UNIVERSIDADE DE LISBOA
FACULDADE DE LETRAS
Shared Mechanisms In Situated Language Production:
A Cross-Linguistic Comparison Between Portuguese
And English
Mário Alexandre Gomes Carvalho
Tese orientada pela Prof.ª Doutora Maria Armanda Costa e pelo Prof.
Doutor Moreno Ignazio Coco, especialmente elaborada para a obtenção do
grau de Mestre em Ciência Cognitiva
Agradecimentos
Começo naturalmente por agradecer aos meus orientadores, a Prof. Armanda Costa e o Prof. Moreno Coco. À Professora Armanda agradeço por acreditar em mim, e por todo o apoio que me deu desde que fui seu aluno de licenciatura, na psicolinguística e em tudo o mais. Ao Professor Moreno agradeço a enorme disponibilidade que teve desde o início deste longo processo, arranjando sempre tempo para ajudar nas frequentes alturas em que foi necessário. Tenho por ambos um enorme respeito e admiração, e espero ter merecido, pelo menos em parte, a fé que depositaram em mim ao aceitarem ser os meus orientadores.
Agradeço às minhas colegas do Laboratório de Psicolinguística, em particular à Paula e à Eunice. À Paula por ter sido, quase desde que a conheci, como uma irmã mais velha dentro do laboratório, mantendo-me sempre debaixo de olho e criticando-me quando necessário, o que de certo lhe custou mais do que parece. À Eunice por toda a ajuda que me deu durante a tese, e pelos conselhos que me foi dando ao longo destes anos. Aproveito também para agradecer à Isabel Falé, que sempre me en-corajou a trabalhar mais para a tese, mesmo quando havia trabalho por fazer.
Agradeço aos meus colegas do mestrado em Ciência Cognitiva, àqueles que ficaram até ao fim, e aos que ficaram a meio. Um especial abraço à Luana, ao Tiago, ao David, ao Marco e ao Santiago. Agradeço a todos os que me ajudaram com a tese. Ao João Silva, pela ajuda com a anotação mor-fológica dos dados, e às Professoras Catarina Magro e Rita Marquilhas do Centro de Linguística, que foram muito prestáveis e disponívels quando procurava uma maneira de anotar os dados. Ao Rui, enquanto participante incansável das minhas experiências e amigo, e por me ter ajudado com burocracia, o que é sempre um feito e tanto. E agradeço, claro a todos os participantes da minha ex-periência, sem os quais não teria dados para anotar.
Agradeço à minha família pelo apoio incondicional, aos meus tios, ao meu avô, e em particular aos meus irmãos, e à minha mãe.
Agradeço aos meus amigos, em particular à Mél e ao Tiago. À Mél por ser a minha parceira no cri -me e na aventura pela linguística que partilhamos desde o início. A paixão e dedicação tão típicas dela são uma fonte de inspiração para mim desde o início da nossa amizade. Ao Tiago, por ser meu amigo há tanto tempo, e por mostrar preocupação pela minha vida académica e profissional apesar de habitarmos esferas tão diferentes.
Finalmente agradeço à Joana, a minha parceira na vida. Não há maior motivação do que tentar ser a pessoa que ela vê em mim, e dar-lhe de volta todo o carinho, apoio e confiança que ela me dá, na vida académica e pessoal.
Resumo
Esta dissertação investiga a produção de linguagem em contexto visualmente situado, com um foco na produção de expressões referenciais e uma abordagem multi linguística que compara dados do Português Europeu com dados do Inglês.
Literatura prévia na área da produção de linguagem visualmente situada tem estudado a produção de expressões referenciais com base na ideia de acessibilidade referencial (e.g. Ariel, 2014; Gundel, Hedberg, & Zacharski, 1993): formas referenciais mais reduzidas ou mais descritivas refletem refer-entes que são mais ou menos cognitivamente acessíveis. Com base neste ideia, houve uma procura dos fatores que informam a acessibilidade dos referentes. Foco-me nesta tese em três fatores previa-mente investigados pela literatura: a animacidade do referente, o nível de visual clutter e a presença de competição referencial. Foram encontrados efeitos para todos estes três fatores na produção de expressões referenciais (Arnold & Griffin, 2007; Clarke, Elsner, & Rohde, 2013; Fukumura & Gompel, 2011; Koolen, Krahmer, & Swerts, 2015), mas de uma forma isolada e testando diferentes aspetos das expressões referenciais.
Através de uma experiência de produção de linguagem guiada, testo a animacidade referencial, o nível de 'visual clutter' (ambas como variáveis independentes) e a presença de competição referen-cial (esta última como constante nas imagens) na descrição de imagens, e nas expressões referenci-ais produzidas como parte das descrições. Comparo os dados obtidos para o Português Europeu com os dados para o Inglês obtidas na experiência de Coco e Keller (2015).
A animacidade do referente teve o maior impacto nos resultados, levando a descrições iniciadas mais rapidamente, estruturalmente mais verbais, e, para o Português, com um maior número de ex-pressões referenciais reduzidas. O Português e o Inglês diferiram também na estrutura das de-scrições, com o Português recorrendo a um maior nível de informação estrutural (com maior uso de Conjunções e Proposições) e o Inglês a mais informação referencial (com maior uso de Nomes e Pronomes). Não foram encontrados efeitos para o nível de visual clutter, talvez devido à natureza guiada da tarefa, e às variáveis testadas (que diferem de literatura prévia que estudou o nível de
vis-ual clutter na produção de expressões referenciais).
De uma forma geral, os resultados reforçam o impacto da animacidade referencial na produção de expressões referenciais e das estruturas línguísticas envolventes, e mostram que este impacto é par-cialmente influenciado pelas estruturas específicas da língua em uso.
Palavras-chave: produção de linguagem visualmente situada, animacidade, referência,
Abstract
This thesis researches visually situated language production, with a focus on the production of re-ferring expressions and a cross-linguistic approach that compares data for European Portuguese with data for English.
Previous literature in visually situated language has studied the production of referring expressions with a basis on the idea of referential accessibility (e.g. Ariel, 2014; Gundel, Hedberg, & Zacharski, 1993): reduced or more informative referring expressions reflect referents that are more or less cog-nitively accessible. Based on this idea, there has been a search for the factors that influence referen-tial accessibility. In this thesis, I focus on three factors that have been previously studied in visually situated language: referent animacy, the level of information of the visual context, and the presence of referential competition. Effects have been found in the production of referring expressions for all three of these factors (Arnold & Griffin, 2007; Clarke, Elsner, & Rohde, 2013; Fukumura & Gom-pel, 2011; Koolen, Krahmer, & Swerts, 2015), but they have been studied in isolation, and with dif-ferent aspects of the referring expressions under analysis.
Through a cued language production experiment, I test the impact of referent animacy, the level of information of the visual context (both as independent variables), and the presence of referring competition (as a a constant and integral property of the stimuli) on the description of images, and on the referring expressions produced as part of the descriptions. I compare the data for European Portuguese obtained in this experiment with the data for English obtained in the experiment of Coco and Keller (2015).
Referent animacy had the largest impact in the results, with animate referents leading to more quickly initiated descriptions that are more verbal in their structure, and, for Portuguese, in a greater number of reduced referring expressions. Portuguese and English also differed in description struc-ture, with Portuguese participants using a higher degree of structural information (through the use of Prepositions and Conjunctions), while the English participants make more use of referential in-formation (with an increased proportion of Nouns and Pronouns). No effects of visual inin-formation were found, maybe due to the guided nature of the task, and the specific tested variables (that differ from previous literature which looked at the impact of visual context information on referring ex-pression production).
Overall, the results support the high impact of referent animacy on both referring expression pro-duction and on the surrounding linguistic structures that has been previously found in literature, while showing that this impact is partially influenced by specific properties of the used language.
Palavras-chave: visually situated language production, animacy, reference, referential accessibility,
Resumo Extenso
Esta dissertação investiga a produção de linguagem em contexto visualmente situado, com um foco na produção de expressões referenciais e uma abordagem multi-linguística que compara dados do Português Europeu com dados do Inglês.
Trabalhos como Griffin e Bock (2000) demonstraram que existe uma relação forte entre visão e pro-dução de linguagem, e em particular a propro-dução de expressões referenciais: a ordem em que as enti-dades representadas numa imagem são vistas prediz a ordem em que são referidas, e existe um in-tervalo previsível de tempo entre visualização e referência – o chamado eye-voice span. Desde en-tão que o campo de produção de linguagem visualmente situada (visually situated language
produc-tion) tem usado esta abordagem multi-modal que cruza conhecimento e ferramentas de cognição
visual e psicolinguística para a investigação de vários tópicos de produção de linguagem.
Como um desses tópicos, a investigação sobre a produção de expressões referenciais continua ativa. Muita dessa investigação tem tido como base a ideia de acessibilidade na escolha de produções ref-erenciais, com base em modelos de produção de expressões referenciais como os de Ariel (2014), e de Gundel, Hedberg e Zacharski (1993). Segundo esta ideia, a escolha de formas de referência mais descritivas ("a senhora") ou mais reduzidas ("ela") está ligada à acessibilidade cognitiva do refer-ente. Um referente mais cognitivamente acessível é referido com formas mais reduzidas, enquanto que os referentes de mais difícil acesso são referidos com expressões mais longas e informativas. A questão que se coloca é quais são os fatores que fazem um referente mais ou menos acessível. Com uma experiência de produção de linguagem guiada, em que os participantes descrevem ima-gens precedidas de uma palavra referente a entidades nelas representadas, estudo o impacto de três potenciais fatores de influência de acessibilidade referencial: a animacidade do referente, o nível de informação do contexto visual e a presença de referentes em competição (este último não enquanto variável dependente, mas como uma constante nos estímulos apresentados). Literatura na área da produção de linguagem visualmente situada encontrou efeitos diversos destes fatores na produção de expressões referenciais (e.g. Arnold & Griffin, 2007; Clarke et al., 2013; Fukumura & Gompel, 2011), mas estudou estes fatores em isolação e testando diferentes aspetos das expressões referenci-ais. Neste estudo, coloco os três fatores em interação e testo o seu efeito em três aspetos diferentes da produção de referências: a constituição lexical das descrições produzidas pelos participantes (medida a nível referencial (através da proporção de Nomes e Pronomes), estrutural (através da pro-porção de Conjunções e Preposições) e verbal (que incorpora tanto informação referencial como es-trutural, através da proporção de verbos); a forma das expressões referenciais usadas em referência à segunda entidade-alvo referida em cada descrição (que categoriza ou como formas mais longas, nomimais, ou como formas mais reduzidas, pronominais); e o tempo de planeamento de discurso dos participantes (o intervalo de tempo entre as imagens serem apresentadas e começarem a ser de-scritas).
Faço também uma comparação dos dados obtidos para o Português Europeu com esta experiência, com aqueles obtidos na experiência de Coco e Keller (2015) para o Inglês. Deste modo, testo o im-pacto de propriedades específicas destas duas línguas na produção das descrições em geral e de
ex-Os resultados encontrados mostram que, tal como acontece na literatura, a animacidade do referente tem um grande impacto, com referentes animados resultando em descrições mais verbais, em fases de planeamento da descrição mais curtas, e, para o Português, num maior número de expressões ref-erenciais reduzidas. As diferenças entre o Português e o Inglês são por sua vez mais pronunciadas na constituição lexical das descrições: os falantes do Português produzem descrições estrutural-mente mais ricas, enquanto os falantes do Inglês produzem descrições com uma maior proporção de informação referencial. Ao contrário do que acontece em literatura prévia (e.g. Clarke et al., 2013; Koolen et al., 2015), o nível de informação visual da imagem não tem nenhum efeito significativo em nenhuma das análises, possivelmente devido a diferenças relativas às variáveis testadas, e à tarefa experimental utilizada.
De uma forma geral, os resultados mostram que a animacidade do referente tem impacto a vários níveis na produção de linguagem visualmente situada, e que esse impacto é parcialmente influenci-ado pelas propriedades estruturais da língua em uso.
Table of Contents
1 - Introduction...3
1.1 - The case for a situated view of language...5
1.2 - Vision and Visual Guidance...7
1.2.1 - The early pillars of research on visual guidance...7
1.2.2 - Animacy in Visual Attention...9
1.2.3 - Saliency and Clutter...9
1.3 - Spoken Language Production...12
1.3.1 - Levelt’s (1999) model of spoken language production...13
1.3.1.1 - Conceptual Preparation...14
1.3.1.2 - Grammatical encoding...15
1.4 - Producing Referring Expressions...16
1.4.1 - Theoretical Framework...17
1.4.2 - What makes a referent more or less accessible?...18
1.4.3 - Reference in Visually Situated Language Production...19
1.5 - Conclusions...25
2 - Experimental Work...27
2.1 - General Concept and Design...27
2.2 - Methodology...27 2.2.1 - Participants...28 2.2.2 - Materials...28 2.2.3 - Procedure...29 2.2.4 - Analysed Measures...30 2.3 - Hypotheses...31 2.3.1 - Animacy...31 2.3.2 - Clutter...32 2.3.3 - Language...33 2.4 - Data Pre-Processing...34 2.5 - Statistical Analysis...39 2.6 - Results...41
2.6.1 - Proportion of Nouns + Pronouns, Verbs and Conjunctions + Prepositions...41
2.6.1.1 - Nouns + Pronouns (NPRO)...41
2.6.1.2 - Verbs...42
2.6.1.3 - Conjunctions + Prepositions (CJPREP)...44
2.6.1.4 - Discussion...45
2.6.2 - Form of Referring Expressions...48
2.6.3 - Looking Times...50
2.6.4 - General Discussion...51
3 - Conclusions...53
References...55
Appendix A Penn-Treebank Tagset...59
Appendix B LX-Tagger Tagset...60
Appendix C Portuguese Data...62
Appendix D English Data...104
Appendix E Distractor Image Stimuli...136
Appendix F Experimental Image Stimuli...138
1 - Introduction
The last few decades have seen the rise of visually situated language processing, a field which com-bines tools and insights from language processing and visual cognition to provide a cross-modal ap-proach to topics from both areas. Language comprehension has benefited from this cross-modal per-spective for a long time, thanks in great part to the development of a paradigm that synchronizes spoken language comprehension with eye-tracking (Cooper, 1974) now known as the visual world paradigm, which has resulted in many new developments of our understanding of language compre-hension (for a review, see Spivey & Huette, 2016).
Language production, however, has also benefited from the integration of visual context and in-sights from visual cognition. Griffin & Bock (2000), through an experiment where participants had to describe images depicting simple events, showed that there was a strong and systematic connec-tion between our eye-movement and speech patterns. Their participants looked at the entities in the images in a way that paralleled their order of reference in the descriptions, regardless of how the thematic and grammatical roles of the entities were manipulated, and there was a predictable time-span between when an entity was looked at and named. These findings show that there is a strong connection between language production and vision, reinforcing the idea that looking at the two processes in interaction is a valuable approach.
A specific research question that has benefited from visually situated language has been that of the choice of referring expressions. When choosing to refer to a given referent, speakers have a number of expressions at their disposal, from fuller, more informative expressions like ‘the blonde lady with the white dress’ to shorter, easier to process pronominal forms like ‘she’. One explanation lies in the idea of accessibility (Ariel, 1988), that referents and their underlying concepts have different levels of cognitive accessibility, with referring expressions being chosen accordingly: more informative expressions are produced to refer to less accessible referents, while pronominal forms are chosen when their referents are more immediately accessible and do not require defined descriptions. What factors make a given referent more or less accessible? Linguistic and discourse-level factors like the referent’s thematic and grammatical roles are known to play a role, but research on visually situated language has shown the importance of some other factors: the conceptual animacy of the referred entities (whether they are animate, like animals and especially people, or inanimate ob-jects), the level of visual information in the image (e.g. the number of objects, under the measure of scene clutter) and the presence of a referential competitor in the visual context have all shown to have some impact on how referring expressions are produced.
There are, however, some gaps in the literature. The first is that these factors have been looked at separately, so it is unclear if and how they interact in the production of referring expressions. The second is that they've tested different aspects of the referring expressions, like their word length (Clarke et al., 2013) and whether or not they are overspecified (i.e. whether they use information that isn’t necessary for a clear reference, Koolen et al., 2015).
In order to address these gaps, this thesis features a cued language production experiment that stud-ies the impact of referent animacy, scene clutter and referential competition in visually situated speech production. 30 European Portuguese speakers were asked to describe naturalistic scenes
(which were manipulated as for their level of visual clutter) while always using a cue-word which preceded each scene. This cue-word was manipulated as for its animacy (referring to either a person or an object), and always referred to an entity which was represented twice in the scene (e.g. if the cue-word was ‘woman’, two women were depicted). I look at how scene clutter and referent ani-macy impact the overall constitution of the produced descriptions (measured through relative pro-portions of nouns plus pronouns as markers of referential information, verbs as markers of verbal information and prepositions plus conjunctions as markers of structural information), the time the participants take to start describing the scene, and the forms of referring expressions produced when both possible referents are mentioned. With this experimental design, I can test how scene clutter and referent animacy impact the choice of referring expressions
Additionally, I take a cross-linguistic perspective by comparing the European Portuguese data ob-tained in the experiment to the English data obob-tained by Coco & Keller (2015), who used the same design and stimuli to study mechanisms of visual guidance. Cross-linguistic approaches have helped the research of many topics in psycholinguistics, including conceptual accessibility (Jaeger & Norcliffe, 2009). Here I compare English and European Portuguese, two languages that have some structural differences that may be relevant in the study of reference production: characteristics of European Portuguese that aren't shared by English, especially its status as a null-subject, pro-drop language may impact the way speakers structure their speech and establish reference, by allowing a wider variety of referring expressions with omitted nouns.
This thesis has two main objectives:
(i) Study the impact of referent animacy and scene clutter on the production of scene
de-scriptions by European Portuguese and English speakers, with an emphasis on how reference is es-tablished;
(ii) Compare how European Portuguese and English speakers produce scene descriptions
and referring expressions, and see if the differences between the languages result in meaningfully different produced sentential and referential structures.
The thesis is structured in three sections:
In Section 1 I go over the relevant background for this thesis. I start by talking about the field vis-ually situated language production, before discussing some of the fundamentals of visual attention and language production. I finish by talking about the problem of reference production.
Section 2 is centred around the experiment that is at the core of this thesis. The experiment’s design,
objectives, hypotheses and results are discussed.
Section 3 serves as the conclusion to the thesis with a short reflection on the results and on possible
1.1 -
The case for a situated view of language
“A picture is worth a thousand words, but that’s the problem.”(Gleitman & Gleitman, 1992)
When we use language in our day-to-day lives, we don’t do it in isolation, but inserted into certain contexts of various natures – social, pragmatic and, as is the focus of discussion here, visual con-texts. Be it with a specialized task like reading a map aloud, telling the time from an analog clock or describing a picture, or with general communicative tasks like a regular conversation, it seems that we use visual cues to some extent when planning our speech: we look at the roads and buildings in the map to find a path, at the hands of a clock to find the hours and minutes, and at the expression of an addressee to see if they’re paying attention and understanding what we’re saying.
Insights from the field of visual cognition that tie visual gaze to attention and tools like eye-tracking that allow for a very quick and precise capture of eye-movements are also of great interest to the study of language processing. For example, visual attention as measured by gaze position can be very attractive for the study of reference: we can study how and when people look at different enti-ties in a scene when hearing or producing speech to research how reference is established in real-time. When describing an image, do visual properties affect what entities are or not mentioned? When hearing such a description, do we pre-emptively look at specific entities, predicting they will be mentioned? When given such a direct look into how our cognitive processes like that provided by the measurement of eye-movements, we get a world of possibilities when researching language processing.
Thus, there are two large gains to be made when incorporating the study of vision and language: it allows us to approximate the study of these processes to the complex context in which they actually occur, and provide us with new ways to look at old questions that have inspired research in visual cognition and psycholinguistics.
Indeed, while the study of language and vision in interaction (which I’ll call visually situated lan-guage comprehension or production) has been mostly localized to the last two decades, it’s already borne valuable insights for our understanding of language processing. This has been especially true of language comprehension: boosted by the development of a paradigm that puts in simultaneous interaction eye-tracked image visualization and speech stimuli (Tanenhaus, Spivey-Knowlton, Eber-hard, & Sedivy, 1995), now known as the ‘visual world paradigm’, the field has made remarkable progress in topics like the resolution of syntactic ambiguities or reference processing (for a review of these and other topics in situated language comprehension, see Spivey & Huette (2016)).
This is not to say that visually situated language production hasn’t been productive. The seminal work in the field is likely Griffin & Bock (2000), appropriately named ‘What the eyes say about speaking’. Griffin and Bock asked participants to look at simple images depicting simple events with two characters (see Figure 1).
The participants were divided into 4 groups, meant to tease apart the different stages of language production: one group described the scenes as they saw them, the second group described the scenes after they saw them, a third group was asked to find which character was the patient in each scene, and a final group was asked only to observe the scenes without any particular task. By looking at the produced utterances and eye-movements and their respective timings, Griffin and Bock had a number of interesting findings:
• The participants appeared to first extract an event structure from the images before starting to formulate a spoken description;
• The allocation of visual attention to the image strongly predicted the order of mention of the entities, regardless of their thematic roles or of sentence structure;
• There was a predictable temporal link (of 902 and 932 ms, for subject and object nouns re-spectively) between when an entity was last gazed upon and when it was first referred, the ‘eye-voice span’.
Taken as a whole, these observations made by Griffin and Bock make a strong case for a view of language in which a general conceptual message is first generated and then produced incrementally, sentence-to-sentence (which is compatible, for example, with Levelt’s (1999) model, discussed pre-viously). They also make clear that there’s a strong connection between eye-movements and speech, setting the stage for further research that integrates the two. In the words of the authors:
“The observations not only show a systematic temporal linkage between eye
movements and the contents of spoken utterances, but also offer new evidence for a tight coupling between the eye and the mind, and lay the ground-work for powerful tools to explore how thought becomes speech.” (Griffin & Bock, 2000, p. 279)
Figure 1: Example of the stimuli used in (Griffin & Bock, 2000), taken from the original paper. This figure actually represents 8 of the images used in the experiment: each character pair (turtle-mouse, man-dog and others not depicted here) represents a scene, and each scene had 4 variations, corresponding to the characters' position in the image and their thematic role in the depicted event (agent or patient). 5 of the scenes depicted active events, which should elicit predominantly active sentences, and 3 depicted passive events, which could also elicit passive sentences depending on the thematic role of a human character.
To work within with the field of visually situated language production, it pays to have an under-standing of how vision and language production work in isolation. If we are to believe that visual context plays a role in language production, then we need to understand what kind of information guides visual attention, so as to know how visual attention informs speech. Accordingly, only by un-derstanding how speech production is structured, can we know at what levels visual attention can be of influence. For this reason, the next two subsections will focus on visual attention and speech production.
1.2 -
Vision and Visual Guidance
1.2.1 -
The early pillars of research on visual guidance
When we look at a complex scene, like a photograph or a painting depicting a landscape, we don’t do so in a erratic fashion, randomly focusing on regions regardless of their visual aspects. Instead, our eyes are attracted to certain distinctive aspects and patterns of the scene, like a lone red flower in a field of green or the curve of the wave in Hokusai’s Great Wave of Kanagawa (as explored in Buswell, 1935). Our own goals as viewers also play a role: if we’re playing a game of Where’s Wally, for instance, our visual attention is likely to be particularly sensible to that red-and-white pat-tern that’s so characteristic of the titular character.
The mechanisms that guide visual attention have typically been divided into two main categories. Included within Low-level factors are stimuli-side visual properties, like colour and shape.
High-level factors, by contrast, refer to mechanisms that are more viewer-related, like knowledge and
in-tention.
The study of these factors of visual guidance owes much to two particular works, those of Buswell (1935) and Yarbus (1967). Buswell (1935) looked at how 200 participants looked at pictures of paintings of various kinds. Buswell found that certain regions generated more visual attention, nam-ing these regions “Centres of Interest”. Buswell interestnam-ingly had mixed results, findnam-ing these “Cen-tres of Interest” in images where he expected a random distribution of attention, while, in other im-ages, some regions which he expected to generate particular patterns of visual attention weren’t as productive. Buswell also found that the level of art education of the subjects had an influence on their eye movements, as did the directions they were given before looking at the image.
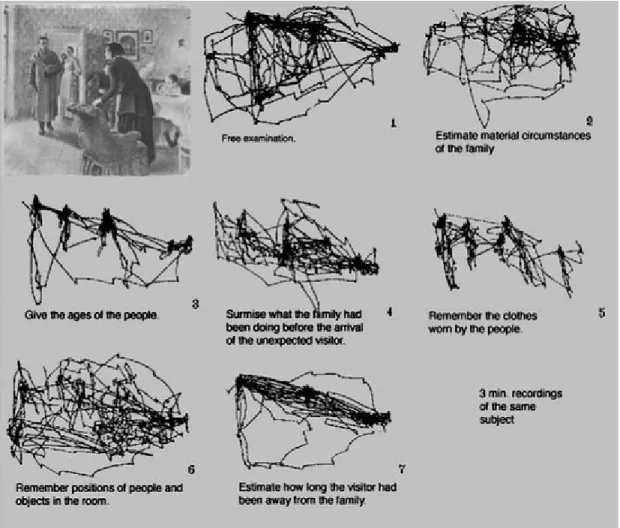
Yarbus (1967) contribution to the field was two-fold. The book details, on one hand, an eye-tracking method based on suction cups developed by Yarbus and, on another, a number of studies with vari-ous methods and stimuli that the author conducted to study eye-movements. The key section of Yarbus (1967) for this study (and his most influential contribution in general) is, however, the very final chapter, in which Yarbus describes his work with the viewing of “complex objects”, including pictures. Yarbus describes a number of interesting phenomena he observes in his studies, most no-tably the effect of a given task when viewing images. Yarbus has a participant look at the same pic-ture 7 different times, each time with a different task and finds that the participant’s eye-movement patterns varies, with the attention given to each region differing with how relevant they are to each task (see 2): “Depending on the task in which a person is engaged, i.e., depending on the character of the information which he must obtain, the distribution of the points of fixation on an object will
vary correspondingly because different items of information are usually localized in different parts of an object.” (Yarbus, 1967, p. 192). By clearly showing how different tasks give rise to different kinds of image-viewing behaviour, Yarbus gave credence to Buswell’s (1935) earlier observation on task effect, and instigated research on how the viewer’s goals and other cognitive factors influence eye-movement behaviour.
Put together, Buswell’s and Yarbus’s works showed that both a stimulus’ visual properties and the viewer’s own goals and intentions play a role in guiding visual attention. Since their studies, a vast body of research has been done on what constitutes low and high-level factors of visual attention (for a review, see Tatler, 2016), and how these factors interact. For this thesis, there are two factors of particular importance: depicted entity animacy, a high-level factor that is connected to the pres-ence of animate entities (particularly people) in the visual scene, and clutter, a low-level factor re-lated to object-level visual information.
Figure 2: An adaption taken from Greene, Liu, & Wolfe (2012) of Yarbus' (1967) Figure 109. A participant saw the same picture seven times, each time with a
different task (described below each scan-path). The resulting scan-paths show clear differences between each session, suggesting a strong effect of task on the allocation of visual attention.
1.2.2 -
Animacy in Visual Attention
When it comes to high-level factors, we know that visual attention seems to be greatly influenced by task, as described early on by Buswell (1935) and Yarbus (1967). We also know that semantic contextual information is taken into account when searching for objects (Biederman, Mezzanotte, & Rabinowitz, 1982) and that objects that are present in semantically incongruent contexts (e.g. a gas pump in a children's playground) attract considerable visual attention when compared to objects that are more typical in their placement (De Graef, Christiaens, & d’Ydewalle, 1990).
Most relevant to this thesis, however, are those factors that related to the concept of animacy, partic-ularly the presence of human, animate figures in an image. Yarbus (1967) observed that human faces appeared to attract more attention than their figures, which in turn attracted more attention than other objects. In particular, the eyes, mouth and nose seemed to attract a lot of interest. Further research has highlighted the attention paid to the eyes, which doesn’t appear to be driven by low-level factors (Birmingham, Bischof, & Kingstone, 2009) and is reinforced when participants are asked to memorize a given scene, suggesting they are particularly informative regions when encod-ing an image into memory (Birmencod-ingham, Bischof, & Kencod-ingstone, 2007).
Additionally, there’s a tendency to follow a depicted person’s gaze and look where they looking (Driver IV et al., 1999), which can put objects they’re gazing upon or manipulating in particular fo-cus (Fletcher-Watson, Findlay, Leekam, & Benson, 2008).
All this adds up to an idea that, when present in an image, people are a major factor in visual guid -ance, both attracting visual attention to themselves and directing it to what they interact with. This is interesting in how it ties into research on psycholinguistics that suggests that animate referents, especially people, have prominent roles in linguistic structures, and appear to be cognitively more accessible when establishing reference (research which I'll discuss in section 1.4.2).
1.2.3 -
Saliency and Clutter
As our understanding of the low-level visual features that guide visual attention has grown, there have been attempts at creating computational models that mimic human visual attention. An early and influential application of such a model, based solely in low-level features, is described by Itti & Koch (2000). Itti and Koch base their model on the idea of a ‘saliency map’ (as described by Koch & Ullman, 1987), itself based on the concept of ‘saliency’ - effectively, how much a given object or region of an image stands out from its surroundings in terms of its low-level visual features. A saliency map is then a map of any given image representing how much its different regions stand out visually – or, as described in Itti & Koch (2000, p. 1490), “an explicit two-dimensional map that encodes the saliency of objects in the visual environment”.
In the model by Itti & Koch (2000), low-level information is extracted from the image to create in-dividual maps accounting for luminance, colour and orientation contrasts. These maps, which add up to a total of 42, compete and are then combined to create the saliency map, to try and account for those low-level features as a whole. Visual attention is then modelled by the way of a Winner Takes All algorithm, which allocates attention towards the most salient location, aided by an inhibition-of-return mechanism which suppresses that location in the saliency map so attention is then directed
towards the next most salient region. Thus, visual attention as modelled by Itti and Koch sequen-tially jumps from region to region in decreasing order of saliency.
The specific model by Itti & Koch (2000) and the general idea of saliency as a measure of low-level factor impact in the guidance of visual attention have proven influential, giving rise to a number of models that incorporate saliency (see Borji & Itti (2013) for a review). It has proven at least some-what effective in predicting human visual attention: for example, Parkhurst, Law and Niebur (2002) had participants look at a series of images, depicting scenes ranging from simple fractals to realistic pictures of rooms, and found that salient regions correlated with fixation locations to a greater degree than chance could predict.
However, models that are solely based on saliency and other visual features have at least two major shortcomings that prevent them from serving as general models of visual attention (see Henderson, (2003) and Tatler (2016) for a more in-depth discussion). The first is that they don't integrate high-level factors, and so don't account for very impactful viewer-related effects like that of task shown in the work of Yarbus (1967); the second is that a correlation between saliency and human visual at-tention doesn’t necessarily imply a causal relation between the two. High-level factors might guide attention to regions that are visually salient, but have interfering high-level information (Tatler, 2016), For example Einhäuser, Spain and Perona (2008) find that maps derived from the location of
Figure 3: A schematic of the model of saliency-based visual attention implemented in (Itti & Koch, 2000), retrieved from the original paper.
In the context of this thesis, saliency is a useful concept to help measure and manipulate image clut-ter (Rosenholtz, Li, Mansfield, & Jin, 2005). In this context, clutclut-ter refers to how densely packed with objects a given image is – the more objects a scene has, the more cluttered it is (see 4 below). By integrating saliency and edge information, as described in Rosenholtz et al. (2005), we can get an effective quantitative measure of scene clutter.
The idea of scene clutter is useful as it allows us to work with varying levels of visual information using a same base image. This is interesting not only for studying visual perception in itself, but also for language production, as it allows us to manipulate the number of objects – and as such the number of entities available to be referred – in any given image. Thus, an image that possesses a higher degree of scene clutter should also be referentially richer, allowing for some interesting pos-sibilities when studying reference production in a situated language environment, as will be dis-cussed in section 1.4.3.
Figure 4: An example of different levels of clutter with the same scene. The left image is considered to be less cluttered than the image in the right, which has a much higher number of objects. These are stimuli used for the experimental work of this thesis and were originally used in Coco & Keller (2015).
1.3 -
Spoken Language Production
Speech production is a complex process, in which multiple steps need to be taken before an initial abstract message to be communicated turns into fully realized speech. The speaker needs to juggle multiple sources of information, from general knowledge to their understanding of the surrounding context and their addressee’s own state of mind. It’s a process that needs to happen at a very high speed for its high degree of complexity, and, consequentially, it often results in errors.
These speech errors have provided us with valuable information in how semantic, phonological and syntactic information work and combine to shape produced utterances (for a review, see Griffin & Ferreira, 2011). The insights provided from speech errors have given rise to a number of attempts at constructing models of spoken language production, aiming at understanding the various stages of language production and how they interact. In order to better understand the inner working of lan-guage production, and how visual information may play a part, I'll briefly review one such model, that of Levelt (1999).
1.3.1 -
Levelt’s (1999) model of spoken language production
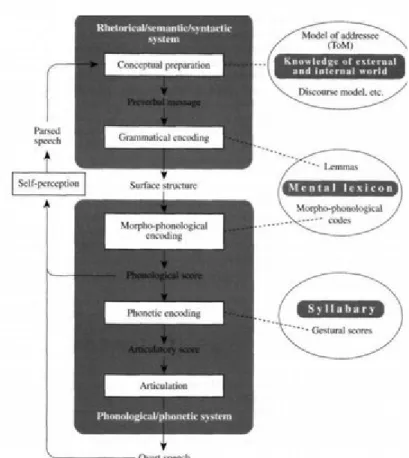
Levelt’s (1999) model, a ‘blueprint of the speaker’, functions roughly as follows:
1) Conceptual Preparation: the speaker first prepares a conceptual, pre-verbal message for what
they want to communicate, based on their mental states, knowledge of the world, their insight into their addressee's mind and a number of other knowledge sources.
2) Grammatical Encoding: this pre-verbal message gains an abstract surface structure based on
its concepts’ corresponding lemmas, and their semantic and syntactic attributes. This structure re-flects the message’s referents, their relations, and their predicates.
3) Morpho-phonological Encoding: The surface structure is then given a phonological score,
where the phonological words are constructed and syllabified in relation to their syntactic context.
4) Phonetic encoding: turns the phonological score into an articulatory score, where the motor
gestures required to produce the needed syllables are mentally accessed.
5) Articulation: the articulatory gestures are physically executed, and overt speech is produced.
The speaker monitors his own speech, to correct for any potential mistakes that might result in com-munication problems.
Figure 5: An illustration of Levelt's (1999) model of spoken language production, taken from the original source.
The conceptual preparation and grammatical encoding stages constitute the first core unit of the model, which Levelt associates with rhetorical, semantic and syntactic systems. The morpho-phono-logical encoding, phonetic encoding and articulatory stages constitute the second unit, which in-volves phonological and phonetic systems.
Levelt’s model takes an incremental view of spoken language production, meaning that while its different stages are sequentially ordered (from top to bottom as seen in Figure 5), they are in inter-action and work partially in parallel. For example, the pre-verbal message need not be entirely final-ized in the conceptual preparation stage for grammatical encoding to start working – instead, gram-matical encoding processes the pre-verbal message while it is received.
In this thesis I'm looking at how language and reference production are influenced by visual con-text, and how this influence manifests itself in language-specific structures. For this reason, from the stages Levelt's model described above, there are two relevant to the analysis that will be per-formed: conceptual preparation, when the linguistic message is being planned, and the visual con-text will play its role; and grammatical encoding, when the syntactical linguistic structures take their form.
1.3.1.1 - Conceptual Preparation
In this stage, the speaker prepares a pre-verbal message, an abstract conceptual structure generated from the concepts the speaker wishes to communicate about. This message is shaped from the speaker’s various knowledge sources, like their knowledge of the external world and their insight into their addressee's mental states (Theory of Mind). Levelt divides this process into two phases. Conceptual preparation in Levelt's model is divided in two stages: macroplanning and microplan-ning. When macroplanning, a speaker decides on what to say next, trying to guide the discourse focus, shared with their addressee, to whichever idea they want to focus on, in pursuit of a larger communication goal. As part of a more complex message, the speaker shifts the discourse focus be-tween the various concepts to be communicated about. When microplanning, the speaker decides on how to shape his message, particularly what perspective to take (for example, when describing a picture depicting a tree and a house, whether to focus on the position of the tree in relation to the house or the opposite - “There’s a tree to the right of an house” versus “There’s an house to the right of a tree” (Levelt, 1999)). These two stages add up to a complicated process of speech-planning, in which a speaker needs to understand and select information to communicate, and decide on best ap-proach to communicate it.
In visually situated language, how might the visual context play a role in this process? It might be, for example, that when the visual context is particularly dense with clutter, the speaker has a more complicated process of macroplanning, as they have more information to potentially address. The presence of animate entities might also play a role, as the speaker might focus on these entities and take a particular perspective that focuses on their role within the scene.
between languages, as they have different ranges of lexical concepts and must obligatorily address different information depending on that language's grammar ('thinking for speaking' - (Slobin, 1996)). This point is, however, fairly controversial, as the degree to which language can have an im-pact on more general thought processes is a heated topic of discussion in the literature (Wolff & Holmes, 2011).
1.3.1.2 - Grammatical encoding
As seen in 5, grammatical encoding takes the pre-verbal message output from the conceptual prepa-ration stage and outputs a surface structure, with the aid of the speaker’s mental lexicon. This is where syntax gets involved: “Surface structures”, says Levelt, “are syntactic in nature” (Levelt, 1999, p. 94). ‘Syntactic words’, or ‘lemmas’, are incrementally generated and ordered left-to-right based on the emerging pre-verbal message. According to the specific language’s syntactic proper-ties, the lemmas are mapped onto phrases with respect to their thematic role structure.
The generation of the surface structure is largely lexically driven. A lexical concept from the pre-verbal message activates a corresponding lemma in the mental lexicon, and that lemma’s syntactic properties become then available for the syntactic construction of the verbal message. As different lexical concepts from the pre-verbal message activate their corresponding lemmas, they start being fit together into a sentence, according to their syntactic constraints, much like a jigsaw puzzle. The most important question here is how exactly a lemma for any specific concept is selected. Lev-elt describes a model of lemma selection as follows:
“Lemma selection is modelled as follows. In the conceptual network, the target concept is in a state of activation. Its activation spreads to all semantically related concepts (for empirical evidence, see Levelt et al. 1991). Each active lexical concept also spreads part of its activation down to its' lemma, down in the lemma stratum. Lemma selection now becomes a probabilistic affair. During any smallest interval in time the probability of selecting the target lemma is its degree of activation divided by the total activation of all active lemmas in the stratum. This is called 'Luce's rule'.” (Levelt, 1999, p. 96)
The final selection can only fall upon the correct lemma, one that “(…) entertains the correct sense relation to the conceptual level” (Levelt, 1999, p. 96). The larger a given concept’s Luce ratio, the quicker its lemma should be selected (see Levelt, Roelofs, & Meyer, 1999).
After lemmas are selected, how are they combined to form the larger verbal message? As mentioned before, when the lemmas are retrieved, so are their syntactic properties. The lemmas are then com-bined in a way that satisfies their respective syntactic constraints, a process named ‘unification’. From the original sentence of ‘Poor Pete believes that the committee selected him’, take the syntac-tic fragment ‘the committee selected him’. There are three active lemmas: ‘select’, ‘committee’, and ‘him’. We can consider ‘select’ to have a S(entence) node as its root, and two Noun Phrase (NP) nodes as its feet. ‘committee’ has NP as a root and several feet: a determiner phrase (DP) and three optional modifiers in an adjectival phrase (AP), a prepositional phrase (PP), and a S node, that could be filled by a relative clause. Finally, the pronoun ‘him’ has NP at its head, and no other feet. The pronoun ‘him’ is selected here, as opposed to a noun, due to the discourse context surrounding this fragment: the referent referred to by ‘him’ is ‘Poor Peter’. According to Levelt (and based on
the work of Schmitt (1997)), one of the references to Peter is marked as ‘in focus’, which makes the encoder generate a pronominal lemma as opposed to the full, nominal form. The matter of selection of pronouns as opposed to nominal forms is of particular importance to this thesis and will be devel-oped further in section 1.4, on referring expressions.
With all the pieces in place, the unification process connects roots to feet. The root node of ‘com-mittee’ unifies with the first NP foot of ‘select’, while ‘him’ unifies with the second. All the optional nodes in ‘committee’ don’t receive unification and are trimmed. This process is illustrated in 6, be-low.
An important aspect of the incremental nature of this model is that since the conceptual information gets processed by the grammatical encoder as it is output by the conceptual preparation stage, con-cepts that are more highly accessible will often be processed first and be placed at a higher syntactic position. Notably, animate referents tend to be more cognitively accessible and to be placed in the subject position and agent role. This is important to keep in mind when studying reference and ani-macy, as is the case in this thesis.
1.4 -
Producing Referring Expressions
As briefly mentioned when discussing Levelt’s (1999) model, when selecting what to refer, there’s a key concept of accessibility. As a given concept is more cognitively accessible, it is more likely to
Figure 6: An illustration of the process of unification for the fragment "the committee selected him". The upper half depicts the syntactic and thematic structure of the three constituent lemmas and the bottom half their unified structure. Adapted from Levelt (1999).
be accessed earlier into the language process, and placed in more prominent structural positions, re-ceiving higher grammatical functions and central semantic roles (Levelt et al., 1999). Another mat-ter where accessibility plays a role is in the how of a given referent is referred, in guiding the choice of referring expressions.
1.4.1 -
Theoretical Framework
A central problem in the study of reference is that a given concept can be referred to in a multitude of ways. This is reflected in language in the many different referring expressions one can use. When speaking English, for example, we can use proper nouns (‘Roosevelt’), demonstrative expressions (‘that car’), definite and indefinite references (‘a car’, ‘the car’), or pronouns (‘it’). It is clear, how-ever, that certain expressions are preferred depending on their linguistic and non-linguistic context. One wouldn’t use an anaphoric pronoun in the absence of a linguistic or contextual clue as to its ref-erent, but rather a definite description like a proper name:
(1) In the absence of a contextual clue, as a first mention: (a) ? She is on vacation in Madrid.
(b) Laura is on vacation in Madrid.
Conversely, when a referent has been established, subsequent mentions don’t need as much infor-mation, and reduced expressions seem to be preferred:
(2) Repeated mentions:
(a) ? Laura is on vacation in Madrid. Laura sent me a postcard just yesterday! (b) Laura is on vacation in Madrid. She sent me a postcard just yesterday!
These phenomena have originated research on why and how referring expressions are chosen and produced. A few theories of reference production have linked these processes to an idea of cognitive accessibility, with referring expressions being produced in relation to how cognitively accessible they are. To illustrate this, I’ll briefly discuss one such theory, the accessibility theory by Ariel (1988, 2014).
The core idea behind the accessibility theory is that the different referring expressions are markers for different levels of cognitive accessibility of their referents. When a speaker produces a particular referring expression, it signals to their addressee how accessible the mental representation to be re-trieved is. Thus, a speaker produces a fuller, more informative form to mark low-accessibility, and a less informative form to mark high-accessibility, providing a more informative form when it is nec-essary, and an easier to produce form when it is not (Ariel, 1988).
(3) Laura [Noun, Low-Accessibility, More informative] is on vacation in Madrid. She
[Pronoun, High-Accessibility, Less informative] sent me a postcard just yesterday!
As another example, let’s go back to Levelt’s (1999) model and recall how, for the sentence “Poor Pete believes that the committee selected him”, the pronoun ‘him’ is selected as an argument for the verb ‘select’. Levelt argues:
“Remember that it refers back to referent X, POOR PETER. In the message, one of the occurrences of argument X will be marked as 'in focus'. That will tell the grammatical encoder that it should select a reduced, pronominal lemma for that occurrence of the lexical concept.” (Levelt, 1999, p. 98)
This idea is compatible with the notion of accessibility as proposed by Ariel. When the speaker first makes reference to the concept of ‘(Poor) Peter’, the concept is in a state of low-accessibility, not having been mentioned before and requiring more information for a precise reference, and so the speaker produces a modified noun, an informative form that serves as a marker of low accessibility. When the concept of ‘(Poor) Peter’ gets mentioned a second time, the concept is in a state of high-accessibility, and speaker produces a lower-information, high-accessibility marker in the pronoun ‘him’.
It should also be noted that the Accessibility Theory is certainly not the only theory of reference that looks at cognitive aspects. As mentioned before, an alternative can be found in the form of the ‘Givenness Hierarchy’ (Gundel et al., 1993), which sees referring expressions as signalling different cognitive statuses of a concept, but in a hierarchical and non-mutually exclusive manner:
“It should also be noted that the GH is not a hierarchy of degrees of accessibility in the sense of Ariel (1988, 1990), for example, as the statuses are in a unidirectional
entailment and are therefore not mutually exclusive” (Gundel, Bassene, Gordon, Humnick, & Khalfaoui, 2010, p. 1771)
For this thesis, more important than any particular model of reference is the core notion of accessi-bility and its relation to choice of referring expressions in language production, a relation which is more generally assumed (Fukumura & Gompel, 2011).
1.4.2 -
What makes a referent more or less accessible?
What kind of information makes a referent more or less accessible, and thus referred to with differ-ent forms?
Let’s remember example (2): (2) Repeated mentions:
(a) ? Laura is on vacation in Madrid. Laura sent me a postcard just yesterday! (b) Laura is on vacation in Madrid. She sent me a postcard just yesterday!
As previously discussed, a clear factor in referential accessibility is prior mention: a referent is more likely to be referred to with a more informative form (‘Laura’ in example (2)) when it is first men-tioned.
It’s not surprising to find out that, as the distance between a referent’s first mention and eventual subsequent mentions grow, there’s a decrease in that referent’s accessibility. Indeed, this is what Ariel (2014) finds: in an analysis of four texts, Ariel finds that pronouns are especially frequent in the same sentence in which their referent is first mentioned with a definite description, and in the
sentence immediately following that. Conversely, in later sentences within the same paragraph, and in later paragraphs, mentions with definite descriptions become more frequent.
Grammatical functions and thematic roles have also been found to play a part. For instance, Arnold (2001) tested sentences containing verbs that selected source and goal arguments, like ‘teach’ (“Melora[source, subject] taught a sonata to Mike[goal, object-of-PP] in an hour and a half.”) and ‘learn’ (“Sonia[goal, subject] quickly learned the steps from Allen[source, object-of-PP].”), and found that subject and source referents were more likely to be referred to with pronouns, denoting higher accessibility.
These factors of accessibility, however, aren’t being explicitly investigated in this thesis. Instead, I’ll be looking at the role of conceptual animacy, referential competition and contextual visual infor-mation. These will be discussed next.
1.4.3 -
Reference in Visually Situated Language Production
Conceptual animacy is a particularly strong candidate as a factor of accessibility. Animate entities are more likely than inanimate objects to serve as agents or actors of an action. Accordingly, studies like Itagaki & Prideaux (1985) have shown that animate entities are more likely to be selected as the subjects of a sentence. Given the large prominence of animate entities in linguistic structures, it seems like an entirely reasonable idea that they occupy an important place in cognitive domains as well, and are more cognitively accessible to reflect this importance.
To test this possible link between animacy and accessibility, Fukumura & van Gompel (2011) con-ducted two sentence-completion experiments, in which participants had to complete sentence frag-ments preceded by a sentence containing both an animate and an inanimate referent, like in (4), be-low:
(4) Examples of stimuli from Fukumura & van Gompel (2011):
(a) The hikers[Subject, Animate] carried the canoes[Object, Inanimate] a long way downstream. Sometimes…
(b) The canoes[Subject, Inanimate] carried the hikers[Object, Animate] a long way downstream. Sometimes...
In both experiments, the participants were asked to complete the sentence fragment (in (4), ‘Some-times”); in the first experiment, participants could complete the fragment freely, while in the second experiment they had to refer to one of the targets, which was visually-cued. The authors found that the animate antecedents were not only more frequently selected as the subject of the continuation sentences, but also more likely to be referred to with pronouns, regardless of their syntactic func-tion. The authors suggest this is clear evidence that animacy affects the choice of referring expres-sions, and that animate concepts and referents are more accessible.
The second factor is that of referential competition, how reference is established when there’s more than one possible referent in the linguistic or visual context.
Arnold & Griffin (2007) studied this issue through two storytelling experiments, in which partici-pants had to complete a story that was contextualized with pictures (see Figure 7, below). The par-ticipants were presented with two-panel cartoons and oral descriptions of the first panel, e.g. “Mickey went for a walk with Daisy in the hills one day”, and were asked to continue the story by describing the second panel, as if they were telling a story to a five-year-old.
The researchers wanted to study how the presence of visual referential competitor influenced how the participants chose to refer to the main character. In a pilot experiment, Arnold and Griffin found that when both the competing referents had the same gender, they would use less pronouns than when they had different genders or that when only one (visual and linguistic) referent was available – a natural effect, given that English pronouns would be ambiguous in that case – but were sur-prised to find that, when the referents had different genders and ambiguity resolution wasn’t at play, the use of pronouns wasn’t as pronounced as the authors expected. Arnold and Griffin then devised two experiments to explicitly compare conditions where there was no referential ambiguity (‘one-character’, mid part of 7) with those where there was a second referent of a different gender (‘two-character’ and, in experiment two, ‘one-two’, left and right sides of 7). The authors found that the presence of a referential competitor in the linguistic context always resulted in a reduced production of pronouns, even when this competitor was absent in the immediate visual context (condition ‘one-two’).
To further study how linguistic and visual information interact in the choice of referring expres-sions, Fukumura, van Gompel, & Pickering (2010) conducted two experiments that manipulated visual and linguistic saliency. Both experiments had a complex, two-stage procedure that involved a participant and a confederate (a non-genuine participant played by an actor). In the first stage, both the participant and the confederate saw a picture, which the confederate had to replicate with the aid of toys. The participant then saw and read out loud a sentence describing the picture. In the second phase, a new picture was shown to the participant, who had to describe it out loud for the
confeder-Figure 7: Example of the visual stimuli used in Arnold & Griffin (2007). This figure depicts the three conditions used across the two experiments described in the paper – on the left is the two-character condition, in which both two-characters are displayed in both pictures; on the middle is the one-character condition, where a single character is shown in both pictures; on the right is the two-one condition, in which the first panel shows two characters, and the bottom panel shows only one.
both linguistic and visual contexts, so that the pictures could have one or no competitor (pictures a and b in 8), and the accompanying context sentence could have one or no prepositional phrase con-taining a second referent (example (5)).
(5) Example of the linguistic stimuli used in Fukumura et al. (2010), Experiment 1: (a) The pirate’s carpet had been cleaned by a prince. (Competitor present)
(b) The pirate’s carpet had been cleaned. (Competitor absent)
The authors measured the frequency of use of pronouns versus that of nouns when the participants described the second picture using the referent character as the sentence subject. They found that both the visual and the linguistic contexts had an impact in the choice of expression: the presence of a competitor, in either the sentence describing the first image or in the images themselves, led to a reduced use of pronouns in reference to the main character.
In the previously discussed Fukumura & van Gompel (2011), the authors also looked at one aspect of referential competition, that of the role of animacy. In a third experiment, where participants also had to produce a sentence referring back to an entity in a previously read sentence, the animacy congruency between the two referents was manipulated; they could both be animate or inanimate, or instead one of each. The authors found that when both referents had the same level of animacy, the use of pronouns was inhibited, an effect they attribute to a reduction of the referent’s accessibil-ity due to the semantic similaraccessibil-ity with its competitor.
Figure 8: An example of the stimuli used in Experiment 1 from Fukumura et al. (2010). Each vertical pair of pictures represents one of the two visual conditions of the
experiment: pair a, on the left, has a referential competitor, pair b, on the right, has none.
Finally, I want to look at the role of visual information in referring expression generation. By vis-ual information I mean here more specifically the role of clutter, a notion previously discussed in the chapter on vision. Thus, I intend to discuss how different degrees of visual information in im-ages – from simpler imim-ages depicting one or two objects to complex scenes with large numbers of items – can affect reference production.
As mentioned on the section on vision, the notion of clutter is closely connected to reference. This is because clutter is effectively connected to the number of objects present in a visual scene – and as the number of objects grow, so does the number of entities that can be referred. As such, when we manipulate the level of visual clutter of a scene, we also increase the possibilities of reference that can be established when said scene serves as visual context for linguistic communication. However, this doesn’t mean that any possible reference will be actually realized: for example, when one de-scribes a picture or a scene, one might not mention entities that they don’t find relevant to the gen-eral idea of the scene (the ‘gist’). Additionally, the level of clutter might have a role to play in how reference is established. The presence of too much visual information and of referable entities, even when they’re irrelevant to the general idea of the scene or message to be communicated, might lead to more concepts being mentally activated and interfering with the accessibility of a referent that a speaker does wish to mention.
Clutter has been used as a factor in the study of overspecification, when, in referring, more informa-tion is given than what is necessary (for example, meninforma-tioning ‘the red chair’ when there’s only a single chair in the visual context). For example, (Koolen et al., 2015) ran an experiment where par-ticipants had to describe a target object pictured in naturalistic scene, which were manipulated as for their level of clutter. The authors found that the cluttered versions of the scenes resulted in more fre-quent production of overspecified forms of reference.
Clarke, Elsner & Rohde (2013) also looked at how clutter affects the generation of referring expres-sions, specifically expression length (in number of words). Participants were asked to produce refer-ring expressions to cued targets in ‘Where’s Wally’ scenes (classified as either less or more
clut-Figure 9: Example of the stimuli used in Koolen et al. (2015). The left and right images represent the less and more cluttered conditions, respectively. Note how the overspecified expression "the red plate" doesn't help distinguish the plates apart.
thetical viewer to locate the target. The authors found that the participants generated lengthier refer-ring expressions in response to more highly-cluttered scenes. Duan, Elsner, & de Marneffe (2013) tested the corpus from Clarke et al. (2013) and found that in the images with a higher level of clut-ter, indefinite expressions were more likely to be produced.
These studies illustrate that clutter does have some impact in the production of referring expressions, but they don’t directly look at how forms are chosen to refer to previously mentioned refer -ents or concepts, so they’re harder to place in relation to literature I discussed that studies factors like animacy and referential competition on this kind of reference.
The work of Coco (Coco, 2011; Coco & Keller, 2015) has focused in large part on studying refer-ence in the shared domain of vision and language. Coco (2011) did a series of studies on both lan-guage comprehension and production, studying various aspects of reference processing and the in-terplay of language and vision. Experiment 4, on the impact of referent animacy and scene clutter on scene description, is of particular interest. This experiment features a cued, web-based written language production task, where the participants were asked to describe a scene that was preceded by a single-word cue, which in turn referred to one of the entities in the scene. Coco manipulated visual and linguistic levels of animacy by changing the number of people (‘actors’) in the presented scenes and the animacy of the cued word. The scenes had versions with a greater or smaller number of objects, to manipulate clutter. Thus, each stimulus had 4 visual conditions and 2 linguistic condi-tions (see Figure 10).
Coco looked at three aspects of the produced descriptions: the associated reaction times (how long the participants took to start and finish describing the scenes), the use of nouns and verbs, and the use of certain syntactic structures. This last aspect isn’t too informative to the purposes of this the-sis, so I won’t describe it here.
The associated reaction times were looking times (how long the participants took from stimulus on-set to begin typing up a response) and description times (how long they took to finish typing the re-sponse). When the cued entity was animate, participants took less time to start describing the image. Coco also found some interesting interactions: Looking times were larger in animate-cue minimal-clutter conditions, and shorter in two-actor animate-cue conditions. This last result is particularly curious, as it might suggest that when there are two people in the scene and one of them is a cued target, the resulting descriptions end up being focused around the two, which in turn results in de-scriptions starting earlier than those involving more inanimate information due to their higher level of accessibility.
These results, however, have some issues if we want to think of them in terms of reference process-ing in spoken language. The biggest issue is that these results are for written language. While they still serve as relevant data points, there are likely enough differences between the systems involved in written and spoken language production that the results can’t be assumed to extend to speech. The second issue, and one that Coco points out, is that the referential information available for cued animate and inanimate targets differed: the cued object always had a duplicate in the scene, while
Figure 10: Example of the stimuli used in Experiment 4 from (Coco, 2011). The number of actors (1 or 2) and the level of clutter (Minimal or Cluttered) was manipulated for each scene, while animacy was manipulated for each preceding cue (Animate vs. Non-Animate).