Gonçalo da Cruz Pereira e Sousa
Document-Based Databases:
Estudo Comparativo no
Âmbito das Bases de Dados NoSql
Gonçalo da Cruz Pereira e Sousa
Document-Based Dat abases: Es tudo Com par ativ
o no Âmbito das Bases de Dados NoSql
Universidade do Minho
Dissertação de Mestrado
Ciclo de Estudos Integrados Conducentes ao Grau de
Mestre em Engenharia e Gestão de Sistemas de Informação
Trabalho efectuado sob a orientação do
Professor Doutor José Luís Mota Pereira
Gonçalo da Cruz Pereira e Sousa
Document-Based Databases:
Estudo Comparativo no
Âmbito das Bases de Dados NoSql
Universidade do Minho
I
O conhecimento é um tesouro, mas a prática é a chave para alcançá-lo. Thomas Fuller
Agradecimentos
_______________________________________________________________________________
III
Agradecimentos
Ao concluir a presente dissertação gostaria de manifestar o meu sincero agradecimento a todos os que contribuiram para a sua realização, não podendo deixar de salientar algumas pessoas em particular:
Ao professor Doutor José Luís Mota Pereira, orientador desta dissertação, agradeço a disponibilidade demonstrada, os esclarecimentos prestados e a partilha de conhecimentos.
Ao Departamento de Sistemas de Informação agradeço pela ajuda sempre prestada ao longo destes anos.
Aos Amigos que tiveram presentes nesta caminhada, Fábio Teixeira, Diogo Silva, José Santos, Jaime Oliveira e Diana Aguiar agradeço todo o apoio.
Ao meu grande amigo José Oliveira agradeço o apoio e camaradagem ao longo destes anos.
À Filipa Neiva realço um agradecimento especial por ter estado sempre presente e sempre me ter apoiado bastante ao longo destes anos.
À minha mãe e ao meu irmão agradeço pela amizade e ajuda pois sem eles nada disto era possível.
Ao meu irmão pequenino, que apesar de ter nascido há pouco tempo também merece um agradecimento.
Ao meu falecido pai agradeço e dedico esta dissertação pois era a vontade dele ver-me formado.
Resumo
_______________________________________________________________________________
V
Resumo
Depois de várias décadas de grande sucesso e bons serviços prestados às organizações, a tecnologia relacional de bases de dados tem vindo a ser desafiada por uma nova classe de tecnologias de bases de dados a que se deu a designação genérica de NoSql. Para este facto contribuíram decisivamente os recentes desenvolvimentos na área a que se tem vindo a chamar Big data, na qual, dada a complexidade e volume dos conjuntos de dados a gerir, o tradicional modelo relacional começou a apresentar dificuldades.
Dentro desta nova classe de tecnologias de Bases de Dados surgiram diferentes propostas, com distintas proveniências e áreas de aplicação, vulgarmente classificadas em quatro grupos, de acordo com o seu modelo de dados: Column, Document, Key/Value e Graph
Based Databases.
Dada a grande diversidade de propostas atualmente existentes em cada um dos modelos de Bases de Dados NoSql, torna-se pertinente compreender as suas características específicas e áreas de aplicação mais relevantes, enquanto, simultaneamente se vincam as suas diferenças relativamente às tradicionais bases de dados relacionais.
Em particular, pretende-se abordar uma das quatro classes de bases de dados em que o mundo NoSql se divide – as Document-Based databases, de que produtos como o MongoDB e o CouchDB são alguns dos principais representantes. Como propósito do trabalho em que esta dissertação se enquadra, pretende-se perceber quais as diferenças, a nível de desempenho, entre soluções suportadas por estes dois produtos, quando utilizados no suporte de bases de dados de dimensão crescente, procurando evidenciar também as diferenças entre estas e soluções construídas recorrendo à bem conhecida tecnologia relacional.
Abstract
_______________________________________________________________________________
VII
Abstract
After many decades of great success and good services provided to organizations, relational databases have been challenged by a new class of database technologies with the generic designation of NoSql. To this fact contributed, decisively, the recent developments in the area called BigData, in which, due to its complexity and volume of data to manage, the traditional relational model has began to present difficulties.
In this new class of database technologies appeared different proposals, with different origins and application areas, commonly classified into four groups, according to its data model: Column, Document, Key/Value and Graph Based Databases.
Given the wide variety of currently existing proposals in each of the NoSql Database families, it is pertinent to understand their most important specific characteristics and application areas, while, simultaneously, clarifying their differences regarding traditional relational databases.
In particular, it is intended to explore one of the four database classes in which the NoSql world is divided – the Document-Based databases, in which products like MongoDB and CouchDB are some of the main representatives. In this thesis, it’s intended to understand what are the differences, in performance, between solutions developed using these two products, when used to support databases of growing dimensions, seeking to highlight the differences between these and solutions built using the well-known relational technology.
Índice _______________________________________________________________________________ IX
Índice
Agradecimentos... III Resumo ... V Abstract ... VII Índice ... IX Índice de Figuras ... XI Índice de Tabelas ... XIII Lista de Siglas e Acrónimos ... XVCapitulo 1- Introdução ... 1
1.1 Enquadramento ... 1
1.2 Objetivos e Resultados Propostos... 2
1.3 Abordagem Metodológica ... 3
1.4 Estrutura da Dissertação ... 4
Capitulo 2- Fundamentos Teóricos ... 5
2.1 Big data ... 5
2.2 Surgimento do conceito NoSql ... 7
2.3 NoSql ... 9
2.3.1 Teorema CAP ... 12
2.3.2 BASE Vs ACID ... 14
2.3.3 Caraterização das Bases de dados NoSql ... 16
2.3.4 Tipos de Bases de Dados NoSql ... 25
2.3.5 Comparação entre os tipos de Bases de Dados NoSql ... 38
2.3.6 Considerações Finais ... 43
Capítulo 3 – Análise e Carregamento dos dados ... 45
3.1 Dados para Carregamento ... 45
3.2 Carregamento dos dados no MySQL ... 46
3.2.1 Modelo conceptual de dados ... 47
3.2.2 Descrição das Entidades ... 47
3.2.3 Carregamento das tabelas filho ... 49
3.2.4 Carregamento das tabelas pai ... 52
3.3 Carregamento de dados no MongoDB ... 54
3.3.1 Estrutura dos Documentos ... 54
3.3.2 Carregamento da coleção ... 55
3.4 Carregamento dos dados no CouchDB ... 56
Capitulo 4 – Benchmarking ... 59
4.1 Consultas MySQL ... 59
Índice _______________________________________________________________________________ X 4.3 Consultas CouchDB ... 61 4.4 Criação de Índices ... 63 4.5 Resultados ... 64 4.5.1 Consulta 1 ... 64 4.5.2 Consulta 2 ... 64 4.5.3 Consulta 3 ... 65 4.6 Discussão de Resultados ... 65
Capítulo 5 – Testes de Carga ... 67
5.1 Base de Dados BD1... 67 5.2 Base de dados BD2 ... 68 5.3 Base de dados BD3 ... 69 5.4 Base de dados BD4 ... 70 5.5 Discussão de resultados ... 71 Capítulo 6 – Conclusões ... 73 6.1 Contribuições ... 73 6.2 Dificuldades ... 73 6.3 Trabalho futuro ... 74 Referências Bibliográficas ... 75 Anexos ... 81 Anexo A ... 83 Anexo B ... 97 Anexo C ... 101 Anexo D ... 105 Anexo E ... 107
Índice de Figuras
_______________________________________________________________________________
XI
Índice de Figuras
Figura 1 - Teorema CAP (Retirado de Indrawan-Santiago, 2012, pag.47) ... 12
Figura 2 - Fluxo do funcionamento do Map Reduce (Retirado de Alexandre & Cavique, 2013,pag.41) ... 19
Figura 3 - Exemplo MapReduce (Adaptado de Bonnet et al., 2011,pag.486) ... 19
Figura 4 - Fluxo de uma execução MapReduce (Retirado de Bonnet et al., 2011,pag.486) ... 20
Figura 5 - Exemplo de sharding (Retirado de Cardoso, 2012,pag.25) ... 22
Figura 6 - Exemplo de sharding de um carrinho e compras (Retirado de Tauro et al., 2012,pag.2)23 Figura 7 - Exemplo de uma chave ligada a um valor (Retirado de Sadalage & Fowler, 2012,pag.58) ... 26
Figura 8 - Estrutura típica das column-based databases (Retirado de Sadalage & Fowler, 2012,pag.46) ... 28
Figura 9 - Exemplo das relações numa graph database (Retirado de Sadalage & Fowler, 2012,pag.52) ... 30
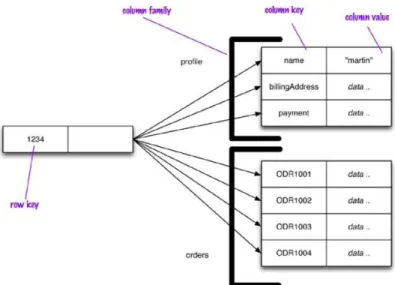
Figura 10 - Exemplo de dois Documentos de uma Document database ... 33
Figura 11 - Documento contendo um exemplo de descrição de um livro (Retirado de Silva, 2011,pag.14) ... 34
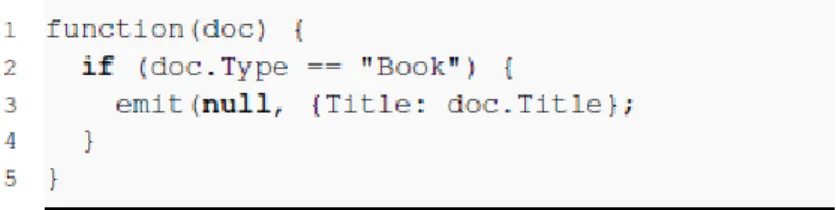
Figura 12 - Exemplo de uma função utilizada para obter o título de todos os livros armazenados na base de dados (Retirado de Silva, 2011,pag.14) ... 35
Figura 13 - Exemplo de um Documento com campos distintos (Retirado de Queiroz et al., 2013,pag.485) ... 36
Figura 14 - Exemplo de uma consulta sobre todos os livros que contêm o título Flatland (Retirado de Silva, 2011,pag.17) ... 37
Figura 15 - Exemplo de duas consultas efetuadas no MongoDB (Retirado de Silva, 2011,pag.17)37 Figura 16 - Consistent hashing (Retirado de Grolinger et al., 2013, pag.13)... 40
Figura 17 – Extrato do csv aviões ... 45
Figura 18 – Extrato do csv companhias aéreas ... 46
Figura 19 – Extrato do csv aeroportos ... 46
Figura 20 – Extrato do csv contendo voos de 1995 ... 46
Figura 21 - Modelo conceptual de dados ... 47
Figura 22 - Import do csv airport ... 50
Figura 23 - Exemplo de um documento criado no MongoDB ... 56
Figura 24 - Exemplo de um documento criado no CouchDB ... 57
Figura 25 - Criação de um índice no MySQL ... 63
Figura 26 - Comparação de desempenhos na Consulta 1... 64
Figura 27 - Comparação de desempenhos na Consulta 2... 65
Figura 28 - Comparação de desempenhos na Consulta 3... 65
Figura 29 - Resultado do Teste de carga utilizando a consulta 1 ... 67
Figura 30 - Resultado do Teste de carga utilizando a consulta 3 ... 68
Figura 31 - Resultado do Teste de carga utilizando a consulta 1 ... 68
Figura 32 - Resultado do Teste de carga utilizando a consulta 3 ... 69
Figura 33 - Resultado do Teste de carga utilizando a consulta 1 ... 69
Figura 34 - Resultado do Teste de carga utilizando a consulta 3 ... 70
Figura 35 - Resultado do Teste de carga utilizando a consulta 1 ... 70
Figura 36 - Resultado do Teste de carga utilizando a consulta 3 ... 71
Figura 37 - Download do MongoDB ... 97
Figura 38 - Instalação do MongoDB ... 97
Figura 39 - Setup type da instalação do MongoDB ... 98
Figura 40 - Correção do erro hotfix ... 98
Figura 41 - Mudança para a diretoria do MongoDB ... 99
Índice de Figuras
_______________________________________________________________________________
XII
Figura 43 - Inicialização do MongoDB ... 100
Figura 44 - Execução do comando "mongo" ... 100
Figura 45 - Download do CouchDB ... 101
Figura 46 - Instalação do CouchDB ... 101
Figura 47 - Seleção da diretoria ... 102
Figura 48 - Alteração das credenciais do CouchDB ... 102
Figura 49 - Execução do CouchDB através do curl ... 103
Figura 50 - Download do Jmeter ... 107
Figura 51 - Inicialização do Jmeter ... 107
Figura 52 - Criação do Thread Group ... 108
Figura 53 - Criação do config element para o MongoDB ... 108
Figura 54 - Criação da sampler para o MongoDB ... 109
Figura 55 - Criação do Listener ... 109
Figura 56 - Criação do Config Element para o MySQL ... 110
Índice de Tabelas
_______________________________________________________________________________
XIII
Índice de Tabelas
Tabela 1- Comparação dos tipos de bases de dados NoSql em termos de segurança (Adaptado de
Grolinger et al., 2013, pag.17) ... 25
Tabela 2 - Comparação entre os tipos de bases de dados NoSql (Adaptado de Indrawan-Santiago, 2012,pag.47) ... 39
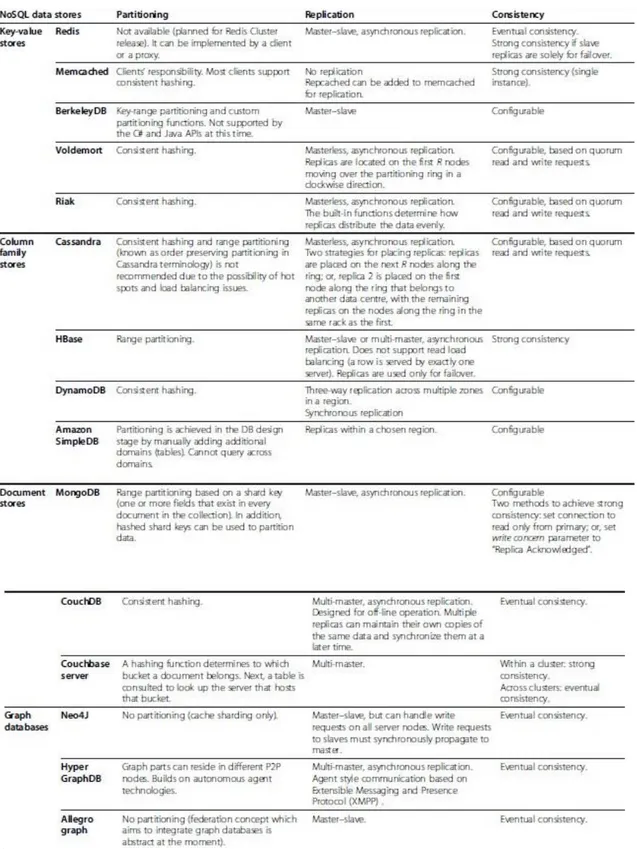
Tabela 3 - Comparação dos tipos de bases de dados NoSql em termos de particionamento, replicação e consistência (Retirado de Grolinger et al., 2013,pag.11) ... 42
Tabela 4 - Descrição dos atributos da entidade airplane ... 47
Tabela 5 - Descrição dos atributos da entidade Airline ... 47
Tabela 6 - Descrição dos atributos da entidade airport ... 48
Tabela 7 - Descrição dos atributos da entidade aircraft type ... 48
Tabela 8 - Descrição dos atributos da entidade engine type ... 48
Tabela 9 - Descrição dos atributos da entidade flight ... 49
Tabela 10 - Descrição dos atributos da entidade manufacturer ... 49
Tabela 11 - Descrição dos atributos da entidade model ... 49
Lista de Siglas e Acrónimos
_______________________________________________________________________________
XV
Lista de Siglas e Acrónimos
XML- Extensible Markup Language
NoSql- Not Only SQL
SQL- Structured Query Language
CAP- Consistency, Availability e Partition Tolerance
PA- Partition Tolerance e Availability
CA- Consistency e Availability
CP- Consistency e Partition Tolerance
BASE- Basically available, soft state, eventually consistent
ACID- Atomicity, Consistency, Isolation, Durability
JSON- JavaScript Object Notation
Introdução
_______________________________________________________________________________
1
Capitulo 1- Introdução
Neste capítulo são contextualizadas as bases de dados NoSql no âmbito do Big data, e o porquê das bases de dados relacionais estarem limitadas nesse contexto. Seguidamente são referidos os objetivos e resultados propostos, e, por fim, é apresentada a estruturação do documento.
1.1 Enquadramento
Com o aparecimento do Big data, no qual a complexidade e volume dos dados aumentou, a tecnologia relacional começou a demonstrar fragilidades principalmente a nível de desempenho. Isto fez com que uma nova tecnologia de base de dados, a NoSql, emergisse e começasse a ser opção para as empresas.
O conceito Big data pode ser resumidamente definido como “uma coleção de bases de dados tão complexa e volumosa que se torna muito difícil fazer algumas operações simples (ex., remoção, ordenação, sumarização) de forma eficiente utilizando Sistemas Gestão de Bases de Dados (SGBD) tradicionais” (Vieira & Figueiredo, 2012).
Nas grandes aplicações web, desktop ou até mesmo móveis está-se a tornar cada vez mais comum lidar com grande volume de dados, sendo que no futuro a situação será mais exigente em termos de armazenamento de dados (Toth, 2012).
Em particular, a necessidade de gerir dados cujos formatos são dificilmente acomodáveis em sistemas relacionais, dispersos por múltiplos servidores, levou ao aparecimento das ditas Bases de Dados NoSql. Sendo assim, este novo tipo de bases de dados vieram para resolver os problemas dos sistemas que precisam de escalabilidade e agilidade nas suas inserções, buscas e alterações (Toth, 2012).
Lidando com tanta quantidade de registos, o desempenho pode diminuir com bases de dados relacionais, assim, esta nova tecnologia veio para colmatar esta diminuição de desempenho, focando-se numa abordagem diferente de persistência de dados que se baseia na disponibilidade, desempenho e escalabilidade das soluções (Toth, 2012).
Dentro desta nova classe de tecnologias de Bases de Dados surgiram diferentes propostas, com distintas proveniências e áreas de aplicação, vulgarmente classificadas em quatro grupos, de acordo com o seu modelo de dados: Column, Document, Key/Value e Graph
Based Databases. Em simultâneo, e reconhecendo a relevância desta área, os próprios
construtores tradicionais de tecnologia relacional começaram também a fazer as suas incursões, como é o caso da Oracle com o Oracle NoSql Database (do tipo
Key/Value-Introdução
_______________________________________________________________________________
2
Based Databases), ou da Microsoft com o DocumentDB (do tipo Document-Based Databases).
Dada a grande diversidade de propostas atualmente existentes em cada um dos modelos de Bases de Dados NoSql, torna-se pertinente compreender as suas características específicas e áreas de aplicação mais relevantes, enquanto, simultaneamente se vincam as suas diferenças relativamente às tradicionais bases de dados relacionais.
Este trabalho vai abordar a tecnologia de Bases de dados NoSql denominada Document
Databases que tem como exemplos o CouchDB e o MongoDB. Este tipo de bases de dados NoSql são parecidas com a abordagem chave/valor com uma grande exceção. Em vez de
armazenar qualquer arquivo binário como valor de uma chave é requisitado que o valor dos dados que serão armazenados possuam um formato que a base de dados possa interpretar. Na maioria das vezes podem ser arquivos de extensão XML, JSON ou qualquer formato descritivo, variando muito de ferramenta para ferramenta (Toth, 2012).
Guardar novos documentos que contenham qualquer tipo de atributos pode ser tão fácil como adicionar novos atributos nos Documentos existentes. Estas Document Databases oferecem API’s mais ricas. Range queries nos valores, secondary indexes, querying nested
documents e operações como "and", "or", "between" são características, que podem ser
utilizadas convenientemente (Hecht & Jablonski, 2011).
Este é um tema atual e interessante de ser abordado pois é uma tecnologia cada vez mais utilizada e que veio resolver muitos problemas. Nomeadamente as Document Databases que através de documentos são guardados os dados. Sendo esta um dos principais tipos de bases de dados NoSql, este trabalho é pertinente e uma mais-valia para aprender mais sobre esta tecnologia.
1.2 Objetivos e Resultados Propostos
Com este trabalho pretende-se, justamente, explorar este novo domínio da tecnologia de bases de dados, em particular as designadas Document Databases, de que produtos como o MongoDB e o CouchDB, são alguns dos principais representantes.
Os objetivos são os seguintes:
Caracterização do contexto Big data e o papel das bases de dados NoSql nesse contexto;
Introdução
_______________________________________________________________________________
3
entre as Document-Based Databases;
Análise comparativa desses produtos com base em casos de estudo representativos das suas áreas de aplicação;
Identificação das vantagens relativamente às bases de dados relacionais.
1.3 Abordagem Metodológica
Estudo Exploratório será a abordagem metodológica a seguir durante a realização da dissertação. Recorrendo a esta abordagem, pretende-se analisar as bases de dados NoSql, nomeadamente as vantagens em relação à tecnologia SQL.
Afunilando para as Document Databases, em que se pretende fazer uma análise a esta tecnologia.
Por fim pegar num caso prático e efetuar uma comparação entre as Document Databases e a tecnologia Relacional.
Explorar novos fenómenos pode ajudar quem pesquisa a testar a viabilidade de um estudo mais alargado, da necessidade da compreensão ou determinar o melhor método a utilizar num estudo posterior.
Piovesan & Temporini (1995) citam Theodorson que refere que é “Um estudo preliminar em que o objetivo principal é familiarizar-se com um fenômeno de investigação, de modo que o estudo que se segue possa ser projetado com uma maior compreensão e precisão. Permite também escolher as técnicas mais adequadas para a pesquisa e decidir sobre as questões que mais necessitam de atenção e investigação detalhada, e pode alertar para possíveis dificuldades, sensibilidades, e áreas de resistência. "
Citam também Polit e Hungler que referem que “é um estudo preliminar designado para desenvolver ou refinar hipóteses, ou para testar e definir métodos de coleção de dados.” Segundo Richardson (1989) “o estudo exploratório procura conhecer as características de um fenômeno para procurar explicações das causas e consequências do dito fenômeno” Já para Mattar (1994) “visa prover quem pesquisa de um maior conhecimento sobre o tema ou problema de pesquisa em perspetiva. Por isso é apropriada para os primeiros estágios da investigação, quando a familiaridade, o conhecimento e a compreensão do fenómeno por parte de quem pesquisa são geralmente insuficientes ou inexistentes”.
Para Sampieri et al. (1991) “os estudos exploratórios servem para aumentar o grau de familiaridade com fenômenos relativamente desconhecidos, obter informações sobre a possibilidade de levar adiante uma investigação mais completa sobre um contexto particular
Introdução
_______________________________________________________________________________
4
da vida real e estabelecer prioridades para investigações posteriores, entre outras utilizações. Porém, os estudos exploratórios em poucas ocasiões constituem um fim em si mesmos. Eles caracterizam-se por serem mais flexíveis na sua metodologia em comparação com os estudos descritivos ou explicativos, e são mais amplos e dispersos que estes dois últimos tipos (por exemplo, procuram observar tantas manifestações do fenômeno estudado quanto for possível) ” (Révillion, 2001).
Segundo Rodrigues (2007) tem como objetivo inteirar quem pesquisa no problema, através de pesquisa bibliográfica ou estudo de caso.
Já Révillion (2001) refere que o objetivo do estudo exploratório é procurar perceber as razões e motivações que estão subjacentes a determinadas atitudes e comportamentos das pessoas.
Sendo assim esta metodologia tem um foco amplo e raramente responde a questões de investigação específicas.
1.4 Estrutura da Dissertação
O presente documento está estruturado em seis capítulos. No Primeiro capítulo é apresentada uma contextualização da origem e necessidade da realização da dissertação. Além disso, os principais objetivos e resultados esperados da dissertação são descritos, bem como a metodologia seguida na presente dissertação.
No Segundo capítulo é apresentado o estado de arte sobre as bases de dados NoSql e todos os termos adjacentes, contextualizando no âmbito da Big data.
No Terceiro capítulo é apresentada a análise e carregamento dos dados, é referido qual o
dataset escolhido e como este foi tratado e carregado para as bases de dados em estudo.
No Quarto capítulo é apresentado o benchmarking, em que escolhidas as consultas a serem efetuadas irá realizar-se um estudo comparativo entre as tecnologias selecionadas.
No Quinto capítulo são apresentados os testes de carga, que para as consultas estudadas no
benchmarking, irá ser analisado o desempenho com utilizadores a aceder concorrentemente
à base de dados e verificar como estas se comportam.
No sexto e último capítulo são apresentadas as conclusões finais, onde é falado da contribuíção desta dissertação, bem como as dificuldades sentidas e trabalho futuro.
Fundamentos Teóricos
_______________________________________________________________________________
Capitulo 2- Fundamentos Teóricos
O crescimento exponencial da web 2.0 resultou na geração de cada vez maiores quantidades de dados, caracterizados por uma grande diversidade de formatos, de que é necessário tirar partido. O armazenamento, a gestão e o processamento destes novos dados veio evidenciar as limitações das bases de dados relacionais, tanto em termos de capacidade de lidar com os grandes volumes de dados, como dos tipos de dados a suportar. Neste contexto, uma nova tecnologia emergiu e está a tornar-se cada vez mais importante no mercado – as bases de dados NoSql.
2.1 Big data
Atualmente o armazenamento e processamento de grandes quantidades de dados na área da computação é um grande desafio. O mundo digital está a crescer a olhos vistos e a tornar-se cada vez mais complexo, quer relativamente ao volume de dados (do Terabyte ao
Petabyte), à sua variedade (dados estruturados, semiestruturados e não estruturados) e à
velocidade a que têm de ser processados (ritmos cada vez mais rápidos).
A este fenómeno chama-se Big data, que pode ser definido como uma grande coleção de dados que cresceu tanto e de forma tão diversificada que não pode ser gerido ou explorado eficientemente com as tradicionais ferramentas da tecnologia relacional (Moniruzzaman & Hossain, 2013).
O termo Big data surgiu como referência a um conjunto de problemas derivados das enormes quantidades de dados produzidos por empresas, organizações e pessoas particulares. Posteriormente, passou a descrever “o conjunto de soluções que visam tratar esses dados, desde o seu armazenamento até à transformação destes em informações relevantes para auxiliarem os gestores nas tomadas de decisões” (Basso & Padua, 2014). Purcell (2013) cita Manyiak et al. (2011) que referem que o nome Big data deriva do facto dos datasets serem maiores que as tradicionais bases de dados, que não têm capacidade para capturar, guardar, e analisar estes.
Segundo Vieira et al. (2012), Big data pode ser resumidamente definido como “uma coleção de bases de dados tão complexa e volumosa que se torna muito difícil e complexo fazer algumas operações simples (ex: remoção, ordenação, sumarização) de forma eficiente utilizando Sistemas de Gestão de Bases de Dados tradicionais.” Também acrescenta que engloba o processamento, de forma eficiente e escalável, de grandes volumes de dados complexos produzidos por diversas aplicações.
Fundamentos Teóricos
_______________________________________________________________________________
6
Segundo Alexandre e Cavique (2013), o fenómeno Big data assenta nos chamados 3V’s: Volume: A necessidade de lidar, de forma sustentada, com o crescimento
exponencial de dados gerados;
Velocidade: A necessidade de processar os dados em tempo real, devido à importância que isso tem para as organizações atuais;
Variedade: O facto dos dados se apresentarem nos mais variados formatos, alguns deles dificilmente acomodáveis em estruturas rígidas como as disponibilizadas pelo modelo relacional.
Segundo Vieira et al. (2012), pode-se resumir as características de Big data em quatro propriedades:
Volume de dados na ordem de dezenas ou centenas de Terabytes; Necessidade de escalabilidade horizontal;
Fácil distribuição dos dados e/ou processamento;
Vários tipos de dados, desde complexos e/ou semiestruturados.
Big data inclui três tipos de dados, sendo eles, dados estruturados, semi-estruturados e não
estruturados.
Purcell (2013) cita Morris & Rob (2013) que referem que dados estruturados são dados formatados para utilizar nos sistemas de gestão de bases de dados. Já em relação aos dados semi-estruturados refere que são uma forma de dados estruturados mas que não estão formatados para os modelos relacionais. Em relação aos dados não estruturados, refere que são dados que estão no formato com que são coletados, não estando formatados.
Purcell (2013) cita também Baltzan e Phillips (2012) que referem alguns exemplos destes tipos de dados. Para os dados semi- estruturados aponta XML. Já para os dados não estruturados refere pdf’s, email’s e documentos.
A quantidade de dados gerada diariamente está-se a tornar abismal, desde redes sociais,
web, entre outros. Isto leva a problemas ao nível do processamento, armazenamento e
manipulação de dados, que faz com que os sistemas relacionais não sejam os mais indicados para lidar com o problema do Big data. Por essa razão foram então criados os Sistemas
NoSql, que dispõem de melhorias ao nível do armazenamento e processamento de grandes
quantidades de dados, quer estruturados quer não estruturados (Vieira et al., 2012).
O NoSql veio resolver o problema da grande quantidade de dados que são gerados e têm de ser tratados. Para além disso deve-se levar em consideração a necessidade das organizações manterem esses dados durante longos períodos de tempo (Alexandre & Cavique, 2013).
Fundamentos Teóricos
_______________________________________________________________________________
2.2
Surgimento do conceito
NoSql
Para entender melhor este novo conceito é importante perceber em que consiste uma base de dados. Esta pode ser definida, muito simplesmente, como um repositório onde se armazenam dados de vários tipos, interligados através de algum mecanismo que permita manter as referências entre si.
Castro & Batista (2013) citam Korth et al. (1999) que refere que “é uma coleção de dados inter-relacionados, representando informações sobre um domínio específico, ou seja, sempre que for possível agrupar informações que se relacionam e tratam de um mesmo assunto pode-se dizer que se possui uma base de dados.”
Castro & Batista (2013) citam também Date (2004) que acrescenta que o propósito principal que era pretendido pelas bases de dados desde o seu aparecimento era oferecer recursos que mantivessem os dados organizados e torná-los disponíveis, quando solicitados.
E.F.Codd propôs o modelo relacional em 1970. Na altura, este veio simplificar o armazenamento de dados e o seu processamento, ao migrar os dados para tabelas relacionadas entre si por campos comuns, manipulados por uma linguagem de alto-nível – a SQL. O que o autor não previu foi que a quantidade de dados que se teria de armazenar no futuro se tornaria gigantesca como é atualmente (Cardoso, 2012).
Em relação ao conceito de NoSql, este foi inicialmente usado em 1998 por Carlo Strozzi para referir uma base de dados open source que não utilizava a referida interface SQL (Abramova et al., 2014; Strauch, 2010).
Pozzani (2013) refere que esta tecnologia foi desenvolvida inicialmente na Google, com o
Bigtable, sendo que o primeiro research paper foi publicado em 2003.
Um dos primeiros movimentos de mudança em direção ao NoSql ocorreu em 2007, quando a Amazon apresentou o NoSql Dynamo. Esta foi das primeiras empresas a guardar os seus dados numa base dados de características não-relacionais (Leavitt, 2010).
A utilização do NoSql que reconhecemos atualmente remonta a um encontro no dia 11 de junho de 2009, em San Francisco, organizado por Johan Oskarsson. O exemplo do Bigtable e Dynamo inspirou muitos projetos com um armazenamento de dados alternativo. Sendo assim, na sua passagem por San Francisco ele queria conseguir visitar todas as empresas que introduziram este novo conceito, mas chegou à conclusão que era impossível, então organizou uma conferência onde todas pudessem estar presentes. Ele pretendia que o nome da conferência fosse curto e memorável e facilmente encontrado no Google, então foi-lhe sugerido o nome “NoSql” (Grolinger et al., 2013; Sadalage & Fowler, 2012).
Fundamentos Teóricos
_______________________________________________________________________________
8
consultas SQL, não é o objetivo crucial destas bases de dados (Grolinger et al., 2013). Ainda neste ano começaram as primeiras conferências sobre NoSql e originou que as pessoas começassem a falar mais deste tema (Stonebraker, 2010).
Atualmente são gerados enormes volumes de dados a todo o instante e por todo o tipo dispositivos, desde eletrodomésticos inteligentes, até ao comércio online. Existem cada vez mais sistemas ligados à internet que comunicam entre si. Nos últimos anos, os avanços nas tecnologias da Web, o incremento na utilização das redes sociais e a proliferação de sensores e dispositivos móveis conectados à internet, resultou na geração de imensos dados que necessitam de ser armazenados e posteriormente processados.
Toth (2011) concorda, referindo que o crescimento da quantidade de dados e informação na
web é indiscutível e percetível de dia para dia. Entretanto, se as aplicações possuem um
grande volume de dados poderão vir a existir problemas em relação à infra-estrutura. Strauch (2010) acrescenta que, com o aparecimento da web 2.0, empresas famosas como
Google, Amazon, entre outras, começaram a largar as tradicionais bases de dados relacionais
como a Oracle para começarem a construir os seus próprios sistemas, isto para armazenar e processar grandes quantidades de dados.
Tomando como exemplo uma das maiores redes sociais do momento, o Facebook, só nesta rede, 2.4 biliões de conteúdos são partilhados entre amigos todos os dias. (Grolinger et al., 2013; Parikh, 2013) Neste tipo de contextos a tecnologia relacional começou a apresentar limitações especialmente relacionadas com a escalabilidade e desempenho.
As novas exigências fizeram com que a indústria das TIC surgisse com novas propostas para estes problemas, resultantes das limitações dos sistemas de armazenamento relacional. Empresas como o Facebook e Google concluíram que seria impossível gerir grandes quantidades de dados com as bases de dados relacionais e começaram então a procurar soluções alternativas aos sistemas relacionais. A alternativa que surgiu denominou-se NoSql (Cardoso, 2012; Guimarães et al., 2013; Hecht & Jablonski, 2011).
Alexandre & Cavique (2013) citam McCreary & Kelly (2013) que concordam e referem também que com o surgimento de tantas fontes de dados e a necessidade de processar toda esta informação surgiu o conceito NoSql.
No entanto, ainda muita gente refere que existe uma carência de estudos que comprovem a real eficácia do modelo NoSql perante o paradigma relacional. Já Rob, Coronel e Crockett (2013) discordam e referem a tecnologia não relacional como o maior avanço para o utilizador comparado com o modelo tradicional de armazenamento.
Fundamentos Teóricos
_______________________________________________________________________________
Frozza et al. (2011) citam Tiwari (2011) que descreve o conceito da seguinte forma, o modelo NoSql “é uma tendência que tende a superar o homólogo modelo relacional no que se refere a escalabilidade horizontal e disponibilidade.”
Guimarães et al. (2013) citam Redmond e Wilson (2012) que referem que as bases de dados
NoSql foram criadas para ir de encontro às necessidades que surgiram com o aumento da
quantidade e diversidade de dados das aplicações atuais, que não são completamente resolvidas pelas bases de dados relacionais, uma vez que estas aplicações exigem cada vez mais espaço de armazenamento.
As organizações estão cada vez mais dependentes dos dados para competirem no mercado, sendo assim, capturar e analisar dados, tornaram-se as chaves para o sucesso no negócio em vez de ser um custo a minimizar (Indrawan-Santiago, 2012). Esta nova tecnologia veio fornecer escalabilidade e agilidade aos sistemas, pois já careciam bastante destas propriedades.
Para Pozzani (2013), NoSql representa uma nova encarnação, e justifica referindo que é devido à grande escalabilidade das aplicações da internet e por estas se basearem em computação distribuída e paralela.
Mas o desempenho não é importante por si só, a disponibilidade também é um requisito considerado importante. Por isso, a Amazon oferecia disponibilidade de serviço de 99,9% durante um ano (DeCandia et al., 2007; Hecht & Jablonski, 2011).
O fator vital para a mudança no armazenamento de dados era a necessidade de suportar grandes volumes de dados em clusters, sendo que, bases de dados relacionais não foram concebidas para correr eficientemente nestes (Sadalage & Fowler, 2012).
Diferentemente das bases de dados relacionais que, de uma forma ou outra, são todas relativamente semelhantes, a área das bases de dados NoSql caracteriza-se por possuir diferentes tipos que variam muito entre si, tendo cada uma as suas próprias caraterísticas e finalidades (Vieira et al., 2012).
A tecnologia NoSql não foi criada com o intuito de substituir o modelo relacional mas sim preencher uma necessidade do mercado que este não servia adequadamente.
2.3 NoSql
NoSql é um termo utilizado para descrever uma classe de tecnologias que fornecem uma
alternativa para o armazenamento de dados em comparação com os sistemas de gestão de bases de dados relacionais. Caracterizam-se por fornecer soluções efetivas de baixo custo para os problemas de disponibilidade e escalabilidade (Schram & Anderson, 2012).
Fundamentos Teóricos
_______________________________________________________________________________
10
Segundo Cardoso (2012), “NoSql é uma coleção de produtos e conceitos sobre a manipulação de grandes volumes de dados sem usar unicamente SQL”. Já para Pozzani (2013) “é um termo para todas as bases de dados e armazenamentos de dados que não seguem os princípios dos sistemas de gestão de bases de dados relacionais”.
Inicialmente, o termo NoSql era suposto significar “No Sql”, mas devido a poucos sistemas eliminarem completamente a tecnologia relacional, foi então atualizado para “not only Sql” (Schram & Anderson, 2012). Esta tecnologia é uma alternativa viável relativamente às bases de dados relacionais, pois garante melhor desempenho nas consultas enquanto mantêm um certo grau de escalabilidade e flexibilidade (Lee et al., 2013).
A internet e a cloud computing evoluíram bastante e, assim, várias aplicações emergiram, o que forçou uma evolução ao nível das tecnologias de bases de dados, para responder aos novos desafios:
Grandes níveis de concorrência na leitura e escrita de dados;
Para não defraudar as expectativas dos utilizadores, as bases de dados têm de fornecer tempos de resposta suficientemente baixos;
Armazenamento de grandes volumes de dados (Big data) eficiente e com determinados requisitos de acesso;
Aplicações muito exigentes em termos de processamento, como motores de pesquisa e plataformas para redes sociais, têm de responder em tempo útil às solicitações de milhões de utilizadores;
Para além da escalabilidade é fundamental uma alta disponibilidade;
Cada vez mais o volume de dados e os pedidos concorrentes aumentam, pelo que as bases de dados necessitam de ser facilmente expandidas sem interrupções;
A juntar a tudo isto, exigem-se baixos custos de gestão e operação das soluções. Já Stonebraker (2009) aponta as seguintes razões que levaram à adoção das bases dados não relacionais:
Flexibilidade: Podem existir dados que não se adaptam aos rígidos modelos relacionais e neste caso deveria existir mais flexibilidade.
Desempenho: Dados em vários sites têm dado problemas na gestão de dados distribuídos nas aplicações (Stonebraker, 2009; Strauch, 2010).
Mesmo que não exista um consenso no que exatamente constitui uma solução NoSql, o seguinte conjunto de caraterísticas é normalmente atribuído a estas: (Grolinger et al., 2013) São completamente livres de esquemas, de modo a lidarem com uma grande
Fundamentos Teóricos
_______________________________________________________________________________
variedade de tipos de dados;
Possibilitam escalar horizontalmente as soluções através da adição incremental de novos nodos (commodity servers);
Focadas na disponibilidade e na tolerância ao particionamento. Sendo assim, estão apontadas para cenários de alta distribuição. Portanto, escolhem comprometer a consistência em favor da disponibilidade;
Normalmente, não suportam transações ACID como são fornecidas pelas relacionais, sendo assim são muitas vezes referidas como sistemas BASE (Pritchett, 2008). No entanto, algumas bases de dados NoSql como o CouchDB fornecem
ACID.
Este tipo de tecnologia possui uma caraterística chave que é o facto de conseguirem escalar horizontalmente, isto é, replicando e particionando dados através de vários servidores. Isto permite que esta tecnologia suporte um grande número de operações simples de leitura e escrita por segundo (Cattell, 2011).
Como já foi referido anteriormente, estas bases de dados vieram responder a várias necessidades, mas um dos maiores desafios que enfrentam é a consistência. Quando se abordar num próximo tópico o teorema CAP e Eventually Consistency, irá perceber-se o tipo de consistência que é necessária no sistema.
Estas bases de dados NoSql, em comparação à tecnologia relacional, diferem na medida em que não são construídas em tabelas e não utilizam a linguagem Sql para a manipulação de dados. Os sistemas de gestão de bases de dados NoSql são ótimos quando se trabalha com uma grande quantidade de dados, em que estes, devido à sua natureza não necessitam de um modelo relacional (Moniruzzaman & Hossain, 2013). Sendo assim, a sua principal vantagem é conseguirem lidar com dados não estruturados. Como são distribuídas, pode-se aumentar o desempenho distribuindo a carga por várias máquinas que não custam tanto como comprar uma máquina mais poderosa. Portanto, são ideais para lidar com grandes volumes de dados (Cardoso, 2012; Moniruzzaman & Hossain, 2013).
Este tipo de tecnologia começa a encontrar-se em operação em grandes centros de dados, onde as falhas são uma ocorrência constante, tanto devido a problemas de disco como comunicação de rede. Esta tecnologia torna-se apropriada nesses contextos já que possui recursos para permitir a replicação de dados em várias máquinas, o que se traduz num aumento da disponibilidade dos sistemas (Queiroz et al., 2013).
Estão também desenhados para escalar para milhares ou até milhões de utilizadores em simultâneo (Moniruzzaman & Hossain, 2013).
Fundamentos Teóricos
_______________________________________________________________________________
12
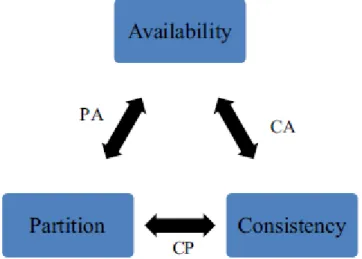
2.3.1 Teorema CAP
O CAP (Consistency, Availability, Partition tolerance) foi introduzido em 2000 pelo cientista de computação Eric Brewer (2000) como uma conjetura e foi formalmente provado em 2002 por Seth Gilbert e Nancy Lynch (2002), sendo assim, estabelecida como teorema (Cardoso, 2012; Silva, 2011).
Toth (2011), Sousa (2010), Brewer (2000) e Lynch (2002) referem que o teorema CAP, enquadrando-se na área da computação distribuída, assenta em três requisitos que descrevem da seguinte forma:
Consistência: Todos os nós de um sistema distribuído necessitam que a versão dos dados que armazenam seja a mesma;
Disponibilidade: Ainda que um nó da rede esteja desligado, todos os clientes podem encontrar, sempre que pretenderem, pelo menos uma cópia dos dados que necessitam;
Tolerância ao particionamento: Caso o sistema seja implementado em servidores diferentes, continua com os seus dados, propriedades e caraterísticas, sempre transparentes para o cliente.
Já de acordo com Ferreira (2012), para um sistema distribuído ser consistente, todos os clientes devem visualizar dados consistentes, independentemente de atualizações e remoções. Para fornecer disponibilidade, todos os clientes devem sempre ser capazes de ler e escrever dados mesmo que um nodo falhe. Para ser tolerante ao particionamento deve continuar a funcionar como planeado, independentemente da rede ou perda de mensagens. Na figura seguinte estão representadas as combinações possíveis.
Fundamentos Teóricos
_______________________________________________________________________________
Segundo Cardoso (2012), Toth (2011), Pozzani (2013) e Vieira et al. (2012), de acordo com este teorema, num sistema de dados distribuído, é impossível ter ao mesmo tempo estes três requisitos, sendo que apenas é possível ter dois deles ao mesmo tempo, o que leva a escolher qual dos três requisitos é o menos necessário.
Pozzani (2013) refere as três combinações possíveis da seguinte forma, isto quando uma caraterística é comprometida.
Comprometer a disponibilidade:
Escolha habitual para bases de dados relacionais com escalabilidade horizontal; Disponibilidade é afetada por vários fatores entre os quais:
o Atrasos devidos a lag na rede; o Escassez de recursos;
o Falha de Hardware que leva a fragmentações.
Comprometer a Tolerância ao particionamento:
Uma moderna interpretação deste teorema é, por exemplo, durante uma falha de rede, um sistema distribuído ter de escolher entre disponibilidade e consistência; Um sistema que não tiver tolerância ao particionamento é forçado a desistir da
consistência ou disponibilidade durante uma falha.
Comprometer a Consistência:
Sendo assim vamos ter fraca consistência, mas é possível aceitar Eventual Consistency, que pode ser interpretada de duas formas:
Dado um período de tempo suficiente, onde nenhuma atualização foi enviada, pode-se esperar que todas as atualizações vão, eventualmente, propagar-pode-se pelo sistema e todas as réplicas serão consistentes;
Na presença de contínuas atualizações, uma atualização aceite, eventualmente atinge a réplica ou esta retira-se do serviço.
Eventual Consistency leva-nos para o conceito BASE que irá ser abordado no seguinte
ponto.Segundo Dimitrov (2010), as combinações possíveis dos três requisitos processa-se da seguinte forma:
CA - Consistência e Disponibilidade
o Clusters únicos, fácil de assegurar devido a todos os nodos estarem sempre em contacto;
o Exemplo: 2 PC;
o Quando um particionamento ocorre o sistema bloqueia. CP - Consistência e Tolerância ao particionamento
Fundamentos Teóricos
_______________________________________________________________________________
14
o Alguns dados podem ser inacessíveis (disponibilidade sacrificada), mas o resto é consistente;
o Exemplo: sharded database.
PA - Disponibilidade e Tolerância ao particionamento
o Sistema está disponível mesmo durante o particionamento, mas alguns dados podem-se revelar inconsistentes;
o Exemplo: DNS, caches, Master/Slave replication;
o Necessita de alguma estratégia de resolução de conflitos.
Sadalage e Fowler (2012) descrevem de uma maneira bastante simples e percetiva os sistemas que utilizam a combinação da consistência com a disponibilidade. É fácil quando se está perante máquinas individuais, pois elas não podem ter particionamentos, sendo assim, não é necessário haver preocupações com o requisito tolerância ao particionamento, pois só existe um nodo. Este é o conjunto de requisitos da maioria das bases de dados relacionais.
Tipicamente as bases de dados NoSql são PA (Partition tolerance/Availability) enquanto a maioria das relacionais são CA (Consistency/Availability).
2.3.2 BASE Vs ACID
Enquanto o ACID fornece um conjunto de propriedades que garantem que as transações das bases de dados são processadas com confiança, o oposto modelo BASE, que é derivado diretamente do teorema CAP, aponta para fornecer um diferente conjunto de propriedades das que o ACID fornece (Silva, 2011).
2.3.2.1 Modelo ACID
O acrónimo ACID significa, Atomicity, Consistency, Isolation e Durability, é usado pela generalidade dos sistemas de gestão de base de dados para assegurar a integridade na base de dados. As suas caraterísticas constituintes significam o seguinte:
Atomicity: Caso exista uma falha na transação, o efeito das suas operações não é aplicado na base de dados;
Consistency: A integridade da base de dados é garantida no final da execução de uma transação;
Isolation: O resultado de uma execução de uma transação concorrente é o mesmo do que uma transação isolada;
Fundamentos Teóricos
_______________________________________________________________________________
resultados são refletidos na base de dados.
ACID fornece um conjunto de propriedades que garantem que as transações das bases de
dados são processadas com confiança e que a base de dados é consistente em acessos concorrentes e falhas do sistema (Silva, 2011).
2.3.2.2 BASE
Em relação ao modelo BASE, Toth (2011) refere que para que seja possível trabalhar com um sistema distribuído foi proposto enfraquecer ou relaxar o requisito de consistência permanente de dados, focando antes na disponibilidade e na tolerância ao particionamento. Deste modo surge o conceito BASE (Basically Available, Soft state, Eventual consistency) com propriedades e filosofia oposta.
O mundo NoSql aponta este teorema, referindo a razão pela qual se deve relaxar na consistência.
Neste sistema não existem transações e são introduzidas ligações no modelo de dados para permitir melhores esquemas de particionamentos (Moniruzzaman & Hossain, 2013). Toth (2011) refere ainda que é considerado um cenário que lida bem com transações distribuídas, tolerância a falhas de consistência e replicação otimista num sistema distribuído.
Vieira et al. (2012) assim como Toth (2011), referem que o paradigma BASE foi criado a partir do teorema CAP. O primeiro autor ainda refere que o facto de não se controlar a consistência, faz com que exista uma sensível diminuição no custo computacional para a garantia de consistência dos dados em relação às bases de dados relacionais. Já o segundo autor refere que este modelo de consistência está normalmente associado a sistemas distribuídos. Refere também, que todas as atualizações pendentes serão propagadas por todos os nós do sistema, caso durante um determinado tempo não existam atualizações, ficando assim no fim, todo o sistema consistente. A partir deste conceito vários tipos de bases de dados NoSql foram criadas, que, como já foi referido não garantem temporariamente consistência dos dados de uma aplicação. Toth (2011) refere grandes empresas como a Google e a Amazon, que aproveitaram a vantagem deste paradigma, isto porque utilizaram um modelo NoSql, aplicado ao conceito de distribuição horizontal. Como não existe garantia de consistência, as configurações de fragmentação no modelo são mais fáceis de efetuar e, por conseguinte, o modelo torna-se mais escalável e com custos mais reduzidos.
Fundamentos Teóricos
_______________________________________________________________________________
16
que as atualizações são eventualmente propagadas em todos os nodos (Cattell, 2011).
Eventual Consistency é uma forma específica de fraca consistência (Vogels, 2009). Um
sistema distribuído que forneça Eventual Consistency garante que, quando nenhuma atualização seja feita num registo, eventualmente o sistema será consistente (exemplo: todos os nodos do sistema aguentarão eventualmente os mesmos valores, embora possa não ser necessário, e todos os acessos de leitura serão retornados ao ultimo valor atualizado (Silva, 2011). Agora considerando um exemplo real, considerando duas pessoas que querem atualizar um número de telefone ao mesmo tempo. Um atualiza e outro atualiza logo a seguir, senão existisse controlo de concorrência um era atualizado e o outro era atualizado por cima do primeiro.
As maneiras para manter consistência nestes casos chamam-se otimista e pessimista. A maneira pessimista trabalha para prevenir que conflitos ocorram, já a otimista deixa os ocorrer, deteta-os e depois toma medidas para os tratar (Sadalage & Fowler, 2012).
Resumindo, “Basically Available” significa que as bases de dados estão disponíveis sempre que são acedidas, mesmo que uma parte esteja indisponível. “Soft State” diz que não precisam sempre de ser consistentes e podem tolerar inconsistência por um certo período de tempo; e “Eventual Consistency” enfatiza que, depois de um certo período de tempo, a base de dados vem para um estado de consistência.
2.3.3
Caraterização das Bases de dados
NoSql
2.3.3.1 Schema-Free
Segundo Rybinski (1987) e Imielinski & Lipski (1982), schema é um conjunto de fórmulas que descrevem a base de dados e as relações de acordo com a sua sintaxe. Esta estrutura provém da normalização que, segundo Codd (1970) citado por Cardoso (2012), é “o processo de simplificação e organização dos campos e das tabelas de uma base de dados de forma a reduzir a redundância dos dados”.
Cardoso (2012) refere que a normalização é importante numa base de dados, pois garante que nas tabelas possam ser inseridos dados sem anomalias (inconsistência de dados, redundância, etc). Jacobs (2009) também salienta que à medida que a quantidade de dados aumenta numa tabela, a base de dados tende a ficar mais lenta. Sendo assim, Schrage (2002) refere que para ganhar rapidez de leitura/obtenção de dados, abdica-se da normalização. Segundo Cardoso (2012), ao ganhar esta rapidez também se ganha redundância nos dados e uma maior interdependência entre os mesmos. No entanto, ainda existem alguns
Fundamentos Teóricos
_______________________________________________________________________________
problemas inerentes à normalização ou à obrigação de possuir um schema, que é o caso de todos os dados terem de obedecer àquela estrutura e caso necessite de modificações por mais pequenas que sejam, podem obrigar a uma restruturação tão grande que pode vir a obrigar a uma restruturação da aplicação que utiliza a base de dados.
Em relação ao Schema-Free pode-se referir como uma base de dados sem estrutura fixa, ou seja, os dados não necessitam de obedecer a uma estrutura previamente definida. Sendo assim, já é permitido um armazenamento de dados não estruturados em qualquer formato, o que garante um bom desempenho para os desafios do Big data (Almeida & Brito, 2012). Cardoso (2012) cita Stainer (2010) que refere que o facto de não possuir um schema também traz desvantagens, como é o caso da possibilidade de possuir dados redundantes e até incoerentes. Cardoso (2012) refere que a garantia das propriedades ACID deixa de ser válida devido à inexistência de um schema, o que leva a um modelo diferente chamado BASE, o qual foi abordado anteriormente.
Cardoso (2012) cita Brewer (2000) que refere que isto é necessário, pois abrindo mão da consistência dos dados ganha na tolerância a falhas e na disponibilidade, que são bastante importantes para lidar com grandes volumes de dados.
Por exemplo, Tweets e atualizações de estado nas redes sociais podem ser inconsistentes, mas o sistema deve ter sempre alto desempenho e alta disponibilidade. Já nas aplicações que lidam com finanças a consistência é a caraterística mais importante, portanto os sistemas
BASE não são os mais indicados para instituições bancárias (Hecht & Jablonski, 2011).
Os sistemas NoSql não assentam completamente em ACID ou BASE, isto porque, a maioria das bases de dados permite personalizar a consistência e a disponibilidade de acordo com as necessidades de cada um (Hecht & Jablonski, 2011).
2.3.3.2 MapReduce
MapReduce é uma tecnologia criada pela Google para dar resposta ao tratamento do enorme
volume de dados com que esta tem de lidar diariamente. Segundo Dean & Ghemawat (2004), “é um modelo de programação e uma implementação associada ao processamento e gestão de grandes datasets”. Refere também que é uma framework de programação que processa datasets de grande porte com hardware regular.
Cardoso (2012) cita White (2012) que refere que é um modelo de dados para processamento paralelo.
Esta tecnologia foi proposta inicialmente para tornar mais simples o processamento de grandes volumes de dados em arquiteturas paralelas e distribuídas, como é o caso dos
Fundamentos Teóricos
_______________________________________________________________________________
18
clusters. Sendo assim, é utilizado nestes e os dados são distribuídos e armazenados
utilizando pares <key, value>, onde, para a mesma chave, vários valores podem ser armazenados. Portanto, a tecnologia MapReduce é ideal para lidar com o processamento intensivo de grandes quantidades de dados pois é uma abordagem bastante escalável. Isto porque a alocação dos dados no mesmo nó confere alto desempenho a esta tecnologia (Vieira et al., 2012).
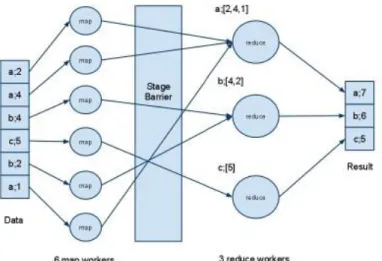
Segundo Alexandre e Cavique (2013), é um conjunto de processos que permite tratar um grande volume de dados de forma distribuída. Refere que duas operações estão subjacentes a esta tecnologia, o Map e o Reduce.
Em relação ao Map trata-se de dividir o problema em subconjuntos mais pequenos que possam ser distribuídos por outros nós do cluster. Já o Reduce pega em todos os subconjuntos de dados, agrega e trata a informação e responde ao problema original. Cardoso (2012) concorda e refere que o MapReduce assenta em dois grandes conceitos:
Uma função de Map, que tem como objetivo separar os grandes volumes de dados em pedaços mais pequenos;
Uma função de Reduce, que tem como objetivo processar e agrupar todos os pequenos fragmentos dos dados.
Segundo Vieira et al. (2012), em relação ao aspeto do processamento dos dados, a tecnologia utilizada pelos produtos NoSql é o MapReduce. Segundo o autor também se divide em dois grandes conceitos, sendo eles:
Map, que tem como objetivo mapear e distribuir os dados pelos diversos nós de processamento e armazenamento;
Reduce, que tem como objetivo agregar e processar os resultados parciais para gerar um resultado final.
Como é possível verificar-se na imagem abaixo, os dados são divididos em pequenos pedaços e, com a função reduce, são processados e agrupados.
Fundamentos Teóricos
_______________________________________________________________________________
Figura 2 - Fluxo do funcionamento do Map Reduce (Retirado de Alexandre & Cavique, 2013,pag.41)
Cardoso (2012) cita Dean & Ghemawat (2004) que referem que o que aconteceu na implementação do Google foi pegar num cluster típico e escolher um nó que seria o Master e que iria receber o dataset gigantesco. Posto isto, divide os dados por algumas máquinas que tomaram o papel de map workers e executaram a função de map aos dados que lhe foram atribuídos. De seguida, os map workers notificaram o Master de que a função de map estava concluída, o Master pôde delegar num ou mais reduce workers o trabalho de obter os dados previamente mapeados pelo map worker e lhes aplicar a função de reduce. Por fim, os dados estão processados
Caso de aplicação Map/Reduce
Figura 3 - Exemplo MapReduce (Adaptado de Bonnet et al., 2011,pag.486)
Em relação aos pontos (3), (4) e (5) pode-se visualizar na imagem seguinte como são processados (Bonnet et al., 2011).
Fundamentos Teóricos
_______________________________________________________________________________
20
Pode-se considerar que está relacionado com o poder de processamento existente em ambientes Cloud. Ambientes MapReduce têm maior facilidade no carregamento de informações quando comparados com ambientes das bases de dados relacionais, pois os dados são armazenados no seu estado original, enquanto na tecnologia relacional a transformação dos dados é feita no momento do processamento das consultas (Vieira et al., 2012).
Outro exemplo é o caso do Hadoop, que para processar dados semi-estruturados e não estruturados, utiliza este paradigma, em que localiza todos os dados relevantes e depois seleciona apenas os dados que respondem à consulta (Purcell, 2013).
2.3.3.3 Escalabilidade
Clarck (2009) define escalabilidade como “alterar o tamanho enquanto mantém proporções”.
Já Forbes (2010) refere que escalabilidade é “Pragmaticamente a medida da capacidade de uma solução de crescer para o mais alto nível de uso realista de um modo possível, mantendo ao mesmo tempo os níveis de serviço aceitáveis”.
Strauch (2010) cita.Clarck (2009) que acrescenta que escalar não está relacionado com ser rápido mas sim com tamanho. Algum sistema que tenha alto desempenho não necessita de escalar.
Existem duas formas de escalar sendo elas:
Escalar verticalmente: aumentar a capacidade do servidor, é limitada e tem custos elevados. Esta está relacionada, segundo Vieira et al. (2012) com o uso de vários núcleos/ CPU que compartilham memória e discos.
Figura 4 - Fluxo de uma execução MapReduce (Retirado de Bonnet et al., 2011,pag.486)
Fundamentos Teóricos
_______________________________________________________________________________
Escalar horizontalmente: aumentar o número de servidores tendo como beneficio a facilidade na distribuição dos dados e existe distribuição de dados e carga por vários servidores mas, contrariamente à escalabilidade vertical, sem haver partilha de memória ou disco. Permite também o uso de hardware mais barato e comum (Castro & Batista, 2013).
Opostamente às bases dados relacionais, as bases dados NoSql escalam melhor horizontalmente e não necessitam de grande disponibilidade de hardware. Pode-se simplesmente adicionar ou retirar mais máquinas sem comprometer o cluster (Strauch, 2010).
Esta capacidade de escalar horizontalmente é uma das principais caraterísticas do NoSql. Segundo Vieira et al. (2012), isto permite que um grande volume de operações de leitura/escrita sejam executadas muito mais eficientemente.
Como já foi abordado anteriormente, as bases de dados relacionais têm problemas com escalabilidade, nomeadamente escalabilidade dinâmica que é uma propriedade fundamental no ambiente Cloud. Para estas bases de dados apenas escalabilidade vertical é fácil de ser atingida, sendo assim, os custos associados chegam a ser exorbitantes.
Vieira et al. (2012) refere então que o facto de um modelo único de SGBD contemplar todos os modelos de dados, vai contra o contexto de Big data. Isto porque, por um lado, os produtos relacionais oferecem diversas funcionalidades de extensão, mas, por outro lado, os custos de manutenção tornam-se inviáveis, pois a maioria das soluções são caras.
Frequentemente, uma base de dados está ocupada porque várias pessoas estão a aceder a diferentes partes do conjunto de dados. Nestas circunstâncias podemos suportar escalabilidade horizontal pondo diferentes partes dos dados em diferentes servidores (Sadalage & Fowler, 2012).
2.3.3.4 Sharding
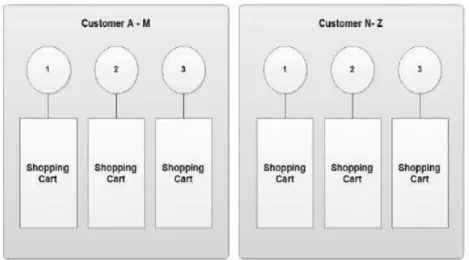
Segundo Bell et al. (2010), sharding consiste em dividir os dados em fragmentos independentes pelos nós existentes, o que faz que quando um cliente necessite dos dados seja redirecionado para o nó que os contém.
Para Shawrtz et al. (2012) é o processo em que se divide os dados em pequenos bocados e se armazenam posteriormente em diferentes nós.
Já Cardoso (2012) cita Warden (2011) que defende que é o esquema usado para decidir em que máquina (nó) os pedaços de informação de uma base de dados vão residir.
Fundamentos Teóricos
_______________________________________________________________________________
22
arquitetura, mas sem compartilhamento de recursos. Nesta técnica refere que os dados são divididos por registos em vez de serem divididos por colunas.
Como é possível visualizar na imagem seguinte, a informação é dividida por outros nós.
Bell et al. (2010) refere algumas razões para se efetuar sharding à base de dados, sendo elas: Os dados serem colocados geograficamente mais perto do utilizador;
Facilitar a pesquisa através da redução do tamanho do Dataset;
Dividir ainda mais os fragmentos que estejam a ser muito utilizados de forma a equilibrar a carga do sistema.
Existem inúmeras vantagens usando esta técnica. Uma delas é em cada tabela do servidor, o número total de linhas é reduzido, isto porque as tabelas estão divididas e distribuídas em vários servidores. Sendo assim, também o tamanho dos índices são reduzidos, o que geralmente melhora o desempenho de consultas. Outra vantagem é que a base de dados pode ser separada por diferentes máquinas, isto onde o shard foi implementado, e vários shards podem ser alocados em diferentes máquinas (Vieira et al., 2012). Portanto, o desempenho aumenta pois a base de dados está distribuída por várias máquinas.
Existem também algumas desvantagens. Cardoso (2012) refere uma que ele considera a mais evidente que “é a mudança de um dataset que vem de uma base de dados não distribuída para um que venha de uma base de dados distribuída em shards.” Segundo Shawrtz et al. (2012), existem também algumas questões na mudança dos fragmentos de um nó para o outro.
Para Vieira et al. (2012) o problema do sistema Master Slave é caso existam mais pedidos de escrita do que uma máquina pode lidar, o que leva à necessidade de efetuar sharding.
Fundamentos Teóricos
_______________________________________________________________________________
Nesta, estruturas completamente isoladas são postas num servidor por ordem alfabética. Na figura 5 é mostrado um exemplo de todos os nomes dos clientes começados por A-M são postos num único servidor e N-Z são postos noutro servidor. Isto certamente pode lidar com o dobro da carga de trabalho. Similarmente pode haver “n” números de máquinas adicionadas para facilitar a carga de trabalho (Tauro et al., 2012).
Figura 6 - Exemplo de sharding de um carrinho e compras (Retirado de Tauro et al., 2012,pag.2)
2.3.3.5 Segurança
Segurança é um aspeto importante das bases de dados que é valorizado pela maioria destas. Sendo assim, irão ser avaliados os vários tipos de bases de dados nos seguintes aspetos de segurança:
Autenticação: São mecanismos que identificam utilizadores que acedem aos dados. São associadas passwords a logins, mas também são possíveis mecanismos mais sofisticados, como certificados. Segundo Grolinger et al. (2013), para muitas empresas um requisito importante para a autenticação é a capacidade de integração com o sistema de diretório de utilizadores da empresa como o Lightweight Directory
Access Control (LDAP)/Active Directory and Kerberos servers.”;
Autorização: É a capacidade de assegurar um controlo de acessos aos recursos das bases de dados. O objetivo é associar a cada utilizador um conjunto de permissões. Por exemplo, em algumas bases de dados pode-se atribuir permissões específicas para pedidos de leitura e escrita nas tabelas, execução de funções de administração e criação de utilizadores;
Encriptação: É um mecanismo que tem como objetivo encriptar dados, para assim não poderem ser lidos por “attackers” e outras pessoas não autorizadas. De acordo com Grolinger et al. (2013), “uma solução de uma completa encriptação deve estar