1
Instituto Superior de Economia e Gestão
U IVERSIDADE TÉC ICA DE LISBOA
Estimação de elasticidades constantes:
Deveremos logaritmizar?
Fábio Alexandre Campos
Orientação: Professora Doutora Isabel Maria Dias Proença
MESTRADO EM: DECISÃO ECO ÓMIA E EMPRESARIAL
i
Agradecimentos
Cabe me neste curto espaço agradecer a todos aqueles que de uma forma ou de outra
contribuíram para a prossecução e concretização deste trabalho.
As minhas primeiras palavras vão para a minha orientadora, a Dra. Isabel Maria Dias
Proença. A ela agradeço a incansável ajuda que me prestou nestes últimos meses, pela
presença sempre constante, pela frequente disponibilidade e pelo interesse que
demonstrou desde o início pela realização deste trabalho. Sem ela, dificilmente este
barco teria atingido o seu porto de chegada.
Quero agradecer também a todos os docentes do mestrado de Decisão Económica e
Empresarial, pelo apoio e conhecimentos transmitidos ao longo do ano e meio, que
durou a componente lectiva deste mestrado.
Agradeço também à Sinase, a empresa de consultadoria onde trabalho e onde sempre
trabalhei desde o inicio deste mestrado, e que me permitiu sempre conciliar a
componente laboral com a prossecução do mestrado.
Quero deixar umas palavras de agradecimento para o Joel e para o Bruno, meus colegas
de mestrado, com quem partilhei muitas horas de estudo, preocupações e bons
momentos. Um grande abraço para vocês.
Por último não quero deixar de agradecer à minha mãe e irmãos por todo o apoio
ii
Resumo
Há muito que os Economistas ignoram as implicações da desigualdade de Jensen. Na
estimação de modelos económicos não lineares, a prática habitual consiste em log
linearizar o modelo. Para que este procedimento seja válido é necessário assumir um
conjunto de hipóteses que na realidade revelam se muito restritas.
Neste trabalho, e seguindo de perto a abordagem de Santos Silva e Tenreyro (2006),
procura se analisar as implicações inerentes à estimação de elasticidades constantes a
partir do modelo não linear e do seu equivalente linear. Estas implicações serão
analisadas dos pontos de vista teórico e empírico.
Do ponto de vista teórico, demonstra se que a prática de estimar modelos linearizados
pode levar a estimativas enviesadas. Por outro lado, a aplicação empírica, não conduz a
uma conclusão tão assertiva. Todavia, a complexidade dos métodos de estimação de
modelos não lineares torna a sua utilização menos atractiva face ao OLS. No entanto, as
razões teóricas são suficientemente fortes para se concluir que o modelo não deverá ser
logaritmizado. Contudo, tal decisão cabe em última análise naturalmente ao utilizador, e
caso este decida não logaritmizar deverá ter em conta as respectivas implicações,
realizar todos os testes de especificação disponíveis e interpretar e analisar as
estimativas obtidas com cautela.
iii
Abstract
Economists have long ignored the implications of Jensen's Inequality. In the estimation
of non linear economic models, the usual practice is to log linearize the model. For this
procedure to be valid it´s necessary to take a set of assumptions which turn out to be
very strict.
This work, follows closely the approach of Santos Silva and Tenreyro (2006), and seeks
to analyze the implications inherent in the estimation of elasticity constants from the
nonlinear model and its linear equivalent. These implications will be considered in a
theoretical and empirical point of view.
From the theoretical point of view, it’s demonstrated that the practice of estimating
linearized models can lead to biased estimates. On the other hand, the empirical
application does not lead to a conclusion so assertive. However, the complexity of the
estimation methods of nonlinear models makes their use less attractive compared to
OLS. However, the theoretical reasons are strong enough to conclude that the model
should not be taken in logarithmic form. However, ultimately this decision belongs to
the user, if it should decide to apply the logarithm form, it should take into account the
implications, perform all the specification tests available, interpret and analyze the
estimates obtained carefully.
iv
Índice
1. Introdução ... 1
2. Enquadramento Teórico ... 3
2.1 Introdução ao conceito de Elasticidade ... 3
2.2 Tipos de Elasticidades ... 3
2.2.1 – Elasticidade Preço da Procura ... 3
2.2.2 Elasticidade Preço da Oferta... 4
2.2.3 Elasticidade Preço Cruzada ... 4
2.2.4 – Elasticidade Rendimento da Procura ... 4
2.3 Definição do conceito de elasticidade ... 5
2.4 A elasticidade no seio da Econometria ... 6
2.4.1 O modelo teórico... 6
2.4.2 O modelo empírico ... 6
2.5. O cálculo da elasticidade: modelos lineares e modelos não lineares ... 7
2.5.1 O cálculo das elasticidades nos modelos lineares ... 7
2.5.2 O cálculo das elasticidades nos modelos não lineares ... 7
2.5.2.1 Introdução da variável residual na forma aditiva ... 8
2.5.2.2 Introdução da variável residual na forma multiplicativa ... 8
2.6 – A Desigualdade de Jensen: linearizar vs não linearizar ... 9
2.7 Estimação ... 12
2.7.1 – O Estimador Ordinary Least Squares (OLS) ... 12
2.7.2 – O Estimador on Linear Least Squares (NLS) ... 13
2.7.3 – O Estimador Pseudo Maximum Likelihood (PML) ... 14
3. Análise Empírica ... 16
3.1 Dados ... 16
3.2 Resultados Empíricos ... 18
3.3 Testes de validade do OLS ... 22
3.3.1 Teste de Park ... 22
3.3.2 Testes de Heterocedasticidade na variável residual multiplicativa... 23
3.3.2.1 Teste 1 ... 23
3.3.2.2 Teste 2 ... 24
3.4 Comparação dos resultados obtidos pela aplicação dos estimadores OLS e PML ... 25
4. Conclusão ... 27
v
Anexos ... 30
Anexo A ... 30
Anexo B ... 34
Anexo C ... 37
Anexo D ... 39
Anexo E ... 41
1
1. Introdução
“Economists have long been aware that Jensen’s inequality implies that ( ) ≠ ( ) , that is, the expected value of a random variable is different from the logarithm of its expected value. This basic fact however, has been neglected in many econometric
applications.” Santos Silva e Tenreyro (2006).
Esta afirmação de Santos Silva e Tenreyro (2006) é o ponto de partida deste trabalho, e
consequentemente da questão: Estimação de elasticidades constantes: Deveremos
logaritmizar?
Em Economia, na estimação de elasticidades, os economistas têm uma clara preferência
por elasticidades constantes, em parte porque as mesmas são mais fáceis de interpretar,
o que os leva a especificarem modelos não lineares do tipo da função de Cobb Douglas.
O procedimento habitual consiste em log linearizar este modelo permitindo de uma
forma rápida e intuitiva obter a elasticidade pretendida. No entanto, como mencionado
por Santos Silva e Tenreyro (2006), há muito que os Economistas ignoram as
implicações da desigualdade de Jensen ao log linearizar o modelo na estimação dos
respectivos parâmetros desconhecidos. De facto, para que este procedimento seja
correcto, é necessário assumir um conjunto de hipóteses que na prática acabam por ser
muito restritas. Assim, neste trabalho, e seguindo de perto a metodologia de Santos
Silva e Tenreyro (2006), procura se analisar as implicações inerentes à estimação de
elasticidades constantes num modelo na sua forma linear e na sua forma não linear.
Estas implicações serão analisadas primeiro sobre o ponto de vista teórico e depois
através da realização de um estudo empírico.
Este trabalho, encontra se assim estruturado em duas partes fulcrais. A primeira parte
inicia se com um enquadramento geral do conceito de elasticidade, seguindo se uma
abordagem deste conceito nos modelos econométricos, distinguindo se entre modelos
lineares e não lineares com diferentes formas de incorporação da variável residual, e
respectivas consequências na estimação das elasticidades. Esta parte culmina com uma
2
A segunda parte recai sobre uma análise empírica com dados cedidos por Yatchew e
utilizados no seu estudo “Household Gasoline Demand in Canada” em Yatchew e
Joungyeo (2001).
A aplicação empírica tem como objectivo estimar as elasticidades preço e rendimento
da procura de combustível, usando o procedimento habitual baseado no OLS e a
proposta inovadora de Santos Silva e Tenreyo (2006) que estima os parâmetros
directamente do modelo não linear através do estimador PML. No final serão
3
2. Enquadramento Teórico
2.1 4 Introdução ao conceito de Elasticidade
A elasticidade no seio da teoria económica é um conceito que assume extrema
importância. Na verdade o conceito de elasticidade é muito útil para compreender o
efeito da variação exógena das variáveis económicas em diversos indicadores
nomeadamente, a incidência de impostos indirectos, conceitos marginais e de como eles
se relacionam com a teoria da empresa, da distribuição da riqueza e de diferentes tipos
de bens, e como a escolha dos bens se relaciona com as escolhas do consumidor. Além
disto é também um conceito crucialmente importante em qualquer debate sobre a
distribuição do bem estar, excedente do consumidor, excedente do produtor e excedente
orçamental.
2.2 4 Tipos de Elasticidades
Em economia a elasticidade aparece indexada a diversos conceitos, que são usados para
determinar reacções e estabelecer algumas relações, sendo exemplos desses conceitos os
referidos a seguir.
2.2.1 – Elasticidade4Preço da Procura
Esta elasticidade, relaciona a variação percentual da quantidade
procurada de um produto com a variação percentual do preço desse
produto sendo usada para determinar as reacções do consumidor às
variações no preço. Este tipo de elasticidade quando conhecida pelos
produtores permite a estes deduzir que tipos de variações deverão incutir
no preço para aumentar a sua receita total;
4
2.2.2 4 Elasticidade4Preço da Oferta
Este tipo de elasticidade relaciona a variação percentual da quantidade
oferecida de um produto com a variação percentual do seu preço, sendo
determinante para saber as reacções do produtor às variações no preço;
!"# $ =∆% ∆% %&ç
2.2.3 4 Elasticidade4Preço Cruzada
A Elasticidade Preço Cruzada, relaciona a variação percentual da
quantidade oferecida de um produto X com a variação percentual do
preço de um produto Y, sendo usada para determinar o tipo de relação de
consumo entre os produtos X e Y, permitindo determinar se estes são
bens complementares (Elasticidade Preço Cruzada <0), substitutos
(Elasticidade Preço Cruzada >0) ou se não tem qualquer relação de
consumo entre si (Elasticidade Preço Cruzada =0);
#ç '( ) * =∆% ∆% ç +
2.2.4 – Elasticidade4Rendimento da Procura
Este tipo de elasticidade, mede a relação entre a variação da quantidade
procurada de um bem em função da variação percentual ocorrida no
rendimento, permitindo assim estabelecer se o bem em causa é um bem
de luxo (Elasticidade Rendimento da Procura> 1), normal (0<
Elasticidade Rendimento da Procura<1) ou inferior(Elasticidade
Rendimento da Procura <0)
5
Os conceitos acima mencionados são de natureza microeconómica, contudo o conceito
de elasticidade estende se a um outro conjunto de áreas, como por exemplo o mercado
cambial e as exportações.
2.3 4 Definição do conceito de elasticidade
Generalizando o conceito de elasticidade, suponha se que existe uma relação funcional
entre e 1, tal que = &(1). A elasticidade de em ordem a 1, representa o grau de sensibilidade da variável , face a variações exógenas na variável 1 que a determina. Algebricamente, a elasticidade é dada pela variação percentual na variável dividida
pela variação percentual na variável 1, sendo determinada pela fórmula
∗( ; 1) = %∆
%∆1 =
∆ × 100 ∆1
1 × 100
= ∆∆1 ×1
No caso particular em que as variáveis e 1 são contínuas e a função f é derivável, a elasticidade pontual de em ordem a 1 será dada por,
( ; 1) = lim∆:→< ∆∆1 ×1 = 1 ×1 = &(1)1 × &(1)1
Com &(1) > 0 e 1 > 0, é o equivalente a ter,
( ; 1) = 1 = &(1) 1
Na maioria das ciências económicas, quando abordamos o conceito de elasticidade, a
fórmula que está em causa é a fórmula (1).
(2) (1)
6 2.4 4 A elasticidade no seio da Econometria
Segundo Goldberger, citado por Silva Ribeiro (2010), a Econometria, pode ser definida
como “ a ciência social em que as ferramentas da teoria económica, da matemática e
da inferência estatística são utilizadas na análise de fenómenos económicos”, pelo que
na Econometria a própria noção de elasticidade, tem de se adaptar ao próprio contexto
estatístico, sem contudo perder o seu sentido intuitivo económico.
2.4.1 4 O modelo teórico
De uma forma geral quando se procura estabelecer a relação entre variáveis, com o
objectivo de determinar, explicar ou prever o seu comportamento, são utilizados
modelos que são especificados tendo por base a teoria económica. Estes modelos
assumem uma relação exacta, sendo designados como modelos teóricos que podem
assumir por exemplo uma relação linear, do género = > + @1, ou uma relação do tipo de função de Cobb Douglas = A1B, entre outros exemplos possíveis. Esta função tem a particularidade de que a elasticidade entre e 1 é constante (não depende nem de 1 nem de ), sendo por isso muito popular entre os economistas.
2.4.2 4 O modelo empírico
Para existir uma maior aderência do modelo à realidade económica e em particular aos
dados, é comum adicionar ao modelo teórico uma variável aleatória que se designa
por variável residual. Esta é não observável e abrange o conjunto de todos os factores
que não foram considerados no modelo teórico, mas que podem afectar o
comportamento da variável explicada, podendo estes factores incluir variáveis não
observáveis, variáveis omitidas e erros de medida. Estes tipos de modelos designam se
por modelos empíricos. Nestes modelos, a relação entre e 1 deixa de ser exacta pois para o mesmo 1 podem corresponder diferentes valores de .
7 : = D |1F1 × D |1F = 1 &(1)1 ×&(1)1
de forma a obter uma expressão semelhante a (2).
Caso D |1F > 0 e 1 > 0, a equação (4), é equivalente a,
: = D ( |1)F (1)
2.5. 4 O cálculo da elasticidade: modelos lineares e modelos não lineares
Em Econometria, podem distinguir se dois grandes grupos de especificação no que
concerne à modelação de dados, os modelos lineares nos parâmetros e os não lineares.
Consoante o tipo de modelo adoptado, o cálculo da elasticidade pode assumir diferentes
expressões.
2.5.1 4 O cálculo das elasticidades nos modelos lineares
No que concerne aos modelos lineares empíricos, estes geralmente assumem a
formulação, = @<+ @G1 + , e a fórmula a usar será a (4). Como D |1F corresponde ao modelo teórico, = @<+ @G1, a elasticidade é igual a,
: = @G×1
2.5.2 4 O cálculo das elasticidades nos modelos não lineares
Relativamente aos modelos não lineares, são geralmente consideradas formulações para
o modelo teórico do tipo = A1BH, com > 0 e 1 > 0 onde, esta formulação é
facilmente linearizável atendendo a que
(4)
8
= A1BH = βIJBHK-: ⟺ =β
<+ @G 1.
Neste modelo, facilmente se deduz a elasticidade de em ordem a 1 recorrendo a (3), obtendo se,
:= 1 = @G
Na construção do modelo não linear empírico, podem distinguir se duas opções que
diferem na forma como a variável residual é incorporada no modelo teórico, podendo
esta ser integrada de um forma aditiva ou multiplicativa.
2.5.2.1 4 Introdução da variável residual na forma aditiva
No que diz respeito à introdução na forma aditiva, iremos incidir sobre a função = βIJBHK-: + M, que é um modelo que não é passível de ser linearizado. Assim
assumindo a hipótese DM|1F = 0 obtêm se D |1F = βIJBHK-:, sendo este o modelo
teórico de partida. Neste caso facilmente se deduz a elasticidade recorrendo a (5) onde,
:= @G.
No entanto, a hipótese DM|1F = 0, pode ser uma hipótese muito restritiva, nomeadamente porque se tem que M > − BIJ BHK-: de forma a que > 0.
2.5.2.2 4 Introdução da variável residual na forma multiplicativa
Por outro lado temos a forma multiplicativa, que é uma abordagem habitualmente mais
usada, pois permite linearizar o modelo. Nesta iremos recorrer à função =
βIJBHK-: × = βIJBHK-:J , que poderá ser linearizada para = β
<+ @G 1 +
9
Assumindo a hipótese D |1F = 1, então D |1)F = βIJBHK-: , :calcular se á com
recurso a (5), e := @G. No entanto, partindo do modelo linearizado = β<+ @G 1 + , e assumindo simultaneamente D |1F = 0, chegaríamos ao mesmo resultado se aplicássemos a seguinte fórmula,
: = D ( |1)F1
O facto de para esta situação particular as fórmulas (5) e (6) conduzirem ao mesmo
resultado, levou a que a forma multiplicativa de adição do termo de erro fosse muito
usada pois a fórmula (6) permite, após a linearização do modelo obter a elasticidade : de uma forma imediata. Este é o procedimento a que habitualmente se recorre,
independentemente de se verificarem as hipóteses mencionadas ou não.
2.6 – A Desigualdade de Jensen: linearizar vs não linearizar
Como verificado, a obtenção da elasticidade :, pode ser independente da linearização ou não do modelo em causa. No entanto as fórmulas (5) e (6) podem não ser
equivalentes, todavia para melhor entender esta situação é importante introduzir o
conceito da Desigualdade de Jensen. Este é um resultado, desenvolvido pelo
matemático holandês Johan Jensen. Na sua forma mais simples esta desigualdade define
que para uma função &(1) convexa, verifica se que D&(1)F ≥ &D (1)F, e um dos corolários desta desigualdade, refere que se verifica a inversão da desigualdade para
funções concavas como é o caso da função logaritmica.
Comparando melhor as fórmulas (5) e (6), generaliza se que segundo a desigualdade de
Jensen, verificar se ia que ln D |1F ≥ D |1F donde as fórmulas (5) e (6) nem sempre conduzem ao mesmo resultado. No entanto e como foi constatado, as duas
fórmulas conduzem a resultados idênticos, se se verificarem as hipóteses D |1F = 0 e D |1F = 1.
Todavia na realidade as hipóteses D |1F = 1 e D |1F = 0 podem ser violadas. Como exemplo considerem se as situações abaixo indicadas onde = βIJBHK-: × .
10
Exemplo A: D |1F = 0 e D |1F ≠ 1
A.i) Se |1~S(0, UV), (UV > 0)) então é conhecido que, D |1F = WX/V;
Com recurso a (5) vem,
: = ln ( D |1F) (1) = ln(
βIJBHK-: × D |1F)
(1) = ln(
βIJBHK-: × WX/V)
(1) = @G
Com recurso a (6) vem,
: = D ( |1)F1 = D (
βIJBHK-: × )F
1 =
(β<+ @G 1 + D |1F)
1 = @G
A.ii) Com heterocedasticidade em que |1~S(0, UV(1)), supondo , por exemplo que UV(1) = ZG 1, com ZG > 0 e 1 > 0 então
D |1F = [V K-:H
e portanto vem,
D |1F = βIJBHK-: × D |1F = βIJBHK-: × \HXK-:
⇔ D |1F = βIJ(BHJ \HX) K-:
Com recurso a (5) vem,
:= ln ( D |1F) (1) = ln(
βIJ(BHJ [V ) K-: H )
(1) =
Dβ<+(@G+ Z2 ) 1FG
(1) = @G + Z2 G
Com recurso a (6) vem
: = D ( |1)F1 = D (
βIJBHK-: × )F
1 =
(β<+ @G 1 + D |1F)
11
Exemplo B: D |1F ≠ 0 e D |1F = 1
B.i) Se |1~S(_, UV), (UV > 0)) então é conhecido que D |1F = `J aXX
e como D |1F = < = 1 vem,
_ +U2 = 0 ⇔ _ = D |1F = − V U2 V
Com recurso a (5) temos,
:= ln ( D |1F) (1) = ln(
βIJBHK-: × D |1F)
(1) = ln(
βIJBHK-: )
(1) = @G
Com recurso a (6) teremos
: = D ( |1)F1 = D (
βIJBHK-: × )F
1 =
(β<+ @G 1 + D |1F) 1
= (β<+ @G 1 − U
V
2 )
1 = @G
B.ii) Com heterocedasticidade em que |1~S(_, UV(1)), supondo , por exemplo que UV(1) = ZG 1, com ZG > 0 e 1 > 0 então
D |1F = `J [V K-(:)H
o que implica que
_ = D |1F = − Z2 (1)G
Com recurso a (5) vem,
:= D ( |1)F (1) = ln(
βIJBHK-: × D |1F)
(1) = ln(
βIJBHK-: )
12
Com recurso a (6) temos,
: = D ( |1)F1 = D (
βIJBHK-: × )F
1 =
(β<+ @G 1 + D |1F) 1
= (β<+ @G 1 − Z1 2 (1))G = (β<+ (@G− Z1 2 ) 1)G = @G− Z2G
Nos exemplos acima mencionados, no caso em que existe homocedasticidade, o efeito
decorrente da violação das hipóteses D |1F = 1 e D |1F = 0, é absorvido pelo termo independente, conduzindo as fórmulas (5) e (6) ao mesmo resultado. Todavia e como
podemos constatar, a existência de heterocedasticidade, tanto no exemplo A como no
exemplo B, leva a que as fórmulas (5) e (6) conduzam a resultados distintos.
2.7 4 Estimação
Até este ponto, o objectivo concentrou se na dedução da elasticidade em função de
diferentes tipos de modelação que podem ser adoptados. Como a elasticidade depende
dos parâmetros desconhecidos do modelo, também é importante abordar o tópico da
estimação destes parâmetros.
2.7.1 – O Estimador Ordinary Least Squares (OLS)
Um dos estimadores mais populares em econometria é o OLS. Este é um método muito
utilizado quando trabalhamos com modelos lineares nos coeficientes do tipo,
= @<+ @G1 +
O OLS permite assim obter as estimativas @b e < @b que minimizam a soma do quadrado G dos resíduos onde c = − c é o resíduo, e,
13
Este estimador verifica o conhecido resultado de ser centrado e de variância mínima
dentro da classe dos estimadores lineares não enviesados, se verificar as hipóteses
designadas como hipóteses de Gauss Markov, enunciadas de seguida:
1. O modelo em causa deve ser linear nos parâmetros;
2. D |1F = 0;
3. Não deve existir multicolinariedade perfeita;
4. O termo de erro deve ser homocedástico e não autocorrelacionado.
Por outro lado o estimador OLS é também consistente desde que e 1 não sejam correlacionados.
No caso do modelo não linear introduzido na secção anterior, o procedimento de
estimação habitual consiste em aplicar o OLS ao modelo linearizado = @<+ @G 1 + assumindo D |1F = 0. No entanto, este procedimento é inapropriado
por um conjunto de razões. A primeira destas razões é a situação em que = 0, neste caso não será possível obter , não sendo possível linearizar o modelo e aplicar o
OLS. A segunda e terceira razão são abordadas por Santos Silva e Tenreyro (2006).
Segundo estes autores, quando dD |1F é heterocedástica, D |1F pode depender de vários aspectos da distribuição condicional de , (veja se o exemplo B da secção
anterior), podendo verificar se D |1F ≠ 0, ser função de 1 não permitindo assim possível estimar os parâmetros do modelo de forma consistente. Santos Silva e Tenreyo
referem no seu artigo, que mesmo que se estime de forma consistente D |1F, este pode não permitir a identificação dos parâmetros de D |1F. É o caso do exemplo A. Sendo esta apontada como a terceira razão para a inadequabilidade do OLS.
2.7.2 – O Estimador ;on Linear Least Squares ( LS)
Dada a inadequabilidade do OLS para estimar o modelo na sua forma log linear, é
necessário estimar o modelo na forma não linear. Para este efeito um dos estimadores
passíveis de ser usado é o estimador NLS. O NLS é um estimador que assenta nas
14
1. D |1F = ℎ(1, @), onde ℎ(1, @) representa uma função que deverá ser diferenciável duas vezes;
2. Os parâmetros do modelo devem ser identificáveis;
3. D |ℎ(1, @)F = 0;
4. O termo de erro deve ser homocedástico e não autocorrelacionado.
Tal como o OLS, o NLS procura obter os @f, que minimizem a soma do quadrado dos resíduos, sendo o resíduo c = − ℎ(1, @f). Em relação às propriedades o estimador NLS, não possui um bom comportamento com amostras pequenas, embora verificando
se as hipótese 1 a 3 enunciadas no parágrafo anterior se prove que é consistente. Não se
verificando a hipótese 4, as variâncias devem ser estimadas de forma robusta1.
2.7.3 – O Estimador Pseudo Maximum Likelihood (PML)
Alternativamente ao estimador NLS, Santos Silva e Tenreyro (2006) sugerem a
utilização de estimador baseado na maximização de uma Pseudo Verosimilhança
(PML). Este procedimento tem como base o resultado teórico de Pseudo
Verosimilhanças obtido por Gourieroux, Monfort e Trognon (1984). Segundo estes
autores, caso a distribuição do modelo a estimar pertença à família das distribuições
exponenciais lineares, e desde que exista uma coincidência das médias condicionais
entre a distribuição verdadeira dos dados e uma outra distribuição conveniente, então, o
ponto que maximiza a função de verosimilhança da distribuição que não é a verdadeira,
será estimador consistente dos parâmetros da média condicional da distribuição
verdadeira dos dados. Contudo neste processo as variâncias têm de ser estimadas de
forma robusta. Santos Silva e Tenreyo (2006) sugerem o uso da distribuição de Poisson
para construir a Pseudo Verosimilhança.
Estes autores conduziram um estudo de simulação com o objectivo de aferir a
performance de diferentes métodos, para estimar modelos de elasticidades constantes na
presença de vários padrões de heterocedasticidade. Para o efeito usaram um modelo
multiplicativo do tipo D |1G, 1VF = 1g(@<+ @G1G+ @V1V), com várias especificações possíveis para d D |1G, 1VF.
1
15
Os resultados obtidos são muito esclarecedores. Por um lado Santos Silva e Tenreyro
(2006), argumentam que o estimador OLS bem como o estimador OLS em que os dados
foram modificados para lidar com a existência de zeros na amostra apresentam uma
baixa performance, concluindo que só em situações excepcionais é que é recomendado
fazer estimações com base em modelos log lineares. Um resultado surpreendente obtido
neste estudo foi o facto do estimador NLS apresentar uma performance muito abaixo da
esperada, devendo se este resultado ao comportamento errático deste estimador na
presença de heterocedasticidade. O estimador PML baseado numa Poisson (PPML)
apresenta resultados encorajadores, apresentando mesmo um comportamento melhor
que o NLS. Por um lado o estimador PPML, apresenta enviesamentos sempre menores,
por outro é um estimador simples de implementar e é confiável para um conjunto de
situações. Com base nestes resultados, e à semelhança de Santos Silva e Tenreyro
(2006), iremos também optar pelo estimador PPML em alternativa ao OLS do modelo
16
3. Análise Empírica
Nesta secção do trabalho serão analisados e comparados os resultados obtidos através da
aplicação dos estimadores PML e OLS. Esta secção encontra se dividida em 4
subsecções. Na primeira serão apresentados os dados a serem utilizados. A segunda
subsecção irá incluir uma análise inicial dos resultados empíricos obtidos decorrentes da
estimação com as metodologias referidas e a aplicação de alguns testes de
especificação. Na terceira subsecção serão abordados alguns testes realizados com o
intuito de avaliar a validade de aplicação do estimador OLS e na última subsecção as
elasticidades obtidas pelos dois métodos de estimação serão comparadas.
3.1 4 Dados
Os dados usados neste trabalho são uma cross section com 2464 observaçõesreferente
ao ano de 1996 dos dados obtidos do ational Private Vehicle Use Survey, conduzido
por um conjunto de técnicos canadianos entre Outubro de 1994 e Setembro de 1996.
Os dados em causa, contêm informação sobre os veículos, padrões de consumo de
combustível e aspectos socioeconómicos de agregados familiares com pelo menos um
condutor. O preço foi obtido dividindo o valor total gasto mensalmente em combustível
pelo nº total de litros consumido. Relativamente ao rendimento, este é reportado ao ano
anterior. Como proxy para o consumo de combustível a base de dados disponível
considerou a distância percorrida pelo agregado familiar. Para agregados familiares com
mais do que um veículo, é seleccionado um aleatoriamente na altura da entrevista,
sendo a variável dependente igual ao número de quilómetros percorridos por este
veículo. Foi ainda recolhida informação relativa à idade do condutor em que, no caso de
existirem mais do que 1 veículo, representa a idade do condutor do veículo
seleccionado. Dado que tendencialmente os condutores que vivem na cidade tendem a
conduzir menos do que os outros com iguais características, foi incluída uma variável
dummy para avaliar este efeito.
Em resumo, as variáveis que irão ser utilizadas no decurso da análise empírica são:
DIST – Representa a distância percorrida por mês pelo condutor seleccionado;
17
INCOME – Rendimento anual do agregado familiar;
DRIVERS – Número de condutores habilitados para conduzir existentes no
agregado familiar;
HHSIZE – Tamanho do agregado familiar;
VEH – Número de veículos do agregado familiar;
AGE – Idade do elemento representante do agregado familiar;
AGE2 – Representa a variável AGE ao quadrado;
MONTH j – Mês em que os dados foram recolhidos (j=1,…,8);
YSINGLE – Variável dummy que assume o valor 1 para indivíduos solteiros
com idade até 35 anos;
RETIRE – Variável dummy que assume o valor 1 para representantes do
agregado familiar com idade superior a 65 anos;
DUR – Variável dummy que assume o valor 1 para indivíduos que sejam da
cidade.
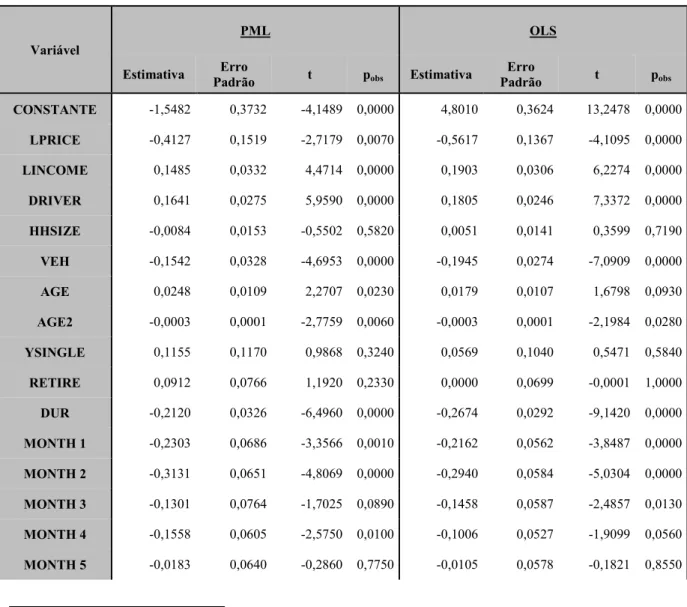
As estatísticas descritivas referentes a estas variáveis encontram se na tabela 1,
Tabela 1 4 Estatísticas descritivas
Variáveis Média Desvio
padrão Mínimo Máximo
DIST 1625,25 1210,11 15 17198
PRICE ($CAD/Litro) 0,588 0,059 0,23 0,81
INCOME ($CAD) 50073,1 25272,3 20000 10000
DRIVER 1,911 0,72 1 6
HHSIZE 2,806 1,315 1 6
VEH 1,518 0,631 1 5
AGE 46,59 12,4 19 66
YSINGLE 0,028 0,165 0 1
RETIRE 0,137 0,344 0 1
DUR 0,713 0,452 0 1
Das estatísticas acima, é de mencionar o facto de que no conjunto de dados estudado, só
existem 2,8% de indivíduos solteiros com mais de 35 anos, e que só existem 13,7% de
indivíduos reformados. Por outro lado constata se que grande parte dos elementos da
amostra (71,3%) são condutores urbanos. É de salientar que em média cada agregado
familiar tem 1,5 veículos, e é constituído por 3 indivíduos, e tem 2 condutores com
18 3.2 4 Resultados Empíricos
Nesta secção apresentam se os resultados obtidos da estimação do seguinte modelo que
explica o consumo de combustível de um agregado familiar, usando como proxy do
consumo a variável DIST,
h i(jklm) = @<+ @G i( 0kn ) + @V i(kSn%o ) + @pj0kd 0 + @qrrlks
+ @td r + @uvw + @xvw V+ @yjz0 + { @yJ|
y
|}G
o%Smr|+
Este modelo foi estimado pelo OLS e o modelo equivalente não linear pelo PML,
recorrendo para o efeito ao programa Time Series Processor (TSP) versão 5.12.
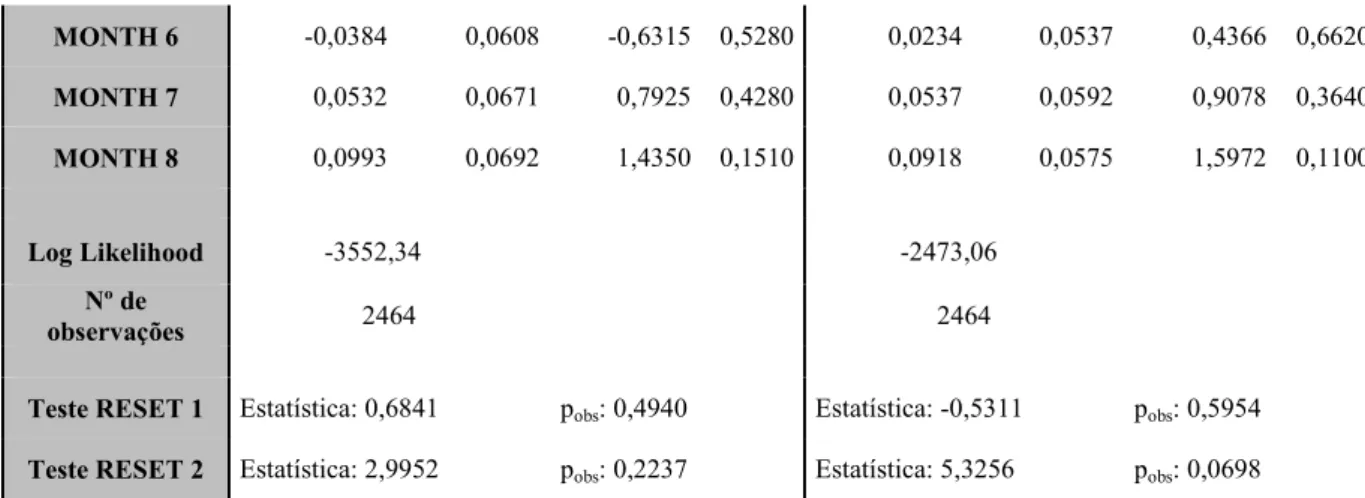
Os resultados obtidos encontram se na tabela 2,
Tabela 2 4 Modelos PML e OLS estimados com todas as variáveis
Variável
PML OLS
Estimativa Erro
Padrão t pobs Estimativa
Erro
Padrão t pobs
CO STA TE 1,5482 0,3732 4,1489 0,0000 4,8010 0,3624 13,2478 0,0000
LPRICE 0,4127 0,1519 2,7179 0,0070 0,5617 0,1367 4,1095 0,0000
LI COME 0,1485 0,0332 4,4714 0,0000 0,1903 0,0306 6,2274 0,0000
DRIVER 0,1641 0,0275 5,9590 0,0000 0,1805 0,0246 7,3372 0,0000
HHSIZE 0,0084 0,0153 0,5502 0,5820 0,0051 0,0141 0,3599 0,7190
VEH 0,1542 0,0328 4,6953 0,0000 0,1945 0,0274 7,0909 0,0000
AGE 0,0248 0,0109 2,2707 0,0230 0,0179 0,0107 1,6798 0,0930
AGE2 0,0003 0,0001 2,7759 0,0060 0,0003 0,0001 2,1984 0,0280
YSI GLE 0,1155 0,1170 0,9868 0,3240 0,0569 0,1040 0,5471 0,5840
RETIRE 0,0912 0,0766 1,1920 0,2330 0,0000 0,0699 0,0001 1,0000
DUR 0,2120 0,0326 6,4960 0,0000 0,2674 0,0292 9,1420 0,0000
MO TH 1 0,2303 0,0686 3,3566 0,0010 0,2162 0,0562 3,8487 0,0000
MO TH 2 0,3131 0,0651 4,8069 0,0000 0,2940 0,0584 5,0304 0,0000
MO TH 3 0,1301 0,0764 1,7025 0,0890 0,1458 0,0587 2,4857 0,0130
MO TH 4 0,1558 0,0605 2,5750 0,0100 0,1006 0,0527 1,9099 0,0560
MO TH 5 0,0183 0,0640 0,2860 0,7750 0,0105 0,0578 0,1821 0,8550
2
19
MO TH 6 0,0384 0,0608 0,6315 0,5280 0,0234 0,0537 0,4366 0,6620
MO TH 7 0,0532 0,0671 0,7925 0,4280 0,0537 0,0592 0,9078 0,3640
MO TH 8 0,0993 0,0692 1,4350 0,1510 0,0918 0,0575 1,5972 0,1100
Log Likelihood 3552,34 2473,06
º de
observações 2464 2464
Teste RESET 1 Estatística: 0,6841 pobs: 0,4940 Estatística: 0,5311 pobs: 0,5954
Teste RESET 2 Estatística: 2,9952 pobs: 0,2237 Estatística: 5,3256 pobs: 0,0698
ota: Estimador robusto das variâncias
As variâncias do PML foram estimadas com o Estimador de Eicker White dado que este
estimador é obtido através de uma pseudo verosimilhança. Relativamente ao OLS e
como podemos constatar pelos resultados evidenciados na tabela 3, os valor p dos testes
efectuados evidenciam a existência de heterocedasticidade e consequentemente as
variâncias foram estimadas com o estimador robusto de White.
Tabela 3 – Resultado dos testes de heterocedasticidade aplicados ao OLS
Teste
Valor da Estatística de
Teste LM
pobs
Breusch Pagan 55,93 0,00001
White
Simplificado 43,49 0,00
Com o intuito de avaliar a forma funcional dos modelos, foram aplicados testes RESET,
com os valores ajustados ao quadrado (teste RESET 1) e com os valores ajustados ao
quadrado e ao cubo (teste RESET 2).Numa primeira análise dos resultados, constata se
que os testes RESET aplicados não evidenciam má especificação dos modelos a 5%.
Salienta se também que as elasticidades associadas às variáveis PRICE e INCOME
apresentam os sinais esperados. Isto é, um aumento do rendimento do agregado familiar
leva a um aumento no consumo da combustível e um aumento no preço da combustível
leva a uma redução no consumo de combustível. Ao analisar as demais variáveis, é de
20
significativas, pelo que se procedeu a um teste de significância conjunta das mesmas.
Os resultados deste teste, evidenciados na tabela 4 e sugerem que estas variáveis não
são conjuntamente significativas, pelo que as mesmas foram removidas dos modelos em
estudo.
Tabela 4 4 Resultados do teste de significância conjunta às variáveis HHSIZE, YSI GLE e
RETIRE
Teste
PML OLS
Estatística
Teste pobs
Estatística
Teste pobs
Teste do rácio das
Verosimilhanças 2,6723 0,44495
Teste de coeficientes de
Wald 0,3669 0,947
A nova estimação dos modelos com exclusão das variáveis HHSIZE, YSINGLE e
RETIRE, levou aos seguintes resultados:
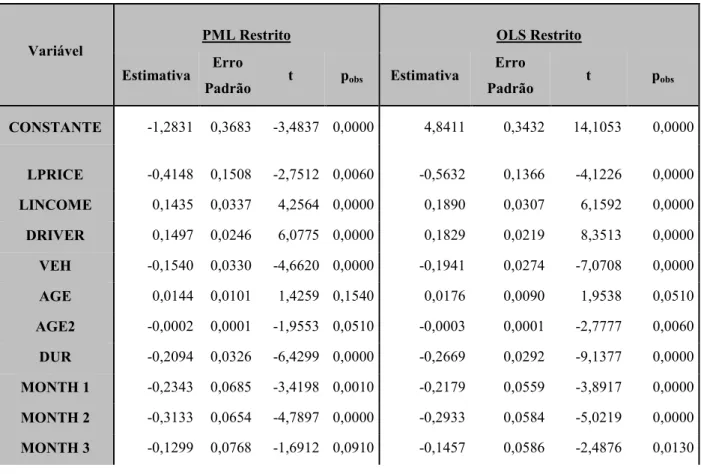
Tabela 5 4 Modelos PML e OLS estimados sem as variáveis HHSIZE, YSI GLE e RETIRE
Variável
PML Restrito OLS Restrito
Estimativa Erro
Padrão t pobs Estimativa
Erro
Padrão t pobs
CO STA TE 1,2831 0,3683 3,4837 0,0000 4,8411 0,3432 14,1053 0,0000
LPRICE 0,4148 0,1508 2,7512 0,0060 0,5632 0,1366 4,1226 0,0000
LI COME 0,1435 0,0337 4,2564 0,0000 0,1890 0,0307 6,1592 0,0000
DRIVER 0,1497 0,0246 6,0775 0,0000 0,1829 0,0219 8,3513 0,0000
VEH 0,1540 0,0330 4,6620 0,0000 0,1941 0,0274 7,0708 0,0000
AGE 0,0144 0,0101 1,4259 0,1540 0,0176 0,0090 1,9538 0,0510
AGE2 0,0002 0,0001 1,9553 0,0510 0,0003 0,0001 2,7777 0,0060
DUR 0,2094 0,0326 6,4299 0,0000 0,2669 0,0292 9,1377 0,0000
MO TH 1 0,2343 0,0685 3,4198 0,0010 0,2179 0,0559 3,8917 0,0000
MO TH 2 0,3133 0,0654 4,7897 0,0000 0,2933 0,0584 5,0219 0,0000
21 MO TH 4 0,1569 0,0608 2,5798 0,0100 0,1004 0,0525 1,9116 0,0560
MO TH 5 0,0203 0,0643 0,3164 0,7520 0,0100 0,0576 0,1740 0,8620
MO TH 6 0,0408 0,0612 0,6668 0,5050 0,0233 0,0536 0,4346 0,6640
MO TH 7 0,0519 0,0676 0,7677 0,4430 0,0545 0,0590 0,9235 0,3560
MO TH 8 0,1008 0,0696 1,4478 0,1480 0,0930 0,0575 1,6172 0,1060
Log Likelihood 3553,68 2473,29
º de
observações 2464 2464
Teste RESET 1 Estatistica: 1,0522 pobs: 0,2930 Estatistica Teste: 0,4774 pobs: 0,6331
Teste RESET 2 Estatistica: 5,6078 pobs: 0,0606 Estatistica Teste: 5,4210 pobs: 0,0665
ota: Estimador robusto das variâncias
Como podemos constatar pela análise da tabela 5, a não inclusão das variáveis HHSIZE,
YSINGLE e RETIRE, pouco influenciou as estimativas das restantes variáveis com
excepção da variável AGE no PML, que passou a ter um valor p superior a 0,05.
Todavia e como a variável AGE2, apresenta significância estatística, resolveu se manter
a variável AGE no modelo.
Nestes novos modelos a variável AGE, apresenta o efeito quadrático que seria de
esperar que tivesse, em que no PML, o aumento de um ano de idade, leva a um aumento
no consumo de combustível de forma decrescente revertendo se este efeito aos 36 anos.
No OLS o ponto de inflexão é atingido pouco depois dos 29 anos.
Relativamente às variáveis, DRIVER e VEH, é de salientar que influenciam o consumo
de combustível em sentidos diferentes. Assim, um aumento de um condutor no
agregado familiar (mantendo tudo o resto constante), faz aumentar o consumo de
combustível, ao passo que, mantendo o número de condutores (e as demais variáveis
constantes), a existência de mais um veículo no agregado familiar fará diminuir o
consumo de combustível no veículo seleccionado.
No que diz respeito à variável DUR, verifica se o esperado ou seja que os condutores
urbanos consomem menos combustível do que os outros com iguais características. Em
que no PML, os condutores urbanos consomem menos 18,97% ao passo que no OLS os
22
Nos modelos estimados, foram incorporadas variáveis dummy que representam o mês
em que os dados foram recolhidos. Para evitar a dummy trap, foi excluída da análise a
variável dummy que assume o valor 1 se os dados foram recolhidos no mês de
Setembro. Esta variável dummy foi assim assumida como sendo a variável base.
Relativamente às variáveis MONTH, tanto no PML como no OLS, só as variáveis
associadas aos meses de Janeiro a Abril, é que são significativas ao nível de 10%.
Salientando se que nestes meses o consumo de combustível é inferior ao do mês de
Setembro.
Pela análise dos testes RESET 1 e RESET 2 aplicados aos modelos, rapidamente se
deduz que a 5%, não existe evidência da má especificação dos modelos. Pelo que a
demais análise será feita com base nestes modelos.
3.3 4 Testes de validade do OLS
Esta secção irá recair sobre um conjunto de testes aplicados com o intuito de testar a
validade do estimador OLS. Em todos estes testes é analisada a hipótese nula de que sob
H0 é válida a estimação de elasticidades através do OLS.
3.3.1 4 Teste de Park
Suponha se que,
. = :~B+ •.
e
. = :~B€.
O teste de Park baseia se na seguinte regressão auxiliar
ln •̂.V = UV+ ‚1.@f + ƒ. = > + ‚1.@f + ƒ.
com
•̂. = . − :„B… e @f obtido através do PML de β.
(1)
23
Este procedimento testa a hipótese H0:‚ = 0 contra H1: ‚ ≠ 0. Rejeitando se H0, existe
evidência de que a estimação de elasticidades através do OLS não é válida.
A natureza desta hipótese pode ser melhor compreendida no parágrafo seguinte.
A partir de (1) e (2), conclui se que,
€. = 1 + •:.~B
Onde para o OLS ser estimado de forma consistente, €. não pode depender de 1., isto é D€.|1.F terá de ser constante. Para que isto aconteça, terá de se verificar a condição,
•. = :~B× M. com DM.|1.F constante
Verifica se,
d D•.|1.F = V:~B× d DM.|1.F e supondo d DM.|1.F igual a uma constante UV então,
d D•.|1.F = UV V:~B
Caso esta condição não seja verificada, então (3) não é verdadeira e assim D€.|1.F não é constante pelo que o OLS não será válido.
3.3.2 4 Testes de Heterocedasticidade na variável residual multiplicativa
Os testes efectuados neste ponto, designados como Teste 1 e Teste 2, avaliam a hipótese
de existência de heterocedasticidade em €..
3.3.2.1 4 Teste 1
Suponha se que,
= 1.@ + €.
onde,
۠
‡ = − b e €ˆ = † K- ‰‡Š,
24
Este teste vai avaliar a existência de heterocedasticidade do tipo,
UV(1) = d (€.|1.) = UV ‹ Œ• :~B…
em que @f, é estimado através dos estimador PML, usando a regressão auxiliar,
€Ž†V = ‚< ‹HK-:~B+ ƒ.
Testando a hipótese H0: ‚G = 0 contra H1: ‚G ≠ 0, e caso exista evidência de que
‚G ≠ 0, então teremos evidência da existência de heterocedasticidade em €., e por
consequência a estimação de elasticidades pelo OLS não será válida.
3.3.2.2 4 Teste 2
Este teste baseia se nos princípios referidos para 3.2.1. com a diferença de que testa a
existência de heterocedasticidade do tipo,
UV(1) = d (€.|1.)
= UV •IJ•HŒ•‘( ,’(“~)J •XŒ•‘(’”(!•“~)J•–—,’˜“,~J•™˜“š~J•›œ•“~J•žœ•“X~J•Ÿ— ,~
recorrendo à regressão auxiliar,
€Ž†V = ‚< ‹HŒ•‘( ,’(“~)J ‹XŒ•‘(’”(!•“~)J‹–—,’˜“,~J‹™˜“š~J‹›œ•“~J‹žœ•“X~J‹Ÿ— ,~
E testa a hipótese H0: ‚G = ⋯ = ‚x = 0 contra H1: ∃ ‚. ≠ 0 ( = 1 … 7), e caso se
rejeite H0, existe evidência da existência de heterocedasticidade em €., e por
consequência a estimação de elasticidades pelo OLS não será válida.
25 Tabela 6 4 Resultados dos testes de validade do OLS
Teste Estatística3 pobs
Teste de
Park 3,7018 0,00022
Teste 1 6,2904 0,00
Teste 2 309,0601 0,00
Pela análise da tabela, todos os testes sugerem que não existe evidência de que o OLS
seja válido.
3.4 4 Comparação dos resultados obtidos pela aplicação dos estimadores OLS e PML
Nesta secção iremos analisar e comparar os resultados obtidos com a estimação dos
modelos restritos incluídos na tabela 5.
No que concerne às variáveis PRICE e INCOME e como já foi referido anteriormente,
estas apresentam os sinais esperados. Assim um aumento de 1% no preço do
combustível, vai diminuir o consumo de combustível em aproximadamente 0,415% de
acordo com o PML e em aproximadamente 0,563% de acordo com o OLS. Por outro
lado de acordo com o PML, um aumento de 1% no rendimento do agregado familiar, ira
fazer aumentar o consumo de combustível em aproximadamente 0,144%. Pelo OLS este
aumento será de 0,189%. Como podemos constatar, as elasticidades estimadas pelo
OLS são maiores em valor absoluto às estimadas pelo PML. Foram construídos os
intervalos de confiança a 90%, 95% e 99% para os coeficientes das variáveis INCOME
e PRICE a fim de se verificar se existe evidência de que existem diferenças
significativas nas elasticidades estimadas pelos dois métodos. Os resultados de tais
intervalos encontram se na tabela 7.
3
26 Tabela 7 4 Intervalos de confiança para as estimativas das variáveis PRICE e I COME
Variavel ivel de significância
PML OLS
Limite inferior
Limite superior
Limite inferior
Limite superior
PRICE
99% 0,8056 0,0262 0,9151 0,2113
95% 0,7124 0,1194 0,8309 0,2955
90% 0,6648 0,1670 0,7879 0,3385
I COME
99% 0,0570 0,2312 0,1099 0,2681
95% 0,0779 0,2103 0,1288 0,2492
90% 0,0885 0,1997 0,1385 0,2395
Como podemos observar pelos dados presentes na tabela, para as duas variáveis, e
independentemente do nível de significância, existe sobreposição dos respectivos
intervalos de confiança. Pelo que não existe evidência de que as elasticidades calculadas
27
4
.
Conclusão
Ao longo deste trabalho, procurou se de uma forma clara e concisa responder à questão:
Estimação de elasticidades constantes: Deveremos logaritmizar? E a resposta a esta
questão terá de ser dada recorrendo primeiro ao ponto de vista teórico e depois ao ponto
de vista da aplicação empírica.
Sob o ponto de vista teórico, e como demonstrado na secção 2.6 a resposta é clara, não
deveremos logaritmizar. Isto porque na presença de heterocedasticidade, a prática
comum de estimar os parâmetros do modelo logaritmizado pelo OLS, pode levar a
conclusões erróneas, como demonstrado pelos exemplos A e B da secção 2.6. Estes
exemplos demonstram claramente que as duas metodologias podem levar a resultados
diferentes, tendo como consequência que as estimativas obtidas pelo OLS para as
elasticidades sejam enviesadas.
Recorrendo à aplicação empírica, a resposta à questão em análise já não é tão clara.
Neste trabalho procurou se estimar um modelo que explica o consumo de combustível
de um agregado familiar, (recorrendo à distância percorrida como proxy deste
consumo), tendo se estimado o modelo linear em causa pelo OLS, o equivalente não
linear pelo PML e comparados os resultados.
Uma primeira análise demonstra que os resultados deverão ser analisados com algum
cuidado. Por um lado, os resultados dos testes de validade do OLS demonstram
claramente que as elasticidades obtidas pelo OLS não são válidas, não sendo por isso
aconselhável o recurso a este estimador. Por outro lado, quando comparamos as
diferenças entre as estimativas obtidas pelos dois métodos, constatamos que as
diferenças entre elas não são substanciais. Esta conclusão é também reforçada pelos
intervalos de confiança obtidos para cada elasticidade com os dois métodos que, ao
interceptarem se, permitem concluir que não existe evidência de que as elasticidades
estimadas pelas duas metodologias sejam estatisticamente diferentes.
Todavia, existe uma importante consideração a ter em conta aquando da realização da
aplicação empírica, que é a dificuldade de implementação dos dois estimadores. O OLS
é um estimador muito usado em Econometria, sendo por isso incorporado em muitos
softwares econométricos permitindo assim que seja usado de forma muito simples e
28
isso incorporado em muitos softwares como é o caso do EVIEWS. A aplicação do PML
obriga o analista a programar a função de maximização de verosimilhança a ser usada,
sendo por isso necessário o recurso a um software que permita esta situação, como é o
caso do TSP.
Culminando, a resposta à questão que deu tema a este trabalho, terá de ser dada de
forma cautelosa. Do ponto de vista teórico existem muitas evidências a favor do PML, e
a própria aplicação prática apoia estas evidências pelo que não se deverá logaritmizar.
Todavia a dificuldade de implementação do método pesa como factor contra. Assim em
suma, na opinião do autor o modelo não deverá ser logarimizado, contudo, tal decisão
cabe em última análise naturalmente ao utilizador. Caso este decida não logaritmizar,
deverá ter em conta as respectivas implicações, realizar todos os testes de especificação
29
Bibliografia
Bernanke, B. e Frank, R., (2001), Principles of Macroeconomics,McGraw Hill.
Bernanke, B. e Frank, R., (2009), Principles of Economics, 4ª Edição,McGraw Hill.
Dougherty, C., (2001), Introduction to Econometrics, 3ª Edição, Oxford.
Greene, W. H., (2002) Econometric Analysis, 5ª Edição, Prentice Hall.
Gourieroux, C., Monfort, A., Trognon, A.,(1984), “Pseudo Maximum Likelihood
Methods: Applications to Poisson Models”, Econometria, Vol. 52, No. 3, p.p. 701 720.
Gujarati, (2004), Basic Econometrics, 4ª Edição, McGraw Hill.
Krugman, P. e Wells, R., (2005), Microeconomics,Worth Publishers.
Manning, W. G., (1999), “Estimating Log Models: To Transform or not to
Transform?”, ational Bureau of Economic Research, Technical Working Paper Series,
246.
Silva Ribeiro, C., (2011), Econometria [Manuscrito].
Santos Silva, J. M.C., e Tenreyro, S., (2006), “The Log of Gravity”, The Review of
Economics and Statistics, 88(4), p.p. 641 658.
Stock, J. H., e Watson, M. W., ( 2007), Introduction to Econometrics, 2ª Edição,
Pearson.
Wooldrige, J. M., (2002) Econometric Analysis of Cross Section and Panel Data, The
MIT Press.
Wooldrige, J. M., (2003) Introductory Econometrics: A Modern Approach, 2ª Edição
Thomson South Western.
Winkelmann, R., (2003), Econometric Analysis of Count Data, 4ªEdição, Springer.
Yatchew, A. e Joungyeo, A. No, (2001), “Household Gasoline Demand in Canada”,
30
Anexos
Anexo A
Comandos TSP 4 Regressões do PML e testes RESET aplicados ao PML.
1 OPTIONS MEMORY=5; 2 options double; 3 options crt; 4
4 freq n;
5 smpl 1 2464; 6
6 read(file='F:\TFM\gashouscons96.xls'); 7
7 ? DIST PRICE INCOME DRIVER HHSIZE VEH AGE MONTH YSINGLE RETIRE DUR
7 GENR DIST2=DIST/1000; 8 GENR LDIST=LOG(DIST2); 9 GENR LPRICE=LOG(PRICE); 10 GENR LINCOME=LOG(INCOME); 11 GENR AGE2=AGE**2;
12
12 title 'Estatisticas Descritivas';
13 MSD DIST PRICE INCOME DRIVER HHSIZE VEH AGE YSINGLE RETIRE DUR; 14
14 dummy MONTH; 15
15 list regressores LPRICE LINCOME DRIVER HHSIZE VEH AGE AGE2 YSINGLE RETIRE DUR MONTH1 MONTH2 MONTH3 MONTH4 MONTH5 MONTH6 MONTH7 MONTH8;
16 ?construção da equação bx sabendo que E(y|x)=exp(bx) 16
16 title 'Regressão pelo PML-completo'; 17 frml bx
31 18
18 frml eql logl=DIST2*bx - exp(bx) - lfact(DIST2); 19 eqsub eql bx;
20
20 param constante bLPrice bLIncome bDriver bHHSize bVeh bAge bAGE2 bM1-bM8 bYSingle bRetire bDur;
21
21 ML(terse,maxit=200,hcov=w) eql; 22 set LLR_PML1=@LOGL;
23
23 MMAKE Xmat c regressores; 24 mat xb=xmat*@coef;
25 unmake xb xbs; 26
26 title 'Teste RESET 1 - PML'; 27 genr xbs2=xbs^2;
28 frml bxreset
constante+bLPrice*LPRICE+bLIncome*LINCOME+bDriver*DRIVER+bHHSize*HH SIZE+bVeh*VEH+bAge*AGE+bAGE2*AGE2+bYSingle*YSINGLE+bRetire*RETIRE+b Dur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4*MONTH4+bM5*MONTH5+bM6* MONTH6+bM7*MONTH7+bM8*MONTH8+breset*xbs2;
29
29 frml eqlreset logl=DIST2*bxreset - exp(bxreset) - lfact(DIST2); 30 eqsub eqlreset bxreset;
31
31 param constante bLPrice bLIncome bDriver bHHSize bVeh bAge bAGE2 bM1-bM8 bYSingle bRetire bDur breset;
32
32 ML(TERSE)(maxit=10000,hcov=w) eqlreset; 33
33 title 'Teste RESET 2 - PML'; 34 genr xbs3=xbs^3;
35 frml bxreset2
constante+bLPrice*LPRICE+bLIncome*LINCOME+bDriver*DRIVER+bHHSize*HH SIZE+bVeh*VEH+bAge*AGE+bAGE2*AGE2+bYSingle*YSINGLE+bRetire*RETIRE+b Dur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4*MONTH4+bM5*MONTH5+bM6* MONTH6+bM7*MONTH7+bM8*MONTH8+breset*xbs2+breset2*xbs3;
32 36 frml eqlreset2 logl=DIST2*bxreset2 - exp(bxreset2) -
lfact(DIST2);
37 eqsub eqlreset2 bxreset2; 38
38 param constante bLPrice bLIncome bDriver bHHSize bVeh bAge bAGE2 bM1-bM8 bYSingle bRetire bDur breset breset2;
39
39 ML(TERSE)(maxit=10000,hcov=w) eqlreset2; 40 set LLR_RESET=@LOGL;
41
41 ?LLR_PML1 - Loglikelihood do modelo PML restricto; 41 ?LLR_RESET - Loglikelihooddo modelo irrestricto; 41
41 set TRV=-2*(LLR_PML1-LLR_RESET); 42 cdf(chisq,df=2)TRV;
43
43 title 'Regressão pelo PML - Restricto'; 44 frml bx
constante+bLPrice*LPRICE+bLIncome*LINCOME+bDriver*DRIVER+bVeh*VEH +bAge*AGE+bAGE2*AGE2+bDur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4* MONTH4+bM5*MONTH5+bM6*MONTH6+bM7*MONTH7+bM8*MONTH8;
45
45 frml eql logl=DIST2*bx - exp(bx) - lfact(DIST2); 46 eqsub eql bx;
47
47 param constante bLPrice bLIncome bDriverbVeh bAge bAGE2 bM1-bM8 bDur;
48
48 ML(terse,maxit=10000,hcov=w) eql; 49 set LLR_PML2=@LOGL;
50
50 set TRV=-2*(LLR_PML2-LLR_PML1); 51
51 cdf(chisq,df=3)TRV;? 52
52 title 'Teste RESET1 PML-Restrito'; 53 genr xbs2=xbs^2;
54 frml bxreset
33 +bAge*AGE+bAGE2*AGE2+bDur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4* MONTH4+bM5*MONTH5+bM6*MONTH6+bM7*MONTH7+bM8*MONTH8+breset*xbs2; 55
55 frml eqlreset logl=DIST2*bxreset - exp(bxreset) - lfact(DIST2); 56 eqsub eqlreset bxreset;
57
57 param constante bLPrice bLIncome bDriver bVeh bAge bAGE2 bM1-bM8 bDur breset;
58
58 ML(TERSE)(maxit=10000,hcov=w) eqlreset; 59
59 title 'Teste RESET2 -PML-Restrito'; 60 genr xbs3=xbs^3;
61 frml bxreset2
constante+bLPrice*LPRICE+bLIncome*LINCOME+bDriver*DRIVER+bVeh*VEH +bAge*AGE+bAGE2*AGE2+bDur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4* MONTH4+bM5*MONTH5+bM6*MONTH6+bM7*MONTH7+bM8*MONTH8+breset*xbs2 +breset2*xbs3;
62
62 frml eqlreset2 logl=DIST2*bxreset2 - exp(bxreset2) - lfact(DIST2);
63 eqsub eqlreset2 bxreset2; 64
64 param constante bLPrice bLIncome bDriver bVeh bAge bAGE2 bM1-bM8 bDur breset breset2;
65
65 ML(TERSE)(maxit=10000,hcov=w) eqlreset2; 66 set LLR_RESET2=@LOGL;
67
67 ?LLR_PML2 - Loglikelihood do modelo PML restricto; 67 ?LLR_RESET - Loglikelihood do modelo irrestricto; 67
34 Anexo B
Comandos TSP 4 Testes de validade do OLS
1 OPTIONS MEMORY=5; 2 options double; 3 options crt; 4
4 freq n;
5 smpl 1 2464; 6
6 read(file='F:\TFM\gashouscons96.xls'); 7
7 ? DIST PRICE INCOME DRIVER HHSIZE VEH AGE MONTH YSINGLE RETIRE DUR
7
7 GENR DIST2=DIST/1000; 8 GENR LDIST=LOG(DIST2); 9 GENR LPRICE=LOG(PRICE); 10 GENR LINCOME=LOG(INCOME); 11 GENR AGE2=AGE**2;
12
12 dummy MONTH; 13
13 list regressores LPRICE LINCOME DRIVER VEH AGE AGE2 DUR MONTH1 MONTH2 MONTH3 MONTH4 MONTH5 MONTH6 MONTH7 MONTH8;
14
14 ?construção da equação bx sabendo que E(y|x)=exp(bx) 14
14 ?title 'Regressão pelo PML-Restricto'; 14 frml bx
constante+bLPrice*LPRICE+bLIncome*LINCOME+bDriver*DRIVER+bVeh*VEH +bAge*AGE+bAGE2*AGE2+bDur*DUR+bM1*MONTH1+bM2*MONTH2+bM3*MONTH3+bM4* MONTH4+bM5*MONTH5+bM6*MONTH6+bM7*MONTH7+bM8*MONTH8;
15
15 frml eql logl=DIST2*bx - exp(bx) - lfact(DIST2); 16 eqsub eql bx;
35 17 param constante bLPrice bLIncome bDriver bVeh bAge bAGE2 bM1-bM8 bDur;
18
18 ML(silent,maxit=200,hcov=w) eql; 19 set LLR_PML=@LOGL;
20
20 title 'Teste de Park'; 21 MMAKE Xmat c regressores; 22 mat xb=xmat*@coef;
23 unmake xb xbs; 24
24 xfit=exp(xbs);
25 res2=(DIST2-xfit)**2; 26 lres2=log(res2); 27 lxfit=log(xfit);
28 ?regressão auxiliar de teste
28 olsq(silent,robustse) lres2 c lxfit; 29
29 title 'Teste de validade do OLS'; 30 set t=(@coef(2)-2)/@ses(2);
31 set gl=@nob-@ncoef; 32 cdf(t,df=gl) t; 33
33 title 'Teste sobre Heterocedasticidade – Teste 1; 34 olsq(silent) ldist c regressores;
35 genr res2=(exp(@res))^2; 36 frml het res2=l0*xfit**l1; 37 param l0 l1;
38 lsq (terse)(maxit=10000)het; 39
39 title 'Teste sobre Heterocedasticidade – Teste 2; 40 olsq(silent) ldist c regressores;
41 genr res2=(exp(@res))^2; 42 frml het
res2=exp(g0+g1*LPRICE+g2*LINCOME+g3*DRIVER+g4*VEH+g5*AGE+g6*AGE2+g7 *DUR);
43 param g0-g7;
36 46 frml het0 res2=exp(g0);
47 param g0;
48 lsq (terse,maxit=10000)het0; 49 set LLRR=@LOGL;
50
37 Anexo C
Comandos TSP 4 Regressões do heterocedasticidade sobre o OLS
1 OPTIONS MEMORY=5; 2 options double; 3 options crt; 4
4 freq n;
5 smpl 1 2464; 6
6 read(file='F:\TFM\gashouscons96.xls'); 7
7 ? DIST PRICE INCOME DRIVER HHSIZE VEH AGE MONTH YSINGLE RETIRE DUR
7
7 GENR LDIST=LOG(DIST); 8 GENR LPRICE=LOG(PRICE); 9 GENR LINCOME=LOG(INCOME); 10 GENR AGE2=AGE**2;
11
11 dummy MONTH; 12
12 list regressores LPRICE LINCOME DRIVER HHSIZE VEH AGE AGE2 YSINGLE RETIRE DUR MONTH1 MONTH2 MONTH3 MONTH4 MONTH5 MONTH6 MONTH7 MONTH8;
13
13 Title 'Regressões - OLS'; 14
14 Title ' OLS ';
15 olsq LDIST c regressores; 16 genr RES2=@res^2;
17 genr YFIT=@FIT; 18 genr YFIT2=YFIT^2; 19
19 title 'Teste de Breusch-Pagan'; 20 OLSQ RES2 c regressores;
38 23
23 cdf(chisq,df=GL)bp; 24
24 title 'Teste de White Simplificado'; 25 olsq RES2 C YFIT YFIT2;
26 set white=@nob*@rsq; 27
27 cdf(chisq,df=2)white; 28
28 Title'OLS Robusto';
29 olsq(robust) LDIST c regressores; 30
30 Title'OLS Robusto-Restricto';
39 Anexo D
Output Eviews 4 Testes RESET 1 e 2 aplicados OLS
!! " ! #
" ! $%$
& ' $%$
( ) * & +,- . / - ' &
- 00 & 1 . , & 2 1
- %1%3 #4 41#4!3! !13 $ 5 1 #34
6- . 1$3$% # 1##5#$ 13% !34 143$3
27 -. ,!1$4$3 !1%% %%% , 13% %# 1433
)) 8. 1 !4 ## 1 $$% 1%$3 3 1#!%
7 .7 1$%! 5 1#4!%3! 13%5 5$ 143%
.) , 1$ 5$$4 1#5%4%% , 13%4 %3 1433
97 , 1%3 %# 153%5!% , 13%55 $ 143#%
: . 1 $##!5 1 #433$ 13$$5 ! 14 34
: .; , 1 %5% 1 5 , 13#44 % 14 4#
7. 7. 1 $453 1 5 $3% 1 % !! 1 # #
< 6 . 1!$$44! 1!33#54 15%#434 1$$$!
<= > 7; , 1! 5 1 4! , 1#4! % 1# #$
6 )?! , 1#$ !! 1%4 4$$ , 13%3435 143#4
6 )? , 15$$! 4 13#%%4! , 13%35$$ 143#!
6 )?4 , 145 5 1$ % 3 , 13% 5 1433$
6 )?$ , 1 #%# 3 1 %%5 , 13%$%%$ 14354
6 )?# , 1 # 4 1 %4%%$ , 1$ 3 34 1%34!
6 )?% 1 # $3! 1 33!$ 1%5$53 1$
6 )?5 1!4 # 1!5 5 3 13 %!!% 1$ 4
6 )?3 1 4#4# 1 5 43 13$4$4# 14 !
7, 1!4! #! ' 51!% $%$
: @ 7, 1! $ # 1 1 ' 15 3 53
1.1 0 A 1%% 3 :* * 0 & 1 44 %
" ! 541%#3 & B C & 1 5 ##
A * , $5 13 $ =, & ! 14 #%
,( 1 !$%$! 2 =, & 1
!! " ! %
" ! $%$
& ' $%$
40
- 00 & 1 . , & 2 1
- ,4 13 3 !551!$!5 ,!15$ $% 1 3 $
6- . , $1$ $5 !$1 ##3$ ,!154%% 5 1 3 %
27 -. 5 1 % 3 $!1$5# % !154%!4# 1 3 5
)) 8. , 1%#! $4 145$%!# ,!1543$4 1 3 4
7 .7 , 41!$ 4 !414443! ,!154%!45 1 3 5
.) $1 4%5! !$14%$ 5 !154# 4 1 3 5
97 4$1 3# % ! 15$# ! !154%4! 1 3 %
: . , 1 3$%! !14 $%#$ ,!154#!$! 1 3 3
: .; 1 4$!%$ 1 ! %3# !154##!5 1 3 3
7. 7. , 1 33% 1 5!# 4 , 1 $ 4## 1 %53
< 6 . ,51 5 $1 # ,!154%! $ 1 3 5
<= > 7; !31!3!% ! 1 454 !155% !4 1 5#
<= > 7;4 , 13#!$3$ 1$5 %%5 ,!13 !$$5 1 5!3
6 )?! 515 3 !#1 % % !154%45! 1 3 %
6 )? 4515 $% !15! 3 !154%##% 1 3 %
6 )?4 !31% $ ! 15% 34 !154% $ 1 3 %
6 )?$ ! 1 5#5 51$4$!#4 !154% #4 1 3 %
6 )?# !14$354$ 155 # !154 ## 1 345
6 )?% ,41 55 !154 3$ ,!1543$3 1 3 4
6 )?5 ,%133## # 41 %5! ,!154#%!$ 1 3 3
6 )?3 ,!!155 % %153 $ 4 ,!154%553 1 3 %
7, 1!4 $# ' 51!% $%$
: @ 7, 1! #3$5 1 1 ' 15 3 53
1.1 0 A 1%% ! :* * 0 & 1 #
" ! 5!14!5 & B C & 1 5!#43
A * , $5 1!4# =, & !315
,( 1 ! $#! 2 =, & 1
(
. .D 4
& 0 2 +
=, & 1%% 3 E $$4 1 5
- , #14 #%!3 1 % 3
6 )+ "" +
6 " C 7 & ? 1 . 1
- ! !31!3!% ! 1 454
- !4 , 13#!$3$ 1$5 %%5
41 Anexo E
Output Eviews 4 Teste à significância conjunta das variáveis YSI GLE, RETIRE e HHSIZE no OLS
(
. .D !
& 0 2 +
=, & 1! 4 4E $$# 1 $5
- , 14%% %# 4 1 $5
6 )+ "" +
6 " C 7 & ? 1 . 1
- $ 1 # 5! 1 !$
- ! ,315#., % 1 % 3!$
- !! 1 #%333 1! 4$%4
42 Anexo F
Output Eviews 4 Testes RESET 1 e 2 aplicados OLS restrito
! !! " 45
" ! $%$
& ' $%$
( ) * & +,- . / - ' &
- 00 & 1 . , & 2 1
- %1% %53 41%# % 3 !13 $!# 1 5!4
6- . 1$#!5 4 1##$ 3 13!#4 1$!$
27 -. ,!14# !1%%54!% , 13 543 1$!3
7 .7 1$43%44 1#433#5 13!$ # 1$!#5
.) , 1$%# $3 1#5#%34 , 13 43 1$!3$
97 , 1%4 % 153#5 3 , 13!$ %$ 1$!#5
: . 1 $!$ 3 1 #!5#4 13 !34$ 1$ 5
: .; , 1 %4 1 553 , 13 # 1$!34
<= >7; , 1 5 % 1 4 # , 1$5545! 1%44!
6 )?! , 1#! %4 1%454 , 13!# $3 1$!#
6 )? , 1% 5 ! 13#$$ , 13!#3%# 1$!$5
6 )?4 , 14$5%$! 1$ $ % , 13 #$3 1$!34
6 )?$ , 1 $ 35 1 #3 3 , 13! # 1$!%3
6 )?# , 1 4 ! 1 % 3 , 14% ! 15! !
6 )?% 1 ##$5 1 3553 1%4! 5 1# 5#
6 )?5 1!4 %5 1!5# 3$ 15#55 3 1$$3%
6 )?3 1 43%! 1 3 % $ 15 !335 1$ 3#
7, 1!4 3# ' 51!% $%$
: @ 7, 1! #!5% 1 1 ' 15 3 53
1.1 0 A 1%% $%% :* * 0 & 1 !!3
" ! 5413 # & B C & 1 %! %$
A * , $541 % =, & 41 %$$
,( 1 !# 2 =, & 1
! !! " 4
" ! $%$
& ' $%$