Object Oriented Intelligent Multi-Agent
System Data Cleaning Architecture
To Clean Email Data
Dr. G. Arumugam1
1Department of Computer Science, Madurai Kamaraj University, Madurai 625021 T. Joshva Devadas2
2Department of Computer Science The American College, Madurai 625002 Abstract:
Agents are software programs that perform tasks on behalf of others and they can be used to mine data with their characteristics. Agents are task oriented with the ability to learn by themselves and they react to the situation. Learning characteristics of an agent is done by verifying its previous experience from its knowledgebase. An agent concept is a complementary approach to the Object Oriented paradigm with respect to the design and implementation of autonomous entities driven by beliefs, goals and plans. Email is one of the common means for communication via text. Email cleaning problem is formalized as non-text filtering and text normalization in a two step process. Agents incorporated in the architectural design of an Email data cleaning process combines both the features of Multi-Agent System (MAS) Framework and MAS with learning (MAS-L) Framework. MAS framework reduces the development time and the complexity of implementing the software agents. The MAS-L framework incorporates the intelligence and learning properties of software agents. MAS-L Framework makes use of the Decision Tree learning and an evaluation function to decide the next best decision that applies to the machine learning technique. This paper proposes the design for Multi-Agent based Data Cleaning Architecture that incorporates the structural design of agents into object model. The design of an architectural model for Multi-Agent based Data Cleaning inherits the features of the MAS and uses the MAS-L framework to design the intelligence and learning characteristics.
Keywords: Email, Agents, MAS, MAS-L, Architecture, Data Cleaning, IMASDC
1. Introduction
The volume of data present in the real world application in the form of files or databases growing at a phenomenal rate. And the users of such files or databases expect more useful information from them and many algorithms are available to extract the information and patterns. The process of bringing the source data in to an useful form needs the selection, preprocessing, transformation, interpretation / evaluation [14]. Selection is made from heterogeneous data source, preprocessing is used to clean the data that contain noisy information, such as errors, incorrect or missing data [5]. Transformation converts the given data into user required format for further processing and requires the data to be encoded or transformed into more usable formats and some data may require data reduction [36]. Interpretation rely on how the data is given to the user. Evaluation is needed for the data that requires mathematical or statistical strategies to be applied.
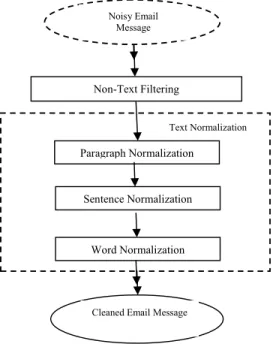
Email is one of the common means for communication via text. Many text mining applications use Email as input for analysis, routing, filtering, summarization, information extraction and newsgroup analysis [21]. Hence to achieve high quality Email mining it is necessary to carryout cleaning [16]. Email cleaning is formalized as Non-Text Filtering (NTF) and Text Normalization (TN) [17]. In other words, Email cleaning is a process of eliminating irrelevant non-text data and transforming relevant text data into canonical form. Non-text filtering removes parts in the Email which are not needed for the text mining. Text normalization is done in a cascaded fashion and the cleaning is done in several passes. Text normalization is done first at paragraph level then at sentence level and finally at word level [25]. Paragraph normalization identifies the extra line breaks and they are removed. Sentence normalization finds the real sentence-ending using a period, a question mark or an exclamation mark and it inserts necessary blank space after it. In word normalization, non-ASCII words, special symbol tokens, and lengthy tokens are identified and removed.
involved in the system can interact with other agents by exchanging knowledge or information in order to carry out the given task. Multi-Agents incorporated in the design of a specific task shares the knowledge by coordinating, cooperating and collaborating with other agents present in the system [33]. The Data Cleaning Process requires some functional elements to do the cleaning task. Such functional elements are represented as architectural components and are interconnected via connectors. These components in turn are transformed into knowledgeable processing elements as agents [15]. Data cleaning process makes use of such agents in the Data Cleaning Multi-Agent (DCMA) architecture whose role and functionalities were described in section 4 of this paper. Further, agents present in the architecture make use of the MAS and MAS-L frameworks establish communication and intelligence capabilities [6]. Combined features of those two object oriented frameworks and the proposed DCMA Architecture makes the system to react with the intelligent behavior refers the system as Intelligent Multi-Agent System Data Cleaning (IMASDC) Architecture[15]. Email data is cleaned with this IMASDC Architecture.
In this paper Section 2 describes about the Object oriented frameworks MAS and MAS-L. Section 3 discusses the Email Data Cleaning Problem in various aspects. Section 4 describes the functionalities of Data Cleaning Multi-Agent Architecture and explains Email Data cleaning using the Architecture. Section 5 introduces Agent learning for Email data cleaning and proposes Decision Tree based learning algorithm for it. Also this section illustrates the significance of Decision tree construction process with sample training example. Section 6 explains Email data cleaning with the use of IMASDC Architecture and describes the implementation process with a sample Email. Section 7 analyses normal Email Data Cleaning method with the method based on IMASDC Architecture.
2. Object Oriented Frameworks
2.1.MAS Framework
Objective of MAS framework is to reduce the development time and the complexity of implementing software agents [31]. The design of this framework is based on Gaiamethodology, which is used to build models in the analysis and the design phase [34]. This framework is composed of one abstract class Agent, two final classes namely ProcessMessageThread and AgentCommunicationLayer and four interfaces [10]. The interfaces are AgentMessage, AgentBlackBoard information, InteractionProtocol and AgentInterface [11].
AgentCommunicationLayer implements the entire communication needed for agents to interact with the distributed system.
2.2.MAS-LFramework
The MAS-L Framework is combined with the MAS framework to implement the learning and intelligence characteristics of software agents [23]. This Framework incorporates two machine learning approaches namely Decision Tree based learning and an Evaluation function. The decision tree approach of software agent learning is based on the current state of environment. The nodes of the tree are intermediate decision points and the leaf nodes are the final states where the searching ends successfully. The search algorithm indicates the best move that leads to successful final state. The Evaluation function is used to determine the next possible move to perform action.
The MAS-L Framework has two abstract classes namely, DecisionSearchTree (DST) and PlayerIntelligence and an interface EvaluationFunction [24]. The first class to be extended is Evaluation function that evaluates the intermediate node of the decision tree. This class emphasises well defined data structure along with the properties of the Decision trees to choose a machine learning technique to implement this function. The next class to be extended is the DecisionSearchTree (DST) that implements the data structure of Decision Tree along with the searching. To reduce the searching time in the DST, pruning techniques are incorporated using the maximum depth search algorithm. This class shall instantiates the class that implements EvaluationFunction to perform the evaluation of intermediate nodes. Finally the PlayerIntelligence class acts as an interface to the software agents. This class shall instantiates the class that extends DecisionSearchTree to decide the next best decision.
3. EMAIL Data Cleaning
3.1.Problem Definition
Email uses text data for communication and many text mining applications take Email as input to perform Email analysis, Email routing (routing of Email messages), Email filtering, Email summarization and information extraction. To achieve higher performance in Email cleaning it is necessary to clean the Email before mining.
Email cleaning problem is formalized as non-text filtering and text normalization in a two step process. Email cleaning is done in a cascaded fashion, first at Email body level and then at paragraph, sentence, and word level [17]. Non-Text filtering phase is done at Email body level which removes the Email header, Email signature, quotations and program code filtering and transforms the remaining portion of the data into canonical form. Text normalization is to normalize the text data present at paragraph, sentence and word level [7]. In Email cleaning, non-text filtering performs header detection, signature detection and program code detection and in paragraph normalization paragraph ending detection is done. These tasks play an important role in the cleaning process and such tasks have not been examined previously.
3.2.EMAIL Data Cleaning Procedure
from paragraph to sentence and then to word is desirable because there are dependencies between the processes. Word normalization needs sentence beginning information, paragraph normalization helps sentence normalization. Since majority of the Emails are stored in the form of plain texts the Email cleaning proposed in this section considers the plain text format of Email data and it does not consider the other HTML and RTF format Emails.
3.3.Existing Email Data Cleaning Tools
There are several products with Email cleaning feature. eClean2000 is a tool which cleans the Email by removing the space between words, removing extra line breaks between paragraphs, removing headers and re-intending forwarded mails. The cleaning is performed by the rules defined by the user. ListCleaner Pro is a data cleaning product which includes a module to identify inaccurate and duplicated Email addresses in a list of Email addresses. Using the normal text cleaning tool to clean the Email does not satisfy the user requirement completely.
3.4.Existing Email Data Cleaning System
Existing Email Data Cleaning makes use of unified machine learning approach for non-text filtering and paragraph normalization. For sentence and word normalization rules are utilized. Non-text filtering and Paragraph normalization are considered to be the main focus of work.
3.4.1. Classification Model
Support Vector Machines (SVM) model is used as classification model. Let (x1,y1), (x2,y2)…….. (xn ,yn) be a training set in which x denotes an instance and yi Є{-1,+1} denotes a classification label. In learning, one attempts to find an optimal separating hyper plane that maximally separates the two classes of training instances. The hyper plane corresponds to a classifier (Linear SVM). This linear classifier may have some errors and is further extended into non-linear SVMs by using kernel functions such as Gaussian and Polynomial kernels. SVM-light is available at http://svmlight.joachims.org/ and is used as classification model in which polynomial kernel is chosen as kernel function and the default values are used for the parameters in SVM-light. Implementation of the Email cleaning process is done using the SVM because it is significantly better than baseline method of cleaning [17].
Fig 3. Flow of Email data cleaning Paragraph Normalization
Sentence Normalization
Word Normalization
Cleaned Email Message Noisy Email
Message
Non-Text Filtering
3.4.2. Outline
Implementation of Email cleaning is carried out as follows: In the preprocessing phase patterns are used to recognize special words and bullets in the list of items. Classification model is used to detect header, footer / signature. In paragraph normalization classification model verifies whether each line breaks as a paragraph ending or not and it removes the line breaks if it is not a paragraph ending. Sentence normalization determines whether each punctuation mark is a sentence ending or not by utilizing the predefined rules and it adds a space if there is no space after the sentence ending. Further it eliminates noisy tokens ( non-ASCII characters ) present in a sentence. Word normalization focuses on case restoration
3.4.3. Header and Signature Detection
Header detection and signature detection are similar problems and are viewed as ‘reverse information extraction’. Two SVM models are used to detect the beginning and ending of a line. SVM uses number of features to detect the Header or Signature. Header detection features are position, positive word, negative word, number of words, person name, ending character, special pattern, and number of line breaks. Signature detection features also has the similar feature along with the case feature.
3.4.4. Program code Detection
Program code can also be viewed as ‘reverse information extraction’ and the detection is identified by detecting the beginning and ending line of a program code using SVMs. The recognized program codes are removed by utilizing the features of SVM. Program code detection features are position, declaration keyword, statement keyword, equation pattern, function pattern, function definition, bracket, percentage of real words, ending character, and the number of line breaks.
3.4.5. Paragraph Ending Detection
A text may contain many line breaks. SVM model is used to verify each of the line breaks as paragraph ending or extra-line break. If it is recognized as extra-line-break it is removed. SVM assigns labels to each of the features. The labels that are assigned determines whether the line break is necessary or not. Paragraph ending features are position, greeting word, ending character, case, bullet and number of line breaks.
3.4.6. Need for Agent based Email Data Cleaning
Though the existing Email data cleaning has significantly improves the performance of the system through information extraction it suffers to have intelligent processing elements that are capable of storing the intermediate / final outcome of the data cleaning process. Agents are such intelligent processing elements that learn from the environment, use the knowledgebase to store the cleaning details, and use it to react with the environment [35]. Also agents are capable of not repeating the same task that is already done for the same or different user [3]. Agents involved in the Email cleaning task use its intelligence to improve the performance of the system and hence role of agents in the Email cleaning process becomes mandatory [20].
4. Data Cleaning Multi-Agent Architecture
Agents are made available with some initial knowledge in order to take initial decisions [2]. Data cleaning architecture describes the interaction and method of communication between the multi-agents present in the system [8][13]. The Data Cleaning Multi-Agent Architecture requires Interface Agent, Data Collection Agent, Data Cleaning Agent, Knowledge Management Agent and Message Handling Agent to perform different tasks [30]. These agents are described in the subsequent paragraphs.
Interface Agent (IA) present in the top most layer interacts with Data Collection Agent, Data Cleaning Agent, Message Handling Agent and Knowledge Management Agent. This agent submits the user provided details to the Data Collection Agent. Also, IA receives user information from the Data Cleaning Agent, interaction dialogues from the Message Handling Agent and mined results from the Data Cleaning Agent. Finally, it returns the result from the interacted agents to the user.
process from the KMA is passed to the Interface Agent. Also, DCOA has the responsibility to handover all the collected information, namely the user name, file name, file type, user preference or the filter key to the Data Cleaning Agent to perform the data cleaning task.
Data collection agent (DCOA) present in the second layer gets user details from Interface Agent (IA) and sends it to the Knowledge Management Agent (KMA) to verify the user information. The result of the verification process from the KMA is passed to the Interface Agent. Also, DCOA has the responsibility to handover all the collected information, namely the user name, file name, file type, user preference or the filter key to the Data Cleaning Agent to perform the data cleaning task.
Data cleaning agent (DCLA) in the second layer receives the user profile and data cleaning details from the Data collection agent (DCOA). The knowledge required for the data cleaning process is received from the KMA. If the KMA instructs to carryout the cleaning process then the data cleaning is performed by executing appropriate methods with the keyword. If the KMA finds that the cleaning has already been done then the result is handed over to the IA by the DCLA. DCLA uses the keyword and the file name given by the user for cleaning either by clustering or by filtering technique. Irrelevant or the inconsistent data are identified by analyzing the data items which are not close to the context and are identified as a group of clusters. These clusters are either omitted or deleted from the database. The remaining data in the database after this process is sent to the IA.
Knowledge Management Agent (KMA) does the process of identification and elimination of user information. KMA possesses some initial knowledge and functions to analyze the knowledgebase. This Agent is capable of learning from the previous experience present in its knowledgebase. The KMA updates with the addition of new knowledge or by the removal of conflicting patterns that may present in the knowledgebase. At this stage either the knowledge is added to the knowledgebase or removed from it. The functionality of the KMA is to receive user details from Data Collection Agent and newly learned knowledge from Data Cleaning Agent. Also, it requests the Message Handling Agent (MHA) to prepare erroneous message or interaction dialogues to handle the situation. With the user profile and preferences it verifies its knowledgebase to decide for initiating the Data Cleaning Agent to perform the cleaning task. If the cleaning process has already been done with the specified preference in a particular file, the KMA decides not to do the cleaning process. Otherwise the cleaning process is initiated in the DCLA by the KMA. The MAS-L framework is designated for KMA-Learning. KMA initiates the Intelligence class of MAS-L Framework by instantiating the Decision Tree that invokes the evaluation function to decide the next best move.
Message Handling Agent (MHA), handles messages among the agents present in the system. KMA initiates the MHA to prepare a message when the requested file is not available in the specified path or directory and/or when the specified preference does not match with the data present in the system. During the cleaning task the Data Cleaning Agent may encounter an erroneous situation or may require the user to provide some additional information. To handle this situation Data Cleaning Agent requests the MHA to prepare either an erroneous message or user interaction dialogue. MHA sends appropriate message to the Interface Agent.
Knowledge Management
Agent Data Cleaning
Agent Data
Collection Agent
Interface Agent
Message Handling Agent User
4.1.Email Data Cleaning using Multi-Agent Architecture
Email data cleaning uses the procedure described in section 3.3 of this paper. Email cleaning is done in two phases such as filtering and normalization and the Email cleaning procedure is repeated whenever the user wants to clean the given set of Email. Agents incorporated in the Email cleaning task make use of the Data Cleaning Multi-Agent (DCMA) Architecture to clean the given Email data. Multi-agent based Email data cleaning system cleans the given Email by applying its intelligence behavior before performing the filtering and normalization procedure. It is done by incorporating the features of the MAS and MAS-L object oriented frameworks in the DCMA Architecture. Also, among the agents in the DCMA Architecture, the Knowledge Management Agent (KMA) is designated to establish the learning activity and it improves the intelligent behavior of the system [27]. In the cleaning process the KMA uses its intelligence before cleaning any Email by checking the existence about the cleaned details of the given Email. Agent based cleaning approach improves its performance by checking the existence of the file [1]. If the file exists it learns not to repeat the cleaning process in the subsequent cleaning task. Further, agents present in the DCMA architecture are made available in such a way that they are working concurrently and sharing the information among them is considered as one of the factors of performance improvement.
5. Agent Learning in Email Data Cleaning
5.1 Agent Learning Process
Machine learning is the area of artificial intelligence that examines how to write programs that can learn. Machine learning is often used for prediction or classification [30]. Prediction is done based on the feed back and an agent learns through examples. When a similar prediction occurs in future the feed back is used to make the same prediction or completely a new prediction. Machine learning applied in the data mining task uses a model to represent the data. The model is a graphical structure such as neural networks or decision trees.
A decision tree is a tree where the root and each internal node are labelled with a question. The arcs emanating from each node represents each possible answer to the associated question. Each leaf node represents a prediction of a solution to the problem under consideration [19]. A Decision Tree is a prediction modelling technique used in classification, clustering, and prediction tasks. Decision Tree uses divide and conquer
technique to split the problem space into subsets. Searching in a decision tree starts at the root node and ends successfully at the leaf node. Leaf nodes represent the successful guess of the object being predicted.
Decision tree based machine learning approach is introduced in the IMASDC architecture describes the examples in terms of attribute-value pairs that range over finitely many fixed possibilities. Also the concept to be learnt may have discrete and disjunctive description may be required to arrive at a decision. Learning decision trees classifies the training example with a finite set of attributes along with its associated values [19]. Attributes and values are used to learn the structure of the decision trees which can be used to decide the category in an unknown situation.
Learning takes place as a result of the interaction between the agent and the environment, and from observation by the agent of its own decision making processes [12]. Learning is used not only to react but also to improve the agent’s ability to act in the future [22]. Agents incorporated in the Text data cleaning process works under unsupervised learning principle and they use machine learning based decision trees as a tool to learn from the environment with its past experience [32].
5.2 Decision Tree based Learning Algorithm for Email Data Cleaning
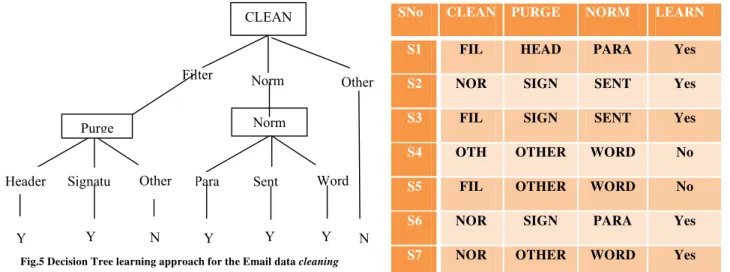
The decision tree learning algorithm for Email data cleaning uses the decision tree (Fig.5) for the agents to learn the Email data cleaning process. Algorithm makes use of the attributes and the values present in the sample training data (Table 1) to train the agents [28]. Email data cleaning identifies ‘Clean’, ‘Purge’ and ‘Norm’ as the node attributes of the decision tree learning process. The node attribute ‘Clean’ has values filter, norm and
other. The values of the node attribute ‘Purge’ are header, signature and other. Para, Sent and Word are the values representing the node attribute ‘Norm’. The algorithm is tested using the training example
If CLEAN = ‘Filter’ then // task is to filter the non-text // data of the given Email
If Purge =’Header’ then //Extracts the header portion of // the Email
Perform HeaderRemoval() function and store it in a separate file
Else if Purge = ‘Signature’ then //Extracts the header //portion of the Email Perform SignatureRemoval() function and store it in a separate file
Else if Purge = ‘Other’ then // Treated as error and //the system don’t respond //Do not perform any operation Elseif CLEAN=‘Norm’ then
// task is to Normalize
//the text data portion of the Email If Norm = ‘Para’ then // Paragraph Normalization is // performed
Make use of the Header / Signature removal file and Perform ParagraphNormalization() function and Store the result in a separate cleaned file Else if Norm = ‘Sent’ then
//Sentence Normalization is done Make use of the Header / Signature removal file and perform SentenceNormalization() function and Store the result in a
separate cleaned file Else if Norm = ‘Word’ then
// Word Normalization is performed Make use of the Header-Signature removal file and Perform WordNormalization() function and Store the result in a separate cleaned file
Else if CLEAN = ‘Other’ then
// agent learns to make use of the cleaned // Email text data for processing
Make use of the Cleaned file to send the required cleaned data.
End if End.
5.3 Decision Tree Construction process for Email Data Cleaning
Decision tree construction process makes use of the ID3 ( Induction Decision Tree Version 3) machine learning inductive algorithm. This algorithm requires computing the measures entropy and information gain. The training data used in the decision tree construction process is built by using the set of node attributes along with its possible values[26]. ID3 algorithm uses this training data as input and constructs the decision tree by placing the attribute node in its place by using the measures entropy and information gain [19]. The entropy and information gain are computed using the following formulae.
Evaluation of the intermediate nodes is done by an Evaluation function that applies the Deterministic Competitive Learning algorithm (DCL) concept. The algorithm found to be more suitable for Boolean valued function and is used in the evaluation function. The DCL algorithm changes its state and moves to one more level down in the decision tree if the Evaluation Function returns true value otherwise it remains in the same state. In other words, the algorithm learns only if the status of the output has been changed compared to the previous iteration. DCL updates the weights using the following procedure [4].
W
j[n+1] = W
j[n] + S
j(y
j)( x –W
j[n] ) Where W is the weight vector and x is the given input
Sj(y
j) ={ 1, if j is the winner
{ 0, otherwise.
The Decision Tree construction process for the Email data cleaning is described in detail as follows: Decision tree construction process needs to compute the measures entropy and information gain for each of the associated node attributes. After computing the measure values for all the node attributes, the algorithm chooses the node attribute with higher information gain as its root node. The children of the root node are obtained by recursively applying the algorithm to the rest of the node attributes. The Learning function is computed using the Decision Tree and is used in the evaluation function to determine the action plan.
KMA makes use of the Training data presented in Table 1 to learn the Email data cleaning process. The training data is constructed using the node attributes clean, purge and norm. KMA initiates the learning process from the root node (CLEAN) of the decision tree. KMA reads the value of the training example and determines the action. If the value of the root node attribute CLEAN is ‘Filtering’ then KMA performs Email cleaning by using the filtering method and initiates the cleaning action by moving one level down in the decision tree and reaches the node PURGE. If the value of the node attribute CLEAN is ‘Normalization’ then KMA performs Email cleaning by using the Normalization method and initiates the cleaning action by moving one level down in the decision tree and reaches the node NORM. The KMA determines not to perform any action / operation for the value ‘other’ of the root node CLEAN. After reaching the node PURGE, KMA reads the value of the node PURGE from the training example. The node attribute PURGE uses the values head, sign, and others to determine the portion to be removed from the Email. If the value of the node attribute is head KMA performs header removal operation, if the value is sign KMA performs signature removal operation and for the value ‘other’ KMA decides not to perform any operation. The node attribute NORM use the values para , sent, and word to determine the category of normalization. KMA make use of these values to perform paragraph
SNo CLEAN PURGE NORM LEARN
S1 FIL HEAD PARA Yes
S2 NOR SIGN SENT Yes
S3 FIL SIGN SENT Yes
S4 OTH OTHER WORD No
S5 FIL OTHER WORD No
S6 NOR SIGN PARA Yes
S7 NOR OTHER WORD Yes
Table 1 Training Example CLEAN
Norm Norm
HPara Signatu
Filter Other
Sent Word
Y Y N Y Y Y N
Header Other
Purge
normalization, sentence normalization and word normalization respectively. The decision variable Learn has two values namely ‘yes’ and ‘No’ to indicate the learning status of the KMA.
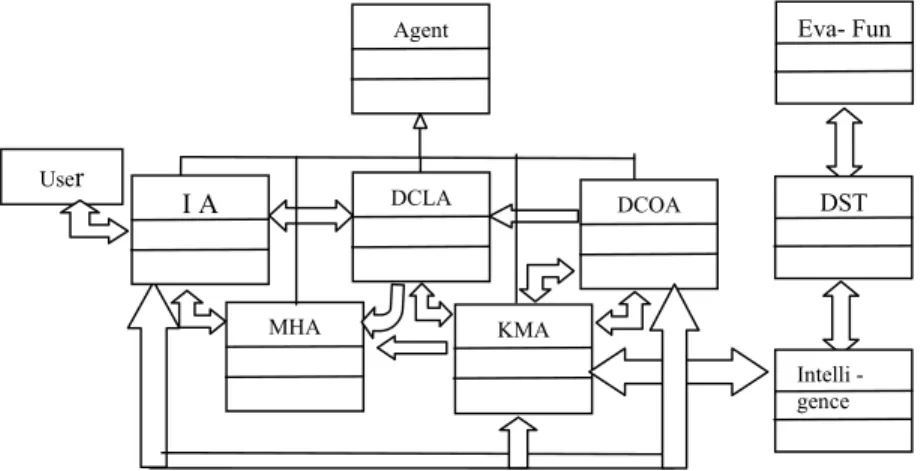
6. Intelligent Multi-Agent System Architecture for Data Cleaning
Intelligent Multi-Agent System Data Cleaning (IMASDC) Architecture combines the features of Multi-Agent data cleaning Architecture, MAS and MAS-L frameworks to carry out data cleaning process (Fig 6). The MAS and MAS-L frameworks are designed using the object oriented concept and IMASDC Architecture makes use of them to improve the performance of the cleaning task. Agents present in the IMASDC Architecture inherit all the classes and interfaces from the Agent Class of the MAS framework, and the learning aspect is initiated by using the intelligent class of the MAS-L Framework. These agents use the InteractionProtocol to interact with the other agents and make use of the AgentCommunicationLayer to implement the communication protocol to interact with the data cleaning system. All communications are done through the InteractionProtocol that uses
AgentBlackBoardInformation to exchange the message. Black board is used to establish communication between the agents available in the data cleaning architecture.
Agent’s communication is visualized through Black Board and is used as a common platform for all the agents to communicate [29]. Interface Agent uses the Agent Interface to initiate other agents. MHA uses
Processmessagethread and Agent Message of the MAS framework to prepare and handle the message. KMA initiates the intelligence class of MAS-L framework to enable the learning activity. The intelligence Class in turn calls the Decision Search Tree class which constructs the nodes for the Decision Tree using the ID3 machine learning algorithm.
6.1 Email Data Cleaning process using IMASDC Architecture
Multi-Agents incorporated in the design of the IMASDC architecture are capable of functioning autonomously and interacting with other agents to share or exchange information. Among the agents present in the system KMA is defined to have learning capabilities. KMA uses its learning characteristics to identify a suitable method/procedure to perform the Email cleaning. KMA initiates the Intelligence component of the IMASDC architecture to use the decision tree to identify the method/ procedure to be used in the cleaning task. The initiation process enables the KMA’s learning characteristics to construct a Decision Tree using ID3 algorithm. First, the algorithm fixes highest information gain attribute value node as the root of the decision tree. The process is repeated till all the rest of the nodes are fixed in their places. The Attributes considered for the decision tree construction are CLEAN, PURGE, and NORMAL (Normalization). Training examples (Table1) are used to train the KMA to learn and choose appropriate cleaning procedure / method. In the learning process KMA starts the search from the root node of the decision tree and the evaluation function evaluates each node to determine the action. Based on the value returned by the evaluation function, the agent learns either to precede one more level down in the decision tree or remain in the same node and it returns the current state.
Once the KMA identifies the cleaning procedure / method, it starts learning from the execution environment. To clean the Email text data the system receives the file name as input. Interface Agent receives the user input
KMA
DCOA
MHA User
Agent
I A DCLA
Intelli -gence
DST Eva- Fun
and sends it to the DCOA for further processing. DCOA in turn sends the user information to the KMA to check the availability of cleaned Email. If the source file involved in the Email cleaning process is new then the DCLA starts the cleaning process by extracting the header and signature portion of the Email text data file and uses the extracted portion of the file to do the normalization process of the cleaning task. If the cleaned Email text file is available with KMA then it sends the cleaned details to the Data Cleaning Agent (DCLA) for forwarding to IA. KMA uses its intelligence and reacts with the system when the same task is repeated.
6.2 Implementation
IMASDC Architecture was developed and implemented using java. Interface Agent receives the input from the user and sends the collected information to the Data Collection Agent (DCOA) for further processing. DCOA in turn sends the information collected to the KMA to verify the existence of the given source file. KMA sends the details of the source file to be cleaned to the Intelligence Component(IC). IC sends the same details to the Decision Search Tree (DST) component to make appropriate decision. DST initiates the search process and makes use of the evaluation function to determine the action. Evaluation function checks the availability of the file with .EC.TXT extension.
If the file is available, the evaluation function returns 0 (without changing the state) and the decision tree chooses the option ‘other’ and determines not to perform cleaning operation. As the result, Decision Search Tree sends the file name with .EC.TXT extension to the intelligence component and the Intelligence component forwards it to the KMA. KMA sends the cleaned file (file with extension as .EC.TXT) to the Data Cleaning Agent (DCLA) for further processing.
If the file with extension .EC.TXT is not present but the file name with .NTF.TXT is present then the evaluation function changes its state and returns a value 1. Now the decision Tree chooses the path with the value ‘norm’ then moves one more level down and reaches the node NORM. Decision tree sends the file name (with .NTF.TXT extension) as the result of search process to the Intelligence component. Intelligence component forwards the file to the KMA and sends the intermediate cleaned file ( ie: with extension .NTF.TXT ) to the DCLA to perform paragraph normalization, sentence normalization and word normalization. DCLA sends the resultant cleaned file to the KMA and Interface Agent as output. KMA reassigns the file with the extension (.EC.TXT) and deletes the file name with .NTF.TXT extension. If both the extensions (.EC.TXT and .NTF.TXT) are not present then the evaluation function changes its state and returns value 1 (with ntf). The Cleaning of Email text data is done in two passes.
Pass1
First the decision Tree uses the value ‘filter’ to choose the path and reaches the node PURGE. Decision Search Tree sends the file name (with .TXT extension) to the Intelligence component. Intelligence component forwards the file to the KMA and this in turn sends the file (with extension .TXT) to the DCLA to perform Header and Signature removal operation. DCLA sends the result of removal of non-text information to the KMA. KMA reassigns the file with the extension (.NTF.TXT) and stores this intermediate version.
Pass2
6.3 Sample Email data and Cleaned Email
The following example is a sample Email given as an input (Fig.7) to perform the Email cleaning process and the corresponding cleaned Email obtained as an output is presented in Fig.8.
1. On Mon, 23 Dec 2002 13:39:42 -0500, "Brendon" 2. <[email protected]> wrote:
3. NETSVC.EXE from the NTReskit. Or use the 4. psexec from
5. sysinternals.com. this lets you run
6. commands remotely - for example net stop 'service'. 7. --
8. --- 9. Best Regards
10. Brendon 11.
12. Delighting our customers is our top priority. We welcome your comments and 13. suggestions about how we can improve the support we provide to you. 14. ---
15. >>---Original Message---
16. >>"Jack" <[email protected]> wrote in message
17. >>news:00a201c2aab2$12154680$d5f82ecf@TK2MSFTNGXA12... 18. >> Is there a command line util that would allow me to
19. >> shutdown services on a remote machine via a batch file? 20. >>Best Regards
21. >>Jack
Fig. 7 Example of Email message
NETSVC.EXE from the NTReskit. Or use the psexec from sysinternals.com. This lets you run commands remotely - for example net stop 'service'.
Fig 8. Cleaned Email message
Fig.7 shows an example Email which includes many typical noises (or errors) for text mining. Lines 1 and 2 are a header; lines from 7 to 14 are a signature; and a quotation lies from line 15 to line 21. All of them are supposed to be irrelevant to text mining. Only lines from 3 to 6 are actual text content. However, the text is not in canonical form. It is separated by extra line breaks mistakenly. The word “this” in line 5 is also not capitalized.
The non-text parts (header, signature and quotation) have been removed in pass 2 and the text has been normalized. Specifically, the extra line breaks have been eliminated. The case of word “this” has been correctly restored. Fig.8 shows an ideal output after cleaning the Email (Fig.7).
6.4 Analysis
The above two charts are the outcome of the analysis made over normal cleaning and agent based cleaning. Agent based Email data cleaning is found to be much better than the normal cleaning procedure. Only for the first time the agent based Email data cleaning and the normal Email data cleaning procedure requires the same amount of time. In the subsequent process the agent makes use of its previous experience (stored in its knowledgebase) for cleaning. Use of Multi-Agents in the data cleaning architecture reduces the computation time and the performance of the data cleaning system is improved by the learning behaviour of the agent. It is observed that IMASDC Architecture based Email data cleaning gives performance over non agent based (normal) Email data cleaning
7. Conclusion
This paper proposes Intelligent Multi-Agent Data Cleaning (IMASDC) Architecture that uses the Object oriented frameworks MAS and MAS-L. Functionalities and the behaviour of the agents present in the architecture are described in detail. Among the agents present in the architecture KMA is designated to be the learning agent. To implement the learning characteristics of KMA a learning algorithm based on the machine learning tool decision trees was used. Email data cleaning using IMASDC Architecture brings the data cleaning system to have intelligence behaviour and improves the functionality of the system with higher performance than ordinary systems. Future work on this paper may use the IMASDC architecture is to clean the text data, clean text database and clean biological database.
Reference
[1] Ayse Yasemin SEYDIM, "Intelligent Agents : A Data Mining Perspective", CiteSeer-IST Scientific Literature Digital Library, 1999.
[2] Alex Bordetsky, "Agent-Based Support for Colloborate Data Mining in System Management", Proceedings of the 34th Hawaii international conference on System Science, 2001,vol ©IEEE, ISBN 0-7695-0981-9/01.
[3] Dae Su Kim, Chang Suk Kim, Kee Wook Rim, "Modeling and Design of Intelligent Agent System", International Journal of Control Automation and Systems, 2003, Vol 1 No 2.
[4] Dong-Chul Park,"Centroid Neural Network for Unsupervised Competitive Learning", IEEE Transactions on Neural Networks, 2000, Vol 11 © IEEE, ISBN S1045-9227(00)02998-2.
[5] Erhard Rahm, Hong Hai Do, "Data Cleaning: Problems and Current Approaches", conference on data cleaning,2000. [6] Fayad. M, D.Schmidt, "Building Application Frameworks: Object-Oriented Foundations of Design",John Wiley & Sons,1999. [7] Feldman R , Fresji M, Hirsh H, Aumann Y, Liphstat O, Schlter Y , Rajman M, "Knowledge Management : A Text Mining Approach" ,Proceedings of the 2nd International conference on Practical Aspects of Knowledge Management(PAKM98),1998. [8] Ferber, J, "Multi-Agent Systems: An Introduction to Distributed Artificial Intelligence", Addison-Wesley Pub Co, 1999.
[9] Garcia, A., Silva, V., Lucena, C., Milidiú, R. "An Aspect-Based Approach for Developing Multi-Agent Object-Oriented Systems", Simpósio Brasileiro de Engenharia de Software Rio de Janeiro, 2001.
[10] Garcia, A., Lucena, C. J., Cowan, D.D., "Engineering Multi-Agent Object-Oriented Software with Aspect-Oriented Programming", Elsevier, 2001.
[11] Garcia, A., Lucena, C. J.,"An Aspect-Based Object-Oriented Model for Multi-Agent Systems", 2nd Advanced Separation of Concerns Workshop at ICSE-2001, 2001.
[12] Garro, A., Palopoli, L.,"An XML Multi-Agent System for e-Learning and Skill Management", Third International Symposium on Multi-Agent Systems-Large Complex Systems and E-Businesses (MALCEB-2002), 2002.
[13] Gerhard Weiss, "Multiagent Systems – A Modern Approach to Distributed Artificial Intelligence", The MIT Press, 1999. [14] Helena Galhardas, Daniela Florescu, Dennis Shasha, Eric Simon, Christian-Augustin Saita, "Declarative Data Cleaning: Lanaguage, Model and Algorithms", Proceedings of the 27th VLDB conference, 2005.
[15] Ioerger, T. R. He, L. Lord, D. Tsang, P , "Modeling Capabilities and Workload in Intelligent Agents for Simulating Teamwork", Proceedings of the Twenty-Fourth Annual Conference of the Cognitive Science Society (CogSci-02),2002, PP482-487.
[16] Jiawei Han , Micheline Kamber, "Data mining: Concepts and Techiniques" , Morgan Kaufmann Publishers- Elsevier, 2001. [17] Jie Tang, Hang Li, Yunbo Cao, Zhaohui Tang , "Email Data Cleaning", Proceedings of the KDD’05 , 2005, vol © ACM, ISBN 1-59593-135-X/05/0008.
[18] Kollayut Kaewbuadee, Yaowadee Temtanapat, Ratchata Peachavanish, "Data Cleaning using FD from Data Mining process", Proceedings of conference, 2003.
[20] Massimo Cossentino, Antonio Chella and Umberto Lo Faso, "Designing agent based systems with UML" ,international conference on agents, 2006.
[21] Raymond J Mooney , Razvan Bunescu, "Mining knowledge from text using information extraction", SIGKDD Explorations, 2003, vol 7 issue 1, pp 3-10.
[22] Russell, S., Norvig, P., "Artificial Intelligence, A Modern Approach", Prentice-Hall, 1995.
[23] Sardinha, J.A.R.P., Ribeiro, P.C., Lucena, C.J.P., Milidiú, R.L., "An Object-Oriented Framework for Building Software Agents", Journal of Object Technology,2003, Vol 2No.1.
[24] Sardinha, J.A.R.P., Milidiú, R.L., Lucena, C.J.P., Paranhos P , "An Object-Oriented Framework for Building Intelligence and learning properties in Software Agents",Journal of object Technology, 2004.
[25] Shahram Rahimi and Norman F. Carver , "A Multi-Agent Architecture for Distributed Domain-Specific Information Integration", Proceedings of the 38th Hawaii International Conference on System Sciences,2005, vol ©IEEE, ISBN 0-7695-2268-8/05.
[26] Soman K P, Shyam Diwakar, Ajay. V, "Insight into Data Mining Theory and Practice", PHI, 2008, ISBN 978-81-203-2897-6. [27] Stader, J., Macintosh, A., "Capability Modeling and Knowledge Management- In Applications and Innovations in Expert Systems VII", 19th Int Conf on Knowledge-Based Systems and AAI Springer-Verlag, 1999, pp 33-50 ISBN 1-85233-230-1.
[28] Symeonidis A L, Chatzidimitriou K C, Athanasiadis I N, Mitkas P A , "Data Mining for agent reasoning : A synergy for training agents", Engineering Applications of Artificial Intelligence- Elsevier, 2007.
[29] Tobin J Lehman, Stephen W. McLaughry, Peter Wyckoff, "T Spaces : The next Wave", Proceedings of international conference on Machine Learning, 1999.
[30] Tom M Mitchell, "Machine Learning", McGrawHill,1997, ISBN 0070428077.
[31] Weiss, G., "Multiagent systems: a modern approach to distributed artificial intelligence", The MIT Press, 2000. [32] William E Winkler, "Data Cleaning Methods", Conference SIGKDD’03 , 2003, vol © ACM, ISBN 1-58113-000. [33] Winston, PH. "Artificial Intelligence", Addison Wesley, 1992.
[34] Wooldridge, M, Jennings, N. R., Kinny, D."The Gaia Methodology for Agent-Oriented Analysis and Design",Kluwer Academic Publishers,2000.
[35] Zili Zhang, Chengqi Zhang and Shichao Zhang, "An Agent-based hybrid framework for database mining", Taylor & Francis Group Applied Artificial Intelligence, 2003,pp 17:383-398.