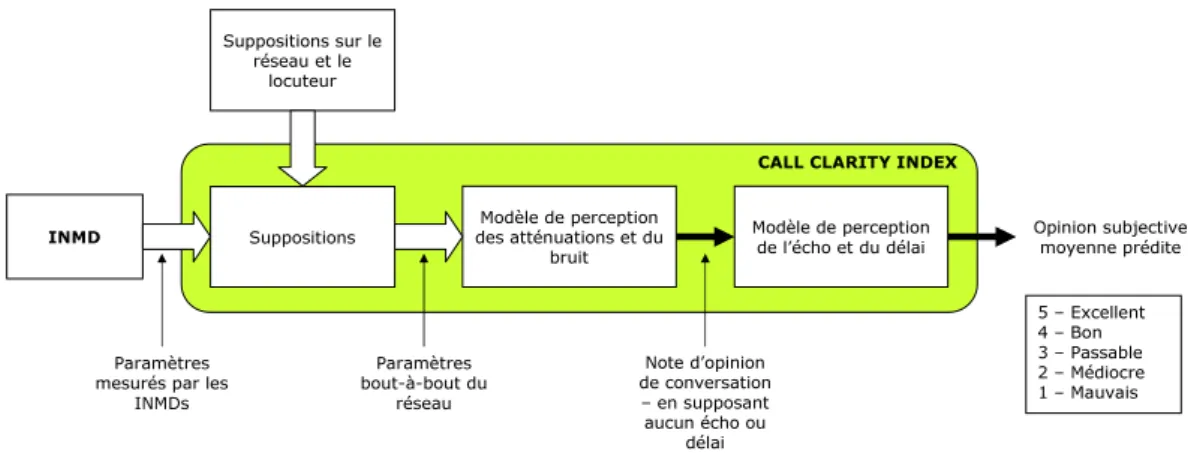
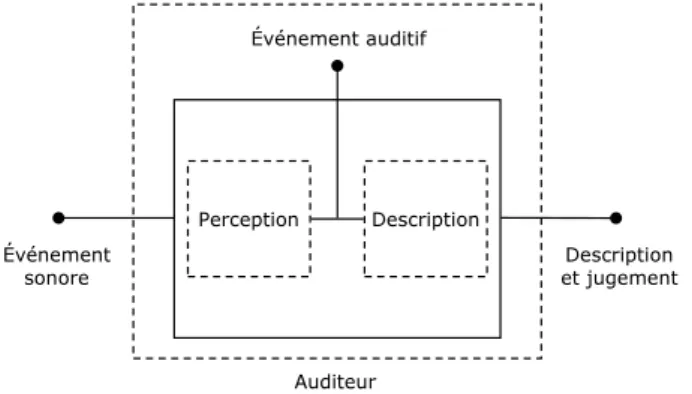
Qualité vocale Expression utilisée pour décrire la qualité de la transmission téléphonique d'un signal vocal. Pour fonctionner, la partie mesure du modèle objectif nécessite un modèle de qualité auditive et un modèle de qualité vocale.
Qualité vocale dans les télécommunications
Considérations sur la qualité vocale
- Subjective par nature
- Critères de qualité
- Contexte
- Synthèse
Ces méthodes d'évaluation de la qualité vocale sont dites analytiques [IEEE 1969], considérant la qualité vocale comme un phénomène multidimensionnel. Pour résumer, le jugement de la qualité de la voix est influencé par plusieurs paramètres, qui peuvent dépendre : (i) de facteurs propres à celui qui la juge (expérience passée, attentes et humeur de chacun), (ii) du contenu de la voix. le signal vocal. le discours lui-même, (iii) les critères de qualité examinés, et (iv) les facteurs extérieurs à l'individu (contexte et environnement).
Évolution des systèmes de télécommunications
- Téléphonie classique
- Systèmes numériques
- Systèmes mobiles
- Réseaux en mode paquet
- Synthèse
La transformation du signal, analogique en numérique et inversement, est alors assurée par le codec situé dans le poste utilisateur. Une des particularités du réseau IP par rapport au RTC réside dans le mode de transport des données.
Évaluation subjective de la qualité vocale
- Choix des sujets
- Méthodes normalisées
- Essais d'opinion d'écoute
- Tests de parole et d'écoute
- Essais d'opinion de conversation
- Synthèse
- Eets subjectifs des diérentes dégradations sur la qualité vocale
- Échos
- Délai
- Distorsion de la parole due au codage
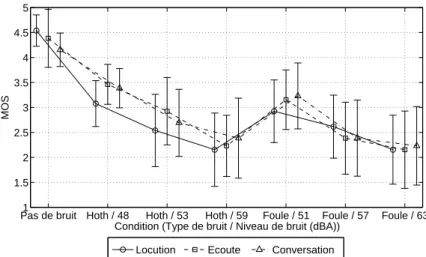
- Bruits
- Pertes de paquets
- Distorsion de l'eet local
- Variations dans le temps des dégradations
- Double parole
- Dispositifs de traitement du signal
- Synthèse
- Limites de l'évaluation subjective
Les conditions testées concernent les dégradations qui affectent la qualité d'écoute, telles que la distorsion de la parole due au codage, le bruit pour l'auditeur et les pertes de paquets. L'impact des pertes de paquets sur la qualité de la parole se manifeste par des coupures et/ou des crépitements dans le signal reçu, qui, dans des cas extrêmes, peuvent rendre la parole inintelligible pour l'auditeur.

Modèles objectifs de la qualité vocale
- Modèles paramétriques
- Modèle E
- Modèle CCI
- Modèle P.564
- Avantages et limites
- Modèles basés sur les signaux avec référence
- Transformation par représentation interne
- Modèle PESQ
- Modèle PESQM
- Avantages et limites
- Modèles basés sur les signaux sans référence
- Évaluation des mesures objectives de la qualité vocale
Un autre modèle asymétrique de qualité d'écoute est décrit dans la Recommandation P.564 [Rec. La difficulté d'évaluer la qualité de la parole réside d'abord dans la définition du signal de référence qui doit être utilisé comme entrée du modèle [Appel et Beerends 2002].

Problématique
Dans ce chapitre, nous présenterons d'abord le problème posé par le développement d'un tel modèle objectif non paramétrique de la qualité de la parole dans un contexte conversationnel. Après avoir déterminé les objectifs que nous souhaitons atteindre avec ce modèle, nous décrirons dans la thèse la méthode proposée pour construire un modèle objectif de qualité vocale conversationnelle.
Objectifs
Un autre objectif de cette thèse consistera donc à concevoir et mettre en œuvre plusieurs tests subjectifs pour étudier l'impact des dégradations survenant dans le contexte d'une conversation sur la qualité vocale perçue.
Méthode proposée
Partie intégration
L'appréciation de la qualité de la conversation est ainsi évaluée en combinant les résultats de la qualité d'écoute et de parole et la valeur du retard présent dans la communication testée. Construction du modèle : des évaluations subjectives de la qualité de la parole, de la qualité d'écoute et de la qualité de la conversation sont obtenues lors de tests subjectifs dans différentes conditions de dégradation.
Partie mesure
À partir de ces scores subjectifs et valeurs de retard, le rapport F entre les trois composantes (évaluation subjective de la qualité de la parole, évaluation subjective de la qualité d'écoute et retard) est déterminé pour estimer l'évaluation subjective de la qualité de la parole. La méthode proposée dans le chapitre 2 consiste à tenter de combiner la qualité d’écoute et de parole et la latence pour estimer la qualité conversationnelle.

Méthodologie de test proposée
- Protocole
- Déroulement des tests
- Choix des conditions de test
- Montage expérimental et enregistrement
- Analyse des résultats subjectifs et rejet des sujets aberrants
Un logiciel de notation a été développé dans le cadre de la thèse pour accélérer et automatiser la collecte et l'analyse des scores fournis par les participants. Les communications effectuées lors des tests subjectifs seront enregistrées afin d'être utilisées pour évaluer les performances du modèle proposé au niveau objectif, discuté au chapitre 5.
Tests subjectifs réalisés
Test 1 : délai et écho
- Objectifs
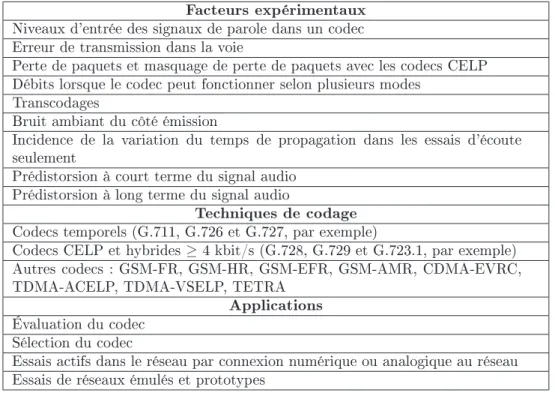
- Conditions et facteurs expérimentaux
- Analyse des résultats
- Synthèse
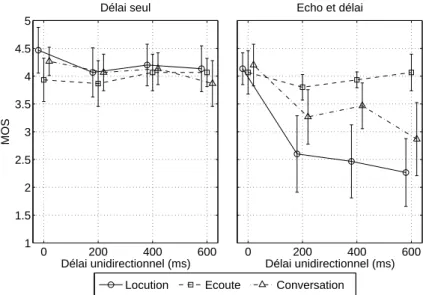
En présence de réverbération, l'effet de retard dépend du contexte dans lequel se situe le sujet (interaction importante entre les deux facteurs), qui résulte essentiellement d'un contexte d'écoute non affecté par la réverbération et pour lequel la note moyenne globale reste relativement stable (autour de 4 MOS), à mesure que le retard augmente. En l’absence de réverbération, le retard n’a pas d’effet significatif sur le jugement, quel que soit le contexte, puisque la question porte sur l’inconfort de la réverbération.

Test 2 : pertes de paquets et bruit
- Objectif
- Conditions et facteurs expérimentaux
- Analyse des résultats
- Synthèse
Dans le cadre de l'écoute, la qualité varie en fonction du taux de perte de paquets et du niveau de bruit à distance. Quant à la mesure globale de la qualité, l’appréciation moyenne des inconvénients liés aux erreurs est affectée par le contexte et le taux de perte de paquets.

Test 3 : bruit
- Objectif
- Conditions et facteurs expérimentaux
- Analyse des résultats
- Synthèse
Quant à la mesure globale de la qualité, l’indice moyen d’interférence sonore est affecté par le contexte et le taux de perte de paquets, mais peu par le bruit. Une ANOVA réalisée sur des mesures de qualité globale et d'interférence sonore confirme que le bruit a un effet très significatif et que le contexte n'a pas d'effet significatif sur les jugements des sujets.

Test 4 : écho, délai et pertes de paquets
- Objectif
- Conditions et facteurs expérimentaux
- Analyse des résultats
- Synthèse
Dans un contexte conversationnel, la qualité semble varier principalement en fonction du taux de perte de paquets et semble moins affectée par le délai et l'écho. Dans le contexte vocal, le score moyen global reste presque stable à mesure que la perte de paquets augmente.

Relation entre les diérentes composantes de la qualité vocale
- Test 1 : délai et écho
- Test 2 : pertes de paquets et bruit
- Test 3 : bruit
- Test 4 : écho, délai et pertes de paquets
- Détection des dégradations
- Tous tests
- Apprentissage
- Validation
Le mappage entre les scores de conversation subjectifs et estimés obtenus de cette manière est présenté dans la figure 3.24. Le mappage entre les scores de conversation subjectifs et estimés obtenus de cette manière est présenté dans la figure 3.25.

Optimisation du modèle de qualité de locution PESQM
Étude préliminaire de PESQM sur deux tests de locution de la littérature 96
- Protocole
- Analyse des résultats
- Enregistrement des signaux de test
- Vérication de la reproductibilité des notes subjectives entre
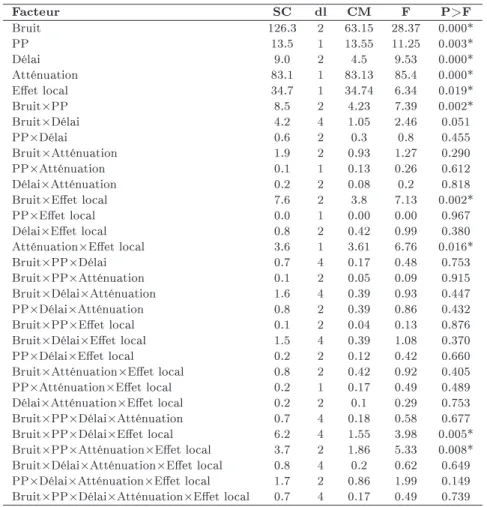
D'après le tableau 4.6, l'effet local a un effet significatif mais faible par rapport aux effets d'autres facteurs. Quatre des cinq facteurs (bruit, pertes de paquets (notés PP), délai et atténuation) ont un effet significatif, tandis que le facteur local Eet n'a aucun effet significatif.
![Tableau 4.1 : Conditions et notes MOS du test de locution avec écho seul - Contribution UIT-T COM 12-16 [Gierlich et Diedrich 2000]](https://thumb-eu.123doks.com/thumbv2/1bibliocom/466687.71341/100.892.323.587.82.444/tableau-conditions-notes-locution-écho-contribution-gierlich-diedrich.webp)
Étude de PESQM sur les résultats de notre test de locution
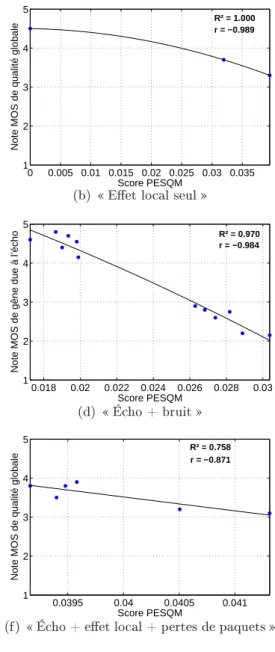
Pour chacune des répartitions, la corrélation r entre les notes subjectives et les scores PESQM correspondants est calculée. La corrélation obtenue entre les scores MOS et les scores PESQM est fortement dépendante des dégradations présentes.
Optimisation et validation de PESQM
- Optimisation
- Choix des paramètres optimaux
- Version optimisée de PESQM appliquée au test de locution . 112
Les trois courbes de mappage (écho uniquement, écho + perte de paquets et écho uniquement et écho + perte de paquets) sont comparées dans la figure 4.9, pour les conditions avec écho uniquement et écho + perte de paquets. Une seule fonction de mappage a été déterminée pour les conditions d'écho uniquement et d'écho + perte de paquets, ce qui a donné une corrélation de Pearson r = 0,9165 entre les scores de parole subjectifs et objectifs.
Découpage des signaux de conversation
La courbe de cartographie obtenue dans toutes les conditions d'écho uniquement et d'écho + perte de paquets donne lieu à la meilleure corrélation Pearsonr entre les scores de parole subjectifs et objectifs. Les scores PESQM sont ensuite convertis en scores MOS à l'aide d'une fonction de mappage unique déterminée pour les conditions d'écho uniquement et d'écho + perte de paquets et résultant en une corrélation de Pearson = 0,9165 entre les scores de parole subjectifs et objectifs.

Application à des signaux de test
- Performances du modèle objectif de qualité d'écoute (PESQ)
- Performances du modèle objectif de qualité de locution (PESQM)
- Performances du modèle objectif de qualité de conversation (CONV) . 123
- Synthèse
Puisque α = 0, le score de qualité vocale n’est pas inclus dans le score de qualité de conversation. Les performances du modèle objectif de qualité d'appel avec détection de bruit dans toutes les conditions de test sont présentées dans la figure 5.5(a).
Application à des signaux de conversation
- Performances du modèle objectif de qualité d'écoute (PESQ)
- Performances du modèle objectif de qualité de locution (PESQM)
- Performances du modèle objectif de qualité de conversation (CONV) . 129
- Synthèse
Nous présentons dans un premier temps les performances du modèle de conversation sans détection de bruit, puis dans le but d'étudier l'apport de la détection de bruit aux signaux conversationnels. Les performances du modèle objectif de qualité de conversation avec détection de bruit sont présentées dans la figure 5.9(a).
Étude de l'interactivité
Motivations
Les rafales de parole et les temps de pause sont détectés à l'aide d'un détecteur d'activité vocale. Le temps de séjour moyen dans l'état I peut être déterminé en fonction de la température de conversation τ.
Application
Les moyennes des temps de séjour, des probabilités d'état et des températures de parole sont tracées en fonction du retard dans un sens dans la figure 5.12. En particulier, les temps de séjour moyens tA et tB sont supérieurs à ceux rapportés dans la recommandation P.59.

Synthèse
Cependant, l'impact du retard sur la qualité de la conversation varie en fonction de l'interactivité de la communication. Il manquait donc un modèle d’évaluation de la qualité de la conversation basé sur l’analyse du signal (avec ou sans référence).
Physique du phénomène sonore
Capacités sensorielles et dimensions de la perception auditive
Bandes critiques
Masquage
Si un son pur est présenté sur fond de bruit blanc de masquage, seules les fréquences de bruit proches de celles du son pur contribuent à l'effet de masquage. Le seuil masqué correspond à l'égalité de l'énergie du signal et de celle du bruit dans la bande critique centrée sur le signal.
Audiogramme masqué
Le son test est perçu dès que son niveau, dans la bande critique autour de 1 kHz, est inférieur d'environ 4 dB au niveau du son de masquage dans la même bande de fréquence.
Perception de l'intensité acoustique
Si l'on applique l'intensité d'un son pur à 1 kHz à celle d'une bande de bruit centrée à 1 kHz, en gardant constante la puissance acoustique du bruit, le bruit est indépendant de la bande passante jusqu'à 160 Hz, ce qui correspond à la bande critique. à 1 kHz. Au-dessus de 160 Hz, le volume sonore augmente avec la largeur si le niveau global est supérieur à 20 dB SPL.
Perception de la hauteur
Dans la plage d'intensité comprise entre 30 et 120 dB, la fonction d'intensité sonore peut être décrite par la loi de puissance de Stevens avec l'exposant 0,6 : S = kp0,6, où S = intensité sonore en sones, p = pression acoustique en µPa et k = constante.
Échelles naturelles de la membrane basilaire
Ce modèle objectif d'évaluation de la qualité de la parole (dans un contexte d'écoute) est le résultat de la fusion de deux modèles : PSQM [Rec. Perte de paquets et masquage de perte de paquets avec des codecs de type MIC Coupure temporaire du signal vocal.
Principe
Échelonnement et alignement temporel
- Échelonnement du niveau
- Filtrage du système IRS
- Alignement temporel
Le modèle ne doit donc pas prendre en compte la différence de niveau entre le signal initial et le signal dégradé. En calculant le temps de propagation n, il est possible de déterminer une valeur exacte du temps de propagation par échantillon, selon les étapes suivantes.

Modèle psychoacoustique
- Initialisations et calibrations
- Transformation temps-fréquence
- Prédistorsion et densité de puissance fondamentale
- Compensations
- Densité de sonie
- Densité de perturbation
- Traitement de l'asymétrie
- Accentuation des parties de silence
- Intégration en temps et fréquence
- Calcul du score PESQ
L'effet de filtrage et les modifications de gain à court terme sont partiellement compensés par le traitement de la densité de puissance sous-jacente image par image. Ce facteur d'asymétrie est égal au rapport de la densité de puissance fondamentale du signal dégradé sur le signal d'origine élevé à la puissance 1,2.

Performances
Dans le cas de la qualité vocale, le signal de référence est beaucoup plus difficile à nier. Cependant, il n'est pas possible ici d'utiliser le signal entrant dans l'embouchure du HATS comme signal de référence.
Équations
- Initialisations et calibrations
- Fenêtrage et densité spectrale de puissance
- Prédistorsion et densité de puissance fondamentale
- Étalement dans le domaine fréquentiel
- Densité de sonie
- Densité de perturbation due au bruit
- Suppression du bruit
- Calcul du score PESQM
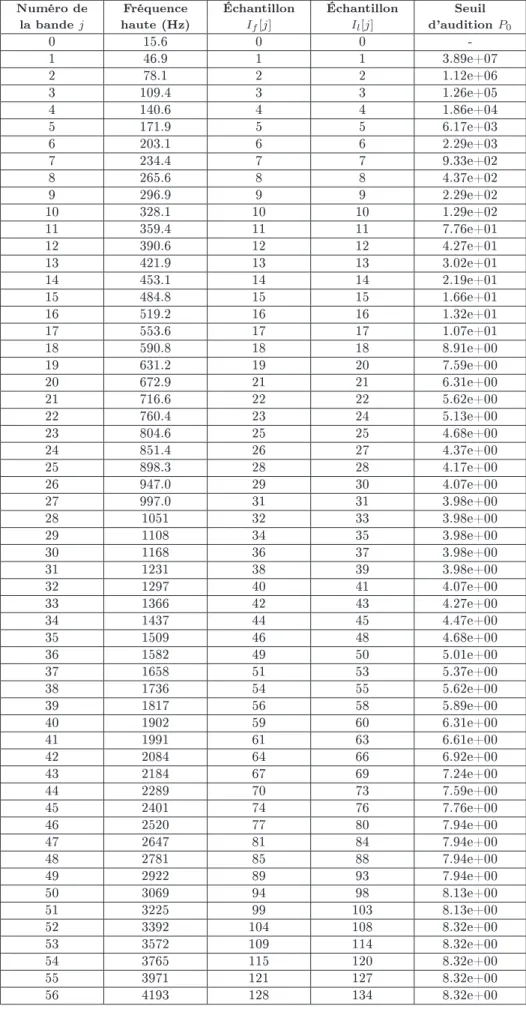
La prédistorsion permet de passer de l'échelle de fréquence en Hertz (indice k) à l'échelle psychophysique des tons dans le domaine des bandes critiques (indice j), pour obtenir une représentation image par image de la densité de puissance fondamentale. L'excitation provoquée par le stimulus sonore sur la membrane basilaire est déterminée par une convolution de la densité de puissance fondamentale avec une fonction d'étalement de fréquence.
![Figure C.1 : Principe de fonctionnement du modèle PESQM ( Perceptual Echo and Sidetone Quality Measure) en version acoustique [Appel et Beerends 2002]](https://thumb-eu.123doks.com/thumbv2/1bibliocom/466687.71341/160.892.181.741.74.846/principe-fonctionnement-perceptual-sidetone-quality-measure-acoustique-beerends.webp)
Performances
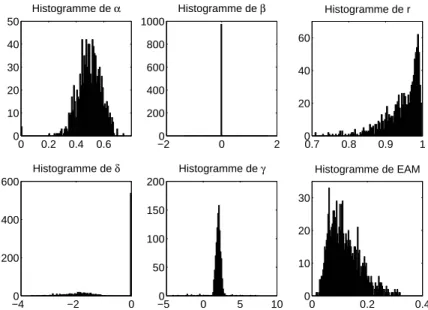
La régression linéaire multiple consiste à expliquer au mieux une quantité y (la réponse) en fonction d'autres quantités x (les régresseurs). Le but de la régression linéaire multiple est de trouver la meilleure estimation desk=p−1 coecientsβ, notée β, qui minimise le vecteur des résidusˆu, c'est-à-dire la différence entre la réponse observée syi et les prédictions correspondantes de modelˆi.
Suppositions
Statistiques
- Sommes des carrés (SC)
- Coecient de détermination
- Coecient de détermination ajusté
- Test de Fisher
- Table d'analyse de variance (ANOVA)
- Intervalles de conance des coecients estimés
- Test de nullité d'un coecient
Si les hypothèses de régression sur les résidus sont satisfaites, la distribution des coefficients de régression estimés est normale avec une variance proportionnelle à l'erreur quadratique moyenne (MC E). Les résultats sont résumés dans un tableau d'analyse des coefficients : Facteur estimé (βˆj) Écart type (ˆσ( ˆβj)) Pr(>|t|).
Analyse des résidus
Multicolinéarité
Sélection des régresseurs
Backward elimination
Forward selection
Répétez les étapes 4 et 5 jusqu'à ce que tous les prédicteurs de la régression soient significatifs et que tous ceux en dehors de la régression soient non significatifs.
Stepwise regression
Méthode de bootstrap
Perceptual Evaluation of Speech Quality (PESQ), the new ITU standard for end-to-end speech quality assessment - Part II: Psychoacoustic model. Perceptual Evaluation of Speech Quality (PESQ), the new ITU standard for end-to-end assessment of speech quality - Part I: Time delay compensation.

![Figure 1.3 : Impact du délai sur la conversation (d'après [Hammer et al. 2005])](https://thumb-eu.123doks.com/thumbv2/1bibliocom/466687.71341/24.892.290.626.78.347/figure-1-impact-délai-conversation-hammer-al-2005.webp)