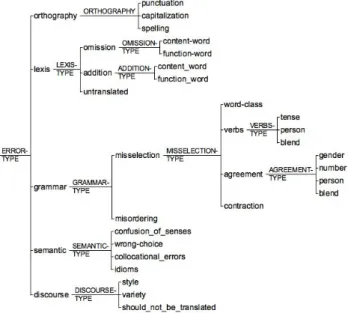
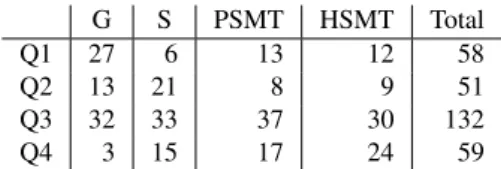
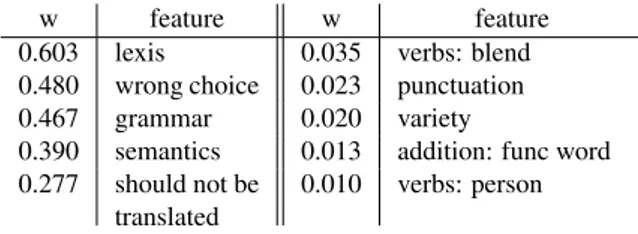
2. Related work - ACosta Building a Corpus of Errors and Quality in Machine Translation Experiments on Error Impact
Texto
Imagem
Documentos relacionados
Após análise do SF-36 nos domínios Dor relacionando Aspectos físicos, foi possível verificar que os resultados foram semelhantes entre os indivíduos estudados, visto que
Procedeu-se à análise da satisfação conjugal (Funcionamento Conjugal e Amor) do homem e da mulher com a percepção que o homem tem sobre si mesmo e sobre o cônjuge relativamente
Also in Wang and Rode‘s (2010) research innovative climate affects employee creativity only as a third-order factor, interacting with transformational leadership and
A Diretiva 2007/60/CE do Parlamento Europeu e do Conselho de 23 de outubro de 2007 relativa à avaliação e gestão dos riscos de inundações prevê a
In both cases, through cross-section examination of each of the years (Tables 1 and 4), we found the following: efficiency during three years (2000, 2001, and 2008); myopia
Para determinar o teor em água, a fonte emite neutrões, quer a partir da superfície do terreno (“transmissão indireta”), quer a partir do interior do mesmo
