A cortical framework for invariant object categorization and recognition
23
0
0
Texto
Imagem
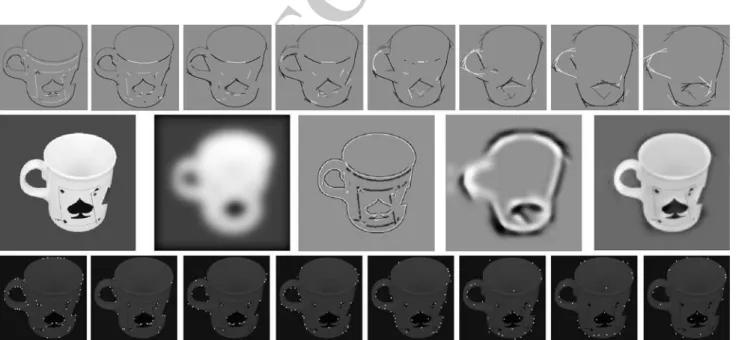
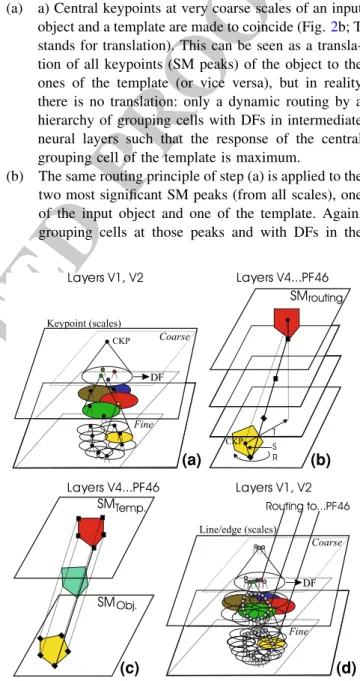
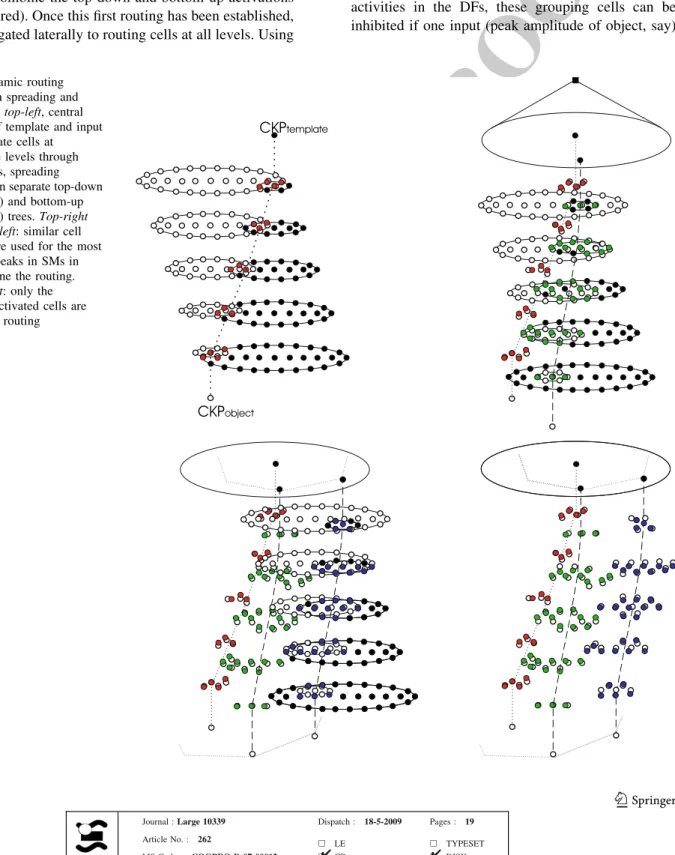

Documentos relacionados