Applying Fuzzy ID3 Decision Tree for Software Effort Estimation
Texto
Imagem
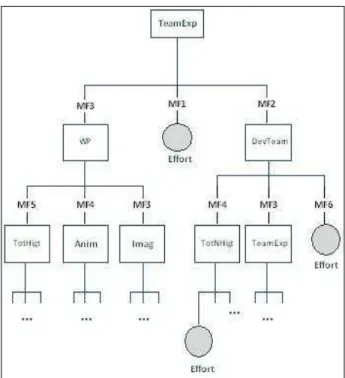

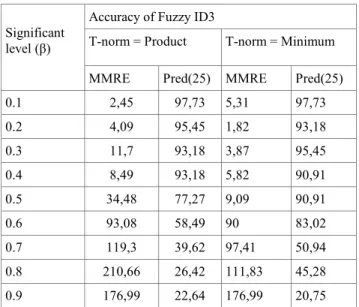
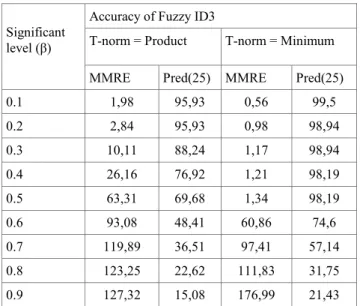
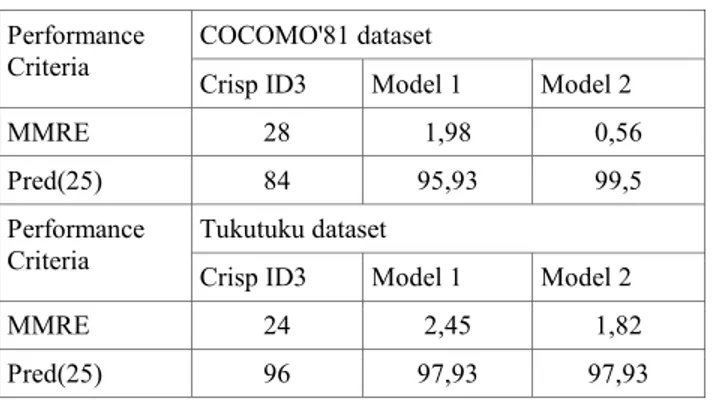
Documentos relacionados
The Genetic Fuzzy Rule Based System set the parameters of input and output variables of the Fuzzy Inference System model in order to increase the prediction accuracy of
Like this, the hydrodynamic fuzzy equation will produce a fuzzy flow field with its membership function calculated by the solution of the fuzzy
Then by using a two-stage multiple-criteria decision making (MCDM) model containing hierarchical Fuzzy Analytical Hierarchal Process (Fuzzy AHP) and TOPSIS methods the data was
Using the Fuzzy Logic-Based Model to Assess Diagnosic Accuracy (1) , which applies fuzzy maximum-minimum composiion, the sotware presents new relaionship values for the NDx
In this study, we propose a new fuzzy TOPSIS decision making model using entropy weight for dealing with multiple criteria decision making (MCDM) problems under intuitionistic fuzzy
We introduced the motion of fuzzy strings of input symbols, where the fuzzy strings from free fuzzy submonoids of the free monoids of input strings.. We show that fuzzy automata
The negotiation model includes negotiating a decision function and uses fuzzy theory and Analytical Hierarchy Process to obtain the product utility.. After that, apply the
The fuzzy AHP model applies the modified fuzzy Logarithmic Least Squares Method (LLSM) in this software criteria models.. The proposed model can help the
