U
NIVERSIDADE DE
L
ISBOA
Faculdade de Ciˆencias
Departamento de Inform´atica
UM ALGORITMO DE DIFUS ˜
AO PARA REDES SEM
FIOS N ˜
AO INFRAESTRUTURADAS
Jo˜ao Lu´ıs Lopes Ludovico
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializac¸˜ao em Arquitectura, Sistemas e Redes de Computadores
U
NIVERSIDADE DE
L
ISBOA
Faculdade de Ciˆencias
Departamento de Inform´atica
UM ALGORITMO DE DIFUS ˜
AO PARA REDES SEM
FIOS N ˜
AO INFRAESTRUTURADAS
Jo˜ao Lu´ıs Lopes Ludovico
DISSERTAC
¸ ˜
AO
Projecto orientado pelo Prof. Doutor Hugo Alexandre Tavares Miranda
MESTRADO EM ENGENHARIA INFORM ´
ATICA
Especializac¸˜ao em Arquitectura, Sistemas e Redes de Computadores
Agradecimentos
Quero agradecer a todas as pessoas que tornaram este trabalho poss´ıvel e que me apoiaram ao longo do curso. Nomeadamente a N´adia Fernandes, Tiago Gonc¸alves, Diogo Reis, David Costa, Daniel Costa, Pedro Feiteira, Maiur Narendra, H´elio Filipe, Miguel Pires, Tˆania Nunes, ao meu orientador Hugo Miranda e como n˜ao podia deixar de ser aos meus pais e irm˜a.
Resumo
A difus˜ao ´e uma operac¸˜ao muito utilizada em redes sem fios n˜ao infra-estruturadas. Nestas redes, os n´os apenas comunicam com outros que estejam dentro do seu raio de transmiss˜ao, n˜ao existindo uma infra-estrutura que conecte e fornec¸a servic¸os aos n´os. Assim, para que uma mensagem seja entregue a todos os n´os da rede esta tem de ser sucessivamente propagada pelos seus participantes.
Os algoritmos de difus˜ao podem ser divididos em dois grupos distintos: os cientes do contexto e os n˜ao cientes do contexto. No primeiro caso, os n´os incluem na sua tomada de decis˜ao informac¸˜ao de contexto referente ao meio onde se encontram inseridos. Alguns destes algoritmos utilizam informac¸˜ao relativa `a localizac¸˜ao geogr´afica dos vizinhos. Ao utilizarem esta informac¸˜ao, estes algoritmos tentam maximizar a ´area de cobertura man-tendo uma taxa de retransmiss˜ao reduzida.
No segundo caso, a tomada de decis˜ao adv´em apenas da informac¸˜ao com que os n´os foram configurados inicialmente. No entanto, os valores utilizados na configurac¸˜ao po-dem levar a um desperd´ıcio de recursos dos n´os ou a diminuic¸˜oes da taxa de entrega.
O algoritmo desenvolvido tenta, tal como nos algoritmos que utilizam informac¸˜ao ge-ogr´afica, maximizar a ´area de cobertura mantendo uma taxa de retransmiss˜ao reduzida. Para isto o algoritmo efectua estimativas, locais a cada n´o, sobre a proximidade dos seus vizinhos. A partir destas estimativas, cada n´o selecciona um sub-conjunto dos seus vizi-nhos que acredita encontrarem-se em regi˜oes suficientemente distintas para assegurarem a continuac¸˜ao da difus˜ao em todas as direcc¸˜oes da rede. No entanto, estas estimativas n˜ao necessitam que os dispositivos disponham de equipamento de localizac¸˜ao, como o GPS.
Palavras-chave: Difus˜ao, ciente do contexto, redes ad hoc, algoritmo
Abstract
Broadcast is an operation widely used in ad hoc networks. In these networks, nodes only communicate with others within ones propagation radius, therefore these networks are characterized by the absence of an infrastructure that connects and provides services to all nodes. This way, in order for a message to be delivered to the entire network, it has to be relayed by its participants.
Broadcast algorithms can be divided in two major groups: aware and context-oblivious. In the first group, nodes collect information about their environment and de-cide to retransmit or not a message according to this information. Some context-aware algorithms use geographical information in order to make these decisions. By using this information these algorithms try to achieve the maximum coverage with the minimum number of retransmissions.
In the second group, the decision to retransmit or not a message is based solely on configuration parameters set at deployment time. However this information can lead to a waste in nodes resources or lower the delivery rate.
The developed broadcast algorithm tries, like the ones that use geographical informa-tion, to maximize the coverage area while keeping a low number of retransmissions. In order to do this, the algorithm performs estimates, local to each node, about the proxim-ity of each node. From these estimates, each node selects a subset of neighbors that he believes being in different regions in order to assure the broadcast of the message in all directions. However, these estimates do not require the usage of a GPS device.
Keywords: Broadcast, context-aware, ad hoc networks, algorithm
Conte ´udo
Lista de Figuras xvi
Lista de Tabelas xix
1 Introduc¸˜ao 1
1.1 Objectivos . . . 2
1.2 Estrutura do documento . . . 2
2 Difus˜ao em redes n˜ao infraestruturadas 5 2.1 N˜ao cientes do contexto . . . 5
2.2 Cientes do contexto . . . 7
2.2.1 Localizac¸˜ao geogr´afica . . . 7
2.2.2 N´umero de vizinhos . . . 10
2.2.3 Dependˆencias entre n´os . . . 10
2.2.4 Tr´afego de dados . . . 11
2.2.5 Distˆancia aos vizinhos . . . 12
2.3 Resumo . . . 13
3 Digest Exchange Broadcast Algorithm 15 3.1 Estruturas de dados . . . 16
3.2 Funcionamento do algoritmo . . . 17
3.3 Concretizac¸˜ao . . . 21
3.4 Resumo . . . 23
4 Avaliac¸˜ao 25 4.1 Caracter´ısticas gerais das simulac¸˜oes . . . 25
4.2 Redes est´aticas . . . 26
4.3 Random Waypoint . . . 28
4.3.1 Velocidade entre [1, 2] metros por segundo . . . 29
4.3.2 Velocidade entre [5, 10] metros por segundo . . . 35
4.4 Manhathan . . . 36
4.5 Cen´arios busca e salvamento . . . 38 xi
4.6 Cen´ario Ponte . . . 39
4.7 Resumo . . . 43
5 Conclus˜ao e Trabalho Futuro 45
Bibliografia 48
Lista de Figuras
2.1 Exemplo de localizac¸˜ao dos pr´oximos retransmissores . . . 8
2.2 Grupos criados pelo n´o R . . . 9
3.1 Exemplo da configurac¸˜ao de uma rede . . . 16
3.2 Estruturas de dados utilizadas pelo algoritmo DEBA . . . 17
4.1 Taxa de entrega - modelo est´atico . . . 27
4.2 Taxa de retransmiss˜ao - modelo est´atico . . . 28
4.3 Taxa de entrega - Random Waypoint [1, 2] . . . 30
4.4 Taxa de retransmiss˜ao - Random Waypoint [1, 2] . . . 30
4.5 Taxa de entrega com diminuic¸˜ao dos intervalos de tempo - Random Way-point [1, 2] . . . 32
4.6 Taxa de retransmiss˜ao com diminuic¸˜ao dos intervalos de tempo - Random Waypoint [1, 2] . . . 32
4.7 Taxa de entrega com aumento das m´etricas utilizadas nas func¸˜oes - Ran-dom Waypoint [1, 2] . . . 33
4.8 Taxa de retransmiss˜ao com aumento das m´etricas utilizadas nas func¸˜oes -Random Waypoint [1, 2] . . . 34
4.9 Taxa de entrega com aumento das m´etricas utilizadas nas func¸˜oes e reduc¸˜ao dos intervalos de tempo - Random Waypoint [1, 2] . . . 34
4.10 Taxa de retransmiss˜ao com aumento das m´etricas utilizadas nas func¸˜oes e reduc¸˜ao dos intervalos de tempo - Random Waypoint [1, 2] . . . 35
4.11 Taxa de entrega - Random Waypoint [5, 10] . . . 36
4.12 Taxa de retransmiss˜ao - Random Waypoint [5, 10] . . . 36
4.13 Taxa de entrega usando o modelo Manhattan Grid . . . 37
4.14 Taxa de retransmiss˜ao usando o modelo Manhattan Grid . . . 38
4.15 Rede gerada para o modelo de Busca e Salvamento . . . 39
4.16 Taxa de entrega para os cen´arios de busca e salvamento . . . 39
4.17 Taxa de retransmiss˜ao para os cen´arios de busca e salvamento . . . 40
4.18 Exemplo de configurac¸˜ao de rede . . . 40
4.19 Taxa de entrega para os cen´arios ponte . . . 41
4.20 Taxa de retransmiss˜ao para os cen´arios ponte . . . 42 xv
4.21 Taxa de entrega com aumento das m´etricas utilizadas nas func¸˜oes - Cen´arios
Ponte . . . 42
4.22 Taxa de retransmiss˜ao com aumento das m´etricas utilizadas nas func¸˜oes
-Cen´arios Ponte . . . 43
Lista de Tabelas
2.1 Algoritmos de difus˜ao . . . 14
4.1 Valores utilizados nas m´etricas deterministas . . . 26
4.2 Valores utilizados nas m´etricas probabilistas . . . 26
4.3 N´umero m´edio de mensagens por n´o - Random Waypoint [1, 2] . . . 31
4.4 N´umero m´edio de n´os que recebem uma mensagem por retransmiss˜ao -Random Waypoint [1, 2] . . . 31
4.5 N´umero m´edio de mensagens por n´o com diminuic¸˜ao dos intervalos de tempo - Random Waypoint [1, 2] . . . 32
4.6 Novos valores utilizados nas m´etricas deterministas . . . 33
4.7 Novos valores utilizados nas m´etricas probabilistas . . . 33
4.8 N´umero m´edio de mensagens por n´o com aumento das m´etricas utilizadas - Random Waypoint [1, 2] . . . 34
4.9 N´umero m´edio de mensagens por n´o com aumento das m´etricas utilizadas e reduc¸˜ao dos intervalos de tempo - Random Waypoint [1, 2] . . . 35
4.10 N´umero m´edio de mensagens por n´o - Random Waypoint [5, 10] . . . 36
Cap´ıtulo 1
Introduc¸˜ao
As redes ad hoc sem fios s˜ao caracterizadas pela ausˆencia de uma infra-estrutura que ligue e fornec¸a servic¸os aos v´arios n´os que a formam. Nestas redes, um n´o s´o comunica directamente com outros que estejam dentro do seu raio de transmiss˜ao. Deste modo, uma mensagem que se pretende que seja difundida por todos os n´os tem de ser propagada sucessivamente pelos participantes ao longo da rede. A difus˜ao de mensagens ´e usada por v´arios servic¸os, como por exemplo, descoberta de rotas [17, 12] e de recursos [8].
O algoritmo de inundac¸˜ao ´e uma concretizac¸˜ao de difus˜ao. Neste caso, todos os n´os retransmitem uma mensagem quando a recebem pela primeira vez. A inundac¸˜ao apre-senta uma elevada taxa de entrega mas, por outro lado, leva a um grande consumo de largura de banda e `a reduc¸˜ao da autonomia dos n´os, uma vez que o envio de mensagens contribui significativamente para o consumo da bateria [7]. Adicionalmente, devido ao elevado n´umero de retransmiss˜oes, muitas delas redundantes, poder´a ocorrer um elevado n´umero de colis˜oes, uma vez que o meio utilizado para a transmiss˜ao de mensagens ´e partilhado por todos os n´os. Na maioria das redes sem fios, os n´os n˜ao conseguem iden-tificar a ocorrˆencia duma colis˜ao. Assim, caso ocorra um grande n´umero de colis˜oes, as mensagens n˜ao ser˜ao reenviadas e, devido a isto, alguns dos destinat´arios dessas mensa-gens poder˜ao n˜ao as receber. Como consequˆencia, a eficiˆencia dos algoritmos de difus˜ao pode diminuir caso o n´o que n˜ao tenha recebido a mensagem seja um n´o cr´ıtico para a propagac¸˜ao da mesma. Isto ´e, um n´o que tem obrigatoriamente de retransmitir as mensa-gens de modo a garantir que estas sejam propagadas por toda a rede.
O desafio na criac¸˜ao de algoritmos de difus˜ao eficientes, ou seja, com uma taxa de en-trega elevada, ´e a reduc¸˜ao do n´umero de retransmiss˜oes, que por sua vez ir´a reduzir o con-sumo de largura de banda e a taxa de colis˜oes. A diminuic¸˜ao do n´umero de retransmiss˜oes pode ser conseguida atrav´es da selecc¸˜ao de um conjunto m´ınimo de n´os respons´aveis por continuar a propagac¸˜ao da mensagem. Esta selecc¸˜ao seria simplificada caso os n´os dis-pusessem de um servic¸o de localizac¸˜ao geogr´afica como o GPS. Atrav´es da informac¸˜ao obtida por este sistema, seria poss´ıvel a execuc¸˜ao de algoritmos de optimizac¸˜ao que iden-tificassem deterministicamente para cada origem, o conjunto m´ınimo de n´os cuja
Cap´ıtulo 1. Introduc¸˜ao 2
miss˜ao resultaria numa cobertura ´optima para uma dada regi˜ao da rede. Contudo, este trabalho assume um modelo de sistema mais gen´erico, em que os n´os n˜ao disp˜oem de um servic¸o de localizac¸˜ao e em que as antenas s˜ao omnidireccionais. Com estas limitac¸˜oes, o objectivo ´e enfraquecido, pretendendo-se apenas determinar um conjunto de transmisso-res t˜ao reduzido quanto poss´ıvel mas que assegure, com grande probabilidade, a cobertura total da rede. Uma aproximac¸˜ao poss´ıvel `a determinac¸˜ao deste conjunto consiste em fazer com que cada n´o seleccione como retransmissores o conjunto de vizinhos que se encon-trem mais distantes entre si. No entanto, dado que os n´os n˜ao s˜ao capazes de determinar a localizac¸˜ao geogr´afica dos seus vizinhos nem a localizac¸˜ao do emissor de uma mensagem recebida, a selecc¸˜ao do conjunto de vizinhos n˜ao ´e trivial. Para se efectuar esta selecc¸˜ao, ´e ent˜ao necess´ario que cada n´o recolha informac¸˜ao de contexto de modo a evitar que as retransmiss˜oes dos n´os seleccionados, para continuar a propagac¸˜ao, sejam redundantes por cobrirem os mesmos n´os deixando outros a descoberto.
1.1
Objectivos
Este trabalho tem como objectivo o desenvolvimento de um algoritmo de difus˜ao para redes sem fios n˜ao infraestruturadas. Tenciona-se com este algoritmo que cada n´o da rede consiga estimar a proximidade dos seus vizinhos de modo a reduzir retransmiss˜oes redundantes. No entanto, pretende-se que esta estimativa n˜ao necessite de informac¸˜ao obtida atrav´es de um mecanismo de localizac¸˜ao geogr´afica, por forma a alargar o le-que de modelos de sistema onde possa ser utilizado. Assim, esta estimativa ter´a por base informac¸˜ao de contexto recebida atrav´es de mensagens de sinalizac¸˜ao peri´odicas que agregam informac¸˜ao relativa `a vizinhanc¸a de cada n´o. Pretende-se tamb´em que o algoritmo seja eficiente, ou seja, contenha uma elevada taxa de entrega e uma reduzida taxa de retransmiss˜ao.
De modo a escolher quais os dispositivos que ir˜ao retransmitir uma dada mensagem, pretende-se desenvolver v´arias func¸˜oes de comparac¸˜ao que, atrav´es da informac¸˜ao rece-bida pelas mensagens de sinalizac¸˜ao, ir˜ao seleccionar o conjunto de vizinhos que dever´a retransmitir a mensagem por forma a assegurar a sua propagac¸˜ao. Para cada uma das func¸˜oes desenvolvidas ir´a proceder-se `a realizac¸˜ao de testes de modo a identificar aquela que apresente um melhor desempenho.
1.2
Estrutura do documento
O presente documento encontra-se estruturado da seguinte forma:
• Cap´ıtulo 2 – Descreve os alguns dos tipos de algoritmos de difus˜ao existentes dis-cutindo as suas vantagens e desvantagens;
Cap´ıtulo 1. Introduc¸˜ao 3
• Cap´ıtulo 3 – Descreve a implementac¸˜ao do algoritmo e as justificac¸˜oes para as decis˜oes tomadas;
• Cap´ıtulo 4 - Apresenta e discute os resultados do algoritmo em v´arios cen´arios de utilizac¸˜ao;
Cap´ıtulo 2
Difus˜ao em redes n˜ao infraestruturadas
Neste cap´ıtulo s˜ao apresentados e discutidos diferentes algoritmos de difus˜ao para redes sem fios n˜ao infraestruturadas.
O cap´ıtulo encontra-se dividido em v´arias secc¸˜oes em que cada uma apresenta uma abordagem diferente para a realizac¸˜ao de algoritmos de difus˜ao em redes sem fios n˜ao infraestruturadas. Em cada secc¸˜ao s˜ao ainda discutidas as vantagens e desvantagens dos algoritmos apresentados.
Difus˜ao A difus˜ao ´e uma operac¸˜ao muito utilizada nas redes sem fios n˜ao infra-estruturadas,
seja para efectuar descoberta de recursos [8], descoberta de rotas entre dois n´os[17, 12] entre outras. Esta operac¸˜ao ´e necess´aria, pois os n´os apenas comunicam com outros que estejam dentro do seu raio de retransmiss˜ao, sendo por isso necess´ario propagar a men-sagem ao longo da rede por forma a determinar, por exemplo, qual o n´o que fornece determinado servic¸o ou qual o caminho para um determinado n´o.
Devido `a sua frequente utilizac¸˜ao, ´e fundamental que estes algoritmos sejam eficien-tes, isto ´e, obtenham uma elevada taxa de entrega com o menor n´umero de retransmiss˜oes poss´ıveis de modo a poupar os recursos dos n´os.
´
E poss´ıvel encontrar variadas propostas de algoritmos de difus˜ao de mensagens para redes sem fios n˜ao infraestruturadas. Segundo [10] estes algoritmos podem ser divididos em dois grupos, os n˜ao cientes do contexto e os cientes do contexto. As secc¸˜oes seguintes descrevem estas duas abordagens.
2.1
N˜ao cientes do contexto
Nos algoritmos n˜ao cientes do contexto, a decis˜ao por parte de um dispositivo de retrans-mitir ou n˜ao retransretrans-mitir uma mensagem adv´em apenas da informac¸˜ao com que foi confi-gurado inicialmente, n˜ao apresentando portanto uma grande complexidade. Por´em, estes algoritmos n˜ao s˜ao capazes de se adaptarem a variac¸˜oes nas caracter´ısticas das redes onde s˜ao utilizados o que pode provocar um desperd´ıcio de recursos dos n´os ou diminuic¸˜oes
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 6
da taxa de entrega. No entanto, ao n˜ao manterem estado, estes algoritmos n˜ao requerem o envio de mensagens de controlo peri´odicas (por forma a actualizar esse estado), n˜ao impondo um tr´afego adicional na rede. Outra vantagem da ausˆencia de estado ´e a maior adaptac¸˜ao, por parte dos algoritmos, a cen´arios em que os n´os apresentem movimento.
Um exemplo de um destes algoritmos ´e a difus˜ao probabilista [11]. Neste algoritmo, cada n´o retransmite uma mensagem recebida pela primeira vez com uma probabilidade p. Quanto maior for esta probabilidade, maior ser´a o n´umero de n´os que ir´a retransmitir a mensagem. A existˆencia de uma probabilidade ideal pi em que para valores de p superi-ores a pi o desempenho do algoritmo decai devido ao aumento do n´umero de colis˜oes foi identificada em [19].
O algoritmo de inundac¸˜ao pode ser considerado o caso particular da difus˜ao proba-bilista em que p = 1. Neste caso, todos os n´os ir˜ao retransmitir a mensagem o que, em condic¸˜oes ideais, garante uma cobertura ´optima da rede. No entanto, muitas das retrans-miss˜oes ser˜ao redundantes, contribuindo apenas para o aumento do consumo da largura de banda dispon´ıvel e para o consumo da bateria dos dispositivos. Al´em disto, dado que o meio de transmiss˜ao ´e partilhado por todos os n´os, com o aumento do n´umero de retrans-miss˜oes a probabilidade de ocorrˆencia de colis˜oes ser´a mais elevada [21]. Devido a isto, as mensagens poder˜ao n˜ao ser recebidas por todos os n´os, o que ir´a diminuir a eficiˆencia do algoritmo. No entanto, esta diminuic¸˜ao poder´a ser mais acentuada, caso o n´o que n˜ao receba a mensagem seja um n´o cr´ıtico para a propagac¸˜ao da mesma. Isto ´e, um n´o que tem obrigatoriamente de retransmitir as mensagens de modo a garantir que estas sejam propagadas por toda a rede.
Os algoritmos probabilistas s˜ao ainda caracterizados pela existˆencia de uma probabi-lidade pm, a qual corresponde `a possibiprobabi-lidade da propagac¸˜ao da mensagem ser interrom-pida, devido `a n˜ao retransmiss˜ao da mensagem por todos os receptores. Esta probabili-dade ´e mais acentuada em fases iniciais da propagac¸˜ao visto que poucos n´os receberam a mensagem. Por forma a impedir que isto acontec¸a, no GOSSIP1(p,k) [11] as mensa-gens s˜ao retransmitidas com probabilidade 1 durante os primeiros k saltos sendo depois retransmitidas com uma probabilidade p < 1. Desta forma, a probabilidade de todos os n´os decidirem n˜ao retransmitir a mensagem vai diminuir, o que faz com que o GOSSIP1 consiga atingir uma melhor taxa de entrega. No entanto, o desempenho do GOSSIP1 passa a depender n˜ao s´o do valor escolhido para p, como tamb´em do valor escolhido para k.
Nos algoritmos probabilistas o n´umero de retransmiss˜oes de cada mensagem pode ser aumentado ou reduzido fazendo variar a probabilidade de retransmiss˜ao. Contudo, uma definic¸˜ao adequada de um valor para p depende das caracter´ısticas da vizinhanc¸a de cada n´o. Em regi˜oes com uma elevada densidade de dispositivos, um n´umero reduzido de re-transmiss˜oes e portanto, um baixo valor de p ´e suficiente para atingir uma elevada taxa de entrega. Em cen´arios cuja densidade ´e baixa, o valor de p tem de ser mais elevado.
Infe-Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 7
lizmente, os algoritmos n˜ao cientes do contexto n˜ao disp˜oem dos mecanismos necess´arios `a regulac¸˜ao de p em func¸˜ao das caracter´ısticas do ambiente, obrigando `a utilizac¸˜ao de va-lores conservadores que tendem em muitos casos a resultar num desperd´ıcio de recursos dos dispositivos. Assim, de modo a obter uma melhor gest˜ao dos recursos dos n´os bem como obter melhores taxas de entrega e de retransmiss˜ao (ou seja, a proporc¸˜ao m´edia de n´os que receberam e retransmitem, respectivamente, cada mensagem) ´e necess´ario que os algoritmos de difus˜ao utilizem informac¸˜ao de contexto.
2.2
Cientes do contexto
Nos algoritmos cientes do contexto, o n´o inclui na sua tomada de decis˜ao informac¸˜ao referente ao meio onde se encontra inserido. Esta informac¸˜ao pode ser, por exemplo, re-ferente `a localizac¸˜ao geogr´afica dos vizinhos, ao n´umero de vizinhos que cada n´o cont´em, `a criac¸˜ao de dependˆencias entre n´os, ao tr´afego de dados na rede ou a sua distˆancia aos outros dispositivos. A informac¸˜ao de contexto permite aos algoritmos adaptarem-se `as diferentes caracter´ısticas das redes onde s˜ao utilizados, obtendo-se assim uma melhor gest˜ao dos recursos dispon´ıveis. Por outro lado, os n´os necessitam armazenar estado o que far´a com que os algoritmos sejam mais complexos requerendo, assim, um maior po-der computacional na sua execuc¸˜ao. Al´em disto, a maioria destes algoritmos, requerem que o estado seja constantemente actualizado (por forma a impedir que este fique inv´alido o que poder´a levar a uma degradac¸˜ao no desempenho do algoritmo) atrav´es de mensa-gens de controlo peri´odicas, o que ir´a impor um tr´afego adicional na rede. Este tr´afego ´e mais acentuado em redes cujos n´os apresentam movimento e, devido ao movimento cons-tante dos n´os, os casos em que o estado est´a incoerente tendem a aumentar o que poder´a provocar uma degradac¸˜ao no desempenho dos algoritmos.
2.2.1
Localizac¸˜ao geogr´afica
No caso da localizac¸˜ao geogr´afica, os dispositivos partilham um sistema de coordenadas comum e obtˆem a sua posic¸˜ao nesse sistema. Esta informac¸˜ao ´e depois utilizada para determinar os pr´oximos retransmissores.
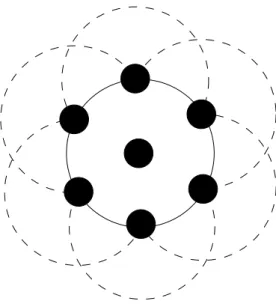
Um exemplo de um algoritmo que utiliza esta informac¸˜ao ´e o six-shot broadcast [9]. Neste algoritmo cada retransmissor difunde, juntamente com a mensagem, as 6 coor-denadas alvo onde se dever˜ao encontrar os pr´oximos retransmissores (Fig. 2.1). Estas coordenadas s˜ao escolhidas tendo por base o estudo realizado por [13], que mostra que a melhor maneira de cobrir uma dada ´area usando c´ırculos de raio r ´e dividir a ´area em hex´agonos (cuja distˆancia do centro aos v´ertices ´e r) em que cada c´ırculo ter´a o seu cen-tro num dos v´ertices do hex´agono. A retransmiss˜ao ´e ent˜ao assegurada pelos n´os que se encontram mais pr´oximos dessas 6 coordenadas. De modo a obter os n´os mais pr´oximos de cada coordenada, cada n´o ao receber a mensagem ir´a esperar um intervalo de tempo
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 8
inversamente proporcional `a sua distˆancia `a coordenada mais pr´oxima. Deste modo, n´os mais pr´oximos ir˜ao retransmitir primeiro.
Figura 2.1: Exemplo de localizac¸˜ao dos pr´oximos retransmissores
O optimized Broadcast Protocol for Sensors networks (BPS) [5] segue a aproximac¸˜ao do algoritmo anterior. No entanto, este algoritmo distingue-se do six-shot uma vez que a posic¸˜ao geogr´afica Pos dos n´os que necessitam retransmitir a mensagem n˜ao ´e enviada no cabec¸alho desta mas sim calculada localmente por cada receptor a partir da localizac¸˜ao do emissor. Cada n´o ao receber uma nova mensagem ir´a verificar se a deve retransmitir. Uma mensagem n˜ao ´e retransmitida se: i) o n´o j´a a tiver retransmitido anteriormente ou ii) se um n´o que esteja a uma distˆancia inferior a um determinado valor de proximidade
vpj´a a tenha retransmitido. Caso o n´o possa retransmitir a mensagem, este calcula a sua
distˆancia `a posic¸˜ao Pos e ir´a esperar um intervalo de tempo inversamente proporcional a esta distˆancia. No final deste intervalo de tempo, o n´o volta a verificar se pode retransmitir a mensagem. Se sim, ent˜ao a mensagem ´e retransmitida, caso contr´ario, a mensagem ´e descartada.
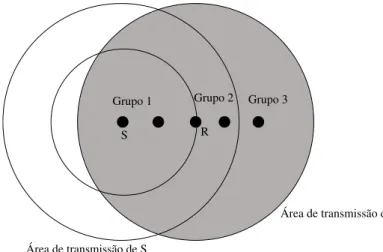
Em [18] cada n´o presente na rede necessita de recolher informac¸˜ao sobre os seus vizinhos directos, isto ´e, os n´os que estejam dentro do seu raio de transmiss˜ao. Esta informac¸˜ao ´e recolhida atrav´es de mensagens de sinalizac¸˜ao peri´odicas e ´e utilizada para determinar se o n´o tem de retransmitir a mensagem. Quando um n´o R recebe uma men-sagem de um n´o S que tem de ser propagada pela rede, R separa os seus vizinhos em trˆes grupos distintos consoante as suas localizac¸˜oes, como pode ser observado na Fig. 2.2. No primeiro grupo encontram-se todos os n´os que s˜ao vizinhos de S e cuja distˆancia a S ´e me-nor que a distˆancia de R a S. No segundo grupo encontram-se todos os n´os vizinhos de S e cuja distˆancia a S ´e maior que a distˆancia de R a S. No terceiro grupo encontram-se todos os vizinhos de R que n˜ao s˜ao vizinhos de S. Caso os n´os do terceiro grupo sejam cobertos
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 9
pelo raio de transmiss˜ao dos n´os do segundo grupo, R n˜ao ir´a retransmitir a mensagem uma vez esta seria redundante. Assim, os n´os respons´aveis por retransmitir a mensagem s˜ao os n´os pertencentes ao segundo grupo visto que cobrem os mesmo n´os que R e, por estarem mais afastados de S, obtˆem uma ´area de cobertura maior.
Área de transmissão de S Área de transmissão de R S Grupo 3 Grupo 2 R Grupo 1
Figura 2.2: Grupos criados pelo n´o R
No Location Aided Broadcast Protocol (LAB) [20] cada n´o guarda informac¸˜ao sobre a localizac¸˜ao geogr´afica dos seus vizinhos. O modo de funcionamento deste algoritmo consiste em seleccionar um sub-conjunto de n´os cuja retransmiss˜ao cubra todos os n´os a dois saltos de distˆancia. Assim, o algoritmo espera garantir uma cobertura da rede semelhante `a conseguida atrav´es da utilizac¸˜ao da inundac¸˜ao.
O algoritmo apresenta trˆes variac¸˜oes distintas: i) LAB-B, ii) LAB-I e iii) LAB-D. No primeiro caso, cada n´o que retransmita uma mensagem ir´a seleccionar os n´os que con-tinuar˜ao a propagac¸˜ao da mesma. Esta escolha tem por base a informac¸˜ao previamente recolhida referente `a localizac¸˜ao geogr´afica dos vizinhos. Assim, quando um n´o recebe uma mensagem este primeiro verifica se tem de a retransmitir. Em caso afirmativo, o n´o selecciona os pr´oximos n´os que continuar˜ao a propagac¸˜ao, caso contr´ario a mensagem ´e descartada.
O LAB-I ´e uma optimizac¸˜ao do LAB-B. Neste caso, assume-se que cada n´o cont´em um identificador ´unico (ID). Assim, quando um n´o r recebe uma mensagem, se for o n´o seleccionado para efectuar a retransmiss˜ao, r primeiro verifica se a sua retransmiss˜ao ´e redundante. A sua retransmiss˜ao ´e redundante caso os seus vizinhos sejam cobertos pelo n´o que previamente retransmitiu a mensagem ou por um outro n´o que necessite de retransmitir a mensagem e cujo ID seja menor que o identificador de r. Caso estas situac¸˜oes se verifiquem, r descarta a mensagem (esta verificac¸˜ao ´e poss´ıvel uma vez que todos os n´os sabem a localizac¸˜ao dos seus vizinhos). Atrav´es deste mecanismo, a taxa de retransmiss˜ao do algoritmo ´e reduzida.
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 10
Neste caso, ´e o receptor que passa a ser respons´avel por verificar se necessita retransmitir a mensagem. Esta verificac¸˜ao ´e feita utilizando a localizac¸˜ao geogr´afica do pr´oprio n´o e do emissor. Esta soluc¸˜ao permite que o cabec¸alho da mensagem seja de tamanho fixo.
Os algoritmos de difus˜ao que utilizam a localizac¸˜ao geogr´afica dos v´arios n´os, por forma a determinarem aqueles que necessitam retransmitir uma mensagem, tˆem como objectivo maximizar a ´area coberta pela nova retransmiss˜ao em relac¸˜ao `a retransmiss˜ao anterior. Assim, estes algoritmos tentam assegurar uma cobertura m´axima da rede, utili-zando o menor n´umero de retransmiss˜oes poss´ıveis, por forma a obter uma elevada taxa de entrega. Contudo, estas aproximac¸˜oes necessitam que os dispositivos disponham de um sistema de posicionamento geogr´afico o que limita a sua aplicabilidade.
2.2.2
N ´umero de vizinhos
Neste caso, a decis˜ao por parte de um n´o de retransmitir uma mensagem depende do n´umero de vizinhos que este cont´em. O GOSSIP2(p1,k,p2,n) [11] ´e um exemplo de um al-goritmo que utiliza esta abordagem. De modo a obter o n´umero de vizinhos, uma poss´ıvel aproximac¸˜ao consiste no envio de mensagens de sinalizac¸˜ao peri´odicas por cada um dos n´os. Um n´o, ao receber uma mensagem de sinalizac¸˜ao, adiciona o emissor `a sua lista de vizinhos.
No GOSSIP2(p1,k,p2,n) um n´o ir´a retransmitir com probabilidade p2 se contiver me-nos vizinhos que um determinado valor n, caso contr´ario ir´a retransmitir utilizando as mesmas regras do GOSSIP1(p1,k). Note-se, no entanto, que p2 > p1 por forma a di-minuir a probabilidade de uma mensagem n˜ao ser difundida em regi˜oes pouco densas da rede. Por´em, o GOSSIP2(p1,k,p2,n) pode apresentar um problema de cobertura. Isto ´e, caso dois n´os que se encontrem muito pr´oximos um do outro decidam retransmitir a mensagem, a ´area de cobertura destas retransmiss˜oes ser´a bastante reduzida e, no pior dos casos, poder´a cobrir os mesmos n´os, levando a um desperd´ıcio de recursos por parte dos n´os.
2.2.3
Dependˆencias entre n´os
Neste caso, os algoritmos tentam estabelecer dependˆencias entre os v´arios n´os que for-mam a rede. O Smart Gossip [14] ´e um exemplo de um destes algoritmos. No Smart Gossip, os n´os tentam estabelecer dependˆencias entre si de modo a ajustarem a probabili-dade de retransmiss˜ao. Para isto os n´os s˜ao agrupados nas seguintes categorias:
• pai - o n´o ´e respons´avel por entregar a mensagem a sub-conjunto dos seus vizinhos (os n´os filhos);
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 11
• irm˜ao - o n´o n˜ao depende de alguns dos seus vizinhos para receber a mensagem nem esses vizinhos dependem do n´o para receber a mensagem.
Assim, ´e poss´ıvel que um n´o n seja pai de um n´o x, filho de um n´o y e irm˜ao de um n´o z. No entanto, um n´o n n˜ao pode ser, por exemplo, simultaneamente pai e irm˜ao de um n´o x.
De modo a estabelecer estas dependˆencias, o Smart Gossip utiliza informac¸˜ao con-tida no cabec¸alho das mensagens. Inicialmente, dado que as dependˆencias dos v´arios n´os ainda n˜ao s˜ao conhecidas, cada n´o ir´a retransmitir com probabilidade p = 1. Ap´os esta fase inicial, a probabilidade de retransmiss˜ao de cada n´o ´e ajustada em func¸˜ao dos seus filhos. Isto ´e, um n´o filho ir´a indicar, ao n´o pai, com que probabilidade ´e que este dever´a retransmitir as mensagens. Por´em, dado que cada n´o pai pode ter v´arios filhos, em que cada um indica uma probabilidade diferente, o n´o pai ir´a escolher como a sua probabilidade de retransmiss˜ao o valor m´aximo das probabilidades indicadas pelos seus filhos.
O Smart Gossip permite identificar n´os cr´ıticos na difus˜ao de mensagens, isto ´e, n´os que tˆem obrigatoriamente de retransmitir as mensagens de modo a garantir que estas sejam propagadas por toda a rede. Assim, ao fazer estes n´os retransmitirem a mensagem, o Smart Gossip permite aumentar a taxa de entrega. No entanto, no Smart Gossip as dependˆencias entre os v´arios n´os variam consoante a origem da mensagem recebida, o que ir´a afectar a probabilidade de retransmiss˜ao dos n´os.
2.2.4
Tr´afego de dados
Nos algoritmos dependentes do tr´afego, os dispositivos tomam a decis˜ao de retransmitir ou n˜ao retransmitir a mensagem de acordo com o n´umero de c´opias recebidas. Estes al-goritmos seguem o princ´ıpio de que a utilidade (medida pelo n´umero de novos n´os que recebem a mensagem) de uma retransmiss˜ao diminui com o n´umero de retransmiss˜oes numa dada vizinhanc¸a [21]. Num destes algoritmos [21], os dispositivos atrasam a re-transmiss˜ao de uma mensagem por um per´ıodo aleat´orio durante o qual contam o n´umero de c´opias escutadas. O n´umero m´ınimo de c´opias escutadas que previne a retransmiss˜ao ´e fixado `a partida e independente da envolvente a cada n´o.
No ProbA [15] a probabilidade de retransmiss˜ao ´e ajustada de acordo com o n´umero de mensagens que o n´o escuta na rede. Isto ´e, quando um n´o recebe uma mensagem pela primeira vez vai iniciar, tal como no algoritmo anterior, um contador para essa mensagem e vai esperar um intervalo de tempo aleat´orio durante o qual escuta a rede. Para cada c´opia da mensagem, o valor do contador ´e incrementado em uma unidade. Caso o valor do contador atinja um limite previamente definido, o n´o ir´a alterar a probabilidade de retransmiss˜ao para um valor inferior. No entanto, ao contr´ario de outras aproximac¸˜oes, este algoritmo cont´em v´arios valores limite, cada um com uma probabilidade associada,
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 12
pelo que a probabilidade de retransmiss˜ao pode ser alterada v´arias vezes ao longo do tempo de espera.
O Dynamic Counter-Based broadcast (DCB) [1] utiliza informac¸˜ao dos seus vizinhos directos por forma a ajustar os seus valores de controlo. Este ajuste pode ser feito atrav´es do n´umero de c´opias escutadas na rede, do intervalo de tempo durante o qual os n´os escutam a rede ou da combinac¸˜ao entre ambos. No primeiro caso, cada n´o ajusta o limite de c´opias escutadas em func¸˜ao da densidade da sua vizinhanc¸a. Assim, caso o dispositivo contenha um n´umero elevado de vizinhos, este vai considerar que a sua vizinhanc¸a ´e densa e vai ajustar o limite para um valor mais reduzido, caso contr´ario o n´o vai considerar que a sua vizinhanc¸a ´e esparsa e vai ajustar o limite para um valor mais elevado. No segundo caso, cada n´o altera o intervalo de tempo em que fica a escutar a rede. Para redes muito densas ou muito esparsas um baixo valor para este intervalo de tempo ´e suficiente. Isto ´e justificado porque, caso a rede seja muito densa ir˜ao ocorrer muitas retransmiss˜oes sendo um pequeno intervalo de tempo suficiente para receber o n´umero m´aximo de c´opias que ir˜ao impedir a retransmiss˜ao da mensagem. Caso as redes sejam muito esparsas, um n´o ir´a receber poucas mensagens independentemente do tempo que ficar `a espera. Assim este tempo pode ser reduzido. Para redes com uma densidade m´edia ´e necess´ario utilizar um intervalo de tempo mais alargado por forma a que o n´o consiga identificar se n˜ao recebeu mensagens porque aquela zona da rede ´e pouco densa ou porque os n´os simplesmente ainda n˜ao retransmitiram a mensagem.
O GOSSIP3(p, k, m) [11] funciona do mesmo modo que o GOSSIP1(p, k) por´em, um n´o que tenha decidido n˜ao retransmitir uma mensagem ir´a retransmiti-la se, ao fim de um intervalo de tempo aleat´orio, n˜ao tiver recebido n c´opias dessa mensagem.
Ao fazer depender o tempo de espera de um gerador de n´umeros aleat´orios, os al-goritmos dependentes do tr´afego de dados mantˆem a aleatoriedade na escolha dos n´os que retransmitem. Esta ´e uma soluc¸˜ao sub-´optima uma vez que os n´os seleccionados para efectuar a retransmiss˜ao podem encontrar-se bastante pr´oximos dos retransmissores anteriores. Esta proximidade pode diminuir a utilidade da retransmiss˜ao, uma vez que o espac¸o coberto pela nova retransmiss˜ao ser´a, em grande parte, semelhante `a retrans-miss˜ao anterior. No entanto, esta aproximac¸˜ao n˜ao imp˜oe um custo/sobrecarga adicional em redes cujos n´os apresentem movimento.
2.2.5
Distˆancia aos vizinhos
Os algoritmos que utilizam a distˆancia dos vizinhos para seleccionar aqueles que ir˜ao retransmitir as mensagens tˆem como objectivo aumentar a eficiˆencia das retransmiss˜oes, ou seja, maximizar a ´area coberta pela nova retransmiss˜ao relativamente `a retransmiss˜ao anterior.
O algoritmo PAMPA [16] ´e um exemplo da classe de algoritmos que inclui a distˆancia entre os n´os na decis˜ao de retransmiss˜ao. O PAMPA aborda este problema
complemen-Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 13
tando os algoritmos dependentes do tr´afego com a preferˆencia de retransmiss˜ao atribu´ıda aos n´os mais distantes. Para tal, o PAMPA faz depender o tempo de espera da forc¸a de sinal com que as mensagens s˜ao recebidas, de forma a que dispositivos mais distantes do emissor tenham um menor tempo de espera e, consequentemente, retransmitam primeiro. Contudo, o processo de selecc¸˜ao de retransmissores do PAMPA ignora particularidades na topologia da rede, que s˜ao acentuadas pela baixa redundˆancia do PAMPA e que, em alguns casos excepcionais, reduzem a taxa de entrega [6]. No entanto, tal como na aproximac¸˜ao anterior, o PAMPA n˜ao imp˜oe um custo/sobrecarga adicional na rede.
2.3
Resumo
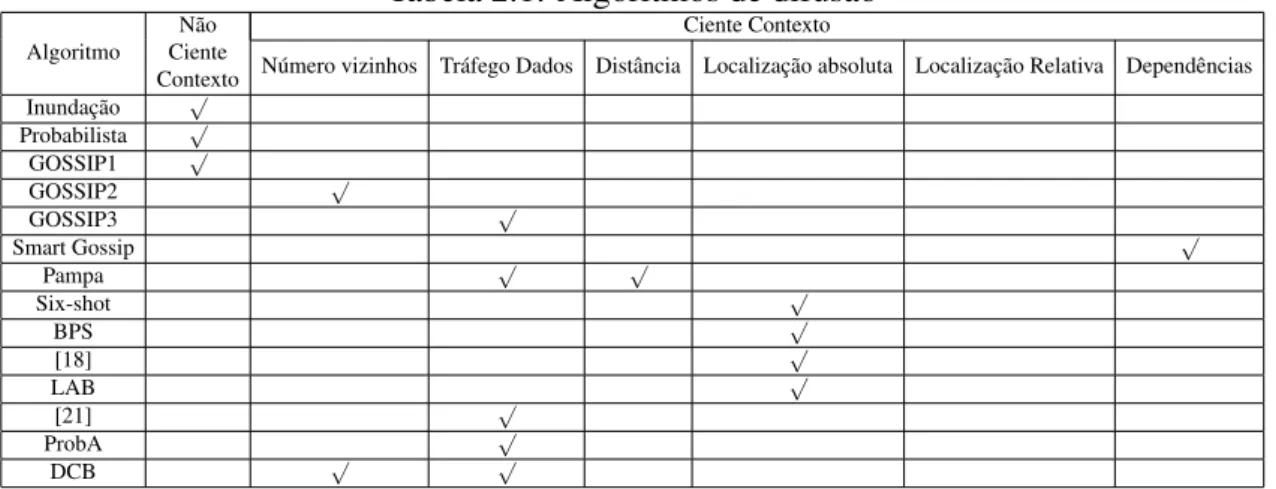
Neste cap´ıtulo foram apresentados e discutidos diferentes algoritmos de difus˜ao para re-des sem fios n˜ao infraestruturadas. Como pode ser observado na Tab. 2.1 os algoritmo de difus˜ao podem ser divididos em dois grupos principais: i) os n˜ao cientes do contexto e ii) os cientes do contexto. Os algoritmos n˜ao cientes do contexto s˜ao mais simples uma vez que apenas utilizam informac¸˜ao com que foram configurados inicialmente, nas suas tomadas de decis˜ao. Por´em, estes algoritmos n˜ao disp˜oem de mecanismos capazes de adaptar esta configurac¸˜ao inicial em func¸˜ao das caracter´ısticas da rede onde est˜ao inseri-dos o que poder´a resultar num desperd´ıcio inseri-dos recursos inseri-dos n´os ou na reduc¸˜ao da taxa de entrega. No entanto, ao n˜ao manterem estado, estes algoritmos n˜ao requerem o envio de mensagens de controlo peri´odicas (por forma a actualizar esse estado), n˜ao impondo um tr´afego adicional na rede. Outra vantagem da ausˆencia de estado ´e a maior adaptac¸˜ao, por parte dos algoritmos, a cen´arios em que os n´os apresentem movimento.
Os algoritmos cientes do contexto, devido `a utilizac¸˜ao de informac¸˜ao proveniente do ambiente onde est˜ao inseridos na sua tomada de decis˜ao e `a necessidade de manter estado, s˜ao mais complexos. Por´em, devido a esta maior complexidade, conseguem obter um me-lhor desempenho poupando assim os recursos dos n´os como, por exemplo, a bateria. No entanto, a actualizac¸˜ao do estado, em alguns algoritmos ´e efectuada `a custa de mensa-gens peri´odicas, que acarretam um custo adicional e, al´em disto, o estado pode estar, em alguns casos, inconsistente o que poder´a diminuir o desempenho dos algoritmos. Estas desvantagens s˜ao mais acentuadas em cen´arios em que os n´os apresentem movimento.
De entre os algoritmos cientes de contexto, os que se baseiam unicamente no tr´afego de dados para decidir se retransmitem uma mensagem, esperam um intervalo de tempo aleat´orio de modo a recolher informac¸˜ao necess´aria para tomarem essa decis˜ao. Por´em, devido ao tempo de espera ser aleat´orio, a eficiˆencia dos algoritmos pode diminuir caso os n´os retransmissores se encontrem muito pr´oximos uns dos outros, diminuindo assim a utilidade da retransmiss˜ao.
Os algoritmos que utilizam o n´umero de vizinhos ajustam a sua probabilidade de retransmiss˜ao consoante este valor. No entanto, estes algoritmo podem apresentar um
Cap´ıtulo 2. Difus˜ao em redes n˜ao infraestruturadas 14
Tabela 2.1: Algoritmos de difus˜ao
Algoritmo
N˜ao Ciente Contexto Ciente
N´umero vizinhos Tr´afego Dados Distˆancia Localizac¸˜ao absoluta Localizac¸˜ao Relativa Dependˆencias Contexto Inundac¸˜ao √ Probabilista √ GOSSIP1 √ GOSSIP2 √ GOSSIP3 √ Smart Gossip √ Pampa √ √ Six-shot √ BPS √ [18] √ LAB √ [21] √ ProbA √ DCB √ √
problema de cobertura. Isto ´e, dois n´os muito pr´oximos poder˜ao retransmitir a mensagem cobrindo, no pior dos casos, os mesmo n´os, levando a um desperd´ıcio de recursos.
Os algoritmos que utilizam as dependˆencias entre os v´arios n´os tentam identificar n´os cr´ıticos na propagac¸˜ao das mensagens por forma a tentar maximizar a taxa de entrega. No entanto, em alguns destes algoritmos as dependˆencias entre os v´arios n´os variam conso-ante a origem da mensagem recebida, o que ir´a afectar a probabilidade de retransmiss˜ao dos n´os.
Os algoritmos que utilizam a distˆancia dos vizinhos para seleccionar aqueles que ir˜ao retransmitir as mensagens tˆem como objectivo aumentar a eficiˆencia das retransmiss˜oes, ou seja, maximizar a ´area coberta pela nova retransmiss˜ao relativamente `a retransmiss˜ao anterior. No entanto, existem casos em que os n´os mais distantes podem n˜ao ser os mais indicados para retransmitir uma mensagem. Estes cen´arios surgem quando existe um n´o cr´ıtico para a propagac¸˜ao da mensagem que n˜ao seja o mais distante.
Os algoritmos que utilizam a localizac¸˜ao geogr´afica para obter os pr´oximos retrans-missores s˜ao os mais proretrans-missores uma vez que conseguem obter uma melhor gest˜ao dos recursos dispon´ıveis e uma cobertura ´optima da rede. No entanto, estas aproximac¸˜oes necessitam que os n´os disponham de um servic¸o de localizac¸˜ao geogr´afica, o que limita a aplicabilidade dos algoritmos. Seria de todo o interesse desenvolver um algoritmo que apresentasse as mesmas vantagens n˜ao sendo dependente de um sistema de posiciona-mento global.
Cap´ıtulo 3
Digest Exchange Broadcast Algorithm
Neste cap´ıtulo ´e apresentado o algoritmo de difus˜ao desenvolvido, intitulado Digest Ex-change Broadcast Algorithm (DEBA), bem como as escolhas tomadas no seu desenvolvi-mento e suas justificac¸˜oes.
Inicialmente, o DEBA ´e apresentado de uma forma mais abstracta, descrevendo-se o seu modo de funcionamento e as estruturas de dados necess´arias, e posteriormente ser´a descrito de forma mais concreta, referindo-se os detalhes de implementac¸˜ao.
O DEBA tem como objectivo beneficiar das vantagens apresentadas pelos algoritmos
cientes do contexto dependentes da localizac¸˜ao geogr´afica mas sem recorrer a um servic¸o de posicionamento global. Para tal, os n´os no DEBA trocam ciclicamente informac¸˜ao que permite estimar a proximidade entre os seus vizinhos. O DEBA tenta reduzir o n´umero de retransmiss˜oes redundantes, ou seja, o n´umero de retransmiss˜oes que cobrem os mesmos n´os que retransmiss˜oes anteriores, visto que para cobrir uma dada regi˜ao bastaria apenas a um dos n´os, presentes nessa regi˜ao, retransmitir a mensagem.
Por forma a estimar as proximidades entre os v´arios n´os, cada n´o cont´em um identi-ficador local, gerado de forma descentralizada, que ser´a posteriormente enviado aos seus vizinhos directos (ou seja, aos n´os que se encontram dentro do seu raio de transmiss˜ao) atrav´es de mensagens de sinalizac¸˜ao peri´odicas. Quando um n´o recebe um identificador de um vizinho, este ir´a agreg´a-lo com o seu pr´oprio identificador, passando a propagar o resultado desta agregac¸˜ao. Assim, o identificador de cada n´o ir´a partilhar parte da informac¸˜ao agregada com os identificadores dos seus vizinhos, mas n˜ao a totalidade uma vez que os n´os ter˜ao vizinhos diferentes entre si. As noc¸˜oes de proximidade s˜ao obtidas atrav´es da comparac¸˜ao dos v´arios identificadores.
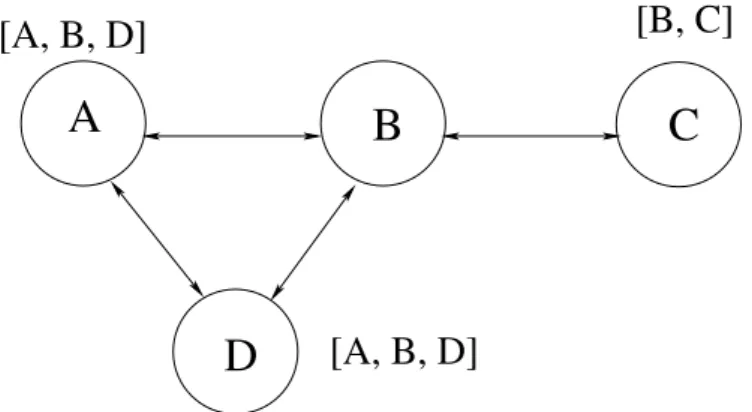
Por forma a ilustrar estes conceitos, a Fig. 3.1 representa uma rede composta por quatro n´os dos quais o n´o A, B e D mantˆem conectividade entre si, e o n´o C apenas mant´em conectividade com o n´o B. Os valores junto dos n´os A, D e C correspondem `a agregac¸˜ao do identificador do n´o com o identificador dos seus vizinhos directos. O n´o B ao receber e comparar a informac¸˜ao dos seus vizinhos ir´a assumir que os n´os A e D s˜ao
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 16
C
A
B
D
[A, B, D]
[A, B, D]
[B, C]
Figura 3.1: Exemplo da configurac¸˜ao de uma rede
vizinhos entre si, uma vez que apresentam identificadores iguais. No caso do n´o C, dado que este apresenta um identificador diferente de A e de D, B ir´a assumir que C se encontra numa localizac¸˜ao distinta.
3.1
Estruturas de dados
O algoritmo desenvolvido ´e totalmente descentralizado e assume que cada n´o n cont´em
um identificador ´unico (En) que pode ser, por exemplo, o seu enderec¸o de rede ou MAC.
Adicionalmente, cada n´o n, mant´em ainda as seguintes estruturas de dados.
Vector Local O vector local de um n´o n (V Ln) (que corresponde ao identificador local
na secc¸˜ao anterior) ´e um conjunto de k inteiros seleccionados aleatoriamente do
inter-valo [0, maxI]. O algoritmo ´e ortogonal ao mecanismo utilizado para a gerac¸˜ao de V Ln,
requerendo apenas que a probabilidade de dois quaisquer n´os seleccionarem o mesmo conjunto seja baixa. Um gerador de n´umeros aleat´orios ou uma sequˆencia de operac¸˜oes
de dispers˜ao (hash) aplicadas a Ens˜ao exemplos de func¸˜oes que podem ser utilizadas.
Vector de Vizinhanc¸a Um vector de vizinhanc¸a de um n´o n (V Vn) ´e a uni˜ao dos
ele-mentos de V Lncom os elementos dos vectores locais de todos os seus vizinhos directos.
No ˆambito do vector de vizinhanc¸a, n˜ao ´e feita qualquer associac¸˜ao entre os seus elemen-tos e o n´o que contribuiu com esses elemenelemen-tos para o vector. De notar que o vector de vizinhanc¸a n˜ao ´e imut´avel, sendo refrescado com a aprendizagem dos vectores locais dos seus vizinhos. Contudo, numa rede onde os dispositivos n˜ao se movem, os vectores de vizinhanc¸a estabilizam ap´os algumas iterac¸˜oes.
Tabela de Vizinhanc¸a A Tabela de Vizinhanc¸a (T Vn) de um n´o n ´e uma associac¸˜ao
entre cada vizinho v a um salto de n e o vector de vizinhanc¸a anunciado por v. A tabela
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 17
apenas na uni˜ao de todos os elementos de T Vn. Por outro, oferece ao n´o uma estimativa da
proximidade dos seus vizinhos, pela comparac¸˜ao dos elementos em comum nos vectores de vizinhanc¸a de cada um dos seus vizinhos.
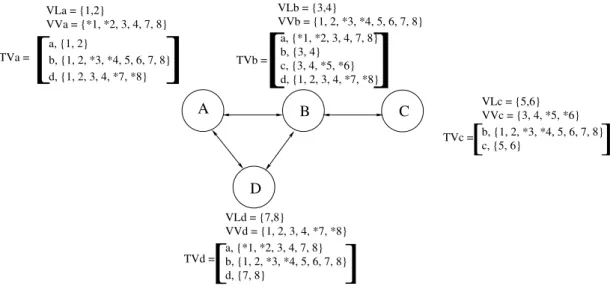
De modo a ilustrar os conceitos anteriores, a Fig. 3.2 apresenta a mesma rede da Fig. 3.1 mas utilizando as estruturas de dados apresentadas. As estruturas V L, V V e T V junto a cada n´o apresentam os valores ap´os a estabilizac¸˜ao do algoritmo. Por clareza da
apresentac¸˜ao, os membros de V Vn que pertencem simultaneamente a V Ln est˜ao
assina-lados com um asterisco (*).
TVb =
[
VLb = {3,4} VVb = {1, 2, *3, *4, 5, 6, 7, 8} d, {1, 2, 3, 4, *7, *8} c, {3, 4, *5, *6} b, {3, 4} a, {*1, *2, 3, 4, 7, 8} VLc = {5,6} VVc = {3, 4, *5, *6} c, {5, 6} TVc =]
b, {1, 2, *3, *4, 5, 6, 7, 8} a, {1, 2} TVa = d, {1, 2, 3, 4, *7, *8} VLa = {1,2} VVa = {*1, *2, 3, 4, 7, 8}[
]
b, {1, 2, *3, *4, 5, 6, 7, 8}[
]
a, {*1, *2, 3, 4, 7, 8} b, {1, 2, *3, *4, 5, 6, 7, 8} VLd = {7,8} VVd = {1, 2, 3, 4, *7, *8} d, {7, 8}[
TVd = A B C D]
Figura 3.2: Estruturas de dados utilizadas pelo algoritmo DEBA
Tal como explicado para a Fig. 3.1, pode observar-se que V VA = V VD o que sugere
ao n´o B que A e D se encontram pr´oximos. Analogamente, T VB mostra uma clara
diferenc¸a entre estes vectores e V VC, o que sugere que os primeiros n˜ao se encontram
no raio de transmiss˜ao do ´ultimo. Por sua vez, os n´os A e D, podem aperceber-se da sua proximidade e da diferenc¸a do vector de vizinhanc¸a de B, por este ´ultimo conter os
elementos em V LC, o que n˜ao acontece com V VAe V VD.
3.2
Funcionamento do algoritmo
Por forma a estimar a proximidade dos v´arios n´os, o DEBA utiliza a informac¸˜ao contida nos Vectores de Vizinhanc¸a anunciados periodicamente pelos n´os que formam a rede. Inicialmente, dado que as tabelas de vizinhanc¸a dos n´os se encontram vazias, os vectores de vizinhanc¸a enviados apenas contˆem o vector local do pr´oprio n´o. Por´em, `a medida que os n´os v˜ao recebendo os vectores de vizinhanc¸a dos seus vizinhos, estes v˜ao sendo gradualmente agregados. No entanto, o Vector Local de cada n´o, contido no Vector de Vizinhanc¸a, s´o ir´a ser propagado a dois saltos de distˆancia. Esta perda de informac¸˜ao ´e necess´aria por forma a evitar que as constantes agregac¸˜oes resultem num ´unico Vector de
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 18
Vizinhanc¸a que seria partilhado por todos os n´os da rede. Caso este cen´ario acontecesse, deixaria de ser poss´ıvel estimar a proximidade entre os v´arios n´os, uma vez que estas s˜ao identificadas pelas diferenc¸as entre os v´arios Vectores de Vizinhanc¸a. Por forma ao n´o identificar as secc¸˜oes do Vector de Vizinhanc¸a que ser˜ao agregadas e as que ser˜ao rejei-tadas (as secc¸˜oes que atingiram o n´umero m´aximo de retransmiss˜oes), esta informac¸˜ao ´e identificada pelo pr´oprio emissor do vector de vizinhanc¸a. Isto ´e, caso o n´o x receba um Vector de Vizinhanc¸a do n´o y, y ir´a indicar, ao n´o x, que parte do seu Vector de Vizinhanc¸a dever´a ser incorporada no Vector de Vizinhanc¸a de x (relativamente `a Fig. 3.2 esta informac¸˜ao corresponde aos valores assinalados com um asterisco (*) no Vector de Vizinhanc¸a). O Alg. 1 apresenta os passos realizados no envio e recepc¸˜ao das mensagem de controlo.
Algoritmo 1 Pseudo-c´odigo do algoritmo desenvolvido - Anuncio de vectores
1: uses Mac Layer (MAC)
2:
3: upon event < Init > do
4: handledM sgs ← ø 5: tv ← ø 6: startT imer(∆) 7: vl = randomN umber 8: E = getM ACAddress(self ) 9:
10: upon event < Timeout > do
11: {vv0 corresponde `a informac¸˜ao que ir´a ser agregada no Vector de Vizinhanc¸a}
12: vv ← ø
13: for all (src → (vv, vv0) ∈ tv do
14: vv = vv ∪ vvn0
15: end for
16: vv = vv ∪ vl
17: trigger < controlMsgsSend |E, vv, vl >
18: startT imer(∆)
19:
20: upon event < controlMsgsDeliver |src, vv, vv0 > do
21: tv[src] = (vv, vv0)
Quando um n´o pretende enviar uma mensagem de difus˜ao este ir´a seleccionar, da sua tabela de vizinhanc¸a, os pr´oximos n´os que ir˜ao retransmitir a mensagem e ir´a incorpo-rar esta informac¸˜ao no cabec¸alho da mesma (Alg. 2). Os n´os seleccionados s˜ao aqueles cujos vectores de vizinhanc¸a sejam suficientemente distintos entre si, garantindo-se as-sim que os pr´oximos retransmissores est˜ao suficientemente distantes por forma a evitar o envio de mensagens redundantes. Al´em da lista de enderec¸os seleccionados para re-transmitir a mensagem, o cabec¸alho de cada mensagem difundida cont´em ainda um iden-tificador ´unico de mensagem gerado pelo emissor (que pode ser obtido por exemplo pela
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 19
concatenac¸˜ao de En com um n´umero de s´erie local ao emissor). O identificador ´unico
de mensagem permite aos n´os identificar duplicados, que ser˜ao descartados. Esta funci-onalidade assegura igualmente a terminac¸˜ao da propagac¸˜ao das mensagens, dispensando estimativas sobre o n´umero m´aximo de saltos que a mensagem ir´a necessitar para cobrir a totalidade da rede e portanto um campo do tipo time-to-live (TTL).
Algoritmo 2 Pseudo-c´odigo do algoritmo desenvolvido continuac¸˜ao
1: upon event < MsgsBroadcast |m > do
2: Cm n ← ø
3: idM sg = newID()
4: handleM sgs = handleM sgs ∪ idM sg
5: ls = obtemRetransmissores(tv, Cm n) 6: Broadcast(E, [idM sg, ls, m]) 7: 8: function obtemRetransmissores(tv, Cm n ) 9: tv = ordenaT V (tv) 10: for all src → (vv, vv0) ∈ tv do 11: val = true
12: for all srca→ (vva) ∈ Cnm&& val do
13: if (metrica(vv, vva) > threshold) then
14: bool = f alse 15: end if 16: end for 17: if (val) then 18: lista = lista ∪ {src} 19: Cnm[src] = (vv) 20: end if 21: end for 22: return lista
A selecc¸˜ao dos retransmissores ´e feita atrav´es de uma func¸˜ao de comparac¸˜ao. Esta func¸˜ao de comparac¸˜ao ´e a parte central do DEBA e ´e executada independentemente por cada n´o que tenha sido seleccionado para retransmitir a mensagem. Como detalhado no Alg. 2 (linha 5), para um n´o n, a func¸˜ao recebe como argumentos a Tabela de Vizinhanc¸a
de n (T Vn) e a lista de vizinhos seleccionados pelo n´o do qual a mensagem foi recebida
(Cnm) e retorna a lista dos vizinhos seleccionados. Genericamente, a func¸˜ao pode ser
decomposta em dois passos: i) ordenac¸˜ao de T Vn, ii) sequencialmente, para cada n´o em
T Vn, decidir se o n´o ´e ou n˜ao seleccionado.
O crit´erio de ordenac¸˜ao de T Vn influencia o algoritmo uma vez que os primeiros
ele-mentos analisados ter˜ao preferˆencia de selecc¸˜ao sobre os restantes. Assim, o passo i)
(Alg. 2 linha 9) ordena T Vnpor ordem decrescente da dimens˜ao do vector de vizinhanc¸a.
Este crit´erio ´e justificado por cada n´o gerar um vector local com o mesmo n´umero de inteiros e portanto, a um Vector de Vizinhanc¸a com mais elementos corresponder um n´o
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 20
com um maior n´umero de vizinhos, ou seja, com uma maior cobertura da retransmiss˜ao. Outros crit´erios testados, mas que avaliac¸˜oes preliminares mostraram n˜ao apresentar me-lhor desempenho foram:
• Ordem crescente da dimens˜ao do vector de vizinhanc¸a - este crit´erio ´e justificado por cada n´o gerar um vector local com o mesmo n´umero de inteiros e portanto, a um Vector de Vizinhanc¸a com menos elementos corresponder um n´o com menor n´umero de vizinhos. Assim, assume-se que o n´o se encontra numa zona pouco densa da rede e ao fazer estes n´os retransmitirem a mensagem garante-se que estes a ir˜ao receber. No entanto, esta abordagem n˜ao obteve bons resultados uma vez que em alguns casos os n´os seleccionados para retransmitir uma mensagem e cujo tama-nho do Vector de Vizinhanc¸a apresentavam menor dimens˜ao estavam cobertos por um outro n´o cujo tamanho do Vector de Vizinhanc¸a apresentava maior dimens˜ao. • Ordenac¸˜ao aleat´oria - neste caso a ordem de T V ´e ditada pela sequˆencia com que
as mensagens de controlo s˜ao recebidas. Devido a isto, o algoritmo em alguns casos apresentava um mau desempenho pois os n´os seleccionados para retransmitir uma mensagem apresentavam um Vector de Vizinhanc¸a de menor dimens˜ao que estaria coberto por um outro n´o cujo tamanho do Vector de Vizinhanc¸a apresentava maior dimens˜ao. Enquanto noutros casos obtinha um bom desempenho devido a serem seleccionados primeiro os n´os com Vectores de Vizinhanc¸a de maior dimens˜ao. Para uma mensagem m, o passo ii) (representado no Alg. 2 linhas 10-21) compara
sequencialmente o vector de vizinhanc¸a de cada um dos elementos de T Vncom cada um
dos elementos de um conjunto Cnm composto pelos vectores de vizinhanc¸a de:
• o n´o do qual foi recebida a mensagem m;
• os n´os que constam da lista de retransmissores em m e que existam tamb´em em
T Vn, ou seja, alguns dos n´os que s˜ao vizinhos tanto do emissor como do receptor
• n´os entretanto j´a seleccionados para retransmiss˜ao em iterac¸˜oes anteriores do passo ii).
Para que um n´o seja seleccionado, este tem de se mostrar suficientemente distinto na
comparac¸˜ao com todos os elementos de Cnm. As comparac¸˜oes podem seguir diferentes
crit´erios. Sejam V Va ∈ T Vn, V Vb ∈ Cnm dois vectores de vizinhanc¸a em comparac¸˜ao.
Foram desenvolvidas e avaliadas as seguintes quatro m´etricas:
R´acio Total Determinista (RTD) quociente do n´umero de inteiros em comum entre os dois vectores pelo n´umero total de inteiros na uni˜ao dos dois vectores, ou seja,
RT D(a, b) = |V Va∩V Vb|
|V Va∪V Vb|. Os vectores s˜ao considerados semelhantes se o quociente
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 21
R´acio Total Probabilista (RTP) como em RTD, contudo, o vector ´e considerado dis-tinto se RTP for inferior a uma constante pr´e-definida. Caso contr´ario, a semelhanc¸a ´e determinada por uma func¸˜ao probabilista que decresce linearmente com o valor de RTP.
R´acio M´ınimo Determinista (RMD) quociente do n´umero de inteiros em comum entre
os dois vectores pela dimens˜ao do menor vector, ou seja, RM D(a, b) = |V Va∩V Vb|
min{|V Va|,|V Vb|}.
Os vectores s˜ao considerados semelhantes se o quociente for superior a uma cons-tante pr´e-definida.
R´acio M´ınimo Probabilista (RMP) como em RMD, contudo, o vector ´e considerado distinto se RMP for inferior a uma constante pr´e-definida. Caso contr´ario, a semelhanc¸a ´e determinada por uma func¸˜ao probabilista que decresce linearmente com o valor de RMP.
De notar que qualquer das m´etricas resulta trivialmente na exclus˜ao de n´os que estejam
j´a presentes em Cm
n uma vez que, para qualquer n´o n, RT D(n, n) = RM D(n, n) =
1. A preparac¸˜ao da retransmiss˜ao termina com a incorporac¸˜ao dos enderec¸os dos n´os seleccionados no cabec¸alho da mensagem.
O Alg. 3 (linhas 4-18), mostra que quando um n´o n recebe uma mensagem de difus˜ao, este ir´a verificar se recebeu anteriormente uma c´opia dessa mensagem. Esta verificac¸˜ao ´e efectuada atrav´es da comparac¸˜ao do identificador ´unico da mensagem com um vector que guarda os identificadores das ´ultimas mensagens recebidas. Caso o vector j´a contenha o identificador da mensagem, esta ´e descartada, caso contr´ario, o n´o adiciona este identi-ficador ao vector e entrega a mensagem `a aplicac¸˜ao. Em seguida, o n´o verifica se o seu
identificador (En) est´a contido na lista de retransmissores no cabec¸alho da mensagem. Se
estiver, o n´o ir´a seleccionar os pr´oximos retransmissores e ir´a propagar a mensagem, caso contr´ario, o n´o n˜ao ir´a realizar qualquer operac¸˜ao.
3.3
Concretizac¸˜ao
Um dos desafios do algoritmo ´e conseguir um equil´ıbrio entre a diminuic¸˜ao da proba-bilidade de repetic¸˜ao de Vectores Locais, a dimens˜ao das Tabelas e dos Vectores de Vizinhanc¸a e a complexidade computacional das operac¸˜oes a realizar.
Caso a probabilidade de repetic¸˜ao dos vectores locais seja elevada, a eficiˆencia do algoritmo ir´a diminuir uma vez que ir´a fornecer informac¸˜oes incorrectas sobre a pro-ximidade dos n´os. Assim, ´e necess´ario alargar, tanto quanto poss´ıvel, o n´umero de
combinac¸˜oes dispon´ıvel nos Vectores Locais V L, atrav´es das constantes maxI e k.
Con-tudo, por forma a diminuir a mem´oria ocupada pela Tabela de Vizinhanc¸a T V , a largura
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 22
Algoritmo 3 Pseudo-c´odigo do algoritmo desenvolvido continuac¸˜ao
1: upon event < Deliver |src, [idM sg, ls, m] > do
2: if (idM sg 6∈ handleM sgs) then
3: handleM sgs = handleM sgs ∪ idM sg
4: deliver(m) 5: if (E ∈ ls) then 6: Cnm ← ø 7: forall srca→ (vv, vv0) ∈ tv do 8: if (srca∈ ls || srca == src) then 9: Cnm[srca] = (vv) 10: end if 11: end for 12: lista = obtemRetransmissores(tv, Cnm)
13: Broadcast(E, [idM sg, lista, m])
14: end if
15: end if
realizadas para selecc¸˜ao dos retransmissores, ´e necess´ario utilizar valores reduzidos para
maxI e k
A concretizac¸˜ao realizada inspira-se no conceito de Bloom Filter [4]. Um Bloom Fil-ter permite representar, de forma compacta, um conjunto de n elementos num vector de m bits inicialmente com todas as posic¸˜oes a zero. Para isto, s˜ao utilizadas k func¸˜oes de hash independentes, cujo resultado est´a contido no intervalo [0, m − 1], sobre cada elemento
ni do conjunto n. Para cada valor obtido nas func¸˜oes de hash o bit correspondente a essa
posic¸˜ao no vector ´e colocado a 1. No DEBA as posic¸˜oes colocadas a 1 correspondem aos k inteiros do Vector Local. De entre as caracter´ısticas que tornam os Bloom Filters apelativos encontra-se a reduzida complexidade computacional das operac¸˜oes de uni˜ao e intersecc¸˜ao de conjuntos, conseguidas utilizando os operadores de disjunc¸˜ao e conjunc¸˜ao bit-a-bit, nativos na maioria dos processadores actuais. Adicionalmente, a utilizac¸˜ao de
Bloom Filtersfixa uma dimens˜ao para os vectores de vizinhanc¸a, que se torna
indepen-dente do n´umero de vizinhos de cada dispositivo. Para a avaliac¸˜ao do algoritmo, foram
definidas as constantes maxI = 1023 e k = 8. Ou seja, cada vector local V Ln´e composto
por 8 inteiros seleccionados aleatoriamente do intervalo [0, 1023], a que corresponder´a um
Bloom Filtercom 1024 bits (128 bytes), dos quais 8 ter˜ao o valor 1.
Contudo, os Bloom Filters n˜ao permitem a contabilizac¸˜ao do n´umero de saltos que tem de ser associada a cada um dos bits. N˜ao sendo assim poss´ıvel obter as secc¸˜oes do Bloom
Filter que j´a atingiram o n´umero m´aximo de retransmiss˜oes e aquelas que necessitam
ser retransmitidas. Esta informac¸˜ao ´e obtida acrescentando `a mensagem, que cont´em o Vector de Vizinhanc¸a, um segundo vector de bits com a mesma dimens˜ao. Neste vector, cada posic¸˜ao i ter´a o valor 1 caso o bit i do Vector de Vizinhanc¸a deva ser propagado pelos receptores e o valor 0 caso contr´ario (os bits com o valor 1 correspondem `as posic¸˜oes do
Cap´ıtulo 3. Digest Exchange Broadcast Algorithm 23
vector de vizinhanc¸a que contˆem um asterisco (*) na Fig. 3.2). A dimens˜ao final das mensagens de an´uncio dos Vectores de Vizinhanc¸a ´e de 2 × 128 = 256 bytes. Note-se, no entanto, que estas constantes podem ser alteradas para atender a restric¸˜oes externas, por exemplo uma dimens˜ao m´axima das tramas ao n´ıvel de ligac¸˜ao de dados ou uma grande quantidade de vizinhos que aumente a probabilidade de repetic¸˜ao de vectores locais.
3.4
Resumo
Este cap´ıtulo apresentou o Digest Exchange Broadcast Algorithm (DEBA). Este algo-ritmo tem como objectivo a difus˜ao eficiente de mensagens em redes n˜ao infraestrutu-radas, estimando as proximidades entre os v´arios n´os que formam a rede sem recorrer a um sistema de posicionamento global. A estimativa das localizac¸˜oes s˜ao realizadas comparando identificac¸˜oes dos vizinhos de cada n´o enviadas em mensagens de controlo peri´odicas. Estas mensagens agregam a identificac¸˜ao do n´o e as identificac¸˜oes, previa-mente recebidas, dos seus vizinhos. O formato desta identificac¸˜ao permite tornar o espac¸o ocupado por uma ou v´arias identificac¸˜oes agregadas idˆentico. Cada n´o ir´a ent˜ao partilhar com os seus vizinhos uma parte da identificac¸˜ao agregada, mas (na maioria dos casos) n˜ao a totalidade, uma vez que cada n´o ter´a vizinhos que n˜ao s˜ao comuns. Desta forma, espera-se que agregac¸˜oes muito distintas representem diferentes localizac¸˜oes geogr´aficas. Quando um n´o pretende enviar uma mensagem de difus˜ao, este compara os vectores de vizinhanc¸a recebidos, atrav´es de um func¸˜ao de comparac¸˜ao, por forma a identificar o sub-conjunto de n´os cujos vectores de vizinhanc¸a sejam suficientemente distintos entre si. Os n´os seleccionados ir˜ao assegurar a continuidade da propagac¸˜ao da mensagem.
A eficiˆencia do algoritmo aumenta com o tempo, uma vez que cada regi˜ao da rede necessita de uma fase de aquecimento, onde s˜ao trocados os Vectores de Vizinhanc¸a. No entanto, em redes em que os n´os n˜ao apresentem movimento (por exemplo, redes de sensores) a informac¸˜ao das tabelas de vizinhanc¸a tende a estabilizar permitindo diminuir progressivamente a frequˆencia dos an´uncios, atenuando desta forma o seu impacto no consumo energ´etico dos dispositivos.
Cap´ıtulo 4
Avaliac¸˜ao
Neste cap´ıtulo s˜ao apresentados e discutidos os resultados obtidos nos testes realizados ao DEBA.
O cap´ıtulo encontra-se dividido em v´arias secc¸˜oes, cada uma descrevendo um di-ferente modelo utilizado na avaliac¸˜ao do DEBA. Os modelos utilizados foram: redes est´aticas, redes em que os n´os apresentam movimento aleat´orio (Random Waypoint), re-des em que os n´os tˆem caminhos pr´e-definidos em forma de grelha (Manhattan Grid), redes que simulam cen´arios de emergˆencia e redes est´aticas com distribuic¸˜ao condicio-nada dos n´os.
4.1
Caracter´ısticas gerais das simulac¸˜oes
Os testes foram realizados utilizando o simulador de redes ns-2 v. 2.34. Os n´os foram configurados para simularem a interface radio Lucent Wave-LAN DSSS a 914 MHz uti-lizando o protocolo IEEE 802.11 a 2 Mb/s. Excepto no modelo que simula cen´arios de emergˆencia em que os n´os apresentam um raio de transmiss˜ao de 50 metros, nos outros modelos o raio de transmiss˜ao utilizado foi de 250 metros. O modelo de propagac¸˜ao utili-zado foi o Two-Ray Ground, que assegura a entrega das mensagens a menos da ocorrˆencia de colis˜oes, o que permite abstrair o desempenho dos algoritmos de factores externos, como as interferˆencias.
As m´etricas estudadas foram a taxa de entrega e a taxa de retransmiss˜ao ou seja, a proporc¸˜ao m´edia de n´os que recebe e retransmite cada mensagem, respectivamente. Estas m´etricas permitem avaliar a efic´acia do algoritmo e o impacto da difus˜ao de mensagens na rede. Para o modelo Random Waypoint foi ainda obtido o n´umero m´edio de mensa-gens enviadas por cada n´o, que contabiliza as mensamensa-gens de difus˜ao e as mensagem de an´uncio dos Vectores de Vizinhanc¸a usadas pelo DEBA, bem como a utilidade de cada retransmiss˜ao, ou seja, o n´umero m´edio de n´os que recebem a mensagem por cada re-transmiss˜ao.
Por forma a validar os resultados obtidos, estes foram comparados com dois algorit-25
Cap´ıtulo 4. Avaliac¸˜ao 26
mos de controlo: a inundac¸˜ao e a difus˜ao cega. No algoritmo de inundac¸˜ao todos os n´os retransmitem ap´os receberem a mensagem pela primeira vez. A inundac¸˜ao apresenta na maioria dos casos a cobertura m´axima poss´ıvel da rede, permitindo distinguir ineficiˆencias dos algoritmos avaliados de incapacidade f´ısica de entrega das mensagens resultante da ocorrˆencia de partic¸˜oes na rede.
Para verificar a eficiˆencia do algoritmo relativamente `a taxa de entrega, este ir´a ser comparado com um algoritmo de difus˜ao cega. Neste algoritmo cada n´o selecciona alea-toriamente os n´os que ir˜ao continuar a propagac¸˜ao das mensagens de difus˜ao. De forma a assegurar condic¸˜oes compar´aveis, o algoritmo selecciona como retransmissores 25% dos vizinhos. Este valor foi seleccionado por representar uma taxa de retransmiss˜ao com-par´avel `a obtida nas func¸˜oes do DEBA em redes com uma densidade interm´edia (cf. Fig. 4.2).
4.2
Redes est´aticas
Nesta secc¸˜ao s˜ao apresentados os resultados obtidos para redes em que os n´os n˜ao apre-sentam movimento. As m´etricas utilizadas para as func¸˜oes descritas no Cap´ıtulo 3 encontram-se apreencontram-sentadas na Tab. 4.1 e 4.2. Estas m´etricas foram encontram-seleccionadas em func¸˜ao de experiˆencias preliminares.
Tabela 4.1: Valores utilizados nas m´etricas deterministas
M´etrica Constante
RTD 0.65
RMD 0.85
Tabela 4.2: Valores utilizados nas m´etricas probabilistas
M´etrica M´ınimo M´aximo Probabilidade
RTP 0.6 0.7 1 − (RT D(a, b) − 0.6) × 10
RMP 0.8 0.9 1 − (RM D(a, b) − 0.8) × 10
Os testes efectuados continham 100 dispositivos distribu´ıdos aleatoriamente em redes com dimens˜oes de 500m × 250m, 500m × 500m, 1000m × 500m, 1000m × 1000m, 2000m × 1000m e 2000m × 2000m a que correspondem a taxas de ocupac¸˜ao entre
1250m2/n´o e 40000m2/n´o. Em cada dimens˜ao de rede foram realizados 100 testes,
com disposic¸˜oes distintas dos n´os. Cada teste consiste na difus˜ao de 100 mensagens, cada uma iniciada por um dos n´os. As mensagens tˆem um tamanho fixo de 682 bytes, o que inclui os cabec¸alhos e hipot´eticos dados da aplicac¸˜ao. Um tamanho fixo de mensagem torna a avaliac¸˜ao ortogonal ao formato utilizado pelos vectores locais dos n´os. Cada teste tem a durac¸˜ao de 1500 segundos. Os primeiros 390 constituem uma fase de aquecimento, em que os n´os anunciam periodicamente os seus vectores de vizinhanc¸a. Os resultados
Cap´ıtulo 4. Avaliac¸˜ao 27
apresentados correspondem aos ´ultimos 1100 segundos, durante os quais s˜ao difundidas as mensagens.
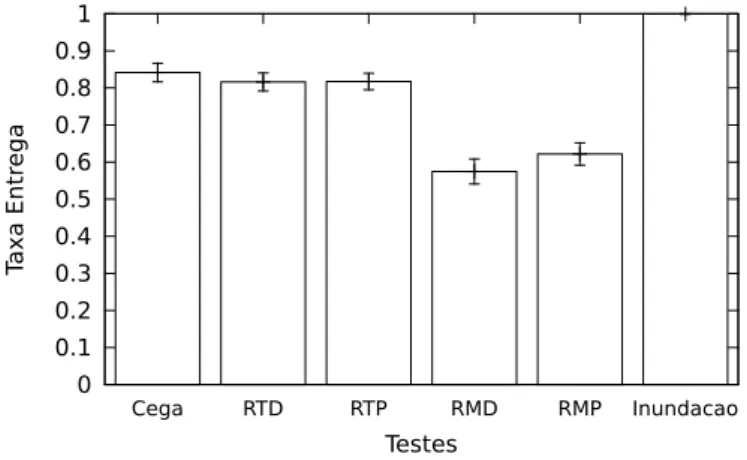
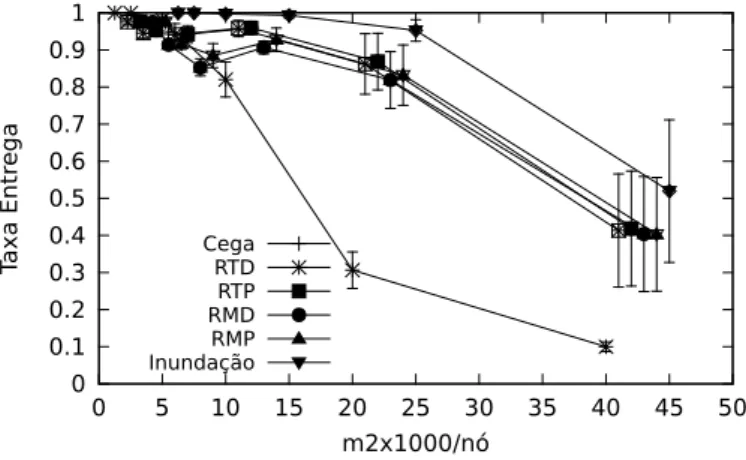
A vantagem das func¸˜oes estudadas sobre aproximac¸˜oes probabilistas ´e vis´ıvel na Fig. 4.1, que compara a taxa de entrega. Na figura, as barras de erro representam a distˆancia do valor m´edio ao desvio padr˜ao da amostra. Ao observarmos os resultados da difus˜ao cega, observa-se que a sua taxa de entrega se afasta significativamente das restan-tes com o aumento da ´area de simulac¸˜ao. Isto ´e atribu´ıdo a escolhas incorrectas, por parte do algoritmo, relativamente aos n´os retransmissores, que impedem assim a propagac¸˜ao da mensagem para algumas regi˜oes da rede. Pelo contr´ario, no DEBA, as taxas de entrega acompanham as da inundac¸˜ao em todas as densidades. No entanto, o DEBA apresenta um desempenho ligeiramente inferior, que no pior caso ´e cerca de 12%. Al´em disto, pode ser observado que as func¸˜oes de r´acio m´ınimo apresentam um desempenho inferior, o que se mant´em constante em todos os cen´arios.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 5 10 15 20 25 30 35 40 45 50 Ta xa En tr ega m2x1000/nó Cega RTD RTP RMD RMP Inundação
Figura 4.1: Taxa de entrega - modelo est´atico
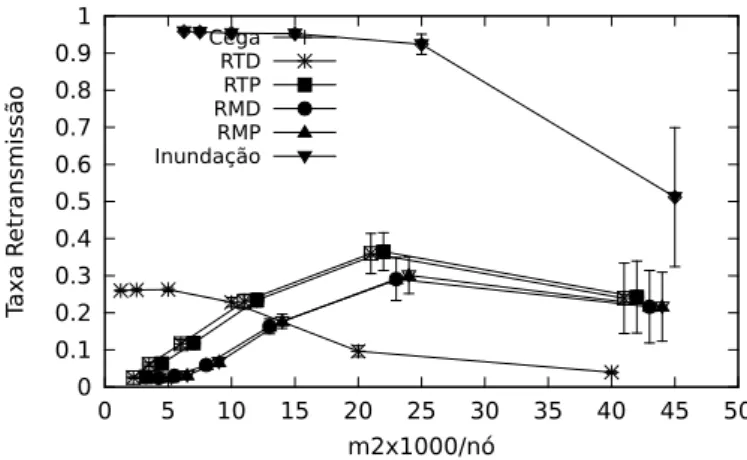
A Fig. 4.2 mostra que a ligeira penalizac¸˜ao da taxa de entrega do DEBA ´e compensada por uma reduc¸˜ao significativa do n´umero de retransmiss˜oes, o que permite ganhos signifi-cativos na autonomia dos dispositivos e na largura de banda consumida. Como desej´avel, o DEBA acompanha o aumento da ´area com um aumento da taxa de retransmiss˜ao. Isto acontece devido `a maior distˆancia entre os dispositivos, sendo portanto necess´arias mais retransmiss˜oes para cobrir o mesmo n´umero de dispositivos. Os decr´escimos da taxa de
retransmiss˜ao para a taxa de ocupac¸˜ao 40000m2/n´o ´e justificada, no caso da inundac¸˜ao
e do DEBA pela impossibilidade de atingir alguns dispositivos devido `a ocorrˆencia de partic¸˜oes que impedem a continuac¸˜ao da propagac¸˜ao.
As figuras mostram ainda que n˜ao existe diferenc¸a significativa entre as func¸˜oes RTD e RTP e entre RMD e RMP. Isto ´e justificado porque, no caso das func¸˜oes probabilistas, `a medida que o resultado da func¸˜ao de comparac¸˜ao se aproxima do valor m´aximo, a pro-babilidade de um dispositivo ser seleccionado diminui. Adicionalmente, esta semelhanc¸a sugere que, na generalidade dos casos, as func¸˜oes estudadas s˜ao resilientes a falhas de
![Figura 4.3: Taxa de entrega - Random Waypoint [1, 2]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18176615.874070/52.892.256.629.115.346/figura-taxa-entrega-random-waypoint.webp)
![Figura 4.6: Taxa de retransmiss˜ao com diminuic¸˜ao dos intervalos de tempo - Random Waypoint [1, 2]](https://thumb-eu.123doks.com/thumbv2/123dok_br/18176615.874070/54.892.250.628.434.661/figura-taxa-retransmiss-diminuic-intervalos-tempo-random-waypoint.webp)