Effective Complex Data Retrieval Mechanism for Mobile Applications
Texto
Imagem
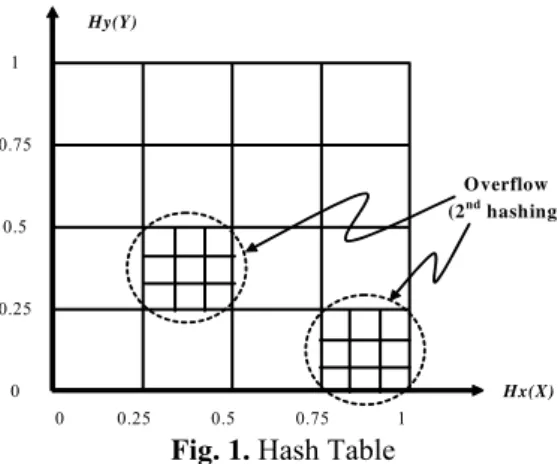

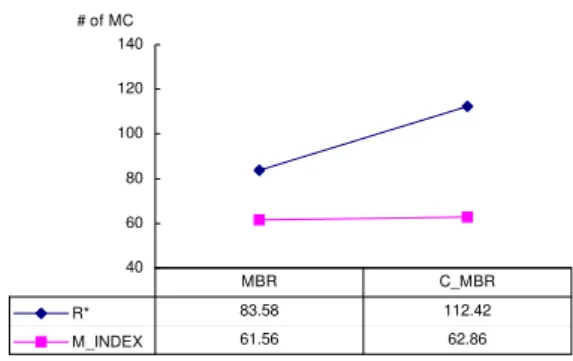

Documentos relacionados
Tendo como base os trabalhos que constam no Catálogo de Teses e Dissertações da CAPES em todo período, a realização da presente pesquisa tinha como objetivo
EE:“Sim, em certa parte… nós tínhamos várias áreas para avaliação no nosso estágio…uma dessas áreas era precisamente a relação com a comunidade
Moreover, these findings indicate an additive effect of nostalgia stimulus into attitudes and perceived quality of second-hand stores when individuals are attributed to buy
Mais tarde, no sinodo provincial de Goa de 1606, tornaram a insistir nas mesmas providências e vale a pena transcrevê-las: «Em algumas igrejas desta província, se representão
Entretanto, reconhece-se que homens e mulheres teriam inclinações e preferências diferentes para cada nível de relacionamento em virtude da aprendizagem social,
Pode-se verificar um aumento do consumo específico, em praticamente todo o intervalo de velocidades de rotação, excetuando três pontos de velocidade de rotação,
A atribuição da mesma designação − variante − para os elementos lexicais diferentes entre dois textos orais de um mesmo romance ou conto popular, como para designar a
Para o desenvolvimento desta pesquisa considerou-se como conceito de governança, a capacidade do Estado de implementar políticas públicas, atender as demandas
