¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿
oo
ss s ss
±¿¿¿¿¿±¿±±¿¿¿¿¿±¿¿±¿¿¿¿
¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿¿
3 3 3 a a a aa
oo
ss s ss
3 3 3 a a a a aa
3 3 a 3 a3 3
ss s s s s s
Agradecimentos
Ao meu orientador, professor Orlando Belo, por se ter mostrado sempre disponível durante o decorrer do desenvolvimento de toda a dissertação. Pela sua dedicação, compreensão, conhecimento e
profissionalismo.
A todos os meus amigos de curso, os que me ajudaram e estiveram ao meu lado durante toda a licenciatura e posterior mestrado. Aos que me deram momentos alegres, de diversão, partilha e amizade.
À minha família, que sempre me ajudou durante toda a minha vida académica, por sempre estarem do meu lado, por serem o porto seguro durante os momentos mais agitados. De agradecer em particular aos meus pais, pelo seu esforço, compreensão e apoio. Ao meu irmão, por me chatear nos momentos em que me precisava de concentrar. E à minha prima Andreia, por me acompanhar durante o desenvolver de toda esta dissertação.
Por último, à minha namorada e amigos, por todo o suporte dado e pela compreensão demonstrada nos momentos de ausência.
Resumo
Sistema de Recomendações Baseado em Preferências
“Recommended for you”, a expressão que está a tornar-se progressivamente numa das mais
vistas no mundo das aplicações. Não é por acaso que, grande parte das aplicações Web (mas não só) por onde navegamos diariamente queiram tentar adivinhar e mostrar-nos o que nos agrada e o que acham recomendado para nós. De facto, esta apresentação de conteúdos orientados ao utilizador, às preferências históricas demonstradas, tem o poder imenso de nos manter a navegar num site, de nos fazer comprar mais produtos, de nos fazer voltar à aplicação. Esta “técnica” de recomendação de conteúdos que tem como base o estudo do historial do utilizador, das suas decisões tomadas e das suas demonstrações de preferências, assenta na extração de padrões que retratam o percurso histórico do mesmo. Por sua vez, as decisões tomadas por este assentam num padrão preferencial exibido pelo utilizador que vai de encontro às características intrínsecas à sua personalidade. Ora, com este estudo facilmente se entende que se podem retirar dados que irão caracterizar de forma inequívoca um utilizador, criando, desta forma, uma assinatura que o traduz, que o define e o torna único em relação aos demais. É nesta tradução de um conjunto de preferências temporais numa assinatura que define intemporalmente um utilizador, que assenta uma parte deste plano de trabalho. É neste contexto que surge todo este estudo, efetuado durante o presente projeto e sobre o qual incidirá esta dissertação. Será difícil encontrar melhores exemplos de conteúdos que caracterizem um indivíduo do que a música que ele ouve. “Start and Play” será o conceito inerente a uma peça de software que se pretende futuramente construir e que procurará recomendar o que o utilizador deve ouvir, com base nas preferências demonstradas por este, assente no seu conjunto alargado de ações passadas. Estas preferências definirão no seu conjunto a assinatura do utilizador, com a qual o sistema irá tentar definir e prever quais os conteúdos musicais que irá recomendar.
Abstract
Recommendations System Based on Preferences
"Recommended for you", the expression that is gradually becoming one of the most popular in the world of applications. It is no coincidence that most of the web applications that we use daily want to guess and show us what we like and what they think that is recommended for us. In fact, this presentation of content oriented towards the user preferences, shown by the history, has the immense power to keep us in a site, make us buy more products or to make us turn back to the application. Is this content recommendation "technique", which is based on the user history study, their decisions and preferences, it‟s based on the extraction of patterns that depict that same history. Meanwhile, the decisions taken by this system are based on a preferred pattern displayed by the user, which meets the intrinsic characteristics of his personality. For that being, with this study we can easily understand that we can pull data that will characterize unequivocally a user, creating, thereby, a signature that reflects, defines and makes him unique when compared to others. It is in this transformation from a set of preferences to a temporal signature (that defines a user timelessly) that is based a part of this work plan. It is in this context that arises the entire study performed during this project and on which this document will focus. It will be difficult to find better examples of content that can characterize an individual than the music he hears. “Start and Play” is the concept inherent to a piece of software that aims to be built in the near future and that will try to recommend what an user should listen to, based on their past actions. These preferences will define the whole signature of the user, with which the system will attempt to define and predict what music content should be recommended.
Índice
Capítulo 1 - Introdução ... 1
1.1 Os sistemas de recomendação no nosso quotidiano ... 1
1.2 Apresentação do caso de estudo... 2
1.3 Motivação e objetivos ... 3
1.4 Estrutura da dissertação ... 4
Capítulo 2 - Obtenção de Conhecimento ... 8
2.1 Apresentação do processo ... 9
2.2 Primeiros passos num processo de obtenção de conhecimento ... 11
2.2.1 Seleção e adição de informação ... 11
2.2.2 O pré-processamento de dados ... 12
2.2.3 Transformação de dados ... 14
2.3 Representação dos dados ... 17
2.3.1 Modelação Dimensional ... 17
2.3.2 Metadados ... 19
2.3.3 Vantagens e desvantagens ... 20
2.4 Métodos usados na procura de conhecimento ... 23
2.4.1 Métodos usados na procura de informação associativa ... 24
2.4.2 Métodos utilizados na classificação, estimação ou regressão ... 24
2.4.3 Métodos utilizados na predição de informação ... 29
2.4.4 Métodos utilizados no agrupamento de informação... 30
2.5 Avaliação e interpretação de resultados ... 32
Capítulo 3 - Sistemas de Recomendação Baseados em Preferências ... 34
3.1 Recomendação baseada em conteúdos ... 36
3.2 Sistemas de recomendação musical existentes ... 37
3.3 Papel das assinaturas nos sistemas de recomendação ... 40
Capítulo 4 - Um Caso de Estudo ... 44
4.1 A Obtenção dos Dados ... 45
4.1.1 Processo de obtenção de dados reais ... 45
4.2 Pré-processamento de dados ... 49
4.2.1 Inconsistências e falta de relacionamento de dados ... 50
4.2.2 Dados escolhidos ... 52
4.2.3 Discretização dos dados ... 54
4.3 Transformação dos dados ... 57
4.4 O Processo de Mineração dos dados... 60
4.4.1 Metodologia envolvente... 60
4.4.3 Algoritmo de Naive Bayes ... 68
4.4.4 Árvores de Decisão ... 73
4.4.5 Redes Neuronais ... 78
4.4.6 Processo de recomendação ... 83
4.4.7 Reflexão sobre a mineração dos dados... 84
Capítulo 5 -Avaliação de Resultados ... 87
5.1 Resultados obtidos ... 87
5.2 Assinaturas ... 88
5.2.1 Processo de Construção de Assinaturas ... 88
5.2.2 Representação Gráfica de Assinaturas ... 92
5.2.3 Variação de Assinaturas ... 99
Capítulo 6 - Conclusão ... 102
6.1 Reflexão sobre o trabalho ... 102
6.2 Trabalho futuro ... 105
Índice de Figuras
Figura 2.1 Top 10 das instituições com as maiores bases de dados do mundo. ... 9
Figura 2.2 O Processo de Descoberta de Conhecimento em Bases de Dados – imagem adaptada de (Fayyad et al., 1996). ... 10
Figura 2.3 Fórmula de cálculo do valor normalizado (Rodrigues et al., n.d.). ... 14
Figura 2.4 Função de normalização segundo o método z-score. ... 15
Figura 2.5 Função de normalização segundo o método de escalonamento decimal. ... 15
Figura 2.6 Ciclo de Desenvolvimento de um DW. ... 22
Figura 2.7 O processo de classificação de dados (Han & Kamber, 2001). ... 26
Figura 2.8 Equação para cálculo de classes seguindo uma combinação linear dos atributos ... 30
Figura 3.1 Fórmula de cálculo de classificação prevista para uma música em particular baseada em modelos baseados em memória. ... 38
Figura 3.2 Fórmula de cálculo de classificação prevista para uma música em particular baseada em modelos baseados em modelos. ... 39
Figura 3.3 Processo de descoberta de assinaturas tendo como base uma framework preparada para o efeito (Bose & Aalst, 2013). ... 42
Figura 4.2 Representação da base de dados seguindo uma tipologia em estrela. ... 59 Figura 4.3 Metodologia usada para obtenção da música a recomendar... 63 Figura 4.4 Dados respetivos ao utilizador selecionado para testes. ... 64 Figura 4.5 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de previsão
apriori para o atributo musical “tempo”. ... 65 Figura 4.6 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Naive Bayes
para o atributo musical “tempo”, utilizando-se um conjunto de dados de treino para o efeito. ... 69 Figura 4.7 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Naive Bayes
para o atributo musical “tempo”, utilizando-se um conjunto de dados de teste para o efeito. 70 Figura 4.8 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Árvores de
Decisão para o atributo musical “tempo”, utilizando-se um conjunto de dados de treino para o efeito. ... 74 Figura 4.9 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Árvores de
Decisão para o atributo musical “tempo”, utilizando-se um conjunto de dados de teste para o efeito. ... 75 Figura 4.10 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Multilayer
Perceptron (Redes Neuronais) para o atributo musical “tempo”, utilizando-se um conjunto de dados de treino para o efeito. ... 79 Figura 4.11 Janela de output apresentada pelo WEKA quando aplicado o algoritmo de Multilayer
Perceptron (Redes Neuronais) para o atributo musical “tempo”, utilizando-se um conjunto de dados de teste para o efeito. ... 80 Figura 5.1 Exemplo de padrões, informalmente apresentados, que poderão ser obtidos pelos
métodos de extração de conhecimento. ... 90 Figura 5.2 Padrões caracterizadores da assinatura musical de dois ouvintes. ... 94 Figura 5.3 Representação gráfica (simplificada) de uma assinatura. ... 95
Figura 5.4 Representação gráfica da assinatura respetiva ao utilizador A. ... 97 Figura 5.5 Representação gráfica da assinatura respetiva ao utilizador B. ... 97
Índice de Tabelas
Tabela 4.1 Lista de atributos caracterizadores selecionados para constituírem as propriedades base das músicas do presente projeto. ... 49 Tabela 4.2 Valores obtidos pela discretização supervisionada de dados contínuos... 56 Tabela 4.3 Informação estatística acerca do resultado obtido pelos modelos criados com uso do
algoritmo de Naive Bayes. ... 72 Tabela 4.4 Informação estatística acerca do resultado obtido pelos modelos criados com uso do
algoritmo de Árvores de Decisão. ... 77 Tabela 4.5 Informação estatística acerca do resultado obtido pelos modelos criados com uso do
algoritmo de Multilayer Perceptron (Redes Neuronais). ... 82 Tabela 4.6 Informação estatística acerca do resultado obtido para todos os modelos criados a
partir de algoritmos classificativos. ... 84 Tabela 5.1 Resultado da conversão dos conjuntos discretos relativos aos atributos musicais, para
Siglas e Acrónimos
API Application Programming Interface BPM Beats Per Minute
CSV Comma-Separated Values
DM Data Mining
DW Data Warehouse
GHCN Global Historical Climatology Network
NCSA National Center for Supercomputing Applications OLAP On-line Analytical Processing
OLTP Online Transaction Processing SDW Sistema de Data Warehousing
SGBD Sistema de Gestão de Bases de Dados SQL Structured Query Language
WEKA Waikato Environment for Knowledge Analysis XML Extensible Markup Language
Capítulo 1
1
Introdução
1.1
Os sistemas de recomendação no nosso quotidiano
O objetivo específico que existia aquando a criação da Internet e, sucessivamente, das aplicações Web (mas não só), tem vindo a ser alterado progressivamente. Esta alteração é paralela e consequente à visão que tem começado a dominar este domínio: a visão de possibilidade de negócio tendo como base este meio frequentado por milhões de pessoas. É neste contexto que surgem funcionalidades como o “recomendado para si”. Este tipo de características objetivam, por exemplo, manter um cliente de uma aplicação Web a utilizar a mesma durante mais tempo e mais frequentemente, conseguindo assim um maior volume de clientes ativos e que, consequentemente, permitirá que possamos negociar com empresas de publicidade valores mais avultados para estes poderem anunciar na nossa aplicação. Numa perspetiva mais e-commerce surge um outro exemplo que facilmente se traduz na expressão “recomendado para si”. Esta frase poderá induzir os clientes a comprar mais produtos através da plataforma disponível e, portanto, aumentará o volume de vendas da loja. Enfim, existe um infindável número de objetivos que podem facilmente ser denunciados por estes sistemas de recomendações baseados no historial de preferências de um utilizador. Neste contexto será importante fazer um paralelo entre os sistemas de recomendação atuais e o que é pretendido para estudo e desenvolvimento do âmbito deste projeto. Grande parte dos sistemas de recomendação atuais procuram extrair padrões do historial de ações dos seus utilizadores para, deste modo, poderem obter os conteúdos que têm maior
probabilidade de se enquadrarem com os gostos dos mesmos. Tomando o exemplo de e-commerce, a extração de padrões pode ter como base a lista de produtos visualizados ou comprados pelo cliente. Neste caso concreto, a recomendação incidirá na mostragem dos produtos que terão maior probabilidade de agradar um cliente e, estes produtos sugeridos, poderão ser obtidos tendo em conta as características dos produtos inicialmente delineados. Isto quer dizer que, através dos últimos produtos visualizados (e, talvez, comprados), poderão extrair-se características como a marca do produto, a cor, a categoria em que o mesmo está inserido, entre outros. Será, portanto, através do conjunto destes atributos caracterizadores do objeto que se poderá indicar os produtos com maior probabilidade de serem vistos como preferenciais para o utilizador em questão. Este é um exemplo de como um sistema de recomendações simples poderá eventualmente funcionar e que se assemelha notoriamente ao abordado no presente projeto.
1.2
Apresentação do caso de estudo
Com o desenvolvimento deste trabalho de dissertação pretende-se concretizar um conjunto de objetivos bem definidos que se enquadram no desenvolvimento de um sistema de recomendações baseado nas preferências de um utilizador. Um destes objetivos surge com a necessidade em se definir e caracterizar a assinatura de um ouvinte que, por sua vez, permitirá suportar e definir o perfil de um qualquer apreciador musical. Com efeito, é necessário que se captem as preferências históricas inerentes a um utilizador, bem como as características das músicas que este costuma ouvir e em que circunstâncias específicas é que as ouve.
Os atributos que podem ser recolhidos aquando a audição de uma determinada música e que, na sua totalidade, definem o momento de audição musical, assentam num espectro muito alargado de características. Tais dimensões caracterizadoras variam desde a simples hora do dia em que uma certa música foi reproduzida até à própria frequência cardíaca apresentada pelo utilizador no momento de audição musical.
Por conseguinte, o desenvolvimento do presente caso de estudo objetiva, também, um estudo de como certas circunstâncias de momento podem influenciar as preferências de cada indivíduo e, ainda, qual a sua preponderância relativa na tomada de decisões do mesmo. Por fim, e apresentando-se como um dos grandes objetivos, surge a concepção e desenvolvimento de um sistema de recomendações (para audição musical) que atue de acordo com a assinatura caracterizante do ouvinte. O algoritmo que se pretende extrair não é mais do que a base de
estudos de padrões provenientes das preferências musicais históricas exercidas e que, no seu conjunto, permitirão que se faça uma previsão e recomendação de qual a música que o utilizador preferirá ouvir em determinadas dimensões definidas. Neste contexto existe, portanto, um distanciamento evidente em relação aos modelos de recomendação atualmente existentes, mais concretamente em relação aos principais produtos de software da área. Por sua vez, estas aplicações procuram fazer as suas recomendações assentes no tipo de música que o utilizador frequentemente ouve e, além disso, baseiam-se ainda no historial de preferências de outros ouvintes registados no sistema que possam apresentar níveis de similaridade altos quando comparados com o utilizador em questão.
Toda a etapa que compreende o estudo e desenvolvimento do caso de estudo sumariamente descrito será apresentada no quarto capítulo do presente documento e, lá, será feita uma abordagem mais exaustiva das etapas que permitiram o solucionamento do problema, bem como o estudo crítico dos resultados provenientes do mesmo.
1.3
Motivação e objetivos
Com o desenvolvimento deste projeto pretende-se concretizar um conjunto bem definido de objetivos que se enquadram no estudo de um sistema de recomendações baseado nas preferências de um utilizador. Um destes objetivos surge com a necessidade de se definir e caracterizar a assinatura de um ouvinte que, no seu conjunto, permita suportar e definir o perfil preferencial do ouvinte.
Com este objetivo delineado surge, agora, a necessidade de recolha de dados respetivos a um conjunto alargado de preferências musicais historicamente apresentadas por um número razoável de ouvintes. Além disso, torna-se ainda imperativa a obtenção de dados que, no seu conjunto, possam definir os atributos respetivos às dimensões do problema e que caracterizam o meio envolvente aquando a audição de cada peça musical. Esta premissa, que assenta na procura e recolha de informação, assume-se como a primeira etapa constituidora do caso de estudo que se encontra apresentado no quarto capítulo.
Depois de obtidos estes dados, que se assumirão como base de informação do projeto aqui proposto, surge a necessidade de pesquisa de conceitos que integrarão todo o desenvolvimento deste trabalho. Deste modo, tornou-se vital o estudo de formas de representação de conhecimento
de forma multidimensional, o estudo de processos que permitam transformar e associar os dados obtidos e, ainda, o estudo de técnicas que auxiliam na procura de conhecimento a partir de padrões previamente encontrados. A tarefa sumariamente apresentada e que constituiu no seu conjunto o estudo do processo de obtenção de conhecimento (KDD), assume-se como o objetivo consecutivo à obtenção de dados.
Por fim, surge ainda um objetivo final que procura concretizar todo o estudo e experiência efetuada: o desenvolvimento de uma peça de software que se defina como sendo um reprodutor musical assente num sistema de recomendações baseados nas preferências exercidas por cada utilizador da aplicação. Este objetivo final não constituiu na sua totalidade uma etapa definida como requisito essencial no desenvolvimento do presente trabalho e, assim, apresenta-se de forma evidente como um dos objetivos perspetivados para trabalho futuro. Contudo será ainda bom referir que, tal peça de software, surge como sendo um dos grandes objetivos do projeto na sua totalidade e que, esta, não será mais do que uma aplicação que permita a audição de músicas que, através das preferências musicais históricas, procurará recomendar qual a música que o utilizador preferirá ouvir numa certa circunstância envolvente. Desta forma, facilmente se compreenderá que esta aplicação servirá como output do estudo discutido no presente trabalho e procurará auxiliar, de forma posterior, à reflexão acerca dos resultados obtidos e apresentados no quinto capítulo.
1.4
Estrutura da dissertação
O objetivo intrínseco ao presente estudo assenta na procura por conhecimento preditivo que, no seu conjunto, permita que se façam recomendações musicais condicionadas pelo momento de audição. Ora, tendo em conta a meta previamente traçada, existe um processo previamente definido e estruturado que se assume como preponderante para o solucionamento deste objetivo. Será acerca deste processo que se baseará o estudo presente no segundo capítulo desta dissertação. No contexto deste tema será primeiramente efetuada uma apresentação sumária do processo referido. Esta apresentação será enquadrada, de forma oportuna, com a explicação inerente à necessidade de obtenção de conhecimento, a partir dos gigantes volumes de dados de interesse existentes. Após esta, serão apresentados de forma sucinta os primeiros passos constituidores do processo de obtenção de conhecimento, dos quais se pode destacar a seleção e adição de informação e o pré-processamento e transformação de dados. Depois de feita a
abordagem explicativa dos primeiros passos constituidores deste processo, surgem apresentadas, de forma mais detalhada, as etapas respetivas à representação dos dados e à procura de padrões. No contexto referente à primeira etapa enunciada serão abordados temos como os DW, metadados e a modelação dimensional da informação. Durante a descrição da etapa referente à procura de padrões, procurar-se-á apresentar alguns algoritmos de DM devidamente agrupados pelo objetivo a que se propõe. Será no decorrer desta apresentação e explicação sucinta, que se procurará fazer uma abordagem esclarecedora do método de funcionamento de cada um dos algoritmos, sempre acompanhada das características e motivações que poderão estar na origem do uso de cada um deles.
Será durante o terceiro capítulo que se apresentará uma definição respetiva ao conceito intrínseco aos sistemas de recomendação baseados em preferências. De forma mais específica, será ainda neste capítulo que será exposto um estudo mais aprofundado acerca dos sistemas de recomendação assentes em conteúdos, pois serão estes os utilizados no âmbito do caso de estudo apresentado no quarto capítulo. O estudo de sistemas previamente existentes e enquadrados no domínio de investigação de um projeto constituiu uma etapa fundamental durante o desenvolvimento de um qualquer trabalho. Deste modo surgiu a necessidade fundamental em se fazer um estudo exaustivo dos sistemas de recomendação já existentes ou, mais concretamente, dos sistemas de recomendação musical previamente construídos. É com base no estudo enunciado que surgem apresentados, no decorrer do terceiro capítulo, dados de interesse relativos a aplicações e investigações pré-existentes, referentes a sistemas de recomendação musical. Por fim será ainda feita uma breve abordagem ao papel desempenhado pelas assinaturas nos sistemas de recomendação. Esta abordagem procurará, no início, caracterizar e definir o que é uma assinatura e, depois desta caracterização, apresentará, a título de exemplo, uma framework construída durante o projeto intitulado de “Discovering Signature Patterns from Event Logs”.
Surgindo como um dos grandes focos deste projeto de investigação, foi desenvolvido um caso de estudo que permitisse pôr em prática o conjunto de conceitos até então abordados. Este caso de estudo encontra-se descrito no quarto capítulo e a sua apresentação será feita de forma paralela ao conjunto de etapas descritas aquando da explicação do processo de obtenção de conhecimento. De facto, durante este capítulo todas as fases constituidoras do processo referido serão devidamente catalogadas e explicadas e, portanto, será apresentada informação respetiva à forma de como foram obtidos os dados reais, serão apresentados os problemas advindos de tal obtenção,
serão expostos os métodos aplicados com vista ao solucionamento destes constrangimentos encontrados, será feita uma abordagem ao modo como foram transformados os dados e, por fim, será feita uma descrição dos algoritmos de mining utilizados. A descrição referida contará ainda com uma breve introdução e reflexão respetiva a cada metodologia utilizada.
A reflexão conclusiva acerca dos resultados obtidos pela aplicação do processo de procura de conhecimento sobre o caso de estudo poderá ser observada no quinto capítulo. Além desta análise final acerca do conhecimento adquirido, será ainda feita uma abordagem relativo ao estudo das assinaturas caracterizadoras de cada ouvinte. Será neste ponto que será explicada a metodologia empregue e os resultados esperados pela atribuição desta característica identificadora de cada utilizador.
As conclusões relativas ao trabalho efetuado, bem como a reflexão sobre as mesmas, podem ser visualizadas no sexto capítulo deste documento. Será aqui que se fará uma abordagem resumida deste estudo e aplicação prática do mesmo no contexto do presente problema. No final do capítulo constarão ainda, detalhadamente explicados, os objetivos intrínsecos a todo o projeto. Será portanto no final deste documento que se apresentará uma descrição respetiva ao trabalho futuro, bem como um enquadramento do presente trabalho relativamente a todo o projeto perspetivado.
Capítulo 2
2
Obtenção de Conhecimento
“Estima-se que a quantidade de informação no mundo duplica-se a cada 20 meses. O tamanho e o número de bases de dados provavelmente aumentam de forma ainda mais rápida.” (Frawley, 1992). O mundo atual está, de facto, a sofrer um crescimento exponencial na recolha e computação de dados e, deste modo, existe muita informação armazenada que não passa de segmentos de dados não estudados e a partir dos quais não é traduzido nenhum conhecimento de interesse.
A título de exemplo, encontram-se apresentadas na figura 2.1 as dez instituições que se acredita terem o maior conjunto de dados armazenados. A partir desta representação estatística pode-se ter uma pequena percepção do enorme conjunto de valores que hoje em dia estão guardados e dos problemas que este armazenamento poderá trazer para a privacidade das pessoas. Não será por acaso que grandes entidades têm tomado medidas que visam regulamentar o armazenamento de informações pessoais (mas não só), feita pelas aplicações informáticas que são frequentadas pelo público em geral. Além disso, surgem ainda interesses, por vezes não muito claros, por parte de algumas instituições, em obter conjuntos razoavelmente grandes de dados que foram previamente recolhidos e que podem expor informação pessoal e preferencial relativa a indivíduos frequentadores de aplicações informáticas. Contudo, apesar deste assunto se assumir como de bastante interesse no momento atual e se estar a tornar cada vez mais mediático, não será abordado de forma mais detalhada no presente capítulo que procurará focar-se apenas na descrição e estudo das etapas presentes no processo de procura de conhecimento.
Figura 2.1 Top 10 das instituições1 com as maiores bases de dados do mundo2.
Deste modo, e voltando à problemática relativa à crescente evolução do número de informações guardadas, será consensual a leitura dos acontecimentos feita por Quoniam, “a capacidade de armazenamento em bases de dados, assim como sua utilização, vem crescendo na mesma proporção dos avanços em novas tecnologias de informação e comunicação- A atividade de extrair informações relevantes, por conseguinte, está a tornar-se bastante complexa. Este processo (…) é chamado de Knowledge Discovery in Databases - Descoberta de Conhecimento em Bases de Dados (KDD)” (Quoniam, 2001). Este estudo e procura de conhecimento em bases de informação previamente existentes será constituidor da reflexão a seguir abordada.
2.1
Apresentação do processo
O que deverá ser feito com tantos e tão grandes conjuntos de informação? Facilmente se entenderá que grande parte deles nunca terão direito a serem observados por olhos humanos e, deste modo, a partir deles, nunca se extrairá conhecimento crítico que possa ser interpretado como válido ou útil. Daqui se entende que tem de existir uma outra forma de se extraírem padrões que se possam traduzir em informação de relevo para um dado domínio. É respondendo a esta necessidade que surgem os processos que buscam a obtenção de conhecimento e que serão amplamente discutidos no presente capítulo.
1 Os logótipos apresentados representam, respetivamente, as instituições: “at&t”, “Youtube”, “LexisNexis”, Biblioteca do
Congresso, “The World Data Center for Climate”, “CIA”, “Google”, “Sprint”, “Amazon” e “Nersc”.
2 Os dados expostos referem-se à data de 2012 e foram obtidos a partir de várias fontes diferentes que corroboram tal
informação. Estas fontes são: “http://realitypod.com/2012/03/10-largest-databases-of-the-world/”,
“http://www.siliconindia.com/news/enterpriseit/Top-10-Largest-Databases-in-the-World-nid-118841-cid-7.html”, “http://jainishah.blogspot.pt/2012/06/top-10-largest-databases-in-world-1.html”.
A comunidade de computação científica tem procurado responder, ao longo dos últimos anos, à necessidade inerente ao estudo dos dados de forma automática e padronizada, desenvolvendo-se cada vez mais metodologias e estruturas de armazenamento que procurem desempenhar esta tarefa de forma eficiente, organizada e com resultados satisfatórios e verificáveis. Neste contexto foi apresentado por Fayyad uma definição que procura caracterizar o processo de busca de conhecimento de base de dados como sendo um “processo não trivial de identificação de padrões em dados que sejam válidos, novos, potencialmente úteis e compreensíveis” (Fayyad, 1996). Várias bibliografias apontam que a metodologia KDD se iniciou nos anos 70 e que esta surge em constante desenvolvimento e estudo até aos dias de hoje. Este modelo de descoberta de conhecimento caracteriza-se por ser automático, modelar e organizado em várias etapas iterativas que, no seu conjunto, definem os passos que devem ser dados se se pretender encontrar padrões que se possam traduzir em conhecimento útil.
O presente estudo referente à forma como se poderá obter conhecimento tendo como base um conjunto de dados previamente formados, seguirá uma metodologia assente na definição descrita por: o processo de descoberta de informações de interesse é definido como sendo iterativo e interativo. Além disso, é apresentado como o resultado de nove etapas que são iterativas por si só, isto é, que podem ser repetidas caso seja necessário iterar o passo anterior a estas (Maimon & Rokach, 2010). Tais etapas são sumariamente apresentadas na figura 2.2.
Figura 2.2 O Processo de Descoberta de Conhecimento em Bases de Dados – imagem adaptada de (Fayyad et al., 1996).
Todo o processo começa com a necessidade primária de se compreender o domínio do problema e de se estabelecerem metas que constituirão os objetivos do projeto a ser desenvolvido. Esta é uma etapa de principal interesse pois será a base sobre a qual todo o processo se irá desenvolver e a sua alteração poderá levar à alteração de todas as etapas posteriores. Por conseguinte existe um conjunto de passos a ser dados que serão de seguida abordados.
2.2 Primeiros passos num processo de obtenção de
conhecimento
2.2.1 Seleção e adição de informação
De uma forma geral, uma base de dados armazena um alargado conjunto de dados, dos quais apenas uma pequena porção tem interesse de ser estudada. Neste contexto, se se objetivar por ter um modelo de obtenção de conhecimento eficiente, dever-se-á filtrar os dados que se revelem importantes para o domínio do problema. Desta forma, o conjunto de informação sobre a qual os algoritmos de procura de padrões ou associações se baseará será menor e, portanto, a sua velocidade de execução será maior. Além disso, é também diminuída a probabilidade de se encontrarem dados “ruidosos” ou inconsistentes que serão tratados na etapa subsequente à seguinte, desta forma diminuir-se-á também o tempo de processamento respetivo a esta etapa. Podem ainda existir situações onde, ao invés de se reduzirem os dados a serem estudados, se tenha de adicionar novas informações que possam revelar-se necessárias para resolução do problema proposto. Nestes casos, além da necessidade evidente em se obterem estes dados de interesse, é ainda preciso estabelecerem-se relações que permitam integrar as novas informações com as já existentes na base de dados
Este conjunto de processos constituiu uma etapa fundamental pois será a partir da informação aqui definida que os algoritmos de procura de informação se irão basear. Uma má definição dos dados que estarão disponíveis para a extração de conhecimento poderá conduzir a conclusões que não traduzam informação útil ou, até, que traduzam informação ambígua e impossível de verificar.
2.2.2 O pré-processamento de dados
Após ser feita a definição dos dados que constituirão a base de estudo para o processo apresentado, surge a necessidade de se pré-processar a informação para que se possam colmatar algumas falhas existentes na mesma. As falhas referidas podem ser dados incompletos, dados “ruidosos” ou ainda dados inconsistentes. Os dados incompletos correspondem a conjuntos de valores que contenham atributos em falta. Por sua vez, os dados classificados como “ruidosos” correspondem a valores considerados de outliers, isto é, dados que, por exemplo, não correspondam ao intervalo de valores possíveis para determinado atributo. Por último, os dados inconsistentes ou contraditórios caracterizam-se por conterem discrepâncias entre si. Isto é, se existem dois atributos que se referem, por exemplo, aos ganhos e prejuízos de uma dada empresa e a eles correspondem valores de 30 e 10, respetivamente, caso haja um atributo que defina o lucro como sendo de 50 este está inconsistente e deverá ser corrigido. Um outro tipo de problema também englobado no grupo de dados inconsistentes depreende-se com a existência de registos duplicados que, por si só, constituem uma das causas pela qual os dados devem ser previamente transformados e limpos.
As razões que estão na causa da existência destes dados considerados ”sujos” podem ser muito variadas e podem estar assentes em motivos como a indisponibilidade aquando da recolha de informação, devido a falhas humanas, de software ou de hardware ou, ainda, tendo como origem o facto de se obterem dados a partir de várias fontes diferentes sem que haja um principal cuidado na integração e verificação de consistência dos mesmos.
Desta forma, torna-se obrigatório transformar os dados para que se consiga maximizar a qualidade da informação disponível e, consequentemente, a qualidade dos resultados obtidos pela aplicação de métodos de DM. Esta transformação engloba um conjunto de tarefas como a limpeza de dados, a discretização de dados com escalas contínuas e a normalização de valor não adequados a serem usados pelos processos de extração de conhecimento e ainda a redução da quantidade de informação a ser explorada.
Por forma a se poderem manipular estes conteúdos existem alguns algoritmos já desenvolvidos que auxiliam em algumas tarefas de pré-processamento da informação e que podem ser divididos segundo o seu objetivo final. Contudo, existem umas outras tarefas cuja resolução pode não ser tão óbvia ou imediata. Neste contexto, se se tiver em vista limpar os dados, ou seja, assegurar que
os dados se encontram completos, verosímeis e devidamente integrados, poderá ter de se proceder à correção manual dos registos que traduzam informação errónea ou inconsistente e, ainda, atribuir valores padrão para os atributos que se encontrem sem informação. Esta correção dos valores em falta pode ser feita pelo preenchimento de forma manual dos dados vazios através de duas ações distintas: pode-se atribuir valores que correspondam à realidade e que foram devidamente encontrados ou calculados; ou pode-se usar um valor constante que procure substituir todos os valores em falta. Além disso, e de um ponto de vista tecnologicamente mais atrativo, podem ainda ser usados métodos automáticos que permitam o preenchimento preditivo dos dados vazios. Os métodos assinalados podem constituir algoritmos de regressão linear, algoritmos assentes na regra de Bayes ou até árvores de decisão.
Com vista à transformação de dados ruidosos em dados limpos existem algumas abordagens que podem ser seguidas e se destacam por, também elas, poderem ser manuais ou com recurso a ferramentas computadorizadas. Algumas destas abordagens serão a seguir exploradas. Uma primeira abordagem que pode ser seguida e se caracteriza por ser notoriamente manual é o processo de exclusão de registos que contenham valores que não se enquadrem no intervalo de valores esperado para determinado atributo. Uma outra abordagem poderá passar pelo uso de algoritmos de clustering que detetem valores reconhecidos como sendo outliers, ou seja, valores cujo desvio padrão em relação aos demais seja relativamente alto, e, posteriormente, procedem à sua remoção. Por fim, tem-se ainda uma última abordagem de interesse que assenta na tentativa de ajustamento dos dados considerados fora do âmbito de valores verosímeis. Este ajustamento é feito tendo como base uma função de regressão que, pelo cálculo da linha que se esperaria obter tenta presumir qual deverá ser o valor correto e que deverá substituir os atributos considerados como outliers.
Por fim, e como já foi referido, os dados inconsistentes podem ter como causa a existência de uma fusão prévia de grupos de valores pertencentes a fontes diferentes. Deste modo, para evitar a existência de incoerência de valores, deve ser feita uma avaliação criteriosa das fontes fornecedoras de conhecimento. Além disso, aquando da fusão de dados devem ser feitos testes de coerência entre os valores recebidos e os formados.
2.2.3 Transformação de dados
Seguindo a bibliografia acima referida, e reafirmando uma vez mais que será com base nesta que se desenvolverá o processo de obtenção de conhecimento presente neste projeto, a fase denominada de transformação de dados constituiu o processo de normalização de dados ou, ainda, de conversão dos mesmos para escalas de valores que sejam requisitadas pelos algoritmos de mining, a aplicar na etapa subsequente. Deste modo, na maioria das vezes é necessário proceder-se à conversão de dados. Assim, existem alguns métodos que objetivam facilitar esta mesma tarefa.
O propósito assente na procura pela normalização dos dados tem como motivo o facto de alguns métodos (como por exemplo, as redes neuronais) precisarem de ter os valores dos atributos compreendidos numa escala comum e transversal a todas as variáveis. Deste modo consegue-se também minimizar os problemas que possam ter origem no uso de unidades distintas entre as diversas variáveis que constituem os registos de informação. Para normalizar o conjunto de valores a ser usado poder-se-ão utilizar algumas abordagens já exploradas e disponibilizadas, das quais serão apresentadas abaixo as que se erguem com maior importância relativamente ao domínio deste projeto, em particular as abordagens segundo a amplitude, a distribuição, a abordagem z-score e, por fim, a decimal.
Ao normalizar os dados tendo em como base uma metodologia assente na amplitude, existe uma fórmula que foi utilizada no contexto de um estudo assente na procura pela previsão de dados relativos ao consumo energético no Rio de Janeiro e que se assume com principal relevo neste domínio. Esta equação encontra-se apresentada na figura 2.3, na qual o e o correspondem ,respetivamente, ao valor mínimo e máximo encontrado no intervalo de valores a normalizar.
Figura 2.3 Fórmula de cálculo do valor normalizado (Rodrigues et al., n.d.).
Por sua vez, uma normalização distribucional surge com principal relevo em situações de remoção de valores considerados como outsiders ou ainda na obtenção de simetria. Neste modelo respetivo à transformação de dados, os valores iniciais atravessam uma função que dará como resultado
final o valor normalizado. Esta função pode constituir um cálculo algoritmo ou ainda o cálculo do inverso negativo do valor dado como input.
A conversão de valores através do método z-score procura normalizar os dados com recurso aos conceitos de média e desvio padrão do conjunto de valores a transformar. Desta forma é usado um cálculo que define o valor final já normalizado a partir da função exibida na figura 2.4.
Figura 2.4 Função de normalização segundo o método z-score.
Por último, o escalonamento decimal constituiu uma metodologia assente na passagem dos valores numéricos a normalizar para valores sempre inferiores à unidade. Graças ao cálculo exposto na figura 2.5, a normalização tem sempre como resultado um conjunto de valores compreendidos entre 0 e 1.
Figura 2.5 Função de normalização segundo o método de escalonamento decimal.
Este conjunto de métodos sumariamente apresentados constituiu uma etapa importante na transformação dos dados, contudo esta pode não ser suficiente e, em certas alturas, tem mesmo de se proceder à realização de mais metodologias que permitam transformar valores em tipos de dados aceites pelas algoritmos subsequentemente utilizados. Um dos casos descritos evidencia-se quando são utilizados algoritmos de extração de conhecimento que só funcionem para dados discretos e não para dados contínuos. Neste contexto surge um novo requisito inerente à natureza dos métodos escolhidos que constituiu a obrigatoriedade de se proceder à discretização da informação. No processo de conversão de valores contínuos em valores discretos existem 2 abordagens principais que podem ser seguidas, uma delas agrega métodos de discretização não supervisionados, a outra caracteriza-se por agregar métodos de discretização supervisionados. É acerca destes métodos que será feita de seguida uma abordagem descritiva dos mesmos.
Os algoritmos de discretização, que se definem como sendo não supervisionados, fazem a transformação dos dados tendo apenas como base a característica que está a ser discretizada.
Este tipo de solução deverá ser empregue quando não existe conhecimento acerca da classe de saída e, deste modo, não existe nenhum atributo que sirva como “modelo” para a passagem de dados contínuos para discretos. Neste caso poder-se-á definir apenas o número de conjuntos que é objetivado para que a discretização se possa efetuar. Além disso, existem ainda abordagens que passam pelo uso de duas estratégias distintas, nomeadamente a discretização tendo como base o cobrimento de intervalos iguais ou o cobrimento de frequências iguais (Matsura, 2003). De qualquer forma será importante realçar que existe uma definição transversal às duas estratégias referidas e a todas as outras assentes numa metodologia não supervisionada, que as distingue dos métodos seguidos em estratégias supervisionadas: todas estas tarefas de classificação têm como premissa o facto do seu objetivo principal ser a determinação dos intervalos de valores discretizados sem haver um conhecimento prévio das classes a que cada instância pertence. Em contraposição, os métodos assentes numa metodologia supervisionada têm sempre conhecimento das classes a que cada atributo pertence e fazem, desta forma, a divisão dos seus dados tendo como referenciação a classe agrupadora de cada um deles. Com vista a cumprir este objetivo existem alguns algoritmos que podem auxiliar nesta tarefa de discretização de dados de forma supervisionada, de onde se evidencia um método que se diferencia dos demais por ter como base o conceito de entropia. Com efeito, e tendo como referência o método anunciado, pode-se proceder à divisão dos dados através da construção de uma árvore de decisão que incida a sua pré-poda no atributo que se pretende discretizar. A partir deste ponto é feita uma discretização progressiva que terá na base do seu critério de divisão o conceito de entropia. Por sua vez o critério de paragem será definido e calculado tendo como filosofia o critério de comprimento de descrição mínima (critério MDL).
Um outro método que surge com especial relevo na discretização de dados de forma supervisionada é o método 1R. Como já sugerido, o método 1R tem como base a classe final a que pertence cada variável e, apesar do seu funcionamento ser bastante simples e intuitivo, surge com resultados bastante positivos, perto dos resultados observados aquando do uso de árvores de decisão. O algoritmo seguido por esta metodologia caracteriza-se por, para cada valor, calcular de forma iterativa o erro associado à atribuição desse a uma dada classe. Desta forma, o cálculo da taxa de erro é primeiro feito após se inserir o valor em causa na classe que tem maior frequência absoluta de atributos e, a partir desta, escolher-se-á a regra associativa que terá como resultado uma taxa de erro menor. Ao longo deste processo repetitivo que trata cada atributo
individualmente e de forma sequencial, são ajustadas as divisões que, no final, irão constituir as regras que definirão a que intervalo de valores pertencerá cada valor contínuo.
Além dos métodos de discretização apresentados existem muitos outros mais ao menos complexos que, no seu conjunto, constituem ferramentas de auxílio para a transformação de valores contínuos em valores discretos.
Além de tudo será importante ainda realçar que existem alguns momentos (não tão frequentes) nos quais é necessário executarem-se operações inversas às discutidas até então. De facto, existem situações em que é necessário converterem-se dados discretos em valores numéricos que procurem representar intervalos de valores contínuos. A causa para este fenómeno tem como base justificativa a mesma que reside na necessidade em se discretizar dados, ou seja, a necessidade requerida pelos algoritmos de extração de conhecimento em trabalhar apenas com uma determinada tipologia de valores. Desta forma, existem também alguns métodos previamente construídos que auxiliam na elaboração destas transformações de valores discretos em contínuos, que surge como tarefa obrigatória quando são usados algoritmos de mining como os métodos baseados em instâncias de vizinho mais próximo ou técnicas de previsão numérica que envolvam regressão (Witten & Frank, 1999).
Como se pode constatar, o processo de transformação aglomera um conjunto de tarefas que se têm de executar incisivamente por forma a preparar os dados que serão usados. O conjunto desta informação devidamente transformada procurará constituir uma base bem formatada que será, de seguida, usada pelos algoritmos que permitem a extração de conhecimento. Neste contexto surge ainda a necessidade intrínseca à organização da informação para que esta possa ser acedida de forma eficiente e rápida. É neste contexto que reside o cuidado de se representarem os dados sob estruturas bem modeladas e devidamente construídas e será sobre este assunto que a próxima secção se debruçará.
2.3
Representação dos dados
2.3.1 Modelação Dimensional
Inserida no âmbito da etapa de transformação de dados, a representação de informação sob estruturas que permitam um acesso de leitura rápida e organizada constituiu uma tarefa
fundamental incluída no processo de procura por obtenção de conhecimento. Neste contexto, e tendo como base estes objetivos, existem algumas estruturas desenvolvidas que permitirão o armazenamento orientado unicamente à pesquisa de informação. Destas estruturas será abordada uma que se assume com especial relevância no domínio deste problema: os DW.
Como formalmente definido em (Jarke & al., 2000), os DW armazenam dados de interesse selecionados para um grupo de clientes particular, com vista a que os acessos possam ser feitos de forma mais rápida, barata e eficiente. Tendo em vista este objetivo primordial, facilmente se entende que, deste modo, o DW tem de organizar a sua estrutura de forma orientada aos desejos propostos por um cliente ou pelo domínio de uma determinada aplicação. De qualquer forma, o que se pode concluir é que irão existir requisitos operacionais assentes no domínio do problema que terão de ser satisfeitos de forma bastante eficiente e que, por si só, irão influenciar a forma de como se orientará a estrutura do DW. Uma outra definição formal de DW que assenta numa perspetiva mais operacional é a apresentada por W.H. Imnom que sugere que “O DW é um conjunto de dados orientados ao assunto, integrados, variáveis com o tempo e não voláteis que auxiliam no processo de tomada de decisões”. Além destas definições já apresentas (que são as que o autor considera definirem de forma mais incisiva o conceito), e por este assunto não ter uma definição simples e imediatamente compreensível, são apresentadas abaixo mais algumas propostas que pretendem explicar de forma formal e alargada o que são os DW na prática (Ferreira, 2002):
É uma base de dados analítica que é usada como base para os sistemas de Suporte à decisão. É planeado para armazenar um grande volume de dados cujo acesso é apenas de leitura, provendo acesso intuitivo (Poe et al., 1998).
É um conjunto de bases de dados integradas e baseadas em assuntos projetados para suportar as funções dos sistemas de suporte à decisão, onde cada unidade de dados está relacionada com um determinado momento (Inmon, 1992).
É um “processo” que aglomera dados de fontes heterogéneas, incluindo dados históricos e dados externos para atender a necessidades de consultas estruturadas e ad-hoc, relatórios analíticos e de suporte à decisão (Harjinder & Rao, 1996).
É um “processo”, não um produto, que visa a construção e administração de dados proveniente de várias fontes com o propósito de obter uma simples e detalhada visão de parte de todo o negócio (Watson & Gray, 1997).
Neste sentido, com base nas definições apresentadas, retiramos de imediato algumas características relativas ao DW, como o facto de esta analisar dados históricos, alterados com o tempo, e não dados estáticos referentes a datas específicas, o facto de os seus dados não serem susceptíveis de alterações e serem apenas de leitura, ou, ainda, o facto, já acima abordado, de se objetivar organizar a informação tendo como premissa principal o assunto que se pretende solucionar.
As características acima apresentadas descrevem de forma ampla as propriedades inerentes aos conjuntos de dados presentes num DW e procuram, desta forma, ajudar a definir melhor o conceito subjacente. Contudo existe uma outra característica que não se verifica explicitamente exposta nestas definições e cujo relevo exige que se faça uma abordagem mais cuidada sobre a mesma. Esta propriedade caracterizadora dos DW descrita é a existências de metadados que, tal como o próprio conceito denuncia, constituiu dados respetivos e descritores dos dados armazenados. Este tema será abordado de forma mais pormenorizada a seguir.
2.3.2 Metadados
Os metadados desempenham um papel bastante importante na compreensão e gestão dos DW. Antes mesmo de um DW ser acedido é necessário que haja uma compreensão global dos dados que este armazena, da fonte de onde estes provêm ou, ainda, do local onde estes dados se encontram. É neste contexto que surgem os metadados que procuram expor dados de interesse relativos aos registos representados nos sistemas de armazenamento. Desta forma, tal como exposto em (Jarke & al., 2000) existe um conjunto informações que podem estar contidas nos metadados, das quais:
Dicionário de dados, que contêm informações acerca das bases de dados que estão sendo mantidas e acerca das relações entre os elementos de dados.
Fluxo de dados, constituídos pelas informações acerca de como estão a ser direcionados (e com que frequência) os dados alimentados.
Transformação dos dados, através da qual é dado conhecimento acerca das informações que foram necessárias aquando da movimentação dos dados.
Controlo de versões, que permite que sejam reveladas as alterações efetuadas nos metadados.
Estatísticas de uso dos dados, nas quais pode ser visualizado um conjunto de valores estatísticos que revelam a frequência de execução de algumas operações sobre os dados.
Informações acerca dos “alias”, que permitem que se possam obter informações sobre quais os “alias” existentes para determinados atributos.
Segurança, que constituiu a representação de quais são os utilizadores autorizados a aceder à informação.
Estes conjuntos de metadados, agrupados pela sua tipologia, encontram-se armazenados num repositório disponível para acessos de leitura ou escrita e, desta forma, permitem que se possam atualizar os valores relativos aos mesmos. Contudo, o desenvolvimento do DW deve assegurar a existência de um mecanismo que faça o povoamento e mantenha o repositório de metadados de forma automática e que todos os atributos representados no DW tenham uma entrada respetiva à descrição dos seus dados. Com acesso a esta informação devidamente preenchida, cada utilizador que não tenha conhecimento sobre o domínio dos dados representados pode facilmente compreender o âmbito dos registos apresentados, bem como a estrutura sobre a qual a informação está definida. É neste aspeto que reside a importância vital em se definirem metadados que procurem descrever e caracterizar corretamente o conjunto dos atributos armazenados.
2.3.3 Vantagens e desvantagens
Depois de apresentada, de forma exaustiva, a definição e as características de um DW, surge agora a necessidade de se perceber quais são as principais vantajens apresentadas por esta estrutura de armazenamento e, ainda, quais as desvantagens que poderão advir do seu uso. Desta forma, podem-se destacar como principais vantagens o facto do uso deste sistema de armazenamento permitir um aumento considerável no desempenho e na velocidade de resposta a pedidos de informação sobre os dados guardados, a existência de disponibilidade de acesso à informação mesmo quando as fontes da mesma não se encontram acessíveis, a facilidade que
fornece para aplicação de metodologias estatísticas que permitam revelar relações até então desconhecidas ou, ainda, a facilidade que concede aquando da preparação de relatórios detalhados sobre a informação armazenada. Neste ponto convém realçar que, para haver um maior desempenho e uma maior velocidade de resposta a pedidos de informação efetuados, existe uma técnica a ser executada que assenta na desnormalização das tabelas que constituem os esquemas de dados DW. Esta técnica permite que seja diminuído o número de “joins” a efetuar quando existe um pedido de informação complexa e proveniente de mais do que uma tabela. Portanto, esta metodologia constituiu uma abordagem simples que permite que se poupe bastante tempo de processamento e que, consequentemente, aumenta a velocidade de execução de pedidos de informação. Contudo, é também nesta propriedade caracterizadora de grande parte dos DW que reside uma das grandes desvantagens do uso de um DW ou, mais concretamente, do uso de estruturas de dados baseadas em tabelas desnormalizadas. De facto, ao abdicar-se do processo de normalização de uma base de dados incorre-se na consequência imediata de se aumentar o volume de dados armazenados e, desta forma, aumentar-se-ão também as tarefas e custos de manutenção inerentes à mesma. Para que esta desvantagem não seja tão notória, no seio da construção de um DW deve-se ter especial cuidado durante a etapa de pré-processamento de dados, onde se deve dar especial importância à eliminação de dados redundantes ou, ainda, de dados duplicados.
2.3.4 Modelação dimensional dos dados
Feita esta primeira abordagem explicativa do que é e como se caracteriza um DW, surge agora a necessidade em se abordar de forma explicativa o processo de construção dos esquemas dimensionais que irão constituir um DW. Nesta perspetiva pode-se apresentar a modelação dimensional segundo a descrição feita em (Kimball & Ross, 2002) e que expõe esta modelação como sendo uma das atividades mais relevantes que usualmente se desenvolve no âmbito de um projeto de concepção e implementação de um sistema de DW. O papel desta atividade enquadra-se na etapa “Modelação dimensional” que constituiu e deenquadra-sempenha um papel importante no ciclo de desenvolvimento de um projeto de construção de um DW, como exposto pela figura 2.6 (Kimball, 1998).
Figura 2.6 Ciclo de Desenvolvimento de um DW.
Esta necessidade em se visualizarem dados sobre múltiplas perspetivas dimensionais advém do facto de existirem perguntas complexas não unidimensionais que precisam de ser respondidas. Um exemplo concreto para este tipo de questões é a necessidade dos gestores de negócio procurarem, por exemplo, saber quantos produtos de um dado grupo foram vendidos, numa determinada área, durante um intervalo de tempo específico. Perguntas como esta surgem frequentemente no âmbito de análises estatísticas, mas não só. Desta forma, a representação de informações assente em várias dimensões tornou-se uma prioridade no processo de estruturação e organização de um sistema de armazenamento de dados.
Uma visão multidimensional dos dados considera que a informação se encontra armazenada em arrays multidimensionais ou em cubos. Um cubo consiste num grupo de dados, apresentados em células, e que se encontram organizadas por dimensões de valores onde, a cada dimensão, corresponde uma lista de membros (Jarke & al., 2000). Por sua vez, as dimensões caracterizam-se por conterem atributos que são variáveis ao longo do tempo e que podem ter a si associadas níveis hierárquicos de agregação de informação que, desta forma, permite a representação de vários níveis de detalhe para cada um dos seus atributos. Desta forma pode-se sumariar uma dimensão como sendo um conjunto de dados hierárquicos e variáveis ao longo do tempo, que suportam uma perspetiva de análise a partir da qual se permite a exploração dos atributos descritos nas tabelas de factos. As tabelas de factos são tabelas centrais que agregam medidas de interesse a ser obtidas por métodos OLAP ou, ainda, por métodos de mining. O conjunto das
tabelas de factos com as dimensões abordadas pode constituir vários esquemas de representação dimensional de informação. Um destes é o “esquema em estrela”. Este esquema consiste numa tabela central armazenadora de factos e em uma ou mais tabelas respetivas às dimensões da informação representada. Existe ainda um outro esquema digno de interesse que é denominado de “floco de neve”. Este último é construído a partir da normalização das tabelas representadas no esquema em estrela e procura, assim, diminuir a quantidade de armazenamento desperdiçado para evitar que se guardem informações redundantes ou repetidas. Desta forma pode-se afirmar que os esquemas apresentados têm como objetivo definir e organizar as relações entre as tabelas dos factos e as dimensões a partir de um esquema que procura representar informações dimensionais.
2.4
Métodos usados na procura de conhecimento
Depois de ter sido feita a recolha dos dados a estudar, a pré-filtragem e pré-processamento dos mesmos e a transformação e representação destes em sistemas de armazenamento de dados especialmente estruturados para que se possam fazer interrogações complexas de forma eficiente, surge agora a etapa que trará como resultado esperado um conjunto de padrões que se expectativa poderem traduzir-se em conhecimento útil e verdadeiro. É portanto nesta etapa que se aplicarão métodos que procurarão obter conhecimento a partir dos dados previamente preparados e organizados. O conjunto de algoritmos que poderão ser seguidos constituiu um intervalo muito alargado de escolhas e, para se proceder à seleção de qual método se deverá seguir, é preciso fazer-se uma abordagem crítica dos objetivos a que o projeto se propõe e, ainda, dos recursos tecnológicos que poderão ser empregues no desenvolvimento do mesmo. Desta forma será preciso avaliar qual o tipo de conhecimento que se procura: preditivo, classificativo, associativo, descritivo ou estimativo, qual a quantidade de dados sobre os quais o estudo se irá basear, qual o tempo que se tem disponível para a obtenção de resultados e, ainda, quais os recursos computacionais que se encontram acessíveis para se proceder aos cálculos de procura de conhecimento. É com base nisto que precisamos agora de expor alguns algoritmos que poderão ser utilizados quando se objetiva a procura de conhecimento em geral ou, mais concretamente, quando se objetiva a procura de informações relativas ao tipo de informação acima enumerada.
2.4.1 Métodos usados na procura de informação associativa
Um método amplamente usado quando se pretende obter conhecimento encontra-se assente na procura de regras associativas que possam ser traduzidas em informação de interesse. Nesta perspetiva, uma primeira etapa constituidora deste método reside na pesquisa das várias regras associativas que possam ser encontradas no conjunto de dados a estudar. Ora, como será de óbvia compreensão, a base de valores de onde se perspetiva extrair conhecimento poderá conter um enorme número de relações associativas entre os seus conjuntos e, portanto, induzirá à obtenção de várias relações que poderão não ter grande interesse por não se verificarem de forma muito assídua. Desta forma torna-se necessário capitalizar o facto de apenas interessarem as regras de associação que possam ser observadas de forma frequente e, deste modo, deve ser estipulado um valor mínimo de frequência ou um valor mínimo de regras a serem obtidas. Deste modo obter-se-á como output um conjunto de associações limitadas que, no seu conjunto, traduzirão um maior relevo relativo ao valor de suporte. O valor de suporte abordado é um atributo numérico respetivo ao número de registos que se se encaixam numa regra e, desta forma, constituirá também um valor descritivo de confiança, ou seja, da percentagem de registos que realmente verificam especificamente a regra descrita. Um exemplo destes métodos usados na procura de informação associativa, é o método PredictiveApriori. Este método caracteriza-se por se basear na premissa de que uma regra será escolhida e adicionada, se a precisão da previsão esperada se encontra entra as „n‟ melhores. Além disso, a regra só será adicionada caso não seja incorporada por uma regra que tenha, pelo menos, o mesmo nível de precisão preditiva esperada (Scheffer, 2001).
2.4.2 Métodos utilizados na classificação, estimação ou regressão
Quando temos a tarefa de classificar um dado grupo de atributos tendo como base um conjunto de valores previamente identificados e classificados, pode-se dizer que temos uma tarefa de classificação ou de estimação. A diferença entre as duas reside no formato dos dados obtidos como resultado da tarefa. Se a tarefa de classificação trouxer como resultado um grupo único e discreto de valores estamos na presença de uma classificação. Por outro lado, se recebermos como output dados contínuos de informação provenientes de uma classificação de dados numéricos, assistimos a uma estimação.
O propósito da utilização de métodos que permitem a classificação, ou estimação de conteúdos, tem frequentemente a si adjacente o objetivo que prima pela previsão de valores. De facto, neste contexto podem-se utilizar os métodos anunciados com vista a se se conseguir prever qual o valor classificativo que determinado conjunto de valores terá a si associado desde que, para tal, exista um conhecimento prévio de associações classificativas já existentes. É desta forma que se podem utilizar regras classificativas devidamente extraídas dos dados de teste para que, assim, se possa prever a classificação provável que os novos registos terão.
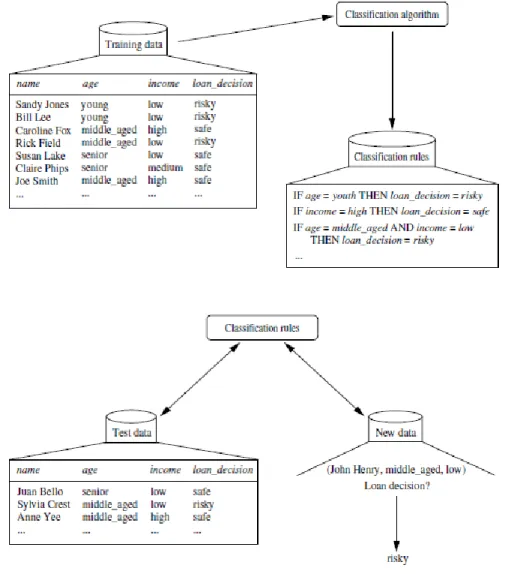
Posta a apresentação dos objetivos que poderão estar intrínsecos à utilização de métodos classificativos, torna-se agora relevante perceber o método geral de funcionamento dos mesmos, bem como descobrir qual o conjunto de algoritmos que poderão auxiliar no desempenho desta função. O processo de classificação assenta em dois grandes passos: descoberta de regras de classificação e classificação de novos dados através das regras obtidas. Neste contexto, e antes ainda de ser feita uma abordagem explicativa dos passos apresentados, deverá clarificar-se que o processo que permite a classificação de registos debruçar-se-á sobre três conjuntos de valores referentes a:
1. dados de treino, que constituirão um conjunto de registos representativo dos valores sobre os quais se pretende proceder à obtenção de regras classificação;
2. dados de teste, que servirão como base para que se possa verificar a qualidade dos resultados obtidos pelo algoritmos;
3. novos dados, que representarão os dados sobre os quais se deverá proceder à classificação.
Como exposto, será durante a procura por regras de classificação que serão utilizados dados que representem conjuntos de valores de teste. Como tal, é imprescindível que os dados de teste tenham a si associados as classes classificativas dos mesmos para que, desta forma, se possam utilizar algoritmos de classificação que permitam atingir o objetivo assente na extração de informação auxiliadora do processo de previsão classificativa. Este procedimento de procura de regras classificativas pode ser sumariamente descrito como “aprendizagem” e constituiu, tal como já referido, o primeiro passo do método que objetiva pela previsão de classificações. Feita a descoberta destas regras existe a necessidade em se perceber se as mesmas representam o modelo de forma verosímil e que, portanto, não falhará com dados desconhecidos ou até quando
forem aplicados dados futuros ao mesmo. Como resposta a este requisito, indispensável a um bom modelo classificativo, deverão ser utilizados estes dados de teste que, desta forma, procurarão estimar a precisão das regras encontradas. Feito o reconhecimento de qualidade do modelo resultante poder-se-á, finalmente, proceder à tentativa de previsão dos valores respetivos às classes caracterizadoras dos registos. Os dois últimos procedimentos apresentados (obtenção de qualidade do modelo e previsão classificativa) constituem no seu conjunto o segundo passo respetivo à classificação ou estimação de dados. Tais passos encontram-se sumariamente descritos na figura 2.7, na qual é apresentado um exemplo prático representativo do processo acima explicado.