Can training enhance face cognition abilities in middle-aged adults?
Texto
Imagem

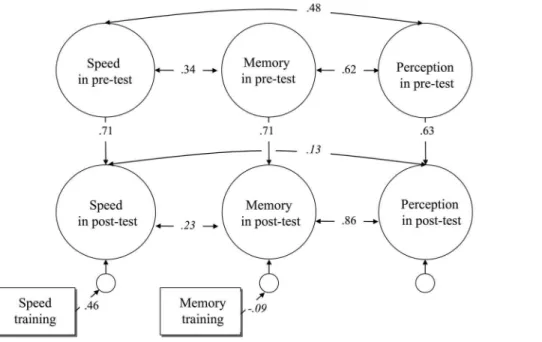
Documentos relacionados
De acordo com a TACO (2011) para o maxixe in natura o valor é 0,70, semelhante ao valor encontrado nesta pesquisa.. O valor do teor de sólidos solúveis totais na amostra do fruto
Thus, for the dimensioning of fish passage mechanisms, it is more usual to utilize prolonged speed (Katopodis, 2005), which allows us to obtain the specific information on how
Therefore, the aim of the present study was to determine the effects of CS on the cognition, mood and functional capacity of adults and elderly individuals who actively
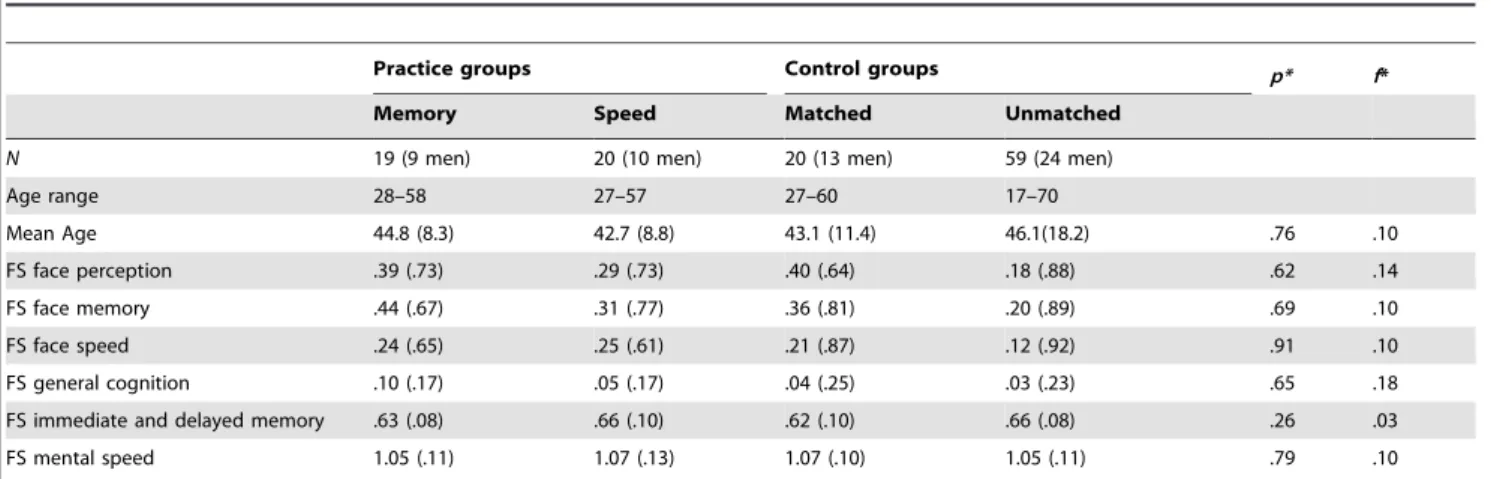
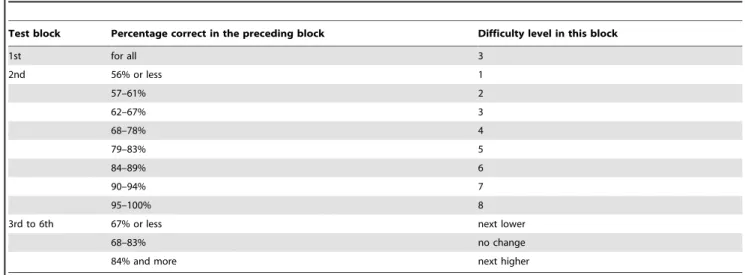
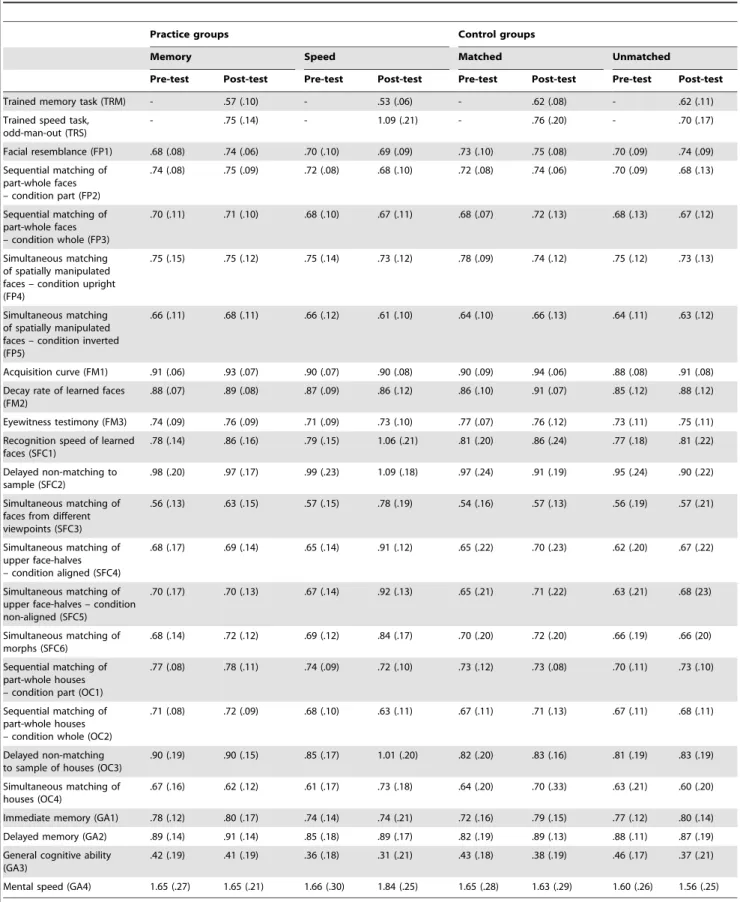
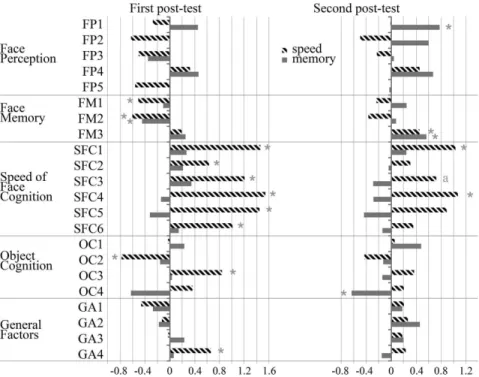
In this study, which evaluated the effects on cognition, mood and functional ability of adults and active elderly who participated in a continuing HE program of a U3A, we ob-
In this study, we investigated the possible influences of two physical exercise modalities (resistance and water-based training) on cognitive function in healthy older adults
On the other hand, in our study, the increase in maximal running speed and running time to exhaustion without changes in running speed corresponding to VT after training
The purpose of this study was to examine to effects of 6-weeks explosive strength training on sprint speed and agility performance in wheelchair basketball
A optimização de formulações de polpa de pêra com introdução de diferentes HF (maçã, ananás, beterraba, cenoura e abóbor a em proporções ≤50%) foi a solução
