F
ACULDADE DEE
NGENHARIA DAU
NIVERSIDADE DOP
ORTODistributed and scalable architecture
for SAF-T processing and analysis
Daniel Silva Reis
Mestrado Integrado em Engenharia Informática e Computação Supervisor: António Miguel Pontes Pimenta Monteiro
Distributed and scalable architecture for SAF-T
processing and analysis
Daniel Silva Reis
Mestrado Integrado em Engenharia Informática e Computação
Abstract
In 2008, Portugal adopted SAF-T (Standard Audit File for Tax). SAF-T is a guideline from OECD (Organization for Economic Cooperation and Development) for electronic inter-exchange (basi-cally an .XML file) of reliable accounting, sales and data distribution within organizations or regulators (Tax Authorities, Chartered Accountants, Central Banks, Statistics Institutes).
Petapilot developed Colbi to provide an easy way for companies to check their financial “health” and ensure compliance to the tax authority, internal audit and other regulatory entities using this standard. Colbi is a product to handle and provide these compliance. The main issue is related to the automatic scalability and provisioning of the platform. The platform will become slower due to the increase in the number of companies and the size of SAF-T documents. This platform must be able to respond to all submitted documents (sometimes with billions of trans-actions) and be always available. The service level is very important as it can imply a delay on submitting a company’s information to the tax authorities, with fine implications.
The main goal is to redesign Colbi’s architecture and allow it to scale horizontally and ver-tically. For now, only one machine is responsible for all the processing and control of the files. Therefore, the performance of the platform will always be dependent on the processing capac-ity of a single machine. The current system architecture cannot scale up or down, adapting the computational resources to the throughput and data input.
As part of the reengineering process of the actual platform, we will find ways to parallelize the system with distribution of tasks aiming for a microservice oriented architecture. The platform must be able to scale in order to automatically allocate computational resources, either by allo-cating more or reducing the number of machines needed for the processing, always considering a deploy-on-demand scenario. In order to evaluate the obtained results, a direct comparison of the execution time of the two architectures will be made, either in a real world scenario, or in an extreme scenario of multiple file analysis. In this way, it will be possible to observe the behavior and response of the new architecture.
Resumo
Em 2008, Portugal adotou o SAF-T (Ficheiro de Auditoria Padrão para Imposto). O SAF-T é uma diretriz da OCDE (Organização para a Cooperação e Desenvolvimento Económico) para o intercâmbio eletrónico (basicamente, um arquivo .XML) de contabilidade confiável, vendas e distribuição de dados dentro de organizações ou reguladores (Autoridades Fiscais, Contabilistas, Bancos Centrais, Institutos Estatísticos).
A Petapilot desenvolveu o Colbi de forma a fornecer uma maneira fácil das empresas verifi-carem a sua situação financeira e garantir a conformidade com a autoridade tributária com recurso á análise do ficheiro SAF-T. O Colbi é um produto desenvolvido para lidar e fornecer essa con-formidade. O principal problema está relacionado com a escalabilidade automática e o provision-amento da plataforma. A plataforma está a tornar-se mais lenta devido ao aumento do número de empresas e ao tamanho dos documentos SAF-T. Esta plataforma deve ser capaz de respon-der a todos os documentos submetidos (muitas vezes com bilhões de transações) e estar sempre disponível. O nível do serviço extremamente importante, pois pode implicar um atraso na apre-sentação das informações de uma empresa às autoridades fiscais, com implicação de multas.
O objetivo principal do projeto é redesenhar a arquitetura da Colbi de forma a que possa escalar horizontalmente e verticalmente. Por enquanto, apenas uma máquina é responsável por todo o processamento e controle dos ficheiros. Portanto, o desempenho da plataforma dependerá sempre da capacidade de processamento de uma única máquina. A arquitetura atual do sistema não consegue escalar e adaptar os recursos computacionais à taxa de transferência e entrada de dados.
Como parte do processo de reengenharia da plataforma atual, encontraram-se formas de par-alelizar o sistema com a distribuição de tarefas, apontando para uma arquitetura orientada a mi-croserviços. A plataforma foi desenvolvida de forma a permitir alocar automaticamente recursos computacionais, seja alocando ou reduzindo o número de máquinas disponíveis para o proces-samento, considerando-se sempre um possível cenário de deploy-on-demand. Para avaliar os re-sultados obtidos, será feita uma comparação direta do tempo de execução das duas arquiteturas, quer num cenário de mundo real, ou num cenário extremo de análise e submissão de múltiplos ficheiros. Desta forma, será possível observar o comportamento e a resposta da nova arquitetura.
Acknowledgements
First of all, I would like to thank António Pimenta Monteiro for supervising this thesis with all its valuable input and help when I needed it most. Secondly, I would like to thank the CEO of Petapi-lot Valter Pinho for the challenge, as well as all the help he gave me during the accomplishment of it. He always believed in me and my abilities to take this project forward. For all of this, I cannot thank him enough the commitment and dedication for making this dissertation not only a more reachable goal, but also an objective of his own.
To the entire Petapilot team, I want to acknowledge the valuable help as well. A special men-tion must be made to Diogo Bastos and Daniel Carvalho who helped me moving this dissertamen-tion forward and never let me down when I most needed.
I am deeply grateful to my grandparents, parents and sister Inês, for always supporting me in the most difficult moments. They dedicated their whole life prioritizing my education and future over theirs. From the bottom of my heart, thank you for supporting me unconditionally.
A special thanks to my girlfriend Maria Guedes for being a fundamental part of my life and for always motivating me to be a better and happier person.
To all my close friends who over the years have helped and contributed to make me grow as a person and being as I am today: Domingos Alexandrino Fernandes, Guilherme Pinto, Luís Duarte, Diogo Moura, Flávio Couto, Pedro Castro, Miguel Botelho, David Baião, João Silva and Sérgio Domingues.
To all these people, staff at FEUP and particularly those involved in my masters degree: my sincerest thanks.
“I’d rather attempt to do something great and fail than to attempt to do nothing and succeed.”
Contents
1 Introduction 1
1.1 Context . . . 1
1.2 Problem . . . 2
1.3 Motivations and Objectives . . . 2
1.4 Challenges . . . 3
1.5 Structure and Planning . . . 3
2 Microservice Architecture 5 2.1 Enterprise Application Architecture . . . 6
2.1.1 Monolithic Architecture . . . 6
2.1.2 Service-Oriented Architecture . . . 7
2.1.3 Microservices Architecture . . . 8
2.2 Monolithic Architecture vs Microservices . . . 9
2.3 Service-Oriented Architecture vs Microservices . . . 14
2.4 Migration from Monolithic . . . 14
2.5 Microservices Showcase . . . 16 2.5.1 SoundCloud . . . 16 2.5.2 Gilt . . . 21 2.6 Technology Overview . . . 24 2.6.1 RabbitMQ . . . 24 2.6.2 Apache Ignite . . . 26 2.6.3 Docker . . . 27 2.7 Conclusions . . . 27 3 Colbi Architecture 29 3.1 General Architecture Overview . . . 29
3.2 Colbi Core Pipeline . . . 30
3.3 Architecture and Pipeline Review . . . 31
3.4 Possible Optimizations . . . 32
4 Scalable Colbi Architecture 35 4.1 Microservice Components . . . 35
4.2 Architecture Description . . . 36
4.3 Fault Tolerance . . . 37
4.4 Scalability . . . 37
5 Colbi Exchanger 43 5.1 Overview . . . 43 5.2 Message Exchange . . . 44 5.3 Microservice Implementation . . . 44 5.4 Configuration . . . 45 5.5 Fault Tolerance . . . 47 6 Colbi Cache 49 6.1 Design . . . 49 6.2 Implementation . . . 50 6.3 Locking System . . . 51 6.4 Fault Tolerance . . . 52
7 Implementation Tests and Results 53 7.1 Evaluation functions . . . 53 7.2 Environment Setup . . . 54 7.3 Benchmark Definition . . . 54 7.3.1 Phase One . . . 56 7.3.2 Phase Two . . . 65 7.4 Conclusion . . . 74
8 Conclusions and Future Work 77 8.1 Conclusion and Expected Results . . . 77
8.2 Future Work . . . 78
List of Figures
2.1 Classic Monolithic Architecture . . . 6
2.2 SOA Architecture . . . 7
2.3 Microservices Architecture [Ara] . . . 8
2.4 Monoliths vs Microservices [Mar] . . . 10
2.5 Organization in a monolithic application 1 [Mar] . . . 11
2.6 Organization in a microservices application 2 [Mar] . . . 12
2.7 Data management comparison [Mar] . . . 13
2.8 SoundCloud Monolithic Architecture [Phia] . . . 17
2.9 Component view of SoundCloud’s monolithic architecture [Phia] . . . 18
2.10 SoundCloud component’s isolation architecture change 1 [Phia] . . . 18
2.11 SoundCloud component’s isolation architecture change 2 [Phia] . . . 19
2.12 SoundCloud component’s isolation architecture change 3 [Phia] . . . 20
2.13 Gilt flash-sales chart . . . 21
2.14 Gilt Architectural Evolution [Eme] . . . 22
2.15 RabbitMQ Standard Message Flow . . . 25
2.16 Apache Ignite Cache . . . 26
3.1 Colbi Architecture . . . 29
3.2 Colbi Architecture . . . 30
3.3 Flow Pipeline execution loop . . . 31
4.1 Colbi Scalable and Distributed Architecture . . . 36
4.2 Colbi New Flow Pipeline . . . 38
4.3 Sequential Rules Execution . . . 40
4.4 Parallel Rules execution 1 . . . 40
4.5 Parallel Rules execution 2 . . . 41
4.6 Parallel Rules execution 3 . . . 41
4.7 Parallel Rules execution 4 . . . 41
5.1 Colbi Exchange Call types . . . 43
5.2 Message Class . . . 44
5.3 Fault Tolerance with Colbi Exchanger . . . 47
6.1 Colbi Cache . . . 51
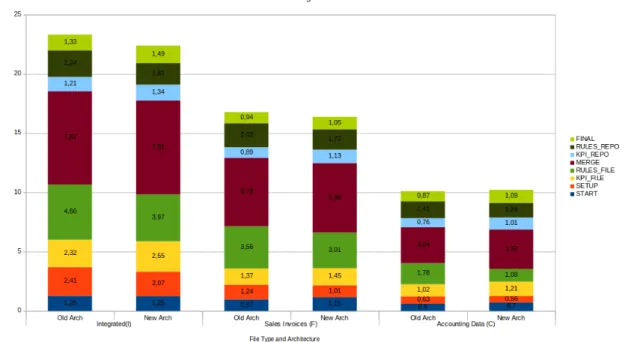
7.1 Total processing time of a single file . . . 54
7.2 Phase 1, Test1 - The processing time of each flow on both architectures with a small file . . . 56
7.3 Phase 1, Test 1 - The processing time of each flow on both architectures with a
medium file . . . 57
7.4 Phase 1, Test 1 - The processing time of each flow on both architectures with a large file . . . 58
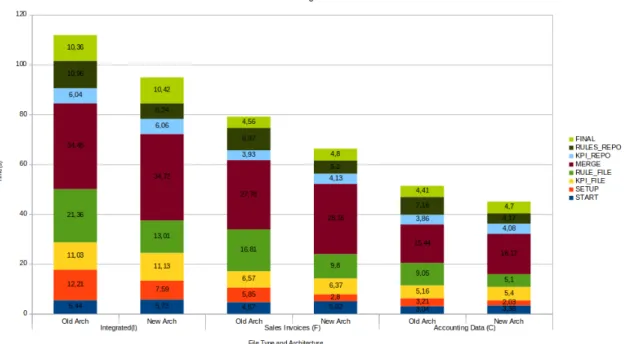
7.5 Phase 1, Test 2 - Average processing time of flows on both architectures with small files . . . 59
7.6 Phase 1, Test 2 - Average processing time of flows on both architectures with medium files . . . 60
7.7 Phase 1, Test 2 - Average processing time of flows on both architectures with large files . . . 61
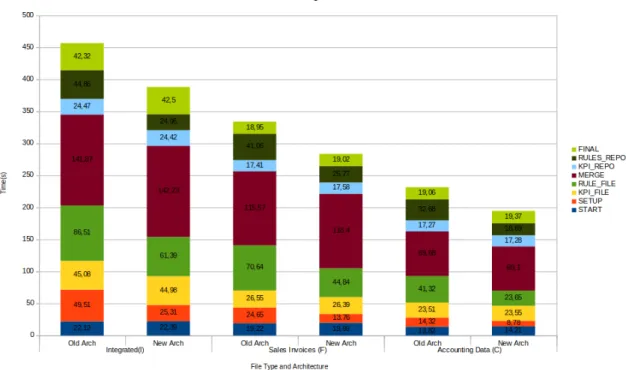
7.8 Phase 1, Test 3 - Average processing time of flows on both architectures with small files . . . 62
7.9 Phase 1, Test 3 - Average processing time of flows on both architectures with medium files . . . 63
7.10 Phase 1, Test 3 - Average processing time of flows on both architectures with large files . . . 64
7.11 Phase 2, Test 1 - Processing time of flows on both architectures with a small file . 65 7.12 Phase 2, Test 1 - Processing time of flows on both architectures with a medium file 66 7.13 Phase 2, Test 1 - Processing time of flows on both architectures with a large file . 67 7.14 Phase 2, Test 2 - Processing time of flows on both architectures with small files . 68 7.15 Phase 2, Test 2 - Processing time of flows on both architectures with medium files 69 7.16 Phase 2, Test 2 - Processing time of flows on both architectures with large files . 70 7.17 Phase 2, Test 3 - Processing time of flows on both architectures with small files . 71 7.18 Phase 2, Test 3 - Processing time of flows on both architectures with medium files 72 7.19 Phase 2, Test 3 - Processing time of flows on both architectures with large files . 73 7.20 Overall System Performance Gain . . . 75
7.21 Architectures Global Processing Time - 1 File . . . 75
7.22 Architectures Global Processing Time - 81 File . . . 76
List of Tables
2.1 SOA vs MSA . . . 14
2.2 Comparison between enterprise architectural styles . . . 15
7.1 File types and sizes . . . 55
7.2 Number of files per type and size for the load tests . . . 55
7.3 Phase 1, Test 1 - Small file flow and delay times . . . 56
7.4 Phase 1, Test 1 - Medium file flow and delay times . . . 57
7.5 Phase 1, Test 1 - Large file flow and delay times . . . 58
7.6 Phase 1, Test 2 - Small files average flow and delay times . . . 59
7.7 Phase 1, Test 2 - Medium files average flow and delay times . . . 60
7.8 Phase 1, Test 2 - Large files average flow and delay times . . . 61
7.9 Phase 1, Test 3 - Small files average flow and delay times . . . 62
7.10 Phase 1, Test 3 - Medium files average flow and delay times . . . 63
7.11 Phase 1, Test 3 - Large files average flow and delay times . . . 64
7.12 Phase 2, Test 1 - Small file flow and delay time . . . 65
7.13 Phase 2, Test 1 - Medium file flow and delay time . . . 66
7.14 Phase 2, Test 1 - Large file flow and delay time . . . 67
7.15 Phase 2, Test 2 - Small file average flow and delay times . . . 68
7.16 Phase 2, Test 2 - Medium file average flow and delay times . . . 69
7.17 Phase 2, Test 2 - Large file average flow and delay times . . . 70
7.18 Phase 2, Test 3 - Small file average flow and delay times . . . 71
7.19 Phase 2, Test 3 - Medium file average flow and delay times . . . 72
Abbreviations
AMQP Advanced Message Queuing Protocol API Application Programming Interface AWS Amazon Web Services
COLBI Collaborative Business Intelligence CSV Comma-separated values
ESB Enterprise Service Bus HTTP Hypertext Transfer Protocol JSON JavaScript Object Notation JVM Java Virtual Machine KPI Key Performance Indicator LE Large Enterprises
LOSA Lots of Small Applications MSA Microservices Architecture NFS Network File System
OECD Organization for Economic Cooperation and Development SaaS Software as a Service
SAF-T Standard Audit File for Tax Purposes
SAFT-PT Standard Audit File for Tax Purposes - Portugal Version SLA Service-level Agreement
SMEs Small to Medium Enterprises SOA Service-Oriented Architecture SQL Structured Query Language VP Vice President
XML eXtensible Markup Language YAML Yet Another Markup Language WWW World Wide Web
Chapter 1
Introduction
1.1
Context
The Standard Audit File for Tax Purposes (SAF-T) is an electronic file format for tax purposes. It’s a XML document regulated by international standards, defined by the OECD and adopted in several European countries.
It allows the collection of periodic fiscal data such as taxes, commercial, financial and ac-counting of an organization. Every company that carries out commercial transactions, is obliged to communicate its monthly invoicing to the Tax Authority [Jas].
SAF-T has been designed to allow auditors access to data in an easily readable format for substantive testing of system controls and data, using proprietary audit software, as part of a methodology that provides increased effectiveness and productivity in computer-assisted audit. It’s intended to be suitable for use by businesses and their auditors across the scale from SME’s to LE’s, with multiple branches and locations, although there may be some differences in its ap-plication. With the SAFT file, it is possible to know if a business has paid the correct tax at the right time, in accordance with tax legislation. It facilitates the extraction and processing of infor-mation, avoiding the need to specialize auditors in the various systems, simplifying procedures [For10,Jas].
Mainly, the Portuguese SAFT-PT can be related to the accounting transactions and sales trans-actions (two file formats and a third with the integration of the two data sets). Since 2008, the communication of this file to the Tax Authority has become mandatory because it facilitates the inspections and audits done to the companies as well the fight against tax fraud [Jas].
In Portugal, PetaPilot (a tech startup company) emerged from the vision of creating a tech-nology for business with a high potential for internationalization. The main goal of this company is the development of technological products and platforms for data analysis of high variety and volume with focus on Business Intelligence, Big Data, Cloud Computing and fraud detection so-lutions, operating in the corporate, governmental and institutional market [Sta].
“Our team has grown motivated by the challenge to provide to the companies, efficient and innovative ways to use their data and information. Today, we deliver products and solutions to the companies, government, regulators and institutions to analyze their data, providing better decisions, infer fraud, diminish risk and ensure compliance. We use Big Data and high-end technologies on our platforms to process data at a massive scale.”
Valter Pinho, CEO The main product of PetaPilot is Colbi (Collaborative Business Intelligence and Audit). Colbi is an analytical tool of commercial and financial information and serves a number of sectors rang-ing from government financial regulation, consultancy companies, industry, distribution and ser-vices. Companies in Portugal and abroad, such as the Portuguese and the Lithuanian Tax Author-ities, Sheraton, Volkswagen, Omya, NOS, Saint-Gobain, BDO, Delta, Barbosa and Almeida (BA Vidro), SUCH, among others, are using this solution for Data Analysis, Decision Support, Audit Inference and fraud detection [Pet].
This platform is something that needs to be efficient and scalable due to its importance in the industry so it also has to be always available to the companies. Having a platform with these characteristics is difficult and a constant challenge. Distributed systems such as SOA (Service-Oriented Architecture) and Microservices address some of these challenges but companies need to implement these solutions in their services in a custom way, in order to archive levels of excellence [Ima].
1.2
Problem
According to Colbi’s current architecture, this platform has some limitations on its scalability. It is a platform that was built on a monolithic architecture whereby all the functionalities of the application are built on a single process. In the long term, this becomes a problem because Colbi is a platform that has to be always available and respond to all requests made by users in a timely manner. As more and more companies use this platform, there is a growing overhead on the machine in both volume and file size. In this way, the machine is getting slower and struggle to run all the processing and analysis required by customers. With such architecture we can only scale Colbi horizontally by running several application instances behind load-balancer, but this is not a durable solution for the company needs [Mar].
1.3
Motivations and Objectives
Migrating a monolithic architecture to microservices is not an easy task. It is necessary to have an overview of the system operation, as well as all the components and dependencies that it holds. This work aims to implement a very current and extremely successful architecture in the industry. The construction of a fast and efficient system with the distribution and parallelization of tasks
Introduction
is a very attractive and constant challenge for the company, since the migration of a monolithic application to a microservice-oriented architecture brings advantages and disadvantages.
1.4
Challenges
Petapilot is a fast-growing company that needs to be able to rapidly adapt to the market needs. The implementation of a new architecture is a goal with many challenges not only for developers but also for the company. It is a stable product and, over time has gained maturity due to the implementation of new functionalities. The product is distributed in several customers either in the Cloud, or on-premises. This way, it is always necessary to ensure that the SLAs that have been defined, are never broken. In addition, any development in the product must always ensure com-patibility with previous versions. Any structural change in the product must always guarantee the data consistency. Therefore, all changes made to the business rules must be thoroughly analyzed and tested before making sure the product is ready to be distributed. In addition, the location and environment where the product is installed, is bounded with rules and regulations. This way, it must be ensured that the product is easy to integrate and deploy in the target environment being compliant with those rules.
1.5
Structure and Planning
This document begins by presenting a literature review in chapter2, and a more detailed overview of the current platform architecture in chapter3, where the work unfolds. The chapters4 spec-ifies the new architecture and explains how it behaves in the system. In chapters 5 and6, it is detailed the operation and implementation of two libraries that supported the developed architec-ture in chapter4. Chapter7contemplates a set of tests that were done to the architecture as well their results. Finally, chapter 8, presents the conclusions of the developed work as well as the identification of possible future work.
Chapter 2
Microservice Architecture
Microservices is a buzzword and a fast-paced topic, although the idea or the term itself are not new in industry. What makes it relevant, are the different experiences from people all over the world, along with the emergence of new technologies [Sam]. This is having a profound effect on how microservices are used. Business houses are no longer interested in developing large applications to manage their end-to-end business functions as they did a few years ago. They rather opt for quick and agile applications which cost them less money as well [Lok]. Implementations of microservices have roots in complex-adaptive theory, service design, technology evolution, domain-driven design, dependency thinking, promise theory, and other backgrounds. They all come together to allow the people of an organization to truly exhibit agile, responsive, learning behaviors to stay competitive in a fast-evolving business world [Pos].
“ "Microservices" became the hot term in 2014, attracting lots of attention as a new way to think about structuring applications. I’d come across this style several years earlier, talking with my contacts both in ThoughtWorks and beyond. It’s a style that many good people find is an effective way to work with a significant class of systems. But to gain any benefit from microservice thinking, you have to understand what it is, how to do it, and why you should usually do something else.”
2.1
Enterprise Application Architecture
In order to understand the full benefits of a migration to a microservice oriented architecture, it is important to understand how enterprise business applications have evolved over time. Although microservices are a good solution and the future of enterprise applications, they are not the only solution. It is necessary to take into account the type of project and its scale in order to better understand what kind of architectural pattern may be the most useful for the project in question.
2.1.1 Monolithic Architecture
Monolithic applications are built as a single unit that bundle together all the functionalities needed by the architecture. At the architectural level, its the simplest form of architecture because it involves less actors than other architectural styles [Ale] . Normally, a tiered approach is taken with a back-end store, middle-tier business logic, and a front-end user interface [Micb].
Figure 2.1: Classic Monolithic Architecture
In figure 2.1, we can observe a classic example of this type of architectural implementation. This kind of monolithic approach is very common in organizations and some of them enjoy good enough results, whereas others encounter some limitations [Ces]. Many things have changed over the last few years. Some developers designed their applications in this model because the tools and infrastructure were too difficult to build SOAs, and they did not see the need until the application grew. But most recently, developers are building distributed applications that are for the cloud and driven by the business [Ant,Ces].
Microservice Architecture
2.1.2 Service-Oriented Architecture
Service-oriented architecture (SOA) is an approach that emerged from the need of modern en-terprises to effectively and quickly respond to the today’s ever more competitiveness and global markets. Is an architectural style in which applications consist of autonomous, interoperable, and reusable services, usually implemented as Web services. Software resources are packaged as "services", which are well defined and self-contained modules that provide standard business functionality and are independent of the state or context of other services. Services can assume different roles based on the context they are used. The two main roles in SOA are the service provider and the service consumer. The service provider defines a service description, and pub-lishes it to a client (or service discovery agency) through which the service description with the service capabilities is advertised and made discoverable. The service consumer client (or service requester) discovers a service (endpoint) and retrieves the service description directly from the service. Services can act in both roles if they are intermediaries in that route and process messages or they are service compositions and need to call other services to complete some given sub-tasks. When comparing SOA with monolithic architectures, is common units of processing logic to be solution-agnostic. This allows loose-coupling and reusability of services. But, processing SOA is highly distributed and services can be spread across the server as required. This helps dealing with different system performance demands. Service communication can be asynchronous and this promotes stateless and autonomous nature of the services. On the other hand, SOA suffers some performance overhead due to the introduction of layers of data processing. Derived from the distributed aspect of SOA, application security becomes more complicated than in the monolithic architecture. There are also some other pitfalls when adopting SOA. Most of them are related to limited understanding of what SOA is and how to correctly use it to accomplish given objectives [PV].
Figure 2.2: SOA Architecture
In the figure 2.2, we can observe a well known implementation of SOA named Enterprise Service Bus (ESB). The ESB acts as the communication center in SOA providing an integration
layer for services. The reduced dependence between services, since they only communicate with the service bus that is responsible for forwarding the requests to the right destination, constitutes a major benefit. It is very useful when a system consists in a large number of services where the management of connections point-to-point would become a nightmare. On the other hand, communication through ESB may introduces overhead on the service calls which may eventually lead to a bottleneck [PV,Ima].
2.1.3 Microservices Architecture
Microservices architecture style is build around business functionality rather than technology like UI (User Interface), middleware and database. Is an approach where it is emphasized the devel-opment of single application as a suit of small services, each one running in their own process, communicating through lightweight mechanisms that are often HTTP resource APIs. A microser-vice is characterized for being a self-contained unit which represents one module’s end to end functionality. As we can observe in the figure 2.3, one application can be a collection of one or more modules. Consequently, a bunch of microservices working together, represents an applica-tion. It is recommended to have a database for each service (where the business’s logic is). As services are built around the business capabilities, they are independently deployable with fully automated deployment machinery. These services can be written in different programming lan-guages and use several different data storage technologies. This is possible because there is a minimum of centralized management of these services [Mar,Ara].
Figure 2.3: Microservices Architecture [Ara]
Some of the main challenges of microservices architecture approach are deciding when it makes sense to use them, and how to partition the application into microservices. The developers need to understand the system requirements and if the system may benefit from service decen-tralization because developing elaborated distributed architectures will slow down development and introduce complexity. Develop complex applications is inherently difficult. Opinions dif-fer from starting developing over the monolithic approach and others don’t recommend starting
Microservice Architecture
with the monolithic. In any case, since the monolithic architecture is the basis for microservices architecture, it is important to understand how the monolithic architecture works [Chr,Ant].
2.2
Monolithic Architecture vs Microservices
After briefly introducing the monolithic and microservice oriented architectures in sections 2.1.1
and 2.1.3respectively, it is now important to review the differences between this two architectures in a more thorough and careful manner, highlighting their advantages and disadvantages.
Review in the section 2.1.1, a monolithic architecture consists in a single application layer which supports the user interface, business rules and data manipulation [Mica]. In figure 2.1, we saw a classic example of a monolithic application where we have an enterprise application built in three parts: a client-side user interface, a database and a server-side application. The server-side application handles the client requests, executes the business logic, retrieves and updates the data in the database and select and populate the views to be sent to the client. This is a monolithic application since there is only a single logical executable. If there is any change in the system, it is required to build and deploy a new version of the server-side application.
The monolithic architecture is the most natural approach for developers to build such sys-tem. It is easier to use the language features to divide the application into classes, functions and namespaces keeping all the application logic for handling request in a single process. Application testing also becomes easier because developers can test the application in their laptops, and use a deployment pipeline, making sure that the changes are properly tested and deployed into produc-tion. Monolithic applications can be successful but we can only scale them horizontally behind a load-balancer. Over time it becomes frustrating, especially with the deployment of more and more applications to the cloud. This because a change in a small part of the application requires a rebuild and deployment of the whole monolith. In the course of time, it is very hard to keep a good modular structure making hard to keep the changes that just affect one module. In order to scale, we need to scale the entire application instead of parts of it.
Figure 2.4: Monoliths vs Microservices [Mar]
With the fact that services are independently deployed and scalable, each service has a firm boundary allowing the possibility of different services being written in different programming languages and managed by different teams.
The microservices architecture style is defined by a set of features that differentiate it from the monolithic architecture and highlight its benefits [Mar]:
• Componetization via Services
• Organized around Business Capabilities • Products not Projects
• Smart endpoints and dumb pipes • Decentralized Governance • Decentralized Data Management • Infrastructure Automation • Design for failure
Componetization via Services
Normally the desire of developers is building reusable code. They archive this by developing common libraries as part of their software that are integrated into microservices. The application componetization results from breaking down of the application into smaller services. Services as components will provide the application with the ability of being independently deployable rather than libraries. With this, we do not need to redeploy the entire application when a change is performed.
Microservice Architecture
Organized around Business Capabilities
When splitting large application into parts, it normally tends to divide it depending on the organizations structure following Conway’s Law.
“ Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
Melvyn Conway, 1967
It is possible to illustrate this law with in common organization. Normally in an organization, there is a set of multidisciplinary teams for different technology layers like the UI team, business logic team and database team. This kind of approach is common when developing a monolithic application.
Figure 2.5: Organization in a monolithic application 1 [Mar]
With a microservice architecture implementation, the organization is different. It tends to divide the large monolithic application into teams with different disciplinary knowledge. Each team is cross-functional, including all the range of the necessary skills to implement a complete software solution.
Figure 2.6: Organization in a microservices application 2 [Mar]
Products not Projects
Another common characteristic with microservices is the way how applications are developed. In a monolithic application there is a model where the main goal is developing a piece of software. After the development of this software, the product is then delivered and the team who developed it is disbanded. In comparison, microservices follows a model that each team should own the product over its full lifetime.
Smart endpoints and dumb pipes
Using microservices, applications aim to be the most decoupled and cohesive as possible fol-lowing smart endpoints and dumb pipes, while in monolithic applications, the components are executing in-process and communication between these components is via method invocation or function calls. Smart endpoints and dumb pipes states that each service is the owner of his own domain logic, applying this logic to a request, and producing a response. This responses are choreographed using RESTful APIs.
Decentralized Governance
With monolithic architecture comes the tendency to focus on just one platform technology due to centralized governance. Microservices technologies allow the possibility to choose the best solution for each service and each different problem, thus decentralizing the system’s governance.
Decentralized Data Management
Decentralized data management means that the data models differ between systems. In a monolithic architecture it is common to use a single database with many tables. This database persists all the data and sometimes some of the application’s logic. The microservice in contrast have their own database persistence, and sometimes a completely different database system.
Microservice Architecture
Figure 2.7: Data management comparison [Mar]
Microservices should manage with eventual consistency using transactionless coordination between services in comparison with monolithic architecture that use strong consistency using transactions.
Continuous Delivery and Infrastructure Automation
Continuous delivery and infrastructure automation benefits the services by facilitating the de-ployment of an application in production, delivering small portions of changes. This lowers the cost of integrating new changes to a production environment compared to iterative methods.
Design for failure
As we have seen, microservices in contrast to monolithic architecture divide the application into services and components. This implies that the software developed must be able to tolerate failures of the service. So, it is important to implement mechanisms of detecting failures as soon as possible because services may fail anytime. This mechanisms should be able to automatically restore the services if the situation allows it. There is a constant need of monitoring and logging setups for each individual service. That’s why it is important to design the application with certain stability patterns to improve its stability. Patterns like Timeouts, Circuit Breakers and Bulkheads [Mar].
2.3
Service-Oriented Architecture vs Microservices
After introducing the service-oriented in sections 2.1.2, it is now important to review the differ-ences between this architecture and microservices. Both architectures rely on services as their main component. Thus, services can be developed in various technologies which brings technol-ogy diversity into the development team [Ste].
Developers must deal with the complexity of architecture and a distributed system. They must implement the inter-service communication mechanism between microservices (if the message queue is used in microservice architectures) or within ESB and services [Ima]. Table2.1presents some of these differences between the two architectures.
SOA MSA
Built on the idea of “share-as-much-as-possible” architecture approach
Built on the idea of “share-as-little-as-possible” architecture approach
More importance on business functionality reuse
More importance on the concept of “bounded context”
Common governance and standards Relaxed governance, with more focus on peo-ple collaboration and freedom of choice Uses enterprise service bus (ESB) for
com-munication
Uses less elaborate and simple messaging system
Supports multiple message protocols Uses lightweight protocols such as HTTP/REST & AMQP
Common platform for all services deployed to it
Application Servers not really used. Plat-forms such as Node.JS could be used
Multi-threaded with more overheads to han-dle I/O
Single-threaded usually with use of Event Loop features for non-locking I/O handling Use of containers (Dockers, Linux
Contain-ers) less popular
Containers work very well in MSA Maximizes application service reusability More focused on decoupling Uses traditional relational databases more
of-ten
Uses modern, non-relational databases A systematic change requires modifying the
monolith
A systematic change is to create a new service DevOps / Continuous Delivery is becoming
popular, but not yet mainstream
Strong focus on DevOps / Continuous Deliv-ery
Table 2.1: SOA vs MSA
2.4
Migration from Monolithic
There are some challenges that organizations will face when attempting to implement a microser-vices architecture at scale.
Microservice Architecture
Before embarking, it is critical that everyone has a common understanding of a microservices ecosystem. Microservices ecosystem is a platform of services each encapsulating a business ca-pability. A business capability represents what a business does in a particular domain to fulfill its objectives and responsibilities.
Each microservice exposes an API that developers can discover and use in a self-serve manner. Microservices have independent life cycle. Developers can build, test and release each microser-vice independently.
The microservices ecosystem enforces an organizational structure of autonomous long stand-ing teams, each responsible for one or multiple services. Usually, in this kind of organization, there is more freedom in the development. A microservice can be structured and developed using different languages, individual infrastructures and launching custom scripts. This can became a problem because the organization may end up with a huge system where there are a thousand ways to do every single thing. It may end up with hundreds or thousands of services some of which are running, most of which are maintained, some of which are forgotten about.
Contrary to general perception and ‘micro’ in microservices, the size of each service matters least and may vary depending on the operational maturity of the organization [TC][Mar].
In order to better understand the difference between architectures and if the migration from one architecture to another is justifiable, table2.2, presents a comparison between them.
Monolith SOA + ESB Microservices
Single large application Several applications shar-ing services
Small autonomous ser-vices
Single deployment unit Multiple units depending on each other
Independently deployable units
Limited clustering possi-bilities
Distributed deployment Distributed deployment Homogeneous technolo-gies Heterogeneous technolo-gies Heterogeneous technolo-gies
Shared data storage Shared data storage Independent data storage Single point of failure Single point of failure
(ESB)
Resilient to failures In-memory function calls Remote calls (through
ESB)
Lightweight remote calls Single large team Multiple teams with
shared knowledge
Independent teams own-ing full lifecycle
2.5
Microservices Showcase
This chapter is an overview of some well-known companies that had to go through a process of architecture migration. This short overview contains the reasons that led these companies to make a change in architecture, as well as the obstacles/challenges they faced, as well what resulted from this migration.
2.5.1 SoundCloud
SoundCloud is an online audio distribution platform that enables its users to upload, record, pro-mote, and share their originally created sounds. This platform was a monolithic Ruby on Rails application. The author, Phil Calçado worked at SoundCloud during this transition period. Ac-cording to his testimony, the main reason for the company to carry out this migration was a matter of productivity and not pure technical matters. When he joined the company, he was integrated into the backend team, the called App team. This team was responsible for a Ruby on Rails mono-lithic application. The App team included everything in the Rails app, including the user interface. There was another team responsible for a single-page JavaScript web application. Teams followed the standard practice for the time and built it as a regular client to their public API, which was implemented in the Rails monolith. Both teams were really isolated and their only communication was during meetings or through issue trackers and IRC. If the development process was asked to any of the collaborators of the two teams, the answer would be something like this:
1. If there is a feature idea, someone write a couple of paragraphs and draw some mockups and discuss it with the team.
2. Designers shape up the user experience. 3. Write the code.
4. Small testing, and after it is deployed.
But during this process, there was a lot of frustration in the air. Managers and partners com-plained that they could never get anything done on time and engineers and developers that they were overworked. Phil Calçado during his stay in the company was able to understand the flow of development in the company and introduce important changes to increase the efficiency of the process and leave managers, partners, developers and designers happier. This new process was able to reduce development time and put all participants in the development of new features even closer, further reducing this development time. During this process improvement, issues such as:
• Why the need for Pull Requests?
Because after some years of experience, people often make silly mistakes, push the change live and take the whole platform down for hours.
• Why do people make mistakes so often?
Microservice Architecture
• Why is the code base so complex?
SoundCloud started as a very simple website. Over time it grew into a large platform with a lot of features, various different client applications, very different types of users, sync and async workflows, and huge scale. The code implements and contains the many components of a now complex system.
• Why the need of a single code base to implement the many components?
The monolithic already has a good deployment process and tooling, has a battle-tested ar-chitecture against peak performance and DDoS, is easy to scale horizontally, etc.
• Why can’t we have economies of scale for multiple, smaller, systems? Uhm..
The fifth question took a bit longer to answer. After a collection of experiences from peers and a survey, it was concluded that there would be two alternatives:
(a) Why not economies of scale for multiple, smaller, systems?
Is not that it’s not possible. The thing is that it won’t be as efficient as if we keep everything in one code base. Instead, we should build better tooling and testing around the monolith and its developer usability.
(b) Why not economies of scale for multiple, smaller, systems?
It’s possible but We will need to do some experimentation to find out what tooling and support we need. Also, depending on how many separate systems are built, we will need to think economies of scale as well.
Neither one of these approaches sounded obviously right or wrong. The biggest question is how much effort each approach would require. Money and resources weren’t a problem, but they didn’t have enough people or time to invest in anything big-bang. A strategy that could be implemented incrementally, but start delivering value from the very beginning was mandatory. Teams always thought that the back-end system was as simple as the figure 2.8.
Figure 2.8: SoundCloud Monolithic Architecture [Phia]
The normal mindset makes it seem obvious to implement this big box as a single monolithic instance. But soon after a more detailed analysis, it was possible to observe that the system was not as simple as the one of the picture above. If we opened that black-box, we would understand that the system was more like the (very simplified) one in the picture 2.9.
Figure 2.9: Component view of SoundCloud’s monolithic architecture [Phia]
The system was not just a simple website, it was a platform with several components. Each of them had their own owners and stakeholders, and independent life cycle. For example, the subscriptions module was only built once, and would only be modified when the payment gateway asked them to change something. But,notifications and several other modules related to growth and retention would suffer daily changes because of the increase of users and content. This because the different service expectations level. It would not be a problem if they could not have notifications working for one hour, but a five minute outage in the playback module would be enough to hit their metrics hardly. While exploring option (a), they came with the conclusion that that the only way to make the monolith work, would be making the components explicit, both in the code and deployment architecture.
At that code level, they needed to make sure that a change made to a single feature could be developed in a relative isolation, not requiring them to touch code from other components. They needed to be sure that changes would not introduce bugs or change the runtime behavior of the system. This is an old problem in the industry, and they knew that they had to make their implicit components explicit Bounded Contexts1, and make sure they knew what modules could depend on others.
Using Rails engines and various other tools to implement it, would look like the figure2.10.
Figure 2.10: SoundCloud component’s isolation architecture change 1 [Phia]
1Bounded Context is a central pattern in Domain-Driven Design. Is the focus of DDD’s strategic design section
which is all about dealing with large models and teams. DDD deals with large models by dividing them into different Bounded Contexts and being explicit about their interrelationships.
Microservice Architecture
On the deployment side, they would need to make sure that a feature could be deployed in isolation. Pushing a change to a module to production should not require new deployment of related modules, and if such deployment went bad and production broke, the only feature that would suffer some kind of impact would be the new one. In order to implement this, they thought of continuing to deploy the same artifact to all servers, but use a load-balancer to ensure that a group of servers was responsible for only one feature, isolating all problems with that feature and other servers2.11.
Figure 2.11: SoundCloud component’s isolation architecture change 2 [Phia]
The work to make this work would not be easy. Even though the above does not require any kind of departure from the stack of technologies and tools, these changes would bring their risks and issues. Even if everything went smoothly, the current code of the monolith would need to be refactored. Their code suffered a lot during the past years. They still needed to update from Rails 2.x to 3, and by itself, is a great effort [Phia]. Those considerations led them re-consider option (b). The team thought it wouldn’t look too different2.12.
At the end, at least they were able to benefit from the approach from day zero. Any new project they intended to build would become a greenfield, and the delay introduced by pull requests wouldn’t be necessary. They gave it a try and eventually build everything required for their first monetisation project as a service, isolated from the monolith. The project introduced several big features and a complete revamp of their subscription model, delivering the project ahead of deadlines. The experience was so good that they decided to keep applying this architecture for anything new they built. Their first services were built using Clojure and JRuby, eventually moving
to Scala and Finagle [Phia,Phib].
Microservice Architecture
2.5.2 Gilt
In 2015, at the Craft Conference, Adrian Trenaman (VP of engineering at Gilt.com) talked about the architectural evolution of Gilt.com from a monolithic architecture to a cloud-based microser-vice platform using Scala, Docker and AWS. Gilt is an online shopping and lifestyle website based out of the United States that has successfully evolved its application architecture. This company is specialized in flash-sales of luxury brands and lifestyle goods. Due to its flash-sales nature, traffic on the website oscillates massively fifteen minutes before the sales start and then, it rapidly reduces over the next two hours before returning to a new low baseline traffic. This results in the risk of the application failing, largely depending on the time of day [Dan].
Figure 2.13: Gilt flash-sales chart
“Our customers are like a herd of bison that basically stampede the site every day at 12pm. It’s our own self-imposed denial of service attack, every day...”
Adrian Trenaman, VP of engineering The Gilt.com website was built in 2007 using a Ruby on Rails monolithic application with a PostgreSQL database.
With the traffic increase, a memcached layer was added, and some business capabilities in the website moved to a series of batch processing jobs in order to try to give some more stability. In the following four years, with the constant increase of traffic, the monolithic nature of the application began to stress and any crash on the server, caused a complete failure of the website and supporting business applications.
In 2011, Gilt.com introduced Java programming language and JVM (Java Virtual Machine) into their application stack, and services based around their business functionality began being extracted from their original monolithic architecture. During this process, the dependencies around their original single database were not extracted as there were parts of the application that could benefit more from greater investment.
Figure 2.14: Gilt Architectural Evolution [Eme]
Adrian Trenaman, during the year of 2011 described Gilt architecture as ’large, loosely-typed JSON/HTTP services’ with exchange of data across service boundaries as a course-grained key/-value map. With the company rapidly evolving and innovating, the development team accidentally created a new java-based monolith in their "Swift" view service that quickly became a bottleneck. The architecture result was a codebase in which ’some parts people cared about, and some they did not’. Gilt needed to reorganize the teams around strategy initiatives (the so-called inverse Conway Maneuver 2) with the main goal of quickly putting code into production. Even without an ex-plicit architect role, a microservice-based architecture emerged called ’Lots of Small Applications (LOSA)’ driven by Gilt’s engineering culture and values. For each team working on any initiative, goals and key performance indicators (KPI) were set, and many other initiatives started, resulting in the creation of 156 microservices by 2015.
When Scala running on JVM was introduced in the company technological stack, the number of microservices grew. At this point, the average service at Gilt, consisted in 2000 lines of code and 5 source files running on three instances in production. During the period of 2011 and 2015, Gilt decided to ’lift and shift’ the legacy application to AWS, and began deploying new microservices into this platform. The vast majority of the services running at Gilt were running on AWS EC2 t2.micro instances 3. These kind of instances have relatively little compute power, but do offer 2Inverse Conway Maneuver: Conway’s Law asserts that organizations are constrained to produce application
de-signs which are copies of their communication structures. This often leads to unintended friction points. The ’Inverse Conway Maneuver’ recommends evolving your team and organizational structure to promote your desired architecture. Ideally your technology architecture will display isomorphism with your business architecture [Tho].
3T2 instances are Burstable Performance Instances that provide a baseline level of CPU performance with the ability
to burst above the baseline. T2 instances receive CPU Credits continuously at a set rate depending on the instance size, accumulating CPU Credits when they are idle, and consuming CPU credits when they are active. T2 instances are a good choice for a variety of general-purpose workloads including micro-services, low-latency interactive applications, small and medium databases, virtual desktops, development, build and stage environments, code repositories, and
Microservice Architecture
’burstable performance’.
Gilt was very positive about the microservice architecture, as it gave their organization some of the following benefits [Dan,Eme] :
• Faster code into production due to less dependencies between teams. • Multiple technologies/languages/frameworks support
• Graceful degradation of service
• Promotes easy innovation through ’disposable code’ - it is easy to fail and move on
But there were also a series of challenges with the implementation of this new microservice-based LOSA architecture:
• Maintaining multiple staging environments across multiple teams and services is hard - Gilt believe that testing in production is the best solution, for example, using ’dark canaries’ • Defining ownership of services is difficult - On Gilt, teams and departments own and
main-tain their services
• Deployment should be automated - Using Docker and AWS
• Lightweight APIs must be defined - Gilt have standardised on REST-style APIs, and are developing ’apidoc’, which they are labelling as ’an AVRO for REST’
• Staying compliant while giving engineers full autonomy in production is challenging -Gilt have developed ’really smart alerting’ within their ’continuous audit vault enterprise (CAVE)’ application
• Managing the I/O explosion requires effort - some inter-service calls may be redundant, and this is still a concern for the Gilt technical team. For example, loops are not currently automatically detected.
• Reporting over multiple service databases is difficult - Gilt are working on using real-time event queues to feed events into a data lake. This is currently implemented using Amazon’s Kinesis and S3 services.
With a large monolithic service, we need to scale everything together. As we can see, Gilt.com was unable to deal with the load being placed on it. Splitting their core parts of its system, they were able to deal with the traffic massive oscillation and today they have more than 450 microser-vices, each of them running in separate machines. When combining this with on-demand provi-sioning systems like the ones provided by AWS, it is possible to even apply scaling on demand for system pieces that need it. Following this kind of approach is even possible to application system costs more effectively. It’s not that often that following an architectural approach can be so closely correlated to an almost immediate cost savings effect [Sam].
Docker can help in other ways such as moving an application components to container, which can help in the implementation of microservices. In addition, this technology helps distribute and ship containers either in a local environment or in the Cloud.
2.6
Technology Overview
2.6.1 RabbitMQ
RabbitMQis an open source message broker that implements the AMQP protocol. This protocol is an application layer protocol specification for asynchronous messaging [Joe09]. In RabbitMQ there are two kinds of applications interacting with a messaging system: producers and consumers. Producers are those, who send (publishes) messages to a broker, and the consumers are those who receive messages from the broker. Usually, this programs runs on different machines and RabbitMQ acts as a communication middleware between them [Bae17]. Producers and consumers communicate through an exchange that can be the default or one that is defined in the settings. Exchanges work as a channel where multiple message queues are bridged between producers and consumers.
Messages are not published directly to a queue, instead, the producer sends messages to an exchange. Exchanges are message routing agents, defined per virtual host within RabbitMQ. An exchange is responsible for the routing of the messages to the different queues. An exchange accepts messages from the producer application and routes them to message queues with help of header attributes, bindings, and routing keys. A binding is a "link" that you set up to bind a queue to an exchange. The routing key is a message attribute. The exchange might look at this key when deciding how to route the message to queues (depending on exchange type). Exchanges, connec-tions, and queues can be configured with parameters such as durable, temporary, and auto delete upon creation. Durable exchanges will survive server restarts and will last until they are explicitly deleted. Temporary exchanges exist until RabbitMQ is shut down. Auto-deleted exchanges are removed once the last bound object unbound from the exchange. In RabbitMQ, there are four dif-ferent types of exchange that route the message difdif-ferently using difdif-ferent parameters and bindings setups [Lov15].
1. Direct Exchange: A direct exchange delivers messages to queues based on a message routing key. The routing key is a message attribute added into the message header by the producer. The routing key can be seen as an "address" that the exchange is using to decide how to route the message. A message goes to the queue(s) whose binding key exactly matches the routing key of the message.
2. Topic Exchange: Topic exchanges route messages to queues based on wildcard matches between the routing key and something called the routing pattern specified by the queue binding. Messages are routed to one or many queues based on a matching between a mes-sage routing key and this pattern.
3. Fanout Exchange: The fanout copies and routes a received message to all queues that are bound to it regardless of routing keys or pattern matching as with direct and topic exchanges. Keys provided will simply be ignored.
Microservice Architecture
4. Headers Exchange: Headers exchanges route based on arguments containing headers and optional values. Headers exchanges are very similar to topic exchanges, but it routes based on header values instead of routing keys. A message is considered matching if the value of the header equals the value specified upon binding.
Clients can create their own exchanges or use the predefined default exchanges, the exchanges created when the server starts for the first time.
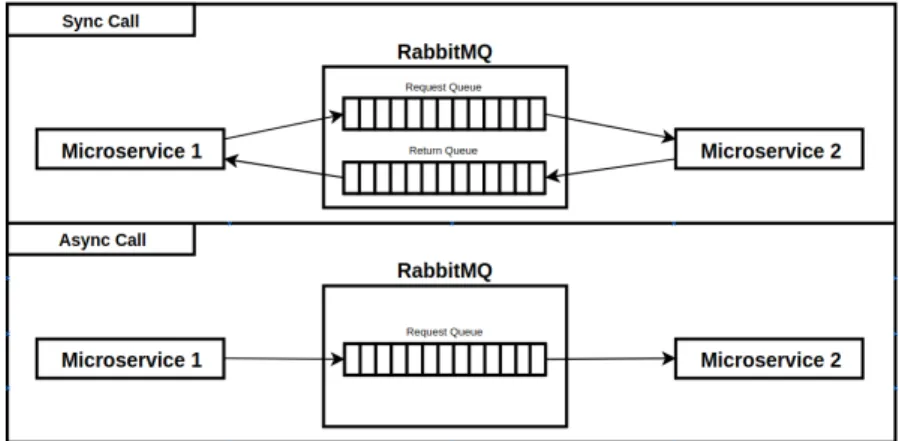
Figure 2.15: RabbitMQ Standard Message Flow
The standard RabbitMQ message flow represented in the figure2.15works as follows: 1. The producer publishes a message to the exchange.
2. The exchange receives the message and is now responsible for the routing of the message. 3. A binding has to be set up between the queue and the exchange. In this case, we have
bindings to two different queues from the exchange. The exchange routes the message in to the queues.
4. The messages stay in the queue until they are handled by a consumer. 5. The consumer handles the message.
2.6.2 Apache Ignite
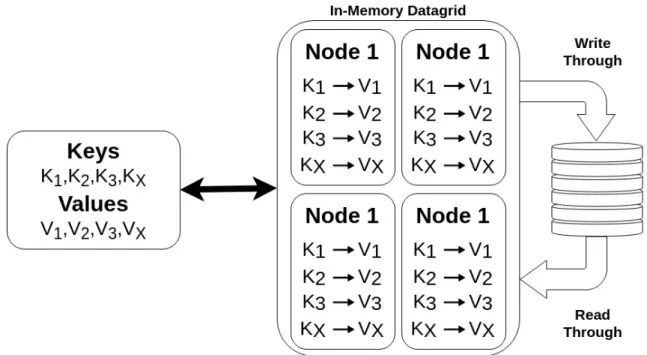
Apache Ignite is an in-memory durable, strongly consistent, and highly available computing plat-form with powerful SQL, key-value, and processing API’s. Data in Ignite is either partitioned or replicated across a cluster of multiple nodes2.16. The option to asynchronously propagate data to the persistence layer is an added advantage. Additionally, the ability to integrate with a variety of databases also makes Ignite an easy choice for developers to use it for database caching. This provides scalability and adds resiliency to the system. Ignite automatically controls how data is partitioned; however, users can plug in their own distribution (affinity) functions and collocate various pieces of data together for efficiency. Ignite provides a feature-rich key-value API that is JCache (JSR-107) compliant and supports Java, C++, and.NET [Dmi17,Pra].
It’s frequently integrated into third party software or SaaS solutions that have business models requiring the highest levels of performance and scalability. All this so that it can deliver an opti-mal user experience or meet SLAs for web-scale applications or data-intensive Internet of Things applications [Ale17].
The Apache Ignite native persistence uses new durable memory architecture that allows storing and processing the most frequently accessed data and indexes both in-memory and on disk. It evenly distributes the data across a cluster of computers in either partitioned or replicated manner as said earlier [Sha17] .
Microservice Architecture
2.6.3 Docker
Docker is a well-known and trendy technology in the industry and highly related to microservices. Is an open source platform for developing, shipping and running applications. Docker enables the separation of application from the infrastructure in order to deliver software quickly. With Docker, it is possible to manage the infrastructure in the same way we manage the applications. Using Docker’s methodologies for shipping, testing and deploying code quickly, it is possible to significantly reduce the delay between writing code and running it in production.
With Docker, it is possible to run an application in a isolated environment called a container. This kind of isolation and security allow us to run several containers simultaneously on a given host. Containers are lightweight because they don’t need the extra load of a hypervisor, but run directly within the host machine’s kernel. This allow us to run more containers on a certain hard-ware combination than if were using virtual machines. It is even possible to run docker containers within host machines that are actually virtual machines [Doc].
2.7
Conclusions
Literature review is a key part of the project. It allowed not only a broad view of the project, but also to understand how robust solutions could be developed for similar problems. This study also helped to understand the current state of paradigms of microservice-based architectures and how companies are responding. More and more companies make use of new technologies capable of promoting the stability and performance of their products. Companies such as SoundCloud and Gilt have had the need to migrate their architectures to respond to market needs. The comparison between the different existing architectures was quite important to understand their strengths as well as their most common advantages and uses. Docker’s technology overview was also impor-tant because Docker and microservices are often tightly connected because of Docker’s properties like isolation, lightweight communication, and easy deployment capabilities.
Chapter 3
Colbi Architecture
Despite Colbi’s architecture being quite simple, the transformation processes and flows that a SAF-T file goes through have some complexity. This complexity is mainly due to business rules inherent to the product. Therefore, it is necessary to make an overview of all these flows in order to understand how some of them could be parallelized and distributed in a new architecture.
3.1
General Architecture Overview
Figure 3.1: Colbi Architecture
The figure3.1represents the architecture of the product that is currently in production. The Ruby on Rails server makes all the interaction between the client and the product. Whenever a new file is submitted, it is responsible for placing it in Colbi’s file system, and registering it in the databases. Once the upload is complete, the file is ready to be consumed by the Colbi Core application. The Colbi Core application makes the entire flow of XML structural validation and file transformation into a more intelligible format. It elaborates these analyses through the
application of fiscal, accounting and auditing rules. All this data is stored at every step in both the Colbi databases and file system. These flows will be discussed in more detail on section3.2. The Colbi file system is an NFS mount that is accessible by both the Ruby server and Core. It consists of three folders: the Inbox stores the files that are ready to be consumed by Colbi Core, the Outbox stores intermediate files in CSV format, and the Processed Data stores the original files submitted by the clients.
3.2
Colbi Core Pipeline
Figure 3.2: Colbi Architecture
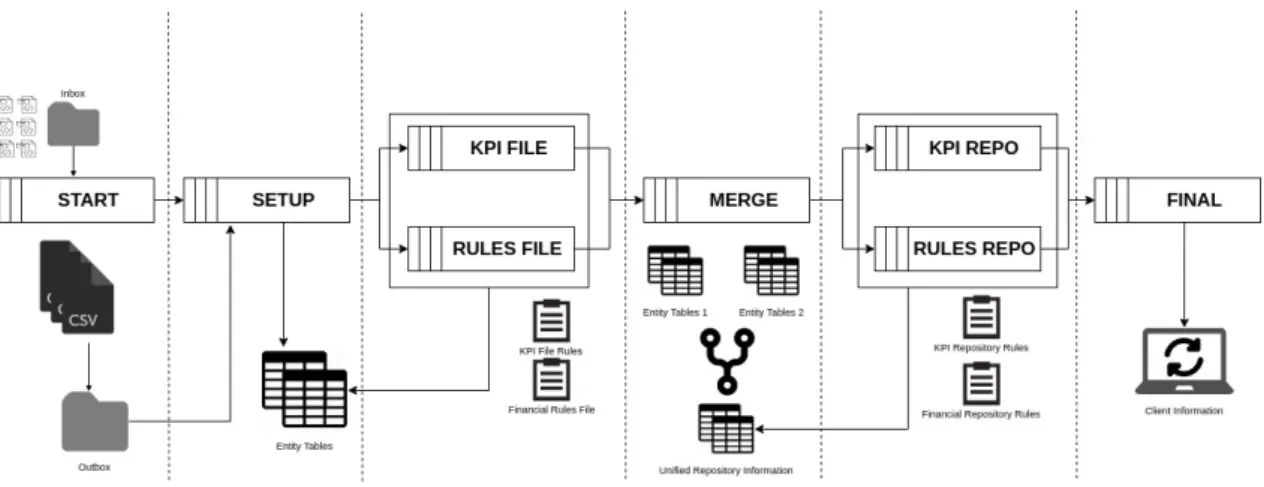
The application of Colbi Core during its analysis and processing, follows the flow pipeline of figure3.2. From the submission of a SAF-T file to the final product that corresponds to information with value, the file go through eight different flows:
• START: In this flow, there is an active reading of the Inbox folder to fetch SAF-T files to process. When it finds files, it starts parsing and transforming them into CSV documents and stores them in the Outbox folder. After transforming the XML file into CSV, the original file is stored in the Processed Data folder.
• SETUP: Injection of the previously generated CSV documents into the database.
• KPI FILE: A set of rules are applied to the previously injected CSV files. These rules have as their main purpose measure and evaluate how effectively a company is achieving key business objectives.
• RULES FILE: It is very similar to the flow described in figure 3.2 with the biggest dif-ference being the type of rules it applies. In this flow, fiscal, accounting, auditing and business-specific rules are applied in order to find fraud or inconsistent data.
• MERGE: Previously created and stored data is combined into a global repository. The repository holds all the client information and previous generated data from older SAF-T submissions.
Colbi Architecture
• KPI REPO: Global client KPI’s are calculated using all the information present in the repository. This allows the client to have a global overview of the business objectives. • RULES REPO: rules identical to Rules File 3.2 are applied, but this time on the global
repository.
• FINAL: file processing finishes and all the client views are updated.
3.3
Architecture and Pipeline Review
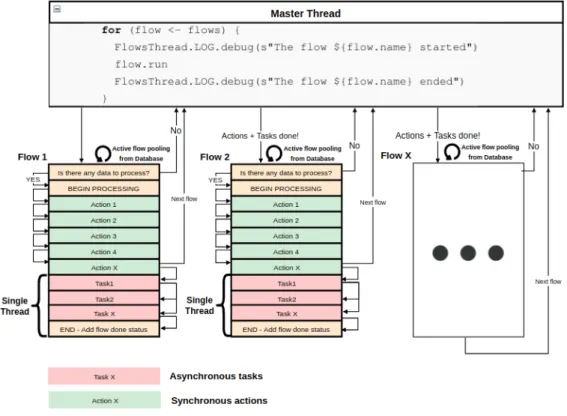
According to section3.1, it is possible to observe that with the current architecture, the platform tends to become slower due to its monolithic base. As there is a trend towards an increase in the number of companies and SAF-T files submissions, the machine responsible for this processing cannot scale horizontally and withstand this demand. This problem is fundamentally due to how the pipeline of section3.2is triggered and the lack of use of machine resources. This problem is of considerable relevance because if the platform is down, it can force companies to delay submitting their files to tax authorities, delay an emergent decision or internal company analysis which may eventually lead to profit loss. Therefore, the performance of the platform cannot be dependent on the processing capacity of a single processing machine. When analyzing the trigger of the flows, it was observed that there was a master thread responsible for the beginning of each of the flows as we can see in the figure3.3.
The ’for’ cycle is the basis of the entire product and runs uninterruptedly over the lifetime of the application. At each iteration of the cycle, the flow attempts to gather data to process through calls to the database. If there is no data to process, it proceeds to the next flow. If there is data to process, it begins its processing through a set of actions and tasks that are associated with it. These tasks and actions are defined in YAML files as represented in the YAML file3.1.
The execution of the actions is purely sequential and when its execution ends, the cycle imme-diately moves on to its next iteration. Tasks are dispatched to another thread that executes them asynchronously from the rest of the flows. In spite of this synchronism, the execution of a flow associated with a file only moves to the next flow, at the end of the tasks and associated actions. In this way, it is possible to observe that during the execution of the various flows, there is a delay of other flows that are ready to be executed because the cycle is trapped in the actions of another flow. 1 name: i m p o r t _ w o r k f l o w 2 t a s k s: 3 − name: p a r s e 4 − t a s k: P a r s e 5 e v e n t s: 6 s u c c e s s: 7 − name: merge 8 t a s k: Merge 9 p a r a m e t e r s: 10 a d a p t e r: o r a c l e 11 e v e n t s: 12 s u c c e s s: 13 − name: c a l c u l a t e _ k p i 14 t a s k: KPI 15 − name: c a l c u l a t e _ t r i a l _ b a l a n c e 16 t a s k: T r i a l B a l a n c e
Listing 3.1: Set of tasks of a flow defined in a Yaml file
Regarding tasks, there are times when they can be performed concurrently. Whenever two or more tasks of an associated flow are at the same level, they are performed concurrently in order to optimize the flow run time. Given the way in which actions and tasks are executed, it is not possible to perform great optimizations because of business logic inherent to the product.
3.4
Possible Optimizations
After analyzing the entire architecture and flow pipeline, although most flows, tasks, and actions are fairly optimized, there are flows that can run in parallel to improve product performance.
The execution of Rules and KPI either at the file level or in the repository, do not present any kind of dependency so that they can be executed in parallel. The SETUP flow can be optimized
![Figure 2.11: SoundCloud component’s isolation architecture change 2 [Phia]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15800627.1079245/39.892.310.625.336.735/figure-soundcloud-component-s-isolation-architecture-change-phia.webp)
![Figure 2.14: Gilt Architectural Evolution [Eme]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15800627.1079245/42.892.110.745.144.470/figure-gilt-architectural-evolution-eme.webp)