Secure and Dependable Multi-Cloud Network Virtualization
“ Documento Definitivo”
Doutoramento em Informática Especialidade de Ciência da Computação
Max Silva Alaluna
Tese orientada por:
Prof. Doutor Fernando Manuel Valente Ramos
FACULDADE DE CIÊNCIAS
Secure and Dependable Multi-Cloud Network Virtualization
Doutoramento em Informática Especialidade de Ciência da Computação
Max Silva Alaluna
Tese orientada por:
Prof. Doutor Fernando Manuel Valente Ramos
Júri: Presidente:
● Doutor Nuno Fuentecilla Maia Ferreira Neves, Professor Cadetrático e membro do Conselho Científico da Universidade de Lisboa
Vogais:
● Doutor Edmundo Heitor Silva Monteiro, Professor Catedrático - Faculdade de Ciências e Tecnologia da Universidade de Coimbra
● Doutor Rui Luís Andrade Aguiar, Professor Catedrático - Departamento de Eletrónica e Telecomunicações e Informática da Universidade de Aveiro
● Doutor João Tiago Medeiros Paulo, Investigador Auxiliar - Intituto de Engenharia de Sistemas e Computação, Tecnologia e Ciências - INESTEC
● Doutora Sara Alexandra Cordeiro Madeira, Professora Associada - Faculdade de Ciências da Universidade de Lisboa
● Doutor Fernando Manual Valente Ramos, Professor Auxiliar - Faculdade de Ciências da Universidade de Lisboa (orientador)
Virtualization is a consolidated technology in modern computers, enabling dis-tinct virtual machines to share the same hardware resources. This technol-ogy underpinned cloud computing, enabling infrastructure providers to ex-tend their services with elastic computing and storage services. Today, the number of virtual servers already surpasses the number of physical servers, in a clear demonstration of the success of this technology. Unfortunately, net-working has lagged behind. Traditional network primitives (e.g., VLANs) do not present the scalability and flexibility that is necessary for the “as-a-service” model of cloud computing. As a result, existing cloud services do not offer network guarantees, hindering their adoption by a large class of applications.
This situation has started changing with Software-defined networking (SDN),
a new paradigm that proposes the logical centralization of network control. Advanced network virtualization platforms use SDN to give cloud users the freedom to specify their virtual network topologies and addressing schemes,
for the first time enabling complete network virtualization. These solutions
were a huge step forward, but they still have limitations. First, they target a single datacenter of a cloud provider. This limits their scalability and is ef-fectively a single point of failure for the tenant’s virtual networks. Second, the virtual network services offered are restricted to traditional services, such as L2 switching, L3 routing, or Access Control List (ACL) filtering. This es-tablishes them as insufficient to support (critical) applications that need to be deployed across multiple trust domains for resiliency while enforcing diverse security requirements. In addition, most solutions that are efficient in mapping the tenant’s virtual network requests to the substrate typically do not scale to large networks. Finally, they also fail to provide the elasticity required in cloud computing, not allowing virtual networks to scale out or scale in.
In this thesis, we address these limitations by proposing Sirius: the first multi-cloud network virtualization platform. Sirius allows virtual networks to
seam-different clouds, tenants avoid any single point of failure, thus addressing the first challenge. Besides enhancing the substrate, Sirius also enhances the vir-tual networks with security and dependability. For this purpose, in this thesis we propose novel network embedding algorithms to find efficient mappings of virtual network requests onto the substrate network that consider security and availability of virtual resources. Specifically, we propose an optimal solution based on Mixed-Integer Linear Programming (MILP), and also heuristics that scale to very large networks, while achieving results close to optimal. These solutions enable us to address challenges two and three. Finally, to address the last challenge we propose new algorithms that allow virtual networks to scale out and scale in, enabling elasticity to tenant’s environments.
We implemented a prototype of Sirius, and evaluated all solutions using both large scale simulations and a real testbed environment running our prototype. The latter consists of a substrate composed of a private datacenter and two pub-lic clouds (Amazon and Google). Our evaluations demonstrate that the system scales well for networks of thousands of switches employing diverse topolo-gies and improves on the virtual network acceptance ratio and provider profit when compared to the state-of-the-art. In particular, the acceptance ratios are less than 1% from the optimal, and the system can provision a 10 thousand container virtual network in approximately 2 minutes.
Overall, the evaluations demonstrate the feasibility of our proposal in achiev-ing good trade-offs concernachiev-ing security and performance, and are therefore a step forward in the enrichment of cloud computing services.
Keywords: Network Virtualization, Cloud Computing, Multi-cloud, Virtual Network Embedding
A virtualização é uma tecnologia consolidada na computação moderna, per-mitindo que máquinas virtuais distintas compartilhem os mesmos recursos de hardware. Esta é a tecnologia base da computação em nuvem, a qual permitiu aos provedores de infraestrutura ampliarem os seus serviços com computação e serviços de armazenamento elásticos. Hoje, o número de servidores virtuais já supera o número de servidores físicos, numa demonstração clara do sucesso desta tecnologia. Infelizmente, o progresso na componente de rede tem sido muito diferente. As primitivas tradicionais de rede (por exemplo, VLANs) não apresentam a escalabilidade e a flexibilidade que são necessárias para o modelo de serviços de computação em núvem. Como resultado, os serviços de nuvem oferecem garantias limitadas no que diz respeito à rede, impedindo a sua adoção por uma grande variedade de aplicações.
Esta situação começou a mudar recentemente com o advento das Redes Definidas por Software (Software-defined networking – SDN), um novo paradigma que propõe a centralização lógica do controle de rede. Plataformas avançadas de virtualização de redes usam SDN para oferecer aos utilizadores (tenants) da nuvem a possibilidade de especificar as topologias de rede virtual e esquemas de endereçamento arbitrários, pela primeira vez possibilitando a virtualização completa de redes. Estas soluções foram um grande avanço, mas possuem lim-itações. Primeiro, são direcionadas para um único provedor de serviço. Isso limita a sua escalabilidade e resulta, efetivamente, num ponto único de falha para os usuários da rede virtual. Em segundo lugar, os serviços de rede
vir-tual oferecidos são restritos aos serviços tradicionais, como oswitching L2, o
roteamento L3 ou a filtragem por meio de Listas de Controle de Acesso (Access Control List – ACL). Esta abordagem apresenta-se assim insuficiente para supor-tar aplicações (críticas) que precisam de ser implantadas em vários domínios de confiança, ao mesmo tempo que exigem diversos requisitos de segurança. Além
escalam para topologias grandes. Finalmente, também não oferecem a elastici-dade requerida na computação em núvem, não permitindo o aumento (scaling out) e a diminuição (scaling in) das redes virtuais.
Nesta tese, abordamos estas limitações propondo oSirius: a primeira plataforma
de virtualização de redes para ambientesmulti-cloud. O Sirius permite que as re-des virtuais se estendam por um substrato composto por várias infraestruturas de nuvem, incluindo nuvens públicas e centro de dados privados. Ao replicar elementos em diferentes nuvens, os utilizadores evitam a existência de pontos únicos de falha, assim resolvendo o primeiro desafio. Além de enriquecer o sub-strato, o Sirius também enriquece as redes virtuais, com requisitos de segurança e confiabilidade. Com este objetivo, nesta tese propomos novos algoritmos de mapeamento de redes virtuais na rede do substrato que consideram requisitos de segurança e de disponibilidade. Especificamente, propomos uma solução ótima baseada em modelos de Programação Linear Inteira Mista (Mixed-integer Lin-ear Programming – MILP), e também heurísticas capazes de escalar para redes muito grandes e atingir resultados próximos do ótimo. Finalmente, propomos novos algoritmos que permitem que as redes virtuais aumentem e diminuam, oferecendo a elasticidade esperada neste tipo de ambiente.
A nossa contribuição inclui o desenvolvimento de um protótipo do Sirius. As soluções propostas são avaliadas recorrendo a simulações de larga escala e a
uma rede real rodando nosso protótipo num ambiente com múltiplasclouds,
públicas e privadas. Os resultados demonstram a viabilidade das propostas, ap-resentando bons compromissos em relação à segurança e desempenho, o que nos leva a acreditar ser um passo em frente no enriquecimento dos serviços de provedores de núvem.
Palavras Chave: Virtualização de Redes, Computação em Nuvem, Multi-cloud, Virtual Network Embedding
A gestão moderna das infraestruturas de computação que levou ao surgimento da computação em nuvem tornou-se possível graças ao advento da virtualiza-ção de servidores. Ao expor uma abstravirtualiza-ção de software (Virtual Machine – VM) aos utilizadores, em vez da própria máquina física, a virtualização possibilitou o grau de flexibilidade necessário para que os operadores de infraestrutura at-injam os seus objetivos operacionais ao mesmo tempo em que satisfazem as necessidades dos clientes da infraestrutura (os “tenants”).
Infelizmente, os atuais requisitos dos utilizadores das infraestruturas de
com-putação em nuvem – por exemplo, a capacidade de migrar os seus workloads
inalterados para a nuvem - não podem ser atendidos apenas com a virtualiza-ção do servidor. A raiz do problema é o fato de que, embora a virtualizavirtualiza-ção da computação e do armazenamento sejam tecnologias bastante avançadas, a vir-tualização de rede ainda não o é. A virvir-tualizaçãocompleta da rede, isto é, o de-sacoplamento total dos serviços lógicos de rede da sua realização física (Casado et al.,2010), não é possível com as primitivas tradicionais de virtualização de rede, como as VLANs. Estas primitivas apenas fornecem formas restritas de isolamento.
Em suma, os mecanismos de virtualização disponíveis são muito rudimenta-res e não possuem a escalabilidade necessária para fornecer uma virtualização
completa da rede (Yuet al.,2011). Esta situação tem como cerne um problema
fundamental: as redes tradicionais são muito difíceis de gerir. No entanto, a mudança recente de paradigma que promove a centralização lógica do controle de rede e o desacoplamento entre o plano de controle e o plano de dados – as
Re-des Definidas por Software (Software-defined networking – SDN) (Kreutzet al.,
2015) – permitiu o desenvolvimento de plataformas de virtualização completa
da rede. Estas soluções permitem a criação de redes virtuais, cada uma com modelos de serviços independentes, e topologias e esquemas de endereçamento arbitrários, compartilhando a mesma infraestrutura física (Koponenet al.,2014).
virtualização de rede, mas apresentam algumas limitações. Em primeiro lugar, consideram um substrato controlado por um único operador. Esta particulari-dade afeta estas soluções do ponto de vista da resiliência, ao criar, por exemplo, um ponto único de falha, e essa restrição pode tornar-se uma barreira impor-tante à medida que aplicações críticas são movidas para a nuvem. Outra con-sequência negativa diz respeito à privacidade. Por exemplo, o cumprimento de
determinada legislação pode exigir que certos tipos deworkloads do cliente
per-maneçam em ambientes específicos (seja um cluster privado ou uma infraestru-tura em nuvem localizada num país específico). Este tipo de requisito é particu-larmente importante no contexto da nova legislação relativa à proteção de dados (nomeadamente, o Regulamento Geral de Proteção de Dados, ou RGPD), que
normalmente exige o recurso a abordagensad-hoc para cumprir os requisitos
legais.
Estes problemas das soluções existentes são a nossa motivação para estender a virtualização de rede para um ambiente multi-nuvem, enriquecendo o substrato
com recursos de mútiplas infraestruturas de núvem, privadas e/ou públicas.
Este enriquecimento do substrato traz benefícios importantes. Primeiro, os serviços de um utilizador (tenant) passam a ser imunes à indisponibilidade de um dado datacenter ou de uma zona da nuvem, ao replicar os serviços de rede em vários provedores. Esta é uma preocupação atual, dado o grande número de incidentes envolvendo falhas acidentais e maliciosas nas infra-estruturas da
nuvem (Khan,2016;Suryateja,2018), os quais mostram que confiar num único
provedor pode trazer problemas de disponibilidade e confiabilidade aos serviços baseados na nuvem. Em segundo lugar, os custos para o utilizador também po-dem ser diminuídos, aproveitando os planos de preços de vários provedores
de nuvem. Um exemplo inclui o uso de instâncias (VMs) spot EC2 da
Ama-zon, que têm sido recentemente exploradas para reduzir significativamente os
custos de certosworkloads quando comparado com custos de instâncias
tradi-cionais (Zhenget al.,2015). À medida que os provedores aumentam o suporte a
também pode ser alcançado ao aproximar os serviços dos clientes ou migrando componentes da rede que, em determinado momento, precisam de cooperar mais.
Uma segunda limitação das atuais soluções de virtualização de rede é a sua oferta ser restrita a serviços de rede convencionais (como conectividade L2 ou rotea-mento L3). Dada a nossa motivação em hospedar serviços críticos na núvem, a não consideração de segurança e confiabilidade é uma restrição importante. Nesta tese, propomos uma solução de virtualização de redes multi-cloud. A nossa proposta parte de duas ideias principais. Primeiro, a rede do substrato é enriquecida com recursos de múltiplas infraestruturas, incluindo centros de da-dos privada-dos e núvens públicas. Segundo, as redes virtuais oferecem serviços de segurança, disponibilidade, e elasticidade inteiramente definidos pelo utilizador da rede virtual.
Conceber uma solução de virtualização de redes multi-núvem envolve vários desafios. Primeiro, é necessário criar uma única abstração de nuvem para os utilizadores, que não devem perceber que o substrato é partilhado. Em
se-gundo lugar, para permitir a virtualizaçãocompleta da rede, é necessário que os
utilizadores tenham a liberdade de especificar as topologias de rede e os esque-mas de endereçamento de forma arbitrária, garantindo o nível de isolamento requerido. Em terceiro lugar, a oferta de redes virtuais com propriedades de segurança e confiabilidade requer a concepção de novos algoritmos para mapea-mento de redes. Em quarto lugar, é necessário que as soluções sejam eficientes e escaláveis, tornando necessária a investigação de otimizações, não apenas no mapeamento, mas também na operação da infraestrutura.
Nesta tese atacamos o primeiro desafio através da criação de uma nova camada de rede que corre em cima dos serviços virtualizados oferecidos pelas núvens. Desta forma, conseguimos mascarar a heterogeneidade dos recursos dos di-ferentes provedores e apresentar ao utilizador uma infraestrutura virtual ho-mogênea. A nossa solução segue uma abordagem SDN: a nova camada de redes
elementos virtuais nos físicos para garantir que a rede virtual seja completa-mente desacoplada da rede física. O controle centralizado oferecido pelo SDN permite ao utilizador utilizar qualquer endereço de rede (de camada L2 e L3), definir topologias de rede arbitrárias e garantir o isolamento entre redes virtu-ais, assim endereçando o segundo desafio.
Para resolver o terceiro desafio, nesta tese investigamos um componente cen-tral da virtualização de redes – o mapeador (embedder) de redes virtuais. Este componente inclui os algoritmos que mapeiam, de forma eficiente, os pedidos de redes virtuais na rede do substrato. A principal inovação da nossa solução prende-se com a consideração de requisitos de segurança e disponibilidade, per-mitindo a definição pelo utilizador de requisitos ao nível de três recursos cen-trais: as ligações virtuais entre elementos da rede, permitindo, por exemplo, que estas ligações sejam redundantes; nos switches virtuais, através de suporte de vários níveis de segurança e redundância; e nas próprias infraestruturas de núvem, que podem ter diversos níveis de segurança e confiabilidade. A nossa primeira solução baseia-se em técnicas matemáticas de Programação Linear In-teira Mista (MILP) de recursos. Propomos, ainda, um algoritmo heurístico de mapeamento de redes virtuais que além de garantir o cumprimentos dos requi-sitos de segurança dos recursos virtuais, escala para redes de grandes dimensões e mantem o mesmo nível de eficiência da solução ótima.
A nossa última contribuição ataca o desafio da elasticidade. Propomos para isso novas primitivas e algoritmos que permitem o aumento (scaling out) e a diminuição (scaling in) das redes virtuais, juntamente com a reconfiguração da rede do substrato de forma a aumentar a eficiência e o uso dos recursos. As nossas soluções atingem eficiências elevadas e simultaneamente minimizam a disrupção nos serviços dos utilizadores.
Palavras Chave: Virtualização de Redes, Computação em Nuvem, Multi-cloud, Virtual Network Embedding
First and foremost, I would like to thank God. Without Him, none of this would be possible.
I want to acknowledge my supervisor, Professor Fernando M. V. Ramos, and Professor Nuno Fuentecilla Maia Ferreira Neves, who while not being my co-supervisor worked as if it were. Their guidance and assistance were essential for the development of the course. And I highlight their acumen and patience. I want to acknowledge the Brazilian Army whose vision of the future let to the decision to value and encourage the improvement of the knowledge of its human resources. I also want to acknowledge Generals Decílio Sales and Ed-uardo Wolski not only for the professionalism and competence, but for the support and help that they had in the process of registration and enrollment in this Ph.D. course. I want to acknowledge Professor Paulo Fernando Ferreira Rosa for your encouragement in the early years of my research and Professor Ricardo Choren Noya for the support as the Master’s supervisor and during the Ph.D. as academic tutor.
I would like to express my special appreciation and thanks to my wife Vivian Vivas, my sons Alex and Pedro, for encouraging, hearing and spending sleepless nights with me and was always my support in the moments when there was no one to support me. A big thank you to my parents, who even from a great physical distance, helped me a lot to overcome this important phase. I want to thank my sister Suzuky and my aunt Sonia for all encouragement and support. I use this opportunity to express a special thanks to Eric Vial for the support and teamwork. Moreover, my gratitude to all colleagues at the Large-Scale In-formatics Systems Laboratory (LaSIGE) research laboratory, for their cama-raderie. In particular, thank you to Pedro Gonçalves, Vinicius Cogo, Pedro
Finally, I would like to acknowledge the members of the SUPERCLOUD project (ref. H2020-643964) for all the experience exchanged and support.
Abstract i
Resumo iii
Resumo Alargado v
List of Figures xiv
List of Tables xvii
1 Introduction 1
1.1 Problem and Motivation . . . 2
1.2 Objective and Challenges . . . 3
1.3 Contributions . . . 4
1.4 Structure of the Thesis . . . 6
2 Background and Related work 9 2.1 Software-defined networks . . . 10
2.1.1 Controllers . . . 12
2.1.2 OpenFlow and OVSDB . . . 13
2.2 Network virtualization . . . 15
2.2.1 Network virtualization for scalability and agility . . . 15
2.2.2 Virtualization of software-defined networks . . . 17
2.2.3 Network virtualization in the cloud era . . . 21
2.2.4 Summary . . . 27
2.3 Virtual network embedding . . . 28
2.3.1 Baseline VNE Solutions . . . 28
2.3.2 Dependable VNE . . . 30
2.3.4 Multi-domain VNE . . . 32
2.3.5 Summary . . . 33
2.4 Multi-cloud systems . . . 34
2.5 Elastic Virtual Networks . . . 37
2.5.1 Enablers for elastic VN . . . 38
2.6 Summary . . . 40
3 Sirius: Multi-cloud Network Virtualization 41 3.1 Motivation . . . 42
3.2 Requirements . . . 43
3.3 Design of Sirius . . . 44
3.3.1 Architecture . . . 45
3.3.2 Overview of Sirius operation . . . 46
3.3.3 The multi-cloud orchestrator . . . 48
3.3.4 Hypervisor architecture and components . . . 50
3.3.5 Virtualization runtime: achieving isolation . . . 52
3.4 Implementation and evaluation . . . 55
3.4.1 Implementation and experimental setup . . . 55
3.4.2 Evaluation results . . . 56
3.5 Summary . . . 59
4 Secure Multi-Cloud Virtual Network Embedding 61 4.1 Introduction . . . 62
4.2 Network model . . . 64
4.3 Secure Virtual Network Embedding Problem . . . 68
4.4 A Policy Language to Specify SecVNE . . . 71
4.5 MILP Formulation . . . 73
4.5.1 Decision variables and auxiliary parameters . . . 74
4.5.2 Objective Function . . . 75
4.5.3 Security Constraints . . . 77
4.5.4 Mapping Constraints . . . 78
4.5.5 Capacity Constraints . . . 83
4.5.6 Discussion on Security Assurances . . . 84
4.6.1 Experimental Setup . . . 85
4.6.2 Metrics . . . 87
4.6.3 Evaluation Results . . . 89
4.7 Summary . . . 92
5 Scalable and Secure Multi-cloud Virtual Network Embedding 93 5.1 Introduction . . . 93
5.2 Enhanced Sirius Design . . . 95
5.2.1 Virtual and Substrate Networks . . . 96
5.3 Network Embedding . . . 97 5.3.1 Network model . . . 98 5.3.2 Scalable SecVNE . . . 100 5.4 Implementation . . . 108 5.5 Evaluation . . . 110 5.5.1 Testing environment . . . 111
5.5.2 Evaluation against optimal solution . . . 112
5.5.3 Large-scale simulations . . . 112
5.5.4 Prototype experiments . . . 117
5.6 Conclusions . . . 123
6 Elastic Virtual Networks 125 6.1 Introduction . . . 126
6.2 Motivating use cases . . . 130
6.3 Abstracting the Network . . . 131
6.4 Elastic Virtual Networks . . . 133
6.4.1 Elastic VN primitives . . . 133
6.4.2 Elastic VNE algorithms . . . 133
6.5 Evaluation . . . 143
6.6 Conclusion . . . 147
7 Summary and Future Work 149 7.1 Summary of Contributions . . . 149
7.2 Future work . . . 151
7.2.2 Secure, dependable and scalable Sirius . . . 151
7.2.3 Programmable Virtual Networks . . . 152
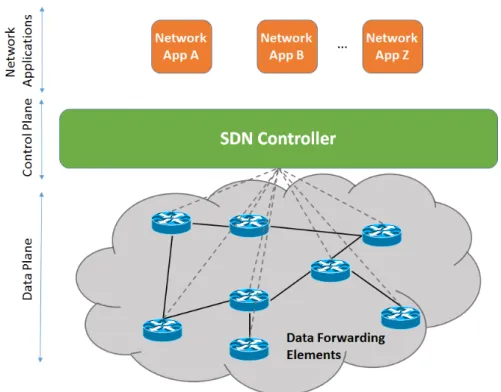
2.1 Simplified view of an SDN architecture (based on Figure 1 ofKreutzet al.
(2015)). . . 11
2.2 OpenFlow table pipeline. . . 13
2.3 Open vSwitch Interfaces. . . 14
2.4 An example of Clos network in VL2 with two separated address sets: LAs and AAs (based on Figure 5 ofGreenberget al.(2009)). . . 16
2.5 FlowVisor architecture (based on Figures 2 and 3 ofSherwoodet al.(2009)). 18 2.6 OpenVirteX architecture (based on Figures 1 and 3 of Al-Shabibiet al.(2014)). 19 2.7 FlowN architecture (based on Figure 1 of Drutskoyet al.(2013)). . . 20
2.8 (a) Virtual Cluster and (b) Virtual Oversubscription Cluster abstractions (based on Figure 2 and 3 ofBallaniet al.(2011)). . . 22
2.9 Network Virtualization Platform architecture. . . 24
2.10 TheVFP Design (based on Figure 1 ofFirestone(2017)). . . 25
2.11 TheAndromeda Stack (based on Figure 1 ofDaltonet al.(2018)). . . 26
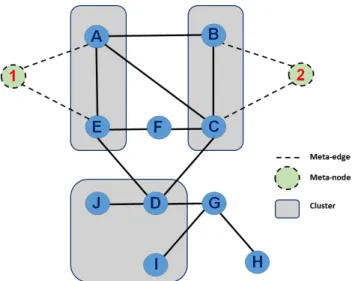
2.12 Example of an augmented substrate graph with clusters, meta-nodes and meta-links (based on Figure 2 ofChowdhuryet al.(2012)) . . . 29
2.13 Example of how topology can influence node mapping (based on Figure 2 ofChenget al.(2011)). . . 29
2.14 A VN not capable of tolerating two link failures (solid edges) and a VN aug-mented that tolerates them (both solid and dashed edges) (based on Figure 2 ofShahriaret al.(2016)). . . 31
2.15 Xen-Blanket overview architecture (based on Figure 1 of Williams et al. (2012)). . . 34
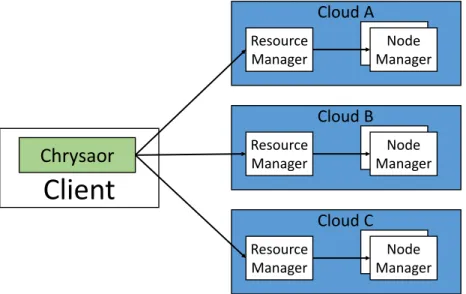
2.16 The multi-cloudChrysaor’s system model (based on Figure 1 ofCostaet al. (2017)). . . 35
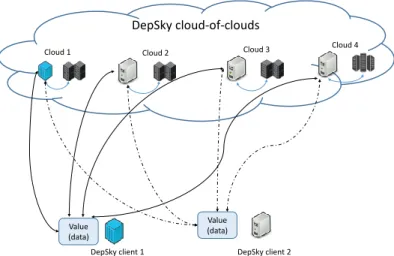
2.17 Architecture ofDepSky (based on Figure 3 ofBessaniet al.(2013)). . . 36
3.1 Sirius architecture. . . 46
3.2 Modular architecture of the multi-cloud orchestrator. . . 48
3.3 Graphical User Interface of Sirius. . . 49
3.4 Intra- and inter-clouds connections. . . 50
3.5 Modular architecture of the network hypervisor. . . 51
3.6 (Switch port, DatapathId)= host ID . . . 54
3.7 Setup time (left: MST; right: full mesh). . . 56
3.8 Control plane overhead . . . 57
3.9 Data plane overhead . . . 58
4.1 Example substrate network encompassing resources from multiple clouds. 65 4.2 Example of the embedding of a virtual network request (top) onto a multi-cloud substrate network (bottom). The figure also illustrates the various constraints and the resulting mapping after the execution of our MILP for-mulation. . . 69
4.3 Network model when no backup is requested (left); and when at least one backup node is requested (right). . . 71
5.1 Virtual networks and substrate. . . 95
5.2 Derived network models from the user specifications for the substrate net-work and a single virtual netnet-work (only considering thec l oud() attribute). 100 5.3 Data structures used in node mapping. . . 106
5.4 VNR acceptance ratio: Sirius vs optimal . . . 112
5.5 Acceptance ratio: ratio of successful VNRs. . . 113
5.6 Acceptance ratio (multi-cloud scenario) and provider revenue. . . 114
5.7 Embedding time for node mapping. . . 114
5.8 Embedding time for link mapping. . . 115
5.9 The effect of coupling node and link mapping with Path Contraction. . . . 116
5.10 Container configuration in-depth. . . 118
5.11 Virtual network provisioning. . . 118
5.12 Prototype measurements: intra- and inter-cloud throughput and latencies. . 119
5.13 Virtual (top) and Substrate (bottom) topologies for experiments consider-ing three embeddconsider-ing algorithms: Sirius, full-greedy (Yuet al.,2008), and the optimal solution (Alalunaet al.,2017). . . 121
5.14 Embedding time for 9 sequential VNRs . . . 122 6.1 ElasticVN primitives . . . 127 6.2 Elastic VN system . . . 129 6.3 VNR acceptance ratio. . . 144 6.4 Resource usage. . . 145 6.5 Cost of Migration. . . 146 6.6 Path lengths. . . 146
2.1 Summary of network virtualization solutions. . . 27
2.2 Summary of the most relevant embedding approaches. . . 33
2.3 Summary of multi-cloud systems. . . 36
2.4 Elastic VNs and enablers. . . 38
4.1 Policy grammar to define SecVNE parameters. . . 72
4.2 MILP formulation variables . . . 74
4.3 MILP additional parameters . . . 75
4.4 Auxiliary sets to facilitate the description of the formulation constraints. . 75
4.5 VNR configurations evaluated in the experiments. . . 86
5.1 VNR configurations that were evaluated. . . 110
6.1 Global variables employed by the algorithms. . . 134
6.2 VNR configurations that were evaluated in the experiments. . . 143
1
Introduction
The management of cloud computing infrastructures was made possible by the advent of server virtualization. By exposing a software abstraction (the Virtual Machine – VM) to cloud users instead of the physical machine itself, virtualization has given the degree of flex-ibility necessary for operators to achieve their operational goals while satisfying customer needs.
Unfortunately, the requirements of today’s cloud users – for example, the ability to mi-grate unchanged workloads to the cloud – can not be met with server virtualization alone. The root of the problem is the fact that, although compute and storage virtualization is
commonplace, network virtualization is not.Complete network virtualization, as required
in current cloud deployments, entails fully decoupling the logical service from its physical realization (Casadoet al.,2010). Traditional network virtualization primitives, such as Vir-tual Local Area Network – VLANs and VirVir-tual Private Network – VPN, do not offer this form of virtualization: they provide only restricted forms of isolation.
Moreover, these network virtualization primitives are too coarse-grained and lack the scal-ability to provide complete virtualization (Yuet al., 2011). This situation is rooted in a fundamental problem: networks are very hard to manage. However, a recent paradigm shift that promotes the logical centralization of network control and the separation of the network’s control logic (the control plane) from the underlying routers and switches that
2015) – has allowed the emergence of production-quality, cloud-scale virtualization plat-forms that allow the creation of virtual networks, each with independent service models,
topologies, and addressing architectures, over the same physical network (Dalton et al.,
2018;Firestoneet al.,2018;Koponenet al.,2014).
1.1 Problem and Motivation
These state-of-the-art platforms for network virtualization (Al-Shabibiet al.,2014;Dalton et al.,2018;Firestone et al., 2018; Koponen et al., 2014) show the feasibility of network virtualization, but they have been confined to a datacenter controlled by a single cloud op-erator. They thus have limitations in terms of resilience, and this restriction can become an important barrier as more critical applications are moved to the cloud. For instance, com-pliance with privacy legislation may demand certain customer data to remain local (either in an on-premise cluster or in a cloud facility located in a specific country). As a concrete ex-ample, to abide by the recently implemented General Data Protection Regulation (GDPR), a virtual switch connecting databases that contain user data may need to be placed at a spe-cific private location under the tenant’s control, while the rest of the network is offloaded to public cloud infrastructures, to take advantage of their elasticity and flexibility.
This offers motivation to extend network virtualization to amulti-cloud environment.
Be-ing able to leverage from several cloud providers can potentiate important benefits. First, a tenant can be made immune to any single data center or cloud availability zone outage by spreading its services across providers. Despite the highly dependable infrastructures employed in cloud facilities, the large number of incidents involving accidental and mali-cious faults in cloud infrastructures (Blodget,2017;Loset al.,2013;Sharwood,2016) show that relying on a single provider can lead to the creation of internet-scale single points of failures for cloud-based services. Second, user costs can potentially be decreased by taking advantage of dynamic pricing plans from multiple cloud providers. Amazon’s EC2 spot pricing is an example, which was recently explored to significantly reduce the costs on
cer-tain workloads when compared to traditional on-demand pricing (Zhenget al.,2015). As
providers increase the support of dynamic prices, the opportunity for further savings in-creases with the user’s ability to move Virtual Networks to less costly locations. Third,
increased performance can also be attained by bringing services closer to clients or by mi-grating workloads that at a certain point in time need to closely cooperate.
Another limitation of current SDN-based network virtualization solutions is that their ser-vice offering is restricted to conventional network serser-vices (such as flat L2 or L3 routing)( Al-Shabibiet al.,2014;Daltonet al.,2018;Firestoneet al.,2018;Koponenet al.,2014). In par-ticular, they do not consider security and dependability aspects when deploying the virtual infrastructures, limiting them with respect to those important non-functional properties. This motivates the need for user-centric virtual networks that leverage from a multi-cloud substrate infrastructure, entailing virtual resources with different levels of security and de-pendability. This brings with it several important benefits for users. First, it increases the resilience of virtual networks. Replicating services across providers avoids single points of failure. Second, it can improve security, by exploring the interaction between different types of clouds (e.g., public vs private) and by allowing users to chose the required security guarantees from their virtual network nodes and links.
As demonstration of the timeless of this problem, the leading virtualization companies have recently started to explore multi-cloud approaches for security. For example, after its acquisition of CloudCoreo, a public cloud security startup, VMware has integrated
Cloud-Coreo’s multi-cloud technology to create a new brand of security services (
VMwareMulti-CloudSec,2019). This type of deployments is trending upwards, with 85% of enterprises reporting to already have a multi-cloud strategy for their business (RightScale,2017).
1.2 Objective and Challenges
In this thesis, we propose a multi-cloud network virtualization solution that improves over the state of the art in two aspects. First, it enriches the network substrate with resources from multiple clouds, including private data centers and public clouds. Second, it enriches the virtual networks with security, dependability and elasticity, enabling, overall, more resilient and flexible virtual infrastructures.
Scaling out network virtualization to multiple clouds entails various challenges. First, it is necessary to create a single cloud abstraction from multiple heterogeneous clouds, as this aspect should be transparent to the users. This is complicated because different cloud
operators expose different APIs to a different set of services. It is, therefore, necessary to create a new software layer to hide these differences while maintaining good performance. Second, it should be possible to provide complete network virtualization, giving tenants the freedom to specify the network topologies and addressing schemes of their choosing, while guaranteeing the required level of isolation among them. As achieving this goal has proved difficult (if not impossible) with traditional network approaches, our goal is to explore SDN for this purpose. The centralization of the control and the global visibility offered by SDN can be used to enforce the required properties for the virtual networks.
Third, increasing the offer of virtual networks with security and dependability requires novel algorithms for network embedding, the process find efficient mappings of virtual networks requests onto the substrate network. The main challenge is to simultaneously fulfill three objectives: to comply with these more advanced requirements of users; to make good use of the substrate resources, maximizing provider’s gains; and to guarantee that the solution scales to very large networks.
Fourth, it is important to be aligned with one of the main goals of a cloud model: elasticity. Towards this goal we investigate algorithms that allow the virtual networks to scale in and scale out. This objective should be achieved without negatively impacting the use of re-sources. For this purpose, it is necessary to investigate optimizations and explore recently proposed enabling solutions, including the ability to migrate network workloads.
1.3 Contributions
To fulfill the goals stated before, we make the following contributions in our work: (i) We propose an architecture that allows network virtualization to extend across multiple cloud providers, including a tenant’s own private facilities, therefore increasing the versa-tility of the network infrastructure. In this setting, the tenant(s) can specify the required network resources as usual but now they can be spread over the data centers of several cloud operators, both public and private. This is achieved by creating a new network layer above the existing cloud hypervisors to hide the heterogeneity of the resources from the different providers while providing the level of control to setup the required (virtual) links among
the VMs. Our solution, Sirius, follows an SDN approach: the proposed new network layer contains network elements that are configured remotely by an SDN controller, in order to perform the necessary virtual-to-physical mappings, and the set up of tunnels to allow the network to be virtualized. The network virtualization platform for multi-cloud
environ-ments we propose allowscomplete virtualization of L2 and L3 addressing, arbitrary network
topologies, and isolation between tenants. This contribution is presented in Chapter3and
enhanced in Chapter5, and was published partially in NetSoft 2016 (Alalunaet al.,2016),
partially in the XDOM0 2017 workshop (Alalunaet al.,2017).
(ii) The second contribution is a novel virtual network embedding (VNE) solution for multi-cloud network virtualization. Our solution considers security as a first-class citi-zen, enabling the definition of flexible policies in three central areas: on the links, where alternative security options can be explored (e.g., encryption); on the switches, support-ing various degrees of protection and redundancy if necessary; and across multiples clouds, including public and private facilities, with the associated trust levels. We formulate the problem as a Mixed Integer Linear Programming (MILP) and evaluate our proposal against the most common alternatives. Our analysis gives insight into the trade-offs involved with the inclusion of security demands into network virtualization, providing evidence that this notion does not preclude high acceptance rates, efficient use of resources and increases in
provider profits. This contribution is presented in Chapter4. An article presenting this
work is currently under evaluation at the Elsevier Computer Communications journal (the chapter corresponds to its last version, which addresses a prior request for a major revision). (iii) The MILP solution we propose makes optimal use of the substrate resources, but it has one problem. It does not scale to large networks. Faced with this challenge, the third contri-bution is a VNE heuristic that scales to very large networks. The evaluation of our new al-gorithms demonstrates the solution to scale well for networks of thousands of switches em-ploying diverse topologies, and improves on the virtual network acceptance rate, provider revenue, and quality of service when compared with the common alternatives. As an ex-ample, our results show that provisioning a 10 thousand container virtual network can be
attained in less than 2 minutes. This contribution is presented in Chapter5and has been
published in Elsevier Computer Networks journal (Alalunaet al.,2019).
(iv) The fourth contribution of our thesis is a VNE solution that adds elasticity to the tenant’s virtual networks. For this purpose, we propose new primitives and develop new
algorithms that allow virtual networks to scale out (increase) and scale in (decrease). To guarantee that resources are used efficiently, our solution includes the possibility of mi-grating specific elements of the network substrate. As migration has a cost, we make a parsimonious use of this technique. As a result, our solution achieves a level of efficiency that is similar to a solution that fully reconfigures the substrate network, while reducing the migration requirements by one order of magnitude. This contribution is presented in
Chapter6and is about to be submitted to IEEE INFOCOM.
(v) We also made our system Sirius available open source1 , including all evaluation data
(scripts and results).
We evaluate our solutions with large-scale simulations that consider realistic network topolo-gies, and our prototype Sirius in a substrate composed of private data centers and public
clouds. Sirius was the core software component of the H2020 SUPERCLOUD project (
SU-PERCLOUD,2019). The prototype was demonstrated, with success, in the final review of the project. The setup included a substrate composed of 7 cloud services from 5 cloud providers across 5 different countries. Two non-trivial virtual networks were shown run-ning two real distributed applications: a laboratory information system from Maxdata, and a medical imaging platform from Phillips. A video of the demonstration is available online, inDemoOfSirius(2019).
1.4 Structure of the Thesis
The thesis is organized as follows: Chapter 2 presents the context of the thesis and the
related work.
Chapter3presents the design and implementation of Sirius, a network virtualization
plat-form for multi-cloud environments.
Chapter4addresses the online network embedding problem for our context, by presenting
a novel solution for this central component of network virtualization: finding efficient mappings of virtual networks requests onto the substrate network.
Chapter5presents a heuristic for virtual network embedding which fit a modern data cen-ter context, scales well, and considers the security of virtual resources.
Chapter6presents new primitives and heuristics for virtual network embedding with the
capacity of scaling out and scaling in virtual networks.
2
Background and Related work
This chapter provides background on the problem at hand, mainly by introducing the
nec-essary concepts and discussing relevant work done in the area. We start, in Section 2.1,
by describing the Software-defined networking (SDN) paradigm. By logically centralizing
network control, SDN allowed the development of solutions forcomplete network
virtu-alization that fully decouple the virtual networks from the substrate. In Section2.2, we
present the state-of-the-art of network virtualization. The role of SDN will be made clear in this section, alongside the limitations of existing approaches, which motivates this work. Then, in Section2.3, we address the central resource allocation problem of network virtual-ization that we tackle in our thesis: virtual network embedding (VNE). The VNE problem consists in finding an efficient mapping of the virtual nodes and links onto the substrate network. Our thesis advances the state of the art on this topic by including security and elasticity into the problem. For the former, it considers an enriched substrate network model that includes resources from multiples clouds. As such, we present recently
pro-posed multi-cloud systems (for storage and computing) in Section2.4. For the latter, we
propose new scaling primitives and mechanisms. We thus close this chapter with related
2.1 Software-defined networks
In traditional IP networks, the control and data planes are coupled inside network
switch-es/routers and network control is fully decentralized. This design has advantages, namely
with respect to resilience, but has an important drawback: leads to networks that are very complex to manage, operate, and control. In addition, the closed nature of networking gear makes it hard to insert new functionalities directly in the network elements, forcing the in-vestment in middleboxes, such as firewalls, intrusion detection systems, and load balancers, that further increase infrastructure complexity. Another characteristic of traditional net-works is that, in order to configure their behavior and to define their policies, it is necessary to intervene in each network element with manually-operated commands or using low-level scripts.
This lack of flexibility has slowed the innovation in, and the evolution of, networking. Ideally, a network should be programmable. The initial step in this direction was given
recently with the advent of Software-defined networking – SDN (Kreutzet al.,2015). This
paradigmseparates the network data and control planes and logically centralizes network
control, enabling its programmability. Figure 2.1depicts the basic view of an SDN
archi-tecture.
SDN decouples the network control and forwarding functions, enabling the former to be-come directly programmable, and allowing the underlying infrastructure to be abstracted
for applications and network services (ONF, 2018b). A software-defined network is an
architecture with four pillars (Kreutzet al.,2015;ONF,2018b):
1. Decoupling the control plane from the data plane. Network devices become simple packet forwarding elements.
2. Forwarding decisions are flow-based, in contrast to destination-based. A flow is a
set of packet field values acting as a filter criterion that defines the set of actions to be applied. The packets of a specific flow receive the same service policies at the forwarding devices.
3. The control logic is moved to an SDN controller. This entity is external and typi-cally runs on a (cluster of) commodity server(s). It provides the main resources and
Figure 2.1: Simplified view of an SDN architecture (based on Figure 1 of Kreutz et al.
(2015)).
abstractions to allow the programming of forwarding devices based on a logically centralized, abstract network view.
4. The network is programmable through control software applications running on the SDN controller.
OpenFlow (ONF,2016) is the most common southbound interface to allow the separation
between control and data planes. It allows specification of the forwarding behavior desired by the network application while hiding details of the underlying hardware. OpenFlow can be seen as the equivalent to a “device driver” in an operating system. This protocol has been added as a feature to most commercial Ethernet equipment, working as a standardized hook to allow researchers to run experiments, without requiring vendors to expose the internal workings of their network devices.
2.1.1 Controllers
The controller is the fundamental element of an SDN architecture, as it is the key support-ing piece for the control logic (applications) to generate the network configuration based on the policies defined by the network operator. The control platform has characteristics that resemble those of an operating system:
• abstracts the lower-level details of the interaction with forwarding devices; • facilitates the creation of Application Programming Interfaces – APIs;
• deals with topology discovery, a fundamental “tool” for network control applica-tions; and
• provides other basic network functionalities.
There is a diverse set of controllers with different design and architectural choices. Exist-ing controllers can be categorized based on many aspects, such as the type of basic network functionalities provided, which southbound or northbound API is supported, etc. One rel-evant architectural aspect is whether the controller is centralized or distributed. A central-ized controller (such as NOX (Gudeet al.,2008) or Floodlight (Floodlight-Project,2019)) is a single entity that manages all forwarding devices of the network. Naturally, it represents a single point of failure and may have scaling limitations. Contrary to a centralized design, a distributed controller (such as Onix (Koponenet al.,2010) or ONOS (Berdeet al.,2014)) can be scaled up to meet the requirements of potentially any environment, from small to large-scale networks.
We choose the Floodlight controller to develop the solutions to be presented in this thesis, for three reasons. First, because its community is very active, making available a large set of tutorials and detailed manuals about the controller. Second, because it uses Java as the main language, facilitating portability. Finally, because Floodlight has been widely adopted by the research community.
2.1.2 OpenFlow and OVSDB
As stated above, OpenFlow has been implemented into the equipment of most major
ven-dors, with many OpenFlow-enabled switches now commercially available (McKeownet al.,
2008;ONF,2016). An OpenFlow Switch is composed of a set of flow tables (with multiple
flow entries each) used to process packets by matching on specific headers and by executing pre-defined actions. To remotely control the forwarding tables, this equipment establishes TCP or TLS communication with, at least, one master controller (and potentially with several slaves). Controllers can insert, delete or update flows in each table to control the
network. Each flow is composed ofmatching rules, counters that keep statistics of matching
packets, anda set of actions to be performed on matching packets (ONF,2018a).
Figure 2.2: OpenFlow table pipeline.
As soon as a packet arrives at an OpenFlow forwarding element, it is handled based on the data on the matching fields. The packet is processed in priority order of the flows in the first table until a match is found. If no such match occurs, it proceeds to the next table
until the end of the pipeline, as shown in Figure2.2(in fact, some actions may point the
packet directly to an output port). If a match is found, an action is executed. Examples of actions include: forwarding to a port, drop the packet, set in a queue, push/pop tag, set field value, change Time to Live (TTL), send the packet to the controller, among others. In
case of no match in any table, atable-miss happens, typically with the packet being sent to
the controller.
A notable example of a software-based OpenFlow switch implementation is Open vSwitch (OVS) (Pfaffet al.,2015). OVS is a software switch that operates within the hypervisor /-management domain and provides connectivity between the virtual machines and the un-derlying physical interfaces. It implements standard Ethernet switching and, in a stan-dalone configuration, it operates much like a basic L2 switch. However, to support
inte-gration into virtual environments, and to allow (logical) switch distribution, OVS exports interfaces for manipulating the forwarding state and managing configuration state at run-time. Since OVS was originally developed, its performance was on par with the Linux Ethernet bridge. Over the past few years, its performance has been gradually optimized to match the requirements of multi-tenant data center workloads (Pfaffet al.,2015). Underly-ing OVS there is a flow-table forwardUnderly-ing model similar to that used by OpenFlow.
Since OpenFlow does not allow to modify the switch configurations (e.g. configure queues
and tunnels, add/remove ports, create/destroy switches), OVS also maintains a database
and exports a configuration interface that enables remote configuration of the virtual switches
via the OVSDB protocol (Pfaff & Davie, 2013). OVSDB is a management protocol that
uses JSON (Crockford,2015). It has a database that holds the configuration for one Open
vSwitch daemon and describes the switching behavior of a virtual switch. The protocol
interface is used to accomplish the configuration operations on the OVS. Figure2.3depicts
the interaction between the main components and the interfaces in OVSDB (Pfaff & Davie,
2013). For instance, using OVSDB it is possible to: initialize the Open vSwitch database,
create OpenFlow bridges, ports, tunnels, and queues, configure controller connections, etc.
2.2 Network virtualization
There are many network primitives for virtualization, like VLANs (virtualized L2 do-main), MPLS (virtualized path) and VPN (Virtual Private Network). However, none of these primitives can supply the full decoupling of the virtual network from the physical
substrate: the main requirement forcomplete network virtualization. A network
hypervi-sor should completely decouple the substrate network from the virtual networks, allowing the freedom to specify the network topologies and addressing schemes of a tenant’s choos-ing while guaranteechoos-ing the required level of isolation among them. With the advent of SDN, it became possible to offer this form of virtualization. In this section we describe the advances in this field over the last 10 years, including the most relevant network virtualiza-tion systems, and their limitavirtualiza-tions.
2.2.1 Network virtualization for scalability and agility
With the advent of cloud computing and the need for very large scale data center infras-tructures to support it, the limitations of traditional networking solutions became evident. Given the difficulty - or even the impossibility - of changing or replacing existing networks, the community started to explore advanced forms of network virtualization. Initial work had the goal of coupling the ease of configuration and management of the Ethernet with the scalability advantage of IP networks. SEATTLE (Kimet al.,2008) was amongst the first sys-tems to provide the plug-and-play functionalities and the linear addressing of the Ethernet, with the high scalability and efficiency of using shortest-path, IP-based routing.
For this purpose, it relies on three main techniques: a one-hop network-layer distributed hash-table (DHT) for address resolution, enabling packet forwarding based on MAC ad-dress while avoiding switches to maintain state for each host; traffic-driven location res-olution and caching in switches to forward packets using shortest paths while avoiding load on the resolution service; and a scalable cache-update protocol used to avoid Ethernet broadcasts. These techniques enable SEATTLE to overcome the scalibility limitations of Ethernet networks, by avoiding flooding to locate hosts and by not relying in the Spanning Tree Protocol, which has its own scalability and dependability limitations.
SEATTLE has one important limitation: it requires switches to be changed. VL2 ( Green-berg et al.,2009), on the other hand, takes an end-host based approach. Its starting goal was to offer each service the abstraction of having all its servers connected by a single non-interfering Ethernet switch. In addition, it should support huge data centers, allowing uniform high capacity on the servers, performance isolation between services, all while maintaining Ethernet semantics.
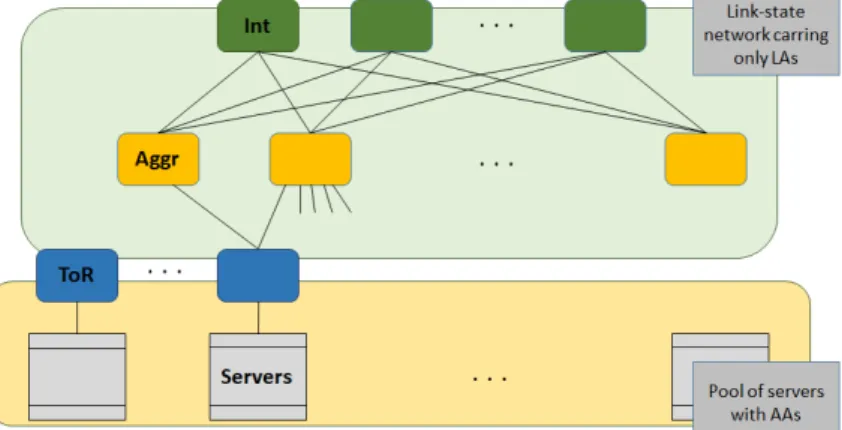
For this purpose,VL2 is a scale out topology built with low cost switch ASIC, managed in
a Clos topology, as presented in Figure2.4. This provides extensive path diversity, which
coupled with the use of Valiant Load-Balancing (Zhang-Shen,2010) enables spreading traffic
without any centralized coordination. VL2 uses different IP addresses to separate a host
location from its identification, an essential feature to enable service migration. There is
a location-specific address (LA) for switches and interfaces (these devices run a link-state
routing protocol to maintain the switch level topology), and anapplication-specific address
(AA) for applications (kept unaltered even if the server changes its location). As a result, the LAs and AAs create an abstraction that all the servers belong to the same layer-2 network, while avoiding ARP and DHCP floods. A directory system is used to maintain the mapping between the two sets of IP addresses.
Figure 2.4: An example of Clos network in VL2 with two separated address sets: LAs and AAs (based on Figure 5 ofGreenberget al.(2009)).
A related effort isPortLand (Mysoreet al.,2009). Its authors propose a lightweight scal-able, fault tolerant Ethernet-compatible network, by leveraging the knowledge about its baseline topology (a fat tree (Leiserson,1985)). A solution tailored to a special topology
facilities flexibility in VM migration, but being based on a specific topology can also be considered a limitation. By contrast,TRILL (Perlmanet al.,2011) enables general topolo-gies, by approaching the L2 challenges differently. Here, an Ethernet broadcast link state protocol is used among switches to identify the network topology, the hosts locations and to separate addressing from location. In addition, it uses MAC-in-MAC encapsulation to limit forwarding table size in the switches. The encapsulated packets are forwarded in the network and are decapsulated at the edge for the end host to remain unmodified.
While these works offer partial forms of virtualization, they are not network virtualization platforms per se. Namely, they do not allow tenant services to define arbitrary topologies
or addressing schemes, and as such do not offercomplete network virtualization.
2.2.2 Virtualization of software-defined networks
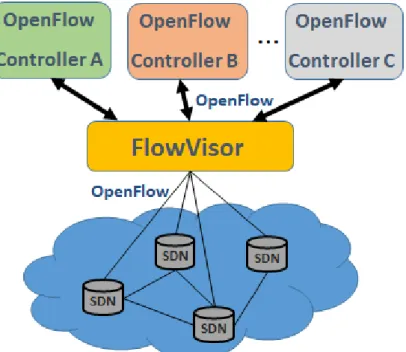
The flexibility advantage of SDNs was demonstrated from the outset with the emergence of platforms that allow virtualizing the SDN itself. FlowVisor (Sherwoodet al.,2009) was the seminal work on this topic. Its basic idea is to allow multiple logical networks to share the same OpenFlow networking infrastructure. For this purpose, it provides an abstraction layer that slices a data plane based on off-the-shelf OpenFlow-enabled switches, allowing multiple and diverse virtual SDNs (vSDN) to co-exist. In general terms, a slice is defined as a particular set of flows in the data plane. Each slice receives a minimum data rate and each guest controller gets its own virtual flow table in the switches. To achieve this goal, FlowVisor assumes control over the entire infrastructure.
FlowVisor sits between the tenant’s SDN controllers and the network switches (Figure2.5).
From a system design perspective, FlowVisor is a transparent proxy that intercepts Open-Flow messages between switches and controllers. By such, Open-FlowVisor controls the view that the tenants’ controllers have of the SDN switches.
Five slicing dimensions are considered in FlowVisor: bandwidth, topology, traffic, device CPU, and forwarding tables. Different mechanisms are used to slice over each dimension. For instance, VLAN priority bits are used for bandwidth isolation, considering all packets in a flow with a specific priority. Thus, all traffic that belongs to a given slice is mapped to the traffic class defined by the resource allocation policy. The proxy-based architecture
Figure 2.5: FlowVisor architecture (based on Figures 2 and 3 ofSherwoodet al.(2009)).
allows packets to be intercepted – both from and to the controller – allowing transparent slicing of topology, forwarding tables, OpenFlow flow counters, etc.
In FlowVisor, each network slice supports a controller, i.e., multiple SDN controllers can co-exist on top of the same physical network infrastructure. Each controller is allowed to act only on its own network slice.
Other slicing approaches based on FlowVisor appeared in the literature afterward. For instance, AutoSlice (Bozakov & Papadimitriou,2012) focuses on the automation of the de-ployment and operation of vSDN topologies with minimal mediation or arbitration by the substrate network operator. Additionally, AutoSlice targets scalability aspects of network hypervisors by optimizing resource utilization and by mitigating the flow-table limita-tions through a precise monitoring of the flow traffic statistics. Similarly, AutoVFlow ( Ya-manakaet al.,2014) also enables multi-domain network virtualization. However, instead of having a single third party to control the mapping of vSDN topologies, as is the case of AutoSlice, AutoVFlow uses a multi-proxy architecture that allows network owners to implement flow space virtualization in an autonomous way by exchanging information among the different domains.
FlowVisor-based slicing approaches do not offer complete network virtualization of an SDN. Building on the design of FlowVisor, also acting as a proxy between the controller
and the forwarding devices (Figure2.6), OpenVirteX (OVX) (Al-Shabibiet al.,2014)
pro-vides virtual SDNs with arbitrary topologies, arbitrary L2 and L3 addresses, and control function virtualization. These are the required properties in a multi-tenant environment where virtual networks need to be flexible to assure quick provisioning and the ability to be migrated across the entire infrastructure, in response to the dynamics of the environ-ment. To enable arbitrary topologies, OVX maps the virtual networks onto the substrate
by relying on network embedding algorithms (to be introduced in Section2.3).
Figure 2.6: OpenVirteX architecture (based on Figures 1 and 3 of Al-Shabibiet al.(2014)). To provide each tenant with the full header space, OVX controls all switches of the physical SDN network, re-writing at the edge the virtually assigned IP and MAC addresses of the hosts, defined by the tenant, into disjoint addresses to be used in the SDN core. With such approach, in theory, the entire flow space can be provided to each virtual network. In practice, the current implementation does not allow the overlap of (virtual) MAC addresses,
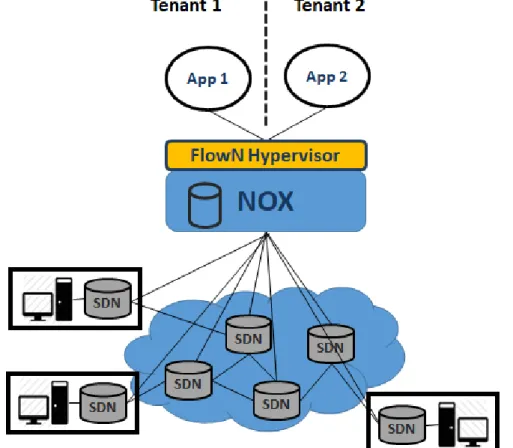
meaning virtual hosts cannot use the same MAC in different virtual networks. In other words, in the current implementation L2 addressing is not virtualized, whereas L3 is. FlowN (Drutskoyet al.,2013) is another solution that offers complete network virtualiza-tion of SDN. In this platform, tenants can also specify their own L3 address space, arbitrary topology, and control logic. Each tenant has full control over its virtual networks and is free to deploy any network application on top of the controller platform. However, whereas FlowVisor can be compared to traditional virtualization technology, FlowN is analogous to container-based virtualization, i.e., it is a lightweight virtualization approach (Figure2.7). It is designed to be scalable by allowing a unique shared controller platform to be used for managing multiple virtual domains in a cloud environment.
Figure 2.7: FlowN architecture (based on Figure 1 of Drutskoyet al.(2013)).
Similarly to OVX, to achieve address virtualization the solution marks incoming packets at the edge switches using VLAN tags to identify the tenant, limiting scalability. Moreover,
FlowN uses database technology for the mapping between physical and virtual network topologies.
A related effort is the compositional SDN hypervisor (Jinet al.,2014), a solution designed with the objective of allowing the cooperative (sequential or parallel) execution of appli-cations developed with different programming languages or conceived for diverse control platforms. It thus offers interoperability and portability in addition to the typical functions of network hypervisors.
One common aspect of all these works is that they aim to virtualize an SDN, and so they
are notgeneric network virtualization solutions.
2.2.3 Network virtualization in the cloud era
The level of maturity of cloud computing technologies has led many companies and Gov-ernment agencies to migrate their IT services to operate in the cloud, both because of ef-ficiency gains and to lower costs (Greer,2010). As cloud services matured, the associated network requirements have grown and network virtualization has had to evolve.
2.2.3.1 Enhanced VN abstractions
Towards this goal,Guoet al.(2010) proposed the virtual data center (VDC) abstraction as
a unit of resource allocation. This abstraction is defined as a set of VMs with a customer-supplied IP address range and an associated service level agreement that includes bandwidth
requirements. To enable the VDC abstraction, the authors proposedSecondNet, a new data
center network virtualization architecture. To scale,SecondNet distributes all the
virtual-to-physical mapping, routing, and bandwidth reservation state.
Also by realizing that cloud application performance critically depends on the network,
Bal-lani et al.(2011) have identified that the VDC abstraction was limited and have proposed the extension of cloud services with two new abstractions. The first is the virtual clus-ter, an abstraction that provides the illusion of having all VMs connected to a single, non-oversubscribed virtual switch. This is motivated by MapReduce-like applications that are characterized by all-to-all traffic patterns. The second, the virtual oversubscribed cluster,
emulates an oversubscribed two-tier cluster that suits applications featuring local communi-cation patterns. The authors further designed a system that implements these abstractions:
Oktopus. Figure2.8presents these two abstractions.
Bandwidth B B
VM 1 VM N
Virtual Switch
Request <N, B>
Each VM can send and receive at rate B
Switch bandwidth need = N*B
(a) (b) Bandwidth B*S/O Root Virtual Switch Group Virtual Switch
Group 1 Group 2 Group N/S VM 1 VM S VM 1 VM S VM 1 VM S
Request <N, S, B, O>
N VMs in groups of S, Oversubscription factor O Group Switch bandwidth = S*B Root switch bandwidth = N*O/O
Figure 2.8: (a) Virtual Cluster and (b) Virtual Oversubscription Cluster abstractions (based on Figure 2 and 3 ofBallaniet al.(2011)).
Xie et al.(2012) extended the previous solution to handle dynamic traffic patterns. The motivation for their design is that the behavior of the most common jobs executed in data centers follows specific patterns. By leveraging this knowledge they are able to increase the utilization of the data center and decrease the tenants’ costs. For this purpose, this work
proposes a temporally-interleaved virtual cluster abstraction which captures the temporal
variations in the network behavior of cloud applications.Rost et al. (2015) went further
and proposed a polynomial-time solution to compute resource-minimal virtual cluster
em-beddings, proving that this special case of embedding was not anNP-hard problem, as was
commonly perceived.
These works enhance virtual networks, but they do not yet providecomplete network
2.2.3.2 Complete Network Virtualization
Simple network abstractions are typically enough for the most basic application workloads that require only a single logical switch connecting a few tens of VMs using a flat L2 ser-vice, with some bandwidth (or sometimes delay) guarantees. However, this leaves aside many typical workloads. For instance, large analytic workloads typically demand for L3 routing, and web services often require multiple tiers. The experience from production-level environments (e.g., (Daltonet al.,2018;Firestoneet al.,2018;Koponenet al.,2014)) confirms this scenario: as deployments mature, tenants migrate to more complicated
work-loads. This strengthens the case for offering tenants witharbitrary virtual networks, with
diverse network topologies.
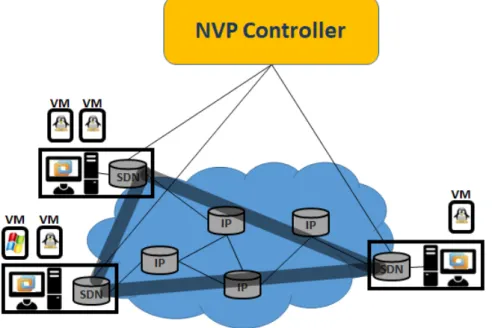
VMware has proposed a network virtualization platform (NVP/NSX) (Koponen et al.,
2014;VMWare,2018) that provides the necessary abstractions to allow the creation of in-dependent virtual networks for large-scale multi-tenant environments. NVP is a complete network virtualization solution that allows the creation of virtual networks, each with in-dependent service models, topologies, and addressing architectures, over the same physical network. In NVP, tenants’ applications are provided with an API to manage their virtual networks, and the network hypervisor translates the tenants’ configurations and require-ments into low-level instruction sets to be installed on the forwarding devices.
For this purpose, the platform uses a cluster of SDN controllers to manipulate the forward-ing tables of the Open vSwitches in the host’s hypervisor. Forwardforward-ing decisions are
there-fore made exclusively at the network edge (Figure2.9). NVP wraps the ONIX controller
platform (Koponenet al.,2010), and thus inherits its distributed controller architecture, allowing it to scale. In order to virtualize the network, NVP creates logical datapaths, at the sending host, simulating the virtual network in order to reach a forwarding decision. After a forwarding decision is made, the packets are tunneled over the physical network to the receiving host hypervisor. As a result, the physical network sees nothing but ordinary IP packets.
An advantage of these systems is that they do not require SDN-based equipment in the infrastructure core. The only requirement is at the edge: the computer hypervisors run software switches that are SDN-controlled. As a consequence, the existing (IP-based) in-frastructure does not need to be replaced nor upgraded.
Figure 2.9: Network Virtualization Platform architecture.
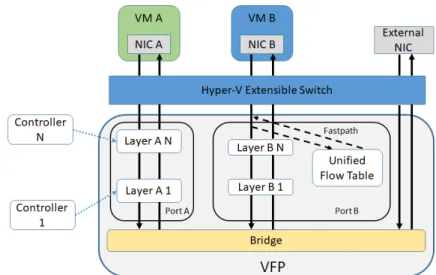
Following an approach similar toNVP to meet its own requirements, Microsoft (Firestone,
2017) developedVFP, a Virtual Switch Platform, currently in production in the Microsoft
Azure public cloud. This platform is capable of handling a data center with a large number of VMs, maintaining the high performance required in the cloud context, providing a pri-vate network using the tenants’ defined addresses space, while allowing network function
such as L4 load balancers, ACLs, etc. TheVFP architecture is presented in Figure2.10and
its design relies on Hyper-V1’s extensible switch.
TheVFP core design is split into four parts: filtering model; programming model; packet
processor and flow compiler; and switching model. For the first part,VFP uses policies to
filter ingress/egress traffic, based on the Match-Action Tables (MATs) in a specific port of the virtual NICs. The programming model is based on a hierarchy of objects: ports (each port holds a match action table policy with a set of layers), layers (a basic MAT for the controllers to specify policies), groups (each with its own set of rules) and rules (responsible for executing an action considering a specific packet match). For performance, the platform includes flow caching and a central packet processor that handles only meta data, avoiding handling the entire packet until the end of the processing. Concerning the switch model,
Figure 2.10: TheVFP Design (based on Figure 1 ofFirestone(2017)).
besides SDN filtering, the platform implements a bridge to forward traffic.
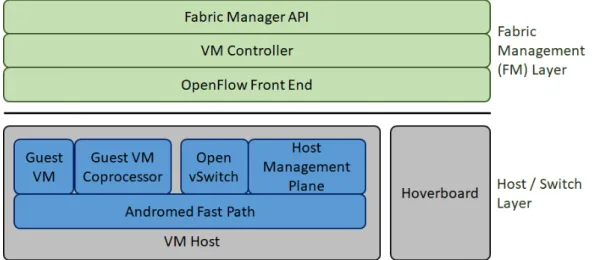
Microsoft identified that the consumption of CPU due the VFP processing adds latency
and penalizes network performance. As follow up to VFP,Firestoneet al.(2018) proposed
Azure Accelerated Network –AccelNet to address this problem. This solution is responsible
for offloading host networking to hardware: a special and customized Field Programmable Gate Array (FPGA). Besides saving CPU cycles and maintaining the VFP programmable
design,AccelNet aims to achieve high performance, making it easy to add new
functionali-ties and enabling 100+ GbE virtual ports in the future.
In the AccelNet platform, the control plane remains the same as with VFP. However, the
data plane is divided into two packet processing units, each one with a packet buffer, a parser, a flow lookup match, and a flow action. In addition to these, the platform may
perform flow tracking and reconciliation (ifVFP policies are updated, the respective flow
actions are updated too). With these changes, including the improvements inVFP and the
processing offload to hardware,AccelNet increases the bandwidth capacity (up to 32 Gbps)
and decreases latency (average of 50µs in some cases), while monitoring more than 500
metrics to allow more accurate system diagnostics.
Similar to Microsoft network virtulization platform, Google also developedAndromeda