Faculdade de Ciˆencias
Departamento de Inform´
atica
Desambigua¸c˜
ao Autom´
atica da Flex˜
ao Verbal em
Contexto
Pedro Lopes Mendes Martins
Mestrado em Engenharia Inform´
atica
Faculdade de Ciˆencias
Departamento de Inform´
atica
Desambigua¸c˜
ao Autom´
atica da Flex˜
ao Verbal em
Contexto
Pedro Lopes Mendes Martins
DISSERTAC
¸ ˜
AO
Disserta¸c˜
ao orientada pelo Prof. Dr. Ant´
onio Horta Branco
Mestrado em Engenharia Inform´
atica
Pedro Lopes Mendes Martins, aluno no
30101 da Faculdade de Ciˆencias da Uni-versidade de Lisboa, declara ceder os seus direitos de c´opia sobre o seu Relat´orio de Projecto em Engenharia Inform´atica, intitulado ”Desambigua¸c˜ao autom´atica da flex˜ao verbal em contexto”, realizado no ano lectivo de 2007/2008 `a Faculdade de Ciˆencias da Universidade de Lisboa para o efeito de arquivo e consulta nas suas bibliotecas e publica¸c˜ao do mesmo em formato electr´onico na Internet.
FCUL, 29 de Outubro de 2008
Ant´onio Horta Branco, supervisor do projecto de Pedro Lopes Mendes Martins, aluno da Faculdade de Ciˆencias da Universidade de Lisboa, declara concordar com a divulga¸c˜ao do Relat´orio do Projecto em Engenharia Inform´atica, intitulado ”De-sambigua¸c˜ao autom´atica da flex˜ao verbal em contexto”.
Este documento descreve o trabalho realizado no ˆambito da disciplina de Projecto em Engenharia Inform´atica do Mestrado em Engenharia Inform´atica da Faculdade de Ciˆencias da Universidade de Lisboa.
O trabalho desenvolvido explora novas abordagens para o problema de desam-bigua¸c˜ao da flex˜ao expressa por uma forma verbal em contexto.
Em vez de tentar criar de raiz novos m´etodos para atacar este problema, podemos olhar para tarefas similares e usar os m´etodos que costumam ter bons resultados nessas tarefas aplicando-os `a tarefa de desambigua¸c˜ao da flex˜ao expressa por uma forma verbal em contexto.
Em trabalho anterior foi usado um m´etodo que costuma ter bons resultados numa tarefa similar, etiqueta¸c˜ao autom´atica. Essa abordagem ficou aqu´em do valor base dado pelo algoritmo de atribui¸c˜ao do valor de flex˜ao mais frequente. Como tal, no presente trabalho exploram-se outros m´etodos usados num problema que tamb´em tem caracter´ısticas similares `a desambigua¸c˜ao da flex˜ao expressa por uma forma verbal em contexto, a saber, a desambigua¸c˜ao da acep¸c˜ao de palavra.
Primeiro ser´a explicado o enquadramento em que o trabalho se insere e a mo-tiva¸c˜ao para a sua realiza¸c˜ao (Cap´ıtulo 1).
Em seguida ser´a exposto o problema em pormenor, dando j´a algumas linhas condutoras quanto `as formas de o abordar e resolver (Cap´ıtulo 2).
No Cap´ıtulo 3 vamos rever o que foi feito em trabalhos anteriores quanto a tarefas iguais ou similares assim como os seus resultados.
Finalmente apresentaremos uma descri¸c˜ao detalhada da implementa¸c˜ao da abor-dagem explorada e os resultados obtidos, comparando-os com os anteriores (Cap´ıtulo 4), terminando com um cap´ıtulo final de conclus˜oes (Cap´ıtulo5).
PALAVRAS-CHAVE:
Processamento de linguagem natural, Desambigua¸c˜ao, Flex˜ao verbal, Aprendizagem autom´atica, Lingua portuguesa.
This document describes the work undertaken in the scope of the course Projecto de Engenharia Inform´atica, of the post-graduation course Mestrado em Engenharia Inform´atica da Faculdade de Ciˆencias da Universidade de Lisboa.
This document presents the work developed to explore new approaches concern-ing the disambiguation of verbal inflection values.
Instead of trying to create new methods, we tried to look at tasks similar to the disambiguation of a verbal inflected value and take advantage of the best methods in use for those tasks.
In previous work, some methods known for having good results in a similar task, automatic tagging of text, were used. However these methods lagged behind the baseline method of simply using the most frequent value. So, in order to try to overcome that barrier, we try a different approach based on the most promising methods frequently used in other similar task, the methods used in word sense disambiguation.
First, the framework and motivation for the development of this work will be explained in (Chapter 1).
Next, this topic will be detailed by providing some clues on how we can try to solve it (Chapter 2).
In Chapter 3, we will take an overview at previous work for the same task or similar ones.
Finally, we will present a fully detailed description of the implementations for our approaches to the problem, as well as a detailed description of the results and a comparison to previous work (Chapter 4), and we will close this document with a final conclusion chapter (Chapter 5).
KEYWORDS:
Natural language processing, Disambiguation, Verbal inflection, Machine-Learning, Portuguese Language.
Gostaria de agradecer a algumas pessoas que foram importantes para a realiza¸c˜ao deste trabalho.
Agrade¸co ao meu orientador, o Prof. Ant´onio Branco, pela disponibilidade e por todos os conselhos e ensinamentos que me transmitiu.
Aos membros do Grupo NLX, por me terem proporcionado um ambiente de trabalho fant´astico, em especial ao Jo˜ao Silva pela ajuda com o LA
TEX. `
A FCT, pelo financiamento atribu´ıdo aos projectos nos quais estive integrado. `
A minha fam´ılia e amigos por me terem apoiado e incentivado quando mais precisei.
Ao Daniel Sousa pelos bons conselhos.
Um agradecimento especial `a Teresa por ter sido sempre o meu porto seguro.
´Indice
Lista de Figuras xii
Lista de Tabelas xiv
1 Introdu¸c˜ao 1
1.1 Enquadramento . . . 1
1.2 Motiva¸c˜ao . . . 1
1.3 Objectivos . . . 2
1.4 Organiza¸c˜ao do documento . . . 2
2 Flex˜ao e desambigua¸c˜ao verbal 3 2.1 Flex˜ao verbal . . . 3
2.2 Conjuga¸c˜ao e lematiza¸c˜ao . . . 5
2.2.1 LX-Conj e LX-Lem . . . 5
2.2.2 Outras ferramentas . . . 6
2.3 Desambigua¸c˜ao verbal em contexto . . . 7
2.4 Desambigua¸c˜ao verbal como tarefa de etiqueta¸c˜ao . . . 8
2.4.1 Tarefa de etiqueta¸c˜ao morfossint´actica . . . 8
2.4.2 Abordagens populares . . . 9
2.5 Desambigua¸c˜ao verbal como tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra . . . 10
2.5.1 Tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra . . . 11
2.5.2 Abordagens populares . . . 11
3 Estado-da-arte 13 3.1 Avalia¸c˜ao e conjunto de dados . . . 13
3.1.1 Caracteriza¸c˜ao do corpus . . . 14
3.1.2 Medidas de avalia¸c˜ao . . . 17
3.2 Heur´ıstica de m´axima verosimilhan¸ca . . . 17
3.3 Modelos de Markov escondidos . . . 19
3.4 Trabalhos relacionados . . . 20
4 Desambigua¸c˜ao de flex˜ao verbal: uma abordagem DAP 22
4.1 Aplica¸c˜ao do classificador Naive Bayes . . . 22
4.2 Aplica¸c˜ao do classificador SVM . . . 25 4.3 Pr´e-processamento . . . 26 4.3.1 O formato .arff . . . 28 4.3.2 O formato .dat . . . 34 4.3.3 Aglomerados . . . 35 4.3.4 Cl´ıticos . . . 37
4.3.5 Classes aberts vs. Classes fechadas . . . 39
4.3.6 Implementa¸c˜ao . . . 40
4.4 Conjuntos de dados . . . 40
4.5 Avalia¸c˜ao . . . 42
4.5.1 Abordagens exploradas . . . 42
4.5.2 Estudo do espa¸co de resultados . . . 64
4.5.3 Compara¸c˜ao com trabalhos anteriores . . . 69
5 Conclus˜ao e trabalho futuro 72
Acr´onimos 74
´Indice remissivo 74
Bibliografia 75
Lista de Figuras
3.1 N´umero de ocorrˆencias de formas verbais por grau de ambiguidade. . 16 3.2 Propor¸c˜ao de ocorrˆencias no corpus de formas verbais lexicalmente
amb´ıguas por tipo de ambiguidade. . . 17 3.3 Modelo de Markov Escondido - representa¸c˜ao temporal. Extra´ıda da
Wikipedia . . . 19
4.1 Discriminante linear. Extra´ıda de (Agirre e Edmonds, 2006). . . 26 4.2 Discriminante linear com margem de erro. Extra´ıda de (Agirre e
Edmonds, 2006). . . 26 4.3 Precis˜ao m´edia por n´umero de instˆancias de treino nos modelos, s´o
para instˆancias amb´ıguas. . . 65 4.4 Precis˜ao m´edia por n´umero de instˆancias de treino nos modelos, com
curva suavizada atrav´es de interpola¸c˜ao, s´o para instˆancias amb´ıguas. 66 4.5 Desvio de padr˜ao por n´umero de instˆancias de treino nos
mode-los, com curva suavizada atrav´es de interpola¸c˜ao, s´o para instˆancias amb´ıguas. . . 67 4.6 Precis˜ao m´edia acumulada `a medida que aumenta o n´umero de instˆancias
de treino, s´o para instˆancias amb´ıguas. . . 68 4.7 N´umero de modelos por n´umero de instˆancias de treino no modelo. . 69
Lista de Tabelas
2.1 Todas as combina¸c˜oes de flex˜ao para formas verbais simples . . . 4 2.2 Modo e tempos verbais dos verbos auxiliares e o seu correspondente
verbo composto. . . 5
4.1 Tabela com valores de desempenho para contexto de t´opicos usando toda as instˆancias. . . 62 4.2 Tabela com valores de desempenho para contexto local usando todas
as instˆancias. . . 62 4.3 Tabela com valores de desempenho para contexto de t´opicos mais
contexto local para todas as instˆancias. . . 63 4.4 Algoritmos A e B de (Nunes, 2007) e Algoritmo A+A+L. Valores nas
condi¸c˜oes de avalia¸c˜ao do presente trabalho usando todas as instˆancias. 63 4.5 Tabela com valores de desempenho para contexto de t´opicos, apenas
instˆancias amb´ıguas. . . 63 4.6 Tabela com valores de desempenho para contexto local, apenas instˆancias
amb´ıguas. . . 64 4.7 Tabela com valores de desempenho para contexto de t´opicos mais
contexto local, apenas instˆancias amb´ıguas. . . 64 4.8 Algoritmos A e B de (Nunes, 2007) e Algoritmo A+A+L. Valores
nas condi¸c˜oes de avalia¸c˜ao do presente trabalho, apenas instˆancias amb´ıguas. . . 64
Cap´ıtulo 1
Introdu¸c˜
ao
Ao ler um texto em l´ıngua portuguesa deparamo-nos v´arias vezes com situa¸c˜oes em que precisamos de desambiguar formas verbais, quando estas s˜ao amb´ıguas. No entanto se virmos escrita, ou nos pronunciarem, uma forma verbal amb´ıgua totalmente desprovida de contexto, n˜ao somos capazes de, dentro das v´arias poss´ıveis flex˜oes que a forma pode expressar, escolher a correcta.
Por outro lado, se tivermos contexto, somos capazes de decidir que flex˜ao expressa uma forma verbal com relativa facilidade.
Nos pr´oximos pontos vamos explicar porque nos interessa abordar esta tarefa de desambigua¸c˜ao da flex˜ao verbal.
1.1
Enquadramento
Este projecto foi realizado no ˆambito da disciplina de Projecto em Engenharia In-form´atica do Mestrado em Engenharia InIn-form´atica da Faculdade de Ciˆencias da Universidade de Lisboa.
O tema enquadra-se no trabalho desenvolvido no grupo de investiga¸c˜ao NLX.1
Neste grupo foram desenvolvidas v´arias ferramentas para a etiqueta¸c˜ao morfos-sint´actica autom´atica de texto. A etiqueta¸c˜ao de formas verbais encontradas num texto, com os seus tra¸cos e lemas, ´e um dos desafios dessa tarefa. Para algumas for-mas verbais, essa etiqueta¸c˜ao inclui escolher os tra¸cos e lefor-mas expressos na ocorrˆencia em causa, ou seja desambiguar a acep¸c˜ao flexional da forma verbal.
1.2
Motiva¸c˜
ao
Em trabalho anterior (Nunes, 2007), este tema foi abordado de duas maneiras, uma abordagem baseada na ocorrˆencia mais frequente de flex˜ao para uma forma verbal (os valores obtidos por este m´etodo s˜ao tidos como o valor base de compara¸c˜ao), e
1
http://nlx.di.fc.ul.pt/
outra abordagem baseada num m´etodo usado em tarefas de etiqueta¸c˜ao autom´atica. No entanto, apesar de mais sofisticado, esse m´etodo n˜ao ficou aqu´em do valor base de compara¸c˜ao.
Tendo isto em conta, vem `a ideia que talvez com outro tipo de abordagens se consiga obter valores acima do valor base de compara¸c˜ao, nomeadamente com as abordagens usadas noutro problema similar, a desambigua¸c˜ao da acep¸c˜ao de palavra.
1.3
Objectivos
O objectivo deste trabalho ´e procurar um m´etodo de desambiguar as formas verbais com melhor desempenho que os conhecidos at´e agora. Isto ser´a feito atrav´es de m´etodos ainda n˜ao explorados para este problema espec´ıfico, mas com os melhores resultados num problema similar, a desambigua¸c˜ao da acep¸c˜ao de palavra.
1.4
Organiza¸c˜
ao do documento
Este documento est´a organizado da seguinte forma:
• Cap´ıtulo 2 - Apresenta uma descri¸c˜ao detalhada do tema da flex˜ao verbal e respectiva desambigua¸c˜ao, bem como poss´ıveis abordagens ao problema.
• Cap´ıtulo 3 - Relata o trabalho previamente realizado para problemas iguais ou semelhantes a este, com os quais podemos comparar este trabalho.
• Cap´ıtulo 4 - Apresenta a implementa¸c˜ao e avalia¸c˜ao das experiˆencias levadas a efeito.
• Cap´ıtulo 5 - Apresenta as conclus˜oes tiradas do trabalho realizado e poss´ıvel trabalho futuro em rela¸c˜ao a este tema.
Cap´ıtulo 2
Flex˜
ao e desambigua¸c˜
ao verbal
2.1
Flex˜
ao verbal
De acordo com a descri¸c˜ao em (Bergstr¨om e Reis, 2004), “A flex˜ao ´e a varia¸c˜ao de uma palavra que permite exprimir atrav´es de certos elementos categorias gramati-cais.” A flex˜ao pode ser nominal ou verbal. N˜ao cabendo ser exaustivo aqui vamos apenas abordar a parte a que esta tese diz respeito, a flex˜ao verbal.
Consultando de novo (Bergstr¨om e Reis, 2004), tem-se que “Um verbo ´e uma palavra de forma vari´avel que exprime o que se passa, isto ´e, um acontecimento representado no tempo.”
Ao flexionar, um verbo pode alterar a sua forma para expressar diferentes val-ores dos tra¸cos de n´umero, pessoa, modo, tempo e aspecto. Os partic´ıpios tˆem caracter´ısticas de verbo e de adjectivo, flexionando em g´enero e n´umero. Vou ap-resentar em promenor apenas os caracter´ısticas que s˜ao usadas na etiqueta¸c˜ao do CINTIL.1
A categoria n´umero tem como valores singular e plural. Singular quando tipi-camente se refere a uma s´o entidade e, plural, quando tipitipi-camente se refere a mais do que uma entidade.
A categoria pessoa est´a relacionada com a pessoa gramatical da express˜ao que serve de sujeito ao verbo. Existem trˆes valores poss´ıveis dentro desta categoria: 1a
pessoa, 2a pessoa e 3a pessoa. Estes podem variar conforme o n´umero, dando origem
a seis valores poss´ıveis. Assim temos, por exemplo, em termos de pronomes pessoais: para a 1a pessoa o eu (singular) e n´os (plural); para a 2a pessoa o tu (singular) e o
v´os (plural); e finalmente para a 3a pessoa o ele/ela (singular) e eles/elas (plural).
Tamb´em nesta categoria pode entrar a 2a pessoa de cortesia, que em termos de
pronomes pessoais se pode realizar atrav´es de vocˆe/vocˆes.
A categoria modo tem por valores indicativo, conjuntivo e imperativo. Este ´
ultimo pode dividir-se em afirmativo e negativo (Cunha e Cintra, 1986, page 378).
1
O corpus descrito na sec¸c˜ao 3.1.1.
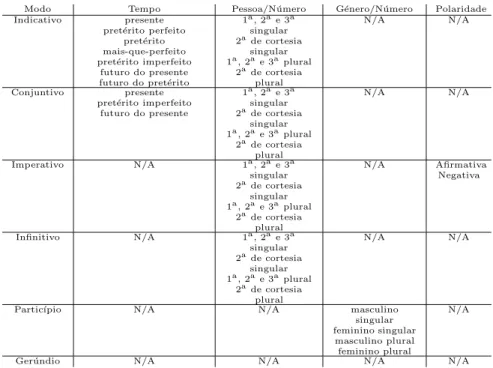
Modo Tempo Pessoa/N´umero G´enero/N´umero Polaridade Indicativo presente
pret´erito perfeito pret´erito mais-que-perfeito pret´erito imperfeito
futuro do presente futuro do pret´erito
1a , 2a e 3a singular 2a de cortesia singular 1a , 2a e 3a plural 2a de cortesia plural N/A N/A Conjuntivo presente pret´erito imperfeito
futuro do presente 1a , 2a e 3a singular 2a de cortesia singular 1a , 2a e 3a plural 2a de cortesia plural N/A N/A Imperativo N/A 1a , 2a e 3a singular 2a de cortesia singular 1a , 2a e 3a plural 2a de cortesia plural N/A Afirmativa Negativa Infinitivo N/A 1a , 2a e 3a singular 2a de cortesia singular 1a , 2a e 3a plural 2a de cortesia plural N/A N/A
Partic´ıpio N/A N/A masculino
singular feminino singular
masculino plural feminino plural
N/A
Ger´undio N/A N/A N/A N/A
Tabela 2.1: Todas as combina¸c˜oes de flex˜ao para formas verbais simples
Segundo alguns autores, estes valores podem indicar a atitude da pessoa que fala em rela¸c˜ao ao facto que enuncia. Tamb´em nesta categoria, e para manter a coerˆencia com trabalho anterior em que o presente projecto se insere, vamos considerar as formas nominais do verbo: infinitivo, que pode ser pessoal (flexionado) ou impessoal (n˜ao flexionado), ger´undio e partic´ıpio.
A categoria tempo contribui para indicar o momento em que ocorre a situa¸c˜ao expressa pelo verbo. Para esta categoria, existem trˆes valores principais presente, pret´erito - que se pode dividir em pret´erito perfeito, pret´erito-mais-que-perfeito e pret´erito imperfeito - e futuro - que se pode dividir em futuro do presente e futuro do pret´erito ou condicional.
Cada valor de modo pode ser conjugado com diferentes combina¸c˜oes de valores de tempo.
Podemos assim ver o leque de possibilidades que a flex˜ao verbal permite. Nem to-das as combina¸c˜oes s˜ao poss´ıveis. Na tabela 2.1 podemos ver a lista de combina¸c˜oes poss´ıveis para as formas verbais simples do portuguˆes.
Aos elementos deste conjunto de possibilidades passaremos, daqui em diante, a chamar tra¸cos flexionais, ou simplesmente tra¸cos.
Quanto `as formas verbais compostas, os seus tra¸cos s˜ao obtidos injectivamente atrav´es das formas simples usando a tabela 2.2.
Cap´ıtulo 2. Flex˜ao e desambigua¸c˜ao verbal 5
Verbo auxilar Tempo composto
indicativo, presente indicativo, pret´erito perfeito composto indicativo, pret´erito imperfeito indicativo, pret´erito mais-que-perfeito composto indicativo, pret´erito mais-que-perfeito indicativo, pret´erito mais-que-perfeito anterior
indicativo, futuro presentei indicativo, futuro do presente composto indicativo, futuro pret´erito indicativo, futuro do pret´erito composto
conjuntivo, presente conjuntivo, pret´erito perfeito conjuntivo, pret´erito imperfeito conjuntivo, pret´erito mais-que-perfeito
conjuntivo, futuro conjuntivo, futuro composto infinitivo pessoal infinitivo pessoal pret´erito infinitivo impessoal infinitivo impessoal pret´erito
ger´undio ger´undio pret´erito
Tabela 2.2: Modo e tempos verbais dos verbos auxiliares e o seu correspondente verbo composto.
2.2
Conjuga¸c˜
ao e lematiza¸c˜
ao
Por conven¸c˜ao, assume-se que o lema de um verbo ´e a sua forma infinitiva n˜ao flexionada.
Como vimos na sec¸c˜ao anterior, o lema de um verbo apresenta um conjunto de possibilidades de flex˜ao bastante elevado. Ao processo que leva o lema mais os tra¸cos de flex˜ao a uma forma flexionada que exprime esses tra¸cos para esse lema chama-se de conjuga¸c˜ao.
Ao processo inverso que leva de uma forma flexionada ao seu lema chama-se de lematiza¸c˜ao.
A conjuga¸c˜ao n˜ao ´e uma fun¸c˜ao injectiva do conjunto dos tra¸cos para o conjunto das formas flexionadas. Por exemplo, se conjugarmos o verbo ser na 1a pessoa do
Pret´erito Imperfeito e na 3apessoa do mesmo tempo verbal obtemos a mesma forma
era. Contudo, este processo n˜ao deixa de ser uma fun¸c˜ao ao passo que a lematiza¸c˜ao n˜ao ´e uma fun¸c˜ao. Neste ´ultimo, para uma dada forma verbal isolada de qualquer conte´udo de ocorrˆencia pode n˜ao ser possivel determinar um ´unico tra¸co de flex˜ao e/ou lema.
Tomando o exemplo anterior, se quisermos lematizar a forma verbal era, temos duas possibilidades de tra¸cos como resultado. Neste caso h´a ambiguidade quanto aos tra¸cos. Por outro lado, por exemplo, a forma fui pode lematizar para o lema ser ou ir. Aqui h´a ambiguidade quanto ao lema.
´
E a necessidade de se determinar lema e tra¸cos associados `a ocorrˆencia de qualquer forma verbal em contexto que move este projecto. Como determinar a verdadeira acep¸c˜ao flexional para cada forma verbal especialmente quando esta ´e amb´ıgua?
2.2.1
LX-Conj e LX-Lem
No grupo de investiga¸c˜ao onde o presente trabalho se insere (NLX), foram desen-volvidas ferramentas para lidar com os processos descritos anteriormente. Assim
temos o LX-Conj2
para lidar com a conjuga¸c˜ao e o LX-Lem3
para lidar com o pro-cesso de lematiza¸c˜ao. ´E de salientar que o processo de lematiza¸c˜ao engloba n˜ao s´o reduzir a forma ao seu lema ou lemas, mas tamb´em determinar a informa¸c˜ao acerca dos tra¸cos que levam esses lemas `a forma em quest˜ao.
O LX-Lem n˜ao faz desambigua¸c˜ao. Ao inv´es, d´a todas as possibilidades de lema/tra¸cos para a forma verbal introduzida.
Incorporado num conjunto de ferramentas denominado LX-Suite,4
que anota au-tomaticamente texto, existe um m´odulo que atribui um lema e os tra¸cos verbais a uma forma verbal que ocorra num texto, sendo que esta informa¸c˜ao faz parte da an-ota¸c˜ao do LX-Suite. Este m´odulo realiza a tarefa de desambigua¸c˜ao utilizando uma heur´ıstica de m´axima verosimilhan¸ca,5
em conjunto com o LX-Lem, que consegue resultados surpreendentemente bons dada a sua simplicidade.
Por sua vez, o LX-Conj permite obter a forma do verbo relevante. Isto ´e, a partir do lema e dos tra¸cos dados, permite obter a instˆancia flexionada correspondente.
Estas ferramentas, s˜ao potencialmente ´uteis para o problema a ser abordado nesta disserta¸c˜ao. Vamos ver mais `a frente como se podem articular para ajudar a abord´a-lo.
2.2.2
Outras ferramentas
Para al´em destas ferramentas desenvolvidas no grupo NLX, existem outras ferra-mentas que desempenham o mesmo papel ou parecido.
Para a conjuga¸c˜ao verbal, existem bastantes ferramentas para o portuguˆes: Conjuga-me,6 PRIBERAM,7 MorDebe,8 INSITE,9 Conjugue10 Por´em, ao contr´ario do LX-Conj, n˜ao permitem conjugar com cl´ıticos, n˜ao apresentam as formas compostas nem s˜ao de input aberto, ou seja, n˜ao permitem conjugar neologismos ou palavras desconhecidas do l´exico do sistema.
CONVER,11
Conjugador da Universidade Federal de Pernambuco, Recife12
e Lin-gua::PT,13
tamb´em n˜ao permitem conjuga¸c˜ao com cl´ıticos nem apresentam formas compostas mas gera as formas para neologismos.
2 http://lxconj.di.fc.ul.pt 3 http://lxlem.di.fc.ul.pt 4 http://lxsuite.di.fc.ul.pt 5 Ver o ponto 3.3 6 http://www.conjuga-me.net/ 7 http://www.priberam.pt/dlpo/ajuda/ajuda conjugacaoverbos.aspx 8 http://www.iltec.pt/mordebe/ 9 http://linguistica.insite.com.br/cgi-bin/conjugue 10 http://www.fpepito.org/utils/conjugue.php 11 http://www.inf.ufrgs.br/ emiliano/conver/ 12 http://www.cin.ufpe.br/ tradutor/conjugad.htm 13
Cap´ıtulo 2. Flex˜ao e desambigua¸c˜ao verbal 7
Tanto quanto nos foi poss´ıvel apurar, s´o existem estes conjugadores para o Por-tuguˆes.
Tamb´em n˜ao foram encontrados lematizadores autom´aticos para o Portuguˆes, al´em do LX-Lem.
As ferramentas que dispomos para apoiar a nossa tarefa, quer para a conjuga¸c˜ao quer para a lematiza¸c˜ao (sem desambigua¸c˜ao), s˜ao pois estado-da-arte.
2.3
Desambigua¸c˜
ao verbal em contexto
Antes demais, apresentamos aqui os trˆes tipos de ambiguidade poss´ıveis para a flex˜ao verbal.
Primeiro temos a ambiguidade de lema:
consumo -> consumir -> consumar
Temos tamb´em ambiguidade de tra¸cos:
deram -> Pret´erito Perfeito do indicativo, 3a
pessoa, plural -> Pret´erito mais-que-perfeito do indicativo, 3a
pessoa, plural
E por ´ultimo a ambiguidade de tra¸cos e lema:
virei -> vir, Futuro do indicativo, 1a
pessoa, singular -> virar, Pret´erito Perfeito do indicativo, 1a
pessoa, singular
Como foi dito anteriormente, para uma dada forma verbal, o LX-Lem devolve os seus lemas e tra¸cos poss´ıveis. Mas como tem apenas acesso `a forma verbal isolada de qualquer contexto de ocorrˆencia, n˜ao consegue fazer qualquer inferˆencia para a desambiguar, ou seja, para decidir qual dos lemas/tra¸cos deve ser retido. Nem os seres humanos conseguiriam fazˆe-lo!
Para o conseguirmos fazer, precisamos de contexto. No contexto est˜ao as pistas que nos levam a perceber se uma forma verbal instancia este ou aquele lema, e expressa estes ou aqueles tra¸cos. Por exemplo, tomando a forma for s´o por si, n˜ao se consegue dizer se esta pertence ao verbo ir ou ao verbo ser, nem se est´a na 1a
pessoa ou na 3a pessoa do singular no futuro do conjuntivo. Mas se nos derem a
frase “Se ele for ao jogo.”, sabemos que a forma verbal for representa a 3a pessoa
do singular do futuro do conjuntivo do verbo ir.
Para um ser humano, fazer esta desambigua¸c˜ao ´e f´acil, mas como desenvolver uma aplica¸c˜ao que consiga fazer esta tarefa, de preferˆencia com os mesmos n´ıveis de acerto?
Talvez com in´umeras regras de co-ocorrˆencia que explorem informa¸c˜ao lingu´ıstica associada automaticamente `as palavras em redor seja poss´ıvel avan¸car. No entanto, isso parece uma tarefa de grande magnitude e, se conseguirmos avan¸car na resolu¸c˜ao do problema com menos esfor¸co e resultados de qualidade equipar´avel, seria ´util explorar esta ´ultima via.
Uma abordagem bastante explorado noutros problemas semelhantes baseia-se nos m´etodos estat´ısticos e/ou de aprendizagem autom´atica. Ser´a que atrav´es de v´arios exemplos de treino se consegue extrair/simular/emular os resultados a obter com as tais regras com os m´etodos estatisticos, de maneira que a percentagem de erro seja m´ınima e aceit´avel?
Nas pr´oximas sec¸c˜oes vamos debru¸car-nos sobre estas abordagens com m´etodos estat´ısticos.
2.4
Desambigua¸c˜
ao verbal como tarefa de etiqueta¸c˜
ao
Uma poss´ıvel abordagem ao problema da desambigua¸c˜ao verbal em contexto ´e en-car´a-lo como uma tarefa de etiqueta¸c˜ao. Vamos primeiro descrever o que ´e uma tarefa de etiqueta¸c˜ao e depois apresentar algumas abordagens populares, para a resolu¸c˜ao deste problema.
2.4.1
Tarefa de etiqueta¸c˜
ao morfossint´
actica
Etiqueta¸c˜ao morfossint´atica ´e uma tarefa que consiste em atribuir etiquetas com a categoria morfossint´actica a cada ocorrˆencia de um lexema em contexto. Por exemplo, para se decidir qual a etiqueta de classe gramatical que se vai atribuir a um dado lexema num dado contexto, vejamos um exemplo concreto: Na frase Eu como o bolo a palavra Eu seria etiquetada como um pronome pessoal, como seria etiquetado como um verbo, o como um artigo e bolo como um nome comum.
Mas este processo tamb´em n˜ao escapa a ter de lidar com a ambiguidade e no exemplo: N˜ao h´a nada como o mar a forma como seria agora etiquetada como um adv´erbio. Por exemplo:
Eu/PRS#gs1 como/V o/DA#ms bolo/BOLO/CN#ms .*//PNT
N~ao/ADV h´a/V nada/IND#ms como/ADV o/DA#ms mar/MAR/CN#ms .*//PNT
Para mais informa¸c˜oes sobre este tema, veja-se (Silva, 2007).
No nosso caso, a etiqueta a ser atribuida a um dado lexema (previamente eti-quetado como verbo) seria o conjunto formado pelo lema e pelos tra¸cos verbais. Por exemplo:
Cap´ıtulo 2. Flex˜ao e desambigua¸c˜ao verbal 9
<contexto> fui/V <contexto> => <contexto> fui/SER/V#ppi-1s <contexto>
Ou seja, seria uma segunda camada de etiqueta¸c˜ao. H´a pois a possibilidade de os m´etodos usados na etiqueta¸c˜ao poderem dar bons resultados tamb´em para o nosso problema.
A grande diferen¸ca para o nosso problema ´e que na etiqueta¸c˜ao morfossint´actica o n´umero de etiquetas ´e bastante menor que o conjunto de tra¸cos/lema dos verbos para o portuguˆes. Assim, para o nosso problema seria preciso uma quantidade bastante maior de dados de treino para cobrir o leque de possibilidades de modo a obter um bom classificador do que para um etiquetador da classe gramatical, por exemplo. Para al´em disso, as classes gramaticais formam um conjunto fechado, ao passo que se admitirmos neologismos,14
o conjunto de etiquetas (lema/tra¸cos), pela parte do lema, ´e potencialmente infinito.15
2.4.2
Abordagens populares
As t´ecnicas de aprendizagem autom´atica baseiam-se em algoritmos que permitam ao computador “aprender” atrav´es de extra¸c˜ao autom´atica de dados, por m´etodos computacionais e estat´ısticos.
A aprendizagem pode ser supervisionada ou n˜ao supervisionada.
Os m´etodos supervisionados requerem um corpus etiquetado, ou revisto manual-mente, para que haja informa¸c˜ao para suportar o funcionamento do algoritmo.
Os m´etodos n˜ao supervisionados n˜ao requerem um corpus etiquetado, no entanto revelam resultados inferiores aos m´etodos supervisionados.
A ideia ´e o computador saber atribuir a etiqueta baseado no que econtrou antes, e na quantidade de dados com a qual foi “treinado”. Assim, usando o exemplo do ponto anterior, em Eu como o bolo o lexema como ser´a etiquetado como verbo se nos dados com que o computador foi treinado esse lexema apareceu como verbo num contexto parecido,16
ie. com alguma palavra Eu, o, bolo, ou com palavras diferentes mas com as mesmas categorias gramaticais, se as estivermos a tomar em considera¸c˜ao.
Os programas de etiqueta¸c˜ao autom´atica, como por exemplo, TnT (Brants, 2000) que se baseia em modelos de Markov escondidos usando trigramas para etiquetar os lexemas, ou MXPOST (Ratnaparkhi, 1996) que usa um modelo de m´axima en-tropia, atribuem sempre etiquetas, mesmo quando o lexema n˜ao ocorreu no corpus de treino. Se o n´umero de classes for fechado e relativamente pequeno como no caso
14
todas as ferramentas no NLX s˜ao abertas a novas palavras
15
com as limita¸c˜oes de tamanho razo´aveis pelo senso comum e regras gramaticais
16
com um dado factor de semelhan¸ca superior `as outras etiquetas que ocorreram para como no treino
de etiqueta¸c˜ao da classe gramatical, sabe-se `a partida que a etiqueta est´a no con-junto de etiquetas recolhidas no treino17
e com o contexto pode ainda ser poss´ıvel acertar na etiqueta correcta.
No entanto, para o nosso caso, isso pode n˜ao acontecer. Por exemplo, se a palavra comunico ou qualquer forma do verbo comunicar n˜ao ocorreu no corpus de treino, n˜ao ´e possivel, com estes etiquetadores, saber que o lema desta palavra ´e comunicar. Existe no entanto um lematizador (Chrupa la, 2006) que funciona como uma tarefa de etiqueta¸c˜ao que usa um m´etodo para contornar este problema baseado no conceito de shortest edit script. Esse m´etodo consiste em aprender que certas termina¸c˜oes lematizam para uma termina¸c˜ao, isto ´e, no exemplo anterior comunico lematizaria para comunicar18
se houvesse outras palavras com a termina¸c˜ao em ico, que tivessem ocorrido no treino, a lematizar com a termina¸c˜ao icar. No entanto esta ferramenta n˜ao se aplica ao nosso problema que requer lematiza¸c˜ao verbal19
e tra¸camento verbal.20
Talvez pud´essemos adaptar esta abordagem para tamb´em atribuir os tra¸cos, con-catenando os tra¸cos ao lema no corpus de treino, mas isso seria aumentar o n´umero de classes a atribuir e, consequentemente, seria preciso um corpus de treino maior para cobrir mais exemplos de cada classe, conseguindo assim obter resultados pelo menos t˜ao bons quanto os resultados sem os tra¸cos. Claro que isto pode depender de muitos outros factores, como a composi¸c˜ao do corpus, e como tal n˜ao ´e linear uma aprecia¸c˜ao a priori ajustada.
Como vamos ver no Cap´ıtulo 3, em (Nunes, 2007) foi usada uma abordagem baseada na etiqueta¸c˜ao autom´atica usando a ferramenta TnT, n˜ao conseguindo no entanto passar o valor base de compara¸c˜ao, para al´em de n˜ao se adequar a parte da tarefa, nomeadamente a lematiza¸c˜ao, o que nos leva a querer experimentar outro tipo de abordagens.
2.5
Desambigua¸c˜
ao verbal como tarefa de
desam-bigua¸c˜
ao da acep¸c˜
ao de palavra
Tamb´em podemos encarar o problema de desambigua¸c˜ao verbal em contexto como uma tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra (word sense disambiguation). Esta tarefa consiste em decidir, de entre um leque de acep¸c˜oes poss´ıveis para uma palavra, qual a acep¸c˜ao expressa no contexto em que a palavra est´a a ocorrer. Vamos descrever a tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra com mais pormenor e depois falar de algumas maneiras de atacar o problema.
17
Dado um conjunto de treino razoavelmente grande
18
De notar que se trata apenas de um exemplo hipot´etico.
19
Isto poderia n˜ao ser um problema se houvesse um filtro para funcionar apenas para os verbos
20
Cap´ıtulo 2. Flex˜ao e desambigua¸c˜ao verbal 11
2.5.1
Tarefa de desambigua¸c˜
ao da acep¸c˜
ao de palavra
A mesma palavra pode ter diferentes significados em diferentes contextos. Vamos considerar o exemplo de bateria. Esta palavra pode significar um instrumento mu-sical, um artefacto de guerra, ou uma pilha el´ectrica. A tarefa de desambigua¸c˜ao de acep¸c˜ao de palavra consiste em decidir segundo o contexto, qual dos significados ´e expresso pelo lexema.
Tamb´em esta tarefa se assemelha ao nosso problema. Podemos encarar a sequˆencia de lema e tra¸cos verbais como “a acep¸c˜ao da palavra” relativa `a ocorrˆencia de um verbo num dado contexto.
Na desambigua¸c˜ao da acep¸c˜ao de palavra, o conjunto de classes que se pode atribuir n˜ao ´e fechado, tal como no nosso caso. Uma palavra pode ter in´umeros significados. Embora se saiba pelas entradas no dicion´ario qual o n´umero m´aximo de significados de cada uma das palavras, esse n´umero n˜ao ´e inalter´avel pois novos significados e novas palavras podem surgir.
2.5.2
Abordagens populares
A tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra tem aspectos comuns com a tarefa de etiqueta¸c˜ao. A diferen¸ca reside nas regras a combinar com os m´etodos usados para os adaptar ao problema. Por exemplo, no problema de etiqueta¸c˜ao podem-se juntar regras que eliminem `a partida algumas combina¸c˜oes de sequˆencias de classes gramaticais que n˜ao s˜ao poss´ıveis, ou no problema de desambigua¸c˜ao da acep¸c˜ao de palavra uma consulta a uma ontologia, como a WordNet,21
pode permitir relacionar as palavras do contexto e a palavra a ser desambiguada com uma medida de “distˆancia semˆantica” entre os n´os das entradas correspondentes ´as palavras na ontologia.
Tal como na tarefa de etiqueta¸c˜ao, os m´etodos com melhores resultados s˜ao os m´etodos supervisionados de aprendizagem autom´atica. De entre estes sobressaem alguns algoritmos que costumam ter os melhores desempenhos para a desambigua¸c˜ao de acep¸c˜ao de palavra (Agirre e Edmonds, 2006).
O classificador Na¨ıve Bayes baseia-se no Teorema de Bayes assumindo in-dependˆencia entre os atributos.22
O Teorema de Bayes consiste em relacionar a probabilidade condicional e marginal de dois eventos aleat´orios. Supondo dois eventos A e B, a rela¸c˜ao ´e expressa pela f´ormula
P (A|B) = P (B |A)P (A) P (B )
21
http://wordnet.princeton.edu/
22
onde P(A) ´e a probabilidade marginal de A, sem conhecimento pr´evio de B. P(A|B ) ´e a probabilidade condicional de A dado o evento B. P(B |A) ´e a probabili-dade de B dado A. P(B ) ´e a probabiliprobabili-dade marginal de B e funciona como constante de normaliza¸c˜ao.
O classificador dos k -vizinhos mais pr´oximos consiste em guardar exemplos de treino, depois os novos exemplos s˜ao classificados de acordo com os k -vizinhos mais pr´oximos segundo uma m´etrica de distˆancia pr´eviamente escolhida, tipicamente a distancia de Hamming.
O classificador Listas de Decis˜ao consiste em criar regras do tipo (condi¸c˜ao, classe, peso). Os exemplos de treino servem para definir o peso de se classificar um novo exemplo dada a ocorrˆencia de uma certa condi¸c˜ao. A lista ´e ordenada por ordem decrescente dos pesos. Para classificar novos exemplos, a lista ´e percorrida at´e se encontrar o peso mais alto que coincide com o novo exemplo.
Outro classificador ´e o AdaBoost, que consiste em combinar classificadores mais fracos, moderadamente precisos, para se obter um classificador com alta precis˜ao.
O algoritmo de Support Vector Machines (SVM) baseia-se no princ´ıpio de Minimiza¸c˜ao do Risco Estrutural da teoria de aprendizagem estat´ıstica (Vapnik, 1998). De uma forma geral os algoritmos de SVM aprendem uma discriminante lin-ear que separa os exemplos negativos dos exemplos positivos com margem m´axima. Segundo (Agirre e Edmonds, 2006), o algoritmo SVM ´e o que tem melhores resultados, sendo que o AdaBoost melhora quando o n´umero de exemplos por classe aumenta, embora a diferen¸ca n˜ao aumente significativamente. Todos os algoritmos estudados neste livro s˜ao executados sobre as mesmas condi¸c˜oes de teste.
Segundo Pederson e Mihalcea (2005), que analisa v´arios testes feitos em diversos trabalhos, indica por sua vez que em geral o Na¨ıve Bayes obt´em melhores resultados ou ao n´ıvel do estado da arte. O mesmo ´e testado por v´arios autores como ´e dito em (Pederson e Mihalcea, 2005, p´agina 90).
Assim, dado que a abordagem ao problema que nos interessa como tarefa de etiqueta¸c˜ao j´a foi explorada sem se conseguir ultrapassar os resultados do valor base de compara¸c˜ao,23
para al´em de n˜ao abranger a totalidade do problema, vamos apostar em explorar uma abordagem de tipo desambigua¸c˜ao da acep¸c˜ao da palavra, focando os algoritmos que em princ´ıpio ter˜ao melhores resultados, Na¨ıve Bayes e SVM.
23
Abordagem explicada no ponto ponto 3.2. Algoritmo de m´axima verosimilhan¸ca ´e tido como a base de compara¸c˜ao do problema.
Cap´ıtulo 3
Estado-da-arte
Neste cap´ıtulo vou descrever os resultados que foram alcan¸cados at´e agora no que diz respeito `a tarefa de desambigua¸c˜ao de flex˜ao verbal em contexto e que se encontram publicados na literatura relevante.
Vou come¸car por descrever como costuma ser feita a avalia¸c˜ao neste tipo de prob-lemas e apresentar a caracteriza¸c˜ao do l´exico, depois apresentarei a caracteriza¸c˜ao do corpus usado na avalia¸c˜ao, o que dar´a uma ideia de como a ambiguidade do l´exico se traduz num exemplo concreto.
Em seguida apresentarei algoritmos j´a explorados para este problema ou proble-mas semelhantes, come¸cando pelo algoritmo que define o valor base (Heur´ıstica de m´axima verosimilhan¸ca) passando depois a outros.
3.1
Avalia¸c˜
ao e conjunto de dados
Para se aplicar m´etodos estat´ısticos, torna-se necess´ario um conjunto de dados de treino, conhecido como corpus de treino. Este corpus pode encontrar-se anotado com etiquetas que veiculam informa¸c˜ao lingu´ıstica associada `as express˜oes que ocor-rem no texto (suportando aprendizagem autom´atica supervisionada) ou n˜ao anotado (suportando aprendizagem autom´atica n˜ao supervisionada). Tipicamente, a dizagem supervisionada leva a resultados superiores aos que se obtˆem com apren-dizagem n˜ao supervisionada, quer se encare a desambigua¸c˜ao verbal como uma tarefa de etiqueta¸c˜ao (Silva, 2007, p´agina 51), quer como uma tarefa de desambigua¸c˜ao da acep¸c˜ao de palavra (Agirre e Edmonds, 2006, p´agina 14). Visto que dispomos de um corpus etiquetado1
vamos focar este trabalho em m´etodos supervisionados. O conjunto de dados de treino serve para o computador “aprender” a tarefa. Atrav´es do processamento dos exemplos no corpus de treino, s˜ao estimados parˆametros estat´ısticos relevantes que o computador usa para procurar classificar novos casos apresentados. Para se avaliar o desempenho deste procedimento de decis˜ao
au-1
O corpus descrito no ponto 3.1.1
tom´atica, ´e preciso determinar se a classifica¸c˜ao est´a correcta ou n˜ao. Isto pode ser conseguido se tivermos exemplos para testar que, em ocasi˜ao pr´evia, tenham sido correctamente anotados manualmente. Assim podemos comparar a anota¸c˜ao correcta com a anota¸c˜ao autom´atica produzida pelo algoritmo de classifica¸c˜ao.
Por conseguinte, ´e comum dividir-se o conjunto de dados anotados em corpus de treino e corpus de teste, usando-se maior quantidade de dados para o corpus de treino. Assim podemos obter uma medida de qu˜ao boa ´e a classifica¸c˜ao autom´atica. Em todos os resultados obtidos por mim ou obtidos previamente coloca-se a quest˜ao de o conjunto de dados utilizado ser ou n˜ao apropriado para a execu¸c˜ao da tarefa e em que medida a existˆencia de diferentes corpora para dom´ınios espec´ıficos poderia ajudar ou n˜ao esta tarefa.
Para o nosso caso, se todo o texto for, por exemplo, um discurso na primeira pessoa, dificilmente vamos conseguir classificar novos exemplos com boa taxa de acerto noutras pessoas verbais. No entanto, e aqui podem surgir resultados de avalia¸c˜ao enganadores, se os exemplos de teste vˆem do mesmo corpus vamos ter medidas de desempenho elevadas, apesar desse poss´ıvel enviesamento.
3.1.1
Caracteriza¸c˜
ao do corpus
Seguindo o que ´e comum na literatura, e face `a escassez de conjuntos de dados de treino e teste, o estudo da adaptabilidade do corpus `a nossa tarefa n˜ao costuma ser feito e n˜ao vai ser feito no presente trabalho.
Deixamos aqui no entanto alguma informa¸c˜ao sobre o corpus que est´a `a nossa dis-posi¸c˜ao, e cuja constitui¸c˜ao est´a em linha com a constitui¸c˜ao que ´e tipico encontrar para corpora usados em processamento de linguagem natural.
O corpus ´e composto por 689.1262
lexemas anotados, cada um verificado manual-mente por especialistas em lingu´ıstica. A anota¸c˜ao inclui informa¸c˜ao sobre a classe morfossint´actica, sobre o lema e a flex˜ao das classes abertas, sobre express˜oes multi-palavra pertencentes `a classe dos adv´erbios e `as classes fechadas, e sobre nomes pr´oprios multi-palavra.
Este corpus inclui 63.4% de texto recolhido de artigos, jornais e revistas. O resto do corpus ´e essencialmente constitu´ıdo por textos liter´arios.3
O corpus ´e composto por excertos como este:
Com/PREP[O] tiros/TIRO/CN\#mp[O] de/PREP[O] ca¸cadeira/CAC¸ADEIRA/CN\#fs[O] ,*//PNT[O] um/UM\#ms[O] desconhecido/DESCONHECIDO/CN\#ms[O] sem/PREP[O] motivo/MOTIVO/CN\#ms[O] aparente/APARENTE/ADJ\#ms[O]
abateu/ABATER/V\#ppi-3s[O] uma/UM\#fs[O] fam´ılia/FAM´ILIA/CN\#fs[O]
2
De notar que apenas me refiro `a parte escrita, o corpus divide-se em duas partes, escrita e oral. No presente trabalho iremos usar apenas a parte escrita
3
Cap´ıtulo 3. Estado-da-arte 15
inteira/INTEIRO/ADJ\#fs[O] .*//PNT[O]
Cada lexema pode ter cinco campos distintos, a forma ortogr´afica (e.g. ca¸cadeira), o lema (CAC¸ ADEIRA),4
a categoria morfossint´actica (CN), a informa¸c˜ao sobre tra¸cos de flex˜ao (fs) e informa¸c˜ao sobre express˜oes multi-palavra ([0]).
Pegando num lexema referente a um verbo deste excerto - abateu/ABATER/V#ppi-3s[O] - o primeiro campo abateu representa a forma ortogr´afica, ABATER representa o lema. Quanto `a informa¸c˜ao morfossint´actica, primeiro vem a categoria gramatical. Depois, separado por um ’#’, vˆem os tra¸cos que levam o lema `a forma flexionada, que ocorre no texto original. Por ´ultimo, entre parˆentesis rectos, vem a informa¸c˜ao relativa ao lexema fazer parte ou n˜ao de uma entidade nomeada e, se sim, de que modo.5
Para a nossa tarefa de desambigua¸c˜ao da flex˜ao verbal vamos precisar ape-nas do conte´udo de trˆes campos: a forma ortogr´afica (abateu), o lema (ABATER) e os tra¸cos de flex˜ao (ppi-3s).
Em (Branco et al., 2007) o problema da ambiguidade verbal foi quantificado. Com o conjugador verbal,6
geraram-se todas as formas flexionadas para os lemas conhecidos.7
Estes ´ultimos perfazem um total de 11.350 entradas que deram origem a 816.830 formas conjugadas. Destas formas, apenas 598.651 s˜ao formas ´unicas, diferentes entre si quando se ignora o conjunto de tra¸cos de flex˜ao que expressam.
Como foi explicado anteriormente na sec¸c˜ao 2.1, a ambiguidade associada `a flex˜ao verbal pode ser de trˆes tipos. Ambiguidade de lema, de tra¸cos, ou de ambos os tipos. Tendo isto em conta, (Branco et al., 2007) determinaram que das 598.651 formas verbais ´unicas, 438.064 s˜ao n˜ao amb´ıguas, sendo 73.18% dessas formas ´unicas. As formas verbais amb´ıguas nos tra¸cos s˜ao 159.376, ou seja 26.62%. Apenas 141 formas tˆem ambiguidade de lema, o que representa 0.02% das formas. A ambiguidade de lema e tra¸co afecta 1.070 formas verbais, representando 0.18%.
No corpus que vou utilizar ocorrem 85.6428
formas verbais, etiquetadas como V, VAUX, INF, INFAUX, GER, PPT, PPA, INFAUX e GERAUX. VAUX etiqueta os verbos auxiliares, como por exemplo tinha sido em que o verbo ter na sua forma tinha est´a a auxiliar o verbo ser na sua forma sido. INF etiqueta os infinitivos, como por exemplo ser em que a forma ortogr´afica ´e igual `a forma lematizada. Contudo, os infinitivos podem ser flexionados em g´enero e n´umero. INFAUX etiqueta os infinitivos auxiliares, como por exemplo ter sido em que a forma infinitiva do verbo ter est´a a auxiliar o verbo ser na sua forma sido. GER etiqueta os ger´undios, como por exemplo tornando, e GERAUX os ger´undios
aux-4
apenas se este puder ser diferente da forma ortogr´afica em resultado da flex˜ao.
5
valores possiveis para os campos de informa¸c˜ao morfossint´actica encontram-se em http://lxcorpus.di.fc.ul.pt/cintilwhatsin.html#pos
6
http://lxconj.di.fc.ul.pt
7
Sem incluir formas com cliticos inerentes e formas de verbos compostos
8
iliares, como por exemplo tendo sido em que o verbo ter na sua forma do ger´undio tendo est´a a auxiliar o verbo ser na sua forma sido. PPT etiqueta os partic´ıpios passados em tempos compostos, como por exemplo sido em tendo sido, etiquetando PPA os partic´ıpios passados que n˜ao ocorrem em tempos compostos, como por ex-emplo reflectida em luz reflectida que ´e um partic´ıpio passado do verbo reflectir. V etiqueta as restantes ocorrˆencias de formas verbais.
Destas 85.642 ocorrˆencias, 57.968 s˜ao lexicalmente amb´ıguas. Por sua vez, es-sas 85.642 ocorrˆencias s˜ao ocorrˆencias de 15.640 formas ´unicas, entre as quais se encontram 7.637 formas ´unicas lexicalmente amb´ıguas.
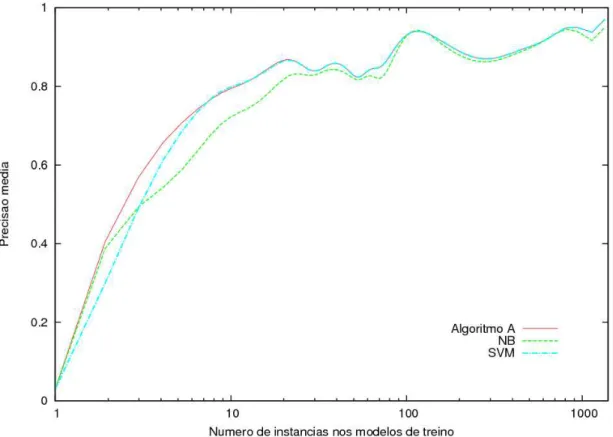
De notar que apenas 2.6% do total de formas ´unicas do l´exico ocorre no corpus. Por´em, quase metade das formas ´unicas que a´ı ocorrem s˜ao amb´ıguas. Sendo que s˜ao aproximadamente 68% as formas amb´ıguas do total de ocorrˆencias no corpus. Na Figura 3.1 apresenta-se a distribui¸c˜ao das formas verbais por grau de ambiguidade, isto ´e, por n´ıvel de diferentes leituras lexicalmente adm´ıssiveis por forma verbal. Verifica-se que o grau de ambiguidade diminui com o aumento de frequˆencia.
Figura 3.1: N´umero de ocorrˆencias de formas verbais por grau de ambiguidade.
Em suma, e no que tem impacto para a tarefa de desambigua¸c˜ao: quase metade dos tipos que tˆem instˆancias no corpus s˜ao amb´ıguos; e cerca de 68% das ocorrˆencias de formas verbais carecem de desambigua¸c˜ao em contexto. Para quantificar por tipo de ambiguidade, ver Figura 3.2.
De notar que nesta estat´ıstica n˜ao s˜ao consideradas formas verbais com cl´ıtico ou compostas.
Cap´ıtulo 3. Estado-da-arte 17
Figura 3.2: Propor¸c˜ao de ocorrˆencias no corpus de formas verbais lexicalmente amb´ıguas por tipo de ambiguidade.
3.1.2
Medidas de avalia¸c˜
ao
Neste tipo de problemas, ´e costume usar dois tipos de avalia¸c˜ao: a precis˜ao e a abrangˆencia.
A precis˜ao ´e uma medida de exactid˜ao do algoritmo. No nosso contexto pode ser definida como o n´umero de exemplos correctamente classificados a dividir pelo n´umero total de exemplos classificados.
A abrangˆencia ´e uma medida de qu˜ao completo ´e o algoritmo, isto ´e, uma medida dos casos que ficam por classificar correctamente. No nosso contexto ´e definida como o n´umero de exemplos correctamente classificados a dividir pelo n´umero total de exemplos a classificar.
Podemos tamb´em juntar estas duas medidas numa s´o, conhecida como medida-f que combina as outras duas medidas com igual peso segundo a f´ormula
2(precis˜ao.abrangˆencia) precis˜ao + abrangˆencia.
Esta medida ´e depois usada para comparar os diversos algoritmos, j´a que ´e uma medida sobre todos os aspectos do algoritmo.
3.2
Heur´ıstica de m´
axima verosimilhan¸ca
A primeira abordagem “natural” a este problema e a que pode permitir definir o valor base de compara¸c˜ao ´e usar uma heur´ıstica de m´axima verosimilhan¸ca. Esta heur´ıstica consiste em extrair o lema e tra¸cos verbais mais frequentes para cada forma
verbal presente no corpus de treino. Depois, para cada forma verbal encontrada no corpus de teste, ´e atribu´ıda a etiqueta mais frequente para essa forma.
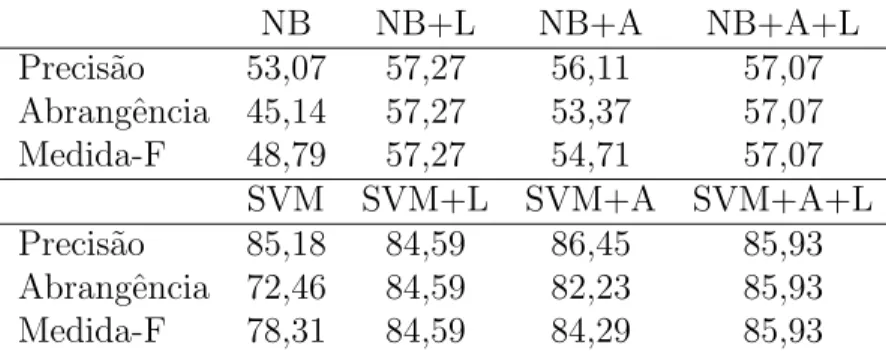
Em trabalho anterior (Nunes, 2007, pag. 65-66) utilizou-se este algoritmo sobre um corpus de 260.000 lexemas.
Este algoritmo mesmo sendo bastante simples conseguiu uma precis˜ao de 95.92% e uma abrangˆencia de 68,68% perfazendo uma medida-f de 80.02% para o corpus usado, incluindo as formas n˜ao amb´ıguas.
Foi feita uma extens˜ao a este algoritmo com o objectivo de aumentar a abrangˆencia. Como tal, a nova vers˜ao do algoritmo deveria ser capaz de classificar tamb´em as formas verbais n˜ao encontradas no corpus de treino. Para tal, usou-se o lemati-zador verbal nas formas verbais desconhecidas no corpus de treino. Das poss´ıveis acep¸c˜oes da forma verbal desconhecida devolvidas pelo lematizador, descartam-se as que tenham lemas desconhecidos se houver candidatos com lemas conhecidos; e descartam-se as que tenham lemas pouco frequentes se houver lemas muito fre-quentes. Depois seleciona-se a acep¸c˜ao que tiver os tra¸cos mais frequentes, depois selecciona-se a que tiver o lema mais frequente. Caso apenas existam lemas descon-hecidos, seleciona-se a que cont´em o lema com a termina¸c˜ao “-ar”, em seguida “-er” e por ´ultimo “-ir”. Em qualquer destes passos, se apenas sobrar uma possibilidade o processo ´e interrompido e devolve-se esse candidato como solu¸c˜ao proposta.
Passos do algortimo:
(1) Se a forma verbal foi vista no corpus de treino atribui-se o par lema e tra¸cos mais frequente.
(2) Caso contr´ario usa-se o lematizador para obter as flex˜oes poss´ıveis para a forma verbal. At´e restar apenas uma solu¸c˜ao:
(3) Descartam-se lemas desconhecidos se houver lemas conhecidos.
(4) Descartam-se lemas pouco frequentes se houver lemas muito fre-quentes.
(5) Escolhe-se a flex˜ao com os tra¸cos mais frequentes.
(6) Escolhe-se a flex˜ao com o lema mais frequente.
(7) Escolhe-se o lema que contenha a termina¸c˜ao em ar”, depois “-er” e por ´ultimo “-ir”.
Cap´ıtulo 3. Estado-da-arte 19
Com esta extens˜ao, (Nunes, 2007) obteve uma precis˜ao de 96.06% e a abrangˆencia aumentou significativamente para 95.79% fazendo uma medida-f de 95.92%.9
O mel-hor resultado at´e ent˜ao para este problema. A diferen¸ca entre o valor de precis˜ao e o valor da abrangˆencia deve-se ao facto de alguns lexemas em que a forma ortogr´afica est´a errada. Quando usados como entrada no lematizador, a ferramenta n˜ao con-segue lidar com eles visto essa forma ortogr´afica ser imposs´ıvel de acordo com as regras gramaticais.
3.3
Modelos de Markov escondidos
Tamb´em em (Nunes, 2007), foram usados modelos de markov escondidos para atacar a tarefa de lematiza¸c˜ao como uma tarefa de etiqueta¸c˜ao.
Os modelos de Markov escondidos baseiam-se na transi¸c˜ao entre v´arios estados escondidos. Cada estado tem associado uma probabilidade para cada transi¸c˜ao poss´ıvel e pode emitir, de um conjunto de sinais observ´aveis, alguns desses sinais com uma probabilidade respectiva. O desafio ´e determinar os parˆametros escondidos atrav´es dos observ´aveis, em particular determinar os estados entre os quais se deram as transi¸c˜oes que originaram os sinais observados.
Assim temos uma vari´avel aleat´oria x(t) que representa o estado escondido no instante de tempo t, com x(t) ∈ {x1, x2, x3, . . .}, conjunto que representa os v´arios
estados poss´ıveis, e temos outra vari´avel aleat´oria y(t) que representa o sinal emitido pelo estado x(t) no mesmo instante t, com y(t) ∈ {y1, y2, y3, . . .}. A vari´avel x(t)
depende exclusivamente do valor da vari´avel escondida x(t-1), ou seja da vari´avel x no instante anterior t-1, esta propriedade ´e chamada de propriedade de Markov. A vari´avel observ´avel y(t) depende da transi¸c˜ao entre dois estados, x(t-1) para x(t), isto ´e, a vari´avel x no mesmo instante t. Abaixo apresentamos um esquema gr´afico do que foi explicado.3.3
Figura 3.3: Modelo de Markov Escondido - representa¸c˜ao temporal. Extra´ıda da Wikipedia
9
Os valores apresentados s˜ao para as tarefas de desambigua¸c˜ao de lema e tra¸cos, incluindo formas n˜ao amb´ıguas.
Nunes (2007) usou uma abordagem de etiqueta¸c˜ao baseada em modelos de Markov escondidos com a ferramenta TnT para a tarefa de atribui¸c˜ao de tra¸cos. Esta abordagem obteve uma medida-f de 94.47%.
No entanto esta experiˆencia n˜ao cobre a totalidade da tarefa em quest˜ao, visto que n˜ao atribui lemas, devido ao que foi explicado em 2.4.2 relativamente a esta abordagem. Sendo com isto apenas aplic´avel aos verbos que tenham ambiguidade de tra¸cos. Nunes (2007) aproveita a etiqueta¸c˜ao morfossint´actica feita pr´eviamente que para alguns verbos tem os tra¸cos inerentes na etiqueta, deste modo a desambigua¸c˜ao quanto a tra¸cos apenas ´e feita para um subconjuncto dos verbos.
3.4
Trabalhos relacionados
N˜ao tenho, at´e `a data, conhecimento de trabalho feito nesta tarefa especifica, sem ter em conta o trabalho previamente realizado no NLX. No entanto existem alguns trabalhos feitos em tarefas relacionadas que passo a citar.
Chrupa la (2006) reporta um f-score de 91.21% para a tarefa de lematiza¸c˜ao no Portuguˆes usando o classificador SVM com a abordagem de Shortest Edit Script. N˜ao ´e limitado aos verbos, mas tamb´em n˜ao faz tra¸camento verbal.
(Moreno-Sandoval e Guirao, 2006), que reportam uma taxa de acerto de 96.8% para a lematiza¸c˜ao e 96.7% para a etiqueta¸c˜ao do portuguˆes, apenas etiqueta os verbos como V ou AUX, n˜ao fazendo qualquer desambigua¸c˜ao quanto aos tra¸cos verbais. Esta ´e a principal fonte de ambiguidade do nosso problema. Ver Figura 3.2. Escudero et al. (2000) usam dois m´etodos para fazer desambigua¸c˜ao de acep¸c˜ao de nomes e verbos. O primeiro ´e o Naive Bayes que, para os verbos permite obter uma taxa de acerto (Accuracy) de 64.8%, usando como atributos um contexto semel-hante ao contexto local10
, e 63.4% usando como atributos um contexto semelhante `a combina¸c˜ao do contexto de t´opicos11
com o contexto local. O outro m´etodo tes-tado ´e chamado de abordagem baseada em exemplos ”Exemplar-based approach” e baseia-se no algoritmo dos k-vizinhos-mais-pr´oximos. Este ´ultimo consegue mel-hores resultados. Nomeadamente 66.4% para a primeira modela¸c˜ao de atributos (contexto local) e 67.0% para a segunda (contexto de t´opicos com contexto local).12
Neste trabalho, o valor base de compara¸c˜ao usa uma medida de acep¸c˜ao mais fre-quente, que para o corpus usado e s´o contando com os verbos tem uma taxa de acerto 48.7%.
Em (Agirre e Edmonds, 2006) compara v´arios algoritmos para fazer desam-bigua¸c˜ao da acep¸c˜ao de nomes e verbos. O resultado base, que consiste na atribui¸c˜ao
10
Descrito no pr´oximo cap´ıtulo
11
Descrito no pr´oximo cap´ıtulo
12
Cap´ıtulo 3. Estado-da-arte 21
da acep¸c˜ao mais frequente, ´e de 46.49% para os verbos.13
Este trabalho reporta que a melhor abordagem ´e permitida pelo algortimo de Support Vector Machines, con-seguindo uma Accuracy de 67.54%, usando uma combina¸c˜ao de atributos que inclui uma variante do Contexto de t´opicos mais a mesma vers˜ao do contexto local usada no presente trabalho.
Tanto (Agirre e Edmonds, 2006) como (Escudero et al., 2000) s˜ao expˆeriencias controladas, sobre um conjunto definido de verbos e nomes, n˜ao fazem qualquer processamento para lidar com palavras desconhecidas.
De notar que quando se fala nestes trabalhos em desambigua¸c˜ao da acep¸c˜ao de um verbo, o tema ´e ligeiramente diferente do problema do presente trabalho. Em (Escudero et al., 2000) e (Agirre e Edmonds, 2006) a acep¸c˜ao prende-se com o significado que o verbo pode ter,14
o estado de coisas que este expressa. No presente trabalho, a desambigua¸c˜ao prende-se com os tra¸cos de flex˜ao verbal que a forma verbal expressa e em parte com o estado de coisas expressa, j´a que tamb´em realiza lematiza¸c˜ao verbal.
Vejamos um exemplo, a palavra bater em termos de significado pode expressar o bater na mesa, bater em retirada, o bater card´ıaco, etc. ´E esta desambigua¸c˜ao que ´e feita nos trabalhos acima mencionados, a tendo por base os conceitos associados a cada verbo na ontologia verbal WordNet.
Resumindo, a nossa tarefa tem por objectivo desambiguar os verbos quanto `a informa¸c˜ao de tra¸cos de flex˜ao e parcialmente quanto ao tipo de evento (j´a que tamb´em realiza lematiza¸c˜ao). As tarefas mencionadas atr´as apenas desambiguam os verbos quanto ao tipo de evento.
13
O corpus usado ´e o mesmo de (Escudero et al., 2000).
14
Cap´ıtulo 4
Desambigua¸c˜
ao de flex˜
ao verbal:
uma abordagem DAP
Como discutimos em cap´ıtulos anteriores, a abordagem da tarefa de desambigua¸c˜ao da flex˜ao verbal como problema de etiqueta¸c˜ao j´a foi explorada em trabalho anterior. Neste trabalho, vamos procurar explorar uma abordagem com base nas t´ecnicas de desambigua¸c˜ao da acep¸c˜ao da palavra (DAP)1
para executar essa tarefa.
Em resultado da experiˆencia documentada na literatura e discutida na sec¸c˜ao 2.5.2, iremos explorar o classificador Naive Bayes (sec¸c˜ao 4.1) e o classificador SVM (sec¸c˜ao 4.2). Por serem os que tˆem permitido alcan¸car os melhores resultados na tarefa DAP em geral.
4.1
Aplica¸c˜
ao do classificador Naive Bayes
Feita a escolha de usar o classificador Naive Bayes, houve que escolher como este iria ser usado. Houve que escolher se implement´avamos a nossa vers˜ao do classificador, ou se tir´avamos partido de uma implementa¸c˜ao j´a feita e disponibilizada para uso geral.
Decidimos usar a conhecida ferramenta Weka,2
que inclui uma implementa¸c˜ao do classificador Naive Bayes. Esta ferramenta ´e bastante usada no meio acad´emico, facto que lhe traz bastante credibilidade como ferramenta est´avel e largamente tes-tada. Com essa seguran¸ca, fica assim ultrapassado o problema da implementa¸c˜ao do algoritmo correspondente.
Cabe ent˜ao, antes de mais, explicar com maior detalhe este classificador, segundo a descri¸c˜ao usada para a implementa¸c˜ao do mesmo no Weka. O classificador Naive Bayes assume que para uma dada classe, os atributos s˜ao condicionalmente indepen-dentes entre si e que nenhum atributo escondido ou latente influencia a classifica¸c˜ao.
1
Word sense disambiguation (WSD).
2
http://www.cs.waikato.ac.nz/ml/weka/
Cap´ıtulo 4. Desambigua¸c˜ao de flex˜ao verbal: uma abordagem DAP 23
Segundo (Mitchell, 1997), estas assun¸c˜oes geram algoritmos bastante eficientes quer para a classifica¸c˜ao quer para a aprendizagem. Vejamos. Seja C uma vari´avel aleat´oria que expressa a classe de uma instˆancia e X o vector de vari´aveis aleat´orias que expressam os valores dos atributos observ´aveis. Seja c a representa¸c˜ao de uma classe em particular, e x a representa¸c˜ao de um valor observ´avel em particular. Dado um caso de teste x a classificar, basta usar a regra de Bayes para calcular a probabilidade de x pertencer a cada classe c, o que permitir´a encontrar a classe com probabilidade maior em ordem a tomar uma decis˜ao quanto `a classifica¸c˜ao desse caso de teste ´e justamente por se escolher essa classe com maior probabilidade.
p(C = c|X = x) = p(C = c)p(X = x|C = c) p(X = x)
Na f´ormula acima, X = x representa o evento em que X1 = x1∧ X2 = x2∧ · · · ∧
Xk = xk. O evento ´e a conjun¸c˜ao dos valores dos atributos, e sendo estes assumidos
como condicionalmente independentes entre si, obtemos
p(C = c|X = x) = p(^ i Xi = xi|C = c) =Y i p(Xi = xi|C = c)
que ´e simples de computar para os casos de teste e de estimar para os casos de treino (Mitchell, 1997).
Tipicamente n˜ao se estima a distribui¸c˜ao no denominador na primeira equa¸c˜ao, j´a que ´e apenas um factor de normaliza¸c˜ao. Em vez disso, ignora-se o denominador e normaliza-se de forma a que a soma de p(C = c|X = x) sobre todas as classes ´e um.
Para o classificador Naive Bayes, os atributos discretos e n´umericos s˜ao tratados de maneira diferente. Cada atributo discreto ´e modelado por um n´umero real entre 0 e 1, representando a probabilidade de o atributo X ter um valor x quando a classe ´e c. Por seu lado, os atributos n´umericos s˜ao modelados por uma distribui¸c˜ao de probabilidade cont´ınua sobre a janela de valores poss´ıveis desses atributos.
Como vimos, o classificador Naive Bayes permite atribuir uma classe a um ex-emplo de teste. Temos ent˜ao de decidir quais v˜ao ser as nossas classes. Como vamos modelar o nosso problema para conseguir usar o este classificador?
Intuitivamente, se estamos a tentar desambiguar o lema e os tra¸cos de um verbo, a classe a atribuir vai ser um tuplo desses mesmos valores, o valor do lema e os valores dos tra¸cos. Como j´a foi referido anteriormente, notar que como algumas etiquetas morfossint´acticas, apresentam informa¸c˜ao inerente sobre os tra¸cos do verbo, estas ser˜ao inclu´ıdas com os tra¸cos.
N˜ao ´e pr´atico por´em treinar o classificador para o conjunto total de valores poss´ıveis pois isto daria origem a uma enorme quantidade de classes poss´ıveis. De acordo com a estimativa de (Branco et al., 2007), apenas tomando em considera¸c˜ao cerca de 11.000 verbos(lemas) atestados do l´exico do portuguˆes, esse conjunto teria mais de 800.000 valores. Isso seria tamb´em desaconselh´avel por outra ordem de raz˜oes, nomeadamente porque para cada caso de teste, para a esmagadora maioria de tuplos, o lema no tuplo lema:tra¸cos nada teria a ver com a forma verbal desse mesmo caso de teste ou seja, n˜ao seria um lema admiss´ıvel para essa forma verbal. De igual modo, para os valores dos tra¸cos de flex˜ao, estar-se-ia a admitir como poss´ıveis valores de tra¸cos, que n˜ao podem ser expressos pelo sufixo flexional presente no caso de teste.
Assim, para aliviar este problema e tamb´em para garantir que os valores do tuplo lema:tra¸cos representam uma classe poss´ıvel para a forma verbal do caso de teste em quest˜ao, vamos construir classificadores para cada forma verbal que ocorra no corpus de treino. Desta forma alivia-se o processamento j´a que para cada classificador o n´umero de classes poss´ıveis ´e bastante menor.
Como atributos, usamos o contexto da frase. Mais `a frente explicarei este uso do contexto na obten¸c˜ao de atributos para o classificador.
Assim, temos como atributo discreto a classe representada por lema:tra¸cos. A probabilidade de uma vari´avel nominal (como ´e o caso) ter um certo valor ´e igual `a sua frequˆencia relativa na amostra, isto ´e, o n´umero de vezes que o valor ocorreu nos exemplos dividido pelo n´umero total de exemplos relevantes.
Para os atributos cont´ınuos, a distribui¸c˜ao de probabilidade cont´ınua costuma ser representada por uma fun¸c˜ao gaussiana, segundo a f´ormula g(x; µ, σ) = √1
2πσe −(x−µ)22σ2
. No nosso caso n˜ao vamos ter atributos cont´ınuos.
Vamos mostrar ent˜ao um exemplo, aplicado ao nosso caso concreto, para ilustrar como s˜ao estimados os parˆametros relevantes.
Supondo que se trata da forma verbal fui, temos como valores de classe ir:v#ppi-1s e ser:v#ppi-ir:v#ppi-1s. Para efeitos de compreens˜ao e simplifica¸c˜ao do exemplo, vamos supor que apenas temos dois atributos de vari´avel discreta, a ocorrˆencia da palavra X1 e a ocorrˆencia da palavra X2, que podem ter o valor 0, indicando a ausˆencia da
palavra, ou 1, indicando a presen¸ca da palavra na frase.
Tendo em conta os seguintes cinco casos de treino: {1s, 0, 0), (ir:v#ppi-1s, 0, 1), (ir:v#ppi-(ir:v#ppi-1s, 1, 1), (ser:v#ppi-(ir:v#ppi-1s, 1, 1), (ser:v#ppi-(ir:v#ppi-1s, 1, 0)}.
Cap´ıtulo 4. Desambigua¸c˜ao de flex˜ao verbal: uma abordagem DAP 25 p(C = ir : v#ppi − 1s) = 3/5 p(X1 = 1 |C = ir : v#ppi − 1s) = 1/3 p(X1 = 0 |C = ir : v#ppi − 1s) = 2/3 p(X2 = 1 |C = ir : v#ppi − 1s) = 2/3 p(X2 = 0 |C = ir : v#ppi − 1s) = 1/3
e de forma an´aloga para a outra classe, ser:v#ppi-1s.
Em resumo, o classificador Naive Bayes ´e uma abordagem simples e eficaz ao problema de indu¸c˜ao. A complexidade deste classificador em n casos de treino e k atributos ´e O(nk ), complexidade temporal, e O(k ), complexidade espacial.
4.2
Aplica¸c˜
ao do classificador SVM
Como foi dito anteriormente, a op¸c˜ao por utilizar este classificador na nossa tarefa de desambigua¸c˜ao de flex ao verbal resulta da an´alise comparativa favor´avel apre-sentada em (Agirre e Edmonds, 2006) para a tarefa DAP em geral. Neste livro, refere-se que a implementa¸c˜ao a´ı utilizada foi o SV Mlight. Este ´e no entanto um
classificador bin´ario, isto ´e separa linearmente os exemplos negativos e positivos. A nossa tarefa requer por´em que a classifica¸c˜ao tenha v´arios valores poss´ıveis e como tal um classificador bin´ario n˜ao ´e suficiente.
Existe no entanto uma ferramenta feita pelo mesmo autor do SV Mlight,
entit-ulada de SV Mmulticlass, que como indica o nome, tem suporte para v´arias classes.
Assim como fizemos para o Naive Bayes, tamb´em para o SVM iremos usar uma implementa¸c˜ao j´a usada e testada.
O classificador SV Mmulticlass´e uma implementa¸c˜ao do multi-class Support Vector
Machine (SVM) descrito em (Crammer e Singer, 2001)
Como foi dito anteriormente, de uma forma geral os algoritmos de SVM apren-dem uma discriminante linear que separa os exemplos negativos dos exemplos posi-tivos com margem m´axima. Ver figura 4.1
A margem ´e definida pela distˆancia da discriminante linear ao exemplo negativo e positivo mais pr´oximos.
As linhas a tracejado s˜ao os chamados vectores de suporte.
Nem sempre ´e poss´ıvel tra¸car um vector que separe linearmente os exemplos negativos dos positivos, ou mesmo que seja poss´ıvel, `as vezes ´e preferivel deixar alguns exemplos errados no treino de modo a conseguir uma separa¸c˜ao que trar´a melhores resultados. Ver figura 4.2
Figura 4.1: Discriminante linear. Extra´ıda de (Agirre e Edmonds, 2006).
Figura 4.2: Discriminante linear com margem de erro. Extra´ıda de (Agirre e Ed-monds, 2006).
h(x) = (
+1 se (w · X) + b ≥ 0 −1 caso contr´ario
Sendo x o exemplo a classificar, w o vector que vai da linha discriminante ao exemplo x e b a distancia da linha discriminate `a origem.
Para aplicar este algortimo bin´ario a um problema com um n´umero finito de valores de classe n˜ao bin´arios, podemos dividir o problema em v´arios problemas bin´arios. Normalmente isto ´e feito de duas maneiras, ou se compara cada classe com todas as outras, e neste caso ´e atribuida a que tiver o valor mais alto, ou se comparam todas as classes entre si e a que tiver mais “vict´orias” ´e a escolhida.
Para o classificador SVM, model´amos o problema da mesma maneira que foi feito para o Naive Bayes. Ou seja, com tuplos de lema:tra¸cos como classes, us-ando o contexto, para obter atributos3
e criando modelos para cada forma verbal individualmente.
4.3
Pr´
e-processamento
Seguindo o que ´e habitual em aprendizagem autom´atica, dividimos o corpus em dois peda¸cos, o nosso objecto de treino e teste ´e o corpus descrito na sec¸c˜ao 3.1.1. 90%
3
Cap´ıtulo 4. Desambigua¸c˜ao de flex˜ao verbal: uma abordagem DAP 27
do corpus fica para treino do classificador e 10% do corpus para efectuar os testes. Decidimos tamb´em escolher os 10% de teste de frases alternadas do corpus total. Isto ´e, em vez de tirar um bloco de 10% do in´ıcio, fim ou meio do corpus, vamos na extra¸c˜ao alternando entre nove frases consecutivas reservadas para o treino, e uma d´ecima para o teste.
A por¸c˜ao do corpus usada para treino cont´em 77029 instˆancias de formas verbais a que corresponde 15786 tipos de formas ´unicas e 17596 s˜ao tipos de tuplos da forma verbal com o seu lema e os seus tra¸cos. Por seu lado, a por¸c˜ao do corpus usada para teste cont´em 8613 formas verbais das quais 3923 s˜ao tipos de formas ´unicas e 4176 s˜ao tipos de tuplos da forma verbal com o seu lema e os seus tra¸cos.4
A etiqueta¸c˜ao morfossint´actica do corpus faz distin¸c˜ao entre diversas categorias verbais, o que ajuda a circunscrever as ocorrˆencias verbais, para as quais ´e pre-ciso fazer desambigua¸c˜ao. Em particular, as ocorrˆencias etiquetadas como GER, GERAUX, PPA ou PPT apenas precisam de ser desambiguadas quanto ao lema j´a que os tra¸cos est˜ao inerentes nessas classes gramaticais. Destes lexemas apenas os etiquetados com PPA requerem etiqueta¸c˜ao de tra¸cos de flex˜ao, por exemplo, a palavra passada quando etiquetada como PPA ter´a os tra¸cos fs - feminino singular. Estes tra¸cos s˜ao no entanto atribu´ıdos num fase de etiqueta¸c˜ao pr´evia atrav´es de um m´odulo de tra¸camento nominal (Silva, 2007).
No entanto, para que possamos avaliar a desambigua¸c˜ao verbal como uma tarefa global independente do tagset usado,5
vamos usar a etiqueta¸c˜ao realizada pelo eti-quetador apenas para saber quais dos lexemas s˜ao verbos.6
Assim, e como j´a foi visto anteriormente, a classe gramatical dos verbos entra em conjunto com os tra¸cos no campo tra¸cos nos tuplos das classes lema:tra¸cos. Por exemplo, para a forma verbal tendo, temos duas classes:
ter:ger
tender:v#pi-1s
Ger ´e a etiqueta morfossint´actica e para al´em disso cont´em informa¸c˜ao sobre os tra¸cos do verbo, neste caso indica que o verbo se encontra na forma temporal do ger´undio. Como tal, o tra¸co referentes a esta entrada ser´a ger.
A etiqueta V n˜ao tem qualquer informa¸c˜ao sobre os tra¸cos verbais. No entanto tamb´em n˜ao interfere na classifica¸c˜ao. N˜ao sobrespecifica nem subespecifica a classe. Por uma quest˜ao de comodidade, vamos manter a etiqueta no tra¸co, sendo este v#pi-1s.
4
Estas contagens j´a incluem as formas com cl´ıticos.
5
Para todos os verbos, e n˜ao apenas para os que no nosso caso foram etiquetados com certas etiquetas
6
O etiquetador ser´a usado tamb´em para determinar outras classes abertas para efeito de se delimitar o contexto a usar nos classificadores.