Brasília - DF
2013
Autor: Anderson Gomes Resende
Orientador: Dr. Osvaldo Cândido da Silva Filho
ANÁLISE DA DEPENDÊNCIA ENTRE OS MERCADOS
SUCROENERGÉTICO, PETRÓLEO, CÂMBIO E BOVESPA POR
MEIO DE
VINE
CÓPULAS
Pró-Reitoria de Pós-Graduação e Pesquisa
ANDERSON GOMES RESENDE
ANÁLISE DA DEPENDÊNCIA ENTRE OS MERCADOS SUCROENERGÉTICO,
PETRÓLEO, CÂMBIO E BOVESPA POR MEIO DE VINE CÓPULAS.
Dissertação apresentada ao Programa de Pós-Graduação Stricto Sensu em Economia da Universidade Católica de Brasília, como requisito para obtenção do Título de Mestre em Economia de Empresas.
Orientador:Prof. Dr. Osvaldo Cândido da Silva Filho
7,5cm
Ficha elaborada pela Biblioteca Pós-Graduação da UCB
R433a Resende, Anderson Gomes
Análise da dependência entre os mercados sucroenergético, petróleo, câmbio e BOVESPA por meio de vine cópulas. / Anderson Gomes Resende – 2013.
52f.; : il. 30 cm
Dissertação (mestrado) – Universidade Católica de Brasília, 2013. Orientação: Prof. Dr. Osvaldo Cândido da Silva Filho.
AGRADECIMENTOS
Primeiramente agradeço a meus pais, Antônio e Lenir, e a meus irmãos, Ailton e Leidiane, pelo apoio incondicional que sempre me deram desde o início dos meus estudos em Belo Horizonte.
À minha esposa Hileana pelo amor e apoio nas horas fáceis e difíceis da vida. Além da inestimável ajuda no processo de finalização desta Dissertação.
Aos amigos Marlon, Gustavo, Washington e Hugo pela ajuda durante todo o tempo do mestrado no âmbito acadêmico e profissional na Eletronorte
Aos amigos Flechas que mesmo de longe sempre foram fonte de inspiração e companheirismo.
A meu orientador Osvaldo pela paciência e dedicação desde o início desta empreitada. Aos membros da banca e a todos os professores do Programa de Pós-Graduação Stricto Sensu em Economia da UCB pelas contribuições neste trabalho e ao longo do curso.
Aos funcionários da UCB, em especial à Maysa pela simpatia e disposição em ajudar. A Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – CAPES pelo suporte financeiro.
RESUMO
RESENDE, Anderson Gomes. Análise da dependência entre os mercados sucroenergético, petróleo, câmbio e BOVESPA por meio de vine cópulas. 52 f. Dissertação de Mestrado em Economia de Empresas – Universidade Católica de Brasília, Brasília, 2013.
Este trabalho tem por objetivo analisar a relação de dependência entre o setor sucroalcooleiro (representado por Etanol e Açúcar), Petróleo, Taxa de Câmbio R$/US$ e o mercado acionário brasileiro (representado pelo índice BOVESPA). A metodologia utilizada é baseada em pair-cópulas e são comparadas três especificações: Regular Vine, a forma mais geral, e dois casos
particulares Vine Canônico e Drawable vine. Os resultados obtidos indicaram relações de
dependência alinhadas com a literatura existente, mas mostraram que estas relações se alteram significativamente quando a dependência condicional é levada em conta.
ABSTRACT
The aim of this study is to assess the dependence relationship among sugarcane sector (represented by Ethanol and Sugar), Oil, BRL/USD Exchange Rate and Brazilian stock market (represented by the BOVESPA index). Our methodology is based on pair-copulas constructions and are compared tree specification: Regular Vine, more general, and two particular cases, Vine Canonical and Drawable vine. Primary results are shown to be aligned with the existing literature but they can change significantly when conditional dependence is taken into account.
SUMÁRIO
1 INTRODUÇÃO ... 7
2. REVISÃO DA LITERATURA ... 9
3. METODOLOGIA ... 15
3.1 MODELAGEM DAS DISTRIBUIÇÕES MARGINAIS ... 15
3.2CÓPULAS ... 17
3.2.1Pair cópulas ... 18
3.2.2Regular vine cópulas ... 19
3.2.3Vine canônico (C-vine) ... 20
3.2.4Drawable vine (D-vine) ... 21
3.3. ESPECIFICAÇÃO PARA UM MODELO DE PAIR CÓPULA ... 22
3.3.1 Seleção das pair-cópulas ... 22
3.3.2 Seleção da família cópula adequada ... 23
3.3.3 Estimação dos parâmetros ... 24
3.3.4 Comparação dos modelos ... 25
4. ESTIMATIVAS E RESULTADOS EMPÍRICOS ... 26
4.1 DESCRIÇÃO DOS DADOS ... 26
4.1 MODELOS MARGINAIS ... 27
4.1 ESTIMAÇÕES CÓPULAS ... 30
5. CONCLUSÕES ... 43
APÊNDICE A – RESULTADOS DOS MODELOS ESTIMADOS ... 45
APÊNDICE B – REFERÊNCIA DAS FAMÍLIAS CÓPULAS ... 48
APÊNDICE C – RESULTADOS DOS MODELOS ESTIMADOS ... 49
1 INTRODUÇÃO
Nos últimos anos o interesse em combustíveis de base renovável tem aumentado em todo o mundo principalmente devido a seu potencial de substituição dos combustíveis fósseis. Alguns fatores contribuíram para a consolidação destes combustíveis no rol de alternativas substitutas factíveis ao uso de combustíveis fósseis. Por um lado, por conta da escalada do preço do petróleo que pressiona pela busca de alternativas substitutas, por outro, devido à discussão sobre aquecimento global e a conseqüente indicação da influência das emissões de CO2 neste processo.
Assim, a produção de biocombustíveis, apesar de ainda pequena, tem crescido continuamente respondendo à meta de muitos países de substituir parte do seu consumo de combustíveis fósseis por combustíveis renováveis. As iniciativas mais consolidadas atualmente, etanol e biodiesel, buscam substituir a gasolina e o óleo diesel respectivamente utilizando como principal insumo commodities agrícolas como; milho,
trigo, cevada, cana de açúcar, soja e o girassol.
A investigação de como os preços das commodities interagem com os preços dos
combustíveis é de suma importância, mas as conclusões sobre esse processo não apresentam consenso. Há correntes que afirmam que a produção de biocombustíveis gera distorções nos preços destes mercados, enquanto há outras que afirmam que não.
Neste contexto, este trabalho tem o objetivo de analisar a dependência entre os mercados sucroalcooleiro, de petróleo, câmbio e BOVESPA. O adequado entendimento desta relação fornece importante suporte para os agentes interessados em investir nestes mercados na medida em que pode melhorar seu posicionamento diante do risco.
Mais especificamente, serão utilizados modelos baseados em pair-cópulas para analisar a relação de dependência multivariada entre o Etanol anidro, Açúcar, Petróleo, Taxa de Câmbio Reais/Dólar e BOVESPA, para o caso brasileiro, e, para isso, utilizamos R-vine cópulas de maneira mais geral e dois casos particulares C-vine e D-vine.
A metodologia de Vine-cópulas apesar de possuir características interessantes
que serão detalhadas mais a frente, ainda é pouco difundida em razão de seu desenvolvimento recente. Sendo, portanto, esta aplicação uma das contribuições deste trabalho.
2 REVISÃO DA LITERATURA
As contribuições para o debate sobre a relação entre preços de commodities, e de combustíveis são muito diversificadas. Mitchell (2008) destaca as principais dificuldades em relação à comparação dos diferentes estudos sobre o tema. As estimativas podem diferir amplamente devido a diferentes períodos de tempo considerados, preços diferentes (exportação, importação, atacado, varejo), e foco em diferentes produtos alimentares. Além disso, as análises dependem da moeda em que os preços são expressos, e se os aumentos de preços são ajustados pela inflação (real) ou não (nominal). Outro ponto levantado é que diferentes metodologias provavelmente, levarão a resultados diferentes.
Algumas abordagens consideram a possibilidade de existência de uma relação de não linearidade entre os preços. Balcombe e Rapsomanikis (2005) utilizaram as transformações logarítmicas de preços semanais, expressos em reais, de petróleo, etanol e açúcar no Brasil, para o período entre julho de 2000 e maio de 2006. Estimaram modelos utilizando algoritmos Bayesian Monte Carlo Markov Chain (MCMC). Os
resultados sugerem que o determinante de longo prazo dos preços do açúcar no Brasil são os preços do petróleo, com relação positiva. Os processos de ajuste de preços do açúcar e do etanol para o preço do petróleo são positivos e não-lineares, mas o ajuste entre o etanol e os preços do açúcar é linear.
As forças de oferta e demanda nos mercados de energia e de alimentos nos permitem inferir que o petróleo, biocombustíveis e commodities agrícolas podem
apresentar co-movimentos a longo prazo. Assim, ao avaliar a relação entre estes preços, deve-se prestar atenção também à noção de cointegração introduzida por Engle e Granger (1987) para capturar as relações de longo prazo ou de equilíbrio entre diferentes séries de tempo. (SERRA e ZILBERMAN 2009).
Para capturar a não linearidade em processos de ajuste de preços, Serra et al. (2008), utilizaram modelos com vetor de correção de erros suave (STVECM) utilizando
preços do petróleo e do milho, quando o sistema está longe de seu equilíbrio, causa uma mudança nos preços do etanol na mesma direção.
Zhang et al. (2010), exploraram os impactos dos biocombustíveis sobre os preços globais das commodities agrícolas sob a perspectiva de curto e longo prazo. Usando séries de tempo mensais de preços para as commodities; milho, arroz, soja,
açúcar e trigo junto com os preços de energia para; etanol, gasolina e óleo de março de 1989 a julho de 2008. O objetivo foi investigar a cointegração de longo prazo destes preços e as interações multivariadas de curto prazo. Os resultados indicam não existirem relações diretas de longo prazo entre os preços dos combustíveis e os preços das
commodities agrícolas. Em termos de movimentos de preços de curto prazo, os preços
do açúcar influenciam todos os outros preços das commodities agrícolas, exceto o arroz.
A investigação das relações entre açúcar e álcool foi o objetivo do trabalho de Alves (2002). Utilizando dados de preços para o período de 1998 a 2002 para álcool anidro, açúcar cristal industrial, açúcar cristal exportado e açúcar cristal empacotado ao produtor e ao varejo. O método utilizado foi um Auto-regressivo Vetorial com Correção de Erro – VEC. Os resultados obtidos pelo autor indicam que um choque positivo no preço do açúcar cristal industrial causa impacto positivo no preço do álcool anidro com um período de defasagem. Já um choque no preço do álcool anidro impacta positivamente, mas em pequena magnitude o preço do açúcar cristal com quatro períodos de defasagem.
Incluindo uma gama mais ampla de variáveis para avaliar como os preços de Etanol e Açúcar se comportam, Campos (2010) investigou os determinantes que afetam os preços do etanol e do açúcar no mercado doméstico e do açúcar no mercado internacional. Para as estimações foram usados modelos de Vetores Auto Regressivos – VAR com análise da função impulso-resposta e decomposição da variância. Segundo a autora, foi possível identificar forte associação entre o preço do açúcar no mercado internacional e o petróleo. De forma mais significativa, concluiu-se que o preço do açúcar no mercado Brasil pode ser predito pela evolução do preço internacional e da taxa de câmbio real/dólar real. Com relação ao etanol, encontrou-se razoável influência dos preços doméstico e internacional do açúcar na sua determinação. Adicionalmente, a autora conclui que o mercado sucroenergético brasileiro se comporta, no que tange ao comportamento de mercado, de forma consistente com os mercados de commodities em
Grôppo (2006) analisou a relação causal entre o índice do mercado acionário brasileiro (BOVESPA) e um conjunto de variáveis monetárias, representadas pela oferta monetária, pela taxa de câmbio, pela taxa de juros de curto e de longo prazo, utilizando o enfoque multivariado (VAR). Utilizou também a função de impulso-resposta e a decomposição da variância do erro de previsão das variáveis de política monetária sobre o índice BOVESPA.
Os resultados obtidos indicaram a presença de dois vetores de co-integração, podendo-se, portanto, inferir que as variáveis possuem relação de longo prazo. Analisando o modelo VEC, os resultados obtidos deixam claro que a taxa de câmbio impacta negativamente e contemporaneamente de forma significativa o índice BOVESPA. Uma depreciação inesperada do câmbio na ordem de 10% impactará negativamente o índice BOVESPA em 11,6%. Assim como na função impulso resposta, a taxa de câmbio é a variável que tem o maior poder explanatório sobre o índice BOVESPA, com parcela média na decomposição da variância do erro de previsão de 22,4%.
Com o objetivo de investigar se a atividade econômica corrente poderia explicar o índice BOVESPA, Silva (2002) utilizou dados mensais de janeiro de 1995 a dezembro de 2007 e a metodologia VAR, análise de causalidade de Granger e função impulso resposta. Os resultados indicaram que o preço do petróleo apresenta uma relação diretamente proporcional ao índice BOVESPA.
Por outro lado, Grôppo (2004), e utilizando metodologia semelhante a Silva (2002), mas com informações mensais de janeiro de 1995 a dezembro de 2003. Encontrou que o preço do petróleo não causa contemporaneamente o índice BOVESPA. Na análise de dependência não contemporânea, o autor encontrou que um choque inesperados de 10% no preço do petróleo irá impactar negativamente o índice BOVESPA em 15,14% no segundo período após o choque.
desencadear problemas para as estimações dependendo das características da série que são assumidas no modelo teórico.
O reconhecimento desses fatos estilizados implica violação de algumas das principais hipóteses contidas na maior parte dos modelos de precificação de ativos, como as hipóteses de normalidade dos retornos e de variância constante.
Para lidar com a inexistência de variância constante, Engle (1982) propôs o modelo Autoregressive Conditional Heteroskedasticity - ARCH que, posteriormente foi
modificado por Bollerslev (1986) se tornando Generalized Autoregressive Conditional
Heteroskedasticity – GARCH. Esta construção teórica se tornou muito popular nos
estudos de séries temporais financeiras e deu origem a uma ampla gama de modelos univariados inicialmente, mas que posteriormente comportou construções multivariadas. Utilizando modelos GARCH multivariados, Serra e Zilberman (2009) investigaram mudanças na volatilidade dos preços e transbordamentos de volatilidade na indústria de etanol. Para tanto, utilizaram um estimador de máxima verossimilhança que estima o modelo de correção de erro e o processo GARCH multivariado em conjunto. Foram utilizados dados semanais para preços internacionais de petróleo e preços para o mercado brasileiro de açúcar e etanol. A amostra utilizada vai de 14 de julho de 2000 a 29 de fevereiro de 2008. Os resultados obtidos indicaram que os preços do petróleo e do etanol são positivamente relacionados no longo prazo, além disso, a análise empírica sugere que os preços do petróleo não só influenciam os níveis de preços do etanol, mas também a sua volatilidade. Assim, o aumento na volatilidade dos mercados de petróleo resulta no aumento da volatilidade nos mercados de etanol. Os preços do etanol, por sua vez, influenciaram preços do açúcar o que leva a uma transmissão indireta da volatilidade dos preços do petróleo para os preços do açúcar.
Zhang et al. (2009), utilizando cointegração através Vector Error Corrections
Model (VECM) e modelo GARCH multivariado (MGARCH), investigaram a
volatilidade do etanol e dos preços de commodities. Para tanto, foram usadas séries
etanol sobre os preços do milho e da soja,os resultados indicaram que o etanol parece influenciar o nível de equilíbrio de longo prazo dos preços destas commodities.
Utilizando séries de preços diárias para etanol, milho e petróleo para a economia dos EUA no período de 2006 a 2011, Trujillo-Barrera et al. (2011) encontraram resultados que indicam a existência de influência da volatilidade dos preços do petróleo nos preços do milho e etanol, resultado oposto ao encontrado por Zhang et al. (2010). Segundo aqueles autores, o efeito da volatilidade do preço do petróleo bruto nas volatilidades do milho e do etanol fica por volta de 20%, mas em períodos de grande turbulência no mercado de petróleo, esse efeito pode atingir 50%.
São comuns nas distribuições univariadas de séries temporais econômicas a presença de características como excesso de curtose, assimetria e não normalidade. Apesar disso, muitos estudos que avaliam a transmissão de preços nos mercados de energia têm assumido normalidade multivariada, o que pode levar a estimativas de parâmetros tendenciosas (SERRA e GIL 2012).
Com o objetivo de superar essa limitação, a metodologia das Cópulas, originalmente descrita em Sklar (1959), tem sido amplamente estendida e aplicada a finanças quantitativas.
A metodologia sobressai-se a outras abordagens alternativas, e.g. valores extremos, por modelar toda a distribuição conjunta das variáveis, fornecendo além de medidas de locação e dispersão, e.g. média e variância, outras medidas de dependência como dependências de cauda e correlações de postos. (SANTOS e PEREIIRA, 2011, p. 3).
Apesar das vantagens em utilizar a metodologia de cópulas há pouca literatura aplicada à análise de dependência entre petróleo e biocombustíveis. A maior parte da literatura sobre o tema se preocupa em desenvolver formas factíveis de aplicação da metodologia e em discutir a vantagem da metodologia em relação a outras. Além disso, as poucas aplicações existentes utilizam o mercado de ações e outras séries do mercado financeiro. Como exemplo destas aplicações podem ser citados os trabalhos de Joe (1996), Kurowicka e Cooke (2006), Aas et al. (2009), Kurowicka e Joe (2011) e Dissmann et al. (2011).
2010. Os autores escolheram a symmetrized Joe-Clayton (SJC) cópula para medir a
3 METODOLOGIA
A metodologia aplicada consiste em primeiramente modelar as séries de log-retorno individualmente, utilizando modelos ARMA-GARCH, e então utilizando os resíduos padronizados de cada modelo aplicar a metodologia de cópulas.
Nesta seção, primeiramente será apresentada a metodologia dos modelos ARMA-GARCH utilizada para modelagem univariada. Posteriormente será apresentada a metodologia de estimação das vine cópulas como proposto por Dissmann et al. (2011).
Para o adequado entendimento da metodologia, o conceito de log-retorno (Rt)
utilizado neste trabalho é definido como:
1 ln t t
t y R
y
(3.1) Em que, “ln(.)” indica o logaritmo natural e “yt e yt-1”são as observações das
séries nos períodos t e t-1 respectivamente.
3.1 MODELAGEM DAS DISTRIBUIÇÕES MARGINAIS
Primeiramente serão apresentados os modelos ARMA e ARFIMA (adaptados de Greene (2003) Cap. 20) seguidos pela modelagem GARCH (adaptada de Greene (2003) Cap. 11).
Considere a série de tempo �. Se ��−1 é todo o conjunto de informações disponíveis no tempo t-1, podemos definir essa forma funcional como:
| 1
t t t t
y E y
(3.2) Onde E
. | . é o operador de esperança condicional eté o termo de erro aleatório, comE
t 0, E t2 e2, eCov
t, s
0, t s.Esta equação pode ser modelada como um processo Autorregressive,
Moving-AverageARMA (P, Q) descrito como.
1 1
Q P
t i t i j t j t
i j
y y
Com média , coeficientes autoregressivos i e coeficientes de média móvel
j
e p e q denotam as defasagens autoregressiva e média móvel, respectivamente. Se P=0 teremos um processo média móvel puro, enquanto se Q=0 teremos um processo
autoregressivo puro.
A modelagem ARMA é adequada para o estudo do comportamento de uma ampla gama de séries de tempo. Porém, para séries temporais que apresentam comportamento de persistência, entendida aqui como a continuidade do efeito de choques durante um longo período, estes modelos não se mostram adequados. Assim, surgiram os modelos autorregressive, fractionally integrated, moving-average
ARFIMA (P,d,Q).
1 1
1 d P Q
t i t i t j t j
i j
L y y
(3.4)Segundo Lopes et al. (2002), o processo apresenta a propriedade de longa
memória quando d
0;0,5
, memória intermediária quando d
0,5;0
e memóriacurta quando d0. Se d0,5 o processo é não estacionário embora para
0,5;1,0
d não há nenhum impacto de longo prazo de inovações no processo,
propriedade que não se mantém quando d 1.Se d 0,5 o processo ARFIMA é não
invertível.
Tanto o modelo ARMA quanto o modelo ARFIMA não comportam a presença de heterocedasticidade, ocorrência típica em séries financeiras. Para que esta limitação não seja um problema, será usada também a modelagem GARCH (p,q). Este modelo foi proposto por Bollerslev (1986) a partir do modelo Autoregressivo de Heterocedasticidade Condicional (ARCH) proposto por Engle (1982).
O termo t da equação (3.3) foi definido por Engle (1982) como um processo ARCH com a seguinte form.
t zt t
(3.5)
Onde � é um processo independente e identicamente distribuído (i.i.d) no qual,
t 0E z ,Var z
t 1. Além disso,t é uma função do conjunto de informaçõesigual zero, sua variância condicional é igual a ��2, portanto, pode variar ao longo do
tempo diferentemente da assunção existente no Modelo de Mínimos Quadrados Ordinários (MQO).
O modelo ARCH generalizado GARCH(p, q) proposto por Bollerslev (1986) pode ser então expresso como:
2 2 2
0
1 1
p q
t i t i j t j
i j
(3.6) Se todos os parâmetros j forem iguais a zero, teremos um modelo ARCH.
3.2 CÓPULAS
Enquanto para formulações de cópulas em duas dimensões há uma gama de modelagens disponíveis e amplamente usadas, para executar modelagens multivariadas a tarefa se mostra complexa. Modelagens padrão, como as cópulas elípticas ou Arquimedianas apresentam inconvenientes graves ao serem aplicadas a dimensões maiores (BRECHMMANN e CZADO, 2011).
Modelagens multivariadas foram inicialmente propostas por Joe (1996) utilizando especificações cópulas bivariadas como modelos de dependência para a distribuição de determinados pares de variáveis condicionais a um determinado conjunto de variáveis. Estes blocos de construção independentes são chamados pair-copulas e foram utilizados para construir as distribuições multivariadas (Dissmann et al.
2011).
Para ajudar a organizá-las, Bedford e Cooke (2001, 2002) introduziram um modelo gráfico denominado vine regular (R-vine), ou construção pair-cópula (PCC),
que são descritos com maiores detalhes em Kurowicka e Cooke (2006) e em Kurowicka e Joe (2011). Esta abordagem hierárquica consiste na decomposição da densidade multivariada em uma sequência de pair-cópulas. Posteriormente, Aas et al. (2009)
introduziu a inferência de dois casos especiais do R-vine, o vine canônico (C-vine) e o
drawable vine (D-vine)
Nas próximas seções será apresentada primeiramente uma breve introdução sobre cópulas e posteriormente um detalhamento das vine cópulas utilizadas no
trabalho. A metodologia aqui apresentadas foi adaptada de Dissmann et al. (2011) a
3.2.1 Pair cópulas
Segundo Cherubini et al. (2004), o ponto de partida do estudo de cópulas é sua relação com as distribuições de probabilidade. Neste contexto, o Teorema de Sklar (1959) faz duas afirmações importantes:
Cópulas são funções de distribuição conjunta cujas distribuições
marginais são uniformes no intervalo
0,1
; A relação de dependência entre duas ou mais funções de distribuição marginal e sua função de distribuição conjunta é totalmente expressa por sua cópula.
Considere um vetor de variáveis aleatórias X
X1, ,Xn
~F comdistribuição marginal ,F ii 1,...,d . O Teorema de Sklar (Sklar, 1959) estabelece que
para toda função de distribuição multivariada F com marginais F1,, Fn, existe uma função única C, chamada cópula, que pode ser escrita como:
1, , n
1
1 , 2
2 , , n
n
F x x C F x F x F x
(3.7) Em termos da função densidade conjunta f, para uma F absolutamente contínua,
com densidades marginais F1,,Fn estritamente crescentes e contínuas, temos:
x xn
c n
F
x Fn
xn
f x fn
xnf 1,, 12 1 1 ,, 1 1 (3.8)
Pela equação (3.8) é possível observar que as cópulas convenientemente permitem separar a modelagem das marginais e a parte de dependência em termos da cópula (BRECHMANN e CZADO, 2011).
De uma forma mais geral e usando a notação vetorial, temos:
x υ c υj
F
x υj F υj
f x υjf j
xj
,
(3.9) Para um dado vetor de variáveis aleatóriasυ de dimensão d. j é uma variável
arbitrariamente escolhida de υ e υj corresponde ao vetor υ, excluindo-se j. Logo,
sobre diferentes distribuições de probabilidade condicionais. Esta construção da distribuição é iterativa por natureza e, utilizando-se uma fatoração específica, permite a elaboração de outras reparametrizações das pair-copulas envolvidas.
A construção de densidades multivariadas utilizando-se pair-copulas envolve distribuições marginais condicionais da forma F
x υ . Para todo j, Joe (1996) mostrouque:
j
j j
υ
υ
υ υ
υ j
j
j x
F
F x
F C
x
F j
,
,
(3.10)
Em que Cijκ é uma cópula bivariada. Quando ampliado o número de variáveis
amplia-se automaticamente a possibilidade de decomposição em pair-cópulas.
3.2.2 Regular vine cópulas
Um R-vine de n elementos é um conjunto de n - 1 árvores tais que as arestas da
árvore j tornam-se os nós da árvore j +1. A condição de proximidade assegura que dois
nós em uma árvore j só são conectados por uma aresta se esses nós compartilham um nó
comum na árvore j. O conjunto de nós na primeira árvore contém todos os índices 1, ..., n, enquanto o conjunto de arestas é um conjunto de n - 1 pares desses índices.
Formalmente, a estrutura R-vine é assim definida1.
Definição 3.1 (Especificação cópula R-vine). ( , , )F V B é uma especificação cópula R-vine se F ( ,..., )F1 Fn é um vetor de funções de distribuição contínuas e
inversíveis, V é um R-vine n dimensional e B
B ie| 1,...,i1;eEi
é um conjuntode cópulas com Be sendo uma cópula bivariada, chamada pair-copula.
A densidade de uma cópula R-vine como definida acima, foi demonstrada em
Bedford e Cooke (2001, 2002) e é igual ao produto das cópulas condicional e incondicional atribuída a suas arestas.
Teorema 3.1Dado ( , , )F V B uma especificação cópula R-vine com n elementos.
Existe uma única distribuição F para essa especificação cópula R-vine com densidade:
1 Esta definição foi retirada de Bedford e Cooke, 2001,2002, Part 4 e Kurowicka e Cooke, 2006, Cap. 4.4
1
1 1 ( ), ( )| ( ) ( ) ( ) ( ) ( )
1
( ( ),..., ( )) ( ( | ), ( | ))
i
d
d d j e k e D e j e D e k e D e
i e E
c F x F x c F x x F x x
(3.11)
Onde xD e( ) denota o sub-vetor x( ,..., )x1 xd indicado pelos índices contidos em D( )e .
3.2.3 Vine canônico (C-vine)
O vine canônico (C-vine) é um caso especial da classe de R-vines que contém
um nó com grau máximo em cada árvore formando uma estrutura de estrela. Como mostrado na Figura 1, nesta estrutura, o índice j identifica as árvores, enquanto i
percorre as arestas em cada árvore. Em um C-vine, cada árvore 2 Tj tem um único nó,
que está conectado a
n j
arestas.Figura 1- Estrutura C-vine pentavariada
A densidade de uma distribuição n-dimensional correspondente a um C-vine é
dada por:
1 1 1 1 1 1 1 1 , , 1 , 1 , , , , , n j j n i j i j j j j i j j n kk c F x x x F x x x
x
f
(3.12)
em que o índice j identifica as árvores, enquanto i percorre as arestas em cada árvore.
1
2 3
5 4 13 15 14 12 13 15 14 23|1 25|1 24|1 23|1 24|1 25|1 34|12 35|12
34|12 35|12
O ajuste de um C-vine pode ser vantajoso quando se sabe que uma variável em
particular é uma variável-chave que governa as interações no conjunto de dados. Neste caso, esta variável pode ser colocada na raiz do C-vine.
3.2.4 Drawable vine (D-vine)
O drawable vine (D-vine) é um R-vine para o qual a primeira árvore tem nós
com dois graus ou menos que formam uma estrutura de caminho. Cada aresta corresponde à densidade de uma pair-copula e o seu rótulo corresponde ao subscrito da densidade da pair-copula. Como apresentado na Figura 2, os nós na árvore Tj são
necessários apenas para determinar os rótulos das arestas na árvore Tj1. Duas arestas
em Tj que se tornam nós em Tj1, são unidas por uma aresta em Tj1 apenas se
apresentam um nó em comum em Tj. A decomposição total é definida pelas n
n1
2arestas e as densidades marginais de cada variável.
Figura 2 – Estrutura D-vine pentavariada
A densidade de uma distribuição n-dimensional em termos de um D-vine é dada
por (Aaas et al. 2009):
1 1 1 1 1 1 1 1 , , 1 , 1 , , , , , n j j n i j i i j i j i i i j i i j i i n kk c F x x x F x x x
x
f
(3.13)
em que o índice j identifica as árvores, enquanto i percorre as arestas em cada árvore.
1 2
12
3 4 5
23 34 45
T1
12 23 34 45
13|2 24|3 35|4
13|2 24|3 35|4
14|23 25|34
14|23 25|34 15|234
T2
T3
3.3 ESPECIFICAÇÃO PARA UM MODELO DE PAIR CÓPULA
A inferência completa para uma decomposição em pair-copulas deve considerar, segundo Dissmann et al. 2011, os seguintes passos:
a) a seleção de uma fatoração específica; b) a escolha dos tipos de pair-copulas; c) a estimação dos parâmetros das cópulas.
Para dimensões mais baixas, como 3 ou 4, é possível estimar os parâmetros de todas as decomposições e comparar as log-verossimilhanças resultantes. Porém, na prática, isto se torna impossível para dimensões mais elevadas.
3.3.1 Seleção das pair-cópulas
Seguindo a metodologia sequencial proposta por Dissmann et al. 2011, para
escolher as pair-copulas que irão compor a estrutura vine deve-se considerar quais são
as relações bivariadas mais importantes para se modelar e permitir que isto determine que decomposição estimar. A idéia é capturar as dependências mais fortes nas primeiras árvores, uma vez que estas são tipicamente as dependências mais importantes a serem modeladas de forma explícita e com precisão.
Dentre as três estruturas utilizadas, o R-vine e o D-vine são mais flexíveis que o
C-vine, uma vez que esta estrutura especifica as relações entre uma variável chave e as
demais, enquanto as demais estruturas permitem selecionar de forma mais livre quais pares modelar.
Para cada pair-copula será obtido o respectivo Tau de Kendall
empírico, uma medida de dependência que se caracteriza por não depender da distribuição assumida, sendo especialmente útil quando há a combinação de diferentes famílias2 de cópulas. O Tau de Kendall empírico é dado por.
4 1
12
n n
n n
P Q
P
n n n
(3.14)
Onde Pn e Qn correspondem aos números de pares concordantes e discordantes
respectivamente. Dois pares
X Yi, i
,
X Yj, j
são concordantes quando
XiXj
YiYj
0 e discordantes quando
XiXj
YiYj
0O valor do Tau de Kendall
se situa no intervalo entre 0 e 1. Se o coeficiente tem valor 1 quer dizer que há dependência positiva entre duas variáveis, por outro lado, se o coeficiente assume valor -1 há dependência negativa. Para valores iguais a 0 as variáveis são completamente independentes.Assim, o critério de escolha de uma determinada árvore será aquela que maximiza a soma dos valores absolutos do Tau de Kendall para o conjunto de pair-cópulas daquela árvore.
3.3.2 Seleção da família cópula adequada
Assumida uma decomposição, o próximo passo é especificar a forma paramétrica de cada pair-copula, ou seja, sua família. As pair-copulas não precisam pertencer à mesma família. A distribuição multivariada resultante será válida se for escolhida para cada par de variáveis a cópula paramétrica que melhor se ajustar aos dados. Se a escolha for não permanecer em uma classe pré-definida de cópulas, é preciso determinar que cópula usar para cada par de observações transformadas.
Para escolher qual família de cópulas mais adequada a cada pair-cópula, será usada a estatística AIC. O processo de seleção consiste em atribuir um valor de AIC para cada possível família e então selecionar a cópula com o menor AIC. Este processo foi descrito em Brechmann 2010, seção 5.4 apud Dissmann et al. 2011.
Há também a possibilidade de inclusão de cópulas independentes através de um teste prévio de independência baseado no Tau de Kendall. Se este teste indicar independência não há necessidade de avaliar as demais famílias de cópulas sendo então escolhida a cópula independente.
Considerando3 que a estatística Tau de Kendall
n se aproxima de uma normalcom média zero e variância 2 2
n5
9n n
1
, em que n representa o tamanho daamostra. Assim, sob hipótese nula de independência H0 será rejeitada com nível de
significância 5% se.
9 1
1,96
2 2 5 n
n n n (3.15)
3.3.3 Estimação dos parâmetros
Após a escolha das pair-cópulas adequadas e de suas respectivas famílias, o passo seguinte é a estimação dos parâmetros das cópulas utilizando a função de log-verossimilhança.
Para o R-vine a função log-verossimilhança é dada por:
1
( ), ( )| ( ) , ( ) , ( ) , ( )| ( ) , ( ) ( ), ( )| ( ) 1 1
ln[ ( ( | ), ( | ) | )]
l
N d
j e k e D e i j e i D e i k e D e i D e j e k e D e
i l e E
c F u u F u u
(3.16)
Para o C-vine, a função de log-verossimilhança é dada por:
11 1 1
, 1 , 1 , , 1 , 1 , 1 , , 1 , , , , , , log n j j n i T t t j t t i j t j t t j j i j
j F x x x F x x x
c
(3.17)
E a log-verossimilhança para o D-vine é:
11 1 1
, 1 , 1 , , 1 , 1 , 1 , , 1 , , , , , , log n j j n i T t t j i t i t j i t j i t i t i j i i j i
i F x x x F x x x
c (3.18)
Como a existência de dependência caudal em séries de retorno é muito comum, serão calculados os coeficientes teóricos de dependência caudal derivados das cópulas bivariadas utilizando os parâmetros estimados para as cópulas. Serão então calculados dois parâmetros, um relativo à dependência caudal inferior L e outro referente à
dependência caudal superior U .
Os coeficientes de dependência caudal inferior e superior referentes a uma determinada família de cópulas são apresentados no APÊNDICE C. Para calculá-los, são utilizados os parâmetros estimados par cada pair-cópula ( para famílias com um parâmetro e para o primeiro parâmetro da t-cópula com v graus de liberdade, e
para famílias com dois parâmetros BB1, BB6, BB7 e BB8).
simultaneamente, enquanto que a dependência caudal inferior se refere a elevados retornos negativos ocorrendo simultaneamente.
3.3.4 Comparação dos modelos
Como forma de comparar as especificações R-vine, C-vine e D-vine, será
aplicado o teste de Vuong. Dados c1 e c2dois vine cópulas que serão comparados em
termos de suas densidades e com parâmetros estimados ˆ1 e ˆ2. Será então computada a
soma padrão v das log-diferenças das probabilidades pontuais
1 1 2 2 ˆ log ˆ i i i c u m c u para as observações ui
0,1 ,i1,...,N . De outra forma.
1 2 1 1 N i i N i i m n v m m
(3.19)Vuong (1989) mostrou que v é assintoticamente normal-padrão. Assim, de
acordo com a hipótese nulaH0:E m
i 0 i 1,...,N.Será então escolhido o modelo1 em detrimento do modelo 2 ao nível de significância se 1 1
2
v
onde
1
denota a inversa da função de distribuição
normal padrão. Se 1
1 2
v
, nenhuma conclusão sobre os modelos pode ser
tomada.
4 ESTIMATIVAS E RESULTADOS EMPÍRICOS
Nesta seção serão apresentados os dados que foram utilizados no trabalho, bem como os resultados obtidos nas estimações.
4.1 DESCRIÇÃO DOS DADOS
Foram usados dados semanais para cinco séries de dados do mercado financeiro, quais sejam, ETANOL4 (eth) cotação em US$/L do etanol anidro, AÇÚCAR5 (sug) cotação US$/50Kg do açúcar cristal, PETRÓLEO6 (oil) Crude Oil WTI Cushing
U$/BBL, CÂMBIO7 (brus) taxa de câmbio R$/Dólar e índice BOVESPA8 (bov) índice da bolsa de valores de São Paulo. Estes dados se referem ao período de 13/07/2000 a 04/10/2012 totalizando 639 observações.
O critério de escolha do período utilizado para a amostra de dados considerou a construção do maior span possível, assim, a amostra foi limitada pela menor série com
dados disponíveis, qual seja, a série de ETANOL.
Ao se realizar estudos relativos ao mercado de bio-combustíveis, a inclusão da variável petróleo se justifica por este ser o principal insumo energético do mundo que concorre com o etanol. Como no Brasil o principal insumo utilizado na produção de etanol é a cana de açúcar, a inclusão da variável açúcar se justifica por este ser um produto substituto do etanol sob a ótica do produtor que pode escolher com facilidade se destinará sua produção de cana de açúcar para um produto ou outro. Por sua vez, as variáveis câmbio e Bovespa foram incluídas para que se possa captar a interação entre o mercado financeiro brasileiro e a produção de biocombustíveis no país, além disso, como açúcar e etanol são commodities, movimentos do Bovespa, mas principalmente no
câmbio deverão impactar nos preços tanto de açúcar quanto de etanol.
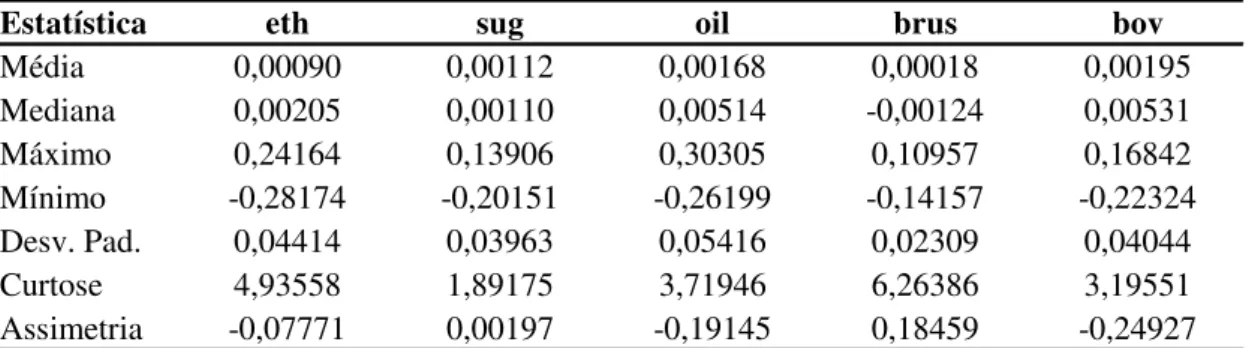
Na Tabela 1 abaixo são apresentadas algumas estatísticas descritivas relativas às séries dos retornos dos ativos analisados.
4 Fonte: Centro de Estudos de Economia Aplicada – CEPEA ESALQ/USP. 5 Fonte: Centro de Estudos de Economia Aplicada – CEPEA ESALQ/USP. 6 Fonte: West Texas Intermediate (WTI) Cushing Oil Spot Price.
7 Fonte: Banco Central do Brasil.
Tabela 1 – Estatísticas descritivas da amostra
Pela Tabela 1 pode-se observar que as séries apresentam curtose acima de três, com exceção da série de retornos açúcar. Isto caracteriza a presença de caudas pesadas indicando que as séries de retorno não possuem distribuição normal. Além disso, as séries de açúcar e câmbio apresentaram coeficientes de assimetria positivos, enquanto as demais séries apresentaram esse coeficiente negativo.
A assimetria negativa das séries PETRÓLEO, ETANOL e BOVESPA podem ser explicadas pela presença na amostra do período referente à crise mundial ocorrida em 2008. Estas três séries foram impactadas negativamente neste período, PETRÓLEO e ETANOL em razão da queda da demanda mundial e BOVESPA pela fuga de investidores do mercado de capitais brasileiro. Nesta mesma linha, a fuga de capitais do Brasil em momentos de crise pode explicar a assimetria positiva do CÂMBIO. Por sua vez, AÇÚCAR foi beneficiado pelo boom de preços de commodities ocorrido nos
últimos anos o que aumentou a ocorrência de retornos positivos na amostra. 4.1 MODELOS MARGINAIS
Para modelar as marginais F1,...,Fn, no nosso caso n=5, foram ajustados
modelos ARMA (P, d, Q) – GARCH (p, q) para cada série de log-retorno. Após a especificação dos modelos mais adequados a cada série de dados, os resíduos padronizados foram obtidos para que a dependência entre estes resíduos seja então modelada usando a metodologia R-vine cópula apresentada.
A escolha das ordens apropriadas (P, d, Q) e (p, q) utilizou o critério da menor ordem que eliminou a correlação nos resíduos padronizados e a correlação do quadrado dos resíduos padronizados. Para testar a presença de autocorrelação foi utilizada a estatística Q de Ljung-Box, até a 20ª defasagem. Os resultados das estimações das marginais são apresentados na Tabela 2.
Estatística eth sug oil brus bov
Tabela 2 – Resultados dos modelos marginais
Os modelos foram estimados levando em conta a possibilidade de que o perfil dos dados poderia se adequar a uma dentre as distribuições Normal, Student-t e Skewed-t, e foram escolhidos através do teste razão de verossimilhança e do critério de
minimização do Akaike Information Criterion - AIC. Os modelos estimados foram: AR
(2)-GARCH (1,1) com distribuição Student-t para ETANOL, AR (4)-GARCH (1,1)
com distribuição Student-t para AÇÚCAR, GARCH (1,1) com distribuição Skewed-t
eth sug oil brus bov
0,000803 0,000517 0,002776 0,000518 0,002102
(0,6735) (0,7853) (0,1408) (0,749) (0,1467)
- - - 0,134837**
-(0,0164)
0,266403*** 0,377456*** - -0,165821**
-(0,000) (0,000) (0,0418)
0,100848** 0,131926*** - -
-(0,0111) (0,0047)
- 0,025231 - -
-(0,5691)
- -0,083522** - -
-(0,0273)
1,111257 1,242364** 1,817989*** 0,220073** 0,594516*
(0,3115) (0,0107) (0,0023) (0,0347) (0,0517)
0,216009** 0,314442*** 0,088228*** 0,219238*** 0,082946***
(0,0425) (0,000) (0,0003) (0,0015) (0,0007)
0,765395*** 0,618541*** 0,840578*** 0,7572*** 0,87977***
(0,0000) (0,000) (0,000) (0,000) (0,000)
- - 9,519557*** 5,653420*** 10,821089**
(0,0025) (0,000) 0,0119
- - -0,250815*** 0,336824*** -0,259935***
(0,0001) (0,0017) (0,000)
19,9487 22,0921 17,6624 27,0131 22,0392
(0,3357) (0,1402) (0,6096) (0,1043) (0,3383)
15,4504 16,2468 11,474 10,2231 11,68
(0,6308) (0,5753) (0,8731) (0,9243) (0,8633)
AIC -3,755697 -4,050045 -3,196026 -5,145204 -3,732258
KS 0,984228 0,942038 0,701932 0,983834 0,793718
BERK 0,636946 0,968043 0,605615 0,733342 0,458789
Nota: (***),(**),(*) - parâmetros significantes a 1%, 5% e 10% respectivamente. Os valores entre parênteses indicam o respectivo p-valor de cada parâmetro estimado Q(20)
Q2(20)
w
i
bi
i
i
AR(4) Cons
d-ARFIMA
AR(1)
AR(2)
para PETRÓLEO, ARFIMA (1, d, 0)-GARCH (1,1) com distribuição Skewed-t para
CÂMBIO e GARCH (1,1) com distribuição Skewed-t para BOVESPA.
Na equação estimada para o ETANOL, o parâmetro referente à constante wi mostrou-se não significativo. Apesar disso, este parâmetro foi mantido na estimação por conter uma interpretação de longo prazo e também para que as propriedades dos estimadores fossem mantidas.
Nos modelos estimados adotando a distribuição Skewed-t, o coeficiente de assimetria i se mostrou significativamente diferente de zero a 1%%. Os modelos marginais de PETRÓLEO e BOVESPA apresentaram sinal negativo, isso indica a presença assimetria para a esquerda para as distribuições marginais, ou seja, retornos negativos são mais prováveis do que retornos positivos. O raciocínio inverso pode ser feito para o caso do modelo marginal para o CÂMBIO que apresentou assimetria positiva em que retornos positivos têm maior probabilidade que grandes negativos. Os sinais dos respectivos coeficientes i são iguais aos obtidos para o coeficiente de assimetria das séries na análise descritiva dos dados apresentados na Tabela 1.
Os valores elevados obtidos para os parâmetros bi, significativamente diferentes de zero a 1%, indicam a existência de persistência na volatilidade das séries.
O modelo mais adequado para a modelagem da série de CÂMBIO apresentou o parâmetro d-ARFIMA, significativo a 5%. Modelos com esta propriedade e com parâmetro d
0;0,5
, no caso igual a 0,13, indicam séries caracterizadas por longas dependências temporais ou memória longa. Isso quer dizer que choques ocorridos em um determinado período mantêm seu efeito por longos períodos.4.1 ESTIMAÇÕES CÓPULAS
Utilizando os modelos univariados especificados anteriormente, são obtidos os resíduos padronizados resultantes de cada modelo. Estes resíduos são então transformados em dados uniformes utilizando a transformação integral de probabilidade. Finalmente, os resíduos transformados serão modelados utilizando a metodologia de cópulas multivariadas proposta.
Como apresentado na seção 3.3, a construção das cópulas bivariadas tem como objetivo principal concentrar a maior parte da dependência entre as variáveis nas primeiras árvores. Para tanto, será utilizada a estatística Tau de Kendall
que se situa no intervalo 1 1. Valores próximos de 1 indicam que dependência perfeita positiva, enquanto valores próximos de -1 indicam dependência perfeita negativa. Por fim coeficiente igual a zero indica independência entre as variáveis.Na Erro! Fonte de referência não encontrada. são apresentadas as estatísticas estimadas Tau de Kendall para cada par de variáveis na matriz triangular inferior da figura.
Na matriz triangular superior da Erro! Fonte de referência não encontrada.
são apresentados os pairs-plots dos pares de variáveis para ilustrar o padrão de
comportamento mencionado acima.
.
Figura 3 - Pairs-plots e Taus de Kendall para os representantes de cada grupo de índice.
eth
0.0 0.4 0.8 0.0 0.4 0.8
0 .0 0 .4 0 .8 0 .0 0 .4 0 .8 0.35 sug
0.074 0.11 oil
0 .0 0 .4 0 .8 0 .0 0 .4 0 .8
-0.41 -0.39 -0.11 brus
0.0 0.4 0.8
0.17 0.20
0.0 0.4 0.8
0.14 -0.31
0.0 0.4 0.8
Para se escolher a estrutura vine mais adequada para um dado conjunto de dados
é necessário decidir quais pares de variáveis serão escolhidos para então especificar as respectivas cópulas. Este processo se inicia na primeira árvore, que será composta pelo conjunto de pares que maximize o somatório dos valores absolutos do Tau de Kendall. A partir da primeira árvore desenhada, o mesmo processo de escolha foi aplicado para as demais árvores até determinação de toda a estrutura vine.
Com a estrutura vine definida, o próximo passo foi escolher a melhor família de
cópulas para cada par de variáveis e estimar os parâmetros por máxima verossimilhança.
A abordagem adotada neste trabalho naturalmente leva ao resultado de que os pair-cópulas situados nas últimas árvores tenham valores próximos de zero para os Tau de Kendall. Apesar disso, é possível realizar as estimativas dos parâmetros das pair-cópulas realizando um teste de independência prévio baseado no próprio Tau de Kendall. Neste teste, se o p-valor for maior que 5% concluímos que há uma cópula independente para este par.
Assim, foram estimados oito diferentes estruturas para que fosse escolhida a que tivesse a melhor aderência aos dados utilizados. As especificações que diferenciam os modelos são:
1. Estrutura utilizada: R-vine, C-vine ou D-vine;
2. Presença do teste de independência prévio;
3. Número de famílias disponíveis para as estimativas das pair-cópulas. As características de cada um dos modelos são apresentadas de forma sucinta abaixo.
Mixed R-vine: termos pair-copula do R-vine escolhidos individualmente entre
31 tipos9 diferentes de cópulas bivariadas. Algumas com um parâmetro estimado (Normal - N, Clayton - C, Gumbel - G, Frank - F, Joe - J, Survival Clayton - SG, Survival Joe - SJ, Clayton 90º - C_90, Gumbel 90º - G_90, Joe 90º - J_90, Clayton 270º - C_270, Gumbel 270º - G_270, Joe 270º - J_270) e outras com dois parâmetros estimados (Student-t - t, BB1, BB1 90º - BB1_90, BB1 180º - SBB1, BB1 270º - BB1_270, BB2, BB2 90º - BB2_90, BB2 180º - SBB2, BB2 270º - BB2_270, BB7, BB7 90º - BB7_90, BB7 180º - SBB7 e BB7 270º - BB7_210);
Mixed R-vinecom teste de independência: termos pair-copula do R-vine
escolhidos individualmente entre 31 tipos diferentes de cópulas bivariadas (como descrito acima);
R-Vine Normal, Student-t: termos pair-copula do R-vine escolhidos
individualmente entre dois tipos de cópulas bivariadas Normal e Student-t. R-Vine Normal, Student-t com teste de independência: termos pair-copula do
R-vine escolhidos individualmente entre dois tipos de cópulas bivariadas Normal
e Student-t.
Mixed C-vine: termos pair-copula do C-vine escolhidos individualmente entre
31 tipos diferentes de cópulas bivariadas (como descritas acima);
Mixed C-vine com teste de independência: termos pair-copula do C-vine
escolhidos individualmente entre 31 tipos diferentes de cópulas bivariadas (como descritas acima);
Mixed D-vine: termos pair-copula do D-vine escolhidos individualmente entre
31 tipos diferentes de cópulas bivariadas (como descritas acima);
Mixed D-vine com teste de independência: termos pair-copula do D-vine
escolhidos individualmente entre 31 tipos diferentes de cópulas bivariadas (como descritas acima).
Figura 4 – Primeiras árvores dos modelos estimados.
R-vine
R-vine Normal e Student-t
C-vine D-vine
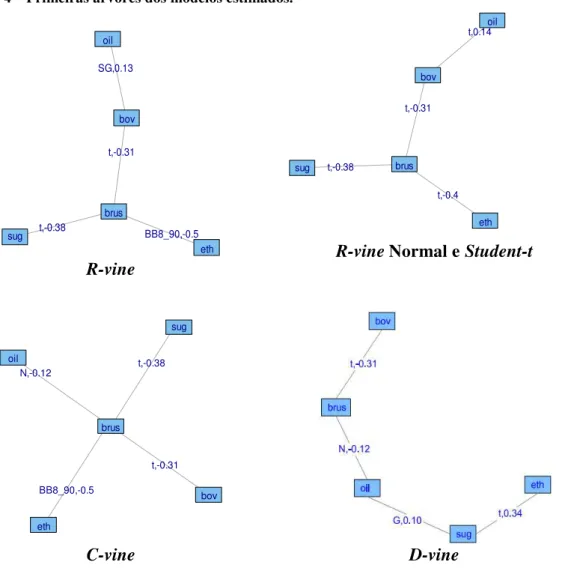
As siglas presentes nas arestas dos gráficos indicam a família de cópulas utilizada para aquele par, enquanto que o número é o respectivo valor para o Tau de Kendall associado a cada função cópula. Assim, na árvore R-vine, parte superior
esquerda da Erro! Fonte de referência não encontrada., a cópula sug,brus foi modelada utilizando a família Student-t (t) e tem um Tau de Kendall igual a -0,38.
Para os modelos com estrutura R-vine e C-vine a variável CÂMBIO teve um
papel central dentro da estrutura da primeira árvore devido à ligação das demais variáveis com o CÂMBIO indicada pelos elevados coeficientes Tau de Kendall associados às cópulas em que ela está presente. Este protagonismo da variável
CÂMBIO pode ser explicado pela influência de importações/exportações sobre as variáveis ETANOL, AÇÚCAR e PETRÓLEO. Por outro lado, a variável BOVESPA
pode ser impactada pelo CÂMBIO através do impacto desta variável sobre as ações negociadas na bolsa.
t,-0.31 SG,0.13
t,-0.38
BB8_90,-0.5 brus
bov oil
sug
eth
t,-0.31
t,0.14
t,-0.38
t,-0.4 brus
bov
oil
sug
eth
t,-0.31 t,-0.38 N,-0.12
BB8_90,-0.5 brus
bov sug
oil
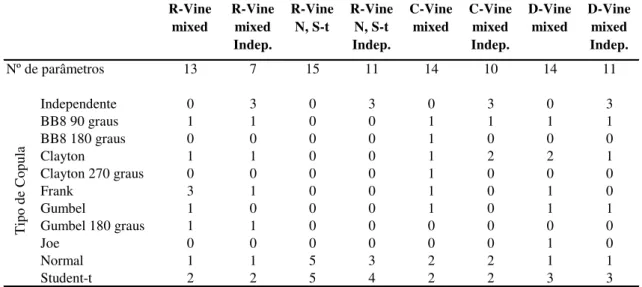
Iniciando a análise e comparação dos modelos estimados, Na Tabela 3 são apresentadas as quantidades de cópulas estimadas de cada uma das famílias e o número de parâmetros.
Tabela 3 – Descrição inicial estimações cópulas
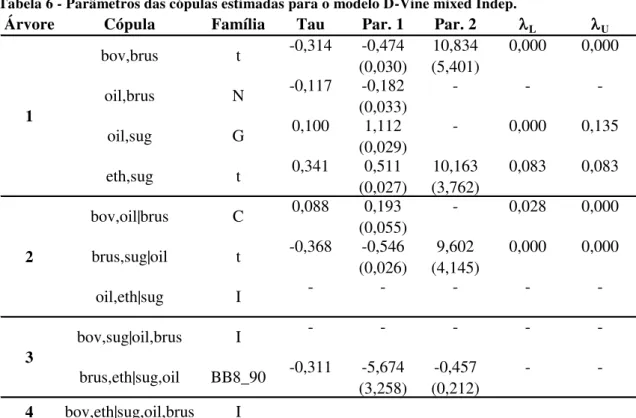
A utilização do teste de independência prévio durante as estimações reduz significativamente o número de parâmetros estimados, principalmente quando são utilizadas muitas séries. A maior redução de parâmetros estimados ocorreu do modelo
R-Vine mixed para R-Vine mixed Indep (6 parâmetros), enquanto que a menor redução
ocorreu do modelo D-Vine mixed para o D-Vine mixed Indep (3 parâmetros).
Na Tabela 4 são apresentados os resultados obtidos para a Máxima Verossimilhança e para o Teste de Vuong (1989) dos oito modelos estimados. Como o teste de Vuong compara modelos aos pares, foram realizados testes comparando o modelo R-Vine mixed (modelo mais geral) com os demais e D-Vine mixed (modelo que
apresentou maior log-verossimilhança com os demais.
R-Vine mixed
R-Vine mixed Indep.
R-Vine N, S-t
R-Vine N, S-t Indep.
C-Vine mixed
C-Vine mixed Indep.
D-Vine mixed
D-Vine mixed Indep.
13 7 15 11 14 10 14 11
Independente 0 3 0 3 0 3 0 3
BB8 90 graus 1 1 0 0 1 1 1 1
BB8 180 graus 0 0 0 0 1 0 0 0
Clayton 1 1 0 0 1 2 2 1
Clayton 270 graus 0 0 0 0 1 0 0 0
Frank 3 1 0 0 1 0 1 0
Gumbel 1 0 0 0 1 0 1 1
Gumbel 180 graus 1 1 0 0 0 0 0 0
Joe 0 0 0 0 0 0 1 0
Normal 1 1 5 3 2 2 1 1
Student-t 2 2 5 4 2 2 3 3
Nº de parâmetros
T
ip
o
de
C
op
Tabela 4 - Estatísticas dos testes de Máxima Verossimilhança e Vuong
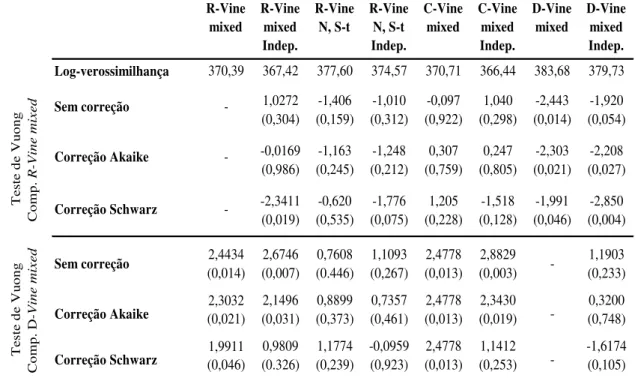
Pelo critério de maximização do valor obtido para Log-verossimilhança o modelo estimado mais adequado é o D-Vine mixed com valor 383,68.
Para o teste de Vuong, foi considerado um nível =5% de significância. Assim, caso a estatística obtida seja menor que -1,96 o modelo alternativo se apresenta como mais adequado. Por sua vez, para estatísticas maiores que 1,96 o modelo base se mostra mais adequado. Por fim, caso a estatística se situe no intervalo [-1,96,1,96] considera-se o teste de Vuong inconclusivo. Este critério para o teste de hipótese é o mesmo tanto para as estatísticas com correção Akaike e Schwarz quanto para as estatísticas sem correção.
As estatísticas de Vuong, comparando os modelos R-vine mixed com o modelo
R-Vine mixed Indep, não permitem escolher qual é o melhor modelo (correção de
Akaike e sem correção) ou indicam o modelo alternativo como melhor (correção de Schwarz). Esse resultado pode ser explicado pelo menor número de parâmetros estimados no modelo R-Vine mixed Indep (7) em comparação com os 13 parâmetros estimados no modelo R-vine mixed penalizando assim esta especificação em detrimento daquela.
Ao analisarmos os três critérios utilizados, a comparação do modelo R-vine mixed com os modelos R-Vine N S-t, R-Vine N S-t Indep, C-Vine mixed, C-Vine
R-Vine mixed R-Vine mixed Indep. R-Vine N, S-t R-Vine N, S-t Indep. C-Vine mixed C-Vine mixed Indep. D-Vine mixed D-Vine mixed Indep.
Log-verossimilhança 370,39 367,42 377,60 374,57 370,71 366,44 383,68 379,73
1,0272 -1,406 -1,010 -0,097 1,040 -2,443 -1,920 (0,304) (0,159) (0,312) (0,922) (0,298) (0,014) (0,054) -0,0169 -1,163 -1,248 0,307 0,247 -2,303 -2,208 (0,986) (0,245) (0,212) (0,759) (0,805) (0,021) (0,027) -2,3411 -0,620 -1,776 1,205 -1,518 -1,991 -2,850 (0,019) (0,535) (0,075) (0,228) (0,128) (0,046) (0,004)
2,4434 2,6746 0,7608 1,1093 2,4778 2,8829 1,1903 (0,014) (0,007) (0.446) (0,267) (0,013) (0,003) (0,233) 2,3032 2,1496 0,8899 0,7357 2,4778 2,3430 0,3200 (0,021) (0,031) (0,373) (0,461) (0,013) (0,019) (0,748) 1,9911 0,9809 1,1774 -0,0959 2,4778 1,1412 -1,6174 (0,046) (0.326) (0,239) (0,923) (0,013) (0,253) (0,105) Nota: os valores entre parênteses correspondem aos p-value das estatísticas.
mixed Indep com o modelo R-vine mixed não nos permitem concluir qual o melhor modelo.
Por sua vez, comparando o D-Vine mixed há indicação pelas três estatísticas calculadas de que o modelo mais adequado não é o R-Vine mixed. Já para o modelo D-Vine mixed Indep, há indicação de que o melhor modelo é o R-vine mixed por duas estatísticas usadas (com correção de Akaike e Schwarz) enquanto que a estatística sem correção indicou a inconclusão do teste.
Analisando as comparações com o modelo D-vine mixed, as três estatísticas de Vuong relativas aos modelos R-Vine N S-t, R-Vine N S-t Indep, D-Vine mixed Indep não nos permitem concluir qual é o modelo mais adequado. Já na comparação com os modelos R-Vine mixed, R-Vine mixed Indep, C-Vine mixed Indep há indicação pelos critérios da estatística de Vuong com correção de Akaike e sem correção, de que o modelo mais adequado é o D-Vine mixed. Finalmente, há a indicação de que o melhor modelo é o D-Vine mixed quando comparado com o modelo C-Vine mixed, de acordo com as três estatísticas calculadas.
Pelo conjunto de resultados obtidos para o teste de Vuong e para a maximização do valor obtido para Log-verossimilhança, há indicação de que o modelo que melhor se adequou aos dados foi o D-Vine mixed.
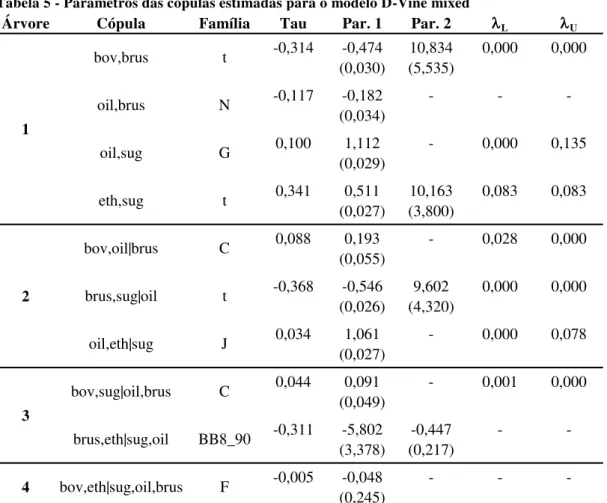
Na Tabela 5 são apresentados os parâmetros obtidos para o modelo D-vine
mixed, juntamente com o cálculo da dependência caudal superior
U e inferior
LTabela 5 - Parâmetros das cópulas estimadas para o modelo D-Vine mixed
A primeira árvore do modelo D-vine mixed apresentou a cópula bov,brus com
Tau de Kendall associado igual a (-0,31). Esse valor indica a existência de dependência negativa entre as variáveis, mesma indicação de relação encontrada por Grôppo (2006) para os primeiros períodos após a ocorrência de um choque. Foi utilizada para modelar a cópula bov,brus a família Student-tem que não houve indicação da existência de
dependência caudal tanto inferior Lquanto superior U .
O pair-cópula eth,sug também modelada pela família Student-t apresentou U e
L
de (0,08) que indica a existência de dependência caudal superior e inferior, ou seja, existe uma dependência 0,08 quando ambas variáveis apresentam elevados valores de retornos positivos e negativos. O Tau de Kendall estimado para o pair-cópula (0,34) indica relação de dependência positiva entre essas variáveis, mesma relação encontrada por Alves (2002) e Serra e Zilberman (2009).
A pair-cópula oil,sug foi modelada por uma cópula Gumbel que é assimétrica à direita, indicando que valores positivos de retorno conjunto de petróleo e açúcar são mais frequentes. Adicionalmente, o parâmetro referente à dependência caudal superior
Árvore Cópula Família Tau Par. 1 Par. 2 L U
-0,314 -0,474 10,834 0,000 0,000 (0,030) (5,535)
-0,117 -0,182 - -
-(0,034)
0,100 1,112 - 0,000 0,135 (0,029)
0,341 0,511 10,163 0,083 0,083 (0,027) (3,800)
0,088 0,193 - 0,028 0,000 (0,055)
-0,368 -0,546 9,602 0,000 0,000 (0,026) (4,320)
0,034 1,061 - 0,000 0,078 (0,027)
0,044 0,091 - 0,001 0,000 (0,049)
-0,311 -5,802 -0,447 - -(3,378) (0,217)
-0,005 -0,048 - -
-(0,245)
Nota: Os valores entre parênteses correspondem aos desvio-padrão dos respectivos parâmetros
BB8_90 brus,eth|sug,oil
bov,eth|sug,oil,brus F
1
2
3
4
brus,sug|oil t
J oil,eth|sug
bov,sug|oil,brus C eth,sug
G
t
bov,oil|brus C bov,brus t
N oil,brus