Cybersecurity Paper Compilation FEUP - Fall 2017
Texto
Imagem
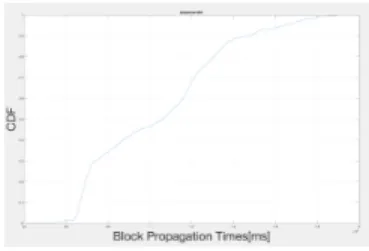
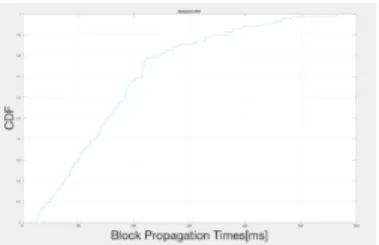
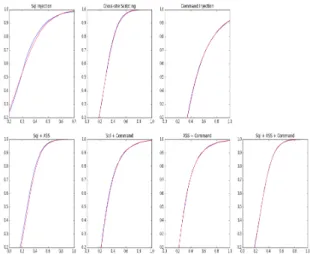
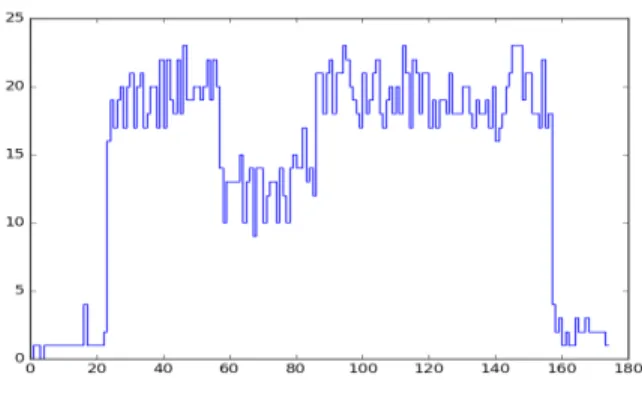



![Fig. 2. Atualizac¸˜ao da RatchetKey. [1, p. 7]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15500780.1045158/28.918.495.819.102.313/fig-atualizac-ao-da-ratchetkey-p.webp)
Documentos relacionados
Este relatório relata as vivências experimentadas durante o estágio curricular, realizado na Farmácia S.Miguel, bem como todas as atividades/formações realizadas
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
No que se refere ao debate entre os relatos de Versão 1 (O governo tem condições de aprovar a proposta de reforma da Previdência) e os relatos de Crítica 1 (Negociação de verbas
A primeira delas diz respeito ao que se denomina pedagogia da alternância. Os cursos do Instituto estão organizados em etapas, cada uma constituída de dois tempos, o tempo escola e
continente europeu, países do norte versus países do sul, verificando se existe uma ou mais dimensões do modelo QH (Empresa, Universidade, Governo e Sociedade) que se
O presente estudo teve como objetivo Validar o Protocolo do Acolhimento Integrativo Humanescente (PAIH) como processo inovador de tecnologia do cuidado em Práticas
Apresento os dados parciais de pesquisa de doutorado, em andamento, com o intuito de refletir sobre o papel da educação na constituição da identidade de mulheres negras, assim
