Departamento de Computação
Mestrado e Doutorado em Ciênia da Computação
Infra-estrutura de Componentes Paralelos
para Apliações de Computação de Alto
Desempenho
Jeerson de Carvalho Silva
Fortaleza Ceará
Centro de Ciênias
Departamento de Computação
Mestrado e Doutorado em Ciênia da Computação
Infra-estrutura de Componentes Paralelos
para Apliações de Computação de Alto
Desempenho
Autor
Jeerson de Carvalho Silva
Orientador
Prof. Dr. Franiso Heron de Carvalho Junior
Dissertação apresentadaàCoordenação
do Programa de Pós-graduação
em Ciênia da Computação da
Universidade Federal do Ceará omo
parte dos requisitos para obtenção do
grau de Mestre em Ciênia da
Computação.
A
onstrução de novas apliações voltadas à Computação de Alto Desempenho (CAD) têm exigido ferramentas que oniliem um alto poder de abstraçãoe integração de software. Dentre as soluções apresentadas pela omunidade
ientía estamos partiularmente interessados naquelas baseadas em tenologia
de omponentes. Os omponentes têm sido usados para abordar novos requisitos
de apliações de alto desempenho, entre as quais destaamos: interoperabilidade,
reusabilidade,manutenibilidadeeprodutividade.
Asabordagensdas apliaçõesatuais baseadas emomponentes, noentanto,não
onseguemabstrairformasmaisgeraisdeparalelismodemaneiraeiente,tornando
ainda o proesso de desenvolvimento difíil, prinipalmente se o usuário for leigo
no onheimento das peuliaridades de arquiteturas de omputação paralela. Um
tempo preioso, o qualdeveria ser utilizadopara a soluçãodo problema, é perdido
naimplementaçãoeientedo ódigo de paralelização.
Diante desse ontexto, esta dissertação apresenta o HPE (Hash Programming
Environment), uma solução baseada no modelo # de omponentes paralelos e
na arquitetura Hash. O HPE dene um onjunto de espéies de omponentes
responsáveispela onstrução,implantaçãoe exeuçãode programas paralelossobre
lusters de multiproessadores. A arquitetura Hash é onstituída de três módulos
distintos: oFront-End,oBak-EndeoCore. Aontribuiçãoprinipaldestetrabalho
reside na implementação de um Bak-End, omo uma plataforma de omponentes
paralelosqueestende oMono,plataformade omponentesde ódigoabertobaseada
no padrão CLI (Common Language Interfae). Feito isso, unimos o Bak-End às
implementações já existentes do Front-End e do Core, ambos em Java e sobre a
plataformade desenvolvimento Elipse, através de serviços web (web servies). Ao
nal, apresentaremos um pequeno teste de oneito, onstituído por um programa
paralelo onstruído a partir de omponentes #, segundo as premissas e oneitos
T
he development ofnew HighPerformane Computing(HPC) appliationshas demandeda set oftoolsfor reonilinghigh levelofabstration withsoftwareintegration. Inpartiular, weareinterested inomponent-basedsolutionspresented
by the sienti ommunity in the last years. Components have been applied to
meet new requirements of high performane appliations suh as: interoperability,
reusability, maintainabilityand produtivity.
Reent approahes foromponentbased developmentin HPContext, however,
have not reoniled more expressive ways of parallel programming and eieny.
Unfortunately, this issue inreases the software development time and gets worse
whenusershavepoorknowledgeofarhiteturaldetailsofparallelomputersandof
requirementsofappliations. Preioustimeislostoptimizingparallelode,probably
with non-portableresults, instead of being appliedto the solution of the problem.
ThisdissertationpresentstheHashProgrammingEnvironment (HPE),asolution
based on the # (reads Hash) Component Model and on the Hash Framework
Arhiteture. HPE denes a set of omponent kinds for building, deploying and
exeuting parallel programs targeted at lusters of multiproessors. The Hash
Framework Arhiteture has three loosely oupled modules: the Front-End, the
Bak-End and the Core. The main ontributionofthis workis the implementation
of the Bak-End, sine we have an early version of the Front-End and Core, both
developed inJava ontop of the Elipse Platform. The Bak-End wasimplemented
asa parallel extensionof Mono, an open soure omponent platform based onCLI
(Common Language Interfae) standard. One independently done, we bound all
the modules together, using web servies tehnology. For evaluating the proposed
Bak-End,we have developed a small oneptual test appliation, omposed by #
G
ostaria de agradeer a todas as pessoas que me inentivaram e apoiaram, possibilitando meu suesso no mestrado, em espeial: ao meu orientadorHeron, pela onança em mim depositada, pela ompetênia e empenho no
desenvolvimento deste trabalho.
A meu ex-orientador de graduação, Vaso Furtado, pela oportunidade de
trabalhoom ogrupo de Engenharia doConheimentodaUNIFOR.
A UFC ea CAPES pelaoportunidade enaniamento deste trabalho.
Aosmeuspais JaquelineeJales porminhaeduação,formaçãoeapoioquetem
alierçadotodasminhasvitórias. AosmeusirmãosLuianaeThomas,pelaamizade
eamor inondiional.
Aosmeus professores eolegas de graduação daUNIFOR.
Aos meus olegas de mestrado e a todos os mestres e funionários do
Abstrat ii
1 Introdução 1
1.1 Motivaçõese Perspetivas . . . 1
1.2 Evolução daComputaçãode AltoDesempenho. . . 2
1.3 Programação Orientada a Componentes e Computação de Alto Desempenho . . . 5
1.4 Objetivos . . . 7
1.5 Organização daDissertação . . . 8
2 Componentes e Computação de Alto Desempenho 9 2.1 Apliaçõesde Computaçãode Alto Desempenho . . . 10
2.2 A Tenologia de Componentes . . . 12
2.3 CORBA . . . 13
2.3.1 PARDIS . . . 16
2.3.2 PACO ePACO++ . . . 17
2.3.3 GridCCM . . . 18
2.4 CCA . . . 19
2.4.1 CCAeine . . . 21
2.4.2 XCAT . . . 22
2.5 Fratal . . . 22
2.5.1 ProAtive . . . 23
2.5.2 Julia . . . 25
2.5.3 AOKell . . . 25
2.6 O Modelo GCM . . . 26
2.7 SPMD Orientada aObjetos . . . 27
2.8 Conlusão . . . 29
3 O Modelo de Componentes # 32 3.1 Fatiamento de Proessos e Agrupamentopor Interesses . . . 32
3.2 Deomposição emInteresses . . . 33
3.3 Tratamento Uniforme a Conetorese Componentes . . . 38
3.4 Sistemas de Programação #- Espéies de Componentes. . . 41
3.5 Sobreposição de Componentes - Semântia . . . 42
4.1 Cilo de Vidade Componentes # . . . 47
4.2 A Arquitetura Hash . . . 49
4.2.1 A Interfae HCoreServie . . . 50
4.2.2 A Interfae HBakEndServie . . . 50
4.2.3 A Interfae HRetrievingServie . . . 51
4.2.4 Componentes Abstratose Conretos . . . 52
4.3 HPE: Hash Programming Environment . . . 53
4.3.1 Front-End . . . 55
4.3.2 Core . . . 55
4.3.3 Bak-End . . . 56
5 Projeto e Implementação do Bak-End do HPE 58 5.1 CLI - Common Language Infrastruture . . . 59
5.2 Tenologia de Web Servies . . . 62
5.3 Representação de Componentes #no Mono . . . 63
5.4 DGAC -Distributed GlobalAssembly Cahe . . . 66
5.5 A Interfae entre o Front-End e oBak-End . . . 68
5.6 Implantação de um Componente #no Bak-End . . . 70
5.7 Exeução de um Componente# noBak-End . . . 71
5.7.1 O Métodode Resolução . . . 72
5.7.2 O Métodode CriaçãoDiâmia . . . 73
6 Estudo de Caso: Desenvolvimento e Implantação de Componentes no HPE 75 6.1 Desrevendo aApliação Exemplo . . . 75
6.2 Componentes Abstratos . . . 78
6.2.1 PartitionStrategy . . . 78
6.2.2 Node . . . 78
6.2.3 Cluster[
N
<:Node℄ . . . 796.2.4 Environment[
C
<:Cluster[N
<:Node℄℄ . . . 796.2.5 MPI[
C
<:Cluster[N
<:Node℄℄ . . . 806.2.6 Data . . . 80
6.2.7 Array1D[
E
<:Data℄ e Array2D[E
<:Data℄ . . . 816.2.8 ParallelData [
C
<:Cluster[N
<:Node℄℄,E
<:Environment[C
℄,D
<:Data,S
<:PartitionStrategy℄ . . . 826.2.9 MatVeProdut [
C
<:Cluster[N
<:Node℄℄,E
<:Environment[C
℄,N
<:Number,S
1
<:PartitionStrategy,S
2
<:PartitionStrategy℄ . . . 826.2.10 RedistributeData [
C
<:Cluster[N
<:Node℄℄,E
<:Environment[C
℄,D
<:Data,S
<:PartitionStrategy℄ . . . 836.2.12 AppExample [
C
<:Cluster[N
<:Node℄℄,E
<:Environment[C
℄,N
<:Number,S
1
<:PartitionStrategy,S
2
<:PartitionStrategy,S
3
<:PartitionStrategy℄ . . . 856.3 Componentes Conretos . . . 87
6.4 Implantação doExemplo . . . 88
6.4.1 Compilando o Componente# Apliação . . . 89
6.4.2 Exeutando oComponente #da Apliação. . . 90
7 Considerações Finais 94 7.1 Trabalhos Futuros. . . 95
Referênias Bibliográas 104
Introdução
O tema desta dissertação insere-se no ontexto da emergente área de
programaçãobaseada emomponentes voltadaaapliaçõesdeComputaçãode Alto
Desempenho,notadamenteoriundasdasiêniasomputaionaiseengenharias. Nas
seções seguintes, apresentamos asmotivações, osobjetivos e as ontribuiçõesdeste
trabalhode dissertação.
1.1 Motivações e Perspetivas
Diversas são as áreas que demandam por Computação de Alto Desempenho
(CAD). Dentre elas, podemos destaar a farmaologia (simulações químias),
otimização aerodinâmia (automobilístia e aeroespaial), área naneira
(Line-of-Business appliations), limatologia(Simulações de lima e tempo), Data
Warehouse, Mineração de dados, biologia omputaional, geologia, astronomia,
meâniade uidos,simulaçõesde fraturas emdutos e baiaspetrolíferas, sistemas
de inteligênia artiial, manipulação de grandes banos de dados et. Essas
apliações, em geral, fazem uso de omplexos modelos matemátios ou apenas
exigemaltopoder omputaionalparaálulossimplesemextensasbases de dados.
Por exemplo, nesse último, uma multipliação de matrizes, representadas de forma
vetorial, possui um algoritmo muito simples. No entanto, dependendo da ordem
das matrizes envolvidas, a resolução pode levar muito tempo. Uma solução para
tal problema seria adaptar o algoritmo para trabalhar em um ambiente paralelo,
aproveitandoao máximo seus reursos.
Emdoumentoproduzidoreentementeomoobjetivodeestabeleertendênias
sobre os grandes desaos ientíos que estão por vir, a omunidade ientía
déada [74℄. Este é um feito que se repete em apliações industriais omo é o
aso das grandes simulações [48℄ que são ada vez mais desaadoras nas indústrias
de petróleo, automobilísita,aeronáutia dentre outras. Todos essas são demandas
extremamenteexigentes dopontodevistaomputaional. Alémdisso,valeressaltar
o reonheimento da indústria do software pelo niho de apliações abordado por
CAD [33,79℄.
1.2 Evolução da Computação de Alto Desempenho
Durante a déada de 80, estações de trabalho (workstations) ouparam o lugar
de miniomputadores e mainframes. Devido ao baixo usto e à grande demanda
por este tipo de máquina, houve um resente e ontínuo investimento neste setor
o que oasionou sua evolução. Assim, o alto poder de proessamento alançado
por estações individuais, motivou o uso desta tenologia em superomputadores, o
qual deu origem a arquiteturas de proessamento paralelo de larga esala(MPP
de Massive Parallel Proessing). Estas máquinas são onstituídas de memória
distribuídaeproessadoresinteronetados porumainterfaede omuniação entre
proessadores de alta veloidade. Podemos itar omo exemplos de MPP's as
seguintes arquiteturas: Intel Paragon, Cray's T3D e T3E, IBM SP2, ASCI Red e
SunHPC. Umaoutraabordagemonsistena ligaçãode várias estaçõesde trabalho
através de uma rede onvenional, formando um omputador paralelo ou NOW
(Network Of Workstations).
Apesar do grande potenial, as MPP's e NOW's não onseguiram aompanhar
a evolução dos proessadores lançados para omputadores pessoais, que ustavam
bem menos. Foi então que perebeu-se que omputadores omuns ligados em
rede e gereniados por um software (ou até mesmo uma middleware omplexa)
podiam equiparar-se, em desempenho, aos superomputadores, om a vantagem
de possuir um preço bem mais onvidativo. Surgem assim os primeiros lusters
formados por omputadores pessoais, om hardware de prateleira. Além disso, o
surgimentode sistemasoperaionaisgratuitoseabertos, omooLinuxesuas várias
distribuições, tornaram ainda menos ustosa a adoção desses tipos de máquinas.
Comamassiaçãodohardware edossistemasoperaionais,oampode pesquisa e
implementaçãode software paragereniamentode apliaçõesvoltadaspara lusters
de relativobaixo usto aumentou. Tais apliações tentam aproveitar ao máximo o
desempenhodestasarquiteturasvistoqueotempodelatêniade omuniaçãoentre
daomputação em luster omo uma das áreas de interesse do IEEE, om aráter
multidisiplinar,em 1999.
Além da omputação em lusters, outro grande avanço na área de alto
desempenho, notadamente a partir da déada de 90, foi a omputação em grades
(gridomputing). Naomputaçãoemgrade,osomputadores estãointeronetados
através de uma infra-estrutura de omuniação omo a Internet, por exemplo,
formando uma infra-estrutura de omputação. Numa grade [30℄, os reursos são,
geralmente, heterogêneos e as apliações não devem requerer intensa omuniação
entre seus proessos para beneiar-se da estrutura emparalelo.
Na déada atual, surgiram as arquiteturas de proessadores de vários núleos
(multi-ore),ondeumúnioproessadorpodepossuirdoisoumaisnúleos,tornando
o paralelismo real em nível de proessador. A indústria de miroproessadores
lançou no merado soluções dual-ore, om dois núleos, quad-ore, om quatro
núleos e ogita-se o lançamento de proessadores oto-ore, om oito núleos
independentes. Apesarde todas assuas vantagens,atenologiamulti-ore desperta
a seguinte preoupação nas disiplinas de desenvolvimento de software: omo
onstruirprogramasqueaproveitemaomáximoadisponibilidadedereursosoiosos
em omputadores om múltiplos núleos? A resposta está na implementação de
programas paralelos, exigindo o partiionamento de dados ou de funionalidades
paraexeução simultânea. Denada adiantaum proessador om múltiplosnúleos,
se um software não é apaz de explorar onorrênia. Mais interessante ainda é o
partiionamentodinâmiode programasdeaordoomadisponibilidadedenúleos
oiosos.
Além das arquiteturas, a área de CAD abrange desenvolvimentos nas áreas
de algoritmos paralelos e ferramentas de programação paralela. As arquiteturas,
omo vimos, estão em onstante evolução e, obedeendo a Lei de Moore 1
, têm
seu desempenho aumentado exponenialmente ao longo do tempo [73℄. Apesar do
hardware evoluir om relativafailidade, aprogramaçãovoltadapara esses tiposde
máquinasnãoétãosimples. Alémdelidaromaimplementaçãodasfunionalidades
do programa, o desenvolvedor deve ser responsável pela oordenação de um
onjunto, às vezes muito grande, de tarefas que oorrem em paralelo, em muitos
proessadores. O programador deve se preoupar om o balaneamento de arga,
gargalos,aessos a dados ompartilhadose deadloks no sistema. Sistemas esritos
1
o número de transistores por polegada quadradaem um iruitointegrado dobraaada 18
em linguagens diferentes terão diuldade de onversar ou podem estar ligados
a uma determinada arquitetura, o que torna sua migração ompliada. Outros
desejam interoperabilidade. No entanto, internamente, assumem representações
de dados diferentes omo, por exemplo, a representação dos tipos booleanos nas
linguagensC++ e Fortran.
Para ontornar talproblema, forampropostos artefatospara omuniação entre
proessos e middlewares para o gereniamento dos nós de uma rede aumentando
o poder de abstração, agilizando assim a implementação. No entanto, oniliar
os requisitos de modularidade, eiênia, abstração, portabilidade e generalidade
emomputação paralela de alto desempenho é ainda reonheido omo um grande
desao entre os pesquisadores [75℄. Paradigmas de programação paralela que
oniliem portabilidade e eiênia om generalidade e abstração estão ainda em
falta [40℄.
Noâmbito omerial, existe umatendênia emdesenvolver softwares omplexos
voltadosamáquinasdesktop simples. Essasapliaçõestemomoprinipalpropósito
atenderasneessidades imediatasde seuslientes semneessariamentesepreoupar
om o uso de reursos da máquina. Obviamente que existe um erto nível de
otimizaçãoporpartedosdesenvolvedores,prinipalmentenaprogramaçãoqueexige
altoproessamento gráo, omo ferramentas de desenho (tratamentode imagens)
ejogos.
A Computação de Alto Desempenho tradiional, poroutro lado, teve seu iníio
om programas não tão omplexos, que apenas efetuavam álulos matemátios
sem a preoupação om interfaes de usuário ou metodologias avançadas de
Engenhariade Software. A diferençaparaomodeloomerialeraqueesses álulos
deveriam, e neessitavam, rodar em arquiteturas omplexas omo os primeiros
superomputadores e os lusters. O reurso mais exigido era o proessamento e
uso de memória, para assim obter um tempo viável de resposta. Era então uma
implementaçãodependente dohardware.
Comopassardoanos,desenvolvedoresCADpereberamaneessidadedeformas
maisomplexasdeabstraçõesdeseusprogramas. Aevoluçãodohardware(inluindo
as redes de omuniação), linguagens e paradigmas de programação bem omo o
suesso da apliação de ténias avançadas de Engenharia de Software na área
omerial, sobretudo o uso de omponentes, a proura por ferramentas de alto
essas, voltadas a arquiteturas omo lusters e grades omputaionais. Enm,
arquiteturasom grandedisponibilidade de reursos. Sendo assim,os anosreentes
testemunharam o resimento na omplexidade do software ientío o qual deve
apresentararobustezexistentenas apliaçõesomeriaiseobomusodasdisiplinas
de Engenharia de Software.
Nos dias atuais, aomputação paralelasesitua em um ambienteextremamente
heterogêneo, tantononíveldaarquitetura (máquinasdiferentes) quantononível se
software (sistemas operaionais e linguagens de programação). As ferramentas de
programação devem ser desenvolvidas para permitir a omputação nesses sistemas
om omínimo de problemas e omáximo de produtividade.
1.3 Programação Orientada a Componentes e Computação de
Alto Desempenho
A partir do momento que perebeu-se que a onstrução de programas deveria
ser onsiderada omo uma questão de engenharia, a noção de unir partes
genérias pré-fabriadas em partes espeías tornou-ser peça have. Essas partes
pré-fabriadas aram onheidas omo omponentes, os quais são utilizados na
soluçãode apliaçõesmaiores.
A motivação portrás douso de omponentes reside não apenas emquestões de
engenharia. Em [71℄, o autor enumera três argumentos para o uso de omponentes
nodesenvolvimentode programas. Oprimeiro deles enfatiza oreuso de ódigo, em
que omponentes feitos por tereiros podem ser agregados a outras apliações. O
desenvolvedor, dessa forma,perde menos tempoe dinheiro onentrando-se apenas
noódigo estratégio da sua apliaçãoe reusando omponentes que podem até ser
deprateleira. Osegundoargumentoexpliaqueomponentespodemserusadosno
proesso de montagem de várias formas diferentes, ou seja,de um mesmo onjunto
de omponentes (ore) podemos onstruir diversos tipos de apliações. O tereiro
e último argumento arma que programas modernos possuem uma dinamiidade
muito grande, tendo portanto que ser reongurados onstantemente. O uso de
omponentes nesse aso diminui o aoplamento geral da apliação e mantém sua
oesão através de interfaes bemdenidas.
Adeniçãode omponentesemomputaçãovariaumpouodeautorparaautor
mas esses em geral onordam que um omponente é uma unidade de programa
sendo assim reusados [3,71℄. Componentes diferem de módulos onvenionais de
programa uma vez que podem ser implantados independentemente, sendo possível
o seu ompartilhamento por diferentes apliações. Na área de desenvolvimento de
programas omeriais, por exemplo, a tenologia de omponentes tem ajudado a
desenvolver apliaçõesfailmenteinteroperáveis (famíliaMSOe,porexemplo) e
interfae gráas(GUIs) de alto nível.
No entanto, a omputação de alto desempenho não foi beneiada om esses
avanços [6℄. Devido a sua grande neessidade de omputação rápida e esalável,
a maioria das plataformas de omponentes voltados às apliações omeriais não
se adequam aos requisitos dos ientistas. A omputação ientía neessita de um
onjunto de ferramentas de omponentes diferentes daquelas enontradas no setor
omerial,quedêemsuporte atiposomplexosequeotimizemaomuniação entre
proessos. Para preenher essa launa, foram propostos modelos de omponentes
voltados aomputação de alto desempenho.
Omodelo CCA [6℄(videCapítulo2)foiinspiradono padrãoindustrialCORBA
e COM. Esse modelo faz uso de um padrão de projeto hamado provides/uses o
qualpossibilitauma onexãodiretaentre osomponentes de umaapliação. Portas
providessãoasinterfaesqueumomponenteCCAoferee. Dependêniasemoutros
omponentes são expressasatravés daporta uses. Alémdisso, CCA ofereesuporte
atiposomunsemCADeapossibilidadedeonguraçãodinâmiadosomponentes
em tempo de exeução. SiRun [34,55℄, XCAT [32℄, Caeine [1℄ e MOCCA [46℄
são exemplosde frameworks que utilizamopadrão CCA. Umframework dene o
esqueleto de uma apliação o qual pode ser ustomizado por um desenvolvedor de
apliações [64℄. Sendoassim,umframework provêumaAPIde serviçosneessários
aum erto domínio espeíopara a onstrução de apliações.
Fratal[13℄ adotaum oneito pareido om oCCA, onde o aráterhierárquio
dos omponentes é explorado. O seu padrão de projeto separa a interfae da
implementação e a forma de omuniação entre os omponentes é assínrona.
ProAtive [14℄ implementao modeloFratale é voltado à programaçãoemgrades.
Infra-estruturas de omponentes disponíveis para o meio ientío devemainda
proverformas de paralelismo,poisesta é umagrande neessidade dasapliaçõesde
ComputaçãodeAltoDesempenho. Aliam-seentãoasvantagensdesetrabalharom
omponentes (interoperabilidadeentre linguagens e suporte a tipos)om o suporte
A espeiação do CCA inlui extensões SCMD (Single Component Multiple
Data) para suportar o estilo de programação paralela onheido omo SPMD
(Single Program, Multiple Data). De aordoom [6℄, o paradigma de programação
SCMD, aoplado om um onjunto uniforme de onexões entre omponentes, irá
produzir um programa om araterístiasSPMD para a apliaçãoomo um todo.
É aresentado, ainda, que o paradigma SCMD pode desrever estruturas mais
gerais de uma apliação, omo por exemplo uma simulação SCMD onetada om
uma ferramenta serial de visualização. Ou ainda múltiplas simulações paralelas,
operandoemonjunto,para simular um ambiente físioomplexo.
Os frameworks baseados em Fratal tratam o paralelismo om o uso de
omuniação em grupo, através de portas oletivas. A omuniação em grupo
permite disparar hamadas de métodos em um grupo de objetos ativos do mesmo
tipo ompatível. De aordo om [25℄, este padrão de omuniação oletiva se
aproxima daquelesenontrados em, porexemplo, MPI.
Devemostambémmenionarasextensões paralelasbaseadas emCORBA,omo
oPARDIS [41℄, GridCCM [57℄ ePao/Pao++ [63℄.
Apesar da sostiação, tais modelos de omponentes não onseguem, ainda,
abstrair formas mais gerais de paralelismo. Além disso, a programação nestes
ambientes é ompliada, exigindo um bom onheimento dos detalhes ténios
de arquitetura. A situação se agrava quando o usuário que quer tirar proveito
das vantagens do paralelismo não possui onheimentos em omputação (físios,
químios, biólogos et.). Um tempo preioso que deveria ser gasto, em sua maior
parte,naresoluçãodoproblemadeumdomínioéusadoparaadaptaroprogramaem
um ambienteparalelo. O Capítulo2 explia emmaiores detalhes o modelo Fratal
eimplementaçõesbaseadas no mesmo.
1.4 Objetivos
Diantedo ontexto exposto, oobjetivo destetrabalho éonstrução doprojeto e
a implementação de parte um ambiente de programação paralela para apliações
de alto desempenho, baseado no modelo de omponentes #. Este ambiente,
hamado HPE (Hash Programming Environment), onsiste no desenvolvimento de
trêsmódulos: oFront-End (módulode interaçãoomoliente),oCore (repositório
de omponentes #) e o Bak-End (implantação de omponentes # em uma
determinada arquitetura omputaional). Esta dissertação pretende onentrar-se
quaisdenem a ontribuiçãoprinipaldo autor.
Dentre as ténias de Engenharia de Software, deve-se ressaltar neste trabalho
o estudo de novos paradigmas de omposição de omponentes paralelos, o qual
inlui a separação de interesses de uma apliação e a omposição de omponentes
naturalmente distribuídos e paralelos, ou seja, a implementação do omponente
de forma hierárquia onde suas subpartes devem estar implantadas nos nodos da
arquitetura alvo. A interoperabilidade de linguagens e o ontrole de versões a a
argodatenologiaimplementadapelalinguagemC#,emMono,um ambientelivre
ompatívelom sistemas Linux.
1.5 Organização da Dissertação
Neste doumento, apresentamos uma solução de implementação para os
problemas itados aima, fazendo uso da tenologia de omponentes. O Capítulo
2 desreve o estado da arte no tema pesquisado nesta dissertação, introduzindo a
tenologia de omponentes e sua apliação em Computação de Alto Desempenho.
O Capítulo 3 apresenta o modelo de omponentes #, enfatizando a noção de
onetores omo omponentes #, por meio de um exemplo prátio. O Capítulo
4 introduz ao leitor os prinipais oneitos do framework HPE, inluindo o ilo
de vida dos omponentes # om detalhes da arquitetura Hash. O Capítulo 5
detalhaaimplementaçãodoBak-End sobreumaplataformaCLI,oMono,prinipal
ontribuição da dissertação proposta. O Capítulo 6 apresenta o estudo de aso, o
qual serve omo um teste de oneito. O Capítulo 7 onlui esta dissertação. Ao
Componentes e Computação de Alto
Desempenho
A rápida evolução dos equipamentos omputaionais (ou hardware, termo
anglianomaisonheidonaárea),assoiadaaoseubarateamentoaolongodosanos,
ampliouo uso de omputadores para solução de problemas que exigem um grande
esforço omputaional. Entretanto,ainda faz-se neessário o estudo de padrões e o
estabeleimentode normasparaqueaimplementaçãodas apliações(ousoftwares)
apazes de realizarestas soluçõessupram asprinipaisaraterístiasde apliações
de CAD,omo, porexemplo, osuporte atiposomplexos eproessamento paralelo
eiente. Os termos anglianos software e hardware serão utilizados por padrão
nesse texto de agora em diante.
Esteapítulotem omoobjetivoapresentar osprinipaisesforçosnadeniçãode
padrões para apliações CAD, além da implementaçãode diversos frameworks. Na
Seção2.1 fazemos uma breve desrição sobre apliaçõese aomplexidade hardware
versus software. Na Seção 2.2 introduzimos a tenologia de omponentes e os seus
benefíios na implementação de omponentes de alto desempenho. A Seção 2.3
apresenta o modelo de omponentes CORBA, seguido de extensões desenvolvidas
para apliações paralelas. A Seção 2.4 introduz o modelo de omponentes CCA,
desenvolvido pela omunidade ientía om o intuito de atender aos requisitos
de apliações de seu interesse. A Seção 2.5 apresenta o modelo hierárquio de
omponentesFratal. ASeção2.6abordaomodeloGCM deomponentes paralelos
voltados a ambientes de grades omputaionais. A Seção 2.7 introduz uma forma
rítiadas soluçõesapresentadas e a ontribuição desta dissertação.
2.1 Apliações de Computação de Alto Desempenho
Apliações de omputação de alto desempenho têm invariavelmente omo alvo
arquiteturasdeproessamentoparalelo,omolustersougradesomputaionais. No
estágioatual, apliaçõesmultidisiplinarespara soluçõesde problemas desaadores
emCiêniasComputaionaiseEngenhariapodemserformadaspordiversosmódulos
que muitas vezes não foram implementados pelos mesmos desenvolvedores e que
podem estar loalizadas em sítios diferentes, onde são divulgados apenas seus
serviços. Para garantir um bom desempenho, muitas usam ódigo nativo ou
biblioteasde omuniação de altodesempenho entre osproessos, omo oMPI.
Como exemplo, podemos imaginar um enário onde uma apliação físia que
deseje fazer alguma simulação preise de um módulo para soluções de problemas
de Álgebra Linear para os álulos. Se partimos do pressuposto que ambas as
apliações, de domínios diferentes, foram modularizadas orretamente, podemos
admitiro reuso dos módulos de omputação algébriapelaapliação físiade uma
formarelativamente simples. Caso os dois problemas onordarementre si quanto
suas interfaes de omuniação, a troade dados deverá oorrer failmente.
Podemosaresentar aindaquedentrodoprópriodomíniodaFísia,poderíamos
implementar submodelos aos quais se omuniariam através de interfaes bem
denidas, om baixo aoplamento. O baixo aoplamento permite que os módulos
sejamtroados emtempode exeuçãoou ompilação,inrementando a quantidade
de testes e possibilidades aodesenvolvedor.
O tipo de apliações de nosso interesse nesta dissertação são tanto omplexas
quanto ao software omo quanto ao hardware o qual servirá omo base de
implantação. Este é um tipo de enário reente em omputação paralela de alto
desempenho. Oenáriomaistradiionalompreendeumsoftwaredearátersimples,
emgeralmonolítio,o queexplia parialmenteapopularidadede linguagensomo
FortraneCatéosdiasatuaisemomputaçãoientía,masumhardware omplexo,
em geral dotado de um onjunto de proessadores e interfaes de omuniações
espeías entre esses, as quais devem ser programadas tendo em vista suas
araterístiaspeuliares.
No meio omerial, tradiionalmente as apliações são omplexas, justiando
o intenso estudo em disiplinas de Engenharia de Software voltadas a essa
máquinassimples, em geral dotadas de um únio proessador ouassumindo algum
meanismo de virtualização, em geral ao nível do sistemaoperaional, que esonde
as araterístias mais peuliares da arquitetura. Esse ontexto no meio omerial
permanee o mesmo om o advento de grades omputaionais omo plataforma
para apliações omeriais, onde há uma tendênia em esonder a omplexidade
da arquitetura em relação às apliações através de middleware. Isso se deve aos
diferentes requisitos de apliações de omputação de alto desempenho perante as
apliaçõesomeriais tradiionais.
O software éomplexo no meio omerialpoisdeve ser implementado seguindo
um onjunto de regras e disiplinas de Engenharia de Software, gerando diversos
tipos de doumentação. Além disso, o mesmo deve agradar ao liente em vários
quesitos, dentre eles a failidade no manuseio (o que motiva os estudos na área de
IHC,InterfaeHumano Computador), otimizaçãopara forneerresposta emtempo
hábil, além da ompatibilidade om diversas tipos de Sistemas Operaionais. Em
ontrapartida,ohardware alvodeapliaçõesomeriaisdeveser simples,geralmente
de prateleira e formado por um únio proessador, omo na maioria dos desktops
omuns. Nãoéomum aneessidadede umaonguraçãoavançadaouainstalação
de uma middleware de gereniamento. A indústria de jogos é um bom exemplo.
Nesse niho, o software possui uma grande omplexidade na implementação, pois
engloba diversas áreas da omputação, mas são voltados e devem ser ompatíveis
om a maioria dos hardwares disponíveis no merado. Dessa forma, atinge-se o
maiornúmero de onsumidores.
O software ientío tradiional, por sua vez, ompreende omputações
omplexas, porém om poua neessidade de um alto grau de modularização e
estruturaçãodosoftware. Ao programador,interessaapenas que oprograma efetue
o álulo desejado e emita a resposta, que muitas vezes é entendida apenas pelo
espeialista.
O hardware alvo por sua vez não é um sistema desktop omum.
São superomputadores ou arquiteturas dediadas omo lusters ou grades
omputaionais. O desenvolvedor deve onheer a fundo detalhes ténios da
máquinaoudas middlewares instaladasparaa exeuçãodoparalelismo de maneira
eientede formaa minimizaro tempode resposta, muitas vezes rítio.
Reentemente, observa-se uma tendêniadaomplexidadedosoftware ientío
por espeialistas, aarretaram uma série de estudos para o desenvolvimento de
padrões a serem seguidos. Paradigmas omo a Orientação a Objetos e Orientação
a Componentes introduziram novas possibilidades às apliações de omputação de
altodesempenho, mas preisam ser adaptadas segundo alguns requisitos peuliares
destas apliações. O hardware alvo em apliações ientías ontinua sendo
máquinas de alto desempenho que exigem um forte aoplamento om o software.
Superomputadores, lusters, e grades omputaionais são largamente usados. Na
realidade, um tempo viável de resposta de um software ientío só é onseguido
nessas arquiteturas. O uso de omponentes auxilia na abstração das tenologias
envolvidas, enapsulando ódigo de omuniação, ódigo de omputação e até
mesmososdadosenvolvidos. Nasseçõesseguintes,examinaremosomoatenologia
de omponentes vem sendousada no domíniodaomputação ientía.
2.2 A Tenologia de Componentes
Dentre as muitas denições do que são omponentes, a de Szyperski [71℄
resume suas prinipais araterístias: Um omponente de software é uma
unidade de omposição om interfaes de ontrato bem espeiadas e que possui
apenas dependênias explíitas de ontexto. Um omponente pode ser implantado
independentemente e ser sujeito à omposiçãopor tereiros.
Visando as neessidades das apliações de alto desempenho, a omunidade
ientía vem adotando o paradigma da orientação a omponentes para melhor
adaptá-lo as suas neessidades [75℄. Como dito, omponentes são módulos
independentes, que podem ser produzidos por tereiros adaptados, om relativa
failidade,aumadeterminadaapliação. UmaapliaçãoCAD,formadapordiversos
módulos, pode ser implementada seguindo a orientação por omponentes. A
omuniação entre esses módulos a a argodas interfaes existentes.
Módulos implementadosem linguagensdiferentes, tão omuns emCAD, podem
interoperar através dessas interfaes. Código nativo ou ódigo MPI, omo
exempliado,pode ser enapsuladoemomponentes adequados eusados onforme
a neessidade. Deve-se ainda aresentar que, dependendo da arquitetura alvo
de implantação do omponente, o mesmo deve ser ompilado de forma a se
adequar a uma grade omputaional, ou a um luster, por exemplo. Enm, a
orientação a omponentes largamente aproveitada no meio omerial, adequa-se às
neessidadesientíastirandoproveitodeseusbenefíiosealiando-seaperformane
Um omponente deve então disponibilizar aos seus lientes as suas
funionalidades por meio de interfaes. Um omponente esrito om a tenologia
deWeb Servies,porexemplo,publiasua interfae pormeiode um arquivoesrito
em XML, o qual desreve os serviços que deverão ser utilizados pelos lientes.
Componentes Java RMI utilizam o oneito de stubs e skeletons, para invoação
remota de métodos entre objetos que residem em espaços de endereçamento de
memóriadisjuntos.
Componentespodemtambémserompostosporoutrosomponentes, atravésda
onexãodesuasinterfaes,formandoapliaçõesmaiores,ouomponentesompostos
(omponentes hierárquios). Destaforma,oaoplamentoentre eles torna-semenor,
permitindo que uma mesma apliação possa esolher várias implementações para
uma mesmafunionalidade.
Épossíveltambémque,emtempode exeução, uma apliaçãoonete-se om
aquele omponente que melhor satisfaça sua neessidade, ou aquele esolhido por
seu liente.
Outra araterístia importante dos omponentes é que os mesmos devem
possuir meta-informações sobre os seus proedimentos de implantação. Um
omponente informa a sua arquitetura alvo de implantação detalhes pertinentes,
porexemplo,a sua dependênia sobre aquantidade de proessadores ouanatureza
dos mesmos. Componentes podem ainda expliitar quais sistemas operaionais são
ompatíveisou quaisoutros omponentes devemestar previamenteinstaladospara
seu funionamento. Além disso, omponentes devem prover suporte a sistemas
distribuídos.
As seções abaixo apresentam diversos modelos baseados em omponentes e se
adequam à Computação de Alto Desempenho, omo interoperabilidade, suporte
a ódigo nativo, suporte a arquiteturas distribuídas, onetores e separação em
interesses. Cada um dos modelos e suas respetivas implementações ontribuíram
para a formação do Estado da Arte deste trabalhobemomo a implementação do
modelodesta dissertação.
2.3 CORBA
Visandoummodeloquegarantisseinteroperabilidadeentrediferenteslinguagens,
através de uma interfae omum e um sistema de mapeamento de tipo, a
infraestrutura CORBA (Commom Objet Request Broker Arhiteture) [26℄ foi
adotada omo um padrão industrial para apliações baseadas em omponentes
e o desenvolvimento de middlewares distribuídos. CORBA foi riado por um
onsóriohamadoObjetMangementGroup (OMG),envolvendomaisdeoitoentas
ompanhias. Com CORBA é possível que programas distribuídos troquem dados
independentemente da linguagem em que foram implementados ou da plataforma
nos quaisestão implantados.
A motivação da sua implementação tem omo objetivo a omuniação e troa
de dados entre apliações, muitas vezes, de diferentes domínios, linguagens de
programação e ambientes de implantação. Obedeendo a sua espeiação, os
desenvolvedores esperam um aumento no reuso de ódigo, ligado em tempo de
exeução e suporte a apliaçõesemsistemas distribuídos.
Figura 2.1: Modelo Cliente-Servidor em CORBA
A primeira versão estável de CORBA, hamada CORBA 1.0, foi lançada em
1991 e apresentava uma Linguagem de Denição de Interfaes (IDL, do inglês
InterfaeDenitionLanguage). Sendoassim,odesenvolvedordessatenologiatinha
apossibilidade de riaruma apliaçãoemuma determinadalinguageme geraruma
interfae esrita numa linguagem omum entre outras tenologias,a IDL.
A ompilação da interfae gera um onjunto de artefatos (proxies)responsáveis
pela omuniação entre a apliação riada e o liente que a usará. Na Figura 2.1
vemos que do lado do liente, uma referênia ao objeto implantado no servidor é
aessada por um ódigo hamado Stub. O servidor disponibilizaformas de onexão
a este objeto remoto por meio de sua lasse Skeleton. O ORB (Objet Request
Broker) é o módulo intermediário responsável em tratar a requisição do liente.
A IDL também suporta diversos tipos de dados, desde primitivos omo inteiros e
booleanos aos mais omplexos,omo objetose matrizes.
Iniialmenteomsuporte dalinguagemC, CORBA hoje possui ompatibilidade
de método, o RMI (Remote Method Interfae) que restringe a omuniação apenas
entre objetos Java. A plataforma .Net também possui uma implementação de
invoaçãoremotade métodos, inlusaemsua biblioteaSystem.Runtime.Remoting.
Avantagemdaabordagemdeinvoaçãoremotaéque,alémdeseremmaiseientes
que CORBA, permitem que uma apliação faça uso de métodos remotos omo
se os mesmos zessem parte de seu ódigo. Entretanto, ambas soluções (Java e
.Net) exigemqueosobjetosnaomuniação estejamimplementadossobreamesma
máquinavirtual (JVM para o Java e CLRpara o .Net).
omponent <nome>
[ : <base> ℄
[ supports <interfae> [, <interfae>℄* ℄
{
<delaração de atributos> *
<delaração de portas> *
};
Figura 2.2: Código CIDLusado em CCM
CCM,ouCORBAComponentModel, diferedomodeloditolássioapresentado
aima em alterar a sua linguagem de denição, a IDL, para a CIDL (Figura 2.2),
objetivando a diminuição na omplexidade de omponentes CORBA (a partir da
versão 3.0). A interfae CIDL é então mapeada em uma IDL equivalente a qual
será usada na omuniação entre omponentes. CCM tem omo premissa diminuir
o tempo de desenvolvimento aumentando a abstração e reuso de ódigo. Usando
a palavra have omponent, na CIDL, o desenvolvedor dene o seu omponente,
as interfaes que o mesmo implementa e as portas (serviços) disponíveis aos seus
lientes.
DeaordoomoCCM,umomponenteéumaunidadedesoftwareauto-ontida
onstituída de seus próprios dados e lógia, om interfaes, ou onexões, bem
denidas. É projetado para uso exaustivo no desenvolvimento de apliações, om
ousem ustomização [16℄.
Asfaetas ouinterfaes de umomponenteCCM denemsuas portas de aesso,
expondosuasfunionalidades. Reeptáulossãotiposdeportasdeonguraçãopara
espeiarserviçosrequeridosdeoutrosomponentes. Muitasvezes,umomponente
CCM neessita usar um outro omponentepara poder onluirsua tarefa.
tem a nalidade de diminuir o aoplamento no proesso de omuniação entre
omponentes.
Apesar do apelo omerial, CORBA e seus similares hamaram a atenção
também da omunidade ientía sobretudo no que diz respeito a área de
Computaçãode AltoDesempenho. Atenologia de omponentes, aliadaaomodelo
CORBA enfatiza as prinipais neessidades de um programa CAD das quais
podemos itar: interoperabilidade entre linguagens; suporte a tipos primitivos e
tiposomplexos;adaptação asistemas distribuídos;independênia de arquitetura e
sistemaoperaional. Assubseçõesabaixoapresentamalgumasferramentasbaseadas
em CORBA para talm.
A espeiação Data Parallel CORBA [27℄, proposto pelo onsório OMG,
onsistenumaextensão aomodeloCORBA paraosuporte àprogramaçãoparalela,
permitindo a implementação de objetos CORBA (baseados em IDL) paralelos.
Objetos paralelos na realidade são um onjunto formado por implementações
pariaisdosmesmosexeutandoemparalelo. PodemserusadosporlientesCORBA
normaise tambémpodemfazer uso objetosCORBA omuns.
Aespeiação paraCORBAparalelodeneumasemântiade partiionamento
edistribuição dos dados e requisições envolvidas nouso de objetos paralelos. Estes
objetos são então, de alguma forma, distribuídos num arquitetura paralela, onde
ada uma de suas partes é implantada em um proessador diferente. Alia-se as
vantagens do modelo CORBA (interoperabilidade e omuniação distribuída) om
asvantagens do proessamento paralelo.
Perebendo o potenialparalelo de CORBA, a omunidade ientía baseou-se
em seu modelo de omponentes para a implementação de diversas infra-estruturas
voltadas a Computaçãode AltoDesempenho. As extensões aseguir representam o
produtodapesquisasobreatenologiade CORBAparalelosobreapliaçõesomuns
no meio aadêmio, voltadas a arquiteturas robustas. É importante ressaltar que
os trabalhos itados a seguir anteedem a proposta da espeiação padrão Data
Parallel CORBA,tendo na realidade exeridoinuênia sobre a denição dele.
2.3.1 PARDIS
PARDIS (PARallel DIStributed) [41℄ éum sistema distribuídona qualobjetos
representam omputações paralelas SPMD. O Fato de usar CORBA em sua
implementação permite que seus objetos possam interoperar om outros objetos
através de interfaes denidas por uma IDL e ada um deles possui uma pequena
apliaçãoenapsulada,servindo omobloo de onstrução para apliaçõesmaiores.
Alémdisso, o suporte a operações não-bloantes entre objetos permite aoPARDIS
aonstrução de enários onorrentes.
Para suportar o paralelismo, PARDIS estende o modelo de objetos CORBA à
noção de objetos SPMD. Objetos SPMD, também hamados de objetos paralelos,
podem ser denidos omo objetos ompostos por vários proessos, visíveis ao
servidoronde o objeto está implantado. Cadaproesso exeuta o mesmoprograma
sobrediferentes dados. Oseu paralelismo étransparente àsrequisiçõesdos lientes.
PARDIS implementaooneito de programaçãoparalelaedistribuída. Ou seja,
objetos SPMD instalados em um determinando sítio fazem uso da omputação
paralela loalmente, gereniada pelo PARDIS naquele domínio. Mas quando
esses objetos omuniam-se om outros domínios (sítios remotos), através de
interfaesCORBA,aessandooutrosobjetos,aentãoaraterizadaaomputação
distribuída(omuniação remota).
Através da manipulação de dados distribuídos entre os proessadores, PARDIS
provê a generalização de sequenes CORBA, hamadas distributed sequenes.
SequenesCORBA éuma versão CORBA de um array unidimensional. Esse array
permite dados de qualquer tipo, inlusive dados omplexos. Distributed sequenes
éuma estrutura quetorna possível amanipulaçãode dados espalhados entre vários
proessadores. A manipulação de estruturas de dados distribuídas busa a divisão
daargaomputaionalentreoproessospartiipantesgerandoeiênianoálulo
doresultado.
2.3.2 PACO e PACO++
Para o projeto PARIS [54℄, PACO [61℄ foi a primeira tentativa de estender
CORBA om paralelismo. Consiste na implementação de objetos paralelos para
estender a IDL existente adiionando novos onstrutores. Estes onstrutores
permitem espeiar o número de objetos CORBA que fazem parte do objeto
paralelo e os parâmetros operaionais de distribuição de dados. PACO faz uso de
Fortranpara denirdistribuição de dados eMPI para omuniação entre proessos
(omponentes CORBA om ódigo MPI enapsulado).
Importante ressaltar que em nossa implementação planejamos a riação de
omponentes que espeiam o ambiente instalado na arquitetura a qual o
enapsulamos ódigo MPI (hamada nativa) ou fazemos uso de outra tenologia
nolugar (algumaoutra formade omuniação inter-proessos).
PACO++[63℄éaontinuaçãodoprojetoPACOqueompartilhaamesmanoção
de objetos distribuídos e os mesmos objetivos que dizem respeito a omputação
distribuída. PACO++ objetiva estender CORBA, não modiando o modelo
e sim denindo uma extensão portável a qual seria ompatível om qualquer
implementação de CORBA. Sendo assim, a prinipal diferença entre PACO++ e
PACO e PARDIS reside no fato de que estas duas últimas modiam a IDL já
existenteemCORBA.AmodiaçãonaIDLrequerumnovoompilador,tornando-o
dependentedaimplementaçãode CORBA.Issotornaoódigodos objetosparalelos
menos portáveis e não possibilita a troa dinâmia de dados devido ao forte
aoplamento entre osomponentes.
OparalelismoemPACO++éfoadoemapliaçõesSPMD,assimomoPACO e
noPARDIS pois,segundo oautor,esse éumdostiposdeproblema maisomumem
omputaçãoparalela. Umaamadadesoftware hamadaPACO++aresponsável
peloparalelismo. ElaéinseridaentreoódigodolienteeaimplementaçãoCORBA.
Essaamadaintereptaashamadas aoCORBAegereniaoparalelismo,tornando
oódigo paralelo independente doCORBA.
Esta independênia do ambiente é um requisito importante de Engenharia de
Software poisgarantequeo programaresponsável pelalógia de negóios possa ser
alteradosem neessariamenteinterferir noódigo responsável pelaomuniação.
2.3.3 GridCCM
GridCCM (CCM de CORBA Component Model) é uma extensão paralela do
CCM, patroinado pela INRIA. Para inorporar o paralelismo, GridCCM não faz
nenhuma modiação na já existente IDL do CORBA. Na verdade, um arquivo
XML auxiliaré usado para desrever o paralelismo entre omponentes.
Assim omo em Pao++, GridCCM não modia o modelo de omponentes
CORBA.Eleapenas insereuma amada,hamadaamadaGridCCM responsável
pelo paralelismo. Essa amada uida do gereniamento de objetos CORBA
paralelos, situando-se entre o ódigo do liente o ódigo de omuniação om
CORBA.
O papel de GridCCM é permitir o gereniamento transparente do paralelismo.
Olienteenvia osdados àamadaGridCCMe essaporsua vez distribuiegerenia
serão distribuídos depende de restrições impostas pelo próprioliente ou restrições
impostas pelo servidor omo a quantidade de reursos disponíveis para exeutar o
omponente, por exemplo.
O ompilador GridCCM neessita de dois arquivos. Um arquivo denindo a
IDL do omponente e um arquivo XML que dene a forma de paralelização do
omponente. A estratégia de partiionamento dos dados é vista nesta dissertação
omoumnovoomponentequedesreveomoosdadosdevemserdistribuídosentre
osproessos. É portanto uma deisãoque abe aoliente.
Deaordoom [5℄,apesar dosmodelosbaseados emobjetosCORBA,oumesmo
outras plataformas de omponentes omeriais inspiradas em CORBA, omo Java
Beans (EJB)[29℄eoCOM daMirosoft [66℄, englobaremumgrandequantidadede
requisitos neessários às apliações de alto desempenho, os mesmos ainda areem
de um suporte maior a tipos de dados voltados espeialmente a esses problemas.
Alémdisso, faz-se neessário padronizar o tipo de omuniação entre omponentes
otimizandoao máximo oenvio de dados.
Em CORBA, não há suporte a tipos ientíos omo arrays multidimensionais
ou números omplexos, enontrados em linguagens omo Fortran. COM, também
voltado a apliações orporativas, não possui abstrações para a onstrução de
dadosparalelosouexistentes emomputaçãoientía. COM tambémnão suporta
failmente a implementação de herança ou herança múltipla, não sendo possível o
uso de polimorsmo.
EJB,desenvolvidopelaSun,éumasoluçãobaseadaemJavaqueompeteom a
implementaçãodaMirosoft. Elanão aborda aquestão da interoperabilidade entre
linguagens não sendo seu uso portanto adequado à omputação ientía. Mesmo
usandoatenologiaJNI parainteroperabilidadeom ódigoCeC++,assuessivas
hamadas a funções nativas pela JVM resultariam em quedas no desempenho da
apliação.
Napróximaseção,introduziremosomodeloCCAqueobjetivaatenderrequisitos
de apliaçõesde omputaçãode altodesempenho.
2.4 CCA
OCommon ComponentArhiteture (CCA) éum modelo de omponentes para
Computação de Alto Desempenho, desenvolvido por um onsório formado por
laboratórios de pesquisa e universidades dos EUA, patroinadas pelo DOE (U.
modelo de omponentes que evita onexões (bindings) dependentes da linguagem
em que foram esritos. Esse artigo arma ainda que, dependendo de omo as
onexões de linguagens são implementadas, apliações que usam CCA não diferem
em desempenho de apliações esritas puramente em sua linguagem original. Isso
se deve ao meanismo de onexão direta do CCA, que permite que hamadas
de funções entre omponentes estejam diretamente onetadas de um módulo para
outro,quando estes residiremno mesmoespaço de memória.
Considerando a variedade de apliaçõesientías esritas emvárias linguagens
deprogramaçãodiferentes, CCApropõeumaSIDL(Sienti InterfaeDesription
Language) [42℄ para garantir a interoperabilidade entre elas. A espeiação CCA
épuramenteesritaemSIDL e, om aonexãode linguagemapropriada, espeia
omodeve ser umomponenteompatívelom Fortran77/90/95, C, C++,Python
ouJava.
AferramentaBabel[9℄,voltadaaviabilizarainteroperabilidadeentrelinguagens
omumente usadas em iênias omputaionais, omo C, C++, Fortran, Python
e Java, tem mantido e desenvolvido a SIDL a qual provê suporte a tipos
únios neessários em omputação paralela omo números omplexos, arrays
multidimensionaise diretivas de omuniação paralela requeridas em omponentes
paralelos. Babelé responsável emanalisare gerar ódigo (proxies) apartir de uma
interfaeSIDL. Oódigo geradopermite atroade dadosentre diversaslinguagens
de programação.
De aordo om sua espeiação, um omponente ompatível om CCA deve
possuir o métodosetServies, para omuniação om oframework de omponentes
(programa que ria e oneta omponentes ompatíveisom a espeiação CCA).
Emdetalhes, atravésdosserviços doframework,oomponentepubliaseuonjunto
deportasaosdemaisomponentes. Umaportaéumreursoquepodeserimportado
(porta dotipo uses) ouexportado (porta dotipoprovides)por omponentes.
O padrão provides/uses é omumente adotado em modelos de omponentes de
apliaçõesonvenionais,omoCORBAeCOM/DCOM,osquaisinspirarammuitas
araterístias do CCA. Neste padrão, uma porta desreve uma interfae SIDL,
ontendo uma oleção de subrotinas implementadas em alguma linguagem. Desta
forma, uma porta do tipo provides pode ser usada por omponentes e uma porta
dotipouses poderá ser registrada para usar uma porta provides. Porexemplo, um
Figura 2.3: CCA
framework,oqualaonetaaumaportaprovidesdemesmotipopertenenteaoutro
omponente B. O omponente A passa então a aessar os serviços do omponente
B através de um objeto dotipo daporta, a qualo representa.
A omuniação entre A e B é possível graças a geração de proxies (Gerador
de Proxy), a partir da SIDL e através de alguma implementação (framework)
do modelo. As denições das entradas e saídas dos omponentes na SIDL são
armazenadas em um repositório, o qual dene uma API para a manipulação dos
omponentesimplantados. OsBuilders são responsáveisemmontaraonguração.
Através da API, o framework omunia aos Builders as atualizaçõesreferentes aos
omponentes.
O paralelismo em CCA é suportado através de suas diversas implementações,
onheidas omo frameworks. Nas subseções seguintes, alguns exemplos de
implementações dopadrãoCCA eo seu suporte a omputaçãoparalela.
2.4.1 CCAeine
CCAeine [1℄ é um framework baseado em Babel e suporta omponentes
paralelos baseados em MPI. Possui uma linguagem de sript para a omposição
de apliações e também uma interfae gráa (GUI). Componentes CCAeine são
riadosdentrodomesmoproessoportantoaomuniaçãoentreomponenteséfeita
2.4.2 XCAT
XCAT [32℄ é um framework distribuído baseado emJava, onde os omponentes
usam oprotoolo SOAP para omuniação entre si (semelhanteaos Web Servies).
XCATpodeusar ssh ouGlobusparainstaniaromponentesomponentes remotos,
tornando-o mais apropriado a ambientes distribuídos. Possui também uma versão
implementadaemC++.
2.5 Fratal
OFrataléum modelodeomponentes modulareextensívelquepode serusado
para projetar, implementar, implantar ereongurar sistemas e apliações quevão
desde sistemasoperaionais a middlewares e interfaes gráas para ousuário.
De aordo om [13℄, o modelo de omponentes Fratal é adepto ao prinípio
da separação em interesses, também usado no modelo desta dissertação. Outras
araterístias inluem a separação nominal da interfae e sua implementação,
programaçãoorientada a omponentes einversão de ontrole.
A separação nominal, também hamada de padrão ponte (bridge pattern),
orresponde naseparação doprojetodos interesses da apliação, diminuindoassim
o aoplamento. O segundo padrão orresponde à separação do interesse de
implementaçãoemváriosinteressesmenores,implementadosementidadesseparadas
hamadasomponentes.
Oúltimo padrãoorresponde à separação de interesses funionaisdos interesses
de onguração. Ou seja, entidades externas de onguração am responsáveis
em implantaros omponentes que dizem respeito aos interesses funionais. Dessa
forma,aso algumaonguraçãodevaoorrer aoomponente, nãoháaneessidade
de o reompilar e o instalar novamente. Bastaria apenas mudar a entidade de
onguraçãorelaionada aomesmo.
O prinípio da separação em interesses é também apliada a estrutura de
omponentes do Fratal, os quais são ompostos de duas partes: o ontent, que
diz respeito ao onteúdo que gerenia os interesses funionais, e a membrane, que
diz respeito aos interesse não funionais (introspeção, onguração, segurança,
transaçõeseet.). Alémdisso, umomponenteFratalpode ser formadoporoutros
omponentes aninhados em seu interior, em diversos níveis (um oneito pareido
om orientação a objetos, só que neste aso um omponente é ompartilhado por
seremimplantadosdinamiamente. Essasinterfaesdeontrolepodemser inseridas
diretamente no ódigo ou através de ferramentas baseadas nelas, tais omo
ferramentasde implantação ousupervisão.
Fratal possui também um linguagem de desrição hamada Fratal ADL
(Arhiteture Desription Language), a qual provê um shema XML DTD
(Doument Type Denition) que tem por nalidade expressar a estrutura de um
arquivo XML. Em Fratal, ele desreve, por exemplo, tipos de omponentes,
implementações de omponentes, hierarquia de omponentes e suas onexões. O
DTD é tambémperfeitamente extensível para englobaroutros interesses, inerentes
auma apliaçãoespeía.
ExtensõesdeFratal,omoasinterfaesoletivasexpliadasnasubseçãoseguinte
failitame elevamo nívelde abstração para apliaçõesparalelas.
Assubseções seguintes irãoexplanar algunsarabouçososquaisimplementam o
modeloFratal.
2.5.1 ProAtive
ProAtive [11℄ é uma middleware em Java para omputação paralela móvel e
distribuída. Ela envolve orientação a omponentes e objetos, a qual faz uso de
omponenteshierárquios. ProAtiveévoltadoparaapliaçõesdemeta-omputação
adaptadaparaapliaçõesemgradesomputaionais,podendoserusadotambémem
outrostipos de arquitetura, omo lusters, porexemplo.
ProAtive foi implementado usando a tenologia Java RMI e também a API
responsável pela reexão (Reetion). Não requer nenhum tipo de modiação no
ambiente de exeução daJVM e nem neessita de um ompilador extra.
Uma apliação distribuída em ProAtive é omposta de pequenas entidades
hamadas de Ative Objets. Cada uma dessas entidades possui apenas um ponto
deentrada,hamadoderoot,epossuisua própriathread de ontrole. Asrequisições
aesta thread de ontrole são automatiamentearmazenadas emuma lade espera
e atendidas de aordo om uma determinada polítia (FIFO por exemplo). Ative
Objets também podem ser movidosentre JVMs diferentes, através de um método
de migração.
Uma outra araterístia muito importante em ProAtive é a omuniação
oletiva ou omuniação em grupo. Comuniação em grupo permite a invoação
remota assínrona para um grupo de objetos. A espeiação de um grupo
nível. O envio de um mensagem para um grupo é reebido por todos o proessos
perteentes ao mesmo.
O objetivo do ProAtive é ombinar os benefíios gerados pela orientação a
omponentes om suas araterístias (Ative Objets e grupos de omuniação).
Osomponentes resultantes são hamados de Componentes para Grade.
Para suportar o paralelismo, distribuição de dados e sinronização, tem sido
proposto ouso de interfaesoletivas (olletive interfaes)[12℄,baseado nomodelo
Fratal e nasua implementação mais importante, o ProAtive. Interfaes oletivas
expõem o omportamento oletivo dos omponentes no nível de interfaes as
quais ofereem serviços de envio de mensagem um-para-muitos (one-to-many) e
muitos-para-um(many-to-one),respetivamentehamadosde interfaesmultiast e
gatherast.
Figura 2.4: O omponenteA usa uma porta provida peloomponente B
Interfaes multiast (Figura 2.4 a) ofereem abstrações de omuniação
um-para-muitos, as quais transformam uma únia invoação em um lista de
invoações. As invoações geradas são enaminhadas para servidores devidamente
onetados. O resultado desta invoação pode ser uma listade resultados ou uma
redução. Invoações múltiplasaos servidoresonetados oorrem emparalelo.
Interfaes gatherast (Figura 2.4 b) ofereem abstrações de omuniação
muitos-para-um, as quais transformam uma lista de invoações em uma únia
invoação. O objetivo é denir barreiras de sinronização e organizar os dados
provindos das outras invoações. Os valores de retorno das hamadas são
automatiamenteenaminhadas aos proessos requisitores.
A distribuição dos dados, usando interfaes oletivas, pode ser feita de duas
maneirasdistintas: o dado éopiado eenviado aada um dos proessos envolvidos
(broadast) na omputação; o dado é partiionado e pedaços menores que serão
Aformade envio(multiast egatherast)eotipode distribuiçãode dadospode
ser ongurado livremente pelo usuário. Através de omponentes ontroladores, o
desenvolvedor dene o tipo de sinronização e o balaneamento de arga entre os
proessos. Ainda em[12℄, o autor arma que ouso de interfaesoletivasfailita o
desenvolvimento de apliaçõesseomparadas aouso expliitode funçõesdo MPI.
2.5.2 Julia
Julia[17℄éumaoutraimplementaçãodomodelodeomponentesFratal. Esrita
nalinguagemJava, Juliafoi projetada paraser uma implementaçãolevee eiente.
Consiste em um framework que permite a riação e onguração de omponentes
Fratal,variandosuas formasde aordoomasemântia assoiada aoomponente.
Juliaprovê um onjunto de semântias de ontrole pré-denidas para omponentes
freqüentemente utilizados além de permitir a riaçãode semântias personalizadas
por usuário. Desta forma é possível redenir ou ustomizar quaisquer aspetos de
ontrole tais omo o gereniamento do ilo de vida, riação de ligações, polítias
denomeação ouqualquer outrotipode serviço ténioquesejadesejado aoplarno
modelode omponentes Fratal.
Julia usa ASM [19℄ para onstrução em tempo de exeução de instânias de
omponentes. ASM é usado em diferentes tipos de situação, dentre elas: gerar
intereptadores e instânias de interfae Fratal; otimizar o ódigo fazendo uso de
estratégiasparameslaródigo,diminuindoousodamemória;modularizaraesrita
delassesdeontroleusandoumalgoritmoquegerabyteode deumalassepormeio
de diversas amadas diferentes desenvolvidas independentemente.
2.5.3 AOKell
AOKell[18℄éimplementaçãodaespeiaçãoFratalpatroinadapeloINRIA e
FraneTeleom. Esteframework éresponsávelpelaimplementaçãodeontroladores
de omponentes e membranas. Uma membrana provê um nível de ontrole e
supervisão do omponente, inueniando no seu ilo de vida e nas ligações entre
omponentes. O prinipal objetivo do AOKell é implementar um framework para
programar ontroladores de omponentes, os quais os usuários possam esolher e
montarlivrementeobjetosontroladores para formarnovas membranas emFratal.
Comparado a outras implementações do modelo Fratal, AOKell distingui-se
em prover uma abordagem baseada em omponentes para implementação de
uma mesmaformaomo são usadasno nível de negóios.
Uma outra araterístia importante a ressaltar sobre o AKOell é que o
mesmo usa noções de Orientação a Aspetos (Aspeted Oriented Programming)
para onfeionar a ola que une a o ódigo de apliação e os omponentes de
ontrole. Cada omponente é assoiado a um aspeto o qual monitora a exeução
do omponente de apliação e delega ao omponente de ontrole a realização das
funionalidade de ontrole. O objetivo desta abordagem é o desaoplamento do
ódigo de ontrole doódigo de apliação, semelhanteaopadrão MVC.
2.6 O Modelo GCM
O modelo GCM (Grid Component Model) [56℄ foi idealizado pela omunidade
CoreGrid, tomando omo referênia o modelo hierárquio de omposição de
omponentes existente no Fratal e objetivando o seu uso em ontextos de grades
omputaionais.
Ahierarquiadeomponentesexistentenestemodelopossibilitaaodesenvolvedor
aomposiçãodeomponentesGCMformadosinternamenteporoutrosomponentes
GCM, e assim por diante. Fia abstrato aos usuários a noção de que seus
omponentessão formadosporoutros,anãoser queomesmoqueiraexpliitamente
explorarseu omponente.
Em adição ao estilo lássio de omuniação RPC (Remote Proedure Call),
baseadoemportas,GCMpermitetambémousodeportasdedados,stream eeventos
no proesso de interação de omponentes. Padrões de interação oletiva também
são suportados. As portas relativas aos dados permitem o ompartilhamento de
dados entre omponentes de forma enapsulada e, ao mesmo tempo, preservam a
realizaçãode otimizaçãoad ho. Portasstream permitemaimplementaçãodouxo
dedadosemapenasumavia. Sendoassim,oseuusoexplíitonaomuniaçãoentre
omponentespermiteotimizaçõesemtempode exeução. Jáasportasbaseadas em
eventospodemserusadasparaproveraomuniaçãoassínronaentre omponentes.
GCMpodesuportartambémdiversostiposdeportasoletivas,inluindoaquelas
quepermitemaomuniaçãoentreumaúniaportauses emúltiplasportasprovides
ou a omuniação de múltiplas portas uses om apenas uma porta provides. Tal
dinamiidade permite a implementação de todos os tipos de padrões de interação
oletiva,derivados douso de omponentes ompostos.
GCM adiiona ao modelo Fratal uma extensão para suporte a grades
dinâmios,GCMprovêdiversosníveisdegereniadoresautnomosemomponentes,
os quais se oupam de interesses não funionais da apliação. Sendo assim,
omponentes em GCM possuem dois tiposde interfaes: as relativas aos interesses
nãofunionaiseasrelativasaos interesses funionais. Implementaçõesde interfaes
nãofunionaisgeramomponentesquedevemgereniarasfunionalidadesreferentes
às araterístias não funionais omo eiênia e segurança. Implementações
funionais devem riar omponentes ujas araterístias afetam diretamente a
omputação. Cada omponente GCM possui um ou mais gereniadores que se
omuniam om outros gereniadores pertenentes a outros omponentes através
de suas interfae não funionais. Gereniadores assumem estar presentes nos
omponentesresponsáveispelosaspetosquedizemrespeito àgradeomputaional,
ontribuindo assim na eiênia de sua exeução.
A arquitetura de omponentes GCM é desrita fazendo uso de ADL
(ArhitetureDesriptionLanguage)aqualdeneosistemadeomponentes usando
omposição e bindings de sub-omponentes. Além disso, GCM também suporta a
interoperabilidade em diversos níveis. O enapsulamento de omponentes GCM
dentrodopadrãodeWebServies permiteainvoaçãodeseus serviços poroutros
omponentes.
Conluindo, é importante notar que este modelo de omponentes é adequado
tanto para a implementação de apliações para Grades omo até mesmo para a
implementação de uma Grade, sendo que as duas se beneiam das araterístias
aimaexpliitadas.
2.7 SPMD Orientada a Objetos
Os autores da referênia [10℄ apresentam uma forma de omuniação em grupo
(funionalidade ruial para apliações CAD) sob a perspetiva de orientação a
objetos, hamada de SPMD Orientada a Objetos. Através de uma fábria objetos,
implementações paralelas ompatíveis om as interfaes das lasses originais são
geradas e a omuniação entre os proessos é feita através de invoação remota de
métodos (RPC). Dessa forma,é possível uma maior exibilidade naonstrução de
omponentespoispermiteaomposiçãoavançadadebloosdeomputaçãoparalelos
voltados a arquiteturas emGrades eClusters.
Também é apresentada uma extensão (generalização) do padrão ponto-a-ponto
mostrado em ProAtive para um modelo de grupos de Objetos Ativos (Ative
grupos failita a implementação de modelos de alto nível omo o mestre-esravo,
além de poder reduziro overhead na omuniação entre seus membros, otimizando
a passagem de mensagens. É possível também alterar a amada de omuniação
para melhorarodesempenho (usar multiast no lugar de RMI, porexemplo).
Agrupar membros que efetuam as mesmas tarefas é uma idéia razoável pois
geralmenteeles trabalhamsobre o mesmoonjuntode dados. No modelo orientado
aobjetos, estaidéia éonretizadaporumgrupode objetosqueimplementamuma
interfae omum. Quando estes objetos pertenem a um só tipo, dizemos que o
grupo é tipado.
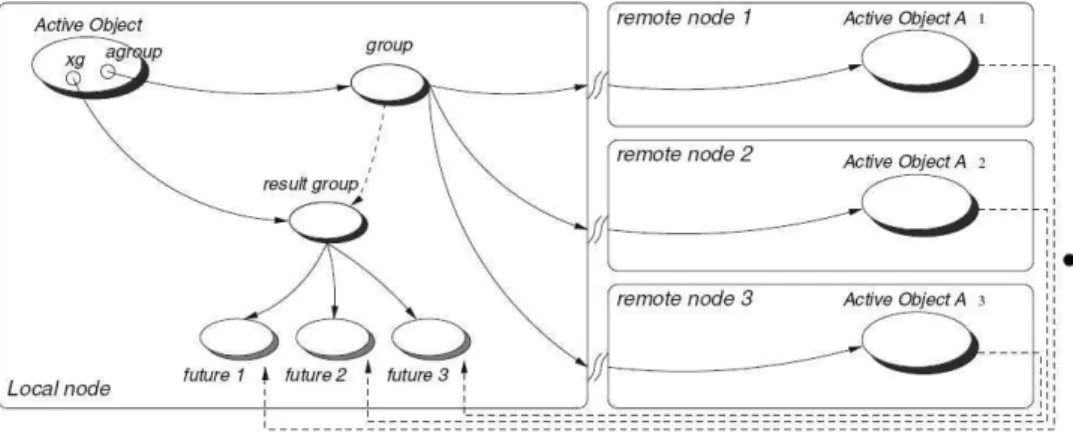
Figura 2.5: Comuniação emgrupo. Fonte: [10℄
A onstrução dos grupos é feita usando o ProAtive. Um stub é responsável
pela omuniação entre os objetos ativos remotos. Chamada a métodos é feita de
formatransparente eumstub ompatívelom otipodoobjetohamadoéesolhido
automatiamente. Uma função é usada para hear se a hamada é feita para
um objeto apenas ou à um grupo de objetos (group). A hamada de método
em um grupo é propagada a seus membros (remote nodes) usando multithreading
(Figura 2.5). Os parâmetros da hamada são passados aos membros através de
broadast. Os resultados das operações são armazenados em um outros grupo, o
grupo de resultados (result group). O grupo de resultados usa o meanismo de
espera-por-neessidade (wait-by-neessity). Quando um objeto invoa um grupo,
fazendo um hamada de método, os resultados de sua hamada são armazenados
em um outro grupo espeío (futures) enquanto ele ontinua sua omputação
normalmente. Ogrupode resultados passaosdadosaluladosapenasnomomento
emqueoobjetohamadortiverneessidade. Oobjetopermaneebloqueadoapartir