Faculdade de Ciˆencias
Departamento de Inform´atica
MARCAC
¸ ˜
AO SEM ˆ
ANTICA DE P ´
AGINAS WEB
APOIADA POR PARSERS DE DEPEND ˆ
ENCIAS
GRAMATICAIS
R ´uben Alberto Mendes Sim˜oes dos Reis
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializac¸˜ao em Sistemas de Informac¸˜ao
Faculdade de Ciˆencias
Departamento de Inform´atica
MARCAC
¸ ˜
AO SEM ˆ
ANTICA DE P ´
AGINAS WEB
APOIADA POR PARSERS DE DEPEND ˆ
ENCIAS
GRAMATICAIS
R ´uben Alberto Mendes Sim˜oes dos Reis
DISSERTAC
¸ ˜
AO
Projecto orientado pelo Prof. Doutor Ant´onio Horta Branco
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializac¸˜ao em Sistemas de Informac¸˜ao
Gostaria de agradecer aos meus pais Lu´ıs Reis e Ana Sim˜oes, aos meus av´os maternos Lu´ıs Lopes e L´ıcia Mendes, `a minha namorada M´onica Magalh˜aes, ao meu cachorro Nilo, aos meus amigos Ant´onio, Freire, David, Serra, S´ergio, F´abio, Marcos, Ricardo, Coelho, `a malta das quintas-feiras de Futebol e claro, aos elementos do Grupo NLX Jo˜ao Silva, Roda Del G´audio, Francisco Costa, Sara Silveira, S´ılvia Pereira, Marcus Guelpeli, Clara Pinto, Catarina Carvalheiro, S´ergio Castro e Patr´ıcia Gonc¸alves por todo o apoio e ajuda que me deram ao longo deste trabalho.
Gostaria tamb´em de agradecer ao meu professor orientador Ant´onio Horta Branco por toda a paciˆencia e ajuda, e `a Fundac¸˜ao da Ciˆencia e Tecnologia pelo financiamento deste trabalho.
O meu sincero Obrigado a todos iii
Com o crescimento exponencial da informac¸˜ao na Web, torna-se necess´ario cada vez mais que o acesso `a informac¸˜ao n˜ao s´o seja r´apido, como eficiente. A procura por informac¸˜ao atrav´es da ocorrˆencia de palavras-chave ´e o m´etodo usado pelos motores de busca na web mais conhecidos. Contudo a busca por informac¸˜ao na Web pode ser opti-mizada usando uma representac¸˜ao semˆantica da informac¸˜ao pela qual se procura.
Este trabalho apresenta o desenvolvimento de uma ferramenta para a anotac¸˜ao semˆantica de p´aginas Web escritas em Portuguˆes, apoiada por Analisadores de Dependˆencias Gra-maticais. Essa ferramenta recebeu o nome de Marcador Semˆantico e tem a capaci-dade de atribuir uma representac¸˜ao semˆantica a frases inseridas num texto e deixar essa representac¸˜ao semˆantica registada na linguagem de marcac¸˜ao RDF/XML.
Neste trabalho, tamb´em ´e documentado uma ferramenta Web, adicionada ao repo-sit´orio de ferramentas on-line do grupo NLX, da Faculdade de Ciˆencias Universidade de Lisboa. Esta ferramenta, chamada de LX Dep Parser, ´e uma Analisador de De-pendˆencias Gramaticais e tem a finalidade de devolver ao utilizador uma representac¸˜ao das dependˆencias gramaticais entre as palavras da frase.
Palavras-chave: Semˆantica, Parser, Dependˆencias, RDF/XML, NLX v
With the exponential growth of the information in the Web, it becomes increasingly necessary that access to information be not only fast, but efficient. The search for in-formation by means of the occurrences of keywords is the method used by Web search engines. However, the search for information on the Web can be optimized using a se-mantic representation of the information that is being sought.
The present work presents a tool for semantic annotation of Web pages written in Portuguese, supported by Dependency Parsers. This tool, named Marcador Semˆantico, has the ability to provide a semantic representation for a number of sentences ocurring in a text, and encode the semantic representation of these sentences in the markup lan-guage RDF/XML. This work also presents a web tool, added to the repository of online tools of the NLX group, the Faculty of Sciences, University of Lisbon. This tool, called LX Dep Parser, is a Grammatical Dependency Parser and aims at returning to the user a representation of grammatical dependencies among the words of the input sentence.
Keywords: Semantic, Parser, Dependency, RDF/XML, NLX vii
Lista de Figuras xiii Lista de Tabelas xv 1 Introduc¸˜ao 1 1.1 Motivac¸˜ao . . . 1 1.2 Contribuic¸˜ao . . . 1 1.3 Estrutura do documento . . . 2 1.4 Parsing de Dependˆencias . . . 2 1.5 Formato CoNLL . . . 4 1.6 Projectividade . . . 7 1.7 Relac¸˜oes Semˆanticas . . . 8
1.7.1 Etiquetas Gramaticais versus Etiquetas Semˆanticas . . . 13
1.8 Considerac¸˜oes Finais . . . 16
2 Selecc¸˜ao do Parser de Dependˆencias 17 2.1 Introduc¸˜ao . . . 17
2.2 Malt Eval . . . 18
2.3 ISBN Dependency Parser . . . 19
2.3.1 Execuc¸˜ao . . . 22
2.3.2 Avaliac¸˜ao . . . 25
2.4 KSDEP / LRDEP . . . 25
2.4.1 Execuc¸˜ao . . . 28
2.4.2 Avaliac¸˜ao . . . 29
2.5 DeSR Dependency Parser . . . 29
2.5.1 Execuc¸˜ao . . . 32 2.5.2 Avaliac¸˜ao . . . 32 2.6 MST Parser . . . 33 2.6.1 Execuc¸˜ao . . . 37 2.6.2 Avaliac¸˜ao . . . 38 2.7 Malt Parser . . . 39 ix
2.8 Considerac¸˜oes Finais . . . 46 3 LX Parser de Dependˆencias 49 3.1 Introduc¸˜ao . . . 49 3.2 Funcionamento . . . 51 3.2.1 Servidor Local . . . 53 3.2.2 Pipeline . . . 55 3.3 Considerac¸˜oes Finais . . . 57 4 Marcador Semˆantico 59 4.1 Introduc¸˜ao . . . 59
4.1.1 Resource Description Framework . . . 61
4.1.2 Corpus . . . 63 4.2 Representac¸˜ao Semˆantica . . . 64 4.3 Funcionamento . . . 67 4.3.1 LX-Suite . . . 67 4.3.2 Pipeline . . . 67 4.3.3 Etiquetador . . . 69 4.3.4 RDF/XML Writer . . . 75 4.4 Considerac¸˜oes Finais . . . 84 5 Conclus˜ao 85 5.1 Coment´arios Finais . . . 85 5.2 Trabalho Futuro . . . 87 A Triplos de algumas Frases do Corpus de Dependˆencias 89
B Documento RDF/XML 103
Bibliografia 133
1.1 Anotac¸˜ao dos relac¸˜oes semˆanticas das palavras na frase: “O Jo˜ao
com-prou uma carroc¸a.” . . . 3
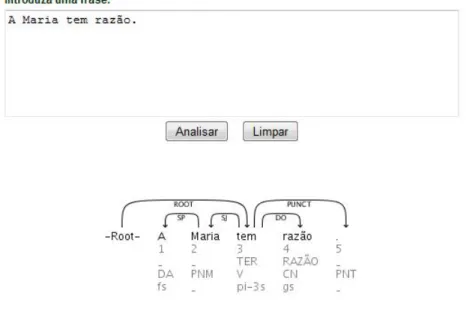
1.2 Ilustrac¸˜ao do grafo de dependˆencias da frase: “A Maria tem raz˜ao.” . . . . 6
1.3 Anotac¸˜ao retirada do corpos TuBa-D/Z treebank. Traduc¸˜ao: “Para esta alegac¸˜ao, Beckmeyer n˜ao forneceu nenhuma prova.” . . . 8
1.4 Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase: “O Jo˜ao com-prou uma carroc¸a.” . . . 11
1.5 Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase na voz activa: “O c˜ao perseguiu o Jo˜ao.” . . . 14
1.6 Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase na voz passiva: “O Jo˜ao foi perseguido pelo c˜ao.” . . . 14
1.7 Anotac¸˜ao dos pap´eis semˆanticas das palavras na frase na voz activa: “O c˜ao perseguiu o Jo˜ao.” . . . 15
1.8 Anotac¸˜ao dos pap´eis semˆanticas das palavras na frase na voz passiva: “O Jo˜ao foi perseguido pelo c˜ao.” . . . 15
3.1 A interface da ferramenta Web LX Dep Parser . . . 50
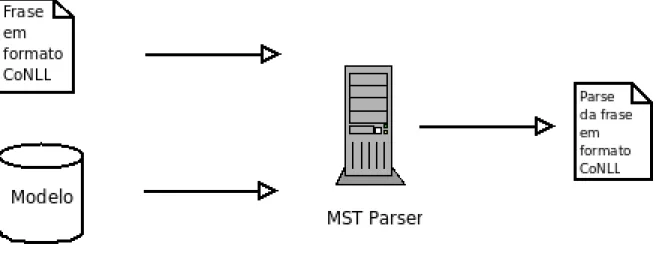
3.2 Diagrama do funcionamento do MST Parser . . . 51
3.3 Diagrama da ferramenta Web LX Dep Parser . . . 52
4.1 Um exemplo de um triplo em RDF que convencionalmente ´e definido pela ordem: sujeito, predicado, objecto. . . 62
4.2 Exemplo de uma etiqueta semˆantica M-LOC e ARG0 . . . 64
4.3 Frase com uma conjunc¸˜ao coordenativa . . . 66
4.4 Diagrama da ferramenta Marcador Semˆantico . . . 68
4.5 Exemplo de relac¸˜ao semˆantica de modificador de Modo. . . 71
4.6 Exemplo de uma relac¸˜ao de dependˆencia gramatical de predicado. . . 72
4.7 Exemplo de uma conjunc¸˜ao coordenativa. . . 72
4.8 Exemplo da relac¸˜ao semˆantica “ARG1”. . . 72
4.9 Exemplo da relac¸˜ao semˆantica “ARG0”. . . 72
4.10 Grafo RDF/XML que define a camisola azul de tamanho 38. . . 76
4.11 Grafo RDF/XML da frase: “A Maria tem raz˜ao.” . . . 82 xiii
1.1 Formato CoNLL 2006 . . . 5 1.2 Grafo de dependˆencias em formato CoNLL 2006, da frase: “A Maria tem
raz˜ao.” . . . 6 1.3 Tabela com as etiquetas gramaticais presentes no corpus de dependˆencias
do Grupo NLX. . . 11 1.4 Tabela com as etiquetas semˆanticas presentes no corpus de dependˆencias
do Grupo NLX. . . 14
Introduc¸˜ao
1.1
Motivac¸˜ao
As exigˆencias na procura de informac¸˜ao tornam-se cada vez maiores num mundo em que essa informac¸˜ao est´a em constante crescimento. A representac¸˜ao semˆantica da informac¸˜ao presente na Web ´e poss´ıvel e torna-se cada vez mais necess´ario pois com o r´apido cresci-mento dessa informac¸˜ao, passa a existir uma necessidade do ser humano em ter um acesso eficiente `a informac¸˜ao que procura.
Na ´area do Processamento da Linguagem Natural, para que seja poss´ıvel trabalhar com a semˆantica de um texto, ´e necess´ario uma representac¸˜ao semˆantica desse mesmo texto de modo a que seja poss´ıvel efectuar algum tipo de processamento sobre esse tipo de informac¸˜ao.
Nos ´ultimos anos tˆem merecido um acrescido interesse, modelos de parsing dos quais resultem estruturas de informac¸˜ao que representem a semˆantica de textos escritos numa linguagem natural. Este interesse ´e facilmente justificado dado que a criac¸˜ao destas es-truturas de informac¸˜ao que contˆem a representac¸˜ao semˆantica de um dado texto apresenta uma boa eficiˆencia em termos de complexidade computacional e tamb´em em termos de taxa de acerto.
Assim sendo, a estrutura que cont´em a representac¸˜ao semˆantica de um dado texto ser´a a chave que tornar´a poss´ıvel melhorar os dispositivos de busca de informac¸˜ao na Web.
1.2
Contribuic¸˜ao
Esta dissertac¸˜ao documenta um projecto de Engenharia Inform´atica do Mestrado em En-genharia Inform´atica do Departamento de Inform´atica da FCUL,1, realizou uma ferra-menta capaz de obter uma estrutura de informac¸˜ao semˆantica a partir de um dado texto na L´ıngua Portuguesa, e efectuar a extracc¸˜ao da representac¸˜ao semˆantica a partir da es-trutura de informac¸˜ao semˆantica desse mesmo texto. Essa ferramenta foi denominada de
1Faculdade de Ciˆencias Universidade de Lisboa
Marcador Semˆantico.
Para ser poss´ıvel gerar uma representac¸˜ao semˆantica de um dado texto, utilizei um tipo de ferramenta chamada de analisador (parser) de dependˆencias. A estrutura de informac¸˜ao criada pelo parser de dependˆencias para cada frase do texto ´e tamb´em conhecida por grafo de dependˆencias, onde cada palavra se relaciona com outra palavra atrav´es de uma func¸˜ao gramatical ou semˆantica.
Esse tipo de relac¸˜oes gramaticais e/ou semˆanticas entre as palavras de uma frase, ser˜ao registados na linguagem RDF/XML, com a finalidade de motores de busca ou agentes artificiais poderem analisar, comparar e processar este tipo de informac¸˜ao. Uma vez que interessa registar a relac¸˜ao semˆantica entre duas palavras, a linguagem RDF/XML ser´a utilizada, pois sendo que esta linguagem ´e orientada a triplos (triplos esses que s˜ao constituidos por: Sujeito, Predicado, Objecto) iremos querer registar duas palavras (que correspondem ao Sujeito e Objecto do triplo), com uma relac¸˜ao “Predicado”.
A ferramenta Marcador Semˆantico, capaz de registar a representac¸˜ao semˆantica de um texto, constitui uma inovac¸˜ao dentro da ´area que ´e o Processamento da Linguagem Natural uma vez que este tipo de ferramentas ´e inexistente.
´
E importante referir que o contributo para o reposit´orio de ferramentas Web do Grupo NLX, foi efectuado com mais uma ferramenta chamada de LX Dep Parser, que possui o objectivo de devolver um grafo de dependˆencias para uma dada frase inserida por um utilizador.
1.3
Estrutura do documento
Este documento est´a estruturado da seguinte forma:
• Cap´ıtulo 1 - Para al´em da “Motivac¸˜ao” e “Contribuic¸˜ao”, neste cap´ıtulo ser´a abor-dado o conceito de parser de dependˆencias bem como um dos formatos (CoNLL) que este tipo de ferramentas utiliza, assim como o conceito de projectividade que pode surgir ou n˜ao, nos grafos de dependˆencias.
• Cap´ıtulo 2 - Neste cap´ıtulo, ser˜ao descritos os parsers de dependˆencias dispon´ıveis e qual o parser escolhido para concretizar a ferramenta Marcador Semˆantico e LX Dep Parser.
• Cap´ıtulo 3 - Neste cap´ıtulo ser´a descrita a ferramenta LX Dep Parser.
• Cap´ıtulo 4 - Ser´a explicada neste cap´ıtulo, a ferramenta Marcador Semˆantico.
1.4
Parsing de Dependˆencias
Um parser de dependˆencias ´e uma ferramenta que recebe como input um ficheiro de texto escrito numa linguagem natural, e devolve um grafo de dependˆencias que cont´em as
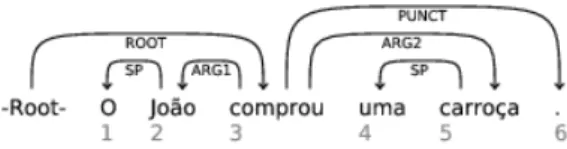
Figura 1.1: Anotac¸˜ao dos relac¸˜oes semˆanticas das palavras na frase: “O Jo˜ao comprou uma carroc¸a.”
func¸˜oes gramaticais entre as palavras das frases desse texto.
Atrav´es de um modelo produzido pelo treino, com um corpus de frases e suas estru-turas de dependˆencias, o parser de dependˆencias procede `a tarefa de parsing sobre o texto dado como input. O resultado b´asico consiste em calcular arcos de dependˆencias entre pa-res de palavras e pa-respectivas etiquetas gram´aticas. Os arcos de dependˆencias e pa-respectivas etiquetas gram´aticas e/ou semˆanticas constituir˜ao o grafo de dependˆencias gramaticais da frase em quest˜ao.
Segundo [8], as gram´aticas e teorias de gram´aticas podem ser classificadas de acordo com a unidade b´asica da estrutura da frase que consideram: o sintagma (“Phrase Structure Grammar”) ou a dependˆencia gramatical entre duas palavras (“Dependency Grammar”). Os parsers de Gram´aticas Sintagm´aticas devolvem uma estrutura baseada nos constituin-tes da respectiva frase de entrada, enquanto que um parser de dependˆencias devolve as func¸˜oes gramaticais e/ou semˆanticas entre palavras dessa frase, na forma de um grafo de dependˆencias:
Na Figura 1.1, pode ser observado o resultado de uma frase analisada atrav´es de um parser de dependˆencias, em que as relac¸˜oes entre as palavras (arcos de dependˆencias) s˜ao:
• “O” ´e especificador de Jo˜ao (Specifier - SP).
• “Jo˜ao” ´e o primeiro argumento do verbo comprou (Argument 1 - ARG1). • “comprou” ´e o n´ucleo da frase (Root - ROOT).
• “uma” ´e o especificador de carroc¸a (Specifier - SP).
• “carroc¸a” ´e o segundo argumento do verbo comprou (Argument 2 - ARG2). • “.” ´e a pontuac¸˜ao final da frase (Punctuation - PUNCT).
Este grafo de dependˆencias pode ser visto como uma ´arvore de dependˆencias em que o n´ucleo (palavra de onde sai o arco de dependˆencia) possui um ou mais filhos (palavras para onde o arco de dependˆencia aponta).
Este tipo de grafos, para representarem uma estrutura de dependˆencias dever˜ao sempre ser bem formados. Um grafo de dependˆencias ´e bem formado se e s´o se:
• Se o grafo for ligado, ou seja, se a partir do n´ucleo da frase ´e poss´ıvel chegar a todos os restantes n´os (palavras).
• Todo o n´o, excepto a raiz, tiver um n´o “pai”. • O grafo for ac´ıclico.
Os parsers de dependˆencias recebem frases de texto como input. A estas frases, dever´a estar agregada informac¸˜ao morfo-sint´actica para auxiliar o parser de dependˆencias nas suas decis˜oes de parsing, de modo a constituir o grafo de dependˆencias de uma dada frase.
Na pr´oxima secc¸˜ao explicar-se-´a um formato generalizado para codificar estruturas de dependˆencias gramaticais, usado por este tipo de ferramentas.
1.5
Formato CoNLL
Os parsers de dependˆencias gramaticais efectuam a tarefa de parsing que consiste em cal-cular os grafos de dependˆencias de cada frase fornecida no input, podendo esse mesmo input estar em v´arios formatos. No entanto existe um formato em particular que foi gene-ralizado para este tipo de ferramentas, chamado de CoNLL. CoNLL (Conference on Na-tural Language Learning)2 ´e uma conferˆencia que se realiza anualmente onde se abordam v´arios t´opicos relacionados com a aprendizagem autom´atica aplicada ao Processamento em Linguagem Natural.
Esta conferˆencia tem vindo a decorrer ao longo dos anos, desde 1997, tendo a ´ultima conferˆencia ocorrido em Fevereiro de 2009. A Conferˆencia de 2010 est´a marcada para dias 15 e 16 de Julho, a decorrer em Uppsala, na Su´ecia.
Esta conferˆencia est´a classificada como a d´ecima-s´etima mais importante,3na ´area da Inteligˆencia Artificial. Com o decorrer das v´arias edic¸˜oes desta conferˆencia, um dos temas que foi sendo definido foi a concepc¸˜ao de analisadores de dependˆencias para que fosse poss´ıvel a an´alise de dependˆencias gramaticais e respectiva etiquetac¸˜ao de uma frase.
Como tal, foi definido um formato de input para os analisadores de dependˆencias gramaticais desta conferˆencia, em que o ficheiro de input cont´em: frases separadas por uma linha em branco, cada palavra ou s´ımbolo (por exemplo pontuac¸˜ao) da frase numa linha sendo que cada linha cont´em dez colunas, separadas por uma espac¸amento tabular (Tab). O formato CoNLL 2006 ´e explicado com o aux´ılio da Tabela 1.1.
Em termos pr´aticos, tomando em conta a seguinte frase: A Maria tem raz˜ao.
2
http://ifarm.nl/signll/conll/
3http://www.cs-conference-ranking.org/conferencerankings/topicsii.
N´umero do Campo: Nome de Campo: Descric¸˜ao:
1 ID Contador de palavras, de acordo com a sua or-dem (da esquerda para a direita) de ocorrˆencia na frase. Comec¸a com o valor 1 para cada nova frase.
2 Form Forma da palavra ou s´ımbolo de pontuac¸˜ao. 3 Lemma Lema da palavra, ou uma sublinha se n˜ao
esti-ver dispon´ıvel.
4 CPOSTAG Etiqueta morfo-sint´actica de alta granulari-dade, em que o conjunto de etiquetas depende da linguagem natural em quest˜ao.
5 POSTAG Etiqueta morfo-sint´actica de baixa granulari-dade, em que o conjunto de etiquetas depende da linguagem natural em quest˜ao. Se n˜ao estiver dispon´ıvel, ´e dada a etiqueta morfo– sint´actica de alta granularidade.
6 FEATS Conjunto n˜ao organizado de caracter´ısticas sint´acticas e/ou morfol´ogicas (dependendo da linguagem natural) separadas por uma barra vertical (—), ou uma sublinha se n˜ao estiver dispon´ıvel.
7 HEAD Head (n´ucleo) do s´ımbolo corrente, que ´e iden-tificado por um inteiro. De referir que depen-dendo da anotac¸˜ao original do treebank, po-der´a haver v´arios s´ımbolos com um ID igual a zero.
8 DEPREL Relac¸˜ao de dependˆencia com a Head. O con-junto de dependˆencias depende da linguagem natural em quest˜ao. De referir que dependendo da anotac¸˜ao original do treebank, a relac¸˜ao de dependˆencia pode ser uma etiqueta atribu´ıda, proveniente da anotac¸˜ao original do treebank, ou ser simplesmente ’ROOT’.
9 PHEAD Head (n´ucleo) projectiva do s´ımbolo corrente, que ou ´e representado por um inteiro (zero clu´ıdo), ou por uma sublinha, se estiver in-dispon´ıvel. De notar que ao depender da anotac¸˜ao original do treebank, poder´a existir v´arios s´ımbolos com um ID de 0. A estrutura de dependˆencia resultante da coluna PHEAD, ´e projectiva (embora tal caracter´ıstica n˜ao es-teja dispon´ıvel em todas as l´ınguas).
10 PDEPREL A relac¸˜ao de dependˆencia da PHEAD, ou uma sublinha se n˜ao estiver dispon´ıvel. O con-junto de relac¸˜oes de dependˆencias depende, da l´ıngua em quest˜ao. De notar que se depen-der da anotac¸˜ao do treebank original, a relac¸˜ao de dependˆencia pode conter algum significado, ou ent˜ao ser representado por ’ROOT’
1 A DA DA fs 2 SP 2 Maria PNM PNM 3 ARG1 3 tem TER V V 0 ROOT 4 raz˜ao RAZ ˜AO CN CN gs 3 ARG2 5 . PNT PNT 3 PUNCT
Tabela 1.2: Grafo de dependˆencias em formato CoNLL 2006, da frase: “A Maria tem raz˜ao.”
Figura 1.2: Ilustrac¸˜ao do grafo de dependˆencias da frase: “A Maria tem raz˜ao.” No formato CoNLL 2006, o grafo de dependˆencias desta frase (com os arcos de de-pendˆencia e respectivas etiquetas gramaticais atribu´ıdas) ficaria como est´a mostrado na Tabela 1.2. A descric¸˜ao do conte´udo de cada coluna encontra-se na Tabela 1.1.
Em que a ilustrac¸˜ao do grafo de dependˆencias com base na frase acima em formato CoNLL 2006 ficaria de acordo com a Figura 1.2.
Uma vez que s´o s˜ao utilizadas etiquetas morfo-sint´acticas de granularidade fina no corpus de dependˆencias do NLX que us´amos para este trabalho, ´e colocada a mesma etiqueta morfo-sint´actica de uma palavra nos campos quatro e cinco.
Ser´a este o formato do corpus de dependˆencias com etiquetas gramaticais e semˆanticas que ser´a usado para treinar o parser de dependˆencias, por forma a que o parser devolva um grafo de dependˆencias, para que seja poss´ıvel proceder a uma extracc¸˜ao da representac¸˜ao semˆantica de uma frase (consequentemente de um texto) e para que posteriormente se registe essa mesma representac¸˜ao semˆantica do texto, em linguagem RDF/XML.
´
E importante referir que as colunas ID, FORM, CPOSTAG, POSTAG, HEAD e DE-REL devem conter valores significativos em vez de, por exemplo, sub-linha, aquando do treino dos parsers de dependˆencias gramaticais.
Tamb´em importa referir que os ´ultimos dois campos, se referem `a projectividade de uma frase. A finalidade destas colunas seria a de serem preenchidas pelo parser de de-pendˆencias em quest˜ao, na tarefa de parsing, caso a frase a ser analisada fosse projectiva. Contudo, n˜ao foi verificado o preenchimento destas duas colunas ap´os a tarefa de par-sing, utilizando os parsers de dependˆencias gramaticais analisados no Cap´ıtulo dois. Uma vez que estas duas colunas n˜ao apresentam quaisquer tipo de contributo para a tarefa de parsing dos parsers de dependˆencias gramaticais, os corpus de treino em formato CoNLL 2006 ter˜ao estas duas colunas preenchidas com uma sub-linha.
As duas colunas ”PHEAD“ e ”PDEPREL“, referem-se `a projectividade de uma frase, como anteriormente referido. Como tal, passaremos ent˜ao a explicar o conceito de ”pro-jectividade“ na pr´oxima secc¸˜ao.
1.6
Projectividade
Um grafo de dependˆencias de uma frase ´e uma representac¸˜ao lingu´ıstica adoptada por um grande n´umero de teorias de gram´atica e formalismos lingu´ısticos, que partilham um n´umero de pressupostos sobre estruturas sint´acticas. Um grafo de dependˆencias ´e constitu´ıdo por n´os lexicais, em que cada n´o ´e dependente de um outro n´o (excepto se for a raiz). Um grafo/´arvore de dependˆencias deve ser segundo [14]:
• Ac´ıclico • Conectado • Projectivo
Existem v´arias definic¸˜oes de projectividade, mas uma vez que todas elas s˜ao equivalentes, passei a utilizar a definic¸˜ao de [14], definindo a projectividade em termos de adjacˆencia (ou seja em termos da posic¸˜ao relativa entre as palavras, de uma dada frase).
• Um grafo de dependˆencias ´e projectivo se e s´o se cada n´o dependente (palavra) for adjacente ao seu n´ucleo (Head).
• Dois n´os (palavras) n e n0
s˜ao adjacentes no grafo se e s´o se todo o n´o n00que ocorre no grafo entre n e n0, for “dominado” por n ou por n0. Este dom´ınio entende-se por exemplo, como o caso em que um n´o m ocorra entre n e n0, mas que o seu n´ucleo seja n00. Se n00 tiver como n´ucleo n ou n0, ent˜ao considera-se que m ´e dominado por n ou n0, o que significa que existe projectividade no grafo de dependˆencias em quest˜ao.
Exemplos de frases n˜ao projectivas podem ser encontradas facilmente na l´ıngua alem˜a. Na Figura 1.3 podemos observar um exemplo de uma frase “n˜ao projectiva”, escrita na l´ıngua alem˜a.
Analisando o arco de dependˆencia na Figura 1.3, que envolve os n´os 1 (“Fur”) e 8 (“Na-chweis”), podemos observar que o n´o 6 (“bisher”) que se encontra dentro do arco de dependˆencia formado entre o n´os 1 e 8. No entanto, o n´o 6 depende do n´o 9 (“geliefert”). N´o este (9 - “geliefert”) que est´a fora do arco de dependˆencia formado pelos n´os 1 e 8. O que de acordo com a definic¸˜ao de projectividade escrita anteriormente, torna esta frase n˜ao projectiva (que em caso geral se caracteriza por existir nos grafos de dependˆencias, cruzamento entre os arcos). Para finalizar, realizei uma experiˆencia para verificar a eficiˆencia
Figura 1.3: Anotac¸˜ao retirada do corpos TuBa-D/Z treebank. Traduc¸˜ao: “Para esta alegac¸˜ao, Beckmeyer n˜ao forneceu nenhuma prova.”
de algoritmos de parsing projectivos ([14], [19]) sobre grafos de dependˆencias projecti-vos. Para tal, foram exclu´ıdas as frases n˜ao projectivas do corpus de dependˆencias do NLX (cento e quatorze frases n˜ao projectivas), e utilizou-se um algoritmo projectivo de parsing e um algoritmo n˜ao projectivo de parsing:
• Com o parser de dependˆencias MST, foi verificado que (correndo o parser com as definic¸˜oes por omiss˜ao) num teste “Ten Fold Cross Validation”, com o algoritmo de parsing n˜ao projectivo foi obtido o valor de 0.8909 para a m´etrica LAS, decorridos 3106 segundos de treino e parsing da ferramenta, enquanto que com o algoritmo projectivo foi obtido o valor de 0.8922 para a m´etrica LAS, decorridos 2769 segun-dos de treino e parsing da ferramenta.
• Com o parser de dependˆencias Malt, foi verificado que (correndo o parser com as definic¸˜oes por omiss˜ao) num teste “Ten Fold Cross Validation” com o algoritmo n˜ao projectivo “Convigton Non Projective” foi obtido o valor de 0.8871 para a m´etrica LAS, decorridos 533 segundos de treino e parsing da ferramenta, enquanto que com o algoritmo projectivo “Nivre - arc standard” foi obtido o valor de 0.8902 para a m´etrica LAS, decorridos 238 segundos de treino e parsing da ferramenta.
(Nota: o tipo de teste “Ten Fold Cross Validation”, a m´etrica de avaliac¸˜ao LAS, MST Parser e Malt Parser ser˜ao conceitos devidamente explicados, no Cap´ıtulo 2.)
1.7
Relac¸˜oes Semˆanticas
Como referido, para que seja poss´ıvel construir o Marcador Semˆantico a fim de se extrair a representac¸˜ao semˆantica de um dado texto (e posteriormente registar a semˆantica das p´aginas web escritas na L´ıngua Portuguesa em linguagem RDF/XML) ser´a necess´ario um parser de dependˆencias atrav´es do qual se obt´em o grafo de dependˆencias, para cada frase de um dado texto.
Este grafo de dependˆencias ter´a de ter definidos os arcos de dependˆencias, bem como as respectivas etiquetas gramaticais e semˆanticas, entre as palavras de uma frase. Para que os grafos de dependˆencias (parse final de uma dada frase) contenham principalmente as relac¸˜oes semˆanticas entre as palavras, ´e necess´ario que o corpus usado para treinar o
parser de dependˆencias contenha os arcos de dependˆencias definidos com as respectivas etiquetas semˆanticas.
A diferenc¸a entre as etiquetas gramaticais e as etiquetas semˆanticas est´a no tipo de relac¸˜ao que se estabelece entre as palavras dentro de uma frase, sendo que as etiquetas gramaticais expressam relac¸˜oes gramaticais entre os constituinte de uma frase.
O termo “relac¸˜ao gramatical” ´e um conceito que tem definic¸˜oes um pouco variadas, mas bastante semelhantes.
Para um futuro esclarecimento, segundo [10], uma orac¸˜ao (como por exemplo, uma frase simples: “O Jo˜ao comprou uma carroc¸a.”) cont´em dois termos importantes: o Predicado (“comprou uma carroc¸a.”), que ´e uma sequˆencia de constituintes formado por um predi-cador e respectivo(s) argumento(s), ou constituinte(s), interno(s); e o Sujeito (“O Jo˜ao”) que se relaciona directamente com o Predicado.
Segundo [1], o termo relac¸˜ao gramatical refere-se `as propriedades morfo-sint´acticas que relacionam um argumento com uma orac¸˜ao, como por exemplo, o Sujeito ou Objecto Directo. Termos alternativos como ”func¸˜ao sint´actica“, ou ”papel sint´actico“ podem ser usados evidenciando o facto que as relac¸˜oes gramaticais s˜ao definidas pela forma como argumentos (constituintes) est˜ao integrados sintacticamente numa orac¸˜ao, por exemplo, funcionando como Sujeito, Objecto Directo, etc. Seja qual for a terminologia, o conceito de ”relac¸˜ao gramatical“ mant´em-se.
Uma definic¸˜ao semelhante ´e apresentada por [6], que defende que os constituintes de uma combinac¸˜ao de palavras desempenham certas func¸˜oes sint´acticas na frase a que pertencem.
Assim, numa orac¸˜ao (ou frase simples), o SV (Sintagma Verbal - a express˜ao que tem como constituinte central o verbo e que denota uma propriedade ou relac¸˜ao, dinˆamica ou n˜ao dinˆamica) tem a func¸˜ao sint´actica de predicado e o SN ou a F constituinte imediato da frase (Sintagma Nominal ou Frase - a express˜ao nominal/fr´asica a que ´e atribu´ıdo tal predicado), tem a relac¸˜ao gramatical de sujeito.
Outra definic¸˜ao de ”relac¸˜ao gramatical“, segundo [10], considerando as seguintes fra-ses:
• (a) O jornalista contou as novidades aos amigos. • (b) A novidade aos amigos o jornalista contou.
(1a) ´e uma frase b´asica do portuguˆes que pode caracterizar-se sintacticamente, numa primeira abordagem, como uma sequˆencia em que:
• cada constituinte tem uma dada relac¸˜ao gramatical; • os constituintes ocorrem segundo uma dada ordem linear.
Esta caracterizac¸˜ao sint´actica reporta-se `a forma final das frases. Em l´ınguas como o portuguˆes, a relac¸˜ao gramatical dos constituintes ´e o principal factor que determina a ordem da sua ocorrˆencia.
Passemos ent˜ao a descrever as relac¸˜oes gramaticais, segundo [10], referidas anterior-mente, bem como outras relac¸˜oes gramaticais: Objecto Directo e Complemento Obl´ıquo, para um melhor entendimento das relac¸˜oes gramaticais entre constituintes, numa dada frase:
• Sujeito - Trata-se da relac¸˜ao gramatical central a que ´e dada maior proeminˆencia sint´actica, em frases b´asicas como a frase na Figura 1.4.
Tipicamente realiza-se fora do predicado, sendo, no entanto, determinado pelo verbo.
Deste modo, o constituinte da frase na Figura 1.4) “O Jo˜ao” ´e o sujeito gramatical da frase.
• Predicado - De um modo geral, uma orac¸˜ao consiste numa frase simples em que (considerando a frase da Figura 1.4) o predicado cont´em pelo menos um elemento verbal. Assim na frase: “O Jo˜ao comprou uma carroc¸a” o Predicado “comprou uma carroc¸a.” ´e constitu´ıdo por um verbo (“comprou”) e por um argumento interno (“uma carroc¸a”).
Um predicado para al´em de ser constitu´ıdo por um verbo, pode tamb´em ser cons-titu´ıdo por:
– Objecto Directo - Tˆem esta relac¸˜ao gramatical os argumentos internos direc-tos de verbos (de dois ou trˆes lugares como, por exemplo, os verbos “dar”, “oferecer”). Como tal, podemos observar na frase da Figura 1.4, a relac¸˜ao de Objecto Directoque envolve “uma carroc¸a” ´e atribu´ıda pelo verbo “comprou”. – Objecto Indirecto - O constituinte que tem esta relac¸˜ao gramatical ´e tipica-mente argumento interno do verbo (de dois ou trˆes lugares como, por exemplo, os verbos “dar”, “oferecer”). Considerando a seguinte frase: “O Jo˜ao ofere-ceu um CD ao Pedro.“, podemos ver que o constituinte ”ao Pedro“ ´e o Objecto Indirectoda frase.
– Complemento Obl´ıquo - As relac¸˜oes gramaticais que se estabelecem com o verbo atrav´es do aux´ılio de preposic¸˜oes (por exemplo, ”na“, ”com“, ”em“), s˜ao chamadas de “obl´ıquas”. Veja-se por exemplo a frase: “O Jo˜ao pˆos o livro na estante”. O Complemento Obl´ıquo da frase requisitado pelo verbo ´e “na estante”.
– Modificador - Um modificador ´e um constituinte cuja presenc¸a na frase n˜ao ´e obrigat´oria, ou seja, n˜ao ´e exigido por nenhum outro constituinte, mas que estando presente na frase pode modificar verbos, nomes (por exemplo), ou at´e
Etiqueta gramatical Significado C Complemento DO Objecto Directo IO Objecto Indirecto M Modificador
N Relac¸˜ao de palavras de nome pr´oprio OBL Complemento Obl´ıquo
PRD Predicador SJ Sujeito SP Especificador COORD Coordenac¸˜ao PUNCT Pontuac¸˜ao
Tabela 1.3: Tabela com as etiquetas gramaticais presentes no corpus de dependˆencias do Grupo NLX.
Figura 1.4: Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase: “O Jo˜ao comprou uma carroc¸a.”
mesmo, toda uma frase. Considerando a seguinte frase: “Os Pol´ıcias traba-lham, sem fardas.”, o modificador do verbo trabalham ´e “sem fardas”.
No entanto, considerando a Tabela 1.3, as etiquetas gramaticais adoptadas ilustram informac¸˜ao gramatical a dois n´ıveis: a um n´ıvel b´asico, que traduz relac¸˜oes entre as pala-vras dentro de um constituinte (SP, C, N, PRD, COORD, PUNCT), e a um n´ıvel superior, que apresenta as relac¸˜oes entre constituintes, (SJ, OBL, IO, DO).
Com algumas das relac¸˜oes gramaticais descritas anteriormente e com base na frase na Figura 1.4 anotada apenas com as etiquetas gram´aticas, ´e poss´ıvel observar as relac¸˜oes gramaticais entre as palavras da frase:
• “O” - Especificador de Jo˜ao (Specifier - SP). • “Jo˜ao” - Sujeito do verbo comprou (Subject - SJ). • “comprou” - N´ucleo da frase (Root - ROOT). • “uma” - Especificador de carroc¸a (Specifier - SP).
• “carroc¸a” - Objecto directo do verbo comprou (Direct Object - DO). • “.” - Pontuac¸˜ao final da frase (Punctuation - PUNCT).
J´a etiquetas semˆanticas definem relac¸˜oes semˆanticas que permitem caracterizar o tipo de relac¸˜ao semˆantica decorrente do relacionamento entre os constituintes de uma frase.
O termo “relac¸˜ao semˆantica”, segundo [11], refere que as relac¸˜oes gramaticais como Sujeito e Objecto Directo nem sempre correspondem de uma maneira natural `as relac¸˜oes semˆanticas existes entre um verbo e os sintagmas nominais (seus argumentos), isto ´e, en-tre um verbo e os sintagmas nominais por ele seleccionados.
Os argumentos de um verbo tˆem uma determinada interpretac¸˜ao semˆantica (ou papel tem´atico) relacionada com a pr´opria interpretac¸˜ao do verbo que os selecciona. `As relac¸˜oes semˆanticas ´e tamb´em atribu´ıdo o nome de “pap´eis tem´aticos” pois estas relac¸˜oes pres-sup˜oem a existˆencia de uma relac¸˜ao semˆantica central - o Tema - sendo que, toda a frase possui um Tema.4
A anotac¸˜ao do corpus de dependˆencias do Grupo NLX com etiquetas semˆanticas (Ta-bela 1.4), teve por base [12], em que as relac¸˜oes semˆanticas definidas s˜ao as seguintes:
• Argumento - Aplica-se a palavras que s˜ao argumento de um nome, adjectivo ou verbo. X representa o n´umero do argumento que uma palavra constitui nome, ad-jectivo ou verbo.
Por exemplo: “O Jo˜ao partiu.”
• Agente causativo de verbos com alternˆancia causativa - Aplica-se ao causador da acc¸˜ao do verbo.
Por exemplo: “O pirata afundou o barco.”
• Modificador de Localizac¸˜ao - Aplica-se a localizac¸˜oes espaciais, quer f´ısicas, quer abstractas.
Por exemplo: “O Pedro mora na av. da Liberdade”, “O Pedro referiu-se ao inci-dente, no seu discurso”
• Modificador de Extens˜ao - Aplica-se a strings que determinem uma extens˜ao, so-bretudo num´erica. Engloba medidas, percentagens, quantificadores e termos com-parativos.
P˜oe exemplo: “O desemprego subiu 15%”; “A melancia pesava 2kg”; “O atleta correu 2 metros”; “A Maria engordou bastante no ´ultimo mˆes”; “o Pedro gastou mais do que o previsto”
• Modificador de Adv´erbio - Engloba todas as strings que n˜ao se possa incluir nas restantes etiquetas.
Por exemplo, genitivos como “a casa da Maria”
• Modificador de Causa - Indica a causa/raz˜ao da acc¸˜ao.
Por exemplo: “A Maria chumbou porque errou todas as perguntas do teste”
• Modificador Temporal - Localiza a acc¸˜ao na linha do tempo e engloba Frequˆencia, Durac¸˜aoe Repetic¸˜ao.
Por exemplo: “O crime aconteceu em 1980”; “O exame realizou-se a semana pas-sada”; “O Pedro est´a sempre a queixar-se”.
• Modificador de Fim - Aplica-se a todas as strings que indiquem o objectivo ou prop´osito da acc¸˜ao descrita.
Por exemplo: “O Pedro comprou um carro para poder viajar ao fim-de-semana”. • Modificador de Modo - Aplica-se a strings que especifiquem a forma/modo como uma acc¸˜ao ´e praticada ou decorre. Devem ser strings que respondam `a pergunta “Como?”
Por exemplo: “O Pedro falou pausadamente”; “A Maria caiu das escadas de forma aparatosa.”
• Modificac¸˜ao de Direcc¸˜ao - Aplica-se a referˆencias direccionais, podendo englobar tanto a “Fonte/Origem” como o “Destino” da deslocac¸˜ao.
Por exemplo: “O comboio fez a primeira viagem para o Alentejo”; “O Pedro ´e natural de Lisboa”; “O Pedro deu um passo em frente e parou.”
• Modificador de Predicac¸˜ao Secund´aria - Aplica-se manualmente em casos de predicados secund´arios (sobretudo com verbos no partic´ıpio passado), e a estruturas predicativas (resultativas, por exemplo)
Por exemplo : “O Pedro trabalha na TAP como comiss´ario de bordo”; “A Ana encontrou o assassino j´a morto”;
• Modificador de Ponto de Vista - Aplica-se em strings que expressem posic¸˜ao ou ponto de vista do autor do enunciado. N˜ao fazem parte da estrutura predicativa. Por exemplo: “Na minha opini˜ao”; “a meu ver”
Considerando a Figura 1.1 com etiquetas gramaticais e semˆanticas, ´e poss´ıvel observar que as palavras “Jo˜ao” e “carroc¸a” denotam entidades relacionadas debaixo da relac¸˜ao de-notada pelo verbo “comprou”. Por outras palavras, o verbo da frase “comprou” define que a entidade Jo˜ao (primeiro argumento) adquiriu a entidade carroc¸a (segundo argumento).
No fundo, as etiquetas semˆanticas definem as relac¸˜oes estabelecidas entre os v´arios constituintes da frase, ao n´ıvel do significado da mesma. Por outro lado, as etiquetas gramaticais ilustram relac¸˜oes sint´acticas entre os constituintes, mas n˜ao possibilitam por si s´o, estabelecer relac¸˜oes semˆanticas entre os mesmos.
1.7.1
Etiquetas Gramaticais versus Etiquetas Semˆanticas
Um bom exemplo para mostrar que com um corpus que apenas contenha etiquetas gra-maticais se torna mais dif´ıcil capturar a semˆantica de uma frase s˜ao as frases na voz activa
Etiqueta gramatical Significado ARGX Argumento
ARGA Agente causativo de verbos com alternˆancia causativa M-ADV Modificador de Adv´erbio
M-MNR Modificador de Modo M-LOC Modificador Locativo
M-PRED Modificador de Predicac¸˜ao Secund´aria M-TEM Modificador Temporal
M-EXT Modificador de Extens˜ao M-PNC Modificador de Fim M-CAU Modificador de Causa
M-POV Modificador de Ponto de Vista M-DIR Modificac¸˜ao de Direcc¸˜ao
Tabela 1.4: Tabela com as etiquetas semˆanticas presentes no corpus de dependˆencias do Grupo NLX.
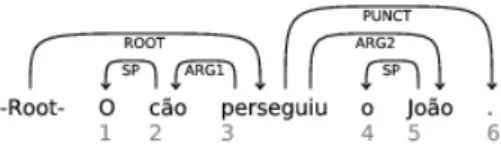
Figura 1.5: Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase na voz activa: “O c˜ao perseguiu o Jo˜ao.”
e na voz passiva.
Consideremos as frases na Figura 1.5 e Figura 1.6 anotadas com os arcos de dependˆencias e respectivas etiquetas gramaticais (apenas).
Podemos observar, numa an´alise geral, que na frase na voz activa (Figura 1.5) a pala-vra “c˜ao” ´e o Sujeito da frase, e que a palapala-vra “Jo˜ao” ´e o Objecto Directo da mesma frase. No entanto, considerando a frase na voz passiva (Figura 1.6) que possui o mesmo signifi-cado que a frase na voz activa, podemos constatar que as palavras “c˜ao” e “Jo˜ao” possuem relac¸˜oes gramaticais diferentes. Na frase na voz passiva, a palavra “Jo˜ao” ´e o Sujeito da frase, e a palavra “c˜ao” ´e o Complemento Obl´ıquo da mesma frase. ´E importante referir
Figura 1.6: Anotac¸˜ao das relac¸˜oes gramaticais das palavras na frase na voz passiva: “O Jo˜ao foi perseguido pelo c˜ao.”
Figura 1.7: Anotac¸˜ao dos pap´eis semˆanticas das palavras na frase na voz activa: “O c˜ao perseguiu o Jo˜ao.”
Figura 1.8: Anotac¸˜ao dos pap´eis semˆanticas das palavras na frase na voz passiva: “O Jo˜ao foi perseguido pelo c˜ao.”
que apesar da proposic¸˜ao “por” (Figura 1.6) depender do verbo “perseguido” com a eti-queta gramatical “OBL”, esta preposic¸˜ao actua como um elo de ligac¸˜ao entre o verbo e a palavra “c˜ao”, sendo que “c˜ao” como j´a referido, ´e o complemento obl´ıquo da frase. Se considerarmos as mesmas frases com os arcos de dependˆencias e respectivas etiquetas gramaticais e tamb´em semˆanticas, na voz activa (Figura 1.7) e na voz passiva (Figura 1.8), podemos ver que a palavra “c˜ao” se relaciona com o verbo contendo a mesma etiqueta semˆantica (ARG1) em ambas as frases, e que a palavra “Jo˜ao” se relaciona com o verbo contendo a mesma etiqueta semˆantica (ARG2) em ambas as frases.
Com este tipo de etiquetas semˆanticas que definem os arcos de dependˆencias entre as palavras de uma frase, ´e poss´ıvel retirar a mesma informac¸˜ao semˆantica entre duas frases com ordem de palavras diferentes, mas possuidoras do mesmo significado.
Contudo interessa referir que apenas o corpus de dependˆencias com as etiquetas grama-ticais estava dispon´ıvel aquando da busca por o melhor parser de dependˆencias para a L´ıngua Portuguesa. Acontece que o processo de adicionar as etiquetas semˆanticas ao corpus de dependˆencias ainda decorria. Assim sendo, no pr´oximo cap´ıtulo em que ser´a explicado detalhadamente a busca pelo melhor parser de dependˆencias para a l´ıngua por-tuguesa, o corpus de dependˆencias usado para treinar e avaliar o resultado deste tipo de ferramentas, conter´a os arcos de dependˆencias definidos apenas com etiquetas gramati-cais.
No Cap´ıtulo 4 em que ser´a explicada a ferramenta de anotac¸˜ao semˆantica de pagi-nas web (Marcador Semˆantico), o corpus de dependˆencias usado j´a conter´a os arcos de dependˆencias definidos com as etiquetas gramaticais e semˆanticas.
1.8
Considerac¸˜oes Finais
Neste cap´ıtulo apresentou-se a “Motivac¸˜ao” e a “Contribuic¸˜ao” desta dissertac¸˜ao. Foram tamb´em explicados alguns conceitos que derivam da utilizac¸˜ao de ferramentas de parsing de dependˆencias, tais como a “Projectividade” e um formato de input aceite por este tipo de ferramentas, chamado de “CoNLL”.
Explicou-se tamb´em a importˆancia das etiquetas semˆanticas na secc¸˜ao Relac¸˜oes Semˆanticas. No pr´oximo cap´ıtulo, descrever-se-´a os parsers de dependˆencias encontrados, assim como o parser de dependˆencias escolhido, que ser´a usado para a concretizac¸˜ao das ferra-mentas LX Dep Parser e Marcador Semˆantico.
Selecc¸˜ao do Parser de Dependˆencias
2.1
Introduc¸˜ao
Uma vez que ser´a necess´ario obter um grafo de dependˆencias a partir de uma frase, para se poder extrair a semˆantica da mesma frase, efectuou-se uma busca por parsers de de-pendˆencias. Efectuada a busca, deu-se in´ıcio a um processo de escolha do melhor parser de dependˆencias para a l´ıngua Portuguesa.
Os Parsers de Dependˆencias que fossem trein´aveis com um corpus, que contivesse frases escritas na L´ıngua Portuguesa anotadas com as dependˆencias de cada palavra da respectiva frase, seriam os de maior interesse. Assim sendo, ap´os uma pesquisa realizada, os Parsers de Dependˆencias encontrados foram os seguintes:
• ISBN Dependency Parser • MST Parser
• DeSR Dependency Parser • Malt Parser
• KSDEP
O processo de busca realizado por parsers de dependˆencias, teve como alvo a mail-ling list Corpora (mailmail-ling list que ´e frequentada por pessoas que pertencem `a ´area de Processamento da Linguagem Natural1. Esta procura tamb´em fora efectuada nos moto-res de busca do Google e Yahoo, e tamb´em em reposit´orios como: Language Tecnology World,2 que ´e um dos servic¸os mais abrangentes da World Wide Web, que possui um vasto report´orio de tecnologias directamente envolvidas na ´area da Linguagem Humana.
1http://gandalf.aksis.uib.no/corpora/ 2beta.lt-world.org
O reposit´orio3Associac¸˜ao Internacional de Lingu´ıstica Computacional, que envolve pes-soas dentro da ´area da Linguagem Natural e Computacional, tamb´em foi outra fonte desta busca.
No processo de escolha do melhor parser de dependˆencias para a L´ıngua Portuguesa, as cinco ferramentas encontradas foram submetidas a um teste chamado de “Ten Fold Cross Validation” (Validac¸˜ao Cruzada de Dez Partic¸˜oes).
De referir que nem todos os parsers de dependˆencias possuem ferramentas de avaliac¸˜ao, pelo que foi necess´ario encontrar um ´unica ferramenta de avaliac¸˜ao, para avaliar o resul-tado do teste “Ten Fold Cross Validation”.
Passemos ent˜ao a descrever a ferramenta de avaliac¸˜ao utilizada assim como o teste “Ten Fold Cross Validation”, sendo que depois seguir-se-´a uma sucinta descric¸˜ao sobre os parsers de dependˆencias encontrados, de modo a revelar e esclarecer qual o parser de dependˆencias que foi escolhido.
2.2
Malt Eval
Como m´etodo de avaliac¸˜ao dos parsers de dependˆencias, foi utilizado um tipo de teste chamado de “Ten Fold Cross Validation” (Validac¸˜ao Cruzada de Dez Partic¸˜oes).
Neste tipo de testes (em que pode ser usado um qualquer n´umero de partic¸˜oes para avaliacao, mas que por norma, s˜ao utilizadas dez partic¸˜oes), a amostra original dos dados ´e partida, sob um determinado crit´erio, em dez partic¸˜oes. Deste modo, nove partic¸˜oes ir˜ao ser usadas como dados de treino pelo parser, enquanto a restante partic¸˜ao ira ser usada como dados de teste, tamb´em pelo parser. A an´alise/processamento do parser sobre esta ultima partic¸˜ao (corpus dourado), ser´a comparada com a mesma partic¸˜ao guardada para ser analisada/processada pelo parser. Com esta comparac¸˜ao, e levando em conta as m´etricas descritas anteriormente, ser´a calculada a taxa de acerto do parser, relativamente aos dados analisados/processados.
Este teste ser´a repetido tantas vezes quanto o n´umero de partic¸˜oes (dez vezes).
De modo a calcular a taxa de acerto dos v´arios parsers de dependˆencias, seria ideal encon-trar um avaliador ´unico para os resultados de parsing dos v´arios parsers de dependˆencias pois nem todos os parsers possuem um avaliador integrado.
Assim sendo, a ferramenta de avaliac¸˜ao Malt Eval foi utilizada para avaliar os resultados de todos os parsers.
Malt Eval ´e uma ferramenta freeware, escrita em Java, para avaliac¸˜ao de ´arvores de de-pendˆencias que oferece v´arias m´etricas de avaliac¸˜ao e permite tamb´em a visualizac¸˜ao das ´arvores de dependˆencias. ´E uma ferramenta flex´ıvel na medida em que permite escolher um elevado n´umero de parˆametros que s˜ao facilmente configur´aveis
As m´etricas usadas para a avaliac¸˜ao dos parsers de dependˆencias, cujo valores variam entre 0 e 1 (ou entre 0% e 100%), foram:
• Unlabeled Attachment Score (UAS) - Um token (s´ımbolo/palavra) ser´a contado com sucesso se o arco de dependˆencias entre duas palavras da frase processada pelo parser de dependˆencias estiver correcto em relac¸˜ao ao corpus dourado.
• Labeled Attachment Score (LAS) - Um token (s´ımbolo/palavra) ser´a contado com sucesso se o arco de dependˆencias e a etiqueta semˆantica entre duas palavras da frase processada pelo parser de dependˆencias estiverem correctas em relac¸˜ao ao corpus dourado.
• Label Right (LA) - Um token (s´ımbolo/palavra) ser´a contado com sucesso se a etiqueta semˆantica do arco de dependˆencias entre duas palavra da frase processada pelo parser de dependˆencias estiver correcto em relac¸˜ao ao corpus dourado. Esta m´etrica servir´a de informac¸˜ao adicional uma vez que esta n˜ao ´e costume usar esta m´etrica em avaliac¸˜oes deste tipo de ferramentas.
As linhas de comandos para correr o Malt Eval s˜ao:
java -jar MaltEval.jar -s parsedSentences -g goldSentences --Metric X
• -s parsedSentences - As frases cujos arcos de dependˆencias e respectivas etiquetas semˆanticas foram calculadas pelo parser de dependˆencias. Este ficheiro dever´a estar em formato CoNLL 2006
• -g goldSentences - As frases cujos os arcos de dependˆencias e respectivas etiquetas semˆanticas s˜ao anotadas `a partida. Este ficheiro, em formato CoNLL 2006 ser´a levado como base de comparac¸˜ao pela ferramenta Malt Eval.
• –Metric X - O tipo de m´etrica a ser usada na avaliac¸˜ao/comparac¸˜ao.
2.3
ISBN Dependency Parser
O ISBN Parser [21, 23] foi desenvolvido em parceria por Ivan Titov e James Henderson, da Universidade de Geneva e da Universidade de Edimburgo, respectivamente.
´
E um parser probabil´ıstico que usa modelos probabil´ısticos baseados num hist´orico de decis˜oes tomadas que prevˆe as derivac¸˜oes mais prov´aveis para a an´alise de dependˆencias. O modelo probabil´ıstico usado ´e um modelo baseado em “Incremental Sigmoid Belief Networks”.
Uma Belief Network (rede de crenc¸a) ´e um grafo ac´ıclico dirigido que codifica de-pendˆencias estat´ısticas entre duas var´aveis. Cada vari´avel Si contida no grafo, tem
asso-ciada uma probabilidade de distribuic¸˜ao
P (Si|P ar(Si)) (2.1)
sobre os seus valores, dados os valores dos seus parentes Par(Si) no grafo.
Uma “Sigmoid Belief Network” s˜ao “Bayesian Network” que possuem vari´aveis bin´arias e probabilidades de distribuic¸˜ao condicionais, na forma de uma func¸˜ao log´ıstica sigm´oide:
P (Si = 1|P ar(Si)) = σ(
X
Sj∈P ar(Si)
JijSj) (2.2)
onde Si representa as vari´aveis, P ar(Si) s˜ao as vari´aveis das quais depende Si, σ denota
a func¸˜ao sigmoid log´ıstica, e Jij ser´a o peso para o arco que ir´a da vari´avel Si, para a
vari`avel Sj.
Para se usar as “Sigmoid Belief Network” de modo a que seja poss´ıvel processar sequˆencias longas de dados, tais como, uma sequˆencia de decis˜oes de uma parser
(D1, . . . , Dm), as “Sigmoid Belief Network” s˜ao extendidas para uma forma de
“Dyna-mic Bayesian Network”.
Numa “Dynamic Bayesian Network”, um novo conjunto de vari´aveis ´e instanciado para cada posic¸˜ao da sequˆencia de decis˜oes, mas os arcos e pesos dos arcos mant´em-se inalte-rados em todas as posic¸˜oes da sequˆencia.
“Incremental Sigmoid Belief Networks” diferem das “Sigmoid Belief Network” dinˆamicas na medida em que permite que o modelo criado seja modificado (arcos e pe-sos dos arcos, por exemplo) incrementalmente, atrav´es da an´alise de cada decis˜ao da sequˆencia de decis˜oes.
Para executar a func¸˜ao de parsing sobre uma determinada frase, o ISBN Parser utiliza um algoritmo que consiste numa pilha S que defini o estado corrente do parser e uma fila I que conter´a as palavras do input que ainda est˜ao por analisar, e a estrutura de dependˆencia parcialmente constru´ıda, a partir de decis˜oes anteriores constru´ıdas por decis˜oes anterio-res do parser.
O algoritmo comec¸a com a pilha S vazia e termina quando a fila I ficar vazia. Este algo-ritmo utiliza quatro tipos de decis˜ao:
• Left-Arcr - cria o arco de dependˆencia entre a pr´oxima palavra da fila (wj) e a
palavra wi no topo da pilha, seleccionando a etiqueta r para o arco entre wi e wj.
A palavra wi ´e retirada (pop) da pilha.
• Right-Arcr - cria o arco de dependˆencia entre a palavra no topo da pilha wi, e a
pr´oxima palavra wj na fila, seleccionando a etiqueta r para a relac¸˜ao/arco entre wi
• Reduce - retira do topo da pilha S, a palavra wi
• Shiftwj - muda a palavra wj da fila, para a pilha.
O modelo de probabil´ıstico utilizado pelo ISBN Parser utiliza um modelo proposto em [13], utilizando parsing probabil´ıstico que usa um m´etodo de “previs˜ao de palavra”, con-tido na acc¸˜ao “Shift” do parser. Esta predic¸˜ao da palavra ´e baseada em etiquetas morfo-sint´acticas e em etiquetas gramaticais de granularidade fina, que s˜ao disponibilizadas no corpus de treino. Predic¸˜ao essa que comec¸a pelas etiquetas gramaticais de granularidade fina da palavra desconhecida, passando pela etiqueta morfo-sint´etica, e finalizando com a pr´opria palavra. Os autores do ISBN Parser afirmam que esta abordagem lhes permitir´a diminuir o efeito de esparssez, evitando uma normalizac¸˜ao (overfiting) das palavras no vocabul´ario.
O modelo probabil´ıstico baseado em hist´orico, do ISBN Parser, decomp˜oe a probabi-lidade de um parse de acordo com as decis˜oes tomadas pelo parser, atrav´es da seguinte formula:
P (T ) = P (D1, . . . , Dm) = Y
t
P (Dt|D1, . . . , Dt−1)
(2.3) onde T ´e o parse e D1, . . . , Dm ´e a sequˆencia das decis˜oes tomadas pelo parser.
Cada decis˜ao Dtdo ISBN Parser, para um determinado parse, pode ser dividida numa sequˆencia de decis˜oes elementares:
P (Dt|D1, . . . , Dt−1) =Y
k
P (dtk|h(t, k)) (2.4) onde h(t, k) denota um hist´orico de decis˜oes tomadas anteriormente.
Resumindo, desde que existe palavras a serem analisadas na fila I, para um dado es-tado S0, ´e tomada uma sequˆencia de decis˜oes em que para cada decis˜ao, s˜ao levadas em conta decis˜oes tomadas anteriormente.
Decis˜oes anteriores essas que s˜ao escolhidas consoante a estrutura de Dependencia (parse) que ate ao momento foi constru´ıda.
Esta nova sequˆencia de decis˜oes definida para o estado actual, levara o parser para um novo estado S00, que terminara a sua execuc¸˜ao, caso n˜ao exista mais palavras na fila I. De referir que ap´os o processo de parsing, ´e utilizado uma variante do algoritmo “beam search” descrito em [22], de modo a determinar qual o parse mais prov´avel. O algoritmo beam search ´e um algoritmo de busca heur´ıstica. ´E uma optimizac¸˜ao do algoritmo de busca “best-first”. O algoritmo de busca “best-first” ´e um grafo de busca que ordena todas as soluc¸˜oes parciais (estados) de acordo com uma heur´ıstica, na tentativa de prever qual a soluc¸˜ao parcial que mais se aproxima da soluc¸˜ao final (estado alvo). No algoritmo ”beam search“, apenas um n´umero pr´e definido de melhor soluc¸˜oes parciais ´e mantido.
De seguida mostra-se resultados obtidos na conferˆencia ”CoNLL-2007 shared task“. Estes resultados s˜ao o fruto de treinar o ISBN Parser e analisar o mesmo, com v´arios corpora de diversas linguagens. Conjuntos esses que possuem entre dois mil a cinco mil tokens.
De referir que nestas experiˆencias foram utilizados “cortes de frequˆencia’. Estes cortes de frequˆencia servem para ignorar uma palavra, lema ou uma caracter´ıstica, que ocorra menos que o valor atribu´ıdo, para o corte de frequˆencia. O corte de frequˆencia com valor 20 foi usado para as l´ınguas Chinesa e Grega. Para as restantes linguagens, o corte de frequˆencia utilizado foi de 5, uma vez que os autores do ISBN Parser notaram que um corpus de treino com um maior n´umero de palavras, lemas e caracter´ısticas de palavras, diminu´ıam a eficiˆencia do parser.
A tabela seguinte demonstra os resultados de avaliac¸˜ao com corpus de v´arias l´ınguas, na conferˆencia CoNLL de 2007:
L´ıngua LAS UAS ´ Arabe 0,7410 0,8320 Basco 0,7550 0,8190 Catal˜ao 0,8740 0,9340 Chinˆes 0,8210 0,8790 Checo 0,7790 0,8420 Inglˆes 0,8840 0,8970 Grego 0,7350 0,8120 H´ungaro 0,7790 0,8220 Italiano 0,8230 0,8630 Turco 0,7980 0,8620
2.3.1
Execuc¸˜ao
Dos cinco parsers de dependˆencias aqui apresentados, este ser´a o que apresenta menos facilidades de interacc¸˜ao.
Para o correcto funcionamento deste parser, ´e necess´ario executar uma s´erie de passos (de notar que os comandos apresentados de seguida s˜ao executados em Linux):
• ./prepare data FREQ CUTOFF UNKN FREQ CUTOFF
PROJECT PATH TRAINING FILE VALIDATION FILE OTHER FILES: Este comando preparar´a uma directoria onde todos os ficheiros que o parser precisa para treinar e analisar ser˜ao colocados:
– PROJECT PATH a directoria a ser criada onde ser˜ao gerados ficheiros de “configurac¸˜ao” para treino e parsing.
– FREQ CUTOFF ´e um inteiro que indica que caso uma palavra, lema, eti-queta morfo-sint´actica, no conjunto de treino, ocorra em menor n´umero de vezes que FREQ CUTOFF, ser´a ignorado.
– UNKN FREQ CUTOFF ´e tamb´em um inteiro caso um item desconhecido (palavra, lema, etiqueta-morfo-sint´actica) ocorra, no corpus de treino, em me-nor n´umero de vezes do que o UNKN FREQ CUTOFF, este item ser´a “fundido” com outro item menos frequente, da mesma categoria.
– TRAINING FILE representa o ficheiro (corpus) em formato CoNLL 2006, que ser´a usado para treinar o parser. O ficheiro indicado por TRAINING FILE ser´a convertido para o formato CoNLL.ext.
– VALIDATION FILE ´e um sub-conjunto do TRAINING FILE que dever´a conter pelo menos dois mil tokens.
– OTHER FILES s˜ao outros ficheiros em formato CoNLL 2006, a serem even-tualmente analisados pelo parser, que ser˜ao convertidos para o formato CoNLL.ext.
• Num segundo passo, ´e necess´ario assegurar que o tamanho das estruturas corres-ponde aos parˆametros do treebank, ou seja, ´e necess´ario configurar no ficheiro idp io spec.h, que est´a na directoria PROJECT PATH, alguns campos como, por exemplo, MAX CPOS SIZE, pois se treinarmos este parser com o corpus de pendˆencias do Grupo NLX, iremos ter mais do que trinta (valor definido por de-feito) etiquetas morfo-sint´acticas (Part-of-Speach Tags).
Ser´a necess´ario tamb´em copiar os ficheiros parser.par, parser.ih e parser.hh da di-rectoria sample para a didi-rectoria PROJECT PATH. Tamb´em ´e necess´ario indicar no ficheiro parser.par, o correcto caminho dos ficheiros de treino e validac¸˜ao criados pelo script ./prepare data.
• De seguida poder-se-´a treinar este parser executando o comando: ./idp -train PROJECT PATH/parser.par
onde se chama o execut´avel “idp”, com a opc¸˜ao “-train”, indicando o ficheiro de configurac¸˜ao parser.par.
• No passo seguinte ´e necess´ario converter o(s) ficheiro(s) de teste (OTHER FILES), que ser˜ao analisados (parsing), para o formato CoNLL.ext. Formato esse que n˜ao ser´a mais do que um formato CoNLL 2006 com valores num´ericos afectos a cada palavra de modo a serem usados pelo parser, no processo de parsing.
O utilizador pode fazer a converc¸˜ao dos ficheiros a analisar logo no in´ıcio da criac¸˜ao da directoria com o script prepare data ou ent˜ao utilizando o script:
conll2ext PROJECT PATH TRAINING FILE.conll FILE TO CONVERT.conll
onde:
– PROJECT PATH ´e a directoria que fora criada com o script prepare data. – TRAINING FILE.conll ´e o mesmo ficheiro de treino que fora usada na criac¸˜ao
da directoria PROJECT PATH.
– FILE TO CONVERT.conll ser´a o ficheiro que queremos fornecer ao parser. Este ficheiro ser´a convertido para o formato conll.ext, para posteriormente ser analisado.
• De seguida podemos proceder ao parsing utilizando o comando:
./idp -parse PROJECT PATH/parser.par TEST FILE OUT FILE: – PROJECT PATH/parser.par o ficheiro de configurac¸˜ao presente na
directo-ria PROJECT PATH.
– TEST FILE ser´a o ficheiro para analisar convertido para o formato CoNLL.ext no passo anterior.
– OUT FILE ´e o resultado do parser ap´os parsing do ficheiro TEST FILE. • O pr´oximo passo ser´a o de converter o resultado do parser (j´a com os arcos de
dependˆencia e respectivas etiquetas semˆanticas calculadas). Para tal utilizar-se-´a o comando:
ext2conll PROJECT PATH test.conll parser res.conll.ext parser res.conll.proj
– PROJECT PATH directoria criada. – parser res.conll.ext o resultado do parser.
– parser res.conll o resultado do parser em formato CoNLL 2006, com projec-tividade.
• Para terminar este ISBN parser vem acompanhado de um avaliador que corre com o seguinte comando:
./eval07.pl -g gold std.conll -s parser res.conll – -g gold std.conll o corpus dourado em formato CoNLL 2006.
– -s parser res.conll o ficheiro analisado e reconvertido para o formato CoNLL 2006.
2.3.2
Avaliac¸˜ao
Ap´os uma experimentac¸˜ao com este parser e seguindo todas as instruc¸˜oes, n˜ao foi poss´ıvel obter resultados com este parser de dependˆencias. Comec¸ando pela interface (entenda-se por comandos in(entenda-seridos de modo a correr a ferramenta) esta n˜ao ´e de todo intuitiva, sendo o parser, dentro de estes cinco parsers recolhidos, o mais dif´ıcil de trabalhar. S˜ao precisos muitos passos at´e se conseguir efectuar o parsing, desde criar uma directoria com ficheiros de treino e teste, at´e desconverter o resultado de parsing (de conll.ext para conll) para serem avaliados. Por outras palavras, certos passos na execuc¸˜ao de este parser deveriam ser “fundidos” para facilitar a tarefa ao utilizador. Para al´em da convers˜ao dos ficheiros de treino e teste em formato CoNLL para um formato CoNLL.ext, ´e necess´ario criar ficheiros de validac¸˜ao para o treino desta ferramenta. Como j´a fora descrito, estes ficheiros de validac¸˜ao dever˜ao conter no m´ınimo dois mil s´ımbolos (tokens), ou seja, frases em formato CoNLL 2006 do ficheiro de treino que perfac¸a os dois mil tokens. Tamb´em se pode colocar o pr´oprio ficheiro de treino como ficheiro de validac¸˜ao, mas isso leva-nos a um treino com uma durac¸˜ao a rondar as cinco horas4.
O mais importante ´e que a “robustez” do funcionamento desta ferramenta n˜ao parece ser a melhor, pois o ficheiro de teste que ser´a analisado pelo parser n˜ao dever´a conter etiquetas morfo-sint´acticas que n˜ao ocorram no ficheiro de treino, pois caso contr´ario a preparac¸˜ao/convers˜ao (com os scripts ./prepare ou ./convert) n˜ao terminar´a com sucesso. Mesmo corrigindo esta quest˜ao s˜ao encontrados problemas durante a execuc¸˜ao do parser ao efectuar o parsing sobre os ficheiros de teste, n˜ao sendo poss´ıvel que se conclua com sucesso o parsing.
2.4
KSDEP / LRDEP
O parser de dependˆencias probabil´ıstico KSDEP [24, 20], ´e um parser desenvolvido por Kenji Sagae e Jun’ichi Tsujii, das universidades de Tokyo e Manchester, respectivamente. O KS/LR Dep Parser define-se como uma variante do algoritmo de parsing LR, para parsing de dependˆencias, sendo tamb´em aplicado um algoritmo de procura “best-first” de modo a ir ao encontro da generalizac¸˜ao do parsing probabil´ıstico de dependˆencias.
Um algoritmo de parsing LR, ´e um parser que lˆe o input da esquerda para a direita, produzindo um resultado final chamado de “Rightmost derivation”, baseado numa dada gram´atica. Um LR parser ´e baseado num algoritmo que tem como base de decis˜ao uma tabela de parsing (parser table), que ´e uma estrutura de dados que cont´em informac¸˜ao sint´actica sobre a linguagem, que se encontra a ser parsada. Como tal, o termo LR parser diz respeito a uma classe de parsers que possuem a capacidade de processar quase todas as linguagens, desde que seja fornecida uma tabela de parsing, gerada por um “parser generator”.
O parsing do algoritmo LR, comparando com outros algoritmos de parsing como por exemplo o LL parsing, consegue manipular um maior n´umero de l´ınguas e consegue tamb´em uma melhor descric¸˜ao sobre erros, ou seja, entre v´arios erros que possam surgir, o algoritmo LR consegue detectar erros de sintaxe, quando o input n˜ao corresponde `a gram´atica, com a maior celeridade poss´ıvel, contrastando com o algoritmo LL que devido ao backtracking, torna a localizac¸˜ao do erro de sintaxe, bastante mais dif´ıcil.
Voltando ao KS Dependency Parser, este parser como j´a fora referido, utiliza uma variante do algoritmo LR, entendida por um algoritmo “best-first”. A variante do LR parser n˜ao utiliza uma tabela de parsing para determinar qual o passo a tomar, no processo de parsing. Ao inv´es, ´e utilizado um classificador para determinar as acc¸˜oes de mudanc¸a e reduc¸˜ao, com informac¸˜ao derivada do input. Informac¸˜ao essa que tamb´em estaria presente numa tabela de parsing (os ficheiros no topo da pilha, e os restantes itens da string de input). A variante do algoritmo LR que constitui o KS Dependency Parser, funciona com base em duas estruturas de dados: uma pilha S que cont´em sub-´arvores da ´arvore de dependˆencias final, para um dado input, e uma fila Q que cont´em as palavras de um dado input. De referir que S ´e inicializado sem nenhum valor, e Q ´e inicializado com as palavras do input.
Este algoritmo executa duas acc¸˜oes principais: mudanc¸a (shift) e reduc¸˜ao (reduce). Quando uma acc¸˜ao de mudanc¸a ´e concretizada, uma palavra ´e transferida do in´ıcio da fila Q, para o topo da pilha S (representando uma ´arvore com apenas um n´o, a pr´opria palavra). Quando uma acc¸˜ao de reduc¸˜ao ´e efectuada, os dois elementos no topo da pilha S (s1 e s2), s˜ao extra´ıdos e um novo item ´e colocado em S. Este novo item representa o
arco de dependˆencia entre s1e s2e respectiva etiqueta.
O parsing termina quando a fila Q estiver vazia (ou seja, quando todas as palavras tiverem sido processadas), e a pilha S contiver apenas uma ´arvore (a ´arvore final de dependˆencias). Se a fila Q estiver vazia, e a pilha S n˜ao estiver vazia e n˜ao for poss´ıvel realizar mais acc¸˜oes de reduc¸˜ao, o parsing termina e o input ´e rejeitado.
Com este modelo determin´ıstico descrito anteriormente, os autores do KS DEP proce-dem a uma extens˜ao da variante do algoritmo LR acima descrita, tornando o KSDEP um parser probabil´ıstico, por outras palavras, ao inv´es do classificador retornar uma acc¸˜ao para o parser executar, o classificador retorna uma s´erie de acc¸˜oes a tomar com as corres-pondentes probabilidades, sendo que a probabilidade de uma ´arvore como resultado de parse, ´e o produto das probabilidades das acc¸˜oes tomadas aquando a sua derivac¸˜ao.
De modo a encontrar o parse mais prov´avel de acordo com o modelo probabil´ıstico LR, ´e necess´ario uma estrat´egia de “best-first”, que implica uma extens˜ao do algoritmo determin´ıstico descrito anteriormente.
Tirepresenta um estado do parser que cont´em uma pilha Si, uma fila Qie uma
probabili-dade Pi. Com o algoritmo “best-first”, ´e criada uma “heap” H que cont´em v´arios estados
do parser (T0. . . Tm).
Estes estados est˜ao ordenados em H de acordo com a probabilidade de cada um. H ´e inicializado de modo a conter um estado T0 que cont´em: uma pilha S0, uma fila Q0e uma
probabilidade associada P0 = 1.0.
O algoritmo “best-first” entra num ciclo que s´o termina quando H estiver vazio. A cada iterac¸˜ao ´e obtido o estado Tcurrent a partir de H. Se Tcurrent corresponde ao estado final
(onde Qcurrent ´e vazio e Scurrent cont´em apenas um item), ´e retornado o item de Scurrent
que consiste na estrutura de Dependencia da frase de input. Se Tcurrentn˜ao corresponder
ao estado final, ´e obtido uma lista de acc¸˜oes do parser (act0. . . actn) em que cada acc¸˜ao
cont´em uma probabilidade associada (P act0. . . P actn).
Para cada acc¸˜ao actj do parser na lista obtida, ´e criado um novo estado do parser Tnew
aplicando actj a Tcurrent, ajustando a probabilidade de Tnew(Pnew= Pcurrent∗ P actj).
No final, o estado Tnew ´e inserido em H. Assim que cada novo estado criado a partir
de cada acc¸˜ao do parser, tiver sido inserido em H, o algoritmo avanc¸a para a pr´oxima iterac¸˜ao.
Para a conferencia CoNLL 2007, os autores de KS Dependency Parser, treinaram trˆes modelos LR com o KSDEP Parser, em que cada input ´e analisado usando os trˆes mode-los LR individualmente, obtendo como resultado trˆes estruturas de dependˆencias para um dado input que s˜ao depois combinadas para formar a ´arvore/grafo de dependˆencias final. Esta combinac¸˜ao das estruturas de dependˆencias resultantes dos trˆes modelos LR, ´e feita atrav´es de acordo com o esquema de combinac¸˜ao “maximum-spanning-tree”, onde cada dependˆencia proposta por cada um dos trˆes modelos possui o mesmo peso.
Dos trˆes modelos LR treinados, o primeiro foi treinado com um classificador de entropia m´axima para determinar as acc¸˜oes a tomar pelo parser e suas probabilidades, o segundo usou tamb´em o classificador baseado em entropia m´axima, mas com o parsing realizado de “tr´as-para-frente”, ou seja, a string de input ´e invertida antes de se proceder ao parsing, pois observado que o procedimento de combinar v´arios parsers finais, poder´a ser ben´efico. O ´ultimo modelo descrito, foi treinado com o classificador support vector machines. De referir que os autores treinaram este ´ultimo modelo com o classificador em modo deter-min´ıstico, uma vez que n˜ao foi observado melhorias nos resultados finais (taxas de acerto) com o classificador support vector machines em “modo” probabil´ıstico.
A seguinte Tabela representa os resultados obtidos no conferencia CoNLL de 2007, com a combinac¸˜ao dos trˆes modelos LR, para as dez l´ınguas diferentes:
L´ıngua LAS UAS ´ Arabe 0,7471 0,8404 Basco 0,7464 0,8119 Catal˜ao 0,8816 0,9334 Chinˆes 0,8469 0,8884 Checo 0,7483 0,8127 Inglˆes 0,8901 0,8987 Grego 0,7358 0,8351 H´ungaro 0,7953 0,8351 Italiano 0,8391 0,8768 Turco 0,7591 0,8272
2.4.1
Execuc¸˜ao
De modo a correr este parser ser´a necess´ario trein´a-lo para um modelo ser criado e usado no parsing de frases em formato CoNLL 2006.
Para se proceder ao treino deste parser, deve-se executar a seguinte linha de comando: ./ksdep -t TRAIN FILE
• -t opc¸˜ao para treinar.
• TRAIN FILE o ficheiro para treinar o parser, em formato CoNLL 2006. J´a o comando para analisar ser´a o seguinte:
./ksdep -m MODEL FILE INPUT FILE • -m opc¸˜ao para carregar um modelo previamente treinado. • MODEL FILE o modelo a ser carregado.
• INPUT FILE o ficheiro a ser analisado, em formato CoNLL 2006.
Tamb´em existem outras opc¸˜oes d´ısponiveis a serem usados com o execut´avel ./ksdep: • -i define o parˆametro de regularizac¸˜ao (valores inteiros menores que 1.0 poder˜ao
provocar “overfit”)
• -m esta opc¸˜ao a ser usada no treino define o nome do modelo
• -b define a “beam width”. Para efectuar um parsing determin´ıstico basta utilizar o valor 1.
• -it define o n´umero de iterac¸˜oes para o treino. A cada cem iterac¸˜oes ´e guardado para o disco uma vers˜ao do modelo de treino.