Universidade Federal Rural de Pernambuco
Unidade Acadêmica de Garanhuns
Curso de Bacharelado em Ciência da Computação
JOÃO VITOR SOARES TENÓRIO
REDUÇÃO DE DIMENSIONALIDADE COM
BUSCA DE SUBGRAFO MAIS DENSO E
AGRUPAMENTO DE CARACTERÍSTICAS
JOÃO VITOR SOARES TENÓRIO
REDUÇÃO DE DIMENSIONALIDADE COM BUSCA
DE SUBGRAFO MAIS DENSO E AGRUPAMENTO DE
CARACTERÍSTICAS
Monografia apresentada ao Curso de Bacha-relado em Ciência da Computação da Uni-versidade Federal Rural de Pernambuco da Unidade Acadêmica de Garanhuns, como re-quisito para obtenção do Grau de Bacharel em Ciência da Computação
Universidade Federal Rural de Pernambuco Unidade Acadêmica de Garanhuns
Curso de Bacharelado em Ciência da Computação
Orientador: Prof. Dr. Tiago Buarque Assunção de Carvalho
REDUÇÃO DE DIMENSIONALIDADE COM BUSCA
DE SUBGRAFO MAIS DENSO E AGRUPAMENTO DE
CARACTERÍSTICAS
Monografia apresentada ao Curso de Bacha-relado em Ciência da Computação da Uni-versidade Federal Rural de Pernambuco da Unidade Acadêmica de Garanhuns, como re-quisito para obtenção do Grau de Bacharel em Ciência da Computação
Trabalho aprovado. Garanhuns - PE, __ de _____________ de 2015:
Prof. Dr. Tiago Buarque Assunção de Carvalho
Orientador
Professor
Convidado 1
Professor
Convidado 2
Resumo
O reconhecimento de padrões é a parte da inteligência artificial que desenvolve métodos para classificar automaticamente objetos de um conjunto de dados. Esses métodos são usados para resolver problemas de diversas áreas, como biometria, mineração de dados, bioinformática entre outros. Na maioria das vezes, os conjuntos de dados sobre esses problemas possuem dimensão muito alta. Além do elevado custo computacional para processar dados de alta dimensionalidade, temos grande quantidade de informação redun-dante que prejudica o treinamento de modelos para reconhecimento de padrões. Diante dos problemas encontrados nesse contexto, é crescente a necessidade de algoritmos para reduzir a dimensão do conjunto de dados descartando informações redundantes.
O presente trabalho apresenta um estudo sobre técnicas de redução de dimensionalidade. Com base nesta pesquisa, foram propostos dois métodos não-supervisionados: O Fast Dense Subgraph Finding with Feature Clustering (FDSFFC), uma técnica para seleção
de características derivada a partir do algoritmo Dense Subgraph Finding with Feature Clustering (DSFFC), que é baseado em busca de subgrafo mais denso e agrupamento de
características. O método desenvolvido consiste em dividir o conjunto de características em subconjuntos menores e utilizar o algoritmo DSFFC para selecionar as características desses subconjuntos, essa técnica consegue diminuir o tempo de execução em relação ao DSFFC e manter a taxa de acerto na classificação dos padrões, o que possibilita aplicar o algoritmo em problemas de alta dimensionalidade. E por último, foi proposto o Extraction with Mutual Information Based K-Medoids (EMIKM), que é uma técnica para extração
de características, derivada a partir do algoritmo Mutual Information Based K-Medoids
(MIKM). O método proposto realiza uma extração dos grupos de atributos formados pelo algoritmo K-Medoids.
No reconhecimento facial e em outras bases de problemas de referências para classificação, as taxas de acertos obtidas nos classificadores com as técnicas propostas, foram comparadas com outros métodos para seleção de características do estado da arte. Os algoritmos propos-tos conseguiram obter taxas de acerto superiores ou próximas nesses testes comparativos. Adicionalmente, foram realizados experimentos qualitativos de visualização de dados com as técnicas abordadas.
Palavras-chave: redução de dimensionalidade. seleção de características. agrupamento
As a branch of Artificial Intelligence, Pattern Recognition develops methods to automati-cally classify objects in a data set. These methods can then be used to solve problems from other fields, such as biometrics, data mining, bioinformatics and many others. Most of the time the data set for these problems is a high dimension set. For this kind of problem not only there will be a high cost for processing the high dimension data, but also there will be lots of redundant information that can negatively affect the training of the model for Pattern Recognition. In this context it’s a growing interest to develop algorithms that can reduce the dimension of the data set by discarding the redundant information.
This work presents a study on techniques to reduce dimension in data sets. As a result of this research there were proposed two non-supervised methods: the Fast Dense Subgraph Finding with Feature Clustering (FDSFFC), a selection algorithm created from the original Dense Subgraph Finding with Feature Clustering (DSFFC), which is based on dense subgraph searching and feature clustering. The method developed consists in dividing the set of features into smaller subsets to then use the DSFFC algorithm and select features from these subsets, this method reduces the time cost for execution of the original DSFFC still keeping its accuracy on classifying the patterns, which makes it possible to apply the algorithm even on problems with high dimension. Lastly we proposed the Extraction with Mutual Information Based K-Medoids (EMIKM), which is an algorithm of feature extraction created from the Mutual Information Based K-Medoids(MIKM). The proposed method extracts features from groups of features formed by the K-Medoids.
On Facial Recognition and other data sets of reference problems for classification, the accuracy obtained with the proposed methods was compared to other feature selection methods from the state of the art. The proposed algorithms had higher or at least close values of accuracy on the tests. Additionally, qualitative experiments of data visualization were made for the addressed techniques.
Keywords: dimensionality reduction. feature selection. feature clustering. machine
Lista de ilustrações
Figura 1 – Ilustração do classificador SVM. Fonte: DUDA et al.,2000. . . 23
Figura 2 – Ilustração do classificador SVM para o caso não-linear. . . 24
Figura 3 – Exemplo da divisão em mxn janelas sem sobreposição, onde m= 4 e n = 4, em um indivíduo de cada base: AT&T, The Sheffield, e Yale, respectivamente. . . 35
Figura 4 – Exemplo da divisão do vetor características em m conjuntos sequenciais. 35 Figura 5 – Ilustração do funcionamento da técnica FDSFFC. . . 35
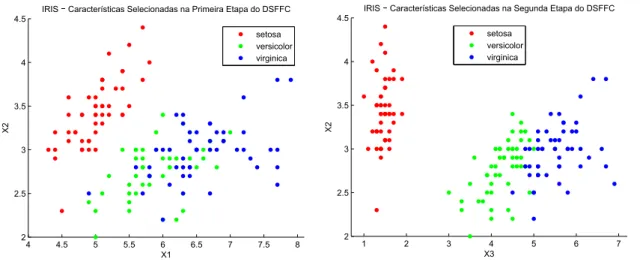
Figura 6 – Grafo gerado pelo algoritmo DSFFC na base Iris. . . 42
Figura 7 – Atributos selecionados com a busca de subgrafo na primeira etapa do DSFFC. . . 42
Figura 8 – Atributos selecionados com o agrupamento na segunda etapa do DSFFC. 43 Figura 9 – Comparação das projeções dos dados da base Iris no espaço bidimen-sional entre os atributos selecionados na primeira e segunda etapa do DSFFC. . . 43
Figura 10 – Gráfico de barras com os resultados apresentados na Tabela 4. . . 46
Figura 11 – Gráfico de barras com os resultados apresentados na Tabela 5. . . 47
Figura 12 – Gráfico de barras com os resultados apresentados na Tabela 7. . . 49
Figura 13 – Gráfico de barras com os resultados apresentados na Tabela 8. . . 50
Figura 14 – Gráfico com os resultados na base AT&T apresentados nas Tabelas 7 e 8. 50 Figura 15 – Gráfico com os resultados na base The Sheffield apresentados nas Tabelas 7 e 8. . . 51
Figura 16 – Gráfico com os resultados na base Yale apresentados nas Tabelas 7 e 8. 51 Figura 17 – Exemplo dos padrões da base Yale utilizados no experimento visual. . . 52
Figura 18 – Projeções dos dados da base Yale no espaço bidimensional geradas pelos algoritmos MIKM e EMIKM. . . 53
Figura 19 – Gráfico com os resultados do 1-NN e SVM na base Isolet. . . 54
Figura 20 – Gráfico com os resultados do 1-NN e SVM na base Spambase. . . 55
Figura 21 – Gráfico com os resultados do 1-NN e SVM na base HDR. . . 56
Figura 22 – Gráfico com os resultados do 1-NN e SVM na Tabela 13. . . 58
Figura 23 – Gráfico com os resultados do 1-NN e SVM na Tabela 14. . . 59
Tabela 1 – Funções de Kernel mais utilizadas, onde xi exj são pontos no espaço. . 24
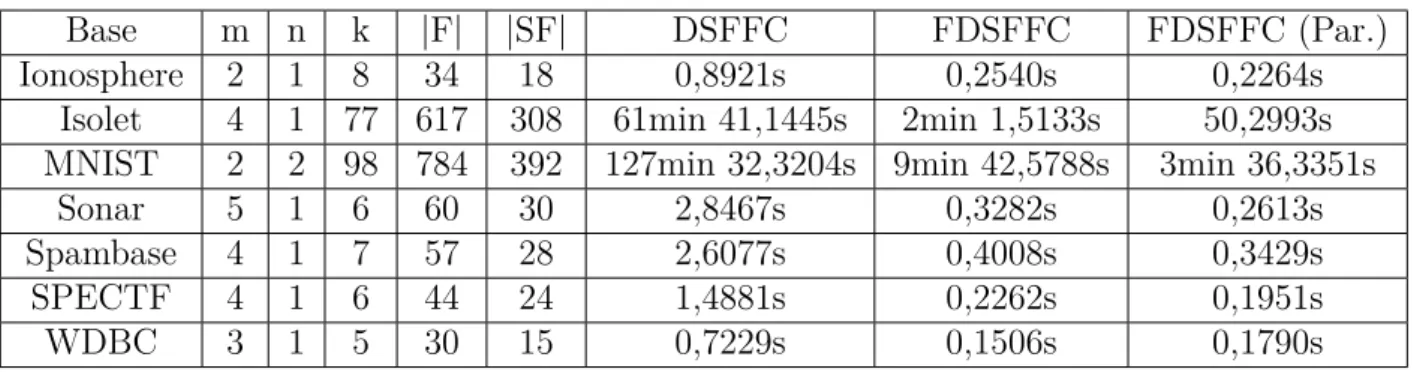
Tabela 2 – Detalhes das bases de dados utilizadas. . . 41 Tabela 3 – Comparativo do tempo de execução entre os métodos DSFFC, FDSFFC
e FDSFFC paralelizado nas bases de dados usadas, as colunas k,m e n são os parâmetros usados no FDSFFC, |F| é o total de características e |SF| é quantidade de caraterísticas selecionadas pelos dois algoritmos. . 44 Tabela 4 – Comparativo da acurácia e desvio padrão entre os métodos DSFFC e
FDSFFC com o 1-NN. |SF| é quantidade de caraterísticas selecionadas pelos algoritmos. . . 45 Tabela 5 – Comparativo da acurácia e desvio padrão entre os métodos DSFFC e
FDSFFC com o SVM. |SF| é quantidade de caraterísticas selecionadas pelos algoritmos. . . 46 Tabela 6 – Resultados dos testes de hipótese e intervalos de confiança sobre as
acurácias obtidas nas Tabelas 4 e 5. . . 48 Tabela 7 – Comparativo da acurácia e desvio padrão entre os métodos FDSFFC,LSFS
e mRMR no experimento de reconhecimento facial com o 1-NN. |SF| é quantidade de caraterísticas selecionadas pelos algoritmos. . . 49 Tabela 8 – Comparativo da acurácia e desvio padrão entre os métodos FDSFFC,LSFS
e mRMR no experimento de reconhecimento facial com o SVM. |SF| é quantidade de caraterísticas selecionadas pelos algoritmos. . . 49 Tabela 9 – Comparação da acurácia média e desvio padrão dos métodos EMIKM
e MIKM na base Isolet com os classificadores 1-NN e SVM. A coluna |D| é a dimensão do espaço de características. . . 53 Tabela 10 – Comparação da acurácia média e desvio padrão dos métodos EMIKM e
MIKM na base Spambase com os classificadores 1-NN e SVM. A coluna |D| é a dimensão do espaço de características. . . 54 Tabela 11 – Comparação da acurácia média e desvio padrão dos métodos EMIKM
e MIKM na base HDR com os classificadores 1-NN e SVM. A coluna |D| é a dimensão do espaço de características. . . 55 Tabela 12 – Resultados dos testes de hipótese entre os métodos EMIKM e MIKM
sobre as acurácias obtidas nos experimentos de classificação. A coluna |D| é a dimensão do espaço de características escolhida para o teste. . . 56 Tabela 13 – Comparação da acurácia média e desvio padrão dos métodos EMIKM
Tabela 14 – Comparação da acurácia média e desvio padrão dos métodos EMIKM e MIKM na base The Sheffield com os classificadores 1-NN e SVM. A coluna |D| é a dimensão do espaço de características. . . 58 Tabela 15 – Comparação da acurácia média e desvio padrão dos métodos EMIKM
e MIKM na base AT&T com o classificador 1-NN. A coluna |D| é a dimensão do espaço de características. . . 59 Tabela 16 – Resultados dos testes de hipótese entre os métodos EMIKM e MIKM
DSFFC Dense Subgraph Finding with Feature Clustering
FDSFFC Fast Dense Subgraph Finding with Feature Clustering
LSFS Laplacian Score For Feature Selection
mRMR Minimal Redundancy Maximal Relevance Criterion
MIKM Mutual Information Based K-Medoids
EMIKM Extraction with Mutual Information Based K-Medoids
K-NN K-Nearest Neighbors
1-NN 1-Nearest Neighbors
Lista de Algoritmos
1 Large Densest Subgraph . . . 20
2 K-NN . . . 23
3 DSFFC . . . 31
4 MIKM . . . 32
5 FDSFFC . . . 36
1 INTRODUÇÃO . . . 12
2 FUNDAMENTAÇÃO TEÓRICA . . . 15
2.1 Reconhecimento de Padrões . . . 15
2.2 Aprendizagem de Máquina . . . 15
2.3 Redução de Dimensionalidade . . . 16
2.3.1 Seleção de Características . . . 16
2.3.2 Extração de Características . . . 17
2.4 Elementos de Teoria da Informação . . . 18
2.4.1 Entropia. . . 18
2.4.2 Informação Mútua . . . 18
2.4.3 Informação Mútua Normalizada . . . 19
2.5 Busca de Subgrafo Mais Denso . . . 19
2.6 Agrupamento . . . 20
2.6.1 K-Médias . . . 21
2.6.2 K-Medóides . . . 21
2.7 Algoritmos Classificadores . . . 22
2.7.1 K-Nearest Neighbors . . . 22
2.7.2 Support Vector Machine . . . 23
2.8 Avaliação de Desempenho dos Classificadores . . . 24
2.9 Teste de Hipótese por Sobreposição de Intervalos de Confiança . . 25
3 TRABALHOS RELACIONADOS . . . 27
3.1 Laplacian Score For Feature Selection. . . 27
3.2 Minimal Redundancy Maximal Relevance Criterion . . . 28
3.3 Dense Subgraph Finding with Feature Clustering . . . 29
3.4 Mutual Information Based K-Medoids. . . 31
4 TRABALHO DESENVOLVIDO . . . 33
4.1 Método Proposto: FDSFFC . . . 33
4.2 Método Proposto: EMIKM . . . 36
5 EXPERIMENTOS E RESULTADOS . . . 39
5.1 Bases de Dados . . . 40
5.2 Experimentos com o FDSFFC . . . 41
5.2.1 Experimento de Visualização de Dados com o DSFFC . . . 41
5.2.3 Avaliação do Desempenho na Classificação . . . 45
5.2.4 Teste de Reconhecimento Facial . . . 48
5.3 Experimentos com o EMIKM . . . 51
5.3.1 Experimento de Visualização de Dados . . . 52
5.3.2 Avaliação do Desempenho na Classificação . . . 53
5.3.3 Teste de Reconhecimento Facial . . . 56
6 CONCLUSÃO E TRABALHOS FUTUROS . . . 62
1 Introdução
Desde décadas passadas, as técnicas para reconhecer padrões estão sendo ampla-mente utilizadas para resolver problemas de diversas áreas, como mineração de dados, biometria, reconhecimento ótico de caracteres, bioinformática, previsões econômicas entres outros (TURK; PENTLAND, 1991; LECUN et al., 1998; KEILIS-BOROK et al., 2005; DOUGHERTY, 2005). A maioria dessas aplicações tem em comum a alta dimensão das bases de dados sobre o problema. Um exemplo desses problemas é o reconhecimento facial, uma imagem com resolução de 100 por 100 pixels, tem tamanho considerado pequeno
levando em conta as resoluções das câmeras encontradas atualmente no mercado. Essa imagem possuí um total de 10000 pixels, como cada pixel é um atributo da imagem,
isso já caracteriza um problema de alta dimensão. Mesmo com o avanço dos dispositivos computacionais, o reconhecimento facial ainda pode ser considerado como uma atividade que demanda alto custo computacional.
Além de ser necessário grande capacidade de armazenamento para as bases de dados, os problemas de alta dimensionalidade ainda demandam elevado poder de processamento para o reconhecimento de padrões. O treinamento de modelos preditivos utilizados para o reconhecimento tem grande complexidade de tempo, o que pode dificultar a execução dessa tarefa em bases de dados de alta dimensionalidade, pois em alguns classificadores a dimensão dos dados tem influência no tempo de execução. Isso pode ser observado no classificador Support Vector Machine (SVM) (VAPNIK, 1995), que foi usado nesse
trabalho e será abordado no Capítulo 2.
Outro problema enfrentado para o reconhecimento de padrões em bases de alta dimensionalidade é a precisão da classificação. Essas bases geralmente tem muitas informa-ções redundantes que compromete o desempenho da predição de classes. Como exemplo, em imagens de face muitos pixels representam o fundo da imagem, essa informação não
é relevante para diferenciar uma pessoa da outra. Ao reduzir a dimensão do problema descartando informações redundantes, os exemplos de mesma classe serão aproximados e os de diferentes classes vão se distanciar no espaço de características, isso melhora a precisão da classificação, pois vários algoritmos seguem o princípio que exemplos mais próximos provavelmente pertencem a mesma classe (HE et al., 2005). Diante dos proble-mas apresentados, para executar tarefas de reconhecimento de padrões nesse contexto é necessário o uso de técnicas para redução de dimensionalidade (LIU; YU, 2005; BLUM; LANGLEY, 1997; BANDYOPADHYAY et al., 2014; BROWN et al., 2012; PENG et al., 2005).
Capítulo 1. Introdução 13
dos atributos originais para compor o espaço reduzido de características. Já os algoritmos de extração reduzem a dimensão do problema executando uma transformação nos dados para gerar novos atributos (SAMMUT; WEBB, 2011).
Considerando o espaço para novas técnicas e a necessidade de melhorias para as existentes nessa linha pesquisa, esse trabalho teve como objetivo estudar, implementar e realizar experimentos com técnicas do estado da arte, para avaliar o desempenho desses métodos e propor novas técnicas que apresentem melhorias. A pesquisa teve foco em métodos para seleção e extração de atributos não-supervisionada com busca de subgrafo mais denso e agrupamento de características. Como base nesse estudo foram propostos dois métodos não-supervisionados, um para seleção e outro para extração. Os métodos propostos foram avaliados e comparados com o estado da arte através de experimentos quantitativos e qualitativos.
O primeiro método proposto, chamado deFast Dense Subgraph Finding with Feature Clustering (FDSFFC), é uma técnica de seleção não-supervisionada derivada a partir do
algoritmoDense Subgraph Finding with Feature Clustering (DSFFC) (BANDYOPADHYAY
et al., 2014). O DSFFC é um método de seleção que é executado em duas etapas: Na primeira etapa, os atributos são modelados como vértices em um grafo completo, onde cada aresta contém peso igual a informação mútua entre cada atributo, em seguida é executada uma busca de subgrafo menos denso (adaptada a partir da busca de subgrafo mais denso) para encontrar as características minimamente redundantes entre si. Na segunda etapa é feito um agrupamento usando os atributos selecionados na primeira etapa com o objetivo de melhorar a solução encontrada. O método proposto FDSFFC apresenta uma estratégia para melhorar o tempo de execução, que consiste em dividir o conjunto de características em subconjuntos menores e utilizar o algoritmo DSFFC para selecionar as características em cada um desses subconjuntos, essa técnica consegue diminuir o tempo de execução em relação ao DSFFC sem perder desempenho na classificação, o que possibilita aplicar o algoritmo em problemas de alta dimensionalidade.
O segundo método proposto, chamado de Extraction with Mutual Information Based K-Medoids (EMIKM), é uma técnica de extração não-supervisionada desenvolvida a partir do algoritmo de seleção Mutual Information Based K-Medoids (MIKM) (JIANG et al., 2011). O MIKM realiza um agrupamento K-Medoids em conjunto com a medida de
Os próximos capítulos desse trabalho estão organizados da seguinte maneira: O Capítulo 2 traz a fundamentação teórica, onde são apresentados os conceitos fundamentais para entendimento do trabalho realizado. No Capítulo 3, são apresentados os trabalhos relacionados Laplacian Score For Feature Selection (LSFS), Minimal Redundancy Maximal Relevance Criterion (mRMR), DSFFC e MIKM. O Capítulo 4 descreve os métodos
15
2 Fundamentação Teórica
Esse capítulo apresenta a fundamentação teórica do trabalho, cada seção descreve os conceitos teóricos necessários para desenvolvimento e entendimento desse trabalho. São abordados os conceitos sobre reconhecimento de padrões, aprendizagem de máquina, redução de dimensionalidade, classificadores entre outros.
2.1
Reconhecimento de Padrões
O ser humano consegue realizar facilmente tarefas como: reconhecer pessoas através da voz, descrever o conteúdo de uma imagem ou interpretar letras e números manuscritos. Porém essas atividades são complexas para um computador, pois sua capacidade de processamento é limitada a operações lógicas e aritméticas.
O reconhecimento de padrões é um subcampo da inteligência artificial que começou a ser desenvolvido antes de 1960 em pesquisas teóricas de estatística. O objetivo dessa disciplina científica é desenvolver métodos que permitem o computador classificar automa-ticamente objetos, que são referidos como padrões, em determinadas categorias ou valores reais, frequentemente chamados de classes ou rótulos. Essa ciência utiliza de ferramentas da probabilidade, estatística, aprendizagem de máquina, processamento de sinais e projeto de algoritmos, para construir modelos os que executam a tarefa de classificação dos padrões (THEODORIDIS; KOUTROUMBAS, 2008; BISHOP, 2006; DUDA et al., 2000).
Para desenvolver um sistema para reconhecer de padrões é necessário realizar uma fase de treinamento, que tem as seguintes etapas comuns a todos problemas: aquisição do conjunto de dados e pré-processamento, escolha das características mais adequadas para o problema e construção do modelo classificação (DUDA et al., 2000). O presente trabalho tem foco em redução de dimensionalidade, essa atividade está relacionada a etapa de escolha das características e será detalhada na Seção 2.3.
2.2
Aprendizagem de Máquina
dos exemplos em determinadas categorias ou valores reais e a experiência as atividades de treinamento.
Podemos classificar os métodos para aprendizagem de máquina em duas categorias: aprendizado supervisionado e não-supervisionado. Na aprendizagem supervisionada temos um professor (DUDA et al., 2000) que fornece as informações sobre a classe de cada exemplo do conjunto de treinamento, o aprendizado é feito com o objetivo de minimizar o erro na predição automática da classe desses exemplos de treinamento. Já o aprendizado é dito como não-supervisionado quando não temos disponível um professor com as infor-mações de classes, o aprendizado nesse caso é feito sobre as características dos padrões (THEODORIDIS; KOUTROUMBAS, 2008).
2.3
Redução de Dimensionalidade
As tarefas para reconhecimento de padrões, frequentemente estão associadas a problemas de alta dimensionalidade, como exemplo o reconhecimento de faces. Quando a dimensão do espaço características é muito alta são enfrentados problemas para a tarefa de classificação, como a complexidade de tempo dos modelos preditivos, o espaço necessário para armazenamento do conjunto de treino e a precisão da classificação que pode ser comprometida, pois essas bases de dados possuem grande quantidade de informações redundantes (WITTEN; FRANK, 2005; BROWN et al., 2012). Esse efeito negativo da grande quantidade de atributos é conhecido como "maldição da dimensionalidade"e foi abordado inicialmente em estudos sobre teoria de controle dos processos (BELLMAN, 1957 apud SAMMUT; WEBB, 2011, p.257).
Devido aos efeitos negativos da alta dimensão, é importante que sejam executados métodos para reduzir a dimensionalidade antes da etapa de classificação (BROWN et al., 2012; BLUM; LANGLEY, 1997; LIU; YU, 2005). Essas técnicas podem ser classificadas em dois tipos de abordagens: seleção ou extração de características (SAMMUT; WEBB, 2011).
2.3.1 Seleção de Características
Uma das abordagens para redução de dimensionalidade bastante utilizada é a seleção de características. Essa abordagem tem o objetivo de identificar e descartar os atributos mais irrelevantes para o problema (BLUM; LANGLEY, 1997; PENG et al., 2005).
A tarefa de seleção pode ser definida de maneira genérica da seguinte forma: Seja o conjunto de atributos X = {x1, . . . , xn}, o algoritmo de seleção busca por um subconjunto
X′ ⊂X tal que |X′|<|X| e X′ contenha os elementos mais representativos do conjunto
Capítulo 2. Fundamentação Teórica 17
características. O critério dessa seleção depende da abordagem que está sendo utilizada, algumas abordagens serão comentadas nos parágrafos seguintes.
Baseando-se na disponibilidade dos rótulos de classe dos padrões, os algoritmos de seleção podem ser divididos em duas categorias: supervisionado e não-supervisionado. Quando é usada as informações de classes no processo de seleção o método é chamado de supervisionado, caso contrário é considerado não-supervisionado. (LIU; YU, 2005).
Os tipos de abordagens dos algoritmos para seleção de características geralmente podem ser dividas em duas categorias: filtros e wrappers. Os filtros normalmente avaliam individualmente a relevância de cada atributo usando uma medida estatística. Os wrappers
avaliam as possíveis combinações de subconjuntos dos atributos com uma medida de performance obtida por um classificador (BLUM; LANGLEY, 1997; LIU; YU, 2005). Exemplos dewrappers bastantes conhecidos na literatura são oFoward Feature Selection e o Backward Feature Selection, esses algoritmos utilizam uma busca heurística para encontrar
o subconjunto de atributos que consegue obter maior acurácia com um determinado classificador (KOHAVI; JOHN, 1997). Os wrappers são bastante criticados pelo alto custo
computacional (JIANG et al., 2011) isso dificulta o uso dessa abordagem em problemas de alta dimensionalidade.
Por outro lado, os filtros são conhecidos pelo custo computacional bastante reduzido em relação aoswrappers. Uma grande partes dos filtros encontrados na literatura utilizam a
medida de informação mútua para avaliar os atributos (CHANDRASHEKAR; SAHIN, 2014; BROWN et al., 2012), como exemplo temos o Minimal Redundancy Maximal Relevance Criterion (mRMR) (PENG et al., 2005), oDense Subgraph Finding with Feature Clustering
(DSFFC) (BANDYOPADHYAY et al., 2014) e o Mutual Information Based K-Medoids
(MIKM) (JIANG et al., 2011), esses métodos serão detalhados no Capítulo 3. Maiores informações sobre o estado da arte dessa abordagem podem ser encontradas no survey
apresentado em (CHANDRASHEKAR; SAHIN, 2014).
2.3.2 Extração de Características
A extração de características é outra abordagem bastante utilizada para redução de dimensionalidade. Esses métodos executam uma transformação no conjunto de dados, para obter novos atributos que podem ter capacidade de discriminação melhor do que um subconjunto dos dados originais (SAMMUT; WEBB, 2011).
A extração pode ser feita através de uma projeção linear dos dados em um espaço de dimensão menor. Essa abordagem pode ser definida de maneira genérica dessa forma: Seja X = [x1, . . . , xm]T o conjunto padrões, onde cadaxi = [f1, . . . , fn] eW = [w1, . . . , wk]
a base da transformação com cada vetor wi = [t1, . . . , tn]T onde k < n. O novo espaço de
características reduzido X′ com dimensão igual a k é dado por X′ =XW. Um exemplo
conjunto de dados nos autovetores da matriz de covariância, que representam os vetores com direção de maior variância nos dados (BISHOP, 2006; THEODORIDIS; KOUTROUMBAS, 2008; SAMMUT; WEBB, 2011).
2.4
Elementos de Teoria da Informação
A Teoria da Informação fornece ferramentas estatísticas para análise de dados, como a entropia e informação mútua (COVER; THOMAS, 2006). Essas ferramentas são amplamente utilizadas nos algoritmos para seleção de características (CHANDRASHEKAR; SAHIN, 2014; BROWN et al., 2012).
2.4.1 Entropia
Uma medida bastante importante para a análise de dados é a entropia. Essa estatística quantifica a incerteza presente na distribuição dos dados (COVER; THOMAS, 2006). A entropia, denotada por H(X), é calculada conforme a Equação 2.1 com X sendo
uma variável aleatória discreta.
H(X) =− X
x∈X
p(x) logbp(x). (2.1)
Como X é uma variável aleatória discreta,x é cada possível valor de X e p(x) é a
função de probabilidade, que no caso discreto pode ser estimada pela frequência dexemX,
sendo ˆp(x) = nx
|X|, em quenx é o número de ocorrências do valorx no conjunto de dados. A
basebdo logaritmo normalmente é usada igual a 2, como foi feito em (BANDYOPADHYAY
et al., 2014).
2.4.2 Informação Mútua
A informação mútua entre duas variáveis aleatórias mede a quantidade de informa-ção que uma variável carrega dado o conhecimento da outra, essa medida pode quantificar a redundância entre duas variáveis (COVER; THOMAS, 2006). A informação mútua assume o valor zero quando as duas variáveis são completamente independentes e assume valores altos quando existe uma dependência entre essas variáveis.
Seja duas variáveis aleatórias discretasX eY,p(x) ep(y) como funções de
probabi-lidade (que já foram discutidas na Seção anterior) e p(x, y) como função de probabilidade
conjunta entreX eY, que pode ser estimada conforme a Equação 2.2, a informação mútua denotada por I(X, Y) é calculada conforme a Equação 2.3, onde temos a propriedade
I(X, Y) = I(Y, X).
Capítulo 2. Fundamentação Teórica 19
I(X, Y) = X
x∈X
X
y∈Y
p(x, y) logb p(x, y)
p(x)p(y). (2.3)
2.4.3 Informação Mútua Normalizada
A informação mútua é medida entre pares de variáveis, quando temos pares com informações mútuas em diferentes intervalos, torna-se inviável a comparação dessas variáveis. Para superar esse problema, a informação mútua pode ser normalizada no intervalo fechado [0,1].
Alguns métodos para normalização são apresentados através das Equações a seguir: O método apresentado pela Equação 2.4 é conhecido como incerteza simétrica (WITTEN; FRANK, 2005). Strehl e Ghosh (2003) propõe que o método da Equação 2.6 é mais adequado que o 2.5 para agrupamento de variáveis.
Ii(X, Y) = 2I(X, Y)
H(X) +H(Y), (2.4)
Ij(X, Y) = I(X, Y)
min(H(X), H(Y)), (2.5)
Ik(X, Y) = q I(X, Y)
H(X)H(Y). (2.6)
No presente trabalho é utilizado o método 2.6, assim como Bandyopadhyay et al. (2014).
2.5
Busca de Subgrafo Mais Denso
O problema de busca do subgrafo mais denso, tanto para grafos direcionados ou não-direcionados, tem uma larga escala de aplicações na comunidade científica, sendo bastante utilizado em mineração de dados para detectar comunidades, em computação biológica para encontrar padrões complexos em genes e até mesmo em detecção de spam
(BAHMANI et al., 2012).
Para um grafoG= (E, V, Wf), ondeE é o conjunto de arestas,V de vértices e Wf
contém os pesos de cada aresta ei ∈E, a busca do subgrafo mais denso tem por objetivo
encontrar um subconjunto de vértices S ⊂V que maximize a função de densidade d(S),
que é definida conforme a equação 2.7.
d(S) =
P
e∈E(S)we∈Wf
|S| . (2.7)
uma restrição sobre a quantidade de vértices que o subgrafo deve possuir, essa busca torna-se um problema NP-difícil (KHULLER; SAHA, 2009). Um algoritmo (3 + 3ǫ)-aproximativo
para esse caso é apresentado em (BAHMANI et al., 2012), chamado de Large Densest Subgraph. Essa busca aproximativa foi amplamente testada em grafos com meio bilhão de
vértices e seis bilhões de arestas.
O pseudocódigo desse método pode ser encontrado no Algoritmo 1. As entradas são o grafo G = (V, E, Wf), a quantidade k de vértices que o subgrafo deve conter e ǫ
como um valor inteiro e positivo que representa o fator de aproximação. Valores altos de ǫ
tornam a execução do algoritmo mais rápida, mas a qualidade da solução encontrada é prejudicada. Nas linhas 1 e 2, os subgrafos auxiliares S e ˆS são iniciados com o conjunto
de vértices V, a busca é executada nas linhas 3 e 10 enquanto o subgrafoS não for vazio. A cada iteração, nas linhas 4 a 7, são removidos deS os ǫ
1+ǫ|S| elementos que possuem os
menores valores da função grausS(i), que calcula a soma dos pesos das arestas incidentes
no vértice ido subgrafo S. Se após essa remoção, a densidade de S for maior que a de ˆS e
a cardinalidade de S for maior quek, então S é atribuído em ˆS. No final do processo, ˆS é
retornado como o subgrafo mais denso.
Algoritmo 1Large Densest Subgraph
Entrada: G= (V, E, Wf),k > 0 e ǫ >0 , em que ǫ é o fator de aproximação.
1: S ←V;
2: Sˆ←V;
3: enquanto S 6=∅ faça
4: Aˆ(S)← {i∈S|grausS(i)≤2(1 +ǫ)densidade(S)};
5: Coloque ˆA(S) em ordem crescente de acordo comgrausS(i);
6: Atribua os 1+ǫǫ|S| primeiros atributos de ˆA(S) em A(S);
7: Remova de S os elementos contidos em A(S);
8: se |S| ≥k e densidade(S)> densidade( ˆS)então
9: Sˆ←S
10: fim se
11: fim enquanto
12: Devolva ˆS
Bandyopadhyay et al. (2014) apresenta uma adaptação do algoritmo aproximativo proposto em (BAHMANI et al., 2012) para o problema de minimização da função de densidade do subgrafo, usada no algoritmo para seleção de características DSFFC, que será detalhado no Capítulo 3.
2.6
Agrupamento
Capítulo 2. Fundamentação Teórica 21
que os objetos de grupos diferentes sejam dissimilares (THEODORIDIS; KOUTROUMBAS, 2008).
Os algoritmos de agrupamento são utilizados para seleção de características, pois além da avaliação individual de cada atributo, eles também permitem avaliar o compor-tamento dos atributos em conjunto. Esse tipo de abordagem trás melhorias significantes para o processo de seleção, pois ao fazer uma avaliação das características apenas a nível individual não considera a dependência mútua entre os atributos, o que dificulta a busca pelo subconjunto de características com melhor desempenho para classificação (BANDYOPADHYAY et al., 2014; JAIN et al., 2007).
Dois algoritmos de agrupamento, chamados de K-Means e K-Medoids (em
Por-tuguês, K-Médias e K-Medóides), são bastante utilizados em métodos para seleção de atributos. Esses dois algoritmos são classificados como agrupamento do tipo rígido, nessa abordagem cada objeto pertence exclusivamente a um único grupo (THEODORIDIS; KOUTROUMBAS, 2008).
2.6.1 K-Médias
O algoritmo K-Means busca particionar os dados de forma iterativa baseando na
minimização do erro quadrado. Para um conjunto de dados X ={x~1, . . . , ~xn}, deseja-se
particionar os dados em k grupos, de forma que a medida de distorção (apresentada na Equação 2.8) seja minimizada.
J(X, C) =
k
X
j=1 X
xi∈Cj
kx~i−µ~j k2 . (2.8)
Nessa abordagem temos o conjunto de protótipos P = {µ~1, . . . , ~µk}, onde cada
elemento de P corresponde a média de todos os elementos contidos em cada grupo C ={C1, . . . , Ck}.
O processo de agrupamento inicia com um conjunto de protótiposP aleatórios. A
cada iteração, os dados de X são associados ao grupo mais próximos, de acordo com uma
medida de distância entre o dado e os protótipos. Para a medida de distorção da Equação 2.8, e para que a cada protótipo seja a média do grupo, esta distância é necessariamente Euclidiana. Ao final da iteração, todos os protótipos são atualizados com o centro de massa dos elementos contido no grupo. O processo dura até a medida de distorção convergir.
2.6.2 K-Medóides
do grupo que possui máxima similaridade média com os outros objetos contidos no mesmo grupo.
OK-Medoids também diferencia-se do K-Means no critério de parada. Em vez de tomar como base a minimização do erro quadrado, esse algoritmo baseia-se na função da Equação 2.9, onde d(x, µ) é uma medida de distância ou similaridade.
ˆ
J(X, C) = X
i=1,xi∈/P X
µj∈P
uijd(x~i, ~µj). (2.9)
uij =
1 se d(xi, µj) =minq∈Pd(xi, µq);
0 caso contrário.
Esse algoritmo é bastante eficiente no agrupamento de características, porque não precisa recalcular as distâncias aos protótipos a cada iteração e apresenta taxas de acerto superiores a alguns métodos, como é mostrado nos experimentos em (JIANG et al., 2011).
2.7
Algoritmos Classificadores
Dentre as diversas possibilidades de algoritmos para realizar a classificação automá-tica de padrões encontrados na literatura, dois foram escolhidos para serem utilizados nesse trabalho: O K-Nearest Neighbors (K-NN) e oSupport Vector Machine (SVM) (DUDA et
al., 2000).
2.7.1 K-Nearest Neighbors
O classificadorK-Nearest Neighbors é um algoritmo de aprendizagem baseada em
instâncias, onde cada exemplo é considerado como um ponto no espaço n-dimensional. A
classificação de cada nova instância é feita observando as classes de seus k vizinhos mais
próximos no espaço, de acordo com uma função de distância ou similaridade d(xi, xj). O
novo padrão recebe a classe com maior quantidade de exemplos entre seus k vizinhos mais próximos. O Algoritmo 2 mostra como funciona esse processo de classificação (MITCHELL, 1997).
Capítulo 2. Fundamentação Teórica 23
Algoritmo 2K-NN
Entrada: Conjunto de treino X = {x1, x2, . . . , xn} com classes Y = {y1, y2, . . . , yn} ;
Parâmetro k >0 e nova instância a ser classificada xq.
Saída: yq como classe da instânciaxq.
1: D← ni = [xi, d(xq, xi)]∀xi ∈X;
2: Ordenar D de acordo comd(xq, xi), se a funçãod(xq, xi) for de distância esta ordem é
crescente, caso contrário a função é de similaridade, esta ordem é decrescente;
3: N ← {xj, . . . , xk} ∀xj ∈nj, j = 1, . . . , k ;
4: yq ←A classe y com maior número de exemplos xj ∈N;
5: Devolva yq como classe de xq;
2.7.2 Support Vector Machine
O métodoSupport Vector Machine, desenvolvido por Vapnik (1995), consiste em um
classificador binário que traz uma abordagem geométrica para a classificação de padrões. Dado um problema linearmente separável, o SVM encontra um hiperplano ótimo que separa os padrões em duas regiões, chamadas de positiva e negativa, onde cada região representa uma classe. O algoritmo define esse hiperplano com padrões que estão nas fronteiras de cada região, chamados vetores de suporte, esses exemplos são encontrados através de uma busca. A classificação de um novo padrão é feita com o produto interno entre o novo exemplo e os vetores de suporte, caso o resultado seja maior que zero, o padrão recebe a classe positiva, caso o resultado seja menor que zero, o padrão recebe a classe negativa (THEODORIDIS; KOUTROUMBAS, 2008; DUDA et al., 2000; VAPNIK, 1995). A Figura 1 mostra um exemplo dos vetores de suporte e hiperplano ótimo em problema linearmente separável.
Figura 1 – Ilustração do classificador SVM. Fonte: DUDA et al.,2000.
espaço (HEARST, 1998). A Figura 2, mostra um exemplo de como é feito esse mapeamento dos dados no SVM não-linear.
Figura 2 – Ilustração do classificador SVM para o caso não-linear.
A Tabela 1 mostra as funções deKernel mais usadas no treinamento do SVM para
problemas não-lineares. Explanações detalhadas sobre essas funções fogem o escopo deste trabalho, informações detalhadas podem ser encontradas em (BURGES, 1998; HEARST, 1998).
Tabela 1 – Funções de Kernel mais utilizadas, onde xi e xj são pontos no espaço.
Tipo de Kernel Função K(xi, xj) Parâmetros
Polinomial (δ(xi·xj) +k)d δ, k ed
Gaussiano (RBF) exp(−γ kxi−xj k2) γ
Sigmoidal tanh(β0(xi ·xj) +β1) β0 eβ1
O SVM é um classificador binário, ou seja, ele foi projetado para resolver problemas envolvendo duas classes. Esse fato não inviabiliza o uso do SVM para problemas com mais de duas classes, pois existem várias estratégias para projetar o SVM para esse caso, uma delas bastante usada é a "one-versus-rest"(WANG; XUE, 2014). Nessa abordagem,
sendo co número de classes, são construídos c SVMs binários, um para cada classe. No
treinamento de cada SVM binário a classecé fixada como positiva, enquanto que as outras são fixadas como negativas. No teste, o padrão de consulta é testado em todos os c SVMs. A classe de saída será a correspondente ao SVM de resposta mais alta.
2.8
Avaliação de Desempenho dos Classificadores
Capítulo 2. Fundamentação Teórica 25
evita que aconteçam problemas como, se temos m exemplos de uma determinada classe e
na divisão todos os m exemplos ficarem no conjunto de teste, o classificador não poderá
aprender nada sobre essa classe (KOHAVI, 1995).
Uma técnica que possibilita o particionamento estratificado bastante utilizada é o
Holdout Cross Validation. Esse método divide o conjunto de dados em dois subconjuntos
mutuamente exclusivos, um será usado para treino e outro para teste. A proporção dos dados nessa divisão é dado por um valorp, em que pexemplos são separados para treino e
(1−p) para teste (KOHAVI, 1995).
Após a divisão dos dados em conjuntos de treino e teste, é necessário usar um índice quantitativo para avaliar a performance do classificador no conjunto de teste. O índice amplamente usado nos trabalhos científicos dessa área é a acurácia (KOHAVI, 1995), dada por um número real no intervalo fechado [0,1], que representa proporção de classificações corretas que o modelo preditivo obteve na etapa de teste. Seja Y ={y1, . . . , yn} as classes
reais dos n padrões do conjunto de teste e Q= {q1, . . . , qn} as classes preditas por um
algoritmo classificador. A acurácia pode ser calculada conforme a Equação 2.10.
A =
Pn
i=1ci
n . (2.10)
ci =
1 se yi =qi;
0 caso contrário.
2.9
Teste de Hipótese por Sobreposição de Intervalos de Confiança
Para avaliar o desempenho na classificação de um método, a técnica de amostragem para validação cruzada pode ser repetida para obter acurácia média e desvio padrão do classificador. Os testes de hipótese permitem verificar se a diferença entre as acurácias médias obtidas por duas técnicas distintas é significativa. Nesse trabalho foi escolhido o teste de hipótese por sobreposição de intervalos de confiança, chamado de t teste, pois os dados seguem uma distribuição t de Student (TRIOLA, 2006). Esse tipo de teste assume
que se os intervalos de confiança das duas amostras não têm sobreposição, então a diferença das médias é significativa.
Nos experimentos comparativos de classificação realizados no presente trabalho, todos os algoritmos para redução dimensionalidade são executados sob as mesmas condições, ou seja, em cada etapa de experimento as acurácias médias de cada algoritmo são obtidas usando o mesmo conjunto de treino e teste gerados por um Holdout. No caso de amostras
colhidas sob mesmas condições é mais adequado executar o teste para dados emparelhados (MONTGOMERY; RUNGER, 2007). O t teste emparelhado, adotado nesse trabalho, pode
Primeiro são formuladas as hipóteses nula (H0) e alternativa (H1).
H0 As acurácias médias comparadas são iguais.
H1 As acurácias médias comparadas são diferentes.
Seja d a diferença individual entre os dois valores em um único par, µd o valor
médio das diferenças d para a população de todos os pares, ˆd valor médio das diferenças d
para os dados amostrais emparelhados, sd o desvio padrão das diferenças d para os dados
amostrais emparelhados e n como número de pares de dados e tα/2 o valor crítico obtido
com a distribuição t. O intervalo de confiança da sobreposição dos dados é calculado sob
um nível de significância α (nesse trabalho foi usado α= 0.05) conforme a Equação 2.11.
ˆ
d−E < µd<dˆ+E, (2.11) E =tα/2
sd
√
n
27
3 Trabalhos Relacionados
Esse capítulo apresenta os trabalhos sobre seleção de características encontrados no estado da arte que serviram como base para os métodos desenvolvidos. Na Seções 3.1 e 3.2, são apresentados, respectivamente, os métodosLaplacian Score For Feature Selection
(LSFS) eMinimal Redundancy Maximal Relevance Criterion (mRMR). Essas duas técnicas
são bastante conhecidas e foram utilizadas em experimentos comparativos nesse trabalho. A Seção 3.3 apresenta o algoritmo Dense Subgraph Finding with Feature Clustering
(DSFFC), esse trabalho serviu de base para o desenvolvimentos de um dos métodos propostos, o Fast Dense Subgraph Finding with Feature Clustering (FDSFFC). Por fim, na
Seção 3.4, é mostrado a técnica Mutual Information Based K-Medoids (MIKM). A partir
dessa técnica foi proposto nesse trabalho o método Extraction with Mutual Information Based K-Medoids (EMIKM).
O foco desse trabalho foi redução de dimensionalidade não-supervisionada. Todos os algoritmos implementados no desenvolvimento, com exceção do mRMR, foram não-supervisionados.
3.1
Laplacian Score For Feature Selection
O LSFS é um método para seleção de características proposto por He et al. (2005), que pode ser implementado de forma supervisionada ou não-supervisionada. Nesse trabalho será abordada a implementação não-supervisionada do método. Essa técnica é um filtro que seleciona os atributos com maior poder de preservação da localidade dos dados, em termos do Laplacian Score. Essa abordagem segue o princípio que os exemplos mais próximos
provavelmente pertencem a mesma classe. Muitos classificadores seguem esse princípio, como o K-NN. Dessa forma a seleção prioriza escolher atributos que conseguem preservar o máximo possível a estrutura de localidade dos dados no espaço de características.
Seja Lr o Laplacian Score dos r-ésimos atributos, comfri representando o valor
da r-ésima característica para o i-ésimo exemplo, ∀i = 1, . . . , m. O algoritmo pode ser
implementado de acordo com os passos a seguir.
1. Construa um grafoGde vizinhos mais próximos commvértices, em que cadai-ésimo
vértice corresponde a um exemplo de treinamento xi. É colocada uma aresta entre i
e j se xi pertence aos k-vizinhos mais próximos de xj, ou xj aos de xi.
2. Faça S como a matriz com os pesos das arestas de G. Se os vértices i e j estão
contrário, Sij = 0.
3. Para os r atributos, defina:
D=SO, O= [1, ...,1]T,
L=
D(1) . . . 0
... ... . . .
0 · · · D(m)
−S;
fr = [fr1, fr2, . . . , frm]T,
ˆ
fr=fr− f T rDO OTDOO
4. Calcule oLaplacian Score para todos r atributos da seguinte forma.
Lr = frˆ T
Lfrˆ
ˆ
frTDfrˆ
5. Selecione a quantidade de atributos desejada com os maiores Laplacian Score
associ-ados.
3.2
Minimal Redundancy Maximal Relevance Criterion
Outro método para seleção de características bastante popular é o mRMR, proposto por Peng et al. (2005). O mRMR faz a seleção considerando dois critérios, a máxima relevância e mínima redundância. Essa estratégia segue um princípio conhecido na literatura por "os m melhores atributos não são os melhores m atributos", pois é possível que as
correlações entre os melhores atributos sejam altas (COVER, 1974).
Esses critérios são avaliados da seguinte maneira: para a máxima relevância, é considerada a informação mútua entre cada atributo e a variável de classes. Para a mínima redundância, considera-se as informações mútuas entre os pares de atributos.
O algoritmo apresentado em (PENG et al., 2005) tem o seguinte funcionamento: SendoX o conjunto de características e Ca variável de classes, para selecionarmatributos
inicialmente é feita uma pré-seleção de m características com oFoward Feature Selection
(KOHAVI; JOHN, 1997). Esses atributos são colocados em um conjunto S. O critério atualiza os atributos de S com elementos não selecionados representados pelo conjunto X−Sm−1, que maximizam a condição apresentada na Equação 3.1. O algoritmo testa os
atributos de X−Sm−1 um após o outro.
max
xj∈X−Sm−1
[I(xj, C)− 1 m−1
X
xi∈Sm−1
Capítulo 3. Trabalhos Relacionados 29
3.3
Dense Subgraph Finding with Feature Clustering
O algoritmo DSFFC, proposto por Bandyopadhyay et al. (2014), apresenta uma solução que integra busca de grafo mais denso e agrupamento para seleção de características não-supervisionada. Essa proposta considera a dependência mútua entre os atributos e a representatividade de cada um, no processo de seleção.
Esse método é executado em duas etapas. Na primeira etapa, um grafo é modelado com a dependência mútua entre as características, para selecionar os atributos minima-mente redundantes entre si. Na segunda etapa é realizado um agrupamento, para que além de considerar a dependência mútua entre os atributos também seja considerada a representatividade de cada atributo selecionado.
O método é executado da seguinte forma: na primeira etapa, é construído um grafo completo G= (V, E, Wf), ondeV é o conjunto de atributos,E representa as arestas entre
cada par de vértices eWf contém os pesos de cada arestaei ∈E. Cada peso Wf representa
a informação mútua normalizada entre dois atributos vi, vj ∈ V conectados por ei. A
técnica para normalização da informação mútua utilizada é a apresentada na Equação 2.6. Após a modelagem, é executada uma adaptação da busca do subgrafo mais denso (apresentada no Algoritmo 1) para o problema de minimização, ou seja, em vez buscar o subgrafo que maximize a função de densidade (apresentada na Equação 2.7) é buscado o que minimize a função. Dessa forma o subconjunto S ⊂V representas os atributos que
são minimamente redundantes entre si.
Na segunda etapa, é realizado um agrupamento com o objetivo de selecionar as características mais representativas do conjunto original. Inicialmente, cada atributo seleci-onado na primeira etapa é colocado como protótipo de um grupo. Todas as características não selecionadas são colocadas no grupo mais próximo em termos da medida de informação mútua entre a característica e os protótipos. Em seguida, o protótipo de cada grupo é atualizado para o atributo do conjunto que possui a maior variância. O processo continua até que não ocorra mudança na estrutura dos protótipos de uma iteração para outra. Dessa forma além de considerar para a seleção as características menos redundantes, também são consideradas as mais representativas, de maneira que o subconjunto selecionado tenha melhor desempenho na classificação (BANDYOPADHYAY et al., 2014).
O pseudocódigo do DSFFC é apresentado no Algoritmo 3. Os parâmetros do método são: k sendo o tamanho mínimo do conjunto de características selecionadas, r
como a quantidade de vértices removidos a cada iteração e lsendo a quantidade de vértices
da iteração passada que podem ser inseridos novamente no subgrafo. Os parâmetros r e l
são análogos ao fator ǫ do Algoritmo 1 apresentado no Capítulo 2.
A cada iteração, nas linhas 3 a 13, são removidos de S os r elementos que possuem os
maiores valores da função grausS(i), que calcula a soma dos pesos das arestas incidentes
no vértice i do subgrafo S. Se após essa remoção, a densidade deS for menor que a de R e a cardinalidade de S for maior que k, então S é atribuído em R. Na linha 18, se a
densidade de S∪Sl, comSl representando osl vértices removidos na iteração passada, for
menor que a de S, os l vértices são inseridos novamente em S. O processo dura até que S
seja um conjunto vazio de vértices e é retornado nessa etapa R como o subgrafo menos denso de G.
Nas linhas 20 até 29 é executada a segunda etapa da seleção com o agrupamento, na linha 22 cada vértice de R é colocado inicialmente como protótipo de cada grupo. O
Capítulo 3. Trabalhos Relacionados 31
Algoritmo 3DSFFC
Entrada: Grafo G = (E, V, Wf); Características F = {f1, f2, . . . , fn}; Parâmetros k >,
l ≤0 e r >0.
Saída: R, como subconjunto de características selecionadas.
1: S ←V, R←V;
2: enquanto S 6= 0 faça
3: A′(S)← {i∈S|grauss(i)≥2·densidade(S)};
4: se |A′(S)|= 0 então 5: Interrompa a repetição; 6: senão se |A′(S)|= 1 então
7: r= 1;
8: senão se |A′(S)|< rentão 9: r= 0.5· |A′(S)|;
10: fim se
11: Coloque A′(S) em ordem decrescente de acordo com somagrauss(i), i∈A′(S); 12: Atribua os r primeiros atributos de A′(S) em A(S);
13: Remova de S os elementos contidos em A(S);
14: se |S| ≥k e densidade(S)< densidade(R) então
15: R←S;
16: fim se
17: se densidade(S∪Sl)< densidade(S) e Sl∩S 6= 0 então
18: S ←S∪Sl;
19: fim se ⊲ Sl representa os l elementos removidos de S na iteração passada.
20: fim enquanto ⊲Fim da busca do subgrafo.
21: k′ =|R|;
22: Atribua pj =Rj, ondeRj é o j-ésimo atributo de R,∀j = 1, . . . , k′ ;
23: Coloque pj como o centro inicial do correspondente j-ésimo grupo Cj,∀j = 1, . . . , k′; 24: Associe cada atributo não selecionado fi, i= 1, . . . ,|V| efi ∈ {/ p1, . . . , pk′}no grupo
Cj,∀j = 1, . . . , k′ se I(fi, pj) =maxk′
m=1I(fi, pm); 25: Selecione o novo protótipo p′
j,∀j = 1, . . . , k′ tal que var(p′j) =max(var(fi)),∀fi ∈Cj;
26: se pj =p′
j,∀j = 1, . . . , k′ então Desvie para 30;
27: senão
28: Desvie para 24; 29: fim se
30: Devolva os k’ protótipos como o subconjunto R;
3.4
Mutual Information Based K-Medoids
O método para seleção de características MIKM, proposto por Jiang et al. (2011), apresenta uma solução rápida e eficiente usando agrupamento para a seleção. Essa abor-dagem usa o algoritmo K-Medoids para agrupar os atributos em termos da medida de
informação mútua. O objetivo dessa estratégia é agrupar as características de forma que em cada grupo estejam contidos os atributos que são maximamente similares entre si e dissimilares com os dos outros grupos. Ao final do agrupamento, a medoid de cada grupo
é selecionada para compor o subconjunto de características. O conjunto de medoids, nesse
O pseudocódigo apresentado no Algoritmo 4 mostra em detalhes o funcionamento desse método. Na linha 1 o conjunto de protótipos P é inicializado com
característi-cas aleatórias do conjunto F. O agrupamento é realizado nas linhas 2 a 5. Em cada
iteração, as características são colocadas no grupo mais próximo em termos da infor-mação mútua entre a característica e ao protótipo de cada grupo. A atualização do conjunto de protótipos em cada iteração pelos fi atributos é feita de acordo com a
fun-ção maxfi∈Cj(P
ft∈Cj,ft6=fiI(fi, ft)). O processo é realizado até a convergência da função Pk
j=1 P
ft∈CjI(ft, pj). Finalmente, o conjunto de protótipos P é retornado como
subcon-junto de características selecionadas.
Algoritmo 4MIKM
Entrada: Características F ={f1, f2, . . . , fn} ; Parâmetro k >0, k <|F|.
Saída: P ={p1, . . . , pk}como subconjunto de características selecionadas.
1: Inicialize P ={p1, . . . , pk} com k atributos aleatórios f ∈F, tal que p1 6=. . .6=pk;
2: enquanto Pk
j=1 P
ft∈CjI(ft, pj) não convergirfaça
3: Associepj,∀j = 1, . . . , k como centro do correspondente grupo Cj,∀j = 1, . . . , k ;
4: Associe cada atributo não selecionado fi, i = 1, . . . ,|F| tal que fi ∈/ P, ao grupo Cj, j = 1, . . . , k seI(fi, pj) = maxk
m=1(I(fi, pm)) ;
5: Atualize osk protótipospj tal que pj =fi se maxfi∈Cj(P
ft∈Cj,ft6=fiI(fi, ft)); 6: fim enquanto
33
4 Trabalho Desenvolvido
Neste capítulo, são apresentados os métodos propostos com base no estudo feito sobre as técnicas DSFFC e MIKM. Os métodos do estado da arte foram implementa-dos e diversos experimentos foram realizaimplementa-dos. De acordo com os resultaimplementa-dos obtiimplementa-dos, foi possível identificar melhorias para cada técnica e propor soluções. As propostas foram implementadas e validadas através de experimentos quantitativos.
A Seção 4.1, apresenta o método para seleção de características FDSFFC, que foi desenvolvido com base no algoritmo DSFFC. Já a Seção 4.2, apresenta o método para extração de características EMIKM, que foi derivado a partir da técnica MIKM.
4.1
Método Proposto: FDSFFC
Um dos problemas encontrados ao usar o método DSFFC em dados de alta dimensionalidade é o custo computacional da busca do subgrafo mais denso. Quando é colocado uma restrição sobre a quantidade de vértices que o subgrafo deve conter, a busca torna-se um problema NP-difícil (KHULLER; SAHA, 2009). Os algoritmos presentes na literatura para resolver esse problema são aproximativos e possuem tempos de execução bastante elevados. O DSFFC utiliza uma adaptação da heurística proposta por Bahmani et al. (2012) para encontrar o subgrafo de menor densidade com uma quantidade restrita de vértices, que possui complexidade O(log1+ǫ nk), em que ǫ é o fator de aproximação, n é cardinalidade do conjunto de vértices e k é a quantidade mínima de vértices que o
subgrafo deve conter. O estudo sobre a complexidade de tempo dessas heurísticas foge o escopo deste trabalho, explicações detalhadas sobre o assunto podem ser encontradas em (GOLDBERG, 1984; KHULLER; SAHA, 2009; BAHMANI et al., 2012).
Devido ao tempo de execução elevado, o uso do DSFFC para bases com imagens de faces torna-se inviável. Uma imagem de face, em escala de cinza, com resolução de 112x93 possui 10304 pixels, na abordagem de reconhecimento facial holístico (JAIN et al.,
2007) cada característica é representada por um pixel da imagem, dessa forma já temos
um problema de alta dimensionalidade.
Bandyopadhyay et al. (2014) só executa experimentos com bases de até 2000 características e não mostra nenhuma avaliação em bases com imagens. Para contornar esse problema, foi desenvolvido um método para utilizar o algoritmo em imagens, que considera a vizinha dos pixels na seleção e reduz significativamente o tempo de execução,
possibilitando utilizar o algoritmo em imagens de faces.
Finding with Feature Clustering (FDSFFC), consiste em dividir o espaço de características
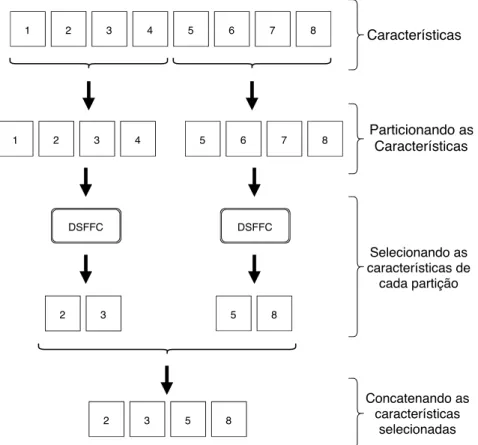
em subconjuntos disjuntos e executar o algoritmo DSFFC para realizar a seleção localmente em cada subconjunto. O conjunto de características resultante é a concatenação dos atributos selecionados em cada subconjunto.
Dessa forma, o tempo de execução da seleção é reduzido, pois a busca usada no DSFFC tem uma complexidade logarítmica em termos da quantidade de vértices, a medida que o tamanho da entrada cresce o tempo da busca aumenta consideravelmente, tornando inviável sua execução em bases de alta dimensionalidade, como cada subconjunto tem cardinalidade bem menor do que o conjunto de características, isso possibilita que o DSFFC execute rapidamente nos subconjuntos. É importante destacar que o FDSFFC pode ser facilmente paralelizado, o que pode diminuir ainda mais o seu tempo de execução.
O desenvolvimento da técnica FDSFFC teve ênfase para a seleção de características em imagens, por isso a divisão dos subconjuntos é feita considerando a vizinhança de cada
pixel, porém a técnica também foi adaptada para ser utilizada em dados genéricos.
Para bases com imagens, cada pixel é considerado como uma característica e cada
janela representa um subconjunto. Para executar a seleção, o algoritmo divide as imagens em janelas de tamanho igual e sem sobreposição de pixels (ver exemplo na Figura 3),
de forma semelhante ao que é feito no algoritmo Local Binary Patterns para descrição
de texturas (GONZALEZ; WOODS, 2006). Após a divisão, uma mesma quantidade de atributos é selecionada em cada janela com o algoritmo DSFFC. Dessa forma, o conjunto de características resultante é a concatenação dos atributos selecionados em cada janela. Outra vantagem desse método, além do tempo de execução, é que a vizinhança dos pixels está sendo considerada nessa abordagem, pois a seleção é feita localmente,
observando apenas ospixels contidos em cada janela. Os pixels de diferentes regiões podem
ser redundantes, mas esses representam elementos distintos. A vantagem de fazer a seleção localmente em imagens é que existe a possibilidade de obter atributos mais representativos de determinadas regiões da imagem.
Para bases com dados genéricos, ou seja, quando o vetor de características tem apenas uma dimensão (ao contrário das imagens onde temos duas) o vetor de características é divido de forma sequencial em conjuntos de tamanho igual. A Figura 4 mostra um exemplo de como é feita essa divisão das características e a Figura 5 mostra um fluxograma com funcionamento do algoritmo.
Os parâmetros de entrada do algoritmo para uso em imagens são: m, n, k >0∈Z,
onde m é a quantidade de janelas na horizontal, n é a quantidade de janelas na vertical e k é a quantidade de atributos selecionados em cada janela. O total de características selecionadas será igual a (m·n·k). Para uso em dados genéricos, é usadon = 1 e m é
Capítulo 4. Trabalho Desenvolvido 35
quantidade mínima de características para serem selecionadas, que é igual a (m·n).
Figura 3 – Exemplo da divisão em mxn janelas sem sobreposição, onde m= 4 e n = 4,
em um indivíduo de cada base: AT&T, The Sheffield, e Yale, respectivamente.
Figura 4 – Exemplo da divisão do vetor características em m conjuntos sequenciais.
Um pseudocódigo do método é apresentado no Algoritmo 5. A estrutura de repetição da linha 1 percorre as m janelas sem sobreposição na direção horizontal, já a estrutura da
linha 2 percorre as n janelas na vertical. Em cada iteraçãoT recebe os atributos contidos
na janela atual. O conjunto T′ recebe as k características deT selecionadas com o DSFFC.
Na linha 5 as características de T′ são concatenadas ao conjunto F, que representa o
subconjunto de características selecionadas em cada iteração. Ao final do processo, F é retorna como o subconjunto de características selecionadas pelo FDSFFC.
Algoritmo 5FDSFFC
Entrada: Atributos: F(x, y) =
f(1,1) . . . f(1,y)
... ... ...
f(x,1) · · · f(x,y)
; Parâmetros: k,m e n.
Saída: F′ tal que |F′|= (k·m·n) , como subconjunto de atributos selecionados.
1: para i← 1, i←i+ (y/m)até y−1 faça
2: para j ← 1, j ←j+ (x/n)até x−1 faça
3: T ←f(t, w),∀t={j, . . . , j+ (x/n)−1},∀w={i, . . . , i+ (y/m)−1};
4: T′ ← Osk atributos selecionados deT com o algoritmo DSFFC;
5: F ←F ∪T′;
6: fim para
7: fim para
4.2
Método Proposto: EMIKM
A seleção e extração de características tem o mesmo objetivo final, que é reduzir a dimensionalidade do conjunto de dados. Optar por uma dessas abordagens é algo que depende do problema aplicado e dos tipos de dados disponíveis. A seleção reduz o espaço de características escolhendo um subconjunto dos dados originais. Já a extração executa uma transformação nos dados com o objetivo de obter atributos que podem classificar melhor os padrões do que um subconjunto dos dados originais.
A técnica de extração desenvolvida, chamada deExtraction with Mutual Information Based K-Medoids, apresenta uma proposta de realizar uma extração em vez da seleção de uma característica em cada grupo, como é feito no algoritmo MIKM. Na proposta apresentada pelo método MIKM, as características são agrupadas de maneira que ao final do processo os atributos mais redundantes entre si vão estar contidos no mesmo grupo. Para isso, a técnica utiliza um algoritmo K-Medoids que baseia-se na informação
mútua entre cada atributo para realizar a tarefa de agrupamento. No final do processo, são selecionadas as características que estão no centro de cada grupo. Já o EMIKM realiza uma extração em cada grupo, onde um novo atributo corresponde a média de todas as características contidas no grupo.
A extração é realizada da seguinte forma: Sendo F = f1, f2, . . . , fn o espaço de