UNIVERSIDADE DE TRÁS-OS MONTES E ALTO DOURO
Ferramenta Educacional de
Simulação para Algoritmos
Genéticos
Mestrado em Informática
Paula Maria Ponte de Araújo Magalhães
Orientadores:
Prof. Eduardo Solteiro Pires Prof. Paulo Moura Oliveira
Algoritmos Genéticos utilizam o conceito de evolução observado na natureza para solucionar problemas computacionais de forma mais eficiente do que com o uso de algoritmos tradicionais. Os problemas comuns que utilizam algoritmos genéticos são os de pesquisa e optimização. Actualmente, esta técnica é utilizada em diversas áreas, inclusive fora do âmbito da computação. Este trabalho descreve a construção de uma ferramenta, FESAG, com fins didácticos que visa aplicar e validar o uso de algoritmos genéticos num ambiente de aprendizagem. A ferramenta utiliza uma interface gráfica que torna mais simples o manuseamento do algoritmo genético. A evolução pode ser observada através de gráficos, com a possibilidade de poder manipular as variáveis que modelam o ambiente de trabalho em tempo real.
Abstract
Genetic Algorithms make use of evolutionary concepts observed in nature to solve computational problems more efficiently than traditional algorithms. These types of algorithms are generally used to solve search and optimization problems. Nowadays, these algorithms are becoming more popular in various areas, many outside computer science. This work describes the construction of a tool, FESAG, which intends to apply and validate the use of genetic algorithms in a learning environment. The tool uses a graphical user interface that simplifies handling the genetic algorithm. The evolution is observed through graphics, with the possibility of manipulating variables that model the environment in real time.
Este trabalho é resultante de um empenhamento em aumentar a minha valorização pessoal e profissional.
Agradeço a paciência e boa vontade dos meus filhos em abdicarem de muita da minha companhia e de compreenderem a minha falta de tempo para lhes dedicar toda a atenção que necessitam, assim como a ajuda e companheirismo do meu marido.
Agradeço também a colaboração do meu orientador, Prof. Eduardo Pires que sempre que necessário disponibilizou o seu tempo para me transmitir o seu saber e auxílio e ainda ao Prof. Paulo Oliveira pelos conselhos úteis que permitiram levar a bom termo a realização deste projecto.
Resumo ... 2 Abstract ... 2 1. Introdução ...12 1.1. Motivação ...12 1.2. Objectivos ...14 1.3. Estrutura da Dissertação ...14 2. Algoritmos Evolutivos ...16
2.1. Algoritmos Evolutivos: Introdução ...17
2.2. Algoritmos Evolutivos e Optimização Global ...18
2.3. Algoritmos Genéticos ...19
2.3.1. Aplicações do Algoritmo Genético ...20
2.3.1.1. Economia e Finanças...20 2.3.1.2. Engenharia de Software ...21 2.3.1.3. Robótica ...21 2.3.1.4. Electrónica e Telecomunicações...21 2.3.1.5. Escalonamento...22 2.3.1.6. Sistemas Gráficos...22 2.3.1.7. Planeamento ...23 2.3.1.8. Redes Neuronais ...23
2.3.2. Terminologia dos AGs ...24
2.4. Operações Básicas de um Algoritmo Genético ...25
2.4.1. Codificação ...26
2.4.1.1. A Codificação Binária de um Cromossoma ...27
2.4.2. Inicialização ...28
2.4.3. Avaliação - Cálculo do valor de Aptidão ...30
2.4.4. Selecção ...32
2.4.4.1. Selecção por Torneio ...33
2.4.4.2. Selecção por Ranking Linear...34
2.4.4.3. Selecção Proporcional ou Roleta...34
2.4.4.4. Amostragem Universal Estocástica ...36
2.4.5. Cruzamento ...37
2.4.6.1.Taxa ou Probabilidade de Mutação...41
2.4.7. Substituição da População ...41
2.8. Formação de Novas Populações...42
2.9. Operador de Diversidade – Sharing...42
3. Optimização de Funções...45
3.1. Exemplo (funções estáticas) ...45
3.1.1. Codificação binária da variável x num vector...46
3.1.2. Iniciação da primeira população ...46
3.1.3. Selecção ...46
3.1.4. Cruzamento de elementos seleccionados aleatoriamente do grupo de acasalamento...47
3.1.5. Mutação ...47
3.1.6. Análise da nova população ...47
4. Implementação ...48
4.1. FESAG – Implementação ...49
4.2. FESAG – Ferramenta Educacional de Simulação para Algoritmos Genéticos...51 4.2.1. Codificação ...52 4.2.2. Inicialização ...53 4.2.3. Avaliação ...53 4.2.4. Selecção ...54 4.2.4.1. Roleta...54 4.3.4.2. Torneio ...54 4.2.4.3. Posto ...55 4.2.5. Cruzamento ...55 4.2.6. Mutação ...55 4.3. Descrição da Aplicação ...55
5. Experimentação e Discussão de Resultados...64
5.1. Análise da probabilidade de mutação ...64
5.1.1. Taxa de Mutação = 0 % (teste 1) ...65
5.1.5. Taxa de Mutação = 30 % (teste 5) ...77
5.1.6. Taxa de Mutação = 50 % (teste 6) ...80
5.1.7. Interpretação dos testes de mutação ...84
5.2. Análise da Probabilidade de Cruzamento ...87
5.2.1. Taxa de Cruzamento = 0.0 % (teste 7) ...87
5.2.2. Taxa de Cruzamento = 0.20 % (teste 8) ...91
5.2.3. Taxa de Cruzamento = 40 % (teste 9) ...93
5.2.4. Taxa de Cruzamento = 60% (teste 10) ...96
5.2.5. Interpretação dos Testes de Cruzamento...99
5.3. Análise da Diversidade - Sharing ... 102
5.3.1. Sigma = 0.0 (teste 11)... 103
5.3.2. Sigma = 0.01 (teste 12) ... 105
5.3.3. Sigma = 0.05 (teste 13) ... 108
5.3.4. Sigma = 0.1 (teste 14) ... 111
5.3.5. Interpretação dos Testes de Sharing ... 113
6. Conclusão e trabalho futuro ... 117
Referências ... 119
Fig. 1 - Fluxograma do Algoritmo Genético ...25
Fig. 2 - Codificação binária usando 16 bits ...28
Fig. 3 - Selecção Torneio ...34
Fig. 4 - Esquema da Roleta ...35
Fig. 5 – Selecção pela roda de roleta ...36
Fig. 6 - Cruzamento Uni-ponto na posição 5 ...38
Fig. 7 - Cruzamento Multi-ponto na posição 2 e 6 ...38
Fig. 8 – Cruzamento uniforme...39
Fig. 9 – Mutação ...40
Fig. 10 – Função Sharing Triangular (Goldberg 1989)...43
Fig. 11 - Gráfico da função f(x)= x2-6x...45
Fig. 12 – Editor de disposição e de alinhamento ...49
Fig. 13 – Edição da ordem tabular...50
Fig. 14 – Disposição dos componentes da interface gráfica ...50
Fig. 15 – Edição do menu principal ...51
Fig. 16 – Aspecto geral da ferramenta FESAG ...52
Fig. 17 – Espaço dedicado a funções ...56
Fig. 18 – Mensagem de erro (introdução de um número impar)...57
Fig. 19 – Opções possíveis...58
Fig. 20 – Activação das simulações ...58
Fig. 21 – Mensagem de fim de simulação ...59
Fig. 22 – Caixa de diálogo para confirmação da saída ...59
Fig. 23 – Gráfico de uma geração...60
Fig. 24 – listbox cromossomas...60
Fig. 25 – Estatísticas da população ...61
Fig. 26 – Menus da FESAG ...61
Fig. 27 - Tutorial da FESAG ...62
Fig. 28 - Opção SOBRE do menu AJUDA...62
Fig. 29 – Ajuda para a mutação e cruzamento ...63
Fig. 30 – Menu de Testes na FESAG...63
Fig. 31 - População Inicial gerada aleatoriamente para o teste 1 ...65
Fig. 33 – Geração 20 ...67
Fig. 34 – Resultado da geração 100 (Última do teste) ...67
Fig. 35 - População Inicial do teste 2 ...68
Fig. 36- Geração 25 do teste2...69
Fig. 37 – Geração 50 do teste 2 ...70
Fig. 38 – Geração 75 do teste 2 ...70
Fig. 39 – Última geração do teste2 ...71
Fig. 40 – População inicial do teste 3 ...72
Fig. 41 – Geração 25 do teste 3 ...72
Fig. 42 – Geração 50 do teste 3 ...73
Fig. 43 - Geração 75 do teste 3 ...73
Fig. 44 - Geração 100 do teste 3 ...74
Fig. 45 - Geração 1 do teste 4 ...75
Fig. 46 – Geração 25 do teste 4 ...75
Fig. 47 - Geração 50 do teste 4 ...76
Fig. 48 - Geração 75 do teste 4 ...76
Fig. 49 - Geração 100 do teste 4 ...77
Fig. 50 – População inicial do teste 5 ...78
Fig. 51 – Geração 25 do teste 5 ...78
Fig. 52 – Geração 50 do teste 5 ...79
Fig. 53 – Geração 75 do teste 5 ...79
Fig. 54– Geração 100 do teste 5 ...80
Fig. 55 - População inicial do teste 6 ...81
Fig. 56- Geração 25 do teste 6...82
Fig. 57 - Geração 50 do teste 6 ...82
Fig. 58 - Geração 75 do teste 6 ...83
Fig. 59 - Geração 100 do teste 6 ...83
Fig. 60 – Gráfico dos melhores obtidos nos testes de mutação ...84
Fig. 61 - Gráfico das médias obtidas nos testes de mutação ...85
Fig. 62- Gráfico Desvio Padrão obtido nos testes de mutação ...85
Fig. 63 - Gráfico Comparativo das Medianas nos testes de Mutação ...86
Fig. 64 – População inicial teste 7...88
Fig. 65 – Geração 25 do teste 7 ...89
Fig. 67 - Geração 75 do teste 7 ...90
Fig. 68 - Geração 100 do teste 7 ...90
Fig. 69 – Primeira população do teste 8 ...91
Fig. 70 – Geração 25 do teste 8 ...91
Fig. 71- Geração 50 do teste 8...92
Fig. 72 – Geração 75 do teste 8 ...93
Fig. 73 - Geração 100 do teste 8 ...93
Fig. 74 – Primeira População do teste 9 ...94
Fig. 75 – Geração 25 do teste 9 ...94
Fig. 76 – Geração 50 do teste 9 ...95
Fig. 77– Geração 75 do teste 9...95
Fig. 78– Geração 100 do teste 9 ...96
Fig. 79- Primeira População do teste 10 ...97
Fig. 80– Geração 25 do teste 10 ...97
Fig. 81- Geração 50 do teste 10 ...98
Fig. 82– Geração 75 do teste 10 ...98
Fig. 83- Geração 100 do teste 10 ...99
Fig. 84- Gráfico do melhor valor obtido nos testes de Cruzamento ... 100
Fig. 85-Gráfico das médias obtidas nos testes de Cruzamento ... 101
Fig. 86- Gráfico Desvio Padrão nos testes de Cruzamento... 101
Fig. 87– Gráfico comparativo das medianas nos testes de Cruzamento ... 102
Fig. 88 - População inicial do teste 11... 103
Fig. 89- Geração 25 do teste 11 ... 104
Fig. 90– Geração 50 e 75 do teste 11 ... 104
Fig. 91-Geração 100 do teste 11... 105
Fig. 92– População inicial teste 12 ... 106
Fig. 93– Geração 25 e 50 do teste 12 ... 106
Fig. 94 - Geração 75 do teste 12 ... 107
Fig. 95- Geração 100 do teste 12 ... 108
Fig. 96– Primeira população do teste 13 ... 108
Fig. 97– Geração 25 e 50 do teste 13 ... 109
Fig. 98- Geração 75 do teste 13 ... 110
Fig. 99- Geração 100 do teste 13 ... 110
Fig. 101– Geração 25 do teste 14 ... 112 Fig. 102- Geração 50 e 75 do teste 14 ... 112 Fig. 103- Geração 100 do teste 14 ... 113 Fig. 104– Gráfico comparativo dos melhores valores nos testes de Sharing.. 114 Fig. 105- Gráfico comparativo das médias nos testes de Sharing... 114 Fig. 106 - Gráfico comparativo do desvio padrão nos testes de Sharing ... 115 Fig. 107- Gráfico comparativo da mediana nos testes de Sharing ... 115
Índice de Tabelas
Tabela 1 – Terminologia dos AGs ...24
Tabela 2 – Exemplo de selecção pelo método da roleta ...35
Tabela 3 – Tabela de estatísticas para a população inicial ...46
Tabela 4 – Cruzamento...47
Tabela 5 – Condições para execução dos testes de mutação...65
Tabela 6 – Condições para execução dos testes do Cruzamento...87
1. Introdução
Os algoritmos genéticos, inspirados em processos evolutivos são uma técnica de pesquisa e de optimização tendo por base operadores como a selecção, o cruzamento e a mutação. A selecção favorece os indivíduos com melhor desempenho de modo a guiar a pesquisa para zonas mais promissoras. Por outro lado, o cruzamento e a mutação permitem gerar novos indivíduos. Desta forma os algoritmos genéticos tornam-se numa ferramenta poderosa que pode ser aplicada a um vasto tipo de problemas.
À semelhança da genética humana, a codificação nos algoritmos genéticos é conseguida através de vectores chamados cromossomas, os quais vão ser sujeitos aos mecanismos de cruzamento, mutação e selecção.
Os Algoritmos Genéticos (AG) diferem dos métodos tradicionais de pesquisa e optimização, principalmente em quatro aspectos:
• Trabalham com uma codificação de um conjunto de parâmetros e não com os próprios parâmetros;
• Utilizam uma população de potenciais soluções e não uma única solução;
• Trabalham sobre informações anteriores e outro conhecimento auxiliar; • Utilizam regras probabilísticas e não determinísticas.
1.1. Motivação
A relevância que os algoritmos genéticos ganharam como ferramenta de pesquisa e optimização faz com que o seu estudo seja efectuado no âmbito de disciplinas de Algoritmia, Inteligência Artificial e Investigação Operacional.
Os algoritmos genéticos têm vindo a ser utilizados com enorme sucesso numa gama alargada de aplicações uma vez que englobam de forma simples e natural todos os conceitos neles contidos e apresentam resultados bastante
aceitáveis, em relação aos recursos utilizados (fáceis de implementar) e úteis na resolução de uma ampla gama de problemas de difícil resolução por outros métodos. São muito flexíveis, aceitam sem grandes dificuldades um grande número de alterações na sua implementação em relação aos outros paradigmas da Computação Evolutiva.
Assim, a utilização de software de ajuda ao ensino deste tipo de algoritmos pode ser uma mais valia e surge então a ideia deste projecto e com ele a criação de uma ferramenta didáctica que possua uma interface gráfica amigável do ponto de vista do utilizador, permitindo facilitar a especificação dos dados do problema e dos parâmetros genéticos.
Na prática, podemos implementar facilmente um AG com o simples uso de
strings de bits, no caso da codificação binária, para representar os
cromossomas e, com simples operações de manipulação de bits podemos implementar as operações de cruzamento, mutação e de outros operadores genéticos.
Este projecto, que inclui a criação de uma ferramenta didáctica, FESAG (Ferramenta Educacional de Simulação para Algoritmos Genéticos), procura facilitar a aprendizagem dos mecanismos de operação do algoritmo genético. A interface gráfica produzida pretende monitorizar a acção do AG e dos seus parâmetros operacionais através da optimização de funções permitindo observar passo a passo a evolução dos resultados obtidos com base em soluções anteriores. Tudo começa na escolha de uma função a optimizar, na geração de uma população (conjunto aleatório de valores dentro de um intervalo), num conjunto de condições escolhidas pelo utilizador, sendo então a população submetida a um processo de evolução artificial com o intuito de eventualmente convergir para o óptimo global, i.e., solução pretendida.
1.2. Objectivos
Este projecto consiste na criação de uma ferramenta didáctica denominada FESAG que permite exemplificar o modo de funcionamento dos algoritmos genéticos. A aplicação possui uma interface gráfica amigável do ponto de vista do utilizador uma vez que facilita a especificação dos dados do problema e dos parâmetros genéticos. O seu objectivo principal será facilitar e reduzir aos estudantes o tempo de aprendizagem necessário para adquirir certos mecanismos inerentes à implementação deste tipo de algoritmos.
Os pontos principais tratados por esta ferramenta são a monitorização e o estudo do Algoritmo Genético através dos operadores de Selecção, de Cruzamento, Mutação e Esquema de Partilha. A definição dos Problemas consiste num conjunto de funções a optimizar e em técnicas de Substituição da população.
A ferramenta FESAG possibilita análises comparativas de diferentes aspectos da evolução de uma população, utilizando diferentes tipos de heurísticas para tal. O sistema permite ainda que os utilizadores manipulem com flexibilidade os operadores genéticos.
Além desse nível de interacção entre o utilizador e o sistema, será possível notar, a partir de comparações de resultados, a importância da escolha de uma boa heurística para se atingir o resultado esperado na população final. Essas funcionalidades possibilitarão à FESAG atingir os objectivos aos quais se propõe: ser uma ferramenta computacional, para fins didácticos.
1.3. Estrutura da Dissertação
No capítulo da introdução é feita uma breve descrição dos algoritmos genéticos, da sua utilidade e apresenta-se motivação para a elaboração do projecto. A partir deste ponto a dissertação está estruturada da seguinte forma:
o No capítulo dois são descritos os algoritmos evolutivos, as operações básicas do algoritmo genético, os métodos de codificação, o cruzamento e a mutação, com referência também ao operador de diversidade e à formação de novas populações;
o No capítulo três são utilizados exemplos da aplicação do algoritmo genético na optimização de funções;
o O capítulo quatro descreve a implementação da ferramenta e apresentação da interface gráfica;
o No capítulo cinco é apresentado um conjunto de testes com a respectiva interpretação e monitorização de resultados;
o A dissertação termina com a conclusão e referência a trabalhos futuros incluídos no capítulo seis.
2. Algoritmos Evolutivos
A computação Evolutiva (CE) é um ramo das Ciências da Computação que propõe um tratamento alternativo ao processamento de dados convencional. Esta nova área, não exige, para resolver um problema, qualquer conhecimento prévio sobre o mesmo, necessitando somente da avaliação do mérito de cada potencial solução. A CE é baseada em mecanismos evolutivos encontrados na natureza, tais como a auto-organização e o comportamento adaptativo [Farmer 1983], [Goldberg 1988]. Estes mecanismos foram descobertos e formalizados por Darwin na sua teoria da evolução natural, segundo a qual, a vida na terra é o resultado de um processo de selecção, pelo meio ambiente, dos mais aptos e adaptados, e por isto mesmo com mais hipóteses de se reproduzirem. A diversidade da vida, associada ao facto de que todos os seres vivos compartilham uma bagagem genética comum, pelo menos em termos dos seus componentes básicos, é um exemplo importante das possibilidades do mecanismo de evolução natural.
Os quatro alicerces fundamentais da computação evolutiva são:
o Estratégias Evolutivas - EEs o Programação Evolutiva - PE o Algoritmos Genéticos AGs o Programação Genética – PG
Umas das técnicas mais utilizadas da computação evolutiva são os Algoritmos Genéticos propostos por John Holland [Holland 1975], que desde então têm sido aplicados em quase todos os domínios científicos [Goldberg 1989]. Os AGs são uma família de modelos computacionais inspirados na teoria da evolução de Darwin e nos mecanismos de selecção natural e na genética. Os problemas são resolvidos através de um processo evolutivo que resulta na melhor (mais adequada) solução (a sobrevivente) [Darwin 1859].
Dada a popularidade granjeada pelos algoritmos genéticos, a utilização de ferramentas informáticas que permitam auxiliar a compreensão do seu
funcionamento é de grande utilidade, quer como suporte didáctico em aulas de licenciatura/mestrado, quer como ferramenta de projecto na resolução de um dado problema.
2.1. Algoritmos Evolutivos: Introdução
Os algoritmos evolutivos baseiam-se no modelo de evolução biológica natural formulado inicialmente por Charles Darwin, conhecido como Teoria da Evolução de Darwin [Darwin 1859]. Esta teoria explica as mudanças de adaptação das espécies pelo Princípio da Selecção Natural, no qual as espécies que melhor se adaptam às suas condições ambientais são as que melhores possibilidades têm de sobreviver e evoluir – Princípio da Sobrevivência do Mais Apto. A ocorrência de pequenas variações (mutações), aparentemente aleatórias entre os fenótipos é o segundo factor importante da evolução de Darwin. As mutações prevalecem através da selecção se provarem o seu valor face ao ambiente actual, no caso contrário, desaparecem.
A selecção tem como força motriz o fenómeno natural da reprodução. Sob condições ambientais favoráveis o tamanho da população cresce exponencialmente. Este processo é limitado de acordo com a escassez de recursos existentes. Quando os recursos não são suficientes para sustentar todos os indivíduos da população, os organismos que os explorem melhor têm vantagens no processo da selecção.
Em termos evolutivos a Aptidão ou Mérito (Fitness) de um indivíduo é medida indirectamente pela sua capacidade de crescimento em comparação com os outros membros da população, i.e., a sua propensão para sobreviver e se reproduzir num dado ambiente. Em termos biológicos o termo adaptação representa um acréscimo de eficiência ecológica ou fisiológica de um indivíduo em relação aos outros membros da população. O termo adaptação é geral, incluindo a adaptação genética.
Os Algoritmos Evolutivos estão também relacionados com a Inteligência Artificial (IA) pois em IA o termo adaptação está relacionado com o tema da Aprendizagem. Os Algoritmos Evolutivos são considerados algoritmos de aprendizagem porque não utilizam ensinamentos, mas geram os seus próprios exemplos. A criação de exemplos pelo algoritmo é uma tentativa indutiva e baseada no conhecimento existente; se a tentativa prova o seu valor é mantida na base do conhecimento do algoritmo (população) – caso contrário – é eliminada por via da selecção.
Numa interpretação formal, o algoritmo genético refere-se ao modelo introduzido e estudado por John Holland [Holland 1985] e desenvolvido por ele e pelos seus alunos e colegas. Deste estudo resultou o livro “Adaptation in
Natural and Artificial systems”. Os AGs foram posteriormente desenvolvidos
na University of Michigan e ainda hoje a maior parte da teoria existente sobre
AGs aplica-se totalmente ou primariamente ao modelo introduzido por Holland. Numa utilização mais abrangente do termo, um algoritmo genético é
qualquer modelo baseado numa população que utiliza operadores de selecção e recombinação e mutação para gerar novos pontos amostrais num espaço de pesquisa.
2.2. Algoritmos Evolutivos e Optimização Global
A simulação de um processo evolucionário pode ser utilizada para resolver um problema de optimização. O objectivo é encontrar um conjunto de parâmetros de tal forma que um determinado critério de qualidade seja maximizado ou minimizado. Problemas deste tipo têm uma enorme importância em vários campos da investigação tais como a Biologia, Química, Ciências da Computação e da Engenharia em geral [Back 1997].
Os problemas de optimização são baseados em três pontos principais: a codificação do problema, a função objectivo que se deseja maximizar ou minimizar e o espaço de soluções associado. Pode-se imaginar um problema de optimização como uma caixa preta com n botões, onde cada botão é um
parâmetro do problema, e uma saída que é o valor da função objectivo, indicando se um determinado conjunto de parâmetros é bom ou não para resolver este problema.
2.3. Algoritmos Genéticos
Os AGs são algoritmos de pesquisa e optimização, que exploram o espaço de pesquisa para encontrar pontos onde são esperados os melhores desempenhos. Isto é feito através de processos iterativos, onde cada iteração é chamada geração.
Durante cada geração, os princípios de selecção e reprodução são aplicados a uma população de soluções candidatas. Através da selecção, pode-se determinar quais os indivíduos capazes de se reproduzir, gerando um número determinado de descendentes para a próxima geração, com uma probabilidade determinada pelo seu índice de aptidão. Em outras palavras, os indivíduos com maior capacidade relativa têm maiores hipóteses de reprodução. Nos algoritmos genéticos, uma população de possíveis soluções para o problema em questão evolui de acordo com operadores genéticos (probabilísticos) concebidos a partir de metáforas biológicas, de modo que existe a tendência de que, em média, os indivíduos representem soluções progressivamente melhores do decorrer do processo evolutivo.
Embora o algoritmo genético use um método heurístico e probabilístico para obter os novos elementos, não pode ser considerado uma simples pesquisa aleatória, uma vez que explora inteligentemente as informações disponíveis de forma a encontrar novos indivíduos ou soluções capazes de melhorar um critério de desempenho.
Os algoritmos genéticos procuram privilegiar os indivíduos com melhores aptidões, tentando dirigir a procura para as regiões do espaço de pesquisa onde é provável que os pontos óptimos estejam. A solução potencial para um
problema específico é apresentada numa estrutura análoga à de um cromossoma à qual se aplicam operadores de selecção, cruzamento e mutação de forma a encontrar informações críticas relativas à solução do problema.
2.3.1. Aplicações do Algoritmo Genético
Normalmente os AGs são vistos como optimizadores de funções, embora a quantidade de problemas em que se aplicam seja bastante abrangente. Uma das vantagens de um algoritmo genético é a simplificação ou abstracção que eles permitem na formulação e resolução de problemas de optimização. Os
AGs padrão trabalham normalmente com descrições de entrada formadas por
cadeias de bits de tamanho fixo, outros podem trabalhar com cadeias de bits de tamanho variável, como por exemplo os usados na Programação Genética [Koza 1992]. A aptidão da solução é tipicamente definida em relação à população actual. A função objectivo de um problema de optimização é construída a partir dos parâmetros envolvidos no problema fornecendo uma medida da proximidade da solução em relação à solução óptima. Esta função permite o cálculo da aptidão bruta de cada indivíduo e fornecerá o valor a ser usado para o cálculo da probabilidade da solução ser ou não seleccionado para reprodução. Além disso, em muitos casos onde outras estratégias de optimização falham na procura de uma solução, os AGs têm sucesso pois são numericamente robustos.
Os AGs possuem uma larga gama de aplicações em muitas áreas científicas, entre as quais podem ser destacadas:
2.3.1.1. Economia e Finanças
Alguns dos possíveis problemas deste domínio onde são aplicados AG’s : Aprovação de crédito, análise de investimentos e planeamento económico. Nesta área o trabalho pode ser feito sobre um grande volume de dados, onde
combinações e optimizações podem dar apoio a decisões importantes no que respeita ao controlo e investimentos [Brás 2002].
2.3.1.2. Engenharia de Software
Em aplicações que incluem a sintetização e optimização de software, são geralmente usados para gerar códigos LISP para produção de soluções para um problema, envolvendo um sistema para gerar números aleatórios utilizando o paradigma de programação genética que pode ser multiplicado geneticamente com performance quase óptima [Jiang 2006].
Podemos ainda encontrar algoritmos genéticos para optimizar a procura de informações numa base de dados, usando métodos para aplicar AG’s de forma a obter desempenho numa procura complexa, com a finalidade de optimizar tarefas em bases de dados relacionais [Barker et al. 2006].
2.3.1.3. Robótica
Os AGs são bastante usados em robótica para optimizar os movimentos dos robôs e gerar trajectórias para estes descrevendo formas de controlos para procura das melhores trajectórias [Pires 2005].
2.3.1.4. Electrónica e Telecomunicações
Informações sobre caminhos em redes de comunicação complexas de redes de computadores, redes móveis ou redes de transferência de dados (Internet e Intranet). Este é um problema, que pesquisas aplicadas ao uso de algoritmos genéticos estão a tentar resolver através de tarefas que procuram ajustar baixos desempenhos de transferência. Os AGs que possibilitam projectar, redes ópticas especializadas, em muito menos tempo do que se utilizasse
especialistas humanos produzindo resultados 10% (dez por cento) melhores que os realizados pelo homem [Lima 2005].
Síntese de circuitos analógicos: para uma certa entrada e uma saída desejada, por exemplo a tensão, o AG gera a topologia, o tipo e o valor dos componentes do circuito. Síntese de protocolos: determinação das funções do protocolo que devem ser implementadas em hardware e quais devem ser implementadas em software para que um certo desempenho seja alcançado [Koza et al. 2003].
2.3.1.5. Escalonamento
O estabelecimento de um tempo pode ser definido como um problema de procura de uma sequência optimizada, com a finalidade de executar um conjunto finito de operações, cujo determinado conjunto de obrigações não será transgredido. Um Estabelecimento de tempo usual procura maximizar a utilização de indivíduos ou maquinarias e minimizar o tempo requerido para completar um processo vinculado ao estabelecimento de tempo inicial. Os conflitos podem surgir quando um indivíduo ou máquina é mantido por mais de 1 (uma) operação durante um tempo concedido ou quando este tempo utiliza mais recursos que são avaliados.
Optimização das urgências médicas hospitalares: onde os Algoritmos Genéticos foram utilizados com o objectivo de dar auxílio na solução das escalas de trabalho dos médicos e diminuir o esforço e o desgaste humano para elaboração das equipas [Moreira 2008].
2.3.1.6. Sistemas Gráficos
Frequentemente num sistema gráfico existe a necessidade de efectuar arranjos automáticos de objectos no ecrã do computador conforme alguns critérios de estética. Isto é específico em computadores com ferramentas de
engenharia de software (ferramentas CASE) e softwares de projectos arquitectónicos (CAD), onde os algoritmos genéticos são usados para optimizar o layout gráfico destas aplicações [Grefenstette 2007].
2.3.1.7. Planeamento
Um problema de planeamento pode ser descrito como um problema de prognóstico de comportamento futuro dos dados históricos, como os mencionados na secção “1.1.1.1. Economia e finanças”. Os AG´s são aplicáveis em outros tipos de problemas de planeamento, tais como: corridas de cavalos, terramotos, estado atmosférico, etc., planeamento baseado sempre em dados históricos [Moreira 2008].
2.3.1.8. Redes Neuronais
Redes neuronais são programas de computador que simulam a interligação dos neurónios cerebrais, de forma a resolver vários problemas. Muitos destes problemas têm sido aplicados de forma semelhante aos usados para aplicações com algoritmos genéticos, entretanto, AG’s tem sido igualmente aplicados para criar melhores redes neuronais, incluindo aplicações de treino de uma rede neuronal e a optimização dos caminhos da mesma [Ritchie 2007].
2.3.1.9. Outras Aplicações
• Problemas de optimização complexos: problemas que envolvem um grande número de variáveis e, consequentemente, espaços de soluções de dimensões elevadas (por exemplo: problema do caixeiro viajante, gestão de carteiras de fundos de investimento, …) [Potvin 1996];
• Evolução musical [Romero e Machado 2007]; • Arte Evolutiva [Romero e Machado 2007]; • …
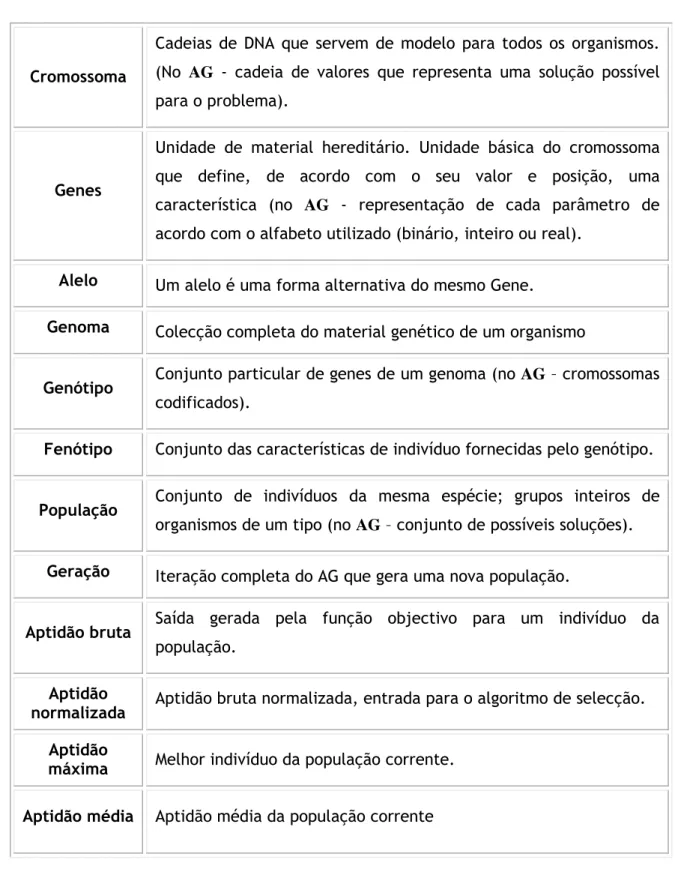
2.3.2. Terminologia dos AGs
Na Tabela 1 apresenta-se uma lista de termos correntes nos AGs e o seu significado.
Tabela 1 – Terminologia dos AGs
Cromossoma
Cadeias de DNA que servem de modelo para todos os organismos. (No AG - cadeia de valores que representa uma solução possível para o problema).
Genes
Unidade de material hereditário. Unidade básica do cromossoma que define, de acordo com o seu valor e posição, uma característica (no AG - representação de cada parâmetro de acordo com o alfabeto utilizado (binário, inteiro ou real).
Alelo Um alelo é uma forma alternativa do mesmo Gene.
Genoma Colecção completa do material genético de um organismo
Genótipo Conjunto particular de genes de um genoma (no AG – cromossomas
codificados).
Fenótipo Conjunto das características de indivíduo fornecidas pelo genótipo.
População Conjunto de indivíduos da mesma espécie; grupos inteiros de
organismos de um tipo (no AG – conjunto de possíveis soluções).
Geração Iteração completa do AG que gera uma nova população.
Aptidão bruta Saída gerada pela função objectivo para um indivíduo da
população.
Aptidão
normalizada Aptidão bruta normalizada, entrada para o algoritmo de selecção.
Aptidão
máxima Melhor indivíduo da população corrente.
2.4. Operações Básicas de um Algoritmo Genético
A implementação de um algoritmo genético começa pela criação de uma população aleatória de cromossomas, que será então, avaliada e associada a probabilidades de reprodução de tal forma que as maiores probabilidades são atribuídas aos cromossomas que representam uma melhor solução para o problema (conjunto de potenciais soluções - cromossomas) que constituem os elementos de um conjunto chamado população. Os elementos da população são avaliados e seleccionados para formar uma nova população. Isto é motivado pela esperança que a nova população será em média melhor que a primeira. Os indivíduos são seleccionadas para formar novos elementos através do cruzamento e mutação de acordo com a sua adequação à resolução do problema – quanto melhores mais possibilidades de reprodução terão. Este processo é repetido até que alguma condição seja satisfeita (por exemplo o número de gerações ou o aperfeiçoamento da melhor solução). A estrutura básica do algoritmo genético é ilustrada na Fig. 1:
Fig. 1 - Fluxograma do Algoritmo Genético
2.4.1. Codificação
A codificação dos cromossomas é das primeiras questões a tratar quando começamos a resolver um problema utilizando AGs. A codificação depende muito do problema e é essencial no desempenho do algoritmo.
Os algoritmos genéticos processam populações de indivíduos ou cromossomas. O cromossoma é uma estrutura de dados, geralmente vectores ou cadeias de valores binários, reais ou combinação de ambas, que representa uma possível solução do problema a ser optimizado. Representações possíveis para codificar os cromossomas podem ser binária, inteira ou real. A essa representação dá-se o nome de alfabeto do AG e de acordo com a classe de problema que se deseja resolver pode usar-se qualquer um dos três tipos, ou até uma combinação destes. Em geral, o cromossoma representa o conjunto de parâmetros da função objectivo cuja resposta será optimizada (por exemplo maximizada ou minimizada). O conjunto de todas as configurações que o cromossoma pode assumir forma o seu espaço de pesquisa. Se o cromossoma representa n parâmetros de uma função, então o espaço de pesquisa é um espaço de dimensão n. A maioria das representações é genotípica. O genótipo é o conjunto de genes que define a constituição genética de um indivíduo e é sobre estes genes que serão aplicados os operadores genéticos. Essas representações utilizam vectores de tamanho finito. Tradicionalmente, o genótipo de um indivíduo é representado por um vector binário, onde cada elemento de um vector denota a ausência ou presença de uma determinada característica relevante para a construção de um indivíduo único. Os elementos podem ser combinados formando as características reais do indivíduo, ou seja o seu fenótipo.
A representação binária é historicamente importante [Goldberg 1989], uma vez que foi utilizada nos trabalhos pioneiros de Holland [Holland 1962]. Além disso, ainda é a representação mais utilizada, por ser de fácil utilização e manipulação, e simples de analisar teoricamente. Mas, se um problema tem parâmetros contínuos e o utilizador desejar trabalhar com maior precisão,
provavelmente acabará por utilizar cromossomas demasiado longos para representar as soluções, aumentando o tempo de processamento.
Outro aspecto a ser observado é a não-uniformidade dos operadores; por exemplo, se o valor real de um gene for codificado por um vector binário, a mutação nos primeiros valores binários do gene afectará mais a aptidão do cromossoma que a mutação nos seus últimos valores. A representação do cromossoma usando valores reais é mais naturalmente compreendida pelo ser humano [Wright 1990] [Michalewicz 1992].
A grande maioria dos algoritmos genéticos propostos na literatura usa uma população com um número fixo de indivíduos e cromossomas também de tamanho constante. Depois de definida a representação cromossómica para o problema, gera-se um conjunto de possíveis soluções, a que chamamos
soluções candidatas. Um conjunto de soluções codificadas de acordo com a
representação seleccionada corresponde a uma população de indivíduos, que representa, ao longo dos ciclos de evolução, o estado actual da solução do problema.
Na população são utilizados diversos valores estatísticos que servem de medida para avaliar se a pesquisa está próxima do fim. Normalmente os parâmetros avaliados são o melhor indivíduo, a média dos objectivos atingidos e o desvio padrão.
2.4.1.1. A Codificação Binária de um Cromossoma
A codificação binária, é a mais comum principalmente porque foi a que os primeiros investigadores de AG usaram e devido à sua relativa simplicidade. Além do mais existem muitos estudos baseados na codificação binária. Um cromossoma deve de alguma maneira conter a informação da solução que ele representa. A forma mais comum de codificar é uma série (string) binária. Na Codificação Binária, cada cromossoma é uma série de bits - 0 ou 1
Apresenta-se na Fig. 2 um exemplo de dois cromossomas que utiliza uma codificação binária com 16 bits:
Fig. 2 - Codificação binária usando 16 bits
A Codificação Binária permite representar muitos possíveis cromossomas, mesmo com pequenos números de alelos {0,1}. Por outro lado, esta codificação não é natural para muitos problemas e algumas vezes é necessário fazer correcções antes dos cruzamentos e/ou mutações. Outra possibilidade é que a série toda possa representar um número. Há muitas outras formas de codificar [Goldberg 1989]. A codificação dependerá principalmente do problema a ser solucionado.
2.4.2. Inicialização
O algoritmo genético começa com uma população inicial de n indivíduos gerada aleatoriamente dentro dos limites do problema proposto. Quando não existe nenhum conhecimento prévio sobre a região do espaço de pesquisa onde se encontra a solução do problema, os indivíduos são gerados aleatoriamente. No entanto, se houver um conhecimento a priori sobre a região em que está localizada a solução, ou seja, forem conhecidas soluções aceitáveis que podem estar próximas à solução óptima, os indivíduos iniciais podem ser definidos de forma determinística.
Cada um dos indivíduos da população representa uma possível solução para o problema, ou seja, um ponto no espaço de soluções. Quanto maior o número de elementos na população, maior é a probabilidade de convergência, tendo em vista que a probabilidade da solução desejada ser constatada entre os
Cromossoma 1 1 0 0 1 1 0 0 1 0 0 1 1 0 1 1 0 Cromossoma 2 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 0
elementos da população aumenta. Em contrapartida, quanto maior for o número de elementos o tempo de processamento também aumenta. Já no caso da população inicial ser muito pequena, ela terá o problema da perda de diversidade e possível convergência prematura [Ursem 2002].
Tamanho da População – O número de elementos da população afecta o desempenho global e a eficiência dos AGs. Com uma população pequena o desempenho pode não ser o melhor, pois deste modo a população fornece uma pequena cobertura do espaço de pesquisa do problema. Por outro lado, uma grande população geralmente fornece uma cobertura representativa do domínio do problema, além de prevenir convergências prematuras para soluções locais ao invés de globais. No entanto, para se trabalhar com grandes populações, são necessários maiores recursos computacionais, ou que o algoritmo trabalhe por um período de tempo muito maior.
Como a representação do espaço de pesquisa deve ser muito sensível, a inicialização deste requer algumas ponderações que se representam por meio dos seguintes tipos:
o Inicialização Aleatória: os indivíduos da população são gerados de forma aleatória;
o Inicialização Determinística: os indivíduos da população são gerados segundo uma determinada heurística.
Tal como no caso biológico, não há evolução sem variedade. Ou seja, a teoria da selecção natural ou lei do mais forte necessita de que indivíduos tenham diferentes graus de adaptação ao ambiente em que vivem. É importante então que a população inicial cubra a maior área possível do espaço de pesquisa.
A população inicial pode ser obtida através da geração de indivíduos, obedecendo a condições previamente estabelecidas pelo utilizador, tendo em vista conhecimento prévio do problema a ser optimizado. Quanto mais restritas forem as condições, mais rápida será a convergência, isso porque os
valores gerados aleatoriamente estarão mais próximos da solução desejada [Lacerda e Carvalho 1999].
O número de indivíduos que deverá compor a população, ainda é motivo de estudos, mas existem várias heurísticas, ou seja, depende muito da experiência do utilizador e do conhecimento prévio que este tem sobre a função a ser optimizada [Soares 1997]. É claro que, quanto maior o número de elementos na população, maior é a probabilidade de convergência, tendo em vista que a probabilidade da solução desejada ser encontrada entre os elementos da população aumenta. Em contrapartida, o tempo de processamento também aumenta. Não é necessário que a população seja criada completamente de modo aleatório, tendo em vista que o objectivo é gerar uma população dentro de certo intervalo onde se acredita estar a resposta. Pode-se obter a população inicial através de um escalonamento do número de indivíduos, pelo intervalo especificado, isto é: se a população é de 50 indivíduos e o intervalo inicial é de 0 a 10, os indivíduos da população inicial deverão estar distribuídos uniformemente neste intervalo.
2.4.3. Avaliação - Cálculo do valor de Aptidão
Para que o processo de selecção privilegie os indivíduos mais aptos, a cada indivíduo da população é atribuído um valor (fitness) dado por uma função f denominada função de aptidão. Esta função recebe como entrada os valores do gene do cromossoma (indivíduo) e fornece como resultado a sua aptidão. A aptidão pode ser vista como uma nota na qual se avalia a solução codificada para um indivíduo. Esta aptidão é baseada no valor da função objectivo, que é específica para cada problema. Para alguns métodos de selecção, é desejável que o valor de aptidão de cada indivíduo seja menor que 1 e que a soma de todos os valores de aptidão de cada indivíduo seja igual a 1. Para isso, para cada indivíduo é calculada a aptidão relativa (frel). A aptidão relativa para um
dado indivíduo é obtida dividindo o valor da sua aptidão pela soma dos valores de aptidão de todos os indivíduos da população.
Uma função Objectivo (ou função de avaliação) é geralmente uma expressão matemática que mede quanto uma solução está próxima ou distante da solução desejada (satisfaz o objectivo do problema). Muitas vezes inclui restrições que devem ser satisfeitas pela solução. Alguns problemas de optimização procuram maximizar o valor da função objectivo, isto é, encontrar soluções que produzam o maior valor possível para a função objectivo; por exemplo definir o número máximo de caixas que podem ser colocadas dentro de um depósito. Outros problemas procuram minimizar o valor da função objectivo; por exemplo, encontrar a solução mais barata. Existem ainda funções que procuram satisfazer mais de um objectivo. Essas funções são encontradas em problemas de optimização multi-objectivo ou multi-critério.
Associada uma nota ou aptidão a cada indivíduo da população, o processo de selecção escolhe então um subconjunto de indivíduos da população actual, gerando uma população intermediária. Vários métodos de selecção têm sido propostos. A maioria deles procura favorecer os indivíduos com maiores valores de aptidão, embora não exclusivamente, a fim de manter a diversidade da população. Essa avaliação pode, por exemplo, ser utilizada para a selecção dos pais para cruzamento.
Na implementação realizada neste trabalho, o fitness de um indivíduo é medido directamente pelo valor da função objectivo do problema em estudo. Os indivíduos são ordenados, conforme a sua aptidão, de acordo com o método de selecção escolhido pelo utilizador e criada uma nova população. A função objectivo dá, a cada indivíduo, uma medida de quão bem adaptado ao ambiente ele está, ou seja, suas hipóteses de sobreviver no ambiente e de se reproduzir, passando o seu material genético às gerações posteriores.
A validação é o processo de expor cada elemento da população à função objectivo e, no final, ordená-los de acordo com a aptidão desta função. Na convergência, analisa-se o desempenho da população em relação ao objectivo. Isto pode ser feito através de várias métricas, como por exemplo a análise dos valores máximos, mínimo e médio da função aptidão. Também, é
relativamente comum utilizar-se o desvio padrão dos valores da função de aptidão, como forma de análise da convergência [Goldberg 1989].
A finalização ou convergência só ocorrerá quando a aptidão média da população estiver suficientemente estável, ou seja, quando houver pouca variação da aptidão média da população actual em relação a anterior. Isto indica que a população se adaptou ao meio, isto é, os elementos da população levam a função ao valor optimizado (desejado) [Lacerda e Carvalho 1999]. Contudo na utilização de algoritmos genéticos pode ocorrer uma rápida convergência para uma solução sub-óptima, porém não o esperado óptimo global. Este problema é denominado convergência prematura, podendo ocorrer devido a população reduzida ou a má distribuição da população inicial, em torno do ponto sub-óptimo. Esta má distribuição, também recebe a denominação de perda de diversidade [Goldberg 1989]. Este problema pode ser amenizado através da escolha criteriosa do número de indivíduos na população, da distribuição dos indivíduos da população inicial no espaço de pesquisa e, também, impedindo a perda de diversidade nas primeiras gerações ou a introdução de mecanismos que preservem a diversidade.
2.4.4. Selecção
O princípio básico do funcionamento dos algoritmos genéticos é que o critério de selecção faça com que, ao longo do processo evolutivo, o conjunto inicial de indivíduos gere indivíduos mais aptos. O algoritmo genético começa com uma população inicial de n indivíduos. Para que o processo de selecção privilegie os indivíduos mais aptos, a cada indivíduo da população é atribuído um valor dado pela função de aptidão. Esta função recebe como entrada os valores do gene do cromossoma (indivíduo) e fornece como resultado a sua aptidão. A aptidão pode ser vista como uma nota (entre 0 e 1)1 na qual se avalia a solução codificada para um indivíduo. Para isso, para cada indivíduo é
1
calculada a aptidão relativa (frel) dividindo o valor de sua aptidão pela soma dos valores de aptidão de todos os indivíduos da população.
A probabilidade de selecção de um cromossoma ou indivíduo x é dada por equação (2.1), onde f(xi) é a função de aptidão.
∑
==
n 1 j j i)
f(x
)
f(x
f(x)
(2.1)Usando a equação (2.1), seleccionam-se n indivíduos. Neste processo, os indivíduos com aptidão mais baixa terão probabilidade mais alta de desaparecerem da população, ou seja, de não contribuírem na construção da população seguinte, enquanto que os indivíduos com aptidão mais alta terão grande hipótese de sobreviverem.
O operador de selecção é utilizado para melhorar a qualidade média da população, dando a indivíduos com alta qualidade, uma alta probabilidade de ser copiado para uma próxima geração. A selecção incide na procura de soluções promissoras dentro do espaço de solução.
2.4.4.1. Selecção por Torneio
Consiste em escolher um conjunto de n indivíduos aleatoriamente de uma população e escolher o melhor indivíduo deste grupo. O processo repete-se até que a população intermediária seja preenchida, geralmente, o valor utilizado para n é 2 [Banzhaf 1999].
Este critério de selecção pode ser implementado muito facilmente, já que não é necessária nenhuma ordenação prévia da população. Na fig.3, é apresentada a utilização de selecção por torneio para n = 3.
Fig. 3 - Selecção Torneio
2.4.4.2. Selecção por Ranking Linear
Este método consiste em ordenar inicialmente os indivíduos de acordo com o seu valor de aptidão, sendo que o melhor indivíduo está na posição N, enquanto que o pior indivíduo está na primeira posição (o pior terá valor 1, o segundo pior terá valor 2 e assim sucessivamente). A probabilidade de cada indivíduo é linearmente designada a cada indivíduo de acordo com a sua posição no ranking. É importante salientar que, mesmo indivíduos com o mesmo fitness possuirão diferentes valores de probabilidade de selecção, dado que estes possuem diferentes posições no ranking. Após a classificação todos os indivíduos têm hipóteses de serem seleccionados.
2.4.4.3. Selecção Proporcional ou Roleta
Neste método, cada indivíduo da população é representado na roleta conforme seu valor de aptidão normalizado. Desta forma, os indivíduos com elevada aptidão receberão um intervalo maior, enquanto aqueles que tem mais baixa aptidão receberão menor intervalo na roleta. Após a distribuição na roleta, são gerados aleatoriamente valores no intervalo entre 0 e 1. É gerado um valor aleatório n de vezes, em que n é o tamanho da população, o indivíduo que na aptidão acumulada tiver o valor mais próximo por excesso do
valor gerado, será seleccionado. Os indivíduos seleccionados são inseridos na população intermediária.
Tabela 2 – Exemplo de selecção pelo método da roleta
Indivíduo Aptidão Roleta Aptidão
Relativa Aptidão Acumulada Percentagem I1 22 22 0.2716 0.27 27% I2 25 47 0.3086 0.58 31% I3 17 64 0.2099 0.79 21% I4 7 71 0.0864 0.87 9% I5 10 81 0.1235 1 12% ∑ 81 1 100%
Para exemplificar este método considera-se a população da Tabela 2. Na primeira coluna estão os indivíduos da população, na segunda está o valor de aptidão correspondente a cada indivíduo e na terceira coluna está a percentagem correspondente a cada um deles.
A representação utilizada para o método da roleta pode ter o aspecto representado na Fig. 4, ainda com o exemplo da tabela 2. Terão maior probabilidade de serem escolhidos os elementos que correspondem ás maiores percentagens.
Fig. 4 - Esquema da Roleta
O algoritmo da roleta é realizado basicamente em três passos:
1. [Soma] Calcular o somatório dos valores da aptidão acumulados de todos os indivíduos - soma S.
2. [Selecção] Gerar um número aleatório dentro do intervalo (0; S) - r.
3. [Loop] Começar a comparar os valores de aptidão acumulados dos indivíduos até atingir ou ultrapassar o valor r. Retornar o último indivíduo utilizado na soma.
A selecção proporcional ou por roleta é o método de solução original proposto por Holland (1975) para os algoritmos genéticos. A probabilidade de um indivíduo ser seleccionado é simplesmente proporcional ao valor do seu
fitness. De acordo com os estudos de diversos autores [Hordijk et al 2008] que
realizaram a comparação entre estes métodos de selecção podemos dizer que de um modo geral, todos os critérios de selecção têm um desempenho satisfatório, sendo que a escolha do melhor critério de selecção dependerá das características do problema a ser tratado.
2.4.4.4. Amostragem Universal Estocástica
Este método é uma variação do Método da Roleta em que, em vez de uma única agulha, n agulhas igualmente espaçadas são utilizadas, onde n é o número de indivíduos a serem seleccionados. Assim, em vez de n vezes, a roleta é girada uma única vez.
Fig. 5 – Selecção pela roda de roleta
Para visualizar uma das variantes deste método considera-se um círculo dividido em n regiões (número de elementos da população, onde a área de cada região é proporcional à aptidão do indivíduo (Fig. 5). Coloca-se sobre
este círculo uma “roleta” com n cursores, igualmente espaçados. Após um giro da roleta a posição dos cursores indica os indivíduos seleccionados. Assim, os indivíduos cujas regiões possuem maior área terão maior probabilidade de serem seleccionados várias vezes. Como consequência, a selecção de indivíduos pode conter várias cópias de um mesmo indivíduo enquanto nenhuma de outros.
2.4.5. Cruzamento
O cruzamento consiste na troca de material genético entre os pais seleccionados com o objectivo de se formarem descendentes com melhor
fitness, empregando o conceito de evolução das espécies.
O processo de recombinação envolve mais do que um indivíduo que emula o fenómeno de cruzamento, ou seja, a troca de fragmentos entre pares de cromossomas. Na forma mais simples, trata-se de um processo aleatório que ocorre com probabilidade fixa (PCruz que deve ser especificada pelo utilizador).
O cruzamento opera entre determinados genes dos cromossomas dos progenitores e cria novas descendências. A maneira mais simples de executar o cruzamento consiste em escolher aleatoriamente um ponto de cruzamento e copiar tudo o que vem antes desse ponto de um dos progenitores e então copiar tudo o que vem depois desse ponto do segundo progenitor.
2.4.5.1. Métodos de cruzamento
De entre os possíveis métodos de cruzamento, destacam-se:
1) Cruzamento uni-ponto
No cruzamento em um único ponto, uma posição para cruzamento k do vector indivíduo é seleccionada aleatoriamente e os bits de cada indivíduo, após este ponto k, são trocados e então dois novos descendentes são criados.
O algoritmo, de acordo com a probabilidade de cruzamento, gera aleatoriamente um ponto a partir do qual os dois cromossomas progenitores trocam o material genético. No exemplo da Fig. 6 é ilustrado o cruzamento num cromossoma de tamanho 16. O ponto de cruzamento foi aleatoriamente seleccionado para a posição 5 onde se dá o corte para troca de material genético.
Cromossoma 1 1 0 0 1 1 0 0 1 0 0 1 1 0 1 1 0 Cromossoma 2 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 0 Descendência 1 1 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 Descendência 2 1 1 0 1 1 0 0 1 0 0 1 1 0 1 1 0
Fig. 6 - Cruzamento Uni-ponto na posição 5
2) Cruzamento em múltiplos pontos
No cruzamento em múltiplos pontos, m diferentes posições de cruzamento k são escolhidas aleatoriamente e ordenadas de forma ascendente. Assim, as variáveis entre sucessivos pontos de cruzamento são trocadas entre os dois progenitores para produzir dois novos descendentes. Neste tipo de cruzamento, a troca de material genético, caso a probabilidade de cruzamento o dite, será efectuada num número de pontos calculado aleatoriamente pelo algoritmo e a troca será então realizada entre esses pontos. Apresenta-se um exemplo deste cruzamento na Fig.7. Para o cruzamento de 2 pontos, sendo o primeiro na segunda posição e o segundo na 6 posição por hipótese.
Cromossoma 1 1 0 0 1 1 0 0 1 0 0 1 1 0 1 1 0 Cromossoma 2 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 0 Descendência 1 1 0 0 1 1 1 1 1 0 0 1 1 0 1 1 0 Descendência 2 1 1 0 1 1 0 0 0 0 0 0 1 1 1 1 0
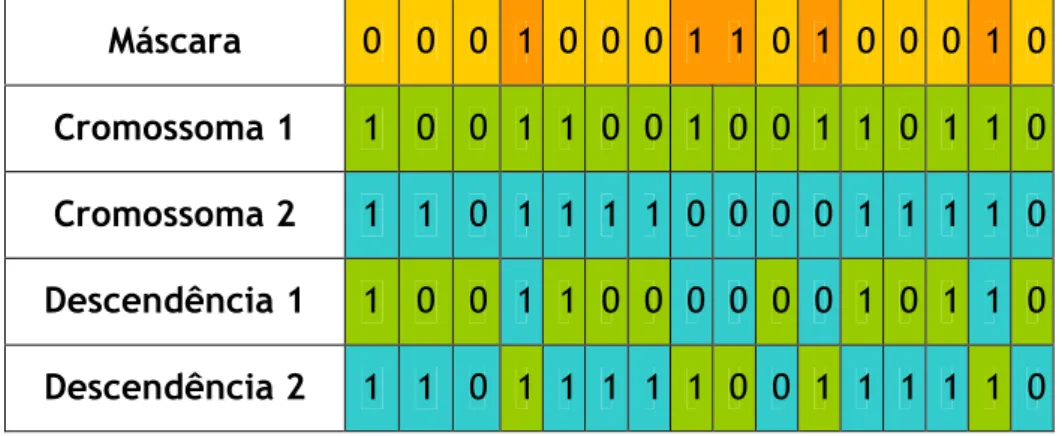
3) Cruzamento Uniforme
Cruzamentos em um único ponto e em múltiplos pontos definem os locais onde cada indivíduo trocará seu material genético. O cruzamento uniforme generaliza este conceito, fazendo cada local como sendo um ponto potencial de cruzamento. É criada aleatoriamente uma "máscara", do mesmo tamanho da estrutura dos indivíduos, e a paridade dos bits na máscara indica quais os valores que serão fornecidos por cada progenitor. A mascara é criada aleatoriamente e a amostra 2 é criada utilizando-se o inverso da amostra 1. Como exemplo temos a Fig. 8:
Fig. 8 – Cruzamento uniforme
O descendente 1 é produzido tomando o bit do indivíduo 1 (pai 1) se o bit da máscara for 0, ou o bit do segundo pai se o bit da máscara for igual a 1. Geralmente o segundo indivíduo é criado utilizando-se o complemento da máscara.
Antes da escolha dos pontos de cruzamento, é verificado se haverá ou não cruzamento de acordo com a probabilidade de cruzamento definida pelo utilizador e é realizada então a troca do material genético entre os dois indivíduos, trocando os genes contidos entre os pontos de cruzamento encontrados. Máscara 0 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 Cromossoma 1 1 0 0 1 1 0 0 1 0 0 1 1 0 1 1 0 Cromossoma 2 1 1 0 1 1 1 1 0 0 0 0 1 1 1 1 0 Descendência 1 1 0 0 1 1 0 0 0 0 0 0 1 0 1 1 0 Descendência 2 1 1 0 1 1 1 1 1 0 0 1 1 1 1 1 0
2.4.5.2.Taxa ou Probabilidade de Cruzamento
Quanto maior for a taxa de cruzamento, mais rapidamente novas estruturas serão introduzidas na população. Mas se esta for muito alta, estruturas com boas aptidões poderão ser retiradas mais rapidamente, a maior parte da população será substituída, podendo ocorrer perda de estruturas de alta aptidão. Com um valor baixo, o algoritmo pode tornar-se muito lento ou estagnar.
2.4.6. Mutação
O operador de mutação, Fig. 9, tem por finalidade aumentar a diversidade da população gerada. Cada bit do descendente pode sofrer uma mutação (mudar de 1 para 0, ou vice versa) com uma pequena probabilidade. A mutação permite a produção de um novo indivíduo por alterações directas no cromossoma. Podemos ilustrar este processo com a (fig.9) onde se vê que o valor do bit na posição 6 alternou o seu valor de 0 para 1.
1 1 0 1 1 0 0 1 0 0 1 1 0 1 1 0
1 1 0 1 1 1 0 1 0 0 1 1 0 1 1 0
Fig. 9 – Mutação
No processo de mutação, basicamente, selecciona-se uma posição num cromossoma e muda-se o valor do gene correspondente aleatoriamente para um outro possível. O processo é geralmente controlado por um parâmetro fixo que indica a probabilidade de um gene sofrer mutação.
A reprodução baseada na aptidão através do cruzamento é a parte fulcral que dá aos AGs o seu poder de processamento. Mas, embora, a selecção e o cruzamento pesquisem de forma eficaz, podem ocasionalmente tornar-se demasiado “zelosos” e perder informação genética importante. A operação de mutação é utilizada para garantir uma maior varredura do espaço de estados
e evitar que o algoritmo genético convirja muito cedo (convergência prematura) para mínimos locais.
2.4.6.1.Taxa ou Probabilidade de Mutação
Uma baixa taxa de mutação pode evitar que a pesquisa fique estagnada mas com uma taxa muito alta a pesquisa torna-se essencialmente aleatória. A mutação no caso da codificação binária consiste na inversão do bit ou bits no caso em que o valor aleatoriamente calculado é menor que a probabilidade de mutação. A probabilidade de mutação utilizada varia normalmente entre pequenos valores compreendidos, na maior parte dos casos, entre 0 e 0.01.
2.4.7. Substituição da População
Este processo controla a percentagem da população corrente que será substituída pela nova população. A população pode ser totalmente substituída de geração para geração ou parcialmente substituída, baseando-se a substituição num critério pré-estabelecido.
Depois de gerada a população de descendentes, existem várias estratégias de substituição da população antiga. Existe o caso onde a população antiga é totalmente substituída pela nova geração. Nesta situação é gerado o número de descendentes igual ao número de indivíduos existentes na população anterior. Esta reposição tem um aspecto negativo uma vez que o melhor vector pode não ser seleccionado para gerar novos descendentes para a geração seguinte. Assim, esta estratégia pode ser combinada com uma estratégia elitista, de modo a que seja introduzido o melhor vector, ou um conjunto dos melhores vectores, da geração presente na geração futura. A estratégia elitista pode levar ao domínio da população por um vector, mas em contrapartida, pode aumentar o desempenho do algoritmo. Nos processos onde é utilizado um número pequeno de vectores é substituído somente uma parte da população pela nova geração de vectores.
A substituição dos progenitores pelos descendentes é também utilizada neste caso. Desta forma evita-se a convergência prematura do algoritmo. Elitismo [Goldberg 1989] é o nome do método que primeiro copia os melhores cromossomas para a nova população evitando a perda da melhor solução já encontrada.
2.8. Formação de Novas Populações
No AG a reprodução é o processo no qual os vectores individuais são copiados de acordo com o seu valor de desempenho obtido através da função objectivo. O que significa que nesta fase os indivíduos mais aptos da geração actual são os que têm mais hipóteses de serem seleccionados. Esses indivíduos são utilizados para gerar uma nova população através do cruzamento e da mutação. Cada indivíduo tem uma probabilidade de ser seleccionado proporcional à sua aptidão.
Como ilustrado na Fig. 1 (pág. 23) os cromossomas são seleccionados a partir de uma população para serem progenitores de um cruzamento. O problema é como seleccionar esses cromossomas. De acordo com a teoria da evolução de Darwin, os melhores sobrevivem para criar a descendência podendo ser utilizados diversos métodos para seleccionar os melhores cromossomas.
2.9. Operador de Diversidade – Sharing
Um dos principais problemas nos algoritmos genéticos é o problema de convergência prematura, onde os genes de alguns indivíduos relativamente bem adaptados, contudo não óptimos, podem rapidamente dominar a população causando que o algoritmo convirja para um máximo local. Para tentar escapar deste problema algumas técnicas podem ser utilizadas como é o caso da partilha de aptidão (Sharing). Este mecanismo tem como objectivo preservar a diversidade da população.
O método de partilha de aptidão baseia-se no princípio de que o ambiente possui recursos limitados e que indivíduos fenotipicamente similares devem partilhar esses recursos. Desta forma, indivíduos similares sofrem penalidades na sua função de aptidão dependendo da sua similaridade (proximidade) com outros indivíduos da população.
A analogia da natureza é que dentro de um ambiente existem diferentes nichos que podem suportar diferentes tipos de vidas (espécies ou organismos). O número de organismos contidos dentro de um nicho é determinado pela fertilidade do nicho e pela eficiência de cada organismo para explorar essa fertilidade.
Goldberg e Richardson [Goldberg 1989] introduziram um mecanismo de partilha de recursos, conhecido como Sharing. Neste mecanismo, o objectivo é reduzir o valor de aptidão de indivíduos que são altamente similares dentro da população. Um esquema prático que usa sharing directamente para induzir um nicho e espécie é mostrado na Fig. 10. Neste esquema, uma função
sharing é definida para determinar a vizinhança e o grau de partilha para cada
indivíduo da população.
Fig. 10 – Função Sharing Triangular (Goldberg 1989)
Para um determinado indivíduo o grau de partilha é determinado somando o valor de função sharing contribuído por todos os outros indivíduos na população. Indivíduos muito similares a outros indivíduos requerem um grau muito alto de partilha, próximo a 1.0, e indivíduos menos similares requerem