Análise de atividade de
instituições de ensino
superior em redes
sociais
Ana Catarina Marinho Ribeiro
Mestrado Integrado em Engenharia de Redes e Sistemas Informáticos
FCUP-DCC 2017
Orientador
Álvaro Figueira, FCUP-DCC
Coorientador
Todas as correções determinadas pelo júri, e só essas, foram efetuadas.
O Presidente do Júri,
Abstract
Over the last few decades there has been an enormous technological evolution in what concerns web services. Not surprisingly, the importance of the Internet in the ten university institutions that have topped the world ranking has been verified over time, particularly in their use of social networks, namely with Facebook, and in the interactivity between them and their target audience.
In this context, arises a need to create a process to analyze the amount of generated information from the published messages by the institutions in social networks, and the response these messages have in order to compare effort with response.
However, in a time when data is always in high quantities (big data) it is practically impossible to undertake this process solely by manual verification and analysis.
In this context, we propose an automatic procedure to assess the behavior and the individual performance of each institution, followed by an analysis of the posts where the topics contained in the messages were identified. A statistical study was also conducted on the frequency and intensity of publications by universities, which included an analysis of the number of responses to publications over time and on a quarterly basis and a similar analysis of the number of posts. Finally, the content of the texts themselves was analyzed according to the topics covered in the messages.
This process allowed us to identify the most efficient institutions in social networks and the institutions that have a more active community. We have also been able to understand which topics are most common in each university’s publications and relate them to the corresponding response from their publics.
Resumo
Ao longo das últimas décadas registou-se uma enorme evolução tecnológica no que diz respeito aos serviços web, nomeadamente na importância da Internet para as dez universidades mais bem classificadas no ranking mundial, que foram analisadas ao longo do tempo, relativamente à utilização que fazem das redes sociais, particularmente o Facebook, e à interatividade gerada entre estas e os seus públicos.
Neste contexto, torna-se premente a criação de um processo que permita analisar a quantidade de informação gerada a partir das mensagens publicadas pelas instituições nas redes sociais, bem como o envolvimento gerado com os fãs, para que seja possível comparar o esforço e a resposta obtida em cada um dos casos.
No entanto, numa altura em que os dados abundam em elevadíssimas quantidades (big data) é praticamente impossível realizar este processo recorrendo exclusivamente a análise e verificação manual.
Neste cenário, propomos um processo automático de avaliação de comportamento e de performance individual para cada instituição, seguido de uma análise das mensagens publicadas por estas, onde foram identificados os respetivos tópicos. Foi ainda conduzido um estudo estatístico acerca da frequência e intensidade de publicação de mensagens por parte das universidades, que inclui uma análise trimestral do número de mensagens e respetivas respostas. Finalmente, foi realizada uma análise de conteúdo dos textos das mensagens, de acordo com os principais temas detetados nestas.
Este processo permitiu-nos identificar quais foram as instituições com atividade mais eficiente em redes sociais ao longo do período analisado, bem como aquelas que possuem comunidades mais ativas. Este trabalho permitiu-nos ainda fazer o levantamento dos temas mais frequentemente abordados por cada instituição e relacioná-los com a quantidade de resposta que estes geram junto das respetivas comunidades de seguidores.
Agradecimentos
Gostaria de agradecer a todas as pessoas que, ao longo deste ano de trabalho, me ajudaram e tornaram possível concluir uma grande etapa da minha vida, pois sem a ajuda de todos, tudo isto não seria possível. Em especial ao professor Álvaro Figueira e Luciana Oliveira que, graças aos seus conselhos e dicas, possibilitaram a conclusão deste projeto.
Aos meus pais que lutaram para que pudesse concluir esta etapa durante estes anos, que mesmo nos meus piores momentos acreditaram sempre em mim e estiveram presentes para me apoiar.
A todos os meus amigos que estiveram presentes, quer nos momentos de estudo, quer nos de lazer, mas que também foram um grande apoio para a conclusão desta etapa.
E a todos que de alguma forma estiveram envolvidos em todo este processo, um muito obrigada.
Conteúdo
Abstract i Resumo iii Agradecimentos v Conteúdo ix Lista de Tabelas xi Lista de Figuras xvLista de Blocos de Código xvii
Acrónimos xix
1 Introdução 1
1.1 Contexto e Motivação . . . 1
1.2 Objetivos . . . 2
1.3 Etapas do projeto. . . 3
1.3.1 Identificação da rede social selecionada e das instituições de ensino superior de topo . . . 3
1.3.2 Recolha de informação das instituições de ensino superior . . . 5
1.3.3 Recolha de posts das instituições educacionais e tratamento de dados. . . 5
1.3.4 Utilização dos métodos de Data Mining . . . 5
1.3.5 Deteção de tópicos . . . 5
1.4 Planificação do projeto . . . 6
1.5 Estrutura da tese . . . 6
2 Conceitos Base e Trabalho Relacionado 9 2.1 Conceitos Base . . . 9 2.1.1 Text Mining . . . 9 2.1.2 Classificadores . . . 10 2.1.3 Seleção de informação . . . 12 2.1.4 Métodos de avaliação . . . 12 2.2 Recursos Utilizados . . . 14 2.2.1 Linguagens de Programação . . . 14 2.2.2 Tecnologias . . . 14 2.3 Projetos relacionados . . . 15 2.4 Problemas esperados . . . 16 3 Análise exploratória 17 3.1 Recolha e tratamento dos dados. . . 17
3.1.1 Configuração de API do Facebook . . . 17
3.1.2 Extração dos dados . . . 18
3.2 Tratamento de dados . . . 19
3.3 Análise dos dados recolhidos . . . 20
3.4 Conclusão . . . 26
4 Análise de comportamento e desempenho 27 4.1 Evolução do comportamento ao longo do tempo . . . 27
4.1.1 Atividade no Facebook ao longo do tempo . . . 28
4.1.2 Interações ao longo do tempo . . . 34
4.2 Análise de desempenho global por trimestres . . . 40
5 Análise de conteúdo 45
5.1 Análise da importância das palavras para o post . . . 45
5.2 Análise dos tópicos das mensagens . . . 51
5.3 Conclusões . . . 55
5.3.1 Importância das palavras . . . 55
5.3.2 Tópicos das mensagens. . . 55
6 Conclusões 57 6.1 Resumo do Trabalho . . . 57
6.2 Conclusões Gerais . . . 57
6.3 Trabalho Futuro . . . 58
Bibliografia 59
A Análise dos tópicos contidos nas mensagens 61
B Calendários escolares 67
Lista de Tabelas
3.1 Síntese dados numéricos . . . 19
3.2 Número de palavras por Instituição . . . 22
3.3 Número de publicações por dia . . . 22
Lista de Figuras
1.1 Planificação . . . 6
2.1 Confusion matrix . . . 13
3.1 Criação da APP para o sistema . . . 17
3.2 Permissões da API . . . 18
3.3 Número de posts por Instituição. . . 20
3.4 Número de interações por Instituição . . . 21
3.5 Número de posts por meses do ano . . . 23
4.1 Agrupamento de posts para Harvard . . . 28
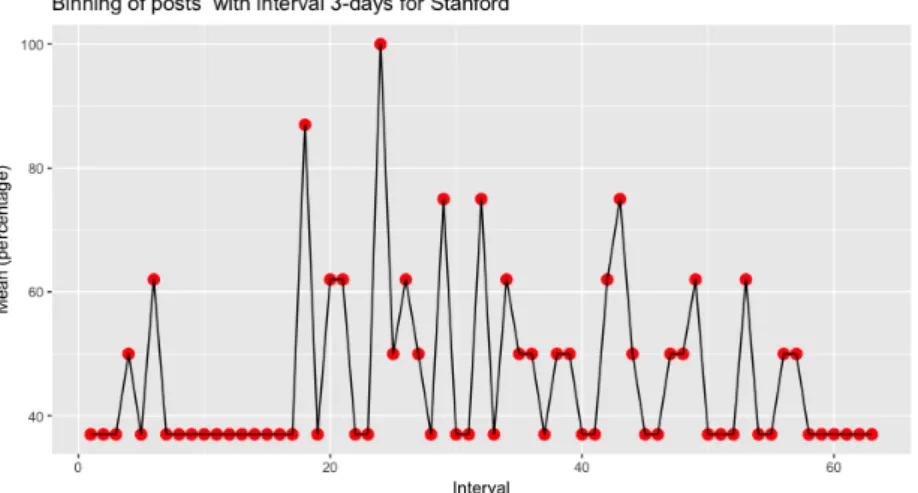
4.2 Agrupamento de posts para Stanford . . . 29
4.3 Agrupamento de posts para MIT . . . 30
4.4 Agrupamento de posts para Cambridge . . . 30
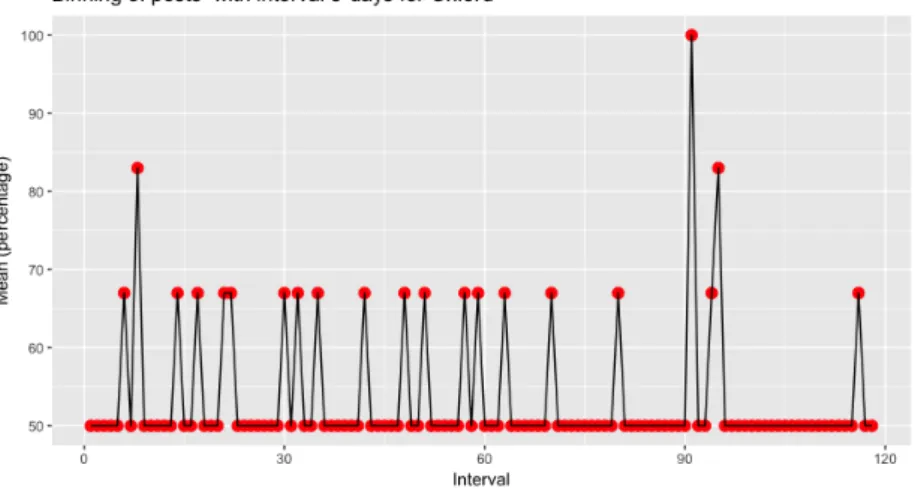
4.5 Agrupamento de posts para Oxford . . . 31
4.6 Agrupamento de posts para Columbia . . . 31
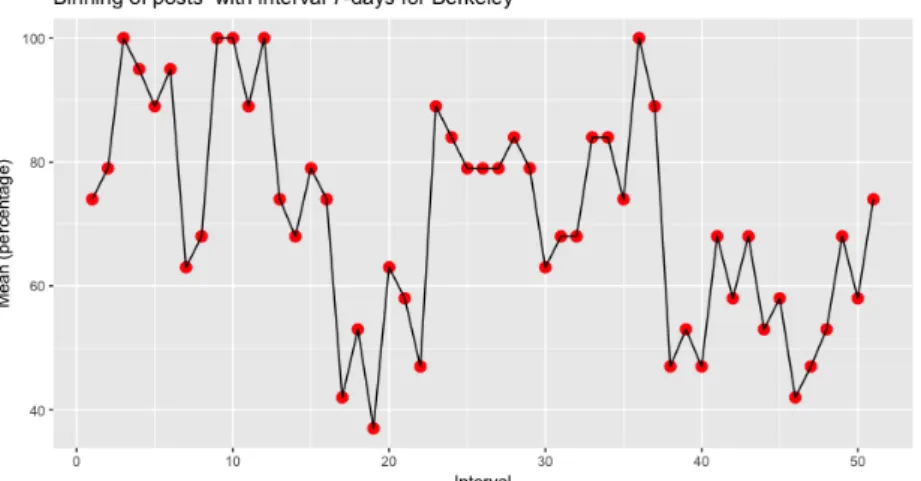
4.7 Agrupamento de posts para Berkeley . . . 32
4.8 Agrupamento de posts para Chicago . . . 33
4.9 Agrupamento de posts para Princeton . . . 33
4.10 Agrupamento de posts para Yale . . . 34
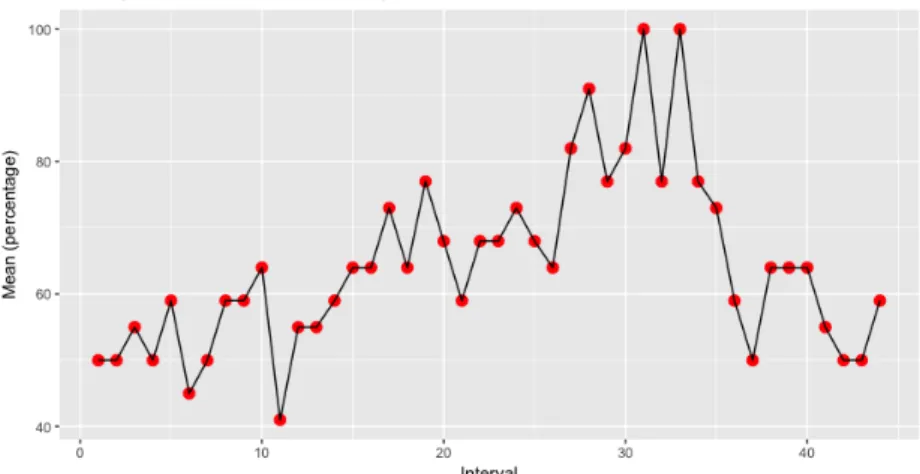
4.11 Agrupamento do número de respostas para Harvard . . . 35
4.12 Agrupamento do número de respostas para Stanford . . . 35
4.13 Agrupamento do número de respostas para MIT . . . 36
4.14 Agrupamento do número de respostas para Cambridge . . . 36
4.15 Agrupamento do número de respostas para Oxford . . . 37
4.16 Agrupamento do número de respostas para Columbia. . . 38
4.17 Agrupamento do número de respostas para Berkeley . . . 38
4.18 Agrupamento do número de respostas para Chicago . . . 39
4.19 Agrupamento do número de respostas para Princeton . . . 39
4.20 Agrupamento do número de respostas para Yale . . . 40
4.21 Desempenho global no primeiro trimestre do ano letivo. . . 41
4.22 Desempenho global no segundo trimestre do ano letivo . . . 41
4.23 Desempenho global no terceiro trimestre do ano letivo . . . 42
4.24 Desempenho global no quarto trimestre do ano letivo. . . 42
5.1 Palavras importantes utilizadas por Harvard University . . . 46
5.2 Palavras importantes utilizadas por Stanford University . . . 46
5.3 Palavras importantes utilizadas por Massachusetts Institute of Technology . . . 47
5.4 Palavras importantes utilizadas por University of Cambridge . . . 47
5.5 Palavras importantes utilizadas por University of Oxford. . . 48
5.6 Palavras importantes utilizadas por Columbia University. . . 48
5.7 Palavras importantes utilizadas por University of California, Berkeley . . . 49
5.8 Palavras importantes utilizadas por University of Chicago . . . 49
5.9 Palavras importantes utilizadas por Princeton University . . . 50
5.10 Palavras importantes utilizadas por Yale University. . . 50
5.11 Agrupamento das instituições Harvard e Yale . . . 51
5.12 Agrupamento das instituições Cambridge, MIT e Chicago . . . 52
5.13 Agrupamento das instituições Columbia e Oxford . . . 53
5.14 Agrupamento das instituições Princeton, Berkeley e Stanford . . . 54
A.1 Tópicos obtidos em Harvard . . . 61
A.2 Tópicos obtidos em Stanford . . . 62
A.3 Tópicos obtidos em MIT . . . 62
A.4 Tópicos obtidos em Cambridge . . . 63
A.5 Tópicos obtidos em Oxford . . . 63
A.6 Tópicos obtidos em Columbia . . . 64
A.7 Tópicos obtidos em Berkeley . . . 64
A.8 Tópicos obtidos em Chicago . . . 65
A.9 Tópicos obtidos em Princeton . . . 65
A.10 Tópicos obtidos em Yale . . . 66
Lista de Blocos de Código
Acrónimos
CRAN Cromprehensive R Archive Network
CU Columbia University
CWUR Center for World University Rankings
DCC Departamento de Ciências de Computadores
FCUP Faculdade de Ciências da Universidade do Porto FN False Negative
FP False Positive
HTTP Hypertext Tranfer Protocol
HU Harvard University
IDF Inverse Document Frequency
KNN K-Nearest Neighbour
KPI Key Performance Indicator
LDA Latent Dirichlet Allocation
MIT Massachusetts Institute of Technology
NLP Neuro-Linguistic Programming
Oxon University of Oxford
PU Princeton University
ROI Retorno sobre investimento
SU Stanford University
SVM Support Vector Machine
TF Term Frequency
TF-IDF Term Frequency - Inverse Document Frequency
TN True Negative
TP True Positive
UC University of Cambridge
UCB University California, Berkeley
UCHI University of Chicago
Capítulo 1
Introdução
1.1
Contexto e Motivação
A complexidade dos novos problemas que a sociedade enfrenta resulta do seu crescimento e rápida evolução científica e tecnológica, sobretudo registada nas últimas décadas. Em consequência, o desenvolvimento de soluções inovadoras que necessariamente resultem do cruzamento e articulação multidisciplinar de áreas de conhecimento, torna-se vital.
Devido à consolidação da Internet como meio preferencial de comunicação na atualidade, as instituições ficam diante do desafio de lidar com o empoderamento dos seus públicos-alvo. A proliferação das redes sociais tem introduzido profundas transformações na sociedade e na comunicação entre pessoas e/ou organizações. Efetivamente as instituições começaram a investir cada vez mais na virtualização e no desenvolvimento da sua presença nestes ambientes digitais, que proporcionam grande interatividade e amplo alcance do público. Nos últimos anos, com o desenvolvimento da Internet e o uso frequente das redes sociais, as instituições de ensino superior têm sentido a necessidade de seguir essa tendência mundial de construir presença nas redes sociais, nomeadamente na rede mais utilizada em todo o mundo, o Facebook.
Um dos grandes desafios impostos às instituições, com a emergência das redes sociais, reside na necessidade de migrar dos modelos de comunicação assimétricos para uma perspetiva mais simétrica de comunicação, ou seja, mais centrada na opinião e nos interesses das audiências, cujo poder de intervenção é cada vez mais ampliado. A pensar nessa interatividade entre as instituições e o seu público, bem como na facilidade dessa comunicação, a quantidade de informação gerada será bastante elevada para ser tratada manualmente.
De facto, as redes sociais criaram a possibilidade de qualquer pessoa ou instituição distribuir informação de forma veloz e dinâmica. Num simples clique é possível obter informações, publicar conteúdos, comentar e partilhar informação de outros utilizadores. Estas redes assumem-se como estruturas que permitem ligar pessoas ou organizações com interesses idênticos, permitindo uma partilha de experiências e informações entre as partes de modo mais acessível.
2 Capítulo 1. Introdução
No entanto, a construção desta presença, através da criação de páginas e perfis em redes sociais, tem vindo a suceder independentemente do fato de as organizações terem, ou não, previamente definido objetivos específicos para estes canais ou uma estratégia de conteúdo orientada às expectativas de um público-alvo também claramente identificado. Em resultado, são muito poucas as instituições que possuem uma estratégia de conteúdo para redes sociais, embora este seja um tema popular entre os profissionais de marketing e uma área crescente de interesse. Neste momento, as instituições encontram-se continuamente a despender tempo, recursos humanos e tecnologias para assegurar a manutenção da sua presença nas redes sociais e esta alocação de recursos torna cada vez mais premente a necessidade de obter e medir o retorno sobre o investimento nestes meios.
1.2
Objetivos
Este projeto tem como objetivo essencial o desenvolvimento de um sistema automático de classificação de mensagens que são colocadas nas redes sociais pelas instituições do ensino superior internacionais. Este objetivo assenta na premissa de que o conjunto de mensagens publicadas por uma instituição de ensino superior pode ser decomposto em grupos de mensagens análogas (orientadas ao mesmo objetivo genérico).
De acordo com outros estudos [14][20][11], é esperado que pelo menos três áreas surjam ao longo da análise, sendo elas a Educação, Investigação e Relacionamento. No entanto, o que se pretende, ao contrário do estudo Figueira e Oliveira [11], e que as áreas editoriais não sejam prescritas, mas que sejam reveladas através da utilização de um sistema não supervisionado que permita classificar as mensagens publicadas em redes sociais em áreas editoriais que sejam reveladas através da análise do conteúdo dessas mesmas mensagens.
Os objetivos específicos deste trabalham consistem em:
1. Identificar as instituições de ensino superior que serão alvo de estudo.
2. Recolher todas as mensagens publicadas nas redes sociais durante um ano letivo completo. 3. Identificar e classificar os termos predominantes das mensagens recolhidas.
4. Computar o envolvimento dos públicos com os temas predominantes identificados, utilizando KPI com likes, reactions. comments e shares.
5. Identificar a geração não-supervisionada de tópicos contidos nas mensagens.
6. Identificar os temas com propensão para gerar mais envolvimentos dos públicos a fim de fornecer recomendações para o desenho de estratégias de conteúdo.
7. Identificar as instituições internacionais mais bem posicionadas em termos de eficiência no desenho de conteúdo e envolvimento gerado nos públicos.
1.3. Etapas do projeto 3
1.3
Etapas do projeto
A abordagem proposta é constituída por 4 fases fundamentais.
Numa primeira fase, verificamos, qual a rede social mais utilizada pelas instituições de ensino superior internacional. A identificação das instituições de ensino superior de topo é resultante do seguimento do ranking internacional Center for World University Rankings (CWUR) [7], para assim ter acesso às melhores e mais qualificadas instituições de ensino superior a nível mundial. Assim, a segunda fase consiste em reunir toda a informação, relativa a um ano letivo, da página oficial do Facebook de cada instituição, através de um crawler desenvolvido com esse propósito, que recolhe todos os posts, comments, shares e reactions. Todos esses dados são submetidos a um processo de limpeza dos dados recolhidos, o que facilita o estudo em causa.
A terceira fase da metodologia centra-se na seleção de métodos para a realização de uma análise aos dados, com a utilização de métodos que simplifiquem a compreensão dos dados recolhidos e permita o estudo do comportamento e desempenho das instituições.
Finalmente, a última fase desta metodologia consiste no desenvolvimento de um estudo exploratório para deteção automática de estratégias de conteúdo de redes sociais com base nas
keywords utilizadas nas mensagens.
1.3.1 Identificação da rede social selecionada e das instituições de ensino
superior de topo
Numa primeira etapa, verificamos, através do estudo Figueira, Á. and Oliveira, L., 2016[13], que o Facebook é a rede social mais significativa no âmbito das instituições de ensino superior, devido ao elevado número de utilizadores, à distribuição desses utilizadores pela rede mundial, aos vários modos e formas de interagir com o seu público.
Para a realização do presente estudo foi seguido um ranking, para assim ter acesso às melhores e mais qualificadas instituições de ensino superior a nível mundial. O Center for World University
Rankings, mais conhecido por CWUR, publica anualmente a classificação internacional das
universidades, em que mede a qualidade na educação e formação dos alunos, o prestígio dos docentes que nelas operam, incluindo a qualidade da investigação por eles produzida [7].
O ranking teve origem na Arábia Saudita, em 2012, com o objetivo de classificar as 100 melhores instituições de ensino superior a nível mundial. O seu sucesso foi de tal forma reconhecido, que rapidamente foi expandido para classificar as melhores 1000 instituições de ensino superior internacionais, tornando-se assim no melhor ranking académico do mundo.
A construção do ranking referido é feita com base em oito objetivos, como se indicam: Quality
of Education, Alumni Employment, Quality of Faculty, Publications, Citations, Broad Impact, Influence e Patents. Cada um destes objetivos tem o seu grau de importância, permitindo assim
4 Capítulo 1. Introdução
criar a classificação das melhores 1000 instituições de ensino superior a nível mundial [7].
Quality of Education é medido pelo número de alunos de uma universidade que ganharam
prémios de renome internacional. Esta relação mede a qualidade da educação de uma instituição com base no futuro académico dos seus alunos. Este objetivo tem uma grande importância no
ranking, uma vez que o seu peso é de 25%.
Alumni Employment é medida pelo número de alunos de uma dada universidade que
ocupam a posição de CEO de grandes empresas de topo em relação ao tamanho da universidade em questão. Tal como o objetivo supra descrito, este tem grande importância no ranking, pois que a percentagem contabilizada é de 25%
Quality of Faculty, este indicador mede o número de professores de uma instituição que
ganharam medalhas e prémios importantes que incorporam praticamente todas medalhas de carisma das disciplinas académicas. Os membros do corpo docente são definidos aqui como aqueles que estavam empregados na instituição no momento de ganhar o prémio ou medalha. Este objetivo tem, também, um peso de 25%.
Publications, neste estudo é medido o número de publicações em revistas conceituadas nas
áreas das Ciências, Ciências Sociais e Humanidades. Este objetivo tem uma percentagem de 5%, que é relativamente baixa em relação aos mencionados anteriormente.
Broad Impact é medido pelo h-index das universidades, ou seja, o h-index é um número
destinado a medir tanto a produtividade como o impacto do trabalho publicado. O peso deste objetivo é de 5% no cálculo final para a realização do ranking.
Influence, para este indicador é considerado o número de trabalhos de pesquisa completos
que foram publicados em jornais e/ou revistas influentes numa dada área de investigação. Este ponto em questão tem um peso no cálculo final de 5%, igualando-o assim a outros objetivos já vistos.
Patents, este é o último objetivo utilizado para a criação do ranking, também com uma
percentagem de 5% no cálculo final. É medido pelo número de pedidos feitos para patentes internacionais, ou seja, as instituições podem então ser classificadas com base no número médio de patentes registadas por ano.
Para a realização deste trabalho considerou-se incluir as 10 instituições melhor posicionadas, visto que elas constituem uma análise representativa das melhores universidades a nível mundial. Por conseguinte, o conjunto de instituições que são objeto de estudo, são: Harvard University,
Stanford University, Massachusetts Institute of Technology, University of Cambridge, University of Oxford, Columbia University, University of California, Berkeley, University of Chicago, Princeton
1.3. Etapas do projeto 5
1.3.2 Recolha de informação das instituições de ensino superior
Esta etapa destina-se à recolha de informação relevante das instituições. Através das páginas
web recolhem-se os calendários escolares que contribuem tanto para a recolha de informação,
uma vez que esses dados indicam o inicio e o fim do ano letivo de cada instituição, como para a análise da informação gerada.
1.3.3 Recolha de posts das instituições educacionais e tratamento de dados
Nesta etapa é desenvolvido um crawler que, para o propósito desta investigação, recolhe todos os posts, número de comments, shares e reactions da página oficial de cada instituição de ensino superior envolvida no presente estudo. Para obter uma análise abrangente, os dados recolhidos estão incluídos num período "representativo", selecionado de forma que contenha um ano letivo de todas as instituições.
Uma vez recolhida toda a informação necessária, realiza-se uma análise léxica, para remover todos os emojis, acentos, pontuações, espaços em excesso e converter todas as letras para minúsculas. De seguida, remove-se todos os stop-words, que são todos os termos considerados irrelevantes e que apenas têm um papel funcional ao longo do post.
Assim que o processo de recolha e tratamento termine, efetua-se um breve estudo exploratório inicial ao conjunto de dados recolhidos das instituições.
1.3.4 Utilização dos métodos de Data Mining
Após o tratamento de todos os dados, são identificados os dados de carácter ruidoso. Para isso são usadas técnicas como binning, que suavizam o ruído existente, agrupando-os em intervalos. Estes agrupamentos são executados tendo em conta o número de publicações divulgadas e as respostas obtidas a esses posts, toda esta analise é elaborada com recurso aos calendários escolares e às páginas oficias de cada instituição. De seguida, efetua-se um estudo que possibilita a análise do comportamento das instituições, criando agrupamentos que incluam o número de posts e a quantidade de interação entre os seguidores e a página oficial da entidade, soma dos likes,
comments e reactions.
1.3.5 Deteção de tópicos
A partir deste momento, todo o estudo é redirecionado para a análise das mensagens divulgadas pelas instituições nas suas páginas do Facebook. Esta etapa tem o propósito de identificar as palavras e os diferentes tópicos que mais se destacam nas publicações realizadas. Para este efeito, os classificadores de DM são adaptados para possibilitar a obtenção de resultados.
6 Capítulo 1. Introdução
1.4
Planificação do projeto
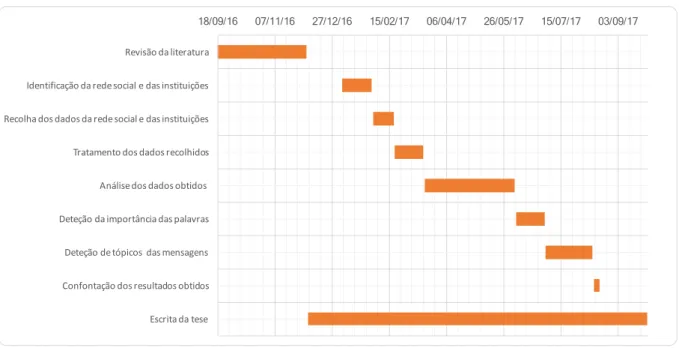
18/09/16 07/11/16 27/12/16 15/02/17 06/04/17 26/05/17 15/07/17 03/09/17 Revisão da literatura Identificação da rede social e das instituições Recolha dos dados da rede social e das instituições Tratamento dos dados recolhidos Análise dos dados obtidos Deteção da importância das palavras Deteção de tópicos das mensagens Confontação dos resultados obtidos Escrita da tese Figura 1.1: PlanificaçãoComo mencionado em cima, a realização deste projeto divide-se em várias etapas, de forma a permitir uma boa gestão da tarefas delineadas para dar resposta aos objetivos do trabalho, o desenho desta planificação é realizado de modo a que as tarefas subsequentes sejam corretamente distribuídas num espaço temporal que permite contar com o input das tarefas precedentes. Para isso, recorre-se ao diagrama de Gantt, para sistematizar as várias fases a serem realizadas, qual a sua duração e de que forma as tarefas previstas se encontram integradas e articuladas num único processo global. Na figura1.1 é ilustrado o planeamento para este projeto. A primeira fase, que se baseia no estudo e na análise das necessidades e das ferramentas posteriormente consideradas na implementação, de seguida temos as etapas relacionadas com o desenvolvimento dos métodos de DM e análise dos resultados obtidos. Por fim, a etapa de redação da tese que acompanha todas as restantes etapas de desenvolvimento do projeto.
1.5
Estrutura da tese
Tendo este documento o objetivo de detalhar o estudo realizado sobre estratégias de conteúdo nas redes sociais pelas instituições de topo de ensino superior, apresentam-se as conclusões obtidas que foram sustentadas em várias etapas realizadas ao longo do processo.
Para além da introdução, são apresentadas todas as etapas utilizadas para a realização do processo e o planeamento para o estudo desenvolvido. Esta tese é composta por mais cinco capítulos.
1.5. Estrutura da tese 7 o desenvolvimento do projeto em causa. Neste capítulo são também apresentados os projetos a que este está relacionado e os problemas esperados na realização do mesmo.
A fase de recolha e tratamento dos dados é descrita ao longo do capítulo3, sendo apresentado os passos necessários utilizados para estabelecer a conexão com a API do Facebook e assim realizar a recolha dos dados pretendidos tratamento dos mesmos. Finalizada esta fase, é realizado um estudo exploratório inicial.
No capítulo4é demonstrado o estudo de desempenho por universidade, onde se examina a quantidade de publicações realizadas e a atividade existente ao longo do tempo entre a comunidade e a rede social. Por fim, é estudada a performance das instituições por trimestre.
No capítulo5 é descrito todo o processo de análise de conteúdo existente nas publicações, em primeiro lugar analisa-se a importância das palavras utilizadas e em seguida, explora-se os tópicos utilizados nas mensagens.
Por fim, são apresentadas as conclusões retiradas com todo este estudo e realizada uma análise ao trabalho futuro possível a ser desenvolvido para completar este trabalho.
Capítulo 2
Conceitos Base e Trabalho Relacionado
2.1
Conceitos Base
O principal objetivo desta secção consiste na apresentação das técnicas existentes na literatura e que são úteis de forma a alcançar os objetivos inicialmente definidos e tentar encontrar outras propostas para os problemas já identificados.
Para ser possível uma melhor resolução do problema proposto, recorre-se ao uso do Text
Mining, em especial às técnicas de classificação de texto, uma vez que o que se pretende é
classificar dados retirados do Facebook.
2.1.1 Text Mining
Normalmente, é definido como um processo que utiliza procedimentos para organizar, encontrar e descobrir informação em documentos escritos na linguagem natural, pelo facto do Text Mining remover informação considerada útil de dados não estruturados e/ou semi-estruturados e por estes serem de difícil tratamento [16].
Text Mining é uma extensão natural do Data Mining, mas aplicado a dados textuais, que
surgiu da conveniência de encontrar informação nos textos, de forma autónoma. Têm ambos uma grande relevância nas áreas de classificação de texto devido ao crescimento da Internet, que nos dias de hoje faz parte do dia-a-dia de muitas pessoas.
O uso desta técnica do Text Mining possibilita a recuperação e extração de informação, classificação de textos, resumos de documentos e possibilita também a realização de análises qualitativas e quantitativas de documentos de texto.
A classificação de texto neste caso, mineração de texto, ou text mining, reporta a dificuldade existente em atribuir categorias pré-definidas automaticamente a documentos de texto. De uma forma geral, os trabalhos referentes à classificação de texto pretendem encontrar um tema central para o texto em questão. Para que isso se concretize, é necessário seguir alguns passos [5]:
10 Capítulo 2. Conceitos Base e Trabalho Relacionado
• Pré-processamento: definido muitas vezes como um processo transformativo, uma vez que transforma o documento inicial de forma a facilitar o processo de classificação. O pré-processamento é aplicado, normalmente, para reduzir o número de termos de um documento de modo a obter uma representação do documento mais adequado para as fases que se seguem. Nesta fase, são realizadas diversas tarefas como:
– Análise léxica: permite remover toda a pontuação, acentos existentes ao longo do documento e todas as letras do texto em maiúsculas passando para minúsculas. – Remoção de Stop-words: as stop-words são todos os termos considerados irrelevantes
que apenas têm um papel funcional ao longo do post. Estas palavras derivam muito do idioma analisado, e normalmente são removidas para assim poder melhorar os métodos de processamento. As palavras que são removidas têm de ser palavras com uma semântica fraca e assim só ficam as palavras realmente importantes.[17]
– Stemming: é um processo que reduz palavras derivadas, transformando-as na sua palavra raíz. Se for aplicado o stemming nas palavras como: computador, computar e computação estas palavras serão reduzidas a "computa", pois é a sua raíz. Com este processo é possível reduzir plurais e conjugações verbais e, assim, o modelo de aprendizagem consegue classificar um documento corretamente, reduzindo também o número de palavras avaliadas, mas tem a desvantagem de, por vezes, existirem palavras com a mesma raíz mas possuírem significados diferentes[9].
• Classificação: nesta etapa realiza-se a criação de classificadores que proporcionam a atribuição de categorias aos documentos. É indispensável a utilização de vários algoritmos de Data Mining mais utilizados para a área de Text Mining.
Text Mining é incluído no package tm da linguagem R que possui algumas ferramentas a partir
das quais é possível classificar documentos automaticamente, ter uma ideia do conteúdo de um dado documento sem ter necessidade de o ler[19].
2.1.2 Classificadores
Existe a possibilidade de se identificarem vários classificadores ou métodos que permitem a resolução de problemas na categorização de texto. Alguns classificadores mais comuns para a área de Text Mining são:
• Support Vector Machines
Um Support Vector Machine, mais conhecido por SVM é um sistema de aprendizagem supervisionado baseado no conceito de planos de decisão que definem limites de decisão. Um plano de decisão é aquele que separa um conjunto de objetos com diferentes classes. Os SVMs podem ser lineares, que encontra um separador (hiperplano) entre duas classes com uma margem máxima, que separa os exemplos positivos e negativos para cada classe. A
2.1. Conceitos Base 11 margem é a distância entre o hiperplano e o ponto mais próximo de cada uma das classes, os pontos mais próximos são definidos de vetores de suporte [1].
Os SVMs não lineares são eficazes na classificação de dados linearmente separáveis ou que tenham uma distribuição aproximadamente linear. Nesses casos, o uso da fronteira curva é o mais adequado para poder separar as classes, assim torna-se possível utilizar diferentes
kernels.
• N-Grams
É um sistema robusto e rápido, com muita utilidade para a classificação de texto. Este sistema é tolerante a erros textuais e baseia-se no cálculo e na comparação de perfis de frequências de N-gramas. Usa-se o sistema para calcular o carácter de data sets de treino que representam as várias categorias. Em seguida, é calculado um perfil para um documento específico que deve ser classificado. Finalmente, calcula uma medida de distância entre o perfil do documento e cada um dos perfis da categoria. O sistema seleciona a categoria cujo perfil tem a menor distância para o perfil do documento [2].
Um N-Gram é uma sequência de n palavras consecutivas: unigram para n=1, bigram para n=2, trigram para n=2, etc. Por exemplo: “Text Classification” tem 2 palavras, é o chamado bigram.
• K-Nearest Neighbour ou KNN
Denominado de vizinho mais próximo, é utilizado para classificação, em que permite armazenar todos os casos disponíveis e classifica novos casos com base numa medida de similaridade. É medido por uma função de distância e se K = 1, então o caso é simplesmente atribuído à classe de seu vizinho mais próximo.
O valor do k, que corresponde ao número de vizinhos a considerar, a função de semelhança que é usada para encontrar os vizinhos mais próximos e a regra de decisão para que seja possível identificar a classe do documento teste são os principais fatores que podem influen-ciar o desempenho deste algoritmo. Além do mais, este algoritmo tem um inconveniente significativo, a sua eficácia, uma vez que ele precisa de comparar o documento teste com todas as amostras do conjunto de treino para assim ser possível classificá-lo [1].
• Decision Trees
Uma decision tree, ou árvore de decisão, é um diagrama de fluxo que oferece a estrutura de uma árvore. Os nós internos que constituem a decision tree são utilizados para testes realizados aos atributos e as suas folhas demonstram as categorias.
Algumas das vantagens na utilização deste modelo centram-se na facilidade de interpretação e implementação, no treino e na classificação que é executada de forma ágil. No entanto, as
decision trees, como qualquer outro método, apresentam inconvenientes: a sua construção
é mais difícil, uma vez que o processo é repetido por todas as subárvores existentes, e é também um modelo instável, ou seja, os pequenos distúrbios no conjunto de treino podem gerar alterações no modelo estudado [15].
12 Capítulo 2. Conceitos Base e Trabalho Relacionado
2.1.3 Seleção de informação
• Term Frequency - Inverse Document Frequency
Term Frequency - Inverse Document Frequency (TF-IDF) é composto por dois termos: term
frequency (TF), que calcula a frequência que uma palavra ocorre num documento, esses
valores são inseridos numa matriz a que se designa de document-term matrix. O segundo termo é inverse document frequency (IDF) que diminui o peso para palavras usualmente usadas e aumenta o peso para palavras que não são usadas com tanta frequência num dado documento. Consequentemente, o TF-IDF mede a importância de uma palavra para um dado documento ou conjunto de documentos. O IDF para qualquer termo é dado por [18]:
idf (term) = ln N documents
N documents cointaining term (2.1)
• Latent Dirichlet Allocation
Latent Dirichlet Allocation ou LDA é um modelo estatístico, que permite descobrir de
forma automática tópicos presentes nos documentos em que este está a ser executado, apresentando a probabilidade de surgimento de cada um desses tópicos. As variáveis ocultas são as distribuições de tópicos, cujos parâmetros são dados previamente, enquanto que as variáveis visíveis são os termos de cada um dos documentos. Tal como indica o nome deste modelo, a distribuição utilizada é a distribuição de Dirichlet, que consiste em alocar dados dos vários tópicos e, posteriormente, preencher os documentos [4].
2.1.4 Métodos de avaliação
Considerada uma fase crítica do processo de Data Mining, esta etapa é necessária para que os especialistas de tratamento de dados possam analisar todos os dados recolhidos ao longo de um estudo/projeto e assim ser possível tirar conclusões mais coerentes. A área de Data Mining permite usar várias medidas que simplifica a avaliação dos resultados. As medidas mais comuns e indicadas para analisar resultados de classificação de texto são: correlação de Pearson, recall,
precision, fallout, accuracy e error, para auxiliar algumas destas medidas, temos a Confusion matrix.
• Correlação de Pearson
Uma das medidas mais usadas para quantificar o grau de associação linear entre duas variáveis quantitativas. O coeficiente de correlação de pearson (r), calcula-se segundo a equação 2.2e quantifica a semelhança que existe entre dois vetores numéricos. Este valor varia entre -1 e 1. Uma relação diretamente proporcional ocorre quando o coeficiente é igual a 1, uma relação inversa exata ocorre quando o coeficiente é igual a -1. Quando o coeficiente é igual a 0, significa que não existe relação linear entre dois valores[22].
r =
P
(xi − ¯x)(yi − ¯y)
p
2.1. Conceitos Base 13 • Confusion matrix
Também conhecida por matriz de confusão, esta matriz ilustrada em 2.1, para uma determinada hipótese h, oferece uma medida efetiva do modelo de classificação, ao mostrar o número de classificações corretas versus as classificações preditas para cada classe, sobre um conjunto de exemplos T. O número de acertos, para cada classe, localiza-se na diagonal principal da matriz M(Ci,Ci) e os demais elementos M(Ci,Cj), para i 6= j, representam erros na classificação. A matriz de confusão de um classificador ideal possui todos esses elementos iguais a zero, uma vez que ele não comete erros. A confusion matrix é constituída por TP, que são os true positive, ou verdadeiros positivos, os TN, mais conhecidos por true
negatives, que são os verdadeiros negativos. Já os FP, false positive, são os falsos positivos
e, por fim, existem ainda os FN, que são os false negative, considerados os falso negativos.
Figura 2.1: Confusion matrix
• Recall
Calcula a percentagem de amostras positivas classificadas corretamente sobre o total de amostras positivas. Pode-se concluir que:
Recall = T P
T P + F N (2.3)
• Precision
Calcula a percentagem de amostras positivas classificadas corretamente sobre o total de amostras classificadas como positivas, ou seja:
P recision = T P
T P + F P (2.4)
• Fallout
É usado para medir a quantidade de documentos irrelevantes recuperados. A melhor taxa atingida é 0, isso significa que não existe nenhum documento encontrado que seja relevante. Uma vez obtido o resultado há necessidade de o analisar bem, pois pode significar que não foi recuperado nenhum documento.
14 Capítulo 2. Conceitos Base e Trabalho Relacionado
• Accuracy
Possibilita a obtenção da relação dos documentos classificados corretamente sobre o número total de documentos avaliados.
Accuracy = T P + T N
P + N (2.5)
• Error
Permite obter a relação entre os documentos classificados incorretamente sobre o número total de documentos avaliados, ou seja, calcula a fração das previsões incorretas.
Error = 1 −T P + T N
P + N (2.6)
2.2
Recursos Utilizados
Para a realização do presente trabalho foram selecionadas como ferramentas a linguagem R e Facebook API, que permitem a implementação de todas as fases propostas.
2.2.1 Linguagens de Programação
A linguagem R é uma linguagem de programação e um ambiente para computação, estatística e gráfica. Existem várias versões para Windows, Unix/Linux e Mac, e é uma linguagem que é executada em diferentes arquiteturas [21]. R possui um vasto conjunto de pacotes, mas também é possível aceder a outros através da rede de distribuição do R, o CRAN (Comprehensive R Archive Network). Esta será a linguagem padrão, uma vez que é ótima para trabalhar com a análise de dados devido à grande dimensão de dados tratados [21].
2.2.2 Tecnologias
A API do Facebook é uma ferramenta que possibilita o desenvolvimento de aplicações para aceder aos dados do Facebook. A API permite, de modo programável, consultar, administrar dados, anúncios e muito mais. Esta informação é recolhida através do Graph API, que é representada por intermédio de nodes, que são elementos como utilizadores, fotos, páginas ou comentários;
edges, que simbolizam ligações que associam os elementos nodes; e, por último, fields, que indicam
informações associadas aos elementos, como o aniversário de uma pessoa ou o nome de uma determinada página. A Graph API é baseada em HTTP e, por isso, funciona com qualquer linguagem que tenha uma biblioteca HTTP [6].
2.3. Projetos relacionados 15
2.3
Projetos relacionados
No decorrer da fase de pesquisa para a elaboração do projeto, focámo-nos em estudos com objetivos semelhantes ao presente projeto, entre eles destacam-se [11], [13] e [12].
Em ambos os estudos, os autores têm como objetivo analisar as mensagens publicadas em redes sociais das Universidades e Politécnicos Portugueses, tendo concluído que a rede social mais utilizada pelas instituições é o Facebook.
Para os estudos analisados, foram utilizados o mesmo número de agentes, que incluíam institutos politécnicos integrados em institutos politécnicos e institutos politécnicos integrados em universidades, começando com 137 agentes e diminuindo, posteriormente, para 94, uma vez que, nesse momento, são foram incluídas instituições que prestam serviços educativos, onde são ignoradas as entidades gestoras de cada instituto e universidade. Nos estudos [11] e [13] foram realizados com ajuda humana, ou seja, antes de a informação ser classificada por algoritmos era categorizada de forma manual para ser possível identificar as categorias utilizadas. O facto de no artigo desenvolvido em [13], todos os posts terem sido colocados numa das sete categorias usadas pelos autores, permitiu-lhes a construção de um modelo estatístico com parâmetros que permitiram a avaliação do ganho em cada mensagem, o que significa que os autores possibilitaram a realização de comparação do número de posts em cada categoria e a resposta que obtiveram através de likes, shares e comments. No entanto, no estudo [13] assenta numa metodologia que faz uso de um modelo editorial prescritivo, ou seja, o modelo editorial é definido à priori e todas as mensagens publicadas em social media são classificadas de acordo com uma das sete categorias desse modelo. Embora o modelo editorial proposto possa ser diversificado em termos de áreas editoriais, estas podem não ser suficientes nem adequadas.
Segundo o estudo [3], Chauhan e Pilai usam um método rigoroso e uma análise sofisticada de conteúdo estatístico, mas a recolha de dados e a categorização são conduzidas, exclusivamente, por humanos, o que não é uma solução viável nem económica para organizações que procuram monitorização nas redes sociais. Por outro lado, Lai e To[10] sugerem uma teoria fundamentada, baseada numa análise léxica assistida por computador com métodos estatísticos e gráficos, para identificar as dimensões dos tópicos, minimizando os erros humanos, bem como os vícios de codificação e categorização. Neste âmbito, a investigação consiste na identificação de frequência das palavras-chaves mediante um software lexical e na aplicação de análise fatorial exploratória para agrupá-los em vários fatores. A principal limitação das técnicas de text mining apresentada na metodologia de Lai e To é que, quando consideradas isoladas/não integradas noutros processos/tecnologias mais robustos, os processos não são consistentes, desse modo os autores propõe essa integração e manipulação das técnicas.
16 Capítulo 2. Conceitos Base e Trabalho Relacionado
2.4
Problemas esperados
A classificação de texto pode levantar problemas, dado que palavras ou expressões muito similares podem levar a inconsistências ou interpretações erradas, podendo originar resultados diferentes dos que inicialmente se podem esperar.
O objetivo da classificação de texto é que, através da análise de posts, o sistema seja capaz de conseguir encontrar, no mínimo, três categorias a que pertencem as informações recolhidas do Facebook. No entanto, a intenção não é que se encontrem muitas categorias com poucos elementos cada, porque isso indicaria a presença de ruído ou outliers, ou seja, a informação não seria plausível. Um vez resolvidas todas as possíveis inconsistências de classificação de texto, surge o fato de estar a ser implementado um classificador que não seja treinado nem tenha ajuda humana. Com este processo, é possível reter informação mais importante e útil para o estudo de forma autónoma, visto que, a partir do classificador, se tornaria possível obter grandes quantidades de informação num espaço curto de tempo, o que não acontece se for realizada com ajuda manual.
Capítulo 3
Análise exploratória
Este capitulo visa relatar detalhadamente, todo o processo de acesso aos dados, o modo de recolha de informação, a forma como esta é trabalhada e utilizada para a análise posteriormente desenvolvida. Neste capítulo, é ainda apresentado um estudo exploratório inicial acerca do conjunto de dados (dataset) recolhido.
3.1
Recolha e tratamento dos dados
3.1.1 Configuração de API do Facebook
Para a recolha de dados que se encontravam no Facebook foi necessário a implementação de algumas etapas prévias à sua realização, sendo a criação e configuração de uma Facebook
API (figura 3.1) de carácter obrigatório, uma vez que permitiu a comunicação do programa
desenvolvido com a rede social.
Figura 3.1: Criação da APP para o sistema
Após a criação da aplicação na API do Facebook verificou-se a necessidade de consultar as permissões da mesma, de forma a verificar se a aplicação continha um perfil público, para
18 Capítulo 3. Análise exploratória
assim possuir as permissões por defeito. Para isso, primeiramente selecionou-se o separador
Tools and Support, seguidamente Graph API Explorer e por fim Get Token que permite um
acesso temporário e seguro às APIs do Facebook. Este Token permite identificar o utilizador, aplicativo ou página, e é apenas válido por duas horas, uma vez que a sessão expira depois disso. Seguidamente, foi necessário verificar o separador das permissões referidas na figura 3.2. Se o perfil for público as permissões estão incluídas por defeito.
Figura 3.2: Permissões da API
Depois de ter em conta as permissões, tivemos o acesso ao Token que permitiu a conexão entre o programa desenvolvido em R para extrair informação e a API do Facebook
3.1.2 Extração dos dados
Terminadas as etapas de criação e configuração da API do Facebook descritas em cima, passou-se à extração dos dados. Neste processo, contou-se com o recurso ao package Rfacebook, que permitiu a utilização de funções, uma vez que é uma coleção de funções R, códigos e dados. Depois de instalado o package, utilizou-se o Token para permitir a conexão entre o programa desenvolvido e a App do Facebook.
Posteriormente, utilizaram-se os IDs das instituições para aceder às páginas oficiais. Foram recolhidos 1100 registos por instituição. A informação recolhida foi guardada num dataset, sendo esta obtida em 45 minutos, e totalizando 11008 registos. Nestes registos recolheram-se os campos ID do post, contagem de likes, ID da universidade, nome da universidade, mensagem publicada, data e hora da publicação, tipos de ligação publicada, link utilizado, story, número de comments,
3.2. Tratamento de dados 19
shares, love, haha, wow, sad e angry.
3.2
Tratamento de dados
Uma vez que todos os dados foram recolhidos e inseridos num dataset, isto é, num conjunto de dados que corresponde ao conteúdo de uma única tabela de base de dados, em que cada coluna da tabela representa uma variável particular e cada linha corresponde a um dado do conjunto de dados em questão, sucedeu-se o tratamentos dos mesmos. Inicialmente, foi criada uma variável que apenas continha a data de publicação da mensagem. Tendo esta informação, uma vez que tencionava estudar as publicações realizadas durante um ano letivo, as mensagens teriam de ser publicadas entre o período de 1 de setembro de 2015 a 31 de agosto de 2016. Tendo isto em conta, todas as publicações recolhidas que não faziam parte deste período foram eliminadas, ficando apenas 5142 registos no dataset para serem analisadas.
Uma vez que os dados contidos no dataset são os que estão dentro do período pretendido, foi adicionada uma nova variável à tabela que indicava o número de palavras que continha cada mensagem publicada na rede social. Posteriormente, foram removidos todos os emojis e a mensagem foi transformada num VCorpus, usado para criar objetos da classe Corpus que contêm um conjunto de dados baseado em texto, para remover a pontuação, os números, as stopwords e os espaços em branco extra, ou seja múltiplos caracteres de espaços em branco são colapsados num único. Todas as letras maiúsculas foram convertidas em minúsculas e por fim reduziram-se as palavras ao mesmo stem. Por fim, o VCorpus foi convertido em dataframe, que é um suporte usado para armazenar tabelas sendo que cada coluna da tabela representa uma variável e a linha corresponde a um dado da tabela. Este dataframe foi adicionado numa variável ao dataset inicial.
Tendo em conta o dataset com as novas varáveis inseridas, foram obtidos os dados numéricos representados na tabela 3.1.
likes_count comments_count shares_count love_count haha_count wow_count sad_count angry_count word_count
Min. 1,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 1,0 1st Qu. 178,2 5,0 15,0 0,0 0,0 0,0 0,0 0,0 17,0 Median 428,0 12,0 43,0 3,0 0,0 0,0 0,0 0,0 26,0 Mean 1057,4 31,33 140,9 19,61 1,246 6,616 4,425 0,5592 29,7 3rd Qu 1140,8 32,00 110,0 14,00 0,0 4,0 0,0 0,0 37,0 Max 42674,0 5323,0 85935,0 1612,0 510,0 1099,0 6683,0 381,0 322,0 NA’s - - - 1 1 1 1 1 96
Tabela 3.1: Síntese dados numéricos
Como se verifica na tabela3.1, existem valores não disponibilizados (NAs), os quais foram convertidos a zero, com o propósito de não encontrar limitações na manipulação dos dados. Os ID’s de cada universidade converteram-se para o tipo numérico e colocado numa nova variável no dataset, para facilitar a manipulação dos dados.
20 Capítulo 3. Análise exploratória
3.3
Análise dos dados recolhidos
Com os dados recolhidos através do Facebook App aplicaram-se métodos com as variáveis numéricas de modo a que se conseguisse perceber o comportamento das universidades ao longo do ano letivo. Posteriormente, realizaram-se somatórios para constatar o comportamentos das instituições a nível de número de publicações, as interações que elas geraram junto do público-alvo e a preferência de publicação em relação aos dias da semana e ao mês do ano. Uma vez realizados estes processo, procedeu-se à analise individual do comportamento de cada universidade. Neste ponto os dados que estão a ser trabalhados são separados por instituição, usando um dataset por entidade. Esses datasets são analisados tendo em conta o calendário escolar1 de cada instituição. Finalmente, utilizou-se correlação de Pearson para encontrar eventuais relações fortes entre as diversas variáveis numéricas do dataset.
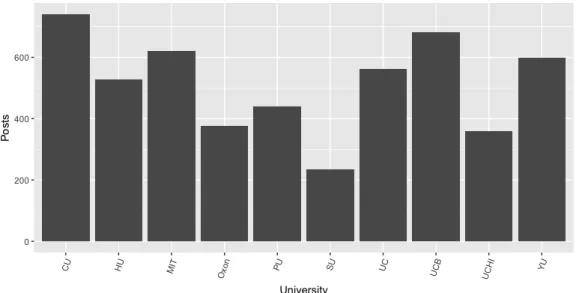
No que se refere ao número de publicações realizadas pelas instituições é possível verificar que, no período de 1 de setembro de 2015 a 31 de agosto de 2016, a instituição com mais publicações é a Columbia University com 740 posts, seguindo-se a UC Berkely com 681 posts, Massachusetts Institute of Technology (MIT) (com 621 posts) e Yale University (com 598 posts) são as duas instituições com o número de publicações mais aproximadas. Seguidamente, encontra-se a universidade de University of Cambridge (com 563 posts) e Harvard University (com 529 posts). É possível verificar números muito próximos de publicações nas três universidades seguintes, Princeton University (com 439 posts), University of Oxford (com 377 publicações) e University of Chicago (apresentando um total de 359 posts). A instituição que se destaca pela negativa, entre as dez estudadas, é Stanford University com um somatório de 235 posts, como ilustrado na figura 3.3.
Figura 3.3: Número de posts por Instituição
1
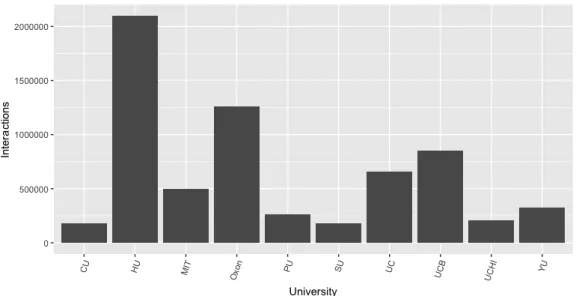
3.3. Análise dos dados recolhidos 21 Apesar de a Columbia University ser a universidade com maior atividade no Facebook, é uma das instituições que apresenta valores mais baixos de interações geradas com os fãs (soma total de comments, likes, shares e reactions), com um total de 181684, juntamente com Stanford University (com 179029 interações). A Harvard University lidera na capacidade de gerar maior número de interações no Facebook, apresentando valores distintamente mais elevados do que as restantes universidades, tal como é possível observar na figura 3.4 (mais de 2 milhões de interações). As instituições com valores mais aproximadas registam cerca de metade deste valor e são a Universidade de University of Oxford (1258035 interações) e a UC Berkeley (com 853327). University of Cambridge aparece posteriormente com 655586 interações, seguida por Massachusetts Institute of Technology (MIT) com 499979 interações. Por fim, com menor número de interações temos as universidades de Yale University (326496 interações), Princeton University (262690 interações) e University of Chicago (com um total de 208878 interações). Note-se que,
regra geral, a quantidade de interações são reduzidas.
Figura 3.4: Número de interações por Instituição
No que diz respeito à contagem de palavras que constituem a mensagem publicada, Columbia University e Yale University são as instituições que mais palavras usam nas publicações, 24084 palavras e 22746 respetivamente. Posteriormente apresentam-se as universidades Harvard University (com 10664 palavras), University of Chicago (usando 11213 palavras) e Massachusetts Institute of Technology (MIT) (com 12816 palavras), sucedendo a University of Cambridge que utiliza 15321 palavras, University of Oxford com 17721 palavras e UC Berkeley com um total de 18665 palavras. Por fim, a Stanford University que usa menos palavras nas suas publicações (7870 palavras) seguindo-se de Princeton University (8756 palavras), como ilustrado na tabela
3.2.
Em relação ao período de publicações, nota-se uma grande preferência na publicação de conteúdos durante os dias úteis da semana, tendo a segunda-feira uma frequência mais baixa comparada com os restantes dias. A quarta-feira é o dia com mais publicações por parte das
22 Capítulo 3. Análise exploratória Universidades Número de palavras
CU 24084 YU 22746 UCB 18665 Oxon 17721 UC 15321 MIT 12816 UCHI 11213 HU 10664 PU 8756 SU 7870
Tabela 3.2: Número de palavras por Instituição
instituições, com um total de 888 posts, seguindo-se a terça-feira e a quinta, que registam o mesmo número, 866 posts. A sexta-feira é o segundo dia útil que conta com o menor número de publicações registadas, contando com 893 posts realizados. Como se verifica na tabela 3.3, aos sábado realizaram-se 465 posts, seguindo-se o domingo com 395 posts, o dia que menos publicações apresenta.
Dias da semana Número de publicações
Quarta-feira 888 Quinta-feira 866 Terça-feira 866 Sexta-feira 863 Segunda-feira 809 Sábado 465 Domingo 385
Tabela 3.3: Número de publicações por dia
No mesmo estudo realizado para os meses do ano, foram detetados quatro meses em que o número de publicações é muito aproximado: o mês de maio lidera a contagem com 530 posts. Abril, março e fevereiro com 517, 515 e 512, respetivamente, sucedendo-se os meses de junho, agosto, janeiro e julho. O mês de dezembro (com 352 posts), outubro (com um total de 347 posts) e novembro (num total de 345 posts), como ilustrado em 3.5. É importante salientar, que o mês de setembro regista menos posts divulgados (com 293 posts).
Como mencionado em cima, realizou-se um estudo exploratório inicial com o propósito de estudar cada universidade e para se poder perceber o seu comportamento individual ao longo do ano letivo, com recurso ao calendário escolar 2.
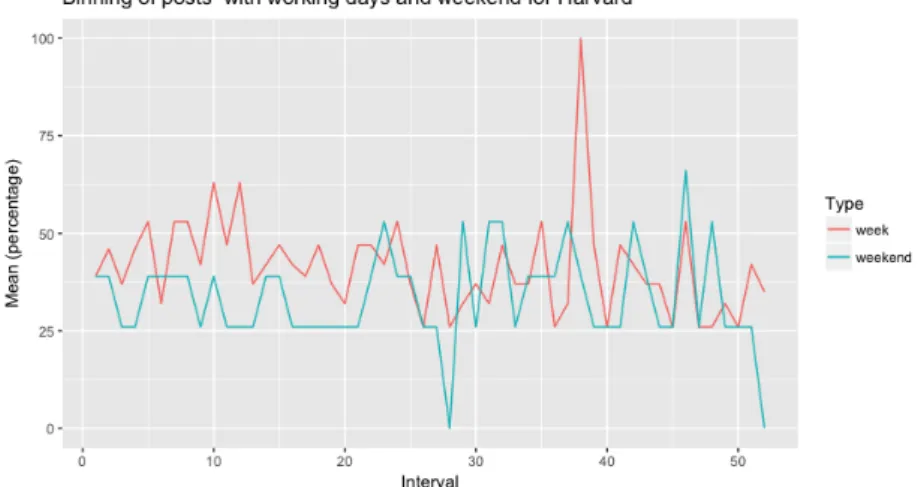
A Harvard University, em média, no período de férias realiza um a dois posts por dia, mas, por vezes registam três publicações. O máximo de posts diários foi de sete publicações registadas no dia 26 de maio de 2016, que corresponde ao dia da formatura, seguindo-se o dia anterior, a véspera do dia da formatura, com 5 posts.
A Harvard University apresentou uma média de 1,511 publicações diárias às quais se registaram uma média de 5223 interações. Os posts com menos reactions não pertencem unicamente às interrupções letivas, uma vez que durante alguns dias, durante o período letivo, se registaram poucas interações, nomeadamente no dia 28 de fevereiro de 2016, onde foram percetíveis 317
3.3. Análise dos dados recolhidos 23
Figura 3.5: Número de posts por meses do ano
reactions.
A Stanford University torna-se difícil de analisar, uma vez que a instituição em causa tem uma relação escassa com as redes sociais. Pelo que foi verificado, os fins-de-semana são muito propícios à não existência de publicações, tal como as pausas letivas que também possuem poucas publicações. A Stanford University registou uma média de 1,243 publicações diárias às quais se verificaram uma média de 796,1 reactions. Através do estudo da presença desta universidade nas redes sociais, constatámos que no dia 6 de dezembro de 2015, referente à época de exames, se registaram 5 posts, sendo assim o dia com mais publicações, às quais se registaram 6658 reactions, tornando-se assim o segundo dia com maior número de reactions. O dia em que se registou o maior número de reactions foi o dia 2 de janeiro de 2016, com 7501 interações sendo referentes à abertura da residência de graduação para o trimestre de inverno.
A Massachusetts Institute of Technology publicou em média 2,023 posts por dia às quais se registaram 1347 reactions. No entanto existe um período de 1 de setembro de 2015 a 13 de outubro de 2015 onde não existe qualquer tipo de atividade na página. Por isso, é possível concluir que a instituição não utilizava esta rede social antes de 13 de outubro de 2015. É possível afirmar que a universidade em estudo é muito participativa na rede social Facebook, apresentando cinco dias com cinco posts, sendo um deles o dia 1 de junho de 2016, correspondente à véspera de cerimónia de doutoramento. É ainda importante frisar que os dias com menos reactions dizem respeito aos dias com menos posts.
A University of Cambridge, mesmo em interrupções letivas, utiliza o Facebook como forma de interação com o público. Os dias em que não existe nenhum post ou que o seu número é bastante reduzido são os sábados e domingos, ou seja os fins-de-semana. Por vezes, também as sextas e segundas são propícias à não existência de publicações. É possível verificar que University of
24 Capítulo 3. Análise exploratória
Cambridge apresentou uma média de 2,298 publicações às quais se registaram 2315 reactions. Os dias com mais posts foram os dias 3 de maio e 26 de maio de 2016, com seis posts cada. Em relação ao maior número de reactions destacaram-se os dias 16 de dezembro de 2015 com 11395
reactions. É de frisar que os dias com maior número de posts não dizem respeito aos dias com
maior número de reactions, uma vez que no dia 16 dezembro de 2015 apenas foram publicados 3
posts e no dia 20 de maio de 2016 apenas se registaram 4 publicações.
Ao contrário das outras instituições, a University of Oxford tem uma atividade regular no
Facebook, inclusive nos meses de julho e agosto, onde houve atividade diária. O mês de abril,
é o que possui menos publicações. Contudo, apenas não publicaram durante três dias, talvez porque nesse mês é a mudança de trimestre. É possível verificar também que no único dia com três posts, dois deles são repetidos e foram publicados com diferença de um minuto. O post do dia 23 de abril só tem likes, não sendo registadas outras reactions. A universidade de Oxford registou uma média de 1,071 publicações, obtendo uma média de 2798 reactions por dia. Note-se que nesta universidade, os dias com mais reactions são registados em dias com menos posts.
A instituição Columbia University começou o ano letivo em agosto, mas até 14 de setembro, não manteve qualquer atividade no Facebook, temporada em que se deu início à mudança de programa. O 18 de maio, dia com maior número de reactions e também um dos dias com maior número de posts, diz respeito ao regresso de todos os estudantes do ensino profissional e à formatura. A média de posts diárias desta universidade é 2,587 obtendo uma média de 546,1
reactions. Esta instituição opta por não publicar com tanta frequência aos fins-de-semana.
Na University of California, Berkeley, são raros os dias em que não existe uma publicação. A partir do momento em que começam as férias académicas e administrativas, contabiliza-se um decréscimo de publicações, ou seja, durante os meses de junho, julho e agosto. UC Berkeley apresentou uma média diária de 1,94 publicações às quais se registaram 2163 reactions. Na página desta universidade observam-se dezasseis dias com quatro posts, destacando-se os dias 9 de maio referente ao fim dos exames de primavera e o dia 13 de maio de 2016, correspondente ao fim do semestre de primavera. Este último dia, 13 de maio de 2016, foi o segundo dia com mais
reactions, registando 12594, existindo apenas o dia 8 de fevereiro de 2016 com 22080.
A University of Chicago aos fins-de-semana, não tem tantos posts, sobretudo aos domingos. Em interrupções letivas mostra um comportamento igual às outras alturas do ano. O dia com mais posts (11 de junho) corresponde ao dia em que termina o quadrimestre de primavera e o dia da cerimónia de "convocação". Em relação ao número de reactions, o dia com maior número de reactions, 4 de janeiro, é o dia que se inicializa o quadrimestre de inverno. A 11 de fevereiro, segundo dia com mais reactions é a véspera da pausa escolar. A média diária desta universidade foi de 1,234 publicações às quais se registaram 600,6 reactions.
A atividade nas redes sociais da Princeton University, iniciou-se a 20 de janeiro de 2016. A partir desta altura manteve um papel bastante ativo, passando a não publicar apenas aos fins-de-semana. O mês de agosto foi o mês em que as publicações diminuíram, visto que foi a única altura do ano em que não existiram publicações durante a semana. O dia com mais
3.3. Análise dos dados recolhidos 25
posts, 5 de fevereiro de 2016, diz respeito ao início do trimestre de primavera, como é referido
no calendário escolar 3, sendo também um dos dias com mais reactions. O dia 16 de março corresponde ao dia com mais reactions, 5788, no que diz respeito às férias de primavera. Esta universidade apresentou uma média de 2,152 publicações diárias e uma média de 1186,2 reactions.
A Yale University, só começou a atividade a 29 de dezembro de 2015. Desde aí registou-se apenas um dia sem publicações. A universidade de Yale registou uma média de 2,431 posts diários obtendo uma média de 1169,8 reactions.
Por ultimo, desenvolve-se um script que permite calcular a correlação de Pearson entre as variáveis empregues no estudo. Note-se que na correlação de Pearson quando os valores de ambas as variáveis aumentam, obtemos uma correlação perto do valor 1, sendo assim linear perfeita ou diretamente proporcional. Por outro lado, quando uma variável aumenta e a outra dimunui obtemos uma correlação de valor -1, sendo também linear perfeita mas inversa. Com a análise do dataset, apenas se encontram correlações positivas, realizando-se agrupamentos das diferentes
reactions, para ser possível entender melhor as variáveis e o conjunto de dados em estudo. É
definido um valor mínimo de correlação, o que possibilita verificar quais as variáveis que, de uma forma ou de outra, se correlacionam. Com a criação de agrupamentos, como é o caso do agrupamento do número de todas as reactions, incluindo os likes, verifica-se que, à medida que este agrupamento cresce, o número de comments também cresce. O mesmo se passa com o agrupamento de reactions positivas (o número de likes, de loves, de haha e de wow), de tal modo que, se este agrupamento cresce, os número de comments também crescem. Verifica-se então que o número de likes aumenta com número de comments, do mesmo modo que o número de shares aumenta com o aumento do número de comments.
É criado um agrupamento, que inclui todos as reactions negativas, incluindo os likes, os haha e os wow, visto que estas reactions podem ser usadas para expressar os ambos polos, negativo e positivo. Este agrupamento cresce à medida que o número de comments aumenta. Outro agrupamento criado para o estudo das correlações é a junção das reactions wow e de haha, que, quando crescem, cresce a reaction love, o mesmo se passa com a reaction wow, que aumenta com o aumento de reaction love, e a reaction angry, que também aumenta com o aumento da reaction
angry.
Nos restantes agrupamentos gerados, um passa por incluir as reactions haha e wow e outro incluí as reactions wow e angry, em que ambas aumentam de acordo com o aumento da reaction
love. Também é possível observar que os valores deste último agrupamento (wow e angry) têm
tendência a subir em conformidade com o agrupamento de reactions love e haha.
26 Capítulo 3. Análise exploratória
3.4
Conclusão
Com isto, é possível concluir que os agrupamentos gerados para a correlação de Pearson não nos transmite muita informação, posto que uma das variáveis dos agrupamentos já se relaciona sozinha com a variável em causa, não sendo encontrada nenhuma variável que dependa diretamente de outra, positivamente, visto que o valor mais alto encontrado foi de 0.8 e não foi encontrado nenhuma correlação com o valor máximo, 1. Em relação às atividades das instituições, em geral todas elas possuem uma atividade ativa com o Facebook, à exceção de Stanford University que apresenta uma atividade bastante escassa. Normalmente, os seguidores das instituições são extremamente participativos.