UNIVERSIDADE FEDERAL DA PARAÍBA
CENTRO DE CIÊNCIAS EXATAS E DA NATUREZA
DEPARTAMENTO DE INFORMÁTICA
EDUARDO FREIRE SANTANA
SEGMENTAÇÃO NÃO SUPERVISIONADA DE IMAGENS DE SENSORIAMENTO REMOTO POR MINIMIZAÇÃO DA ENTROPIA CRUZADA
EDUARDO FREIRE SANTANA
SEGMENTAÇÃO NÃO SUPERVISIONADA DE IMAGENS DE SENSORIAMENTO REMOTO POR MINIMIZAÇÃO DA ENTROPIA CRUZADA
Dissertação apresentada em cumprimento às exigências do Programa de Pós-Graduação em Informática da Universidade Federal da Paraíba como requisito parcial para a obtenção do título de Mestre.
Orientador: Leonardo Vidal Batista Coordenadora: Tatiana Aires Tavares
S232s Santana, Eduardo Freire.
Segmentação não supervisionada de imagens de
sensoriamento remoto por minimização da entropia cruzada / Eduardo Freire Santana.- João Pessoa, 2012.
87p. : il.
Orientador: Leonardo Vidal Batista Coorientadora: Tatiana Aires Tavares Dissertação (Mestrado) - UFPB/CI
1. Informática. 2. Segmentação não supervisionada de imagens. 3. Modelos estatísticos. 4. Informação. 5. Entropia. 6.Sensoriamento remoto.
A meus pais, por todo o apoio que recebi na formação da minha educação.
AGRADECIMENTOS
Agradeço a meu orientador, o professor Leonardo, pela contribuição na minha formação e por ter me apresentado problemas interessantes, não só durante o período de mestrado, mas também durante a graduação.
Ao professor Richarde, por ter dado direção ao trabalho e ter proporcionado melhor entendimento da área de sensoriamento remoto.
A toda minha família, pais, irmãos, avós e tios, pelo apoio e pela torcida. Aos amigos Roger, Adriano, Yuri, Bruno e Amanda, pela companhia e pelo interesse sobre o andamento do trabalho.
SUMÁRIO
LISTA DE FIGURAS ... 13
LISTA DE TABELAS ... 15
LISTA DE ALGORITMOS ... 17
RESUMO... 19
ABSTRACT ... 21
1 INTRODUÇÃO ... 24
1.1 JUSTIFICATIVA ... 25
1.2 OBJETIVO ... 26
2 FUNDAMENTAÇÃO TEÓRICA ... 28
2.1 CLASSIFICAÇÃO SUPERVISIONADA E NÃO SUPERVISIONADA ... 28
2.2 TEORIA BAYESIANA DE DECISÃO ... 29
2.3 ESTIMAÇÃO DE UMA FUNÇÃO DENSIDADE DE PROBABILIDADE ... 30
2.4 ENTROPIA E MODELOS ESTATÍSTICOS ... 31
2.5 K-MÉDIAS ... 33
2.6 INICIALIZAÇÃO DE SEMENTES A PARTIR DO MÉTODO MAX-MIN ... 35
2.7 TRANSFORMADA WATERSHED ... 36
2.8 PROCESSAMENTO DIGITAL DE IMAGENS EM SENSORIAMENTO REMOTO ... 39
2.9 SISTEMAS DE INFORMAÇÃO GEOGRÁFICA ... 40
2.9.1 SPRING ... 42
2.10 TRABALHOS RELACIONADOS ... 42
3 MATERIAIS E MÉTODOS ... 46
3.1 BANCO DE DADOS UTILIZADO PARA TESTES ... 46
3.2 IMAGENS TEMÁTICAS ... 48
3.3 SEGMENTAÇÃO POR MINIMIZAÇÃO DA ENTROPIA CRUZADA ... 50
3.3.1 Segmentação Pixel a Pixel ... 52
3.3.2 Segmentação por Região ... 53
3.4 MEDIDAS UTILIZADAS NA AVALIAÇÃO DE DESEMPENHO ... 55
4 RESULTADOS ... 60
4.1 SEGMENTAÇÃO DAS IMAGENS DO BANCO ... 60
4.2 SEGMENTAÇÃO DOS DETALHES DE IMAGEM ... 76
5 DISCUSSÃO E CONCLUSÕES... 82
LISTA DE FIGURAS
FIGURA 1 - EXEMPLOS DE ESTIMAÇÃO PARAMÉTRICA ... 30
FIGURA 2 - EXEMPLOS DE ESTIMAÇÃO NÃO PARAMÉTRICA ... 31
FIGURA 3 - DISTRIBUIÇÕES ESTIMADAS PARA ÁREA URBANA E HIDROGRAFIA ... 33
FIGURA 4 - ILUSTRAÇÃO DO K-MÉDIAS ... 35
FIGURA 5 – IMAGEM E IMAGEM GRADIENTE ... 37
FIGURA 6 - TOPOGRAFIA DA IMAGEM GRADIENTE ... 37
FIGURA 7 - ILUSTRAÇÃO DA TRANSFORMADA WATERSHED ... 38
FIGURA 8 - ESQUEMA GERAL DOS MÓDULOS DE UM SIG ... 41
FIGURA 9 – CENÁRIO VISTO EM DIFERENTES BANDAS ... 48
FIGURA 10 - INTERPOLAÇÃO DE VALORES NO HISTOGRAMA ... 51
FIGURA 11 - SUAVIZAÇÃO DA FUNÇÃO R ... 52
FIGURA 12 - REDUÇÃO DA ENTROPIA CRUZADA ... 54
FIGURA 13 - SEGMENTAÇÃO DA IMAGEM 01 ... 61
FIGURA 14 - SEGMENTAÇÃO DA IMAGEM 02 ... 62
FIGURA 15 - SEGMENTAÇÃO DA IMAGEM 03 ... 63
FIGURA 16 - SEGMENTAÇÃO DA IMAGEM 04 ... 64
FIGURA 17 - SEGMENTAÇÃO DA IMAGEM 05 ... 65
FIGURA 18 - SEGMENTAÇÃO DA IMAGEM 06 ... 66
FIGURA 19 - SEGMENTAÇÃO DA IMAGEM 07 ... 67
FIGURA 20 - SEGMENTAÇÃO DA IMAGEM 08 ... 68
FIGURA 21 - SEGMENTAÇÃO DA IMAGEM 09 ... 69
FIGURA 22 - SEGMENTAÇÃO DA IMAGEM 10 ... 70
FIGURA 23 - SEGMENTAÇÃO DA IMAGEM 11 ... 71
FIGURA 24 - SEGMENTAÇÃO DA IMAGEM 12 ... 72
FIGURA 25 - SEGMENTAÇÃO DA IMAGEM 13 ... 73
FIGURA 26 - SEGMENTAÇÃO DA IMAGEM 14 ... 74
FIGURA 27 - SEGMENTAÇÃO DA IMAGEM 15 ... 75
FIGURA 28 - SEGMENTAÇÃO DO DETALHE DE IMAGEM 01 ... 77
FIGURA 29 - SEGMENTAÇÃO DO DETALHE DE IMAGEM 02 ... 78
FIGURA 30 - SEGMENTAÇÃO DO DETALHE DE IMAGEM 03 ... 79
LISTA DE TABELAS
TABELA 1 - RELAÇÃO ENTRE REDUÇÃO DA ENTROPIA E AUMENTO DA
CONCORDÂNCIA ... 55 TABELA 2 - CONCORDÂNCIA OBSERVADA E ÍNDICE KAPPA ... 60 TABELA 3 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 01 ... 61 TABELA 4 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 02 ... 62 TABELA 5 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 03 ... 63 TABELA 6 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 04 ... 64 TABELA 7 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 05 ... 65 TABELA 8 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 06 ... 66 TABELA 9 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 07 ... 67 TABELA 10 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 08 ... 68 TABELA 11 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 09 ... 69 TABELA 12 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 10 ... 70 TABELA 13 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 11 ... 71 TABELA 14 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 12 ... 72 TABELA 15 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 13 ... 73 TABELA 16 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 14 ... 74 TABELA 17 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NA IMAGEM 15 ... 75 TABELA 18 - CONCORDÂNCIA OBSERVADA EM DIFERENTES MÉTODOS DE
SEGMENTAÇÃO... 76 TABELA 19 - CONCORDÂNCIA OBSERVADA E ÍNDICE KAPPA PARA
DETALHES DE IMAGEM ... 76 TABELA 20 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
TABELA 21 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NO DETALHE DE IMAGEM 02 ... 78 TABELA 22 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
NO DETALHE DE IMAGEM 03 ... 79 TABELA 23 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES
LISTA DE ALGORITMOS
ALGORITMO 1 - K-MÉDIAS ... 34
ALGORITMO 2 - MAX-MIN ... 36
ALGORITMO 3 - TRANSFORMADA WATERSHED ... 39
ALGORITMO 4 - MINIMIZAÇÃO DA ENTROPIA CRUZADA ... 53
RESUMO
SEGMENTAÇÃO NÃO SUPERVISIONADA DE IMAGENS DE SENSORIAMENTO REMOTO POR MINIMIZAÇÃO DA ENTROPIA CRUZADA.
Sensoriamento remoto é uma das tecnologias que mais rapidamente cresceu durante o final do século XX e início do século XXI. O uso mais comum deste termo refere-se à observação da superfície terrestre por meio de satélites. Em sensoriamento remoto, segmentação de imagens é um processo frequentemente utilizado no auxílio à detecção de mudança de paisagens e classificação do uso do solo. Este trabalho se propõe à pesquisa e ao desenvolvimento de um método para segmentação não supervisionada de imagens de sensoriamento remoto baseado na minimização da entropia cruzada entre a distribuição de probabilidade da imagem e um modelo estatístico. Para os testes realizados, foram utilizadas quinze imagens capturadas pelo sensor TM (Thematic Mapper) do satélite Landsat 5. A partir do banco de dados do projeto de mapeamento do uso do solo da região amazônica TerraClass, foram derivadas imagens temáticas utilizadas como referência para medir o desempenho do classificador desenvolvido. O algoritmo proposto parte de uma segmentação inicial e busca iterativamente melhorar o modelo estatístico que descreve a imagem, de forma a reduzir a entropia cruzada em relação à iteração anterior. Os resultados indicam que a minimização da entropia cruzada está relacionada com uma segmentação coerente das imagens. Duas abordagens de segmentação foram desenvolvidas, uma realizando classificação pixel a pixel e outra classificando regiões obtidas pela transformada Watershed. Na abordagem por pixel, a concordância média entre o classificador e a imagem temática de referência foi de 88,75% para as quinze imagens selecionadas e de 91,81% para quatro pequenas regiões que representam detalhes de transição entre hidrografia, vegetação e outras paisagens, como área urbana, pastos e solo exposto. Na abordagem por região, a concordância média foi de 87,33% para as imagens e 91,81% para os detalhes. As imagens de referência dos detalhes foram preparadas manualmente por um especialista.
ABSTRACT
UNSUPERVISED SEGMENTATION OF REMOTE SENSING IMAGES BY CROSS ENTROPY MINIMIZATION
Remote sensing is one of the fastest growing technologies of late twentieth and early twenty-first century. The most common use of this term is related to the optical sensing of Earth's surface through satellites. In remote sensing, image segmentation is a process often used to aid in landscape change detection and land use classification. This study aims the research and development of a new method for unsupervised segmentation of remote sensing images by minimizing the cross entropy between the probability distribution of the image and some statistical model. Images used for tests were captured by the Thematic Mapper sensor on Landsat 5 satellite. The proposed algorithm takes an initial segmentation and progresses iteratively, trying to improve the statistical model and reduce the cross entropy with respect to previous iterations. Results indicate that the cross entropy minimization is related to a consistent image segmentation. Two approaches were developed, one by performing a per-pixel classification and the other by classifying regions obtained by the Watershed transform. In per-pixel approach, the average agreement between the classifier and the thematic image used as ground truth was 88.75% for fifteen selected images and 91.81% for four small regions that represent details of land use transitions, such as vegetation, rivers, pastures and exposed soil. In region approach, the average agreement was 87.33% for images and 91.81% for details. The ground truth for image details was manually created by an expert.
24 INTRODUÇÃO
1 INTRODUÇÃO
Imagem digital é uma função de duas variáveis discretas em um domínio finito, cuja amplitude em cada ponto (pixel) é também discreta e finita. A facilidade de captura, transmissão, armazenamento, organização e processamento são fatores que fizeram esse formato de imagem substituir o formato analógico. Processamento digital de imagens refere-se a operações realizadas sobre imagens digitais por meio de computadores. O interesse em processamento digital de imagens deve-se principalmente a duas aplicações: melhorias para interpretação visual humana e processamento para armazenamento, transmissão e representação da informação contida em uma imagem para percepção por máquinas (GONZALEZ; WOODS, 2002). Atualmente, diversas áreas técnicas de estudo sofrem impactos com os avanços obtidos em processamento digital de imagens. Algumas aplicações incluem correções de iluminação, cores e contraste em fotografias; auxílio ao diagnóstico de doenças em imagens médicas; controle de acesso por biometria e atividades envolvendo imagens astronômicas, meteorológicas e da superfície terrestre.
O processamento digital de imagens está correlacionado com outras áreas, como a computação gráfica e a visão computacional, e faz amplo uso de reconhecimento de padrões para atingir seus objetivos. Reconhecimento de padrões é a disciplina da ciência cujo objetivo é a classificação de objetos em categorias (THEODORIDIS; KOUTROUMBAS, 2009). Esses objetos podem ser, entre outros, sinais em formato de onda, textos e imagens. A classificação de imagens consiste em agrupar imagens com conteúdo semelhante, de acordo com algum critério estabelecido. A segmentação de imagens tem por objetivo a criação de regiões homogêneas, de modo que a união entre regiões adjacentes seja não homogênea (PAL; PAL, 1993). O nível de detalhamento no processo de segmentação depende do problema que está sendo resolvido e deve ser ajustado de maneira a isolar os objetos de interesse.
INTRODUÇÃO 25
um numero à surpresa causada pela observação de uma mensagem sob a prespectiva de um determinado modelo estatístico. Essa surpresa é a entropia cruzada entre o modelo estatístico e a distribuição de probabilidade da mensagem, e pode ser utilizada, por exemplo, como medida de dissimilaridade para dividir uma imagem em regiões.
O problema de segmentar imagens aparece com frequência em sensoriamento remoto, sob a forma de detecção de mudança de paisagens e classificação do uso do solo. Sensoriamento remoto refere-se à aquisição de informações sobre um objeto de estudo sem que haja contato direto com este objeto. Esse trabalho utiliza o termo Sensoriamento Remoto para designar o sensoriamento óptico da superfície terrestre por meio de satélites. Imagens da superfície terrestre capturadas do espaço estão disponíveis desde a década de 1960, embora possuíssem baixa resolução espacial e espectral e fossem frequentemente registradas em ângulos oblíquos. A partir da década de 1970, com o lançamento da série de satélites Landsat e, posteriormente, com o lançamento da série SPOT, na década de 1980, foi possível a captura de imagens com ângulos quase verticais e resolução capaz de mapear recursos terrestres de forma útil (LILLESAND; KIEFER, 1999). Aplicações modernas de sensoriamento remoto envolvem a análise multiespectral de objetos localizados na superfície da Terra por meio de satélites, aeronaves e estações espaciais. A informação é obtida por sensores que captam a energia eletromagnética refletida pela superfície terrestre em determinadas faixas de comprimento de onda. Superfícies compostas por diferentes materiais, como vegetação, água, solo, áreas construídas, em geral, refletem diferentes proporções de energia nas faixas do espectro eletromagnético (azul, verde, vermelho, infravermelho próximo, etc.). As áreas da ciência auxiliadas por sensoriamento remoto incluem meteorologia, geologia, agricultura e demografia (JENSEN, 2007).
1.1 JUSTIFICATIVA
26 INTRODUÇÃO
utilizado (RICHARDS; JIA, 2006). A utilização de técnicas de segmentação presentes em sistemas de informação geográfica ajuda a reduzir o trabalho manual de interpretação das imagens, embora ainda seja tarefa do especialista a construção de um conjunto de treinamento no caso da classificação supervisionada. A segmentação de imagens não triviais é uma das tarefas mais difíceis em processamento digital de imagens, além de ser um fator crucial para o sucesso de uma análise feita por computador (GONZALEZ; WOODS, 2002). Embora haja muitos estudos sobre segmentação de imagens em geral e segmentação de imagens de sensoriamento remoto, este problema permanece em aberto, até mesmo por sua natureza subjetiva. Dessa forma, a investigação de um método de segmentação não supervisionada que utiliza conceitos da Teoria da Informação pode contribuir para avanços na área.
1.2 OBJETIVO
Este trabalho tem como objetivo geral a pesquisa, o desenvolvimento e a validação de um novo método para segmentação não supervisionada de imagens de sensoriamento remoto por minimização da entropia cruzada entre a distribuição de probabilidade da imagem e um modelo estatístico.
Os objetivos específicos são:
Programar técnicas de clusterização e processamento de imagens presentes na literatura: K-Médias, Transformada Watershed, convolução realizada no domínio da frequência, filtro gaussiano.
Pesquisar e desenvolver métodos para a inicialização de algoritmos de classificação não supervisionada.
Realizar testes de segmentação em imagens de sensoriamento remoto.
Desenvolver um conversor de imagem vetorial shapefile para raster, para a utilização de imagens temáticas pelo sistema desenvolvido. Comparar os resultados obtidos com imagens temáticas disponíveis no
projeto TerraClass e com imagens segmentadas manualmente por um especialista.
28 FUNDAMENTAÇÃO TEÓRICA
2 FUNDAMENTAÇÃO TEÓRICA
Este capítulo tem como objetivo descrever os conceitos necessários para o desenvolvimento do método de segmentação proposto. São apresentadas as formas de classificação supervisionada e não supervisionada, além de classificadores baseados na Teoria Bayesiana de Decisão. Também são apresentados alguns conceitos de estimações paramétricas e não paramétricas para funções de densidade de probabilidade. Em seguida, são discutidos conceitos de Teoria da Informação, como o cálculo da informação associada a um símbolo, entropia e entropia cruzada, além da relação que existe entre informação e estimativas estatísticas. São apresentados algoritmos utilizados na construção do método de segmentação: K-Médias, seleção de sementes por máxima distância mínima e a transformada Watershed. Em sequência, sistemas de informação geográfica são introduzidos e são apresentados alguns de seus recursos para o processamento de imagens, com destaque para o sistema brasileiro de código aberto SPRING. Por fim, são apresentadas algumas das principais técnicas utilizadas na segmentação de imagens de sensoriamento remoto e trabalhos relacionados presentes na literatura.
2.1 CLASSIFICAÇÃO SUPERVISIONADA E NÃO SUPERVISIONADA
O primeiro passo para a classificação de objetos é a definição de características relevantes que os descrevem. A extração de características tem como propósito a redução dos dados a partir da substituição do objeto em si por um conjunto de propriedades que o represente (DUDA; HART; STORK, 2001). Essas propriedades formam um conjunto de valores numéricos que identifica um objeto, denominado vetor de características. O classificador opera sobre os vetores de características para tomar decisões sobre a qual classe pertence cada objeto.
FUNDAMENTAÇÃO TEÓRICA 29
inicialmente, este conjunto de dados destinado ao treinamento. Para esses casos, é preciso achar as similaridades que estão ocultas no conjunto de objetos e agrupar os objetos com características semelhantes (THEODORIDIS; KOUTROUMBAS, 2009). Nesse processo, chamado de classificação não supervisionada ou clusterização, o conjunto de dados é dividido em classes desconhecidas e é prevista a tarefa manual de nomear os clusters após sua conclusão (RICHARDS; JIA, 2006).
2.2 TEORIA BAYESIANA DE DECISÃO
A Teoria Bayesiana de Decisão é uma abordagem estatística fundamental para o problema de reconhecimento de padrões. Essa abordagem assume o problema de decisão em termos probabilísticos e considera que os valores relevantes para a tomada de decisão são todos conhecidos (DUDA; HART; STORK, 2001).
A classificação de objetos com base na Teoria Bayesiana pode ser vista como uma formalização do senso comum. Classificadores Bayesianos calculam as probabilidades de um objeto pertencer a cada uma das possíveis classes e atribui este objeto à classe mais provável.De acordo com a fórmula de Bayes (Equação 1), a probabilidade de um objeto representado pelo vetor pertencer à classe é:
| = | (1)
na qual:
| representa a função densidade de probabilidade condicionada à classe , i. e., como estão distribuídos os vetores dessa classe;
indica a probabilidade de ocorrência da classe ; indica a probabilidade de ocorrência do vetor .
O termo pode ser desprezado pelo classificador, pois não depende das classes e não influencia a decisão. Quando não há conhecimento inicial sobre a probabilidade de ocorrência das classes, considera-se que possui o mesmo valor para todo , e o termo também pode ser omitido do classificador. Nessas condições, a decisão tomada pelo classificador é definida por:
30 FUNDAMENTAÇÃO TEÓRICA
Essa regra de decisão é um caso especial de uma regra geral, onde pode haver diferentes penalidades atribuídas a diferentes classificações incorretas. Nessas condições, o desempenho do classificador depende de boas estimações para as funções densidade de probabilidade, pois a tomada de decisão fica condicionada apenas à distribuição dos vetores de cada classe.
2.3 ESTIMAÇÃO DE UMA FUNÇÃO DENSIDADE DE PROBABILIDADE
Em muitos problemas, a função densidade de probabilidade é desconhecida e precisa ser estimada a partir dos dados disponíveis. Em alguns casos, o tipo de distribuição é conhecido (distribuição normal, distribuição de Poisson, etc.), sendo necessário estimar apenas os parâmetros da função, como média ou desvio-padrão. Quando o tipo de distribuição é desconhecido, é preciso utilizar técnicas para estimação de forma não paramétrica (THEODORIDIS; KOUTROUMBAS, 2009).
Uma estimação paramétrica assume um determinado tipo de distribuição e obtém os parâmetros necessários para a construção da função de distribuição por meio das amostras observadas (YONEYAMA, 2009). Quando o tipo de distribuição estimado é o mesmo tipo da distribuição real da qual as amostras foram coletadas, uma boa estimação pode ser alcançada mesmo com um número reduzido de amostras. Caso contrário, a estimação poderá ficar distante da distribuição real, como pode ser observado na Figura 1.
FIGURA 1 - EXEMPLOS DE ESTIMAÇÃO PARAMÉTRICA
FUNDAMENTAÇÃO TEÓRICA 31
Estimações não paramétricas são basicamente variações de aproximações feitas por histograma de uma função densidade de probabilidade desconhecida (THEODORIDIS; KOUTROUMBAS, 2009). Nenhuma suposição é feita a priori sobre o tipo de distribuição em questão. A função de distribuição é estimada a partir das observações realizadas, recebendo maior probabilidade as regiões onde os dados observados estão mais concentrados. A Figura 2 ilustra a estimação por um método não paramétrico, aplicado a dois diferentes tipos de distribuições.
FIGURA 2 - EXEMPLOS DE ESTIMAÇÃO NÃO PARAMÉTRICA
(a) Estimação não paramétrica por histograma de uma distribuição normal; (b) Distribuição bimodal. Nos dois casos a distribuição estimada conseguiu se aproximar da distribuição real, embora tenha sido necessário um número elevado de amostras. Fonte: Yoneyama (2009).
Abordagens não paramétricas possuem maior flexibilidade, pois se adaptam aos diferentes tipos de distribuição. Em contrapartida, precisam de um número maior de amostras para que se possa atingir uma estimação próxima à distribuição real (YONEYAMA, 2009).
2.4 ENTROPIA E MODELOS ESTATÍSTICOS
32 FUNDAMENTAÇÃO TEÓRICA
A informação de uma variável aleatória x está relacionada com a surpresa causada pela observação de seu valor (BISHOP, 2006). A Equação 2 apresenta o cálculo da informação ℎ � em função da probabilidade de ocorrência � :
ℎ � = − log � . (2)
A função ℎ � decresce monotonicamente em relação a � , i.e., quanto maior for a probabilidade de ocorrência de �, menor será a informação observada. Caso seja utilizada a base logarítmica dois, a informação será quantificada em bits.
A entropia de uma distribuição refere-se ao grau de incerteza de uma sequência de símbolos retirados desta distribuição (DUDA; HART; STORK, 2001). A entropia de uma distribuição de probabilidade discreta � sobre um alfabeto � é:
= − ∑ �
∈�
log � . (3)
Em um processo de comunicação, a informação presente em uma mensagem está associada às expectativas do receptor. Entropia cruzada entre duas densidades de probabilidade é a informação média necessária para representar um símbolo, quando utilizada uma distribuição estimada por um modelo estatístico � em vez da distribuição real � (BISHOP, 2006):
, = − ∑ �
∈�
log � . (4)
Em muitas situações, a densidade real é desconhecida e a entropia cruzada não pode ser calculada diretamente pela Equação 4. Uma aproximação é feita a partir da informação observada sobre determinada mensagem retirada da densidade real. A Equação 5 permite calcular a entropia cruzada a partir da informação média de uma mensagem de tamanho e uma densidade estimada � :
= − ∑ log �i �
i=
. (5)
FUNDAMENTAÇÃO TEÓRICA 33
FIGURA 3 - DISTRIBUIÇÕES ESTIMADAS PARA ÁREA URBANA E HIDROGRAFIA
Fonte: autoria própria.
É esperado que a distribuição de uma região possua baixa entropia cruzada com a distribuição de outra região de mesma classe, enquanto as distribuições de regiões de classes diferentes possuam alta entropia cruzada entre si.
2.5 K-MÉDIAS
Uma das estratégias mais comuns para a clusterização baseia-se na otimização de uma função de custo dos vetores do conjunto de dados, parametrizada em termos de um vetor desconhecido, � (DUDA; HART; STORK, 2001). Para a maioria dos esquemas de clusterização, assume-se que o número de clusters é conhecido. A meta desses algoritmos é estimar os parâmetros que melhor caracterizam os clusters, ocultos no conjunto de dados. Para clusters compactos, é razoável adotar como parâmetros um conjunto de pontos no espaço n-dimensional, onde cada ponto representa o centroide de um cluster (THEODORIDIS; KOUTROUMBAS, 2009).
34 FUNDAMENTAÇÃO TEÓRICA = ∑ ∑ ‖ − � ‖ � = ∈� , (6) na qual:
� é conjunto de dados;
é um vetor do conjunto de dados; � é o número de clusters;
� é o centroide do cluster ;
é uma função com valor 1, caso o vetor pertença ao cluster e valor 0, caso contrário.
Achar o vetor de parâmetros � que minimiza a Equação 6 não é uma tarefa trivial.O K-Médias propõe a minimização iterativa da função de custo a partir de uma estimativa inicial para �. Os passos do K-Médias são descritos no Algoritmo 1.
ALGORITMO 1 - K-MÉDIAS
Escolher estimativas iniciais para os centroides dos clusters. Repetir:
Atribuir cada objeto ao cluster mais próximo.
Determinar o novo centroide de cada cluster.
Enquanto houver alterações nos centroides dos clusters.
Fonte: Duda, Hart e Stork (2001, p. 526).
FUNDAMENTAÇÃO TEÓRICA 35
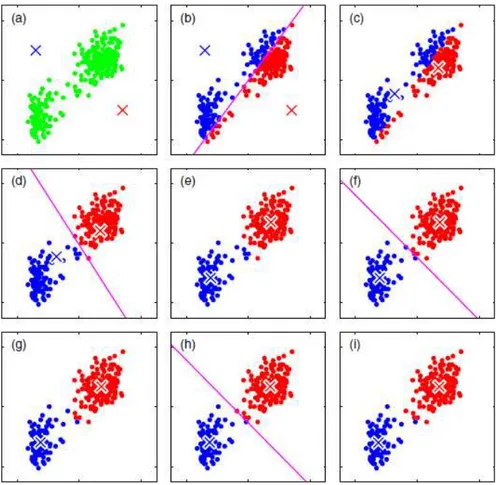
FIGURA 4 - ILUSTRAÇÃO DO K-MÉDIAS
(a) Objetos ainda não classificados, representados por pontos verdes em um espaço euclidiano de duas
dimensões. Os centroides dos clusters são representados por cruzes e são inicializados de acordo com
um critério qualquer; (b) Os objetos são atribuídos ao cluster mais próximo; (c) Os centroides dos
clusters são recalculados pela média dos vetores; (d)-(i) Sucessivas iterações ocorrem até a
convergência. Fonte: adaptada de Bishop (2006, p. 426).
O algoritmo K-Médias possui aplicação em processamento de imagens como uma forma de segmentação não supervisionada. O vetor de características dos objetos é derivado dos valores do pixel em cada banda da imagem e os clusters representam regiões segmentadas.
2.6 INICIALIZAÇÃO DE SEMENTES A PARTIR DO MÉTODO MAX-MIN
36 FUNDAMENTAÇÃO TEÓRICA
entre si (MIRKIN, 2005). O processo de seleção das sementes é descrito no Algoritmo 2.
ALGORITMO 2 - MAX-MIN
Calcular todas as distâncias entre pares de vetores no conjunto de dados. Selecionar como sementes os dois vetores com maior distância entre si. Até o número desejado de sementes, repetir:
Selecionar como nova semente o vetor cuja distância mínima para as atuais sementes seja a maior possível.
Fonte: Maitra, Peterson e Ghosh (2010).
Caso o conjunto de dados seja muito grande, esse método pode tornar-se computacionalmente custoso, pois apresenta complexidade O(n2). Para contornar esse problema é preciso substituir a maneira como as duas primeiras sementes são escolhidas, eliminando o cálculo das distâncias entre todos os pares de vetores. No caso de imagens, pode-se atribuir a primeira semente à região mais homogênea, por exemplo, e as demais sementes podem ser determinadas pela máxima distância mínima.
2.7 TRANSFORMADA WATERSHED
A transformada Watershed é uma abordagem para a segmentação de imagens que gera regiões com base em uma situação real de inundação (BEUCHER, 1992). A primeira etapa dessa transformada é o cálculo da imagem gradiente obtida por um operador de diferenciação, por exemplo, o operador de Sobel. Esse operador possui duas componentes, e , que indicam a variação da função na direção horizontal e vertical, respectivamente, calculadas a partir da convolução entre uma imagem � e matrizes apropriadas, como mostrado nas Equações 7 e 8:
FUNDAMENTAÇÃO TEÓRICA 37
A Equação 9 representa a construção da imagem gradiente, , pela combinação de suas componentes nas duas dimensões:
= √ + (9)
A imagem gradiente pode ser interpretada como o módulo do vetor gradiente em cada pixel, i.e., a variação dos valores da imagem em cada ponto (Figura 5).
FIGURA 5 – IMAGEM E IMAGEM GRADIENTE
(a) Detalhe de imagem capturada pelo satélite Landsat-5, banda 4; (b) Imagem gradiente calculada pelo
operador de Sobel. Fonte: autoria própria.
A imagem gradiente é tratada como uma superfície topográfica, onde o valor em cada pixel significa a elevação da superfície naquele local (Figura 6).
FIGURA 6 - TOPOGRAFIA DA IMAGEM GRADIENTE
38 FUNDAMENTAÇÃO TEÓRICA
O processo de inundação é então iniciado e a água começa a fluir a partir dos mínimos locais. Quando a água que parte de dois mínimos se encontra, é construída uma represa delimitando as duas regiões. O processo de inundação e a construção das represas são ilustrados na Figura 7.
FIGURA 7 - ILUSTRAÇÃO DA TRANSFORMADA WATERSHED
(a) Mínimos locais identificados por pontos vermelhos; (b) e (c) Quando a água encontra um ponto onde pode transbordar, uma represa é construída; (d) Quando a inundação atinge o ponto mais alto, as regiões delimitadas pelas represas determinam a segmentação final da imagem. Fonte: adaptada de Beucher (1992).
FUNDAMENTAÇÃO TEÓRICA 39
ALGORITMO 3 - TRANSFORMADA WATERSHED
Calcular a imagem gradiente.
Localizar os mínimos locais da imagem gradiente. Para cada mínimo local:
Criar uma região a partir do mínimo local. Repetir:
Adicionar à região os pixels da vizinhança cujo valor na imagem gradiente é maior que o valor da região na fronteira.
Enquanto houver pixels para serem adicionados na fronteira da região.
Fonte: Beucher (1992).
2.8 PROCESSAMENTO DIGITAL DE IMAGENS EM SENSORIAMENTO REMOTO
Processamento digital de imagens é fundamental para o sensoriamento remoto como uma ferramenta que auxilia a visualização e a extração de informações dos dados coletados. Avanços significativos foram alcançados em processamento digital de imagens para dados coletados de forma remota. A análise das imagens faz uso de diversos elementos de interpretação, como cor, tamanho e formato de regiões, textura, padrões e presença de sombra e nuvens (JENSEN, 2007). Entre as principais operações de processamento de imagens presentes em sistemas de informação geográfica podem ser citadas:
Aplicação de filtros para redução de ruído, detecção e aguçamento de bordas, caracterização de texturas por matrizes de coocorrência e detecção de formas;
Melhorias para a visualização humana, tais como ajuste de contraste, equalização de histograma, ajuste do histograma de uma imagem em relação ao histograma de outra e aplicação de pseudocor;
Classificação supervisionada e não supervisionada dos pixels da imagem.
40 FUNDAMENTAÇÃO TEÓRICA
uma forma geral, o processo de classificação supervisionada pode ser descrito nos passos a seguir:
Decidir quantas e quais classes farão parte do processo de segmentação: água, área urbana, vegetação, etc;
Selecionar manualmente um conjunto de pixels que represente cada uma dessas classes;
Utilizar os pixels destinados ao treinamento para construir modelos estatísticos ou equações que definam partições no espaço de atributos; Classificar cada pixel da imagem e gerar um mapa temático para
representar a segmentação obtida.
A classificação por máxima verossimilhança é o método supervisionado mais comum utilizado em imagens de sensoriamento remoto (RICHARDS; JIA, 2006). Os dados de treinamento são utilizados para estimar as funções densidade de probabilidade de cada classe e a tomada de decisão é definida pelo teorema de Bayes. Para a classificação não supervisionada, muitos sistemas de informação geográfica disponibilizam o algoritmo K-Médias.
2.9 SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
FUNDAMENTAÇÃO TEÓRICA 41
FIGURA 8 - ESQUEMA GERAL DOS MÓDULOS DE UM SIG
Fonte: adaptada de Felgueiras (2006).
Felgueiras (2006) apresenta as funções de cada módulo de um SIG:
O módulo de gerenciamento dados é responsável pelo armazenamento e recuperação das informações na memória do computador. O gerenciador é responsável pela eficiência do SIG em relação ao acesso, leitura e escrita aos dados da base.
O módulo de entrada e integração de dados oferece as funcionalidades de entrada de imagens digitais, dados temáticos, dados topográficos, dados cadastrais, entre outros.
O módulo de visualização contém funções para exibição de imagens e dados em geral.
O módulo de análise contém o conjunto de procedimentos para análise espacial, possibilitando a obtenção de produtos derivados, mapas e relatórios.
O módulo de interface é responsável pela interação com o usuário para acesso às ferramentas disponibilizadas pelo software.
42 FUNDAMENTAÇÃO TEÓRICA
2.9.1 SPRING
O SPRING é um SIG desenvolvido pela Divisão de Processamento de Imagens do INPE com funções de processamento de imagens, análise espacial, modelagem numérica de terreno e consulta a bancos de dados espaciais. Segundo Câmara et al. (1996), são objetivos do projeto SPRING:
Construir um sistema de informações geográficas para aplicações em Agricultura, Floresta, Gestão Ambiental, Geografia, Geologia, Planejamento Urbano e Regional;
Tornar acessível para a comunidade brasileira um SIG de rápido aprendizado;
Fornecer um ambiente unificado de Geoprocessamento e Sensoriamento Remoto para aplicações urbanas e ambientais;
Ser um mecanismo de difusão do conhecimento desenvolvido pelo INPE e seus parceiros, sob a forma de novos algoritmos e metodologias.
O Sistema SPRING possui ferramentas para a segmentação supervisionada e não supervisionada. Na abordagem supervisionada, estão disponíveis os métodos Bhattacharya, distância de Mahalanobis e da classificação por máxima verossimilhança. Os algoritmos ISODATA e ISOSEG são utilizados para a abordagem não supervisionada.
2.10 TRABALHOS RELACIONADOS
Com o crescimento das pesquisas em segmentação de imagens de sensoriamento remoto, tornou-se importante fazer distinção entre as diferentes técnicas utilizadas na literatura ao longo dos anos. O trabalho desenvolvido por Dey, Zhang e Zhong (2010) contem uma revisão das principais técnicas utilizadas e alguns trabalhos relacionados. As principais abordagens listadas nesse trabalho são baseadas em limiares definidos no histograma da imagem, detecção de bordas, campos aleatórios de Markov, lógica fuzzy e segmentação em multirresolução.
FUNDAMENTAÇÃO TEÓRICA 43
segmentação traçando um limiar diretamente no histograma da imagem (ROSENFELD; DAVIS, 1979). Atualmente, métodos de segmentação baseados em limiares não são muito utilizados em sensoriamento remoto, especialmente em imagens de alta resolução, onde a variação do histograma é elevada.
Algumas abordagens para segmentação baseiam-se na extração de características derivadas diretamente da análise dos pixels da própria imagem, sendo na maioria dos casos técnicas baseadas em detecção de bordas (MAXWELL, 2005). Atualmente, a transformada Watershed é uma técnica baseada em detecção de bordas bastante utilizada na segmentação de imagens de sensoriamento remoto (CARLEER; DEBEIR; WOLFF, 2005). A partir das regiões segmentadas pela transformada, é possível extrair características da imagem e iniciar uma nova abordagem para a segmentação, por exemplo, com a construção de modelos estatísticos ou com a definição de um campo aleatório de Markov sobre as regiões.
Em Sensoriamento Remoto, as primeiras publicações envolvendo campos aleatórios de Markov e segmentação de imagens apareceram em 1992 (DEY; ZHANG; ZHONG, 2010). Sarkar et al. (2002) propuseram a segmentação de imagens multiespectrais pela minimização da energia associada a um campo aleatório de Markov, definido sobre regiões extraídas pela transformada Watershed. Modelos baseados em campos aleatórios de Markov têm atraído a atenção de pesquisadores pela capacidade de integrar propriedades espectrais, espaciais e de textura das imagens. O custo computacional, porém, é um fator negativo (DEY; ZHANG; ZHONG, 2010).
44 FUNDAMENTAÇÃO TEÓRICA
Segmentação em multirresolução é atualmente a abordagem mais utilizada nas pesquisas envolvendo imagens de sensoriamento remoto de alta resolução. As abordagens empregadas podem ser tanto bottom-up, partindo da resolução máxima para uma resolução mais baixa, quanto top-down, percorrendo o caminho inverso (DEY; ZHANG; ZHONG, 2010). Baatz e Schäpe (2000) trouxeram grande desenvolvimento para esta área com a introdução de uma técnica de segmentação hierárquica de multirresolução com abordagem bottom-up. O processo se inicia com cada pixel sendo um objeto e vai criando regiões à medida que se reduz a resolução da imagem. As regiões criadas não podem ultrapassar um limiar de heterogeneidade. Esse método está incorporado ao software comercial eCognition, de grande impacto para o campo de segmentação em sensoriamento remoto e considerado o estado da arte nessa área (BLASCHKE, 2010).
46 MATERIAIS E MÉTODOS
3 MATERIAIS E MÉTODOS
Neste capítulo, é descrita a origem das imagens de sensoriamento remoto e imagens temáticas utilizadas nos testes realizados. Também são descritos aspectos técnicos das imagens capturadas pelo sensor TM do satélite Landsat-5. Em seguida, é mostrada a forma como o algoritmo de segmentação atua na minimização da entropia cruzada. Ao final do capítulo, são apresentadas as medidas de avaliação para o método proposto.
3.1 BANCO DE DADOS UTILIZADO PARA TESTES
Para testar o desempenho do algoritmo de segmentação proposto, foram utilizadas imagens de sensoriamento remoto da região amazônica, capturadas pelo sensor TM do satélite Landsat-5 no ano de 2008, disponíveis no site do Instituto Nacional de Pesquisas Espaciais (INPE). A escolha dessa base de dados deve-se ao fato de se encontrar, também no site do INPE, a classificação do uso do solo para essa região, gerada pelo projeto TerraClass.
Iniciado em 1967, o programa de satélites Landsat planejou o lançamento de seis satélites com o objetivo principal de realizar um mapeamento multispectral em alta resolução (para aquela época) da superfície da Terra (LILLESAND; KIEFER, 1999). Lançados em 1982 e 1984, os satélites Landsat-4 e Landsat-5 foram projetados com os mesmos instrumentos sensores. Esses satélites tiveram vida útil prolongada, especialmente após a falha de lançamento do Landsat-6. O sensor TM (Thematic Mapper) do Landsat-5 continua em atividade até os dias atuais.
MATERIAIS E MÉTODOS 47
QUADRO 1 - BANDAS ESPECTRAIS PRESENTES NO SENSOR TM DO LANDSAT 5
Banda Comprimento de Onda (µm) Principais Aplicações
1 - Azul 0,45 – 0,52
Mapeamento de águas costeiras e tipos florestais, discriminação de solo e vegetação e identificação de características de culturas.
2 - Verde 0,52 – 0,60 Medição dos picos de refletância verde da vegetação para avaliação do vigor e discriminação de vegetação; identificação de características de culturas.
3 - Vermelho 0,63 – 0,69
Identificação de regiões de absorção da clorofila, auxiliando na diferenciação de espécies de plantas; identificação de características culturais.
4 - Infravermelho
Próximo 0,76 – 0,90
Determinação de tipos de vegetação, vigor e volume de biomassa, delineamento de corpos d'água e discriminação de umidade do solo.
5 - Infravermelho
Médio 1,55 – 1,75
Indicação do teor de umidade da vegetação e do solo; diferenciação entre neve e nuvens.
6 - Infravermelho
Termal 10,4 – 12,5
Análise de estresse de vegetação, discriminação de umidade do solo e aplicações de mapeamento termal.
7 - Infravermelho
Médio 2,08 – 2,35
Discriminação de tipos de minerais e rochas; identificação do teor de umidade da vegetação.
Fonte: Adaptado de Lillesand e Kiefer (1999, p. 396).
48 MATERIAIS E MÉTODOS
FIGURA 9 – CENÁRIO VISTO EM DIFERENTES BANDAS
(a)-(f) Detalhe de imagem do Pará, cena 224/061, capturada em 21/08/2008. Bandas 1, 2, 3, 4, 5 e 7. Fonte: Autoria própria.
Conforme ilustrado na Figura 9, a água se destaca por possuir baixa resposta espectral nas bandas 4, 5 e 7. Por outro lado, a região de agropecuária (localizada à margem do rio) confunde-se com a floresta na banda 4, mas pode ser facilmente distinguida na banda 5.
3.2 IMAGENS TEMÁTICAS
MATERIAIS E MÉTODOS 49
2008. Os dados digitais resultantes do mapeamento encontram-se disponíveis no site do INPE (www.inpe.br).
Para a avaliação do método de segmentação proposto, foram utilizadas imagens classificadas do projeto TerraClass. Essas imagens estão divididas por cena e encontram-se no formato shapefile, um formato popular de arquivo que contém dados vetoriais comumente utilizados por Sistemas de Informações Geográficas. As classes temáticas consideradas nos testes realizados são três: Hidrografia, Vegetação e Outros, derivadas das classes consideradas pelo projeto TerraClass. No Quadro 2, tem-se a descrição e a legenda de cor adotada para as classes consideradas. Os pixels marcados na imagem temática como área não observada não participam do processo de classificação.
QUADRO 2 - LEGENDA E DESCRIÇÃO DAS CLASSES TEMÁTICAS
Cor Classe Descrição
Hidrografia Rios.
Vegetação Floresta, vegetação secundária e agricultura.
Outros Área urbana, pastos, áreas desmatadas e áreas com solo exposto. Área não
Observada Áreas que tiveram sua interpretação impossibilitada pela presença de nuvens ou sombra de nuvens.
Fonte: Autoria própria.
50 MATERIAIS E MÉTODOS
3.3 SEGMENTAÇÃO POR MINIMIZAÇÃO DA ENTROPIA CRUZADA
A entropia cruzada é calculada pela informação média de uma mensagem sob a perspectiva de um modelo estatístico. A Equação 10 contém o cálculo da entropia cruzada de acordo com a modelagem proposta:
= − |�|∑ ∑ (log �+∑log �
� �= ) � = ∈� (10) na qual:
|�| é o número de pixels da imagem �. é um pixel da imagem.
� é número total de clusters presentes na segmentação.
é uma função que assume valor ‘1’ caso o pixel pertença ao cluster e ‘0’ caso contrário.
é o número de bandas que compõem a imagem.
� é a função densidade de probabilidade do cluster para os valores de na banda .
As funções são utilizadas para a construção dos modelos estatísticos de cada cluster por meio de estimação não paramétrica. O modelo estatístico de um cluster é construído de modo que haja estimativa (maior que zero) para cada um dos 256 possíveis valores que um pixel pode assumir em cada banda da imagem. Dessa forma, cada cluster possui funções independentes para estimação de probabilidades, uma para cada banda, construídas por meio de histogramas. A Equação 11 contém o cálculo da probabilidade estimada por um cluster para a ocorrência de um determinado valor na banda :
� = + ∑�∈�+ ∑� ��, ��
�∈� (11)
MATERIAIS E MÉTODOS 51
em todas as bandas que compõem a imagem. A probabilidade estimada inicialmente para a ocorrência de qualquer valor em qualquer banda é, portanto, 1/256. Ao final do treinamento, a probabilidade estimada para um determinado valor em uma banda será a frequência relativa desse valor naquela banda.
Conforme discutido no Capítulo 2, estimações não paramétricas precisam de um número maior de amostras que estimações paramétricas. Caso o total de pixels atribuídos a um cluster seja baixo, a estimação para a iteração seguinte ficará comprometida, com aspecto ruidoso, pois na estimação por histograma a observação de um valor não interfere na estimação para valores vizinhos. Para contornar essa deficiência, é aplicado um filtro gaussiano sobre o histograma (Figura 10). Utilizando um raio como parâmetro, o filtro gaussiano é construído com média zero e desvio padrão igual a um terço do valor do raio.
FIGURA 10 - INTERPOLAÇÃO DE VALORES NO HISTOGRAMA
Em destaque, conjunto de pixels utilizado para o treinamento, determinado pela função r do cluster que
pode ser classificado como “outros”. Ao lado, histograma antes e após a aplicação do filtro gaussiano.
Fonte: autoria própria.
O algoritmo desenvolvido tem por objetivo minimizar a Equação 10 por meio da manipulação das funções rk. Duas abordagens foram desenvolvidas para a
52 MATERIAIS E MÉTODOS
3.3.1 Segmentação Pixel a Pixel
A etapa inicial da segmentação pixel a pixel é o treinamento realizado a partir da classificação do algoritmo K-Médias. O K-Médias recebe como entrada o número de clusters e tem como saída as regiões na qual se divide a imagem inicialmente, representadas pelas funções rk, e que serão utilizadas para estimação
das densidades de probabilidade de cada classe. Para adicionar contexto espacial ao algoritmo, é aplicado um filtro gaussiano sobre as funções rk, o que torna as
regiões temporariamente borradas, com valores entre ‘0’ e ‘1’. Em seguida, as funções tornam-se binárias novamente, recebendo valor ‘1’ o ponto com maior valor entre todas as funções, e recebendo valor ‘0’ os pontos correspondentes das demais funções. Esse processo baseia-se na segmentação desenvolvida por Awate et al. (2006). A Figura 11 ilustra a adição de contexto espacial a uma segmentação por meio da suavização por um filtro gaussiano.
FIGURA 11 - SUAVIZAÇÃO DA FUNÇÃO R
Composição RGB 543 (a); Função r da classe hidrografia (b); Suavização da função r por um filtro
MATERIAIS E MÉTODOS 53
É importante destacar que esse processo de suavização não altera diretamente a classificação final dos pixels, mas sim os conjuntos de treinamento que serão utilizados na próxima iteração do algoritmo. Ao final de cada iteração, cada cluster terá calculado a informação de cada pixel, que ficará armazenada sob a forma de uma matriz. Essa matriz de informação é suavizada por um filtro gaussiano com o intuito de controlar o nível de detalhe da segmentação. Após consultar a matriz de informação de cada cluster num determinado ponto, o pixel correspondente será atribuído ao cluster cuja matriz apresentar menor valor. O Algoritmo 4 descreve os passos para a redução da entropia cruzada.
ALGORITMO 4 - MINIMIZAÇÃO DA ENTROPIA CRUZADA
Selecionar sementes para o K-Médias pelo método Max-Min.
Executar o K-Médias. Repetir:
Realizar convolução entre a função r de cada classe e um filtro gaussiano.
Atribuir cada pixel da imagem à classe que possuir maior valor de r naquele ponto.
Estimar a densidade de probabilidade das classes de acordo com as funções r.
Calcular a matriz de informação para todas as classes.
Realizar convolução entre a matriz de informação de cada classe e um filtro gaussiano. Atribuir cada pixel da imagem à classe que obtiver menor informação naquele ponto. Enquanto houver redução da entropia cruzada.
Fonte: Autoria própria.
3.3.2 Segmentação por Região
Uma segunda abordagem de segmentação foi desenvolvida com a finalidade de eliminar o treinamento realizado a partir da classificação pelo K-Médias, tornando a segmentação baseada puramente na entropia cruzada entre regiões, obtidas pela transformada Watershed. A Equação 10 passa a ter a seguinte restrição:
, ∈ � ⇒ =
54 MATERIAIS E MÉTODOS
= max≤�≤�√ � + � , (12)
onde Gx(xb) e Gy(xb) são as componentes horizontal e vertical do vetor gradiente no
pixel x, banda b. O Algoritmo 5 resume a segmentação baseada em regiões. Para a escolha das sementes, o método Max-Min foi modificado para selecionar primeiramente a região que possuir mais pixels e adotar a entropia cruzada como medida de dissimilaridade.
ALGORITMO 5 - MINIMIZAÇÃO DA ENTROPIA CRUZADA COM REGIÕES
Executar a Transformada Watershed.
Selecionar sementes (regiões) pelo método Max-Min.
Repetir:
Estimar a densidade de probabilidade das classes de acordo com suas regiões. Atribuir cada região à classe que obtiver menor informação.
Enquanto houver redução da entropia cruzada.
Fonte: autoria própria.
Na Figura 12 é ilustrada a escolha das sementes e o processo de minimização da entropia cruzada com a utilização de regiões. A abordagem por pixel é semelhante.
FIGURA 12 - REDUÇÃO DA ENTROPIA CRUZADA
MATERIAIS E MÉTODOS 55
No exemplo da Figura 12, percebe-se que já existe distinção entre as classes hidrografia, vegetação e outros na primeira iteração, onde as densidades de probabilidade de cada cluster são estimadas apenas com as amostras de cada semente selecionada. As iterações seguintes utilizam o resultado da segmentação anterior para determinar um novo conjunto de treinamento para cada classe e, assim, obter um modelo estatístico mais preciso, capaz de reduzir a entropia cruzada e obter uma melhor segmentação. A Tabela 1 relaciona a entropia cruzada com a concordância observada para as iterações do algoritmo ilustradas na Figura 12.
TABELA 1 - RELAÇÃO ENTRE REDUÇÃO DA ENTROPIA E AUMENTO DA CONCORDÂNCIA Iteração Entropia Cruzada (bits/símbolo) Concordância Observada
1 14,84 62,08%
6 10,58 76,64%
42 10,49 92,18%
Fonte: autoria própria.
A entropia cruzada tende a ser reduzida ao longo das iterações do algoritmo, ao mesmo tempo em que a concordância observada tende a aumentar.
3.4 MEDIDAS UTILIZADAS NA AVALIAÇÃO DE DESEMPENHO
O desempenho do classificador desenvolvido foi aferido levando-se em consideração medidas relacionadas a cada imagem e medidas relacionadas a cada uma das classes (hidrografia, vegetação e outros). Para a avaliação das imagens, as medidas adotadas foram a concordância observada e o índice kappa. Para as classes, as medidas de sensibilidade, especificidade e precisão foram utilizadas. Além dessas medidas, a concordância observada entre o classificador proposto e a imagem de referência é exibida ao lado da concordância observada para o K-Médias e o método da máxima verossimilhança com estimação de distribuição normal, duas técnicas bastante comuns em sistemas de informação geográfica.
56 MATERIAIS E MÉTODOS
QUADRO 3 - CONCORDÂNCIA OBSERVADA
Observados Imagem de Referência Totais
Marginais
Água Solo
Classificador Água 1175 26 1201
Solo 118 1181 1299
Totais Marginais 1293 1207 2500
A concordância observada é a razão entre o total de concordâncias e o total de observações (valores da diagonal da matriz). Neste caso a concordância observada é de 94,24%. Fonte: autoria própria.
O índice Kappa é um teste de concordância entre observadores que corrige a concordância por acaso (PANETH, 2005). A partir dos totais marginais, calculados sobre as observações, é montada uma nova matriz para a concordância esperada (acaso de concordâncias). Cada célula que compõe a diagonal da nova matriz é a proporção de um total marginal aplicada ao outro total marginal da mesma classe (Quadro 4).
QUADRO 4 - CONCORDÂNCIA ESPERADA
Esperados Imagem de Referência Totais
Marginais
Água Solo
Classificador Água 621,1572 - 1201
Solo - 627,1572 1299
Totais Marginais 1293 1207 2500
O classificador respondeu “água” em 48,04% dos casos. Aplicando essa proporção ao total de pixels indicados como água pela imagem de referência (1293), chega-se ao valor 621,1572. O mesmo procedimento é aplicado às demais classes. A concordância esperada é calculada pela razão entre o total de concordâncias esperadas e o total de observações (49,93% neste caso). Fonte: autoria própria.
A fórmula para o cálculo do índice kappa é:
= . − .� − . (13)
Um índice kappa de valor ‘1’ significa que os observadores concordam perfeitamente. O índice ‘0’ indica que não há relação entre as classificações dos observadores além do acaso (PANETH, 2005).
As medidas de sensibilidade, especificidade e precisão descrevem o comportamento de cada classe de acordo com os acertos e os erros de atribuição e rejeição. As equações para cada uma dessas medidas são:
MATERIAIS E MÉTODOS 57
= � +� (15)
ã =� + � +� + � + (16)
onde:
VP (Verdadeiros Positivos): número de objetos atribuídos corretamente a uma classe.
VN (Verdadeiros Negativos): número de objetos rejeitados corretamente.
FP (Falsos Positivos): número de objetos atribuídos erroneamente a uma classe.
60 RESULTADOS
4 RESULTADOS
Neste capítulo apresentam-se as tabelas referentes aos resultados obtidos a partir da segmentação das imagens do banco de dados pelas abordagens de segmentação pixel a pixel e de segmentação por região. Para a comparação direta com as imagens de referência, é exibido ao lado de cada tabela o mapa temático resultante da segmentação. Por fim, também é apresentada uma tabela que permite comparar o desempenho do método proposto com o K-Médias e com a classificação por máxima verossimilhança.
4.1 SEGMENTAÇÃO DAS IMAGENS DO BANCO
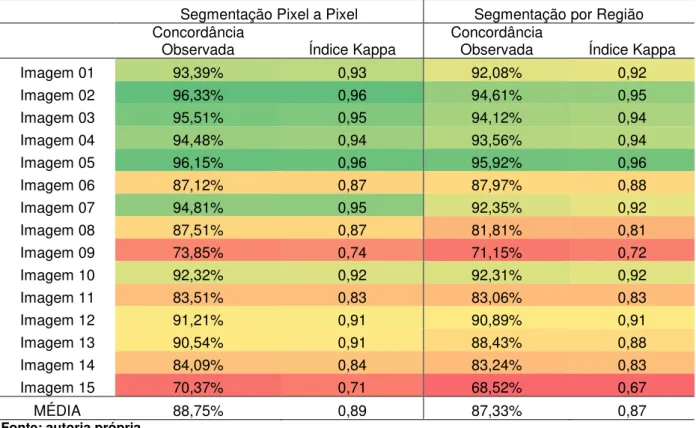
Na abordagem de segmentação pixel a pixel, a suavização das funções r e da matriz de informação são feitas por filtros gaussianos com raios de 10 pixels e de 5 pixels, respectivamente. A suavização do histograma é feita por um filtro gaussiano de raio 20. A concordância e o índice kappa obtidos nos testes sobre essas imagens são apresentados na Tabela 2.
TABELA 2 - CONCORDÂNCIA OBSERVADA E ÍNDICE KAPPA
Segmentação Pixel a Pixel Segmentação por Região Concordância
Observada Índice Kappa Concordância Observada Índice Kappa
Imagem 01 93,39% 0,93 92,08% 0,92
Imagem 02 96,33% 0,96 94,61% 0,95
Imagem 03 95,51% 0,95 94,12% 0,94
Imagem 04 94,48% 0,94 93,56% 0,94
Imagem 05 96,15% 0,96 95,92% 0,96
Imagem 06 87,12% 0,87 87,97% 0,88
Imagem 07 94,81% 0,95 92,35% 0,92
Imagem 08 87,51% 0,87 81,81% 0,81
Imagem 09 73,85% 0,74 71,15% 0,72
Imagem 10 92,32% 0,92 92,31% 0,92
Imagem 11 83,51% 0,83 83,06% 0,83
Imagem 12 91,21% 0,91 90,89% 0,91
Imagem 13 90,54% 0,91 88,43% 0,88
Imagem 14 84,09% 0,84 83,24% 0,83
Imagem 15 70,37% 0,71 68,52% 0,67
MÉDIA 88,75% 0,89 87,33% 0,87
RESULTADOS 61
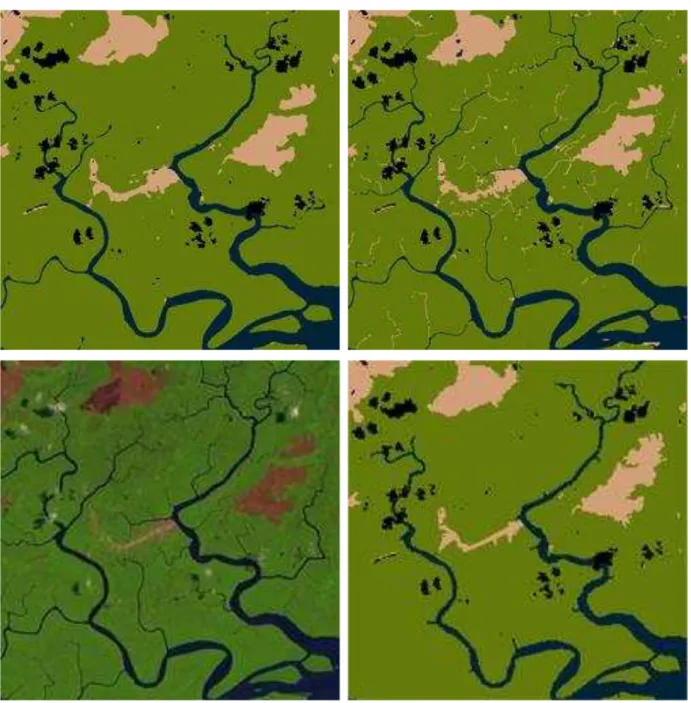
FIGURA 13 - SEGMENTAÇÃO DA IMAGEM 01
Segmentação pixel a pixel, segmentação por região, Imagem 01 e imagem temática de referência. Fonte: autoria própria.
TABELA 3 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 01 Segmentação pixel a pixel Segmentação por região
Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 95,01% 99,09% 98,55% 93,63% 98,93% 98,23% Vegetação 93,95% 92,94% 93,61% 93,09% 90,98% 92,37% Outros 90,62% 95,68% 94,62% 87,96% 95,06% 93,57%
62 RESULTADOS
FIGURA 14 - SEGMENTAÇÃO DA IMAGEM 02
Segmentação pixel a pixel, segmentação por região, Imagem 02 e imagem temática de referência. Fonte: autoria própria.
TABELA 4 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 02 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 91,13% 98,94% 98,27% 90,72% 98,23% 97,59% Vegetação 97,62% 89,66% 96,34% 95,89% 88,62% 94,72% Outros 87,81% 98,87% 98,04% 84,79% 97,90% 96,91%
RESULTADOS 63
FIGURA 15 - SEGMENTAÇÃO DA IMAGEM 03
Segmentação pixel a pixel, segmentação por região, Imagem 03 e imagem temática de referência. Fonte: autoria própria.
TABELA 5 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 03 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 91,49% 99,20% 98,60% 91,85% 97,76% 97,30% Vegetação 97,05% 91,32% 95,53% 95,96% 90,20% 94,44% Outros 91,15% 98,21% 96,90% 87,76% 98,48% 96,48%
64 RESULTADOS
FIGURA 16 - SEGMENTAÇÃO DA IMAGEM 04
Segmentação pixel a pixel, segmentação por região, Imagem 04 e imagem temática de referência. Fonte: autoria própria.
TABELA 6 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 04 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 92,48% 99,63% 98,83% 92,70% 99,38% 98,63% Vegetação 97,57% 87,37% 94,60% 96,89% 86,12% 93,75% Outros 83,54% 98,15% 95,52% 80,97% 97,75% 94,73%
RESULTADOS 65
FIGURA 17 - SEGMENTAÇÃO DA IMAGEM 05
Segmentação pixel a pixel, segmentação por região, Imagem 05 e imagem temática de referência. Fonte: autoria própria.
TABELA 7 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 05 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 97,53% 99,37% 98,18% 98,78% 97,56% 98,34% Vegetação 94,42% 97,64% 96,61% 91,61% 98,08% 96,00% Outros 86,84% 97,90% 97,50% 83,09% 98,02% 97,49%
66 RESULTADOS
FIGURA 18 - SEGMENTAÇÃO DA IMAGEM 06
Segmentação pixel a pixel, segmentação por região, Imagem 06 e imagem temática de referência. Fonte: autoria própria.
TABELA 8 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 06 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 96,94% 99,47% 99,01% 96,53% 99,35% 98,83% Vegetação 98,43% 78,08% 87,24% 95,93% 81,85% 88,18% Outros 68,41% 99,38% 87,99% 73,97% 97,60% 88,91%
RESULTADOS 67
FIGURA 19 - SEGMENTAÇÃO DA IMAGEM 07
Segmentação pixel a pixel, segmentação por região, Imagem 07 e imagem temática de referência. Fonte: autoria própria.
TABELA 9 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 07 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 96,29% 99,57% 98,74% 95,60% 99,14% 98,23% Vegetação 95,39% 94,38% 95,01% 92,66% 93,45% 92,96% Outros 88,84% 96,87% 95,88% 84,04% 94,83 93,50%
68 RESULTADOS
FIGURA 20 - SEGMENTAÇÃO DA IMAGEM 08
Segmentação pixel a pixel, segmentação por região, Imagem 08 e imagem temática de referência. Fonte: autoria própria.
TABELA 10 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 08 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 85,64% 97,46% 95,07% 85,81% 96,44% 94,29% Vegetação 88,68% 94,63% 92,11% 94,37% 81,29% 86,84% Outros 87,19% 88,24% 87,85% 65,36% 92,69% 82,49%
RESULTADOS 69
FIGURA 21 - SEGMENTAÇÃO DA IMAGEM 09
Segmentação pixel a pixel, segmentação por região, Imagem 09 e imagem temática de referência. Fonte: autoria própria.
TABELA 11 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 09 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 82,49% 97,08 92,93% 82,96% 96,53% 92,67% Vegetação 80,37% 78,40% 78,95% 84,36% 73,02% 76,16% Outros 64,12% 84,95% 75,82% 55,15% 87,78% 73,46%
70 RESULTADOS
FIGURA 22 - SEGMENTAÇÃO DA IMAGEM 10
Segmentação pixel a pixel, segmentação por região, Imagem 10 e imagem temática de referência. Fonte: autoria própria.
TABELA 12 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 10 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 95,01% 98,73% 98,22% 91,57% 99,17% 98,13% Vegetação 91,66% 96,30% 93,30% 94,58% 90,76% 93,23% Outros 92,61% 93,27% 93,13% 85,96% 95,26% 93,25%
RESULTADOS 71
FIGURA 23 - SEGMENTAÇÃO DA IMAGEM 11
Segmentação pixel a pixel, segmentação por região, Imagem 11 e imagem temática de referência. Fonte: autoria própria.
TABELA 13 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 11 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 88,43% 99,08% 96,27% 87,50% 98,85% 95,86% Vegetação 96,93% 78,45% 84,35% 94,35% 79,35 84,14% Outros 70,14% 98,03% 86,38% 71,64% 96,50% 86,12%
72 RESULTADOS
FIGURA 24 - SEGMENTAÇÃO DA IMAGEM 12
Segmentação pixel a pixel, segmentação por região, Imagem 12 e imagem temática de referência. Fonte: autoria própria.
TABELA 14 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 12 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 91,63% 99,81% 97,16% 92,54% 99,61% 97,32% Vegetação 95,34% 91,06% 92,94% 95,95% 89,38% 92,26% Outros 83,01% 95,21% 92,31% 79,31% 96,21% 92,19%
RESULTADOS 73
FIGURA 25 - SEGMENTAÇÃO DA IMAGEM 13
Segmentação pixel a pixel, segmentação por região, Imagem 13 e imagem temática de referência. Fonte: autoria própria.
TABELA 15 - SENSIBILIDADE, ESPECIFICIDADE E PRECISÃO DAS CLASSES NA IMAGEM 13 Segmentação pixel a pixel Segmentação por região Classe Sensibilidade Especificidade Precisão Sensibilidade Especificidade Precisão Hidrografia 94,71% 99,67% 97,66% 96,54% 98,59% 97,76% Vegetação 95,76% 88,56% 90,95% 95,17% 85,96% 89,02% Outros 77,55% 97,80% 92,47% 67,44% 98,16% 90,08%