Desenvolvimento de uma Abordagem
para o Reconhecimento de Gestos
Manuais Dinˆ
amicos e Est´
aticos
Edwin Jonathan Escobedo C´
ardenas
Universidade Federal de Ouro Preto
UNIVERSIDADE FEDERAL DE OURO PRETO
Orientador: Guillermo C´amara Ch´avez
Disserta¸c˜ao submetida ao Instituto de Ciˆencias
Exatas e Biol´ogicas da Universidade Federal de
Ouro Preto para obten¸c˜ao do t´ıtulo de Mestre
em Ciˆencia da Computa¸c˜ao
Desenvolvimento de uma Abordagem
para o Reconhecimento de Gestos
Manuais Dinˆ
amicos e Est´
aticos
Edwin Jonathan Escobedo C´
ardenas
Universidade Federal de Ouro Preto
Catalogação: www.sisbin.ufop.br
E746d Escobedo Cardenas, Edwin Jonathan.
Desenvolvimento de uma abordagem para o reconhecimento de gestos manuais dinâmicos e estáticos [manuscrito] / Edwin Jonathan Escobedo Cardenas. - 2015.
114f.: il.: color; tabs.
Orientador: Prof. Dr. Guillermo Cámara Chávez.
Dissertação (Mestrado) - Universidade Federal de Ouro Preto. Instituto de Ciências Exatas e Biológicas. Departamento de Computação. Programa de Pos graduação em Ciências da Computação.
1. Reconhecimento de padrões. 2. Gestos. 3. Linguagem corporal. I. Cámara Chávez, Guillermo. II. Universidade Federal de Ouro Preto. III. Titulo.
Dedico este trabalho a minha fam´ılia, especialmente a meus pais que sempre me apoiaram na realiza¸c˜ao dos meus sonhos mostrando-me o caminho para que eu pudesse realiz´a-los. A meus amigos que sempre me apoiaram nos bons e maus momentos. Gra¸cas a todos eles eu consegui alcan¸car meus objetivos.
Desenvolvimento de uma Abordagem para o
Reconhecimento de Gestos Manuais Dinˆ
amicos e
Est´
aticos
Resumo
Durante os ´ultimos anos, tˆem sido desenvolvidas diversas abordagens para o reconhe-cimento de gestos manuais, tanto est´aticos como dinˆamicos. Todas com o objetivo de melhorar a intera¸c˜ao homem-computador. Muitas dessas abordagens, inicialmente baseados nas informa¸c˜oes de intensidade, n˜ao fornecem dados suficientes para uma boa caracteriza¸c˜ao. Devido ao avan¸co da tecnologia, novos dispositivos est˜ao surgindo como ´e o caso do sensor Kinect o qual, al´em da informa¸c˜ao de intensidade, provˆe as informa¸c˜oes de profundidade e posi¸c˜oes das articula¸c˜oes do corpo. Dessa maneira, obt´em-se uma maior vantagem no desenvolvimento de um modelo para reconhecimento de gestos, pois ajuda reduzindo alguns processos complexos como ´e o caso da segmenta¸c˜ao e localiza¸c˜ao da m˜ao. Contudo as novas informa¸c˜oes de profundidade e posi¸c˜ao podem tamb´em ser usadas para a gera¸c˜ao de novas caracter´ısticas e melhorar as taxas de reconhecimento. Nesta disserta¸c˜ao apresentamos dois modelos para o reconhecimento de gestos, tanto est´aticos como dinˆamicos, usando as informa¸c˜oes de intensidade e profundidade (RGB-D), al´em da informa¸c˜ao das posi¸c˜oes das principais articula¸c˜oes do corpo.
No modelo para reconhecer gestos est´aticos, usou-se a informa¸c˜ao de profundidade, propondo um m´etodo baseado na representa¸c˜ao da m˜ao em uma nuvem de pontos. Logo, usando a teoria de cossenos de dire¸c˜ao, gerou-se um vetor de Histogramas de Magnitudes Acumuladas, o qual representa as novas caracter´ısticas locais da m˜ao. Finalmente, usando o classificador SVM (Support Vector Machine), geraram-se resultados superiores a outros modelos da literatura, sendo o melhor resultado de 99.21% de acur´acia media.
Hidden Markov Models (HMM) ou Dinamyc Time Warping (DTW). Depois, geraram-se trˆes vetores: o vetor de informa¸c˜ao espacial VSI, o vetor de informa¸c˜ao temporal VT I
e o vetor de mudan¸cas da posi¸c˜ao da m˜ao VHC, os quais representam as caracter´ısticas globais do gesto. Tamb´em, o descritor local SIFT foi usado nas imagens de intensidade e profundidade para obter caracter´ısticas das m˜aos. A partir dessas caracter´ısticas, foram gerados atributos de n´ıvel m´edio usando a t´ecnicaBag-of-Words (BoW), gerando o vetor de caracter´ısticas locais. Esse modelo fui testado usando o classificador SVM (Support Vector Machine) usando trˆes bases de dados diferentes, gerando resultados superiores a outros modelos da literatura em cada caso (100%, 88.38% e 98.28%).
Development of an Approach for Dynamic and Static
Manual Gesture Recognition
Abstract
During the last years, different approaches have been developed for hand gestures recog-nition, both static and dynamic. All with the goal of improving the human-computer interaction. Many of these approaches, initially based on the intensity information, do not provide sufficient data for a good characterization. Due to advancement in techno-logy, new devices are emerging such as the Kinect sensor which, in addition to intensity information, provides information and depth positions of the joints of the body. Thus, we obtain a greater advantage in developing a model for gesture recognition, it helps reduce some complex processes such as the segmentation and hand location. However the new depth and position information can also be used for new features generation and improved recognition rates. In this thesis we present two models for gesture recognition, both static and dynamic, using the intensity and depth of information (RGB-D), and the positions information of the main joints of the body.
In the model to recognize static gestures, was used the depth information, proposing a method based on hand representation in a point cloud. Thus, using the theory of direction cosines, was generated a Accumulated Magnitude Histogram vector, which represents the new hand local characteristics. Finally, using the SVM classifier (Support Vector Machine ), the results are superior results to other models in the literature, the average accuracy best result was 99.21%.
In the model for recognizing dynamic gestures, was used information from the hand positions to generate the trajectory of gesture and propose a key frames extraction
SI T I
the vector of hand position changesVHC , which represent global gesture features. Also,
the local descriptor SIfT was used in the intensity and depth images for the hands characteristics. As from these characteristics, were generated mid-level attributes using the technique Bag-of-Words (BoW), generating the local characteristics vector. This model was tested using the SVM classifier (Support Vector Machine) using three different databases, generating superior results to other published models in each case (100%, 88.38% and 98.28%).
Declara¸c˜
ao
Esta disserta¸c˜ao ´e resultado de meu pr´oprio trabalho, exceto onde referˆencia expl´ıcita ´e feita ao trabalho de outros, e n˜ao foi submetida para outra qualifica¸c˜ao nesta nem em outra universidade.
Edwin Jonathan Escobedo C´ardenas
Agradecimentos
Primeiramente agrade¸co aDeus por me amparar nos momentos dif´ıceis e por ter me dado a for¸ca para lograr com sucesso minhas metas.
Aos meus pais pelo apoio espiritual que eles me deram sempre e pela confian¸ca que me demonstraram em todo momento. A toda minha fam´ılia, por sempre acreditar em mim.
Agrade¸co ao meu orientador Guillermo C´amara Ch´avez e sua esposa Yudy pela opor-tunidade concedida e pelo suporte dado durante o desenvolvimento desta diserta¸c˜ao.
Alem deles, tamb´em agrade¸co a todos meus amigos que me apoiaram ao longo destes dois anos e gostaria agradecˆe-lhes: Emilia Alves, Fernanda Jardim, Jorge Cristalino, Isabela Alves, Marcelo Siqueira e especialmente Lourdes Ramirez por quem guardo um enorme apre¸co e carinho. Tamb´em aos senhores Briza Cerna e Julton Ramirez, que sem-pre me apoiaram mediante suas bˆen¸c˜aos e palavras de motiva¸c˜ao, estou muito agradecido com vocˆes.
Tamb´em agrade¸co a meus colegas Rensso, Edward e Karla, os ”Jovenes pulpines fiesteros, g´argolas de la noche, viajeros de la vida - REK”, pelo apoio e os conselhos prestados.
Sum´
ario
Lista de Figuras xix
Lista de Tabelas xxiii
1 Introdu¸c˜ao 1
1.1 Introdu¸c˜ao . . . 1
1.2 Motiva¸c˜ao . . . 2
1.3 Objetivos . . . 5
1.3.1 Objetivo Geral . . . 5
1.3.2 Objetivos Espec´ıficos . . . 5
1.4 Contribui¸c˜oes . . . 5
1.5 Organiza¸c˜ao . . . 7
2 Revis˜ao Bibliogr´afica 9 2.1 Detec¸c˜ao e rastreamento . . . 9
2.2 Reconhecimento . . . 11
2.2.1 M´etodos para o reconhecimento de gestos est´aticos . . . 11
2.2.2 M´etodos para o reconhecimento de gestos dinˆamicos . . . 14
2.3 Considera¸c˜oes Finais . . . 17
3.1.1 Gestos Manuais . . . 20
3.2 Aquisi¸c˜ao de Dados . . . 23
3.2.1 Luvas . . . 23
3.2.2 Kinect . . . 25
3.3 Extra¸c˜ao de Caracter´ısticas . . . 27
3.3.1 Scale-Invariant Feature Transform (SIFT) . . . 27
3.3.2 Bag-of-Visual-Words . . . 30
3.4 Algoritmos de aprendizagem de maquina . . . 32
3.4.1 K-means . . . 33
3.4.2 Maquinas de Vetores de Suporte . . . 34
3.4.3 Outros m´etodos de classifica¸c˜ao . . . 36
3.5 Considera¸c˜oes Finais . . . 36
4 Modelo Proposto 37 4.1 Modelo proposto para o Reconhecimento de Gestos Est´aticos . . . 37
4.1.1 Segmenta¸c˜ao . . . 38
4.1.2 Pr´e-Processamento . . . 39
4.1.3 Extra¸c˜ao de Caracter´ısticas . . . 40
4.2 Modelo proposto para o Reconhecimento de Gestos Dinˆamicos . . . 43
4.2.1 Captura da Informa¸c˜ao . . . 44
4.2.2 Desenho da Trajet´oria . . . 45
4.2.3 Convers˜ao em Coordenadas Esf´ericas. . . 45
4.2.4 Extra¸c˜ao dos Quadros Principais . . . 46
4.2.5 Segmenta¸c˜ao . . . 48
4.2.6 Extra¸c˜ao de Caracter´ısticas . . . 48
4.3 Reconhecimento e Valida¸c˜ao . . . 53
4.4 Considera¸c˜oes Finais . . . 53
5 Experimentos para o Modelo de Gestos Est´aticos 55 5.1 Base de Dados . . . 55
5.2 Defini¸c˜ao de parˆametros . . . 56
5.3 Avalia¸c˜ao dos modelos . . . 57
5.4 Experimentos . . . 58
5.4.1 An´alise de Resultados . . . 59
5.5 Considera¸c˜oes Finais . . . 62
6 Experimentos para o Modelo de Gestos Dinˆamicos 63 6.1 Base de Dados . . . 63
6.1.1 The SDUSign Database . . . 64
6.1.2 The ChaLearn 2013 Database . . . 65
6.1.3 The LIBRAS Database . . . 65
6.2 Defini¸c˜ao de parˆametros . . . 66
6.3 Avalia¸c˜ao dos modelos . . . 67
6.4 Experimentos . . . 68
6.4.1 Resultados usando a base de dados SDUSign . . . 68
6.4.2 Resultados usando a base de dados ChaLearn 2013 . . . 68
6.4.3 Resultados usando a base de dados LIBRAS . . . 70
6.5 Considera¸c˜oes Finais . . . 74
Referˆencias Bibliogr´aficas 79
Lista de Figuras
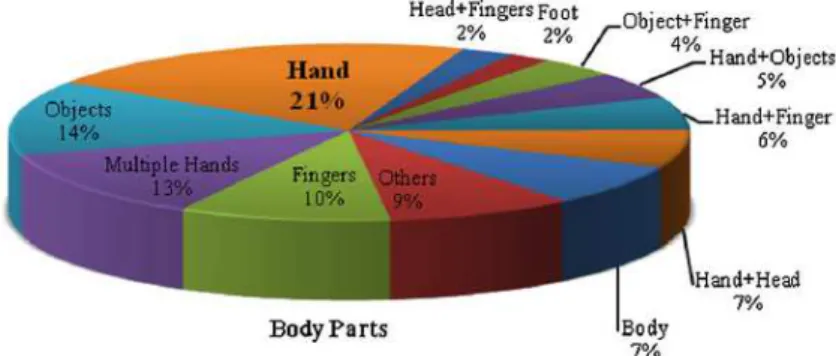
1.1 Gr´afico das diferentes partes do corpo ou objetos usados para o reconhe-cimento de gestos. . . 3
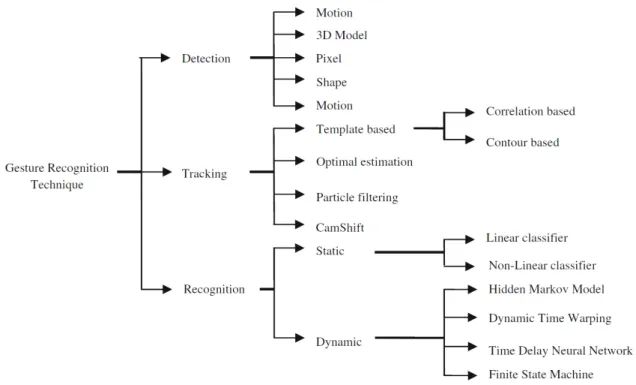
2.1 T´ecnicas para o reconhecimento de gestos. Rautaray and Agrawal (2015) 10
3.1 Exemplos de sinais com as mesmas configura¸c˜oes da m˜ao. (Felipe and Monteiro 2007) . . . 21
3.2 Lugares onde incide a m˜ao predominante. (Felipe and Monteiro 2007) . . 21
3.3 Exemplos de sinais com e sem movimento. (Felipe and Monteiro 2007) . 22
3.4 Exemplos de sinais com diferentes orienta¸c˜oes.(Felipe and Monteiro 2007) 22
3.5 Exemplos de express˜oes faciais em diferentes sinais.(Felipe and Monteiro 2007) . . . 23
3.6 Luvas coloridas. a) Luvas usadas por (Lamberti and Camastra 2011). b)Luvas usadas por (Wang and Popovi´c 2009). . . 24
3.7 Modelos de luvas de sensores. a) CyberGlove. b) Humanglove. c) 5DT Data Glove. d) Pinch Glove. e)Didjiglove. f) Fingernail Sensor. g)
AcceleGlove. h) Upper limb garment prototype. . . 24
3.8 Inicialmente o Kinect foi desenvolvido para ser usado em jogos noXBOX
360. . . 25
3.9 Sensor Kinect e suas partes. Imagens de cor e profundidade captadas pelo dispositivo. . . 26
3.10 Pontos das articula¸c˜oes do corpo obtidos pelo Kinect. . . 26
3.12 Representa¸c˜ao de uma pirˆamide de diferencias de Gaussianas (DoG) apli-cadas em diferentes escalas para uma imagem. . . 29
3.13 Compara¸c˜ao do pixel com seus oito vizinhos e os nove vizinhos das escalas superior e inferior. . . 29
3.14 Representa¸c˜ao do funcionamento do modelo Bag-of-Visual-Words (BoW). 32
3.15 Exemplo do funcionamento do algoritmo K-means para trˆes grupos. . . . 34
3.16 Classifica¸c˜ao dos exemplos da classe 1 e 2 mediante um hiperplano. . . . 34
3.17 Representa¸c˜ao de uma fun¸c˜ao Kernel φ projetando um espa¸co de entrada
R2 a uma dimens˜ao R3 onde os dados podem ser linearmente separ´aveis. 35
4.1 Modelo proposto para o reconhecimento de gestos est´aticos. . . 38
4.2 Exemplo do processo da segmenta¸c˜ao da m˜ao. . . 39
4.3 Pr´e-processamento: alinhamento da m˜ao em rela¸c˜ao ao eixoY e sua con-vers˜ao em uma nuvem de pontos. . . 40
4.4 Representa¸c˜ao espacial dos cossenos de dire¸c˜ao. . . 41
4.5 Exemplo da gera¸c˜ao de histogramas Acumulados em duas sub-regi˜oes S1
eS2 para os gestos S e E. . . 43
4.6 Processo da gera¸c˜ao dos histogramas de Magnitudes AcumuladasHx, Hy
eHz. . . 44
4.7 Modelo Proposto para o reconhecimento de gestos dinˆamicos . . . 44
4.8 Exemplo das seis trajet´orias que representam um gesto da m˜ao . . . 45
4.9 Representa¸c˜ao geom´etrica do Sistema de Coordenadas Esf´ericas. . . 47
4.10 Representa¸c˜ao da divis˜ao em octantes para os eixos XY e XZ. . . 47
4.11 Exemplo da extra¸c˜ao dos quadros principais para dois v´ıdeos com o mesmo gesto. Primeiro, s˜ao escolhidos os pontos principais das trajet´orias, e logo para cada ponto principal, extrai-se seu correspondente quadro principal. 49
4.12 Exemplos de segmenta¸c˜ao das m˜ao para dois gestos: justi¸ca (topo) e brilhar (base). . . 49
4.13 Exemplos de mudan¸cas da posi¸c˜ao da m˜ao em dois gestos: justi¸ca (direita) e brilhar (esquerda). O vector VHC ´e diferente para ambos sinais. Cada c´odigo bin´ario representa uma posi¸c˜ao do octante. . . 51
4.14 Exemplos de pontos caracter´ısticos extra´ıdos usando o descritor SIFT tanto das imagens de intensidade (no topo de cor vermelho) como nas imagens de profundidade (na base de cor amarelo). O descritor SIFT foi usado nos quadros principais de um gesto dinˆamico. . . 53
5.1 Ilustra¸c˜ao da variedade nas amostras da base de dados ASL. A matriz mostra uma imagem de cada usu´ario e de cada letra. . . 56
5.2 Ilustra¸c˜ao da semelhan¸ca no conjunto de dados entre as diferentes classes. Todos os sinais s˜ao representados por um punho fechado, e diferem apenas pela posi¸c˜ao do dedo polegar. . . 56
5.3 Exemplo dos sinais M, N, S, E representados no espa¸co. . . 62
6.1 Representa¸c˜ao dos 20 sinais chineses da base de dadosSDUSign . . . 64
6.2 Exemplo de um gesto manual da base de dados ChaLearn 2013 . . . 65
6.3 Exemplo de dois sinais na base LIBRAS que apresentam as duas primeiras configura¸c˜oes. . . 66
Lista de Tabelas
5.1 Resultados da classifica¸c˜ao dos sinais est´aticos usando os protocolosA eB. 59
5.2 Acur´acia e Desvio Padr˜ao (DP) obtidos para diferentes porcentagens de treino e teste. . . 60
5.3 Matriz de confus˜ao da classifica¸c˜ao dos 24 sinais usando o m´etodo de extra¸c˜ao de caracter´ısticas globais imagem de profundidade. . . 61
6.1 Resultados usando a base de dados SDUSign. . . 68
6.2 Resultados usando The ChaLearn database . . . 69
6.3 Resultados e compara¸c˜ao dos trˆes experimentos usando The ChaLearn database. . . 70
6.4 Resultados gerais com a base de dados LIBRAS para diferentes valores deK. . . 71
6.5 Matriz de confus˜ao media dos 18 sinais da base de dados LIBRAS usando caracter´ısticas temporais. . . 71
6.6 Matriz de confus˜ao media dos 18 sinais da base de dados LIBRAS usando caracter´ısticas globais. . . 73
6.7 Matriz de confus˜ao media dos 18 sinais da base de dados LIBRAS usando caracter´ısticas temporais e globais. . . 73
“A tarefa n˜ao ´e tanto ver aquilo que ningu´em viu, mas pensar o que ningu´em ainda pensou sobre aquilo que todo mundo vˆe.”
— Arthur Schopenhauer
Cap´ıtulo 1
Introdu¸c˜
ao
Neste capitulo ser˜ao apresentadas a introdu¸c˜ao e motiva¸c˜ao desta disserta¸c˜ao, alem dos objetivos propostos e as contribui¸c˜oes atingidas.
1.1
Introdu¸c˜
ao
Nas aplica¸c˜oes de intera¸c˜ao humano-computador (HCI), o reconhecimento de gestos tem o potencial de fornecer uma forma natural de comunica¸c˜ao entre os humanos e as m´aquinas. Mesmo assumindo a inven¸c˜ao do mouse e do teclado como um grande progresso, ainda h´a situa¸c˜oes em que tais dispositivos s˜ao inadequados para uma boa intera¸c˜ao humano-computador (HCI) pois as interfaces de usu´ario (UI) precisam ser o mais intuitivas e naturais poss´ıveis. O usu´ario deve, idealmente, interagir com as m´aquinas sem a necessidade de outros dispositivos pesados (como marcadores coloridos ou luvas) ou aparelhos como controles remotos e os j´a mencionados mouse e teclado.
Normalmente usam-se gestos para a express˜ao de sentimentos e pensamentos. Os gestos s˜ao, portanto, um meio de comunica¸c˜ao n˜ao-verbal, que v˜ao desde a¸c˜oes simples (apontando para objetos, por exemplo) at´e as mais complexas (como expressar sentimen-tos ou comunicar-se com outros). Neste sentido, os gessentimen-tos n˜ao s˜ao apenas um ornamento da linguagem falada, s˜ao tamb´em componentes essenciais do processo de gera¸c˜ao da lin-guagem em si. Um gesto pode ser definido como um movimento f´ısico das m˜aos, bra¸cos, rosto e corpo com a inten¸c˜ao de transmitir informa¸c˜oes ou significado. Em particular, a interpreta¸c˜ao visual de gestos manuais pode ajudar a alcan¸car a facilidade e naturali-dade desejada para HCI. Usar as m˜aos como um dispositivo, pode ajudar `as pessoas a
comunicar-se com os computadores de uma forma mais intuitiva pois os movimentos da m˜ao desempenham um papel importante na transmiss˜ao de informa¸c˜ao.
Os gestos manuais podem ser est´aticos e dinˆamicos. Os est´aticos (quando o usu´ario assume certa pose ou configura¸c˜ao da m˜ao) s˜ao definidos pela orienta¸c˜ao e a posi¸c˜ao da m˜ao fixa no espa¸co. Nos dinˆamicos, um gesto ´e representado por um conjunto de poses e configura¸c˜oes da m˜ao num determinado tempo. Alguns gestos tamb´em tˆem elementos est´aticos e dinˆamicos, como no caso das l´ınguas de sinais onde os gestos est´aticos s˜ao representados pelas letras do alfabeto (com algumas exce¸c˜oes) e os dinˆamicos pelas palavras ou frases.
Diferentes modelos foram propostos para o reconhecimento de gestos. Para gestos est´aticos s˜ao encontrados por exemplo os modelos de Bretzner et al. (2002), Gupta et al. (2012), Pugeault and Bowden (2011a), Vamplew (1996) e Feng and Yuan (2013). Quando trata-se de gestos dinˆamicos, temos os modelos de Hern´andez-Vela et al. (2013), Rakun et al. (2013), Ramamoorthy et al. (2003), Wang, Yang, Wu, Xu and Li (2012),
etc.
Portanto, o reconhecimento de gestos pode revolucionar a forma de como usamos a tecnologia em nossas atividades di´arias. Especialmente os gestos manuais, pois na ´area de reconhecimento, as m˜aos est˜ao sendo amplamente utilizadas em compara¸c˜ao com outras partes do corpo ou objetos (Rautaray and Agrawal 2015), como ´e mostrado na Figura 1.1. As aplica¸c˜oes bem sucedidas de sistemas de gestos manuais podem ser encontradas em v´arias ´areas de investiga¸c˜ao e da ind´ustria, tais como: jogos, realidade virtual, rob´otica, casas inteligentes e no reconhecimento das l´ınguas de sinais (Mitra and Acharya 2007, Murthy and Jadon 2009). Novos m´etodos nessa ´area, ainda est˜ao sendo desenvolvidos, al´em de que novas formas de aquisi¸c˜ao de informa¸c˜ao est˜ao surgindo, incentivando assim `a proposta de novos descritores que procuram incrementar as taxas de reconhecimento dos m´etodos j´a propostos.
1.2
Motiva¸c˜
ao
Pesquisas em vis˜ao computacional estabeleceram a importˆancia dos sistemas de reco-nhecimento de gestos com o prop´osito de melhorar a intera¸c˜ao humano-computador (Derpanis 2004, Mitra and Acharya 2007).
Introdu¸c˜ao 3
Figura 1.1: Gr´afico das diferentes partes do corpo ou objetos usados para o reconheci-mento de gestos.
um deles focado em um tipo de informa¸c˜ao de acordo com a aquisi¸c˜ao dos dados.
• M´etodos baseados em dispositivos: os quais usam sensores (mecˆanicos ou ´opticos) ligados a uma luva que transduz as flex˜oes dos dedos em sinais el´etricos para de-terminar a postura da m˜ao e assim poder fornecer medi¸c˜oes precisas de seus mo-vimentos. Infelizmente, estes m´etodos requerem calibragem e obrigam ao usu´ario a transportar uma carga de cabos que est˜ao ligados ao computador, dificultando o movimento natural das m˜aos do usu´ario e a intera¸c˜ao dele com seu entorno. Tamb´em s˜ao muitas vezes de alto custo econˆomico.
• M´etodos baseados em Vis˜ao Computacional: onde dispositivos de v´ıdeo s˜ao usa-dos para capturar os gestos e posteriormente detectar as m˜aos. S˜ao t´ecnicas n˜ao invasivas e baseadas na forma como os seres humanos percebem informa¸c˜oes sobre seu entorno. A Vis˜ao Computacional tem o potencial para obter uma riqueza de informa¸c˜oes com um baixo custo, e constitui uma modalidade de detec¸c˜ao muito atraente para o desenvolvimento de reconhecimento de gestos manuais.
Portanto, a vis˜ao computacional facilita o acesso dos usu´arios `a tecnologia sem exigir gastos adicionais e sem alterar o movimento natural da m˜ao. Tornando-se a ´area que atualmente recebe a maior aten¸c˜ao dos pesquisadores pois durante os ´ultimos anos, tˆem sido desenvolvidas diversas abordagens para o reconhecimento de gestos manuais. No entanto, o desenvolvimento de um sistema de reconhecimento de gestos baseado em vis˜ao, n˜ao ´e uma tarefa f´acil, pois exige um conjunto de restri¸c˜oes impostas que permitam obter uma intera¸c˜ao em tempo real mais natural. Por exemplo, o uso de fundos controlados, de roupas que cobrem todo o bra¸co, a limita¸c˜ao da regi˜ao da cˆamera,
tais como a invariˆancia da ilumina¸c˜ao ou existˆencia de ambientes com fundo irregular em uma cena.
Outro problema no reconhecimento de gestos ´e a complexidade morfol´ogica da m˜ao, pois o elevado n´umero de graus de liberdade da m˜ao e dos dedos causa uma infinidade de posi¸c˜oes a serem adotadas al´em das oclus˜oes que se podem apresentar. Este ´e um dos aspectos mais dif´ıcil na segmenta¸c˜ao e torna-se um problema interessante para resolver. Apresentando-se processos complexos para segmentar e rastrear as m˜aos.
Contudo, devido ao avan¸co da tecnologia, novos dispositivos est˜ao surgindo como ´e o caso das cˆameras de profundidade (Time-of-Flight - ToF) usadas nos modelos propostos por Liu and Fujimura (2004), Oprisescu et al. (2012), Uebersax et al. (2011); e do sensor
Microsoft KinectTMo qual proporciona novas informa¸c˜oes como os dados RGB-D, mesmo
as posi¸c˜oes das articula¸c˜oes do corpo. Al´em de possuir uma grande vantagem a qual ´e essencialmente a independˆencia de restri¸c˜oes ambientais como a ilumina¸c˜ao, fundos complexo, etc. Dessa maneira, podem-se reduzir alguns processos complexos como no caso da segmenta¸c˜ao e rastreamento da m˜ao, como foi usado nos modelos propostos por Frati and Prattichizzo (2011), Li (2012), Ren et al. (2011), entre outros.
Essa vantagem proporcionada pelo sensor KinectTM permite explorar os mapas de
profundidade dos gestos e permite analisar as trajet´orias das principais partes do corpo. Assim, podem-se gerar novas caracter´ısticas globais e locais que melhorem o desempenho dos sistemas de reconhecimento de gestos. Biswas and Basu (2011), Geetha et al. (2013), Masood et al. (2014), Otiniano Rodriguez and Camara Chavez (2013), Takimoto et al. (2013), Wang, Xia, Cai, Gao and Cattani (2012), Wang, Yang, Wu, Xu and Li (2012),
etc. Aproveitam os dados do sensor KinectTM e apresentam novos modelos para o
reconhecimento de gestos manuais.
Introdu¸c˜ao 5
1.3
Objetivos
Nessa sec¸c˜ao, o objetivo geral e os objetivos espec´ıficos perseguidos nesta disserta¸c˜ao ser˜ao apresentados.
1.3.1
Objetivo Geral
Objetivo geral desta pesquisa ´e desenvolver uma nova abordagem para o Reconhecimento de gestos manuais dinˆamicos e est´aticos, usando a informa¸c˜ao espacial, de intensidade e profundidade dos gestos.
1.3.2
Objetivos Espec´ıficos
• Definir os tipos de caracter´ısticas espaciais e globais que melhor descrevam o sinal.
• Avaliar a importˆancia da informa¸c˜ao espacial, de intensidade e profundidade de um sinal dinˆamico.
• Avaliar a importˆancia da informa¸c˜ao de profundidade de um sinal est´atico.
• Analisar a robustez de um sistema que trabalha com caracter´ısticas espaciais e globais, em compara¸c˜ao com um sistema que s´o trabalha com um tipo de carac-ter´ısticas.
• Propor um novo m´etodo de reconhecimento tanto para sinais dinˆamicos como est´aticos, com boa acur´acia e r´apido tempo de processamento.
• Avaliar e comparar os resultados obtidos com outros modelos propostos.
1.4
Contribui¸c˜
oes
Nessa disserta¸c˜ao, s˜ao propostos dois novos m´etodos para o reconhecimento de gestos manuais, um para gestos est´aticos e outro para gestos dinˆamicos, explorando as vanta-gens das novas informa¸c˜oes fornecidas pelo sensor de profundidade Microsoft KinectTM
.
• A primeira principal contribui¸c˜ao desta disserta¸c˜ao ´e apresentar um novo m´etodo para o reconhecimento de gestos manuais est´aticos aproveitando a informa¸c˜ao de profundidade da m˜ao. Este m´etodo foi aceito e ser´a publicado na XXVII Confe-rence on Graphics, Patterns and Images (SIBGRAPI) - 20151.
• Explorar as vantagens dos dados de profundidade, como a invariˆancia de ilu-mina¸c˜ao para facilitar o processo de segmenta¸c˜ao das m˜aos, removendo o fundo e algumas partes do corpo que n˜ao ajudam no reconhecimento.
• A representa¸c˜ao da m˜ao mediante uma nuvem de pontos e a gera¸c˜ao de Histogra-mas de Magnitudes Acumuladas mediante o uso de cossenos de dire¸c˜ao os quais representam com maior robustez as caracter´ısticas globais da m˜ao.
• A segunda principal contribui¸c˜ao desta disserta¸c˜ao ´e apresentar um novo m´etodo para o reconhecimento de gestos dinˆamicos combinando informa¸c˜oes globais e tem-porais obtidas a partir dos dados RGB-D e das posi¸c˜oes dos pontos das articula¸c˜oes. Este m´etodo foi aceito e ser´a publicado noInternational Conference on Image Pro-cessing (ICIP) - 20152.
• A proposta de um algoritmo de extra¸c˜ao dos quadros mais relevantes do gesto. Assim, o m´etodo desenvolvido, fica independente das varia¸c˜oes temporais evitando o uso reiterado de t´ecnicas invari´aveis ao tempo como os Hidden Markov Model
(HMM) ou Dinamyc Time Warping (DTW). Portanto, ao reduzir o gesto para um n´umero discreto de quadros, podem-se usar e testar mais classificadores para o processo de reconhecimento.
• A convers˜ao da trajet´oria em coordenadas esf´ericas e sua representa¸c˜ao mediante trˆes vetores principais: vetor de informa¸c˜ao espacial (VSI), vetor de informa¸c˜ao
temporal (VT I) e vetor de mudan¸cas de posi¸c˜ao (VHC).
• A busca de informa¸c˜ao semˆantica a partir das informa¸c˜oes globais das m˜aos nos quadros principais obtidos, gerando caracter´ısticas globais mais robustas.
• A proposta de uma nova base de dados de gestos dinˆamicos correspondente `a L´ıngua Brasileira de Sinais (LIBRAS), constitu´ıda por sinais desafiantes a qual ser´a disponibilizada para ser utilizada por outros pesquisadores.
Introdu¸c˜ao 7
1.5
Organiza¸c˜
ao
Cap´ıtulo 2
Revis˜
ao Bibliogr´
afica
O reconhecimento de gestos manuais ´e uma ´area extensa dividida em duas categorias: os m´etodos baseados em dispositivos (uso de luvas) e os m´etodos baseados em vis˜ao. Como foi mencionado no capitulo anterior, os m´etodos baseados em dispositivos dificultam o movimento natural da m˜ao e por tanto os m´etodos baseados em vis˜ao s˜ao os que apresentam uma maior pesquisa nessa ´area. Assim, esta diserta¸c˜ao foi baseada em vis˜ao.
Rautaray and Agrawal (2015) apresentam as t´ecnicas usadas para o reconhecimento de gestos manuais baseados em vis˜ao (Figura 2.1). Elas est˜ao divididas em trˆes fases: detec¸c˜ao, rastreamento e reconhecimento do gesto.
2.1
Detec¸c˜
ao e rastreamento
Na fase de detec¸c˜ao da m˜ao, desenvolveram-se t´ecnicas para localizar e segmentar as m˜aos. A segmenta¸c˜ao ´e fundamental porque isola os dados relevantes do fundo da ima-gem antes de pass´a-los para as fases subsequentes de rastreamento e reconhecimento. Um grande n´umero de m´etodos tˆem sido propostos na literatura que utilizam de v´arios tipos de caracter´ısticas visuais e, em muitos casos, a sua combina¸c˜ao. Entre eles te-mos m´etodos baseados na cor da pele, onde sao propostos diversos espa¸cos de cor, tais como: RGB, RGB normalizado, HSV, YCrCb, YUV, etc. Kurata et al. (2001), Sigal et al. (2004), Yang et al. (1997) e Chai and Ngan (1998), apresentam diversas propostas para a detec¸c˜ao da pele usando diferentes espa¸cos de cor. Em Terrillon et al. (2000) ´e apresentado um estudo comparativo de diferentes modelos de an´alise da pele onde ´e
Figura 2.1: T´ecnicas para o reconhecimento de gestos. Rautaray and Agrawal (2015)
avaliando o desempenho dos mesmos. Tamb´em, desenvolveram-se m´etodos de detec¸c˜ao baseados na forma da m˜ao (Argyros et al. 2006, Song and Takatsuka 2005, Yin and Xie 2003), no valor dos pixels (Cui and Weng 1996, Wu and Huang 2000), em modelos 3D (Wu and Huang 1999, Wu et al. 2001), entre outros.
Revis˜ao Bibliogr´afica 11
2.2
Reconhecimento
O objetivo geral do reconhecimento de gestos manuais ´e a interpreta¸c˜ao semˆantica que a m˜ao ou as m˜aos transmitem. As t´ecnicas de reconhecimento de gestos manuais base-adas em vis˜ao podem ser classificbase-adas sobre dois tipos de gestos: est´aticos e dinˆamicos. Para detectar gestos est´aticos (ou seja, posturas), um classificador geral ou um template-matcher pode ser utilizado. No entanto, os gestos dinˆamicos tˆem um aspecto temporal e necessitam de t´ecnicas que lidam com esta dimens˜ao, como os Hidden Markov Mo-dels(HMM) ouDynamic Time Warping. A continua¸c˜ao ser˜ao apresentados os trabalhos desenvolvidos para o reconhecimento de gestos est´aticos e dinˆamicos.
2.2.1
M´
etodos para o reconhecimento de gestos est´
aticos
Na categoria do reconhecimento de gestos est´aticos, apresentam-se diferentes abordagens focadas na caracteriza¸c˜ao do gesto as quais usam diferentes t´ecnicas de classifica¸c˜ao. Um dos primeiros trabalhos foi desenvolvido por Vamplew (1996), quem cria um sistema cha-mado SLARTI (Sign Language Recognition), o qual contem uma arquitetura modular que envolve m´ultiplas redes neurais (ANN, do ingles Artificial Neural Network) e o classificador dos K-vizinhos mais pr´oximos para reconhecer gestos est´aticos da l´ıngua de sinais australiana. A forma, a orienta¸c˜ao, a localiza¸c˜ao e o movimento da m˜ao, s˜ao usadas como caracter´ısticas onde cada ANN ´e usada para classificar cada uma dessas ca-racter´ısticas. O classificador dosK-Vizinhos mais pr´oximos foi usado como classificador final usando as sa´ıdas das ANNs como sua entrada. Em Stergiopoulou and Papamar-kos (2009), foi proposto um novo m´etodo baseado em um procedimento de ajuste do gesto atrav´es de uma nova redeSelf-Growing and Self-Organized Neural Gas (SGONG). Inicialmente, a regi˜ao da m˜ao ´e detectada atrav´es da aplica¸c˜ao de uma t´ecnica de seg-menta¸c˜ao de cor com base em um processo de filtragem da cor da pele no espa¸co YCbCr. Logo, a rede SGONG ´e aplicada sobre a ´area da m˜ao, para assim aproximar a sua forma. Com base na grelha de neur´onios produzidos pela rede neural de sa´ıda, as caracter´ısticas morfol´ogicas da palma s˜ao extra´ıdas, as quais junto com as caracter´ısticas do dedo, per-mitem a identifica¸c˜ao do numero de dedos levantados.
da l´ıngua Ar´abica de sinais e Symeonidis (1996) que convertem as imagens das m˜aos em mascaras espaciais 3D bin´arias e usam um supervised feed-forward neural net based training and back propagation algorithm para classificar gestos manuais em diferentes categorias.
Al´em das redes neurais e suas varia¸c˜oes, usaram-se tamb´em as Maquinas de Vetores de Suporte (SVM, do inglˆes Support Vector Machine). Em (Gupta et al. 2012) por exemplo, s˜ao usados filtros de Gabor para a extra¸c˜ao de caracter´ısticas as quais s˜ao combinadas com PCA e LDA para reduzir suas dimens˜oes gerando proje¸c˜oes lineares. Logo uma maquina de vetores de suporte (SVM) e utilizada para a classifica¸c˜ao obtendo boas taxas de reconhecimento. Feng and Yuan (2013) utilizam histogramas de gradien-tes orientados (HOG) para extrair caracter´ısticas dos gestos. Depois uma maquina de vetores de suporte SVM ´e usada para treinar esses vetores de caracter´ısticas, Na hora de fazer os testes, uma decis˜ao ´e tomada utilizando as SVMs aprendidas anteriormente, e se faz a compara¸c˜ao do mesmo gesto em diferentes condi¸c˜oes de ilumina¸c˜ao. Em (Bretzner et al. 2002), apresenta-se um sistema para o rastreamento e reconhecimento de posturas da m˜ao que s˜ao representadas mediante caracter´ısticas hierarquias multi-escala em ima-gens de cor em termos de posi¸c˜ao, escala e orienta¸c˜ao. Em cada imagem, caracter´ısticas de cores multi-escala foram calculadas e os estados das m˜aos foram simultaneamente detectados e rastreados usando particle filtering. Os experimentos mostraram que o de-sempenho do sistema foi melhorado atrav´es da detec¸c˜ao de caracter´ısticas no espa¸co de cor. Esses componentes foram integrados em um prot´otipo de sistema em tempo real, aplicado a um problema de teste de controle de eletrˆonicos de consumo usando gestos manuais.
Outros m´etodos foram desenvolvidos tamb´em usando Naive Bayes Classifier ( Zi-aie et al. (2008, 2009)) e K-Nearest Neighbors ( Pizzolato et al. (2010), Rautaray and Agrawal (2010)) como classificadores.
Revis˜ao Bibliogr´afica 13
uso destas novas tecnologias, ajuda a reduzir a complexidade dos processos de dete¸c˜ao, segmenta¸c˜ao e rastreamento da m˜ao Frati and Prattichizzo (2011), Li (2012), Mo and Neumann (2006), Ren et al. (2011), al´em de fornecer novos conhecimentos para a gera¸c˜ao de novas caracter´ısticas. Fazendo aos pesquisadores, focar-se principalmente na fase do reconhecimento. Entre eles temos as cˆameras de profundidadeTime-of-Flight (ToF) e o sensor KinectT M da Microsoft.
Em (Liu and Fujimura 2004), ´e apresentado um m´etodo para o reconhecimento de gestos, utilizando uma sequˆencia de imagens de profundidade em tempo real adquiridos por uma cˆamera ToF. A postura da m˜ao e as informa¸c˜oes de movimento s˜ao extra´ıdos a partir de um v´ıdeo ´e representados num espa¸co de gestos. Nesse espa¸co, mostrou-se que ´e poss´ıvel reconhecer os diferentes tipos de gestos. Mais tarde, Uebersax et al. (2011) desenvolveram um sistema para o reconhecimento de letras e de algumas pala-vras simples usando tamb´em uma cˆamera ToF. O sistema retornava a palavra descrita mais prov´avel. Foi introduzido um algoritmo de segmenta¸c˜ao da m˜ao aproveitando a informa¸c˜ao de profundidade e usaram-se trˆes classificadores. O primeiro calculava as diferen¸cas de profundidade. O segundo calculava a media de maximiza¸c˜ao de margem do vizinho mais pr´oximo para detectar qual era o sinal est´atico e o terceiro estimava a orienta¸c˜ao da m˜ao para descartar erros. Depois, combinaram-se os trˆes m´etodos de clas-sifica¸c˜ao e usou-se palavras predefinidas armazenadas num dicion´ario para reconhecer o gesto. Em, Oprisescu et al. (2012), usou-se tamb´em uma cˆamera ToF e apresentou-se um algoritmo autom´atico para reconhecimento de gestos manuais aproveitando as in-forma¸c˜oes de profundidade e intensidade. A combina¸c˜ao dessas inin-forma¸c˜oes facilitou o processo de segmenta¸c˜ao, mesmo com a presen¸ca de um fundo complexo. A classi-fica¸c˜ao dos gestos foi baseada em uma ´arvore de decis˜ao usando descri¸c˜oes estruturais de segmentos de contorno particionados.
Outros trabalhos, usaram o sensor KinectT M como no caso de Biswas and Basu (2011) que usaram as imagens de profundidade para remover o fundo e Logo gerar um perfil da profundidade da pessoa que realizava o gesto. Alem disso, a diferen¸ca entre os quadros consecutivos gerou o perfil de movimento da pessoa o qual foi utili-zado para o reconhecimento dos gestos fazendo uso eficiente da cˆamera de profundidade para reconhecer com sucesso v´arios gestos. O sistema foi treinado usando m´aquinas de vetores de suporte (SVM). Pugeault and Bowden (2011b) usaram tamb´em um disposi-tivo KinectT M para coletar imagens de intensidade e de profundidade (dados RGB-D).
Lan-guage - ASL). Van den Bergh and Van Gool (2011) propuseram um m´etodo baseado na concatena¸c˜ao das imagens de intensidade e profundidade segmentadas, usando uma combina¸c˜ao de Haar wavelets e redes neurais para 6 gestos feitos por um ´unico usu´ario.
(Zhu and Wong 2012) apresentaram um m´etodo onde primeiro s˜ao extra´ıdas as carac-ter´ısticas de baixo n´ıvel (low level features) em janelas, e logo estas s˜ao combinadas por meio de descritores kernel. Esta abordagem usou apenas um pequeno n´umero de amos-tras de treinamento (40 amosamos-tras por sinal) e as restantes foram usadas para teste. Eles fizeram dois experimentos diferentes. O primeiro foi realizado usando imagem piramidal e obtiveram 88% de acur´acia. No segundo caso, a imagem piramidal n˜ao foi usada e obtiveram uma acur´acia de 77%. Otiniano Rodriguez and Camara Chavez (2013) desen-volveram um sistema h´ıbrido para o reconhecimento da l´ıngua de sinais usando imagens RGB-D a partir de informa¸c˜oes do sensor KinectT M. Primeiro segmentaram a ´area da m˜ao do fundo usando o mapa de profundidade, depois e usaram tamb´em descritores Kernels para a extra¸c˜ao de caracter´ısticas, al´em, o Scale-Invariant Feature Transform
(SIFT) foi usado para descrever o conte´udo da imagem RGB e finalmente a classifica¸c˜ao foi feita usando maquinas de vetores de suporte (SVM).
Por´em, os trabalhos mencionados anteriormente utilizaram os dados de profundi-dade como apoio para a segmenta¸c˜ao das m˜aos ou como refor¸co para a extra¸c˜ao de caracter´ısticas. Tamb´em alguns trabalhos utilizaram descritores desenhados para traba-lhar e extrair caracter´ısticas dos dados de profundidade, mas apresentando um elevado tempo de processamento para a extra¸c˜ao delas. Assim, surgiu a necessidade de desenvol-ver um novo m´etodo para extrair caracter´ısticas aproveitando os dados de profundidade, o qual seja simples e r´apido de processar apresentando um bom desempenho no reconhe-cimento, similar o melhor que os trabalhos mencionados anteriormente. Este m´etodo foi desenvolvido e apresentado nesta disserta¸c˜ao como primeira contribui¸c˜ao principal.
2.2.2
M´
etodos para o reconhecimento de gestos dinˆ
amicos
Na categoria do reconhecimento de gestos dinˆamicos, apresentam-se diferentes aborda-gens focadas na trajet´oria percorrida pelo gesto. Como foi mencionado anteriormente, os gestos dinˆamicos tˆem um aspecto temporal e requerem de t´ecnicas que lidam com esta dimens˜ao para poder fazer a classifica¸c˜ao.
Um dos classificadores mais usados s˜ao os Modelos Ocultos de Markov (HMM, do
Revis˜ao Bibliogr´afica 15
tempo e amplitude dos gestos. Devido a esta caracter´ıstica, as HMMs aparecem como uma abordagem ideal para o reconhecer gestos que contenham informa¸c˜oes temporais e s˜ao conhecidos por terem taxas elevadas de classifica¸c˜ao. Em Ramamoorthy et al. (2003), por exemplo, apresentou-se um sistema para reconhecer gestos dinˆamicos con-siderando aos gestos com poses de m˜ao distintas. Nestes gestos as poses apresentavam movimento e altera¸c˜oes discretas mas sem permitir deforma¸c˜oes cont´ınuas da forma da m˜ao. Foi desenvolvido um motor de reconhecimento capaz de reconhecer esses gestos apesar das varia¸c˜oes individuais. A estrat´egia de reconhecimento utilizou uma com-bina¸c˜ao de reconhecimento est´atico de forma (realizada por meio de an´alise de contorno discriminante), filtro Kalman baseado no rastreamento da m˜ao e um esquema de carac-teriza¸c˜ao temporal, baseado em HMM. O sistema demonstrou ser robusto para fundos complexos apresentando um bom desempenho. Em Elmezain et al. (2008), foi proposto um sistema autom´atico para reconhecer n´umeros ar´abicos (0-9) baseados novamente no modelo oculto de Markov (HMM) usando caracter´ısticas dinˆamicas de orienta¸c˜ao do gesto obtidas a partir das trajet´orias da m˜ao. Kurakin et al. (2012) apresentam tamb´em um sistema em tempo real para o reconhecimento de gesto manuais dinˆamicos invariante `as varia¸c˜oes da velocidade e `as orienta¸c˜oes da m˜ao. O m´etodo foi baseado em um grafo de a¸c˜oes que contem propriedades robustas semelhantes com um HMM padr˜ao, mas re-quer menos dados de treinamento. Para lidar com as orienta¸c˜oes da m˜ao, desenvolveram uma t´ecnica de segmenta¸c˜ao da m˜ao e normaliza¸c˜ao da orienta¸c˜ao avaliando o sistema proposto em um conjunto de dados desafiante.
Wang, Xia, Cai, Gao and Cattani (2012), apresentam um novo m´etodo baseado igual-mente em Hidden Markov Models(HMM) para o modelagem das trajet´orias de gestos dinˆamicos e seu reconhecimento, usando o algoritmo AdaBoost para detectar a m˜ao do usu´ario. Al´em, de um rastreador de m˜aos baseado em contornos. Logo, uma B-spline
obtendo-se rapidamente e com precis˜ao, as coordenadas da posi¸c˜ao de palma, logo, usou-se um Hidden Markov Models (HMM) para o reconhecimento apresentando uma bom desempenho nos resultados experimentais.
Outras propostas, usaram o algoritmoDynamic Time Warping (DTW) para a clas-sifica¸c˜ao de gestos dinˆamicos pois este algoritmo encontra o alinhamento ´optimo de dois sinais, calculando a distˆancia entre cada par poss´ıvel de pontos em dois sinais em ter-mos de seus valores de caracter´ısticos associados. Em (Hern´andez-Vela et al. 2013), por exemplo, apresentou-se uma metodologia para resolver o problema da segmenta¸c˜ao das m˜aos e reconhecimento dos gestos em imagens de v´ıdeo e profundidade, introduzindo um modelo Bag-of-Visual-and-Depth-Words (BoVDW) como uma extens˜ao do modelo
Bag-of-visual-words. Tamb´em, um novo descritor de profundidade foi usado integrando um Human Gesture Recognition pipeline junto com um novo algoritmo probability-based Dynamic Time Warping (PDTW). Celebi et al. (2013), tamb´em usaram um m´etodo baseado emDynamic time warping (DTW) ponderado atribuindo pesos `as articula¸c˜oes, otimizando uma rela¸c˜ao discriminante, demonstrando que o desempenho do m´etodo pro-posto superava a outros m´etodos baseados no DTW convencional. Masood et al. (2014) apresentaram um novo m´etodo para o reconhecimento doPakistani Sign Language uti-lizando o dispositivo KinectT M para obter a informa¸c˜ao espacial do sinal. Os dados
obtidos do KinectT M foram normalizados devido `as varia¸c˜oes de posi¸c˜ao do usu´ario,
fazendo a convers˜ao das coordenadas cartesianas `as coordenadas esf´ericas. Depois foi feita uma opera¸c˜ao de casamento das caracter´ısticas com um dicion´ario de gestos usando novamente o algoritmo Dynamic Time Warping. Tamb´em, utilizaram-se outros classifi-cadores comoMultiple Extreme Learning Machines que foi usado por Chen and Koskela (2014) para propor um m´etodo RGB-D multi-modal. extraindo caracter´ısticas mediante o corpo e mascaras da m˜ao nas imagens RGB e de profundidade.
Revis˜ao Bibliogr´afica 17
igualmente a sele¸c˜ao de um determinado numero de pontos da trajet´oria, combinando informa¸c˜ao espacial e informa¸c˜ao das imagens de intensidade usando como classificador o Random Forest. Em (Geetha et al. 2013), foi proposto um m´etodo para extrair os 25 pontos mais relevantes da trajet´oria de um sinal, calculando os pontos de m´axima curvatura (M CP) e as distancias de cada ponto `a linha do eixo de menor inercia (ALI) as quais foram consideradas como caracter´ısticas temporais. Para a extra¸c˜ao das carac-ter´ısticas locais, calculou-se a distancia de cada dedo ao centro da m˜ao. Dessa forma gerou-se um vetor com informa¸c˜ao global e local do sinal. Os experimentos feitos foram divididos em trˆes categorias: melhor caso, caso m´edio e pior caso, obtendo acur´acias do 100%, 40% e 25% respectivamente.
No entanto, os m´etodos propostos por Faria and Dias (2009), Geetha et al. (2013), Rakun et al. (2013) usaram bases de dados com gestos de movimentos simples e bem feitos sem apresentar muitas varia¸c˜oes em suas trajet´orias o qual restringe e limita um pouco o a realiza¸c˜ao de um gesto pois cada movimento apresenta ligeiras varia¸c˜oes no ˆangulo de vis˜ao e perspectiva. Al´em, a forma de escolher os pontos representativos da trajet´oria foi baseada em que a trajet´oria ´e perfeita o qual n˜ao sempre acontece. Portanto, surgiu a necessidade de propor um novo m´etodo para extrair esses pontos representativos de uma forma mais precisa, diminuindo assim o tempo de processamento e contribuindo com novas caracter´ısticas temporais e globais para distinguir gestos mais desafiantes. Esse m´etodo foi desenvolvido e apresentado nesta diserta¸c˜ao como segunda contribui¸c˜ao principal.
2.3
Considera¸c˜
oes Finais
Neste capitulo, apresentou-se as t´ecnicas para o reconhecimento de gestos, as quais s˜ao divididas em trˆes fases: detec¸c˜ao, rastreamento e reconhecimento. Para cada fase, foram apresentadas as diversas abordagens desenvolvidas. Tamb´em, ressaltou-se a importˆancia dos sensores de profundidade, os quais ajudam reduzindo a complexidade de processos pr´evios como no caso da detec¸c˜ao e rastreamento da m˜ao, al´em de proporcionar novas informa¸c˜oes o que facilita a intera¸c˜ao com o usu´ario.
Cap´ıtulo 3
Referencial Te´
orico
Para facilitar o entendimento da descri¸c˜ao dos m´etodos propostos nessa disserta¸c˜ao, s˜ao descritos os conceitos pertinentes ao reconhecimento de gestos, gestos manuais, extra¸c˜ao de caracter´ısticas e t´ecnicas de aprendizagem de maquina.
3.1
Reconhecimento de Gestos
O termo Reconhecimento de gestos, refere-se coletivamente a todo o processo do se-guimento dos gestos humanos para a sua representa¸c˜ao e convers˜ao em comandos com significado semˆantico (Rautaray and Agrawal 2015).
Os gestos s˜ao expressivos, s˜ao movimentos significativos do corpo que envolvem mo-vimentos f´ısicos dos dedos, m˜aos, bra¸cos, cabe¸ca e face com a inten¸c˜ao de: (i) transmitir informa¸c˜oes significativas ou (ii) interagir com o ambiente. Um gesto pode tamb´em ser percebido pelo ambiente como uma t´ecnica de compress˜ao para transmitir a informa¸c˜ao para outro lugar e ser subsequentemente reconstru´ıda pelo receptor.
Al´em disso, os gestos s˜ao frequentemente espec´ıficos para cada idioma e cultura (Mitra and Acharya 2007). Eles, genericamente, podem ser dos seguintes tipos:
1. Gestos manuais e de bra¸cos: o reconhecimento de poses da m˜ao, l´ınguas de sinais, e aplica¸c˜oes de entretenimento (permitindo aos usu´arios interagir em ambientes virtuais).
2. Gestos de faces e cabe¸ca: alguns exemplos s˜ao (a) Acenando com a cabe¸ca ou
balan¸cando-a. (b) Dire¸c˜ao do olhar. (c) Eleva¸c˜ao das sobrancelhas. (d) Abrir a boca para falar. (e) Piscando os olhos. (f) Dilatando as narinas. (g) Olhar surpreendido, de gosto, de medo, de raiva, de tristeza, de desprezo, etc.
3. Gestos do corpo: Envolvimento do movimento do corpo inteiro, como em: (a) Acom-panhamento dos movimentos de duas pessoas interagindo ao ar livre. (b) An´alise dos movimentos de uma dan¸carina para gerar uma correspondˆencia com a m´usica e os gr´aficos. (c) Reconhecimento do andar humana para reabilita¸c˜ao m´edica e treinamento atl´etico, etc.
3.1.1
Gestos Manuais
Os gestos humanos constituem tipicamente um conjunto de movimentos expressados pelo corpo, face e/ou m˜aos. Destes, os gestos manuais s˜ao muitas vezes os mais expressivos e os mais utilizados. Isto envolve: a) uma postura, configura¸c˜ao est´atica dos dedos sem movimento da m˜ao e b) um gesto, o movimento dinˆamico da m˜ao, com ou sem movimento dos dedos.
Esses gestos podem ser categorizados dentro da seguinte lista:
• Gesticula¸c˜ao: movimentos espontˆaneos das m˜aos e bra¸cos, acompanhados da fala. Estes movimentos espontˆaneos constituem cerca do 90% dos gestos humanos.
• Linguagem como gestos: gesticula¸c˜ao integrada em uma express˜ao falada, substi-tuindo uma palavra particular ou uma frase falada.
• Pantomimas: gestos que descrevem objetos ou a¸c˜oes, acompanhados ou n˜ao da fala.
• Emblemas: sinais familiares tais como ”V”para a vit´oria, ou outros gestos”rudes”
culturais espec´ıficos.
Referencial Te´orico 21
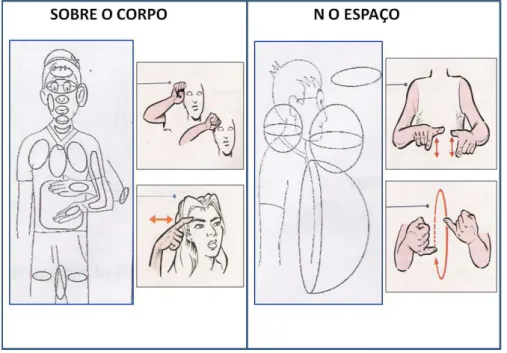
morfemas, s˜ao chamadas de parˆametros (Felipe and Monteiro 2007). Nas l´ınguas de sinais podem ser encontrados os seguintes parˆametros:
1. Configura¸c˜ao das m˜aos: s˜ao formas das m˜aos que podem ser da datilologia (alfabeto manual) ou outras formas executadas pela m˜ao predominante ou ambas m˜aos do emissor ou sinalizado (Figura 3.1).
Figura 3.1: Exemplos de sinais com as mesmas configura¸c˜oes da m˜ao. (Felipe and Monteiro 2007)
2. Ponto de articula¸c˜ao: ´e o lugar onde incide a m˜ao predominante, podendo esta tocar alguma parte do corpo ou estar em um espa¸co neutro vertical (do meio do corpo at´e `a cabe¸ca) e horizontal (`a frente do emissor (Figura 3.2).
Figura 3.2: Lugares onde incide a m˜ao predominante. (Felipe and Monteiro 2007)
Figura 3.3: Exemplos de sinais com e sem movimento. (Felipe and Monteiro 2007)
4. Orienta¸c˜ao: Os sinais podem ter uma dire¸c˜ao e a inversa desta pode significar a id´eia contr´aria. (Figura 3.4).
Figura 3.4: Exemplos de sinais com diferentes orienta¸c˜oes.(Felipe and Monteiro 2007)
Referencial Te´orico 23
Figura 3.5: Exemplos de express˜oes faciais em diferentes sinais.(Felipe and Monteiro 2007)
3.2
Aquisi¸c˜
ao de Dados
A aquisi¸c˜ao de dados ´e o primeiro passo em qualquer m´etodo. Para a obten¸c˜ao da informa¸c˜ao dos gestos manuais, existem diversos dispositivos que podem ser utilizados e ajudam na obten¸c˜ao dos dados como ´e no caso de luvas e sensores de profundidade, entre eles o sensor KinectTM .
3.2.1
Luvas
Os primeiros sistemas baseados em luvas foram desenhados na d´ecada de 1970 e, desde ent˜ao, tˆem sido propostos uma s´erie de desenhos diferentes. Eles surgiram como apoio para as cˆameras simples que s˜ao dispositivos b´asicos na obten¸c˜ao de imagens de cor. Estas podem ser coloridas e/ou com sensores.
No caso de luvas coloridas, Lamberti and Camastra (2011) apresentam um desenho de luvas para um sistema de reconhecimento de gestos manuais em tempo real e Wang and Popovi´c (2009), prop˜oem outro desenho de luvas para uma aplica¸c˜ao de seguimento de m˜aos em tempo real. A Figura 3.6, mostra os desenhos de luvas coloridas propostos anteriormente.
AcceleGlove e Upper limb garment prototype. Na Figura 3.7, se mostram os modelos mencionados anteriormente.
Figura 3.6: Luvas coloridas. a) Luvas usadas por (Lamberti and Camastra 2011). b)Luvas usadas por (Wang and Popovi´c 2009).
Referencial Te´orico 25
3.2.2
Kinect
O KinectTM ´e um sensor RGB-D o qual proporciona imagens de cor e profundidade
sincronizadas. Foi inicialmente usado como um dispositivo de entrada pela Microsoft
para a consola de jogos Xbox 360TM (Figura 3.8). Possui um algoritmo de captura de
movimento humano 3D que permite intera¸c˜oes entre usu´arios e um jogo sem a neces-sidade de gamepads ou de outros dispositivos de intera¸c˜ao, pois em vez disso, o sensor reconhece os gestos do usu´ario e comandos de voz (Han et al. 2013).
Figura 3.8: Inicialmente o Kinect foi desenvolvido para ser usado em jogos no XBOX
360.
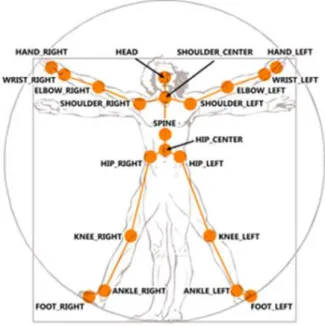
A chave para o reconhecimento de gestos ´e a cˆamera de profundidade do dispositivo que consiste em um projetor de laser infravermelho e uma cˆamera de v´ıdeo infravermelha montada dentro da barra do sensor. A barra do sensor tamb´em possui uma cˆamera de v´ıdeo de cor que fornece os dados de intensidade (RGB cˆamera) (Figura 3.9). Tamb´em cont´em um conjunto de quatro microfones e est´a ligado a uma base motorizada que permite para a barra do sensor ser inclinada para cima e para baixo. Al´em desta in-forma¸c˜ao, tamb´em fornece informa¸c˜ao das articula¸c˜oes do corpo. S˜ao vinte pontos de articula¸c˜ao e podem ser vistos em detalhe na Figura 3.10. A tecnologia foi desenvolvida por PrimeSence e ´e descrito em detalhe nas suas patentes ((Dutta 2012)).
humano-Figura 3.9: Sensor Kinect e suas partes. Imagens de cor e profundidade captadas pelo dispositivo.
Figura 3.10: Pontos das articula¸c˜oes do corpo obtidos pelo Kinect.
computador. Com esse fim, o 1◦ de Fevereiro do 2012, Microsoft lan¸cou o Kit de
Desen-volvimento de Software Kinect (Kinect Software Development Kit-SDK) para Windows1
(Zhang 2012).
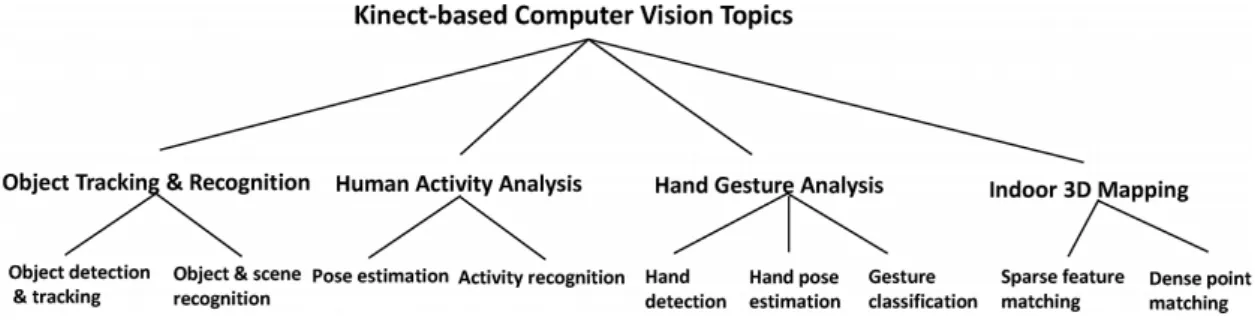
A Figura 3.11, ilustra uma taxonomia estruturada indicando o tipo de problemas de vis˜ao que podem ser resolvidas ou melhoradas por meio do sensor Kinect. Mais especifi-camente, os t´opicos analisados incluem reconhecimento e acompanhamento de objetos, an´alise de atividades humanas, reconhecimento de gestos manuais e mapeamento 3D. A ampla diversidade de t´opicos mostra claramente o impacto potencial do Kinect no
Referencial Te´orico 27
campo da vis˜ao computacional.
Figura 3.11: Taxonomia do tipo de problemas de vis˜ao que podem ser resolvidas ou melhoradas por meio do sensor Kinect.
3.3
Extra¸c˜
ao de Caracter´ısticas
A extra¸c˜ao e sele¸c˜ao de caracter´ısticas ´e um passo muito importante para o processo de reconhecimento. A tarefa b´asica da extra¸c˜ao e sele¸c˜ao de caracter´ısticas ´e encon-trar um grupo de caracter´ısticas importantes, as quais devem representar da melhor forma poss´ıvel a imagem em quest˜ao para utiliza-las durante a etapa da classifica¸c˜ao. A continua¸c˜ao definiremos os descritores usados em nosso modelo.
3.3.1
Scale-Invariant Feature Transform (SIFT)
Um dos m´etodos para extrair pontos invariantes, amplamente utilizado na literatura ´e o algoritmo SIFT (Scale-Invariant Feature Transform). SIFT ´e um m´etodo proposto por Lowe (1999) utilizado em vis˜ao computacional para detectar e descrever caracter´ısticas locais em imagens. SIFT extrai caracter´ısticas invariantes `a escala, rota¸c˜ao e, em certa medida, invariantes `a mudan¸ca de ilumina¸c˜ao e as diferentes vistas de um objeto ou de uma cena, gerando caracter´ısticas com uma elevada probabilidade de ser casadas corretamente.
computacional. Com a apari¸c˜ao do SIFT, este minimizou o custo de extrair as carac-ter´ısticas usando uma abordagem de filtragem em cascata, aplicando opera¸c˜oes custosas somente nos pontos locais que passam um teste inicial.
O algoritmo consiste de quatro etapas distintas para extrair as caracter´ısticas de uma imagem:
• Constru¸c˜ao de um espa¸co de escala: O primeiro passo para detectar os pontos de interesse de uma imagem ´e identificar as localiza¸c˜oes e escalas que se repetem continuamente ao usar diferentes vistas do mesmo objeto. Para detectar essas localiza¸c˜oes, procuram-se caracter´ısticas est´aveis em todas as escalas. Para isso, utiliza-se uma fun¸c˜ao continua conhecida como espa¸co de escala. O espa¸co de escala se define como uma fun¸c˜ao L(x, y, σ) obtida depois de aplicar a fun¸c˜ao Gaussiana G(x,y,σ) com a imagem I(x, y), onde
G(x, y, σ) = 1 2πσ2e
−(x2+y2)/2σ2
. (3.1)
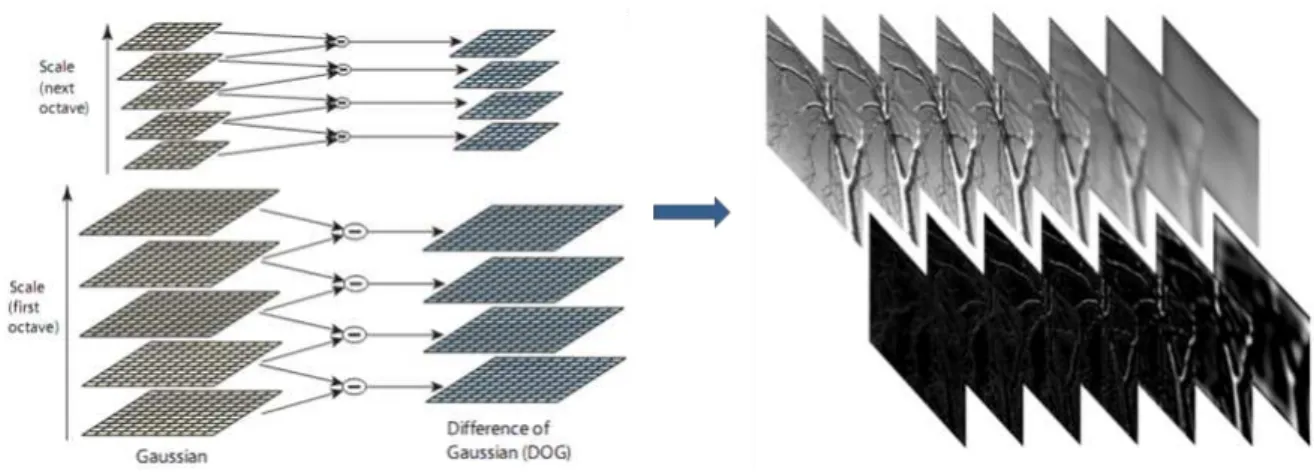
Para que a detec¸c˜ao dos pontos seja eficaz, o algoritmo utiliza a diferencia de Gaussianas (DoG) na imagem. Essa diferencia pode ser obtida das diferencias entre duas escalas vizinhas separadas pelo um fator K constante. A Figura 3.12, mostra um exemplo do exposto anteriormente. A fun¸c˜ao de detec¸c˜ao ´e determinada da seguinte forma:
D(x, y, σ) = (G(x, y, kσ)−G(x, y, σ))∗I(x, y) =L(x, y, kσ)−L(x, y, σ). (3.2)
Referencial Te´orico 29
Figura 3.12: Representa¸c˜ao de uma pirˆamide de diferencias de Gaussianas (DoG) apli-cadas em diferentes escalas para uma imagem.
em imagens com baixa resolu¸c˜ao. Para isso, s˜ao descartados os pontos extremos mediante uma limiariza¸c˜ao.
Figura 3.13: Compara¸c˜ao do pixel com seus oito vizinhos e os nove vizinhos das escalas superior e inferior.
Como a fun¸c˜ao diferencia de Gaussianas (DoG) retorna muitos pontos de interesse nas bordas e esquinas dos objetos, eles s˜ao eliminados para manter a estabilidade dos pontos. Para isso, s˜ao calculadas duas gradientes no ponto de interesse. Ambas perpendiculares entre si. A imagem em torno do ponto de interesse pode ser: 1. Uma regi˜ao plana, se os dois gradientes s˜ao pequenos. 2. Uma borda, se um gradiente ´e grande e o outro ´e pequeno. 3. Uma quina, se ambos os gradientes s˜ao grandes. As quinas s˜ao ´otimas candidatas para serem pontos de interesse, portanto, valores elevados de gradientes s˜ao procurados, sendo rejeitados aqueles pontos de interesse que n˜ao possuem essa caracter´ıstica.
pon-tos sens´ıveis ao ru´ıdo, os que est˜ao localizados nas bordas dos objepon-tos, ´e atribu´ıda uma orienta¸c˜ao para cada ponto caracter´ıstico.
Para cada imagem L(x, y) com uma determinada escala, calcula-se a magnitude do gradiente m(x, y) e a orienta¸c˜ao θ(x, y) usando as diferen¸cas entres pixels:
m(x, y) =p(L(x+ 1, y)−L(x−1, y))2+ (L(x, y+ 1)−L(x, y−1))2, (3.3)
θ(x, y) = arctanL(x, y+ 1)−L(x, y−1)
L(x+ 1, y)−L(x−1, y). (3.4)
• Calculo do descritor dos pontos de interesse: Depois de obter para cada ponto de interesse uma localiza¸c˜ao, orienta¸c˜ao e escala. O seguinte passo ser´a calcular um descritor para as regi˜oes locais da imagem. Para obter o descritor de cada ponto, calculam-se as magnitudes e orienta¸c˜oes dos vizinhos do ponto. Depois disso, para garantir a invariˆancia a orienta¸c˜ao, as coordenadas do descritor e as orienta¸c˜oes do gradiente s˜ao rodados em rela¸c˜ao `a orienta¸c˜ao extra´ıda anteriormente.
Todo esse processo, da como resultado, uma serie de pontos caracter´ısticos esparsos, cada um deles com um descritor final de 128 componentes, os quais s˜ao invariantes `a transla¸c˜ao, escala, orienta¸c˜ao e parcialmente `a mudan¸cas de ilumina¸c˜ao.
3.3.2
Bag-of-Visual-Words
Bag-of-Visual-Words (BoW) ´e um m´etodo amplamente utilizado na ´area de recupera¸c˜ao de informa¸c˜ao na parte de categoriza¸c˜ao de textos. Nesta categoriza¸c˜ao, o documento ´e tratado como um histograma onde o n´umero de ocorrˆencias de cada palavra ´e contado (Mukherjee et al. 2014). Na vis˜ao computacional, um conceito semelhante ´e utilizado, onde uma imagem ´e representada por um histograma que conta o n´umero de ocorrˆencias de certas caracter´ısticas multidimensionais (pontos SIFT, numero de quinas, cores,etc).
Sivic and Zisserman (2003) usaram por primeira vez o modeloBag-of-Visual-Words
Referencial Te´orico 31
que pertencem a um conjunto de vetores de caracter´ısticas chamado vocabul´ario visual oucodebook.
Para implementar o modelo BoW aplicado em vis˜ao computacional requerem-se as se-guintes etapas: identifica¸c˜ao das caracter´ısticas, gera¸c˜ao do vocabul´ario visual e gera¸c˜ao do histograma de palavras visuais.
• Identifica¸c˜ao de caracter´ısticas: antes de gerar o vocabul´ario visual, ´e preciso ex-trair uma s´erie de caracter´ısticas de baixo n´ıvel de todas as imagens. Essas ca-racter´ısticas tamb´em chamadas de pontos caracter´ısticos ou pontos de interesse caracterizam as imagens. Os detectores dos pontos de interesse tentam encontrar caracter´ısticas como bordas, quinas, cor,etc. Ap´os a detec¸c˜ao das caracter´ısticas, cada imagem ´e representada por meio de suas caracter´ısticas locais. Os m´etodos de representa¸c˜ao, descrevem essas caracter´ısticas como vetores num´ericos, chamados descritores de caracter´ısticas. O descritor deve ter a capacidade de lidar com: a intensidade, rota¸c˜ao, escala e outras varia¸c˜oes. Entre os descritores locais, temos, por exemplo, o SIFT e SURF (Speeded Up Robust Features).
• Gera¸c˜ao do vocabul´ario visual: Uma vez caracterizadas todas as imagens, ´e gerado o denominado dicion´ario ou vocabul´ario visual das caracter´ısticas. Este voca-bul´ario ´e chamado decodebook e serve para descrever as imagens usando o mesmo n´umero de caracter´ısticas, agrupando-as em um mesmo grupo chamado “cluster”. Cada elemento que representa a cada grupo ´e de chamado de codeword. A cons-tru¸c˜ao de umcodebook pode ser feito de v´arias maneiras. Tipicamente, os m´etodos mais comumente usados para a gera¸c˜ao de clusters s˜ao algoritmos de agrupamento como oK-means.
• Gera¸c˜ao do histograma de palavras visuais: Ap´os da gera¸c˜ao do vocabul´ario vi-sual, um histograma de palavras visuais e criado contando as ocorrˆencias de cada
codeword. Essas ocorrˆencias s˜ao organizadas em um vetor. Onde cada vetor re-presenta as caracter´ısticas para uma imagem.
Na Figura 3.14 ´e apresentada uma representa¸c˜ao geral do funcionamento do modelo
Figura 3.14: Representa¸c˜ao do funcionamento do modelo Bag-of-Visual-Words (BoW).
3.4
Algoritmos de aprendizagem de maquina
Referencial Te´orico 33
3.4.1
K
-means
O algoritmo de agrupamento K-means (tamb´em chamado de K-M´edias), proposto por MacQueen et al. (1967), ´e um m´etodo que tem como objetivo a parti¸c˜ao de um conjunto de N observa¸c˜oes em K grupos (ou clusters) onde cada observa¸c˜ao corresponde ao grupo mais pr´oximo. ´E um m´etodo muito utilizado e provavelmente ´e o algoritmo de agrupamento mais conhecido.
O objetivo do algoritmo K-means ´e fornecer uma classifica¸c˜ao autom´atica sem a necessidade de supervis˜ao, isto ´e, sem nenhuma pr´e-classifica¸c˜ao existente. Por causa disso, o K-means ´e considerado, como um algoritmo n˜ao supervisionado.
Para simplificar, o algoritmo funciona em cinco passos principais:
1. Escolher os valores para os K centr´oides iniciais: neste passo, se escolhem arbi-trariamente K pontos como os centros iniciais para cada grupo ou cluster.
2. Gera¸c˜ao da matriz de distˆancias: neste passo, calcula-se a distˆancia entre cada ponto e os centr´oides. Aqui, acontece a parte com maior processamento devido ao numero de c´alculos a se realizar, pois ter˜ao que ser calculadas N×K distˆancias.
3. Agrupar os pontos de acordo com a sua distˆancia: nessa parte, os pontos s˜ao agru-pados em rela¸c˜ao aos centr´oides, distribuindo-os ao grupo com quem possuem a menor distancia (maior similaridade). No caso que nenhum ponto seja incorporado a um grupo diferente de onde ele estava, o algoritmo termina.
4. Calcular os novos centr´oides para cada grupo: ap´os agrupar todos os pontos, os valores das coordenadas dos centr´oides s˜ao recalculados pela m´edia de cada atri-buto de todos os pontos que pertencem a esse cluster, procura-se encontrar uma parti¸c˜ao melhor do que a gerada arbitrariamente.
5. Repetir at´e a convergˆencia: Repetir iterativamente desde o passo 2 at´e que os grupos convirjam. Isto ´e, refinando os grupos at´e que n˜ao existam mais altera¸c˜oes neles.
Figura 3.15: Exemplo do funcionamento do algoritmo K-means para trˆes grupos.
3.4.2
Maquinas de Vetores de Suporte
As Maquinas de Vetores de Suporte (Support Vector Machines - SVM) s˜ao usadas na literatura na fase de classifica¸c˜ao dos dados de treinamento, porem ´e importante para o usu´ario conhecer a teoria e o funcionamento dos SVMs.
As SVMs representam as caracter´ısticas do conjunto de dados de entrada como pontos em um espa¸co dimensional (Cortes and Vapnik 1995). Ent˜ao, ´e tra¸cado um hiperplano (ou fronteira de decis˜ao) que separa os pontos atrav´es de margens associadas (linhas paralelas) que determinam a qual lado ou classe cada ponto pertence, esse processo ´e chamado de separa¸c˜ao ou classifica¸c˜ao linear. Os pontos no limite encontrados sobre ou bem pr´oximos as margens entre as classes, s˜ao chamados de vetores de suporte. Um exemplo pode ser visualizado na Figura 3.16, cujos pontos correspondem `as classes 1 e 2 e est˜ao distribu´ıdos no espa¸co de caracter´ısticas.
Referencial Te´orico 35
O objetivo ´e encontrar o hiperplano de separa¸c˜ao ´otima que minimiza o erro de classifica¸c˜ao e generaliza os novos pontos ainda n˜ao conhecidos do conjunto de teste, maximizando a distˆancia entre as margens e os pontos de cada classe. Quando os dados n˜ao s˜ao linearmente separ´aveis, o hiperplano com margem m´axima n˜ao pode ser encontrado. Em tais casos, utiliza-se uma fun¸c˜ao Kernel que calcula os vetores de suporte para cada ponto, e os projeta a um espa¸co de dimens˜oes superiores, onde os dados se tornam linearmente separ´aveis. A Figura 3.17 mostra um exemplo de uma fun¸c˜ao
Kernel φ, que projeta dados do espa¸coR2 a uma dimens˜aoR3 para poder encontrar um hiperplano de separa¸c˜ao. ´E por isso, que uma importante caracter´ıstica do classificador SVM ´e que permite a classifica¸c˜ao n˜ao linear sem requerer explicitamente um algoritmo n˜ao-linear.
Os Kernels mais comuns s˜ao: linear, polinomial, Radial Basis Function (RBF), distˆancia χ2 e triangular. Al´em de escolher o tipo de Kernel tamb´em e importante normalizar os dados. Recomenda-se escalar cada atributo para o intervalo [-1,1] ou [0,1].
As SVMs tˆem sido aplicadas com sucesso em muitos problemas da vida real e em diversas ´areas como: detec¸c˜ao e reconhecimento de faces, reconhecimento de objetos, re-conhecimento de caracteres manuscritos, rere-conhecimento de voz, categoriza¸c˜ao de texto,
etc. (Byun and Lee 2003)
Figura 3.17: Representa¸c˜ao de uma fun¸c˜ao Kernel φ projetando um espa¸co de entrada
3.4.3
Outros m´
etodos de classifica¸c˜
ao
Enquanto o reconhecimento de gestos est´aticos geralmente pode ser realizado atrav´es de modelos de matching, reconhecimento de padr˜oes standard, redes neurais, etc. O problema de reconhecimento de gestos dinˆamicos envolve o uso de t´ecnicas como Hid-den Markov model, Dynamic time warping, Time delay neural networks, Finite state machine,etc.
3.5
Considera¸c˜
oes Finais
Este cap´ıtulo descreveu os conceitos pertinentes para o entendimento da disserta¸c˜ao apresentada. Foi definido o conceito de reconhecimento de gestos, analisando particu-larmente o tipo de gestos manuais, onde se apresentaram as categorias desses gestos fazendo ˆenfase nas l´ınguas de sinais. Tamb´em, foram apresentados os tipos de dispositi-vos mais usados na aquisi¸c˜ao de dados dos gestos manuais: as luvas e o sensor KinectTM
o qual provˆe tanto a informa¸c˜ao RGB-D como a informa¸c˜ao das posi¸c˜oes das articula¸c˜oes do corpo. Logo, explicou-se as defini¸c˜oes dos m´etodos usados para a extra¸c˜ao de carac-ter´ısticas locais e gera¸c˜ao de palavras visuais. Tamb´em foi explicado o algoritmo de agrupamento K-means e o algoritmo de classifica¸c˜ao SVM.