informa¸c˜ao se d´a atrav´es do Teorema de Bayes,
π(θ|x) = f(x;θ)
f(x) =
f(x|θ)π(θ)
f(x) =
f(x|θ)π(θ)
R
f(θ, x)dθ =
f(x|θ)π(θ)
R
f(x|θ)π(θ)dθ, (4.4)
sendoπ(θ|x) a distribui¸c˜ao a posteriori de θ eπ(θ) a distribui¸c˜ao a priori de θ.
Observe que 1/f(x) funciona como uma constante normalizadora n˜ao depen-dendo do parˆametro. Assim, utilizando o teorema de Bayes, podemos reescrever a distribui¸c˜ao a posteriori como sendo:
π(θ|x)∝f(x|θ)π(θ). (4.5)
4.2.2 Est´
agios da Inferˆ
encia Bayesiana
A metodologia Bayesiana fornece n˜ao s´o a possibilidade de atualiza¸c˜ao do co-nhecimento dos parˆametros do modelo, e posteriormente a tomada de decis˜oes, como tamb´em ´e um ferramental simples e flex´ıvel a partir do qual faz-se inferˆencias usando modelos param´etricos. No entanto, esta flexibilidade traz alguns obst´aculos compu-tacionais. Basicamente, tais problemas computacionais se resumem em opera¸c˜oes de integra¸c˜ao, que muitas vezes possui alto grau de complexidade.
Nas ´ultimas d´ecadas muitos algoritmos de resolu¸c˜oes de integrais foram pro-postos, e outros modificados, com o objetivo de contornar tais dificuldades. Vale salientar que, a utliza¸c˜ao de muitos destes algor´ıtmos s´o foi poss´ıvel devido aos avan¸cos computacionais, e foi devido a isto que a inferˆencia Bayesiana progrediu tanto nos ´ultimos anos.
4.2 Inferˆencia Bayesiana 36
a implementa¸c˜ao computacional, nem restri¸c˜oes quanto ao n´umero de parˆametros a serem estimados.
A distribui¸c˜ao a posteriori ´e convenientemente resumida em termos da espe-ran¸ca condicional de uma fun¸c˜ao deθ, ou seja,
E[g(θ)|x] =
Z
g(θ)π(θ|x)dθ. (4.6)
Se o parˆametro for multidimensional pode-se encontrar as distribui¸c˜oes mar-ginais a posteriori. Sejaθ= (θ1,θ2), ent˜ao,
π(θ1|x) =
Z
π(θ|x)dθ2. (4.7)
4.2.3 Distribui¸c˜
oes de Probabilidade a Priori
A distribui¸c˜ao a priori constitui-se em um importante elemento na an´alise Bayesiana e a determina¸c˜ao desta distribui¸c˜ao ´e subjetiva. Espera-se que a distri-bui¸c˜ao de probabilidade a priori represente o estado atual de conhecimento sobre os parˆametros, antes de serem analisados os resultados experimentais.
Pode-se ter propostas para a obten¸c˜ao da distribui¸c˜ao a priori de diversas formas, como por exemplo, prioris conjugadas, prioris n˜ao informativas e prioris hier´arquicas.
Prioris N˜ao Informativas
Em alguns problemas pr´aticos, podemos nos deparar com situa¸c˜oes em que n˜ao temos informa¸c˜oes suficientes para a tomada de decis˜ao a respeito da distribui¸c˜ao a priori do parˆametro do modelo. Nesses casos, sugere-se propor uma distribui¸c˜ao a priori que reflita no m´ınimo de influˆencia sobre a posteriori resultante. Observe que, neste caso, o maior peso da distribui¸c˜ao a posteriori ser´a dado pela fun¸c˜ao de verossimilhan¸ca.
Reconhece-se a necessidade de an´alise que consiga captar esta no¸c˜ao de uma priori que tenha um efeito m´ınimo, relativamente aos dados, na inferˆencia final. Tal an´alise pode ser pensada como um ponto de partida quando n˜ao se consegue fazer uma elicita¸c˜ao detalhada do conhecimento a priori (Ehlers, 2011).
4.2 Inferˆencia Bayesiana 37
Uma poss´ıvel fam´ılia de distribui¸c˜ao a priori informativas
Para o modelo de tempo de promo¸c˜ao foi visto que a fra¸c˜ao de curados era dada por θ = exp(−ϕ). No entanto, o parˆametro de interesse est´a vinculado na interpreta¸c˜ao direta de θ e n˜ao de ϕ. Logo, como ϕ > 0 ´e vi´avel pensar para a distribui¸c˜ao de probabilidade a priori deϕ, uma distribui¸c˜ao Uniforme.
Seja ϕ ∼ Unif(0;A), A > 0 “grande”, com f.d.p. fϕ(φ) = 1[0,A] (φ)
A . Como o interesse ´e uma interpreta¸c˜ao em θ, vejamos o comportamento da distribui¸c˜ao de probabilidade a priori para θ.
Seja,θ= exp(−ϕ)⇒ϕ=−log(θ) e Π(·) a fun¸c˜ao de distribui¸c˜ao deθ. Logo, teremos que:
Π(θ∗) = P(θ≤θ∗) =P(exp(−ϕ)≤θ∗) =P(ϕ >−log(θ∗)) = 1−
Z −log(θ∗)
0
1 Adϕ
= 1− 1 Aϕ
−log(θ
∗)
0 = 1− 1
A(−log(θ
∗)
−0) = 1 + log(θ
∗)
A .
Ent˜ao, a distribui¸c˜ao a priori deθ ´e dada por:
π(θ) = dΠ(θ) dθ =
1 θ
1[0,A](φ) A .
Note ainda que:
Z 1 0 π(θ)dθ= Z 1 0 1 A 1 θdθ=
1
Alog(θ)
1
0 = 0− ∞,
ou seja, a escolha de uma distribui¸c˜ao Uniforme (0;A), como sendo uma distribui¸c˜ao de probabilidade a priori para ϕ, nos remete a uma distribui¸c˜ao de probabilidade a priori impr´opria para θ.
Vale salientar que, uma distribui¸c˜ao a priori impr´opria n˜ao implica, necessari-amente, em uma distribui¸c˜ao a posteriori tamb´em impr´opria.
Uma outra distribui¸c˜ao natural a se pensar para θ´e a distribui¸c˜ao Beta, visto que esta modela vari´aveis no intervalo (0;1). Vejamos ent˜ao, como se comporta ϕ com tal proposta paraθ.
Tomemosθ∼Beta(α;β), ou seja,π(θ) = Γ(Γ(αα)Γ(+ββ))θα−1(1−θ)β−1,0< θ <1, α > 0, β > 0.
Seja ϕ = −log(θ) e dθ
4.2 Inferˆencia Bayesiana 38
sendo:
π(ϕ) = π(θ)
dθ dϕ
=
Γ(α+β) Γ(α)Γ(β)θ
α−1(1
−θ)β−1|−exp(−ϕ)|
= Γ(α+β)
Γ(α)Γ(β)[exp(−ϕ)] α−1[1
−exp(−ϕ)]β−1exp(−ϕ)
= Γ(α+β)
Γ(α)Γ(β)[exp(−ϕ)] α[1
−exp(−ϕ)]β−1;ϕ >0.
Portanto, a distribui¸c˜ao de probabilidade a priori para ϕ ´e uma distribui¸c˜ao Beta(α+ 1, β) analisada em exp(-ϕ).
Como casos particulares, observe que:
i) com α livre e β= 1, temos θ∼Beta(α,1) e ϕ∼ Exp(α);
ii) com α= 1 eβ = 1, temosθ ∼Unif(0,1) eϕ∼ Exp(1).
4.2.4 Distribui¸c˜
ao de Probabilidade
a Posteriori
A seguir descrevemos as distribui¸c˜oes de probabilidade a posteriori para os modelos de longa dura¸c˜ao descritos no Cap´ıtulo 3.
• Distribui¸c˜ao de probabilidade a posteriori para o Modelo de Mistura Padr˜ao Exponencial (MMPexp).
π(θ|t) ∝ π(θ)×[λ(1−θ)]Pni=1exp
(
−λ
n
X
i=1 δiti
)
×
n
Y
i=1
[θ+ (1−θ) exp(−λti)]1−δi, (4.8)
sendoθ = (θ, λ).
• Distribui¸c˜ao de probabilidade a posteriori para o Modelo de Mistura Padr˜ao Pareto (MMPpar).
4.2 Inferˆencia Bayesiana 39
π(θ|t) ∝ π(θ)×((1−θ)pkp)Pni=1δi
n
Y
i=1
"
1 k+ti
p+1#δi
×
n
Y
i=1
θ+ (1−θ)
k
k+ti
p1−δi
, (4.9)
sendoθ = (θ, p, k).
• Distribui¸c˜ao de probabilidade a posteriori para o Modelo de Mistura Padr˜ao Weibull (MMPwei).
π(θ|t) ∝ π(θ)×(1−θ)α−γγ
Pn i=1δi
n
Y
i=1
tγi−1exp
−
ti α
γδi
×
n
Y
i=1
θ+ (1−θ) exp
−
ti α
γ1−δi
, (4.10)
sendoθ = (θ, α, γ).
• Distribui¸c˜ao de probabilidadea posterioripara o Modelo de Tempo de Promo¸c˜ao Exponencial (MTPexp).
π(θ|t) ∝ π(θ)×(ϕλ)Pni=1δiexp
(
−λ
n
X
i=1 δiti
)
× exp
(
−ϕ[1−exp(−λti)] n
X
i=1 δi+
n
X
i=1
(1−δi)
!)
, (4.11)
sendoθ = (ϕ, λ).
• Distribui¸c˜ao de probabilidadea posterioripara o Modelo de Tempo de Promo¸c˜ao Pareto (MTPpar).
π(θ|t) ∝ π(θ)×(ϕpkp)Pni=1δi
n
Y
i=1
"
1 k+ti
p+1#δi
× exp ( −ϕ 1− k
k+ti
p "Xn
i=1 δi+
n
X
i=1
(1−δi)
#)
, (4.12)
4.3 M´etodo de Laplace 40
• Distribui¸c˜ao de probabilidadea posterioripara o Modelo de Tempo de Promo¸c˜ao Weibull (MTPwei).
π(θ|t) ∝ π(θ)×ϕγα−γ
Pn i=1δi
n
Y
i=1
tγi−1δi
× exp ( n X i=1 δi − ti α γ −ϕ
1−exp
− ti α γ) × exp ( −ϕ n X i=1
(1−δi)
1−exp
− ti α γ) , (4.13)
sendoθ = (ϕ, γ, α).
As distribui¸c˜oes de probabilidade a prioriπ(θ) de cada modelo s˜ao destacadas
na aplica¸c˜ao (Cap´ıtulo 5).
4.3 M´
etodo de Laplace
No referido trabalho utilizaremos a abordagem proposta por Tierney e Kadane (1986) para o c´alculo de integrais atrav´es do m´etodo de Laplace. Os fundamentos do m´etodo de Laplace, datam do s´eculo XIII (Laplace, 1774). Consideremos integrais da forma
I =
Z
f(θ) exp(−nΨ(θ))dθ. (4.14)
Seja Ψ uma fun¸c˜ao regular de um parˆametro n-dimensional, θ, e θbo m´aximo
de −Ψ(·). A aproxima¸c˜ao para a integral acima ´e dada atrav´es do desenvolvimento em s´erie de Taylor de Ψ(θ) e f(θ) em torno de θˆ.
Queremos encontrar a esperan¸ca condicional a posteriori de uma fun¸c˜ao do parˆametro, ou seja,
E[g(θ)|x] =
R
g(θ)f(x|θ)π(θ)dθ
R
f(x|θ)π(θ)dθ , (4.15)
sendo esta obtida pela substitui¸c˜ao de (4.14) em (4.16).
Para aplicar o m´etodo de Laplace a integral deve estar na forma (4.14). Con-sideremos ent˜ao:
i) exp(−nΨ(θ)) =f(x|θ)π(θ),
ii) g(θ) =f(θ) no numerador e f(θ) = 1 no denominador.
4.3 M´etodo de Laplace 41
Logo, a equa¸c˜ao (4.15) pode ser reescrita na forma:
E[g(θ)|x] =
R
exp(−nΨ∗(θ))dθ
R
exp(−nΨ(θ))dθ. (4.16)
sendo,
−nΨ(θ) = lnf(x|θ) + lnπ(θ),
−nΨ∗(θ) = lng(θ) + lnf(x|θ) + lnπ(θ).
Tomemos agora, ˆθ e θ∗ com sendo argumentos m´aximo das fun¸c˜oes −Ψ(θ) e −Ψ∗(θ).
O que nos leva as aproxima¸c˜oes para as respectivas integrais:
Z
exp(−nΨ∗(θ))dθ≈√2πσ∗n−1/2exp(−nΨ∗(θ∗)), (4.17)
Z
exp(−nΨ(θ))dθ ≈√2πˆσn−1/2exp(−nΨ(ˆθ)). (4.18)
Portanto, uma aproxima¸c˜ao para esperan¸ca a posteriori (4.16) ´e dada por:
E[g(θ)|x] =
R
exp(−nΨ∗(θ))dθ
R
exp(−nΨ(θ))dθ ≈ √
2πσ∗n−1/2exp(−nΨ∗(θ∗))
√
2πˆσn−1/2exp(−nΨ(ˆθ))
≈ σ
∗
ˆ
σ exp(−n[Ψ
∗(θ∗)
−Ψ(ˆθ)]). (4.19)
No qual, σ∗ = [det(∇2Ψ∗(θ∗))]−1/2; ˆσ = [det(∇2Ψ(ˆθ))]−1/2, sendo ∇2 a matriz Hessiana.
A id´eia da integra¸c˜ao via m´etodo de Laplace, est´a em aplicar separadamente o m´etodo nas integrais do numerador e do denominador. Tierney e Kadane (1986) ressaltam que o esfor¸co computacional ´e reduzido, visto que s´o ´e necess´ario encontrar as derivadas de ordem 1 e 2, e maximizar as duas fun¸c˜oes integrantes, que em resumo s˜ao apenas fun¸c˜oes de verossimilhan¸ca ligeiramente modificadas.
Outra contribui¸c˜ao deste m´etodo ´e em rela¸c˜ao ao erro de aproxima¸c˜ao, pois tanto no numerado como no denominador deE[g(θ)|x] o erro ´e da ordem den−1.
4.4 M´etodos de Simula¸c˜ao Estoc´astica 42
4.4 M´
etodos de Simula¸c˜
ao Estoc´
astica
O objetivo dos m´etodos de Monte Carlo via cadeias de Markov ´e simular uma cadeia de Markov no espa¸co do parˆametro que tenha como distribui¸c˜ao estacion´aria a distribui¸c˜ao a posteriori, π(θ|·).
Nos m´etodos de simula¸c˜ao estoc´astica, cada valor obtido na simula¸c˜ao depende do valor gerado anteriormente, ou seja, cria-se uma cadeia de valores dependentes entre si. Um maneira de evitar a forte dependˆencia dos valores gerados, com rela¸c˜ao ao valor inicial fornecido para gera¸c˜ao da cadeia, ´e descartando os primeiros valores simulados. Dada a convergˆencia da cadeia, dizemos que foi obtido a distribui¸c˜ao estacion´aria objetivo.
As amostras iniciais descartadas s˜ao obtidas no per´ıodo de aquecimento da cadeia tamb´em conhecido comoburn-in. Na simula¸c˜ao pode-se optar por gerar uma longa cadeia e a seguir tomar valores apenas a cada certo n´umero de amostras simuladas, tal procedimento ´e conhecido comoraleamento, saltos outhinning.
4.4.1 Cadeias de Markov
Pode-se definir uma cadeia de Markov, como sendo uma sequˆencia,θ0,θ1, ...,θn,
tal queP(θi ∈A|θ0,θ1, ...,θi−1)=P(θi ∈A|θi−1), i= 1, ..., n, para qualquer evento
A, ou seja, o valor seguinte da sequˆencia gerada,θi, depende apenas do valor atual
da cadeia,θi−1, e n˜ao dos valores anteriores aθi−1.
Dada uma sequˆencia de Markov com distribui¸c˜ao estacion´aria π(·|x), note-se que θ ∼pi(·|θi−1) e sob condi¸c˜oes de regularidade (Robert e Casella, 2004) tem-se
quepi se aproxima de π(·|x) `a medida que i→ ∞, e ainda temos, segundo a lei dos grandes n´umeros que, definindoµg =E(g(θ|x)) e bµn = 1nPni=1g(θi), ent˜ao:
b
µn q.c
→µg, n→ ∞. (4.20)
H´a tamb´em condi¸c˜ao para Normalidade assint´otica (Robert e Casella, 2004), ou seja,
√
n(bµn−µg)→D N(0;σ2g), (4.21)
sendo σ2
g a variˆancia assint´otica de g(θ), que pode ser estimada por diferentes m´etodos (Robert e Casella, 2004).
4.4 M´etodos de Simula¸c˜ao Estoc´astica 43
4.4.2 Diagn´
ostico de Convergˆ
encia
Um m´etodo preliminar para verificar a convergˆencia da cadeia simulada ´e feito analisando os gr´aficos das quantidades estimadas ao longo das itera¸c˜oes, bem como o gr´afico da distribui¸c˜ao marginal a posteriori do parˆametro. Al´em da an´alise gr´afica, outras t´ecnicas de convergˆencias podem ser utilizadas. Tais t´ecnicas podem ser vistas com mais detalhes em Gelman e Rubin (1992) e Geweke (1992).
Para verificar a convergˆencia das cadeias fez-se uso do programaCODA( Conver-gence Diagnosis and Output Analysis Software for Gibbs Sampling Output) (Best, et al. (1997)). Tal programa consiste em um conjunto de fun¸c˜oes utilizadas para an´alise estat´ıstica e gr´afica das cadeias geradas pelo m´etodo de Monte Carlo via Cadeias de Markov.
Os m´etodos gr´aficos podem ser utilizados em conjunto com outros m´etodos para verificar a convergˆencia da cadeia. Este procedimento em conjunto ´e prefer´ıvel `a escolha de apenas um deles. Inclusive, segundo Best et al. (1997), Cowles e Carlin (1996) testaram alguns dos m´etodos implementados no CODA e verificaram que em alguns exemplos em espec´ıfico o software falhou na detec¸c˜ao da convergˆencia.
4.4.3 Amostrador de Gibbs
O amostrador de Gibbs est´a caracterizado como um m´etodo de simula¸c˜ao de Monte Carlo via cadeias de Markov. O nome do m´etodo se deve a distribui¸c˜ao de Gibbs, que ´e bastante utilizada nas ´areas da Mecˆanica estat´ıstica e F´ısica Estat´ıstica. O amostrador de Gibbs foi originalmente proposto por Geman e Geman(1984) na ´area de processamento de imagens, mas somente em 1990 com o trabalho de Gel-fand e Smith (1990) que este m´etodo se tornou mais conhecido na comunidade estat´ıstica. Mais detalhes a respeito deste m´etodo s˜ao encontrados em Gamerman e Lopes (2006). O referido m´etodo est´a implementado no software OpenBugs e WinBugs, e Lunn et al. (2009) discutem conceitos b´asicos, estrutura e extens˜ao do software.
Este algoritmo ´e utilizado para simular distribui¸c˜oes desconhecidas de um vetor de parˆametros θ = (θ1, θ2, ..., θk), a partir de simula¸c˜oes de distribui¸c˜oes
condicio-nais, π(θj|θ−j), j= 1,2, ..., k. Pode-se descrever o algoritmo nos seguinte passos:
1o) considere um vetor inicial do tipo(θ(0) 1 , θ
(0) 2 , ..., θ
4.4 M´etodos de Simula¸c˜ao Estoc´astica 44
• simuleθ1(i) de π(θ1(i−1)|θ2(i−1), θ(3i−1), ..., θ(ki−1)),
• simuleθ2(i) de π(θ(2i−1)|θ1(i), θ(3i−1), ..., θk(i−1)), ...
• simuleθk(i) de π(θ(ki−1)|θ1(i), θ(2i), ..., θk(i−)1).
O algoritmo acima ainda pode ser descrito como segue. Suponha que πθ(θ) =
π(θ1, θ2, ..., θk). Seja a fun¸c˜ao de densidade de probabilidade do vetorθ = (θ1, θ2, ..., θk), al´em disso represente θ
−j = (θ1, θ2, ..., θj−1, θj+1, ..., θk) o vetor obtido a partir de θ
com exclus˜ao da j-´esima vari´avel, e por fim, sejaπθj|θ−j(θj|θ−j) a fun¸c˜ao de densidade
de θj condicionada a θ−j. Portanto para gerar uma amostra de θ = (θ1, θ2, ..., θk)
realiza-se os passos descritos acima.
Este algoritmo fornece uma cadeia de Markov com espa¸co de estado E, onde a fun¸c˜ao de transi¸c˜ao deθ(i−1) para θ(i) ´e dada por:
p(θ(i−1), θ(i)) = k
Y
j=1
π(θ(ji−1)|θ1(i), ..., θj(i−)1, θ(j+1i−1), ..., θ(ki−1)).
Cap´ıtulo 5
Aplica¸c˜
ao
5.1 Introdu¸c˜
ao
Neste trabalho foi utilizado uma base de dados com 28,26% de censura, corres-pondente a um grupo de 46 pacientes acometidos por leucemia e submetidos a um transplante de medula ´ossea, conhecido como transplante alogˆenico, ou seja, quando o paciente recebe, de um familiar, material gen´etico compat´ıvel. Os tempos foram medidos em anos, que variam de 0,03 a 5 anos. Mais detalhes a respeito da base de dados podem ser encontrados em Maller e Zhou (1996) e em Kersey et al. (1987).
Fez-se uma an´alise de sobrevivˆencia convencional, sem a suposi¸c˜ao da fra¸c˜ao de cura, para verificar qual modelo probabil´ıstico se adequava melhor ao ajuste dos dados utilizando-se as distribui¸c˜oes de probabilidade usuais para tempos de sobre-vida (exponencial, Weibull e Pareto). Em seguida, ajustou-se os modelos demistura padr˜ao e detempo de promo¸c˜ao, considerando as mesmas distribui¸c˜oes para os tem-pos de falhas. Os m´etodos num´ericos para as estima¸c˜oes foram: BFGS (m´axima verossimilhan¸ca - MV), m´etodo de Laplace e amostrador de Gibbs.
As an´alises foram realizadas utilizando os pacotes R vers˜ao 2.15 (MV e Laplace) e OpenBUGS vers˜ao 3.2.1 (Gibbs).
5.1.1 An´
alise Convencional
Para a aplica¸c˜ao em estudo, as express˜oes das estimativas das fun¸c˜oes de so-brevivˆencia dos modelos exponencial, Weibull e Pareto, obtidos pelo m´etodo da m´axima verossimilhan¸ca s˜ao, respectivamente:
ˆ