Hierarchical Bayesian space-time interpolation versus spatio-temporal BME approach
6
0
0
Texto
(2)
(3)
(4)
Imagem
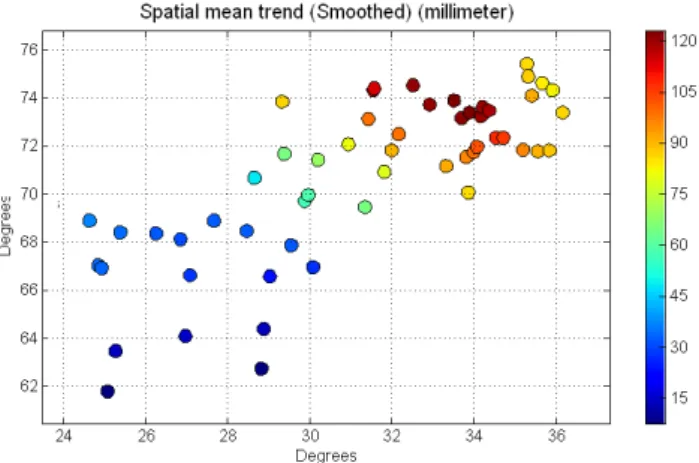
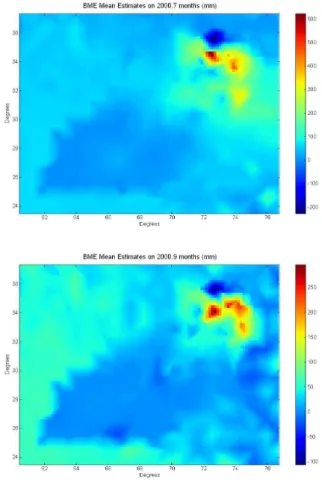
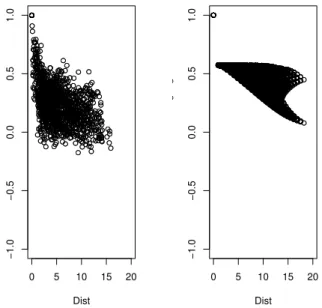
Documentos relacionados
Here we estimated the sensitivity of fish assemblages in a set of estuaries distributed worldwide (based on species vulnerability and resilience), and the exposure to
Os dados dos recebidos do Alarm Dosimeter são processados obtendo-se os níveis de radiação presentes nas diferentes salas e depois são adicionados aos gráficos da interface
Silva, Departamento de Matemática, Instituto Superior Técnico, Universidade Técnica de Lisboa, "A Bayesian spatio-temporal analysis of forest fires in Portugal"..
Existindo a possibilidade de análise da granulometria obtida através do recurso a uma fotografia digital, a presente dissertação aborda o contributo da análise
We present a velocity-based approach for modeling animal movement in space and time that allows for temporal heterogeneity in an animal’s response to the environment, allows
We present a randomised algorithm that accelerates the clustering of time series data using the Bayesian Hierarchical Clustering (BHC) statistical method.. BHC is a general method for
Characteristics of networks of interventions: a description of a database of 186 published networks.
Finally we extracted data about the method used to derive indirect inference (Bucher method, meta-regression, Bayesian hierarchical model or multi- variate meta-analysis) and the
Vale salientar que há dificuldade, especialmente nos países da América Latina, de formar coalizões capazes de equacionar minimamente políticas públicas capazes de
