Adaptation and learning of intelligent agents in interactive environments
Texto
Imagem


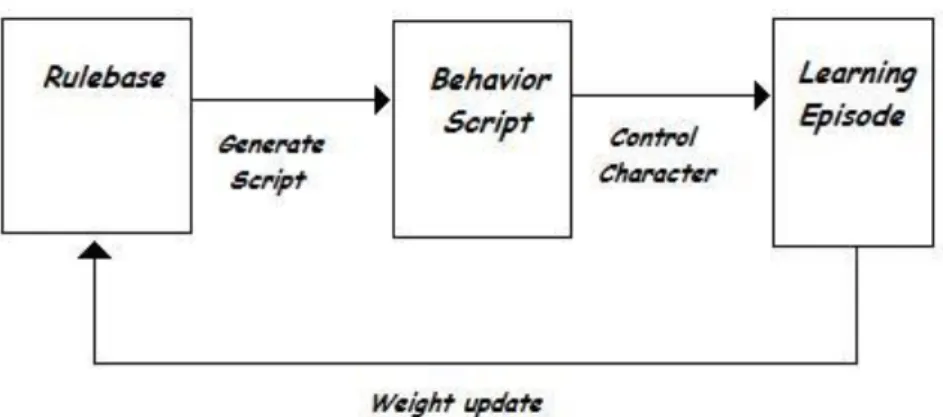
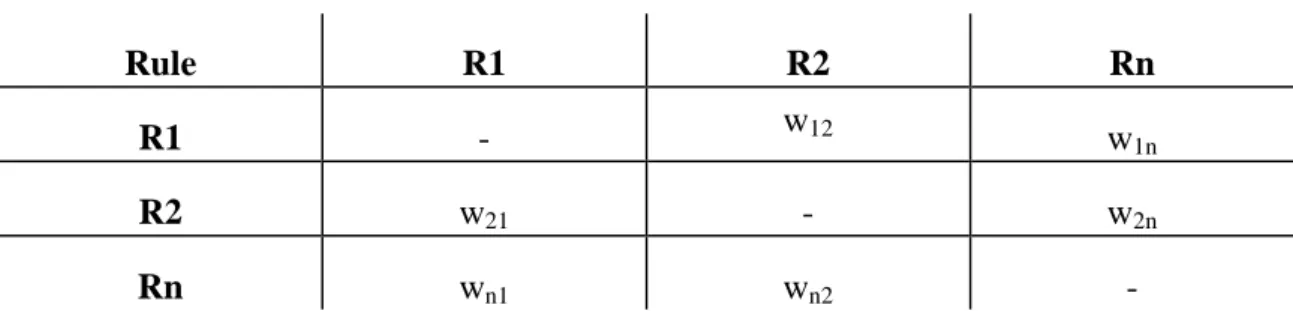
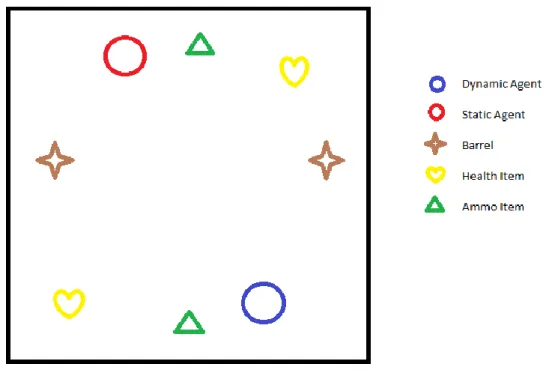
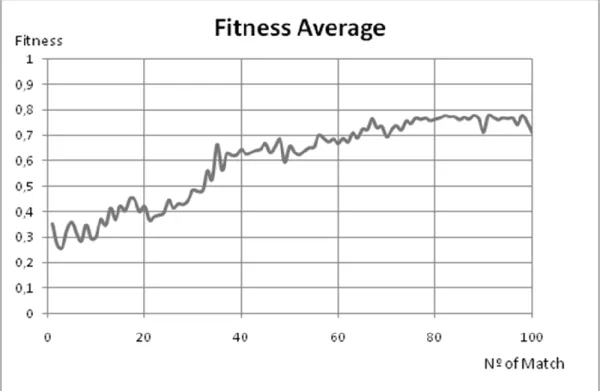
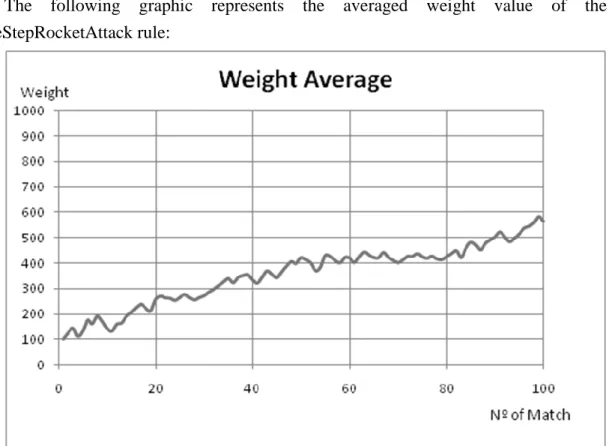
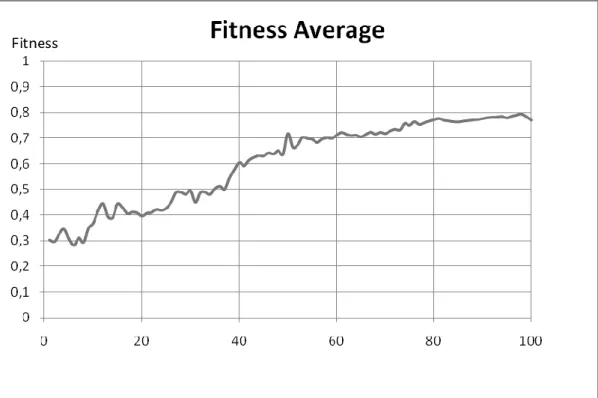
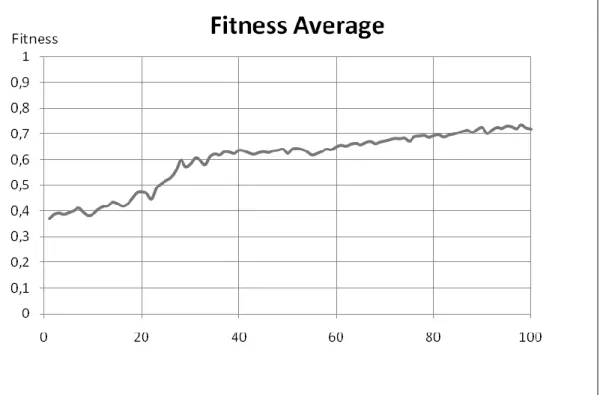

Documentos relacionados
Therefore, both the additive variance and the deviations of dominance contribute to the estimated gains via selection indexes and for the gains expressed by the progenies
Ousasse apontar algumas hipóteses para a solução desse problema público a partir do exposto dos autores usados como base para fundamentação teórica, da análise dos dados
Em sua pesquisa sobre a história da imprensa social no Brasil, por exemplo, apesar de deixar claro que “sua investigação está distante de ser um trabalho completo”, ele
Having examined the amendments to the Staff Rules of the Pan American Sanitary Bureau, as set forth in the annex to Document CE52/14 presented by the Director; and.
210.3(a) A spouse whose net occupa- tional earnings do not exceed the entrance salary level of the Bureauns local net salary scale for the area in which the spouse is
A staff member who leaves the Bureau on completion of, or while holding a fixed-term appointment of at least one year but less than five years and on completion of at least a
The 44th Meeting of the Executive Committee completed the review of the Amendments to the Staff Rules of the Pan American Sanitary Bureau, initiated at the 43rd Meeting,
710.1 All full-time staff members appointed for a period of one year or more shall participate in, and their dependents enjoy the benefits of, the Bureau's Staff Health
