CAMPUS QUIXADÁ
BACHARELADO EM ENGENHARIA DE SOFTWARE
GUSTAVO AIRES MATOS
IMPLEMENTAÇÃO DE MELHORIAS NO FRAMEWORK SHAREMINING PARA MINERAÇÃO DE TEXTO DO TWITTER
IMPLEMENTAÇÃO DE MELHORIAS NO FRAMEWORK SHAREMINING PARA MINERAÇÃO DE TEXTO DO TWITTER
Monografia apresentada no curso de Engenharia de Software da Universidade Federal do Ceará, como requisito parcial à obtenção do título de bacharel em Engenharia de Software. Área de concentração: Computação.
Orientadora: Dra. Ticiana Linhares Coelho da Silva
Gerada automaticamente pelo módulo Catalog, mediante os dados fornecidos pelo(a) autor(a)
M381i Matos, Gustavo Aires.
Implementação de melhorias no framework ShareMining para mineração de texto do Twitter / Gustavo Aires Matos. – 2017.
73 f. : il. color.
Trabalho de Conclusão de Curso (graduação) – Universidade Federal do Ceará, Campus de Quixadá, Curso de Engenharia de Software, Quixadá, 2017.
Orientação: Profa. Dra. Ticiana Linhares Coelho da Silva.
1. Mineração de texto. 2. Framework (Programa de computador). 3. Twitter (Redes sociais on-line). I. Título.
IMPLEMENTAÇÃO DE MELHORIAS NO FRAMEWORK SHAREMINING PARA MINERAÇÃO DE TEXTO DO TWITTER
Monografia apresentada no curso de Engenharia de Software da Universidade Federal do Ceará, como requisito parcial à obtenção do título de bacharel em Engenharia de Software. Área de concentração: Computação.
Aprovado em: ____/_____/______
BANCA EXAMINADORA
Dra. Ticiana Linhares Coelho da Silva (Orientadora) Universidade Federal do Ceará – UFC
Dr. Marcos Antônio de Oliveira Universidade Federal do Ceará - UFC
Agradeço a Deus por ter me ajudado durante toda a trajetória da minha vida até esse ponto. Sou muito grato à minha família, principalmente meus pais, Josemir e Cláudia, que foram extremamente importante para o meu sucesso durante toda minha vida e faculdade. Agradeço também aos meus avós que sempre, José e Delice, que sempre se importaram muito e fizeram parte da minha educação e formação.
Agradeço também à minha namorada, Gabriela Jácome, por todo o suporte durante todos esse anos, fornecendo grande apoio moral e paz nos momentos de muita ansiedade e correria. Um agradecimento muito especial à minha orientadora, Ticiana Linhares Coelho da Silva, que foi de fundamental importância nos últimos semestres da faculdade, durante o desenvolvimento deste trabalho e também por me fazer entrar nesse área de pesquisa. Com certeza, sem sua dedicação as coisas teriam sido bem mais difíceis.
Aos professores participantes da banca examinadora, Regis Pires Magalhães e Marcos Antônio de Oliveira pelas valiosas colaborações e sugestões.
Aos meus colegas da faculdade, Caio, Davi, Eduardo, Wanderson, Gabriel, Júlio, Letícia, Lucas, Isac, Isaías, Kayo, Felipe, Marcelo, Marcos, Matheus e Sérgio, por todas as noites mal dormidas e trabalhos feitos com grande comprometimento, além dos momentos de descontração e divertimento. Levo vocês comigo para vida!
work, one finishes nothing. The prize will not be sent to you. You have to win it.”
Nas redes sociais, muitos dados são gerados em forma de texto contendo opiniões sobre temas diversos. O que fazer com essa informação tem tido grande destaque nos últimos tempos. Empresas como Twitter ou Facebook são capazes de gerar informações relevantes com as publicações dos perfis. Como fazer isso é um desafio para os especialistas que em geral implementam seus próprios algoritmos ou utilizam variadas ferramentas para processar esses dados. A mineração de texto é uma área da mineração de dados que envolve extração de padrões e conhecimento de documentos em formato de texto. Sendo assim, muitas vezes os especialistas podem implementar os mesmos algoritmos mais de uma vez tornando o processo muito manual e repetitivo, já que há passos em comum quando se executa o processo de mineração de texto, como foi identificado em alguns trabalhos. Os passos em comum para mineração de texto podem ser resumidos em coleta, pré-processamento, análise e visualização. Este trabalho propõe melhorias para a ferramenta Sharemining que implementa todas estas etapas de forma automatizada e integrada. Dessa forma, os usuários podem empregar maior foco na avaliação dos resultados do que na implementação de todo o processo, fazendo uso do framework. Este trabalho também
realiza uma validação das melhorias aplicadas utilizando dados do Twitter sobre a reforma da previdência social brasileira.
In social networks, many data are generated in the form of text containing opinions on various topics. What you have to do with this information has been very prominent in recent times. Text mining is an area of data mining that involves extracting patterns and knowledge from text documents. Companies like Twitter or Facebook are able to generate relevant information with its profiles’ posts. How to do this analysis is a challenge for experts who often implement their own algorithms or use a variety of tools to process this data. Therefore, specialists can often implement the same algorithms more than once, making the process very manual and repetitive, since there are common steps when executing the text mining process, as has been identified in some works. Common steps for text mining can be summarized in collection, pre-processing, analysis and visualization. This work proposes improvements for Sharemining tool that implements all these steps in an automated and integrated way. Thus, the users can use more focus in the evaluation of the results than in the implementation of the whole process, making use of theframework. This paper also validates the improvements applied using Twitter
data on the Brazilian social security reform.
Figura 1 – Etapas do processo de mineração de texto. . . 20 Figura 2 – Exemplos declustersdescobertos pelo DBScan para dados espaciais. . . . 24
Figura 3 – Diagrama de uso dos módulos doframework. . . 36
Figura 4 – Soma dos quadrados dos erros do mês de agosto utilizando a distância de
Jaccard. . . 44
Figura 5 – Soma dos quadrados dos erros do mês de agosto utilizando a distância de
Levenshtein. . . 45
Figura 6 – Nuvem de palavras do primeiroclusterde agosto. . . 46
Figura 7 – Nuvem de palavras do segundoclusterde agosto. . . 46
Figura 8 – Soma dos quadrados dos erros do mês de março utilizando a distância de
Jaccard. . . 55
Figura 9 – Soma dos quadrados dos erros do mês de abril utilizando a distância de
Jaccard. . . 56
Figura 10 – Soma dos quadrados dos erros do mês de maio utilizando a distância de
Jaccard. . . 56
Figura 11 – Soma dos quadrados dos erros do mês de junho utilizando a distância de
Jaccard. . . 57
Figura 12 – Soma dos quadrados dos erros do mês de julho utilizando a distância de
Jaccard. . . 57
Figura 13 – Soma dos quadrados dos erros do mês de março utilizando a distância de
Levenshtein. . . 58
Figura 14 – Soma dos quadrados dos erros do mês de abril utilizando a distância de
Levenshtein. . . 59
Figura 15 – Soma dos quadrados dos erros do mês de maio utilizando a distância de
Levenshtein. . . 59
Figura 16 – Soma dos quadrados dos erros do mês de junho utilizando a distância de
Levenshtein. . . 60
Figura 17 – Soma dos quadrados dos erros do mês de julho utilizando a distância de
Levenshtein. . . 60
Figura 18 – Nuvem de palavras do primeiroclusterde março. . . 61
Figura 21 – Nuvem de palavras do quartoclusterde março. . . 63
Figura 22 – Nuvem de palavras do quintoclusterde março. . . 63
Figura 23 – Nuvem de palavras do primeiroclusterde abril. . . 64
Figura 24 – Nuvem de palavras do segundoclusterde abril. . . 64
Figura 25 – Nuvem de palavras do terceiroclusterde abril. . . 65
Figura 26 – Nuvem de palavras do quartoclusterde abril. . . 65
Figura 27 – Nuvem de palavras do quintoclusterde abril. . . 66
Figura 28 – Nuvem de palavras do primeiroclusterde maio. . . 66
Figura 29 – Nuvem de palavras do segundoclusterde maio. . . 67
Figura 30 – Nuvem de palavras do terceiroclusterde maio. . . 67
Figura 31 – Nuvem de palavras do quartoclusterde maio. . . 68
Figura 32 – Nuvem de palavras do quintoclusterde maio. . . 68
Figura 33 – Nuvem de palavras do primeiroclusterde junho. . . 69
Figura 34 – Nuvem de palavras do segundoclusterde junho. . . 69
Figura 35 – Nuvem de palavras do terceiroclusterde junho. . . 70
Figura 36 – Nuvem de palavras do quartoclusterde junho. . . 70
Figura 37 – Nuvem de palavras do quintoclusterde junho. . . 71
Figura 38 – Primeiroclusterde julho. . . 71
Figura 39 – Nuvem de palavras do segundoclusterde julho. . . 72
Figura 40 – Nuvem de palavras do terceiroclusterde julho. . . 72
Figura 41 – Nuvem de palavras do quartoclusterde julho. . . 73
Quadro 1 – Comparativo das características de coleta, pré-processamento e processamento usados pelas pesquisas ou disponíveis em ferramentas. . . . 30 Quadro 2 – Quantidade detweetspor mês. . . 43
Quadro 3 – Resultado da classificação baseada no uso dosclusterscompletos do mês de
agosto comretweets. . . 47
Quadro 4 – Resultado da classificação baseada no uso dosclustersparciais do mês de
agosto comretweets. . . 47
Quadro 5 – Resultado da classificação baseada no uso dosclusterscompletos do mês de
agosto semretweets. . . 48
Quadro 6 – Resultado da classificação baseada no uso dosclustersparciais do mês de
agosto semretweets. . . 48
Quadro 7 – Resultado da classificação baseada no uso dosclustersparciais do mês de
agosto sem retweetse conjunto de teste de tamanho igual para notícias e
negativos. . . 49 Quadro 8 – Resultado da classificação baseada no uso dosclustersparciais do mês de
agosto semretweetse conjunto de treino de tamanho igual para notícias e
negativos. . . 49 Quadro 9 – Resultado da classificação baseada no uso dosclustersparciais do mês de
agosto sem retweetse conjunto de teste de tamanho igual para notícias e
PLN Processamento de Linguagem Natural
NLP Natural Language Processing
SVM Support Vector Machine
CRF Conditional Random Fields
API Application Interface Programming
1 INTRODUÇÃO . . . 15
2 OBJETIVOS . . . 18
2.1 Objetivo Geral . . . 18
2.2 Objetivos Específicos . . . 18
3 FUNDAMENTAÇÃO TEÓRICA . . . 19
3.1 Mineração de Texto. . . 19
3.1.1 Coleta . . . 20
3.1.2 Pré-processamento - Processamento de Linguagem Natural (PLN) . . . . 20
3.1.3 Indexação . . . 21
3.1.4 Mineração . . . 21
3.1.5 Análise . . . 22
3.2 Medidas de Similaridade . . . 22
3.2.1 Jaccard. . . 22
3.2.2 Levenshtein . . . 22
3.3 Clusterização . . . 23
3.3.1 DBScan . . . 23
3.3.2 K-medoids . . . 25
3.3.2.1 Método do cotovelo . . . 25
3.4 Classificação. . . 25
3.4.1 Naive Bayes . . . 26
4 TRABALHOS RELACIONADOS . . . 27
4.1 Um Framework para Mineração de Texto em Redes Sociais . . . 27
4.2 Classificação de Sentimentos no Twitter usando supervisão distante . . . 27
4.3 Twitter como um corpus para análise de sentimentos e mineração de opinião . . . 28
4.4 Ferramentas. . . 28
5 O FRAMEWORK SHAREMINING . . . 31
5.1 Coleta . . . 31
5.2 Pré-processamento . . . 31
5.3 Processamento . . . 31
6 PROCEDIMENTOS METODOLÓGICOS . . . 33
6.1 Melhorias aplicadas aoframework . . . 33
6.1.1 Algoritmos de coleta . . . 34
6.1.2 Pré-processamento . . . 34
6.1.3 Medidas de similaridade . . . 35
6.1.4 Algoritmos de Mineração de Dados . . . 35
6.1.5 Módulo de visualização . . . 35
6.1.6 Arquitetura do framework . . . 36
6.2 Validação doframework . . . 36
6.2.1 Dados utilizados . . . 37
6.2.2 Pré-processamento . . . 37
6.2.3 Categorização do conjunto de treino . . . 38
6.2.4 Classificação dos dados . . . 38
7 RESULTADOS . . . 40
7.1 Melhorias aplicadas . . . 40
7.1.1 Coleta . . . 40
7.1.2 Pré-processamento . . . 40
7.1.3 Gerenciamento de arquivos . . . 41
7.1.4 Processamento. . . 41
7.1.5 Análise . . . 42
7.2 Validação das melhorias . . . 42
7.2.1 Coleta . . . 42
7.2.2 Pré-processamento . . . 43
7.2.3 Processamento. . . 43
7.2.4 Análise . . . 45
7.2.4.1 Clusterização . . . 45
7.2.4.2 Classificação . . . 47
8 CONSIDERAÇÕES FINAIS . . . 51
COTOVELO USANDO A DISTÂNCIA DE JACCARD DOS MESES DE MARÇO A JULHO . . 55
APÊNDICE B – RESULTADO DA APLICAÇÃO DO MÉTODO DO
COTOVELO USANDO A DISTÂNCIA DE
LEVENSHTEIN DOS MESES DE MARÇO A JULHO 58
1 INTRODUÇÃO
Diariamente, tem-se uma quantidade massiva de dados sendo gerada em diversos tipos de sistemas e aplicativos. Junior et al. (2014) apontam alguns tipos de fontes desses dados, como: serviços e sistemas web, e-commerce, sistemas corporativos, transações financeiras e redes sociais. Juntos, esses sistemas geram petabytes de dados todo dia (JUNIOR et al., 2014). Enquanto humanos, as pessoas desejam obter informações da forma mais fácil e rápida possível. Querem também satisfazer suas curiosidades e serem ouvidos. Isso impulsiona o sucesso de redes sociais como Facebook e Twitter e o surgimento de tantas outras nos últimos anos (RUSSEL, 2013).
Somente no Twitter, há mais de meio bilhão de usuários (RUSSEL, 2013) e mais de 347 miltweetsgerados por segundo (SIMOS, 2015). Essa quantidade de dados talvez se dê
pela possibilidade de usuários fazerem postagens na "velocidade do pensamento", o que é um fator importante para uma rede social ser bem sucedida (RUSSEL, 2013). Entender essa grande quantidade de dados disponíveis em redes sociais é uma chave para, por exemplo, tomadas de decisões.
Os dados de forma bruta e individual não dizem muito mas, em conjunto, possuem uma capacidade de gerar informações sobre o que um grupo de pessoas pode estar falando, por exemplo. Para tanto, é necessário que seja realizado algum tipo de análise, dando um novo propósito para os dados individuais, como, por exemplo, direcionamento de campanhas publicitárias. Essa análise pode ser feita utilizando técnicas de mineração de dados.
Mineração de dados envolve um conjunto de técnicas que, por meio de algoritmos baseados em modelos computacionais, são capazes de extrair informações, trazendo à tona padrões presentes nos dados analisados, possibilitando expor o conhecimento inserido no conjunto bruto analisado (SILVA et al., 2013).
Rodrigues et al. (2016) fazem uma análise temporal das postagens do Twitter utilizando evolução declusters(um agrupamento de dados similares). Leite (2015) por sua vez,
analisatweetsutilizando a técnica de classificação Naive Bayes. Viana (2014) aplica técnicas de
Os trabalhos de Go, Bhayani e Huang (2009) e de Pak e Paroubek (2010) realizam classificação de dados do Twitter utilizando uma técnica não supervisionada para categorização doconjunto de treino. Para isso, foram usadosemoticonsnas consultas enviados para a API do
Twitter. Ambos compararam algoritmos de classificação Naive Bayes, SVM e outros. Em todos os trabalhos citados, as etapas seguidas, de forma geral, foram: 1) coleta; 2) pré-processamento, que compreende às etapas do processamento em linguagem natural; 3) aplicação de um algoritmo de mineração de dados, e; 4) avaliação de resultados utilizando alguma medida de qualidade, como inspeção visual ou acurácia da solução.
No cenário atual de mineração de texto em redes sociais, muitas etapas do processo de extração de conhecimento se assemelham bastante. Seguindo os mesmos passos, os trabalhos, em geral, se assemelham nas etapas de mineração de texto. Esse esforço se torna repetitivo, mesmo em se tratando de trabalhos com propósitos diferentes. Dada a sua estrutura similar, é possível diminuir o retrabalho e concentrar mais esforços na análise e avaliação dos resultados obtidos.
Com os padrões observados no processo de mineração de dados, é possível que uma ferramenta como Scikit-Learn1possa reduzir o número de atividades desempenhadas por um especialista, evitando retrabalhos de codificação. Mais especificamente para mineração de texto, Junior (2016) desenvolveu oframework ShareMining que contempla todas as etapas citadas
anteriormente, resultando em uma redução de trabalho para o especialista.
Anteriormente, o framework ShareMining apresentava implementações de
algoritmos para pré-processamento de texto, Processamento de Linguagem Natural (PLN), algoritmos de coleta de dados do Twitter e um algoritmo de clusterização chamado DBSCAN. Todos esses algoritmos estavam em diferentes projetos, diferentes repositórios no GitHub e não funcionavam como uma ferramenta única. A arquitetura doframeworkShareMining não era a
mais adequada para uma ferramenta que visa facilitar trabalhos na área de mineração de texto. Este trabalho se propõe a dar continuidade aoframeworkShareMining desenvolvido
por Junior (2016), promovendo algumas mudanças, visando sua melhoria geral, adição de algumas funcionalidades e padronização do que foi implementado. Por exemplo, melhoria por meio da adição dos algoritmos Naive Bayes e K-Medoids. As alterações visam que a ferramenta possa ser utilizada por analistas que desejam concentrar-se mais na avaliação dos resultados obtidos a partir da análise. Também está previsto que o framework ShareMining apresente
diferentes algoritmos de mineração de dados para redes sociais e que seja feita uma validação do
framework.
Este trabalho está dividido da seguinte forma: na Seção 2, o estado atual do
frameworké apresentado. A Seção 3 informa os objetivos do trabalho, geral e específicos. Na
2 OBJETIVOS
A seguir, são apresentados os objetivos deste trabalho.
2.1 Objetivo Geral
Dada a estrutura do processo de mineração de textos, é necessária uma ferramenta para diminuição de retrabalho nas etapas envolvidas no processo de mineração de textos. Portanto, este trabalho tem o objetivo de melhorar oframeworkShareMining para mineração de texto do
Twitter de Junior (2016), no sentido de adicionar novos meios de coleta de dados e adicionar novos algoritmos de mineração de dados, além de possibilitar formas de visualização desses resultados.
2.2 Objetivos Específicos
a) Implementar os scripts de coleta de dados com uso das APIs de Search e Streamingdo Twitter e método deScrapingpara dados publicados no Twitter há
mais de uma semana.
b) Criar um módulo para gerenciamento de arquivos.
c) Implementar o algoritmo de classificação Naive Bayes, bastante utilizado na classificação de textos.
d) Implementar mais um algoritmo de clusterização.
e) Implementar novas medidas de similaridade para a clusterização. f) Implementar visualização de resultados.
3 FUNDAMENTAÇÃO TEÓRICA
Nesta seção, serão apresentados os conceitos fundamentais deste trabalho.
3.1 Mineração de Texto
A Mineração de Texto (Text Mining) é um processo que conta com um conjunto de
técnicas para análise de documentos em forma de texto. É considerada uma evolução da área de Recuperação de Informações, estando voltada para a descoberta de conhecimento em dados não estruturados - dados que não possuem formato ou padrão de armazenamento. Algoritmos são aplicados para a identificação de informações úteis, dentro de qualquer domínio que disponha de documentos textuais, onde tais informações dificilmente seriam extraídas de forma tradicional (MORAIS; AMBRÓSIO, 2007).
Mineração de Texto está ligada à descoberta de padrões relevantes e não-triviais a partir de documentos de texto. Atualmente, um número expressivo de empresas tem trabalhado na área de Mineração de Texto, dada a grande importância que tem ganhado, pela sua capacidade de gerar conhecimento (TAN et al., 1999).
Vários trabalhos definem etapas diferentes para o processo de mineração de texto. Morais e Ambrósio (2007) dividem em seleção de documentos, definição do tipo de abordagem dos dados (análise estatística ou semântica), preparação dos dados, indexação e normalização, cálculo da relevância dos termos, seleção dos termos e análise dos resultados.
análise se concentra em interpretar os resultados da etapa anterior, cruzando os resultados com o conhecimento que se tem do domínio.
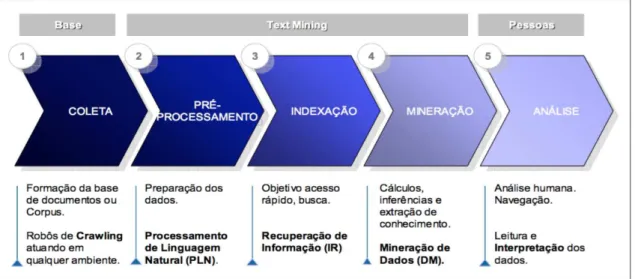
A prática de mineração de texto pode ser aplicada a diversos contextos onde haja a disponibilidade de documentos que possam ser analisados. Neste trabalho, postagens do Twitter serão analisadas seguindo três passos gerais baseados nas etapas definidas por Aranha e Vellasco (2007): coleta, pré-processamento (PLN e IR, de acordo com a Figura 1) e processamento (mineração).
Figura 1 – Etapas do processo de mineração de texto.
Fonte – Aranha e Vellasco (2007).
3.1.1 Coleta
Basicamente, essa etapa pode ser resumida como o ponto onde os dados são escolhidos e coletados. Essa decisão de que dados utilizar, geralmente é tomada pensando previamente no que se quer ter como resultado, para que possa-se pensar sobre de onde é possível extrair tais informações. Uma das possíveis técnicas utilizadas nessa etapa é a de
crawling, que pode ser resumido como ler alguma página web e extrair informações de sua
estrutura HTML.
3.1.2 Pré-processamento - Processamento de Linguagem Natural (PLN)
dos níveis de análise linguística referentes aos processos de produção e compreensão de linguagem utilizados pelos humanos. Dois dos objetivos do PLN são responder perguntas sobre o conteúdo de um texto e fazer inferências a partir do texto. Particularmente, esse último objetivo será um dos objetivos deste trabalho.
Processamento de Linguagem Natural é um campo de estudo que foca em como fazer um computador entender linguagem natural (inglês, português etc), para a realização de outras tarefas úteis. As pesquisas sobre PLN tentam entender como os seres humanos usam e entendem a linguagem, para que possa ser possível desenvolver algoritmos que ajudem computadores a entenderem linguagem natural (CHOWDHURY, 2003). Para entender linguagem natural, Chowdhury (2003) lista sete níveis de análise linguística usados para extrair-se informações de textos ou linguagem falada: fonético, morfológico, léxico, sintático, semântico, discurso e pragmático. Um PLN pode conter todos ou alguns destes níveis.
O nível morfológico trabalha com as partes das palavras que contém sentido, sufixos e prefixos. Já o nível sintático, lida com a gramática e a estrutura das sentenças do texto (CHOWDHURY, 2003). Neste trabalho, apenas os níveis morfológico e sintático serão usados, visando estruturar os textos coletados do Twitter para a fase de processamento dos dados, de acordo com o que está descrito na Seção 6.2.2.
Dois conceitos importantes ligados a essa etapa são: tokenização e stopwords.
Tokenização é o processo de separar as palavras de um documento, tornando-as em documentos com apenas uma palavra. Esse processo de tokenização é útil, por exemplo, para a detecção de
stopwords, que são palavras que não possuem significado e, portanto, podem ser removidas do
documento,
3.1.3 Indexação
Na etapa de indexação, realiza-se a separação dos dados para facilitar o uso e as buscas. Por exemplo, pode-se dividir os dados em dias, para um resultado de processamento por dias.
3.1.4 Mineração
se agrupar dados, pode-se usar algoritmos de clusterização.
3.1.5 Análise
Na etapa de análise, o especialista deve observar os resultados para conseguir formar informações coerentes que possam ser úteis. As formas de exibir esses resultados são variadas, e de acordo com os algoritmos de mineração que foram aplicados, podem existir diferentes formas de se visualizar esses dados de saída.
3.2 Medidas de Similaridade
Na mineração de dados, medidas de similaridade são muito utilizadas. As medidas servem para informar um grau de diferença ou semelhança entre dois objetos. Algoritmos de clusterização se utilizam dessas medidas para agrupar dados similares e separar dados diferentes. Essas medidas podem se basear em dados de texto, dados numéricos e geoespaciais. A seguir, duas medidas presentes na ferramenta ShareMining são demonstradas.
3.2.1 Jaccard
A medida de Jaccard calcula a diferença, semelhança e distância entre dois conjuntos que, no caso da ferramenta, serão conjuntos de palavras. Essa medida é o resultado da divisão entre o número de palavras que são comuns entre os conjuntos dividido pelo número total de palavras presentes e nos conjuntos, como visto na Fórmula 3.1 (NIWATTANAKUL et al., 2013). Quanto mais próximo de 1 é o resultado, maior é a semelhança entre os conjuntos.
J(A,B) =
|A∩B|
|A∪B| (3.1)
3.2.2 Levenshtein
edições necessárias para cada índice.
3.3 Clusterização
Clusterização é o processo que organiza dados multidimensionais emclusters(grupos
ou partições) de acordo com uma medida de similaridade. Logo, itens de um mesmo cluster
devem ser mais similares (próximos ou parecidos) entre si do que entre itens declustersdiferentes.
Assim, clusterizar é agrupar dados que possuem padrões desconhecidos, e cadaclusterpassa a
ter um significado revelado pelos dados que o constituem. Esse processo pode ser utilizado para análise de padrões, agrupamento, classificação de padrões, segmentação de imagens e tomada de decisão (JAIN; MURTY; FLYNN, 1999).
Guha et al. (2003) caracterizam clusterização como o problema de encontrar partições de um conjunto de dados em que itens similares estejam em um mesmo grupo e itens diferentes estejam em grupos diferentes. Os grupos são formados baseados em alguma definição de similaridade.
Para a realização do estudo de caso deste trabalho, clusterização será utilizada para categorizar os dados coletados do Twitter, com intuito de posteriormente gerar o modelo para o algoritmo de classificação.
3.3.1 DBScan
O algoritmo DBScan foi proposto para bases de dados espaciais e leva em consideração a densidade dos clusters, tornando automática a definição da quantidade de clustersa serem formados. Um valor máximo de distância é definido para que seja possível
dizer, de acordo com o contexto, se pontos são vizinhos (similares) ou não. Cadaclusterdeve
respeitar umthreshold(limite) mínimo de pontos similares em sua composição (ESTER et al.,
1996).
Ester et al. (1996) define dois parâmetros importantes: Eps eMinPts. Epsindica
qual a diferença máxima permitida entre dois pontos para que sejam considerados similares. Espacialmente, isso pode ser considerado o raio de distância máxima entre os pontos. Para texto, pode variar de acordo com o modo de calcular, mas a diferença ou similaridade estará ligada diretamente as palavras ou caracteres diferentes nos documentos. MinPtsdetermina qual a menor
Existem três tipos de pontos no DBScan. CorePoint é um ponto que tem uma
quantidade de vizinhos maior ou igual aMinPts. Já umborderPointé um ponto que tem como
um de seus vizinhos umcorePoint, mas não possui a quantidade mínima de vizinhos (MinPts).
Por último,noisePointé um ponto que não tem em seus vizinhos umcorePointnem possui uma
quantidade mínima de vizinhos (ESTER et al., 1996).
Os valores de Eps e MinPts são fornecidos pelo especialista e podem variar
dependendo do conjunto de dados. A forma indicada para se definir oEpse oMinPts, é usar os
valores que servem para oclustermenos denso da base, para que esse valor possa ser aplicado
para todos os outros, já que não é possível saber o valor aplicável individualmente para cada
cluster(ESTER et al., 1996).
De forma geral, o algoritmo seleciona um pontoP1aleatório para iniciar e percorrer
todos os outros pontos que ainda não foram visitados em busca de pontos com uma distância máxima igual aEps. Caso o pontoP1possua o número mínimo (minPts) de vizinhos (de acordo
com uma função de distância ou de similaridade), um novocluster C é criado comP1e seus vizinhos. Em seguida, os vizinhos deP1são usados para alcançar novos pontos do conjunto de
dados e expandir ocluster. Para cada vizinhoPxdeP1, os vizinhos dePxsão adicionados ao
cluster C, sePxpossui no mínimominPtsde vizinhos. Quando todos os vizinhos deP1forem visitados, um outro ponto não visitado é escolhido e o processo é recomeçado. O algoritmo pára quando todos os pontos foram visitados. Exemplos de visualização de resultados do DBScan podem ser vistos na Figura 2.
Figura 2 – Exemplos declustersdescobertos pelo DBScan para dados espaciais.
3.3.2 K-medoids
K-medoids é um algoritmo de clusterização particional, ou seja, divide o conjunto de dados em grupos distintos, tentando minimizar a distância entre os pontos, formando um
clustere definindo também um determinado ponto como o centro destecluster. Inicialmente,
são escolhidoskobjetos do conjunto de dados e eles são nomeados comomedoids. Cadamedoid
representa umcluster. Ao final, o algoritmo devolvek clusters, em que os objetos do conjunto
de dados são associados ao cluster cujo medoid é o de menor distância (VELMURUGAN;
SANTHANAM, 2010).
3.3.2.1 Método do cotovelo
O método do cotovelo1consiste em calcular a soma dos erros de cada integrante do
cluster para seumedoid. Dessa forma, é possível visualizar os erros totais para um determinado
valor dek, e quando aplicado para valores em sequência é possível ver se há uma diminuição ou
não dos erros. Em geral, os erros tendem a diminuir conforme o número declustersaumentam,
ao passo queclusterscom tamanho 1 tem o menor erro possível.
3.4 Classificação
Classificação é o processo de estabelecer uma categoria, ou classe, para um objeto, sendo essa categoria parte de um grupo predefinido (TAN; STEINBACH; KUMAR, 2005). A classificação é feita com base em um modelo criado a partir de um conjunto de dados já categorizado, podendo-se prever as categorias de dados ainda não analisados. É uma técnica supervisionada, isto é, é necessário categorizar um conjunto inicial para a construção do modelo.
Na pesquisa de Hotho, Nürnberger e Paaß (2005), classificação de texto visa atribuir classes predefinidas à documentos de texto. Essas classes podem ser, por exemplo, "bom", "muito bom", "ruim"e "muito ruim". Han, Pei e Kamber (2011) descrevem classificação como a predição de classes de objetos através da construção de um modelo baseado em umconjunto de treinousado para classificar novos dados. A classificação envolve dois passos: 1) a construção
do modelo, que consiste em descrever as classes predeterminadas de objetos conhecidos do
conjunto de treino, e; 2) o uso do modelo para classificar dados desconhecidos. O modelo pode
Todas as definições de classificação citadas aqui se complementam, e este trabalho adiciona esse método aoframeworkpara a predição de classes por possuir um grande uso em
análise de textos com o algoritmo descrito na próxima Seção.
3.4.1 Naive Bayes
Alguns dos algoritmos para classificar texto são: Naive Bayes, SVM e Maximum Entropy. Esses algoritmos podem possuir variações em suas implementações. O algoritmo Naive Bayes, por exemplo, pode lidar com diferentes tipos de dados e formas diferentes de calcular a probabilidade de uma classe para um objeto. Algumas das formas de aplicação do algoritmo Naive Bayes são (METSIS; ANDROUTSOPOULOS; PALIOURAS, 2006): Bernoulli multivariado, multinomial com frequência de termos (palavras), multinomial com atributos booleanos, Gauss multivariado e Bayes Flexível.
O algoritmo Naive Bayes se baseia no Teorema de Bayes, também conhecido como probabilidade condicional (METSIS; ANDROUTSOPOULOS; PALIOURAS, 2006). O Teorema de Bayes calcula a probabilidade de um eventoCocorrer dado que o eventot ocorreu. Nesse
caso, o cálculo da probabilidade de um textot ser da classeCé resumido na Fórmula 3.2:
P(C|t) =P(t|C)P(C)
P(t) (3.2)
Partindo disso, o algoritmo Naive Bayes calcula a probabilidade de um determinado textot ser de uma classe, usandoP(C), como a probabilidade da classeC, multiplicada pelo
produto da probabilidade condicional de cada palavra presente no texto ser da classeC. O valor
deqtd(wi,C)expressa a quantidade de vezes que a palavraW ocorre na classeC, enquanto que
wc expressa a quantidade total de palavras presentes na classeC(Fórmula 3.3).
P(t|C) =P(C)·
n
∏
i
qtd(wi,C)
wc
(3.3)
Dessa forma, o uso desse classificador se divide em dois passos, sendo o primeiro calcular a probabilidade das palavras para cada classe de acordo com sua frequência nos documentos doconjunto de treinoque estão categorizados com uma determinada classe. Já o
4 TRABALHOS RELACIONADOS
4.1 Um Framework para Mineração de Texto em Redes Sociais
Junior (2016) inicia a construção do framework ShareMining para mineração de
textos do Twitter, a partir de alguns trabalhos já existentes na época. Ele utiliza algoritmos como o de coleta1e o de pré-processamento2implementados por Filho (2014), e disponibiliza um algoritmo de clusterização DBScan. Ao mesmo tempo, realiza um estudo de caso com dados referentes ao impeachment da ex presidente Dilma Rousseff. Além disso, desenvolve
uma aplicação web para a visualização dos resultados com nuvens de palavras, onde é possível visualizar dados da pesquisa feita: total detweetscoletados,clusterscriados, gráficos e outras
informações.
Este trabalho pretende dar continuidade ao que foi iniciado por Junior (2016), dado o potencial do desenvolvimento de um framework para mineração de dados poder ajudar a
comunidade diretamente. No decorrer do desenvolvimento de novas funcionalidades para o
framework, algumas alterações podem ser feitas, caso seja necessário. As principais novidades
no framework serão as novas opções de coleta e o algoritmo de classificação Naive Bayes.
Apesar doframeworkShareMining já desenvolvido por Junior (2016) ser um bom ponto de
partida para realizar mineração de texto do Twitter, busca-se aqui expandir a sua capacidade de aplicação. Para tal, novas medidas de similaridade serão adicionadas, uma maior integração entre os módulos será realizada, além de correção da estrutura do código existente.
4.2 Classificação de Sentimentos no Twitter usando supervisão distante
Go, Bhayani e Huang (2009) realizaram um processo de classificação não supervisionado com textos do Twitter. É proposta uma forma de identificar automaticamente o sentimento de um tweetdotranining sete, para tanto,emoticonssão utilizados. Os dados do conjunto de treinoforam coletados usando a API de Search do Twitter, com consultas contendo
osemoticons. Por exemplo, quando oemoticon":)"está presente em umtweetretornado pela
API de Search, ele expressa que o texto escrito é positivo, e a presença doemoticon“:("indica
que otweeté negativo. Oconjunto de treinoé utilizado para criar um modelo de classificação
para qualquer outrotweet. Em seguida, a etapa de pré-processamento foi realizada, removendo
nomes de usuários, links e outras partes do texto que pudessem alterar os resultados negativamente ou que não tinham impacto positivo na acurácia. Finalmente, os dados foram processados por algoritmos como Naive Bayes, baseado em palavra-chave, Maximum Entropy e Support Vector Machines (SVM).
A coleta de dados realizada por Go, Bhayani e Huang (2009), por meio da API de Search do Twitter, é uma das funcionalidades que estarão noframeworka ser construído. Logo,
a análise de emoticonspara separar os tweetspositivos e negativos já no momento da coleta
poderá ser executada com o auxílio doframework. A limpeza dos dados, ou pré-processamento,
descrita no artigo é, de certa forma, simples e já está disponível noframework. A diferença que
pode ser a mais significativa entre a pesquisa de Go, Bhayani e Huang (2009) e este trabalho é a utilização de outros algoritmos para o processamento, como SVM e Maximum Entropy.
4.3 Twitter como um corpus para análise de sentimentos e mineração de opinião
A pesquisa de Pak e Paroubek (2010) também tem o propósito de classificar textos do Twitter. A técnica de categorização doconjunto de treinoé a mesma de Go, Bhayani e Huang
(2009), mas se difere por considerar a presença detweetsneutros. Na etapa de pré-processamento,
Pak e Paroubek (2010) consideram um Processamento de Linguagem Natural (PLN) diferente, pois houve preocupação com a retirada destopwordse um processo de tokenização de palavras
mais elaborado. Para o processamento dos dados, o algoritmo Naive Bayes foi escolhido em detrimento dos algoritmos SVM e CRF (Conditional Random Fields); mais uma vez, o algoritmo usado é o mesmo a ser implementado noframeworkdeste trabalho.
De forma geral, os dois estudos descritos fizeram uma coleta utilizando a mesma API do Twitter para coletar os dados. Para diminuir o trabalho de classificação dotraning set,
ambos categorizaram ostweetspelosemoticonsque continham, o que parece ser interessante
mas acarreta alguns problemas, como para o caso detweets com sentimento de ironia. Mas,
comoframeworkpermite o acesso à API do Twitter, essa coleta e automação da categorização
doconjunto de treinopodem ser realizadas por meio doframework.
4.4 Ferramentas
presente é a coleta de dados, provavelmente porque a ferramenta tenta ser mais genérica em relação a origem dos dados. A ferramenta cobre também alguns passos, embora bem específicos, de pré-processamento. Porém, não estão disponíveis meios para aplicação de PLN. Scikit-Learn não conta, por exemplo, com remoção destopwordsou sufixos.
Ela conta com diferentes algoritmos para para processamento dos dados. Há os algoritmos para classificação, como SVM, Naive Bayes, Árvore de Decisão e Redes Neurais. Para clusterização, também há diferentes algoritmos, como DBScan, K-means, e Propagação de Afinidade.
Outra ferramenta interessante e disponível na internet para um uso mais simples é a SentiStrenght3. A ferramenta é capaz de classificar textos em categorias binárias (positivo e negativo), ternárias (positivo, neutro e negativo) e escala única de classificação (de -4, muito negativo, a 4, muito positivo). Na versão web da ferramenta, lê-se apenas um texto por vez, porém, na sua versão para download a ferramenta tem seu uso melhorado, podendo processar até 16.000tweetspor segundo. Mas assim como Scikit, SentiStrenght não está presente em todas as
etapas do processo de mineração de texto. SentiStrenght não possui coleta e outras opções de PLN dentro da etapa de pré-processamento, bem como não possui outras opções de algoritmos para mineração de texto, nem para classificação ou para clusterização, por exemplo.
Para cada trabalho ou ferramenta descrita, o Quadro 1 sumariza o que é feito ou utilizado dentro de cada uma das três principais etapas do processo de mineração de dados.
Como é possível ver pelos quadros, nenhum dos trabalhos possui todas as funcionalidades citadas, mas a proposta deste trabalho é estar em todas as etapas de mineração de texto. Assim, por mais que alguns algoritmos não estejam presentes, ou alguma outra funcionalidade, a ideia geral é adequar o frameworkpara cenários de mineração de texto que
envolvam todo o processo e possa funcionar de forma automatizada dentro de qualquer aplicação que o use.
Quadro 1 – Comparativo das características de coleta, pré-processamento e processamento usados pelas pesquisas ou disponíveis em ferramentas.
Trabalho/Ferramenta Coleta Pré-processamento Processamento
Junior (2016) Stream de Dados. Remoção de caracteres repetidos, sufixos, acentos, stopwords, links, nomes próprios, nomes de usuário; Substituição de emoticons e abreviações.
Clusterização (DBScan).
Go, Bhayani e Huang (2009)
Dados até 7 dias. Substituição de nomes de usuários, links e palavras com letras repetidas.
Classificação (Naive
Bayes, Maximum
Entropy, SVM, palavra-chave).
Pak e Paroubek (2010) Dados até 7 dias. Remoção de stopwords, url, nomes de usuários e emoticons; tokenização; n-gramas.
Classificação (Naive Bayes, SVM, CRF).
Scikit-Learn Não
implementado.
Padronização, Normalização, Binarização, Codificação de Categorias, Atribuição de Valores Perdidos e Redução de Dimensões.
Classificação, Clusterização e Regressão. Gensim Não implementado. Padronização, Normalização, Binarização, Codificação de Categorias, Atribuição de Valores Perdidos e Redução de Dimensões.
Classificação,
Clusterização e
Regressão.
NLTK Não
implementado. Padronização,Binarização, CodificaçãoNormalização,de Categorias, Atribuição de Valores Perdidos e Redução de Dimensões.
Classificação,
Clusterização e
Regressão.
SentiStrenght Não
implementado.
Tokenização. Classificação
(palavra-chave).
Este trabalho Dados até 7
dias, Stream de Dados e Dados históricos.
Remoção de caracteres repetidos, sufixos, acentos, stopwords, links, nomes próprios, nomes de usuário; Substituição de emoticons e abreviações.
Clusterização (DBScan) e classificação (Naive Bayes).
5 O FRAMEWORK SHAREMINING
Nesta seção é exibido umsnapshotde como oframework1ShareMining estava no
início deste trabalho, a partir de uma visão das etapas gerais de um processo de mineração de texto. O trabalho feito por Junior (2016), inicia fazendo uma revisão das abordagens utilizadas para mineração de texto na Universidade Federal do Ceará para identificar suas semelhanças. Essa análise foi utilizada para desenvolver oframeworkde forma a ser reutilizável dentro das
etapas de mineração de texto.
5.1 Coleta
Para a etapa de coleta oframeworkconta com as implementações feitas por Filho
(2014). Esse módulo foi implementado em Java e faz uso da API deStreamingdo Twitter para
realizar a coleta. Essa abordagem permite a coleta detweetsem tempo real, gerando arquivos
JSON. Para outros casos, como coletartweetsantigos, não é possível utilizar a ferramenta2.
5.2 Pré-processamento
Na segunda etapa do processo, o módulo doframeworkfoi implementado em Python,
e conta com muitas funcionalidades para Processamento de Linguagem Natural (PLN). O PLN implementado suporta tratamentos para a língua portuguesa e inglesa. Essa implementação lida com um arquivo .txt, no qual é possível realizar a normalização dos documentos3.
5.3 Processamento
A etapa de processamento da ferramenta conta apenas com um método de clusterização. É importante ressaltar que não há muita flexibilidade quanto ao uso da ferramenta no que diz respeito ao formato dos documentos. Em geral foram utilizados arquivos .txt e .csv (e variantes). Inclusive os arquivos JSON gerados na primeira etapa precisam ser convertidos para .txt ou .csv para o uso nas etapas subsequentes.
5.3.1 Clusterização
Para realizar a clusterização, só havia o algoritmo DBScan4. A implementação do algoritmo pode fazer uso de medidas de similaridade como Euclidiana,Fading(Rodrigues et al.
(2016)) eJaccard. Muitas das decisões de processamento de texto são refletidas no código de
formahard coded. Isso implica que não é disponibilizada uma API para o uso da ferramenta
como um todo, mas, na verdade, é necessário modificar o código onde é necessário. Um exemplo disso pode ser visto na implementação do DBScan, onde para escolher a medida de similaridade é necessário alterar as chamadas de funções. Isso torna o uso muito inflexível, já que os valores são fixos e não parametrizados.
5.4 Análise
Depois de todas as etapas, a ferramenta conta com um módulo de exibição dos
clusters gerados pela etapa de processamento. As nuvens de palavras foram geradas com o
auxílio de uma ferramenta web de terceiros5. O módulo em si que foi criado no trabalho de Junior (2016) envolve um aplicativo web que exibe essas imagens dos resultados. O processo de criação das nuvens de palavras é ainda bem rústico, pois é feito de forma bem manual, colocando os dados na ferramenta web que gera as nuvens de cadacluster.
6 PROCEDIMENTOS METODOLÓGICOS
Dado o que já foi desenvolvido na versão anterior doframeworka ser expandido, os
procedimentos para o desenvolvimento da nova versão foram divididos em duas partes, sendo uma relacionada aoframeworke outra ao estudo de caso. A divisão ficou da seguinte forma:
1. Melhorias aplicadas aoframework;
– Algoritmos de coleta; – Pré-processamento; – Medidas de similaridade;
– Algoritmos de Mineração de Dados; – Módulo de visualização.
– Arquitetura doframework.
2. Validação doframework.
– Dados utilizados; – Pré-processamento;
– Categorização doconjunto de treino;
– Classificação dos dados;
– Comparação dos métodos de classificação;
6.1 Melhorias aplicadas aoframework
O framework conta atualmente com algoritmos para as três etapas gerais da
mineração de texto discutidas até agora. Este trabalho visa disponibilizar novas possibilidades para os futuros usuários do framework, que estarão disponíveis na parte de coleta, onde
alterações serão feitas, e processamento, onde um novo algoritmo estará disponível para uso. Além disso, o framework estará disponível completamente na linguagem de
programação Python1, por já contar com as fases de pré-processamento e processamento da versão atual nessa linguagem, e por Python ser uma linguagem com muito suporte da comunidade, disponibilizando de muitas bibliotecas que são próprias para análise de dados. Isso facilita ainda mais o surgimento de possíveis novas versões para oframework.
6.1.1 Algoritmos de coleta
Existem três formas de se coletar os dados do Twitter. A primeira é por meio da API REST do Twitter buscando portweetsque foram postados até no máximo sete dias atrás.
A segunda forma de coleta é por meio da API de Stream do Twitter: ela disponibiliza dados em tempo real. Todos ostweetspostados a partir do momento em que se inicia a coleta serão
retornados pela API de Stream.
A terceira forma de coleta, soluciona o problema do Twitter retornar dados de no máximo uma semana atrás com o uso da API REST. Essa forma consiste em utilizar umscraper
para buscar as páginas do Twitter que possuem os dados desejados. A grande diferença é que a API REST não é acessada diretamente para se ter apenas os dados, mas é carregada toda a página HTML com ostweetse o algoritmo é responsável por analisar o conteúdo em busca dos dados.
Para a coleta de dados usando o método descrapingserá utilizada a biblioteca TwitterScraper2.
A documetação do Twitter recomenda uma série de bibliotecas para acessar sua API3e a que será utilizada neste estudo é a Tweepy4, para acessar a API REST e a de Streaming.
Por meio do uso do framework será possível ter dois tipos detweetscomo saída.
Utilizando o método descraping, umtweetserá composto peloscreen name, id,created at,name
etext, que representam respectivamente o nome de usuário (ouusername), id dotweet, data de
postagem, nome real do perfil e o texto postado. O outro tipo detweeté obtido através das APIs
do Twitter, que contam com os mesmos dados do método de scrapinge vários outros, como
Russel (2013) descreve.
Na versão atual do framework, apenas a forma de coleta por meio do streamde tweetsestá implementada. Essa implementação foi feita em Java, e para deixar oframework
unificado em apenas uma linguagem, um algoritmo será feito para coletar os dados destreamem
Python. Além disso, as outras duas formas de coleta estão implementadas para dar ao especialista a oportunidade de trabalhar com os três tipos de acesso aos dados.
6.1.2 Pré-processamento
Todos os passos que serão listados na Seção 6.2.2 já estão presentes noframework,
exceto a remoção de pontuação do texto, de caracteres como "?", "!"e outros. Essa deve ser a 2 https://github.com/taspinar/TwitterScraper
3 https://dev.twitter.com/resources/twitter-libraries
única alteração na parte de pré-processamento doframeworkatual, dado que a existência desses
caracteres poderiam influenciar nas outras etapas de PLN, como na remoção de sufixos. Para a coleta dos dados, oframeworkprocessa arquivos JSON5(JavaScript Object Notation) direto
das APIs do Twitter. Para armazenar os dados pré-processados, o usuário doframeworkterá as
opções de armazenamento em JSON, CSV (Comma Separated Values) e TSV (Tab Separated Values). Na versão anterior, apenas o formato TSV era suportado para o armazenamento de
tweetspré-processados.
6.1.3 Medidas de similaridade
O framework já disponibiliza algumas medidas de similaridade, como: Fading,
Euclidiana e Jaccard. Sendo que destas, para texto, a mais apropriada é a de Jaccard, por considerar apenas a diferença entre os textos e nenhum outro atributo. Visando ter mais possibilidades para melhores resultados para a clusterização de texto, outra medida de similaridade para texto, chamada de Levenshtein, é implementada.
6.1.4 Algoritmos de Mineração de Dados
O algoritmo de classificação a ser implementado é o Naive Bayes e é baseado em uma versão desenvolvida disponível no GitHub6. Além disso, o K-medoids está implementado. Oframeworkpassa a contar com três algoritmos para mineração de dados, DBScan, Naive Bayes
e K-medoids. Isso deve trazer ainda mais utilidade à ferramenta, por contar com uma quantidade maior de opções de análise para dados.
6.1.5 Módulo de visualização
Para auxiliar na análise dos resultados, o framework conta com um módulo de
visualização. Com o uso desse módulo é possível gerar nuvens de palavras, gráficos e também cálculos de erro para resultados de classificação.
5 http://www.json.org/json-pt.html
6.1.6 Arquitetura do framework
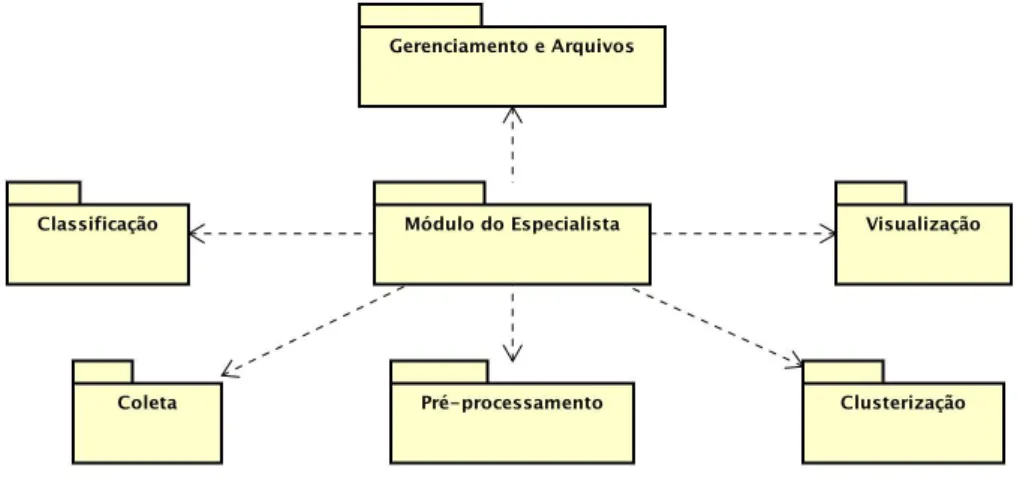
Para uma maior modularidade e organização do código do framework, o código
será divido em módulos. Haverá um módulo responsável apenas por coletar os tweets, um
módulo para pré-processar os dados, um módulo para algoritmos de classificação, um módulo para algoritmos de clusterização e um módulo responsável por lidar somente com leitura e escrita em arquivos (ver Figura 3). Dessa forma, em todos os pontos doframeworkonde existe
manipulação de arquivos, será realizada uma refatoração visando estabelecer módulos mais coesos. Isso facilita o uso de partes doframeworkindividualmente, no caso de algum módulo
não ser necessário quando usado por um especialista.
Figura 3 – Diagrama de uso dos módulos doframework.
Fonte – Elaborado pelo autor.
6.2 Validação doframework
Como um meio de garantir que oframeworktem um bom desempenho, este trabalho
6.2.1 Dados utilizados
Para a realização do estudo de caso, dados sobre a reforma da previdência social do Brasil (sistema de aposentadoria público) serão analisados. Para isso, as palavras "previdencia social", "reforma da previdencia", "reforma da presidencia"e "previdencia"serão utilizadas na
stringde busca enviada para o Twitter. Somentetweetspostados em português serão analisados.
O tema foi escolhido devido à sua grande relevância político-social e para que seus dados pudessem ser utilizados na validação da ferramenta.
6.2.2 Pré-processamento
A etapa de limpeza dos dados visa estruturar os dados de maneira que a análise feita pelos algoritmos não seja prejudicada. Na versão atual doframework, há uma versão bem
completa de algoritmos para pré-processamento. Oframeworkconta com análise de textos em
inglês e português, dando suporte para leitura de arquivos JSON e arquivos CSV.
Considerando o texto original de umtweetpara um exemplo de aplicação dos passos
de pré-processamento, como "Botaram grades no Congresso para impedir o povo de participar. Pq se o povo estiver aqui, a reforma da Previdência não passa @fulanodetal http://link.com", pode-se observar a seguinte estrutura:
1. Transformação dos caracteres para minúsculo: "botaram grades no congresso para impedir o povo de participar. pq se o povo estiver aqui, a reforma da previdência não passa. @fulanodetal http://link.com".
2. Remoção de links: "botaram grades no congresso para impedir o povo de participar. pq se o povo estiver aqui, a reforma da previdência não passa @fulanodetal".
3. Remoção de pontuação (caracteres especiais): "botaram grades no congresso para impedir o povo de participar pq se o povo estiver aqui a reforma da previdência não passa @fulanodetal".
4. Remoção de acentos: "botaram grades no congresso para impedir o povo de participar pq se o povo estiver aqui a reforma da previdencia nao passa @fulanodetal"
5. Remoção destopwords: "botaram grades congresso impedir povo participar pq
6. Remoção de sufixos: "bot grad congress imped pov particip pq pov aqu reform previdenc nao pass @fulanodetal".
7. Remoção de nomes de usuário: "bot grad congress imped pov particip pq pov aqu reform previdenc nao pass".
Stopwordssão palavras sem muito significado importante para a análise do texto,
tais como artigos e preposições, e por isso devem ser removidas. Assim como os sufixos das palavras foram removidos por não haver diferença entre, por exemplo, "participa", "participará"ou "participou".
Os dados, depois de limpos, deverão ser armazenados em arquivos para futuras análises, sem a necessidade de repetição do processo, a menos que seja necessário realizar diferentes passos de pré-processamento.
6.2.3 Categorização do conjunto de treino
Uma parte muito importante deste estudo de caso é a utilização de diferentes tipos de categorização doconjunto de treino. Duas formas de categorização são aplicadas: com auxílio
do DBScan e de um especialista.
Com o uso do algoritmo DBScan implementado noframework, espera-se que seja
possível verificar as categorias existentes nos dados, para que a classificação possa ser mais representativa. Também se espera tornar o processo de categorização do traning set mais
automatizado, embora ainda seja necessário um especialista analisar osclustersgerados. Dessa
forma, o DBScan funcionaria como um sumarizador das categorias que auxilia na detecção mais realista do que os dados representam. Esse método também possibilita uma categorização de um maior número detweetsque estarão noconjunto de treino, o que pode levar a uma melhor
acurácia do modelo.
Outra forma de categorizar os dados é com o auxílio de um especialista. Esse método é manual, dependendo completamente de uma pessoa para categorizar umtweetpor vez. Por
conta do esforço exigido, um menorconjunto de treinoé gerado e uma representatividade menor
de palavras é alcançada.
6.2.4 Classificação dos dados
executar o algoritmo para a criação dos modelos e então executar alguns testes de classificação para novostweets, que fazem parte de um conjunto de teste. Esse conjunto de teste deverá ser
7 RESULTADOS
Este capítulo apresenta os resultados alcançados neste trabalho.
7.1 Melhorias aplicadas
A partir da versão da ferramenta descrita no Capítulo 5, melhorias e novas funcionalidades foram aplicadas. No geral, essas melhorias visam tornar a ferramenta unificada e agregar valor com as novas funcionalidades, permitindo um processo de mineração de texto mais completo. A ideia é que a ferramenta seja utilizada como uma biblioteca Python, e com essas modificações possa ser utilizada dentro de outras aplicações.
7.1.1 Coleta
O módulo de coleta foi totalmente reescrito. Na versão anterior havia apenas a coleta por meio da API deStreamingdo Twitter, e agora é possível realizar a coleta com API de Streaming, API de Busca (SearchAPI) e utilizando o método descrapingpara coletartweets
mais antigos. Para os casos de uso da API deStreamou de Busca, é necessário informar alguns
dados que dão acesso a API que são disponibilizados pelo Twitter, como a Chave,Secret, Token
de Accesso e o Secret do Token1.
7.1.2 Pré-processamento
Considerando a versão anterior doframework, o módulo de pré-processamento2é o
que mais se aproxima da nova arquitetura da ferramenta e, portanto, sofreu menos modificações. Um exemplo de melhoria nesse módulo foi adicionar mais símbolos para o conjunto de símbolos de caracteres especiais.
Uma decisão tomada para tornar a ferramenta mais flexível, foi usar dicionários baseados nos arquivos JSON gerados, para facilitar a descrição dos documentos processados. Uma vez que para acessar uma dada informação só é necessário saber qual a chave para se obter o valor, e dessa forma, é possível passar os nomes das chaves que cada algoritmo precisará utilizar para realizar o processamento.
7.1.3 Gerenciamento de arquivos
Uma outra melhoria importante foi o desacoplamento dos módulos existentes em relação ao gerenciamento de entrada e saída de resultados. Foi criado um módulo responsável por lidar apenas com leitura e escrita de arquivos, tanto JSON, como CSV e variantes. Isso ajuda a reduzir a complexidade dos outros módulos, aumentando a coesão e diminuindo a quantidade de responsabilidades delegadas aos outros módulos. Isso possibilita ao usuário ler e escrever os dados somente uma vez durante o processo de mineração.
7.1.4 Processamento
Na versão anterior doframeworkhavia apenas um algoritmo de mineração de dados,
chamado DBScan, e ainda algumas medidas de similaridades: Fading, Euclidiana e Jaccard.
Havia um nível muito alto de acoplamento entre o algoritmo e as medidas. Uma das primeiras melhorias feitas foi separar essas medidas a fim de facilitar a adição de novas, bem como diminuir o acoplamento. Em seguida, foi possível adicionar a distância de Levenshtein ao módulo de clusterização.
Além dessa melhoria arquitetural, houve também a adição de mais um algoritmo de clusterização, o K-medoids3. Isso dá uma possibilidade a mais para o especialista, dado que a proposta do K-medoids (clusterização por partição) é diferente da proposta do DBScan (clusterização por densidade). Para auxiliar no uso do K-medoids, foi adicionada uma funcionalidade que faz uso do método do cotovelo para ajudar na decisão do valor de K.
Para esta etapa de processamento, foi também adicionado o algoritmo Naive Bayes para classificação4. A implementação desses algoritmos busca ser a mais genérica possível para que o especialista consiga usar para os seus dados que podem ter estruturas diferentes. Isso significa dizer que, as estruturas de dicionários do Python foram utilizadas para facilitar a descrição dos documentos, no qual é possível informar os nomes dos campos que precisam ser analisados durante a execução do algoritmo.
7.1.5 Análise
Para a etapa de análise, o trabalho que deu inicio aoframeworkfez uso de nuvens
de palavras geradas com o auxílio de uma ferramenta web de terceiros. As nuvens de palavras mostram em maior destaque as palavras com mais ocorrências para os documentos analisados. Essa é uma forma de conseguir observar os padrões dosclusters. Na nova versão doframework
é possível gerar as nuvens de palavras sem a necessidade de usar uma outra ferramenta. Isso diminui o trabalho manual que pode ser criar nuvens de palavras, além de poder gerar resultados mais claros utilizando-se de funcionalidades que acompanham esse módulo de visualização. Por exemplo, após a etapa de pré-processamento muitas palavras podem ficar ilegíveis, mas com o uso da ferramenta é possível recuperar os dados originais e utilizá-los para gerar as nuvens de palavras. Para ajudar na exibição das palavras, é possível fornecer um conjunto de palavras que não devem aparecer na imagem, além de ser possível reutilizar o módulo de pré-processamento para remover artigos, preposições, stopwords, entre outros para deixar a nuvem de palavras
gerada mais legível e exibir as palavras mais importantes.
Aproveitando também que o método do cotovelo foi adicionado a ferramenta, uma funcionalidade para visualização desses valores também foi adicionada, na qual é gerado um gráfico que torna mais compreensível em qual valor de K os erros calculados param de decrescer. Essa visualização não é um resultado gerado de uma clusterização, mas ajuda na tomada de decisão sobre qual K usar.
7.2 Validação das melhorias
Nesta seção são apresentados os passos para a validação das etapas de mineração de texto com o auxílio doframework.
7.2.1 Coleta
A etapa de coleta durou de março de 2017 à agosto de 2017 e foram coletados dados sobre a reforma da previdência social brasileira. Infelizmente, o tema escolhido não rendeu uma quantidade de tweetstão grande assim (ver Quadro 2), mas para o contexto desse trabalho, o
postagens de notícias sobre a reforma da previdência. Para a realização da coleta, oframework
disponibiliza uma API simples para uso, encapsulando funcionalidades obtidas com o auxílio de outras bibliotecas. Esses dados coletados foram persistidos no formato JSON para facilitar posteriormente as manipulações dos documentos, fazendo uso de dicionário em Python, que tem uma representação igual. Dessestweetscoletados, apenas alguns serão utilizados para realizar a
clusterização e a classificação.
Quadro 2 – Quantidade detweetspor mês.
Mês Total detweets
Março 55.237 Abril 63.577 Maio 32.671 Junho 18.079 Julho 9.877 Agosto 9.458
Fonte – Elaborado pelo autor
Um provável motivo para a diminuição da quantidade detweetscoletados, é ida e
vinda dos trâmites legais para aprovação da reforma da previdência. O tema oscilou bastante no período e, provavelmente, deixou de ser um tema mais chamativo como era no princípio da coleta.
7.2.2 Pré-processamento
O PLN aplicado inclui transformar o texto em minúsculo, remover acentos, remover caracteres especiais, remover sufixos de palavras, remover links e nomes de usuários, conforme explicado na Seção 6. Após o pré-processamento, o texto é salvo também em formato JSON e está pronto para ser processado. Obviamente, os documentos não precisavam ser salvos a cada etapa, mas para fins de repetição da validação isso foi feito.
7.2.3 Processamento
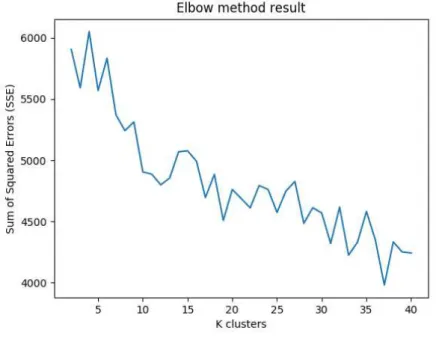
Após a etapa de pré-processamento, os documentos estavam prontos para serem processados pelos algoritmos K-medoids e Naive Bayes. Para a utilização do K-medoids, antes foi aplicado o método do cotovelo para descobrir qual o melhor valor de K utilizar para gerar
clusterscom o menor índice de erros. Utilizando a medida de distância de Jaccard, que é o
mês de março a julho. O resultado do mês de agosto pode ser visto na Figura 4.
Figura 4 – Soma dos quadrados dos erros do mês de agosto utilizando a distância deJaccard.
Fonte – Elaborado pelo autor.
Dados os valores desses erros, é possível perceber que o valor decresce de forma irregular. Provavelmente, o uso da distância de Jaccard aliado aosmedoids aleatórios possa
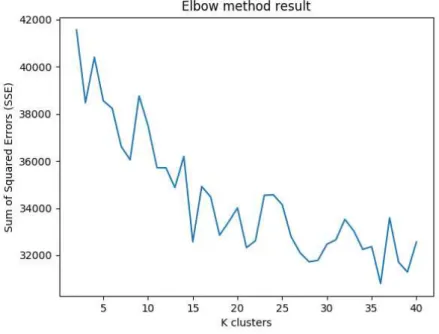
causar isso. Para tentar buscar outros resultados e ver de que maneira os erros vão se comportar, foi então usada a distância de Levenshtein e os resultados podem ser vistos no Apêndice B para os meses de março a julho. O resultado do mês de agosto pode ser visto na Figura 5.
De acordo com a Figura 5, é possível ver que a variação dos valores dos erros é muito maior para o uso da distância de Levenshtein, mas de acordo com a natureza dos dados é provável de que não haja tantosclusterscomo é exibido com os gráficos deJaccard. Muito
provavelmente, existem menos de 10clusterspara cada mês, o que é possível notar por conta de
haver sempre uma grande queda nos valores dos erros e depois uma variância perto de um valor comum quando a distância de Levenshtein é utilizada.
Aproximadamente 200 miltweetsforam processados. Com esses dados, 2clusters
Figura 5 – Soma dos quadrados dos erros do mês de agosto utilizando a distância deLevenshtein.
Fonte – Elaborado pelo autor.
7.2.4 Análise
Nesta Seção, os resultados da clusterização e classificação serão discutidos, bem como o processo para obtê-los.
7.2.4.1 Clusterização
Após a etapa de processamento, foram geradas as imagens dosclusterse com base
nessas imagens são analisadas as classes que podem surgir para a entrada do algoritmo de classificação. Para fins de simplificação, apenas os dados do mês de agosto serão exibidos nessa seção e os dados dos outros meses estão disponíveis no Apêndice C. No geral, o que é possível notar é que muitos dostweetspublicados sobre esse tema eram notícias ou eram contra a reforma.
Os clustersdas Figura 6 e Figura 7 descrevem tweets no geral contra a reforma
da previdência. Muitas publicações chamando a reforma da previdência de farsa, criticando os políticos que as defendem. Os termos mais comuns são "não", "contra", "temer"e mais alguns. Além de falarem da reforma da previdência, alguns dostweetstambém comentam sobre
a reforma trabalhista que de fato ocorreu. Sobre os dois temas essesclustersse mostram contra.
Figura 6 – Nuvem de palavras do primeiroclusterde agosto.
Fonte – Elaborado pelo autor.
notícias.
Figura 7 – Nuvem de palavras do segundoclusterde agosto.
Fonte – Elaborado pelo autor.
O segundocluster, Figura 7, vai ser usado como uma categoria negativa ou contra a
positivo, nem quando o valor dekera aumentado.
7.2.4.2 Classificação
Após realizar alguns testes, foi possível perceber que os clusters são em geral
negativos ou notícias. Ostweetsque são positivos acabam sendo minoria e não formando seus
próprios clusters. Como resultado disso, é difícil dar nomes aos clustersque posteriormente
precisam virar classes. Dessa forma, apenas 2clustersvão ser criados.
A classificação dos dados se baseou nas duas categorias geradas a partir osclusters.
Para realizar a classificação, vários testes foram feitos para que a acurácia do modelo fosse alta. Na primeira tentativa, a clusterização dos dados foi feita de forma direta, como explicada nos Procedimentos Metodológicos. Os resultados não foram bons. O modelo gerado não foi capaz de prever as classes de forma correta (Quadro 3).
Quadro 3 – Resultado da classificação baseada no uso dos
clusterscompletos do mês de agosto comretweets.
Tweetsclassificados corretamente (traning set) 4,89% (324) Tweetsclassificados incorretamente (traning set) 95,11% (6.297) Tweetsclassificados corretamente (test set) 4,37% (124) Tweetsclassificados incorretamente (test set) 95,63% (2.713)
Total detweetsutilizados 9.458
Fonte – Elaborado pelo autor
Por conta do resultado ruim, imaginou-se que a desproporção de tamanho entre os
clustersgerados pudesse estar gerando um modelo enviesado. Para tentar sanar esse problema,
usou-se a abordagem onde é utilizada apenas a quantidade do menorclusterpara criar o modelo.
Isto é, para os doisclustersgerados anteriormente, apenas 500tweetsde cadaclusterfoi utilizado
para a execução do algoritmo de classificação, já que o menorclusterpossuía apenas 500tweets
(Quadro 4).
Quadro 4 – Resultado da classificação baseada no uso dos
clustersparciais do mês de agosto comretweets.
Tweetsclassificados corretamente (traning set) 50% (500) Tweetsclassificados incorretamente (traning set) 50% (500) Tweetsclassificados corretamente (test set) 100% (300) Tweetsclassificados incorretamente (test set) 0% (0)
Total detweetsutilizados 1.300
Com o uso dessa nova abordagem, pode-se perceber que o modelo melhorou e que ele não está viciado nas entradas, já que a classificação do conjunto de treino teve 50% de erro. Mas os resultados do teste são muito satisfatórios, com 100% de precisão. Ainda assim, foi investigado se a remoção deretweetspoderia ser benéfica para a classificação desses textos, e o
resultado pode ser visto no Quadro 5.
Quadro 5 – Resultado da classificação baseada no uso dos
clusterscompletos do mês de agosto semretweets.
Tweetsclassificados corretamente (traning set) 1,75% (116) Tweetsclassificados incorretamente (traning set) 98,25% (6.505) Tweetsclassificados corretamente (test set) 2,36% (50) Tweetsclassificados incorretamente (test set) 97,64% (2.069)
Total detweetsutilizados 8.740
Fonte – Elaborado pelo autor
Em comparação ao resultado do Quadro 3, o resultado do Quadro 5 não é melhor. Foi repetido o processo então de classificação, mas com o tamanho do menorclusteraplicado
para todos os outrosclusters, e o resultado está no Quadro 6. Esse resultado é tão bom quanto o
o resultado do Quadro 4, já que ele possui uma amostra bem maior e o erro aumentou pouco.
Quadro 6 – Resultado da classificação baseada no uso dos
clustersparciais do mês de agosto semretweets.
Tweetsclassificados corretamente (traning set) 48,25% (3.657) Tweetsclassificados incorretamente (traning set) 51,75% (3.923) Tweetsclassificados corretamente (test set) 95,57% (1.058) Tweetsclassificados incorretamente (test set) 4,43% (42)
Total detweetsutilizados 8.680
Fonte – Elaborado pelo autor
A maior parte da dificuldade de lidar com maisclustersestá contida na existência de
muitostweetsnegativos e de notícias. Por fim, acabariam existindo mais de umclusterpara cada
classe, o que prejudicaria a classificação. Como é possível ver no Apêndice C, 5clustersforam
gerados para cada mês, e em sua maioria eles possuem palavras de tom negativo sobre a reforma em destaque.
Possivelmente, essa abordagem de utilizar osclusterscomo categorias de entradas
para um modelo bayesiano, não seja a melhor alternativa. Pelo menos no caso onde os dados são muito parecidos ou osclusterspossuem intersecção de sentimento, parece não ser a abordagem