CENTRO DE CIÊNCIAS EXATAS E DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO
UTILIZAÇÃO DE CONDIÇÕES DE CONTORNO PARA
COMBINAÇÃO DE MÚLTIPLOS DESCRITORES EM
CONSULTAS POR SIMILARIDADE
R
ODRIGOF
ERNANDESB
ARROSOO
RIENTADOR:
P
ROF.
D
R.
R
ENATOB
UENOUNIVERSIDADE FEDERAL DE SÃO CARLOS
CENTRO DE CIÊNCIAS EXATAS E DE TECNOLOGIAPROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO
UTILIZAÇÃO DE CONDIÇÕES DE CONTORNO PARA
COMBINAÇÃO DE MÚLTIPLOS DESCRITORES EM
CONSULTAS POR SIMILARIDADE
R
ODRIGOF
ERNANDESB
ARROSODissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação da Universidade Federal de São Carlos, como parte dos requisitos para a obtenção do título de Mestre em Ciência da Computação, área de concentração: Engenharia de Software, Banco de Dados e Interação Humano Computador.
Orientador: Prof. Dr. Renato Bueno.
Ficha catalográfica elaborada pelo DePT da Biblioteca Comunitária da UFSCar
B277cc
Barroso, Rodrigo Fernandes.
Utilização de condições de contorno para combinação de múltiplos descritores em consultas por similaridade / Rodrigo Fernandes Barroso. -- São Carlos : UFSCar, 2014.
78 f.
Dissertação (Mestrado) -- Universidade Federal de São Carlos, 2014.
1. Banco de dados. 2. Dados complexos. 3. Consultas por similaridade. 4. Gap semântico. 5. Combinação de múltiplos descritores. I. Título.
UNIVERSIDADE FEDERAL DE SÃO CARLOS
CENTRO DE CIÊNCIAS EXATAS E DE TECNOLOGIAPROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO
UTILIZAÇÃO DE CONDIÇÕES DE CONTORNO PARA
COMBINAÇÃO DE MÚLTIPLOS DESCRITORES EM
CONSULTAS POR SIMILARIDADE
RODRIGO FERNANDES BARROSO
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação da Universidade Federal de São Carlos, como parte dos requisitos para a obtenção do título de Mestre em Ciência da Computação, área de concentração: Engenharia de Software, Banco de Dados e Interação Humano Computador.
Aprovado em
Membros da Banca:
Prof. Dr. Renato Bueno (Orientador – UFSCar/DC)
Prof. Dr. Ricardo Rodrigues Ciferri (UFSCar/DC)
Prof. Dr. Joaquim Cezar Felipe (USP/ DCM – FFCLRP)
Dedico este trabalho aos meus pais José Francisco Barroso e Maria Regina Fernandes Barroso, e a minha esposa Michelle Sandrin dos Santos Barroso que estão sempre do meu lado me apoiando e dando força para seguir em frente e lutar pelos meus sonhos. E as minhas irmãs, familiares e amigos que fazem parte e completam minha vida.
Em memória de meu pai José Francisco Barroso, sempre do meu lado.
A
GRADECIMENTO
Agradeço primeiramente a Deus, pela oportunidade de realizar mais esta
etapa muito importante na minha vida e por sempre estar ao meu lado. Agradeço
também ao meu orientador, professor doutor Renato Bueno por ter acreditado em
mim, pela paciência com as minhas limitações, serei eternamente grato pela
oportunidade de conhecer e trabalhar juntos. Também aos companheiros alunos e
professores do Grupo de Banco de Dados do Programa de Pós-Graduação em
Ciência da Computação da Universidade Federal de São Carlos, das quais
engrandeceram muito este trabalho com diversas opiniões e pontos de vista. Aos
amigos do Departamento de Computação da UFSCar, foi um prazer compartilhar de
vários momentos juntos durante os três anos do mestrado. Agradeço também a
todos os meus amigos que me apoiaram e acreditaram sempre no meu potencial
para realização deste trabalho. Agradeço também pelo apoio financeiro recebido
R
ESUMO
Dados complexos, como imagens, enfrentam problemas semânticos em suas consultas que comprometem a qualidade dos resultados. Esses problemas são caracterizados pela divergência entre a interpretação semântica desses dados e a forma como são representados computacionalmente em características de baixo nível. Nessa representação são utilizados vetores de características que descrevem características intrínsecas (como cor, forma e textura) em atributos qualificadores. Ao analisar a similaridade em dados complexos percebe-se que essas características intrínsecas se complementam na representação do dado, bem como é realizada pela percepção humana e por este motivo a utilização de múltiplos descritores tende a melhorar a capacidade de discriminação dos dados. Nesse contexto, outro fato relevante é que em um conjunto de dados, alguns subconjuntos podem apresentar características intrínsecas específicas essenciais que melhor evidenciam seus elementos do restante dos dados. Com base nesses preceitos, este trabalho propõe a utilização de condições de contorno para delimitar estes subconjuntos e determinar o melhor balanceamento de
múltiplos descritores para cada um deles, com o objetivo de diminuir o “gap
semântico” nas consultas por similaridade. Em todos os experimentos realizados a utilização da técnica proposta sempre apresentou melhores resultados. Em comparação a utilização de descritores individuais com as mesmas condições de contorno e sem condições de contorno, e também a combinação de descritores para o conjunto todo sem a utilização de condições de contorno.
A
BSTRACT
Complex data, like images, face semantic problems in your queries that might
compromise results quality. Such problems have their source on the
differences found between the semantic interpretation of the data and its low level machine language. In this representation are utilized feature vectors that describe intrinsic characteristics (like color, shape and texture) into qualifying attributes. Analyzing the similarity in complex data, perceives that these intrinsic characteristics complemented the representation of data, as well as is carried out by human perception and for this reason the use of multiple descriptors tend to improve the ability of discrimination data. In this context, another relevant fact is that in a data set, some subsets may present essential specific intrinsic characteristics to better show their rest of the data elements. Based in such premises, this work proposes the use of boundary conditions to identify these subsets and then use the best descriptor combination balancing for each of these, aiming to decrease the existing
“semantic gap” in similarity queries. Throughout the conducted experiments the use of the proposed technique had better results when compared to use individual descriptor using the same boundary conditions and also using descriptors combination for the whole set without the use of boundary conditions.
L
ISTA DE
F
IGURAS
Figura 2.1 – Imagens com seus respectivos histogramas. ... 23
Figura 2.2 – Consulta por Abrangência. ... 24
Figura 2.3 – Consulta por k-vizinhos mais próximos (k=4). ... 25
Figura 2.4 – Exemplo de Histograma extraído de uma imagem. ... 27
Figura 2.5 – Exemplo de Vetor de Características extraído de uma imagem... 28
Figura 3.1 – Gráfico da variação da precisão média na combinação de descritores. (BUENO et al., 2009) ... 33
Figura 4.1 – Gráfico da média de precisão do conjunto de dados MRI_704. (BUENO et al.,2011) ... 40
Figura 4.2 – Arquitetura do ambiente de treinamento do método proposto. ... 45
Figura 4.3 – Arquitetura do ambiente de utilização do método proposto. ... 46
Figura 5.1– a) Imagem Original, b) Imagem resultante do janelamento para Histograma Baixo– realça regiões mais brilhantes, c) Imagem resultante do janelamento para Histograma Alto – realça regiões mais escuras (PONCIANO-SILVA et al., 2009). ... 50
Figura 5.2 – Amostragem das Classes de Imagens de Exames de Ressonância Magnética. ... 51
Figura 5.3 – Curvas de Precisão x Revocação de consultas TC_Pulmão utilizando Textura com as Funções de Distância Minkowski e Canberra. ... 53
Figura 5.4 – Curvas de Precisão x Revocação das consultas executadas para o conjunto de dados TC_Pulmão. ... 55
Figura 5.5 – Precisões médias obtidas nas consultas realizadas no conjunto de dados TC_Pulmão. ... 56
Figura 5.6 – Curvas de Precisão x Revocação das consultas executadas no conjunto de dados TC_Pulmão. ... 57
Figura 5.7 – Precisões médias obtidas nas consultas realizadas no conjunto de dados TC_Pulmão. ... 58
Figura 5.8 – Curvas de Precisão x Revocação das consultas executadas no conjunto de dados ROI_TCPulmão (fase de treinamento). ... 60
Figura 5.10 – Precisões médias obtidas nas consultas realizadas no conjunto de dados ROI_TCPulmão (conjunto todo) ... 61 Figura 5.11 – Precisões médias obtidas nas consultas realizadas no conjunto de
dados ROI_TCPulmão(conjunto todo). ... 61 Figura 5.12 – Curvas de Precisão x Revocação das consultas executadas no
conjunto de dados MRI_704... 63 Figura 5.13 – Precisões médias obtidas nas consultas realizadas no conjunto de
dados MRI_704. ... 63 Figura 5.14 – Precisão média combinando linearmente Histograma Baixo – L2 / w
Textura - Canberra. ... 65 Figura 5.15 – Precisão média combinando linearmente (Histograma Baixo – L2 +
(0.11 * Textura – Canberra)) / w Histograma Tradicional - LInf ... 66 Figura 5.16 – Precisão média combinando linearmente (Histograma Baixo – L2 +
(0.11 * Textura – Canberra) + (0.10 * Histograma Tradicional – LInf)) / w Histograma Alto – L2 ... 67 Figura 5.17 – Curva de Precisão x Revocação da Combinação de Descritores feito
por algoritmos exaustivos e a Combinação de Descritores realizado neste experimento 4. ... 68 Figura 5.18 –Curvas de Precisão x Revocação das consultas executadas para o
conjunto de dados TC_Pulmão comparando com a Combinação por Condição de Contorno partindo do melhor descritor. ... 69 Figura 5.19 –Precisão média das consultas executadas para o conjunto de dados
L
ISTA DE
T
ABELAS
Tabela 5.1 Conjunto de Características Usadas nos experimentos ... 51
Tabela 5.2 Definição dos Descritores ... 54
Tabela 5.3 Métricas por Condição de Contorno ... 54
Tabela 5.4 Definição dos Descritores ... 56
Tabela 5.5 Métricas por Condição de Contorno ... 57
Tabela 5.6 Métricas por Condição de Contorno ... 59
S
UMÁRIO
CAPÍTULO 1 - INTRODUÇÃO ... 12
1.1 Contexto do Trabalho ... 12
1.2 Motivação ... 14
1.3 Objetivo ... 16
1.4 Organização da Monografia ... 17
CAPÍTULO 2 - FUNDAMENTAÇÃO TEÓRICA ... 18
2.1 Estruturação do Capítulo ... 18
2.2 Dados Complexos ... 19
2.3 Espaço Métrico ... 21
2.4 Consulta por Similaridade ... 22
2.5 Funções de Distância ... 25
2.6 Extrator de características ... 27
2.7 Considerações Finais ... 29
CAPÍTULO 3 - TRABALHOS CORRELATOS ... 30
3.1 Estruturação do Capítulo ... 30
3.2 Combinação de Características ... 31
3.2.1 Abordagem Básica ... 31
3.2.2 Combinação de Múltiplos Descritores ... 32
3.3 Condições de Contorno ... 35
3.4 Considerações Finais ... 37
CAPÍTULO 4 - COMBINAÇÃO DE MÚLTIPLOS DESCRITORES UTILIZANDO CONDIÇÕES DE CONTORNO ... 38
4.1 Estruturação do Capítulo ... 38
4.2 Introdução ... 39
4.3 Metodologia ... 42
4.4 Combinação de Múltiplos Descritores Utilizando Condições de Contorno ... 43
4.5 Considerações Finais ... 47
5.2 Experimentos ... 49
5.2.1 Definição de descritores ... 52
5.2.2 Conjunto de Imagens de Tomografia Computadorizada de Pulmão (TC_Pulmão) ... 54
5.2.3 Conjunto de Imagens de Áreas de Interesse (ROI) de Tomografia Computadorizada de Pulmão (ROI_TCPulmão) ... 58
5.2.4 Conjunto de Imagens de Ressonância Magnética (MRI_704) ... 62
5.2.5 Combinação de múltiplos descritores partindo do melhor descritor ... 64
5.3 Análise dos resultados obtidos ... 70
CAPÍTULO 6 - CONCLUSÃO ... 71
6.1 Considerações Finais ... 71
6.2 Principais Contribuições ... 72
6.3 Trabalho Futuros ... 72
Capítulo 1
CAPÍTULO 1 -
I
NTRODUÇÃO
Este capítulo apresenta o contexto em que este trabalho está inserido e a motivação que deu origem a este projeto de pesquisa. Em seguida são discutidos os objetivos a serem alcançados, finalizando com a descrição da organização desta dissertação de mestrado.
1.1 Contexto do Trabalho
A necessidade de armazenar e manipular dados não tradicionais (como imagens, sons e vídeos) vem se tornando cada vez mais comum em diversos sistemas de computação, exigindo que o gerenciamento e a recuperação desses dados ocorram de forma mais eficiente e efetiva. Esses dados são comumente chamados de dados complexos.
Sistemas de computadores que utilizam modelos de dados relacionais e objeto-relacionais tratam de uma forma geral dados dos domínios de texto curto ou numérico. Para tratar estes domínios de informação os Sistemas de Gerenciamento de Banco de Dados (SGBDs) atuais utilizam-se de uma propriedade chamada de relação de ordem total (ROT) que permite comparar quaisquer pares de elementos do conjunto, determinando a antecedência/precedência entre eles, podendo assim ser denominados de conjunto totalmente ordenáveis.
Porém, nem sempre esses tipos de dados irão satisfazer a propriedade de relação de ordem total.
Esses tipos de dados são comumente chamados de dados complexos e em muitos casos não possuem o conceito de dimensão associado, o que impossibilita consultas topológicas ou cardinais.
Em muitos dos sistemas existentes a recuperação desses dados complexos é efetuada sobre a descrição textual sobre o conteúdo (KEIM et al., 2002), como por exemplo, para encontrar uma música pelo nome do compositor ou procurar uma paisagem informando o tipo de imagem desejada. No entanto, esse formato nem sempre retorna um bom resultado, além de não oferecer recursos satisfatórios para interagir com vários tipos de mídia (MORIKAWA & SILVA, 2012).
Para comparar conjuntos de dados complexos utiliza-se a similaridade entre pares de elementos que indica o quão um objeto é parecido ou distinto de outro. Essa comparação proporciona um grau de similaridade (ou dissimilaridade) entre cada par de elementos do conjunto, possibilitando, por exemplo, trazer os k elementos mais parecidos com um elemento central de consulta. Este tipo de consulta é denominado Consulta por Similaridade.
Usualmente nas consultas por Similaridade não são comparados os elementos de dados complexos em si, e sim características intrínsecas que foram extraídas desses elementos, como exemplo, em imagens pode-se extrair características relativas à textura, forma ou cor e comparar todos os elementos através destas características. Consultas por similaridade que utilizam informações extraídas do conteúdo do dado complexo também são chamadas de Consultas Baseadas em Conteúdo. Este conteúdo é extraído comumente no formato de um vetor de características e representa algum aspecto do elemento.
Após a obtenção desses vetores de características, são utilizadas funções matemáticas sobre eles para calcular a similaridade entre pares de elementos, sendo estas denominadas funções de distância ou funções de similaridade.
Capítulo 1 - Introdução 14
1.2 Motivação
Cada vez mais, a utilização de sistemas caracterizados pela manipulação com dados mais complexos e variados em relação às aplicações tradicionais comerciais e negócios tem sido explorada e tornou-se de grande interesse para a comunidade científica (da SILVA TORRES & FALCÃO, 2006) (DEEPAK et al., 2012) (GARGANO, NARDELLI, TALAMO, 1991) (LIU et al., 2007) (SILVA et al., 2012) (SINGH & KOTHARI, 2003) (VASCONCELOS & KUNT, 2001).
Um problema enfrentado pelas consultas por similaridade é o “gap semântico” (DESERNO, 2009) existente na forma como o dado é interpretado computacionalmente. Em outras palavras, estes problemas são caracterizados pela divergência entre como os dados são interpretados pela percepção humana realizada a partir de análises de conteúdo de alto nível e a forma como são representados computacionalmente em características de baixo nível.
Tem-se como exemplo, dado uma imagem de um animal como referência, é possível que a pesquisa por similaridade retorne imagens de veículos, paisagens ou qualquer outra imagem semanticamente diferente ao objetivo da consulta e ao resultado esperado porque essas imagens foram consideradas similares pelo algoritmo de busca em sua representação computacional.
Atualmente existem inúmeras pesquisas que atuam sobre dados complexos, bancos de dados multimídia e vários exemplos de aplicabilidade de consultas por similaridades podem ser observadas. Nessas pesquisas é possível observar a definição de uma melhor configuração entre o vetor de características e uma função de distância, tendo essa combinação empregada ao termo descritor ou binômio (BUGATTI, 2008) onde ressalta a importância do inter-relacionamento entre uma função de distância sobre o vetor de características.
Portanto, devem ser encontrados quais descritores melhor evidenciam cada subconjunto do restante dos elementos, e assim utilizá-los em pesquisas direcionadas, certificando que em cada pesquisa está sendo utilizada a melhor característica para evidenciar o elemento e o subconjunto a qual ele possa pertencer.
Considerando como exemplo um banco de imagens médicas com característica específicas que delimitem cada subconjunto, seja uma doença ou uma lesão que permita ser caracterizada por uma hipótese de diagnóstico, então a hipótese de diagnóstico será a condição que pré-define todos os subconjuntos da pesquisa. Tendo em vista a hipótese de diagnóstico como delimitador desses subconjuntos, possibilita-se que a consulta por similaridade recorra ao descritor que melhor evidencia seus elementos do restante do conjunto de dados.
Sendo assim, é possível definir que cada subgrupo de elementos, apoiando em condições de contorno, utilize de uma função de distância própria com o intuito de aumentar o grau de precisão das pesquisas (PONCIANO-SILVA, 2009) (PONCIANO-SILVA et al., 2009).
Outro fator comum em estudos recentes que se mostra muito efetivo na diminuição do gap semântico em consultas por similaridade é a utilização de combinação de múltiplos descritores (AREVALILLO-HERRÁEZ, FERRI & DOMINGO, 2010) (BROILO & NATALE, 2010) (BUENO et al., 2010) (BUENO et al. 2011) (BUSTOS et al. 2004) (CAICEDO et al., 2007) (FERREIRA et al. 2008) (FERREIRA et al. 2011) (HEESCH & RÜGER, 2002) pois as características acabam se complementando para representarem o conteúdo da imagem.
Porém, geralmente define-se um único balanceamento entre descritores para atender a relação toda. O balanceamento ou função de distância resultante deste produto pode ter maior grau de precisão média para o conjunto como um todo e não atender de forma efetiva certos grupos de elementos do conjunto.
O presente trabalho propõe que para cada subconjunto definido pelas condições de contorno, exista um balanceamento de descritores relacionado que lhe atenda com um melhor grau de precisão.
Capítulo 1 - Introdução 16
especificadamente para atender aquele grupo, seria uma hipótese para melhorar a precisão das consultas por similaridade e diminuir o gap semântico da interpretação dos dados complexos.
1.3 Objetivo
Para um mesmo objeto é possível serem extraídos vários conjuntos de características que descrevem diferentes aspectos dos dados, por exemplo, em imagens são comumente utilizados forma, distribuição de cores e textura. Na literatura é possível analisar que consultas usando combinações de características apresentam resultados melhores levando em consideração seu grau de precisão (BUENO et al., 2011).
A utilização de condições de contorno e a combinação de múltiplos descritores se mostraram individualmente com grande potencial para auxiliar na diminuição do gap semântico em consultas por similaridade, se tornando uma grande motivação para serem utilizadas juntas.
As condições de contorno possibilitam utilizar características que melhor representam subconjuntos de imagens que possuem um comportamento semelhante na consulta por similaridade, e a combinação de múltiplos descritores por sua vez permite uma melhor representação de cada elemento já que cada característica se complementa.
A proposta deste trabalho é utilizar condições de contorno para delimitar subconjuntos de dados e então determinar o balanceamento ideal de descritores para cada um deles, possibilitando que consultas por similaridade utilizem a combinação de múltiplos descritores que melhor representa cada um desses subconjuntos, aumentando assim o grau de precisão das consultas.
Uma vez realizado o balanceamento de descritores, este ficará atrelado a uma condição de contorno, sendo possível utilizá-lo ao realizar as consultas por similaridade de forma transparente, a fim de retornar um resultado mais próximo do esperado.
devem ser informados apenas a imagem de referência para pesquisa e a condição de contorno, o melhor balanceamento será então determinado automaticamente.
Os experimentos para comprovar o método proposto foram realizados em três bancos de dados de imagens médicas pré-classificados e o grau de precisão obtido pelas consultas foram comparados com as técnicas: um descritor individualmente para o conjunto todo, um descritor individualmente para cada classe e a combinação de múltiplos descritores para o conjunto todo.
1.4 Organização da Monografia
Além desta introdução, esta monografia está organizada da seguinte forma:
O Capítulo 2 descreve os fundamentos teóricos necessários para a compreensão deste trabalho. Serão contextualizadas as definições sobre Dados Complexos, Espaço Métrico e Métodos de Acesso Métrico, Consultas por Similaridade, Funções de Distância e Extrator de Características com ênfase para imagens;
O Capítulo 3 faz uma contextualização sobre a combinação de múltiplos descritores e como é realizado o balanceamento entre eles, como as condições de contorno podem ser aplicadas e como elas agregam a pesquisa. Ainda são citadas algumas pesquisas correlatas e a relação entre elas e o tema proposto;
O Capítulo 4 apresenta a metodologia para utilização de condições de contorno para determinar a combinação de múltiplos descritores, método este sendo a contribuição inovadora do trabalho;
O Capítulo 5 descreve os experimentos realizados para validação do método proposto, junto a ele os desafios encontrados e outras sugestões de desenvolvimento; e
Capítulo 2
CAPÍTULO 2 -
F
UNDAMENTAÇÃO
T
EÓRICA
Este capítulo descreve os principais conceitos relacionados à esta dissertação de mestrado. O capítulo é iniciado com as definições e conceitos sobre Dados Complexos definições estas primordiais para entender o tipo da informação que é trabalhada na pesquisa. Logo em seguida é contextualizado Espaço Métrico e Métodos de Acesso Métrico (MAM). Na sequência são apresentadas definições sobre Consulta por Similaridade e Funções de Distância, essenciais para o gerenciamento de dados complexos. E por fim os Extratores de Características são definidos e exemplificados, com o foco voltado para o domínio de imagens.
2.1 Estruturação do Capítulo
2.2 Dados Complexos
É cada vez mais comum a necessidade de armazenar e utilizar não apenas dados tradicionais em bancos de dados, mas também dados mais complexos, como por exemplo: textos longos, imagens, arquivos de áudio e vídeo, onde certamente o tipo imagem é o mais utilizado, aplicados em diversas áreas como: astronomia, museus (HACID & ZIGHED 2006) e medicina se destacando no apoio ao diagnóstico e sistemas de suporte a decisão clínica (DEEPAK et al., 2012).
Em algumas aplicações as imagens são os dados mais importantes ou o único dado extraído (EURIPIDES & FALOUTSOS, 1997), como em sensoriamento remoto e astronomia, que coletam grandes quantidades de dados de imagem através de estações terrestres para processamento, análise e arquivamento. Outras necessidades são identificadas em aplicações relacionadas à cartografia e meteorologia, contemplando imagens de mapas, entretenimento, história da arte, publicidade e na indústria (BERRETTI, DEL BIMBO & PALA, 2002). Por fim a medicina, onde um grande número de imagens de diversas modalidades (por exemplo, tomografia computadorizada, ressonância magnética, etc.) são produzidas diariamente e usadas no apoio à decisão clínica ou diagnóstico. (MÜLLER et al., 2004)
No apoio ao diagnóstico por imagens podemos citar o PACS (Picture Archiving and Comunication System), como sendo o sistema responsável por receber as imagens de diversas origens ou diversos dispositivos de aquisição como aparelhos de tomografia, raio-x, etc., e disponibilizá-las para que médicos e outros sistemas possam acessá-las (PARE et al., 2005) (DEEPAK et al., 2012). Estes sistemas PACS são exemplos da utilização eficaz do uso de imagens para apoio ao diagnóstico, sendo que devem ter uma resposta rápida e seus resultados atenderem a expectativa do especialista (BUENO et al., 2009).
Capítulo 2 - Fundamentação Teórica 20
complexos, é necessário utilizar características intrínsecas extraídas dos elementos, comumente denominadas vetor de características.
Devido à complexidade dos elementos de um domínio de dados complexos, o mais comum é utilizar vetores de características extraídos para fazer a comparação dos elementos, calculando a distância entre eles, (BUENO, 2009). As consultas por similaridade serão realizadas sobre os vetores de características extraídos dos elementos (recuperação de dados por conteúdo), e serão estas características que vão determinar a distância entre os elementos, determinando a similaridade entre eles.
A partir deste vetor de características, é possível comparar um determinado elemento do tipo complexo com todos os elementos do conjunto, aplicando uma função de distância para determinar quais são os elementos mais parecidos (próximos) com o elemento de pesquisa.
Desta forma, um especialista no domínio da aplicação é o mais indicado para definir como serão comparados os dados (TRAINA & TRAINA JR., 2003). Esta concepção de funções de distância apropriadas entre os elementos é a questão essencial do processo de busca e depende da forma que será aplicada (EURIPIDES & FALOUTSOS, 1997).
Este processo de comparação é denominado Recuperação de Dados por Conteúdo (Content-based Retrieval) ou CBR, em imagens é conhecido por CBIR (Content-based Image Retrieval) sendo uma tecnologia de apoio ao gerenciamento de arquivos de imagens organizadas pelo seu conteúdo visual (VELTKAMP & TANASE, 2002) (DATTA et al., 2008) (AREVALILLO-HERRÁEZ, FERRI & MORENO-PICOT, 2011). Este processo de recuperação por conteúdo de imagens não deve ser tratado como um processo exato, pois raramente duas imagens são idênticas.
2.3 Espaço Métrico
Dado uma função de distância que calcule e retorne um valor que indica à semelhança entre cada elemento do domínio de acordo com os critérios de busca, a comparação por similaridade de tais dados leva naturalmente a sua representação em espaços métricos ou multidimensionais.
Bancos de dados métricos são bases onde uma função de distância métrica é definida para pares de objetos do banco de dados, em destaque também aos bancos de dados de objetos de um espaço vetorial, onde os vetores são compostos de atributos numéricos (BRAUNMÜLLER et al., 2001).
Um Espaço Métrico M, é definido por M = (S,d) onde S é o conjunto de todos os elementos que atendem a propriedade do domínio, e d uma função de distância (ou métrica), entre esses elementos, definida como d: S x S → R+. Sendo que tal
função determina quão distante um elemento esta de outro e esta distância determina o grau de similaridade (ou melhor, dissimilaridade) entre estes elementos.
Dados quaisquer elementos s1, s2 e s3 S, a função de distância deve satisfazer as seguintes propriedades, para ser considerada uma métrica:
I. Simetria: a distância retornada pela função d do elemento s1 ao elemento s2 deve ser a mesma distância do elemento s2 ao elemento s1: d(s1,s2) = d(s2,s1);
II. Não Negatividade: a distância d entre quaisquer elementos distintos deve ser sempre maior que 0 (zero) e menor ou igual a ∞ (infinito): 0
d(s1,s2) ∞, e a distância d entre um elemento a ele mesmo é 0 (zero): d(s1,s1) = 0;
Capítulo 2 - Fundamentação Teórica 22
Dentre os métodos de acesso métrico existe um grupo que se baseia em armazenamento de dados em estruturas de páginas, blocos de dados, e árvores (AMATO et al., 2003) onde é possível encontrar na literatura diversos exemplos, dentre eles a M-Tree (CIACCIA, PATELLA & ZEZULA, 1997), Slim-Tree (TRAINA JR. et al., 2002), DBM-Tree (VIEIRA et al., 2004), Onion-Tree (CARÉLO et al., 2009) e cx-Sim (SOARES & KASTER, 2013).
2.4 Consulta por Similaridade
As consultas por similaridade são comuns em diversas áreas. Além da recuperação de informação multimídia, também é comum sua aplicação em data mining, reconhecimento de padrões, aprendizado de máquina, visão computacional, compressão de dados e análise estatística dos dados. (AMATO et al., 2003).
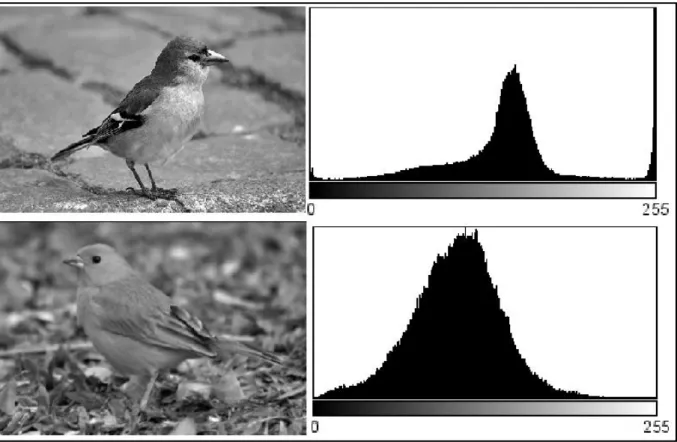
Figura 2.1 – Imagens com seus respectivos histogramas.
Em bancos de dados multimídia, pesquisas por similaridade visam recuperar objetos semelhantes ao objeto de pesquisa com base em suas características visuais (HUANG et al., 2011). Existem dois tipos de consultas principais por similaridade em domínios métricos: consultas por abrangência (“range queries”) e consultas por k-vizinhos mais próximos (“k-nearest neighbor queries”). Estas consultas têm um papel importante em aplicações, tais como sistemas multimídia, sistemas de apoio à decisão, e mineração de dados (BRAUNMÜLLER et al., 2001).
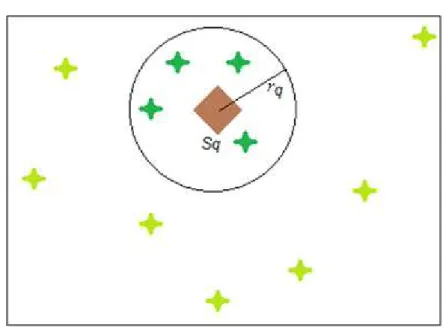
Em consultas por abrangência são considerados os elementos que estejam até uma distância máxima do elemento de referência (ou elemento de busca). Por sua vez a consulta aos k vizinhos mais próximos limita os elementos do conjunto de resposta a um número máximo k.
Considerando um conjunto de elementos S = {s1, s2, ... , sn} de um domínio de
dados S, S ⊂S e uma função de distância (métrica) d entre seus elementos.
Ambas as consultas recebem um elemento do domínio de dados
s
q S, sendoCapítulo 2 - Fundamentação Teórica 24
No caso da consulta por abrangência existe também o parâmetro
r
q ≥ 0,referente a abrangência (ou grau de dissimilaridade máximo) para a resposta, representando a tolerância para recuperação das informações (TRAINA JR., TRAINA, FILHO & FALOUTSOS, 2002) (AMATO et al. 2003).
Tal consulta obtém todos os elementos da base de dados S com grau de dissimilaridade máxima
r
q do elemento central de consultas
q. Esta função érepresentada formalmente como:
range(s
q,r
q) = {s
i| s
iS, d(s
i, s
q)<r
q}
A consulta por abrangência é ilustrada na Figura 2.2.
Figura 2.2 – Consulta por Abrangência.
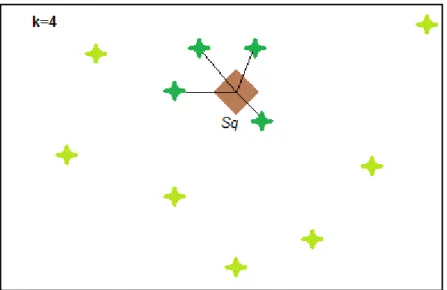
Já na consulta por k-vizinhos mais próximos, o operador deve receber um parâmetro com o máximo k > 0 de vizinhos que a consulta deve retornar (TRAINA JR., TRAINA, FILHO & FALOUTSOS, 2002). Esta consulta obtém os k elementos da base de dados S mais próximos do elemento de consulta
s
q. Ela é representadaformalmente por:
k-nn (s
q, k) = {s
i, s
iA, A
⊆
S, |A| = k,
∀
s
iA, s
jS
–
A, d(s
q, s
i) < d(s
q,s
j)}
Figura 2.3 – Consulta por k-vizinhos mais próximos (k=4).
A semelhança entre elementos é expressa pela função de distância tal que um baixo valor de distância corresponde a um grau elevado de semelhança, ao passo que dois elementos com um alto valor de distância são considerados com um baixo grau de semelhança. (BRAUNMÜLLER et al., 2001).
As características extraídas são usadas para efetuar a pesquisa e determinar qual o grau de similaridade (ou dissimilaridade) entre os elementos. Os elementos recuperados não são necessariamente iguais ao elemento de busca, ao invés disto, a pesquisa deve ser realizada de forma aproximada, onde todos os elementos parecidos com o elemento de pesquisa serão retornados respeitando um grau de tolerância, ou seja, a representação dos dados utilizando vetores de características permite organizar os objetos de acordo com a semelhança entre eles (BUENO et al, 2011).
2.5 Funções de Distância
Capítulo 2 - Fundamentação Teórica 26
estes elementos são, onde quanto mais próximo de zero for o valor, mais similares são os elementos, e quanto maior o valor menos similar eles serão (BUGATTI, 2008).Em outras palavras, a função de distância compara um par de elementos do domínio de dados e retorna um valor que representa a diferença entre eles (BUENO et al., 2009).
A escolha da função deve ser bem criteriosa, pois muitas vezes, é possível que a função selecionada não tenha o grau de precisão esperado. Por exemplo, aplicar a função de distância Euclidiana para forma onde funções de distância quadrática podem ter uma maior precisão para um banco de imagens (BRAUNMÜLLER et al., 2001).
Funções de distância amplamente utilizadas são da Família de Distâncias Minkowski, também conhecidas como funções de distância da Família Lp.
Elas são definidas como:
onde d é a dimensão do espaço. x e y são elementos de dimensão d.
De acordo com o valor definido a p, são obtidas as variações da família Minkowski, dentre elas, podemos citar: função de distância LInf, chamada de Infinity ou Chebychev, representado pela maior diferença de suas coordenadas ao longo de todas suas dimensões; função de distância L1, conhecida como City Block ou Manhattan e corresponde a soma das diferenças entre cada coordenada; por fim a função de distância L2, denominada distância euclidiana.
Outra função de distância comum e também utilizada por este trabalho é a Função de Distância Canberra. O seu cálculo é realizado pela diferença absoluta das características dos vetores dividida pela soma absoluta dos mesmos ao longo de todas suas dimensões, o que a torna sensível a pequenas variações e por este motivo é muito utilizada nas áreas de sequências de DNA e bioinformática. Ela é representada matematicamente como:
Canberra (x, y)
=
d-1
∑
|x
i– y
i|
________________________________|x
i| + |y
i|
2.6 Extrator de características
Na maioria dos conjuntos de dados complexos, é possível extrair vários conjuntos de características de um mesmo elemento, onde cada domínio de dados complexos possui distintos extratores de características. Por exemplo, em aplicações científicas na área de astronomia é medido um grande volume de características numéricas para cada elemento do banco de dados, tal como, a amplitude emitida em algumas frequências de banda (BRAUNMÜLLER et al., 2001).
No caso de bancos de dados de imagens, podemos exemplificar por algumas características, tais como: o histograma normalizado para cor (GONZALEZ & WOODS, 2010), Haralick para textura (HARALICK, SHANMUGAM & DINSTEIN, 1973) (HARALICK, 1979) e Zernike para forma (KHOTANZAD & HONG, 1990) (AMATO, MAINETTO & SAVINO, 1997).
Figura 2.4 – Exemplo de Histograma extraído de uma imagem.
Capítulo 2 - Fundamentação Teórica 28
Figura 2.5 – Exemplo de Vetor de Características extraído de uma imagem.
A extração das características de imagens ocorre quando as mesmas são submetidas a algoritmos de processamento de imagem, conhecidos como extratores de características, que resultam em um vetor numérico, chamado vetor de características, que descreve tais características em forma de assinatura matemática.
Com esses valores numéricos é possível através das funções de distância compará-los e identificar a semelhança entre os objetos (BUENO et al., 2010). A comparação feita pela consulta de similaridade é baseada diretamente no vetor de características, ao invés de utilizar o elemento (dado complexo) propriamente dito. Vale ressaltar que o binomio formado pelo vetor de características e a função de distância dá-se o nome de descritor.
2.7 Considerações Finais
Neste capítulo foram descritos os principais conceitos sobre dados complexos e alguns recursos utilizados para possibilitar que estes dados sejam recuperados em consultas por similaridade.
O capítulo focou na contextualização sobre dados complexos, consultas por conteúdo, espaço métrico que oferece estruturas de indexação para este tipo de dados, como são realizadas as consultas por similaridade possibilitando entender melhor porque sofrem com problemas de gap semântico e as funções de distância com alguns exemplos, por fim os extratores de características que são feitos para extração do conteúdo intrínseco dos dados, resultando nos vetores de características possibilitando assim, junto com as funções de distância, realizar as consultas por similaridade.
Capítulo 3
CAPÍTULO 3 -
T
RABALHOS
C
ORRELATOS
Este capítulo apresenta algumas técnicas utilizadas na combinação de características. No início são realizadas definições sobre essa técnica iniciando com sua abordagem básica e seguindo pela combinação de descritores da forma que é usada por este estudo. Na sequência são apresentados e discutidos trabalhos correlatos que utilizam a combinação de múltiplos descritores. Por fim são apresentados os conceitos da utilização de condições de contorno e de que forma ela colabora para a diminuição do gap semântico em consultas por similaridade.
3.1 Estruturação do Capítulo
3.2 Combinação de Características
3.2.1 Abordagem Básica
Consultas por similaridade em dados complexos podem tratar um único conjunto de características (e.g. em imagens cor, textura ou forma) ou fazer uma combinação dos vetores de características (e.g. em imagens cor e textura, cor e forma, etc.).
Uma maneira trivial para combinar vários conjuntos de características é concatenar todos os vetores extraídos, formando assim um “super-vetor” e a partir disto utilizar alguma função de distância para comparar os dados. Porém é provável que os conjuntos apresentem atributos com valores bem diferentes, o que necessita que esses valores sejam normalizados, evitando qualquer prevalência das características que possuem valores mais altos sobre o resultado.
O aumento da dimensionalidade também torna os espaços multi-dimensionais mais esparsos, ocasionando na “maldição da dimensionalidade” (KORN, PAGEL & FALOUTSOS, 2001) e o desempenho das estruturas de indexação se degradam rapidamente. Esse aumento indiscriminado no número de características ainda prejudica a precisão dos resultados (BUSTOS et al. 2004).
Outro fator relevante é a relação existente entre a característica e a função de distância, onde conjuntos distintos de características que descrevem o mesmo objeto podem obter melhores resultados utilizando funções de distância distintas (BUGATTI, TRAINA & TRAINA JR., 2008) (BUGATTI, 2008). Por isso a utilização de “super-vetores” com uma única função de distância pode deixar de utilizar todo o poder discriminatório de cada característica, diminuindo a possibilidade de alcançar os melhores resultados, pois se utiliza da mesma métrica para comparar diferentes conjuntos de características.
Capítulo 3 - Trabalhos Correlatos 32
3.2.2 Combinação de Múltiplos Descritores
Neste método é feita a extração de diversas características intrínsecas no formato de vetores, como por exemplo, as propriedades de imagens normalmente são descritas pela cor, textura e forma extraídos a partir de algoritmos de processamento de imagem. Cada um desses vetores deve ser vinculado à função de distância que melhor se aplique àquela característica formando os descritores.
Feito isso, esses descritores são combinados aplicando-se um peso para cada um dos valores calculados por cada descritor. Este balanceamento tende a melhorar a precisão das consultas, sendo fundamental equilibrar adequadamente a participação de cada descritor à necessidade de cada consulta por similaridade.
Esta prática também requer cuidados perante o aumento descontrolado dos vetores de características, onde o mesmo pode degradar tanto o desempenho quanto a precisão dos resultados (BUENO et al., 2009). Isso ocorre porque conforme há um aumento na dimensionalidade, os espaços multidimensionais tendem a ser mais esparsos e a distribuição dos elementos homogênea, este fenômeno é conhecido como “maldição da dimensionalidade”.
Neste cenário as características que melhor poderiam evidenciar os elementos tem seu poder de discriminação diminuído devido ao aumento na quantidade de outras características, esta por sua vez resulta em valores mais parecidos de distâncias entre seus elementos, ou seja a distribuição dos elementos no espaço torna-se cada vez mais homogênea.
Outro ponto a ser levado em consideração é a ponderação entre os pesos atribuídos a cada descritor, cuidando para não superestimar ou subestimar seus valores, causando problemas com o balanceamento e consequentemente comprometendo a precisão das consultas.
No balanceamento de múltiplos descritores o método comum para agregá-los de forma linear, é dado por: uma imagem x é representada pelas características
x1,..., xn, com as métricas δ1,..., δn, definidas sobre o domínio dos respectivos
n
δ
(x,y) =
∑
ω
i.δ
i(
x
i,
y
i)
i =1, onde
ωi
é o peso respectivo atribuído a cada descritor.A utilização deste método permite definir como cada descritor contribui para o cálculo de similaridade.
É possível destacar trabalhos que utilizam a combinação de múltiplos descritores para o conjunto todo. Como (BUENO et al., 2009) que propôs uma técnica de balanceamento não supervisionado para descritores baseado na dimensionalidade intrínseca dos conjuntos de dados. Os resultados podem ser observados na Figura 3.1, que apresenta a variação da precisão média na combinação entre os descritores de acordo com a variação dos pesos atribuídos.
Figura 3.1 – Gráfico da variação da precisão média na combinação de descritores. (BUENO et al., 2009)
A linha vertical que corta cada gráfico mostra a estimativa do método proposto para o melhor balanceamento para o conjunto todo É possível observar que essa precisão não é alcançada pela utilização dos descritores individualmente.
Capítulo 3 - Trabalhos Correlatos 34
proporcionando assim melhores resultados nas consultas por similaridade. A mesma definição pode ser observada pelo autor, onde os experimentos ponderados alcançaram melhores precisões nas consultas.
Nos trabalhos de (LIU et al., 2007) (LIU, JIA & WANG, 2007) (LIU, JIA & WANG, 2008) é proposto a combinação de descritores de cor, textura e forma em conjuntos de dados de imagens. Para o balanceamento, a técnica utiliza operadores para atribuição adaptativa de pesos baseadas em estatísticas das características extraídas. Através de simulações que exploram essa combinação de múltiplos descritores, são extraídas informações que mostram a significância da participação de cada um nessa combinação e como ela afetou na precisão das consultas por similaridade. Essas informações são utilizadas para adaptar o balanceamento entre os descritores, de forma a utilizar um peso maior ao descritor que melhor colabora para discriminação dos dados.
No estudo de (FANG, HAIMEI & WEI, 2010) é empregado a teoria da análise de correspondência para integrar os recursos de imagem. Neste trabalho são feitas transformações nos elementos de dados onde é realizada uma extração de diversas características intrínsecas dos elementos além das comumente extraídas (cor, textura e forma), tais como, características relacionadas a pontos, linhas e traços das imagens objetivando obter recursos mais precisos da imagem ou que colaborem mais na sua representação. A consulta por similaridade então equipara cada uma dessas transformações formando uma matriz de resultados, essas informações são usadas para fazer o ranking dos elementos.
similaridade. Dentre as vantagens desta técnica que se utiliza de algoritmos evolutivos é a possibilidade de utilizar funções de balanceamento mais complexas do que a simples combinação linear de descritores, o que pode proporcionar uma melhor discriminação dos dados.
Nas pesquisas de (WANG & ZHU, 2010) (RUI et al., 1998) (ZHUANG & WANG, 2010) são propostos métodos flexíveis, que possuem algoritmos para recalculo dos pesos utilizando realimentação por relevância de acordo com preferências do usuário para encontrar um melhor balanceamento entre os descritores. As técnicas de realimentação por relevância proporcionam interações entre as consultas e o usuário do sistema, onde a cada iteração o usuário indica em uma amostra de dados quais estão mais próximos do esperado. Uma das maiores vantagem apresentadas por esta técnica é justamente a sua forma adaptativa, possibilitando que o algoritmo de busca aprimore a métrica e refaça a pesquisa que tende a obter resultados cada vez mais próximos à expectativa do usuário.
Em (FERREIRA et al., 2011) (SINGH & KOTHARI, 2003) são combinadas as duas estratégias acima. Utiliza-se realimentação por relevância para evoluir os elementos (as métricas) através de algoritmos evolutivos de programação genética. As iteração com o usuário do sistema ocorrem pelo processo de realimentação por relevância, o que possibilita que a métrica seja aprimorada de acordo com as necessidades do usuário.
3.3 Condições de Contorno
Capítulo 3 - Trabalhos Correlatos 36
Na pesquisa o autor utiliza como parâmetro perceptual o “achado” radiológico de imagens médicas de exames radiológicos que analisa: lesões, anormalidades e alterações na estrutura normal de um tecido. Seriam essas as características reconhecidas visualmente na imagem de maior relevância perceptual em uma determinada situação diagnóstica (PONCIANO-SILVA et al., 2009).
O trabalho utilizou a análise de exames torácicos por tomografia computadorizada, com foco em análise de lesões pulmonares. As imagens foram classificadas em seis classes distintas, delimitadas pelas condições de contorno (achados radiológicos) presentes nas imagens. Estes subconjuntos foram: Consolidação, Enfisema, Vidro Fosco, Favo de Mel, Espessamento e Normal. E cada imagem foi classificada exclusivamente em uma das classes.
Foram identificados os relacionamentos entre descritores individuais e as classes, delimitadas pelas condições de contorno, e definidos os descritores que melhor representavam as características visuais dos elementos de cada classe. Em experimentos, o autor mostrou que para cada subconjunto de dados (classes), existia um determinado descritor que apresentava melhores resultados. A partir disto, de acordo com a condição de contorno de cada elemento de consulta é determinado qual o descritor que deve ser usado na consulta por similaridade.
O estudo destaca a contribuição que a utilização dessa “tríade” (vetor de característica, função de distância e parâmetro visual), diminui o gap semântico e melhorou a precisão de consultas por similaridade.
Portanto, podemos concluir sobre este trabalho, a importância que cada característica tem no papel de representação dos dados e o poder de cada uma delas para melhor evidenciar uma determinada classe de elementos do conjunto. Nem sempre uma característica muito relevante para expressar atributos visuais de uma determinada classe tem o mesmo poder de discriminação para evidenciar outra do restante do conjunto.
A relevância com que cada característica irá contribuir na consulta por similaridade deve ser analisada individualmente para cada uma das classes pois cada característica colabora de forma diferente, fazendo-se necessário serem ponderadas de acordo com o poder de representação que cada uma possui para a classe que se deseja evidenciar do restante do conjunto.
simples: pode ser utilizado o sexo do paciente como condição de contorno, enquanto que as imagens utilizadas foram classificadas de acordo com a doença identificada na imagem. Neste caso, a combinação de múltiplos descritores usado seria o que melhor realça a doença que deve ser encontrada (classes) para cada um dos subconjuntos de imagens identificadas pela condição de contorno (homens e mulheres).
3.4 Considerações Finais
Neste capítulo foram descritos vários métodos para combinação de características e descritores. No decorrer do capítulo foi possível esclarecer o quanto a combinação de descritores colabora com a diminuição do gap semântico em consultas por similaridade.
Foram descritas formas de utilizar a combinação de múltiplos descritores, seja pelo recalculo dinâmico dos pesos em combinações lineares ou utilizando técnicas de realimentação por relevância e algoritmos adaptativos, que aperfeiçoa a métrica utilizada com as necessidades do utilizador do sistema.
Também foi discutida a utilização de condições de contorno em consultas por similaridade. Elas proporcionam a possibilidade de utilizar uma métrica que ressalta melhor um grupo de elementos que possuam um comportamento em comum nas consultas e com isso é possível diminuir o gap semântico.
Capítulo 4
CAPÍTULO 4 -
C
OMBINAÇÃO DE
M
ÚLTIPLOS
D
ESCRITORES
U
TILIZANDO
C
ONDIÇÕES DE
C
ONTORNO
Este capítulo apresenta o método proposto que utiliza condições de contorno para determinar a combinação de múltiplos descritores. Neste é apresentada a metodologia e a arquitetura referente à proposta deste trabalho.
4.1 Estruturação do Capítulo
4.2 Introdução
Este trabalho tem como objetivo propor maneiras de melhorar a precisão de consultas por similaridade aplicando combinação de múltiplos descritores, com balanceamentos específicos para subconjuntos delimitados do conjunto de dados, definidos por condições de contorno.
A combinação de múltiplos descritores mostra-se com grande capacidade de melhorar os resultados de consultas por similaridade, sendo que tal fato é explicado pelas características serem complementares ao fazer a identificação de atributos visuais das imagens, de forma similar ao comportamento humano para sua interpretação.
Tal fato pode ser explicado pela forma como um ser humano visualiza e interpreta uma imagem. Ao olhar para uma imagem, o comportamento humano não utiliza apenas as cores da imagem, ou o formato, ou utiliza exclusivamente uma de suas características individualmente, e sim todas as características da imagem são utilizadas para interpreta-la.
Experimentos realizados em (BUENO et al., 2011) apresentaram a precisão dos resultados das consultas por similaridade com combinação de características (Zernike e Haralick) variando os pesos de cada descritor. A Figura 4.1, apresenta o gráfico resultante destes experimentos realizados com uma coleção de dados composta por 704 imagens de imagens de exames de ressonância magnética (MRI_704). Neste conjunto as imagens foram classificadas em 40 classes distintas de acordo com a região do corpo, plano de digitalização e posição do corte, conjunto este também utilizado nos experimentos do presente trabalho.
Capítulo 4 - Combinação de Múltiplos Descritores Utilizando Condições de Contorno 40
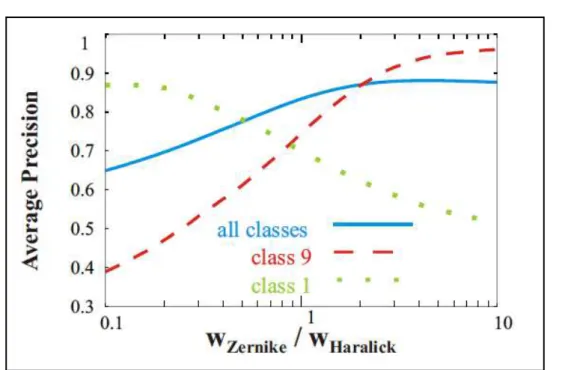
Figura 4.1 – Gráfico da média de precisão do conjunto de dados MRI_704. (BUENO et al.,2011)
O gráfico possibilita observar a influência da proporção dos pesos de cada descritor no resultado da consulta. O melhor resultado obtido, na média para o conjunto todo, aparece quando temos aproximadamente a proporção do triplo de Zernike sobre Haralick.
Já para consultas sobre elementos da “Classe 1”, os melhores resultados acontecem quando peso de Haralick é aproximadamente 10 vezes maior que o peso de Zernike. Porém, para elementos da “Classe 9”, a melhor proporção variou aproximadamente entre 5 e 10 vezes o peso para Zernike sobre Haralick.
O gráfico ainda mostrou que subconjuntos diferentes são melhor identificados por balanceamentos diferentes. Se fosse utilizado apenas um balanceamento para o conjunto todo, não seriam alcançadas as melhores precisões nas consultas para elementos da “Classe 1” e da “Classe 9”, obtidos com o balanceamento específico para cada uma delas. Além disso, se fosse utilizado um balanceamento ideal para o conjunto como um todo, os resultados para a “Classe 1” seriam ainda mais comprometidos, pois a curva das linhas no gráfico vão em direções opostas.
Imagine por exemplo em um banco de imagens médicas, pode ser utilizada a hipótese de diagnóstico como condições de contorno para delimitar esses subconjuntos. Em muitos casos a hipótese de diagnóstico já vem definida no pedido do exame, se tratando de algo que levou o médico a solicitá-lo a partir do que ele identificou na primeira investigação ou pelo histórico do paciente.
Um exemplo deste cenário permite considerar que um paciente chega com queixas que levam o médico a identificar possíveis sintomas de pneumonia, solicita um raio-x do pulmão para verificar e constatar se a hipótese lançada inicialmente é comprovada pelos exames. Neste caso, a hipótese de diagnóstico inicial de “pneumonia” já acompanha o pedido de exame. Essa hipótese pode ser utilizada como uma condição de contorno, visando definir o melhor balanceamento para evidenciar imagens similares, ou seja, imagens de exames com pneumonia.
Portanto, pretende-se vincular uma condição de contorno a um balanceamento otimizado de múltiplos descritores para cada subconjunto de dados delimitado por tal condição. Neste mesmo banco de imagens poderiam existir outros subconjuntos (p.e. “carcinoma”, “enfisema pulmonar”, etc.) identificados por cada uma das hipóteses de diagnóstico (condição de contorno) onde cada subconjunto estaria vinculado a um balanceamento ideal de múltiplos descritores e desta forma poderia ser utilizado no momento da consulta por similaridade.
Capítulo 4 - Combinação de Múltiplos Descritores Utilizando Condições de Contorno 42
4.3 Metodologia
A metodologia utilizada por este trabalho incluiu a constante pesquisa sobre o estado da arte em consultas por similaridade, CBIR e combinação de múltiplos descritores. Foram realizados diversos estudos teóricos sobre esses temas por meio da leitura de livros, dissertações de mestrado, teses de doutorado e principalmente artigos e revistas disponibilizados pelas bibliotecas digitais IEEE, ACM, Scopus, Springer, DBLP, Google Acadêmico e Microsoft Academic.
Esses estudos ofereceram a fundamentação para o desenvolvimento das atividades propostas. Ademais, foram realizadas reuniões periódicas com o orientador, além da participação e realização de seminários nas reuniões periódicas do Grupo de Banco de Dados da UFSCar, as quais permitiram a realização de discussões a respeito das soluções propostas para este projeto de mestrado.
Primeiramente, foi realizado um estudo teórico de todos os conceitos fundamentais relacionados a consultas por similaridade, sendo elas: arquiteturas e métodos, recuperação por conteúdo, CBIR, vetores de características, funções de distância e métodos de acesso métrico. Na sequência foram estudados os problemas enfrentados por este tipo de consulta em relação ao gap semântico. Posteriormente, os estudos ficaram focados em métodos que visavam à diminuição do gap semântico como as combinações de múltiplos descritores e a utilização de condições de contorno, técnicas estas utilizadas por este trabalho por se mostrarem eficientes na melhora da precisão em consultas por similaridade.
Finalizando estes estudos, com o método proposto pelo trabalho definido, foram focados os experimentos, realizando a combinação de descritores em três bases de dados de imagens médicas disponibilizados pelo Centro de Ciência das Imagens e Física Médica (CCIFM) do Hospital das Clínicas da Faculdade de Medicina de Ribeirão Preto – USP (HCFMRP). As bases de imagens foram previamente classificadas por especialistas e foram utilizadas como condições de contorno nos experimentos, que contaram com esta informação também para validação dos resultados obtidos nos experimentos.
Com os resultados dos experimentos em mãos, os mesmos foram comparados com três práticas da literatura: os descritores utilizados individualmente (apenas um descritor para o conjunto todo), o melhor descritor para cada condição de contorno (tríade), e a combinação de descritores para o conjunto todo (BUENO et al. 2009). Para avaliação dos resultados, foram utilizadas curvas de precisão e revocação das consultas (BAEZA-YATES & RIBEIRO-NETO, 1999) um dos métodos mais eficientes para avaliação de sistemas de busca (MÜLLER et al., 2004).
Na implementação dos algoritmos, foi utilizado à linguagem de programação C++ e os resultados foram plotados em gráficos e tabelas para melhor visualização e análise.
4.4 Combinação de Múltiplos Descritores Utilizando Condições de
Contorno
Vários estudos se baseiam em técnicas para combinação de múltiplos descritores, que tem se mostrado muito eficiente para melhorar a precisão de resultados de consultas por similaridade (BUENO et al., 2009) (BUENO et al., 2011) (BUSTOS et al. 2004) (CHEN et al.,2010) (da SILVA TORRES et al., 2009) (FANG, HAIMEI & WEI, 2010) (FERREIRA et al., 2011) (LIU, JIA & WANG, 2008) (RUI et al., 1998) (SINGH & KOTHARI, 2003) (WANG & ZHU, 2010) (ZHUANG & WANG, 2010). Além disso, os estudos de (PONCIANO-SILVA, 2009) (PONCIANO-SILVA et al., 2009) mostraram que também é possível aumentar a precisão dos resultados de consultas por similaridade através de condições de contorno.
Este trabalho propõe o uso de condições de contorno para delimitar subconjuntos de imagens e assim determinar o balanceamento de múltiplos descritores de forma a usar combinação ideal para cada uma desses subconjuntos de imagens nas consultas por similaridade.
Capítulo 4 - Combinação de Múltiplos Descritores Utilizando Condições de Contorno 44
Tomando como exemplo as aplicações de imagens médicas, as condições de contorno podem ser definidas através de dados associados, tais como, a hipótese de diagnóstico determinado pelo médico ao solicitar o exame ou até mesmo partindo de uma análise inicial das imagens fornecidas por um especialista, que pode pré classificá-las com base em alterações encontradas (achado radiológico).
Com as imagens pré-classificadas de acordo com as condições de contorno definidas pelo especialista do domínio, é realizada a combinação de múltiplos descritores em uma fase de treinamento. São realizados experimentos para combinar descritores variando a razão entre seus pesos (um algoritmo de combinação linear simples) e a partir disto, é possível encontrar o balanceamento ideal para cada condição de contorno.
Nos experimentos apresentados a combinação de descritores é feita de forma linear exaustiva, onde a distância final entre os elementos é calculada através da soma ponderada de cada uma das distâncias, onde as mesmas devem ser divididas pela sua distancia máxima correspondente para que haja uma normalização entre a contribuição de cada descritor.
Este método é dado por: uma imagem x é representada pelas características
x
1,..., xn, com as métricas δ1,..., δn, definidas sobre o domínio dos respectivos
conjuntos de características. A composição da função de distância entre a imagem x
e y é a combinação das distâncias δi ( xi, yi) dado por:
n
δ
(x,y) =
∑
ω
i. δ
i(
x
i,
y
i)
i =1dmax
i, onde ωi é o peso respectivo atribuído ao descritor e dmaxi representa a
distância máxima feita pela comparação entre todos os elementos do conjunto e é utilizado para equilibrar a participação de cada descritor ao representar o elemento.
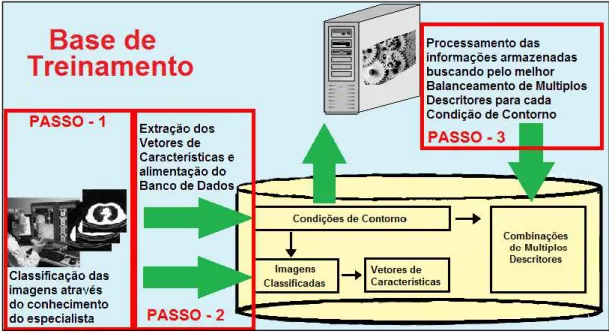
Os passos realizados pelo método proposto são descritos na Figura 4.2. Na figura são ilustrados os passos realizados pela fase de treinamento. No quadro a esquerda da imagem destacado como “PASSO – 1” é o primeiro estágio onde o especialista prepara uma amostragem de imagens pré-classificadas para serem utilizadas de acordo com cada uma das condições de contorno definidas de acordo com a necessidade do especialista. No quadro destacado como “PASSO – 2” são aplicados algoritmos de extração de características nos elementos e estes carregados para uma base de dados. Já com a base de dados alimentada com as características extraídas dos elementos, cada qual vinculada a uma condição de contorno, é realizado o processamento de algoritmos de combinação de múltiplos descritores, destacado na imagem como “PASSO – 3” (quadro mais a direita da figura), objetivando encontrar o melhor balanceamento entre eles para cada uma das condições de contorno.
Figura 4.2 – Arquitetura do ambiente de treinamento do método proposto.
Esta primeira fase resulta basicamente em uma tabela T que relaciona o balanceamento ideal de múltiplos descritores (CMD) a cada uma das Condições de Contorno (CC) do conjunto, onde temos os elementos T = {(CC1, CMD1), ..., (CCi,
CMDi)} , onde i representa a quantidade de condições de contorno.
Capítulo 4 - Combinação de Múltiplos Descritores Utilizando Condições de Contorno 46
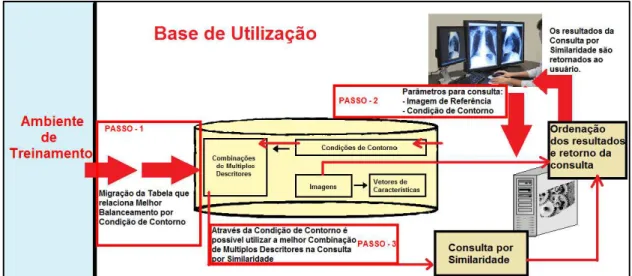
A figura se inicia no quadro mais a esquerda destacado como “PASSO – 1”. Neste ponto é realizada a importação da tabela resultante da fase de treinamento. Esta tabela se torna o recurso mais importante a ser utilizado pelo método por relacionar o balanceamento de múltiplos descritores ideal a cada condição de contorno, o que possibilita utilizar sempre este balanceamento nas consultas de similaridade.
Seguindo sua estrutura, segue para o quadro destacado como “PASSO 2” da figura, esta etapa esta relacionada com o inicio da consulta por similaridade. Neste devem ser passadas como parâmetros para a consulta a imagem de referência para e a condição de contorno, sendo esta informação fundamental pois é através dela que será recuperado o melhor balanceamento de descritores para ser utilizado pela consulta por similaridade.
Neste cenário a condição de contorno é utilizada então para identificar (ou estimar) a qual subconjunto esta imagem de referência pertence e então utilizar a combinação de múltiplos descritores que melhor o evidencie do restante do conjunto e a partir disto utilizar esta combinação na consulta por similaridade.
Tal operação corresponde ao quadro destacado como “PASSO –3” da figura. Uma vez selecionado a melhor combinação de múltiplos descritores ela pode ser utilizada na consulta por similaridade, que é executada e então os elementos são ranqueados e retornados como resultado.