F
ACULDADE DEE
NGENHARIA DAU
NIVERSIDADE DOP
ORTOAnálise de som cardíaco pediátrico para
identificação de sopro
Marisa Oliveira
Mestrado Integrado em Engenharia Informática e Computação
Supervisor: Rui Camacho (FEUP)
Co-Supervisor: Carlos Ferreira (ISEP), Jorge Oliveira (FCUP)
Análise de som cardíaco pediátrico para identificação de sopro
Marisa Oliveira
Mestrado Integrado em Engenharia Informática e Computação
Abstract
Cardiovascular diseases are one of the leading causes of death in the world. Heart auscultation is the most used method to monitor the heartbeat because it is the simplest and cheapest procedure. Using a stethoscope it is possible to detect cardiac anomalies but only specialized and experienced persons are capable of performing a correct diagnosis.
Nowadays the use of technology is increasing, especially in the area of Medicine. New technological developments can be seen in consultations, screening and echocardiograms, electronic stethoscopes and digital devices for the acquisition of cardiovascular data (rhythm, systolic and diastolic times). Within this broad area the focus of this work is on the analysis of cardiovascular data in order to identify heart murmurs in pediatric patients. The available data will be used to construct tools to make early detection of cardiac anomalies and to optimize medical assessment and to also to support medical diagnosis in remote areas where doctors are limited, there is no sophisticated medical diagnostic equipment and to be able to assist the diagnosis in economically poor populations.
The goal of our work is to use Artificial Intelligence (Machine Learning in particular) to analyze the data collected in order to be able to predict if a patient has a heart murmur. Achieving this goal, with the help of this tool, it will be possible to make a diagnosis faster, less expensive and remote from hospital locations.
Keywords: Heart sounds, data processing, heart auscultation, cardiovascular data, machine learning, data mining
Resumo
As doenças cardiovasculares são uma das principais causas de morte no mundo. A auscultação do coração é o método mais usado para monitorizar o batimento cardíaco porque é o mais simples e económico. Ao usar um estetoscópio para auscultação do batimento cardíaco é possível detetar anomalias cardíacas, mas apenas pessoas especializadas e com experiência conseguem fazer um correto diagnóstico.
Nos dias de hoje, o uso da tecnologia é cada vez maior e tem vindo a intensificar-se, especialmente na área de Medicina. Novos desenvolvimentos tecnológicos podem ser encontrados em consultas, triagens e ecocardiogramas, estetoscópios eletrónicos e dispositivos digitais para aquisição de dados cardiovasculares (ritmo, tempos sistólicos e diastólicos). Assim, dentro desta área abrangente, o foco recai na análise dos da-dos cardiovasculares recolhida-dos, de forma a identificar sopros cardíacos em pacientes pediátricos. Os dada-dos disponíveis vão ser usados na construção de ferramentas para detetar anomalias cardíacas com antecedência e otimizar a avaliação médica em áreas remotas, onde os médicos são escassos e não existe equipamento sofisticado, de forma a auxiliar o diagnóstico de população economicamente pobre.
O objetivo incide no uso de Inteligência Artificial (em particular, aprendizagem computacional) nos dados recolhidos a fim de que se consiga prever se um paciente contenha um sopro ou não. Por consequência, com o auxílio desta ferramenta, será possível realizar um diagnóstico de patologias cardíacas à população de forma mais rápida e menos custosa.
Keywords: Heart sounds, data processing, heart auscultation, cardiovascular data, machine learning, data mining
Agradecimentos
A realização deste trabalho não seria possível sem a contribuição de muitos e quero, desde já, deixar aqui o meu sincero obrigada.
Agradeço aos meus orientadores Rui Camacho, Jorge Oliveira e Carlos Ferreira por todo o acompanha-mento, pelos imensos conselhos fornecidos, por se mostrarem sempre dispostos a ajudar e estarem sempre disponíveis para me esclarecerem as dúvidas.
Agradeço aos amigos e colegas que ao longo desta jornada académica me forneceram ajuda em momen-tos de necessidade mas principalmente alegria nos tempos de pausa. Deixo um obrigada especial à Inês, por me tirar algumas dúvidas relacionadas com cardiologia e por me deixar à vontade para ir falar com ela quando mais dúvidas surgissem, à Diana e à Verónica, por me terem acompanhado sempre ao longo deste percurso, por nunca me deixarem desanimar nos momentos de maior dificuldade e por celebrarem comigo as pequenas vitórias, à Beatriz e à Márcia que, mesmo longe geograficamente, conseguiram apoiar-me sempre e à Triz por todas as mensagens de força e por me lembrar várias vezes de manter o foco.
Por fim, agradeço à minha família, em especial aos meus pais e irmãs por todo o apoio, por todos os conselhos, por toda a confiança em mim depositada, por estarem sempre comigo nos bons e maus momentos e serem sempre o meu porto seguro. Sem vocês, não teria sido a mesma coisa.
Muito, muito obrigada!
Marisa Oliveira
“A completely predictable future is already the past.”
Alan Watts
Conteúdo
1 Introdução 1 1.1 Motivação . . . 1 1.2 Objetivos e contribuições . . . 2 1.3 Estrutura da dissertação . . . 2 2 Fisiologia Clínica 3 2.1 Conceitos básicos sobre o coração e patologias associadas . . . 32.1.1 Fisiologia do coração . . . 3 2.1.2 Ciclo cardíaco . . . 4 2.1.3 Som cardíaco . . . 5 2.1.4 Patologias . . . 6 2.1.5 Auscultação . . . 8 3 Estado da Arte 9 3.1 Revisão bibliográfica . . . 9
3.2 Cadeia do processamento do sinal do som cardíaco . . . 10
3.2.1 Pré-processamento: . . . 10
3.2.2 Segmentação . . . 12
3.2.3 Deteção e Classificação . . . 12
4 Conceitos de aprendizagem computacional 15 4.1 Visão geral . . . 15
4.2 Preparação do conjunto de dados: . . . 16
4.2.1 Butterworth . . . 16
4.2.2 Chebyshev . . . 17
4.3 Modelação: . . . 17
4.3.1 Validação cruzada: . . . 17
4.3.2 Máquinas de vetores de suporte (SVM) . . . 17
4.3.3 K-Nearest Neighbors(KNN) . . . 18
4.3.4 Random Forest . . . 19
4.3.5 Regressão logística . . . 20
4.3.6 XGBoost . . . 20
4.3.7 LightGBM . . . 22
4.3.8 Redes neuronais artificiais (ANN) . . . 23
4.4 Avaliação: . . . 24
4.4.1 Accuracy: . . . 25
4.4.2 Precision: . . . 25
4.4.3 Recall: . . . 25
x CONTEÚDO 4.4.4 F1-Score: . . . 26 5 Metodologia 27 5.1 Dados utilizados . . . 27 5.2 Visão geral . . . 28 5.3 Pré-processamento . . . 29
5.4 Extração e normalização de características . . . 30
5.5 Algoritmos de aprendizagem computacional . . . 31
6 Experiências e Resultados 33 7 Conclusões e trabalho futuro 39 A Anexos 41 A.1 Análise multi-foco . . . 41
A.1.1 Quatro focos de auscultação . . . 41
A.1.2 Três focos de auscultação . . . 43
A.1.3 Dois focos de auscultação . . . 44
A.1.4 Um foco de auscultação . . . 46
A.2 Análise por algoritmo . . . 47
A.2.1 Precision . . . 47
A.2.2 Accuracy . . . 51
A.2.3 Recall . . . 55
A.2.4 F1-Score . . . 59
A.3 Tabelas de resultados . . . 63
Lista de Figuras
2.1 Estrutura do coração e curso do sangue através das cavidades e válvulas . . . 4
2.2 Diagrama de Wiggers . . . 5
2.3 Diagrama de auxílio ao diagnóstico de sopro cardíaco através da auscultação . . . 7
2.4 Áreas de auscultação . . . 8
3.1 Diagrama da cadeia do processamento se sinal padrão do som cardíaco . . . 10
3.2 a) Sinal PCG com ruído b) Sinal PCG sem ruído . . . 11
4.1 Butterworth vs Chebyshev . . . 16
4.2 SVM . . . 18
4.3 KNN . . . 19
4.4 Random Forest . . . 20
4.5 Regressão logística . . . 21
4.6 Esquema de um algoritmo baseado em Gradient Boosting . . . 22
4.7 Crescimento de árvore XGBoost vs LightGBM . . . 23
4.8 Esquema de uma rede neuronal . . . 24
5.1 Diagrama do esquema da metodologia . . . 28
5.2 Exemplo do filtro de Butterworth aplicado a um som cardíaco . . . 29
5.3 Exemplo do filtro de Chebyshev aplicado a um som cardíaco . . . 29
6.1 Variação média da métrica precision de acordo com o número de focos de auscultação em todos os algoritmos utilizados . . . 34
6.2 Variação média da métrica accuracy de acordo com o número de focos de auscultação em todos os algoritmos utilizados . . . 34
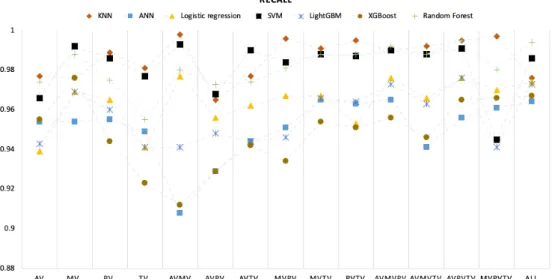
6.3 Variação média da métrica recall de acordo com o número de focos de auscultação em todos os algoritmos utilizados . . . 35
6.4 Variação média da métrica f1-score de acordo com o número de focos de auscultação em todos os algoritmos utilizados . . . 35
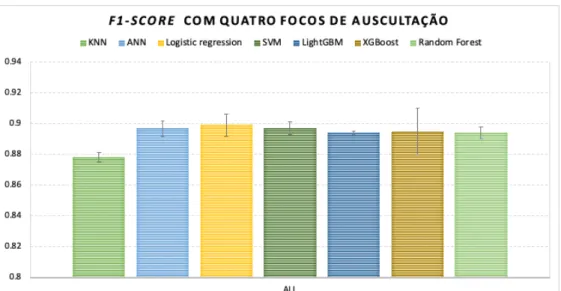
6.5 Variação da métrica f1-score em todos os algoritmos utilizados com quatro focos de auscul-tação e o seu respetivo desvio padrão . . . 36
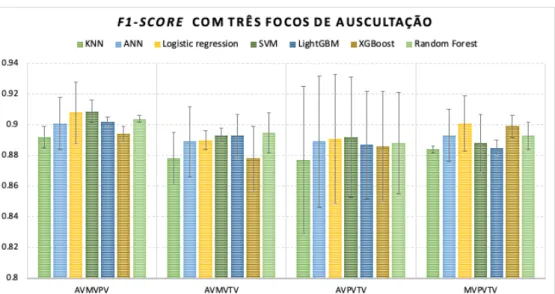
6.6 Variação da métrica f1-score em todos os algoritmos utilizados com três focos de ausculta-ção e o seu respetivo desvio padrão . . . 37
6.7 Variação da métrica f1-score em todos os algoritmos utilizados com dois focos de ausculta-ção e o seu respetivo desvio padrão . . . 37
6.8 Variação da métrica f1-score em todos os algoritmos utilizados com dois focos de ausculta-ção e o seu respetivo desvio padrão . . . 38
xii LISTA DE FIGURAS
A.1 Variação da métrica accuracy em todos os algoritmos utilizados com quatro focos de aus-cultação . . . 41
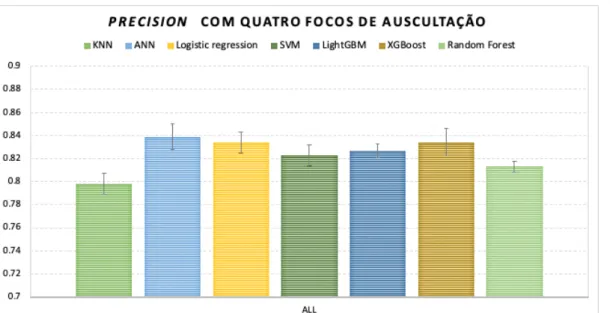
A.2 Variação da métrica precision em todos os algoritmos utilizados com quatro focos de aus-cultação . . . 42
A.3 Variação da métrica recall em todos os algoritmos utilizados com quatro focos de auscultação 42
A.4 Variação da métrica accuracy em todos os algoritmos utilizados com três focos de auscultação 43
A.5 Variação da métrica precision em todos os algoritmos utilizados com três focos de auscultação 43
A.6 Variação da métrica recall em todos os algoritmos utilizados com três focos de auscultação . 44
A.7 Variação da métrica accuracy em todos os algoritmos utilizados com dois focos de auscultação 44
A.8 Variação da métrica precision em todos os algoritmos utilizados com dois focos de auscultação 45
A.9 Variação da métrica recall em todos os algoritmos utilizados com dois focos de auscultação . 45
A.10 Variação da métrica accuracy em todos os algoritmos utilizados com um foco de auscultação 46
A.11 Variação da métrica precision em todos os algoritmos utilizados com um foco de auscultação 46
A.12 Variação da métrica recall em todos os algoritmos utilizados com um foco de auscultação . . 47
A.13 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo KNN . 47
A.14 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo ANN . 48
A.15 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo Ran-dom Forest . . . 48
A.16 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo SVM . 49
A.17 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo LightGBM 49
A.18 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo Lo-gistic Regression . . . 50
A.19 Evolução da métrica precision com o aumento dos focos de auscultação do algoritmo XGBoost 50
A.20 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo KNN . 51
A.21 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo ANN . 51
A.22 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo Ran-dom Forest . . . 52
A.23 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo SVM . 52
A.24 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo LightGBM 53
A.25 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo Lo-gistic Regression . . . 53
A.26 Evolução da métrica accuracy com o aumento dos focos de auscultação do algoritmo XGBoost 54
A.27 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo KNN . . . 55
A.28 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo ANN . . . 55
A.29 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo Random Forest . . . 56
A.30 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo SVM . . . 56
A.31 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo LightGBM 57
A.32 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo Logistic Regression . . . 57
A.33 Evolução da métrica recall com o aumento dos focos de auscultação do algoritmo XGBoost . 58
A.34 Evolução da métrica f1-score com o aumento dos focos de auscultação do algoritmo KNN . 59
A.35 Evolução da métrica f1-score com o aumento dos focos de auscultação do algoritmo ANN . 59
A.36 Evolução da métrica f1-score com o aumento dos focos de auscultação do algoritmo Random Forest . . . 60
A.37 Evolução da métrica f1-score com o aumento dos focos de auscultação do algoritmo SVM . 60
LISTA DE FIGURAS xiii
A.39 Evolução da métrica f1-score com o aumento dos focos de auscultação do algoritmo Logistic Regression . . . 61
Lista de Tabelas
3.1 Sumário dos algoritmos de classificação do som cardíaco utilizados . . . 14
4.1 Matriz de confusão . . . 24
5.1 Número de vezes que cada foco de auscultação foi considerado como o foco mais audível . . 28
A.1 Resumo dos resultados obtidos com todos os algoritmos e o foco de auscultação AV . . . 63
A.2 Resumo dos resultados obtidos com todos os algoritmos e o foco de auscultação MV . . . . 63
A.3 Resumo dos resultados obtidos com todos os algoritmos e o foco de auscultação PV . . . 64
A.4 Resumo dos resultados obtidos com todos os algoritmos e o foco de auscultação TV . . . 64
A.5 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVMV . 64
A.6 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVPV . . 65
A.7 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVTV . . 65
A.8 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação MVPV . 65
A.9 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação MVTV . 66
A.10 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação PVTV . . 66
A.11 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVMVPV 66
A.12 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVMVTV 67
A.13 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação AVPVTV 67
A.14 Resumo dos resultados obtidos com todos os algoritmos e os focos de auscultação MVPVTV 67
A.15 Resumo dos resultados obtidos com todos os algoritmos e os quatro focos de auscultação . . 68
Acrónimos
ANN Artificial Neural Networks(Redes neuronais artificiais)
CNN Convolutional Neural Network(Redes neuronais convolucionais) RNN Recurrent Neural Network(Redes neuronais recorrentes)
DWT Discrete Wavelet Transform(Transformada discreta de wavelet) FIR Finite Impulse Response(Resposta de impulso finito)
IIR Ininite Impulse Response(Resposta de impulso infinito) IPM Índice de Pobreza Multidimensional
PCG Phonocardiogram(Fonocardiograma) S1 Primeiro som cardíaco
S2 Segundo som cardíaco
SVM Support Vector Machines(Máquinas de vetores de suporte) SGD Stochastic Gradient Descent (Gradiente Descendente Estocástico)
AV Foco aórtico
MV Foco mitral
PV Foco pulmonar
TV Foco tricúspide
Capítulo 1
Introdução
Ao longo deste capítulo é introduzido o problema encontrado, o contexto e o trabalho desenvolvido com a elaboração desta dissertação. Além disso, é apresentada a estrutura desta dissertação.
1.1
Motivação
Doenças cardiovasculares são a principal causa de morte em países desenvolvidos. Estima-se que, em 2015, 17,7 milhões de pessoas morreram por causa de doenças cardiovasculares, o que representa cerca 31% das mortes a nível mundial [45]. Estas são de particular relevo em recém-nascidos e em população infantojuvenil, nomeadamente crianças que nascem com malformação congénita, tendo em conta que a cardiopatia é o tipo de doença congénita responsável por mais mortes no primeiro ano de vida do que qualquer outra condição, quando são excluídas etiologias epidémicas [33].
No Brasil, este problema é ainda mais acentuado devido a problemas socioeconómicos. De acordo com o Índice da Pobreza Multidimensional (IPM), em 2015, 3,8% da população brasileira, o que equivale a cerca de 7,8 milhões de pessoas, vivia em situação de pobreza, ou seja, falta de infraestruturas, poucos recursos financeiros para um rastreio eficiente de doenças cardiovasculares, falta de assistência médico sanitária, privações no acesso à saúde, no acesso à educação, no acesso a água potável, ao saneamento e à eletricidade [47]. De acordo com a investigação, a mortalidade infantil tem uma grande influência sobre a taxa de mortalidade do Brasil [47].
No estado de Pernambuco, no Brasil, todos os anos existem campanhas de rastreio, nomeadamente, a Caravana do Coração que tem como objetivo atender crianças e gestantes com problemas cardíacos. Atra-vés da Caravana do Coração, é possível providenciar assistência composta por triagens, consultas e exames cardiológicos a centenas de pessoas o que torna possível a redução do número de óbitos, principalmente de pacientes pediátricos que é a população mais atingida por doenças cardiovasculares congénitas [13]. Em 2015 a equipa da Caravana do coração atendeu 1.349 crianças e destas foram identificadas 473 com cardio-patia, das quais 30 a 50 crianças precisarão de cirurgia [18]. Se assumirmos que os números correspondem a uma amostra representativa da população infantil do estado de Pernambuco, significa que 35% da população pode ter cardiopatia e, aproximadamente, de 3 a 5 crianças em 50 pode precisar de cirurgia, o que leva à
2 Introdução
seguinte questão, que constitui o foco da presente dissertação: como se pode diminuir o número de mortes precoces de crianças devido a doenças cardiovasculares?
1.2
Objetivos e contribuições
Uma possível solução passa por desenhar sistemas inteligentes e automáticos para a deteção precoce de sopro cardíaco com base em auscultação. A auscultação foi o método escolhido porque é um método não invasivo, simples e rápido para conhecer o estado do coração e é mais económico do que, por exemplo, a ecocardiografia [23]. Além disso, a auscultação médica é uma competência difícil de dominar. Requer um extenso e contínuo treino e, mesmo assim, um estudante de medicina precisa de ouvir cerca de 500 repeti-ções de cada tipo de sopro até conseguir classificá-lo corretamente e apenas 20% dos estudantes graduados conseguem detetar sons anormais do coração [44].
Estas limitações podem ser endereçadas através da criação de um sistema de apoio à decisão. Um sistema que utiliza os dados adquiridos pela Caravana do Coração e com base em modelos matemáticos, processamento de sinal e aprendizagem computacional, nomeadamente técnicas de machine learning, será capaz de identificar se o coração se encontra saudável ou se tem alguma anomalia. Assim, será possível reduzir a dificuldade e a margem de erro da auscultação tradicional o que poderá vir a desempenhar um papel crucial no futuro pois auxiliará a realização de um diagnóstico e executar um diagnóstico precocemente diminui drasticamente os fatores de risco de doenças cardiovasculares [27].
1.3
Estrutura da dissertação
Além do capítulo da introdução esta dissertação é composta pelos seguintes capítulos:
• Fisiologia Clínica (Capítulo 2): neste capítulo são apresentados conceitos básicos sobre o coração, desde fisiologia cardíaca, ciclo cardíaco, som cardíaco e patologias associadas.
• Revisão Bibliográfica (Capítulo3): neste capítulo são abordadas as tecnologias existentes relativas ao processamento de sinal e aprendizagem computacional.
• Conceitos de aprendizagem computacional (Capítulo 4): neste capítulo serão abordados os tópicos relativos a aprendizagem computacional desde o pré-processamento, passando pelos algoritmos de aprendizagem computacional até às métricas utilizadas para avaliar modelos de classificação.
• Metodologia (Capítulo5): neste capítulo é exposto o conjunto de dados utilizados, uma visão geral do trabalho elaborado e uma explicação mais detalhada de cada etapa da realização desta dissertação. • Experiências e Resultados (Capítulo 6): neste capítulo são exibidos os resultados das experiências
realizadas durante o desenvolvimento deste projeto
• Conclusões e trabalho futuro (Capítulo7): este capítulo é reservado às conclusões obtidas pelo de-senvolvimento do projeto e por sugestões de trabalho futuro.
Capítulo 2
Fisiologia Clínica
Durante este capítulo são introduzidos conceitos básicos sobre o coração, a sua fisiologia e patologias associadas. Inicia-se pelo ciclo cardíaco onde são introduzidos os conceitos de sístole e diástole. De seguida, é apresentada uma breve explicação de como o som cardíaco é produzido e de como através do som se consegue identificar malformações cardíacas e, por fim, uma lista de patologias que se conseguem identificar através da auscultação do som cardíaco.
2.1
Conceitos básicos sobre o coração e patologias associadas
O coração é um órgão muscular responsável pelo fluxo de sangue para os vasos sanguíneos e cavidades do corpo [4]. As duas principais funções do coração são [23]:
• recolher o sangue rico em oxigénio dos pulmões (sangue arterial) e enviá-lo para todos os tecidos do corpo (grande circulação);
• recolher o sangue rico em dióxido de carbono (sangue venoso) e enviá-lo para os pulmões (pequena circulação);
2.1.1 Fisiologia do coração
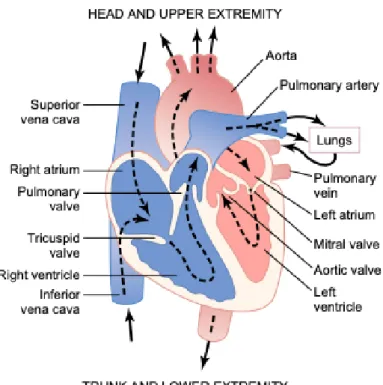
O coração é dividido em quatro cavidades: a aurícula esquerda, o ventrículo esquerdo, a aurícula direita e o ventrículo direito [14], como se pode observar na figura2.1. A circulação do sangue é feita num único sentido e esta circulação unidireccional é assegurada por um sistema de válvulas que permite a passagem do sangue de uma cavidade para outra evitando o seu refluxo [39].
O coração é constituído por dois conjuntos de válvulas: as válvulas auriculoventriculares e as válvulas semilunares. As válvulas auriculoventriculares separam as aurículas dos ventrículos. Existem duas válvulas auriculoventriculares: a válvula tricúspide, que separa a aurícula direita do ventrículo direito, e a válvula mitral, que separa a aurícula esquerda do ventrículo esquerdo [14]. As válvulas semilunares separam os ventrículos das grandes artérias. A válvula pulmonar separa o ventrículo direito da artéria pulmonar e a válvula aórtica separa o ventrículo esquerdo da artéria aorta [14].
1http://www.sohailuniversity.edu.pk/wp-content/uploads/2018/12/Guyton-Physiology-11th-edition.pdf
4 Fisiologia Clínica
Figura 2.1: Estrutura do coração e curso do sangue através das cavidades e válvulas. Figura adaptada de Textbook of Medical Physiology1
2.1.2 Ciclo cardíaco
O ciclo cardíaco é um conjunto de mudanças de pressão que acontecem no coração que resultam no movimento do sangue através das diferentes cavidades do coração e do corpo. Estas mudanças de pressão e volume podem ser representadas graficamente em forma de diagrama de Wiggers, como representado na figura2.2. O ciclo cardíaco é constituído por [48]:
• sístole: que corresponde à contração do ventrículo. Começa quando a válvula mitral fecha e acaba quando a válvula aórtica fecha.
• diástole: que corresponde ao relaxamento do coração. Começa quando a válvula aórtica fecha e acaba quando a válvula mitral fecha.
A diástole começa com o fecho da válvula aórtica e, neste período, o sangue flui pelas válvulas auricu-loventriculares enchendo os ventrículos [48]. O período de enchimento dos ventrículos corresponde a 2/3 do tempo da diástole e, o último 1/3, corresponde à contracção auricular. Esse enchimento resulta no au-mento da pressão nos ventrículos, traduzindo-se no final da diástole, onde as válvulas auriculoventriculares fecham e a vibração resultante do fecho dessas válvulas dá origem ao primeiro som cardíaco (S1) [23]. Mas, as válvulas semilunares não abrem imediatamente. São necessários 0.02 a 0.03 segundos adicionais para os ventrículos acumularem pressão suficiente para abrir as válvulas semilunares (aórtica e pulmonar) [22].
2.1 Conceitos básicos sobre o coração e patologias associadas 5
Figura 2.2: Diagrama de Wiggers. Figura adaptada de Wiggers diagram2
As válvulas semilunares abrem quando a pressão do ventrículo esquerdo atingir ligeiramente mais de 80 mm Hg (e a pressão do ventrículo direito atingir ligeiramente mais de 8 mm Hg). Nessa altura o sangue é ejectado para fora dos ventrículos, o que corresponde à sístole [23]. No final desse período, os ventrículos começam a relaxar permitindo que as pressões intra ventriculares diminuam. Contrariamente, a pressão nas artérias é muito alta. Nesse período algum sangue esperado flui de volta para os ventrículos, forçando as válvulas aórtica e pulmonar a fechar, resultando no segundo som cardíaco (S2) [23].
2.1.3 Som cardíaco
As vibrações e sequente abertura das válvulas cardíacas causadas pela pressão sanguínea durante o ciclo cardíaco, são a origem dos sons cardíacos [14]. Como vimos anteriormente, o som S1 do coração é produzido quando as válvulas mitral e tricúspide fecham em sístole e o som S2 do coração é produzido quando as válvulas pulmonar e a aórtica fecham em diástole [14].
Estes sons são completamente não patológicos e correspondem à turbulência da pressão sanguínea cau-sada pelo fecho das válvulas cardíacas. São geralmente descritos como lub e dub que ocorrem a cada batimento cardíaco. Estes sons podem ser usados como limites entre sístole e diástole. A sístole ocorre de S1 a S2 e a diástole ocorre de S2 a S2. S1 e S2 são normalmente os eventos com maiores amplitudes num si-nal de fonocardiograma (PCG) e têm frequências entre 20-200 Hz. As durações normais desses sons variam entre 70ms a 140ms. A frequência do espetro é muito semelhante, mas mostrou-se que S2 tem frequências maiores do que S1, acima de 150 Hz [43].
6 Fisiologia Clínica
2.1.3.1 Ritmos de Galope
Além dos sons cardíacos S1 e S2 existem os denominados ritmos de galope (S3 ou S4). O termo ritmos de galope deve-se ao facto de, em vez de ouvirmos a sequência lub-dub, é escutado um som adicional o que resulta num som semelhante a um galope (lub-dub-ta ou ta-lub-dub). A ocorrência desses sons acontece na diástole e o S3 vem logo após o S2 e o S4 vem logo após o S1. Acredita-se que este som é causado pelo fluxo de sangue dentro do ventrículo que causa vibrações das válvulas e das cordas tendíneas [6]. Em crianças e jovens podem corresponder ao som normal mas em indivíduos com mais idade corresponde a patologia cardíaca. O S4 corresponde sempre a uma patologia [6]. S3 e S4 têm amplitudes e frequências baixas entre 15-65Hz. A duração desses sons varia de 40ms a 60ms [43].
2.1.3.2 Sopros
Consegue-se distinguir os sopros cardíacos devido à sua maior duração. Em idade pediátrica podem-se delinear três tipos de sopros [3]:
• Sopro inocente: Geralmente, acontece num coração bem estruturado e funcional;
• Sopro funcional ou fisiológico: Apesar de não apresentar anomalia cardiovascular, encontra-se uma modificação hemodinâmica que pode alterar o fluxo normal do sangue;
• Sopro patológico ou orgânico: Quando anomalias funcionais e estruturais estão presentes no sistema cardiovascular.
Geralmente, os sopros são causados pelo fluxo sanguíneo turbulento que pode resultar no estreitamento ou vazamento das válvulas cardíacas ou devido a passagens anormais de sangue no coração [6]. De acordo com a situação fisiológica que leva ao sopro diferentes sons são gerados. Na secção2.1.4serão expostas um conjunto de patologias e sopros associados.
2.1.4 Patologias
Existe um conjunto de doenças cardiovasculares com sopros associados [58] e que podemos observar na figura2.3. Cada sopro, normalmente, tem características que permite distinguir a patologia. De seguida são representadas o conjunto de doenças cardiovasculares audíveis com o estetoscópio [58]:
• Estenose aórtica: corresponde ao estreitamento da válvula aórtica. A auscultação é descrita como um severo crescendo-decrescendo sopro sistólico.
• Regurgitação aórtica: corresponde ao mau fecho da válvula aórtica, permitindo ao sangue fluir em sentido contrário, saindo da artéria aorta e regressando aos ventrículos. A auscultação é descrita como um decrescendo sopro diastólico.
2.1 Conceitos básicos sobre o coração e patologias associadas 7
Figura 2.3: Diagrama de auxílio ao diagnóstico de sopro cardíaco através da auscultação. Figura adaptada de Design, characterization and application of a multiple input stehoscope apparatus3
• Estenose mitral: corresponde ao estreitamento da válvula mitral. A auscultação é descrita como um sopro diastólico.
• Regurgitação mitral: corresponde ao mau fecho da válvula mitral, permitindo ao sangue fluir em sentido contrário, saindo do ventrículo esquerdo e voltando à aurícula esquerda. A auscultação é descrita como um sopro sistólico.
• Prolapso da válvula mitral: distúrbio em que as abas da válvula (cúspides) sofrem prolapso para o átrio esquerdo quando o ventrículo esquerdo se contrai, às vezes permitindo o vazamento (regur-gitação) de sangue para a aurícula. A auscultação apresenta um clique sistólico inicial, por vezes acompanhado de um sopro sistólico tardio.
• Estenose pulmonar: corresponde ao estreitamento da válvula pulmonar. A auscultação é descrita como um crescendo-decrescendo sopro de ejeção sistólico.
• Estenose tricúspida: corresponde ao estreitamento da válvula tricúspida. A auscultação é descrita como um sopro diastólico.
• Regurgitação tricúspida: corresponde ao mau fecho da válvula tricúspida, permitindo ao sangue fluir em sentido contrário, saindo do ventrículo direito e regressando a aurícula direita. A auscultação é descrita como um decrescendo sopro sistólico.
• Defeito do septo: roturas no septo (parede) que separa a aurícula direita da esquerda (defeito do septo atrial) ou a parede que separa o ventrículo esquerdo do ventrículo direito (defeito do septo ventricular).
8 Fisiologia Clínica
Figura 2.4: Áreas de auscultação. Figura adaptada de Tricuspid murmur4
A auscultação dos defeitos do septo atrial apresentam um S1 alto e um largo, com divisão fixa S2. A auscultação dos defeitos no septo ventricular apresentam um sopro holossistólico (que ocupa toda a sístole) alto.
• Cardiomiopatia hipertrófica: doença do miocárdio hereditária em que as paredes sofrem variações hipertróficas, ou seja, tornam-se espessas (hipertrofia) e rígidas. A ausultação apresenta um sopro de ejeção sistólico.
• Persistência do canal arterial: o vaso sanguíneo que conecta a artéria pulmonar à aorta (canal arte-rial) não se fecha. A auscultação é descrita como um contínuo sopro semelhante a uma "máquina".
2.1.5 Auscultação
Para conhecer o estado do coração existem inúmeros procedimentos que permitem verificar o estado do coração como, por exemplo, a auscultação cardíaca, exame do pulso arterial, electrocardiograma (ECG) e a ecocardiografia [39]. Esta dissertação foca-se em auscultação porque é um método não invasivo e eficaz para conhecer o estado do coração, é mais económico do que, por exemplo, a ecocardiografia e o design compacto dos estetoscópios facilita o seu transporte para ambientes de com pouca acessibilidade. Além disso, a auscultação médica é uma competência difícil de dominar. Requer um extenso e contínuo treino e, mesmo assim, um estudante de medicina para conseguir classificar corretamente um sopro, precisa de ouvir cerca de 500 repetições de cada tipo de sopro e apenas 20% dos estudantes graduados conseguem detetar sons anormais do coração [44].
O estetoscópio pode ser usado para auscultar as quatro válvulas cardíacas, sendo posicionado em de-terminada área específica para ouvir a válvula pretendida, como podemos observar na figura2.4: a válvula aórtica ouve-se melhor no segundo espaço intercostal (direito), justo ao esterno; a válvula pulmonar ouve-se melhor no segundo espaço intercostal (esquerdo), justo ao esterno; a válvula tricúspide ouve-se melhor no quarto espaço intercostal (esquerdo) (linha paraesternal) e a válvula mitral ouve-se melhor no quinto espaço intercostal (esquerdo) (linha médio clavicular) [14].
Capítulo 3
Estado da Arte
Neste capítulo é apresentado o estado da arte. Inicialmente explicar-se-á como foi elaborado o respetivo estado da arte e como foram selecionados os trabalhos para análise. De seguida, para reconhecimento dos sons cardíacos, uma cadeia para processar o sinal cardíaco é revelada, onde são exibidos algoritmos utilizados para remoção de ruído dos sons cardíacos, para divisão do som auscultado em ciclos cardíacos e também algoritmos usados para classificar o som auscultado como anormal ou normal.
3.1
Revisão bibliográfica
Para elaborar a revisão bibliográfica foi feita uma pesquisa na ferramenta Google Scholar usando o conjunto de palavras-chave seguinte: heart sound, murmurs, classification, deep learning, neural networks e machine learning. Foram escolhidas estas palavras chave porque esta tese vai combinar algoritmos de aprendizagem computacional, nomeadamente algoritmos de classificação para detecção de doenças con-génitas com base em auscultação. Ao fazer a combinação das palavras-chave referidas foi construída a seguinte query: "intitle:"heart sound"AND "murmurs"AND ("classification"OR "deep learning"OR "neural networks"OR "machine learning"). Esta query foi executada no dia 27 de Janeiro de 2020, com patentes excluídas da pesquisa, e retornou 364 resultados para analisar. A análise foi feita nos passos seguintes: 1. escolher artigos com base no título, isto é, se o título estiver relacionado com a tese é selecionado; 2. Com a leitura do resumo dos artigos selecionados fazer a exclusão daqueles que não são adequados ao propósito da tese. Além disso, a acessibilidade online dos artigos também foi um dos critérios usados para a escolha dos artigos. Após a aplicação de todos os critérios mencionados acima foram selecionados 27 artigos que se tornam a base da análise.
Nesta dissertação vão ser usadas técnicas de Machine Learning para analisar o som cardíaco de forma a ser possível distinguir sons de batimento cardíaco normais de sons de batimentos cardíacos anormais. O objetivo passa por transformar os dados em subconjuntos para ser possível retirar conclusões [40]. De seguida utilizar-se-ão métodos de Machine Learning de forma a construir um sistema de apoio à decisão capaz de analisar o som cardíaco e identificar se possui sopro ou não. Para tornar isso possível é necessário passar pelas quatro fases que irão ser apresentadas de seguida.
10 Estado da Arte
Figura 3.1: Diagrama da cadeia do processamento se sinal padrão do som cardíaco
3.2
Cadeia do processamento do sinal do som cardíaco
Para reconhecer e distinguir os sons cardíacos normais dos sons cardíacos anormais será preciso seguir os passos seguintes que também se encontram representados na figura3.1.
• Pré-processamento: remoção ou atenuação do ruído e aprimoramento das características do sinal. Isto normalmente é alcançado com um processo de filtragem, isto é, remoção de altas ou baixas frequências indesejadas.
• Segmentação: após a filtragem do som, geralmente faz-se a divisão em ciclos cardíacos. Cada ciclo cardíaco é composto pelo primeiro som do coração (S1), sístole, pelo segundo som do coração (S2) e diástole e com a segmentação torna se possível extrair características de cada ciclo.
• Deteção e Classificação: os sons cardíacos são classificados como som com sopro ou som sem sopro de acordo com critérios específicos. Por exemplo, para classificar os sons cardíacos é usado o tempo, duração, qualidade, intensidade. São características utilizadas pelos médicos para fazer a classificação do sopro cardíaco existente no som.
De seguida entrar-se-á em detalhe de cada um dos passos da cadeia de processamento do sinal do som cardíaco com exemplos de técnicas usadas em trabalhos já elaborados. Começa-se com o passo de proces-samento de sinal.
3.2.1 Pré-processamento:
Auscultação computacional tem sido um assunto com várias investigações e muitos métodos diferentes têm sido aplicados para resolver os problemas, não apenas em termos de algoritmos de classificação mas também nas formas de como os dados são recolhidos. Processamento do sinal pode ser dividido em duas principais áreas:
• deteção de sons, como S1 e S2, para executar a segmentação do sinal em ciclos cardíacos • deteção de sopro cardíaco
Ambas as abordagens têm o sinal PCG como base, sendo que ambas partilham as mesmas ferramentas de processamento [35]. O estetoscópio provou a sua utilidade e continua a ser uma ferramenta importante no
3.2 Cadeia do processamento do sinal do som cardíaco 11
Figura 3.2: a) Sinal PCG com ruído b) Sinal PCG sem ruído. Figura adaptada de Heart detection and diagnosis based on ECG and EPCG relationships1
diagnóstico cardiovascular [2] onde os sons produzidos pela atividade cardíaca podem ser registados através da fonocardiografia (sinais PCG) de forma a examinar os sinais PCG tendo em conta padrões patológicos, tais como: variações de intensidade, tempo e duração dos eventos [2]. Mas, a gravação do som cardíaco pode ser corrompida por sons externos, por exemplo, a respiração, o movimento do peito, sons do ambiente, etc [23]. Podemos visualizar na figura3.2uma amostra de um sinal PCG com ruído e sem ruído.
Ao analisar os trabalhos elaborados reparamos que para remover o ruído do sinal PCG os métodos existentes normalmente aplicam filtros passa-banda digitais, sendo os mais comuns os filtros IIR (Infinite Impulse Response) ou FIR (Finite Impulse Response) [23]. Sinha et al. [53] usaram o filtro IIR de But-terworth para remover o ruído do sinal PCG.
Outra abordagem passa pelo uso de transformadas wavelet, nomeadamente Discrete Wavelet Transform. Por exemplo, Chebil et al. [7] usaram DWT (Discrete Wavelet Transform), que pode ser representada como uma árvore de filtros passa-baixo e passa-alto, para decompor o sinal sucessivamente e representá-lo de forma eficiente com o menor número de parâmetros e o menor tempo de computação. Nabih-Ali et al. [42] utiliza métodos DWT para remover o ruído do sinal PCG e conclui que apresentam um desempenho superior na redução do ruído devido à suas propriedades de multi-resolução e a técnica de janela.
Em alguns outros trabalhos são utilizados os filtros Chebyshev, por exemplo, Tang et al. [55] usaram filtros passa-baixo para eliminar o ruído. Um filtro passa baixo filtra as frequências altas das frequências baixas, e Tang et al. usaram um filtro Chebyshev de ordem 8. Martinez et al. [36] usaram filtros passa baixo Chebyshev do tipo I e de quarta ordem para remover as frequências altas devido ao barulho do ambiente e interferências e depois usaram um filtro passa-alto Chebyshev do tipo I (de quarta ordem) para remover
1Phanphaisarn, W.Roeksabutr, Athikom Wardkein, Paramote Koseeyaporn, J. Yupapin, Preecha.(2011). Heart detection and
12 Estado da Arte
as frequências baixas devido aos movimentos musculares. Deperlioglu [12] para filtrar o sinal usa o filtro elíptico. O filtro elíptico combina as propriedades dos filtros Chebyshev (tipo 1 e tipo 2).
A fase de pré-processamento engloba a seleção, remoção do ruído e transformação dos dados. Quando os dados estão aptos para ser analisados segue-se para o passo seguinte: a segmentação.
3.2.2 Segmentação
Nas últimas décadas muitos métodos de segmentação do som do coração foram investigados. Os algorit-mos padrão fazem a extração de envelogramas dos sinais originais e outros critérios temporais para detectar e classificar os sons do coração. [23] O envelograma de energia Shannon é utilizado em vários estudos. Sinha et al. [53] para detectar o primeiro som S1 e o segundo som S2 usaram dois procedimentos indepen-dentes: cálculo da energia de Shannon do sinal wavelet filtrado (0-300Hz) ao longo do tempo e cálculo da energia total ao longo do tempo calculada pela soma de todos os coeficientes por janela do menor tempo da transformada de Fourier.
Outros estudos usam DWT para segmentação do sinal PCG. Low et al. [34] usam DWT para segmenta-ção do sinal PCG.
Verbancic et al. [61] apresentaram um novo método para segmentação automática dos sinais do som cardíaco usando redes neuronais convolucionais profundas. Os sinais usados para avaliar a proposta foram capturados com ruído mas o método utilizado por Verbancic não utiliza as técnicas de processamento co-muns. Definem uma arquitetura de redes neuronais profundas de várias camadas, adaptadas ao processo de segmentação do sinal. Desta maneira, o método realiza a segmentação e deteta os batimentos cardíacos de forma automática.
Modelos semi-Markov também são usados como método de segmentação. Rubin et al. [10] utilizam um modelo semi-Markov oculto de regressão logística para segmentar instâncias de som cardíaco de entrada em segmentos mais curtos. Latif et al. [27] usaram redes neuronais recorrentes (RNN) para detetar sons anor-mais do batimento cardíaco e chegaram a conclusão que os resultados forma significativamente melhores do que os modelos com redes neuronais convencionais.
Após o passo de segmentação estar completo, segue-se para o próximo passo: deteção e classificação.
3.2.3 Deteção e Classificação
A próxima etapa é para detetar e classificar a presença de anormalidades no som cardíaco, ou seja, ondas relacionadas com sopros cardíacos. Esta técnica é o foco desta dissertação porque o objetivo é classificar o som cardíaco como som normal ou anormal. Após a análise de vários trabalhos existentes, redes neuronais são muito utilizadas para a classificação do som do coração. Usualmente, as características usadas como entrada são: tempo, tempo-frequência, frequência, complexidade e características baseadas em escala de tempo [23].
Muitos estudos usam redes neuronais artificiais (ANN). Sinha et al. [53] usaram redes neuronais de backpropagationcom uma camada de entrada de 64 nós. Escrevem um programa para simulação de uma ANN de backpropagation para diferenciar os dados wavelet do PCG entre as válvulas mitrais anormais e
3.2 Cadeia do processamento do sinal do som cardíaco 13
normais. Ali et al. [62] usam ANN com o algoritmo de backpropagation para reconhecer padrões no som cardíaco.
Chebil et al. [7] utilizou um algoritmo que usa DWT para identificação automática de S1 e S2 e classifica o sinal em normal, sopro sistólico ou sopro diastólico. Rubin et al. [10] utilizou RNN profundas à tarefa de classificação automatizada dos sons cardíacos para reconhecimento de sons normais e anormais.
Redes neuronais convolucionais (CNN) e redes neuronais recorrentes (RNN) são também um método aplicado para a classificação de sons cardíacos. Rubin et al. [10] utiliza rede neural convolucional para realizar a extração automática de características e distinguir entre espectrogramas bidimensionais normais e anormais. Deperlioglu [12] usou redes neuronais artificiais (ANN) e redes neuronais convolucionais (CNN) e mostrou que a classificação feita por CNN dava melhores resultados do que a classificação feita por ANN. Low et al. [34] usa redes neuronais convolucionais (CNN) de 2 e 3 camadas para classificação. Tang et al. [55] usaram redes neuronais profundas que combinam componentes de redes neuronais convolucionais (CNN) e redes neuronais recorrentes (RNN) de forma a ser possível analizar e aprender características espaciais e temporais das ondas sonoras.
Outras abordagens utilizam transformadas wavelet de dispersão support vector machines (SVMs). Li et al. [30] propõe um algoritmo para classificação baseado em transformadas wavelet de dispersão (wavelet scattering transform) e twin support vector machine (TWSVM). Kocygit [26] executa com análise linear descriminada (LDA), support vector machines (SVMs) e algoritmos de Naive Bayes (NB).
Na tabela 3.2.3é apresentado um resumo dos trabalhos analisados onde se expõem o autor, o ano de publicação, o conjunto de dados utilizado, as métricas para a avaliação e as suas contribuições.
14 Estado da Arte
Autor Ano Dataset Métricas Contribuição
Latif[27] 2018 Physionet Challenge 2016 Sensitivity, specificity, accuracy
Solução baseada em redes neuronais recorrentes (RNNs)
Leung[29] 2000 56 sons foram recolhidos de crianças, 21 normais e 35 com anormais
Sensitivity Classificação feita por
redes neuronais de proba-bilidade (PNNs)
Vepa[59] 2009 130 sons cardíacos, dos quais 45 sons normais, 42 com sopro sistólico e 43 com sopro diastólico
Accuracy Experiências de
classi-ficação feitas com SVM e k-nearest neighbor (k-NN)
Li [30] 2019 Physionet Challenge 2016 Sensitivity, specificity, accuracy, precision, F1Score
Extração e classificação de características do si-nal do som cardíaco com uma combinação de trans-formadas de dispersão de waveletse SVMs
Sunjing [1] 2017 1000 dados recolhidos do primeiro hospital afiliado da Univeridade de Medi-cina de Kunming, onde 349 batimentos normais e 651 batimentos anormais
Accuracy Uso de CNN para
identi-ficar o padrão do som do coração
Bozkurt [5] 2018 UoC-murmur database e Physionet challenge 2016 Sensitivity, specificity, accuracy Detecção automática de risco de anormalidade estrutural do coração a partir de sinais do PCG, com o uso de CNN Gjoreski [19] 2020 Conjunto de dados
pró-prio e, adicionalemente, 6 conjuntos de dados do Physionet Challenge 2016 Sensitivity, specificity, accuracy Combinação de Machine Learninge Deep Lear-ningpara deteção de do-enças cardiovasculares a partir de sinais PCG Tabela 3.1: Sumário dos algoritmos de classificação do som cardíaco utilizados
Capítulo 4
Conceitos de aprendizagem computacional
Neste capítulo são abordados os tópicos relativos a aprendizagem computacional. Iniciar-se-á por uma visão geral, nomeadamente o processo CRISP-DM, seguido pelo pré-processamento, onde será elaborada uma pe-quena explicação dos filtros utilizados, depois são explicados os algoritmos de aprendizagem computacional e, para terminar, uma secção sobre as métricas utilizadas para avaliar modelos de classificação.4.1
Visão geral
O processo de aprendizagem é composto por várias fases e a elaboração desta dissertação foi baseada nos passos do processo CRISP-DM (CRoss Industry Standard Process for Data Mining). Este processo é com-posto pelas seis fases seguintes [52]:
• Compreensão do problema: Esta fase foca-se na compreensão dos objetivos do projeto. Verificam-se os recursos, os riscos, determinam-Verificam-se os objetivos e os critérios de sucesso de data mining. • Conhecimento do conjunto de dados: Nesta fase, os dados são recolhidos, descritos e explorados
para verificar se têm qualidade e para estudar o que se tem e pode fazer com os dados.
• Preparação do conjunto de dados: Nesta fase são elaboradas atividades para construir o conjunto final de dados para a aplicação dos modelos. Aqui são aplicados os filtros, extraídas as características, feitas divisões em conjunto de treino e teste para posteriormente seguir-se para a fase de modelação. É aqui onde os filtros de Butterworth e de Chebyshev são aplicados.
• Modelação: Nesta fase, várias modelos de aprendizagem computacional são escolhidos e aplicados e os parâmetros são ajustados para se conseguir obter os melhores valores. Nesta dissertação são aplicados modelos de machine learning, nomeadamente, regressão logística, KNN, SVM,Random Forest, LighGBM, XGBoost e ANN.
• Avaliação: Esta fase é a fase onde os modelos utilizados são avaliadas. Aqui serão utilizadas as mé-tricas de classificação para avaliar os modelos mencionados na etapa anterior. As mémé-tricas utilizadas são precision, accuracy, recall e f1-score.
16 Conceitos de aprendizagem computacional
• Implementação: Esta é a fase para rever o que foi elaborado e analisar se os objetivos foram alcan-çados.
De seguida, serão introduzidos conceitos das fase de preparação do conjunto de dados, modelação e avalia-ção para uma melhor compreensão da metodologia elaborada no capítulo5.
4.2
Preparação do conjunto de dados:
Para reduzir o ruído de fundo e suprimir as interferências dos sinais do som cardíaco é necessário remover algumas das frequências dos sons gravados porque as gravações normalmente possuem ruídos e para isso são utilizados filtros. Os filtros podem ser classificados com base em diferentes critérios, tais como sendo linear ou não linear, ativo ou passivo, analógico ou digital, entre outros [17]. Os dois maiores grupos de filtros digitais usados são os filtros de impulso finito (FIR) e os filtros de impulso infinito (IIR). Geralmente, um filtro dá-nos uma certa resposta a um certo sinal de entrada e se soubermos a resposta do filtro podemos calcular a amplitude e o comportamento da fase do filtro [9]. Num sistema digital um sinal é um conjunto de amostras e cada uma das amostras no sinal corresponde a um pulso e com os filtros IIR, temos uma entrada e recebemos infinitos pulsos de saída. No entanto, com os filtros FIR temos finitos pulsos de saída [9]. De seguida, segue-se uma breve explicação dos filtros IIR de Butterworth e de Chebyshev e podemos observar na figura4.1a resposta do filtro de Butterworth e do filtro Chebyshev.
Figura 4.1: Resposta dos filtros IRR de Butterworth e Chebyshev. Figura adaptada de Design and Imple-mentation of Butterworth, Chebyshev-I and Elliptic Filter for Speech Signal Analysis1
4.2.1 Butterworth
O filtro IIR de Butterworth é um filtro baseado em frequência e considerado o mais plano na banda de passagem, ou seja, não possui ondulações. Este filtro é o único filtro que mantém o mesmo formato para ordens mais elevadas. Se compararmos o filtro Butterworth com o Chebyshev ou o Elíptico, o filtro de Butterworth possui uma queda mais lenta o que faz com que tenha de ser implementado com uma ordem maior para eliminar o ruído desejado. No entanto, o filtro de Butterworth apresentará uma resposta em fase mais linear na banda de passagem do que os outros filtros mencionados [16].
4.3 Modelação: 17
4.2.2 Chebyshev
O filtro de Chebyshev é utilizado para separar uma banda de frequências de outra. Normalmente têm uma atenuação de frequência mas íngreme. Existem os filtros de tipo 1, que contêm mais ondulação na banda de passagem, e os filtros de tipo 2, que têm uma ondulação mais parada do que o filtro de Butterworth [8]. Algumas das características do filtro de Chebyshev estão resumidas de seguida [8]:
• Roll-off: um dos principais aspetos deste filtro é possuir um bom declive na banda de transição. Atinge o seu ultimo estado de roll-off mais rapidamente do que os outros filtros existentes. Por isso, onde for necessária uma transição acentuada entre a banda de passagem e a banda de atenuação, o filtro de Chebyshev é amplamente utilizado.
• Ondulação (Ripple): o filtro Chebyshev fornece um roll-off acentuado mas isso ocorre devido à ondulação.
• Frequência de corte: Nos filtros Chebyshev o corte é considerado o ponto em que o ganho desce para o valor da ondulação no tempo final. Isso é visível no diagrama da resposta típica de um filtro Chebyshev.
• Tipo do filtro Chebyshev: O tipo do filtro Chebyshev tem origem nos cálculos do filtro, que são baseados em polinómios de Chebyshev. Existem os filtros Chebyshev de tipo I e os filtros Chebyshev de tipo II. Os filtros de Chebyshev de tipo I são mais comuns do que os de tipo II.
Na próxima secção segue-se uma breve descrição da validação cruzada e dos algoritmos de aprendizagem computacional.
4.3
Modelação:
4.3.1 Validação cruzada:
A validação cruzada é um método estatístico para avaliar e comparar algoritmos de aprendizagem com-putacional que avalia a capacidade de generalização de cada modelo. Para isto ser possível, os dados são divididos em dois conjuntos: um conjunto para treinar o modelo e outro para validar. Geralmente, a distri-buição dos dados pelos subconjuntos é de 70% para o conjunto de treino e de 30% para o conjunto de teste [46].
O objetivo da validação cruzada é avaliar a capacidade de previsão do modelo com dados que nunca foram utilizados antes de forma a obter uma estimativa mais precisa do desempenho da previsão do modelo. Após o particionamento do conjunto de dados em subconjuntos de treino e teste são realizados múltiplas rondas de usando diferentes partições e os resultados de validação cruzada das rondas são combinados com os cálculos da média e desvio padrão [46].
4.3.2 Máquinas de vetores de suporte (SVM)
As máquinas de vetores de suporte (SVM) utilizam um conjunto de métodos de aprendizagem supervisio-nada para análise e reconhecimento de padrões, o que significa que o conjunto de dados para treinar e testar
18 Conceitos de aprendizagem computacional
são conhecidos a priori [24]. O SVM recebe um conjunto de dados como entrada e, para cada, o objetivo passa por identificar a classe a que pertence, sendo que, o SVM é um classificador linear binário não pro-babilístico [40]. Para um conjunto de dados de treino com os dados previamente identificados, isto é, cada um dos dados do conjunto pertence a uma de duas categorias, o algoritmo de treino do SVM constrói um modelo para classificar novos exemplos, ou seja, para um conjunto de pontos de duas classes, o objetivo do algoritmo é decidir qual a classe de um novo ponto dado [50].
Figura 4.2: SVM. Figura adaptada de A brief Introduction to SVM(Support Vector Machine)2
Cada ponto é visto como um vetor n-dimensional num espaço n-dimensional Rn e pretende-se separar os
pontos de classes diferentes com um hiperplano (n − 1) dimensional. Se isto for possível, um classificador linear é construído, [50] ou seja, o SVM encontra uma linha que separa duas classes designado de hiper-plano, como podemos observar na figura 4.2, com o objetivo de maximizar a distância entre dois pontos próximos de cada uma das classes [40]. A distância entre o primeiro ponto de cada classe e o hiperplano denomina-se de margem.
4.3.3 K-Nearest Neighbors (KNN)
O algoritmo K-Nearest Neighbors (KNN) também é um algoritmo de aprendizagem supervisionada para análise e reconhecimento de padrões. O KNN baseia-se no cálculo de distâncias entre os elementos do conjunto de dados de treino, ou seja, calcula a distância de um elemento dado aos elementos do conjunto de treino. De seguida, ordena os elementos do conjunto de treino dos mais próximos (distância menor) ao mais afastados (distância maior) como podemos observar na figura4.3. Após esta ordenação, são selecionados os primeiros k elementos para serem utilizados como parâmetros na regra de classificação [24].
Para classificar um novo elemento, o KNN, mede a distância (Euclidiana, Manhattan, Minkowski ou Pon-derada) entre esse elemento com os dados já classificados. Assim, obtém-se as distâncias e são verificadas
4.3 Modelação: 19
as classes de cada um dos dados que tiveram a menor distância. A classe que mais vezes apareceu entre os dados mais próximos é o resultado da classificação do novo dado [25].
Figura 4.3: KNN. Figura adaptada de K Nearest neighbor: step by step tutorial3
4.3.4 Random Forest
Para entender o algoritmo de Random Forest é necessário entender as árvores de decisão.
4.3.4.1 Árvores de decisão:
As árvores de decisão são estruturas de dados, semelhante a um fluxograma, onde as condições são verificadas nos "nós"e "ramos"para estabelecer as ligações entre os "nós", como podemos ver na figura4.4. As árvores de decisão são métodos de aprendizagem supervisionada que ao aprender com o conjunto de dados, vão-se aproximando de uma curva sinusoidal através de conjunto de regras de decisão [51]. As árvores dividem um conjunto de dados em subconjuntos cada vez mais pequenos enquanto que, ao mesmo tempo, uma árvore de decisão associada é desenvolvida de forma incremental. O resultado final é uma árvore com nós de decisão e nós folha. Um nó de decisão possui dois ou mais ramos. O nó folha representa uma classificação ou decisão [51].
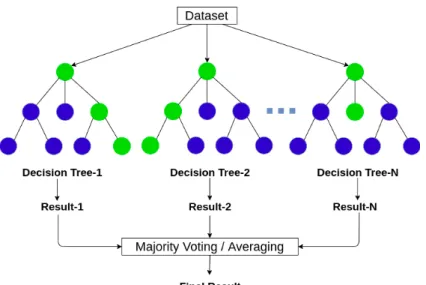
O algoritmo Random Forest faz parte dos métodos ensemble que são métodos que combinam diferentes mo-delos para se obter um único resultado. Por serem mais robustos são mais exigentes a nível computacional [63]. O algoritmo cria várias árvores de decisão. Cada árvore do algoritmo Random Forest é gerada com base num subconjunto aleatório do conjunto de dados original o que torna cada subconjunto independente dos outros. Essa aleatoriedade ajuda a reduzir a correlação entre as árvores de decisão, o que significa que o erro de generalização do método de ensemble pode ser melhorado.
3https://www.listendata.com/2017/12/k-nearest-neighbor-step-by-step-tutorial.html 4https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/
20 Conceitos de aprendizagem computacional
Figura 4.4: Random Forest. Figura adaptada de Decision Tree vs. Random Forest – Which Algorithm Should you Use?4
4.3.5 Regressão logística
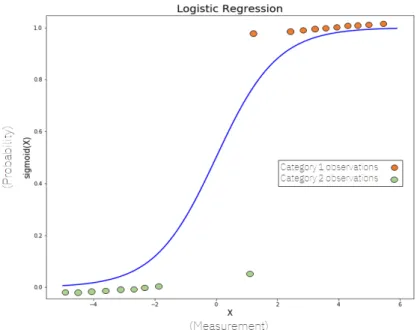
A regressão logística é um modelo baseado em estatística para classificação. Utiliza um número fixo de parâmetros que dependem do número de características de entrada e da saída [64]. Pertence ao grupo de classificadores lineares que fornece funções analíticas [57]. É essencialmente um método de classificação binária mas pode ser também aplicado a problemas de várias classes.
Na regressão logística são feitos ajustes a uma curva em forma de ’S’, denominada sigmóide, conforme podemos ver na figura4.5. A curva é definida pela seguinte fórmula:
sigmoid(x) = 1
1 + e−x (4.1)
onde x é a soma ponderada das características de entrada.
Ao calcular esta função obtém-se uma probabilidade (entre 0 e 1) que se pode traduzir à probabilidade de pertencer a uma das classes [64].
4.3.6 XGBoost
XGBoost ou Extreme Gradient Boosting é uma biblioteca baseado em árvores de decisão que implementa algoritmos de aprendizado de máquina, sob a estrutura de Gradient Boosting [41]. O algoritmo de Gradient Boostingtreina modelos de acordo com o erro obtido nos modelos anteriores, isto é, em vez de tentar prever diretamente o objetivo, faz uma previsão do erro de acordo com o erro residual obtido nos modelos anteriores [15]. Ao executar várias iterações do mesmo processo cada vez obtemos menos erro [15]. Os modelos que utilizam esta biblioteca têm uma abordagem mais iterativa, ou seja, em vez dos modelos serem treinados de forma isolada são treinados sucessivamente onde o novo modelo corrige os erros do modelo anterior. A
4.3 Modelação: 21
Figura 4.5: Regressão logística. Figura adaptada de Logistic Regression Explained5
vantagem nesta abordagem é que os modelos que vão sendo adicionados focam-se na correção do erro do anterior ao contrário dos tradicionais métodos ensemble onde os modelos são executados de forma isolada e, por isso, podem estar sempre a cometer o mesmo erro. Podemos observar o esquema na figura4.6. A biblioteca XGBoost é focada em rapidez computacional e no desempenho dos modelos e, por isso, oferece várias características únicas tais como [54]:
• Regularização: para ajudar a evitar que modelos lineares sobreajustem exemplos de treino, ou seja, para prevenir o overfitting, o XGBoost tem a capacidade de penalizar valores de peso extremos através da regularização L1 e L2, onde a regularização L1 reduz o número de características usadas no mo-delo ao empurrar para zero o peso de características. A regularização L2 resulta em valores de peso menores, o que estabiliza os pesos quando há alta correlação entre as características.
• Tratamento de dados esparsos: é capaz de lidar com diferentes tipos de padrões de dispersão nos dados pois incorpora um algoritmo ciente da dispersão.
• Esboço de quantil ponderado: normalmente, os algoritmos baseados em árvore encontram pontos de divisão quando os dados têm pesos iguais utilizando o algoritmo de esboço de quantis não estando preparados para lidar com dados ponderados. O XGBoost consegue lidar com dados ponderados de forma eficaz porque utiliza um algoritmo de esboço de quantil ponderado.
• Estrutura de blocos para aprendizagem paralela: o XGBoost consegue usar vários núcleos do CPU devido a uma estrutura de bloco no design do sistema do XGBoost, o que permite uma computação mais rápida.
22 Conceitos de aprendizagem computacional
Figura 4.6: Esquema de um algoritmo baseado em Gradient Boosting. Figura adaptada de A Beginner’s guide to XGBoost6
• Reconhecimento de cache: o XGBoost foi concebido para utilizar o hardware de forma otimizada, ou seja, aloca buffers internos em cada thread para guardar as características do gradiente. Assim, o acesso contínuo à memória não é necessário para obter as estatísticas de gradiente por índice de linha. • Computação out-of-core: ao lidar com grandes conjuntos de dados que ultrapassam a memória, este
recurso permite otimizar o espaço em disco disponível e maximizar seu uso.
4.3.7 LightGBM
Tal como o XGBoost, o LightGBM é uma ferramenta que utiliza gradient boosting e os seus algoritmos são baseados em aprendizagem de árvore [31]. O LightGBM possui as seguintes vantagens [31]:
• Velocidade de treino menor e maior eficiência • Menor consumo de memória
• Melhor rigor
• Suporta aprendizagem paralela e GPU
• É capaz de lidar com uma enorme quantidade de dados
A diferença entre XGBoost e LightGBM são as especificidades das otimizações, por exemplo, o algoritmo LightGBMcontém parâmetros que permite escolher como é realizado o crescimento da árvore. Na figura4.7
4.3 Modelação: 23
Figura 4.7: Crescimento de árvore XGBoost vs LightGBM. Figura adaptada de XGBoost, LightGBM or CatBoost — which boosting algorithm should I use?7
4.3.8 Redes neuronais artificiais (ANN)
As redes neuronais artificiais apresentam um modelo matemático inspirado no sistema nervoso, nomeada-mente nos neurónios, ou seja, simulam o sistema nervoso através da modelação de sistemas com várias unidades de processamento, normalmente ligadas por canais de comunicação com um determinado peso as-sociado e com a capacidade de adquirir conhecimento através da experiência [11]. Podemos ver um exemplo na figura4.8.
As redes neuronais artificiais são utilizadas para solucionar problemas de inteligência artificial, geralmente usadas no reconhecimento de padrões. As redes neuronais conseguem calcular qualquer função computa-cionalmente possível, ou seja, têm a capacidade para modelar relações lineares e não lineares. De seguida, apresentam-se as principais características das redes neuronais artificiais [56]:
• Capacidade de aprender e de generalizar a aprendizagem de forma a identificar elementos novos e idênticos;
• Bom desempenho em tarefas com escassez de conhecimento explícito para resolução; • Integridade do conjunto de treino;
• Credibilidade do conjunto de treino, isto é, quando uma rede neuronal é utilizada para classificar padrões, a rede neuronal pode informar sobre os padrões que devem ser selecionados em função do grau de confiança fornecido;
• Possui tolerância a falhas.
7
https://medium.com/riskified-technology/xgboost-lightgbm-or-catboost-which-boosting-algorithm-should-i-use-e7fda7bb36bc
8
24 Conceitos de aprendizagem computacional
Figura 4.8: Esquema de uma rede neuronal. Figura adaptada de Inteligência artificial: Portal da Tecnologia.
8
4.4
Avaliação:
Para saber se um modelo de aprendizagem computacional atende aos requisitos necessários existem métricas a ser utilizadas [28]. A avaliação, no caso de uma classificação binária, é realizada com a comparação entre as classes verdadeiras e as classes preditas de cada exemplo [28]. De seguida são apresentadas as métricas utilizadas nesta dissertação, começando pela matriz de confusão. A matriz de confusão é uma forma simples para visualizar quantos exemplos foram bem ou mal classificados em cada classe [28].
De seguida apresenta se a definição de cada célula da tabela4.1[60]:
• Verdadeiro Positivo (TP): quando no conjunto real a classe que estamos a prever é prevista correta-mente. No caso desta dissertação, acontece quando um som tem um sopro e o modelo prevê que esse som possui um sopro;
• Falso Positivo (FP): quando no conjunto real a classe que estamos a prever é prevista incorretamente. No caso desta dissertação, acontece quando um som não tem sopro mas o modelo prevê que tem;
• Verdadeiro Negativo (TN): ocorre quando no conjunto real a classe que não estamos a prever é prevista corretamente. No caso desta dissertação acontece quando um som não tem sopro e o modelo prevê que não tem sopro;
Tabela 4.1: Matriz de confusão Valor predito
Sim Não
Sim Verdadeiro Positivo (TP)
Falso Negativo (FN) Real Não Falso Positivo
(FP)
Verdadeiro Negativo (TN)
4.4 Avaliação: 25
• Falso Negativo (FN): ocorre quando no conjunto real a classe que estamos a prever é prevista incor-retamente. No caso desta dissertação acontece quando um som tem um sopro e o modelo prevê que o som não tem sopro.
Através da matriz de confusão conseguimos obter as métricas que irão ser explicadas de seguida.
4.4.1 Accuracy:
A accuracy [49] é a métrica que diz quando o modelo acerta nas previsões. Por exemplo, se o modelo obter uma accuracy de 80% significa que em 10 acerta 8 previsões. Traduz-se na seguinte fórmula:
accuracy= T P+ T N
T P+ T N + FP + FN =
previsões corretas
todas as previsões (4.2)
onde:
TP é a quantidade de verdadeiros positivos True Positives TN é a quantidade de verdadeiros negativos True Negatives FP é a quantidade de falsos positivos False Positives FN é a quantidade de falsos negativos False Negatives
4.4.2 Precision:
A precision [49] é a métrica que nos indica previsões daquela classe está correta. No caso desta dissertação, é a habilidade do classificador não prever um sopro negativo como um sopro positivo. É dada pela seguinte equação:
precision= T P
T P+ FP (4.3)
onde:
TP é a quantidade de verdadeiros positivos True Positives FP é a quantidade de falsos positivos False Positives
4.4.3 Recall:
Recallou sensitivity [49] é a métrica que relaciona o número de elementos positivos corretamente previstos com o número total de elementos positivos. Traduz-se na equação seguinte, onde o número de positivos verdadeiros é divido pelo número de elementos que deviam ser parte daquela classe.
recall= T P
T P+ FN (4.4)
onde:
26 Conceitos de aprendizagem computacional
FN é a quantidade de falsos negativos False Negatives
4.4.4 F1-Score:
A métrica F1-score [49] é uma média harmónica entre precision e recall sendo que o melhor corresponde a 1.0 e o pior a 0.0. Traduz-se pela seguinte equação:
f-score= 2 ∗ precision∗ recall
Capítulo 5
Metodologia
Neste capítulo é apresentado o conjunto de dados utilizado sendo seguido por uma visão geral da meto-dologia. Posteriormente entra-se em detalhe na metodologia, começando pelo pré-processamento onde se explica como foram os filtros utilizados, seguindo-se para a extração e normalização de características e posteriormente como foram utilizados os algoritmos de aprendizagem computacional.
5.1
Dados utilizados
O conjunto de dados foi recolhido, na sua totalidade, em rastreios feitos pela Caravana do Coração – uma ação que consiste na execução de rastreios, consultas com cardiologistas e testes especializados e que pro-move a despistagem de patologias cardíacas [18]. Os rastreios foram feitos no Brasil, no estado do Pernam-buco, em 2014 e 2015, e durante esta campanha de rastreio todos os participantes que apareciam voluntari-amente eram incluídos, mas os pacientes com menos de 21 anos precisavam de um consentimento parental assinado. Como parte do protocolo todos os participantes completaram questionários sociodemográficos e foram analisados sendo feita uma examinação clínica (física e mental), uma triagem (medidas fisiológicas) e investigações cardíacas (radiografia, eletrocardiograma e ecocardiograma). Adicionalmente foram feitas auscultações eletrónicas, a cada um dos pacientes, em quatro dos principais pontos de auscultação sendo recolhida uma amostra individual do áudio, de cada um dos pontos de auscultação, para posterior análise. O conjunto de dados utilizado contem 687 pacientes, dos quais 545 (70.3%) possuem um batimento car-díaco normal, o que corresponde a 2180 sons e 142 (20.7%) estão identificados com sopro carcar-díaco, o que corresponde a 568 sons. O dataset foi recolhido no âmbito do projeto DigiScope 2.0 e a equipa verificou que as anotações feitas inicialmente estavam rudimentares. Desta forma, decidiram contratar uma aluna de medicina para fazer anotações ao dataset e uma das anotações feitas é de qual dos focos se onde melhor o sopro e os resultados da análise feita a 81 pacientes, estão apresentados na tabela5.1.
A tabela5.1apresenta o número de vezes que cada foco de auscultação foi considerado como o foco mais audível, onde se verifica que o foco ’AV’ é o foco que aparece menos vezes como mais audível e o foco ’MV’ é o que aparece mais vezes como mais audível. Para a elaboração desta dissertação vão ser utilizados os sinais de todos os focos de auscultação com várias combinações.