Processing temporal information in unstructured documents
Texto
Imagem

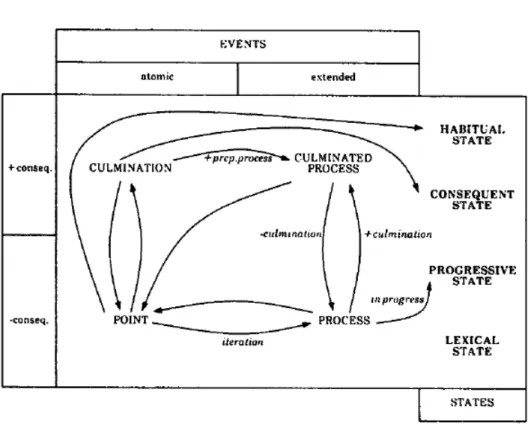
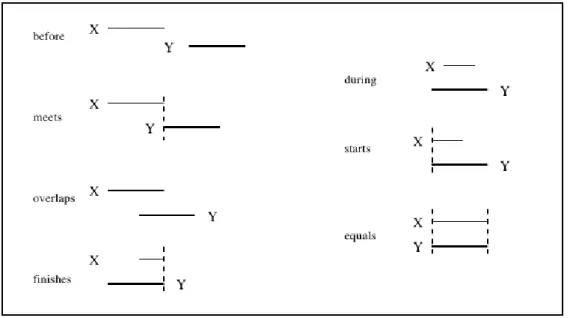
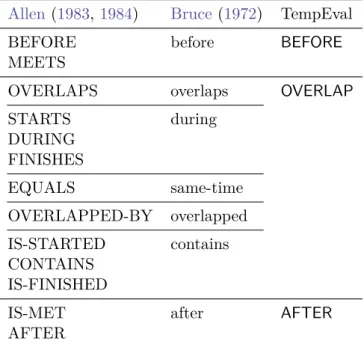
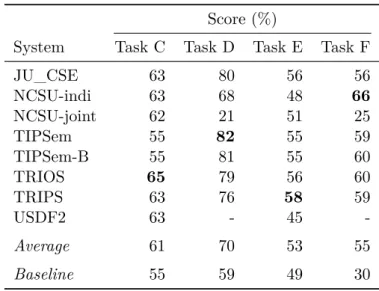

Documentos relacionados
As for the tense relations between epidemiology, policymaking, health planning and management, and social and human sciences in health, I believe it is necessary (without
The present study showed that all of correspondence relations between the categories of temporal variables and performance indicated performance decline for horses that remained
3 shows the relations between the effective indices of the fundamental mode and the second mode versus wave- length, and the relations between the effective indices of the modes in
lateral branch of the supraorbital nerve passes adjacent to the periosteum on the forehead and the temporal branches of the facial nerve are located in the superficial temporal
Aim: to compare the performance of children in auditory temporal processing tests according to different temporal variables such as inter-stimulus interval, stimuli duration and type
Therefore, the aim of the present study is to analyze the correlation between the abilities: temporal ordering and inter-hemispheric transference of the temporal auditory
Furthermore, the frequency pattern test showed the same likelihood of abnormal results in the dyslexia and CAPD groups, which may indicate a correlation between temporal
Results point out to an association between pesticide exposure and changes in the skills of ordering and temporal resolution in the Temporal Auditory Processing, and it was
