La agregación de datos en la medición de desigualdades e inequidades en la salud de las poblaciones
Texto
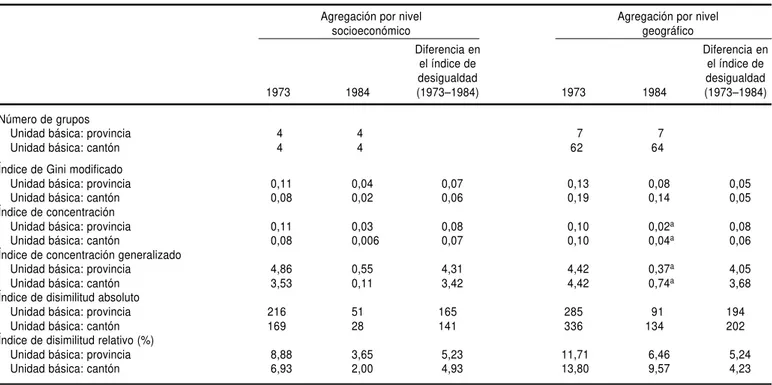
Imagem
Documentos relacionados
Entre la II Guerra Mundial y la década de 1970 se produjo un predominio del poder político sobre el financiero, no solo en los países centrales, sino asimismo en los periféricos que
La Declaración de Alma-Ata (1978) reconoce la salud como un derecho humano fundamental, con- siderando inaceptable las desigualdades e inequidades respecto a la salud de
Para el año 2008 el 43,8% de las entidades fe- derativas presentaron cifras por arriba de la tasa nacional y se encontró que la disminución en las tasas de mortalidad infantil
le compete a CSP defender las políticas que contribuyan a la salud de las poblaciones, en este caso específico el de las mujeres frente a la infección por el virus Zika durante
Considerando que la salud autoevaluada como mala está signiicativamente asociada con la mortalidad, las mujeres del presente estudio se encuentran en desventaja, en el
El Servicio de Salubridad Pública de los Estados Unidos y la Asociación Nacional de Tuberculosis cooperan en la producción de materiales para la educa- ción
Médico Jefe del Departamento de Enferme- dades Crónicas e Higiene del Adulto del Ministerio de Sanidad 3: Asistencia Social, S-enezuela. segunda sesión nos
(1) Organizar el estudio, en todas las unidades sanitarias, de las causas de la mortalidad infantil de acuerdo con la clasificación expuesta en este trabajo y
