A Container-based architecture for
accelerating software tests via setup
state caching and parallelization
Nuno Miguel Ladeira Neto
Mestrado Integrado em Engenharia Informática e Computação Supervisor: João Miguel Rocha da Silva, PhD
tests via setup state caching and parallelization
Nuno Miguel Ladeira Neto
Mestrado Integrado em Engenharia Informática e Computação
Approved in oral examination by the committee:
Chair: Prof. João Correia Lopes
External Examiner: Prof. José Paulo Leal Supervisor: Prof. João Miguel Rocha da Silva
In software testing, the scope of the tests can be represented as a pyramid, often called the “Test Pyramid” [31], which categorizes tests along 3 levels: Unit, Service, and End-to-end. The latter traverses the entire system attempting to simulate real user interaction and are the focus of this dissertation.
The referred problem in this project will target the long execution times typically associated with end-to-end tests. This challenging and interesting problem was encountered during the de-velopment of Dendro [7], a data management platform for researchers, developed at FEUP Info-Lab [13]. With over 2000 end-to-end tests and 4 hours to complete the pipeline, the developers found it hard to get quick feedback on their work and to integrate with CI tools like Travis.CI which typically have a timeout period of 1 hour.
Several tools have been developed in an attempt to optimize the execution times of tests and builds. Like: “CUT” [12]; “A Service Framework for Parallel Test Execution on a Developer’s Local Development Workstation” [35]; “Cloudbuild" [11]; and “Bazel” [2]. Although the first two target unit testing and the last two were designed to optimize builds, they all provide interest-ing solutions regardinterest-ing time optimization. Some of these design solutions can be considered and adapted for optimizing local end-to-end execution.
The approach implemented will: 1. accelerate end-to-end tests by using a setup caching mech-anism. This will prevent repetition patterns at the beginning of every end-to-end test by creating and saving the state previously; 2. parallelize the tests by instantiating multiple namespaced en-vironments. This would take advantage of the currently under-utilized CPU and I/O resources, which can only run a single build at a time.
This dissertation aims to: develop or deploy a framework to improve the execution times of end-to-end tests; successfully completing the test stage under 1 hour so that common CI tools do not report timeout failures; publish a research paper on container-driven testing.
The evaluation will be carried out through experiments with the large set of end-to-end tests for Dendro, running on the same hardware, and comparing the execution times with and without the developed solution.
After a successful implementation, the tests proved that it is possible to reduce execution times by 75% only by implementing setup-caching. By introducing parallelization with 4 instances, the times can be further reduced by 66%. This solution converts a conventional run that takes 4 hours and 23 minutes to a run that takes 22 minutes with setup-caching and 4 parallel instances.
Keywords: DevOps, software testing, pipelines, end-to-end tests, setup caching, parallelization, containers, Docker
Nos testes de software o escopo dos testes pode ser representado por uma pirâmide, também vulgarmente conhecia como a “Pirâmida de Testes” [31], a qual categoriza os testes em de 3 níveis: Unitários, Serviço e End-to-End. Estes últimos percorrem todo o sistema, procurando simular interacções reais do utilizador. Serão o foco desta dissertação.
O problema referido neste projecto tem como objetivo o problema do longo tempo de exe-cução tipicamente associada aos testes end-to-end. Este desafiante e interessante problema surgiu aquando do desenvolvimento do Dendro [7], uma plataforma de gestão para investigadores, de-senvolvida no Infolab [13] FEUP. Com cerca de 2000 testes end-to-end e 4 horas para concluir a pipeline, os programadores começaram a ter dificuldades para ter rápido feedback no trabalho desenvolvido. Para além disso, a integração com plataformas de CI ficaram cada vez mais difíceis visto que tipicamente têm um intervalo de timeout de cerca de 1 hora.
Várias ferramentas foram desenvolvidas numa tentativa de otimizar os tempos de execução de testes e builds. Por exemplo: “CUT” [12]; “A Service Framework for Parallel Test Execution on a Developer’s Local Development Workstation” [35]; “Cloudbuild" [11]; e “Bazel” [2]. Apesar de as duas primeiras terem como alvo testes unitários e as duas últimas terem sido desenhadas para otimizar builds, todas propõem soluções interessantes para otimizar tempos de execução. Algumas delas podem ser consideradas e adaptadas para otimizar execução local de testes end-to-end.
Espera-se que a abordagem consiga: 1. acelerar os testes end-to-end através do uso do mecan-ismo de setup caching. Isto irá prevenir a repetição de padrões no início de cada teste através da persistência do estado numa fase prévia. E 2. paralelizar os testes através do instanciamento de containers nomeados. Isto tirará vantagem de possíveis recursos de CPU e I/O não utilizados, os quais, neste momento, só executam uma build de cada vez.
Esta dissertação procura: desenvolver e criar uma framework para melhor a execução local dos testes end-to-end; Completar com sucesso a fase de teste em menos de 1 hora de modo a que as típicas ferramentas de CI não reportem falha por timeout; publicar um artigo relacionado com execução de testes orientado a containers.
A avaliação vai ser executada através de várias experiências tendo como base a grande quanti-dade de testes end-to-end do Dendro. As experiências irão correr na mesma máquina e comparar os tempos de execução com e sem a solução desenvolvida.
Depois de uma implementação bem sucedida, os testes provaram que é possivel reduzir os tempos de execução em cerca de 75% apenas por implementar setup-caching. Ao introduzir par-alelismo com 4 instâncias, os tempos são reduzidos em mais 66%. A solução converte uma ex-ecução convencial que demora 4 horas e 23 minutos numa que demora apenas 22 minutos com setup-caching e 4 instâncias paralelas.
Palavras-chave: DevOps, teste de software, pipelines, testes end-to-end, caching de setup, par-alelização, containers, Docker
In this section, I will give my acknowledgements to everyone that helped during the course of the last five years and this dissertation.
First I would like to give a special thanks to my supervisor, João Rocha da Silva. He is an example of what a true supervisor should be. Always available to help, charismatic and organized. Throughout the dissertation process, he provided multiple enlightening meetings that were full of creative ideas and solutions. The results of this dissertation would not be the same without his guidance.
I would also like to thank my family. Even though they do not fully understand the topics of the course and my struggles, they were always supportive and never stopped believing in me. Without their inexhaustible support, I wouldn’t be here in the first place.
Finally, I would like to thank all my former colleagues. Those colleagues, which are now close friends, provided a pleasant environment—both academic and personal—where we shared both our problems and happiness. It was key to look forward and finish this cycle.
Nuno Neto
Funding Acknowledgments
This work is financed by the ERDF – European Regional Development Fund through the Operational Programme for Competitiveness and Internationalisation - COMPETE 2020 Programme, and by National Funds through the Portuguese funding agency, FCT - Fundação para a Ciência e a Tecnologia, within project POCI-01-0145-FEDER-016736.
Theodore Roosevelt
1 Introduction 1
1.1 Context . . . 1
1.2 Motivation . . . 1
1.3 Objectives . . . 2
2 Background and State of the Art 5 2.1 Software quality assurance . . . 5
2.1.1 Levels of tests . . . 6
2.1.2 Black box testing vs. white box testing . . . 7
2.1.3 The test pyramid . . . 8
2.1.3.1 Unit tests . . . 8
2.1.3.2 Service tests . . . 8
2.1.3.3 End-to-end tests . . . 9
2.1.3.4 Test environment virtualization . . . 9
2.1.4 Structure of a test . . . 9 2.1.5 TDD and BDD . . . 10 2.1.6 Continuous integration . . . 10 2.1.7 Continuous delivery . . . 12 2.1.8 Continuous deployment . . . 12 2.1.9 Pipelines . . . 12
2.2 Virtual environments for automated testing and deployment . . . 12
2.2.1 Virtual machine architecture . . . 13
2.2.2 Container-based architecture . . . 15
2.2.2.1 Orchestration . . . 16
2.2.2.2 Applications . . . 16
2.2.3 Virtual machines vs. containers . . . 18
2.3 State of the Art . . . 19
2.3.1 Discussion . . . 23
3 Approach 25 3.1 Setup caching . . . 25
3.1.1 Test execution behaviour with setup caching with 3 distinct tests . . . 31
3.2 Test parallelization . . . 35
3.3 Integration tool . . . 39
4 Implementation 41 4.1 Goal, tools and frameworks . . . 41
4.2 Docker-mocha . . . 43
4.2.1 Tests and setups file . . . 44
4.2.2 Compose file . . . 45
4.2.3 Execution and options . . . 45
4.3 Architecture . . . 47 4.3.1 Runner . . . 47 4.3.2 Manager . . . 49 4.3.3 DockerMocha . . . 49 4.3.4 NoDocker . . . 50 4.3.5 Other . . . 50
4.4 Class execution architecture . . . 50
4.5 Graph extraction . . . 51
4.6 Issues . . . 51
4.6.1 Docker for Windows and macOS . . . 51
4.6.2 Ambiguous networks . . . 55
4.6.3 No-volumes images . . . 55
5 Validation and Results 57 5.1 Preliminary test prototype . . . 57
5.2 Dendro: a research data management platform . . . 58
5.2.1 Dendro technology stack . . . 58
5.2.2 Current CI pipeline . . . 60
5.3 A preliminary benchmark . . . 60
5.4 Evaluation experiment . . . 61
5.5 Results . . . 63
5.5.1 Total execution time . . . 64
5.5.2 CPU usage . . . 65 5.5.3 Memory usage . . . 66 5.5.4 Disk read . . . 67 5.5.5 Disk write . . . 68 6 Conclusions 71 A Appendix 73 References 81
2.1 Test Levels [42] . . . 7
2.2 Test Pyramid by Sam Newman [31, p. 234] . . . 8
2.3 Structure of a test by Gerard Meszaros [27] . . . 9
2.4 Typical build pipeline . . . 13
2.5 Comparison between Virtual Machines and Docker Container based architecture [16] 18 2.6 Comparison the different existing solutions for test execution optimization . . . . 24
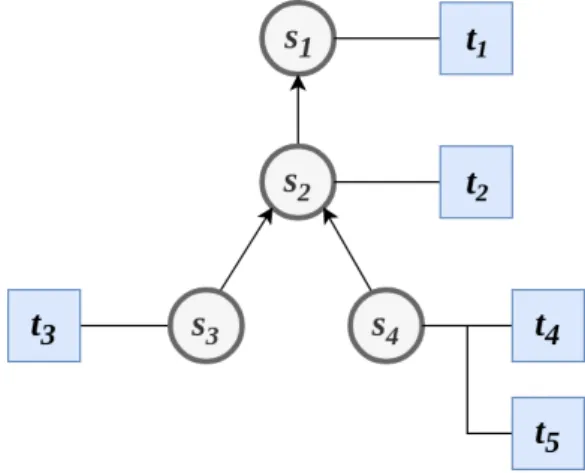
3.1 Example of test dependency tree . . . 26
3.2 Environment State before t1. . . 31
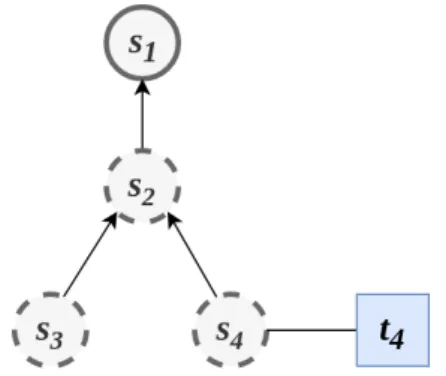
3.3 Environment State before t4. . . 33
3.4 Environment State before t2. . . 33
3.5 Estimated end-to-end tests without state caching . . . 36
3.6 Estimated end-to-end tests with state caching . . . 36
3.7 Environment before parallel approach . . . 37
3.8 Environment after parallel approach . . . 38
3.9 Expected CPU usage after parallelization . . . 38
4.1 Docker-Mocha Architecture . . . 47
4.2 Setup Class . . . 50
4.3 Graph Example . . . 52
4.4 Docker in Windows Architecture . . . 53
5.1 Application Prototype Dependencies . . . 57
5.2 The current CI pipeline for Dendro . . . 60
5.3 Specifications of the test machine . . . 61
5.4 Total dependencies passing . . . 62
5.5 Hardware specifications of the test machine . . . 63
5.6 Software Configuration . . . 63
5.7 Time Gains . . . 65
5.8 Average CPU usage throughout the test runs . . . 67
5.9 Memory Used . . . 67
5.10 Disk Read . . . 68
5.11 Disk Write . . . 69
A.1 Docker-Mocha Class . . . 80
4.1 Additional parameters for each setup . . . 44
4.2 Additional parameters for each test . . . 44
4.3 Additional flags fordocker-mocha. . . 46
4.5 Environment and Example for the modes . . . 48
5.1 Evaluation Scenario with Results . . . 63
A.1 Functions of the Manager . . . 73
A.2 Fields of Docker Mocha . . . 76
A.5 Methods of DockerMocha . . . 77
A.3 Possible arguments indocker-mochacalls . . . 79
API Application Programming Interface
ASE Automated Software Engineering Conference BDD Behaviour-Driven Development
CD Continuous Delivery CDdep Continuous Deployment CI Continuous Integration CPU Central Processing Unit DSL Domain Specific Language DevOps Development Operations HDD Hard Disk Drive
I/O Input and Output IoT Internet of Things
JSON JavaScript Object Notation NPM Node Package Manager OS Operating System
PTP Predictive Test Prioritization SDK Software Development Kit SSD Solid-State Drive
TDD Test-Driven Development UI User Interface
UI User interface
YAML YAML Ain’t Markup Language
Introduction
This chapter is dedicated to introducing this dissertation. First, it will be presented the context where it is inserted, followed by the motivation behind it and the objectives.
1.1
Context
This dissertation can be placed in software engineering research. More specifically, in the soft-ware debugging sub-area. It is also inserted in an area of engineering softsoft-ware called “DevOps” (Development Operations) [8]. The main goal of DevOps is to support all software development phases with automation and monitoring practices.
1.2
Motivation
With the ever-increasing complexity of software development, the automation of builds and the presence of a comprehensive test suite is essential. Not only because it is increasingly necessary to verify software reliability, but also because developers should maintain software quality at higher levels of development complexity.
Testing is an essential aspect of software production. Not only it allows the developers to understand the isolated bugs that they introduce but it also allows them to understand how reliable and sturdy the system is.
This is only possible if the software is covered by a good test suite. Inside these test suites, there are many types of tests: tests with a high scope and test which are very isolated and fast (Unit tests). The higher-scoped tests (also known as End-to-end tests) validate the entire scope of a system. They usually simulate entire user interactions. A consequence of this high scope is the execution time, they tend to consume a considerable amount of time.
The good practices of software engineering state that in a test suite there should plenty of unit tests, and only the essential amount of End-to-End tests. If the development feedback cycle starts to suffer due to the amount of time the End-to-End tests consume, then they should be converted and replaced with more lower scope tests [31, p. 240]. But what if the developers need to have
a high amount of End-to-End tests anyway? What if they need to have this high quantity of high scope tests to validate the reliability of the system? What tools are there to allow the developers to locally optimize the execution of end-to-end tests?
This work tackles the optimization of local builds where end-to-end tests are numerous and take a long time to run. Our hypothesis can be expressed along the following lines.
It is possible to reduce the overall execution time of service and end-to-end tests through setup state caching and parallel execution mechanisms, provided by sets of isolated containers.
To prove the previous hypotheses, the following research questions should be proved:
1. RQ1: Is it possible to reduce build and test execution times by using containers with state caching and/or parallelization?
2. RQ2: How does the execution time scale with the number of parallel test instances? With the research question 1it is intended to understand it is possible to reduce the time it takes to execute the test phase of software projects with the introduction of the two mechanisms enumerated.
With the research question 2 it is intended to understand if the parallelization mechanism scales linearly with a negative slope or with an inverted yield by incrementing the number of parallel instances.
1.3
Objectives
In order to solve the given problem, different approaches will be explored and combined to create a complete solution. The different objectives are listed below:
1. Accelerate end-to-end tests by using a setup caching mechanism.
2. Parallelize the tests to take advantage of unused CPU and I/O resources in order to speed up builds.
3. Ensure state isolation of separate tests implementing each in different microservice groups. The first objective relates to the optimization of end-to-end tests using a setup caching ap-proach. When starting an end-to-end test, there is usually a setup phase in which several services need to be initialized and the system put into a certain state—a process that can consume a con-siderable amount of time. Currently, this phase is constantly repeated for each test.
What the Setup Caching approach will do is to create a state and save it when the setup phase of a test is concluded. The next tests will verify if the given state exists and load it if so. Using this method, the setup phase can be reduced by simply loading saved states. Repeating this process for each test allows saving a lot of time.
The second objective is to take advantage of unused CPU and I/O resources by using a parallel approach. When running tests, usually only a single process is created. It is in this process that the sequence of tests will be executed. However, this process only runs in one CPU core. Multiple other CPU cores are probably available. If these CPU cores are used to run other test sequences then the overall time of the test execution can be reduced.
The third objective is to use containers to isolate tests. When running tests in parallel, concur-rency problems and race conditions might become a serious issue. One way to solve this drawback is to use containers. Containers allow the isolation of any service from the current machine. By initializing multiple containers and running the tests in each isolated container, no more concur-rency problems or race conditions should occur. Also, using containers it is a good way to manage the multiple stages of the build pipeline.
Background and State of the Art
This chapter is an overview of existing works that relate to the subject of this dissertation. The research that supports this state of the art was structured based on the initial concept idea of this dissertation.
The main focus of this dissertation is the implementation of setup caching and parallelization in the test phase of a given project pipeline.
The first section will discuss if it is possible to obtain software quality assurance when applied in Agile Methods. Different standards will be presented and discussed. Starting with levels of testing, followed by a comparison between Black Box testing and White Box Testing. Next, the concept of test pyramid complemented with the types of tests, according to their scope is introduced; the structure of a test, as well as the differences between Test Driven Development and Behaviour Driven development is discussed next. Finally, the concepts of Continuous Integration, Continuous Delivery, Continuous Deployment and Build pipelines are introduced at the end.
The second section will discuss different infrastructures for automated testing and deployment. Each type of infrastructure will be supported with multiple platforms and solutions supporting the given architecture.
The third section focuses on the main approaches used in order to optimize test execution. First, research of different scientific papers will be discussed, followed by different existing tools. After that, we present a comparison table with an evaluation and comparison between all studied solutions. A discussion section is included at the end, which lists the multiple conclusions derived from this research.
2.1
Software quality assurance
The rate at which software is produced nowadays creates a necessity to ensure software qual-ity. Sequential methods, such as Waterfall, can not provide support for continuous integration, development and delivery when creating software. To cope with rapidly changing requirements, agile methods were introduced, aiming to accelerate software development. However, with this speed-up comes the necessity of equally faster software validation processes.
The article “Software Quality and Agile Methods” [28] identifies multiple techniques that are used to ensure software quality in agile methods. These methods belong in different development phases. For the Requirements and analysis phase, techniques like System Metaphor, Architectural Spike and On-site customer feedback can be used. In the implementation phase, different tests can be written, or, in order to directly review the code, techniques like Refactoring, Pair Programming and Stand Up meetings help to identify early bugs. Finally, in the integration phase using Contin-uous Integration and Acceptance Testing techniques can be used to test the overall quality of the system before a release or a direct integration with existing instances. After a release, there are other ways to certify software quality. Having, for example, direct Customer Feedback can be used to understand customer needs, missing features or unplanned interactions. In the context of this dissertation, the main focus is the Integration Phase, and more specifically Continuous Integration techniques, which will be addressed later in section2.1.6.
Although the topic of this dissertation is not primarily about the importance of software quality assurance, it is essential to understand that it is because of it that the problem addressed in this dissertation exists. To ensure software quality, developers are often faced with other problems— particularly, the validation phase itself, which can take a considerable amount of time. Such a long time between test execution is undesirable, as it brings unforeseen consequences like not having feedback in good time or breaking the DevOps continuous integration and development pipeline.
It is also important to address that Agile Methods differ from Waterfall methods by iteratively repeating the implementation and integration phases. While in Waterfall methods these phases are sequential, in Agile they can be repeated multiple times in order to adjust the changing require-ments.
2.1.1 Levels of tests
The V-model [42] defines multiple levels of tests when validating software. The model integrates different levels for the development phase, but this section will focus on the Testing phase only. The V-Model is a standard model to follow when using Waterfall Methods. However, the Testing phase of the V-Model can be applied both in Waterfall and Agile Methods; the only difference is that in Waterfall this phase will only occur once. In Agile, however, this process can be repeated multiple times along the multiple development iterations.
An illustration of the V-model can be seen in figure2.1. The arrow defines the elapsed time along with the implementation phase. It starts with the creation of Component Tests all the way to the Acceptance Tests. Next, we will detail each of these levels of tests.
Component Tests test the software units. They can also be defined as Unit tests. Their main focus is to test the software methods, modules or classes.
Integration Tests test the integration between multiple subsystems. Their main focus is to validate whether the produced software is able to integrate with other software modules in order for them to cooperate with each other without introducing faults.
System Tests test the overall system. Their main focus is to validate the correct bahaviour of the system after every subsystem is successfully integrated. Inside System testing, there are several
Figure 2.1: Test Levels [42]
techniques that allow the validation of the system. One of them is Regression testing. Regression testing is a common technique that will run previously executed tests in order to verify if the new changes did not introduce bugs.
Acceptance Tests cover the release of the system. They can be carried by the customer and their main focus is to validate if the released software is up to the customer requirements and needs.
2.1.2 Black box testing vs. white box testing
Black box testing, also known as Specification-Based testing [17], is a type of test that hides the test code from the user by simply feeding it with input and analyzing the output. Using black-box testing has some advantages such as being independent of how software is implemented and that the testing can occur in parallel with the implementation. However, it also brings some disadvan-tages such as the existence of redundancies between test cases.
White box testing, also known as Code-Based testing [17], is another type of test case. This one allows the tester to see the implementation that would be inside a black box test. By using this method, it is possible to obtain test coverage metrics. However, using a white-box method, the relation between the implementation and tests is no longer independent.
Both methods can be used in different perspectives and contexts, if there is a need to create software-independent tests, black-box testing is the best approach. If the intent of the test is to analyze the system implementation, then white-box testing is the best approach.
There is no relation between these two testing methods and the types of test referred in the test pyramid.
2.1.3 The test pyramid
In software testing, the scope of the tests can be represented as a pyramid, otherwise called as the “Test Pyramid” [31]. This pyramid categorizes tests along 3 levels. On the bottom reside the tests with more isolation. On the top, tests with more confidence in the system. A representation of this pyramid can be observed in figure2.2.
In the next sub-sections, it will be discussed in detail each level of the pyramid.
Figure 2.2: Test Pyramid by Sam Newman [31, p. 234]
2.1.3.1 Unit tests
This type of test resides in the lowest level of the pyramid. It provides the highest level of isolation, helping pinpoint the root cause of unexpected behaviours. They typically test a function or a method very quickly.
These tests exist to give very fast feedback and they help to find the majority of bugs given their isolation and small scope. They are usually written by the same developer that designed the function/method.
These tests can also be seen as validating small parts of a given service. They do not test services, but only some of its isolated and small components.
2.1.3.2 Service tests
A service test, as the name implies, tests an entire service by bypassing the UI (User Interface) layer. They provide a higher level of abstraction but less isolation than unit tests.
The main purpose is to validate and find bugs in a single service, it might prove useful when testing against a multiple service platform.
In terms of performance, they can be as quick as unit tests, depending on how simple the service is. E.g: it can be a simple service; a service running through a network; a service using a database; a service being virtualized or containerized, etc.
2.1.3.3 End-to-end tests
End-to-end tests are tests running against an entire system, attempting to simulate real user inter-actions. When running end-to-end tests it is necessary to set up the entire system including setting up the services, databases, UI’s, etc.
When an end-to-end test passes, there is a high level of confidence the system works. However, when it fails, it is more difficult to identify the root cause of the malfunction.
Before the actual tests and assertions are verified, these tests tend to take the highest amount of time to execute. It is recommended to reduce the number of these tests since they might slow the development pipeline.
2.1.3.4 Test environment virtualization
It is common practice in Software Testing to isolate or virtualize the testing environment, and there are multiple reasons for this tendency [31].
The first is the possibility of tests creating defects in particular running environments. They might even fail because they are running in a particular environment that is not into accordance with the test environment specifications. Another reason is the need to run the same tests across multiple operating systems.
For this, virtualization and isolation strategies are usually required by the developers or De-vOps team to run this kind of tests.
2.1.4 Structure of a test
A test can be seen as a series of phases in order to report the validation status of a given feature. The author Gerard Meszaros in his book “Xunit Test patterns” talks about the Four-Phase Test Pattern [27]. This pattern is displayed in Figure2.3.
Figure 2.3: Structure of a test by Gerard Meszaros [27]
The initial phase, Setup, is tasked with mounting the required specifications of the test envi-ronment. The Exercise phase will execute the given test in the previously configured envienvi-ronment. The Verify phase is where the outcome is validated with the expected values; finally, the last phase, Teardown is a shutdown phase where the original state of the system, prior to the test, is restored.
2.1.5 TDD and BDD
Test-driven development (TDD) is a testing methodology that developers can adopt when building software. Instead of writing code, they first write a test that initially fails (since the code is not written yet) describing the given feature. Next, they write enough code to make it pass. That way, the developers will be encouraged to write clear, better-designed, easier-to-maintain code with lower defect counts. However, there are some disadvantages with TDD such as developers having difficulty knowing where to start; developers becoming focused on small details; and the number of unit tests becomes difficult to maintain [41,3].
Behaviour-Driven Development (BDD) is a set of practices that help software development teams create and deliver better software and faster. It is a common language based on structured sentences that aim to simplify the communication between the development team and other mem-bers like customers or project owners. BDD has several advantages, such as the reduction of waste by focusing on developing the needed features only. Another feature is the reduction of costs given the reduction of bugs discovered by tests. Additionally, it is possible to introduce easier and safer changes given the easier communication with non-developer personal. This ultimately leads to faster releases. Some disadvantages are present when using BDD as well: it needs high business commitment and cooperation; it is suited mostly for Agile development; does not work well when the requirements analysis is done by the business team alone; might lead to difficult to maintain tests [41].
The use of TDD or BDD in a project depends on the team, the project itself and the additional people associated with the project. They must understand the advantages and disadvantages of both processes and create trade-offs between them in order to understand if any of them adds value to the project development.
2.1.6 Continuous integration
Continuous integration (CI) is a set of techniques that support software development and deploy-ment and is especially relevant in agile environdeploy-ments. It provides support to teams with a consid-erable member size, high project complexity and rapidly-changing requirements.
By building, testing and integrating the newly added or changed code to the version control repository, continuous integration provides fast feedback and synchronizes the whole development team about the current state of the project. In order for this process to work, it is usually backed up by a remote server, also known as the integration server. It is this server that is responsible for checking out the new version, building and testing it [8]. The following sections describe some of the existing Continuous Integration tools.
Codacy
Codacy1is a continuous integration that automatically reviews code, it provides feedback regard-ing security, code coverage, code duplication and code complexity. It works in an online platform
with support for cloud services and 28 different languages. Besides the free Startup version, it also has available a Pro and Enterprise version with additional features.
Travis.ci
Travis.ci is an open-source, free service to test and deploy projects providing full continuous integration and deployment support. By updating the project to a new version into a given ver-sion control repository, travis.ci can be triggered in order to build and test the new changes [4]. If all stages succeed, the new code can be merged, deployed and reported using additional ser-vices. Some services available include virtualization, containerization and pre-installed databases. An additional Rest API is available in order to retrieve related information regarding builds and pipeline status.
Teamcity
Teamcity is a continuous integration and deployment server developed by JetBrains2. It supports
several features like automatic detection of tool versions, framework testing support, code cover-age, static code analysis, etc. Provides additional interoperability between different version control services and is able to integrate between other 3rd party tools like cloud providers [25]. It has a free service, but, additional paid licenses are available which provide other premium features. Bamboo
Bamboo3is a continuous integration and deployment server developed by Atlassian4. It supports multi-stage build plans, triggers and agent assignment. It can run tests in parallel and automate process providing faster feedback. Finally, it is also able to deploy the project automatically between several distributors. Only paid subscriptions are available in order to use Bamboo. Jenkins
Jenkins is a free and open-source automation server providing hundreds of plugins to support building, deployment and automating projects. It has great support for multiple Operative Sys-tems and hardware, proving that it is an excellent solution when one of the problems is dynamic requirements. It is able to distribute work across multiple machines allowing tests, builds and deployment to be faster. In order to define pipelines and other tasks, the users can make use of the Jenkins DSL or Groovy languages. These languages allow Jenkins to encapsulate specific functionalities by parsing unique keywords [23].
In order to write the pipelines, the users must create and define them in a Jenkinsfile or im-port other external files written using the Jenkins DSL. By using external files, users can manage multiple jobs, track history, check code differences, etc.
2JetBrainshttps://www.jetbrains.com/
3Bamboohttps://www.atlassian.com/software/bamboo 4Atlassianhttps://www.atlassian.com/
With Jenkins, the pipelines can be easily structured into multiple steps and the users can be notified of their status via integration tools. Additional support for exception handling is available with simple try-catch-finally blocks.
Jenkins also provides an intuitive and simple to use interface called Blue Ocean. In Blue Ocean, the graphical interface displays the pipeline structure, current stage and progress. It pro-vides logs in order to be easier to track the information regarding the progress of the pipelines. And, additionally, a basic visual editor is available as well.
2.1.7 Continuous delivery
Continuous Delivery (CD) is a set of principles that complement continuous integration. Instead of only making sure the software can be integrated and merged with a previous version, continuous delivery allows the new changes to be deployed and create a new version to be released [8].
2.1.8 Continuous deployment
Continuous Deployment (CDep) is the complement of continuous integration and continuous de-livery. While CI only assures that the new software can be integrated with a previously exist-ing version and Continuous Delivery only assures the new changes can be deployed, Continuous Deployment is the act of actually deploying the new changes into a running and production in-stance [8].
2.1.9 Pipelines
A pipeline [31, p. 217–224] is a process, made up of different stages, running as a dependency net, with parallel and sequential steps. Each stage has a different job assigned.
It is very common to see a deployment pipeline in current software development projects. Current Continuous Integration, Development and Deployment tools are very useful when work-ing with considerable large teams and/or under agile methodologies.
A basic deployment pipeline typically comprises 3 distinct stages. The Build Stage, where the current developed project is built and checked for setup errors: the Test stage, were all the project undergoes a considerable amount of tests of a different kind. These are the tests that will check the interaction with the software in order to detect implementation errors; finally, the Deployment stage is where the current version of the project is deployed to a machine ready to be used for the developers and end-users. It can also be used to upload to other build version control platforms.
In Figure2.4it is possible to see a representation of a typical Build Pipeline, with a beginning and an end. Also, with a build, test and deploy stage.
2.2
Virtual environments for automated testing and deployment
This section will provide detail on several infrastructures and approaches that can be used to automatically test and deploy software.Figure 2.4: Typical build pipeline
Local deployment is the easiest way of deploying software. Usually, it is only necessary to create shell scripts or even manually run tests and manually start the system. This method also works for remote machines, usually via Secure Shells. This practice, although trivial and easy to use, is not recommended when working with complex projects. Using this mechanism might ultimately result in the invalidation of the machine for other configurations, builds or setups. By installing new features and setting up the system, it is altering the operating system layer. The only solution in many cases is the re-installation of the entire operating system and consecutive installation of the platform and associated services from scratch.
Another problem when using local deployment is the fact that the deployment will become dependent on specific hardware and software configurations. In this case, it will depend on the software and hardware where the application is being deployed. Eventually, it will become harder to maintain the solution and deploy it across different environments.
Besides local deployment, another common solution is Virtual deployment. This solution al-lows the deployment software in disposable scenarios that are independent of the operating system and the physical hardware that they run on. There are two architectures that support Virtual de-ployment: Virtual Machine Architecture and Container-Based Architecture.
2.2.1 Virtual machine architecture
A virtual machine is a software that emulates an entire operating system on top of another oper-ating system. In the topic of virtualization, there are two concepts that need to be clarified: host and guest [31, p. 217–224]. The host is the native operating system that is installed and runs on the physical hardware. This “host” allows the instantiation of multiple “Guests”. Guests are also Operating Systems. However, instead of being originally installed in the physical machine, they are being emulated in order to run on top of the native operating system, hence the name, “Virtual Machines”. Another concept that needs to be clarified is the term: instance. When talking about an instance, it refers to a currently running virtual machine.
Hosts can have multiple Guests instantiated and supported via a module called Hypervisor [31, p. 217–224]. The Hypervisor can be seen as the supervisor of the multiple virtual machine in-stances. It is the Hypervisor that controls and manipulates the Guests and it is also the Hypervisor that is responsible for mapping resources from the physical machine to the virtual machine.
Instead of having different machines with native installations or having other operating sys-tems accessible via dual-boot methods, virtual machines make it possible to run and manage dif-ferent operating systems independently of the physical hardware configuration.
This infrastructure is very useful when wanting to use different operating systems in the same machine and at the same time. Also, any alteration done inside the virtual environment will not af-fect the host. A virtual machine provides the entire software support as if it was originally installed in a machine. It supports features like desktop environments, peripherals, hardware configuration access, etc. However, given the architecture nature of these virtual machines, they can consume considerable amounts of resources and time to start, run and execute.
Virtual Machines are interesting for continuous integration because they allow the CI process to become hardware and software independent. By using virtual machines as disposable build and test environments, the developers can use any machine that supports virtualization to install the test environment or deployment instance. This way, they become independent of the native operating system and do not harmfully modify the host.
In order to instantiate a virtual machine, a lot of resources must be allocated. Memory is immediately allocated and reserved for that instance, resulting in a shortage of memory capacity for the host and other possible Guests to work with. In a virtual machine, the entire operating system kernel is emulated resulting in higher processing load. In terms of storage, it is very similar to the memory process. The only difference is that storage becomes indefinitely allocated to that instance, even if is not occupied. Some virtual machines also emulate complete Desktop environments resulting in allocation for graphical resources and video memory.
Virtualbox
Virtualbox is a free open-source solution for virtualizing different Operating Systems. Developed by Oracle5, Virtualbox provides several features and supports virtualization for the most common operating systems. It provides high performance for both home and enterprise solutions [36].
Vagrant
Vagrant is a tool for building and managing virtual machines. It is free and open-source software developed by HashiCorp 6. It focuses on automation and attempts to improve setup time and production parity. It also provides portable work environments built on top of industry-standard technology [14].
VMware Workstation
VMware Workstation is a tool that provides cloud computing and virtualization of software and services. It is developed by VMware7and distributed in two different versions: VMware Work-station Player, free and allowing only one virtual machine to be instantiated; VMware WorkWork-station Pro, a paid solution with unlimited options and features. Besides creating and managing virtual machines it is also able to manage servers and virtual machines hosted in the cloud [46].
5Oraclehttps://www.oracle.com/index.html 6HashiCorphttps://www.hashicorp.com/ 7VMwarehttps://www.vmware.com/
2.2.2 Container-based architecture
Containers are the main approach to support microservices as a platform. A container is also a virtual machine but in a lower level of virtualization. Many simplifications are visible when comparing a Virtual Machine and Containers. The first visible simplification is the elimination of the Hypervisor. Instead of having the Hypervisor controlling and allocating resources, con-tainers initialize their own process space and live there. For the resource allocation process, it is the responsibility of the native operating system kernel. This simplification and relocation of responsibilities allow containers to have resources dynamically allocated. The memory no longer stays immediately allocated and is able to scale with the container needs. The same happens with storage as well [31, p. 217–224].
Usually, a container does not emulate an entire operating system, it reuses the native operating system kernel and it will only emulate what it is required in order to complete the task. Some features such as the desktop environment are not supported. This results in a middle ground be-tween a local machine and a virtual machine. A container provides the isolation and replaceability required for some operations that are also provided by the virtual machines, but it also enables the container to be very efficient in terms of resources and time, much like a local machine [31, p. 217–224]. In figure2.5 it is displayed a comparison between standard virtualization (Virtual Machines) and container-based virtualization. By the figure alone it is possible to understand just how simplified the container-based architecture is in comparison with standard virtualization.
Kubernetes
Kubernetes is an open-source system designed to automatically deploy, scale and manage con-tainerized applications, providing a software platform for a container-based architecture. It was originally developed by Google and is constantly being improved by the large community around it. One of the benefits of using Kubernetes is speed. Container software like Kubernetes needs to ensure that tools that move quickly also need to stay available for possible interaction. Another benefit is being able to scale without the need to increase the development operations team size. It is highly flexible; being able to run locally or in an enterprise environment. They can be inte-grated very easily with common continuous integration tools and have another important feature: the self-healing system. Kubernetes containers are continuously taking action to make sure they match the desired state every instant [15].
Docker
Docker is another tool that provides a solution for container-based architectures. It is developed by Docker, Inc.8 which provides a free open-source version, and an additional paid version, Docker Enterprise, aimed at large corporations. By using Docker developers can create their containers more easily using pre-existing container images available in the huge repository of Docker Hub.
Docker increases productivity and reduces the time it takes to bring applications to the market. It is also easily integrated with common continuous integration tools and runs in every standard operating system [39,24,1] [31, p. 217–224].
An important aspect when using Docker is the familiarization with Dockerfiles. A Dockerfile is a file that describes the steps required to create the image in question. Writing a Dockerfile usually starts by specifying the image, version and revision, in which the new image will be based from. Additional parameters allow to register environment variables, specify different users, change the working directory, run shell commands, etc [24].
2.2.2.1 Orchestration
“Orchestration is the automated configuration, coordination, and management of computer sys-tems and software” [10]. This kind of tool is usually used when automating tests and deployment. They are tools that instantiate and configure all the services needed in order to run the platform and tests in order to communicate with each other. These configurations can be port numbers, I/O locations, virtual machines or container initialization. They can be seen implemented in multiple solutions, being one of them, the container-based architecture solutions.
Vagrant orchestrate Vagrant orchestrate9 is a Vagrant plugin that allows orchestration deploy-ments to already provisioned servers. To use this plugin the developers are required to write a file in which they specify all the configuration desired to instantiate the platform using the different services. It supports a cross-platform deployment environment.
Docker Compose Docker Compose is a tool for defining and running multi-container Docker applications in a coordinated manner. The users are required to write a configuration file in which they specify all the configurations needed for the different services as well as links in order to communicate between them [39].
2.2.2.2 Applications
In this paragraph, it will be discussed multiple real applications for using containers. First, the concept of microservices will be presented, which is one of the most common applications of containers. Then other research documents will be presented that makes use of container-based architectures to solve multiple problems.
Given the high level of virtualization needed to instantiate a virtual machine, it might be inef-ficient to run the continuous integration and deployment process using virtual machines. Another concept called “Microservices” helps to surpass this inconvenient. When working with microser-vices problems like resource allocation and full kernel emulations cease to exist. They can be seen as simple processes that only run the needed emulated operating system components in order to make a given service to work [31, p. 15–34].
“Microservices are small, autonomous services that work together” [31, p. 15–34]
Microservices, as the name implies, are small services that interact and work together. They are usually very resilient, scale very well, are easy to deploy, help maximize organizational align-ment and are an easy solution to implealign-ment when considering the replacealign-ment of a previous exist-ing monolithic one. They have two key characteristics: they are small—in order to focus on doexist-ing one thing well—and are completely autonomous [31, p. 15–34].
When referring to microservices as being small it is important to understand what is small in this context. It depends a lot regarding the service that is being considered. A good implementation of a service downsizing (into multiple microservices) happens when each microservice starts to gain some independence and becomes easier to maintain. When the management complexity of having several moving parts distributed between several microservices increases, then the desired limit was reached [31, p. 15–34].
Another key characteristic of microservices is their isolation. This is an important key to describing a microservice. Typically, they can be deployed as an isolated service or might be their own operating system process. They typically have an exposed application programming interface (API) in which they use network calls in order to communicate with each other. Isolation is also very important in a microservice. A microservice must have the ability to deploy and change itself without changing anything else [31, p. 15–34].
Studies have been carried out to determine if it is possible to leverage the microservice ar-chitecture with Docker [26]. Despite identifying some limitations, this research concluded that Docker, when combined with with other tools, is able to improve efficiency.
An interesting idea to use containers is to implement an Elastic Cloud platform. DoCloud [18] attempts to create one using Docker and is composed of several sub-systems, including a Load Balancer, the Monitor and Provisioning module, and the Private Docker Registry. This solution proved to be quite useful when implemented in platforms that are very inconstant regarding their users’ needs. In particular, it scales very well in cases of daily peaks or unexpected peaks. It also proved to work very well in an environment where resource requirements remain stable.
Another document [37] shows an application of Docker in a distributed IoT system. Several low-level hardware components with support for Docker virtualization create a complex system that is able to provide reliability, system recovery and resilience.
Another example of a real application that makes use of Docker is Dockemu [44]. Dockemu is a network emulation tool that uses Docker as the virtualization framework. The tool is able to emulate both wired and wireless networks. Although there is still room for improvements, it turned out to be efficient and accurate given the Docker virtualization architecture.
The Docker application described in [35] is relevant to the context of this dissertation. It is a framework that runs unit tests in a parallel environment by using isolated Docker containers. This document will be better detailed in the next sub-section.
2.2.3 Virtual machines vs. containers
Figure2.5represents a comparison between a common virtual machine architecture and the Docker architecture. Docker is a tool with a container-based architecture. One of the visible differences is the replacement of the Virtual Machines Hypervisor with the Docker Engine. The Docker Engine is the bridge between the User interface and the Containers. It will receive input from them and interact with the containers accordingly.
Another important difference is regarding the containers. The guest OS present in the Virtual Machines is removed. The containers will use the host operating system layer and will be executed as simple processes.
Figure 2.5: Comparison between Virtual Machines and Docker Container based architecture [16] The document [38] further compares Virtual Machines and Containers. The comparison was made by testing multiple benchmarks for an application running in a Virtual Machine and in Con-tainers. In terms of responses, the Containers were able to process 306% more requests. Making them more useful to handle peaks. In terms of memory, the study showed that the containers are able to reduce 82% of memory utilization comparing with Virtual Machines.
Regarding provisioning, it was observed that containers are more flexible and are able to pre-pare and serve at higher speeds when compre-pared with virtual machines. These speeds also reflect the failover mechanism. By consuming less time to boot up, containers provide a more reliable and faster recovery mechanism.
Not everything is perfect for containers, since the comparison also showed that some bench-marks favoured Virtual Machines; It is the case of inter-virtual machine communication. Virtual Machines proved that they are better when there is a need to perform several heavy tasks inside the same isolated environment.
2.3
State of the Art
As stated and discussed in previous sections, testing is essential in software engineering projects. If the testing process takes to much time, it might become a bottleneck in the development process, which is utterly undesirable. Multiple solutions are available. However, not all of them solve specific problems. This section will review several solutions and understand in which specific cases they are useful.
A possible solution comes from the work “Test case permutation to improve execution time” [43], which focuses on studying how the cache misses affect test execution time. The authors realized that the execution priority affected the time it took to run the test suite. This happens because if several different tests are run in a non-orderly fashion, the cached data for specific instructions will expire before a similar test will be executed. In theory, if similar tests are run consecutively, the cached data will be reused and the overall execution time will be faster. They propose an algo-rithm that studies the similarities between the unit tests and attempts to minimize execution time by grouping similar tests and leaving tests with more dependencies for last. The study concluded that by reordering test execution in order to reduce cache misses does in fact matter. The study showed a boost of up to 57% in the execution time in local execution.
Another proposed solution comes from the paper “Optimizing Test Prioritization via Test Dis-tribution Analysis” [6]. This project proposes a PTP (Predictive Test Prioritization) technique based on machine learning. It is mainly focused on projects that constantly use regressive testing techniques. Its main approach is to reorganize test execution in order to detect failures earlier and to provide faster feedback. To evaluate and reorganize the unit tests order, it uses three heuristics: test coverage; testing time; coverage per unit time. These heuristics are only to study and evaluate each test. They will help develop the prioritization order when applied with the different Algo-rithms proposed. In terms of AlgoAlgo-rithms, they propose three different algoAlgo-rithms based on three types of prioritization techniques:
• Cost-unware refers to techniques without balancing testing time and other factors • Cost-aware which balances testing time and other factors;
• Cost-only refers to techniques that only balance testing time.
To evaluate the proposed scenario, over 50 GitHub open-source projects were tested in a local execution environment. The results proved that in general, the developed model was able to suc-cessfully predict the optimal prioritization algorithm for the given project.
“Prioritizing Browser Environments for Web Application Test Execution” [21] is another pro-posed solution. This case the focus is to prioritize the browser environments. As client-side appli-cations get more complex and changes become more frequent, the tests also get more complex— that is where regression testing techniques are used intensively. However, these techniques are resource-intensive and don’t provide fast feedback for the developers.
In this paper the focus is on web applications, so the testing environment is mainly the browsers. Since there are dozens of browsers nowadays, testing an application in all of them is very time-consuming and the faulty tests only start being reported in the end. The final goal is to make the tests in the browser environments to fail earlier.
This paper proposes 6 techniques and compares with 2 more. All of them will take into account the browser fail history to choose between the different approaches.
The two baseline techniques considered in the comparison are “No prioritization”, where where no optimization is carried out, and “Random”, a reordering technique that chooses the browser order randomly. Six possible techniques were then compared to the baselines:
• Exact matching-based prioritizes the browsers that failed recently;
• Similarity matching considers similarities between the browsers and gives priority to browsers that share more similarities;
• Failure frequency considers the environments that overall fail more and assigns them a higher priority;
• Machine learning learns the failure pattern and attempts to predict the failure probabil-ity for each browser. Assigns higher priorprobabil-ity to the browsers that have a higher predicted probability of failing;
• Exact matching + Failure frequency is a combination of two previous techniques; • Exact matching + Machine Learning is a combination of two previous techniques. Overall, the 6 proposed techniques worked better in failure detection for the tested web apps when compared with the random and no prioritization techniques. However, it depends on the project being tested.
“CUT: Automatic Unit Testing in the Cloud” [22], is an automatic unit testing tool designed to provide both virtual machine and container environments to support unit testing. The main goal is to minimize test suites and regression testing selection. The solution makes several advances: full automation transparency, which automatically distributes the execution of tests over remote resources and hides low level mechanisms; efficient resource allocation and flexibility providing the ability for the developer to allocate resources and choose if they want to run locally or remotely; test dependencies, the tool takes into account the dependencies between test cases to achieve deterministic executions. The tool is developed in Java and uses JUnit as the testing framework.
The distribution environment consists of using and reusing several Docker containers and vir-tual machines available in the cloud. By using this distribution and virvir-tualization mechanisms,
the tool proved to reduce by half the execution time by doubling the number of containers until 8 concurrent containers were running. No more concurrent containers were tested.
“Test suite parallelization in open-source projects: A study on its usage and impact” [5] is a paper that studies the usage and impact of test suite parallelization. The study discovered that the developers prefer high predictability than high performance and that only 15.45% of large projects use a parallel testing approach. The developers also assert that they do not use more parallelism because of concurrency issues and the extra work in preparing the test suite.
It was tested in open-source Java projects with the main goal of speeding up test execution. The analysis conducted considered four factors to evaluate the scenarios tested:
• Feasibility, which measures the potential of parallelization to reduce testing costs.
• Adoption, which evaluates how often the open-source projects use parallelization and how the developers involved will perceive the technology involved.
• Speedup, which measures the impact in terms of execution time when running the tests in parallel.
• Trade-offs, which evaluates the observed impact between the execution time and possible problems that emerged.
The testing framework used for the tests was JUnit given that the projects were mainly Maven projects. The study considered four methods when testing the parallelization suite:
• Fully sequential, where no parallelism is involved;
• Sequential classes and parallel methods, a configuration where the test classes are run sequentially and the test methods in parallel.
• Parallel classes and sequential methods, a configuration where the test methods are run sequentially and the test classes in parallel.
• Parallel classes and parallel methods, both classes and methods of the test are run in parallel.
The study concludes that, on average, using a parallel approach optimizes the execution time by 3.53%. In the tested projects, around 73% can be executed in a distributed environment without introducing of flaky tests (tests that can pass or fail in the same configuration).
Another solution is “A service framework for parallel test execution on a developer’s local development workstation” [34]. This solution proposes a service framework for parallel test ex-ecution by using Virtual Machines and also Docker Containers. The framework was created to support agile development methods such as Test-Driven Development and Behaviour Driven De-velopment, which were already discussed in this chapter.
When tackling complex and large projects, the main problem faced by developers when im-plementing parallelism is concurrency in the file system, resources and databases. There is a need to isolate multiple services in order to prevent race conditions and fixture dependencies.
The main goal of this framework is to solve problems like faster feedback, fest execution environments on the go, avoiding fixture dependencies and race conditions and providing instant emulation of real-world scenarios. Conversely, the main challenges faced with this framework were providing process emulation, the existence of race conditions in tests and the challenges in providing emulation of real-world environments.
The developed architecture is composed by several modules: the parallel runner, which is tasked with kicking off multiple instances, the test job and target configuration, that provides the test list with the configurations required, and the worker template generator, tasked with generating the blueprint for the environment.
One of the features required by the users is the ability to manually configure the test groups (each group runs in parallel) and the running environment. The framework was therefore designed to support projects with multiple services running such as databases, which run in a separate environment and in their own server. The tests were executed using PHPUnit complemented with a PostgreSQL database service. Execution time dropped from 45 min to 15 min.
“JExample”: Exploiting dependencies between tests to improve defect localization” [20] is a paper that proposes a solution to improve defect localization. It is a framework of JUnit and proposes several new tags. By using those tags, JExample is able to recognize test dependencies and their relationships. The framework proved to work very well and reduce the overall time of the test suite by simply ignoring tests in which their parent test failed.
Another solution is “Finding and Breaking Test Dependencies to Speed Up Test Execution” [19]. This solution attempts to speed up test execution by devising a test detection technique that can suitably balance efficiency and accuracy. The ultimate goal is to find test dependencies and break them. The algorithm proposed creates a directed acyclic graph, where tests are the nodes and dependencies are the edges, and then creates a cluster of tests that can be run in parallel. In order to execute the multiple independent tests, the solution first runs a topological sort algorithm to linearize them and obtain a schedule which respects the test dependencies and enables parallel test execution. Conclusions in terms of efficiency and time proved to be counter-intuitive. However, the solution proved that it is possible to run tests in parallel by breaking down test dependencies, all without introducing flaky tests.
An important solution to discuss is “CloudBuild: Microsoft’s Distributed and Caching Build Service” [11]. This project was developed by Microsoft and was design to be a new in-house continuous integration tool. CloudBuild has several main goals: to execute builds, tests, and tasks as fast as possible; to be on-board as many product groups as effortlessly as possible; to integrate into existing workflows; to ensure high reliability of builds and their necessary infrastructure; to reduce costs by avoiding separate build labs per organization; to leverage Microsoft’s resources in the cloud for scale and elasticity, and to consolidate disparate engineering efforts into one common service.
Regarding its design, it follows several principles:
• Commitment to compatibility: given its goal of integration with existing build pipelines, it must be compatible with other tools and SDKs
• Minimal new constraints: the system must be designed to assist legacy specifications and to maintain them without losing constraints.
• Permissive execution environment: CloudBuild ensures that the build results are deter-ministic
It supports a wide range of testing frameworks and languages such as VSTest, nUnit and xUnit. It has a different set of models in terms of architecture. First, it is built on top of Autopilot from Microsoft. Then, several worker machines are created and managed. These workers are responsible for the builds. In order to detect build dependencies, it extracts the dependency graph and plans the build distribution according to that graph. For several builds, it uses build caches. What this means is that if there is a task with the same input as another task, it uses the cache for that build if available. The results of the tested scenarios reported that with CloudBuild, the execution time can improve from 1.3 to 10 times the original execution speed.
Overall, Microsoft CloudBuild is not a solution for tests. It is a solution to improve overall continuous integration execution time, with special focus on the build phase. For the build, it uses several approaches. Parallelization, with dependency graph extraction, and build caches. These approaches help to increase the overall continuous integration pipeline execution time.
“Bazel” [2] is another solution that aims to improve continuous integration execution time. Bazel is open-source and developed by Google. It uses high-level build languages and supports multiple languages and outputs formats. Bazel offers several advantages:
• High-level build language, by using an abstract and human-readable language to describe the build, it provides flexibility and intuition for the users.
• Fast and reliable, caches previously done work and track the changes. This way it only rebuilds what is necessary
• Multi-platform, running on all of the most common Operating Systems • Scalable, it works well in complex projects.
• Extensible, it supports a wide range of languages.
Bazel is a tool to optimize continuous integration time. However, it has a special focus on the build phase. It is also possible to write tests using Bazel with a parallel approach. No results were found comparing Bazel before and after build execution times.
Another solution is “SeleniumGrid” [40]. This solution runs several End to End tests over a Network grid in a parallelized environment. No results were found comparing SeleniumGrid before and after build execution times.
2.3.1 Discussion
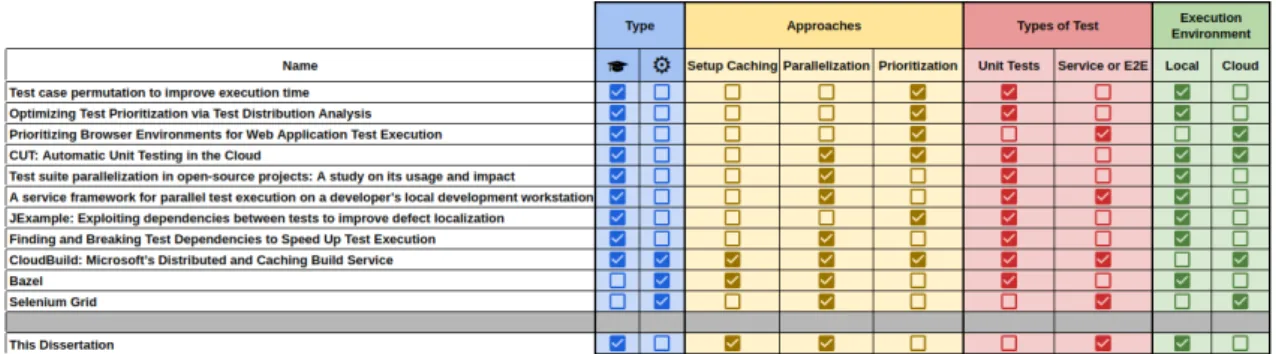
Figure2.6is a table comparing the different existing tools. This comparison will serve as a guide and comparison data when introducing the objectives and goals of this dissertation.
Figure 2.6: Comparison the different existing solutions for test execution optimization
The evaluation was made using four evaluation topics: The first (Type) checks if the tool is developed for a scientific context or industrial. The second topic (Approaches) relates to the approaches that the solutions use to improve test execution time. The third topic (Types of Test) evaluates the solutions in terms of types of tests supported. Finally, the Execution Environment topic defines if the solution is designed to support local, cloud-level test execution, or both. For the purpose of this dissertation, service test or end to end tests reside in the same evaluation space. They can be considered the same, given their similarities in terms of structure and execution process. The last topic relates to the place of execution. Which can be a local execution in the developer’s workspace or in the cloud.
The first conclusion that it is possible to take is that there is a lack of tools in the industrial context that attempt to optimize end-to-end tests. The majority is made only for academic purposes which creates opportunities to explore the problem referred in a more technical and industrial context.
Secondly, the parallelization approach is the most common one, followed by a prioritization technique. The setup caching technique is only used for Microsoft CloudBuild and Bazel, but unfortunately only for the build process.
In terms of types of tests, Unit tests are preferred. leaving Service tests and End-to-End tests with a lack of support for improvement. Regarding the execution place, local execution is widely favoured, with cloud execution falling short.
Another important conclusion is that tools that support execution of Service and End-to-End tests are mostly associated with the Cloud execution environment. This might be due to the large amount of resources and time that the execution of Service and End-To-End tests take to execute.
![Figure 2.1: Test Levels [42]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18230528.878067/27.892.370.565.137.440/figure-test-levels.webp)
![Figure 2.2: Test Pyramid by Sam Newman [31, p. 234]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18230528.878067/28.892.292.547.329.537/figure-test-pyramid-by-sam-newman-p.webp)
![Figure 2.3: Structure of a test by Gerard Meszaros [27]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18230528.878067/29.892.372.563.772.990/figure-structure-of-a-test-by-gerard-meszaros.webp)

![Figure 2.5: Comparison between Virtual Machines and Docker Container based architecture [16]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18230528.878067/38.892.202.730.433.854/figure-comparison-virtual-machines-docker-container-based-architecture.webp)