Universidade de Lisboa
Faculdade de Letras
Departamento de Linguística Geral e Românica
em associação com
Universidade Técnica de Lisboa
Instituto Superior Técnico
Departamento de Informática
Processing Disfluencies in European Portuguese
Helena Gorete Silva Moniz
Doutoramento em Linguística
(Linguística Educacional)
Universidade de Lisboa
Faculdade de Letras
Departamento de Linguística Geral e Românica
em associação com
Universidade Técnica de Lisboa
Instituto Superior Técnico
Departamento de Informática
Processing Disfluencies in European Portuguese
Helena Gorete Silva Moniz
Tese orientada pelas Professoras Doutoras
Ana Isabel Mata e Isabel Trancoso
Tese especialmente elaborada para a obtenção do grau de doutor em
Linguística (Linguística Educacional)
Esta tese foi realizada com o apoio da Fundação para a Ciência e a
Tecnologia, financiamento comparticipado pelo Fundo Social Europeu
e por fundos nacionais do MCTES, através da bolsa de investigação
com a referência SFRH/44671/2008
Aos meus pais.
Resumo
A presente tese centra-se na análise de disfluências com o duplo objectivo de caracterizar os padrões regulares associados à sua produção e contribuir para o processamento automático de um conjunto mais alargado de eventos designados no inglês “structural metadata events” (Liu et al. (2006b); Ostendorf et al. (2008); Jurafsky and Martin (2009)), nomeadamente, a recu-peração automática de pontuação e maiúsculas em fronteiras de frase, bem como a anotação e filtragem de disfluências. A análise apresentada tem como base o processamento automático de propriedades prosódicas em corpora de natureza distinta.
Para validar a metodologia de extracção automática de propriedades prosódicas, dese-nhada no âmbito deste trabalho, a primeira experiência incide sobre o processamento automá-tico de interrogativas, um tópico ainda por explorar no português. A literatura crítica da área não é consensual relativamente ao contributo de diversas pistas linguísticas, nomeadamente le-xicais e prosódicas, para a identificação de marcas de pontuação. Com o objectivo de verificar se o contributo destas pistas linguísticas varia em função da natureza específica de um corpus ou dos tipos de interrogativas, procedeu-se à análise da distribuição das interrogativas em qua-tro corpora distintos: noticiários televisivos, aulas universitárias, diálogos espontâneos e, para efeitos de comparação, notícias do jornal Público. Os resultados evidenciam uma correlação en-tre a natureza dos corpora e a frequência e distribuição de tipos de interrogativas, permitindo um claro contraste entre diálogos espontâneos e aulas universitárias, por um lado, e noticiários televisivos e notícias do jornal, por outro. Na distribuição dos diferentes tipos, verifica-se que o corpus de aulas universitárias contém sobretudo interrogativas Qu- e tags, enquanto que o de diálogos espontâneos tem uma significativa percentagem de interrogativas de sim/não, e o de notícias televisivas apresenta uma distribuição semelhante entre Qu- e interrogativas de sim/não. Os resultados da detecção automática de interrogativas demonstram que: i) quando são apenas utilizadas pistas lexicais (categoria morfológica, n-gramas de palavras mais fre-quentes, número e posição das palavras na frase, inter alia), apenas as interrogativas Qu- são detectadas vs. ii) quando são adicionadas pistas prosódicas (energia, duração e frequência fun-damental das unidades sílaba e palavra), as interrogativas globais e as tags passam, então, a ser detectadas. Os resultados apontam, assim, para um efeito determinante da combinação de pis-tas linguísticas na identificação das diferentes estruturas interrogativas do Português Europeu (PE). Os resultados desta experiência constituem um dos principais contributos desta tese.
Um segundo conjunto de experiências é dedicado à predição dos sinais de pontuação mais frequentes nos corpora (vírgulas, pontos finais e pontos de interrogação) e à discriminação
en-tre frases, ou constituintes similares a frase (do inglês “sentence-like unit”), e disfluências, num corpus de aulas universitárias. Com recurso à aplicação de acesso público Weka, utilizaram-se vários métodos de aprendizagem, utilizaram-sendo que as Árvores de Decisão e Regressão (CART) evidenciam os melhores resultados.
Para a discriminação destas classes de eventos é determinante o seguinte conjunto de pis-tas linguísticas: contornos de frequência fundamental ( f0), níveis de energia, duração relativa
das unidades de análise e grau de confiança dessas mesmas unidades. Em primeiro lugar, as pistas que mais contribuem para a predição da reposição de fluência a seguir a uma sequência disfluente integram: i) duas palavras contíguas idênticas; ii) subida dos níveis de f0e de
ener-gia na palavra que inicia uma reposição de fluência e um contorno estacionário de f0na palavra
anterior; iii) grau de confiança da palavra que inicia a reposição, superior ao da disfluência pro-priamente dita. Relativamente às pistas associadas à predição de pontos finais, estas incluem: i) contorno descendente na palavra antes de um ponto final; ii) nível estacionário de energia na mesma palavra; iii) duração relativa entre essa palavra e a seguinte; e iv) grau superior de con-fiança em relação à palavra seguinte. Este conjunto de pistas é ilustrativo do comportamento de uma declarativa neutra no PE. Quanto aos pontos de interrogação, estes são caracterizados por dois padrões diferenciados: i) contorno de f0ascendente na palavra antes de um ponto de
interrogação e declive (do inglês “slope”) de energia ascendente nessa e na palavra seguinte; ii) contorno de f0estacionário na palavra antes de um ponto de interrogação e declive de
ener-gia descendente nessa mesma palavra. As vírgulas são o evento que menos depende de uma caracterização prosódica. Nas experiências até agora realizadas para o PE, elas são sobretudo classificadas com base em pistas morfo-sintácticas, não sendo claramente desambiguadas por meio de pistas prosódicas. Este segundo conjunto de experiências constitui-se como um pri-meiro contributo para a sistematização das propriedades linguísticas associadas a sinais de pontuação e a reposição de fluência em PE.
O terceiro conjunto de experiências integrado nesta tese concentrou-se na investigação do comportamento prosódico das disfluências em aulas universitárias e em diálogos espontâneos. Relativamente às aulas universitárias, foram encontrados dois padrões essenciais: i) declives de f0 e de energia estatisticamente significativos entre os contextos adjacentes e a disfluência
propriamente dita; ii) aumentos de f0 e de energia (marcação prosódica por contraste) entre
a disfluência e a reposição da fluência para a maioria das categorias disfluentes, embora com diferentes graus de contraste. Deve notar-se que os aumentos de f0 e de energia entre a
dis-fluência e a reposição da dis-fluência são produzidos por todos os falantes. O primeiro padrão ilustra a forma como o falante sinaliza de forma económica as diferentes regiões, utilizando apenas uma palavra antes e depois da sequência disfluente, e pode ser interpretado como uma estratégia do falante para auxiliar os ouvintes a processar as pistas produzidas num curto in-tervalo de tempo. No segundo padrão, os aumentos mais elevados de f0 estão associados às
categorias pausas preenchidas e apagamentos e os de energia à categoria repetições, o que aponta para combinatórias de parâmetros prosódicos ao serviço de propósitos funcionais distintos.
A estratégia de marcação prosódica por contraste de disfluência para reposição de fluência é realizada por todos os falantes.
Quanto aos diálogos e seguindo a mesma ordem de padrões: i) o contexto adjacente ante-rior a uma disfluência não apresenta diferenças significativas; ii) metade das categorias disflu-entes é produzida com aumentos de f0da disfluência para a reposição da fluência; há aumentos
de energia constantes por falante, mas não por categoria (apagamentos e fragmentos não são produzidos com aumentos de energia). Note-se que a estratégia de marcação prosódica por contraste é realizada por 71% dos falantes. Os padrões temporais das unidades de análise são em média mais breves do que nas aulas.
A comparação inter-corpora aponta efeitos de estilo de fala na distribuição das disfluências, nos padrões temporais e mesmo na marcação prosódica por contraste da disfluência para a reposição da fluência entre aulas universitárias e diálogos. Embora as pausas preenchidas sejam a categoria mais representativa em ambos os corpora, as restantes categorias apresentam uma distribuição distinta. Nas aulas, as sequências complexas (e.g., repetições e substituições utili-zadas para procura/precisão lexical) são mais frequentes do que as repetições, enquanto nos diálogos ambas têm distribuições similares. Nos diálogos, os fragmentos correspondem a mais do dobro dos fragmentos produzidos nas aulas e os apagamentos são residuais. Estas diferen-ças na distribuição das categorias disfluentes podem ser interpretadas em função da natureza dos diálogos em análise, nomeadamente das restrições temporais a que estão sujeitos, com re-curso mais frequente a categorias como repetições e fragmentos e menos a sequências complexas e apagamentos. Os padrões temporais também apontam para a natureza mais dinâmica dos diálogos por comparação com as aulas, com produção de menos palavras, tanto em frases flu-entes como em frases que contêm disfluências. O encadeamento das interacções comunicativas num diálogo está sujeito a restrições temporais, evidentes também na duração dos silêncios, na disfluência e nos próprios contextos adjacentes. Uma vez mais, todas as unidades referidas são mais breves nos diálogos do que nas aulas. Mesmo a estratégia de marcação prosódica por contraste da disfluência para a reposição da fluência está sujeita a variação inter-corpora, sendo esta marcação mais forte nas aulas que nos diálogos. Nas aulas, pistas de f0e de energia
são produzidas por todos os falantes, para a maioria das categorias, tanto para as disfluên-cias como para os contextos adjacentes. O conjunto de padrões apresentado é um contributo para a diferenciação entre estilos de fala, nomeadamente entre fala espontânea e fala preparada não-lida.
Espera-se que esta análise para o português europeu possa contribuir para questões de investigação ainda em aberto relativas ao impacto de pistas linguísticas distintas por tarefas, domínios e línguas.
Abstract
This thesis focuses on the analysis of disfluencies, aiming at a characterization of the regu-lar patterns in their production in European Portuguese, and at contributing towards the fully automatic processing of structural metadata events. This analysis was strongly supported on prosodic feature processing, and involved corpora of very different characteristics.
In terms of structural metadata, one of the main contributions concerns the automatic pro-cessing of interrogatives, an unexplored topic in Portuguese. When using only lexical cues in the automatic detection of interrogatives, mostly wh- questions are detected. By adding prosodic features, yes/no and tag questions are then increasingly identified, showing the ad-vantages of combining both lexical and prosodic features. The corpora analysis of inter-rogatives evidenced that there are domain specific distributional patterns.
Prosodic features also played a dominant role in the discrimination between commas, full-stops, question marks and disfluencies. Our data-driven approach revealed a very distinctive set of prosodic features for each event, going beyond the established evidences for our lan-guage.
In terms of disfluencies, we analyzed university lectures and map-task dialogues, showing that the selection of specific disfluency types is corpus dependent. Pitch, energy and tempo parameters display inter-corpora similarities, showing a cross-speaking style prosodic strat-egy of contrast marking in the disfluency-fluency repair, and also relative tempo symmetries regarding the length of the structured elements of a disfluency and its context. However, in the lectures, pitch and energy cues are given both for the units inside disfluent regions and between these and the adjacent contexts, showing a stronger prosodic contrast marking when compared to dialogues. As for tempo patterns, the length of the structured elements in the dialogues is smaller, reinforcing their dynamic and interactive character.
This analysis will hopefully contribute to the open debate on the relative impact of distinct linguistic features across tasks, domains and languages.
Palavras Chave
Keywords
Palavras chave
Fala, disfluências, pontuação, prosódia e processamento de fala.Keywords
Speech, disfluencies, punctuation, prosody, and speech processing.Acknowledgements
This work is the outcome of many generous contributions and of an overwhelming sup-port, both components shaped me as an intermediary in this process.
I am deeply grateful to my supervisors, Professors Ana Isabel Mata and Isabel Trancoso, for all their support, critics, challenges, and their guidance. Thank you for allowing me to understand the realms of research and to enjoy it. Thank you also for the true friendship that bind us for quite a while.
I am also very grateful to my dissertation committee, Professors Maria do Céu Viana, David de Matos, and Inês Duarte, for their very helpful comments and suggestions. A special thanks to Céu Viana, for being a constant presence in the cooperation process between linguistics (FLUL) and automatic speech processing (INESC-ID, L2F). Much beyond that, I am grateful for her accurate questions along my research path.
To Professors Julia Hirschberg and Nick Campbell, for their scientific generosity in super-vising my visit to Columbia and in guiding my short term scientific mission at Trinity College, respectively. Those experiences will always be valuable lessons along my way.
To Professor Anna Esposito, coordinator of COST-2102 (Cross-Modal Analysis of Verbal and Non-verbal Communication). Under her auspices, I did my first review and had my first professional experience abroad. Thank you for believing and for enriching my research path.
To my colleagues at Spoken Language Laboratory at INESC-ID, thank you for the knowl-edge and the laughs shared. Research and life are much more fun with a generous combination of chocolates and valuable research discussions. Within my colleagues at lab, I should say a special thanks to Fernando Batista, from whom I learned so much, for all the work done in straight cooperation, for his patience, and for our scientific discussions.
Thank you Aida Cardoso, Vera Cabarrão, and Silvana Abalada, for the precise annotations and for helping me with some of the experiments conducted on this thesis.
Thanks, Vera, for making days lighter.
To my beautiful family. For all the sacrifices you did and for demanding just a smile. To Pedro and Tomás, my melopoeia of truth.
Contents
1 Introduction 1
2 State-of-the-art on disfluencies 5
2.1 Typology . . . 6
2.2 Structure of a disfluent sequence . . . 8
2.3 Contrast and parallelism between disfluent regions . . . 9
2.4 Studies on disfluencies for EP . . . 11
2.5 Summary . . . 13
3 State-of-the-art on prosody processing 15 3.1 Prosody . . . 15
3.2 ToBI system . . . 16
3.3 AuToBI . . . 17
3.4 Prosodic and lexical cues for structural metadata . . . 18
3.5 Overview for European Portuguese . . . 19
3.6 Summary . . . 21
4 Corpora 23 4.1 The CORAL corpus . . . 23
4.1.1 Contents of the maps . . . 24
4.1.2 Number and type of speakers . . . 24
4.1.3 Recording conditions . . . 25
4.1.4 Corpus division . . . 25
4.2 The CPE-FACES corpus . . . 25
4.2.1 Recording conditions . . . 26
4.2.2 Subset selection . . . 26
4.3 The ALERT corpus . . . 26
4.3.1 Data collection . . . 27
4.4 The LECTRA corpus . . . 27
4.4.1 Recording conditions . . . 28
4.4.2 Corpus division . . . 28
4.5 The newspaper data from Público . . . 29
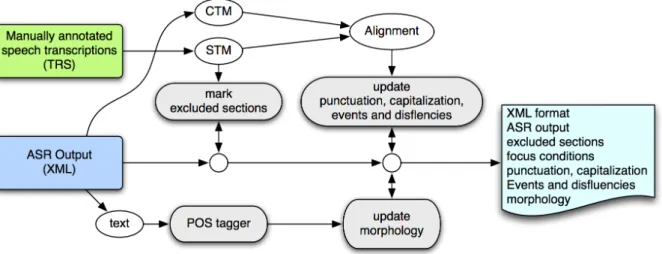
4.6 Corpora annotation . . . 29 4.6.1 Orthographic tier . . . 30 4.6.2 Disfluency tier . . . 30 4.6.3 Syntactic tier . . . 31 4.6.4 Morphological information . . . 32 4.6.5 Inter-transcriber agreement . . . 32 4.7 Corpora alignment . . . 34 4.8 Summary . . . 38
5 Towards an Automatic Prosodic Description 39 5.1 Recognizer output . . . 39
5.2 Adjusting phone boundaries . . . 40
5.3 Marking syllable boundaries and stress . . . 41
5.4 Adjusting word boundaries and silent pauses . . . 41
5.4.1 Impact on acoustic models . . . 43
5.5 Pitch and energy . . . 45
5.6 Integration of prosodic information in transcription files . . . 46
5.7 Extended set of prosodic features . . . 49
5.8 Towards an Automatic ToBI annotation system for EP . . . 49
5.8.1 Preliminary results . . . 50
5.9 Summary . . . 53
6 Analysis of interrogatives: a case-study 55
6.1 Statistical Analysis of Interrogatives . . . 56
6.1.1 Overall frequency of interrogative types in the training corpora . . . 56
6.2 Punctuation experiments for interrogatives . . . 58
6.2.1 Baseline experiments . . . 59
6.2.2 Experiments with lexical and speaker related-features . . . 59
6.2.3 Experiments with prosodic features . . . 60
6.3 Summary . . . 62
7 Automatic structural metadata classification 65 7.1 Data and methods . . . 66
7.2 Predicting structural metadata events . . . 66
7.2.1 Results . . . 67
7.2.2 Most salient features . . . 68
7.3 Summary . . . 70
8 Disfluencies and their fluent perspective 71 8.1 Definitions of fluency . . . 71
8.2 Perceptual test . . . 72
8.3 Discussion . . . 74
8.4 CART experiment . . . 77
8.5 Summary . . . 79
9 Analysis of disfluencies in the LECTRA corpus 81 9.1 Data and methods . . . 81
9.2 Rate of disfluencies per speaker . . . 83
9.3 Rate of disfluencies per lecture and per speaker . . . 84
9.4 Rate of disfluencies per sentence . . . 85
9.5 Patterns in the reparandum . . . 87
9.6 Prosodic analysis . . . 90
9.6.1 Overall prosodic characterization . . . 90 9.6.2 Speaker and type of disfluency . . . 91 9.6.3 Tempo characteristics . . . 93 9.7 Summary . . . 95
10 Analysis of disfluencies in the CORAL corpus 97
10.1 Data and methods . . . 97 10.2 Rate of disfluencies per speaker . . . 98 10.3 Rate of disfluencies per dialogue and per speaker . . . 100 10.4 Rate of disfluencies per sentence . . . 100 10.5 Prosodic analysis . . . 103 10.5.1 Overall prosodic characterization . . . 103 10.5.2 Speaker and type of disfluency . . . 105 10.5.3 Tempo characteristics . . . 107 10.6 Summary . . . 109
11 Speaking style effects in the production of disfluencies 111
11.1 Related work . . . 111 11.2 Inter-corpora distribution . . . 112 11.3 Inter-corpora prosodic analysis . . . 115 11.4 Summary . . . 120
12 Conclusions 121
12.1 Main contributions . . . 122 12.1.1 Automatic processing of prosodic cues . . . 122 12.1.2 Prosodic and lexical cues to interrogative types distinction . . . 122 12.1.3 Prosodic cues to structural metadata classification . . . 123 12.1.4 Prosodic contrast marking of disfluency/fluency repair . . . 124 12.2 Overcoming the limitations of this work . . . 125 12.3 Directions for future research . . . 126
Bibliography 129
A Features in the LECTRA corpus per speaker 141
B Features in the CORAL corpus per speaker 143
List of Figures
2.1 Structure of a disfluent sequence. . . 8
3.1 Example of a TextGrid file annotated with ToBI. . . 17
4.1 Example of CORAL maps. . . 24 4.2 The LECTRA division. . . 29 4.3 AUDIMUS processing pipeline. . . 35 4.4 Corpus-processing. . . 35 4.5 Example of an ASR transcript segment, enriched with reference data. . . 36 4.6 Excerpt of an enriched ASR output with marked disfluencies. . . 37 4.7 Disfluency and other events alignment examples. . . 38
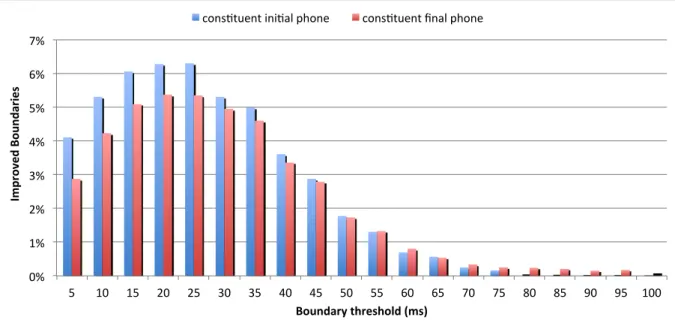
5.1 Example of a file containing the phones/diphones produced by the ASR system. 40 5.2 PCTM of monophones, marked with syllable boundary and stress. . . 42 5.3 Improvement in terms of correct word boundaries, after post-processing. . . 43 5.4 Phone segmentation before and after post-processing. . . 44 5.5 Example of an erroneous segmentation due to a fricated plosive. . . 44 5.6 Improvement of correct word boundaries, after retraining. . . 45 5.7 Pitch adjustment. . . 46 5.8 Workflow of prosodic information. . . 47 5.9 Excerpt of the final XML. . . 48 5.10 Excerpt of an input TextGrid file from LECTRA. . . 51 5.11 Excerpt of an output TextGrid file. . . 52 5.12 Excerpt of a manual output TextGrid file. . . 52
8.1 Median values for disfluencies scores. . . 73
8.2 Tonal scaling of prolongations, filled pauses and repetitions. . . 74 8.3 Felicitous example. . . 75 8.4 Infelicitous example. . . 76 8.5 CART results. . . 78
9.1 Total time and useful time between disfluencies per lecture. . . 85 9.2 Mean of words uttered between disfluent sequences per lecture. . . 86 9.3 Total words and disfluent words per lecture. . . 87 9.4 Sequences of events of the same category. . . 88 9.5 Distribution of disfluencies in the reparandum. . . 89 9.6 Distribution of disfluencies in the reparandum per speaker. . . 89 9.7 Pitch and energy slopes in the LECTRA corpus. . . 91 9.8 Pitch differences per type and speaker in LECTRA. . . 92 9.9 Energy slopes per type and speaker in LECTRA. . . 93 9.10 Duration of all the events in LECTRA. . . 93 9.11 Duration of all the events per disfluency type in LECTRA. . . 94
10.1 Total time and useful time between disfluencies per dialogue. . . 102 10.2 Total words and disfluent words per dialogue. . . 102 10.3 Mean of words uttered between disfluent sequences per dialogue. . . 103 10.4 Pitch and energy slopes in the CORAL corpus. . . 105 10.5 Pitch differences per type and speaker in CORAL. . . 106 10.6 Energy slopes per type and speaker in CORAL. . . 107 10.7 Duration of all the events in CORAL. . . 107 10.8 Duration of all the events per disfluency type in CORAL. . . 108
11.1 Pitch differences between units based on the average for university lectures. . . . 116 11.2 Pitch differences between units based on the average for dialogues. . . 117 11.3 Energy slopes per type and speaker in LECTRA. . . 118 11.5 Duration of the disfluency (in ms), of the adjacent words and silent pauses. . . . 118
11.4 Energy slopes per type and speaker in CORAL. . . 119
List of Tables
2.1 Prosodic properties of disfluent regions. . . 10
4.1 LECTRA corpus. . . 28 4.2 Symbols used in the orthographic tier. . . 30 4.3 Labels used in the disfluency tier. . . 31 4.4 Morphological tag set. . . 33 4.5 Evaluation of the inter-transcriber agreement. . . 34
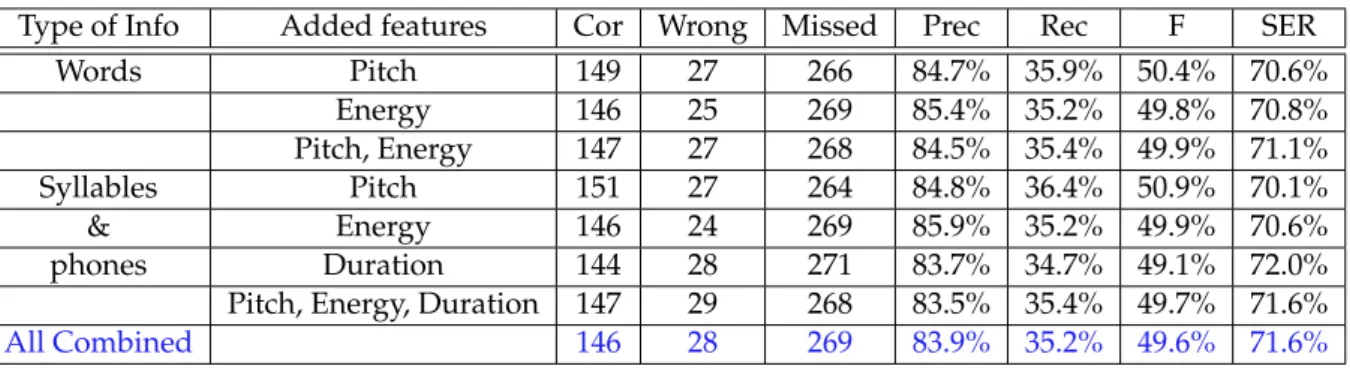
5.1 Extended set of prosodic features. . . 50 5.2 Results for the AuToBI performance on EP data . . . 53
6.1 Overall punctuation marks frequency in the training sets. . . 56 6.2 Overall frequency of interrogative types in training corpora. . . 57 6.3 Automatic and manual classification of interrogative types in the test sets. . . 58 6.4 Baseline results, achieved with lexical features only. . . 59 6.5 Results after re-training with transcriptions and adding acoustic features. . . 60 6.6 Recovering the question mark over the LECTRA corpus, using prosodic features. . 61 6.7 Recovering the question mark over the Alert corpus, using prosodic features. . . . 61
7.1 Corpus properties and number of metadata events. . . 66 7.2 CART classification results for prosodic features. . . 67 7.3 Confusion matrix between events. . . 67 7.4 Top most relevant features, sorted by relevance. . . 69
9.1 Overall characteristics of the LECTRA training subset. . . 82 9.2 Distribution of disfluencies per speaker in LECTRA. . . 84
9.3 Means of fluent and disfluent words per sentence in LECTRA. . . 88 9.4 Ratios per speaker in LECTRA. . . 95
10.1 Overall characteristics of the CORAL training subset. . . 99 10.2 Distribution of disfluencies per speaker. . . 101 10.3 Means of fluent and disfluent words per sentence in CORAL. . . 104 10.4 Ratios per speaker in CORAL. . . 109
11.1 Overall characteristics of lectures and dialogues. . . 113 11.2 Mean words in distinct corpora. . . 114 11.3 Distribution of disfluencies per corpora. . . 115
1
Introduction
Disfluencies are on-line editing strategies with several (para)linguistic functions. They ac-count for a representative portion of our spoken interactions. Everyday we are analists of our own speech and of others, monitoring distinct linguistic and paralinguistic factors in our communications, using disfluencies to make speech a more error-free system, a more edited message, and a more structured system with coherent and cohesive mechanisms.
Disfluencies are an important research topic in several areas of knowledge, namely, Psy-cholinguistics, Linguistics, Automatic Speech Recognition, and more recently in Text-to-Speech conversion and even in Speech-to-Speech translation. Yet, whereas for several languages one can find much literature on disfluencies, for others, such as European Portuguese, the literature is quite scarce.
Detecting and filtering disfluencies is one of the hardest problems in rich transcription of spontaneous speech. Enriching speech transcripts with structural metadata (Ostendorf et al., 2008) is of crucial importance for many speech and language processing tasks, and com-prises several metadata extraction/annotation tasks besides dealing with disfluencies such as: speaker diarization (i.e. assigning the different parts of the speech to the correspond-ing speakers); sentence segmentation (also known as sentence boundary detection); punctu-ation and capitalizpunctu-ation recovery; topic and story segmentpunctu-ation, etc.. Such metadata extrac-tion/annotation technologies are recently receiving increasing attention (Liu et al., 2006b; Juraf-sky and Martin, 2009; Ostendorf et al., 2008), and demand multi-layered linguistic information to perform such tasks. A simple segmentation method, for instance, may rely only on informa-tion about pauses. More complex methods, however, may involve as well lexical cues, dialog acts cues, etc.. In fact, the term structural segmentation encompasses all algorithms based on linguistic information that delimit spoken sentences (units that may not be isomorphic to written sentences), topics and stories.
Inscribed in this research trend, this study will target the analysis of disfluencies in different corpora, aiming at two main objectives: to characterize the regular patterns in the production of disfluencies in European Portuguese, and to contribute towards a fully automatic process-ing of disfluencies, and other structural metadata events. In fact, structural metadata may be almost regarded as a satellite research trend in our work, quickly growing from a side topic to a very prominent one, as the role of prosodic features extended much beyond the scope of
dis-2 CHAPTER 1. INTRODUCTION
fluencies, becoming more and more pervasive in different automatic speech processing tasks in our research group.
One of these first tasks was word boundary delimitation, resulting in a more stable au-tomatic speech recognition system. But the greatest impact was on recovering punctuation marks, specially in what concerned the detection of interrogatives, a hitherto unexplored topic in our language. Therefore, this work cannot be read as a book concerning disfluencies as an exclusive topic, due to the fact that much parallel work had to be done in terms of prosodic feature processing for Portuguese.
This thesis starts with an overview of the core concepts regarding disfluencies and prosody in Chapters 2 and 3, respectively. The corpora and annotation schemas will be presented in Chapter 4. The first chapters after this introductory part cover our main contributions in terms of structured metadata. The integration of prosodic information into the automatic speech recognizer output towards an automatic prosodic description will be described in Chapter 5. Chapter 6 will report our experiments in integrating interrogatives into the punctuation mod-ule, and in evaluating the impact of several linguistic features. Our latest work towards auto-matic structural metadata classification will be described in Chapter 7.
The remaining of the thesis is devoted to disfluencies. They can be described from two main perspectives: as speech errors that disrupt the ideal delivery of speech or as fluent linguistic devices used to manage speech. Chapter 8 will report on two main experiments, a percep-tual test and a CART, which were conducted to validate the assumption of the fluent prosodic properties of disfluencies.
The next two chapters are devoted to a study of the distributional trends and the prosodic patterns of disfluencies, and of their adjacent contexts. Chapter 9 will do this for a corpus of University lectures, and 10 for a corpus of map-task dialogues. Their comparison will be cov-ered in Chapter 11, aiming at verifying speaking style effects in the production of disfluencies. Finally, our conclusions and future work trends will be presented in Chapter 12.
A note to our reader. Much of the work presented in this thesis was already published in international peer-reviewed publications. Therefore, the majority of the chapters are a direct re-flex of those publications. For sake of clarity and ethics, we will list the publications integrated in this thesis and the correspondent chapters:
1. Thomas Pellegrini, Helena Moniz, Fernando Batista, Isabel Trancoso & Ramon Astudillo, “Extension of the LECTRA corpus: classroom LECture TRAnscriptions in European Por-tuguese”, in Speech and Corpora, Belo Horizonte, March 2012. (Chapter 4)
2. Isabel Trancoso, Rui Martins, Helena Moniz, Ana Isabel Mata & Maria do Céu Viana, “The LECTRA Corpus - Classroom Lecture Transcriptions in European Portuguese”, in LREC 2008 - Language Resources and Evaluation Conference, Marrakesh, Morocco, May 2008. (Chapter 4)
3
3. Helena Moniz, Fernando Batista, Hugo Meinedo, Alberto Abad, Isabel Trancoso, Ana Isabel Mata & Nuno Mamede, “Prosodically-based automatic segmentation and punctu-ation”, in Speech Prosody 2010, ISCA, Chicago, USA, May 2010. (Chapter 5)
4. Fernando Batista, Helena Moniz, Isabel Trancoso, Nuno Mamede & Ana Isabel Mata, “Extending Automatic Transcripts in a Unified Data Representation towards a Prosodic-based Metadata Annotation and Evaluation”, In Journal of Speech Sciences, Luso-Brazilian Association of Speech Sciences, vol. 2, n. 2, December 2012. (Chapter 5)
5. Helena Moniz, Fernando Batista, Isabel Trancoso & Ana Isabel Mata, “Analysis of inter-rogatives in different domains”, in A. Esposito, A. M. Esposito, R. Martone, V. Müller & G. Scarpetta (Eds.), Towards Autonomous, Adaptive, and Context-Aware Multimodal In-terfaces: Theoretical and Practical Issues. Third COST 2102 International Training School, Springer Berlin / Heidelberg, series Book series: Lecture Notes in Computer Science, pages 136-148, Caserta, Italy, January 2011. (Chapter 6)
6. Fernando Batista, Helena Moniz, Isabel Trancoso & Nuno Mamede, “Bilingual Experi-ments on Automatic Recovery of Capitalization and Punctuation of Automatic Speech Transcripts”, in IEEE Transactions on Audio, Speech, and Language Processing, IEEE Signal Processing Society, vol. 20, n. 2, pages 474 – 485, doi: 10.1109/TASL.2011.2159594, Febru-ary 2012. (Chapter 6)
7. Helena Moniz, Fernando Batista, Isabel Trancoso & Ana Isabel Mata, “Automatic struc-tural metadata identification based on multilayer prosodic information”, in DISS 2013, the 6th Workshop on Disfluency in Spontaneous Speech, KTH Royal Institute of Technology, Sweden, August 2013. (Chapter 7)
8. Helena Moniz, Isabel Trancoso & Ana Isabel Mata, “Disfluencies and the perspective of prosodic fluency”, in A. Esposito, N. Campbell, C. Vogel, A. Hussain, A. Nijholt (Eds.), Development of Multimodal Interfaces: Active Listening and Synchrony, Springer Berlin / Hei-delberg, Book series: Lecture Notes in Computer Science. DOI: 10.1007/978-3-642-12397-9, April 2010. (Chapter 8)
9. Helena Moniz, Fernando Batista, Isabel Trancoso & Ana Isabel Mata, “Prosodic context-based analysis of disfluencies”, in Interspeech 2012, ISCA, Portland, Oregon, U.S.A., September 2012. (Chapter 9)
10. Helena Moniz, Fernando Batista, Ana Isabel Mata & Isabel Trancoso, “Analysis of disflu-encies in a corpus of university lectures”, in ExLing 2012, August 2012. (Chapter 9)
2
State-of-the-art on dis uencies
Disfluencies, e.g., filled pauses, prolongations, repetitions, substitutions, deletions, inser-tions, characterize spontaneous speech and play a major role in speech structuring (Levelt, 1983; Allwood et al., 1990; Swerts, 1998; Clark and Fox Tree, 2002). They have been studied from different perspectives. For speech processing, the analysis of the regular patterns of those phenomena is crucial (Nakatani and Hirschberg, 1994; Shriberg, 1994). In automatic speech recognition (ASR), their identification accounts for more robust language and acoustic models (Liu et al., 2006a) and even in text to speech synthesis (TTS) these phenomena are being mod-eled to improve the naturalness of synthetic speech (Adell et al., 2008). Moreover, when com-bining ASR and TTS with machine translation to achieve spontaneous speech translation, deal-ing with disfluencies is one of the aspects where substantial improvements are most needed (Tomokiyo et al., 2006). Recent studies in psycholinguistics (e.g., Esposito and Marinaro, 2007) have also targeted the relation of non-verbal communication (gestures) with silent and filled pauses, highlighting the pragmatic and semantic similarities between them. The multifaceted analysis of filled pauses can also be accounted for on an emotion oriented perspective or even on social behavior detection, such as in Benus et al. (2006); Gravano et al. (2011); Benus et al. (2012); Ranganath et al. (2013).
There are two main perspectives in the literature to describe disfluencies: i) as speech errors that disrupt the ideal delivery of speech or ii) as fluent linguistic devices used to manage speech. For a survey on these perspectives, vide Kowal and O’Connell (2008). Disfluencies may be used for different purposes related to, e.g., speech structuring (Clark and Fox Tree, 2002), introduc-ing new information (Arnold et al., 2003) and producintroduc-ing fluent strategies in second language learning (Rose, 1998). The fluent component of these phenomena is still rather controversial, even though Heike (1981) and Allwood et al. (1990) have already pointed out the benefits of disfluencies for communicative purposes, and their contribution for on-line planning efforts.
Although the word disfluencies still exhibit the depreciating connotation linked to error, this term will be used for sake of terminological simplicity and for a contribution for direct comparisons with other studies. For an overview of the historical perspective of the termino-logical aspects associated with positive/negative connotations of the terms and of the realms of linguistic studies vide Erard (2007).
6 CHAPTER 2. STATE-OF-THE-ART ON DISFLUENCIES
specific regularities (Allwood et al., 1990; Eklund and Shriberg, 1998; Vasilescu and Adda-decker, 2007), both segmental and prosodic. As in Allwood et al. (1990), we concentrate on phenomena which indicate "normal spontaneous management of speech": )repairs, (self-)correction, hesitation phenomena, (self-)repetition, (self-)reformulation, substitution and editing.
The experiments conducted in this work will focus on prosodic features and its role for the analysis of disfluencies. Therefore, we will briefly introduce the most used typology, the structure of a disfluent sequence, prosodic contrast and parallelism strategies in the production of disfluencies, and finally an overview of the work done for European Portuguese.
2.1
Typology
As in other areas, terminology regarding disfluent events is rather diverse. However, in the last decades, since the influential work of Shriberg (1994), there is a common-ground typology that speech scientists have been using, promoting direct comparisons of the results achieved in different areas. Shriberg’s typology encompasses the following set of disfluent categories.
(i) Filled pauses - schwa-like quality vowel and/or nasal murmur for European Por-tuguese; for languages such as Spanish it may also be demonstratives, e.g.,“este”.
ou pode estar <%aa> trancada (or it can be <%uh> closed)
(ii) Repetitions- linguistic material repeated e <vocês sabem> vocês sabem que
(and <you know> you know that)
(iii) Substitutions -linguistic material replaced, it usually corresponds to the same mor-phological category.
que, aliás, <sai> saiu na vossa ficha
(Which, alias, <comes out> came out in your test)
(iv) Deletions -abandoned linguistic material, correspond to a complete refresh.
<Significa isto que se nós considerarmos nós temos aqui> Ah, e no fim, e no fim, diz aí que
vocês tinham ainda um stock de cento e cinquenta traves,
(<This means that if we consider that we have here> Oh, and at the end, and at the end says here that you still had a stock of hundred and fifty beams,)
(v) Insertions -linguistic material inserted, usually with repetitions to clarify an idea. <em +que é que> em que medida é que o padrão é útil?
2.1. TYPOLOGY 7
(vi) Editing terms/expressions -overt expressions regarding on-line message editing. <parou quer dizer %aa> acabou o tempo
(<stopped I mean %uh> time ran out)
(vii) Word fragments -linguistic material truncated or incompleted.
<comp-> complementar
(<addi-> additional)
(viii) Mispronunciations -linguistic material pronounced in an erroneous way. pode-nos <servir~> servir pronounced as[S1r’nir]instead of [s1r’vir]
(can <serve~> serve us)
(ix) Complex sequences -linguistic material comprising distinct disfluent categories (e.g., repetitions and substitutions)
O ano passado houve uns colegas vossos da matemática que <fizeram o projecto só qua-> queriam fazer o projecto quase só com strings.
(Last year there were some of your colleagues from math who <did the project only al-> wanted to do the project almost only with strings.)
(x) Others- sometimes simultaneous - phonetic-phonological, lexical, morphological and syntactic.
With the work of Eklund (2004), an overview of prolongations in Sweden and in other lan-guages is described, observing regularities in the segmental properties of the elongated lexical material, which provides evidence for another category per se - prolongations. Two contribu-tions were taken from the mentioned study. Besides the category prolongation, this study will also consider the disfluent events index system proposed by Eklund (2004), establishing corre-lations between the material to be corrected and the correction itself and the order in which the linguistic material is uttered.
(xi) Segmental prolongations -elongated segmental linguistic material. Procedurally, pro-longations can be measured and compared with linguistic material in other locations. In EP, prolongations in the sense of management of speech are often related with specific lexical items, e. g., functional words with elongated vowels in a context where we would expect reduction or elision of those vowels. In our previous studies we have found that we may also have lexi-cal words elongated with two effects: prolongation affecting more than the last syllable of the word and final lengthening corresponding to an interval of more than 1 second.
E= o que é que acontecia? (pronounced as[i:])
8 CHAPTER 2. STATE-OF-THE-ART ON DISFLUENCIES
Figure 2.1: Structure of a disfluent sequence. Figure extracted from Shriberg (1994).
2.2
Structure of a disfluent sequence
As Figure 2.1 shows, disfluencies have a specific structure: reparandum, interruption point, interregnum, and repair of fluency (Levelt, 1989; Nakatani and Hirschberg, 1994; Shriberg, 1994). The reparandum is the region to repair. The interruption point is the moment when the speaker stops his/her production to correct the linguistic material uttered, ultimately, it is the frontier between disfluent and fluent speech. The interregnum is an optional part and it may have silent pauses, filled pauses (uh, um) or explicit editing expressions (I mean, no). The repair is the corrected linguistic material.
It is known that each of these regions has idiosyncratic acoustic properties that distinguish them from each other (Hindle, 1983; Levelt and Cutler, 1983; Nakatani and Hirschberg, 1994; Shriberg, 1994, 2001; Liu et al., 2006a). There is in fact an edit signal process (Hindle, 1983), meaning that speakers signal an upcoming repair to their listeners. The edit signal is mani-fested by means of repetition patterns, production of fragments, glottalizations, co-articulatory gestures and voice quality attributes, such as jitter (perturbations in the pitch period) in the reparanda. Sequentially, it is also edited by means of significantly different pause durations from fluent boundaries and by specific lexical items in the interregnum. Finally, it is edited via pitch and energy increases in the repair.
2.3. CONTRAST AND PARALLELISM BETWEEN DISFLUENT REGIONS 9
2.3
Contrast and parallelism between disfluent regions
As stated before, in a disfluent sequence there are several regions to be considered (Levelt and Cutler, 1983; Nakatani and Hirschberg, 1994; Shriberg, 1994). The possible connections between the reparandum and the repair have been explored from different perspectives in the literature. Since Levelt and Cutler (1983) there is a binary tendency towards the classification of the prosodic properties of (certain) disfluencies as either copying the pitch contour of the reparandum or contrasting the onset of fluency in the repair with the reparandum, by means of increasing f0 and energy. The first strategy is classified as a parallelism between the two
regions and is mainly related to appropriateness (involving, for instance, repetition and inser-tion), whereas the second is classified as contrast marking and is productive with error correc-tions (mostly substitucorrec-tions). The literature is not consensual about this dichotomy. For Plauché and Shriberg (1999), repetitions per se can behave as parallelistic prosodic structures (copying the pitch contour of the reparandum) and also have some degree of contrast (a rising pattern in the repetition is related to an emphasis in the new unit), although not the one reported by Levelt and Cutler (1983). For Savova and Bachenko (2003a,b), distinct categories, such as repetitions and substitutions seem to copy the patterns of their counterparts in the reparandum. Moreover, for the authors there is only partial support for the contrastive nature of substitutions when this is manifested by a higher pitch range. Cole et al. (2005) sustains the parallelistic nature of both repetitions and error corrections and considers parallelism the most frequent strategy.
Table 2.1 shows the overall prosodic characteristics of the distinct regions of a disfluent sequence. In the overview presented by Savova and Bachenko (2003a), there are differences regarding pitch properties between the reparandum and the repair across domains. However, in the majority of the studies targeted in the overview, results point out to higher pitch levels in the repair than in the reparandum.
The contrast and parallelism strategies may also be regarded from a comprehension per-spective (Levelt, 1983; Levelt and Cutler, 1983; Levelt, 1989). In comprehension tasks, the in-formation available in disfluencies can help listeners compensate for disruptions and delays in spontaneous utterances (Brennan and Schober, 2001). Cues are not exclusively the presence of a (certain type of) disfluency, but also the linguistic properties of the structured regions of a disfluent event (Hindle, 1983; Nakatani and Hirschberg, 1994; Shriberg, 1994, 1999, 2001), namely the transition to the repair of fluency, which is of crucial importance for the process of understanding a message. However, the literature does not focus on how those cues may vary accordingly to speaking style due to underlying situational contexts and communicative purposes.
10 CHAPTER 2. STATE-OF-THE-ART ON DISFLUENCIES
Table 2.1: Prosodic properties of disfluent regions. Table extracted from Savova and Bachenko (2003a). “rm” stands for reparandum, “df” for disfluency, “rr” for repair, and “fp” for filled pause.
2.4. STUDIES ON DISFLUENCIES FOR EP 11
2.4
Studies on disfluencies for EP
For European Portuguese, much has been said for silent pauses, filled pauses and prolon-gations (e.g., Moniz (2006); Moniz et al. (2007, 2008a); Veiga et al. (2011)), whereas the other categories are poorly described. Silent and filled pauses in European Portuguese (EP) were first studied by Freitas (1990). Its main focus was the temporal organization of discourse and the syntactic distribution of silent and filled pauses. Based on reading and spontaneous speech data, the author pointed out that, as expected, filled pauses were only uttered in spontaneous speech, making them speech style discriminating events. The syntactic distribution of silent and filled pauses was also accounted as a distinctive feature. Filled pauses were mainly ut-tered within a phrase, while silent pauses had two different patterns: in the reading corpus they were essentially located at syntactically higher positions, i.e., sentences and clauses; and in the spontaneous data at or within phrase boundaries.
In EP the first study to present the relative frequency of different disfluency types, their distribution, the way they may associate with each other, and with different intonational and durational patterns was the one by Moniz (2006). Filled pauses and segmental prolongations have also been detailed in Moniz et al. (2007) and Moniz et al. (2008b).
The definition of filled pauses does not seem to be ambiguous across languages, corre-sponding to elongated segments (in EP, [5:]; [@:]; [1:]; [m:] or one of these vowels with the nasal coda [m:], like [5:m]). There are distinct forms for FPs: (i) an elongated central vowel only; (ii) a nasal murmur only; and (iii) a central vowel followed by a nasal murmur, spelled as aa, mm and aam, respectively, as the quality of the central vowel most often coincides with the one of unstressed /a/. Although a schwa-like quality ([5:] or[@:]), appears to be the most commonly used, in a quick survey of other speech corpora available for EP, we have found, however, some speakers consistently using the neutral vowel[1:] instead, and others both[1:] and[5:], some-times in the same sentence, depending on the quality of the previous word last vowel. Our point here is not to acknowledge that FP vocalizations may be built around central vowels and speakers may differ in their preferences, but that FPs do not appear to behave as other words in the language. In EP,[1]and[5]correspond to reduced forms of different vowels in unstressed position (/i/, /e/, /E/ vs /a/, respectively) and words homophones to aa (the preposition a or the feminine determinant a) do not undergo this type of contextual variation (Moniz, 2006; Moniz et al., 2007).
In EP, as in other languages, final lengthening is a cue for intonational phrase boundaries (Falé, 1995; Mata, 1999; Frota, 2009). These are not the elongations accounted for in this work. The prolongations that we have been studying are mainly elongated functional words (e.g., conjunctions and prepositions, such as [i:], e - and; [k1:], que - that; [d1:], de - of ) that appear in contexts where a strong reduction or a deletion are the expected processes in EP. We also have been analyzing lexical/functional words elongated in sequences with self repairs or with ad-ditional clarifications. Both of them can be automatically identified by comparing the relative
12 CHAPTER 2. STATE-OF-THE-ART ON DISFLUENCIES
durations of the same words or segments in fluent contexts for the same speaker. The length-ening of words ending in a coronal fricative, for instance, could be obtained by prolonging the entire rhyme and/or the fricative only. Most of the time, however, the neutral vowel [1]
is appended to achieve the desired effect. Contrarily to regular sandhi phenomena generally observed within as well as across word boundaries, the final fricative is never realized as[z], but as[Z].
Different disfluency types tend to occur in different prosodic contexts. Prosodic studies for EP (Martins, 1986; Viana, 1987; Falé, 1995; Mata, 1999; Frota, 2000; Vigário, 2003; Frota, 2009) have pointed out the need for at least two levels of phrasing, major and minor intonational phrases (IP). The main distinction is that major IP shows a wider pitch range and bigger final lengthening than the minor IP boundary, indicating (as pointed out by Frota, 2000 and Viana et al., 2007) that these constituents correspond to boundaries with different strength. These two levels of boundary strength are marked with 3 (minor IP) and 4 (major IP), as in ToBI (Silverman et al., 1998).
In our work we have been using break indices 3 and 4 as well. In spontaneous data, the break index 3 seems crucial to account for sentence internal chunks, advantageous for the de-scription of disfluencies, and the way they relate to adjacent prosodic constituents. Moreover, in the joint attempt to propose a ToBI system for European Portuguese (Viana et al., 2007), the authors pointed out the importance of having the break index 3 as well. The use of a com-mon system of annotation is also beneficial for comparison with other languages, aiming at a cross-linguistic validation of the behavior of the so called disfluencies.
Different filled pauses, for instance, tend to occur in different prosodic contexts: (i) aam generally occurs at major intonational phrase boundaries, (ii) aa is most likely found at minor intonational phrase boundaries; (iii) mm occurs mainly in coda position (e.g., [qu1:m], [5:m]). Segmental prolongations are most likely found at internal clause boundaries and at intona-tional phrase boundaries, behaving as aa. Previous studies also pointed out that filled pauses are uttered mainly with plateau contours or with gradual falling contours, whereas segmental prolongations exhibit more complex f0contours.
Silent pauses are consistently used as a cue to either automatically recognize disfluencies (Stolcke et al., 1998) or to analyze their psycholinguistic implications (Levelt, 1989; Clark and Fox Tree, 2002). Our previous study (Moniz et al., 2008a) pointed out that more than 80% of prolongations and filled pauses are followed by silent pauses of a reasonable length, supporting the view that their presence may effectively be used by listeners as a cue to an upcoming delay. The absence of such a pause is strongly penalized as misleading information.
Filled pauses and prolongations have also been targeted by Veiga et al. (2011, 2012) with two main goals. Firstly, automatically detect both disfluent categories in a broadcast news corpus; secondly, differentiate between speech styles, meaning, spontaneous from prepared speech in the same domain. The authors used a combined set of segmental features in their
2.5. SUMMARY 13
experiments to perform both tasks.
Disfluencies have also been targeted in a stuttering perspective by Cruz (2009). Melodic patterns of stutters vs. non-stutters were presented, pointing out that stutters produce more tonal events per intonational phrase, being those constituents shorter than the ones produced by non-stutters, and also that such tonal events are distinct from the non-stutters, characterized by a preference for boundary tones !H% rather than L% and for simple tonal pitch accents.
2.5
Summary
This chapter adressed the working-definitions of several core aspects regarding disfluen-cies: most used typologic categories of disfluencies, structural regions of a disfluent sequence, and prosodic strategies applied to disfluency-fluency repair. An overview of the European Portuguese studies focusing on disfluencies was also given.
3
State-of-the-art on prosody
processing
Prosody will be a pervasive concept throughout this work. Two main perspectives will be reviewed: the first one is related to the prosodic characterization of structured metadata events and the second one is centered in the automatic modeling of prosodic properties. Therefore, this chapter will focus on the core aspects associated with prosodic parameters, the prosodic annotation system adopted and its automatic counterpart, and will end with an overview of studies conducted for European Portuguese.
3.1
Prosody
A working-definition of prosody is provided by Shattuck-Hufnagel and Turk (1996): “we specify prosody as both (1) acoustic patterns of F0, duration, amplitude, spectral tilt, and segmental reduction, and their articulatory correlates, that can be best accounted for by reference to higher-level structures, and (2) the higher-level structures that best account for these patterns ... it is ‘the organizational structure of speech’.” (Shattuck-Hufnagel & Turk, p. 196)
In the above definition, prosody has two components: firstly, the acoustic correlates and, secondly, their relation to the organizational structure of speech. Detailed analysis have been conducted to describe the properties of the prosodic constituents and their functions (e.g., Liber-man (1975); Bruce (1977); Pierrehumbert (1980); Pierrehumbert and Hirschberg (1990); Beck-man and Pierrehumbert (1986); Nespor and Vogel (1986); Bolinger (1989); Gussenhoven (2004); Ladd (1996, 2008)). Since the focus of this thesis is on the acoustic correlates of structural meta-data events, we will briefly comment the higher-level structures described in the literature.
In the Intonational Phonology framework, based on the study of Pierrehumbert (1980) and much subsequent work (e.g., Beckman and Pierrehumbert (1986); Pierrehumbert and Beck-man (1988); Pierrehumbert and Hirschberg (1990); BeckBeck-man et al. (2005)), inspired in LiberBeck-man (1975) and Bruce (1977), the prosodic structure involves a hierarchy of prosodic constituents, encompassing from mora or syllable, the smallest constituents, to intonation phrase or utter-ance, the largest ones. This hierarchical structure vary in what regards intermediate levels, namely the intermediate intonational phrase (Selkirk, 1984; Beckman and Pierrehumbert, 1986;
16 CHAPTER 3. STATE-OF-THE-ART ON PROSODY PROCESSING
Nespor and Vogel, 1986; Gussenhoven, 2004; Nespor and Vogel, 2007; Ladd, 2008; Frota, 2012). Although the levels of the prosodic structure may vary within the framework and languages may display different prosodic constituents Beckman and Pierrehumbert (1986); Pierrehumbert and Beckman (1988); Jun (2005), cross-language studies point out to two important strengths of the framework: the hierarchical organization of speech and the knowledge that allows the assessment of cross-language similarities and differences.
Cross-language studies have also investigated the acoustic correlates that better character-ize sentence-like units boundaries (Vassière, 1983; Vaissière, 2005). Features that are known to characterize higher-level structures, such as pause at the boundary, pitch declination over sen-tences, post-boundary pitch and energy resets, pre-boundary lengthening, and voice quality changes, are amongst the most salient cues to detect sentence-like units. This set of prosodic properties has been used in the literature to successfully detect punctuation marks and disflu-encies. By studying the acoustic correlates of sentence-like units and disfluencies in Portuguese we expect to detect higher-level structures of speech as intonational phrases and utterances.
3.2
ToBI system
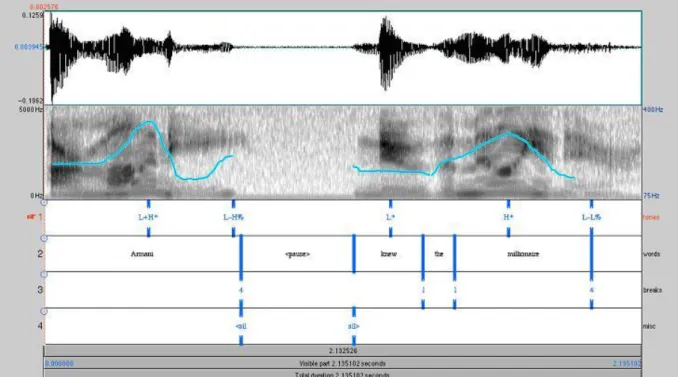
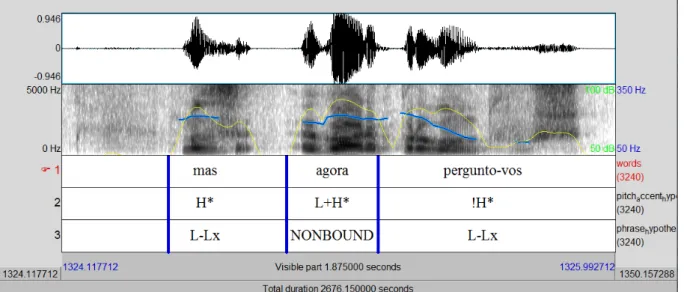
The seminal work of (Pierrehumbert, 1980) inspired the creation of an annotation system called ToBI (Silverman et al., 1998; Pitrelli et al., 1994), which stands for Tones and Break In-dices. ToBI is one of the most well-known systems used to describe intonation across languages and dialects (for an overview on the original ToBI, vide Beckman et al. (2005), and for intona-tional comparisons between languages, vide Jun (2005)). ToBI contains 4 tiers: tones, breaks, orthographic, and miscellaneous tiers, as illustrated in Figure 3.1. The tone tier, displaying the intonation contours decomposed into high (H) and low (L) tones, stems from the work of Pierrehumbert (1980); Beckman and Pierrehumbert (1986) and also from the work of Ladd (1983) for the analysis of downstep (!). The break tier, with the analysis of perceived disjuncture between words, is built upon the work of Price et al. (1991).
The tone tier, as established for Standard American English, consists of pitch accents (as-sociated with accented syllables) and boundary tones (as(as-sociated with phrase boundaries). Phrase boundaries correspond to two types: intermediate phrase and intonational phrase boundaries. The intermediate phrase consists of at least one pitch accent and a phrase accent (H-, !H-, and L-, marked with the diacritic “-”), used to describe the pitch movement between the last pitch accent and the phrase boundary. The intonational phrase boundary is formed by one or more intermediate phrases. The intonational phrase boundary has an additional bound-ary tone (marked with the diacritic “%”), use to describe a final pitch movement (either H% or L%). Pitch accents can either be simple or bitonal (e.g., L*, H*, L+H*, L*+H). The star * diacritic marks the tone associated with the accented syllable and the diacritic “!” is used whenever the H pitch range is compressed, resulting in a !H label.
3.3. AUTOBI 17
Figure 3.1: This example was extracted from the AME ToBI transcription course vide http://anita.simmons.edu/~tobi/iap.htm
Break indices are degrees of perceived disjuncture between words, ranging from 0 to 4. The level 0 means the strongest link between words and it marks a high co-articulation between two consecutive words, e.g., in European Portuguese it would be the index for a sequence like [’tESt 5’gOr5](test know) with the ellipsis of the schwa vowel [’tESt 5’gOr5] instead of [’tESt1 5’gOr5]. The level 1 is the common index between two connected words within a phrase. The level 2 stands for dubious interpretations (either perceived as a break 1, but displaying tonal and lengthening cues; or perceived as 3 or 4, but without phrase accent/ boundary tone). The levels 3 and 4 represent intermediate intonational phrase boundaries and intonational phrase boundaries, respectively.
The miscellaneous tier is used for comments (e.g., silence, laughter, disfluencies, inter alia) and those should be temporally delimited.
3.3
AuToBI
Automatic ToBI annotation system (AuToBI) was done for Standard American English (SAE) by Rosenberg (2009, 2010). AuToBI is a publicly available tool1, which detects and
classi-fies prosodic events following SAE intonational patterns. The AuToBI relies in the fundamen-tals of the ToBI system, meaning, it predicts and classifies tones and break indices.
18 CHAPTER 3. STATE-OF-THE-ART ON PROSODY PROCESSING
AuToBI is a modular architecture, which allows for the performance of six tasks separately and provides English trained models for spontaneous and read speech (for further details, vide Rosenberg (2009) and references therein). The six tasks correspond to: i) detection of pitch accents; ii) classification of pitch accent types; iii) detection of intonational phrase boundaries; iv) detection of intermediate phrase boundaries; v) classification of intonational phrase ending tones; and vi) classification of intermediate phrase ending tones. In all tasks raw and speaker z-score normalization2for pitch and energy are used.
Each task relies on different sets of features in order to capture the acoustic properties of different regions of analysis. Thus, Pitch accent detection is performed with mean, minimum, maximum, standard deviation, and z-score of the maximum of raw and speaker normalized pitch and intensity contours and their slopes, in order to capture pitch and energy excursions in a word-based context window of 8 words (zero, one, two previous and following words). Spectral information regarding the energy contained in the frequency region between 2-20 bark and the ratio of the energy in this frequency region to the total energy of the frame is also used. Pitch accent classification focuses mainly in the pseudo-syllable with the maximum intensity values in a word and in its duration. The syllable contour is capture with the same features used in pitch accent detection but now for the highest syllable in the word.
Phrase detection tasks (for both intermediate and intonational phrases) are associated with silence, pre-boundary lengthening, and pitch and energy resets. To account for these, all the features used in pitch accent detection are applied, but now the unit is the word previous to a possible boundary. Additionally, differences between two consecutive words are calculated and the duration of the word prior to a possible boundary is also measured.
Phrase boundary tones classification is done simultaneously to account for both intermediate and intonational phrases. Based on the assumption that every intonational phrase boundary is also an intermediate phrase boundary, they are merged into a single unit - the intonational phrase boundary, resulting in the fixed set of the following labels: L-L%, L-H%, H-L%, !H-L%, H-H%. The same features used for the phrase detection are required, but on this specific task they are extracted from the final 200 ms of phrase final words.
The accuracy values of the tasks range from a minimum of 54.95% in the classification of intonational phrase boundary tones to a maximum of 93.13% for intonational phrase boundary detection (values reported in Rosenberg (2010)).
3.4
Prosodic and lexical cues for structural metadata
Recovering punctuation marks, capitalization and disfluencies are three relevant MDA (Metadata Annotation) tasks. The impact of the methods and of the linguistic information on
2z= q−m
3.5. OVERVIEW FOR EUROPEAN PORTUGUESE 19
structural metadata tasks has been discussed in the literature. Kim and Woodland (2001); Chris-tensen et al. (2001) report a general HMM (Hidden Markov Model) framework that allows the combination of lexical and prosodic clues for recovering full stops, commas and question marks. A similar approach was also used by Liu et al. (2006b); Gotoh and Renals (2000); Shriberg et al. (2000) for detecting sentence boundaries. Kim and Woodland (2001) also combines 4-gram lan-guage models with a CART (Classification and Regression Tree) and concludes that prosodic information highly improves punctuation generation results. A Maximum Entropy (ME) based method is described by Huang and Zweig (2002) for inserting punctuation marks into sponta-neous conversational speech, where the punctuation task is considered as a tagging task and words are tagged with the appropriate punctuation. It covers three punctuation marks: comma, full stop, and question mark; and the best results on the ASR output are achieved by combining lexical and prosodic features. A multi-pass linear fold algorithm for sentence boundary detec-tion in spontaneous speech is proposed by Wang and Narayanan (2004), which uses prosodic features, focusing on the relation between sentence boundaries and break indices and duration, covering their local and global structural properties. Other recent studies have shown that the best performance for the punctuation task is achieved when prosodic, morphological, and syn-tactic information is combined (Liu et al., 2006b; Ostendorf et al., 2008; Shriberg et al., 2009; Favre et al., 2009; Batista et al., 2012a).
Much of the features and the methods used for sentence-like unit detection may be applied in disfluency detection tasks. What is specific of the latter is that disfluencies have a specific structure, as previously described in Chapter 2. It is known that the reparandum, the interrup-tion point, the interregnum, and the repair may display idiosyncratic acoustic properties that distinguish them from each other, inscribed in the edit signal theory (Hindle, 1983), meaning that speakers signal an upcoming repair to their listeners. The signal is edited by means of pat-terns of repetitions, production of fragments, glottalizations, co-articulatory gestures and voice quality attributes, such as jitter (perturbations in the pitch period) in the reparanda. Sequentially, it is also edited by means of significantly different pause durations from fluent boundaries and by specific lexical items in the interregnum. Finally, it is edited via f0 and energy contrastive
or parallelistic patterns in the repair. The main focus is thus to detect the interruption point or the frontier between disfluent and fluent speech. Based on the edit signal theory, Nakatani and Hirschberg (1994); Shriberg (1997, 1999) used CARTs to identify different prosodic features of the interruption point. Kim and Woodland (2004); Liu et al. (2006b) used features based on previous studies and added language models to predict both prosodic and lexical features of sentence boundaries and disfluencies.
3.5
Overview for European Portuguese
Researchers working on Portuguese intonation, on laboratory and spontaneous speech, gathered in 2007 with the aim of combining efforts towards a Portuguese_ToBI system,
search-20 CHAPTER 3. STATE-OF-THE-ART ON PROSODY PROCESSING
ing for “a unified transcription for some aspects of Portuguese intonation”. The results were built upon several previous studies (e.g., Viana 1987; Mata 1999; Frota 2000, 2002; Viana et al. 2003; Vigário 2003; Falé 2005) and were summarized in Viana et al. (2007) at the Workshop on the Intonation in Ibero-Romance, PaPI 2007. The core results are mostly related to intonational properties of sentence-form types (declaratives, interrogatives, imperatives, parentheticals) in several varieties of Portuguese (in the Lisbon variety; in the Northern variety spoken in Braga; and in the Brazilian variety spoken in São Paulo); to intonational properties of discourse func-tions in European Portuguese; and to prosodic levels relevant for phrasing in Portuguese. We will describe the most salient intonational and phrasing properties in line with the present work.
Regarding sentence-form types, in EP, declaratives are the most studied sentence type (e.g., Viana, 1987; Vigário, 1995; Falé, 1995; Cruz-Ferreira, 1998; Frota, 2000; Viana et al., 2007). The intonational contour generally associated with a declarative is a falling one, expressed as a prenuclear H* (in the first accented syllable), a nuclear bitonal event H+L*, and a boundary tone L%. A similar intonational contour is found in wh- questions3. By contrast, the contour associated with a yes/no question is a rising one, expressed either as H* H+L* H% or (H) H+L* LH% (the latter proposed by Frota, 2002). Mata (1990) also observes falling contours in yes/no questions in spontaneous speech. As for alternative questions, only Viana (1987) and Mata (1990) have described them prosodically. The first intonational unit is described with the contour rising-fall-rising, whereas the second unit exhibits a rising-fall contour. The prosody of tags is still studied too sparsely in EP (Mata 1990, for high school lectures, and Cruz-Ferreira (1998) for laboratory speech). For Cruz-Ferreira (1998), the tags are described with falling contours, while for Mata (1990), these structures are associated with rising ones. Furthermore, Falé (2005); Falé and Faria (2006) offer evidence for the categorical perception of intonational contrasts between statements and interrogatives, showing that the most striking clue associated with the perception of interrogatives is pitch range (the H% boundary tone has to be higher than 2 semitones), whereas declaratives are mostly perceived based on final falls in the stressed syllable. The phonetic features of imperative intonation (encompassing imperatives, orders and requests) are also targeted in Falé and Faria (2007). Higher pitch global values and a pitch contour characterized by an initial rise from the onset to the f0peak and a
falling movement of large amplitude towards the end of the sentence are the two most salient features to phonetically describe imperatives.
As for prosodic phrasing, Frota (2000); Viana et al. (2007) consider two different levels of phrasing equating both of them to the intonational phrase (IP): the major IP and the minor IP, in line with Ladd (1996). Both minor and major IPs are marked with breaks 3 and 4, respectively, and the diacritics “-” and “%” are used for boundary tones to represent the different strengths of the IP. See also Frota (2009) for a reanalysis of this proposal, ascribing both levels to the IP and marking both as “%”.
3.6. SUMMARY 21
3.6
Summary
This chapter focused on the working-definitions of prosody, on the overview of the core aspects of the original ToBI system, and also its automatic application, the AuToBI. Finally, an overview of studies conducted for European Portuguese was also presented.